

-
摘要: 多模态数据间交互式任务的兴起对于综合利用不同模态的知识提出了更高的要求, 因此融合不同模态知识的多模态知识图谱应运而生. 然而, 现有多模态知识图谱存在图谱知识不完整的问题, 严重阻碍对信息的有效利用. 缓解此问题的有效方法是通过实体对齐进行知识图谱补全. 当前多模态实体对齐方法以固定权重融合多种模态信息, 在融合过程中忽略不同模态信息贡献的差异性. 为解决上述问题, 设计一套自适应特征融合机制, 根据不同模态数据质量动态融合实体结构信息和视觉信息. 此外, 考虑到视觉信息质量不高、知识图谱之间的结构差异也影响实体对齐的效果, 本文分别设计提升视觉信息有效利用率的视觉特征处理模块以及缓和结构差异性的三元组筛选模块. 在多模态实体对齐任务上的实验结果表明, 提出的多模态实体对齐方法的性能优于当前最好的方法.Abstract: The recent surge of interactive tasks involving multi-modal data brings a high demand for utilizing knowledge in different modalities. This facilitated the birth of multi-modal knowledge graphs, which aggregate multi-modal knowledge to meet the demands of the tasks. However, they are known to suffer from the knowledge incompleteness problem that hinders the utilization of information. To mitigate this problem, it is of great need to improve the knowledge coverage via entity alignment. Current entity alignment methods fuse multi-modal information by fixed weighting, which ignores the different contributions of individual modalities. To solve this challenge, we propose an adaptive feature fusion mechanism, that combines entity structure information and visual information via dynamic fusion according to the data quality. Besides, considering that low quality visual information and structural difference between knowledge graphs further impact the performance of entity alignment, we design a visual feature processing module to improve the effective utilization of visual information and a triple filtering module to ease structural differences. Experiments on multi-modal entity alignment indicate that our method outperforms the state-of-the-arts.
-
Key words:
- Multi-modal knowledge graph /
- entity alignment /
- pre-trained model /
- feature fusion
-
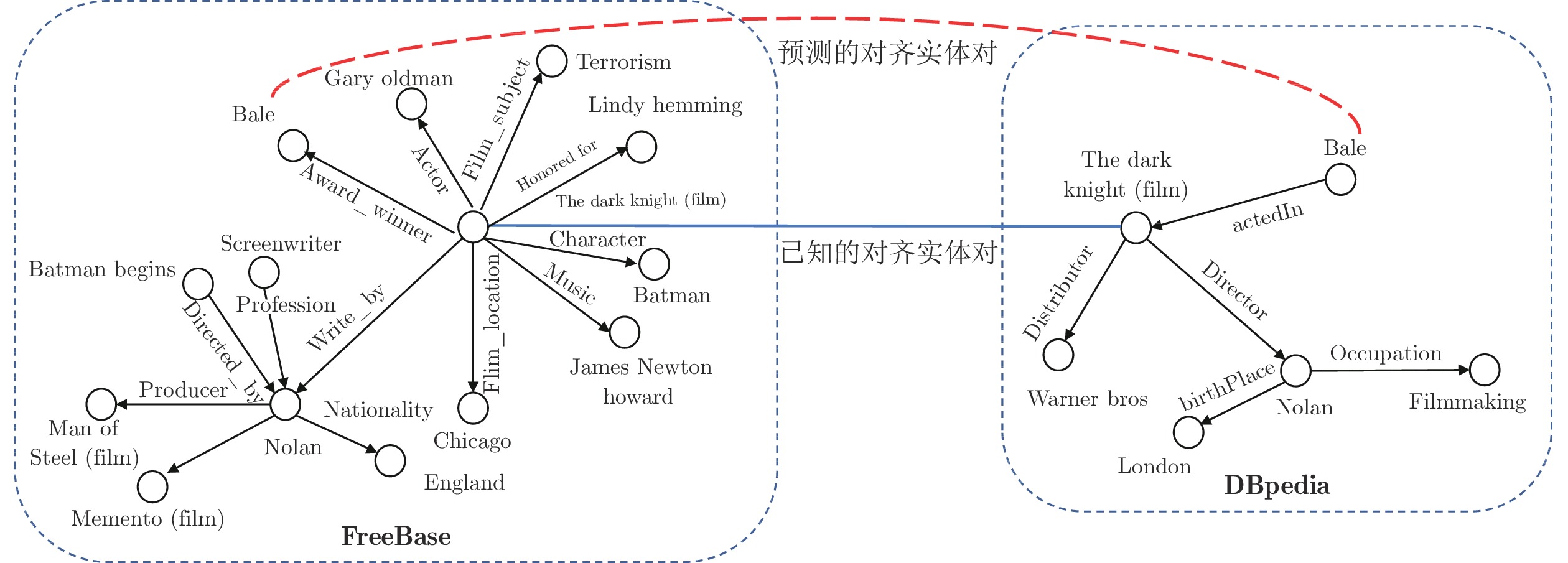
图 1 知识图谱FreeBase和DBpedia的结构差异性表现
Fig. 1 Structural differences between knowledge graphs FreeBase and DBpedia

图 2 自适应特征融合的多模态实体对齐框架
Fig. 2 Multi-modal entity alignment framework based on adaptive feature fusion
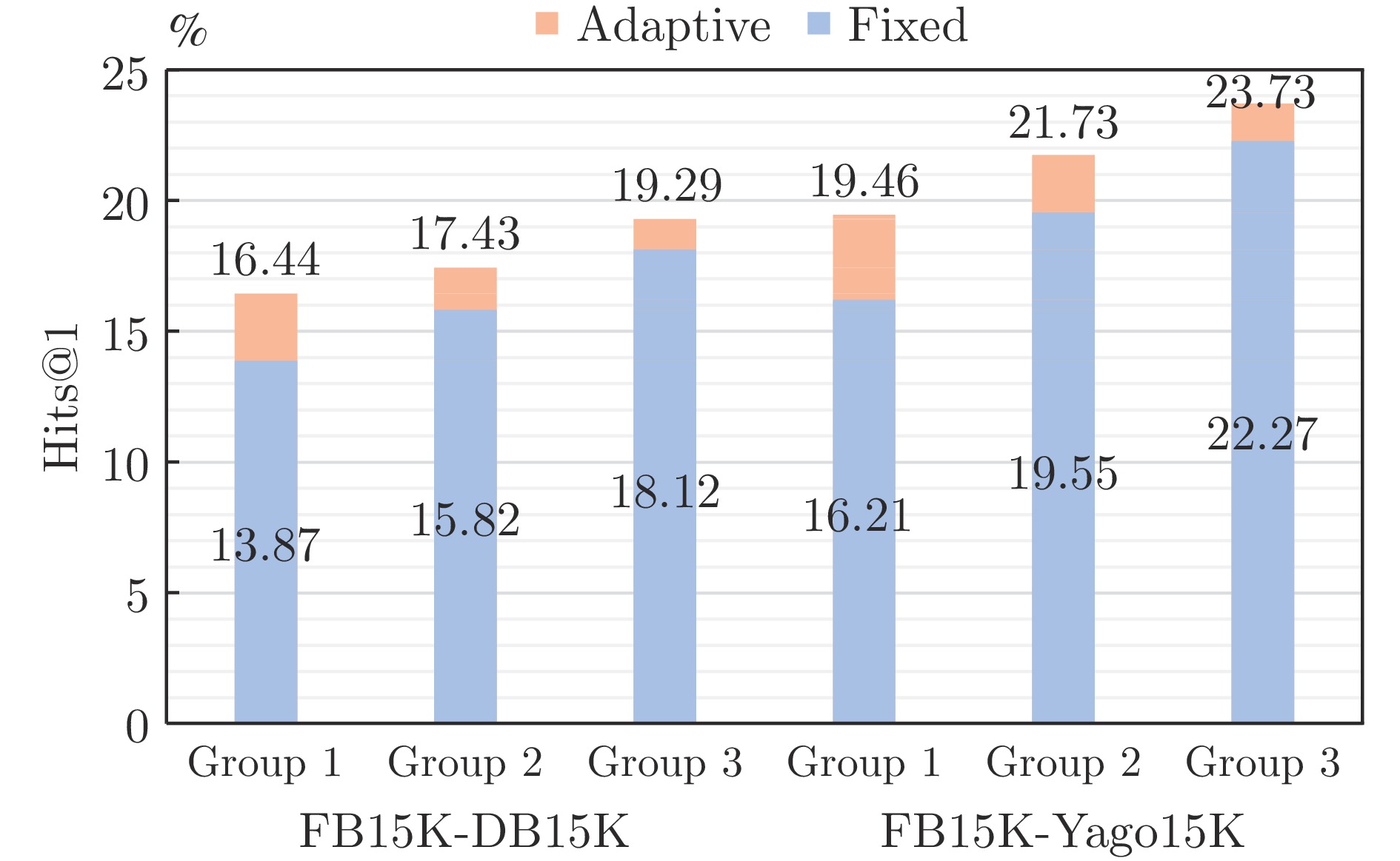
图 5 自适应特征融合与固定权重融合的实体对齐Hits@1对比
Fig. 5 Entity alignment Hits@1's comparison of adaptive feature fusion and fixed feature fusion
表 1 多模态知识图谱数据集数据统计
Table 1 Statistic of the MMKGs datasets
数据集 实体 关系 三元组 图片 SameAs FB15K 14 915 1 345 592 213 13 444 DB15K 14 777 279 99 028 12 841 12 846 Yago15K 15 404 32 122 886 11 194 11 199  下载: 导出CSV
下载: 导出CSV
表 2 多模态实体对齐结果
Table 2 Results of multi-modal entity alignment
