

-
摘要: 开放集文字识别 (Open-set text recognition, OSTR) 是一项新任务, 旨在解决开放环境下文字识别应用中的语言模型偏差及新字符识别与拒识问题. 最近的 OSTR 方法通过将上下文信息与视觉信息分离来解决语言模型偏差问题. 然而, 这些方法往往忽视了字符视觉细节的重要性. 考虑到上下文信息的偏差, 局部细节信息在区分视觉上接近的字符时变得更加重要. 本文提出一种基于自适应字符部件表示的开放集文字识别框架, 构建基于文字局部结构相似度量的开放集文字识别方法, 通过对不同字符部件进行显式建模来改进对局部细节特征的建模能力. 与基于字根 (Radical) 的方法不同, 所提出的框架采用数据驱动的部件设计, 具有语言无关的特性和跨语言泛化识别的能力. 此外, 还提出一种局部性约束正则项来使模型训练更加稳定. 大量的对比实验表明, 本文方法在开放集、传统闭集文字识别任务上均具有良好的性能.Abstract: Open-set text recognition (OSTR) is an emerging task that aims to address language bias and novel characters in open-world text recognition applications. Recent OSTR methods have achieved some success by decoupling the potentially biased context information with visual information. However, they tend to overlook the increasing importance of visual details. Given the biases in contextual information, detailed visual information became much more important in differentiating visually close characters. This work proposes an adaptive part-representation-based open-set text recognition framework and an open-set text recognition method via part-based similarly to improve the visual details modeling by explicitly modeling different character parts. Unlike radical-based methods, the proposed framework adopts a data-driven parting scheme, hence is language agnostic. A localization constraint is further proposed to address the instability caused by the parting scheme. The full framework steadily outperforms its baseline and yields reasonable performance on the close-set benchmarks.1)
1 1 代码, 模型, 文档见:https://github.com/lancercat/OAPR 2)2 2 注意, 字符在特征空间的区域可能有交集. -

图 1 基于整字符识别方法的形近字混淆
Fig. 1 The confusion among close characters of the whole-character-based method
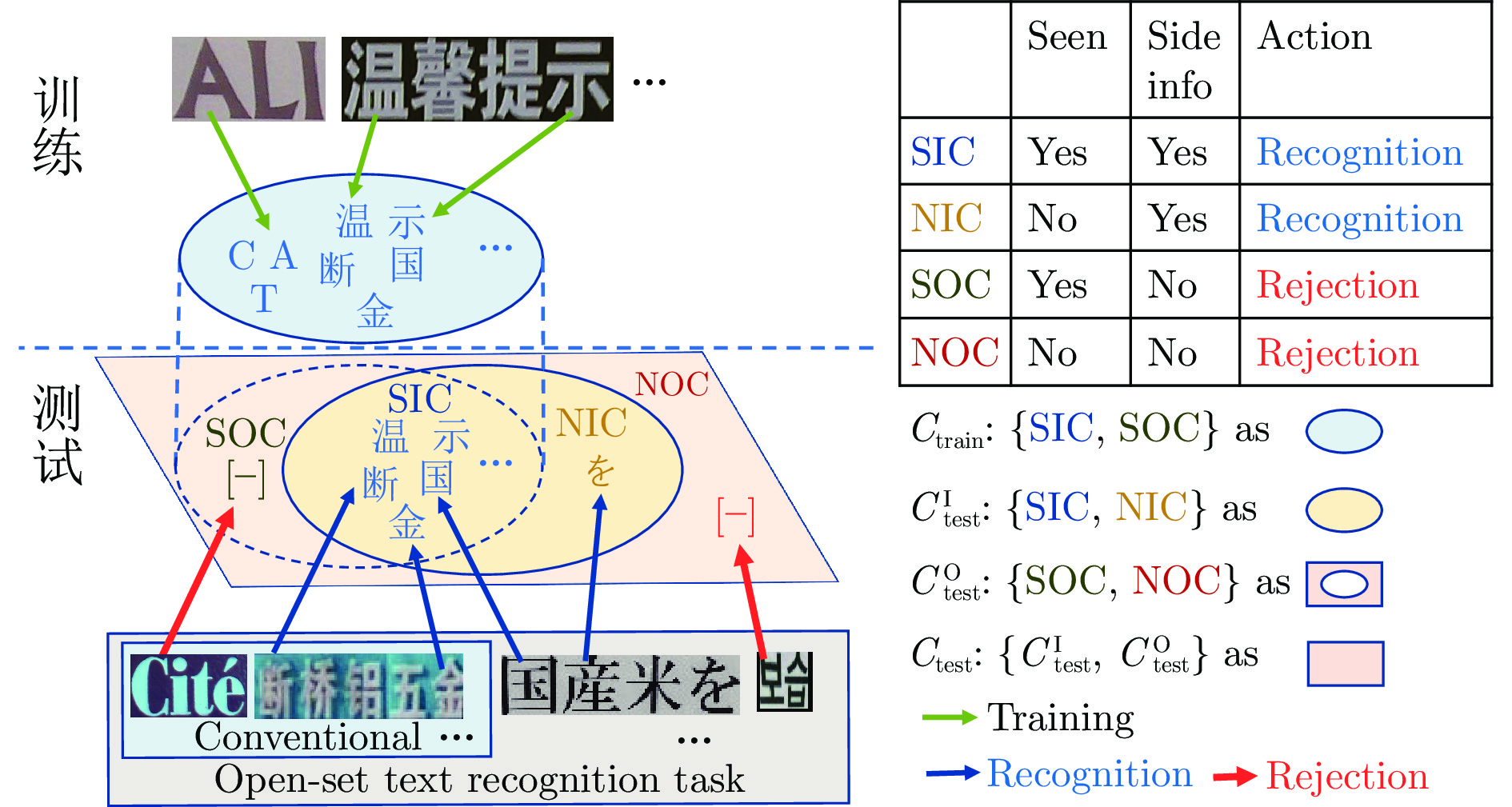
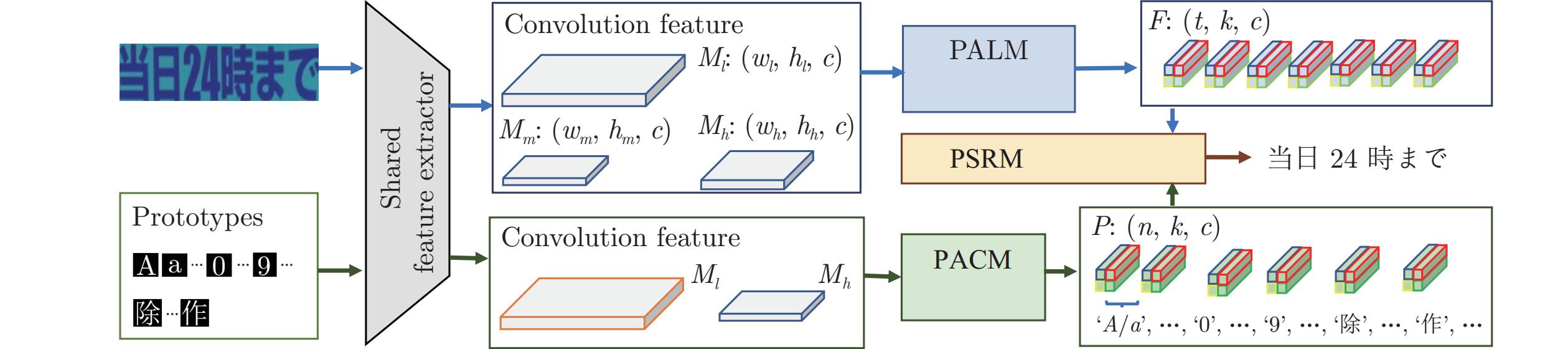
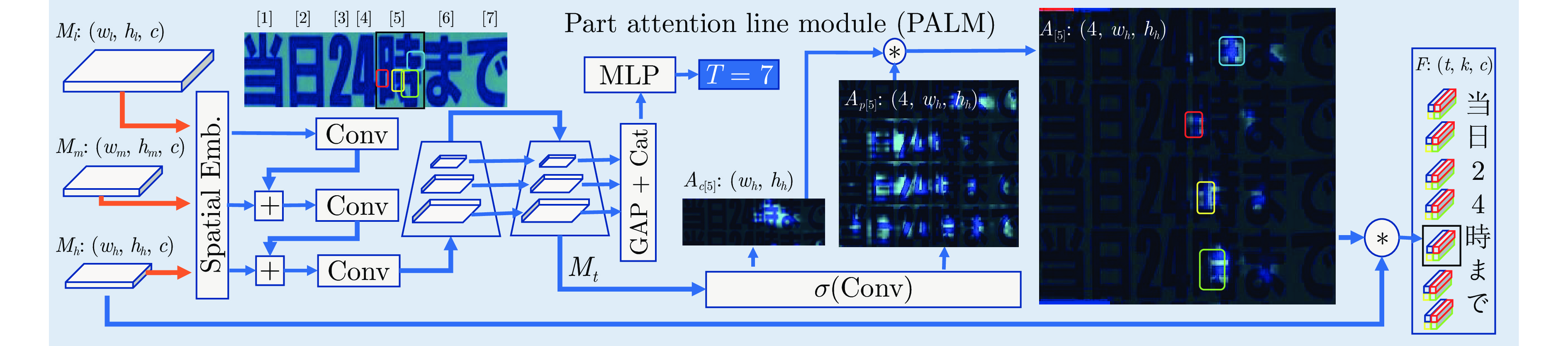
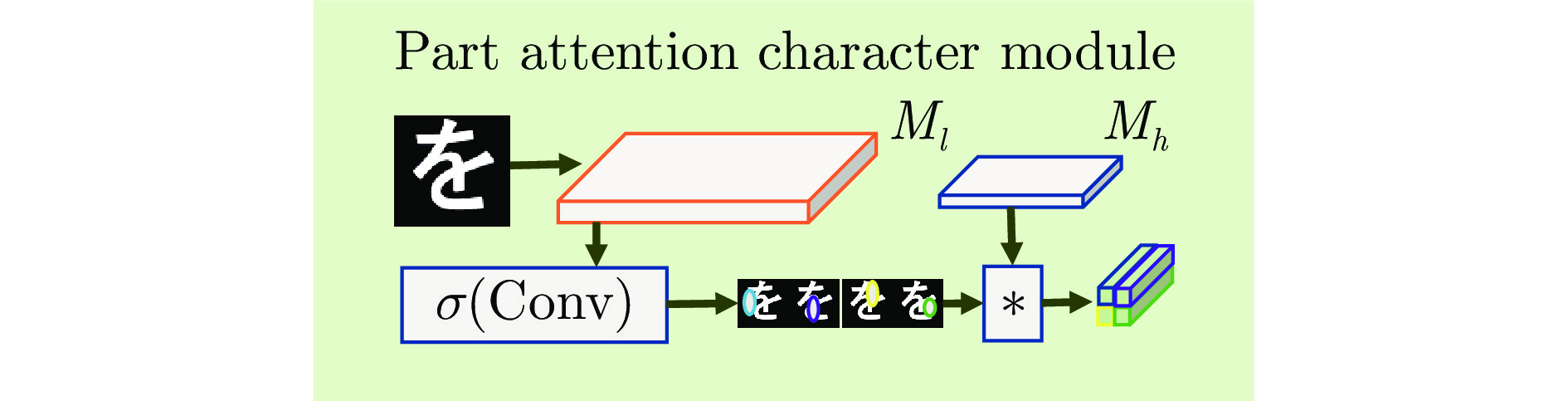
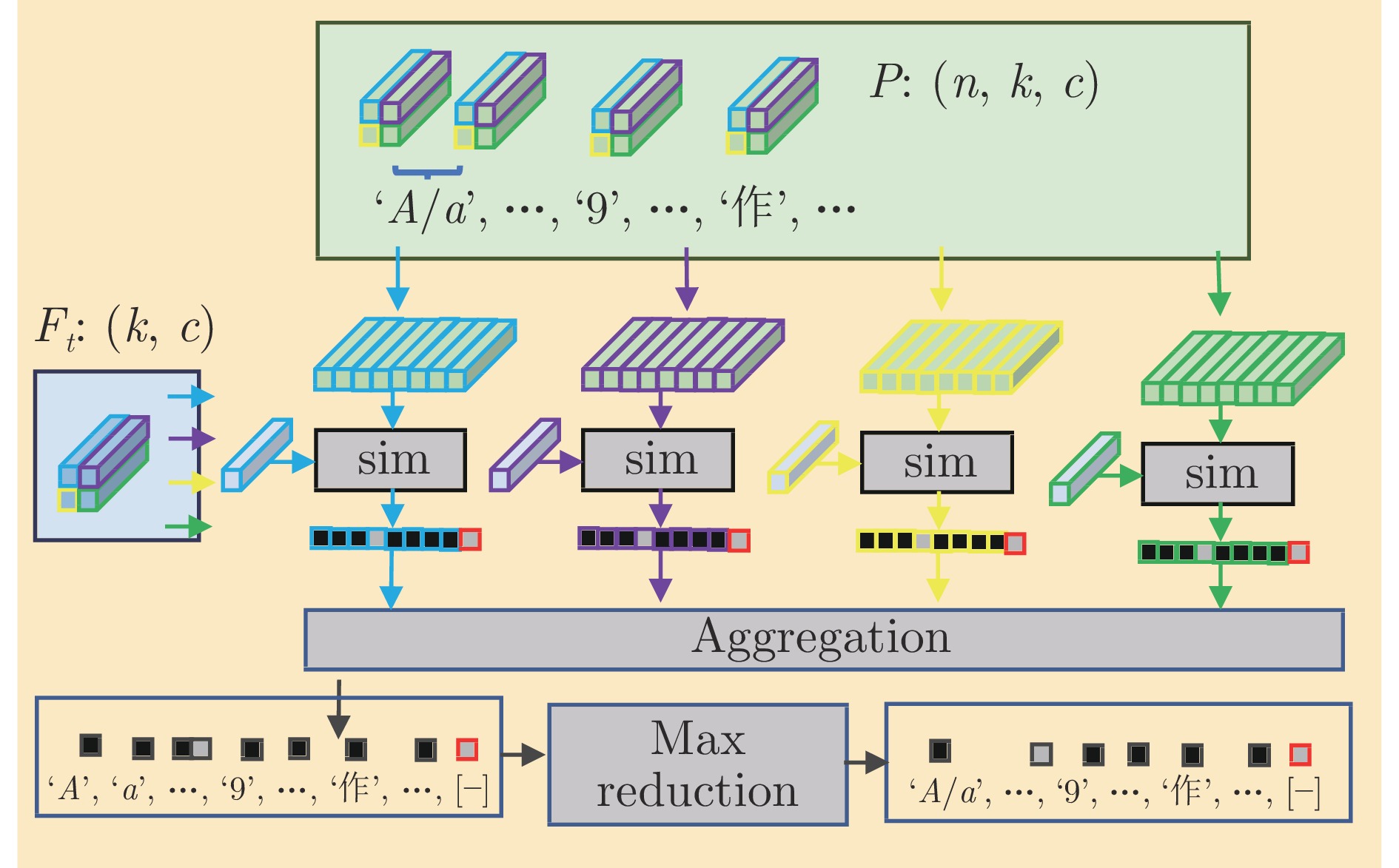
图 3 本文提出的基于自适应字符部件表示的开放集文字识别框架
Fig. 3 The proposed open-set text recognition framework with adaptive part representation

