

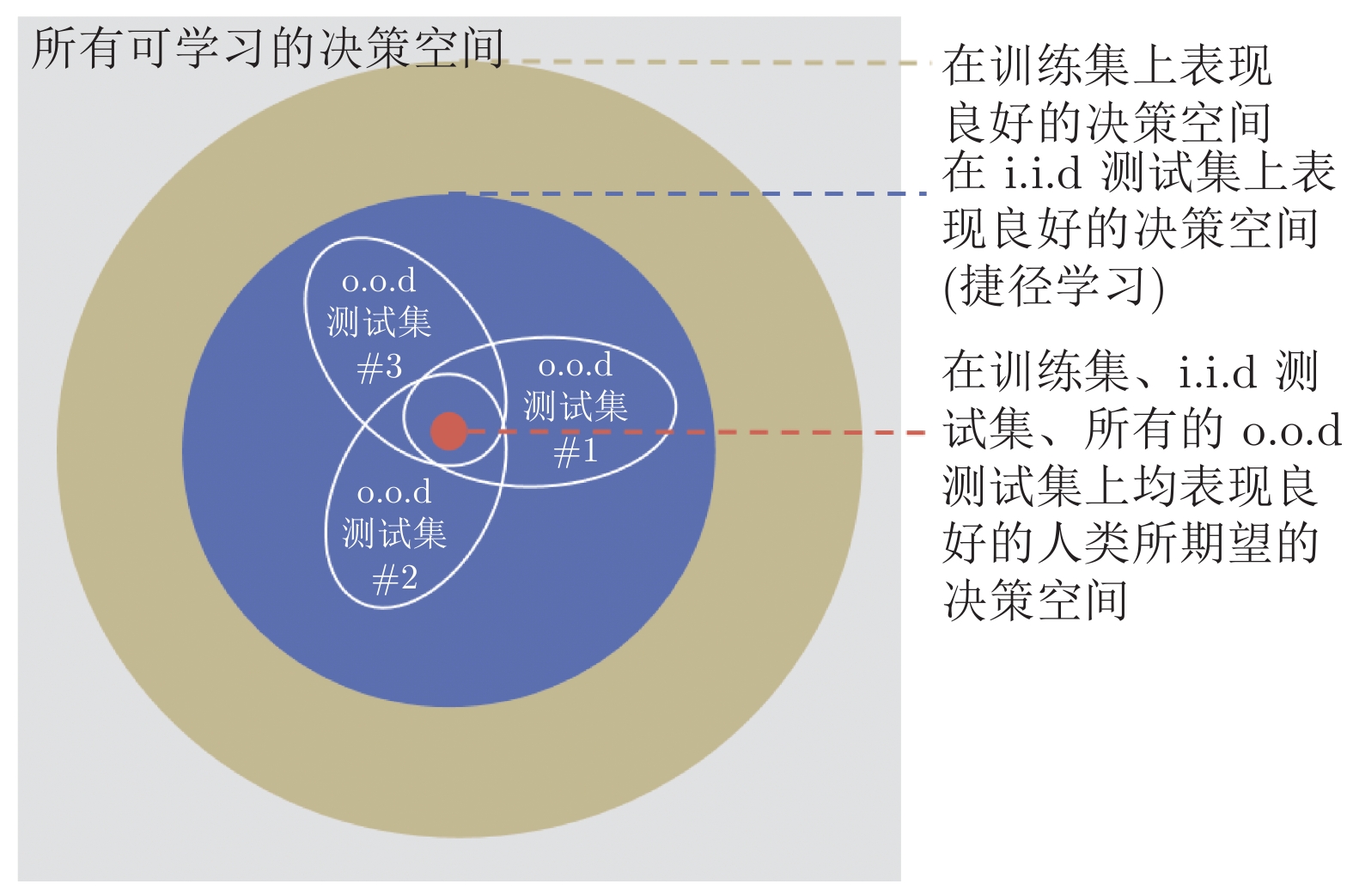
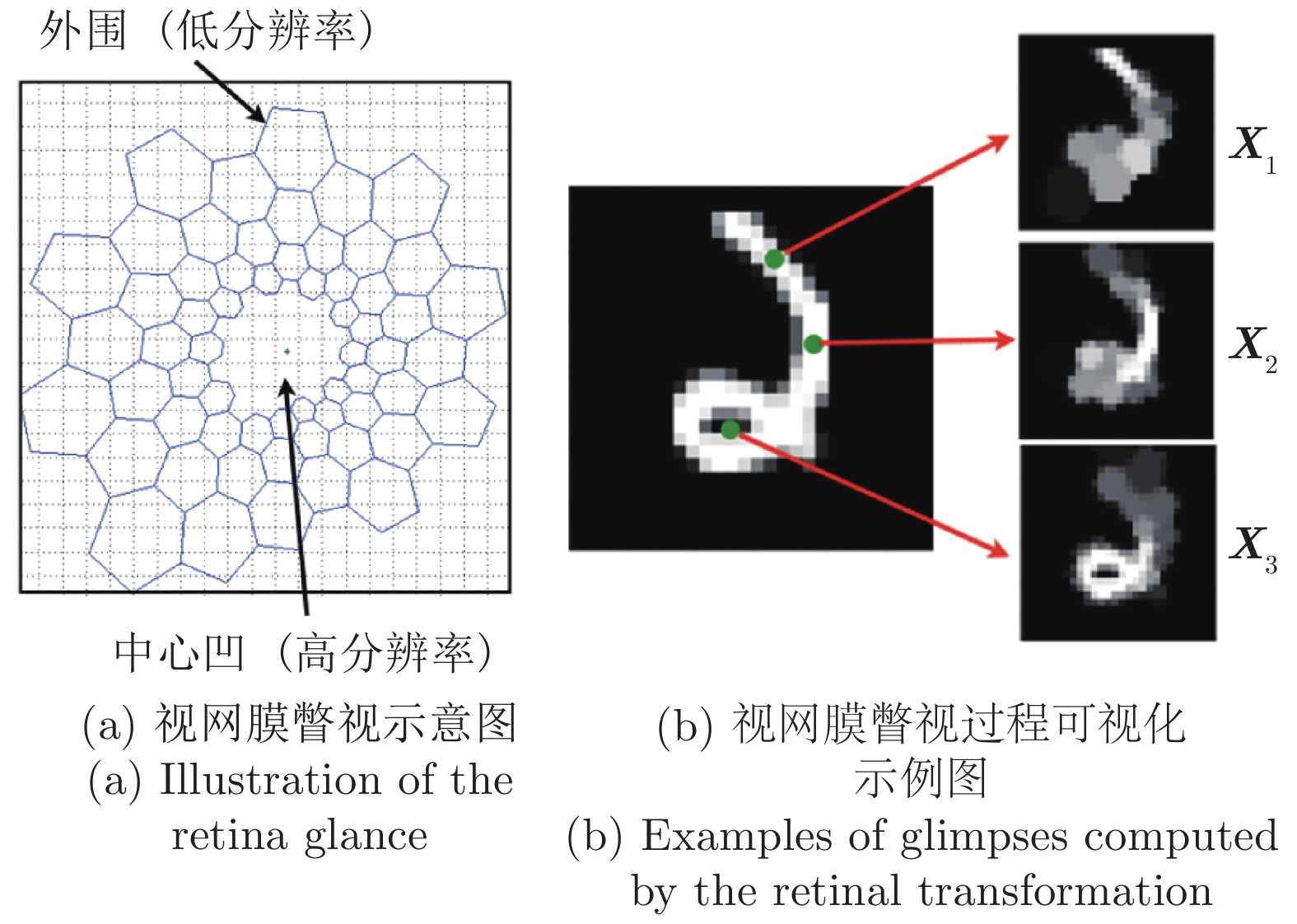
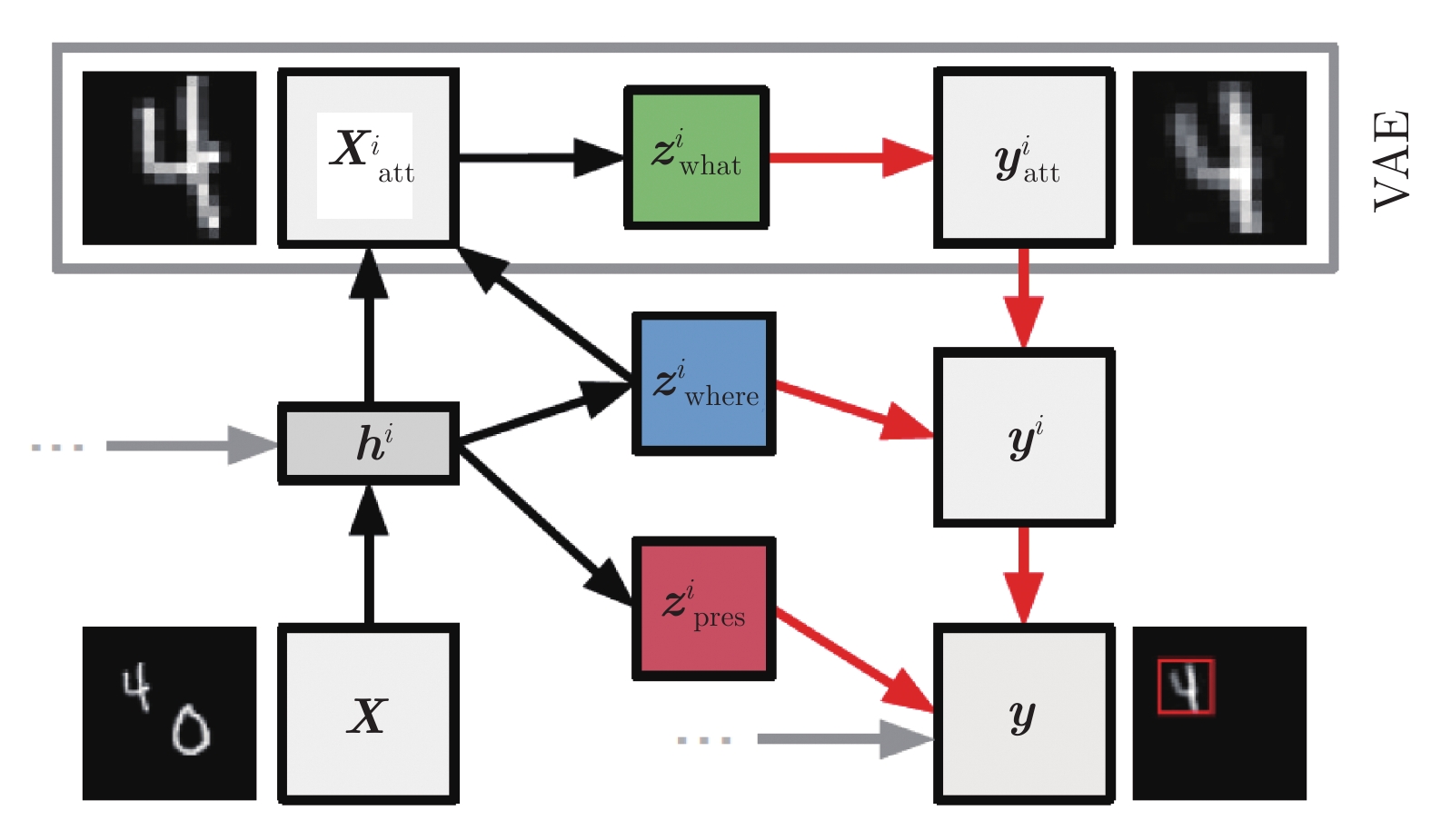
-
摘要: 在大数据时代下, 以高效自主隐式特征提取能力闻名的深度学习引发了新一代人工智能的热潮, 然而其背后黑箱不可解释的“捷径学习”现象成为制约其进一步发展的关键性瓶颈问题. 解耦表征学习通过探索大数据内部蕴含的物理机制和逻辑关系复杂性, 从数据生成的角度解耦数据内部多层次、多尺度的潜在生成因子, 促使深度网络模型学会像人类一样对数据进行自主智能感知, 逐渐成为新一代基于复杂性的可解释深度学习领域内重要研究方向, 具有重大的理论意义和应用价值. 本文系统地综述了解耦表征学习的研究进展, 对当前解耦表征学习中的关键技术及典型方法进行了分类阐述, 分析并汇总了现有各类算法的适用场景并对此进行了可视化实验性能展示, 最后指明了解耦表征学习今后的发展趋势以及未来值得研究的方向.Abstract: In the era of big data, deep learning has triggered the current rise of artificial intelligence which is known for its ability of efficient autonomous implicit feature extraction. However, the unexplainable “shortcut learning” phenomenon behind it has become a key bottleneck restricting its further development. By exploring the complexity of physical mechanism and logical relationship contained in big data, the disentangled representation learning aims to explore the multi-level and multi-scale explanatory generative latent factors behind the data, and prompts the deep neural network model to learn the ability of intelligent human perception. It has gradually become an important research direction in the field of deep learning, with huge theoretical significance and application value. This article systematically reviews the research of disentangled representation learning, classifies and elaborates state-of-the-art algorithms in disentangled representation learning, summarizes the applications of the existing algorithms and compares the performance of existing algorithms through experiments. Finally, the challenges and research trends in the field of disentangled representation learning are discussed.
-
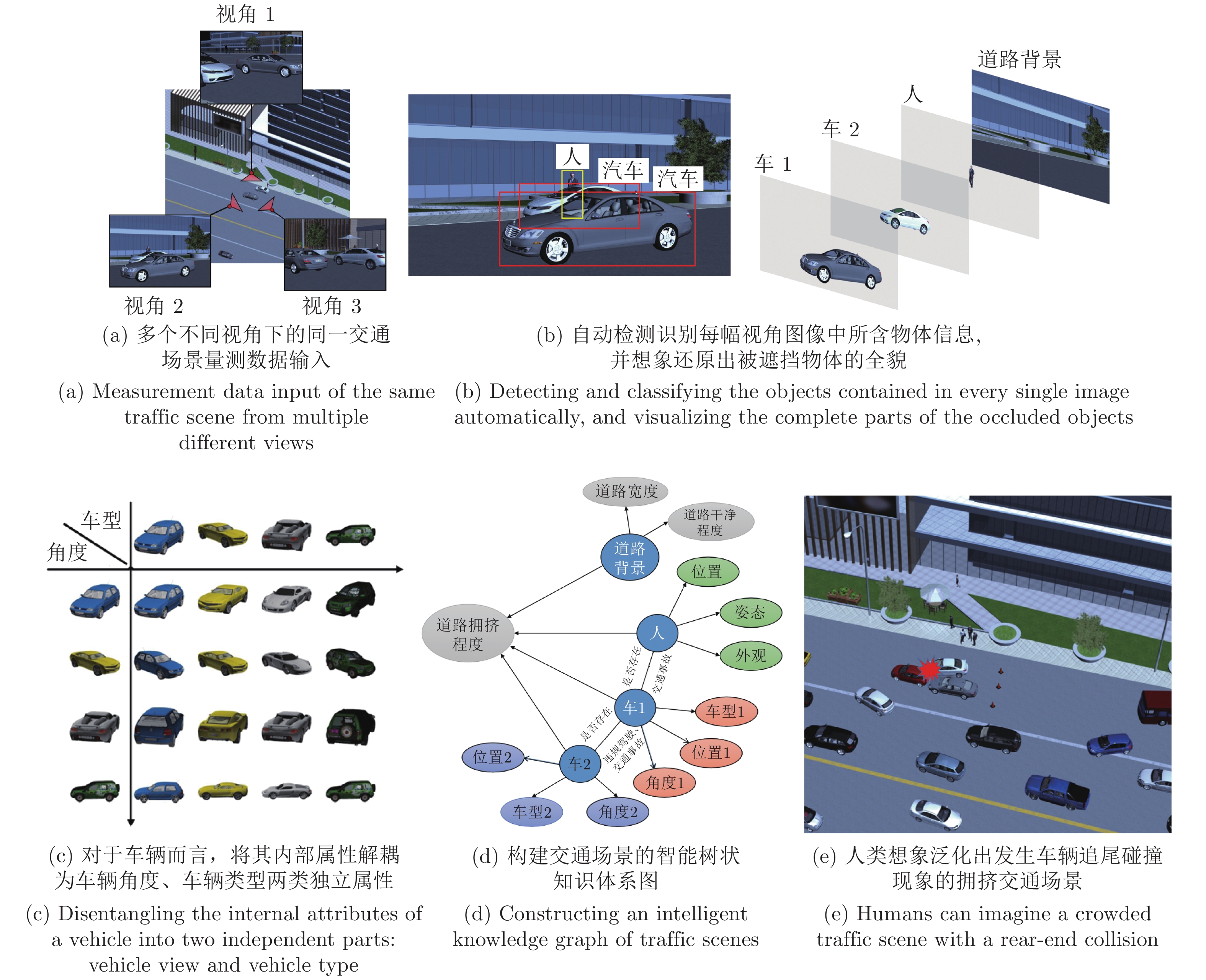
图 1 人类对于交通场景量测数据的层次化智能感知示意图
Fig. 1 Humans' hierarchical intelligent perception of a traffic scene
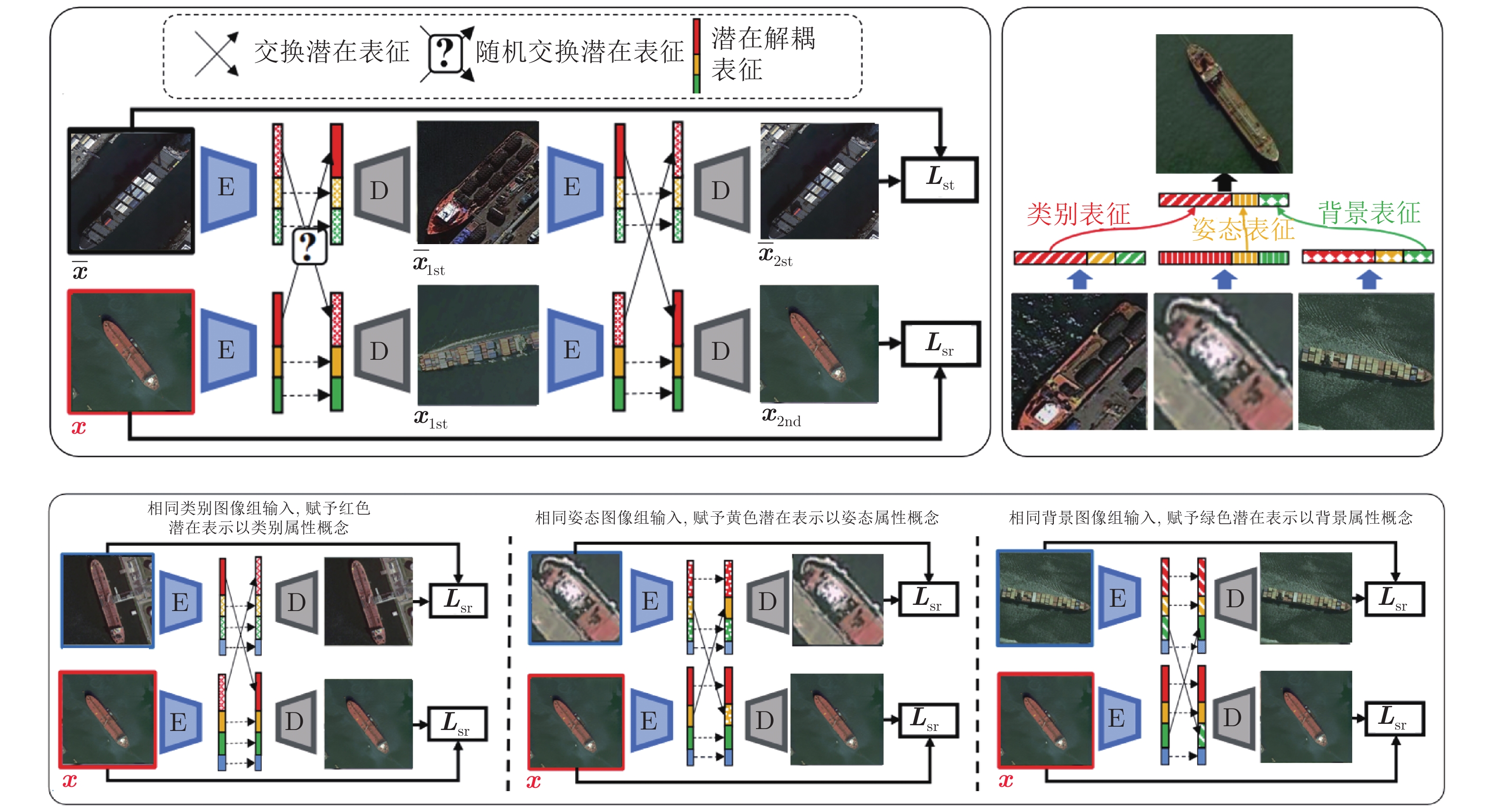
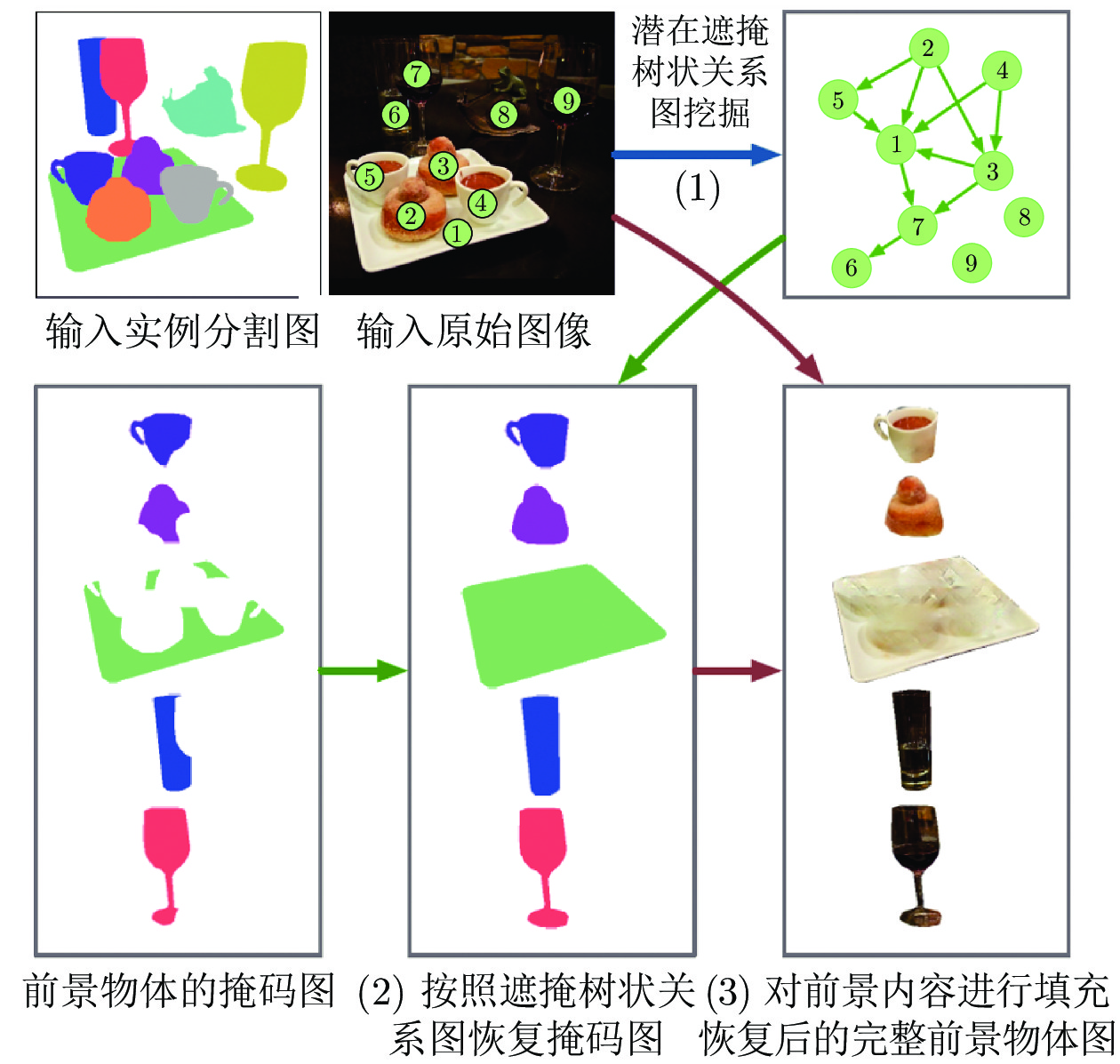

图 14 Factor-VAE[51]算法在3D chairs[103]以及3D faces[104]数据集上的解耦性能展示图. 每一行代表仅有左侧标注的潜在表征取值发生改变时所对应的重构图像变化
Fig. 14 The disentangled performance of Factor-VAE[51] for 3D chairs[103] and 3D faces[104] data sets. Each row represents the change in the image reconstruction when only the specific latent marked on the left change

图 15 AAE[48]算法对于MNIST[99]和SVHN[100]数字数据集中类别与风格属性的解耦表征结果展示图. 图中每一行代表风格类潜在表征保持不变的情况下, 改变类别类潜在表征取值所对应的重构图像变化; 每一列代表类别类潜在表征保持不变的情况下, 改变风格类潜在表征取值所对应的重构图像变化
Fig. 15 The disentangled performance of AAE[48] in the MNIST[99] and SVHN[100] data set. Each row represents the change of the reconstructed images corresponding to the category latent while the style latent remains unchanged; when each column represents the change of the reconstructed images corresponding to the style latent while the category latent is unchanged






表 1 非结构化表征先验归纳偏好方法对比
Table 1 Comparison of unstructured representation priori induction preference methods
工作 正则项 优点 缺点 $\beta$-VAE[46] $-\beta {D_{\mathrm{KL}}}\left( {{q_\phi }(\boldsymbol{z}|\boldsymbol{x})\;{\rm{||}}\;p(\boldsymbol{z})} \right)$ 高$\beta$值促使网络所学到的后验分布与先验分布尽可能服从相似的独立统计特性, 提升解耦性能. 高$\beta$值在提升解耦性能的同时会限制网络的数据表征能力, 直观反映为重构性能降低, 无法很好权衡二者. Understanding
disentangling in
$\beta$-VAE[47]$ -\gamma \left| {\mathrm{KL}\left( {q(\boldsymbol{z}|\boldsymbol{x})\;{\rm{||}}\;p(\boldsymbol{z})} \right) - C} \right| $ 从信息瓶颈角度分析$\beta$-VAE, 在训练过程中渐进增大潜在变量的信息容量$ C $, 能够在一定程度上改善了网络对于数据表征能力与解耦能力间的权衡. 该设计下的潜在变量依旧缺乏明确的物理语义, 且网络增加了信息容量$ C $这一超参数, 需要人为设计其渐进增长趋势. Joint-VAE[53] $- \gamma \left| {\mathrm{KL}\left( { {q_\phi }(\boldsymbol{z}|\boldsymbol{x})\;{\rm{||} }\;p(\boldsymbol{z})} \right) - {C_{ {z} } } } \right|\\- \gamma \left| {\mathrm{KL}\left( { {q_\phi }(\boldsymbol{c}|\boldsymbol{x})\;{\rm{||} }\;p(\boldsymbol{c})} \right) - {C_{ {c} } } } \right|\;$ 运用 Concrete 分布[54] 解决离散型潜在变量的解耦问题. 潜在变量缺乏明确物理语义. AAE[48] ${D_\mathrm{JS} }\left[ { {{\rm{E}}_\phi }\left( \boldsymbol{z} \right)||p\left( \boldsymbol{z} \right)} \right]$ 利用对抗网络完成累积后验分布与先验分布间的相似性度量, 使得潜在变量的表达空间更大, 表达能力更强. 