

-
摘要: 为解决缓冲区设置不合理带来的项目间工序松弛、工期延误等问题, 基于信息熵理论提出了一种关键链缓冲区设置方法. 首先, 提出了复杂熵、资源熵和人因熵的概念及其度量方法, 运用熵的概念量化诸多不确定因素对工序造成的影响; 其次, 提出了基于区间直觉梯形模糊数的人因熵度量步骤与方法; 最后, 给出了工序工期、项目缓冲和汇入缓冲的熵模型与修正模型, 充分考虑了人的行为因素对项目进度的影响, 并通过算例验证了模型的实用性.Abstract: In order to solve the problems caused by unreasonable buffer setting, such as process slacking and project delaying, this paper proposes a buffer setting method of critical chain based on information entropy. Firstly, it presents concepts and measurement method of complex entropy, resource entropy and human factor entropy, which are used to quantify the influence of uncertain factors on the process. Secondly, the steps and methods of human factor entropy based on interval-valued intuitionistic trapezoidal fuzzy numbers are proposed. Finally, fully considering the influence to project schedule of human behavior, it presents entropy models and modification models of procedure duration, project buffer and feeding buffer. The examples given in the end vividly convey the practicability.
-
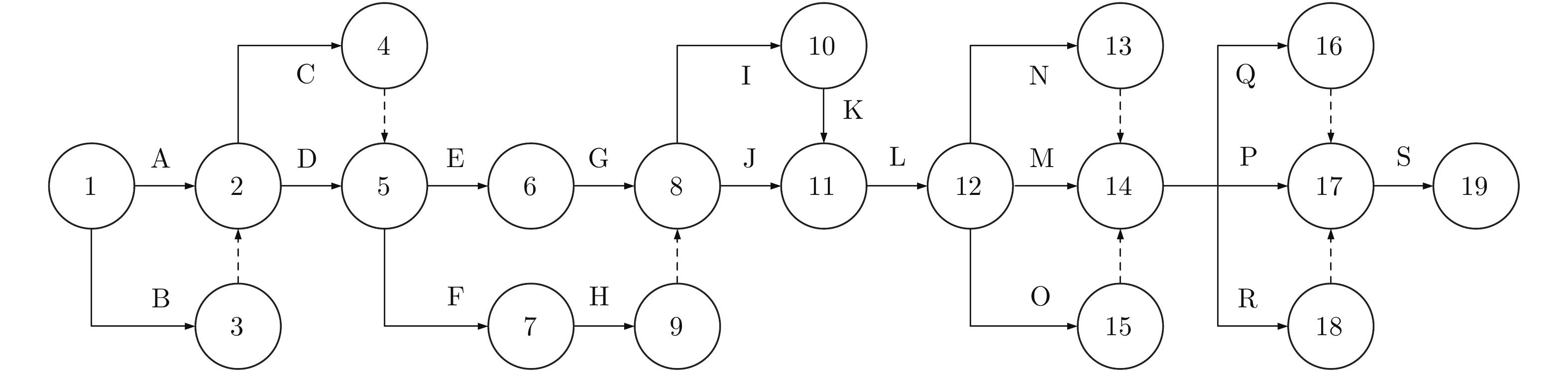
表 1 项目中各工序基本信息
Table 1 Information of process in the program
工序编号 紧前工序 紧后工序 最乐观时间 (d) 最可能时间 (d) 最悲观时间 (d) 所需资源数量 p1 p2 p3 A − C, D 6 8 12 4 5 2 B − C, D 3 6 8 3 2 1 C A, B E, F 7 10 12 4 4 1 D A, B E, F 5 6 9 4 3 2 E G G 8 10 11 3 2 1 F H H 4 6 7 5 3 1 G E I, J 8 9 12 4 3 2 H F I, J 4 6 9 5 2 1 I G, H K 2 4 5 5 3 0 J G, H L 10 12 16 3 2 1 K I L 9 11 13 3 4 3 L J, K M, N, O 8 9 12 4 2 2 M L P, Q, R 15 20 22 6 1 1 N L P, Q, R 7 10 12 4 3 0 O L P, Q, R 4 5 6 4 3 2 P M, N, O S 8 9 12 4 4 2 Q M, N, O S 6 8 9 7 5 1 R M, N, O S 3 5 6 4 3 1 S P, Q, R − 4 5 8 7 3 1 资源限量 8 7 3  下载: 导出CSV
下载: 导出CSV
表 2 缓冲区参数计算
Table 2 Value of buffer parameters
类型 编号 三角分布 $T_{50 {\text{%} } }$ $T_{95 {\text{%} } }$ $\sigma_{i}$ $H_{f}$ $H_{z_{i}}$ $H_{r_{i}}$ $d_{i}^{X}$ ${ FB}$ $PB$ ${ FB}^{X}$ ${ PB}^{X}$ 关键链工序 A (6, 8, 12) 8.35 11.19 2.84 0.13 0.13 0.15 7.10 − 7.50 − 8.02 C (7, 10, 12) 10.38 11.42 1.04 0.12 0.18 8.51 − − E (8, 10, 11) 10.22 10.64 0.42 0.08 0.20 8.18 − − G (8, 9, 12) 9.48 11.04 1.56 0.13 0.21 7.49 − − H (4, 6, 9) 6.25 8.45 2.20 0.10 0.10 