图 8 基线方法(上侧) 与我们的模型 (下侧) 的识别结果对比
Fig. 8 More comparison between base method (top) and the proposed framework (bottom)

图 9 日文测试数据集上的识别结果(GZSL 划分)
Fig. 9 Sample results from the Japanese testing data set (With GZSL split)
表 1 消融实验
Table 1 Ablative studies
自适应字符
部件表示局部性
约束Avg LA $ \uparrow $ Gap LA $ \downarrow $ Ours $\checkmark $ $\checkmark $ 39.61 4.91 仅自适应字符部件表示 $\checkmark $ 38.91 6.54 字符整体特征 34.04 2.27  下载: 导出CSV
下载: 导出CSV
表 2 开放集文字识别性能
Table 2 Performance on open-set text recognition benchmarks
任务 $ {\boldsymbol{C}}_{test}^k $ $ {\boldsymbol{C}}_{test}^u $ 方法 来源 LA (%) Recall (%) Precision (%) F-measure (%) Unique Kanji OSOCR-Large[8] PR' 2023 30.83 — — — GZSL Shared Kanji $ \emptyset $ OpenCCD[9] CVPR' 2022 36.57 — — — Kana, Latin OpenCCD-Large[9] CVPR' 2022 41.31 — — — Ours — 39.61 — — — Ours-Large — 40.91 — — — OSR Shared Kanji Unique Kanji OSOCR-Large[8] PR' 2023 74.35 11.27 98.28 20.23 Latin Kana OpenCCD-Large*[9] CVPR' 2022 84.76 30.63 98.90 46.78 Ours — 73.56 64.30 96.21 76.66 Ours-Large — 77.15 60.59 96.80 74.52 GOSR Shared Kanji Kana OSOCR-Large[8] PR' 2023 56.03 3.03 63.52 5.78 Unique Kanji OpenCCD-Large*[9] CVPR' 2022 68.29 3.47 86.11 6.68 Latin Ours — 65.07 54.12 82.52 64.65 Ours-Large — 67.40 47.64 82.99 60.53 OSTR Shared Kanji Kana OSOCR-Large[8] PR' 2023 58.57 24.46 93.78 38.80 Unique Kanji Latin OpenCCD-Large*[9] CVPR' 2022 69.82 35.95 97.03 52.47 Ours — 68.20 81.04 89.86 85.07 Ours-Large — 69.87 75.97 91.18 82.88 注: * 表示原论文中未报告的性能, 数据来自原作者代码仓库和释出的模型.
下载: 导出CSV
表 3 封闭集文字识别基准测试性能及单批次推理速度
Table 3 Performance on close-set text recognition benchmarks and single batch inference speed
方法 来源 IIIT5K CUTE SVT IC03 IC13 GPU TFlops FPS CA-FCN*[22] AAAI'19 92.0 79.9 82.1 — 91.4 Titan XP 12.0 45.0 Comb.Best[23] ICCV'19 87.9 74.0 87.5 94.4 92.3 Tesla P40 12.0 36.0 PERN[47] CVPR'21 92.1 81.3 92.0 94.9 94.7 Tesla V100 14.0 44.0 JVSR[48] ICCV'21 95.2 89.7 92.2 — 95.5 RTX 2080Ti 13.6 38.0 ABINet[49] T-PAMI'23 96.2 89.2 93.5 97.4 95.7 