数据集 方法 seed = 20% seed = 50% Hits@1 Hits@10 MRR Hits@1 Hits@10 MRR FB15K-DB15K IKRL 2.96 11.45 0.059 5.53 24.41 0.121 GCN-align 6.26 18.81 0.105 13.79 34.60 0.210 PoE 11.10 17.80 — 23.50 33.00 — HMEA 12.16 34.86 0.191 27.24 51.77 0.354 AF2MEA 17.75 34.14 0.233 29.45 50.25 0.365 FB15K-Yago15K IKRL 3.84 12.50 0.075 6.16 20.45 0.111 GCN-align 6.44 18.72 0.106 14.09 34.80 0.209 PoE 8.70 13.30 — 18.50 24.70 — HMEA 10.03 29.38 0.168 27.91 55.31 0.371 AF2MEA 21.65 40.22 0.282 35.72 56.03 0.423
下载: 导出CSV
表 3 消融实验实体对齐结果
Table 3 Entity alignment results of ablation study
数据集 方法 seed = 20% seed = 50% Hits@1 Hits@10 MRR Hits@1 Hits@10 MRR FB15K-DB15K AF2MEA 17.75 34.14 0.233 29.45 50.25 0.365 AF2MEA-Adaptive 16.03 31.01 0.212 26.29 45.35 0.331 AF2MEA-Visual 16.19 30.71 0.212 26.14 45.38 0.323 AF2MEA-Filter 14.13 28.77 0.191 22.91 43.08 0.297 FB15K-Yago15K AF2MEA 21.65 40.22 0.282 35.72 56.25 0.423 AF2MEA-Adaptive 19.32 37.38 0.255 31.77 53.24 0.393 AF2MEA-Visual 19.75 36.38 0.254 32.08 51.53 0.388 AF2MEA-Filter 15.84 32.36 0.216 27.38 48.14 0.345
下载: 导出CSV
表 4 实体视觉特征的对齐结果
Table 4 Entity alignment results of visual feature
数据集 方法 seed = 20% seed = 50% Hits@1 Hits@10 MRR Hits@1 Hits@10 MRR FB15K-DB15K HMEA-v 2.07 9.82 0.058 3.91 14.41 0.086 Att 8.81 20.16 0.128 9.57 21.13 0.139 Att+Filter 8.98 20.52 0.131 9.96 22.58 0.144 FB15K-Yago15K HMEA-v 2.77 11.49 0.072 4.28 15.38 0.095 Att 9.25 21.38 0.137 10.56 23.55 0.157 Att+Filter 9.43 21.91 0.138 11.07 24.51 0.158
下载: 导出CSV
表 5 不同三元组筛选机制下实体结构特征对齐结果
Table 5 Entity alignment results of structure feature in different filtering mechanism
数据集 方法 seed = 20% seed = 50% Hits@1 Hits@10 MRR Hits@1 Hits@10 MRR FB15K-DB15K Baseline 6.26 18.81 0.105 13.79 34.60 0.210 ${\rm{F}}_{\text{PageRank}}$ 8.03 21.37 0.125 18.90 39.25 0.259 ${\rm{F}}_{\text{random}}$ 7.57 20.76 0.120 16.32 36.48 0.231 ${\rm{F}}_{\text{our}}$ 9.74 25.28 0.150 22.09 44.85 0.297 FB15K-Yago15K Baseline 6.44 18.72 0.106 15.88 36.70 0.229 ${\rm{F}}_{\text{PageRank}}$ 9.54 23.45 0.144 21.67 42.30 0.290 ${\rm{F}}_{\text{random}}$ 8.17 20.86 0.126 18.22 38.55 0.254 ${\rm{F}}_{\text{our}}$ 11.59 28.44 0.175 24.88 47.85 0.327
下载: 导出CSV
表 6 自适应特征融合与固定权重融合多模态实体对齐结果
Table 6 Multi-modal entity alignment results of fixed feature fusion and adaptive feature fusion
方法 Group 1 Group 2 Group 3 Hits@1 Hits@10 Hits@1 Hits@10 Hits@1 Hits@10 FB15K-DB15K Adaptive 16.44 32.97 17.43 33.47 19.29 35.40 Fixed 13.87 28.91 15.82 31.08 18.12 34.33 FB15K-Yago15K Adaptive 16.44 32.97 17.43 33.47 19.29 35.40 Fixed 16.21 33.23 19.55 37.11 22.27 45.52