面临对抗网络所存在的鞍点等训练问题[50]. DIP-VAE[49] $- {\lambda _{od} }\sum\nolimits_{i \ne j} {\left[ {Co{v_{ {q_\phi }\left( \boldsymbol{z} \right)} }\left[ \boldsymbol{z} \right]} \right]} _{ij}^2\\- {\lambda _d}\sum\nolimits_i { { {\left( { { {\left[ {Co{v_{ {q_\phi }\left( \boldsymbol{z} \right)} }\left[ \boldsymbol{z} \right]} \right]}_{ii} } - {1 } } \right)}^2} }$ 设计更简便的矩估计项替代 AAE[48] 中对抗网络的设计, 计算更为简洁有效. 该设计仅适用于潜在变量服从高斯分布的情况且并未限制均值矩或更高阶矩, 适用范围有限. Factor-VAE[51] ${D_\mathrm{JS}}(q(\boldsymbol{z})||\prod\nolimits_{i = 1}^d {q({z_i})})$ 设计对抗网络直接鼓励累积后验分布$q({\boldsymbol{z}})$服从因子分布, 进一步改善了网络在强表征能力与强解耦能力间的权衡. 面临对抗网络所存在的鞍点等训练问题[50]. RF-VAE[56] ${D_\mathrm{JS}}(q(\boldsymbol{r} \circ \boldsymbol{z})||\prod\nolimits_{i = 1}^d {q({r_i \circ z_i})})$ 引入相关性指标${\boldsymbol{r}}$使得网络对于无关隐变量间的解耦程度不作约束. 相关性指标${\boldsymbol{r}}$也需要由网络学习得到, 加深了网络训练的复杂性. $\beta $-TCVAE[52] $- \alpha {I_q}(\boldsymbol{x};\boldsymbol{z}) -\\ \beta \mathrm{KL}\left( {q\left( \boldsymbol{z} \right)||\prod\nolimits_{i = 1}^d {q\left( { {z_i} } \right)} } \right)\\- \gamma \sum\nolimits_j {{\rm{KL}}(q({z_j})||p({z_i}))}$ 证明了TC总相关项$\mathrm{KL}(q(\boldsymbol{z})||\prod\nolimits_{i = 1}^d q({z_i}) )$
的重要性并赋予各个正则项不同的权重值构成新的优化函数使其具有更强的表示能力.引入更多的超参需要人为调试.  下载: 导出CSV
下载: 导出CSV
表 2 不同归纳偏好方法对比
Table 2 Comparisons of methods based on different inductive bias
归纳偏好分类 模型 简要描述 适用范围 数据集 非结构化表征先验 $ \beta $-VAE[46]
InfoGAN[55]
文献 [47]
Joint-VAE[53]
AAE[48]
DIP-VAE[49]
Factor-VAE[51]
RF-VAE[56]
$ \beta $-TCVAE[52]在网络优化过程中施加表1中不同的先验正则项, 能够促使网络学习到的潜在表征具备一定的解耦性能. 但该类方法并未涉及足够的显式物理语义约束, 网络不一定按照人类理解的方式进行解耦, 因此该类方法一般用于规律性较强的简易数据集中. 适用于解耦表征存在显著可分离属性的简易数据集, 如人脸数据集、数字数据集等. MNIST[99]; SVHN[100]; CelebA[101]; 2D Shapes[102]; 3D Chairs[103]; dSprites[102]; 3D Faces[104] 结构化模型
先验顺序深度递归网络 DRAW[62]
AIR[64]
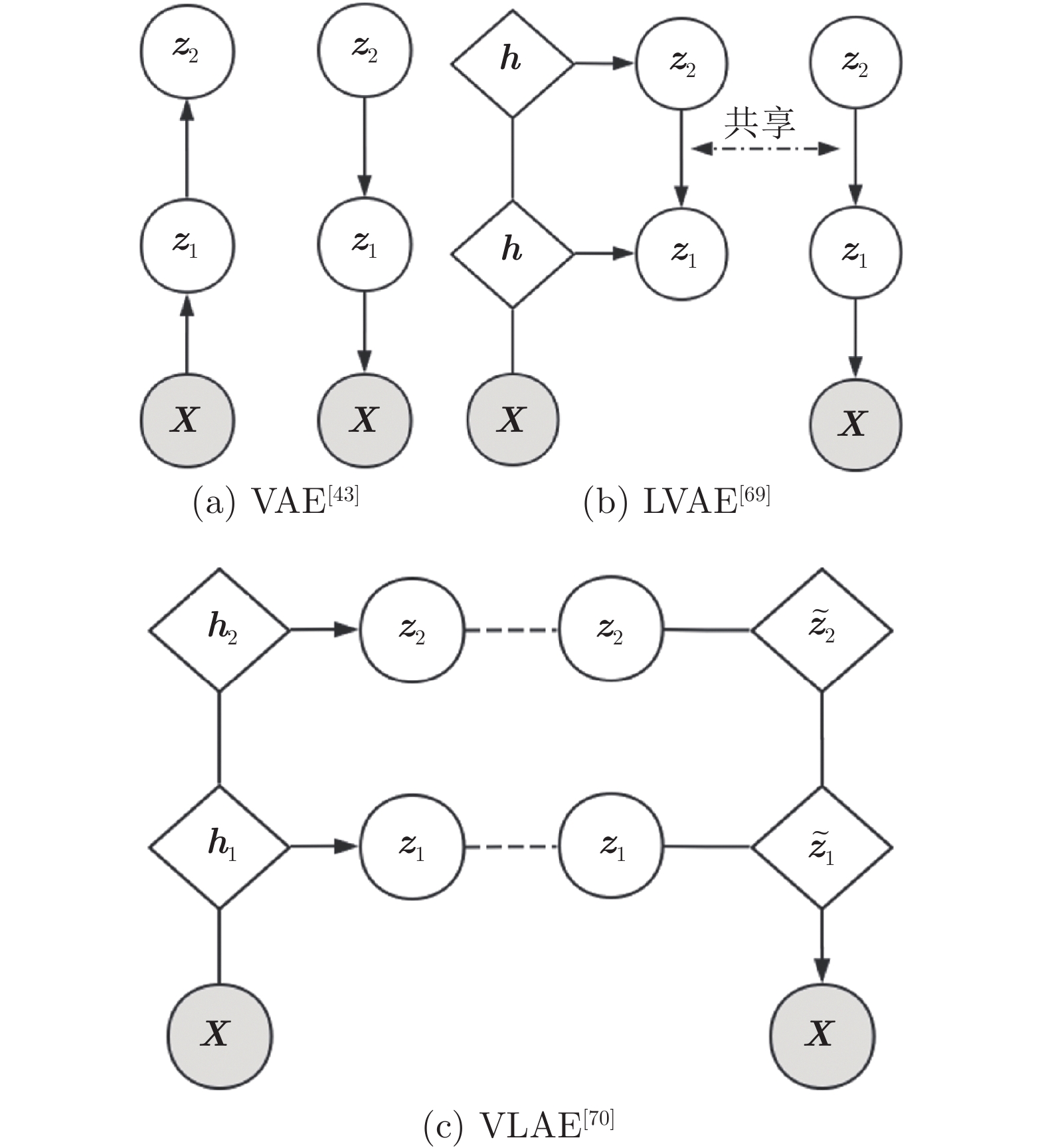
SQAIR[66]通过构建顺序深度递归网络架构, 可以在执行决策时反复结合历史状态特征, 实现如简易场景下的检测、跟踪等. 适用于需要关联记忆的多次决策任务场景. 3D scenes[64]; Multi-MNIST[64]; dSprites[102]; Moving-MNIST[66]; Omniglot[105]; Pedestrian CCTV data[106] 层次深度梯形网络 VLAE[70]
文献 [71]
HFVAE[72]使用层次梯形网络模拟人类由浅入深的层次化认知过程, 促使每层潜在变量代表着不同的涵义, 可用作聚类等任务. 适用于简易数据集下由浅入深的属性挖掘. MNIST[99]; CelebA[101]; SVHN[100]; dSprites[102] 树形网络 RCN[74]
LTVAE[73]使用树形网络模拟人类高级神经元间的横向交互过程, 完成底层特征解耦的同时高层特征语义交互, 可用作聚类、自然场景文本识别等任务. 适用于底层特征解耦共享, 高级特征耦合交互的场景任务. CAPTCHA[107]; ICDAR-13 Robust Reading[107]; MNIST[99]; HHAR[73]; Reuters[108]; STL-10[73] 物理知识
先验分组数据的相关性 MLVAE[75]
文献 [77]
GSL[78]
文献 [81]
文献 [82]
文献 [83]
文献 [85]
文献 [86]通过交换、共享潜在表征、限制互信息相关性、循环回归等方式, 实现分组数据相关因子的解耦表征. 后续可单独利用有效因子表征实现分类、分割、属性迁移数据集生成等任务. 适用于分组数据的相关有效属性挖掘. MNIST[99]; RaFD[109]; Fonts[78]; CelebA[101]; Colored-MNIST[81]; dSprites[102]; MS-Celeb-1M[110]; CUB birds[111]; ShapeNet[112]; iLab-20M[113]; 3D Shapes[81]; IAM[114]; PKU vehicle id[115]; Sentinel-2[116]; Norb[117]; BBC Pose dataset[118]; NTU[119]; KTH[120]; Deep fashion[121]; Cat head[122]; Human3.6M[123]; Penn action[124]; 3D cars[125] 基于对象的物理空间组合关系 MixNMatch[89] 结合数据组件化、层次化生成过程实现单目标场景的背景、姿态、纹理、形状解耦表征. 适用于单目标场景属性迁移的数据集生成. CUB birds[111]; Stanford dogs[126]; Stanford cars[125] 文献 [83] 考虑单目标多部件间的组合关系. 适用于人类特定部位、面部表情转换等数据生成. Cat head[122]; Human 3.6M[123]; Penn action[124] SCAE[92] 提出了胶囊网络的新思想, 考虑多目标、多部件间的组合关联关系. 适用于简易数据集的目标、部件挖掘. MNIST[99]; SVHN[100]; CIFAR10 TAGGER[88]
IODINE[95]
MONET[96]考虑多目标场景的逐次单目标解耦表征方式. 适用于简易多目标场景的目标自主解译任务. Shapes[127]; Textured MNIST[88]; CLEVR[128]; dSprites[102]; Tetris[95]; Objects room[96] 文献 [87] 引入目标空间逻辑树状图, 解耦多目标复杂场景的遮掩关系, 可用于去遮挡等任务. 适用于自然复杂场景下少量目标的去遮挡任务. KINS[129]; COCOA[112] 文献 [98] 将目标三维本体特征视为目标内禀不变属性进行挖掘, 解决视角、尺度大差异问题, 有望实现检测、识别、智能问答等高级场景理解任务. 适用于简易数据集的高级场景理解. CLEVR[128]
下载: 导出CSV
-
[1] 段艳杰, 吕宜生, 张杰, 赵学亮, 王飞跃. 深度学习在控制领域的研究现状与展望. 自动化学报, 2016, 42(5): 643−654Duan Yan-Jie, Lv Yi-Sheng, Zhang Jie, Zhao Xue-Liang, Wang Fei-Yue. Deep learning for control: The state of the art and prospects. Acta Automatica Sinica, 2016, 42(5): 634−654 [2] 王晓峰, 杨亚东. 基于生态演化的通用智能系统结构模型研究. 自动化学报, 2020, 46(5): 1017−1030Wang Xiao-Feng, Yang Ya-Dong. Research on structure model of general intelligent system based on ecological evolution. Acta Automatica Sinica, 2020, 46(5): 1017−1030 [3] Amizadeh S, Palangi H, Polozov O, Huang Y C, Koishida K. Neuro-Symbolic visual reasoning: Disentangling “visual” from “reasoning”. In: Proceedings of the 37th International Conference on Machine Learning. Vienna, Austria: PMLR, 2020. 