

-
摘要: 视频标题生成与描述是使用自然语言对视频进行总结与重新表达. 由于视频与语言之间存在异构特性, 其数据处理过程较为复杂. 本文主要对基于“编码−解码” 架构的模型做了详细阐述, 以视频特征编码与使用方式为依据, 将其分为基于视觉特征均值/最大值的方法、基于视频序列记忆建模的方法、基于三维卷积特征的方法及混合方法, 并对各类模型进行了归纳与总结. 最后, 对当前存在的问题及可能趋势进行了总结与展望, 指出需要生成融合情感、逻辑等信息的结构化语段, 并在模型优化、数据集构建、评价指标等方面进行更为深入的研究.Abstract: The task of video captioning and description is to summarize and re-express the visual content of video with natural language/text. It is challenging because it involves the transformation of different modal information, and there exists heterogeneity between the visual data and language. In this work, the models based on the “encoder-decoder” pipeline are mainly elaborated in detail. According to the encoding and usage of visual features, the current models are classified into four types: the models based on mean/max pooling feature, the models based on video sequential memory, the models based on 3D CNN feature, and the models based on hybrid features. A number of popular works of each type are described and analyzed. Finally, the existing problems and possible trends worth studying are summarized. It is pointed out that the prior knowledge including emotion and logical semantics in complex videos should be further mined and embedded for the generation of logical paragraph description. Moreover, it is still desired to further investigate the techniques of model optimization, dataset construction and evaluation metrics for video captioning and description.1) 1
https://github.com/vsubhashini/caffe/tree/recurrent/examples/youtube 2) 2https://github.com/vsubhashini/caffe/tree/recurrent/examples/s2vt 3) 3https://github.com/gtoderici/sports-1m-dataset/blob/wiki/ProjectHome.md 4) 4https://github.com/google-research/bert 5) 5https://github.com/tylin/coco-caption 6http://ms-multimedia-challenge.com/2017/challenge 6) 6http://ms-multimedia-challenge.com/2017/challenge 7) 7http://www.cs.utexas.edu/users/ml/clamp/videoDescription/YouTubeClips.tar 8http://ms-multimedia-challenge.com/2017/dataset 8) 8http://ms-multimedia-challenge.com/2017/dataset 9) 9https://cs.stanford.edu/people/ranjaykrishna/densevid/ 10http://youcook2.eecs.umich.edu/ 10) 10http://youcook2.eecs.umich.edu/ -
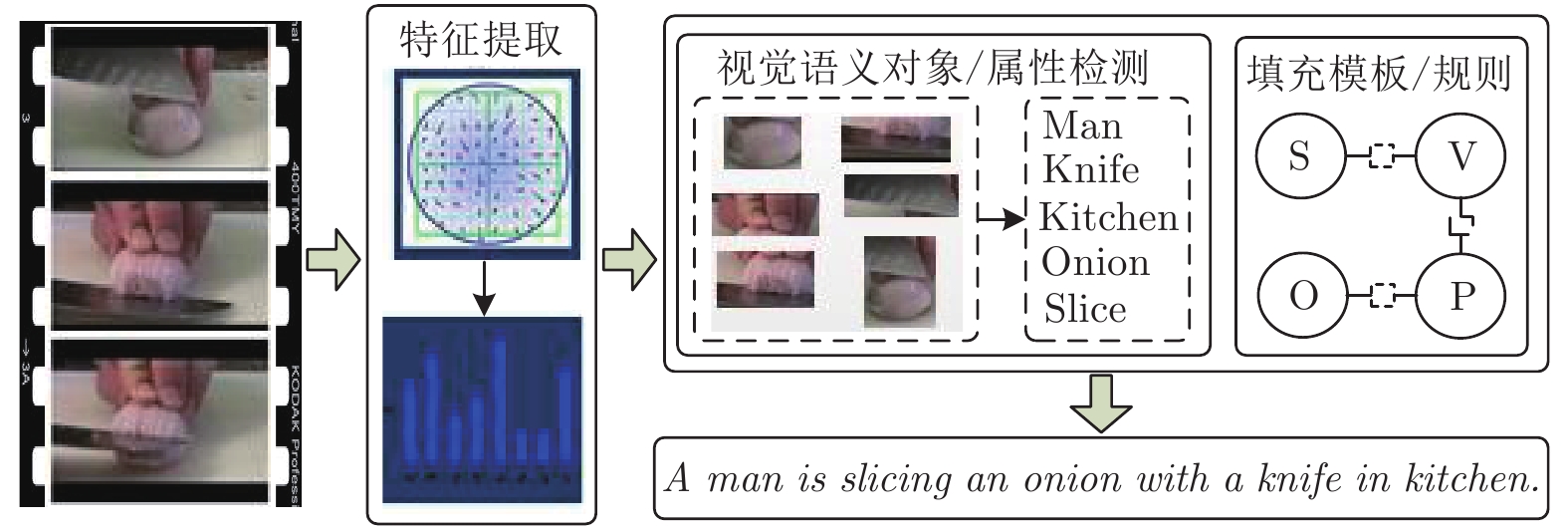
图 2 基于模板/规则的视频描述框架
Fig. 2 The template/rule based framework for video captioning and description

图 3 基于视觉均值/最大值特征的视频描述框架
Fig. 3 The mean/max pooling visual feature based framework for video captioning and description
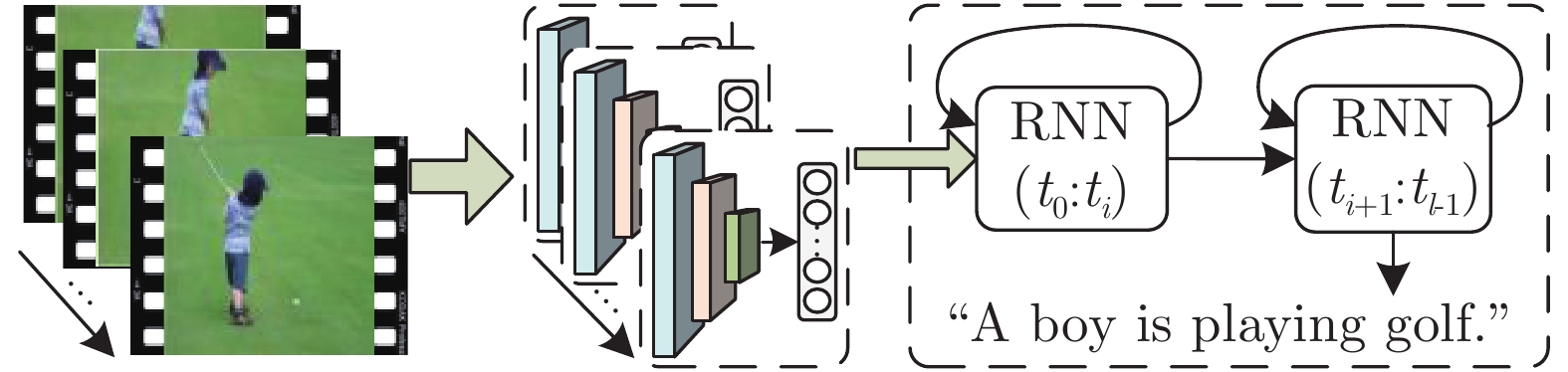
图 4 基于RNN序列建模的视频描述框架
Fig. 4 The RNN based framework for video captioning and description

图 5 Res-F2F视频描述生成流程
Fig. 5 The framework of Res-F2F for video captioning and description

图 7 基于强化学习的层次化视频描述框架
Fig. 7 The reinforcement learning based framework for video captioning and description
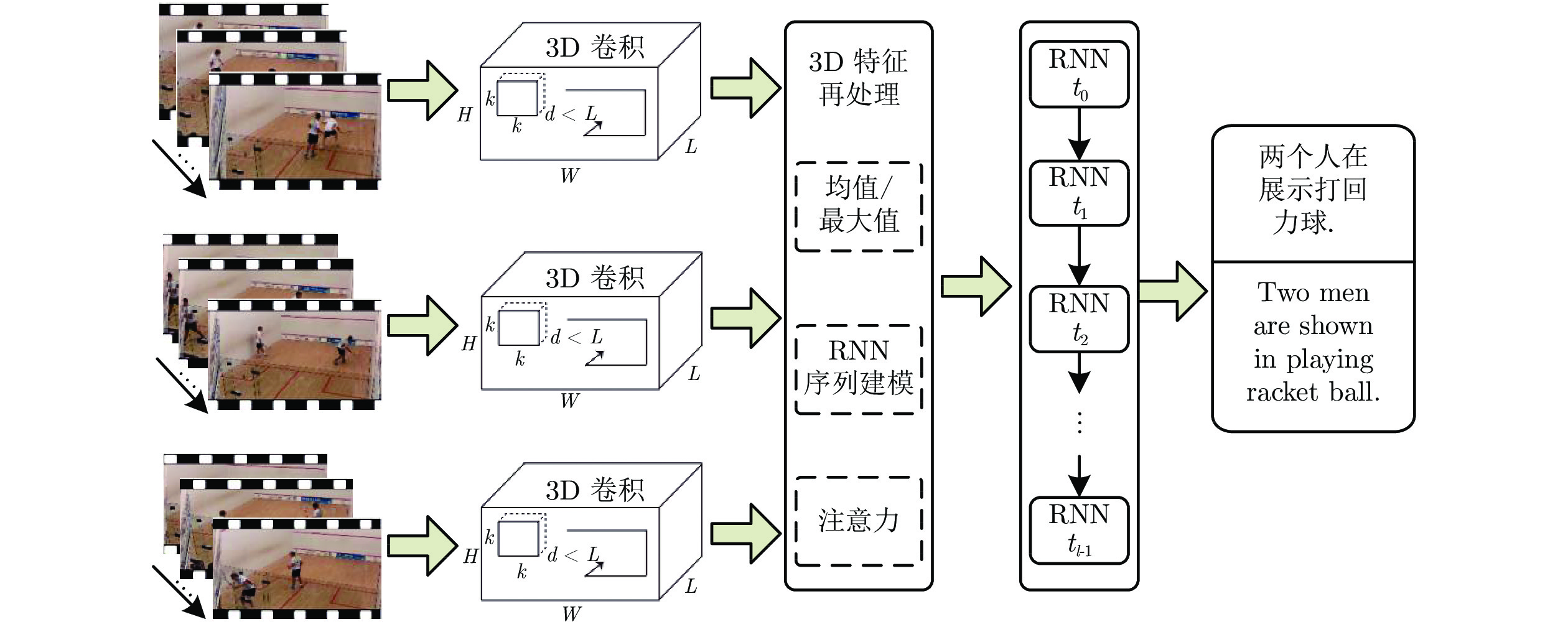
图 8 基于3D卷积特征的视频描述基本框架
Fig. 8 The 3D CNN based framework for video captioning and description

图 12 SAAT模型生成描述句子示例( “RF”表示参考句子, “SAAT” 表示模型所生成的句子)
Fig. 12 Candidate sentence examples with SAAT model ( “RF” stands for references, and “SAAT” denotes the generated sentences with SAAT)

图 13 SDVC模型生成的部分描述示例( “RF-e”表示参考语句, “SDVC-e” 表示SDVC模型生成的句子)
Fig. 13 Description examples with SDVC model ( “RF-e” stands for the references, and “SDVC-e” denotes the generated sentences with SDVC)
表 1 部分基于视觉序列特征均值/最大值的模型在MSVD数据集上的性能表现(%)
Table 1 Performance (%) of a few popular models based on visual sequential feature with mean/max pooling on MSVD
 下载: 导出CSV
下载: 导出CSV
表 2 部分基于序列RNN视觉特征建模的模型在MSVD数据集上的性能表现(%)
Table 2 Performance (%) of a few popular models based on visual sequential feature with RNN on MSVD
