

-
摘要: 针对复杂三维障碍环境, 提出一种基于深度强化学习的无人机(Unmanned aerial vehicles, UAV) 反应式扰动流体路径规划架构. 该架构以一种受约束扰动流体动态系统算法作为路径规划的基本方法, 根据无人机与各障碍的相对状态以及障碍物类型, 通过经深度确定性策略梯度算法训练得到的动作网络在线生成对应障碍的反应系数和方向系数, 继而可计算相应的总和扰动矩阵并以此修正无人机的飞行路径, 实现反应式避障. 此外, 还研究了与所提路径规划方法相适配的深度强化学习训练环境规范性建模方法. 仿真结果表明, 在路径质量大致相同的情况下, 该方法在实时性方面明显优于基于预测控制的在线路径规划方法.
-
关键词:
- 无人机 /
- 反应式路径规划 /
- 受约束扰动流体动态系统 /
- 深度强化学习 /
- 训练环境
Abstract: In this paper, aiming at complex 3D obstacle environments, a reactive interfered fluid path planning framework is proposed for unmanned aerial vehicles (UAV) based on deep reinforcement learning. The constrained interfered fluid dynamical system algorithm is used as the fundamental path planning method in the framework. According to relative states between unmanned aerial vehicles and each obstacle, and categories of obstacles, the reaction and direction coefficients of the corresponding obstacle are generated online using the actor networks trained by deep deterministic policy gradient. On this basis, the total modulation matrices in constrained interfered fluid dynamical system can be resolved and the flight path is accordingly modified to realize the reactive obstacle avoidance. In addition, the normative modeling method of deep