

Asynchronous Updating Reinforcement Learning Algorithm for Decision-making Operational Indices of Uncertain Industrial Processes
-
摘要: 运行指标决策问题是实现工业过程运行安全和生产指标优化的关键. 考虑到多运行指标决策问题求解的复杂性和工业过程生产条件动态波动引发生产指标状态的不确定性, 提出了一种策略异步更新强化学习算法自学习决策运行指标, 并给出算法收敛性的理论证明. 该算法在随机自适应动态规划框架下, 利用样本均值代替计算生产指标状态转移概率矩阵, 因此无需要求生产指标状态转移概率矩阵已知. 并且通过引入时钟和定义其阈值, 采用集中式策略评估、多策略异步更新方式用以简化求解多运行指标决策问题, 提高强化学习的学习效率. 利用可测量数据, 自学习得到的运行指标能够保证生产指标优化, 并且限制在规定范围之内. 最后, 采用中国西部某大型选矿厂的实际数据进行仿真验证, 表明该方法的有效性.Abstract: The decision-making operational index has been a key issue for achieving safe and optimal operation of industrial processes. Considering the complexity of decision making of multiple operational indices and the uncertainty of production indices caused by changes of working condition in industrial processes, this paper proposes a reinforcement learning algorithm with policy asynchronous updating for the first time aiming at self-learning operational indices, followed by the theoretical proof of convergence of the proposed algorithm. To this end, under the framework of stochastic adaptive dynamic programming, the sample mean is utilized rather than calculating the state transition probability matrix of production indices, with the outcome that the state transition probability matrix of