

-
摘要: 离线强化学习通过减小分布偏移实现了习得策略向行为策略的逼近, 但离线经验缓存的数据分布往往会直接影响习得策略的质量. 通过优化采样模型来改善强化学习智能体的训练效果, 提出两种离线优先采样模型: 基于时序差分误差的采样模型和基于鞅的采样模型. 基于时序差分误差的采样模型可以使智能体更多地学习值估计不准确的经验数据, 通过估计更准确的值函数来应对可能出现的分布外状态. 基于鞅的采样模型可以使智能体更多地学习对策略优化有利的正样本, 减少负样本对值函数迭代的影响. 进一步, 将所提离线优先采样模型分别与批约束深度Q学习(Batch-constrained deep Q-learning, BCQ)相结合, 提出基于时序差分误差的优先BCQ和基于鞅的优先BCQ. D4RL和Torcs数据集上的实验结果表明: 所提离线优先采样模型可以有针对性地选择有利于值函数估计或策略优化的经验数据, 获得更高的回报.Abstract: Offline reinforcement learning algorithms realize the approximation of learned policy to behavior policy by reducing the distribution shift, but the data distribution of offline experience buffer often directly affects the quality of learned policy. In this paper, two offline prioritized sampling models including temporal difference error-based and martingale-based are proposed to improve the training effect of reinforcement learning agent. The temporal difference error-based sampling model enables agents to learn more experience data with inaccurate value estimation, thus deals with possible out-of-distribution states by estimating more accurate value functions. The martingale-based sampling model enables agents to learn more positive samples beneficial to policy optimization and reduces the impact of negative samples on value function iteration. Furthermore, the proposed offline prioritized sampling models are combined with the batch-constrained deep Q-learning (BCQ) respectively, to propose temporal difference error-based prioritized BCQ and martingale-based prioritized BCQ. Experimental results on D4RL and Torcs datasets show that the proposed two offline prioritized sampling models can be targeted to select the experience data that are conducive to value function estimation or policy optimization, so as to obtain higher rewards.
-
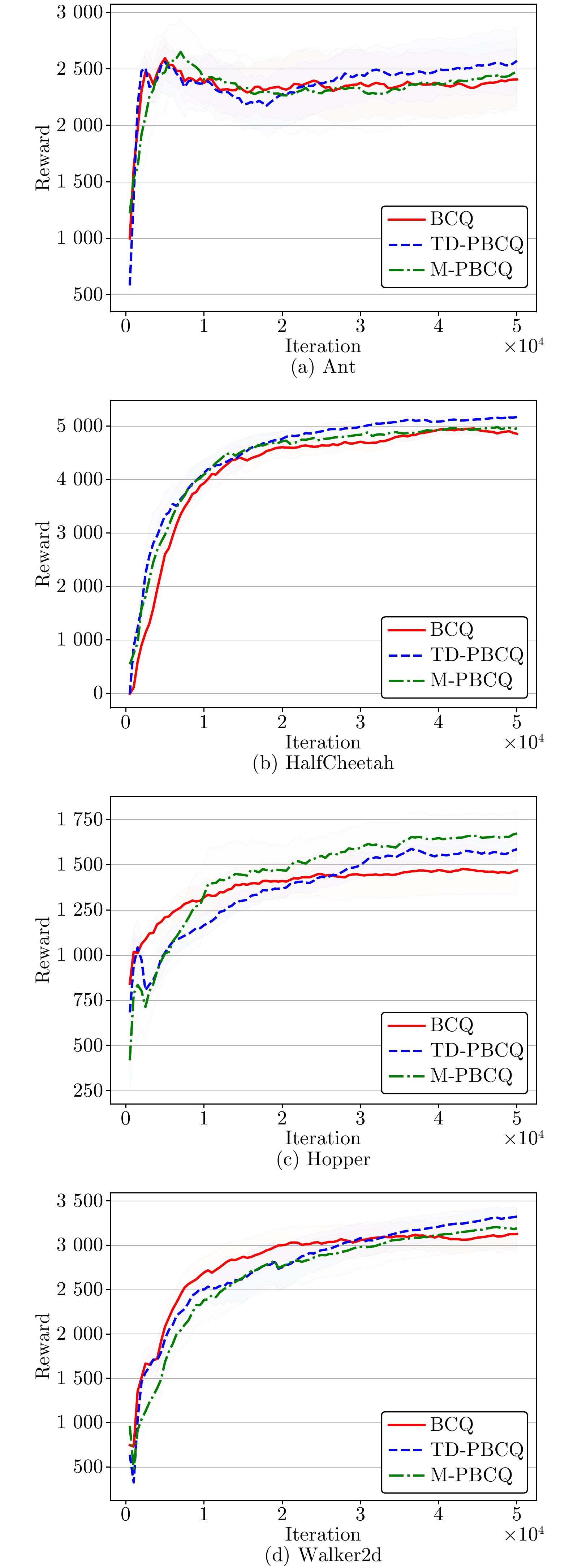
图 3 平均回报曲线对比(medium经验数据)
Fig. 3 Comparison of average reward curves (medium experience data)
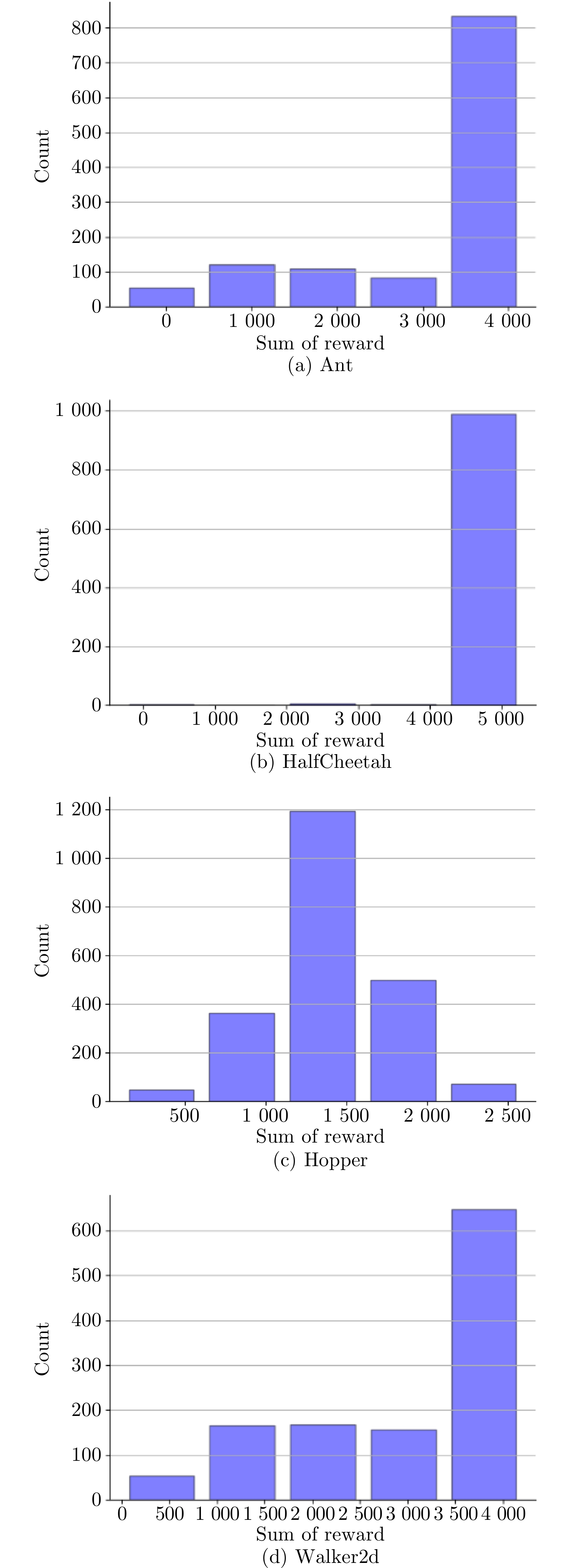
图 4 回报的统计直方图(medium经验数据)
Fig. 4 Statistical histogram of reward (medium experience data)

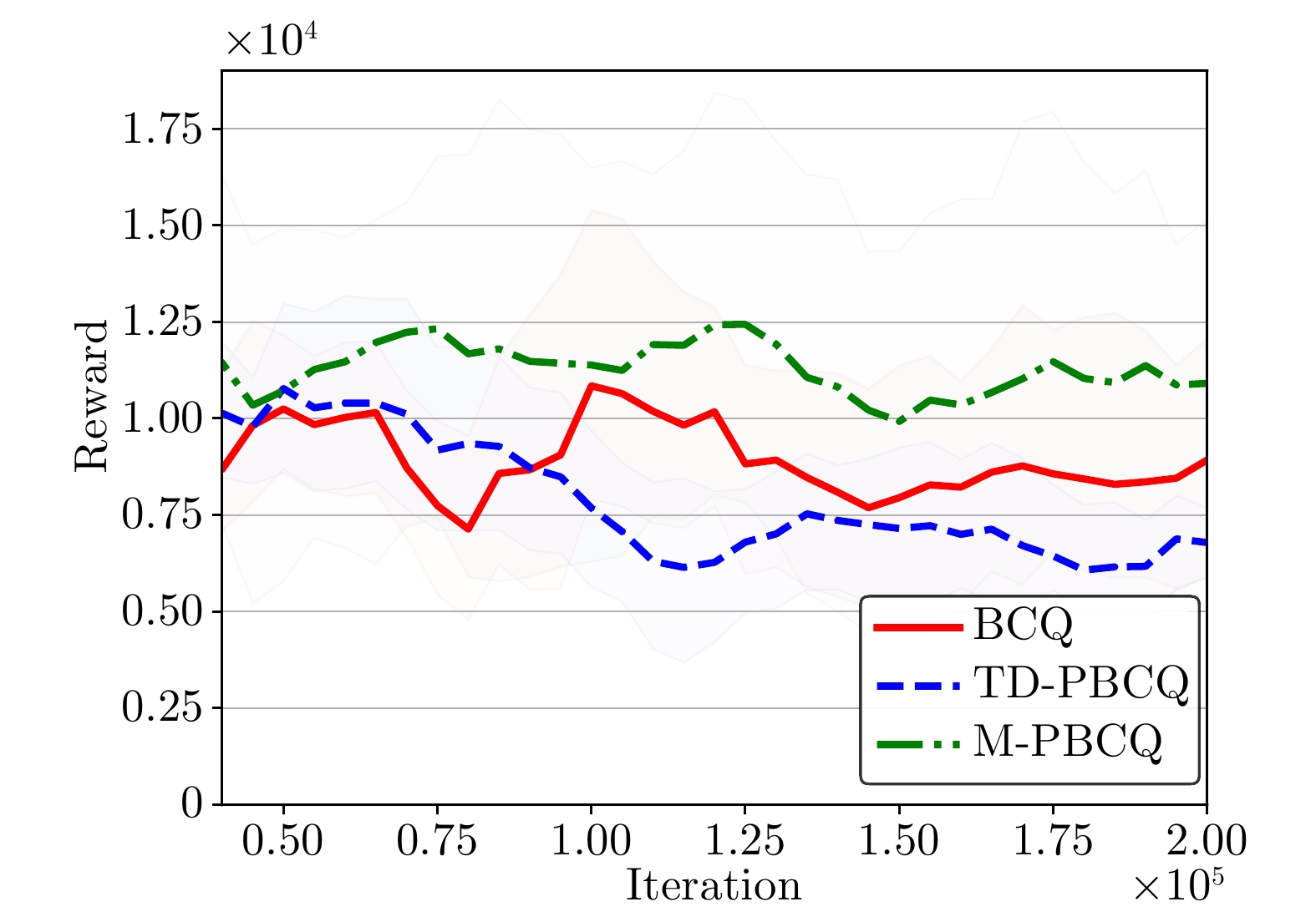
图 5 平均回报曲线对比(expert经验数据)
Fig. 5 Comparison of average reward curves (expert experience data)
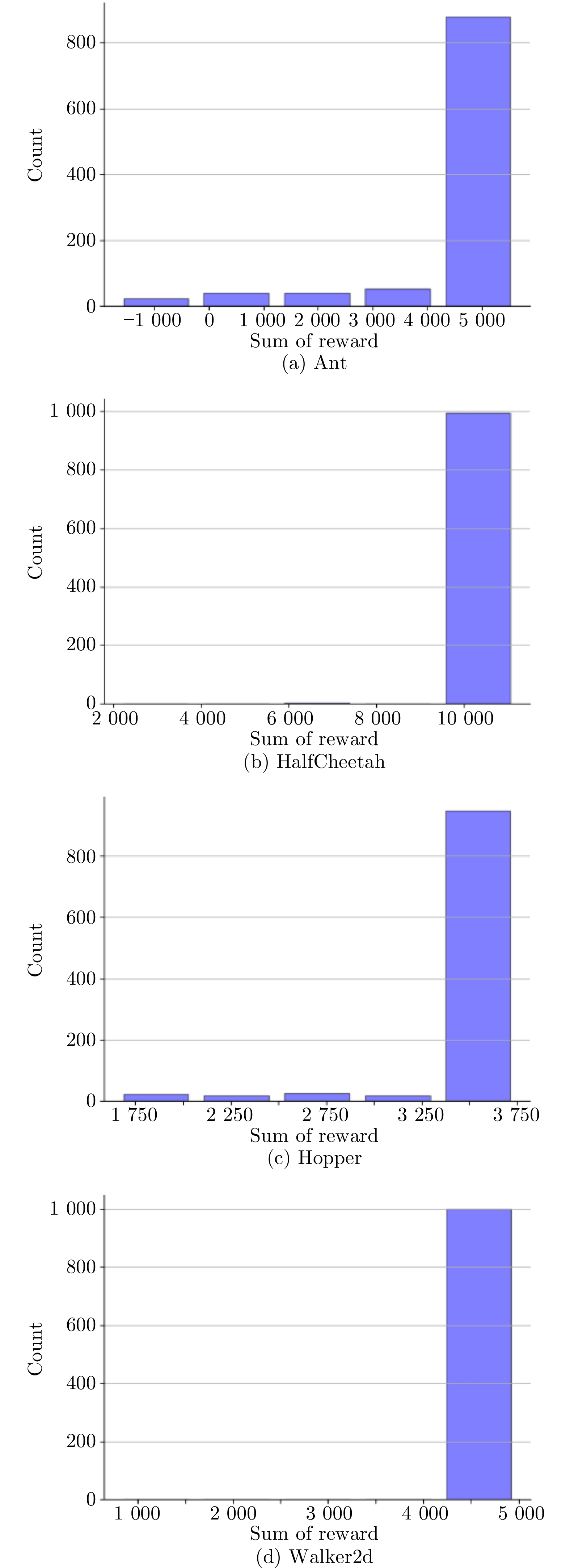
图 6 回报的统计直方图(expert经验数据)
Fig. 6 Statistical histogram of reward (expert experience data)
表 1 参数设置
Table 1 Parameter settings
参数名称 参数数值 扰动网络各层神经元个数 400、300 两个Q值网络各层神经元个数 400、300 $E_{\omega1}$网络各层神经元个数 750、750 $D_{\omega2}$网络各层神经元个数 750、750 优先级修正系数$\sigma$ $10^{-7}$ 折扣因子$\gamma$ 0.99 软更新参数$\tau$ 0.5 步长$\eta$ $2.5 \times 10^{-4}$  下载: 导出CSV
下载: 导出CSV
表 2 Torcs任务上平均回报对比
Table 2 Comparison of average reward on Torcs task
算法 平均回报 BCQ 8304.852 TD-PBCQ 7121.107 M-PBCQ 11097.551
下载: 导出CSV
-