Methods (方法) B-1 B-2 B-3 B-4 METEOR CIDEr S2VT[32] — — — — 29.8 — Res-F2F(G-R101-152)[34] 82.8 71.7 62.4 52.4 35.7 84.3 Joint-BiLSTM reinforced[35] — — — — 30.3 — HRNE with attention[38] 79.2 66.3 55.1 43.8 33.1 — Boundary-aware encoder[39] — — — 42.5 32.4 63.5 hLSTMat[41] 82.9 72.2 63.0 53.0 33.6 — Li et al[42] — — — 48.0 31.6 68.8 MGSA(I+C)[43] — — — 53.4 35.0 86.7 LSTM-GAN[113] — — — 42.9 30.4 — PickNet(V+L+C)[114] — — — 52.3 33.3 76.5
下载: 导出CSV
表 3 部分基于3D卷积特征的模型在MSVD数据集上的性能表现(%)
Table 3 Performance (%) of a few popular models based on 3D visual feature on MSVD
下载: 导出CSV
表 5 部分基于视觉序列均值/最大值的模型在MSR-VTT2016数据集上的性能表现(%)
Table 5 Performance (%) of visual sequential feature based models with mean/max pooling on MSR-VTT2016
下载: 导出CSV
表 8 其他主流模型在MSR-VTT2016上的性能(%)
Table 8 Performance (%) of other popular models on MRT-VTT2016
下载: 导出CSV
表 6 部分基于RNN视觉序列特征建模的模型在MSR-VTT2016数据集上的性能表现(%)
Table 6 Performance (%) of a few popular models based on visual sequential feature with RNN on MRT-VTT2016
Methods (方法) B-1 B-2 B-3 B-4 METEOR CIDEr Res-F2F (G-R101-152)[34] 81.1 67.2 53.7 41.4 29.0 48.9 hLSTMat[41] — — — 38.3 26.3 — Li et al[42] 76.1 62.1 49.1 37.5 26.4 — MGSA(I+A+C)[43] — — — 45.4 28.6 50.1 LSTM-GAN[113] — — — 36.0 26.1 — aLSTM[117] — — — 38.0 26.1 — VideoLAB[118] — — — 39.5 27.7 44.2 PickNet(V+L+C)[114] — — — 41.3 27.7 44.1 DenseVidCap[49] — — — 44.2 29.4 50.5 ETS(Local+Global)[48] 77.8 62.2 48.1 37.1 28.4 —
下载: 导出CSV
表 7 部分基于3D卷积特征的模型在MSR-VTT2016数据集上的性能表现(%)
Table 7 Performance (%) of a few popular models based on 3D visual sequential feature on MRT-VTT2016
下载: 导出CSV
表 9 部分基于RNN视觉序列特征建模的模型在ActivityNet captions数据集(验证集)上的性能表现 (%)
Table 9 Performance (%) of a few popular models based on visual sequential feature with RNN on ActivityNet captions dataset (validation set)
下载: 导出CSV
表 10 部分基于3D卷积特征的模型在ActivityNet captions数据集(验证集)上的性能表现 (%)
Table 10 Performance (%) of a few popular models based on 3D visual sequential feature on ActivityNet captions dataset (validation set)
下载: 导出CSV
-
[1] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2): 91-110 doi: 10.1023/B:VISI.0000029664.99615.94 [2] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). San Diego, CA, USA: IEEE, 2005. 886−893 [3] Nagel H H. A vision of “vision and language” comprises action: An example from road traffic. Artificial Intelligence Review, 1994, 8(2): 189-214 [4] Kojima A, Tamura T, Fukunaga K. Natural language description of human activities from video images based on concept hierarchy of actions. International Journal of Computer Vision, 2002, 50(2): 171-184 doi: 10.1023/A:1020346032608 [5] Gupta A, Srinivasan P, Shi J B, Davis L S. Understanding videos, constructing plots learning a visually grounded storyline model from annotated videos. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009. 2012−2019 [6] Guadarrama S, Krishnamoorthy N, Malkarnenkar G, Venugopalan S, Mooney R, Darrell T, et al. YouTube2Text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013. 2712−2719 [7] Rohrbach M, Qiu W, Titov I, Thater S, Pinkal M, Schiele B. Translating video content to natural language descriptions. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013. 433−440 [8] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada: Curran Associates Inc., 2012. 1097−1105 [9] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, CA, USA, 2015. [10] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 1−9 [11] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 770−778 [12] 胡建芳, 王熊辉, 郑伟诗, 赖剑煌. RGB-D行为识别研究进展及展望. 自动化学报, 2019, 45(5): 829-840Hu Jian-Fang, Wang Xiong-Hui, Zheng Wei-Shi, Lai Jian-Huang. RGB-D action recognition: Recent advances and future perspectives. Acta Automatica Sinica, 2019, 45(5): 829-840 [13] 周波, 李俊峰. 