下载: 导出CSV
表 7 补充实验多模态实体对齐结果
Table 7 Multi-modal entity alignment results of additional experiment
方法 seed = 20% seed = 50% Hits@1 Hits@10 MRR Hits@1 Hits@10 MRR PoE 16.44 32.97 17.430 34.70 53.60 0.414 MMEA 13.87 28.91 15.820 40.26 64.51 0.486 AF2MEA 28.65 48.22 0.382 48.25 75.83 0.569
下载: 导出CSV
-
[1] Zhu S G, Cheng X, Su S. Knowledge-based question answering by tree-to-sequence learning. Neurocomputing, 2020, 372: 64−72 doi: 10.1016/j.neucom.2019.09.003 [2] Martinez-Rodriguez J L, Hogan A, Lopez-Arevalo I. Information extraction meets the semantic web: A survey. Semantic Web, 2020, 11(2): 255−335 doi: 10.3233/SW-180333 [3] Yao X C, Van Durme B. Information extraction over structured data: Question answering with freebase. In: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore, USA: ACL, 2014. 956−966 [4] Sun Z, Yang J, Zhang J, Bozzon A, Huang L K, Xu C. Recurrent knowledge graph embedding for effective recommendation. In: Proceedings of the 12th ACM Conference on Recommender Systems. Vancouver, Canada: ACM, 2018. 297−305 [5] Wang M, Qi G L, Wang H F, Zheng Q S. Richpedia: A comprehensive multi-modal knowledge graph. In: Proceedings of the 9th Joint International Conference on Semantic Technology. Hangzhou, China: Springer, 2019. 130−145 [6] Liu Y, Li H, Garcia-Duran A, Niepert M, Onoro-Rubio D, Rosenblum D S. MMKG: Multi-modal knowledge graphs. In: Proceedings of the 16th International Conference on the Semantic Web. Portorož, Slovenia: Springer, 2019. 459−474 [7] Shen L, Hong R C, Hao Y B. Advance on large scale near-duplicate video retrieval. Frontiers of Computer Science, 2020, 14(5): Article No. 145702 doi: 10.1007/s11704-019-8229-7 [8] Han Y H, Wu A M, Zhu L C, Yang Y. Visual commonsense reasoning with directional visual connections. Frontiers of Information Technology & Electronic Engineering, 2021, 22(5): 625−637 [9] Zheng W F, Yin L R, Chen X B, Ma Z Y, Liu S, Yang B. Knowledge base graph embedding module design for visual question answering model. Pattern Recognition, 2021, 120: Article No. 108153 doi: 10.1016/j.patcog.2021.108153 [10] Zeng W X, Zhao X, Wang W, Tang J Y, Tan Z. Degree-aware alignment for entities in tail. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Virtual Event: ACM, 2020. 811−820 [11] Zhao X, Zeng W X, Tang J Y, Wang W, Suchanek F. An experimental study of state-of-the-art entity alignment approaches. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(6): 2610−2625 [12] Zeng W X, Zhao X, Tang J Y, Li X Y, Luo M N, Zheng Q H. Towards entity alignment in the open world: An unsupervised approach. In: Proceedings of the 26th International Conference Database Systems for Advanced Applications. Taipei, China: Springer, 2021. 272−289 [13] Guo H, Tang J Y, Zeng W X, Zhao X, Liu L. Multi-modal entity alignment in hyperbolic space. Neurocomputing, 2021, 461: 598−607 doi: 10.1016/j.neucom.2021.03.132 [14] Wang Z C, Lv Q S, Lan X H, Zhang Y. Cross-lingual knowledge graph alignment via graph convolutional networks. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: ACL, 2018. 349−357 [15] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [16] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [17] Chen M H, Tian Y T, Yang M H, Zaniolo C. Multilingual knowledge graph embeddings for cross-lingual knowledge alignment. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: IJCAI.org, 2017. 1511−1517 [18] Sun Z Q, Hu W, Zhang Q H, Qu Y Z. Bootstrapping entity alignment with knowledge graph embedding. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden: IJCAI.org, 2018. 4396−4402 [19] Chen L Y, Li Z, Wang Y J, Xu T, Wang Z F, Chen E H. MMEA: Entity alignment for multi-modal knowledge graph. In: Proceedings of the 13th International Conference on Knowledge Science, Engineering and Management. Hangzhou, China: Springer, 2020. 134−147 [20] Guo L B, Sun Z Q, Hu W. Learning to exploit long-term relational dependencies in knowledge graphs. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 2505−2514 [21] 庄严, 李国良, 冯建华. 知识库实体对齐技术综述. 计算机研究与发展, 2016, 53(1): 165−192 doi: 10.7544/issn1000-1239.2016.20150661Zhuang Yan, Li Guo-Liang, Feng Jian-Hua. A survey on entity alignment of knowledge base. Journal of Computer Research and Development, 2016, 53(1): 165−192 doi: 10.7544/issn1000-1239.2016.20150661 [22] 乔晶晶, 段利国, 李爱萍. 融合多种特征的实体对齐算法. 计算机工程与设计, 2018, 39(11): 3395−3400Qiao Jing-Jing, Duan Li-Guo, Li Ai-Ping. Entity alignment algorithm based on multi-features. Computer Engineering and Design, 2018, 39(11): 3395−3400 [23] Trisedya B D, Qi J Z, Zhang R. Entity alignment between knowledge graphs using attribute embeddings. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI Press, 2019. 297−304 [24] Zhu H, Xie R B, Liu Z Y, Sun M S. Iterative entity alignment via joint knowledge embeddings. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: IJCAI.org, 2017. 