

-
摘要: 序列推荐(Sequential recommendation, SR)旨在建模用户序列中的动态兴趣, 预测下一个行为. 现有基于知识蒸馏(Knowledge distillation, KD)的多模型集成方法通常将教师模型预测的概率分布作为学生模型样本学习的软标签, 不利于关注低置信度序列样本中的动态兴趣. 为此, 提出一种同伴知识互增强下的序列推荐方法(Sequential recommendation enhanced by peer knowledge, PeerRec), 使多个具有差异的同伴网络按照人类由易到难的认知过程进行两阶段的互相学习. 在第1阶段知识蒸馏的基础上, 第2阶段的刻意训练通过动态最小组策略协调多个同伴从低置信度样本中挖掘出可被加强训练的潜在样本. 然后, 受训的网络利用同伴对潜在样本预测的概率分布调节自身对该样本学习的权重, 从解空间中探索更优的兴趣表示. 3个公开数据集上的实验结果表明, 提出的PeerRec方法相比于最新的基线方法在基于Top-k的指标上不仅获得了更佳的推荐精度, 且具有良好的在线推荐效率.Abstract: Sequential recommendation (SR) aims to model dynamic interests within users' interaction sequences and predict the next behaviour. Current knowledge distillation (KD)-based multi-model ensemble methods generally adopt teacher's probability distributions as soft labels to guide the sample learning of its students, posing a significant challenge to focus on the samples with less confidence. To this end, we propose a novel sequential recommendation method enhanced by peer knowledge (PeerRec) that makes multiple sequential prediction networks (peer for each other) with distinct knowledge conduct two-stage mutual learning by following the easy to hard human cognition. Based on the knowledge distillation in the first stage, the deliberate practice in the second stage mines the potential samples from the low confidence samples by combining multiple peers through a dynamic minimum group strategy. The training network can further employ the probability distributions from peers to adjust itself learning weight where better representations of dynamic interests can be derived. Extensive experiments on three public recommendation datasets show that the proposed PeerRec not only outperforms the state-of-the-art methods, but also achieves good efficiency in online recommendation.1)