结合目标检测的人体行为识别. 自动化学报, 2020, 46(9): 1961-1970Zhou Bo, Li Jun-Feng. Human action recognition combined with object detection. Acta Automatica Sinica, 2020, 46(9): 1961-1970 [14] Wu J C, Wang L M, Wang L, Guo J, Wu G S. Learning actor relation graphs for group activity recognition. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 9956−9966 [15] Ji S W, Xu W, Yang M, Yu K. 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221-231 doi: 10.1109/TPAMI.2012.59 [16] Tran D, Bourdev L, Fergus R, Torresani L, Paluri M. Learning spatiotemporal features with 3D convolutional networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4489−4497 [17] Cho K, van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: ACL, 2014. 1724−1734 [18] Xu K, Ba J L, Kiros R, Cho K, Courville A, Salakhutdinov R, et al. Show, attend and tell: Neural image caption generation with visual attention. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: JMLR.org, 2015. 2048−2057 [19] Yao T, Pan Y W, Li Y H, Qiu Z F, Mei T. Boosting image captioning with attributes. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 4904−4912 [20] Aafaq N, Mian A, Liu W, Gilani S Z, Shah M. Video description: A survey of methods, datasets, and evaluation metrics. ACM Computing Surveys, 2020, 52(6): Article No. 115 [21] Li S, Tao Z Q, Li K, Fu Y. Visual to text: Survey of image and video captioning. IEEE Transactions on Emerging Topics in Computational Intelligence, 2019, 3(4): 297-312 doi: 10.1109/TETCI.2019.2892755 [22] Xu R, Xiong C M, Chen W, Corso J J. Jointly modeling deep video and compositional text to bridge vision and language in a unified framework. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin, Texas: AAAI Press, 2015. 2346−2352 [23] Venugopalan S, Xu H J, Donahue J, Rohrbach M, Mooney R, Saenko K. Translating videos to natural language using deep recurrent neural networks. In: Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Denver, Colorado: ACL, 2015. 1494−1504 [24] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S A, et al. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3): 211-252 doi: 10.1007/s11263-015-0816-y [25] Pan Y W, Mei T, Yao T, Li H Q, Rui Y. Jointly modeling embedding and translation to bridge video and language. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 4594−4602 [26] Pan Y W, Yao T, Li H Q, Mei T. Video captioning with transferred semantic attributes. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 984−992 [27] 汤鹏杰, 谭云兰, 李金忠, 谭彬. 密集帧率采样的视频标题生成. 计算机科学与探索, 2018, 12(6): 981-993 doi: 10.3778/j.issn.1673-9418.1705058Tang Peng-Jie, Tan Yun-Lan, Li Jin-Zhong, Tan Bin. Dense frame rate sampling based model for video caption generation. Journal of Frontiers of Computer Science and Technology, 2018, 12(6): 981-993 doi: 10.3778/j.issn.1673-9418.1705058 [28] Dalal N, Triggs B, Schmid C. Human detection using oriented histograms of flow and appearance. In: Proceedings of the 9th European Conference on Computer Vision. Graz, Austria: Springer, 2006. 428−441 [29] Wang H, Kläser A, Schmid C, Liu C L. Dense trajectories and motion boundary descriptors for action recognition. International Journal of Computer Vision, 2013, 103(1): 60-79 doi: 10.1007/s11263-012-0594-8 [30] Wang H, Schmid C. Action recognition with improved trajectories. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013. 3551−3558 [31] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 568−576 [32] Venugopalan S, Rohrbach M, Donahue J, Mooney R, Darrell T, Saenko K. Sequence to sequence-video to text. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4534−4542 [33] Venugopalan S, Hendricks L A, Mooney R, Saenko K. Improving lstm-based video description with linguistic knowledge mined from text. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas: ACL, 2016. 1961−1966 [34] Tang P J, Wang H L, Li Q Y. Rich visual and language representation with complementary semantics for video captioning. ACM Transactions on Multimedia Computing, Communications, and Applications, 2019, 15(2): Article No. 31 [35] Bin Y, Yang Y, Shen F M, Xu X, Shen H T. Bidirectional long-short term memory for video description. In: Proceedings of the 24th ACM International Conference on Multimedia. Amsterdam, The Netherlands: ACM, 2016. 436−440 [36] Pasunuru R, Bansal M. Multi-task video captioning with video and entailment generation. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: ACL, 2017. 1273−1283 [37] Li L J, Gong B Q. End-to-end video captioning with multitask reinforcement learning. In: Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). Waikoloa, HI, USA: IEEE, 2019. 339−348 [38] Pan P B, Xu Z W, Yang Y, Wu F, Zhuang Y T. Hierarchical recurrent neural encoder for video representation with application to captioning. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 1029−1038 [39] Baraldi L, Grana C, Cucchiara R. Hierarchical boundary-aware neural encoder for video captioning. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 3185−3194 [40] Xu J, Yao T, Zhang Y D, Mei T. Learning multimodal attention LSTM networks for video captioning. In: Proceedings of the 25th ACM International Conference on Multimedia. Mountain View, California, USA: ACM, 2017. 537−545 [41] Song J K, Gao L L, Guo Z, Liu W, Zhang D X, Shen H T. Hierarchical LSTM with adjusted temporal attention for video captioning. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: AAAI Press, 2017. 2737−2743 [42] Li W, Guo D S, Fang X Z. Multimodal architecture for video captioning with memory networks and an attention mechanism. Pattern Recognition Letters, 2018, 105: 23-29 doi: 10.1016/j.patrec.2017.10.012 [43] Chen S X, Jiang Y G. Motion guided spatial attention for video captioning. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 8191-8198 [44] Zhang J C, Peng Y X. Object-aware aggregation with bidirectional temporal graph for video captioning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 8319−8328 [45] Zhang J C, Peng Y X. Video captioning with object-aware spatio-temporal correlation and aggregation. IEEE Transactions on Image Processing, 2020, 29: 6209-6222 doi: 10.1109/TIP.2020.2988435 [46] Wang B R, Ma L, Zhang W, Liu W. Reconstruction network for video captioning. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 7622−7631 [47] Zhang W, Wang B R, Ma L, Liu W. Reconstruct and represent video contents for captioning via reinforcement learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(12): 3088-3101 doi: 10.1109/TPAMI.2019.2920899 [48] Yao L, Torabi A, Cho K, Ballas N, Pal C, Larochelle H, et al. Describing videos by exploiting temporal structure. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4507−4515 [49] Shen Z Q, Li J G, Su Z, Li M J, Chen Y R, Jiang Y G, et al. Weakly supervised dense video captioning. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 5159−5167 [50] Johnson J, Karpathy A, Fei-Fei L. DenseCap: Fully convolutional localization networks for dense captioning. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 4565−4574 [51] Wang J W, Jiang W H, Ma L, Liu W, Xu Y. Bidirectional attentive fusion with context gating for dense video captioning. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 7190−7198 [52] Zhou L W, Zhou Y B, Corso J J, Socher R, Xiong C M. End-to-end dense video captioning with masked transformer. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 8739−8748 [53] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, California, USA: Curran Associates Inc., 2017. 6000−6010 [54] Zhou L W, Kalantidis Y, Chen X L, Corso J J, Rohrbach M. Grounded video description. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 6571−6580 [55] Mun J, Yang L J, Zhou Z, Xu N, Han B. Streamlined dense video captioning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 6581−6590 [56] Wang X, Chen W H, Wu J W, Wang Y F, Wang W Y. Video captioning via hierarchical reinforcement learning. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 4213−4222 [57] Xiong Y L, Dai B, Lin D H. Move forward and tell: A progressive generator of video descriptions. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 489−505 [58] Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Fei-Fei L. Large-scale video classification with convolutional neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 1725−1732 [59] Heilbron F C, Escorcia V, Ghanem B, Niebles J C. ActivityNet: A large-scale video benchmark for human activity understanding. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 961−970 [60] Shetty R, Laaksonen J. Frame- and segment-level features and candidate pool evaluation for video caption generation. In: Proceedings of the 24th ACM International Conference on Multimedia. Amsterdam, The Netherlands: ACM, 2016. 1073−1076 [61] Yu Y J, Choi J, Kim Y, Yoo K, Lee S H, Kim G. Supervising neural attention models for video captioning by human gaze data. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 6119−6127 [62] Wang J B, Wang W, Huang Y, Wang L, Tan T N. M3: Multimodal memory modelling for video captioning. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 7512−7520 [63] Donahue J, Hendricks L A, Guadarrama S, Rohrbach M, Venugopalan S, Darrell T, et al. Long-term recurrent convolutional networks for visual recognition and description. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 2625−2634 [64] Tang P J, Wang H L, Kwong S. Deep sequential fusion LSTM network for image description. Neurocomputing, 2018, 312: 154-164 doi: 10.1016/j.neucom.2018.05.086 [65] Pei W J, Zhang J Y, Wang X R, Ke L, Shen X Y, Tai Y W. Memory-attended recurrent network for video captioning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 8339−8348 [66] Li X L, Zhao B, Lu X Q. Mam-RNN: Multi-level attention model based RNN for video captioning. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: AAAI Press, 2017. 2208−2214 [67] Zhao B, Li X L, Lu X Q. Cam-RNN: Co-attention model based RNN for video captioning. IEEE Transactions on Image Processing, 2019, 28(11): 5552-5565 doi: 10.1109/TIP.2019.2916757 [68] Chen S Z, Jin Q, Chen J, Hauptmann A G. Generating video descriptions with latent topic guidance. IEEE Transactions on Multimedia, 2019, 21(9): 2407-2418 doi: 10.1109/TMM.2019.2896515 [69] Gan C, Gan Z, He X D, Gao J F, Deng L. StyleNet: Generating attractive visual captions with styles. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 955−964 [70] Pan B X, Cai H Y, Huang D A, Lee K H, Gaidon A, Adeli E, Niebles J C. Spatio-temporal graph for video captioning with knowledge distillation. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020. 10867−10876 [71] Hemalatha M, Sekhar C C. Domain-specific semantics guided approach to video captioning. In: Proceedings of the 2020 Winter Conference on Applications of Computer Vision. Snowmass, CO, USA: IEEE, 2020. 