production indices is not required to be known a priori. Distinctly from traditional synchronized policy updating, the centralized policy evaluation and asynchronous updating of multiple policies are implemented in the proposed algorithm based on the introduction of a time clock with its threshold, such that solving the concerned decision-making problem of multiple operational indices becomes easier and the learning efficiency of reinforcement learning is improved. Thus, the self-learned operational indices using measured data can ensure the optimality of production indices and limit them within the prescribed range. Experiments are conducted using the real date collected from a large-scale mineral processing plant in west China in order to illustrate the effectiveness of the approach.
-

图 1 工业过程运行指标决策问题
Fig. 1 Decision-making problem of operational indices in industrial processes
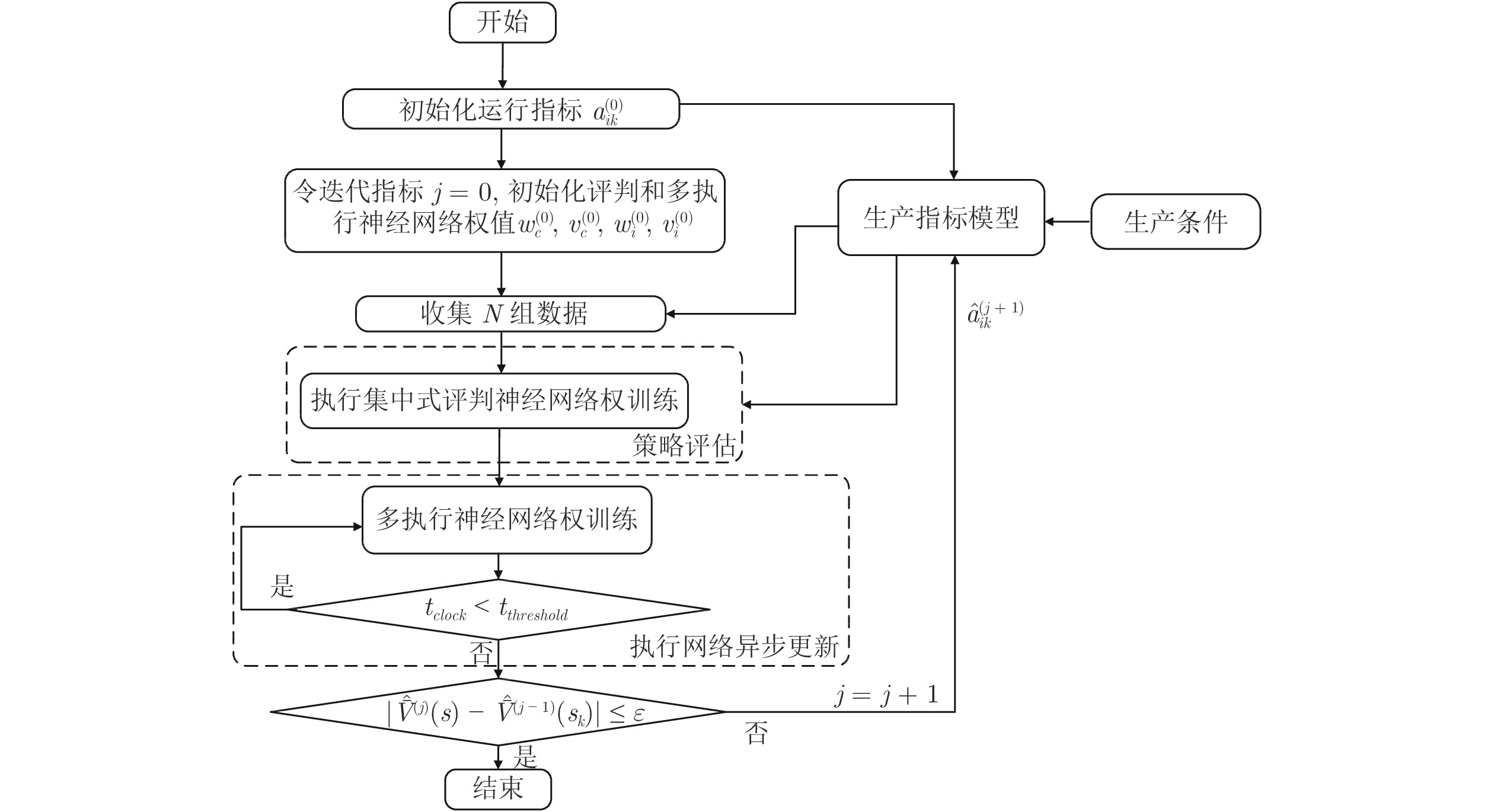
图 3 多执行-评判结构下运行指标自学习决策流程图
Fig. 3 Flowchart of self-learning decision making of operational indices with multiple actors-critic structure
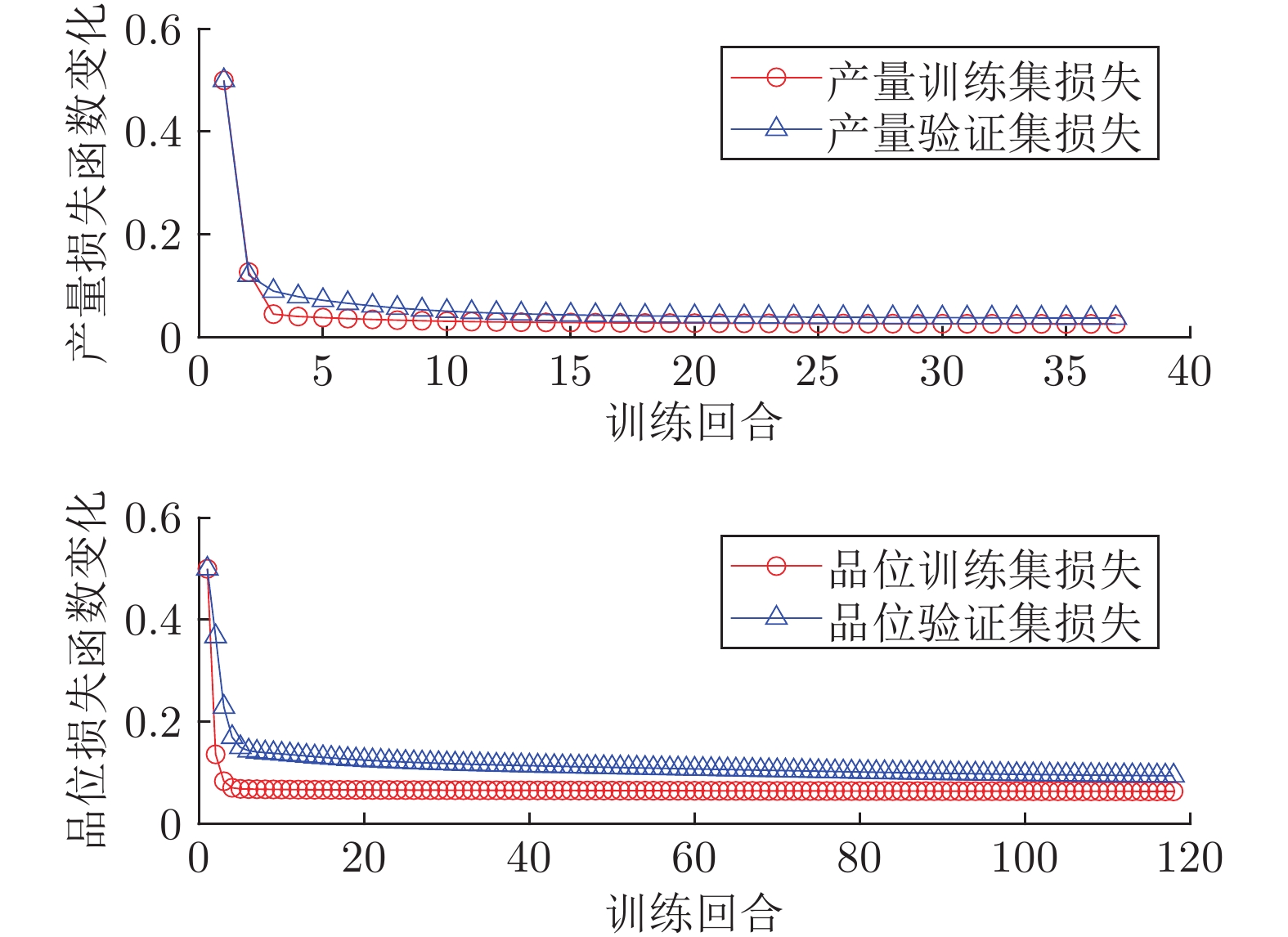
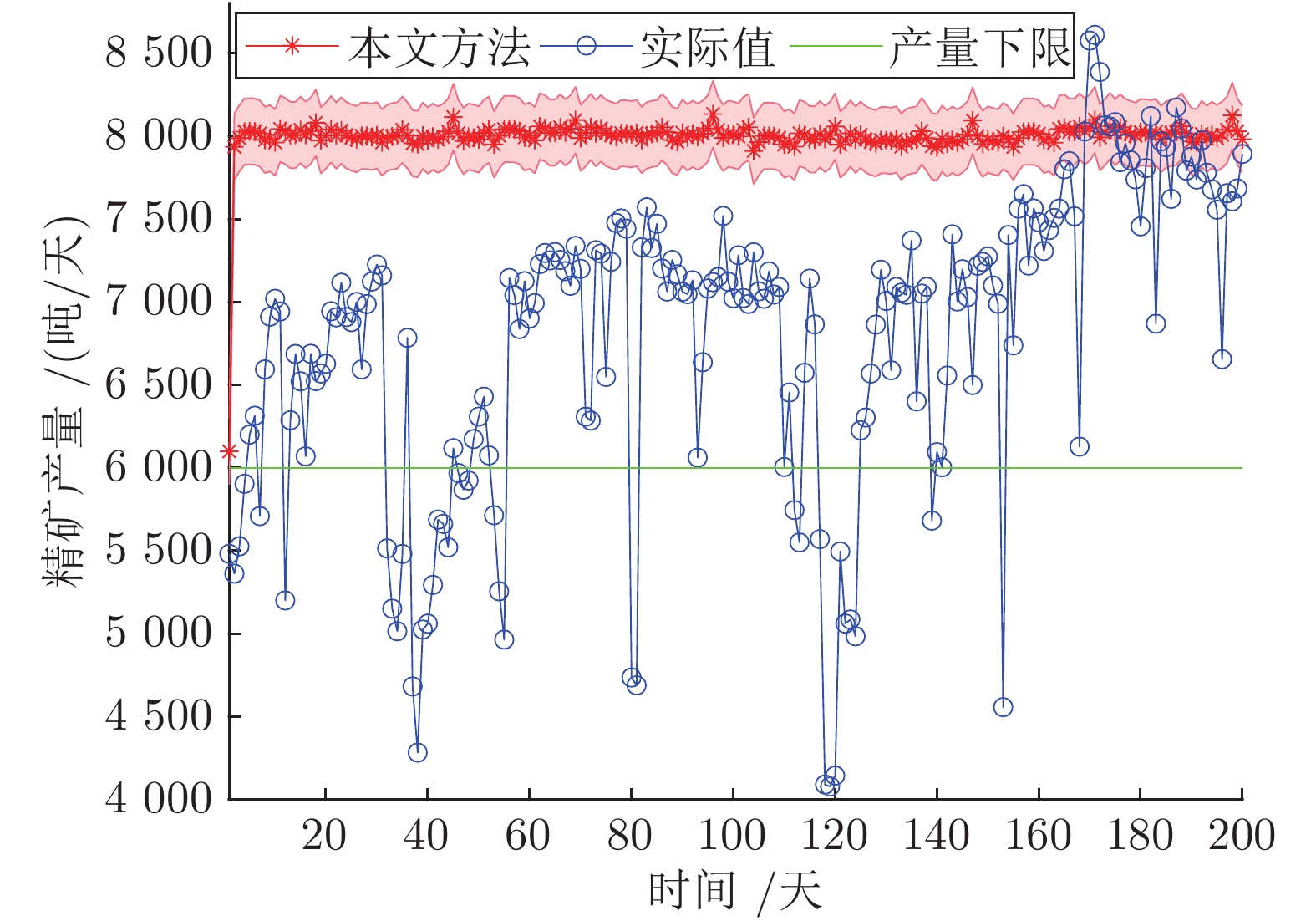
图 5 精矿产量和精矿品位损失函数
Fig. 5 Loss functions of the concentrate yield and concentrate grade

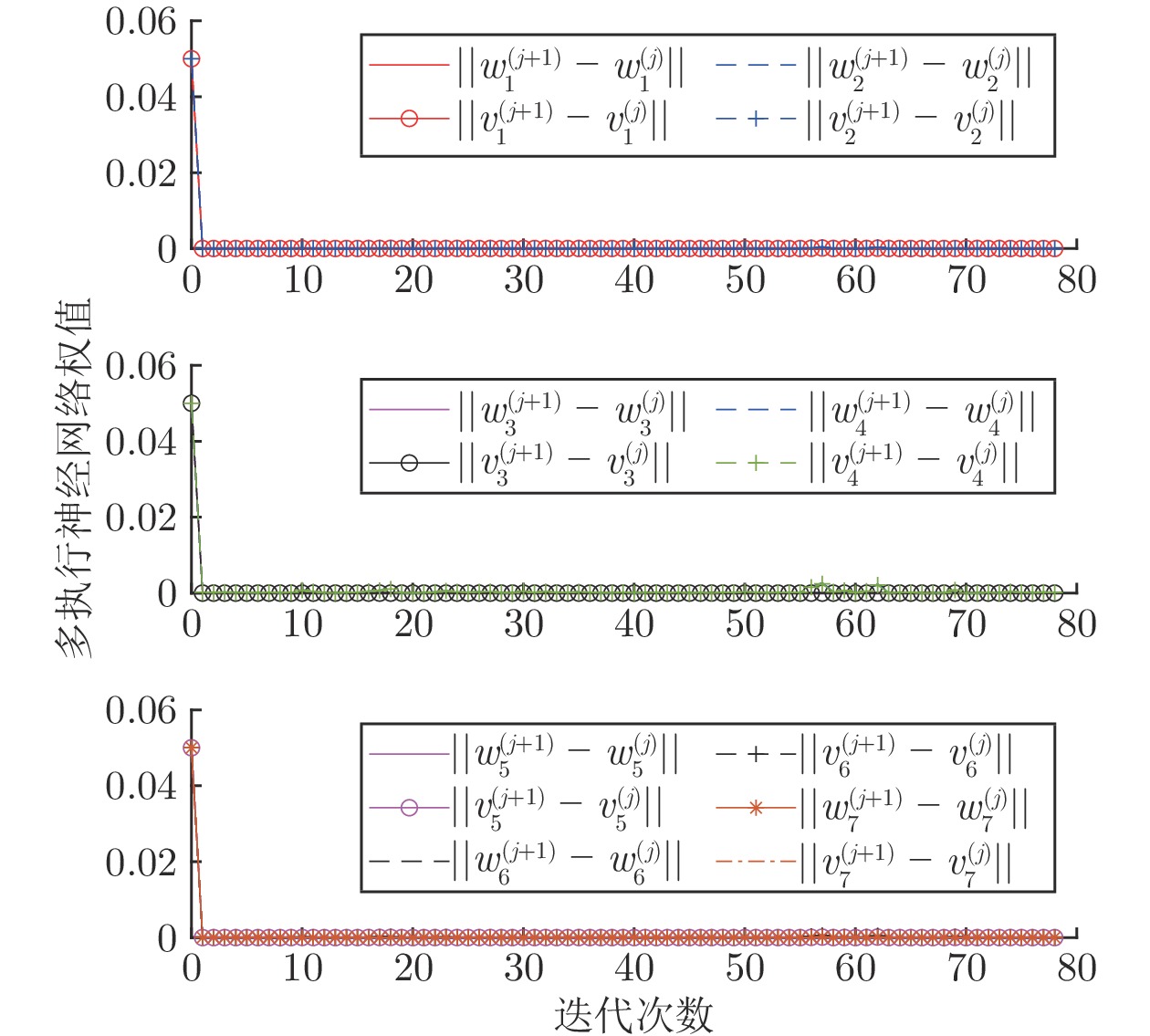