reinforcement learning training environments, which is matched with the proposed path planning method, is studied. Finally, simulation results show that the proposed method is obviously superior to the online path planning method based on predictive control in real-time performance under the condition that the path qualities are approximately the same. -
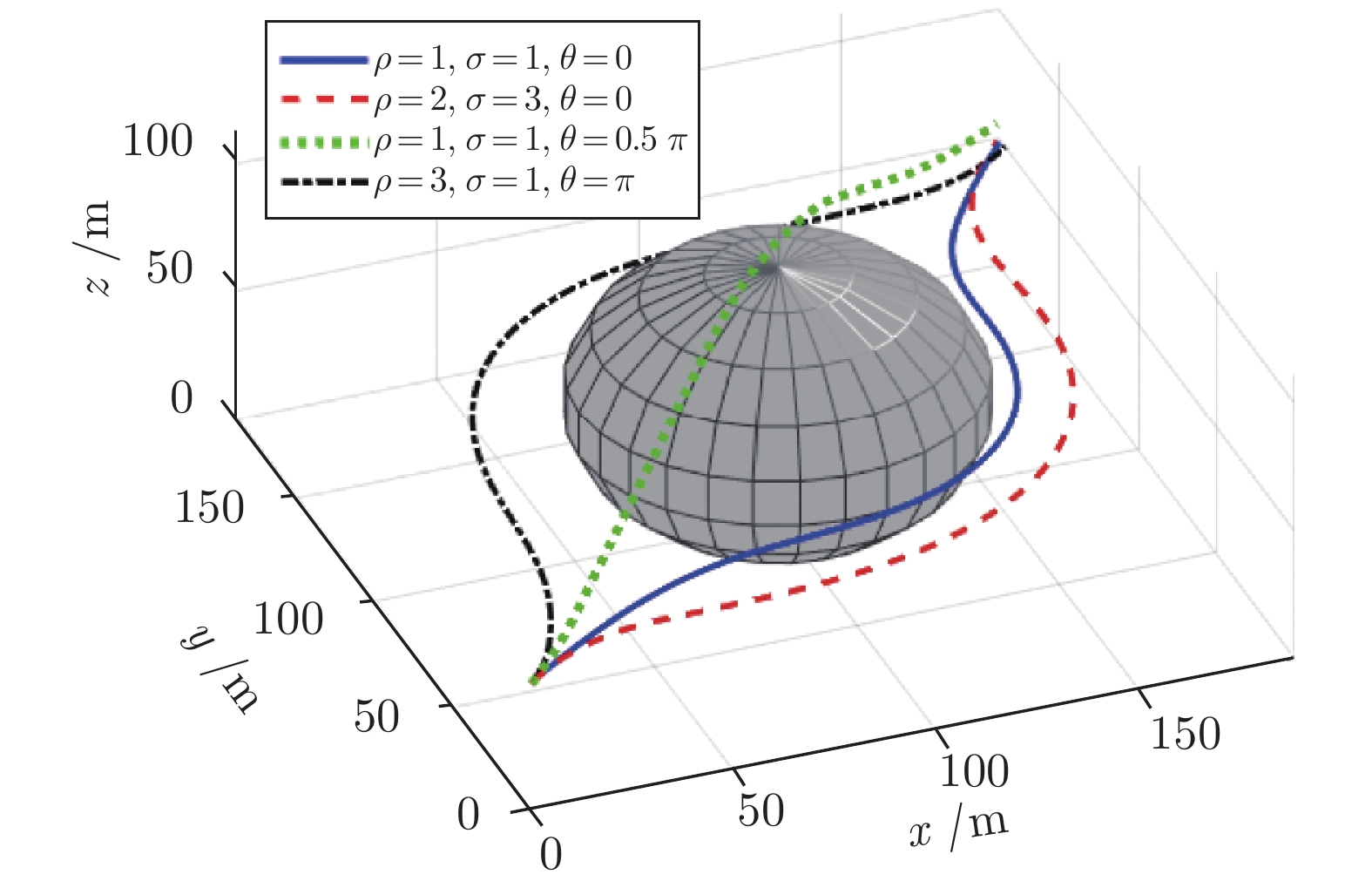
图 1 不同反应系数和方向系数组合对规划路径的影响
Fig. 1 Effects of different combinations of reactioncoefficients and direction coefficients onplanned paths
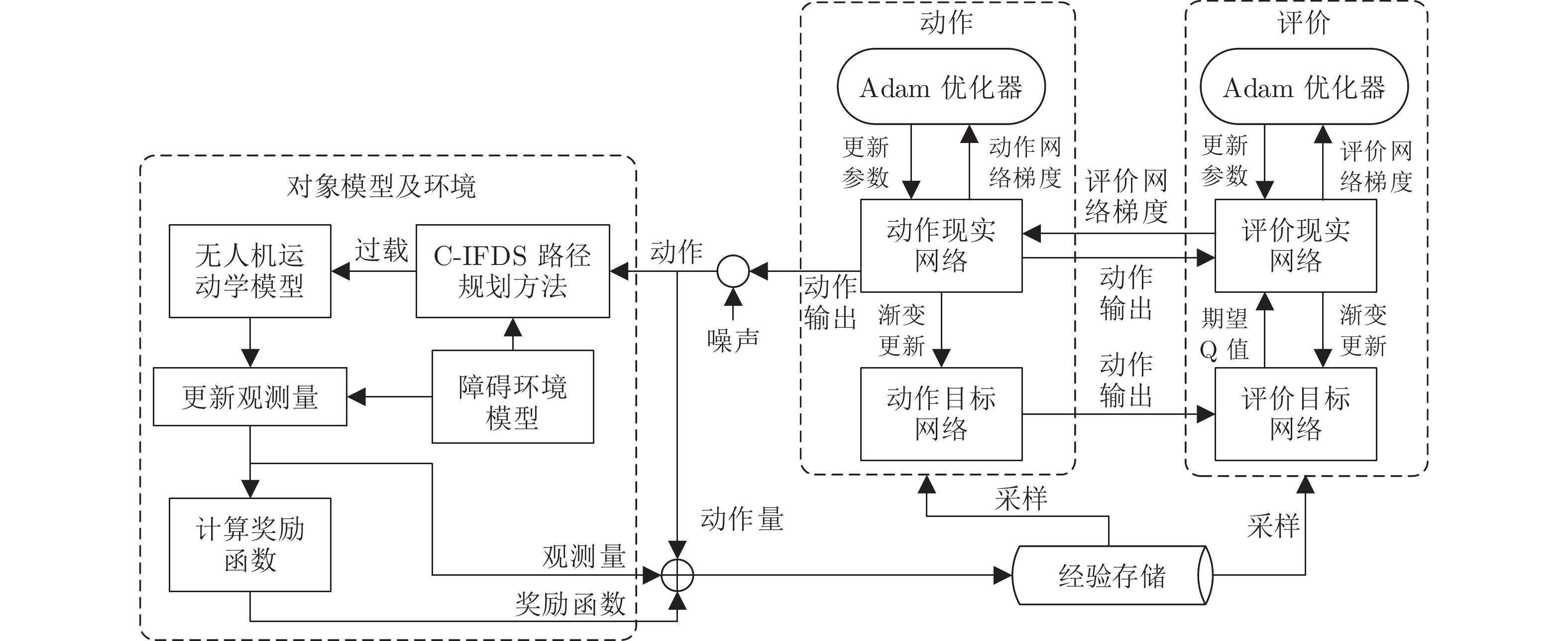
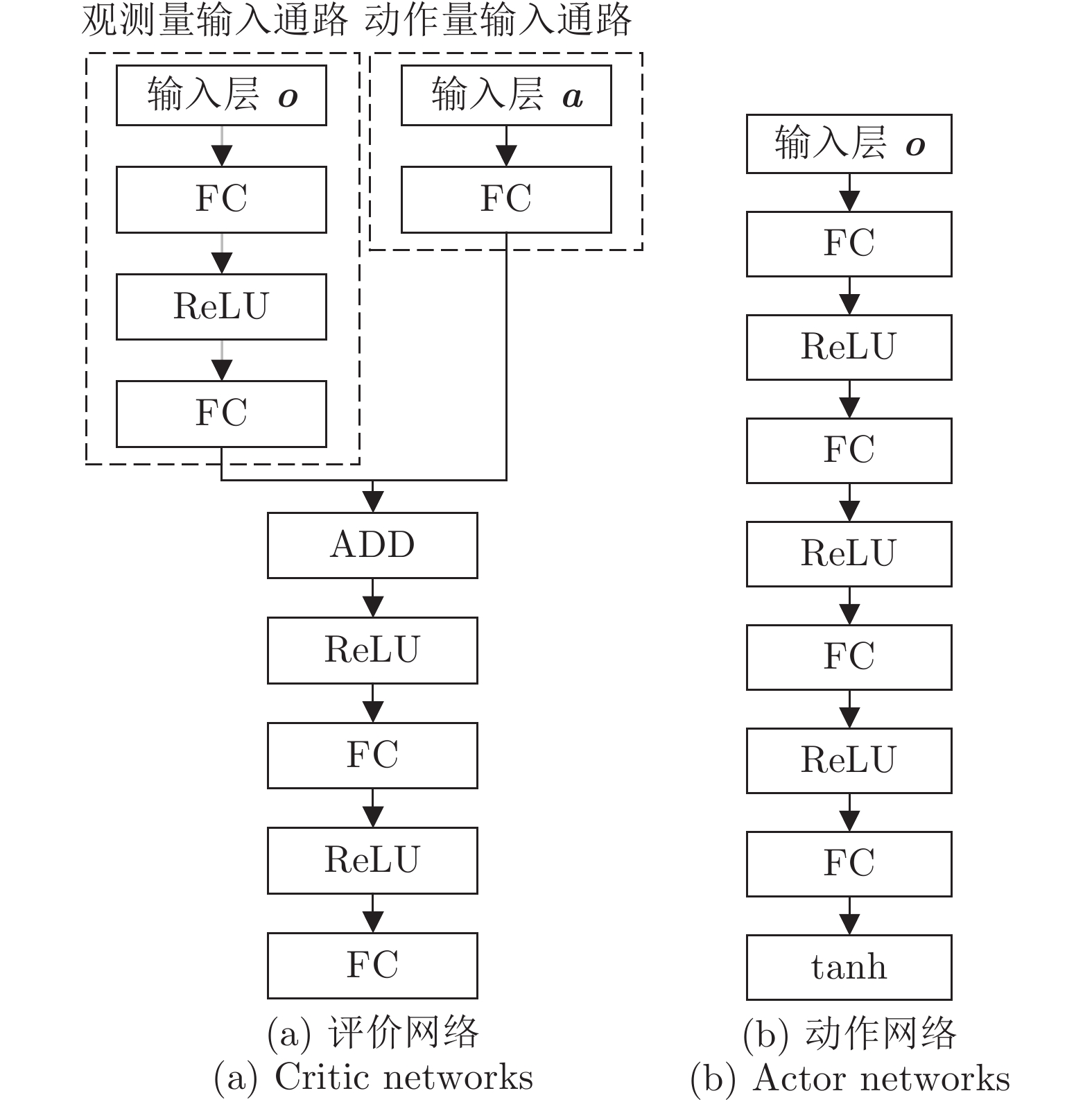
图 2 所提反应式路径规划的DDPG训练机制
Fig. 2 DDPG training mechanism of the proposed reaction path planning
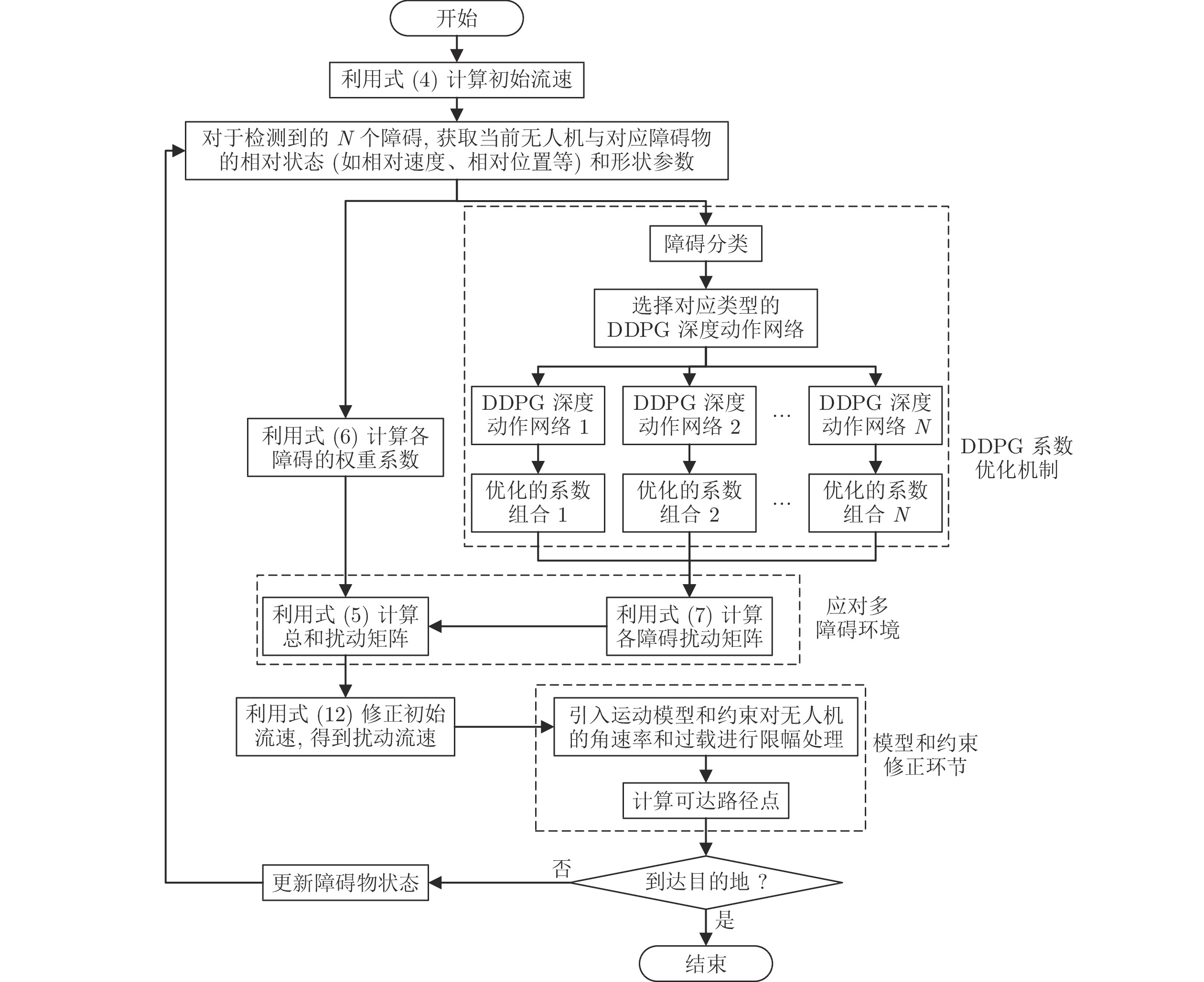
图 4 基于深度强化学习的反应式扰动流体路径规划总体流程图
Fig. 4 Overview flow chart of the DRL-based reaction interfered fluid path planning

图 5 无人机相对初始位置设定的差异: 以静态半球体障碍和动态球体威胁为例
Fig. 5 Differences in the setting of UAV initial locations: Taking the static hemispherical obstacle and thedynamic spherical threat as examples
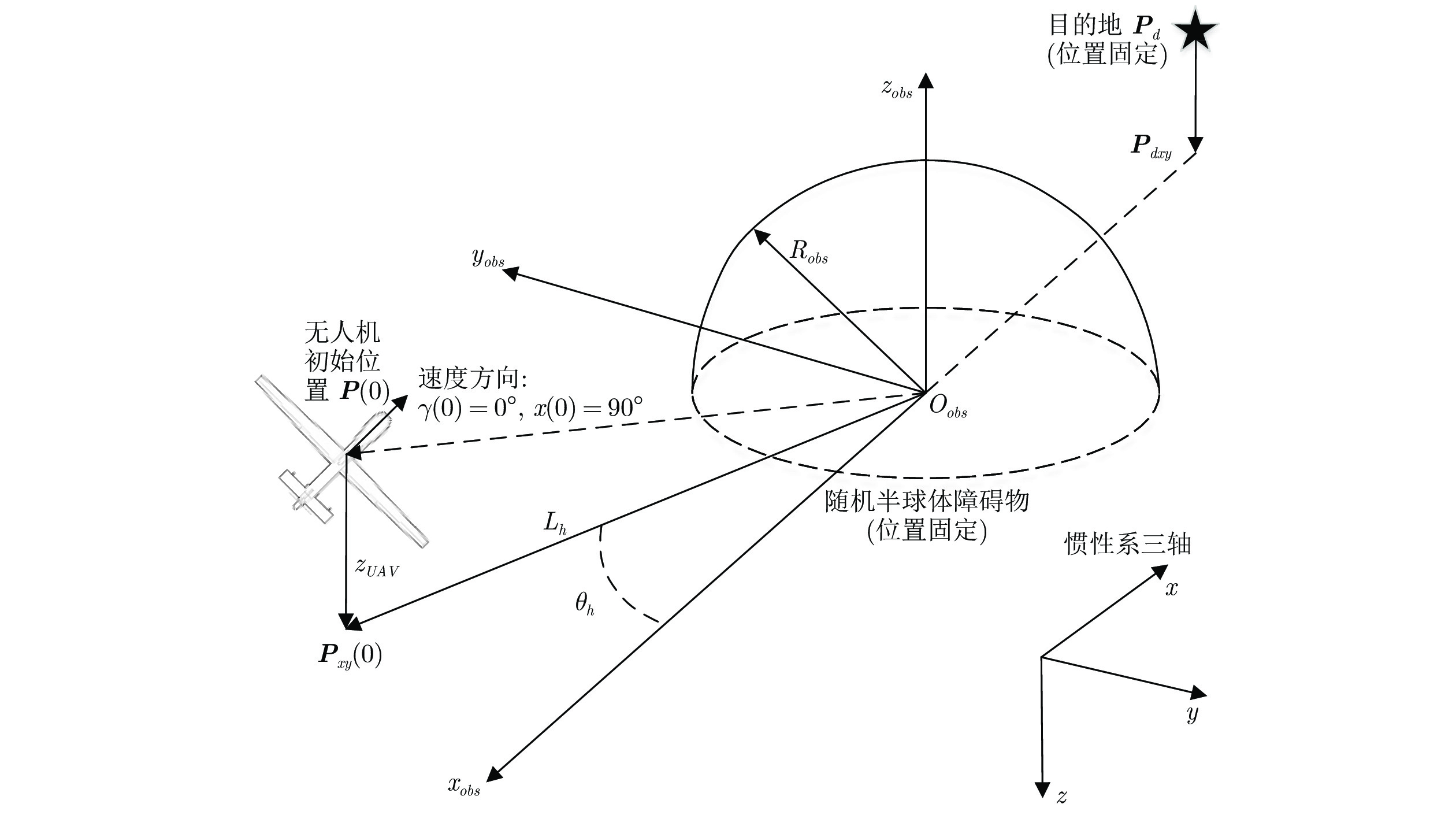
图 6 针对静态半球体障碍的无人机反应式路径规划训练环境
Fig. 6 Training environment of UAV reaction path planning for static hemispherical obstacles
