

Survey on Image Classification Technology Based on Small Sample Learning
-
摘要: 图像分类的应用场景非常广泛, 很多场景下难以收集到足够多的数据来训练模型, 利用小样本学习进行图像分类可解决训练数据量小的问题. 本文对近年来的小样本图像分类算法进行了详细综述, 根据不同的建模方式, 将现有算法分为卷积神经网络模型和图神经网络模型两大类, 其中基于卷积神经网络模型的算法包括四种学习范式: 迁移学习、元学习、对偶学习和贝叶斯学习; 基于图神经网络模型的算法原本适用于非欧几里得结构数据, 但有部分学者将其应用于解决小样本下欧几里得数据的图像分类任务, 有关的研究成果目前相对较少. 此外, 本文汇总了现有文献中出现的数据集并通过实验结果对现有算法的性能进行了比较. 最后, 讨论了小样本图像分类技术的难点及未来研究趋势.Abstract: Image classification is widely used in different fields. However in many scenarios, it is difficult to collect sufficient data to train the model for classification. Small sample learning provides a solution to this problem. This paper provides a comprehensive survey on recent small sample learning techniques for image classification. Existing algorithms are divided into two categories based on different modeling methods: Convolution based neural network model and graph based neural network model. The algorithms based on convolution neural network model include four learning paradigms: transfer learning, meta learning, dual learning and Bayesian learning. The algorithm based on graph neural network model was originally suitable for non Euclidean data, but some scholars applied it to solve the image classification task of Euclidean data under small samples, which is relatively scarce. In addition, this paper summarizes the existing data sets in literature and compares the performance of existing algorithms through experiments. Finally, the challenges and research trends in small sample image classification are discussed.
-
Key words:
- Transfer learning /
- meta learning /
- dual learning /
- Bayesian learning /
- graph neural network
-
表 2 基于元学习的Omniglot实验结果
Table 2 Experimental results of Omniglot based on meta learning
Omniglot 5way-1shot 5way-5shot 20way-1shot 20way-5shot 基于度量的元学习 MN[9] 98.12 99.63 94.40 98.78 文献 [40] 90.80 96.70 77.00 91.00 MMN[42] 99.28 99.77 97.16 98.93 PN[29] 98.80 99.18 92.11 97.57 RN[30] 99.48 99.60 97.67 98.97 基于模型的元学习 Meta-Nets[78] 98.00 99.60 96.90 98.50 基于优化的元学习 MAML[79] 98.79 99.48 93.43 95.33 文献 [88] — — 97.65 99.33 Reptile[89] 97.50 99.87 93.75 97.68  下载: 导出CSV
下载: 导出CSV
表 3 基于元学习的Mini-ImageNet实验结果
Table 3 Experimental results of Mini-ImageNet based on meta learning
下载: 导出CSV
表 4 基于图卷积网络的Mini-ImageNet、Omniglot实验结果
Table 4 Experimental results of Mini-ImageNet and Omniglot based on graph convolutional network
下载: 导出CSV
表 5 迁移学习、元学习、对偶学习和图神经网络模型实验结果
Table 5 Experimental results of transfer learning, meta learning, dual learning and graph neural network model
下载: 导出CSV
表 6 在轮胎花纹数据集上的测试结果对比
Table 6 Test results comparison of various algorithms on tire patterns data set
算法 轮胎数据集 分类精度 5way-1shot 5way-5shot 文献 [79] 表面 67.09 85.55 压痕 77.66 87.32 混合 46.03 64.00 文献 [78] 表面 53.46 78.42 压痕 66.13 80.45 混合 42.80 63.53 文献 [107] 表面 77.46 89.52 压痕 77.76 92.00 混合 58.04 79.98 文献 [31] 表面 72.71 91.03 压痕 76.42 91.76 混合 51.84 81.02 文献 [30] 表面 63.97 81.60 压痕 73.71 84.54 混合 48.21 65.20
下载: 导出CSV
表 7 小样本图像分类算法的对比
Table 7 Comparison of small sample image classification algorithms