图 11 策略异步更新和策略同步更新强化学习算法时间消耗对比
Fig. 11 Comparison of time consumption betweenasynchronous policy update and synchronouspolicy update
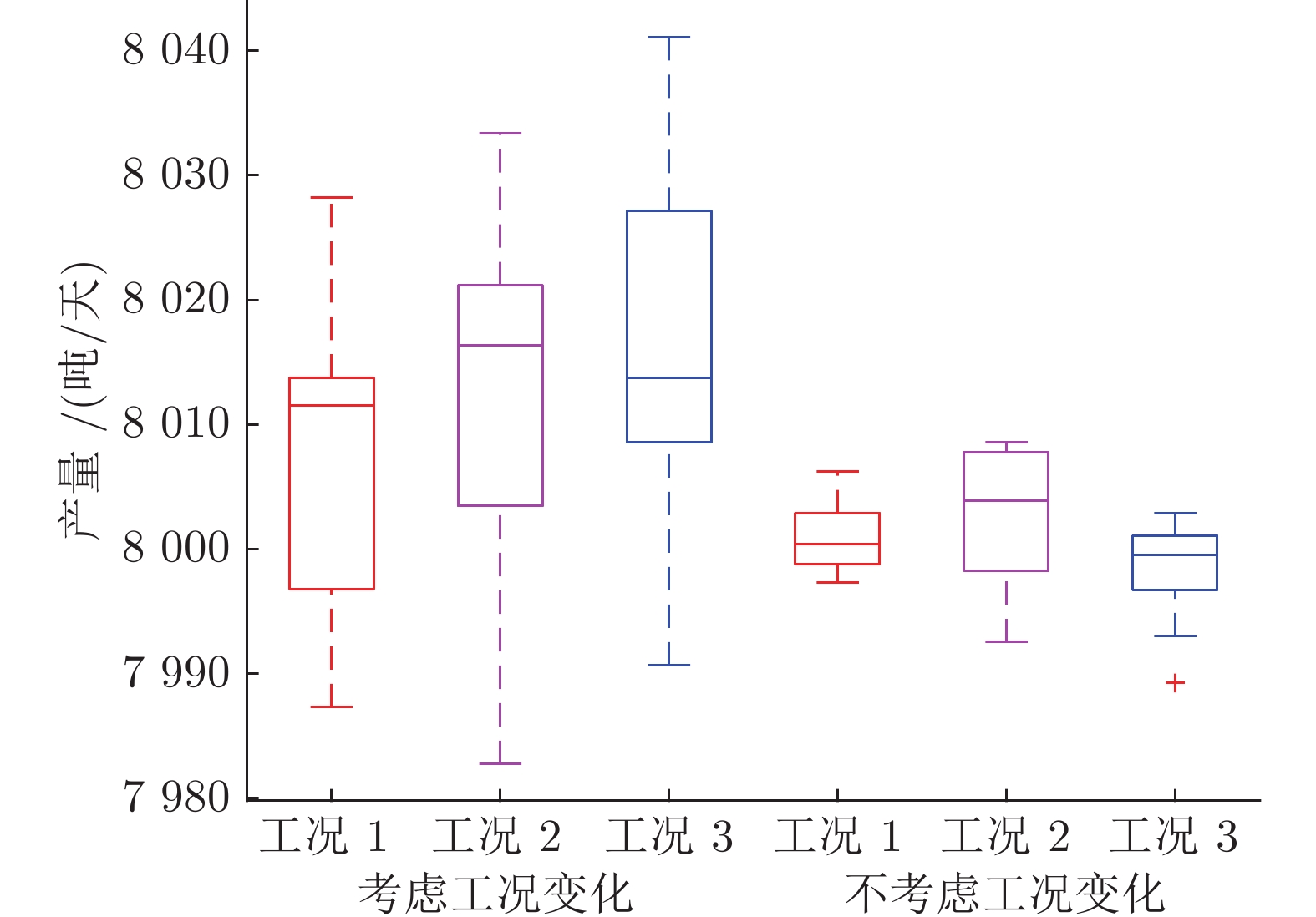
图 12 考虑工况变化和不考虑工况变化统计结果对比
Fig. 12 Statistic results with and without consideration of dynamics of production condition
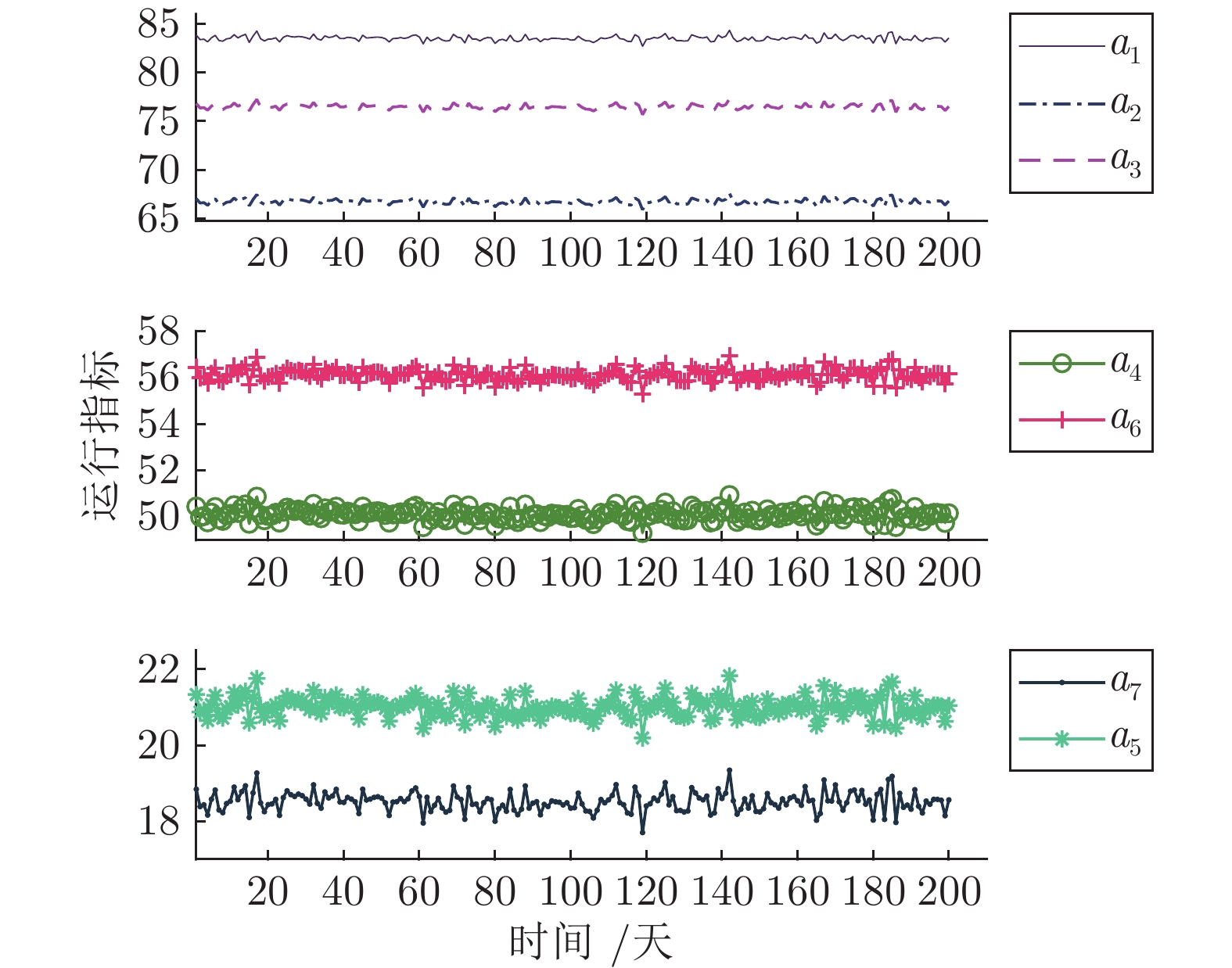
表 1 运行指标
Table 1 Operational indices
单元 运行指标 取值范围 (%) 竖炉 $a_1$: 磁管回收率 $a_{1\max} =84.8$ $a_{1\min} =81.3$ 磨矿单元1 $a_2$: 磨矿粒度 $a_{2\max} =84.0$ $a_{2\min} =48.6$ 磨矿单元2 $a_3$: 磨矿粒度 $a_{3\max} =88.8$ $a_{3\min} =63.3$ 强磁选 $a_4$: 精矿品位 $a_{4\max} =53.4$ $a_{4\min} =45.9$ $a_5$: 尾矿品位 $a_{5\max} =23.2$ $a_{5\min} =17.9$ 弱磁选 $a_6$: 精矿品位 $a_{6\max} =57.8$ $a_{6\min} =53.5$ $a_7$: 尾矿品位 $a_{7\max} =20.2$ $a_{7\min} =15.9$  下载: 导出CSV
下载: 导出CSV
-
[1] 柴天佑. 生产制造全流程优化控制对控制与优化理论方法的挑战. 自动化学报, 2009, 35(6): 641-649 doi: 10.3724/SP.J.1004.2009.00641Chai Tian-You. Challenges of optimal control for plant-wide production processes in terms of control and optimization theories. Acta Automatica Sinica, 2009, 35(6): 641-649 doi: 10.3724/SP.J.1004.2009.00641 [2] 丁进良, 杨翠娥, 陈远东, 柴天佑. 复杂工业过程智能优化决策系统的现状与展望. 自动化学报, 2018, 44(11): 1931-1943Ding Jin-Liang, Yang Cui-E, Chen Yuan-Dong, Chai Tian-You. Research progress and prospects of intelligent optimization decision making in complex industrial process. Acta Automatica Sinica, 2018, 44(11): 1931-1943 [3] 柴天佑, 丁进良, 王宏, 苏春翌. 