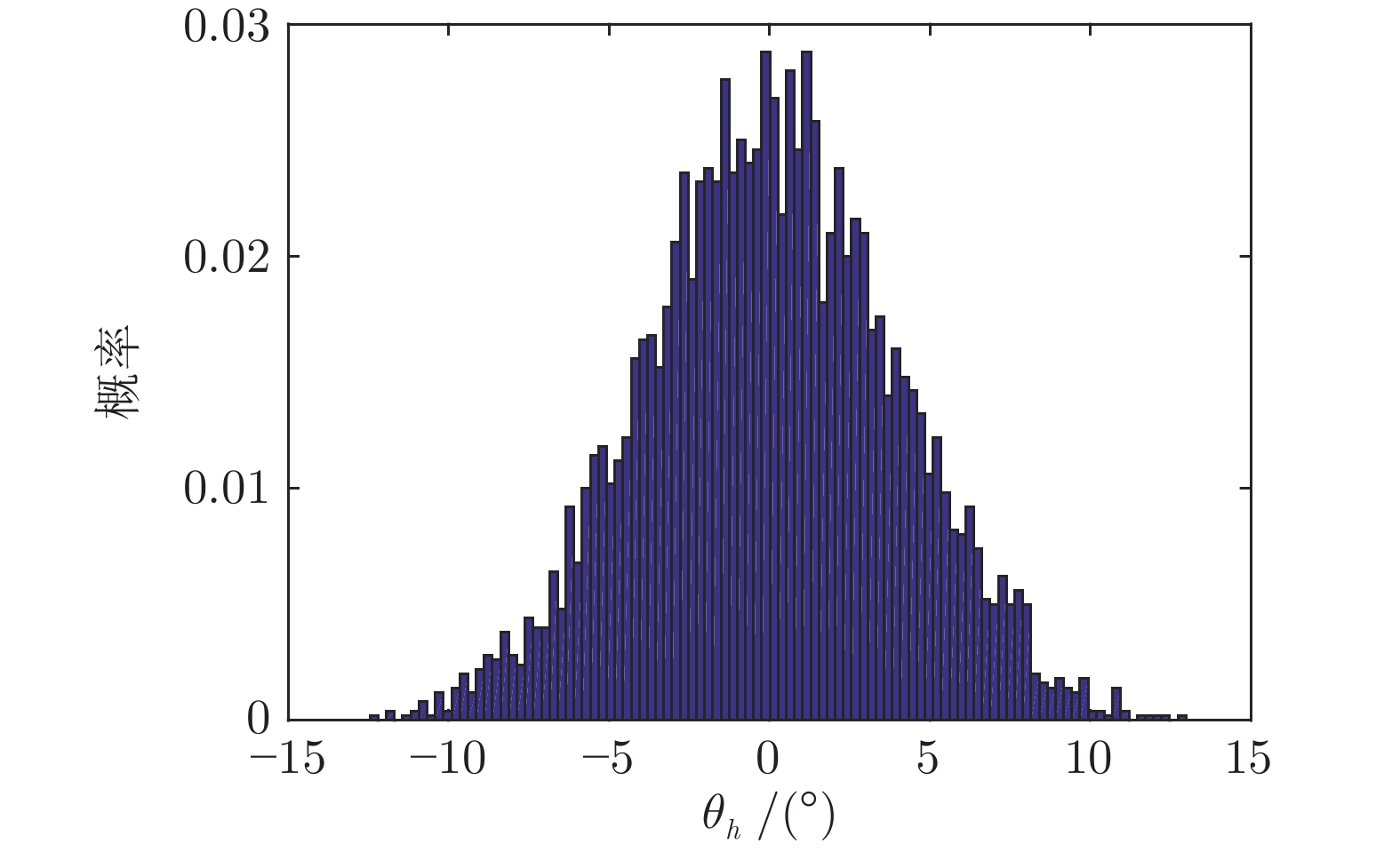
图 7 初始
$ {\theta _h} $ 的概率分布Fig. 7 Probability distribution of the initial
$ {\theta _h} $ 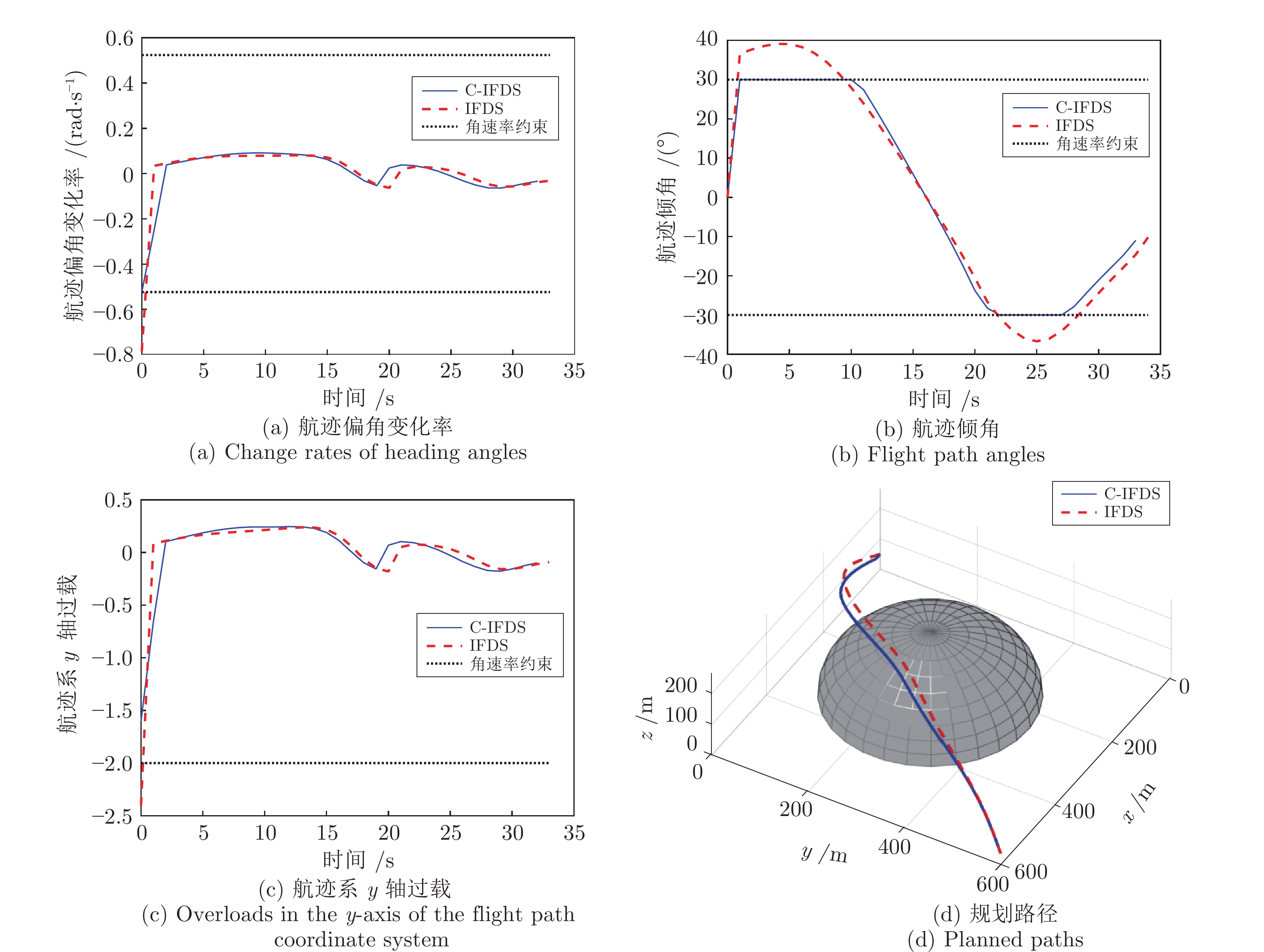
图 8 采用IFDS和C-IFDS时部分受约束的状态和规划路径的对比情况
Fig. 8 Comparisons of some constrained states and planned paths when using IFDS and C-IFDS
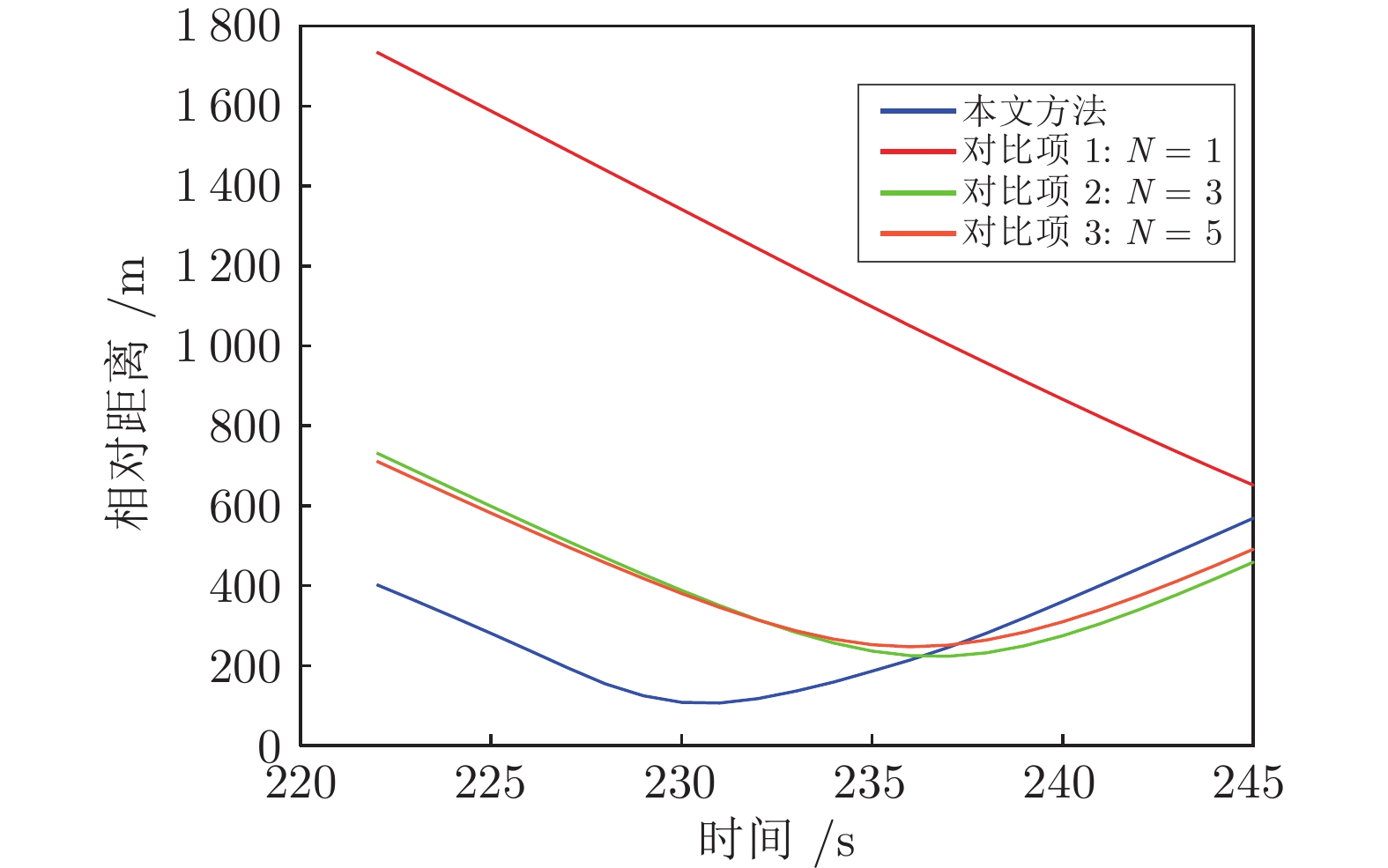
图 11 案例2中与动态威胁等效表面的最近距离
Fig. 11 Closest distances to the equivalent surface of the dynamic threat in case 2

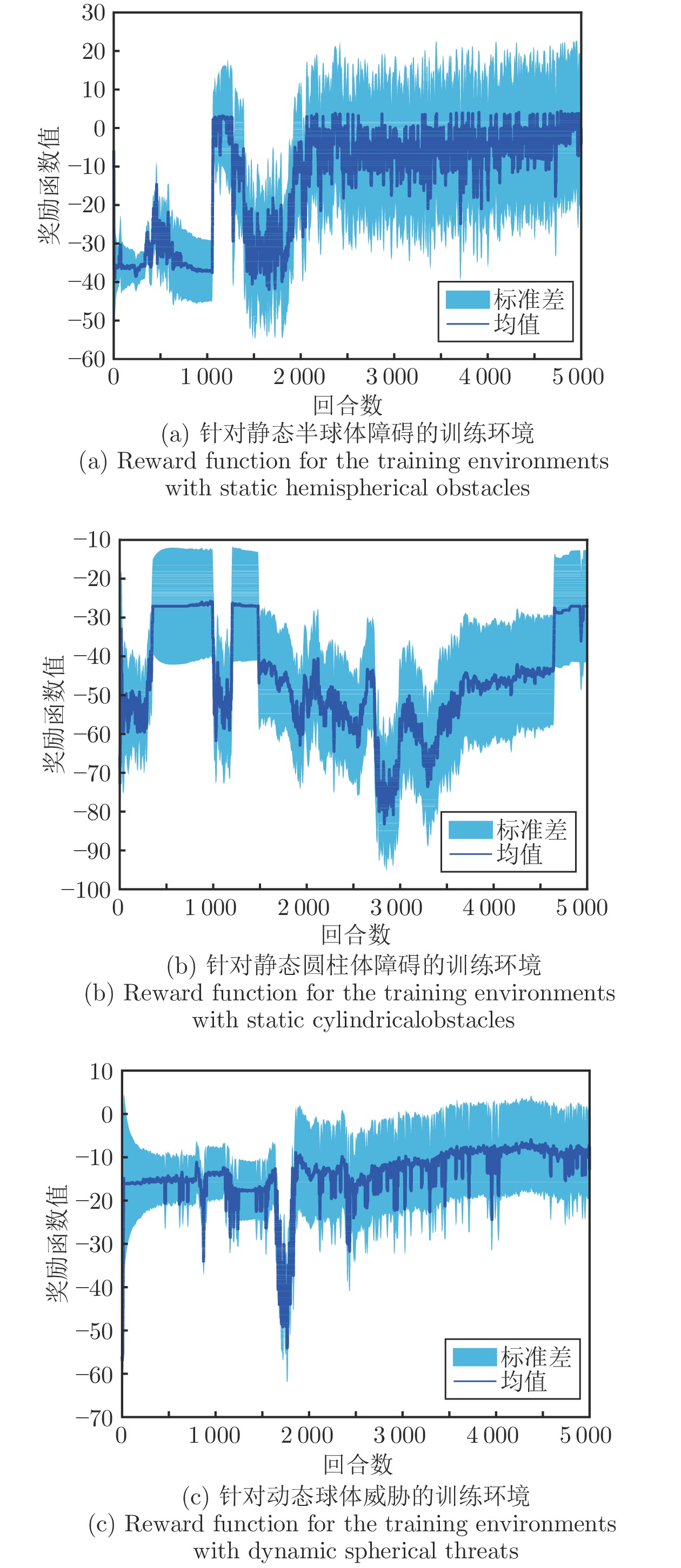
图 13 未采用所提环境建模方法时, DDPG训练过程中的奖励函数情况: 以静态半球体障碍为例
Fig. 13 Reward functions in the DDPG training process when the proposed environment modeling methodis not adopted: Taking the static hemisphericalobstacle as an example
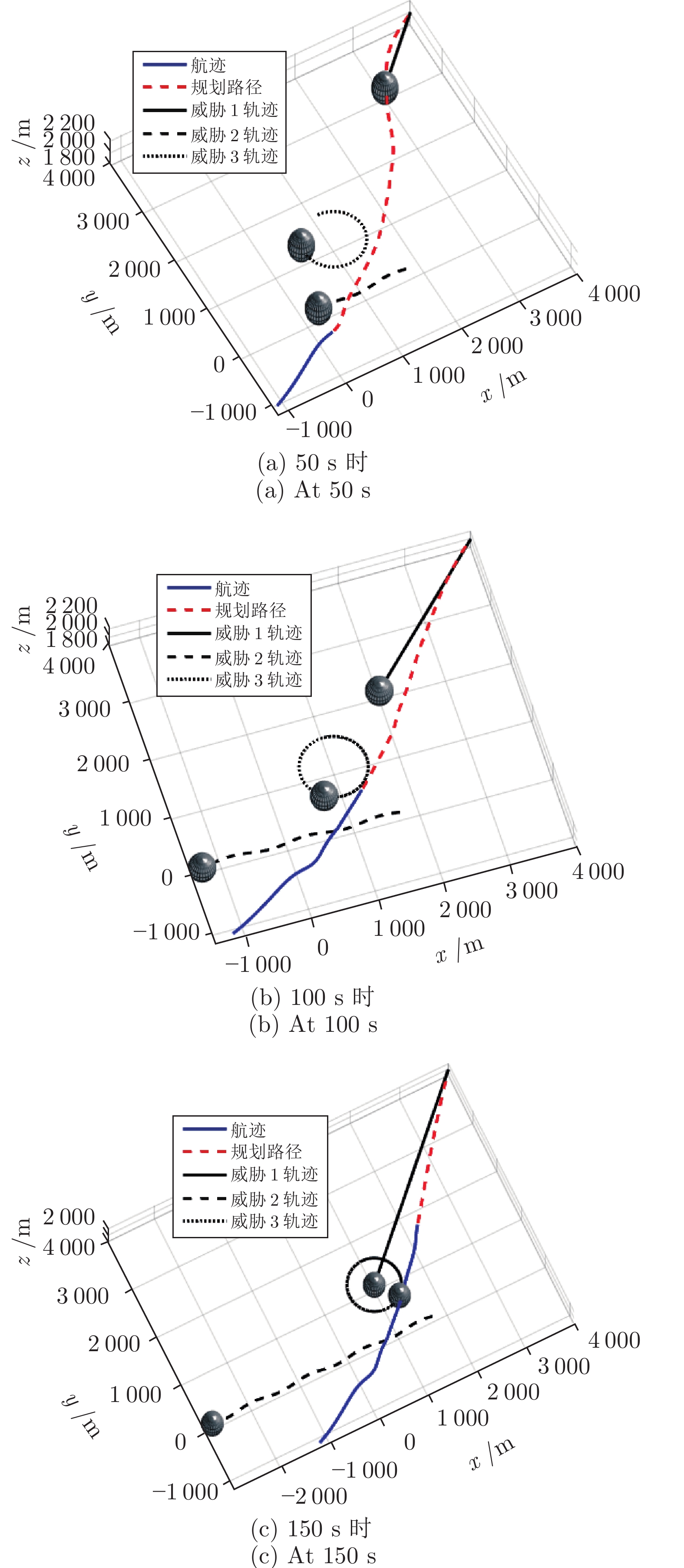
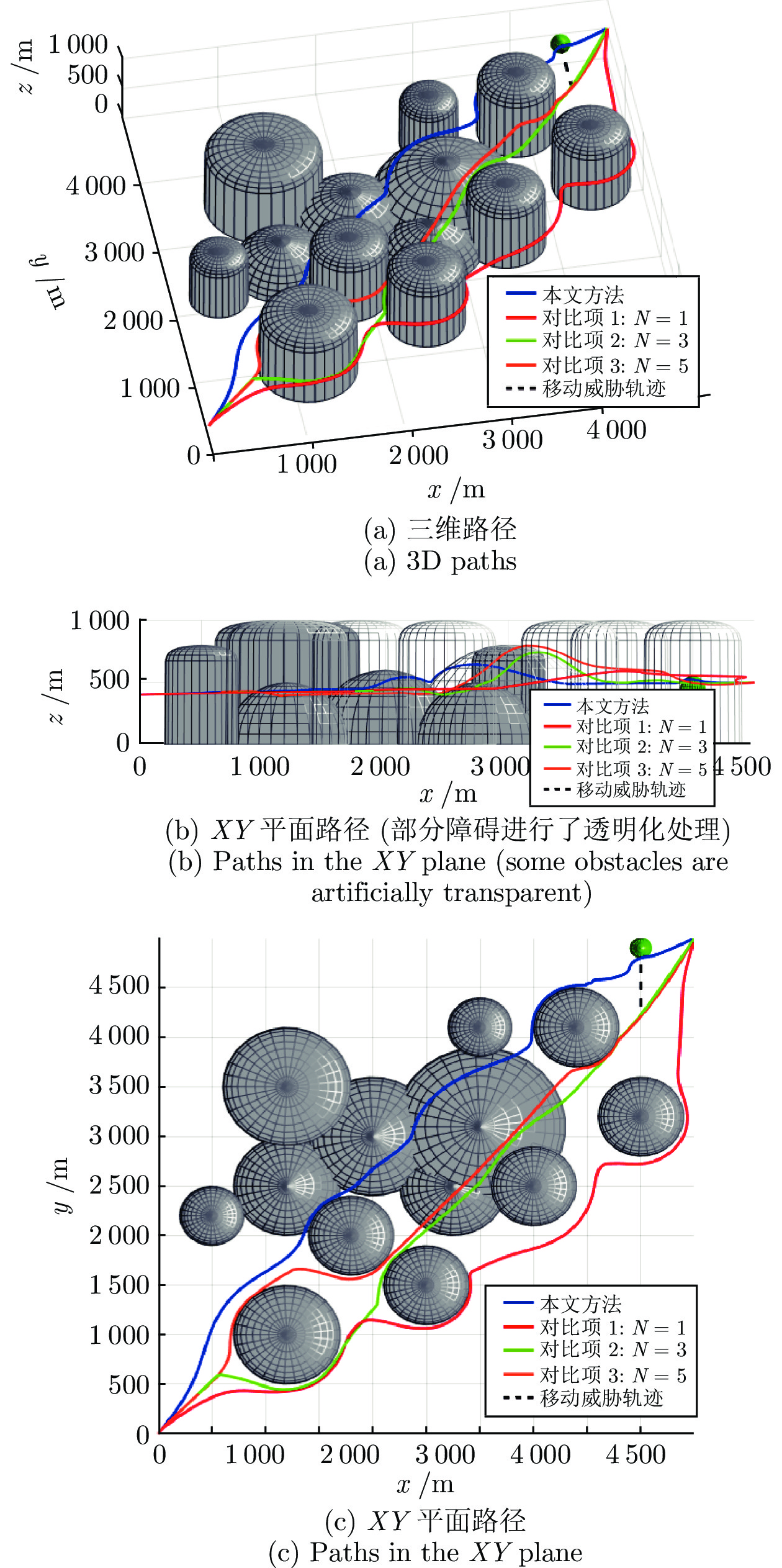
图 14 案例3中不同时刻无人机的航迹与规划路径
Fig. 14 UAV flight paths and planned paths at different times in case 3
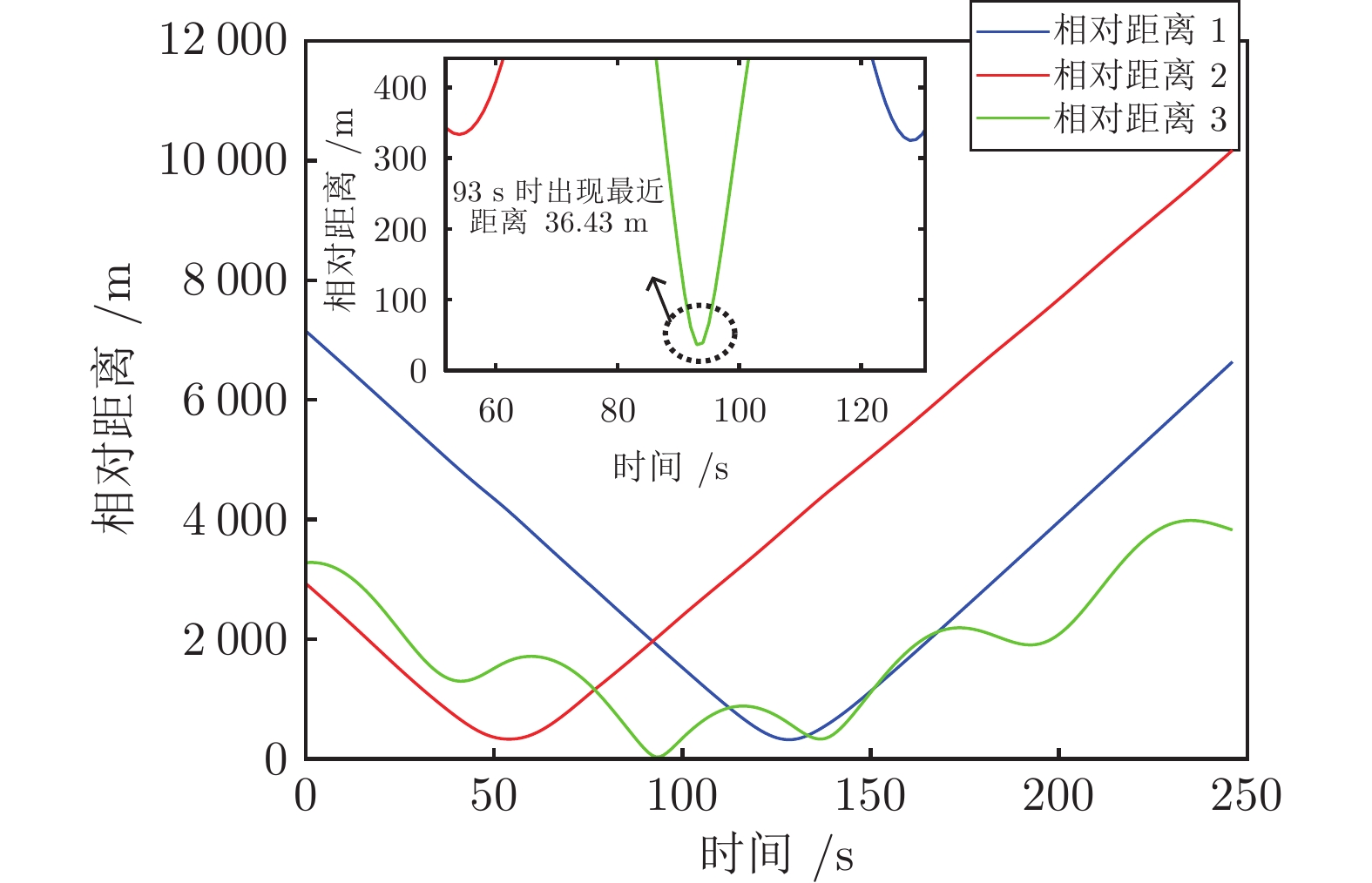
图 15 案例3中与各动态威胁等效表面的最近距离
Fig. 15 Closest distances to the equivalent surface of each dynamic threat in case 3
表 1 案例2中规划路径长度和平滑性指标对比
Table 1 Comparison of the length and the smooth indexes for planned paths in Case 2
指标 本文方法 对比项 1 对比项 2 对比项 3 长度 (km) 7.56 8.49 7.68 7.65 平滑性 0.1318 0.3506 0.1593 0.1528  下载: 导出CSV