[1] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301-1312 doi: 10.16383/j.aas.c200159Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301-1312 doi: 10.16383/j.aas.c200159 [2] 吴晓光, 刘绍维, 杨磊, 邓文强, 贾哲恒. 基于深度强化学习的双足机器人斜坡步态控制方法. 自动化学报, 2021, 47(8)1976-1987 doi: 10.16383/j.aas.c190547Wu Xiao-Guang, Liu Shao-Wei, Yang Lei, Deng Wen-Qiang, Jia Zhe-Heng. A gait control method for biped robot on slope based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(8): 1976-1987 doi: 10.16383/j.aas.c190547 [3] 殷林飞, 陈吕鹏, 余涛, 张孝顺. 基于CPSS平行系统懒惰强化学习算法的实时发电调控. 自动化学报, 2019, 45(4): 706-719 doi: 10.16383/j.aas.c180215Yin Lin-Fei, Chen Lv-Peng, Yu Tao, Zhang Xiao-Shun. Lazy reinforcement learning through parallel systems and social system for real-time economic generation dispatch and control. Acta Automatica Sinica, 2019, 45(4): 706-719 doi: 10.16383/j.aas.c180215 [4] 陈晋音, 章燕, 王雪柯, 蔡鸿斌, 王珏, 纪守领. 深度强化学习的攻防与安全性分析综述. 自动化学报, 2022, 48(1): 21-39 doi: 10.16383/j.aas.c200166Chen Jin-Yin, Zhang Yan, Wang Xue-Ke, Cai Hong-Wu, Wang Jue, Ji Shou-Ling. A survey of attack, defense and related security analysis for deep reinforcement learning. Acta Automatica Sinica, 2022, 48(1): 21-39 doi: 10.16383/j.aas.c200166 [5] 唐振韬, 梁荣钦, 朱圆恒, 赵动斌. 实时格斗游戏的智能决策方法. 控制理论与应用, 2022, 39(6): 969-985 doi: 10.7641/CTA.2022.10995Tang Zhen-Tao, Liang Rong-Qin, Zhu Yuan-Heng, Zhao Dong-Bin. Intelligent decision making approaches for real time fighting game. Control Theory & Applications, 2022, 39(6): 969-985 doi: 10.7641/CTA.2022.10995 [6] Sun Y X. Performance of reinforcement learning on traditional video games. In: Proceedings of the 3rd International Conference on Artificial Intelligence and Advanced Manufacture (AIAM). Manchester, United Kingdom: IEEE, 2021. 276−279 [7] 刘健, 顾扬, 程玉虎, 王雪松. 基于多智能体强化学习的乳腺癌致病基因预测. 自动化学报, 2022, 48(5): 1246-1258 doi: 10.16383/j.aas.c210583Liu Jian, Gu Yang, Cheng Yu-Hu, Wang Xue-Song. Prediction of breast cancer pathogenic genes based on multi-agent reinforcement learning. Acta Automatica Sinica, 2022, 48(5): 1246-1258 doi: 10.16383/j.aas.c210583 [8] Kiran B R, Sobh I, Talpaert V, Mannion P, Al Sallab A A, Yogamani S, et al. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(6): 4909-4926 doi: 10.1109/TITS.2021.3054625 [9] 张兴龙, 陆阳, 李文璋, 徐昕. 基于滚动时域强化学习的智能车辆侧向控制算法. 自动化学报 doi: 10.16383/j.aas.c210555Zhang Xing-Long, Lu Yang, Li Wen-Zhang, Xu Xin. Receding horizon reinforcement learning algorithm for lateral control of intelligent vehicles. Acta Automatica Sinica, doi: 10.16383/j.aas.c210555 [10] Levine S, Kumar A, Tucker G, Fu J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv: 2005.01643, 2020. [11] Huang Z H, Xu X, He H B, Tan J, Sun Z P. Parameterized batch reinforcement learning for longitudinal control of autonomous land vehicles. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 49(4): 730-741 doi: 10.1109/TSMC.2017.2712561 [12] Agarwal R, Schuurmans D, Norouzi M. An optimistic perspective on offline reinforcement learning. arXiv preprint arXiv: 1907.04543, 2020. [13] Fujimoto S, Gu S S. A minimalist approach to offline reinforcement learning. arXiv preprint arXiv: 2106.06860, 2021. [14] Rashidinejad P, Zhu B H, Ma C, Jiao J T, Russell S. Bridging offline reinforcement learning and imitation learning: a tale of pessimism. IEEE Transactions on Information Theory, 2022, 68(12): 8156-8196 doi: 10.1109/TIT.2022.3185139 [15] Fujimoto S, Meger D, Precup D. Off-policy deep reinforcement learning without exploration. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 2052−2062 [16] Kumar A, Fu J, Soh M, Tucker G, Levine S. Stabilizing off-policy Q-learning via bootstrapping error reduction. In: Proceedings of the 33rd Annual Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2019. 11784−11794 [17] Gretton A, Borgwardt K M, Rasch M, Scholköpf B, Smola A J. A kernel approach to comparing distributions. In: Proceedings of the 22nd National Conference on Artificial Intelligence. Vancouver British Columbia, Canada: AAAI Press, 2007. 1637−1641 [18] Jaques N, Ghandeharioun A, Shen J H, Ferguson C, Lapedriza G, Jones N, et al. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog. arXiv preprint arXiv: 1907.00456, 2019. [19] Maran D, Metelli A M, Restelli M. Tight performance guarantees of imitator policies with continuous actions. In: Proceedings of the 37th AAAI Conference on Artificial Intelligence. Washington, USA: AAAI Press, 2023. 