复杂工业过程运行的混合智能优化控制方法. 自动化学报, 2008, 34(5): 505−515Chai Tian-You, Ding Jin-Liang, Wang Hong, Su Chun-Yi. Hybrid intelligent optimal control method for operation of complex industrial processes. Acta Automatica Sinica, 2008, 34(5): 505−515 [4] Huang X, Chu Y, Hu Y, Chai T. Production process management system for production indices optimization of mineral processing. IFAC Proceedings Volumes, 2005, 38(1): 178−183 [5] Ochoa S, Wozny G, Repke J U. Plantwide optimizing control of a continuous bioethanol production process. Journal of process Control, 2010, 20(9): 983−998 doi: 10.1016/j.jprocont.2010.06.010 [6] Ding J, Chai T, Wang H, Wang J, Zheng X. An intelligent factory-wide optimal operation system for continuous production process. Enterprise Information Systems, 2016, 10(3): 286−302 doi: 10.1080/17517575.2015.1065346 [7] Ding J, Modares H, Chai T, Lewis F L. Data-based multiobjective plant-wide performance optimization of industrial processes under dynamic environments. IEEE Transactions on Industrial Informatics, 2016, 12(2): 454−465 doi: 10.1109/TII.2016.2516973 [8] Chai T, Ding J, Wang H. Multi-objective hybrid intelligent optimization of operational