下载: 导出CSV
-
[1] 吕洋, 康童娜, 潘泉, 赵春晖, 胡劲文. 无人机感知与规避: 概念, 技术与系统. 中国科学: 信息科学, 2019, 49(5): 520-537 doi: 10.1360/N112018-00318Lyu Yang, Kang Tong-Na, Pan Quan, Zhao Chun-Hui, Hu Jin-Wen. UAV sense and avoidance: Concepts, technologies, and systems. Scientia Sinica Informationis, 2019, 49(5): 520-537 doi: 10.1360/N112018-00318 [2] 刘磊, 高岩, 吴越鹏. 基于生存理论的非完整约束轮式机器人高速避障控制. 控制与决策, 2014, 29(9): 1623-1628Liu Lei, Gao Yan, Wu Yue-Peng. High speed obstacle avoidance control of wheeled mobile robots with non-homonymic constraint based on viability theory. Control and Decision, 2014, 29(9): 1623-1628 [3] Steiner J A, He X, Bourne J R, Leang K K. Open-sector rapid-reactive collision avoidance: Application in aerial robot navigation through outdoor unstructured environments. Robotics and Autonomous Systems, 2019, 112: 211-220 doi: 10.1016/j.robot.2018.11.016 [4] Lindqvist B, Mansouri S S, Agha-mohammadi A, Nikolakopoulos G. Nonlinear MPC for collision avoidance and control of UAVs with dynamic obstacles. IEEE Robotics and Automation Letters, 2020, 5(4): 6001-6008 doi: 10.1109/LRA.2020.3010730 [5] 茹常剑, 魏瑞轩, 戴静, 沈东, 张立鹏. 基于纳什议价的无人机编队自主重构控制方法. 