V100 14.0 29.4 CRNN[21, 23] T-PAMI'17 82.9 65.5 81.6 92.6 89.2 Tesla P40 12.0 227.0 Rosetta[23, 50] KDD'18 84.3 69.2 84.7 92.9 89.0 Tesla P40 12.0 212.0 ViTSTR[51] ICDAR'21 88.4 81.3 87.7 94.3 92.4 RTX 2080Ti 13.6 102.0 GLaLT-Big-Aug[52] TNNLS'23 90.4 77.1 90.0 95.2 95.3 — — 62.1 Ours-Large — 89.06 77.77 80.68 89.61 87.98 Tesla P40 12.0 85.7
下载: 导出CSV
-
[1] 李文英, 曹斌, 曹春水, 黄永祯. 一种基于深度学习的青铜器铭文识别方法. 自动化学报, 2018, 44(11): 2023−2030Li Wen-Ying, Cao Bin, Cao Chun-Shui, Huang Yong-Zhen. A deep learning based method for bronze inscription recognition. Acta Automatica Sinica, 2018, 44(11): 2023−2030 [2] Zheng T L, Chen Z N, Huang B C, Zhang W, Jiang Y G. MRN: Multiplexed routing network for incremental multilingual text recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 18598−18607 [3] 麻斯亮, 许勇. 叠层模型驱动的书法文字识别方法研究. 自动化学报, 2024, 50(5): 947−957Ma Si-Liang, Xu Yong. Calligraphy character recognition method driven by stacked model. Acta Automatica Sinica, 2024, 50(5): 947−957 [4] 张颐康, 张恒, 刘永革, 刘成林. 基于跨模态深度度量学习的甲骨文字识别. 自动化学报, 2021, 47(4): 791−800Zhang Yi-Kang, Zhang Heng, Liu Yong-Ge, Liu Cheng-Lin. Oracle character recognition based on cross-modal deep metric learning. Acta Automatica Sinica, 2021, 47(4): 791−800 [5] Zhang C H, Gupta A, Zisserman A. Adaptive text recognition through visual matching. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 51−67 [6] Souibgui M A, Fornés A, Kessentini Y, Megyesi B. Few shots are all you need: A progressive learning approach for low resource handwritten text recognition. Pattern Recognition Letters, 2022, 160: 43−49 doi: 10.1016/j.patrec.2022.06.003 [7] Kordon F, Weichselbaumer N, Herz R, Mossman S, Potten E, Seuret M, et al. Classification of incunable glyphs and out-of-distribution detection with joint energy-based models. International Journal on Document Analysis and Recognition, 2023, 26(3): 223−240 doi: 10.1007/s10032-023-00442-x [8] Liu C, Yang C, Qin H B, Zhu X B, Liu C L, Yin X C. Towards open-set text recognition via