5.63 − − I (2, 4, 5) 4.54 4.83 0.29 0.08 0.13 3.85 − − K (9, 11, 13) 11.00 12.28 1.28 0.22 0.05 10.15 − − L (8, 9, 12) 9.16 11.25 2.09 0.13 0.14 7.88 − − N (6, 10, 12) 10.42 11.72 1.30 0.10 0.08 9.59 − − M (15, 20, 22) 20.08 21.16 1.08 0.22 0.27 14.66 − − Q (6, 8, 9) 8.35 8.78 0.43 0.16 0.08 7.68 − − P (8, 9, 12) 9.38 11.12 1.74 0.13 0.15 7.97 − − S (4, 5, 8) 4.92 7.34 2.42 0.11 0.23 3.79 − − 非关键链工序 B (3, 6, 8) 6.26 7.68 1.42 0 0.11 0.14 5.38 4.17 − 4.17 − D (5, 6, 9) 5.86 8.26 2.40 0.35 0.19 0.09 5.33 − − F (4, 6,7) 6.15 6.71 0.56 0 0.18 0.28 4.43 0.66 − 0.66 − J (10, 12, 16) 12.12 14.98 2.86 0 0.14 0.13 10.54 3.98 − 3.46 − O (4, 5, 6) 5.08 6.62 1.54 0 0.17 0.11 4.52 1.80 − 1.80 − R (3, 5, 6) 5.14 6.68 1.54 0 0.13 0.08 4.73 1.74 − 1.74 −
下载: 导出CSV
表 3 不同方法缓冲区消耗对比
Table 3 Comparison of buffer consumption by different methods
方法名称 汇入缓冲 (d)/汇入缓冲平均消耗率 (%) 项目缓冲 (d) 项目缓冲平均消耗率 (%) ${ FB}_{BD}$ ${ FB}_{F}$ ${ FB}_{J}$ ${ FB}_{O}$ ${ FB}_{R}$ 1) 关键路线法 − − − − − − − 2) 根方差法 2.79/8.73 0.56/10.82 2.86/2.93 1.54/8.24 1.54/9.55 5.84 91.62 3) APRT法 6.64/2.24 1.31/3.18 5.78/0.10 3.91/1.35 3.74/1.02 12.96 26.98 4) 胡晨 3.06/8.14 0.58/10.62 2.98/2.13 1.58/6.98 1.59/7.54 6.75 88.54 5) 蒋红妍 3.78/5.08 0.60/7.95 3.24/1.09 1.75/2.68 1.62/3.40 7.58 75.76 6) 张俊光 4.04/4.86 0.64/6.76 3.31/0.72 1.72/3.35 1.66/2.08 7.89 69.20 7) 本文方法 4.17/4.68 0.66/6.79 3.46/0.36 1.80/1.95 1.74/1.26 8.02 57.03
下载: 导出CSV
表 4 不同方法完工情况对比
Table 4 Completion comparison of different methods
方法名称 缓冲区主要考虑因素 计划总工期 (d) 项目平均完工率 (%) 1) 关键路线法 − 90.50 15.14 2) 根方差法 工序方差 112.76 89.62 3) APRT法 资源紧张度 124.58 98.98 4) 胡晨 活动工期分布、资源紧张度 115.82 93.56 5) 蒋红妍 工期分布、信息综合约束、资源受限程度等 118.35 96.45 6) 张俊光 资源紧张度、工序复杂度、位置系数、技术与需求不确定性等 120.30 97.68 7) 本文方法 网络复杂度、资源约束、人的行为因素 110.50 95.20
下载: 导出CSV
-
[1] 李俊亭. 关键链多项目管理理论与方法. 北京: 中国社会科学出版社, 2016. 77−99Li Jun-Ting. Critical Chain Multi-project Management Theory and Methods. Beijing: China Social Science Press, 2016. 77−99 [2] Tukel O I, Rom W O, Eksioglu S D. An investigation of buffer sizing techniques in critical chain scheduling. European Journal of Operational Research, 2006, 172 (2): 401-416 doi: 10.1016/j.ejor.2004.10.019 [3] 徐小峰,郝俊,邓忆瑞.