1 1 一种基于最优传输理论衡量两个分布间距离的度量方式, 目前只在一维分布、高斯分布等少数几种分布上存在闭式解. -
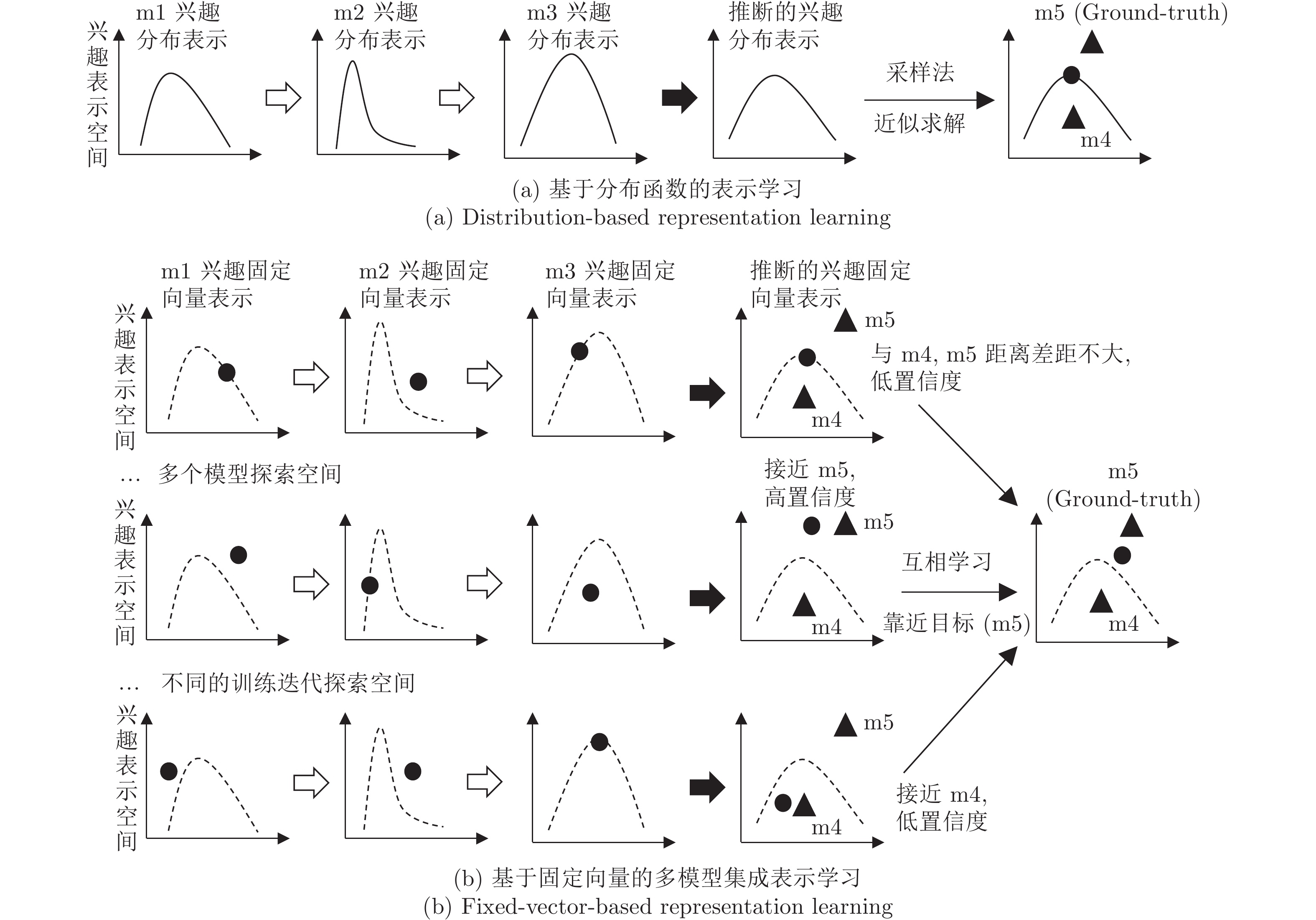
图 1 用户动态兴趣在潜在空间中的表示与推断
Fig. 1 The representation and inference of dynamic interests in latent representation spaces

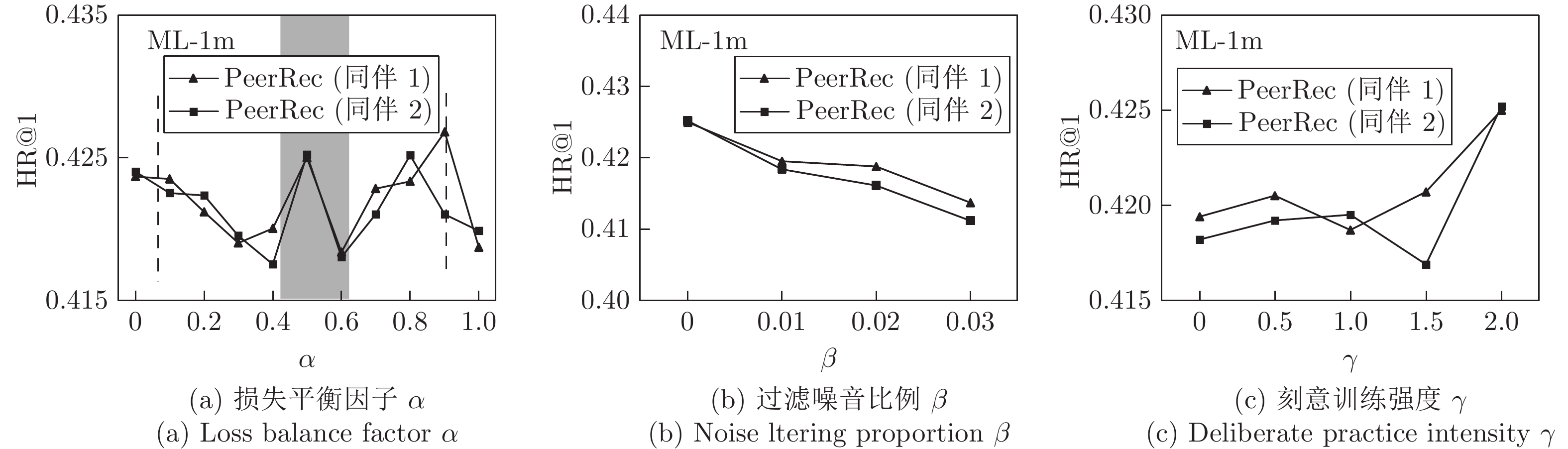
图 4 PeerRec变体在HR@1指标上的对比
Fig. 4 The comparison between the variants of PeerRec in terms of HR@1
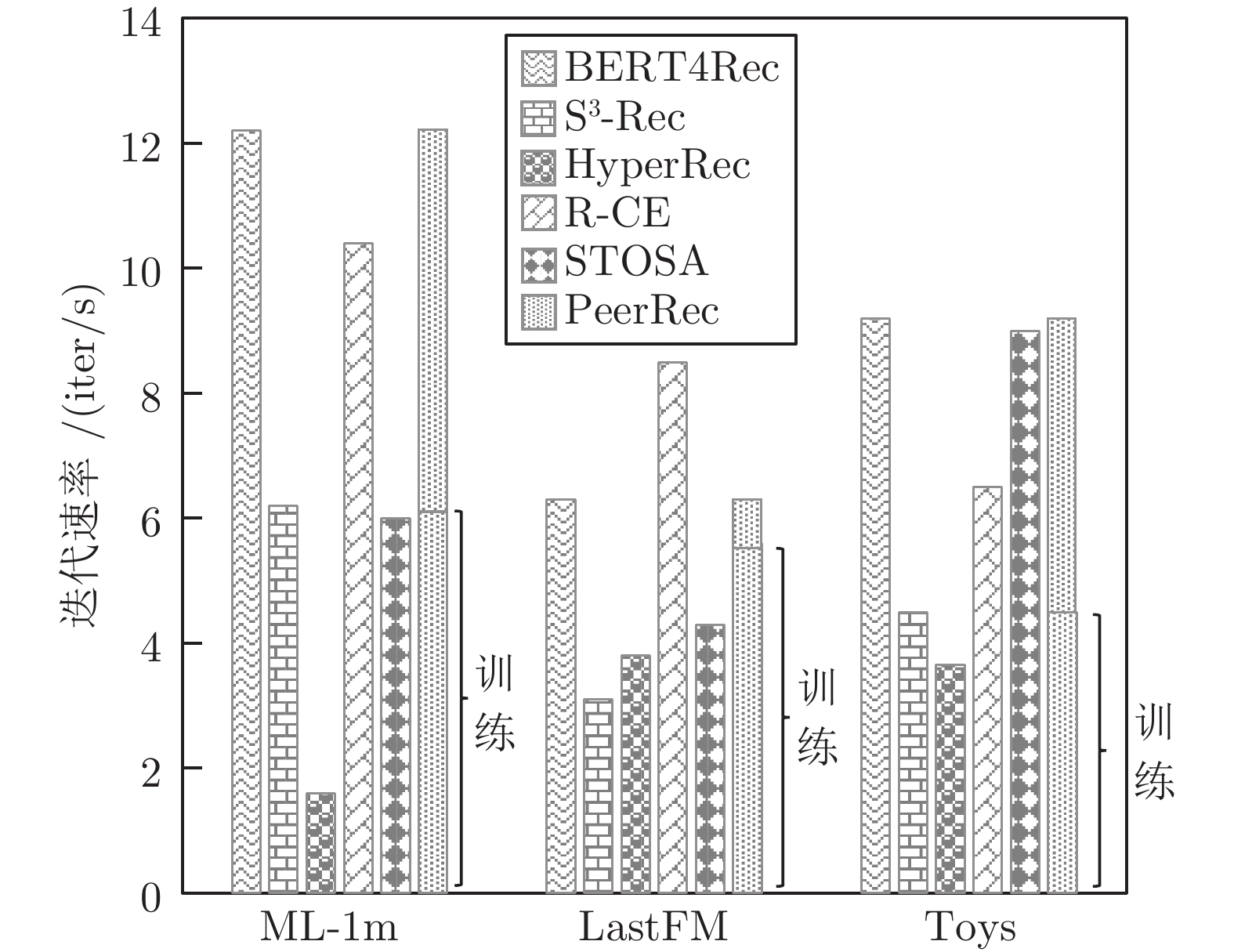
图 6 Batch大小设置为256时, 模型的迭代速率
Fig. 6 The running speed of different models with batch size 256
表 1 实验集数据统计表
Table 1 Statistics of dataset
ML-1m LastFM Toys 用户数量 6 040 1 090 19 412 行为类别数量 3 416 3 646 11 924 最长序列的行为数量 2 275 897 548 最短序列的行为数量 16 3 3 序列的平均行为数量 163.50 46.21 6.63 序列行为数量的方差 192.53 77.69 8.50  下载: 导出CSV
下载: 导出CSV
表 2 与基线模型在精度指标上的对比
Table 2 The comparison with baselines in terms of accuracy based metrics
数据集 模型 HR@1 HR@5 HR@10 NDCG@5 NDCG@10 MRR ML-1m POP 0.0407 0.1603 0.2775 0.1008 0.1383 0.1233 BERT4Rec[17] 0.3695 0.6851 0.7823 0.5375 0.5690 0.5108 S3-Rec[1] 0.2897 0.6575 0.7911 0.4557 0.5266 0.4535 HyperRec[9] 0.3180 0.6631 0.7738 0.5014 0.5375 0.4731 R-CE[11] 0.3988 0.6478 0.7404 0.5327 0.5627 0.5179 STOSA[14] 0.3222 0.6546 0.7844 0.4967 0.5389 0.4716 PeerRec (同伴1) 0.4250 0.7197 0.8141 0.5843 0.6150 0.5600 PeerRec (同伴2) 0.4252 0.7225 0.8141 0.5860 0.6157 0.5610 LastFM POP 0.0202 0.0908 0.1780 0.0544 0.0825 0.0771 BERT4Rec[17] 0.1091 0.3294 0.4614 0.2227 0.2648 0.2266 S3-Rec[1] 0.1156 0.2844 0.4229 0.2003 0.2452 0.2148 HyperRec[9] 0.1146 0.3147 0.4688 0.2150 0.2646 0.2241 R-CE[11] 0.0651 0.1835 0.2862 0.1243 0.1570 0.1397 STOSA[14] 0.0752 0.2165 0.3412 0.1458 0.1860 0.1556 PeerRec (同伴1) 0.1294 0.3495 0.4789 0.2339 0.2755 0.2341 PeerRec (同伴2) 0.1248 0.3358 0.4835 0.2318 0.2796 0.2378 Toys POP 0.0260 0.1046 0.1848 0.0652 0.0909 0.0861 BERT4Rec[17] 0.1390 0.3379 0.4596 0.2409 0.2802 0.2444 S3-Rec[1] 0.0990 0.3023 0.4393 0.2021 0.2463 0.2081 HyperRec[9] 0.1147 0.2875 0.3909 0.2031 0.2365 0.2087 R-CE[11] 0.1130 0.3189 0.4529 0.2179 0.2611 0.2233 STOSA[14] 0.1838 0.3587 0.4550 0.2749 0.3059 0.2732 PeerRec (同伴 1) 0.1794 0.3703 0.4785 0.2785 0.3134 0.2810 PeerRec (同伴 2) 0.1782 0.3706 0.4778 0.2781 0.3127 0.2803
下载: 导出CSV
表 3 知识蒸馏与刻意训练对比
Table 3 The comparison between knowledge distillation and deliberate practice
数据集 HR@1 NDCG@5 MRR 知识蒸馏[39] ML-1m 0.3952 0.5656 0.5386 LastFM 0.1119 0.2301 0.2314 Toys 0.1693 0.2761 0.2767 刻意训练 PeerRec ML-1m 0.4251 0.5852 0.5605 LastFM 0.1271 0.2329 0.2360 Toys 0.1788 0.2783 0.2807
下载: 导出CSV
表 4 PeerRec模型采用不同初始化的性能对比
Table 4 The performance comparison between different initializations of our PeerRec
数据集 初始化方式 HR@1 NDCG@5 MRR ML-1m TND 0.4251 0.5852 0.5605 Xavier 0.4263 0.5852 0.5600 Kaiming 0.4278 0.5911 0.5652 LastFM TND 0.1271 0.2329 0.2360 Xavier 0.1294 0.2397 0.2424 Kaiming 0.1247 0.2257 0.2342 Toys TND 0.1788 0.2783 0.2807 Xavier 0.1775 0.2794 0.2811 Kaiming 0.1806 0.2776 0.2804
下载: 导出CSV
-
[1] Zhou K, Wang H, Zhao W X, Zhu Y T, Wang S R, Zhang F Z, et al. S3-Rec: Self-supervised learning for sequential recommendation with mutual information maximization. In: Proceedings of the 29th ACM International Conference on Information & Knowledge Management. New York, USA: ACM, 2020. 1893−1902 [2] 饶子昀, 张毅, 刘俊涛, 曹万华. 应用知识图谱的推荐方法与系统. 