label-to-prototype learning. Pattern Recognition, 2023, 134: Article No. 109109 doi: 10.1016/j.patcog.2022.109109 [9] Liu C, Yang C, Yin X C. Open-set text recognition via character-context decoupling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 4513−4522 [10] Liu C, Yang C, Yin X C. Open-set text recognition via shape-awareness visual reconstruction. In: Proceedings of the 17th International Conference on Document Analysis and Recognition. San José, USA: Springer, 2023. 89−105 [11] Yu H Y, Chen J Y, Li B, Ma J, Guan M N, Xu X X, et al. Benchmarking Chinese text recognition: Datasets, baselines, and an empirical study. arXiv: 2112.15093, 2021.Yu H Y, Chen J Y, Li B, Ma J, Guan M N, Xu X X, et al. Benchmarking Chinese text recognition: Datasets, baselines, and an empirical study. arXiv: 2112.15093, 2021. [12] Wan Z Y, Zhang J L, Zhang L, Luo J B, Yao C. On vocabulary reliance in scene text recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 11422−11431 [13] Zhang J Y, Liu C, Yang C. SAN: Structure-aware network for complex and long-tailed Chinese text recognition. In: Proceedings of the 17th International Conference on Document Analysis and Recognition. San José, USA: Springer, 2023. 244−258 [14] Yao C, Bai X, Shi B G, Liu W Y. Strokelets: A learned multi-scale representation for scene text recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 4042−4049 [15] Seok J H, Kim J H. Scene text recognition using a Hough forest implicit shape model and semi-Markov conditional random fields. Pattern Recognition, 2015, 48(11): 3584−3599 doi: 10.1016/j.patcog.2015.05.004 [16] Li B C, Tang X, Qi X B, Chen Y H, Xiao R. Hamming OCR: A locality sensitive hashing neural network for scene text recognition. arXiv: 2009.10874, 2020.Li B C, Tang X, Qi X B, Chen Y H, Xiao R. Hamming OCR: A locality sensitive hashing neural network for scene text recognition. arXiv: 2009.10874, 2020. [17] Wang T, Xie Z, Li Z, Wang T, Xie Z, Li Z, et al. Radical aggregation network for