

-
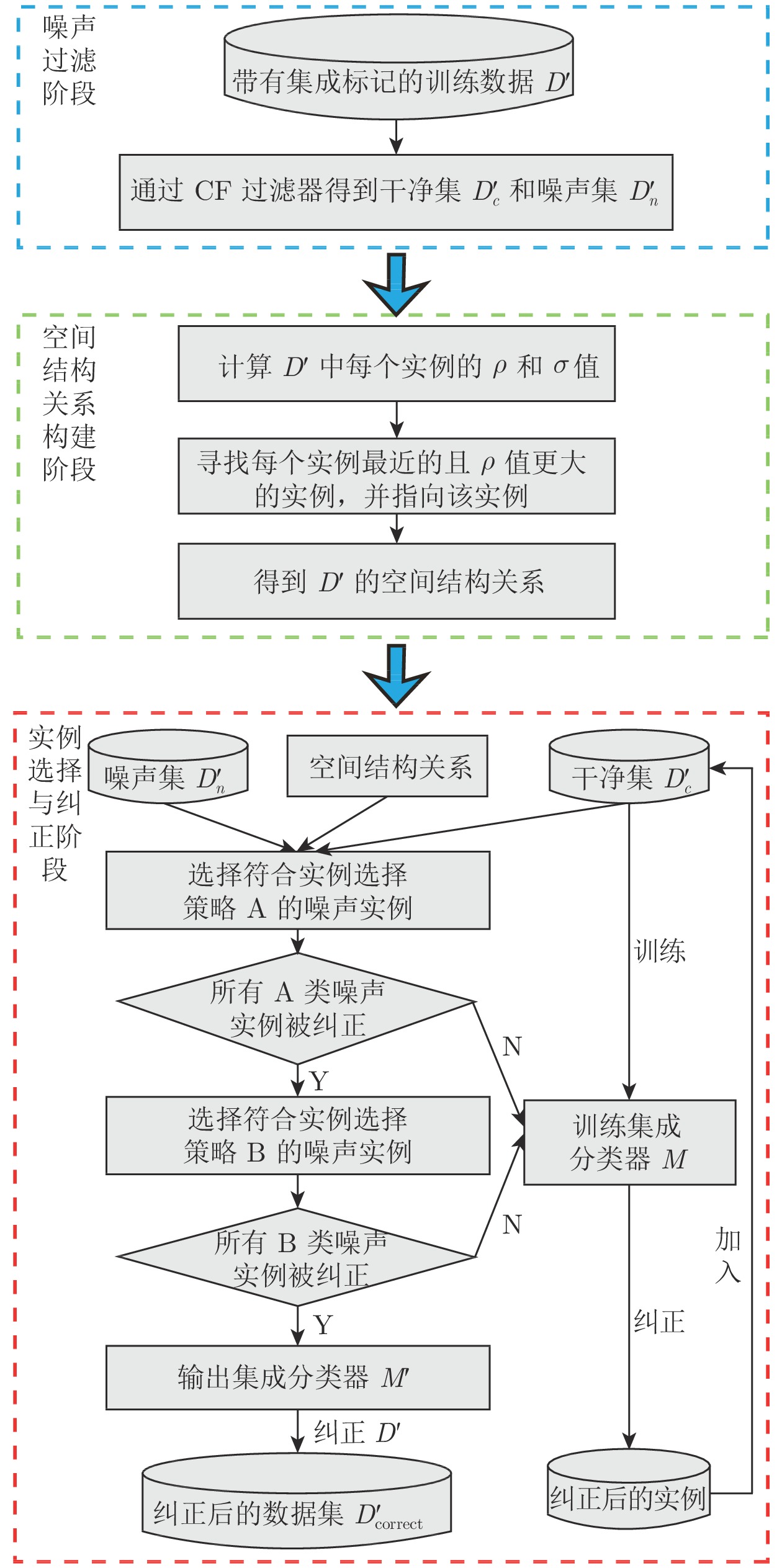
摘要: 针对众包标记经过标记集成后仍然存在噪声的问题, 提出了一种基于自训练的众包标记噪声纠正算法(Self-training-based label noise correction, STLNC). STLNC整体分为3个阶段: 第1阶段利用过滤器将带集成标记的众包数据集分为噪声集和干净集. 第2阶段利用加权密度峰值聚类算法构建数据集中低密度实例指向高密度实例的空间结构关系. 第3阶段首先根据发现的空间结构关系设计噪声实例选择策略; 然后利用在干净集上训练的集成分类器对选择的噪声实例按照设计的实例纠正策略进行纠正, 并将纠正后的实例加入到干净集, 再重新训练集成分类器; 重复实例选择与纠正过程直到噪声集中所有的实例被纠正; 最后用最后一轮训练得到的集成分类器对所有实例进行纠正. 在仿真标准数据集和真实众包数据集上的实验结果表明STLNC比其他5种最先进的噪声纠正算法在噪声比和模型质量两个度量指标上表现更优.Abstract: In order to solve the problem that a certain level of label noise exists in integrated labels obtained by label integration algorithms, this paper proposes a self-training-based label noise correction (STLNC) algorithm for crowdsourcing. There are three stages in STLNC. At the first stage, STLNC employs a filter to get a clean set and a noisy set. At the second stage, the weighted density peak clustering algorithm is used to construct the spatial structure relationship between low-density instances and high-density instances in the dataset. At the third stage, a noise instance selection strategy is at first designed according to the found spatial structure relationship. Then, these selected noise instances are corrected by the ensemble classifier trained on the clean set according to the designed instance correction strategy, and the corrected instances are added into the clean set and the ensemble classifier is retrained. The process of instance selection and correction is repeated until all noise instances are corrected. Finally, the ensemble classifier trained from the last round is used to correct all the instances. Experimental results on both simulated benchmark datasets and real-world crowdsourced datasets show that STLNC significantly outperforms other five state-of-the-art noise correction algorithms in team of the noise ratio and the model quality.