自动化学报, 2021, 47(9): 2061-2077Rao Zi-Yun, Zhang Yi, Liu Jun-Tao, Cao Wan-Hua. Recommendation methods and systems using knowledge graph. Acta Automatica Sinica, 2021, 47(9): 2061-2077 [3] Li X C, Liang J, Liu X L, Zhang Y. Adversarial filtering modeling on long-term user behavior sequences for click-through rate prediction. In: Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. Madrid, Spain: ACM, 2022. 1969−1973 [4] 汤文兵, 任正云, 韩芳. 基于注意力机制的协同卷积动态推荐网络. 自动化学报, 2021, 47(10): 2438-2448Tang Wen-Bing, Ren Zheng-Yun, Han Fang. Attention-based collaborative convolutional dynamic network for recommendation. Acta Automatica Sinica, 2021, 47(10): 2438-2448 [5] 郭磊, 李秋菊, 刘方爱, 王新华. 基于自注意力网络的共享账户跨域序列推荐. 计算机研究与发展, 2021, 58(11): 2524-2537Guo Lei, Li Qiu-Ju, Liu Fang-Ai, Wang Xin-Hua. Shared-account cross-domain sequential recommendation with self-attention network. Journal of Computer Research and Development, 2021, 58(11): 2524-2537 [6] Rao X, Chen L S, Liu Y, Shang S, Yao B, Han P. Graph-flashback network for next location recommendation. In: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Washington, USA: ACM, 2022. 1463−1471 [7] 孟祥武, 梁弼, 杜雨露, 张玉洁. 基于位置的移动推荐系统效用评价研究. 计算机学报, 2019, 42(12): 2695-2721Meng Xiang-Wu, Liang Bi, Du Yu-Lu, Zhang Yu-Jie. A survey of evaluation for location-based mobile recommender systems. Chinese Journal of Computers, 2019, 42(12): 2695-2721 [8] Hu K X, Li L, Liu J Q, Sun D. DuroNet: A dual-robust enhanced spatial-temporal learning network for urban crime prediction. ACM Transactions on Internet Technology, 2021, 21(1): Article No. 24 [9] Wang J L, Ding K Z, Hong L J, Liu H, Caverlee J. Next-item recommendation with sequential hypergraphs. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, USA: ACM, 2020. 1101−1110 [10] 陈聪, 张伟, 王骏. 带有时间预测辅助任务的会话式序列推荐. 