算法 数据增强 训练策略 分类度量方式 数据集 基于特征的迁移学习 文献 [61] 函数变换增加训练样本 CNN 表示学习阶段 + 小样本学习阶段 全连接层 + Softmax ImageNet SSMN[62] CNN + LSTM 局部特征度量 + 全局特征度量 嵌入向量 + 点乘 DiPART、PPM、Cross-DiPART-PPM 基于关系的迁移学习 文献 [39] 采用伪样本数据 CNN 知识蒸馏 全连接层 + Softmax MNIST 文献 [75] CNN 1×1卷积核知识蒸馏 全连接层 + Softmax CIFAR-10、CIFAR-100 基于共享参 数的迁移
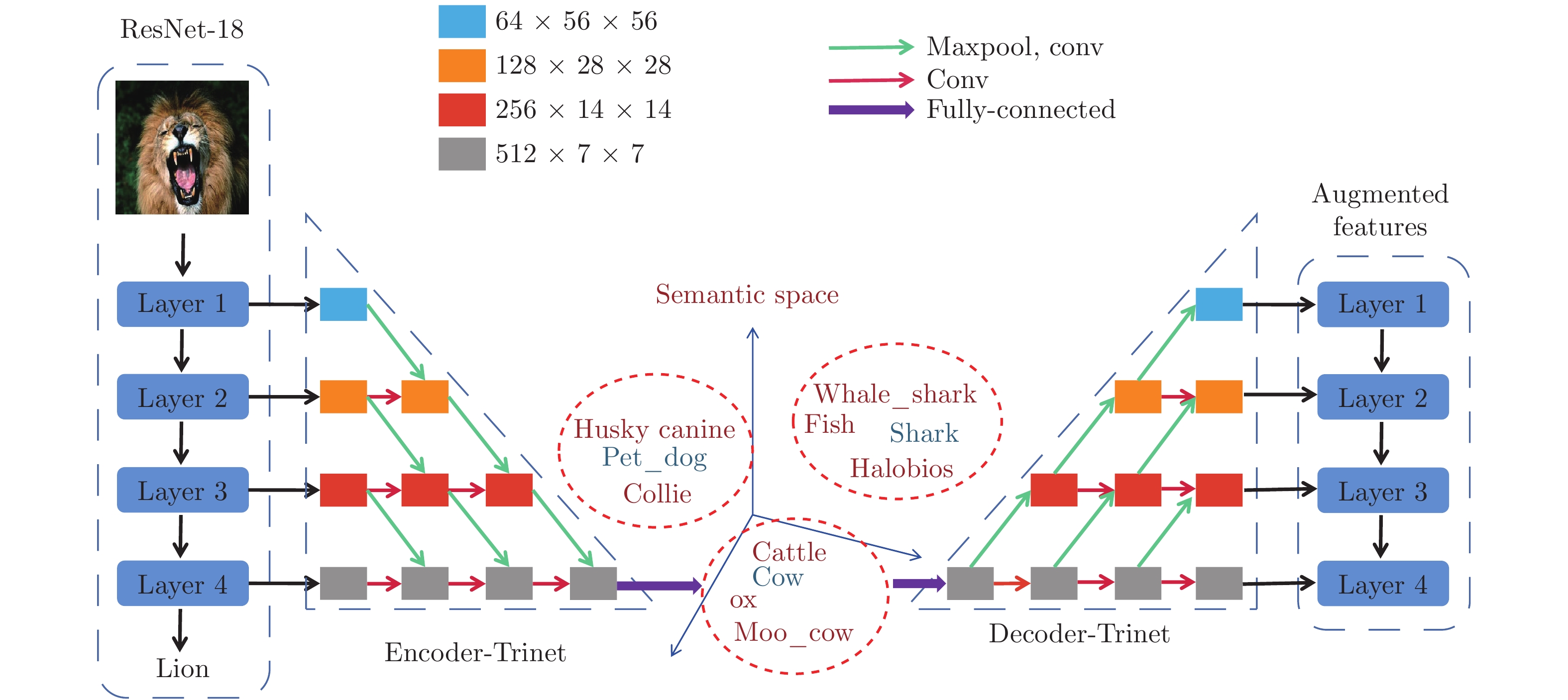
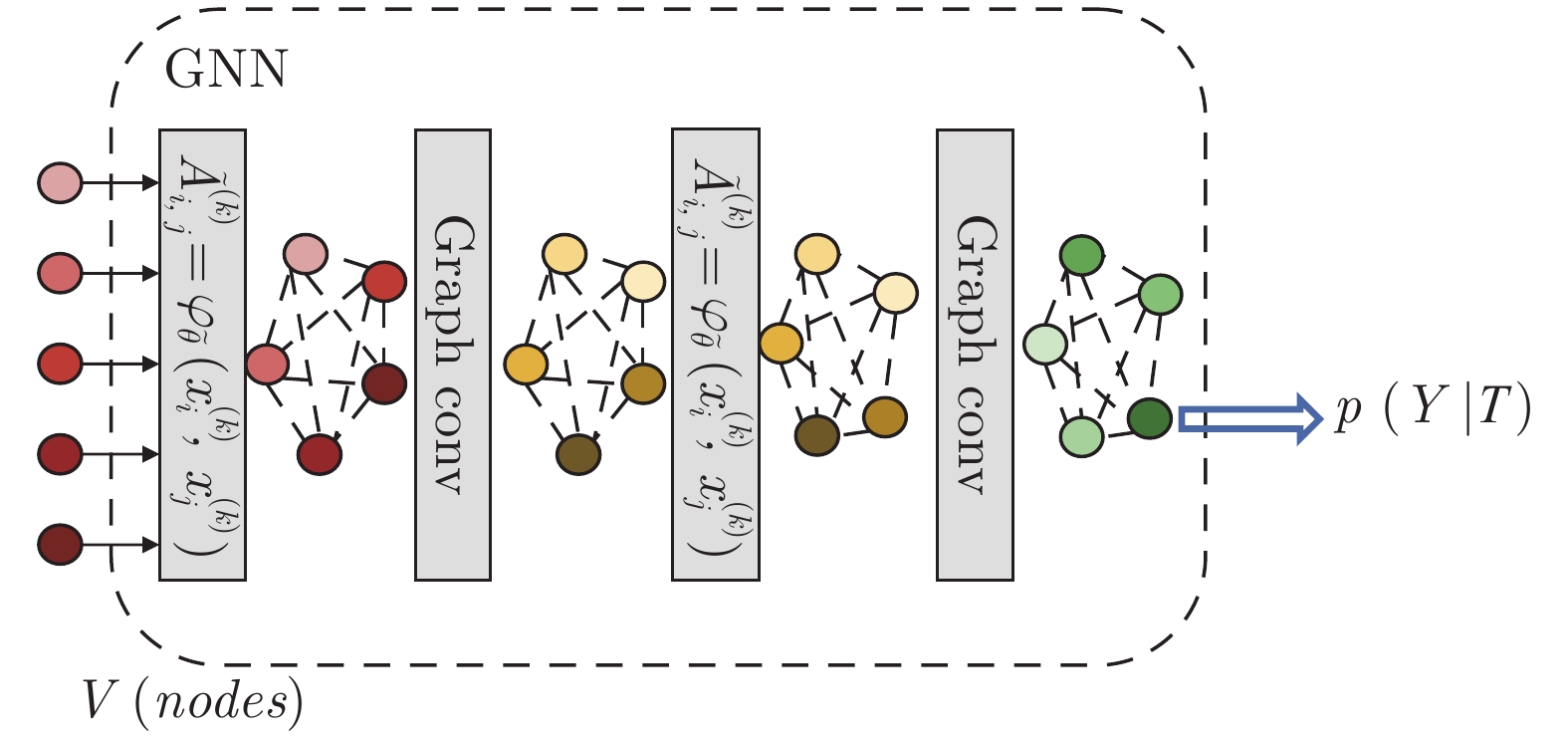
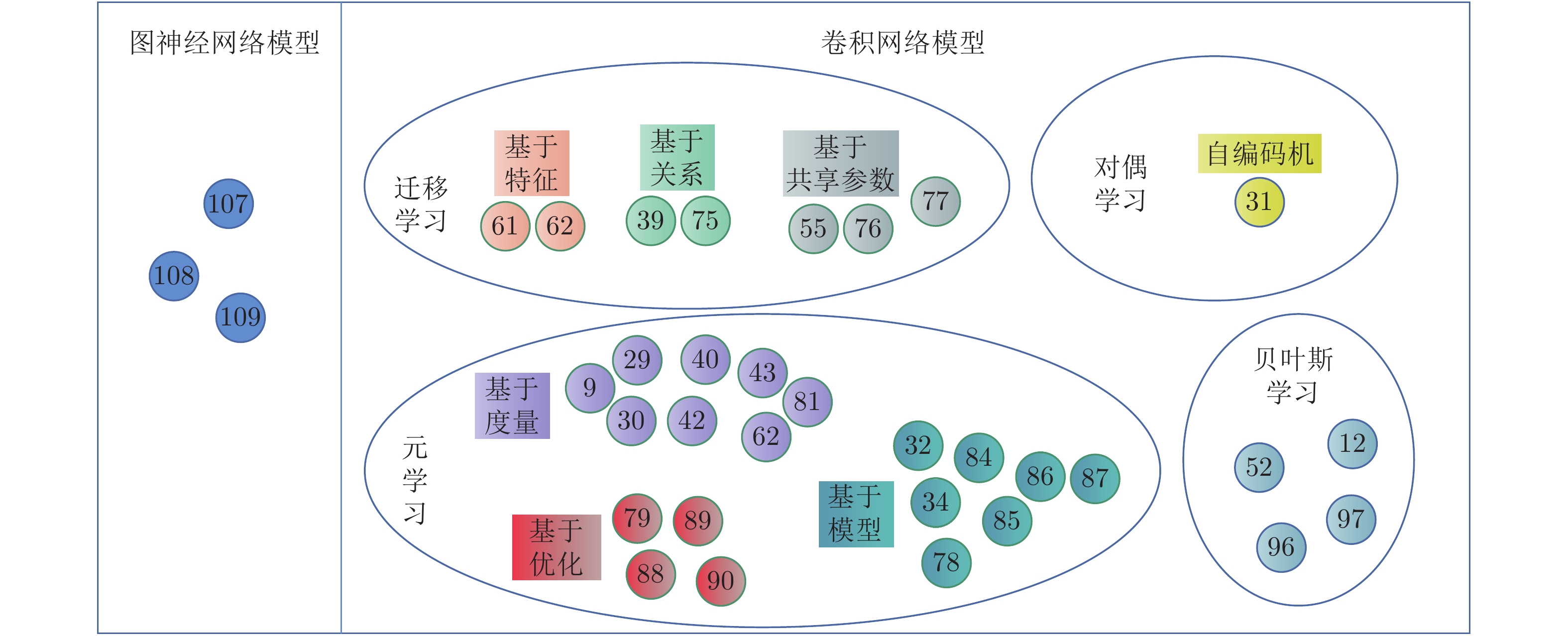
学习文献 [76] 裁剪 CNN 预训练模型 + 微调 全连接层 + Softmax PASCAL VOC 2007、PASCALVOC 2012 文献 [77] CNN 分类权重嵌入 全连接层 + Softmax CUB-200 PPA[55] CNN 在激活函数和 Softmax 之间建模, 预测类别的分类参数 全连接层 + Softmax Mini-ImageNet 基于度量的元学习 文献 [43] CNN 孪生网络 + 距离度量 嵌入向量 + 欧氏距离 Omniglot MN[9] 仿射变换 CNN + LSTM 注意力模块 + 样本间匹配 嵌入向量 + 余弦距离 Omniglot、Mini-ImageNet MMN[42] CNN + bi-LSTM 记忆读写控制模块 + 样本间匹配 嵌入向量 + 点乘 Omniglot、Mini-ImageNet PN[29] CNN 聚类 + 样本间原型度量 嵌入向量 + 欧氏距离 Omniglot、Mini-ImageNet RN[30] 旋转 CNN 不同样本在特征空间比较 全连接层 + Softmax Omniglot、Mini-ImageNet 文献 [81] CNN 利用嵌入特征回归分类参数 + 不同样本映射到同一嵌入空间进行相似性度量 全连接层 + Softmax Omniglot、Mini-ImageNet 基于优化的元学习 MAML[79] 旋转 利用基于梯度的学习来更新每个元任务的参数 Omniglot、Mini-ImageNet Reptile[89] 将梯度下降计算的参数与初始化参数的差用于参数梯度更新 Omniglot、Mini-ImageNet 文献 [90] 利用 LSTM 模型学习优化算法 Mini-ImageNet 基于模型的元学习 Meta-Nets[78] 旋转 CNN + LSTM记忆模块 + Meta learner + Base learner 全连接层 + Softmax Omniglot、Mini-ImageNet DML[32] CNN 概念生成器 + 概念判决器 + Meta learner 全连接层 + Softmax CUB-200、CIFAR-100、Mini-ImageNet 文献 [34] CNN + LSTM对样本和标签进行绑定编码使用外部记忆存储模块 全连接层 + Softmax Omniglot 基于模型的元学习 文献 [85] 函数变换增加训练样本 CNN 利用数据增强提升元学习 全连接层 + Softmax ImageNet 文献 [86] CNN 减小大数据集和小数据集分类器间的差异 SVM CUB-200 AAN[87] CNN 注意力模块 + 增量学习 + 元学习针对样本生成相应的分类参数 全连接层 + Softmax Mini-ImageNe、Tiered-ImageNet 自动编码机 SFA[31] 使用编码 − 解码机制进行特征增加 CNN 通过扰动语义空间特征实现样本特征增加 全连接层 + Softmax CUB-200、CIFAR-100、Mini-ImageNet 图卷积神经网络 GCN[107] GCN 利用图节点标签信息, 隐式地对类内和类间样本关系进行建模 全连接层 + Softmax Omniglot、Mini-ImageNet EGNN[108] GCN 通过预测边标签, 显式地对类内和类间样本进行建模 全连接层 + Softmax Mini-ImageNet、Tiered-ImageNet TPN[109] GCN 流型假设 + 标签传播 全连接层 + Softmax Mini-ImageNet、Tiered-ImageNet
下载: 导出CSV
-
[1] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2): 91−110 doi: 10.1023/B:VISI.0000029664.99615.94 [2] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). San Diego, USA: IEEE, 2005. 886−893 [3] Csurka G, Dance C R, Fan L X, Willamowski J, Bray C. Visual categorization with bags of keypoints. In: Workshop on Statistical Learning in Computer Vision, Proceedings of the European Conference on Computer Vision. Prague, Heidelberg, Berlin: Springer 2004. 1−22 [4] Lazebnik S, Schmid C, Ponce J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06). New York, USA: IEEE, 2006. 2169−2178 [5] Perronnin F, Sánchez J, Mensink T. Improving the fisher kernel for large-scale image classification. In: Proceedings of the 11th European Conference on Computer Vision. Heraklion, Greece: Springer, 2010. 143−156 [6] Sivic J, Zisserman A. Video google: A text retrieval approach to object matching in videos. In: Proceedings of the 9th IEEE International Conference on Computer Vision. Nice, France: IEEE, 2003. 1470−1477 [7] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors. Nature, 1986, 323(6088): 533−536 doi: 10.1038/323533a0 [8] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: ACM, 2012. 1106−1114 [9] Vinyals O, Blundell C, Lillicrap T, Kavukcuoglu K. Matching networks for one shot learning. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: ACM, 2016. 3637−3645 [10] Li F F, Fergus R, Perona P. One-shot learning of object categories. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(4): 594−611 doi: 10.1109/TPAMI.2006.79 [11] Li F F, Fergus R, Perona P. A bayesian approach to unsupervised one-shot learning of object categories. In: Proceedings of the 9th IEEE International Conference on Computer Vision. Nice, France: IEEE, 2003. 1134−1141 [12] Lake B M, Salakhutdinov R, Gross J, Tenenbaum J B. One shot learning of simple visual concepts. Cognitive Science Society, 2011, 33: 2568−2573 [13] Hariharan B, Girshick R. Low-shot visual object recognition. arXiv: 1606.02819, 2016. [14] Shaban A, Bansal S, Liu Z, Essa I, Boots B. One-shot learning for semantic segmentation. In: Proceedings of the 2017 British Machine Vision Conference. London, UK: BMVC, 2017. [15] Gui L K, Wang Y X, Hebert M. Few-shot hash learning for image retrieval. In: Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW). Venice, Italy: IEEE, 2017. 1228−1237 [16] Qi G J, Luo J B. Small data challenges in big data era: A survey of recent progress on unsupervised and semi-supervised methods. IEEE Transactions on Pattern Analysis and Machine Intelligence, DOI: 10.1109/TPAMI.2020.3031898 [17] Shu J, Xu Z B, Meng D Y. Small sample learning in big data era. arXiv: 1808.04572, 2018. [18] Wang Y Q, Yao Q M, Kwok J, Ni L M. Generalizing from a few examples: A survey on few-shot learning. arXiv: 1904.05046, 2019. [19] Wang Y Q, Yao Q M. Few-shot learning: A survey. arXiv: 1904.05046, 2019. [20] Mensink T, Verbeek J, Perronnin F, Csurka G. Metric learning for large scale image classification: Generalizing to new classes at near-zero cost. In: Proceedings of the 12th European Conference on Computer Vision. Florence, Italy: Springer, 2012. 488−501 [21] Mensink T, Verbeek J, Perronnin F, Csurka G. Distance-based image classification: Generalizing to new classes at near-zero cost. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2624−2637 doi: 10.1109/TPAMI.2013.83 [22] Rohrbach M, Ebert S, Schiele B. Transfer learning in a transductive setting. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: ACM, 2013. 46−54 [23] Lampert C H, Nickisch H, Harmeling S. Attribute-based classification for zero-shot visual object categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(3): 453−465 doi: 10.1109/TPAMI.2013.140 [24] Deng J, Dong W, Socher R, Li L J, Li K, Li F F. Imagenet: A large-scale hierarchical image database. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, Florida, USA: IEEE, 2009. [25] Rohrbach M, Stark M, Schiele B. Evaluating knowledge transfer and zero-shot learning in a large-scale setting. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2011. 1641−1648 [26] Fu Y W, Hospedales T M, Xiang T, Gong S G. Transductive multi-view zero-shot learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(11): 2332−2345 doi: 10.1109/TPAMI.2015.2408354 [27] Wah C, Branson S, Welinder P, Perona P, Belongie S. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011. [28] Fu Y W, Hospedales T M, Xiang T, Gong S G. Learning multimodal latent attributes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(2): 303−316 doi: 10.1109/TPAMI.2013.128 [29] Snell J, Swersky K, Zemel R. Prototypical networks for few-shot learning. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: ACM, 2017. 4077−4087 [30] Sung F, Yang Y X, Zhang L, Xiang T, Torr P H S, Hospedales T M. Learning to compare: Relation network for few-shot learning. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1199−1208 [31] Chen Z T, Fu Y W, Zhang Y D, Jiang Y G, Xue X Y, Sigal L. Semantic feature augmentation in few-shot learning. In: Proceedings of the European Conference on Computer Vision. Prague, Heidelberg, Berlin: Springer, 2018. [32] Zhou F W, Wu B, Li Z G. Deep meta-learning: Learning to learn in the concept space. arXiv: 1802.03596, 2018. [33] 甘英俊, 翟懿奎, 黄聿, 增军英, 姜开永. 基于双激活层深度卷积特征的人脸美丽预测研究. 电子学报, 2019, 47(3): 636−642Gan Ying-Jun, Zhai Yi-Kui, Huang Yu, Zeng Jun-Ying, Jiang Kai-Yong. Research of facial beauty prediction based on deep convolutional features using double activation layer. Acta Electronica Sinica, 2019, 47(3): 636−642 [34] Santoro A, Bartunov S, Botvinick M, Wierstra D, Lillicrap T. Meta-learning with memory-augmented neural networks. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: ACM, 2016. 1842−1850 [35] Jia Y Q, Darrell T. Latent task adaptation with large-scale hierarchies. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 2080−2087 [36] Mehrotra A, Dukkipati A. Generative adversarial residual pairwise networks for one shot learning. arXiv: 1703.08033, 2017. [37] Bromley J, Guyon I, LeCun Y, Säckinger E, Shah R. Signature verification using a “Siamese” time delay neural network. In: Proceedings of the 6th International Conference on Neural Information Processing Systems. Denver, USA: ACM, 1993. 737−744 [38] Dixit M, Kwitt R, Niethammer M, Vasconcelos N. AGA: Attribute-guided augmentation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 7455−7463 [39] Kimura A, Ghahramani Z, Takeuchi K, Iwata T, Ueda N. Few-shot learning of neural networks from scratch by pseudo example optimization. In: Proceedings of the 2018 British Machine Vision Conference. Newcastle, UK: British Machine Vision Association, 2018. [40] Bartunov S, Vetrov D. Few-shot generative modelling with generative matching networks. In: Proceedings of the 21st International Conference on Artificial Intelligence and Statistics. Playa Blanca, Spain: JMLR, 2018. 670−678 [41] Wang P, Liu L Q, Shen C H, Huang Z, Van Den Hengel A, Shen H T. Multi-attention network for one shot learning. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 2721−2729 [42] Cai Q, Pan Y W, Yao T, Yan C G, Mei T. Memory matching networks for one-shot image recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 4080−4088 [43] Koch G, Zemel R, Salakhutdinov R. Siamese neural networks for one-shot image recognition. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: International Machine Learning Society, 2015. [44] Schroff F, Kalenichenko D, Philbin J. FaceNet: A unified embedding for face recognition and clustering. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 815−823 [45] Taigman Y, Yang M, Ranzato M A, Wolf L. Web-scale training for face identification. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 2746−2754 [46] 马跃峰, 梁循, 周小平. 一种基于全局代表点的快速最小二乘支持向量机稀疏化算法. 自动化学报, 2017, 43(1): 132−141Ma Yue-Feng, Liang Xun, Zhou Xiao-Ping. A fast sparse algorithm for least squares support vector machine based on global representative points. Acta Automatica Sinica, 2017, 43(1): 132−141 [47] Goldberger J, Roweis S, Hinton G, Salakhutdinov R. Neighbourhood components analysis. In: Proceedings of the 17th International Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2004. 513−520 [48] Salakhutdinov R, Hinton G. Learning a nonlinear embedding by preserving class neighbourhood structure. In: Proceedings of the 11th International Conference on Artificial Intelligence and Statistics. Naha, Japan: JMLR, 2007. 412−419 [49] Weinberger K Q, Saul L K. Distance metric learning for large margin nearest neighbor classification. The Journal of Machine Learning Research, 2009, 10: 207−244 [50] Gidaris S, Komodakis N. Dynamic few-shot visual learning without forgetting. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 4367−4375 [51] Chen W Y, Liu Y C, Kira Z, Wang Y C F, Huang J B. A closer look at few-shot classification. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, Louisiana, United States: arXiv.org, 2019. [52] Lake B M, Salakhutdinov R, Tenenbaum J B. Human-level concept learning through probabilistic program induction. Science, 2015, 350(6266): 1332−1338 doi: 10.1126/science.aab3050 [53] Krizhevsky A. Learning multiple layers of features from tiny images. Technical Report, University of Toronto, Canada, 2009. [54] Ren M Y, Triantafillou E, Ravi S, Snell J, Swersky K, Tenenbaum J B, et al. Meta-learning for semi-supervised few-shot classification. In: Proceedings of the 6th International Conference on Learning Representations, ICLR 2018 - Conference Track Proceedings. Vancouver, Canada: arXiv.org, 2018. [55] Qiao S Y, Liu C X, Shen W, Yuille A L. Few-shot image recognition by predicting parameters from activations. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7229−7238 [56] Aytar Y, Zisserman A. Tabula rasa: Model transfer for object category detection. In: Proceedings of the 2011 International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 2252−2259 [57] Tommasi T, Orabona F, Caputo B. Safety in numbers: Learning categories from few examples with multi model knowledge transfer. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 3081−3088 [58] Thrun S. Is learning the n-th thing any easier than learning the first? In: Proceedings of the 8th International Conference on Neural Information Processing Systems. Denver, USA: MIT Press, 1996. 640−646 [59] Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345−1359 doi: 10.1109/TKDE.2009.191 [60] 季鼎承, 蒋亦樟, 王士同. 基于域与样例平衡的多源迁移学习方法. 电子学报, 2019, 47(3): 692−699Ji Ding-Cheng, Jiang Yi-Zhang, Wang Shi-Tong. Multi-source transfer learning method by balancing both the domains and instances. Acta Electronica Sinica, 2019, 47(3): 692−699 [61] Hariharan B, Girshick R. Low-shot visual recognition by shrinking and hallucinating features. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 3018−3027 [62] Choi J, Krishnamurthy J, Kembhavi A, Farhadi A. Structured set matching networks for one-shot part labeling. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake, USA: IEEE, 2018. 3627−3636 [63] Bucilua C, Caruana R, Niculescu-Mizil A. Model compression. In: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2006. 535−541 [64] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. Computer ence, 2015, 14(7):38−39 [65] Ba L J, Caruana R. Do deep nets really need to be deep? In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2654−2662 [66] Han S, Mao H Z, Dally W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding. In: Proceedings of the 2016 International Conference on Learning Representations. Barcelona, Spain: MIT Press, 2016. 2654−2662 [67] Li H, Kadav A, Durdanovic I, Samet H, Graf H P. Pruning filters for efficient ConvNets. In: Proceedings of the 5th International Conference on Learning Representations, ICLR 2017 - Conference Track Proceedings. Toulon, France: arXiv.org, 2017. [68] Liu Z, Li J G, Shen Z Q, Huang G, Yan S M, Zhang C S. Learning efficient convolutional networks through network slimming. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2736−2744 [69] Denton E, Zaremba W, Bruna J, LeCun Y, Fergus R. Exploiting linear structure within convolutional networks for efficient evaluation. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 1269−1277 [70] Jaderberg M, Vedaldi A, Zisserman A. Speeding up convolutional neural networks with low rank expansions. In: Proceedings of the 2014 Conference on British Machine Vision Conference. Nottingham, UK: British Machine Vision Association, 2014. [71] Zhang X Y, Zou J H, He K M, Sun J. Accelerating very deep convolutional networks for classification and detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 1943−1955 doi: 10.1109/TPAMI.2015.2502579 [72] Kim Y D, Park E, Yoo S, Choi T, Yang L, Shin D. Compression of deep convolutional neural networks for fast and low power mobile applications. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico: IEEE, 2016. [73] Snelson E, Ghahramani Z. Sparse Gaussian processes using pseudo-inputs. In: Proceedings of the 18th International Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2005. 1257−1264 [74] Lin M, Chen Q, Yan S C. Network in network. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, AB, Canada: arXiv.org, 2014. [75] Li T H, Li J G, Liu Z, Zhang C S. Knowledge distillation from few samples. arXiv: 1812.01839, 2018. [76] Oquab M, Bottou L, Laptev I, Sivic J. Learning and transferring mid-Level image representations using convolutional neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 1717−1724 [77] Qi H, Brown M, Lowe D G. Low-shot learning with imprinted weights. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 5822−5830 [78] Munkhdalai T, Yu H. Meta networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: ACM, 2017. 2554−2563 [79] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: ACM, 2017. 1126−1135 [80] Hochreiter S, Schmidhuber J. Long Short-term memory. Neural Computation, 1997, 9(8): 1735−1780 doi: 10.1162/neco.1997.9.8.1735 [81] Zhou L J, Cui P, Yang S Q, Zhu W W, Tian Q. Learning to learn image classifiers with informative visual analogy. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019. [82] Mitchell T M, Thrun S. Explanation-based neural network learning for robot control. In: Advances in Neural Information Processing Systems 5. Denver, USA: ACM, 1992. 287−294 [83] Vilalta R, Drissi Y. A perspective view and survey of meta-learning. Artificial Intelligence Review, 2002, 18(2): 77−95 doi: 10.1023/A:1019956318069 [84] Sun Q R, Liu Y Y, Chua T S, Schiele B. Meta-transfer learning for few-shot learning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 403−412 [85] Wang Y X, Girshick R, Hebert M, Hariharan B. Low-shot learning from imaginary data. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7278−7286 [86] Wang Y X, Hebert M. Learning to learn: Model regression networks for easy small sample learning. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, Netherlands: Springer, 2016. 616−634 [87] Ren M Y, Liao R J, Fetaya E, Zemel R S. Incremental few-Shot learning with attention attractor networks. In: Advances in Neural Information Processing Systems 32. Vancouver, Canada: MIT Press, 2019. [88] Antoniou A, Edwards H, Storkey A. Antoniou A, Edwards H, Storkey A. How to train your MAML. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: arXiv.org, 2019. [89] Nichol A, Schulman J. Reptile: A scalable metalearning algorithm. arXiv: 1803.02999, 2018. [90] Ravi S, Larochelle H. Optimization as a model for few-shot learning. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: IEEE, 2017. [91] Qin Tao. Dual learning: A new paradigm of machine learning [Online], available: https://mp.weixin.qq.com/s/gwzyQu9YzxVyLT-L_mOicw, December 7, 2016. [92] Vincent P, Larochelle H, Bengio Y, Manzagol P A. Extracting and composing robust features with denoising autoencoders. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008. 1096−1103 [93] Masci J, Meier U, Cirešan D, Schmidhuber J. Stacked convolutional auto-encoders for hierarchical feature extraction. In: Proceedings of the 21st International Conference on Artificial Neural Networks. Espoo, Finland: Springer, 2011. 52−59 [94] Kingma D P, Welling M. Auto-encoding variational bayes. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, Canada: arXiv.org, 2014. [95] Chen Xiao-Liang, Human like concept learning of small sample and deep reinforcement learning of big data [Online], avaliable: http://blog.sciencenet.cn/blog-1375795-964076.html, May 22, 2016. [96] Lake B M, Salakhutdinov R, Tenenbaum J B. One-shot learning by inverting a compositional causal process. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, Spain: ACM, 2013. 2526−2534 [97] Kim T, Yoon J, Dia O, Kim S, Bengio Y, Ahn S. Bayesian model-agnostic meta-learning. In: Advances in Neural Information Processing Systems 31. Montréal, Canada: MIT Press, 2018. [98] 毛国勇, 张宁. 从节点度数生成无向简单连通图. 计算机工程与应用, 2011, 47(29): 40−41, 106 doi: 10.3778/j.issn.1002-8331.2011.29.011Mao Guo-Yong, Zhang Ning. Building connected undirected simple graph from degree of vertex. Computer Engineering and Applications, 2011, 47(29): 40−41, 106 doi: 10.3778/j.issn.1002-8331.2011.29.011 [99] Gori M, Monfardini G, Scarselli F. A new model for learning in graph domains. In: Proceedings of the 2005 IEEE International Joint Conference on Neural Networks. Montreal, Canada: IEEE, 2005. 