

-
摘要: 数据稀疏和冷启动是当前推荐系统面临的两大挑战. 以知识图谱为表现形式的附加信息能够在某种程度上缓解数据稀疏和冷启动带来的负面影响, 进而提高推荐的准确度. 本文综述了最近提出的应用知识图谱的推荐方法和系统, 并依据知识图谱来源与构建方法、推荐系统利用知识图谱的方式, 提出了应用知识图谱的推荐方法和系统的分类框架, 进一步分析了本领域的研究难点. 本文还给出了文献中常用的数据集. 最后讨论了未来有价值的研究方向.Abstract: Data sparsity and cold-start problems are two major challenges for current recommendation systems. The additional information in the form of a knowledge graph can alleviate these challenges to a certain extent, and integrating this information into recommender systems can improve the accuracy of the recommendation. This paper reviews recommendation methods and systems using knowledge graphs proposed recently, and proposes a classification framework for this kind of recommendation methods according to the source and construction methods of knowledge graphs and the way the recommendation systems use knowledge graph. We further analyze the research difficulties in this field. We also present commonly used datasets in the literature. Finally, future valuable research directions are discussed.
-
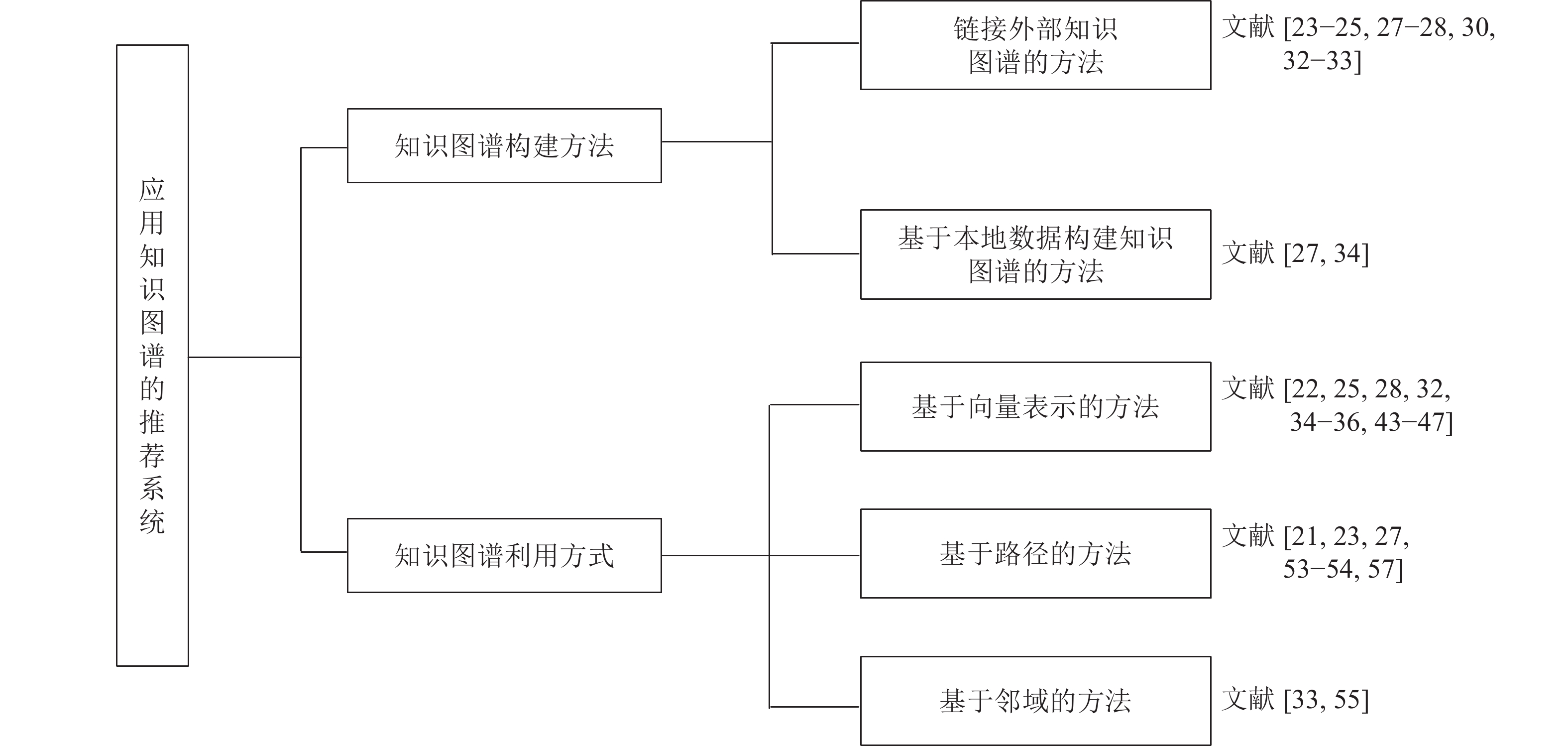
图 2 应用知识图谱的推荐系统分类树形图
Fig. 2 Classification tree diagram of recommendation system using knowledge graph
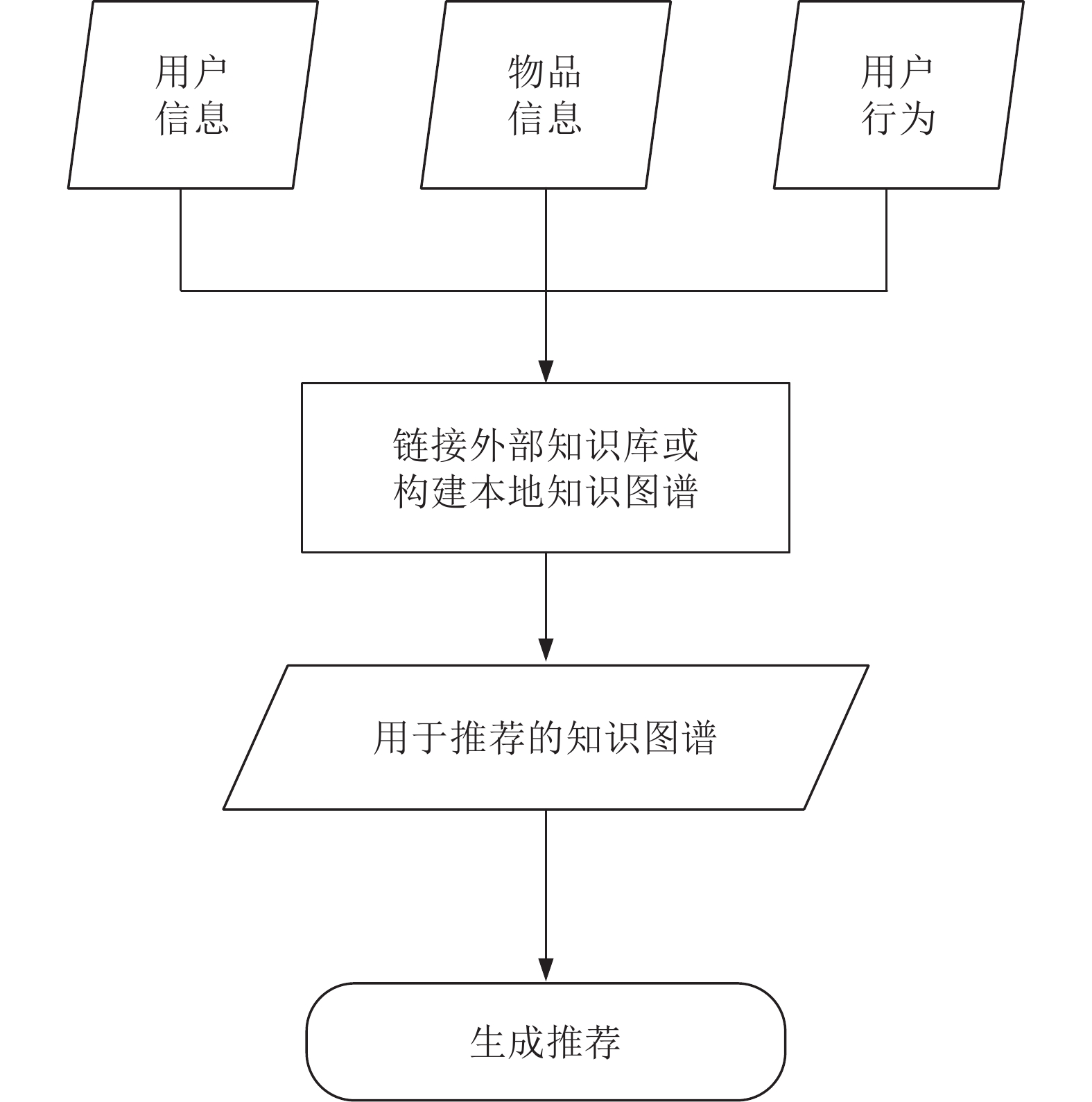
图 3 应用知识图谱的推荐系统框架流程
Fig. 3 Framework flow of recommendation system using knowledge graph
表 1 主要推荐系统数据集信息
Table 1 Main recommendation system datasets information
数据集 类别 内容 在本文综述的文献
中应用次数MovieLens-1M 电影 包含 6000 个用户对 4000 部电影上的 1 M 个评价 9 MovieLens-20M 电影 包含 138493 个用户对 27278 部电影的 20000263 个评价 3 Book-Crossings 书籍 90000 个用户, 270000 本书, 1100000 个评分, 评分范围从 1 到 10 5 Last.FM 音乐 用户 992, 音乐播放记录 19150868 , 对于每个用户, 包含他们最喜欢的艺术家的列表以及播放次数 5 Yelp 商业点评 4700000 条用户评价, 150000 条商户信息, 200000 张图片, 12 个大都市, 1200000 条商家属性, 随着时间推移在每家商户签到的总用户数 3 Bing News 新闻 2016 年 10 月 16 日至 2017 年 8 月 11 日从 Bing News8 的服务器日志中收集的
1025192 条隐式反馈和每条新闻的标题和摘要3 Drug interactions 医学 印第安那大学医学院提供, 药物相互作用表 1 IntentBooks[60] 书籍 从 Microsoft 的 Bing 搜索引擎和 Microsoft 的 Satori 知识库中收集 1 ICD-9 ontology 医学 13000 条国际诊断标准代码以及它们之间的关系 1 Freesound[61] 音乐 3275092 用户, 183246 声音, 48636182 下载记录 1 MIMIC-III 医学 46520 名患者, 650987 个患者诊断, 1517702 张处方记录(与 6985 种不同疾病和
4525 种药物相关)1 CEM 旅游 814 919 位单人旅行者, 4800000 笔预订 1 Amazon-book 书籍 来自 Amazon Review, 65125 用户, 69975 书籍, 828560 用户交互 1 Amazon 购物 数据集包括四个类别: CD, 服装, 手机和美容 1 e-commerce datasets collection All Music Guide 音乐 3000000 专辑信息, 自 1991 年以来专家评论数据 1 Alibaba Taobao 购物 482 M 用户数据, 9.14 M 物品数据, 7952 M 点击数据, 144 M 购买数据 1 MovieLens-100k 电影 包含 943 个用户对 1682 部电影的 100 K 个评价 1  下载: 导出CSV