自动化学报, 2013, 39(8): 1349-1359Ru Chang-Jian, Wei Rui-Xuan, Dai Jing, Shen Dong, Zhang Li-Peng. Autonomous reconflguration control method for UAV’s formation based on Nash bargain. Acta Automatica Sinica, 2013, 39(8): 1349-1359 [6] Luo G, Yu J, Mei Y, Zhang S. UAV path planning in mixed-obstacle environment via artificial potential field method improved by additional control force. Asian Journal of Control, 2015, 17(5): 1600-1610 doi: 10.1002/asjc.960 [7] Wu J, Wang H, Zhang M, Yu Y. On obstacle avoidance path planning in unknown 3D environments: A fluid-based framework. ISA Transactions, 2021, 111: 249-264 doi: 10.1016/j.isatra.2020.11.017 [8] 魏瑞轩, 何仁珂, 张启瑞, 许卓凡, 赵晓林. 基于Skinner理论的无人机应急威胁规避方法. 北京理工大学学报, 2016, 36(6): 620-624Wei Rui-Xuan, He Ren-Ke, Zhang Qi-Rui, Xu Zhuo-Fan, Zhao Xiao-Lin. Skinner-based emergency collision avoidance mechanism for UAV. Transactions of Beijing Institute of Technology, 2016, 36(6): 620-624 [9] Hebecker T, Buchholz R, Ortmeier F. Model-based local path planning for UAVs. Journal of Intelligent and Robotic Systems, 2015, 78(1): 127-142 doi: 10.1007/s10846-014-0097-7 [10] 李凯文, 张涛, 王锐, 覃伟健, 贺惠晖, 黄鸿. 基于深度强化学习的组合优化研究进展. 自动化学报, 2021, 47(11): 1001-1028Li Kai-Wen, Zhang Tao, Wang Rui, Qin Wei-Jian, Huang Hong. Research reviews of combinatorial optimization methods based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(11): 1001-1028 [11] 王鼎. 