indices for industrial processes and application. IFAC Proceedings Volumes, 2011, 44(1): 10517−10522 doi: 10.3182/20110828-6-IT-1002.01753 [9] Ding J, Yang C, Chai T. Recent progress on data-based optimization for mineral processing plants. Engineering, 2017, 3(2): 183−187 doi: 10.1016/J.ENG.2017.02.015 [10] Li J, Ding J, Chai T, Lewis F L. Nonzero-sum game reinforcement learning for performance optimization in large-scale industrial processes. IEEE Transactions on Cybernetics, 2019, 50(9): 4132−4145 [11] Liu C, Ding J, Sun J. Reinforcement learning based decision making of operational indices in process industry under changing environment. IEEE Transactions on Industrial Informatics, 2021, 17(4): 2727−2736 doi: 10.1109/TII.2020.3005207 [12] Lewis F L, Vrabie D, Vamvoudakis K. Reinforcement learning and feedback control. IEEE Control Systems, 2012, 32(6): 76−105 doi: 10.1109/MCS.2012.2214134 [13] Bertsekas D P, Tsitsiklis J N. Neuro-Dynamic Programming. Nashua: Athena Scientific, 1996. [14] Bertsekas D P. Proper policies in infinite-state stochastic shortest path problems. IEEE Transactions on Automatic Control, 2018, 63(11): 3787−3792 doi: 10.1109/TAC.2018.2811781 [15] Liu D, Wang D, Li H. Decentralized stabilization for a class of continuous-time nonlinear