下载: 导出CSV
-
[1] 王立才, 孟祥武, 张玉洁. 上下文感知推荐系统. 软件学报, 2012, 23(1): 1−20 doi: 10.3724/SP.J.1001.2012.04100Wang Li-Cai, Meng Xiang-Wu, Zhang Yu-Jie. Context-aware recommender systems. Journal of Software, 2012, 23(1): 1−20 doi: 10.3724/SP.J.1001.2012.04100 [2] Amit S. Introducing the Knowledge Graph. Official Blog of Google, America, 2012. [3] 常亮, 张伟涛, 古天龙, 孙文平, 宾辰忠. 知识图谱的推荐系统综述. 智能系统学报, 2019, 14(2): 207−216Chang Liang, Zhang Wei-Tao, Gu Tian-Long, Sun Wen-Ping, Bin Chen-Zhong. Review of recommendation systems based on knowledge graph. CAAI Transactions on Intelligent Systems, 2019, 14(2): 207−216 [4] Ricci F, Rokach L, Shapira B [著], 李艳民, 吴宾, 潘微科, 刘淇, 蒋凡, 等 [译]. 推荐系统. 北京: 机械出版社, 2018.Ricci F, Rokach L, Shapira B [Author], Li Yan-Min, Wu Bin, Pan Wei-Ke, Liu Qi, Jiang Fan, et al. [Translator]. Recommender Systems Handbook. Beijing: China Machine Press, 2018. [5] 王国霞, 刘贺平. 个性化推荐系统综述. 计算机工程与应用, 2012, 48(7): 66−76 doi: 10.3778/j.issn.1002-8331.2012.07.018Wang Guo-Xia, Liu He-Ping. Survey of personalized recommendation system. Computer Engineering and Applications, 2012, 48(7): 66−76 doi: 10.3778/j.issn.1002-8331.2012.07.018 [6] 邓爱林. 电子商务推荐系统关键技术研究 [博士学位论文]. 复旦大学, 中国, 2003.Deng Ai-Lin. The Research on Key Technologies of Recommendation System in E-Commerce [Ph.D. dissertation]. Fudan University, China, 2003. [7] 刘庆华. 个性化推荐技术及其在电子商务中的应用 [硕士学位论文]. 南昌大学, 中国, 2007.Liu Qing-Hua. Personalized Recommendation Techniques and its Applications for E-Commerce [Master thesis]. Nanchang University, China, 2007. [8] Balabanović M, Shoham Y. Fab: Content-based, collaborative recommendation. Communications of the ACM, 1997, 40(3): 66−72 doi: 10.1145/245108.245124 [9] Basu C, Hirsh H, Cohen W. Recommendation as classification: Using social and content-based information in recommendation. In: Proceedings of the 15th National/10th Conference on Artificial Intelligence/Innovative Applications of Artificial Intelligence. Madison, Wisconsin, USA: AAAI, 1998. 714−720 [10] Claypool M, Gokhale A, Miranda T, Murnikov P, Netes D, Sartin M. Combining content-based and collaborative filters in an online newspaper. In: Proceedings of the 1999 ACM SIGIR'99 Workshop on Recommender Systems: Algorithms and Evaluation. Berkeley, California, USA: ACM, 1999. [11] Pazzani M J. A framework for collaborative, content-based and demographic filtering. Artificial Intelligence Review, 1999, 13(5−6): 393−408 [12] Wang Q, Mao Z D, Wang B, Guo L. Knowledge graph embedding: A survey of approaches and applications. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(12): 2724−2743 doi: 10.1109/TKDE.2017.2754499 [13] Bordes A, Usunier N, Garcia-Durán A, Weston J, Yakhnenko O. Translating embeddings for modeling multi-relational data. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates Inc., 2013. 2787−2795 [14] Wang Z, Zhang J W, Feng J L, Chen Z. Knowledge graph embedding by translating on hyperplanes. In: Proceedings of the 28th AAAI Conference on Artificial Intelligence. Québec City, Québec, Canada: AAAI Press, 2014. 1112−1119 [15] Lin Y K, Liu Z Y, Sun M S, Liu Y, Zhu X. Learning entity and relation embeddings for knowledge graph completion. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin, Texas, USA: AAAI Press, 2015. 2181−2187 [16] Mikolov T, Sutskever I, Chen K, Corrado G, Dean J. Distributed representations of words and phrases and their compositionality. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates Inc., 2013. 3111−3119 [17] Ji G L, He S Z, Xu L H, Liu K, Zhao J. Knowledge graph embedding via dynamic mapping matrix. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing, China: Association for Computational Linguistics, 2015. 687−696 [18] Xiao H, Huang M L, Hao Y, Zhu X Y. TransG: A generative mixture model for knowledge graph embedding. arXiv preprint arXiv: 1509.05488, 2017. [19] 中国中文信息学会语言与知识计算专业委员会. 2018 知识图谱发展报告, 中国, 2018.CIPS. Knowledge Graph Development Report, China, 2018. [20] 徐增林, 盛泳潘, 贺丽荣, 王雅芳. 知识图谱技术综述. 电子科技大学学报, 2016, 45(4): 589−606 doi: 10.3969/j.issn.1001-0548.2016.04.012Xu Zeng-Lin, Sheng Yong-Pan, He Li-Rong, Wang Ya-Fan. Review on knowledge graph techniques. Journal of University of Electronic Science and Technology of China, 2016, 45(4): 589−606 doi: 10.3969/j.issn.1001-0548.2016.04.012 [21] Catherine R, Cohen W. Personalized recommendations using knowledge graphs: A probabilistic logic programming approach. In: Proceedings of the 10th ACM Conference on Recommender Systems. Boston, Massachusetts, USA: ACM, 2016. 325−332 [22] Cao Y X, Wang X, He X N, Hu Z K, Chua T S. Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences. In: Proceedings of the 2019 World Wide Web Conference. San Francisco, CA, USA: ACM, 2019. 