基于学习的鲁棒自适应评判控制研究进展. 自动化学报, 2019, 45(6): 1031-1043Wang Ding. Research progress on learning-based robust adaptive critic control. Acta Automatica Sinica, 2019, 45(6): 1031-1043 [12] Wang D, Ha M, Qiao J. Self-learning optimal regulation for discrete-time nonlinear systems under event-driven formulation. IEEE Transactions on Automatic Control, 2019, 65(3): 1272-1279 [13] Guo T, Jiang N, Li B, Zhu X, Wang Y, Du W. UAV navigation in high dynamic environments: A deep reinforcement learning approach. Chinese Journal of Aeronautics, 2021, 34(2): 479-489 doi: 10.1016/j.cja.2020.05.011 [14] Tai L, Paolo G, Liu M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2017. 31−36 [15] Wang C, Wang J, Shen Y, Zhang X. Autonomous navigation of UAVs in large-scale complex environments: A deep reinforcement learning approach. IEEE Transactions on Vehicular Technology, 2019, 68(3): 2124-2136 doi: 10.1109/TVT.2018.2890773 [16] Wang C, Wang J, Wang J, Zhang X. Deep-reinforcement-learning-based autonomous UAV navigation with sparse rewards. IEEE Internet of Things Journal, 2020, 7(7): 6180-6190 doi: 10.1109/JIOT.2020.2973193 [17] Hu Z, Gao X, Wang K, Zhai