interconnected systems using online learning optimal control approach. IEEE Transactions on Neural Networks and Learning Systems, 2013, 25(2): 418−428 [16] Na J, hao J, Gao G, Li Z. Output-feedback robust control of uncertain systems via online data-Driven learning. IEEE Transactions on Neural Networks and Learning Systems, 2020, 32(6): 2650−2662 [17] Song R, Lewis F L, Wei Q. Off-policy integral reinforcement learning method to solve nonlinear continuous-time multiplayer nonzero-sum games. IEEE Transactions on Neural Networks and Learning Systems, 2016, 28(3): 704−713 [18] Modares H, Nageshrao S P, Lopes G A D, Babuska R, Lewis F L. Optimal model-free output synchronization of heterogeneous systems using off-policy reinforcement learning. Automatica, 2016, 71: 334−341 doi: 10.1016/j.automatica.2016.05.017 [19] Bertsekas D P. Multiagent reinforcement learning: rollout and policy iteration. IEEE/CAA Journal of Automatica Sinica, 2021, 8(2): 249−272 doi: 10.1109/JAS.2021.1003814 [20] Liang M, Wang D, Liu D. Neuro-optimal control for discrete stochastic processes via a novel policy iteration algorithm. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 50(11): 3972−3985 [21] Zhang H, Luo Y, Liu D. Neural-network-based near-optimal control for a class of discrete-time affine nonlinear systems with control constraints. IEEE Transactions on Neural Networks, 2009, 20(9): 1490−1503 doi: 10.1109/TNN.2009.2027233 [22] Marvi Z, Kiumarsi B. Safe reinforcement learning: a control barrier function optimization approach. International Journal of Robust and Nonlinear Control, 2021, 31(6): 1923−1940 doi: 10.1002/rnc.5132 [23] Greene M L, Deptula P, Nivison S, Dixon W E. Sparse learning-based approximate dynamic programming with barrier constraints. IEEE Control Systems Letters, 2020, 4(3): 743−748 doi: 10.1109/LCSYS.2020.2977927 [24] Bellman R, Åström K J. On structural identifiability. Mathematical Biosciences, 1970, 7(3-4): 329−339 doi: 10.1016/0025-5564(70)90132-X [25] Luo B, Yang Y, Liu D. Policy iteration Q-learning for data-based two-player zero-sum game of linear discrete-time systems. IEEE Transactions on Cybernetics, 2021, 51(7): 3630−3640 doi: 10.1109/TCYB.2020.2970969 [26] Kiumarsi B, Lewis F L. Actor-critic-based optimal tracking for partially unknown nonlinear discrete-time systems. IEEE Transactions on Neural Networks and Learning Systems, 2014, 26(1): 140−151 [27] Zhang R, Tao J. Data-driven modeling using improved multi-objective optimization based neural network for coke furnace system. IEEE Transactions