151−161 [23] Sun Z, Yang J, Zhang J, Bozzon A, Huang L K, Xu C. Recurrent knowledge graph embedding for effective recommendation. In: Proceedings of the 12th ACM Conference on Recommender Systems. Vancouver, British, Columbia, Canada: ACM, 2018. 297−305 [24] Wang X, Wang D X, Xu C R, He X N, Cao Y X, Chua T S. Explainable reasoning over knowledge graphs for recommendation. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 5329−5336 [25] Zhang F Z, Yuan N J, Lian D F, Xie X, Ma W Y. Collaborative knowledge base embedding for recommender systems. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, California, USA: ACM, 2016. 353−362 [26] Scheffler T, Schirru R, Lehmann P. Matching points of interest from different social networking sites. In: Proceedings of the 2012 Annual Conference on Artificial Intelligence. Saarbrücken, Germany: Springer, 2012. 245−248 [27] Wang X, He X N, Cao Y X, Liu M, Chua T S. KGAT: Knowledge graph attention network for recommendation. arXiv preprint arXiv: 1905.07854, 2019. [28] Wang M, Liu M Y, Liu J, Wang S, Long G D, Qian B Y. Safe medicine recommendation via medical knowledge graph embedding. arXiv preprint arXiv: 1710.05980, 2017. [29] Wang M, Zhang J H, Liu J, Hu W, Wang S, Li X, et al. PDD graph: Bridging electronic medical records and biomedical knowledge graphs via entity linking. In: Proceedings of the 2017 International Semantic Web Conference. Vienna, Austria: Springer, 2017. 219−227 [30] Oramas S, Ostuni V C, Di Noia T, Serra X, Di Sciascio E. Sound and music recommendation with knowledge graphs. ACM Transactions on Intelligent Systems and Technology, 2017, 8(2): Article No. 21 [31] Moro A, Raganato A, Navigli R. Entity linking meets word sense disambiguation: A unified approach. Transactions of the Association for Computational Linguistics, 2014, 2: 231−244 doi: 10.1162/tacl_a_00179 [32] Wang H W, Zhang F Z, Xie X, Guo M Y. DKN: Deep knowledge-aware network for news recommendation. In: Proceedings of the 2018 World Wide Web Conference. Lyon. France: International World Wide Web Conferences Steering Committee, 2018. 1835−1844 [33] Wang H W, Zhao M, Xie X, Li W J, Guo M Y. Knowledge graph convolutional networks for recommender systems. In: Proceedings of the 2019 World Wide Web Conference. San Francisco, CA, USA: ACM, 2019. 3307−3313 [34] Dadoun A, Troncy R, Ratier O, Petitti R. Location embeddings for next trip recommendation. In: Companion Proceedings of the 2019 World Wide Web Conference. San Francisco, USA: ACM, 2019. 