-
Key words:
- Crowdsourcing learning /
- self-training /
- integrated labels /
- label noise /
- noise correction
1) 1http://www.mturk.com 2http://www.crowdflower.com 3http://www.clickworker.com 2) http://www.crowdflower.com3) http://www.clickworker.com -
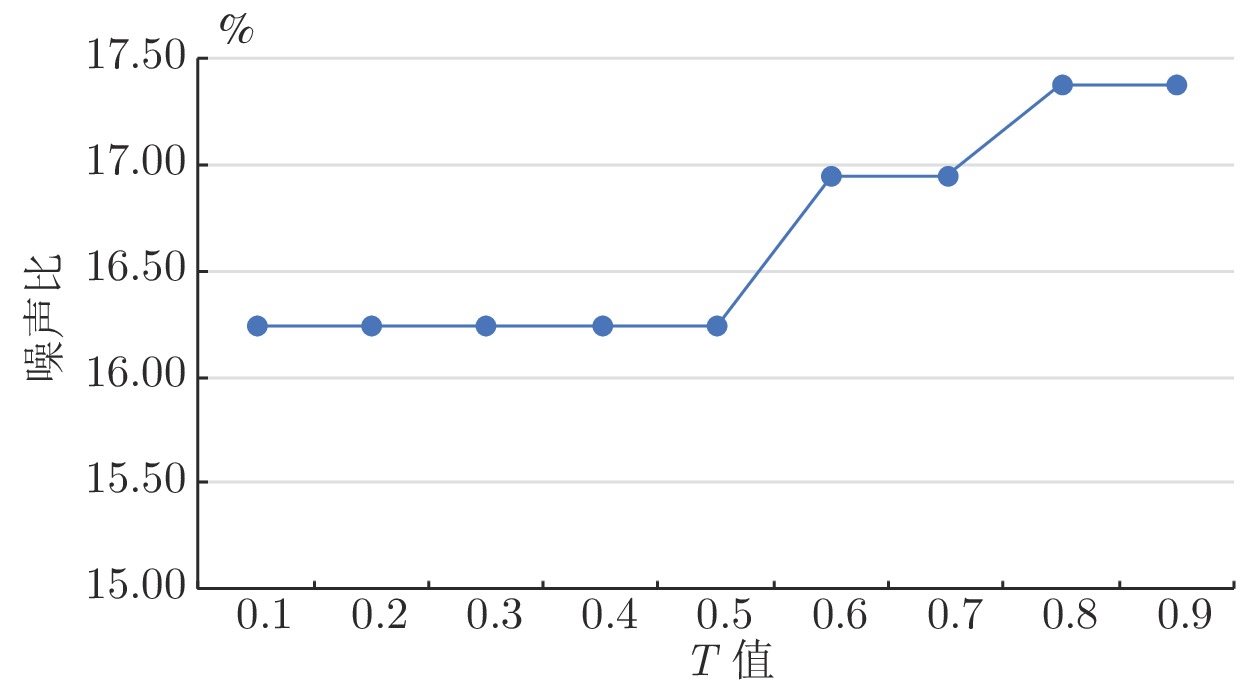
图 2 不同T值的STLNC在ionosphere数据集上的噪声比结果
Fig. 2 Noise ratio of STLNC with different T values on ionosphere dataset
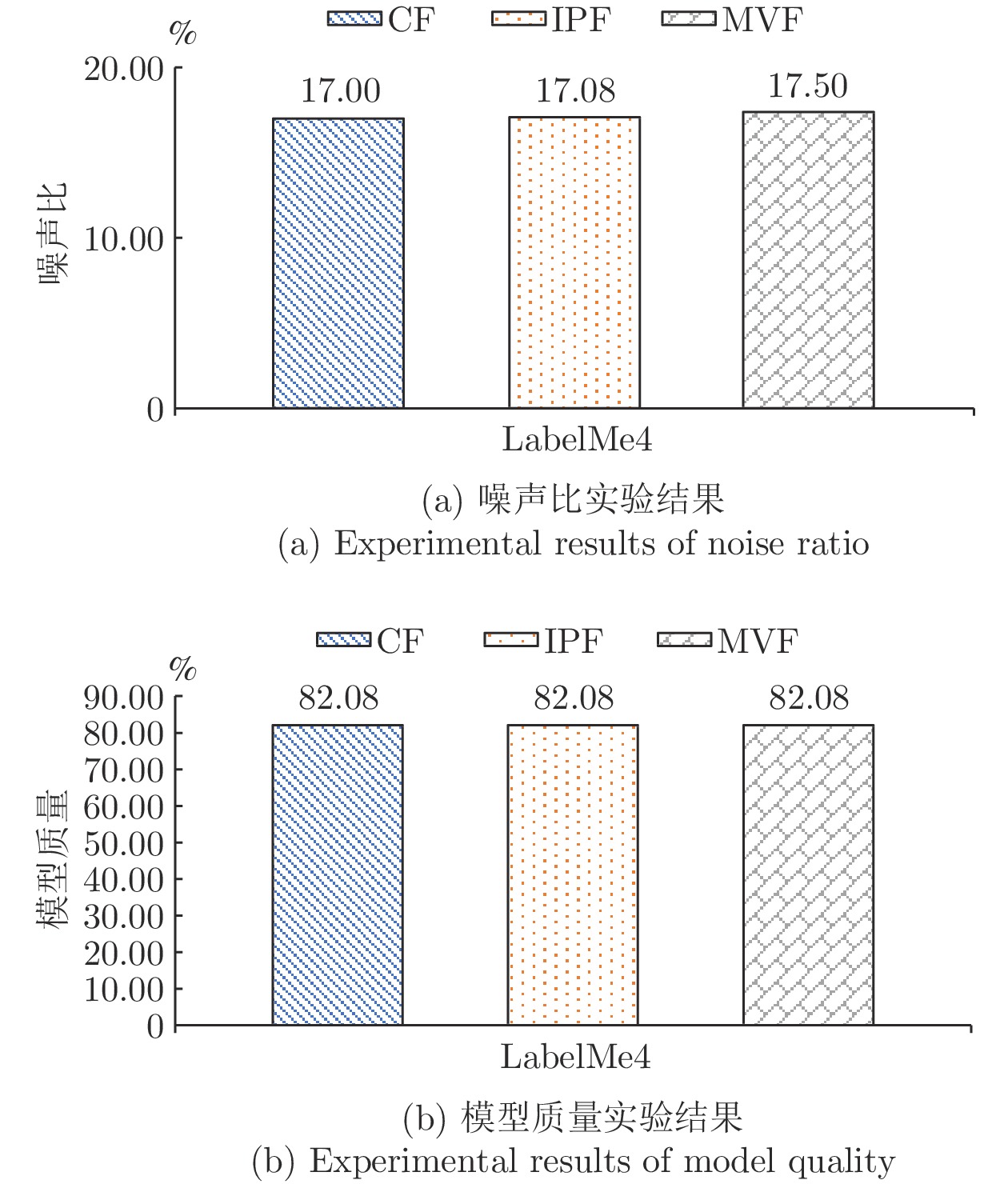
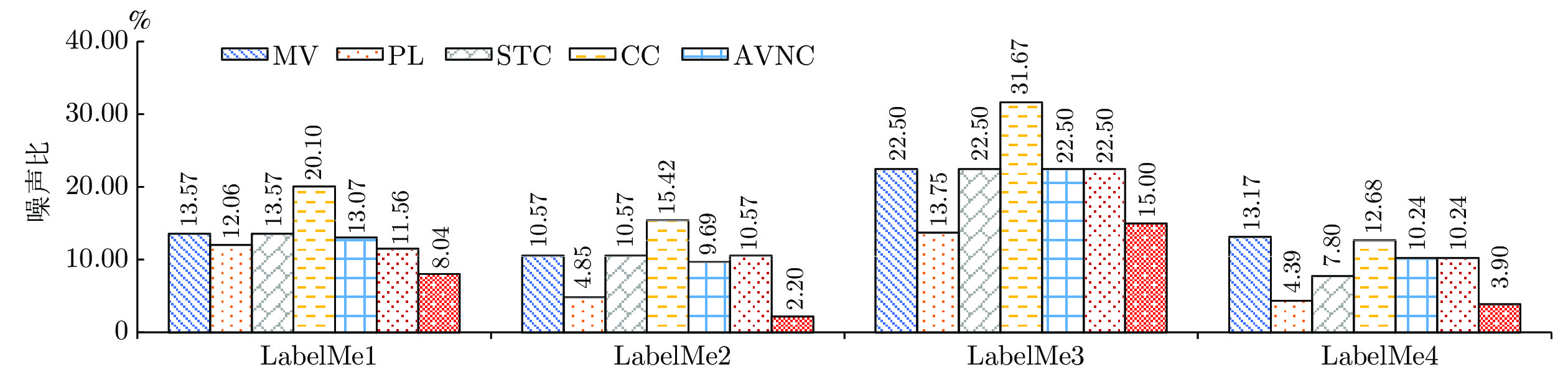
图 7 STLNC基于不同过滤器在LabelMe4数据集上的实验结果
Fig. 7 Experimental results of STLNC with different filters on LabelMe4 dataset

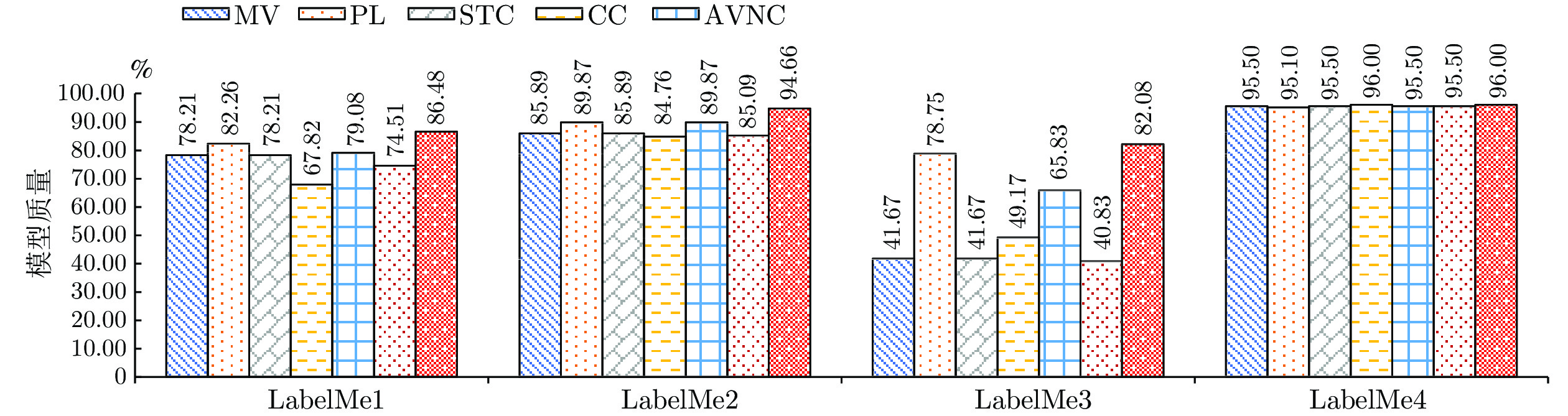
图 8 STLNC在LabelMe4数据集上的消融实验结果
Fig. 8 Results of STLNC ablation experiment on LabelMe4 dataset
表 1 22个仿真标准数据集详细描述
Table 1 Description of 22 simulated benchmark datasets
数据集 #Ins #Att #Pos #Neg biodeg 1055 41 356 699 breast-cancer 268 9 85 201 breast-w 699 10 241 458 credit-a 690 16 383 307 credit-g 1000 21 300 700 diabetes 768 8 268 500 heart-statlog 270 14 120 32 hepatitis 155 20 123 32 horse-colic 368 22 232 136 ionosphere 351 35 225 126 kr-vs-kp 3196 37 1527 1669 labor 57 16 37 20 mushroom 8124 23 3916 4208 sick 3772 30 231 3541 sonar 208 61 111 97 spambase 4601 57 813 2788 tic-tac-toe 958 10 332 626 vote 435 17 168 267 climate 540 20 494 46 colic 368 22 136 232 monks 432 6 228 204 steel-plates-faults 1941 33 673 1268  下载: 导出CSV
下载: 导出CSV
表 2 工人质量0.6时的噪声比对比结果 (%)
Table 2 Noise ratio comparisons with pj = 0.6 (%)
数据集 MV PL STC CC AVNC CENC STLNC biodeg 28.25 29.95 28.34 19.53 18.48 21.90 15.83 breast-cancer 27.62 26.92 25.87 31.12 26.57 29.37 24.84 breast-w 28.76 9.01 19.31 10.30 9.16 8.44 7.30 credit-a 26.67 20.00 15.94 18.84 13.04 13.33 12.90 credit-g 26.60 27.40 28.40 26.60 25.30 27.50 26.40 diabetes 26.69 32.29 26.56 26.95 23.70 23.96 22.79 heart-statlog 25.19 19.26 23.70 22.96 24.07 25.93 18.52 hepatitis 30.32 19.35 26.45 20.65 27.74 25.16 