on Industrial Electronics, 2017, 64(4): 3147−3155 doi: 10.1109/TIE.2016.2645498 [28] Wang D, Ha M, Qiao J. Self-learning optimal regulation for discrete-time nonlinear systems under event-driven formulation. IEEE Transactions on Automatic Control, 2020, 65(3): 1272−1279 doi: 10.1109/TAC.2019.2926167 [29] Lewis F L, Liu D. Reinforcement Learning and Approximate Dynamic Programming for Feedback Control. New York: John Wiley & Sons, 2013. [30] Li J, Ding J, Chai T, Lewis F L, Jagannathan S. Adaptive interleaved reinforcement learning: robust stability of affine nonlinear systems with unknown uncertainty. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(1): 270-280 doi: 10.1109/TNNLS.2020.3027653 [31] 袁兆麟, 何润姿, 姚超, 李佳, 班晓娟. 基于强化学习的浓密机底流浓度在线控制算法. 自动化学报, 2021, 47(7): 1558-1571Yuan Zhao-Lin, He Run-Zi, Yao Chao, Li Jia, Ban Xiao-Juan. Online reinforcement learning control algorithm for concentration of thickener underflow. Acta Automatica Sinica, 2021, 47(7): 1558-1571 [32] Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. Advances in Neural Information Processing Systems, 2017, 6379-6390 [33] Sutton R S, Barto A G. Reinforcement Learning: An Introduction. Cambridge: MIT press, 2018. -

 下载:
下载:




计量
- 文章访问数: 1810
- HTML全文浏览量: 457
- PDF下载量: 362
- 被引次数: 0