896−903 [35] Grad-Gyenge L, Kiss A, Filzmoser P. Graph embedding based recommendation techniques on the knowledge graph. In: Proceedings of the 2017 Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization. Bratislava, Slovakia: ACM, 2017. 354−359 [36] Huang H H. An MPD player with expert knowledge-based single user music recommendation. In: Proceedings of the 2019 IEEE/WIC/ACM International Conference on Web Intelligence-Companion Volume. Thessaloniki, Greece: ACM, 2019. 318−321 [37] Tang J, Qu M, Wang M Z, Zhang M, Yan J, Mei Q Z. LINE: Large-scale information network embedding. In: Proceedings of the 24th International Conference on World Wide Web. Florence, Italy: International World Wide Web Conferences Steering Committee, 2015. 1067−1077 [38] Kim Y. Convolutional neural networks for sentence classification. arXiv preprint arXiv: 1408.5882, 2014. [39] Fruchterman T M J, Reingold E M. Graph drawing by force-directed placement. Software: Practice and Experience, 1991, 21(11): 1129−1164 doi: 10.1002/spe.4380211102 [40] Meyer B. Self-organizing graphs — a neural network perspective of graph layout. In: Proceedings of the 1998 International Symposium on Graph Drawing. Montreal, QC, Canada: Springer, 1998. 246−262 [41] O'Madadhain J, Fisher D, White S, Boey Y B. The JUNG (Java universal network/graph) framework. University of California, Irvine, California, USA, 2003. [42] Kamada T, Kawai S. An algorithm for drawing general undirected graphs. Information Processing Letters, 1989, 31(1): 7−15 doi: 10.1016/0020-0190(89)90102-6 [43] Tang X L, Wang T Y, Yang H Z, Song H J. AKUPM: Attention-enhanced knowledge-aware user preference model for recommendation. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Anchorage, AK, USA: ACM, 2019. 1891−1899 [44] Hamilton W L, Bajaj P, Zitnik M, Jurafsky D, Leskovec J. Embedding logical queries on knowledge graphs. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: Curran Associates Inc., 2018. 2030−2041 [45] Palumbo E, Rizzo G, Troncy R. Entity2rec: Learning user-item relatedness from knowledge graphs for top-N item recommendation. In: Proceedings of the 11th ACM Conference on Recommender Systems. Como, Italy: ACM, 2017. 32−36 [46] Wang H W, Zhang F Z, Zhao M, Li W J, Xie X, Guo M Y. Multi-task feature learning for knowledge graph enhanced recommendation. In: Proceedings of the 2019 World Wide Web Conference. San Francisco, CA, USA: ACM, 2019. 