279−290 [4] Adel T, Zhao H, Turner R E. Continual learning with adaptive weights (CLAW). In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. [5] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504−507 doi: 10.1126/science.1127647 [6] Lee G, Li H Z. Modeling code-switch languages using bilingual parallel corpus. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA, USA: ACL, 2020. 860−870 [7] Chen X H. Simulation of English speech emotion recognition based on transfer learning and CNN neural network. Journal of Intelligent & Fuzzy Systems, 2021, 40(2): 2349−2360 [8] Lü Y, Lin H, Wu P P, Chen Y T. Feature compensation based on independent noise estimation for robust speech recognition. EURASIP Journal on Audio, Speech, and Music Processing, 2021, 2021(1): Article No. 22 doi: 10.1186/s13636-021-00213-8 [9] Torfi A, Shirvani R A, Keneshloo Y, Tavaf N, Fox E A. Natural language processing advancements by deep learning: A survey. [Online], available: https://arxiv.org/abs/2003.01200, February 27, 2020 [10] Stoll S, Camgoz N C, Hadfield S, Bowden R. Text2Sign: Towards sign language production using neural machine translation and generative adversarial networks. International Journal of Computer Vision, 2020, 128(4): 891−908 doi: 10.1007/s11263-019-01281-2 [11] He P C, Liu X D, Gao J F, Chen W Z. DeBERTa: Decoding-enhanced Bert with disentangled attention. In: Proceedings of the 9th International Conference on Learning Representations. Austria: ICLR, 2021. [12] Shi Y C, Yu X, Sohn K, Chandraker M, Jain A K. Towards universal representation learning for deep face recognition. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 6816−6825 [13] Ni T G, Gu X Q, Zhang C, Wang W B, Fan Y Q. Multi-Task deep metric learning with boundary discriminative information for cross-age face verification. Journal of Grid Computing, 2020, 18(2): 197−210 doi: 10.1007/s10723-019-09495-x [14] Shi X, Yang C X, Xia X, Chai X J. Deep cross-species feature learning for animal face recognition via residual interspecies equivariant network. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 667−682 [15] Chen J T, Lei B W, Song Q Y, Ying H C, Chen D Z, Wu J. A hierarchical graph network for 3D object detection on point clouds. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 389−398 [16] 蒋弘毅, 王永娟, 康锦煜. 目标检测模型及其优化方法综述. 自动化学报, 2021, 47(6): 1232−1255Jiang Hong-Yi, Wang Yong-Juan, Kang Jin-Yu. A survey of object detection models and its optimization methods. Acta Automatica Sinica, 2021, 47(6): 1232−1255 [17] Xu Z J, Hrustic E, Vivet D. CenterNet heatmap propagation for real-time video object detection. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 220−234 [18] Zhang D W, Tian H B, Han J G. Few-cost salient object detection with adversarial-paced learning. [Online], available: https://arxiv.org/abs/2104.01928, April 5, 2021 [19] 张慧, 王坤峰, 王飞跃. 深度学习在目标视觉检测中的应用进展与展望. 自动化学报, 2017, 43(8): 1289−1305Zhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances and perspectives on applications of deep learning in visual object detection. Acta Automatica Sinica, 2017, 43(8): 1289−1305 [20] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436−444 doi: 10.1038/nature14539 [21] Geirhos R, Jacobsen J H, Michaelis C, Zemel R, Brendel W, Bethge M, et al. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2020, 2(11): 665−673 doi: 10.1038/s42256-020-00257-z [22] Minderer M, Bachem O, Houlsby N, Tschannen M. Automatic shortcut removal for self-supervised representation learning. In: Proceedings of the 37th International Conference on Machine Learning. San Diego, USA: JMLR, 2020. 6927−6937 [23] Ran X M, Xu M K, Mei L R, Xu Q, Liu Q Y. Detecting out-of-distribution samples via variational auto-encoder with reliable uncertainty estimation. [Online], available: https://arxiv.org/abs/2007.08128v3, November 1, 2020 [24] Charakorn R, Thawornwattana Y, Itthipuripat S, Pawlowski N, Manoonpong P, Dilokthanakul N. An explicit local and global representation disentanglement framework with applications in deep clustering and unsupervised object detection. [Online], available: https://arxiv.org/abs/2001.08957, February 24, 2020 [25] 张钹, 朱军, 苏航. 