few-shot offline handwritten Chinese character recognition. Pattern Recognition Letters, 2019, 125: 821−827 doi: 10.1016/j.patrec.2019.08.005 [18] Cao Z, Lu J, Cui S, Zhang C S. Zero-shot handwritten Chinese character recognition with hierarchical decomposition embedding. Pattern Recognition, 2020, 107: Article No. 107488 doi: 10.1016/j.patcog.2020.107488 [19] Chen J Y, Li B, Xue X Y. Zero-shot Chinese character recognition with stroke-level decomposition. In: Proceedings of the 30th International Joint Conference on Artificial Intelligence. Montreal, Canada: IJCAI, 2021. 615−621 [20] Zu X Y, Yu H Y, Li B, Xue X Y. Chinese character recognition with augmented character profile matching. In: Proceedings of the 30th ACM International Conference on Multimedia. Lisboa, Portugal: ACM, 2022. 6094−6102 [21] Shi B G, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(11): 2298−2304 doi: 10.1109/TPAMI.2016.2646371 [22] Liao M H, Zhang J, Wan Z Y, Xie F M, Liang J J, Lyu P Y, et al. Scene text recognition from two-dimensional perspective. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence, the 31st Innovative Applications of Artificial Intelligence Conference, the 9th AAAI Symposium on Educational Advances in Artificial Intelligence. Honolulu, USA: AAAI Press, 2019. 8714−8721 [23] Baek J, Kim G, Lee J, Park S, Han D, Yun S, et al. What is wrong with scene text recognition model comparisons? Dataset and model analysis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 4714−4722 [24] 杨春, 刘畅, 方治屿, 韩铮, 刘成林, 殷绪成. 开放集文字识别技术. 中国图象图形学报, 2023, 28(6): 1767−1791 doi: 10.11834/jig.230018Yang Chun, Liu Chang, Fang Zhi-Yu, Han Zheng, Liu Cheng-Lin, Yin Xu-Cheng. Open set text recognition technology. Journal of Image and Graphics, 2023, 28(6): 1767−1791 doi: 10.11834/jig.230018 [25] He J, Chen J N, Lin M X, Yu Q H, Yuille A. Compositor: Bottom-up clustering and compositing for robust part and object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 11259−11268 [26] Pourpanah F, Abdar M, Luo Y X, Zhou X L, Wang R, Lim C P, et al. A review of generalized zero-shot learning methods. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(4): 4051−4070 [27] Zhang J S, Du J, Dai L R. Radical analysis network for learning hierarchies of Chinese characters. Pattern Recognition, 2020, 103: Article No. 107305 doi: 10.1016/j.patcog.2020.107305 [28] He S, Schomaker L. Open set Chinese character recognition using multi-typed attributes. arXiv: 1808.08993, 2018.He S, Schomaker L. Open set Chinese character recognition using multi-typed attributes. arXiv: 1808.08993, 2018. [29] Huang Y H, Jin L W, Peng D Z. Zero-shot Chinese text recognition via matching class embedding. In: Proceedings of the 16th International Conference on Document Analysis and Recognition. Lausanne, Switzerland: Springer, 2021. 127−141 [30] Wang W C, Zhang J S, Du J, Wang Z R, Zhu Y X. DenseRAN for offline handwritten Chinese character recognition. In: Proceedings of the 16th International Conference on Frontiers in Handwriting Recognition (ICFHR). Niagara Falls, USA: IEEE, 2018. 104−109 [31] Chen S, Zhao Q. Divide and conquer: Answering questions with object factorization and compositional reasoning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 6736−6745 [32] Geng Z G, Wang C Y, Wei Y X, Liu Z, Li H Q, Hu H. Human pose as compositional tokens. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 660−671 [33] Zhang H, Li F, Liu S L, Zhang L, Su H, Zhu J, et al. DINO: DETR with improved DeNoising anchor boxes for end-to-end object detection. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: OpenReview.net, 2023. [34] Chng C K, Liu Y L, Sun Y P, Ng C C, Luo C J, Ni Z H, et al. ICDAR2019 robust reading challenge on arbitrary-shaped text-RRC-ArT. In: Proceedings of the International Conference on Document Analysis and Recognition (ICDAR). Sydney, Australia: IEEE, 2019. 