计算机学报, 2021, 44(9): 1841-1853Chen Cong, Zhang Wei, Wang Jun. Session-based sequential recommendation with auxiliary time prediction. Chinese Journal of Computers, 2021, 44(9): 1841-1853 [11] Wang W J, Feng F L, He X N, Nie L Q, Chua T S. Denoising implicit feedback for recommendation. In: Proceedings of the 14th ACM International Conference on Web Search and Data Mining. New York, USA: ACM, 2021. 373−381 [12] Neupane K P, Zheng E, Yu Q. MetaEDL: Meta evidential learning for uncertainty-aware cold-start recommendations. In: Proceedings of the IEEE International Conference on Data Mining (ICDM). Auckland, New Zealand: IEEE, 2021. 1258−1263 [13] Fan Z W, Liu Z W, Wang S, Zheng L, Yu P S. Modeling sequences as distributions with uncertainty for sequential recommendation. In: Proceedings of the 30th ACM International Conference on Information and Knowledge Management. Queensland, Australia: ACM, 2021. 3019−3023 [14] Fan Z W, Liu Z W, Wang Y, Wang A, Nazari Z, Zheng L, et al. Sequential recommendation via stochastic self-attention. In: Proceedings of the ACM Web Conference. Lyon, France: ACM, 2022. 2036−2047 [15] Jiang J Y, Yang D Q, Xiao Y H, Shen C L. Convolutional Gaussian embeddings for personalized recommendation with uncertainty. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao, China: AAAI Press, 2019. 2642−2648 [16] Zhou X L, Liu H, Pourpanah F, Zeng T Y, Wang X Z. A survey on epistemic (model) uncertainty in supervised learning: Recent advances and applications. Neurocomputing, 2022, 489: 449-465 doi: 10.1016/j.neucom.2021.10.119 [17] Sun F, Liu J, Wu J, Pei C H, Lin X, Ou W W, et al. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management. Beijing, China: ACM, 2019. 1441−1450 [18] Ovadia Y, Fertig E, Ren J, Nado Z, Sculley D, Nowozin S, et al. Can you trust your model's uncertainty? Evaluating predictive uncertainty under dataset shift. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2019. Article No. 1254 [19] Fort S, Hu H Y, Lakshminarayanan B. Deep ensembles: A loss landscape perspective. arXiv preprint arXiv: 1912.02757, 2019. [20] Lakshminarayanan B, Pritzel A, Blundell C. Simple and scalable predictive uncertainty estimation using deep ensembles. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6405−6416 [21] Renda A, Barsacchi M, Bechini A, Marcelloni F. Comparing ensemble strategies for deep learning: An application to facial expression recognition. Expert Systems With Applications, 2019, 136: 1-11 doi: 10.1016/j.eswa.2019.06.025 [22] Deng D D, Wu L, Shi B E. Iterative distillation for better uncertainty estimates in multitask emotion recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). Montreal, Canada: IEEE, 2021. 3550−3559 [23] Reich S, Mueller D, Andrews N. Ensemble distillation for structured prediction: Calibrated, accurate, fast —— Choose three. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Stroudsburg, USA: ACL, 2020. 5583−5595 [24] Jiao X Q, Yin Y C, Shang L F, Jiang X, Chen X, Li L L, et al. TinyBERT: Distilling BERT for natural language understanding. In: Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg, USA: ACL, 2020. 4163−4174 [25] Zhu J M, Liu J Y, Li W Q, Lai J C, He X Q, Chen L, et al. Ensembled CTR prediction via knowledge distillation. In: Proceedings of the 29th ACM International Conference on Information and Knowledge Management. New York, USA: ACM, 2020. 2941−2958 [26] Kang S K, Hwang J, Kweon W, Yu H. DE-RRD: A knowledge distillation framework for recommender system. In: Proceedings of the 29th ACM International Conference on Information and Knowledge Management. New York, USA: ACM, 2020. 