Y, Wang Q. Relevant experience learning: A deep reinforcement learning method for UAV auto-nomous motion planning in complex unknown environments. Chinese Journal of Aeronautics, 2021, 34(12): 187-204 [18] Yao P, Wang H, Su Z. Real-time path planning of unmanned aerial vehicle for target tracking and obstacle avoidance in complex dynamic environment. Aerospace Science and Technology, 2015, 47: 269-279 doi: 10.1016/j.ast.2015.09.037 [19] Yao P, Wang H, Su Z. Cooperative path planning with applications to target tracking and obstacle avoidance for multi-UAVs. Aerospace Science and Technology, 2016, 54: 10-22 doi: 10.1016/j.ast.2016.04.002 [20] Wu J, Wang H, Zhang M, Su Z. Cooperative dynamic fuzzy perimeter surveillance: Modeling and fluid-based framework. IEEE Systems Journal, 2020, 14(4): 5210-5220 doi: 10.1109/JSYST.2020.2974869 [21] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning. arXiv preprint arXiv: 1509.02971, 2015. [22] Schaul T, Quan J, Antonoglou I, Silver D. Prioritized experience replay. arXiv preprint arXiv: 1511.05952, 2016. [23] Hou Y, Liu L, Wei Q, Xu X, Chen C. A novel DDPG method with prioritized experience replay. In: Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics. Piscataway, USA: IEEE, 2017. 