4258−4264 [25] Chen M H, Tian Y T, Chang K W, Skiena S, Zaniolo C. Co-training embeddings of knowledge graphs and entity descriptions for cross-lingual entity alignment. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden: IJCAI.org, 2018. 3998−4004 [26] Cao Y X, Liu Z Y, Li C J, Liu Z Y, Li J Z, Chua T S. Multi-channel graph neural network for entity alignment. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 1452−1461 [27] Li C J, Cao Y X, Hou L, Shi J X, Li J Z, Chua T S. Semi-supervised entity alignment via joint knowledge embedding model and cross-graph model. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: ACL, 2019. 2723−2732 [28] Mao X, Wang W T, Xu H M, Lan M, Wu Y B. MRAEA: An efficient and robust entity alignment approach for cross-lingual knowledge graph. In: Proceedings of the 13th International Conference on Web Search and Data Mining. Houston, USA: ACM, 2020. 420−428 [29] Sun Z Q, Hu W, Li C K. Cross-lingual entity alignment via joint attribute-preserving embedding. In: Proceedings of the 16th International Semantic Web Conference on the Semantic Web (ISWC). Vienna, Austria: Springer, 2018. 628−644 [30] Galárraga L, Razniewski S, Amarilli A, Suchanek F M. Predicting completeness in knowledge bases. In: Proceedings of the 10th ACM International Conference on Web Search and Data Mining. Cambridge, United Kingdom: ACM, 2017. 375−383 [31] Ferrada S, Bustos B, Hogan A. IMGpedia: A linked dataset with content-based analysis of Wikimedia images. In: Proceedings of the 16th International Semantic Web Conference on the Semantic Web (ISWC). Vienna, Austria: Springer, 2017. 84−93 [32] Xie R B, Liu Z Y, Luan H B, Sun M S. Image-embodied knowledge representation learning. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: IJCAI.org, 2017. 3140−3146 [33] Mousselly-Sergieh H, Botschen T, Gurevych I, Roth S. A multimodal translation-based approach for knowledge graph representation learning. In: Proceedings of the 7th Joint Conference on Lexical and Computational Semantics. New Orleans, USA: ACL, 2018. 225−234 [34] Tan H, Bansal M. LXMERT: Learning cross-modality encoder representations from transformers. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: ACL, 2019. 5100−5111 [35] Li L H, Yatskar M, Yin D, Hsieh C J, Chang K W. What does BERT with vision look at? In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Virtual Event: ACL, 2020. 