2000−2010 [47] Ye Y T, Wang X W, Yao J C, Jia K Y, Zhou J R, Xiao Y H, et al. Bayes EMbedding (BEM): Refining representation by integrating knowledge graphs and behavior-specific networks. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management. Beijing, China: ACM, 2019. 679−688 [48] Grover A, Leskovec J. node2vec: Scalable feature learning for networks. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, California, USA: ACM, 2016. 855−864 [49] Wang H W, Zhang F Z, Zhang M D, Leskovec J, Zhao M, Li W J, et al. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Anchorage, AK, USA: ACM, 2019. 968−977 [50] Zhang X H, Lee W S. Hyperparameter learning for graph based semi-supervised learning algorithms. In: Proceedings of the 19th International Conference on Neural Information Processing Systems. Canada: MIT Press, 2006. 1585−1592 [51] Zhu X J, Ghahramani Z, Lafferty J D. Semi-supervised learning using Gaussian fields and harmonic functions. In: Proceedings of the 20th International Conference on Machine Learning. Washington, DC, USA: AAAI Press, 2003. 912−919 [52] Vincent P, Larochelle H, Lajoie I, Bengio Y, Manzagol P A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. The Journal of Machine Learning Research, 2010, 11: 3371−3408 [53] Huang X W, Fang Q, Qian S S, Sang J T, Li Y, Xu C S. Explainable interaction-driven user modeling over knowledge graph for sequential recommendation. In: Proceedings of the 27th ACM International Conference on Multimedia. Nice, France: ACM, 2019. 548−556 [54] Xian Y K, Fu Z H, Muthukrishnan S, de Melo G, Zhang Y F. Reinforcement knowledge graph reasoning for explainable recommendation. arXiv preprint arXiv: 1906.05237, 2019. [55] Wang H W, Zhang F Z, Wang J L, Zhao M, Li W J, Xie X, et al. RippleNet: Propagating user preferences on the knowledge graph for recommender systems. In: Proceedings of the 27th ACM International Conference on Information and Knowledge Management. Torino, Italy: ACM, 2018. 417−426 [56] Rendle S, Freudenthaler C, Schmidt-Thieme L. Factorizing personalized Markov chains for next-basket recommendation. In: Proceedings of the 19th International Conference on World Wide Web. Raleigh, North Carolina, USA: ACM, 2010. 811−820 [57] Ma W Z, Zhang M, Cao Y, Jin W, Wang C Y, Liu Y Q, et al. Jointly learning explainable rules for recommendation with knowledge graph. In: Proceedings of the 2019 World Wide Web Conference. San Francisco, CA, USA: ACM, 2019. 