1576−1585 [72] Cherian A, Wang J, Hori C, Marks T M. Spatio-temporal ranked-attention networks for video captioning. In: Proceedings of the 2020 Winter Conference on Applications of Computer Vision (WACV). Snowmass, CO, USA: IEEE, 2020. 1606−1615 [73] Carreira J, Zisserman A. Quo vadis, action recognition? A new model and the kinetics dataset. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 4724−4733 [74] Wang L X, Shang C, Qiu H Q, Zhao T J, Qiu B L, Li H L. Multi-stage tag guidance network in video caption. In: Proceedings of the 28th ACM International Conference on Multimedia. Seattle, WA, USA: ACM, 2020. 4610−4614 [75] Hou J Y, Wu X X, Zhao W T, Luo J B, Jia Y D. Joint syntax representation learning and visual cue translation for video captioning. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 8917−8926 [76] Zhang Z Q, Shi Y Y, Yuan C F, Li B, Wang P J, Hu W M, et al. Object relational graph with teacher-recommended learning for video captioning. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020. 13275−13285 [77] Zheng Q, Wang C Y, Tao D C. Syntax-aware action targeting for video captioning. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020. 13093−13102 [78] Hou J Y, Wu X X, Zhang X X, Qi Y Y, Jia Y D, Luo J B. Joint commonsense and relation reasoning for image and video captioning. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 10973-10980 doi: 10.1609/aaai.v34i07.6731 [79] Chen J W, Pan Y W, Li Y H, Yao T, Chao H Y, Mei T. Temporal deformable convolutional encoder-decoder networks for video captioning. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 8167-8174 [80] Liu S, Ren Z, Yuan J S. SibNet: Sibling convolutional encoder for video captioning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(9): 3259-3272 doi: 10.1109/TPAMI.2019.2940007 [81] Aafaq N, Akhtar N, Liu W, Gilani S Z, Mian A. Spatio-temporal dynamics and semantic attribute enriched visual encoding for video captioning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 12479−12488 [82] Yu H N, Wang J, Huang Z H, Yang Y, Xu W. Video paragraph captioning using hierarchical recurrent neural networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 4584−4593 [83] Iashin V, Rahtu E. A better use of audio-visual cues: Dense video captioning with bi-modal transformer. In: Proceedings of the British Machine Vision Conference (BMVC). Online (Virtual): Springer, 2020. 1−13 [84] Park J S, Darrell T, Rohrbach A. Identity-aware multi-sentence video description. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 360−378 [85] Krishna R, Hata K, Ren F, Li F F, Niebles J C. Dense-captioning events in videos. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 706−715 [86] Escorcia V, Heilbron F C, Niebles J C, Ghanem B. DAPs: Deep action proposals for action understanding. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 768−784 [87] Li Y H, Yao T, Pan Y W, Chao H Y, Mei T. Jointly localizing and describing events for dense video captioning. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 7492−7500 [88] Wang T, Zheng H C, Yu M J, Tian Q, Hu H F. Event-centric hierarchical representation for dense video captioning. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(5): 1890-1900 doi: 10.1109/TCSVT.2020.3014606 [89] Park J S, Rohrbach M, Darrell T, Rohrbach A. Adversarial inference for multi-sentence video description. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 6591−6601 [90] Sun C, Myers A, Vondrick C, Murphy K, Schmid C. VideoBERT: A joint model for video and language representation learning. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 7463−7472 [91] Devlin J, Chang M W, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, Minnesota: ACL, 2019. 4171−4186 [92] Xie S N, Sun C, Huang J, Tu Z W, Murphy K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 318−335 [93] Sun C, Baradel F, Murphy K, Schmid C. Learning video representations using contrastive bidirectional transformer. arXiv: 1906.05743, 2019 [94] Luo H S, Ji L, Shi B T, Huang H Y, Duan N, Li T R, et al. UniVL: A unified video and language pre-training model for multimodal understanding and generation. arXiv: 2002.06353, 2020 [95] Mathews A P, Xie L X, He X M. SentiCap: Generating image descriptions with sentiments. In: Proceedings of the 13th AAAI Conference on Artificial Intelligence. Phoenix, Arizona: AAAI Press, 2016. 3574−3580 [96] Guo L T, Liu J, Yao P, Li J W, Lu H Q. MSCap: Multi-style image captioning with unpaired stylized text. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 4199−4208 [97] Park C C, Kim B, Kim G. Attend to you: Personalized image captioning with context sequence memory networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 6432−6440 [98] Shuster K, Humeau S, Hu H X, Bordes A, Weston J. Engaging image captioning via personality. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 12508−12518 [99] Chen T L, Zhang Z P, You Q Z, Fang C, Wang Z W, Jin H L, et al. “Factual” or “Emotional”: Stylized image captioning with adaptive learning and attention. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 527−543 [100] Zhao W T, Wu X X, Zhang X X. MemCap: Memorizing style knowledge for image captioning. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12984-12992 doi: 10.1609/aaai.v34i07.6998 [101] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 580−587 [102] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1440−1448 [103] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149 doi: 10.1109/TPAMI.2016.2577031 [104] Yandex A B, Lempitsky V. Aggregating local deep features for image retrieval. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1269−1277 [105] Kalantidis K, Mellina C, Osindero S. Cross-dimensional weighting for aggregated deep convolutional features. In: Proceedings of the European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 685−701 [106] Papineni K, Roukos S, Ward T, Zhu W J. BLEU: A method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia, Pennsylvania: ACL, 2002. 311−318 [107] Banerjee S, Lavie A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In: Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Ann Arbor, Michigan: ACL, 2005. 65−72 [108] Lin C Y, Och F J. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In: Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04). Barcelona, Spain: ACL, 2004. 605−612 [109] Vedantam R, Zitnick C L, Parikh D. CIDEr: Consensus-based image description evaluation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 4566−4575 [110] Anderson P, Fernando B, Johnson M, Gould S. SPICE: Semantic propositional image caption evaluation. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 382−398 [111] Xu J, Mei T, Yao T, Rui Y. MSR-VTT: A large video description dataset for bridging video and language. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 5288−5296 [112] Song J, Guo Y Y, Gao L L, Li X L, Hanjalic A, Shen H T. From deterministic to generative: Multimodal stochastic RNNs for video captioning. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(10): 3047-3058 doi: 10.1109/TNNLS.2018.2851077 [113] Yang Y, Zhou J, Ai J B, Bin Y, Hanjalic A, Shen H T, et al. Video captioning by adversarial LSTM. IEEE Transactions on Image Processing, 2018, 27(11): 5600-5611 doi: 10.1109/TIP.2018.2855422 [114] Chen Y Y, Wang S H, Zhang W G, Huang Q M. Less is more: Picking informative frames for video captioning. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 367−384 [115] Thomason J, Venugopalan S, Guadarrama S, Saenko K, Mooney R. Integrating language and vision to generate natural language descriptions of videos in the wild. In: Proceedings of the 25th International Conference on Computational Linguistics. Dublin, Ireland: Dublin City University and Association for Computational Linguistics, 2014. 1218−1227 [116] Dong J F, Li X R, Lan W Y, Huo Y J, Snoek C G M. Early embedding and late reranking for video captioning. In: Proceedings of the 24th ACM International Conference on Multimedia. Amsterdam, The Netherlands: ACM, 2016. 1082−1086 [117] Gao L L, Guo Z, Zhang H W, Xu X, Shen H T. Video captioning with attention-based LSTM and semantic consistency. IEEE Transactions on Multimedia, 2017, 19(9): 2045-2055 doi: 10.1109/TMM.2017.2729019 [118] Ramanishka V, Das A, Park D H, Venugopalan S, Hendricks L A, Rohrbach M, et al. Multimodal video description. In: Proceedings of the 24th ACM International Conference on Multimedia. Amsterdam, The Netherlands: ACM, 2016. 1092−1096 [119] Jin Q, Chen J, Chen S Z, Xiong Y F, Hauptmann A. Describing videos using multi-modal fusion. In: Proceedings of the 24th ACM International Conference on Multimedia. Amsterdam, The Netherlands: ACM, 2016. 1087−1091 [120] Zhou L W, Xu C L, Corso J J. Towards automatic learning of procedures from web instructional videos. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, Louisiana, USA: AAAI Press, 2018. 7590−7598 [121] Vinyals O, Toshev A, Bengio S, Erhan D. Show and tell: A neural image caption generator. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 3156−3164 [122] Zhang M X, Yang Y, Zhang H W, Ji Y L, Shen H T, Chua T S. More is better: Precise and detailed image captioning using online positive recall and missing concepts mining. IEEE Transactions on Image Processing, 2019, 28(1): 32-44 doi: 10.1109/TIP.2018.2855415 [123] Yang L Y, Wang H L, Tang P J, Li Q Y. CaptionNet: A tailor-made recurrent neural network for generating image descriptions. IEEE Transactions on Multimedia, 2020, 23: 835-845 [124] 汤鹏杰, 王瀚漓, 许恺晟. LSTM逐层多目标优化及多层概率融合的图像描述. 自动化学报, 2018, 44(7): 1237-1249Tang Peng-Jie, Wang Han-Li, Xu Kai-Sheng. Multi-objective layer-wise optimization and multi-level probability fusion for image description generation using LSTM. Acta Automatica Sinica, 2018, 44(7): 1237-1249 [125] Li X Y, Jiang S Q, Han J G. Learning object context for dense captioning. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 8650-8657 [126] Yin G J, Sheng L, Liu B, Yu N H, Wang X G, Shao J. Context and attribute grounded dense captioning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 6234−6243 [127] Kim D J, Choi J, Oh T H, Kweon I S. Dense relational captioning: Triple-stream networks for relationship-based captioning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 6264−6273 [128] Chatterjee M, Schwing A G. Diverse and coherent paragraph generation from images. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 747−763 [129] Wang J, Pan Y W, Yao T, Tang J H, Mei T. Convolutional auto-encoding of sentence topics for image paragraph generation. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao, China: AAAI Press, 2019. 940−946 -

 下载:
下载:






计量
- 文章访问数: 3761
- HTML全文浏览量: 2856
- PDF下载量: 649
- 被引次数: 0