729−734 [100] Scarselli F, Gori M, Tsoi A C, Hagenbuchner M, Monfardini G. The graph neural network model. IEEE Transactions on Neural Networks, 2009, 20(1): 61−80 doi: 10.1109/TNN.2008.2005605 [101] Bruna J, Zaremba W, Szlam A, LeCun Y. Spectral networks and locally connected networks on graphs. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, Canada: arXiv.org, 2014. [102] Henaff M, Bruna J, LeCun Y. Deep convolutional networks on graph-structured data. arXiv: 1506.05163, 2015. [103] Defferrard M, Bresson X, Vandergheynst P. Convolutional neural networks on graphs with fast localized spectral filtering. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: ACM, 2016. 3837−3845 [104] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: arXiv.org, 2017. [105] Li Y J, Tarlow D, Brockschmidt M, Zemel R S. Gated graph sequence neural networks. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico: IEEE, 2016. [106] Sukhbaatar S, Szlam A, Fergus R. Learning multiagent communication with backpropagation. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: ACM, 2016. 2244−2252 [107] Satorras V G, Bruna J. Few-shot learning with graph neural networks. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: IEEE, 2018. [108] Kim J, Kim T, Kim S, Yoo C D. Edge-labeling graph neural network for few-shot learning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 114−20 [109] Liu Y B, Lee J, Park M, Kim S, Yang E, Hwang S J, Yang Y. Learning to propagate labels: Transductive propagation network for few-shot learning. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, LA, USA: IEEE, 2019. [110] Key Laboratory of Electronic Information Processing for Applications in Crime Scene Investigation, Ministry of Public Security. The pattern image database of image processing team of Xi' an University of Posts and Telecommunications [Online], available :http://www.xuptciip.com.cn/show.html?database-lthhhw, January 1, 2019. [111] Li J W, Monroe W, Jurafsky D. Understanding neural networks through representation erasure. In: Proceedings of the 34nd International Conference on Machine Learning. Sydney, Australia: ACM, 2017. [112] Xu K, Ba J L, Kiros R, Cho K, Courville A, Salakhutdinov R, et al. Show, attend and tell: Neural image caption generation with visual attention. In: Proceedings of the 32nd International Conference on International Conference on Machine Learning. Lille, France: ACM, 2015. 2048−2057 [113] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing systems. Long Beach, USA: ACM, 2017. 5998−6008 [114] Hou R B, Chang H, Ma B P, Shan S G, Chen X L. Cross attention network for few-shot classification. In: Advances in Neural Information Processing Systems 32. Vancouver, Canada: MIT Press, 2019. 4005−4016 [115] Sabour S, Frosst N, Hinton G E. Dynamic routing between capsules. In: Advances in Neural Information Processing Systems 30. Long Beach, USA: MIT Press, 2017. 3856−3866 -

 下载:
下载:



计量
- 文章访问数: 8558
- HTML全文浏览量: 5177
- PDF下载量: 2921
- 被引次数: 0