9073−9080 [20] Wu Y F, Tucker G, Nachum O. Behavior regularized offline reinforcement learning. arXiv preprint arXiv: 1911.11361, 2019. [21] Schaul T, Quan J, Antonoglou I, Silver D. Prioritized experience replay. arXiv preprint arXiv: 1511.05952, 2016. [22] Horgan D, Quan J, Budden D, Barth-Maron G, Hessel M, van Hasselt H, et al. Distributed prioritized experience replay. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: OpenReview.net, 2018. [23] Mandl P. A connection between controlled Markov chains and martingales. Kybernetika, 1973, 9(4): 237-241 [24] Hernández-Lerma O, de Ozak M M. Discrete-time Markov control processes with discounted unbounded costs: Optimality criteria. Kybernetika, 1992, 28(3): 191-212 [25] Even-Dar E, Mansour Y. Learning rates for Q-learning. In: Proceedings of the 14th Annual Conference on Computational Learning Theory. Berlin, Germany: Springer Verlag, 2001. 589−604 [26] Hu Y L, Skyrms B, Tarrès P. Reinforcement learning in signaling game. arXiv preprint arXiv: 1103.5818, 2011. [27] Chow Y, Nachum O, Duenez-Guzman E, Ghavamzadeh M. A Lyapunov-based approach to safe reinforcement learning. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montreal, Canada: Curran Associates Inc., 2018. 8092−8101 -

 下载:
下载:



计量
- 文章访问数: 1286
- HTML全文浏览量: 446
- PDF下载量: 300
- 被引次数: 0