605−614 [27] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. In: Proceedings of the 28th Conference on Neural Information Processing Systems. Montreal, Canada: Curran Associates, 2014. 1−9 [28] Shen Z Q, Liu Z C, Xu D J, Chen Z T, Cheng K T, Savvides M. Is label smoothing truly incompatible with knowledge distillation: An empirical study. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event, Austria: ICLR, 2020. 1−17 [29] Furlanello T, Lipton Z C, Tschannen M, Itti L, Anandkumar A. Born-again neural networks. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 1602−1611 [30] Romero A, Ballas N, Kahou S E, Chassang A, Gatta C, Bengio Y. FitNets: Hints for thin deep nets. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. 1−13 [31] Lin T Y, Goyal P, Girshick R, He K M, Dollár P. Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2999−3007 [32] Bengio Y, Louradour J, Collobert R, Weston J. Curriculum learning. In: Proceedings of the 26th Annual International Conference on Machine Learning. Montreal, Canada: ACM, 2009. 41−48 [33] Ericsson K A. Deliberate practice and acquisition of expert performance: A general overview. Academic Emergency Medicine, 2008, 15(11): 988-994 doi: 10.1111/j.1553-2712.2008.00227.x [34] Song W P, Shi C C, Xiao Z P, Duan Z J, Xu Y W, Zhang M, et al. Autoint: Automatic feature interaction learning via self-attentive neural networks. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management. Beijing, China: ACM, 2019. 1161−1170 [35] Qin Y Q, Wang P F, Li C L. The world is binary: Contrastive learning for denoising next basket recommendation. In: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, USA: ACM, 2021. 