30.97 horse-colic 27.72 32.34 17.39 21.20 17.66 14.13 14.13 ionosphere 27.92 16.24 21.65 9.12 10.83 13.39 11.68 kr-vs-kp 27.38 21.96 10.45 19.34 2.19 2.85 2.28 labor 31.58 24.56 24.56 15.79 12.28 31.58 7.02 mushroom 26.71 12.65 6.43 4.30 0.04 0.10 0 sick 27.60 2.60 8.83 10.31 1.78 2.28 3.37 sonar 26.92 31.73 29.33 24.04 25.00 24.52 18.75 spambase 27.02 27.47 19.50 14.78 9.11 10.56 8.06 tic-tac-toe 26.20 34.13 23.07 24.43 22.44 22.23 14.61 vote 25.98 4.60 10.34 11.26 3.91 4.14 4.14 climate 27.41 8.52 27.41 14.07 8.52 8.52 8.52 colic 27.45 22.28 20.92 23.10 14.13 14.95 13.59 monks 26.39 25.00 11.34 21.76 5.32 6.71 2.78 steel-plates-faults 27.51 34.98 9.22 18.70 0 0.10 0.15 平均值 27.45 21.97 19.77 18.60 13.69 15.08 12.21
下载: 导出CSV
表 3 工人质量0.6时的模型质量对比结果(%)
Table 3 Model quality comparisons with pj = 0.6 (%)
数据集 MV PL STC CC AVNC CENC STLNC biodeg 71.37 75.91 72.13 78.77 74.34 74.21 78.29 breast-cancer 67.00 71.28 69.98 69.08 70.92 68.13 69.73 breast-w 92.85 92.47 90.68 93.38 94.00 92.85 95.54 credit-a 82.03 84.78 84.49 84.78 83.91 83.04 83.48 credit-g 62.20 68.30 67.40 69.70 67.30 63.90 70.40 diabetes 71.74 70.56 71.50 70.80 71.72 72.12 74.00 heart-statlog 65.56 74.81 67.78 70.00 74.07 69.26 78.15 hepatitis 69.00 77.67 71.33 77.50 72.00 70.17 74.17 horse-colic 77.42 78.11 80.00 80.15 81.62 81.36 82.35 ionosphere 83.48 85.45 86.90 85.19 85.77 84.04 85.76 kr-vs-kp 95.18 95.49 96.62 90.29 96.81 96.59 97.03 labor 70.67 61.83 73.50 68.33 68.33 72.33 76.33 mushroom 99.85 98.56 99.88 99.90 99.90 99.86 99.83 sick 96.74 94.62 96.98 94.48 97.77 97.75 97.11 sonar 58.93 55.57 50.07 58.29 55.00 59.14 58.29 spambase 85.92 88.87 87.44 84.20 89.68 88.98 90.39 tic-tac-toe 77.17 69.74 74.54 71.63 74.63 74.63 78.36 vote 89.89 95.37 94.21 90.59 94.21 93.98 94.21 climate 91.48 91.48 91.48 91.48 91.48 91.48 91.48 colic 79.97 81.09 81.09 82.47 81.09 82.47 81.09 monks 90.75 90.73 93.51 83.35 93.51 93.51 93.28 steel-plates-faults 100.00 89.64 100.00 92.01 100.00 100.00 100.00 平均值 80.87 81.47 81.89 81.20 82.64 82.26 84.06