1210−1221 [58] Koren Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In: Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas, Nevada, USA: ACM, 2008. 426−434 [59] Yu X, Ren X, Sun Y Z, Gu Q Q, Sturt B, Khandelwal U, et al. Personalized entity recommendation: A heterogeneous information network approach. In: Proceedings of the 7th ACM International Conference on Web Search and Data Mining. New York, USA: ACM, 2014. 283−292 [60] Uyar A, Aliyu F M. Evaluating search features of Google Knowledge Graph and Bing Satori: Entity types, list searches and query interfaces. Online Information Review, 2015, 39(2): 197−213 doi: 10.1108/OIR-10-2014-0257 [61] Font F, Oramas S, Fazekas G, Serra X. Extending tagging ontologies with domain specific knowledge. In: International Semantic Web Conference (Posters and Demos). Riva del Garda, Italy, 2014. 209−212 [62] Bizer C, Lehmann J, Kobilarov G, Auer S, Becker C, Cyganiak R, et al. DBpedia-A crystallization point for the Web of Data. Journal of Web Semantics, 2009, 7(3): 154−165 doi: 10.1016/j.websem.2009.07.002 [63] WMF. Wikidata [Online]. available: https://www.wikidata.org/wiki/Wikidata:Main_Page, December 30, 2019 [64] Bollacker K, Cook R, Tufts P. Freebase: A shared database of structured general human knowledge. In: Proceedings of the 22nd National Conference on Artificial Intelligence. Vancouver, British, Columbia, Canada: AAAI Press, 2007. 1962−1963 [65] Suchanek F M, Kasneci G, Weikum G. YAGO: A large ontology from Wikipedia and WordNet. Journal of Web Semantics, 2008, 6(3): 203−217 doi: 10.1016/j.websem.2008.06.001 [66] Zhao W X, He G L, Yang K L, Dou H J, Huang J, Ouyang S Q, et al. KB4Rec: A data set for linking knowledge bases with recommender systems. Data Intelligence, 2019, 1(2): 121−136 doi: 10.1162/dint_a_00008 [67] 冯永, 陈以刚, 强保华. 融合社交因素和评论文本卷积网络模型的汽车推荐研究. 自动化学报, 2019, 45(3): 518−529Feng Yong, Chen Yi-Gang, Qiang Bao-Hua. Social and comment text CNN model based automobile recommendation. Acta Automatica Sinica, 2019, 45(3): 518−529 [68] 李慧, 马小平, 施珺, 李存华, 仲兆满, 蔡虹. 复杂网络环境下基于信任传递的推荐模型研究. 自动化学报, 2018, 44(2): 363−376Li Hui, Ma Xiao-Ping, Shi Jun, Li Cun-Hua, Zhong Zhao-Man, Cai Hong. A recommendation model by means of trust transition in complex network environment. Acta Automatica Sinica, 2018, 44(2): 363−376 -

 下载:
下载:

图(3) / 表(1)
计量
- 文章访问数: 4821
- HTML全文浏览量: 2672
- PDF下载量: 970
- 被引次数: 0