考虑多因素扰动的项目关键链缓冲区间设置及控制模型.系统工程理论与实践, 2017, 37 (6): 1593-1601 doi: 10.12011/1000-6788(2017)06-1593-09Xu Xiao-Feng, Hao Jun, Deng Yi-Rui. Project critical chain buffer setting and control model considered multiple factors disturbance. Systems Engineering-Theory & Practice, 2017, 37 (6): 1593-1601 doi: 10.12011/1000-6788(2017)06-1593-09 [4] 刘书庆,罗丹,刘佳,陈丹丹. EPC项目关键链缓冲区设置模型研究.运筹与管理, 2015, 24 (5): 270-280 doi: 10.12005/orms.2015.0187Lie Shu-Qing, Luo Dan, Liu Jia, Chen Dan-Dan. Research on the critical chain buffer setting model of EPC project. Operations Research and Management Science, 2015, 24(5): 270-280 doi: 10.12005/orms.2015.0187 [5] 胡晨,徐哲,于静.基于工期分布和多资源约束的关键链缓冲区大小计算方法.系统管理学报, 2015, 24 (2): 237-242Hu Chen, Xu Zhe, Yu Jing. Calculation method of buffer size on critical chain with duration distribution and multiresource constraints. Journal of Civil Engineering and Management, 2019, 36 (1): 34-41 [6] 蒋红妍,彭颖,谢雪海.基于信息和多资源约束的关键链缓冲区大小计算方法.土木工程与管理学报, 2019, 36 (1): 34-41 doi: 10.3969/j.issn.2095-0985.2019.01.006Jiang Hong-Yan, Peng Yin, Xie X ue-Hai. Calculation method of buffer size on critical chain with information and multi-resource constraints. Journal of Civil Engineering and Management, 2019, 36 (1): 34-41 doi: 10.3969/j.issn.2095-0985.2019.01.006 [7] 张俊光,宋喜伟,杨双.基于熵权法的关键链项目缓冲确定方法.管理评论, 2017, 29 (1): 211-219Zhang Jun-Guang, Song Xi-Wei, Yang Shuang. Buffer sizing of a critical chain project based on the entropy method. Management Review, 2017, 29 (1): 211-219 [8] Zhang J, Song X, D´ıaz E. Project buffer sizing of a critical chain based on comprehensive resource tightness. European Journal of Operational Research, 2016, 248: 174-182 doi: 10.1016/j.ejor.2015.07.009 [9] 谢志强,张晓欢,辛宇,杨静.考虑后续工序的择时综合调度算法.自动化学报, 2018, 44 (2): 344-362XIE Zhi-Qiang, ZHANG Xiao-Huan, XIN Yu, YANG Jing. Time-selective integrated scheduling algorithm considering posterior processes. Acta Automatica Sinica, 2018, 44 (2): 344-362 [10] 邱菀华. 管理决策熵学及其应用. 北京: 中国电力出版社, 2011. 160−163Qiu Wan-Hua. Management Decesion Entropy and Application. Beijing: China Power Press, 2011. 