下载: 导出CSV
表 4 工人质量0.6时的噪声比的威尔科克森测试结果
Table 4 Noise ratio summary of Wilcoxon tests with pj = 0.6
MV PL STC CC AVNC CENC STLNC MV — ◦ ◦ ◦ ◦ ◦ ◦ PL — ◦ ◦ ◦ ◦ STC • — ◦ ◦ ◦ CC • — ◦ ◦ ◦ AVNC • • • • — • ◦ CENC • • • • ◦ — ◦ STLNC • • • • • • —
下载: 导出CSV
表 5 工人质量0.6时的模型质量的威尔科克森测试结果
Table 5 Model quality summary of Wilcoxon tests with pj = 0.6
MV PL STC CC AVNC CENC TTLNC MV — ◦ ◦ ◦ ◦ PL — ◦ STC — ◦ ◦ CC — ◦ AVNC • • — • ◦ CENC • — ◦ STLNC • • • • • • —
下载: 导出CSV
表 6 工人质量[0.55, 0.75]时的噪声比对比结果 (%)
Table 6 Noise ratio comparisons with pj ∈ [0.55, 0.75] (%)
数据集 MV PL STC CC AVNC CENC STLNC biodeg 14.22 21.14 16.02 13.84 13.46 13.08 12.89 breast-cancer 16.43 26.22 20.98 19.93 23.43 24.83 24.48 breast-w 20.46 3.72 10.01 4.15 4.15 4.43 3.72 credit-a 18.41 20.58 14.93 13.62 13.77 13.04 12.17 credit-g 17.70 29.60 22.70 22.90 21.60 22.30 24.60 diabetes 20.18 22.66 24.09 22.27 23.44 22.66 23.44 heart-statlog 16.30 20.37 15.19 20.00 16.67 16.67 18.52 hepatitis 12.26 20.65 14.19 14.84 16.77 12.90 12.26 horse-colic 17.66 15.49 13.86 18.75 14.67 14.13 15.22 ionosphere 17.38 18.80 13.68 9.69 11.11 10.83 13.96 kr-vs-kp 17.43 25.19 5.60 11.55 1.31 1.88 2.44 labor 17.54 29.82 17.54 12.28 21.05 21.05 14.04 mushroom 18.07 4.94 4.84 1.67 0.10 0.11 0 sick 13.94 1.78 4.98 3.76 1.46 1.54 2.04 sonar 15.38 37.50 21.63 25.96 19.23 22.60 20.67 spambase 19.32 37.54 15.11 9.04 7.00 7.04 6.67 tic-tac-toe 20.67 27.45 19.31 17.54 15.76 14.41 6.47 vote 22.07 6.90 10.57 8.97 4.37 4.83 4.60 climate 22.96 8.52 22.96 10.74 8.52 8.52 8.52 colic 16.58 19.57 15.49 17.93 15.22 14.40 15.49 monks 17.13 12.73 7.18 23.38 2.78 4.86 2.78 steel-plates-faults 22.46 34.83 7.32 15.92 0.26 0.26 0.21 平均值 17.93 20.27 14.46 14.49 11.64 11.65 11.15
下载: 导出CSV
表 7 工人质量[0.55, 0.75]时的模型质量对比结果 (%)
Table 7 Model quality comparisons with pj ∈ [0.55, 0.75] (%)