859−868 [36] 黄震华, 杨顺志, 林威, 倪娟, 孙圣力, 陈运文, 等. 知识蒸馏研究综述. 计算计学报, 2022, 45(3): 624-653Hung Zhen-Hua, Yang Shun-Zhi, Lin Wei, Ni Juan, Sun Sheng-Li, Chen Yun-Wen, et al. Knowledge distillation: A survey. Chinese Journal of Computers, 2022, 45(3): 624-653 [37] 潘瑞东, 孔维健, 齐洁. 基于预训练模型与知识蒸馏的法律判决预测算法. 控制与决策, 2022, 37(1): 67-76Pan Rui-Dong, Kong Wei-Jian, Qi Jie. Legal judgment prediction based on pre-training model and knowledge distillation. Control and Decision, 2022, 37(1): 67-76 [38] Zhao B R, Cui Q, Song R J, Qiu Y Y, Liang J J. Decoupled knowledge distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 11943−11952 [39] Zhang Y, Xiang T, Hospedales T M, Lu H C. Deep mutual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 4320−4328 [40] Zhao H J, Yang G, Wang D, Lu H C. Deep mutual learning for visual object tracking. Pattern Recognition, 2021, 112: Article No. 107796 doi: 10.1016/j.patcog.2020.107796 [41] Chen D F, Mei J P, Wang C, Feng Y, Chen C. Online knowledge distillation with diverse peers. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 3430−3437 [42] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6000−6010 [43] Toneva M, Sordoni A, des Combes R T, Trischler A, Bengio Y, Gordon G J. An empirical study of example forgetting during deep neural network learning. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: ICLR, 2019. 1−19 [44] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Sardinia, Italy: JMLR, 2010. 249−256 [45] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1026−1034 -

 下载:
下载:
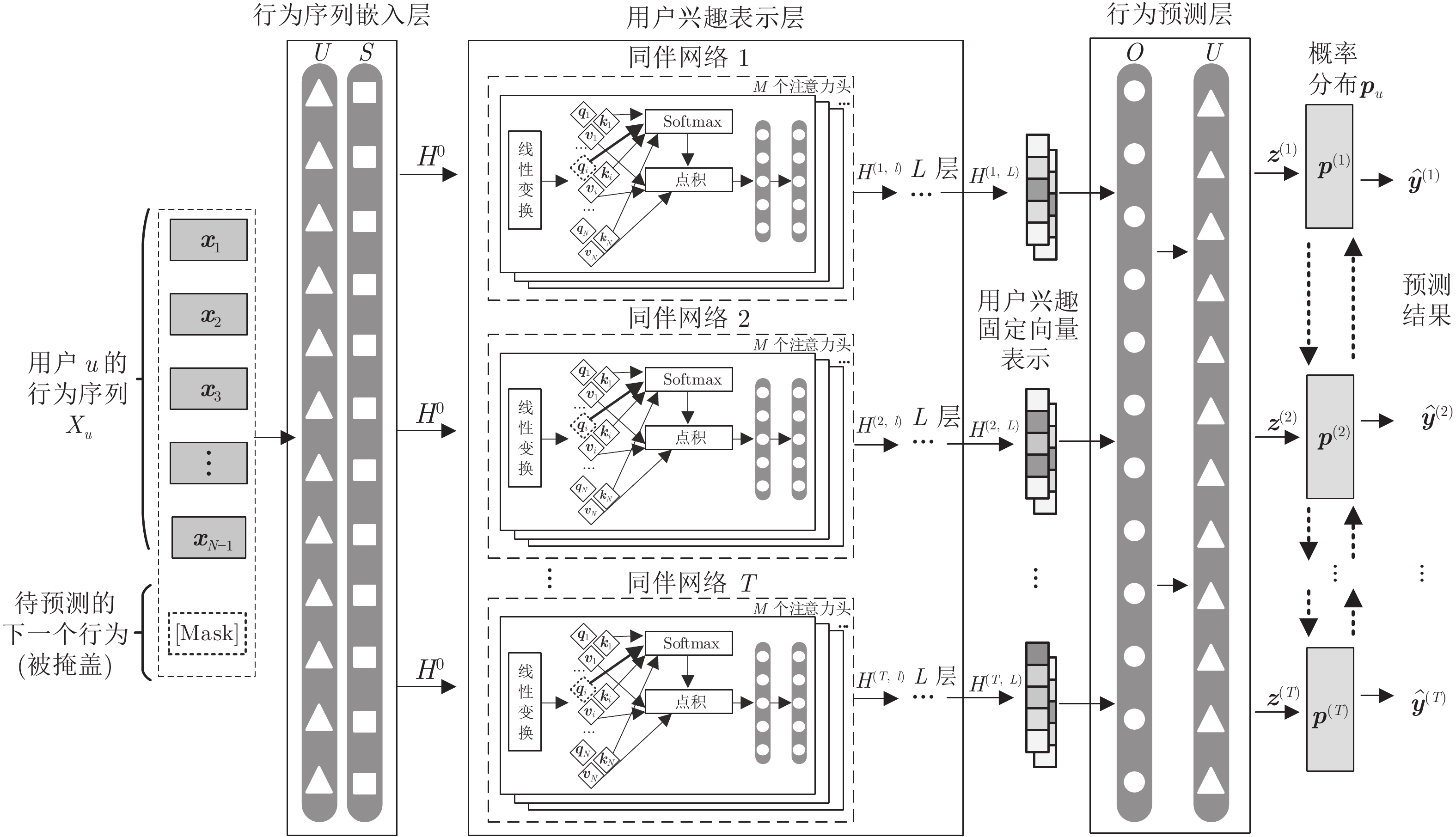
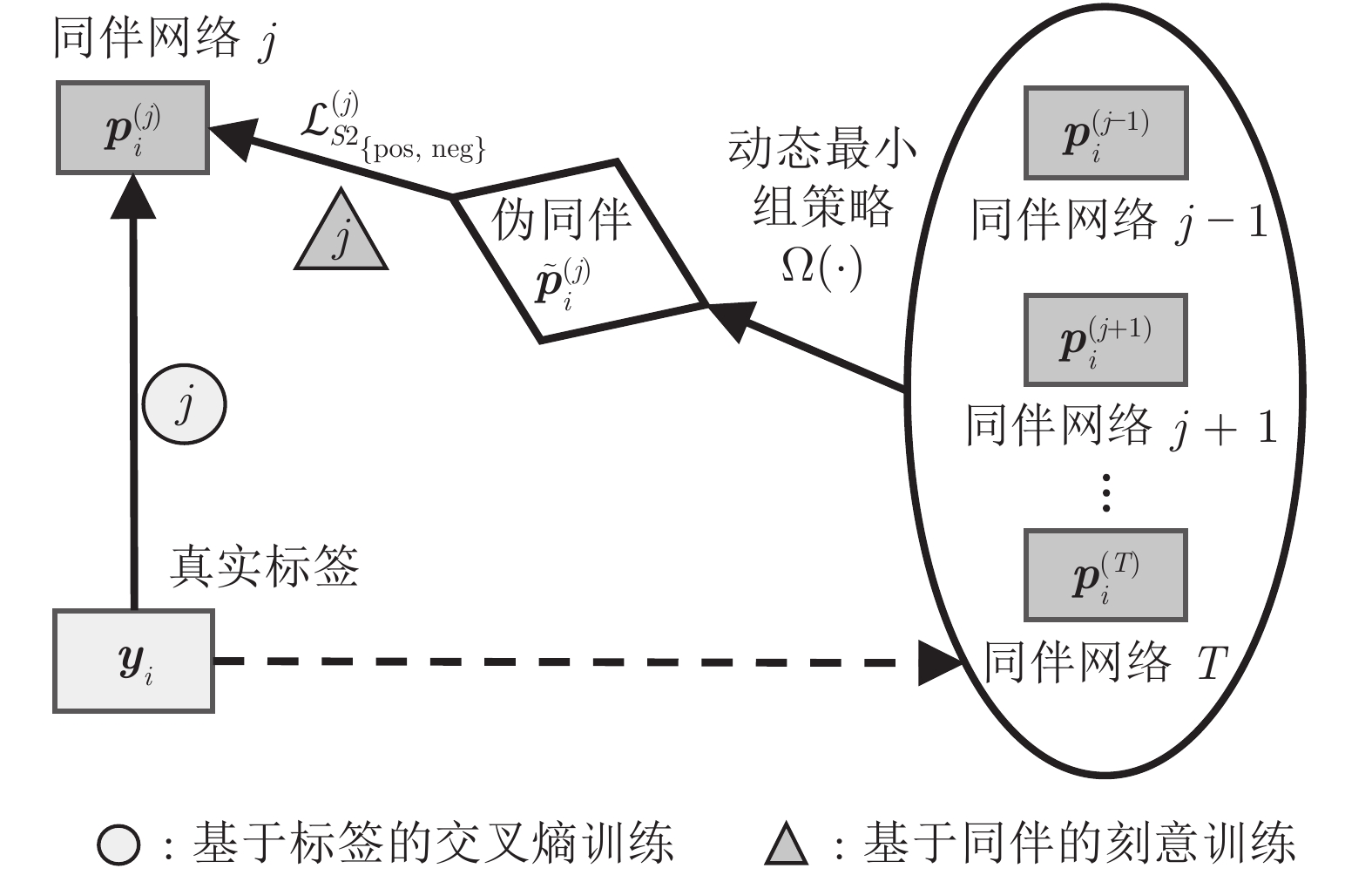


计量
- 文章访问数: 1361
- HTML全文浏览量: 1525
- PDF下载量: 207
- 被引次数: 0