迈向第三代人工智能. 中国科学: 信息科学, 2020, 50(9): 1281−1302 doi: 10.1360/SSI-2020-0204Zhang Bo, Zhu Jun, Su Hang. Toward the third generation of artificial intelligence. Scientia Sinica Informationis, 2020, 50(9): 1281−1302 doi: 10.1360/SSI-2020-0204 [26] Lake B M, Ullman T D, Tenenbaum J B, Gershman S J. Building machines that learn and think like people. Behavioral and Brain Sciences, 2017, 40: Article No. e253 doi: 10.1017/S0140525X16001837 [27] Geirhos R, Meding K, Wichmann F A. Beyond accuracy: Quantifying trial-by-trial behaviour of CNNs and humans by measuring error consistency. [Online], available: https://arxiv.org/abs/2006.16736v3, December 18, 2020 [28] Regazzoni C S, Marcenaro L, Campo D, Rinner B. Multisensorial generative and descriptive self-awareness models for autonomous systems. Proceedings of the IEEE, 2020, 108(7): 987−1010 doi: 10.1109/JPROC.2020.2986602 [29] Wang T, Huang J Q, Zhang H W, Sun Q R. Visual commonsense R-CNN. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 10757−10767 [30] Wang T, Huang J Q, Zhang H W, Sun Q R. Visual commonsense representation learning via causal inference. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, USA: IEEE, 2020. 1547−1550 [31] Schölkopf B, Locatello F, Bauer S, Ke N R, Kalchbrenner N, Goyal A, et al. Toward causal representation learning. Proceedings of the IEEE, 2021, 109(5): 612−634 doi: 10.1109/JPROC.2021.3058954 [32] Locatello F, Tschannen M, Bauer S, Rätsch G, Schölkopf B, Bachem O. Disentangling factors of variations using few labels. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. [33] Dittadi A, Träuble F, Locatello F, Wüthrich M, Agrawal V, Winther O, et al. On the transfer of disentangled representations in realistic settings. In: Proceedings of the 9th International Conference on Learning Representations. Austria: ICLR, 2021. [34] Tschannen M, Bachem O, Lucic M. Recent advances in autoencoder-based representation learning. [Online], available: https://arxiv.org/abs/1812.05069, December 12, 2018 [35] Shu R, Chen Y N, Kumar A, Ermon S, Poole B. Weakly supervised disentanglement with guarantees. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. [36] Kim H, Shin S, Jang J, Song K, Joo W, Kang W, et al. Counterfactual fairness with disentangled causal effect variational autoencoder. In: Proceedings of the 35th Conference on Artificial Intelligence. Palo Alto, USA, 2021. 8128−8136 [37] Locatello F, Bauer S, Lucic M, Rätsch G, Gelly S, Schölkopf B, et al. Challenging common assumptions in the unsupervised learning of disentangled representations. In: Proceedings of the 36th International Conference on Machine Learning. JMLR, 2019. 4114−4124 [38] Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1798−1828 doi: 10.1109/TPAMI.2013.50 [39] Sikka H. A Deeper Look at the unsupervised learning of disentangled representations in Beta-VAE from the perspective of core object recognition. [Online], available: https://arxiv.org/abs/2005.07114, April 25, 2020. [40] Locatello F, Poole B, Rätsch G, Schölkopf B, Bachem O, Tschannen M. Weakly-supervised disentanglement without compromises. In: Proceedings of the 37th International Conference on Machine Learning. San Diego, USA: JMLR, 2020. 6348−6359 [41] 翟正利, 梁振明, 周炜, 孙霞. 变分自编码器模型综述. 计算机工程与应用, 2019, 55(3): 1−9 doi: 10.3778/j.issn.1002-8331.1810-0284Zhai Zheng-Li, Liang Zhen-Ming, Zhou Wei, Sun Xia. Research overview of variational auto-encoders models. Computer Engineering and Applications, 2019, 55(3): 1−9 doi: 10.3778/j.issn.1002-8331.1810-0284 [42] Schmidhuber J. Learning factorial codes by predictability minimization. Neural Computation, 1992, 4(6): 863−879 doi: 10.1162/neco.1992.4.6.863 [43] Kingma D P, Welling M. Auto-encoding variational Bayes. [Online], available: https://arxiv.org/abs/1312.6114, May 1, 2014 [44] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2014. 2672−2680 [45] 林懿伦, 戴星原, 李力, 王晓, 王飞跃. 人工智能研究的新前线: 生成式对抗网络. 