数据集 MV PL STC CC AVNC CENC STLNC biodeg 74.58 81.87 76.36 79.99 81.59 80.25 81.78 breast-cancer 69.43 71.81 69.50 70.27 71.28 71.64 71.64 breast-w 90.76 94.54 91.10 94.34 93.85 92.40 94.69 credit-a 82.17 85.36 84.78 85.65 85.65 84.64 84.93 credit-g 69.50 69.80 70.50 69.60 71.10 69.00 72.00 diabetes 71.67 74.44 71.15 74.21 73.13 72.87 74.56 heart-statlog 70.00 78.89 76.30 75.93 79.63 78.52 80.37 hepatitis 76.17 79.17 77.33 80.50 76.83 77.83 79.00 horse-colic 82.50 80.35 81.57 82.63 83.51 83.01 82.68 ionosphere 80.62 83.48 82.33 88.03 87.73 86.90 84.07 kr-vs-kp 97.94 95.34 97.66 92.86 98.28 98.00 98.06 labor 78.33 68.17 78.33 64.33 77.17 77.17 84.33 mushroom 99.99 98.52 99.95 99.96 100.00 100.00 99.95 sick 97.72 96.95 97.48 95.47 97.64 97.83 97.14 sonar 63.79 68.93 67.14 70.36 69.29 69.50 70.86 spambase 86.65 88.87 88.07 84.83 90.37 88.96 90.76 tic-tac-toe 77.83 73.00 77.58 76.30 77.89 76.85 80.08 vote 93.35 93.79 94.98 92.68 95.24 95.00 94.77 climate 91.48 91.48 91.48 91.48 91.48 91.48 91.48 colic 83.74 77.90 84.19 79.17 82.53 82.63 81.84 monks 98.37 85.21 98.60 88.16 100.00 100.00 100.00 steel-plates-faults 99.90 100.00 100.00 99.69 100.00 100.00 100.00 平均值 83.48 83.54 84.38 83.47 85.65 85.20 86.14
下载: 导出CSV
表 8 工人质量[0.55, 0.75]时的噪声比的威尔科克森测试结果
Table 8 Noise ratio summary of Wilcoxon tests with pj ∈ [0.55, 0.75]
MV PL STC CC AVNC CENC STLNC MV — ◦ ◦ ◦ ◦ ◦ PL — ◦ ◦ ◦ ◦ ◦ STC • — ◦ ◦ ◦ CC • — ◦ ◦ ◦ AVNC • • • • — CENC • • • • — STLNC • • • • —
下载: 导出CSV
表 9 工人质量[0.55, 0.75]时的模型质量的威尔科克森测试结果
Table 9 Model quality summary of Wilcoxon tests with pj ∈ [0.55, 0.75]
MV PL STC CC AVNC CENC STLNC MV — ◦ ◦ ◦ ◦ PL — ◦ ◦ ◦ STC • — ◦ ◦ ◦ CC — ◦ ◦ ◦ AVNC • • • • — • CENC • • ◦ — ◦ STLNC • • • • • —
下载: 导出CSV
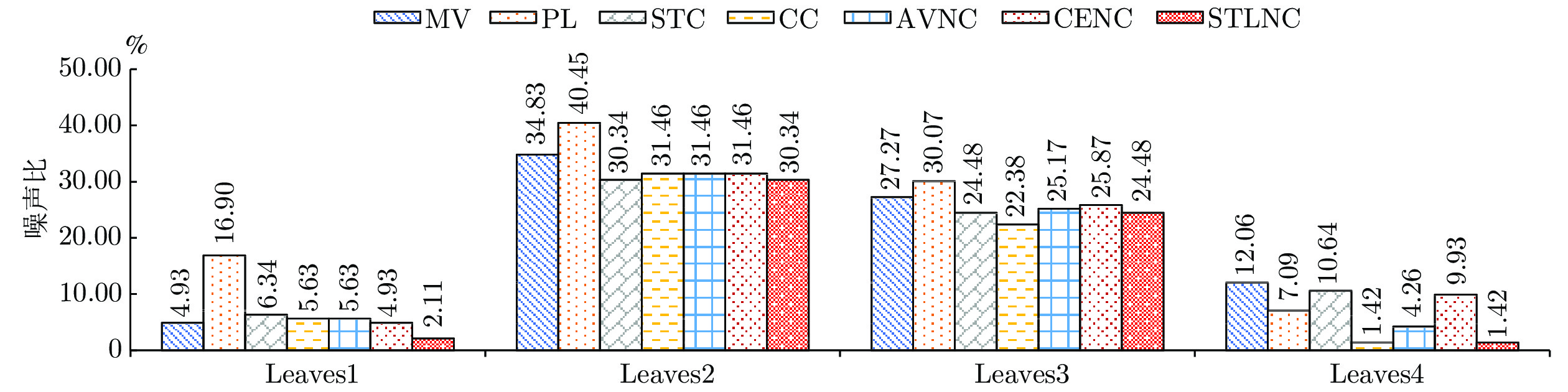
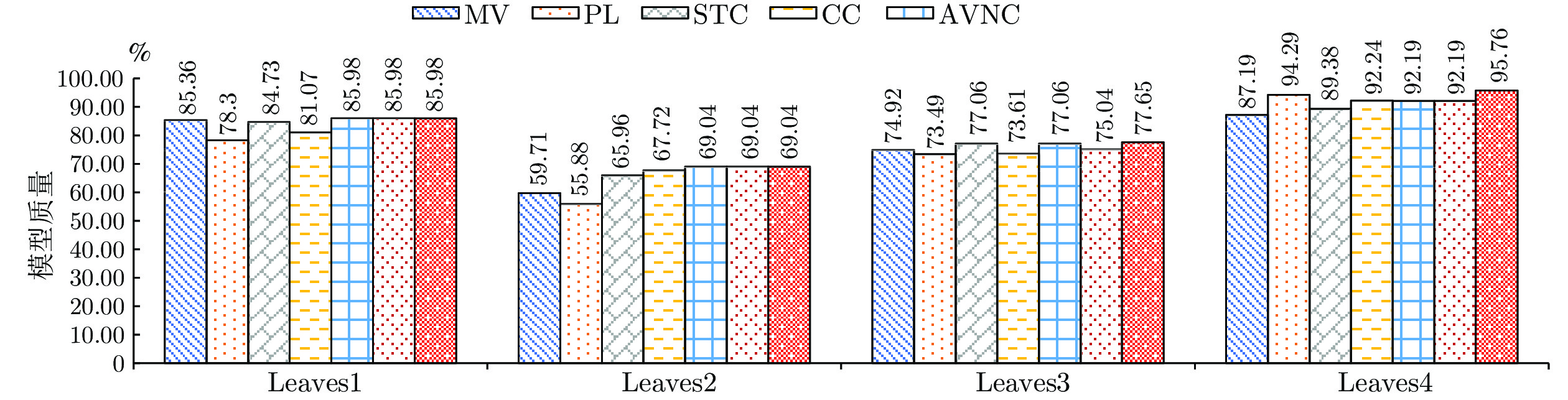
表 10 8个真实众包数据的详细描述
Table 10 Description of eight real-world crowdsourced datasets