160−163 [11] 白思俊.活动网络计划约束的复杂性度量及其应用.宇航学报, 1994, 15 (7): 891-894Bai Si-Jun. Choice model for large scale organization of project management based on information entropy. Journal of systems science, 1994, 15 (7): 891-894 [12] Atanassov K. Intuitionistic fuzzy sets. Fuzzy Sets and Systems, 1986, 20:87-96 doi: 10.1016/S0165-0114(86)80034-3 [13] 万树平.基于分式规划的区间梯形直觉模糊数多属性决策方法.控制与决策, 2012, 27 (3): 455-458Wan Shu-Ping. Multi-attribute decision making method based on inter-valued trapezoidal intuitionistic fuzzy number. Control and Decision, 2012, 27 (3): 455-458 [14] 万树平.基于区间直觉梯形模糊数的多属性决策方法.控制与决策, 2011, 26 (6): 857-860, 866Wan Shu-Ping. Multi-attribute decision making method based on trapezoidal intuitionistic fuzzy number. Control and Decision, 2011, 26 (6): 857-860, 866 [15] 汪新凡,杨小娟.基于区间直觉梯形模糊数的群决策方法.湖南工业大学学报, 2012, 26 (3): 2-8, 51Wang Xin-Fan, Yang Xiao-Juan. Approach to group decision making based on interval-valued intuitionistic trapezoidal fuzzy number. Journal of Hunan University of Technology, 2012, 26 (3): 2-8, 51 [16] 汪新凡. 直觉语言多准则决策方法研究. 北京: 知识产权出版社, 2017. 20−35Wang Xin-Fan. Study on Multi-criteria Decision Making Method Based on Trapezoidal Intuitionistic Fuzzy Number. Beijing: Intellectual Property Press, 2017. 20−35 [17] 徐泽水. 基于语言信息的决策理论与方法. 北京: 科学出版社, 2016. 118−140Xu Ze-Shui. Decesion Theories and Methods Based on Linguistic Information. Beijing: Science Press, 2016. 118−140 [18] 李喜华,王傅强,陈晓红.基于证据理论的直觉梯形模糊IOWA算子及其应用.系统工程理论与实践, 2016, 36 (11): 2915-2923 doi: 10.12011/1000-6788(2016)11-2915-09Li Xi-Hua, Wang Fu-Qiang, Chen Xiao-Hong. Intuitionistic trapezoidal fuzzy IOWA operator based on dempster-shafer theory and its application. Systems Engineering-Theory & Practice, 2016, 36 (11): 2915-2923 doi: 10.12011/1000-6788(2016)11-2915-09 [19] 付亚男,毛军军,徐丹青.基于区间直觉梯形模糊数的改进TOPSIS多属性决策方法.数学的实践与认识, 2014, 44(17):134-140Fu Ya-Nan, Mao Jun-Jun, Xu Dan-Qing. Improced topsis of multiple attribute decision making method based on interval-valued ITFN. Mathematics in Practice and Theory, 2014, 44(17): 134-140 -

 下载:
下载:


图(3) / 表(4)
计量
- 文章访问数: 3101
- HTML全文浏览量: 1593
- PDF下载量: 166
- 被引次数: 0