1571−1576 [35] Sun Y P, Ni Z H, Chng C K, Liu Y L, Luo C J, Ng C C, et al. ICDAR 2019 competition on large-scale street view text with partial labeling-RRC-LSVT. In: Proceedings of the International Conference on Document Analysis and Recognition (ICDAR). Sydney, Australia: IEEE, 2019. 1557−1562 [36] Yuan T L, Zhu Z, Xu K, Li C J, Mu T J, Hu S M. A large Chinese text dataset in the wild. Journal of Computer Science and Technology, 2019, 34(3): 509−521 doi: 10.1007/s11390-019-1923-y [37] Shi B G, Yao C, Liao M H, Yang M K, Xu P, Cui L Y, et al. ICDAR2017 competition on reading Chinese text in the wild (RCTW-17). In: Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). Kyoto, Japan: IEEE, 2017. 1429−1434 [38] Nayef N, Patel Y, Busta M, Chowdhury P N, Karatzas D, Khlif W, et al. ICDAR2019 robust reading challenge on multi-lingual scene text detection and recognition-RRC-MLT-2019. In: Proceedings of the International Conference on Document Analysis and Recognition (ICDAR). Sydney, Australia: IEEE, 2019. 1582−1587 [39] Jaderberg M, Simonyan K, Vedaldi A, Zisserman A. Synthetic data and artificial neural networks for natural scene text recognition. arXiv: 1406.2227, 2014.Jaderberg M, Simonyan K, Vedaldi A, Zisserman A. Synthetic data and artificial neural networks for natural scene text recognition. arXiv: 1406.2227, 2014. [40] Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE Computer Society, 2016. 2315−2324 [41] Mishra A, Alahari K, Jawahar C V. Scene text recognition using higher order language priors. In: Proceedings of the British Machine Vision Conference. Surrey, UK: BMVA Press, 2012. 1−11 [42] Risnumawan A, Shivakumara P, Chan C S, Tan C L. A robust arbitrary text detection system for natural scene images. Expert Systems With Applications, 2014, 41(18): 8027−8048 doi: 10.1016/j.eswa.2014.07.008 [43] Wang K, Babenko B, Belongie S. End-to-end scene text recognition. In: Proceedings of the IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE Computer Society, 2011. 