数据集 分类任务 #Instances #Positives #Negatives #Labelers #Labels Leaves1 maple/alder 142 96 46 70 1093 Leaves2 maple/tilia 140 96 44 74 1044 Leaves3 alder/eucalyptus 93 46 47 58 407 Leaves4 alder/poplar 89 46 43 54 400 LabelMe1 highway/street 199 89 110 50 395 LabelMe2 highway/forest 227 89 138 54 476 LabelMe3 highway/opencountry 240 89 151 54 375 LabelMe4 highway/insidecity 205 89 116 49 339
下载: 导出CSV
-
[1] Pollicelli D, Coscarella M, Delrieux C. RoI detection and segmentation algorithms for marine mammals photo-identification. Ecological Informatics, 2020, 56: Article No. 101038 [2] Wang H, Zhao D, Ma H D. Informative image selection for crowdsourcing-based mobile location recognition. Multimedia Systems, 2019, 25(5): 513−523 doi: 10.1007/s00530-017-0562-9 [3] Lotfian R, Busso C. Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings. IEEE Transactions on Affective Computing, 2019, 10(4): 471−483 doi: 10.1109/TAFFC.2017.2736999 [4] Sheng V S, Provost F, Ipeirotis P G. Get another label? Improving data quality and data mining using multiple, noisy labelers. In: Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas, USA: ACM, 2008. 614−622 [5] Demartini G, Difallah D E, Cudré-Mauroux P. ZenCrowd: Leveraging probabilistic reasoning and crowdsourcing techniques for large-scale entity linking. In: Proceedings of the 21st International Conference on World Wide Web. Lyon, France: ACM, 2012. 469−478 [6] Zhang H, Jiang L Z, Xu W Q. Multiple noisy label distribution propagation for crowdsourcing. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao, China: AAAI Press, 2019. 1473−1479 [7] Tian T, Zhu J, You Q B. Max-margin majority voting for learning from crowds. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(10): 2480−2494 doi: 10.1109/TPAMI.2018.2860987 [8] Zhong J H, Yang P, Tang K. A quality-sensitive method for learning from crowds. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(12): 2643−2654 doi: 10.1109/TKDE.2017.2738643 [9] Nicholson B, Sheng V S, Zhang J. Label noise correction and application in crowdsourcing. Expert Systems With Applications, 2016, 66: 149−162 doi: 10.1016/j.eswa.2016.09.003 [10] Xu W Q, Jiang L X, Li C Q. Resampling-based noise correction for crowdsourcing. Journal of Experimental & Theoretical Artificial Intelligence, 2021, 33(6): 985−999 [11] Zhang J, Sheng V S, Li T, Wu X D. Improving crowdsourced label quality using noise correction. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(5): 1675−1688 doi: 10.1109/TNNLS.2017.2677468 [12] Li C Q, Jiang L X, Xu W Q. Noise correction to improve data and model quality for crowdsourcing. Engineering Applications of Artificial Intelligence, 2019, 82: 184−191 doi: 10.1016/j.engappai.2019.04.004 [13] Xu W Q, Jiang L X, Li C Q. Improving data and model quality in crowdsourcing using cross-entropy-based noise correction. Information Sciences, 2021, 546: 803−814 doi: 10.1016/j.ins.2020.08.117 [14] Wu D, Shang M S, Luo X, Xu J, Yan H Y, Deng W H, et al. Self-training semi-supervised classification based on density peaks of data. Neurocomputing, 2018, 275: 180−191 doi: 10.1016/j.neucom.2017.05.072 [15] Khuri S A, Sayfy A. A laplace variational iteration strategy for the solution of differential equations. Applied Mathematics Letters, 2012, 25(12): 2298−2305 doi: 10.1016/j.aml.2012.06.020 [16] Hershey J R, Olsen P A. Approximating the kullback leibler divergence between Gaussian mixture models. In: Proceedings of the 32nd IEEE International Conference on Acoustics, Speech and Signal Processing. Honolulu, USA: IEEE, 2007. IV-317−IV-320 [17] Zhang J, Sheng V S, Nicholson B, Wu X D. CEKA: A tool for mining the wisdom of crowds. The Journal of Machine Learning Research, 2015, 16(1): 2853−2858 [18] Witten I H, Frank E. Data Mining: Practical Machine Learning Tools and Techniques. (3rd edition). Beijing: China Machine Press, 2005. [19] Gamberger D, Lavrac N, Groselj C. Experiments with noise filtering in a medical domain. In: Proceedings of the 16th International Conference on Machine Learning. Bled, Slovenia: ACM, 1999. 