5265−5275 [36] Wang H R, Zhang Y, Ji Z, Pang Y W, Ma L. Consensus-aware visual-semantic embedding for image-text matching. In: Proceedings of the 16th European Conference on Computer Vision (ECCV). Glasgow, UK: Springer, 2020. 18−34 [37] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft coco: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision (ECCV). Zurich, Switzerland: Springer, 2014. 740−755 [38] Plummer B A, Wang L W, Cervantes C M, Caicedo J C, Hockenmaier J, Lazebnik S. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 2641−2649 [39] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137−1149 doi: 10.1109/TPAMI.2016.2577031 [40] Schuster M, Paliwal K K. Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing, 1997, 45(11): 2673–2681 [41] Hamilton W L, Ying R, Leskovec J. Inductive representation learning on large graphs. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 1025−1035 [42] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: OpenReview.net, 2017. [43] Wu Y T, Liu X, Feng Y S, Wang Z, Yan R, Zhao D Y. Relation-aware entity alignment for heterogeneous knowledge graphs. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao, China: IJCAI, 2019. 5278−5284 [44] Xing W P, Ghorbani A. Weighted pagerank algorithm. In: Proceedings of the 2nd Annual Conference on Communication Networks and Services Research. Fredericton, Canada: IEEE, 2004. 305−314 [45] Zhang Q H, Sun Z Q, Hu W, Chen M H, Guo L B, Qu Y Z. Multi-view knowledge graph embedding for entity alignment. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao, China: IJCAI.org, 2019. 5429−5435 [46] Pang N, Zeng W X, Tang J Y, Tan Z, Zhao X. Iterative entity alignment with improved neural attribute embedding. In: Proceedings of the Workshop on Deep Learning for Knowledge Graphs (DL4KG2019) Co-located With the 16th Extended Semantic Web Conference (ESWC). Portorož, Slovenia: CEUR-WS, 2019. 41−46 [47] Huang B, Yang F, Yin M X, Mo X Y, Zhong C. A review of multimodal medical image fusion techniques. Computational and Mathematical Methods in Medicine, 2020, 2020: Article No. 8279342 [48] Atrey P K, Hossain M A, El Saddik A, Kankanhalli M S. Multimodal fusion for multimedia analysis: A survey. Multimedia Systems, 2010, 16(6): 345−379 doi: 10.1007/s00530-010-0182-0 [49] Poria S, Cambria E, Bajpai R, Hussain A. A review of affective computing: From unimodal analysis to multimodal fusion. Information Fusion, 2017, 37: 98−125 doi: 10.1016/j.inffus.2017.02.003 -

 下载:
下载:

计量
- 文章访问数: 4328
- HTML全文浏览量: 2933
- PDF下载量: 612
- 被引次数: 0