自动化学报, 2018, 44(5): 775−792Lin Yi-Lun, Dai Xing-Yuan, Li Li, Wang Xiao, Wang Fei-Yue. The new frontier of AI research: Generative adversarial networks. Acta Automatica Sinica, 2018, 44(5): 775−792 [46] Higgins I, Matthey L, Pal A, Burgess C, Glorot X, Botvinick M, et al. Beta-vae: Learning basic visual concepts with a constrained variational framework. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: ICLR, 2017. [47] Burgess C P, Higgins I, Pal A, Matthey L, Watters N, Desjardins G, et al. Understanding disentangling in Beta-VAE. [Online], available: https://arxiv.org/abs/1804.03599, April 10, 2018 [48] Makhzani A, Shlens J, Jaitly N, Goodfellow I, Frey B. Adversarial autoencoders. [Online], available: https://arxiv.org/abs/1511.05644, May 25, 2016. [49] Kumar A, Sattigeri P, Balakrishnan A. Variational inference of disentangled latent concepts from unlabeled observations. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. [50] Arjovsky M, Bottou L. Towards principled methods for training generative adversarial networks. [Online], available: https://arxiv.org/abs/1701.04862, January 17, 2017 [51] Kim H, Mnih A. Disentangling by factorising. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: JMLR, 2018. 2649−2658 [52] Chen T Q, Li X C, Grosse R B, Duvenaud D. Isolating sources of disentanglement in variational autoencoders. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: NIPS, 2018. 2615−2625 [53] Dupont E. Learning disentangled joint continuous and discrete representations. [Online], available: https://arxiv.org/abs/1804.00104v3, October 22, 2018. [54] Maddison C J, Mnih A, Teh Y W. The concrete distribution: A continuous relaxation of discrete random variables. [Online], available: https://arxiv.org/abs/1611.00712, March 5, 2017. [55] Chen X, Duan Y, Houthooft R, Schulman J, Sutskever I, Abbeel P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. NIPS, 2016. 2180−2188 [56] Kim M, Wang Y T, Sahu P, Pavlovic V. Relevance factor VAE: Learning and identifying disentangled factors. [Online], available: https://arxiv.org/abs/1902.01568, February 5, 2019. [57] Grathwohl W, Wilson A. Disentangling space and time in video with hierarchical variational auto-encoders. [Online], available: https://arxiv.org/abs/1612.04440, December 19, 2016. [58] Kim M, Wang Y T, Sahu P, Pavlovic V. Bayes-factor-VAE: Hierarchical Bayesian deep auto-encoder models for factor disentanglement. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 2979−2987 [59] Montero M L, Ludwig C J H, Costa R P, Malhotra G, Bowers J S. The role of disentanglement in generalisation. In: Proceedings of the 9th International Conference on Learning Representations. Austria: ICLR, 2021. [60] Larochelle H, Hinton G E. Learning to combine foveal glimpses with a third-order boltzmann machine. Advances in Neural Information Processing Systems, 2010, 23: 1243−1251 [61] Mnih V, Heess N, Graves A, Kavukcuoglu K. Recurrent models of visual attention. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2014. 2204−2212 [62] Gregor K, Danihelka I, Graves A, Rezende D J, Wierstra D. DRAW: A recurrent neural network for image generation. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: JMLR, 2015. 1462−1471 [63] Henderson J M, Hollingworth A. High-level scene perception. Annual Review of Psychology, 1999, 50(1): 243−271 doi: 10.1146/annurev.psych.50.1.243 [64] Eslami S M A, Heess N, Weber T, Tassa Y, Szepesvari D, Kavukcuoglu K, et al. Attend, infer, repeat: Fast scene understanding with generative models. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 3233−3241 [65] Crawford E, Pineau J. Spatially invariant unsupervised object detection with convolutional neural networks. In: Proceedings of the 33rd Conference on Artificial Intelligence. California, USA: AAAI, 2019. 3412−3420 [66] Kosiorek A R, Kim H, Posner I, Teh Y W. Sequential attend, infer, repeat: Generative modelling of moving objects. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: NIPS, 2018. 8615−8625 [67] Santoro A, Raposo D, Barrett D G T, Malinowski M, Pascanu R, Battaglia P W, et al. A simple neural network module for relational reasoning. In: Proceedings of the 31th International Conference on Neural Information Processing Systems. Long Beach, USA: NIPS, 2017. 