316−321 [24] Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv: 1412.6980, 2017. [25] Wang Y, He H, Sun C. Learning to navigate through complex dynamic environment with modular deep reinforcement learning. IEEE Transactions on Games, 2018, 10(4): 400-412 doi: 10.1109/TG.2018.2849942 [26] Sutton R S, Modayil J, Delp M, Degris T, Pilarski P M, White A. Horde: A scalable real-time architecture for learning knowledge from unsupervised sensorimotor interaction. In: Proceedings of the 10th International Conference on Autonomous Agen-ts and Multiagent Systems. Richland, USA: 2011. 761−768 [27] Haarnoja T, Zhou A, Abbeel P, Levine S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: Proceedings of the 35th International Conference on Machine Learning. New York, USA: 2018. 1861−1870 [28] Fujimoto S, Hoof H, Meger D. Addressing function approximation error in actor-critic methods. In: Proceedings of the 35th International Conference on Machine Learning. New York, USA: 2018. 1587−1596 [29] Wu J, Wang H, Li N, Su Z. Formation obstacle avoidance: A fluid-based solution. IEEE Systems Journal, 2019, 14(1): 1479-1490 -

 下载:
下载:




计量
- 文章访问数: 2456
- HTML全文浏览量: 1477
- PDF下载量: 536
- 被引次数: 0