143−151 [20] García S, Herrera F. An extension on “statistical comparisons of classifiers over multiple data sets” for all pairwise comparisons. Journal of Machine Learning Research, 2008, 9(12): 2677−2694 [21] Jiang L X, Zhang L G, Li C Q, Wu J. A correlation-based feature weighting filter for naive Bayes. IEEE Transactions on Knowledge and Data Engineering, 2019, 31(2): 201−213 doi: 10.1109/TKDE.2018.2836440 [22] Rodrigues F, Lourenčo M, Ribeiro B, Pereira F C. Learning supervised topic models for classification and regression from crowds. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2409−2422 doi: 10.1109/TPAMI.2017.2648786 [23] Li F F, Perona P. A Bayesian hierarchical model for learning natural scene categories. In: Proceedings of the 14th IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, USA: IEEE, 2005. 524−531 [24] McCallum A, Nigam K. A comparison of event models for naive Bayes text classification. In: Proceedings of the AAAI-98 Workshop on Learning for Text Categorization. Palo Alto, USA: AAAI Press, 1998. 41−48 [25] Rennie J D M, Shih L, Teevan J, Karger D R. Tackling the poor assumptions of naive Bayes text classifiers. In: Proceedings of the 20th International Conference on Machine Learning. Washington, USA: AAAI Press, 2003. 616−623 [26] Khoshgoftaar T M, Rebours P. Improving software quality prediction by noise filtering techniques. Journal of Computer Science and Technology, 2007, 22(3): 387−396 doi: 10.1007/s11390-007-9054-2 [27] Brodley C E, Friedl M A. Identifying mislabeled training data. Journal of Artificial Intelligence Research, 1999, 11(1): 131−167 -

 下载:
下载:

计量
- 文章访问数: 1888
- HTML全文浏览量: 653
- PDF下载量: 237
- 被引次数: 0