4967−4976 [68] Massague A C, Zhang C, Feric Z, Camps O I, Yu R. Learning disentangled representations of video with missing data. In: Proceedings of the 34th Conference on Neural Information Processing Systems. Vancouver, Canada: California, USA, 2020. 3625−3635 [69] Sønderby C K, Raiko T, Maaløe L, Sønderby S K, Winther O. Ladder variational autoencoders. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 3745−3753 [70] Zhao S J, Song J M, Ermon S. Learning hierarchical features from deep generative models. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: JMLR, 2017. 4091−4099 [71] Willetts M, Roberts S, Holmes C. Disentangling to cluster: Gaussian mixture variational Ladder autoencoders. [Online], available: https://arxiv.org/abs/1909.11501, December 4, 2019. [72] Esmaeili B, Wu H, Jain S, Bozkurt A, Siddharth N, Paige B, et al. Structured disentangled representations. In: Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics. Okinawa, Japan: AISTATS, 2019. 2525−2534 [73] Li X P, Chen Z R, Poon L K M, Zhang N L. Learning latent superstructures in variational autoencoders for deep multidimensional clustering. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: ICLR, 2019. [74] George D, Lehrach W, Kansky K, Lázaro-Gredilla M, Laan C, Marthi B, et al. A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs. Science, 2017, 358(6368): eaag2612 doi: 10.1126/science.aag2612 [75] Bouchacourt D, Tomioka R, Nowozin S. Multi-level variational autoencoder: Learning disentangled representations from grouped observations. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 2095−2102 [76] Hwang H J, Kim G H, Hong S, Kim K E. Variational interaction information maximization for cross-domain disentanglement. In: Proceedings of the 34th Conference on Neural Information Processing Systems. Vancouver, Canada: California, USA, 2020. 22479−22491 [77] Szabó A, Hu Q Y, Portenier T, Zwicker M, Favaro P. Understanding degeneracies and ambiguities in attribute transfer. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 721−736 [78] Ge Y H, Abu-El-Haija S, Xin G, Itti L. Zero-shot synthesis with group-supervised learning. In: Proceedings of the 9th International Conference on Learning Representations. Austria: ICLR, 2021. [79] Lee S, Cho S, Im S. DRANet: Disentangling representation and adaptation networks for unsupervised cross-domain adaptation. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 15247−15256 [80] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017: 2242−2251 [81] Sanchez E H, Serrurier M, Ortner M. Learning disentangled representations via mutual information estimation. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 205−221 [82] Esser P, Haux J, Ommer B. Unsupervised robust disentangling of latent characteristics for image synthesis. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 2699−2709 [83] Lorenz D, Bereska L, Milbich T, Ommer B. Unsupervised part-based disentangling of object shape and appearance. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 10947−10956 [84] Liu S L, Zhang L, Yang X, Su H, Zhu J. Unsupervised part segmentation through disentangling appearance and shape. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 8351−8360 [85] Dundar A, Shih K, Garg A, Pottorff R, Tao A, Catanzaro B. Unsupervised disentanglement of pose, appearance and background from images and videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, DOI: 10.1109/TPAMI.2021.3055560 [86] Vowels M J, Camgoz N C, Bowden R. Gated variational autoencoders: Incorporating weak supervision to encourage disentanglement. In: Proceedings of the 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020). Buenos Aires, Argentina: IEEE, 2020. 125−132 [87] Zhan X H, Pan X G, Dai B, Liu Z W, Lin D H, Loy C C. Self-supervised scene de-occlusion. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 3783−3791 [88] Greff K, Rasmus A, Berglund M, Hao T H, Schmidhuber J, Valpola H. Tagger: Deep unsupervised perceptual grouping. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 4491−4499 [89] Li Y H, Singh K K, Ojha U, Lee Y J. MixNMatch: Multifactor disentanglement and encoding for conditional image generation. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 8036−8045 [90] Singh K K, Ojha U, Lee Y J. FineGAN: Unsupervised hierarchical disentanglement for fine-grained object generation and discovery. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 6483−6492 [91] Ojha U, Singh K K, Lee Y J. Generating furry cars: Disentangling object shape & Appearance across Multiple Domains. In: Proceedings of the 9th International Conference on Learning Representations. Austria: ICLR, 2021. [92] Kosiorek A R, Sabour S, Teh Y W, Hinton G E. Stacked capsule autoencoders. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: NIPS, 2019. 15512−15522 [93] Lee J, Lee Y, Kim J, Kosiorek A R, Choi S, Teh Y W. Set transformer: A framework for attention-based permutation-invariant neural networks. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: JMLR, 2019. 3744−3753 [94] Yang M Y, Liu F R, Chen Z T, Shen X W, Hao J Y, Wang J. CausalVAE: Disentangled representation learning via neural structural causal models. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 9588−9597 [95] Greff K, Kaufman R L, Kabra R, Watters N, Burgess C, Zoran D, et al. Multi-object representation learning with iterative variational inference. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: JMLR, 2019. 2424−2433 [96] Burgess C P, Matthey L, Watters N, Kabra R, Higgins I, Botvinick M, et al. MONet: Unsupervised scene decomposition and representation. [Online], available: https://arxiv.org/abs/1901.11390, January 22, 2019 [97] Marino J, Yue Y, Mandt S. Iterative amortized inference. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: JMLR, 2018. 3400−3409 [98] Prabhudesai M, Lal S, Patil D, Tung H Y, Harley A W, Fragkiadaki K. Disentangling 3D prototypical networks for few-shot concept learning. [Online], available: https://arxiv.org/abs/2011.03367, July 20, 2021 [99] Lecun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278−2324 doi: 10.1109/5.726791 [100] Netzer Y, Wang T, Coates A, Bissacco A, Wu B, Ng A Y. Reading digits in natural images with unsupervised feature learning. In: Proceedings of Advances in Neural Information Processing Systems. Workshop on Deep Learning and Unsupervised Feature Learning. Granada, Spain: NIPS, 2011. 1−9 [101] Liu Z W, Luo P, Wang X G, Tang X O. Deep learning face attributes in the wild. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 3730−3738 [102] Matthey L, Higgins I, Hassabis D, Lerchner A. dSprites: Disentanglement testing sprites dataset [Online], available: https://github.com/deepmind/dsprites-dataset, Jun 2, 2017 [103] Aubry M, Maturana D, Efros A A, Russell B C, Sivic J. Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 3762−3769 [104] Paysan P, Knothe R, Amberg B, Romdhani S, Vetter T. A 3D face model for pose and illumination invariant face recognition. In: Proceedings of the 6th IEEE International Conference on Advanced Video and Signal Based Surveillance. Genova, Italy: IEEE, 2009. 296−301 [105] Lake B M, Salakhutdinov R, Tenenbaum J B. Human-level concept learning through probabilistic program induction. Science, 2015, 350(6266): 1332−1338 doi: 10.1126/science.aab3050 [106] Ristani E, Solera F, Zou R S, Cucchiara R, Tomasi C. Performance measures and a data set for multi-target, multi-camera tracking. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 17−35 [107] Karatzas D, Shafait F, Uchida S, Iwamura M, Bigorda L G I, Mestre S R, et al. ICDAR 2013 robust reading competition. In: Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, USA: IEEE, 2013. 1484−1493 [108] Xie J Y, Girshick R B, Farhadi A. Unsupervised deep embedding for clustering analysis. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: JMLR, 2016. 478−487 [109] Langner O, Dotsch R, Bijlstra G, Wigboldus D H J, Hawk S T, Van Knippenberg A. Presentation and validation of the Radboud Faces Database. Cognition and Emotion, 2010, 24(8): 1377−1388 doi: 10.1080/02699930903485076 [110] Guo Y D, Zhang L, Hu Y X, He X D, Gao J F. MS-Celeb-1M: A dataset and benchmark for large-scale face recognition. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 87−102 [111] Wah C, Branson S, Welinder P, Perona P, Belongie S. The Caltech-UCSD birds-200-2011 dataset [Online], available: http://www.vision.caltech.edu/visipedia/CUB-200-2011.html, November 6, 2011 [112] Zhu Y, Tian Y D, Metaxas D, Dollár P. Semantic amodal segmentation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 3001−3009 [113] Borji A, Izadi S, Itti L. iLab-20M: A large-scale controlled object dataset to investigate deep learning. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2221−2230 [114] Marti U V, Bunke H. The IAM-database: An English sentence database for offline handwriting recognition. International Journal on Document Analysis and Recognition, 2002, 5(1): 39−46 doi: 10.1007/s100320200071 [115] Liu H Y, Tian Y H, Wang Y W, Pang L, Huang T J. Deep relative distance learning: Tell the difference between similar vehicles. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2167−2175 [116] Drusch M, Del Bello U, Carlier S, Colin O, Fernandez V, Gascon F, et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sensing of Environment, 2012, 120: 25−36 doi: 10.1016/j.rse.2011.11.026 [117] LeCun Y, Huang F J, Bottou L. Learning methods for generic object recognition with invariance to pose and lighting. In: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004. Washington, USA: IEEE, 2004. II−104 [118] Charles J, Pfister T, Everingham M, Zisserman A. Automatic and efficient human pose estimation for sign language videos. International Journal of Computer Vision, 2014, 110(1): 70−90 doi: 10.1007/s11263-013-0672-6 [119] Shahroudy A, Liu J, Ng T T, Wang G. NTU RGB+D: A large scale dataset for 3D human activity analysis. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 1010−1019 [120] Schuldt C, Laptev I, Caputo B. Recognizing human actions: A local SVM approach. In: Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004. Cambridge, UK: IEEE, 2004. 32−36 [121] Liu Z W, Luo P, Qiu S, Wang X G, Tang X O. DeepFashion: Powering robust clothes recognition and retrieval with rich annotations. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 1096−1104 [122] Zhang W W, Sun J, Tang X O. Cat head detection - how to effectively exploit shape and texture features. In: Proceedings of the 10th European Conference on Computer Vision. Marseille, France: Springer, 2008. 802−816 [123] Ionescu C, Papava D, Olaru V, Sminchisescu C. Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 36(7): 1325−1339 [124] Zhang W Y, Zhu M L, Derpanis K G. From actemes to action: A strongly-supervised representation for detailed action understanding. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 2248−2255 [125] Krause J, Stark M, Deng J, Li F F. 3D object representations for fine-grained categorization. In: Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops. Sydney, Australia: IEEE, 2013. 554−561 [126] Khosla A, Jayadevaprakash N, Yao B, Li F F. Novel dataset for fine-grained image categorization: Stanford dogs. In: Proceedings of the 1st Workshop on Fine-Grained Visual Categorization. Colorado Springs, USA: IEEE, 2011. 1−2 [127] Reichert D P, Seriès P, Storkey A J. A hierarchical generative model of recurrent object-based attention in the visual cortex. In: Proceedings of the 21st International Conference on Artificial Neural Networks. Espoo, Finland: ICANN, 2011. 18−25 [128] Johnson J, Hariharan B, Van Der Maaten L, Li F F, Zitnick C L, Girshick R. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 1988−1997 [129] Qi L, Jiang L, Liu S, Shen X Y, Jia J Y. Amodal instance segmentation with KINS dataset. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 3009−3018 [130] Eastwood C, Williams C K I. A framework for the quantitative evaluation of disentangled representations. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. [131] Wu Z Z, Lischinski D, Shechtman E. StyleSpace analysis: Disentangled controls for StyleGAN image generation. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 12858−12867 -

 下载:
下载:




计量
- 文章访问数: 10924
- HTML全文浏览量: 7166
- PDF下载量: 3100
- 被引次数: 0