1457−1464 [44] Lucas S M, Panaretos A, Sosa L, Tang A, Wong S, Young R, et al. ICDAR 2003 robust reading competitions: Entries, results, and future directions. International Journal of Document Analysis and Recognition, 2005, 7(2−3): 105−122 doi: 10.1007/s10032-004-0134-3 [45] Karatzas D, Shafait F, Uchida S, Iwamura M, Bigorda L G I, Mestre S R, et al. ICDAR 2013 robust reading competition. In: Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, USA: IEEE Computer Society, 2013. 1484−1493 [46] Geng C X, Huang S J, Chen S C. Recent advances in open set recognition: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10): 3614−3631 doi: 10.1109/TPAMI.2020.2981604 [47] Yan R J, Peng L R, Xiao S Y, Yao G. Primitive representation learning for scene text recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 284−293 [48] Bhunia A K, Sain A, Kumar A, Ghose S, Chowdhury P N, Song Y Z. Joint visual semantic reasoning: Multi-stage decoder for text recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 14920−14929 [49] Fang S C, Mao Z D, Xie H T, Wang Y X, Yan C G, Zhang Y D. ABINet++: Autonomous, bidirectional and iterative language modeling for scene text spotting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(6): 7123−7141 doi: 10.1109/TPAMI.2022.3223908 [50] Borisyuk F, Gordo A, Sivakumar V. Rosetta: Large scale system for text detection and recognition in images. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. London, UK: ACM, 2018. 71−79 [51] Atienza R. Vision transformer for fast and efficient scene text recognition. In: Proceedings of the 16th International Conference on Document Analysis and Recognition. Lausanne, Switzerland: Springer, 2021. 319−334 [52] Zhang H, Luo G Y, Kang J, Huang S, Wang X, Wang F Y. GLaLT: Global-local attention-augmented light transformer for scene text recognition. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2023.3239696 [53] Fang S C, Xie H T, Wang Y X, Mao Z D, Zhang Y D. Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 7098−7107 -

 下载:
下载:



计量
- 文章访问数: 654
- HTML全文浏览量: 501
- PDF下载量: 142
- 被引次数: 0
