

A Gait Control Method for Biped Robot on Slope Based on Deep Reinforcement Learning
-
摘要:
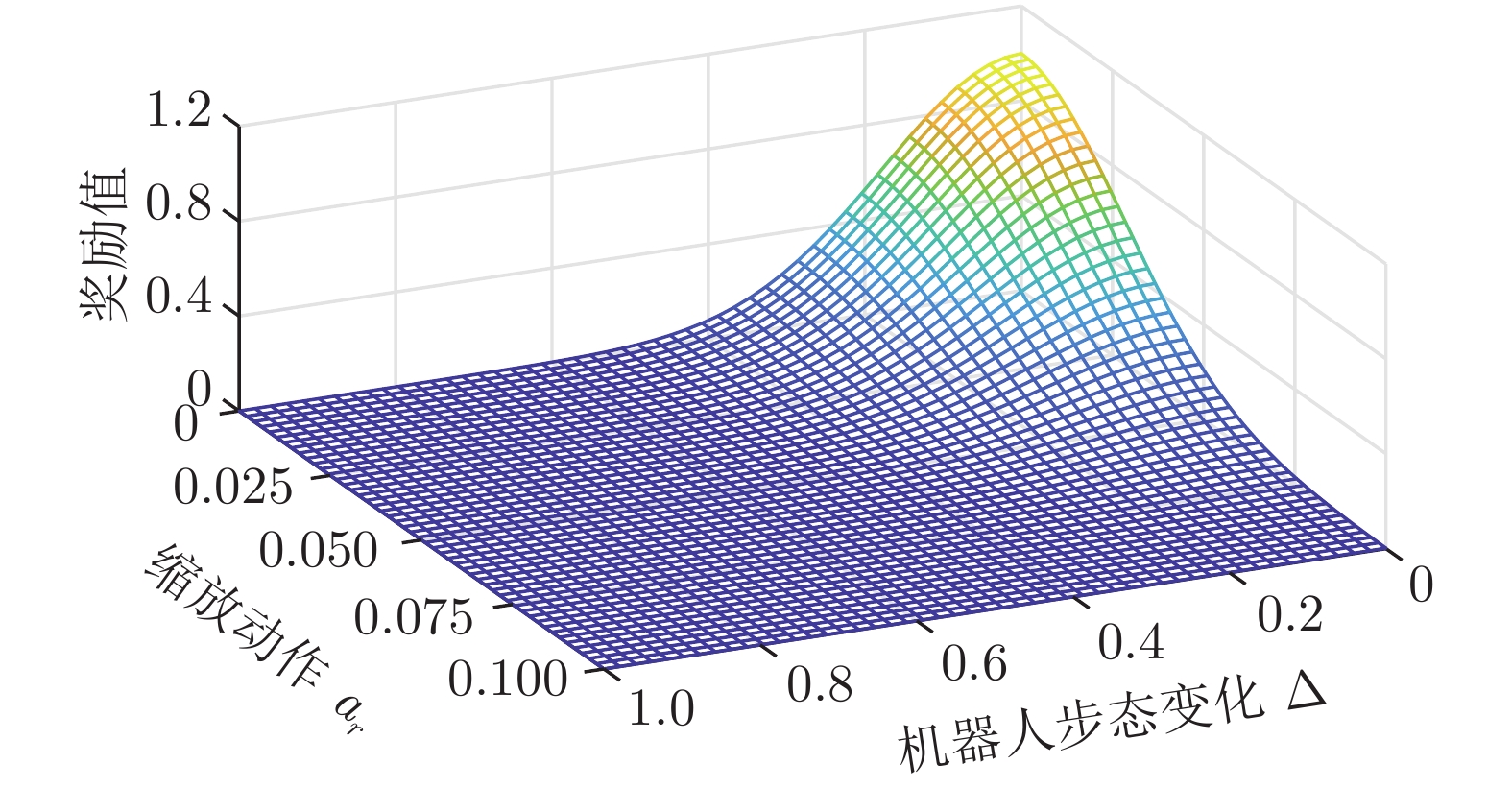
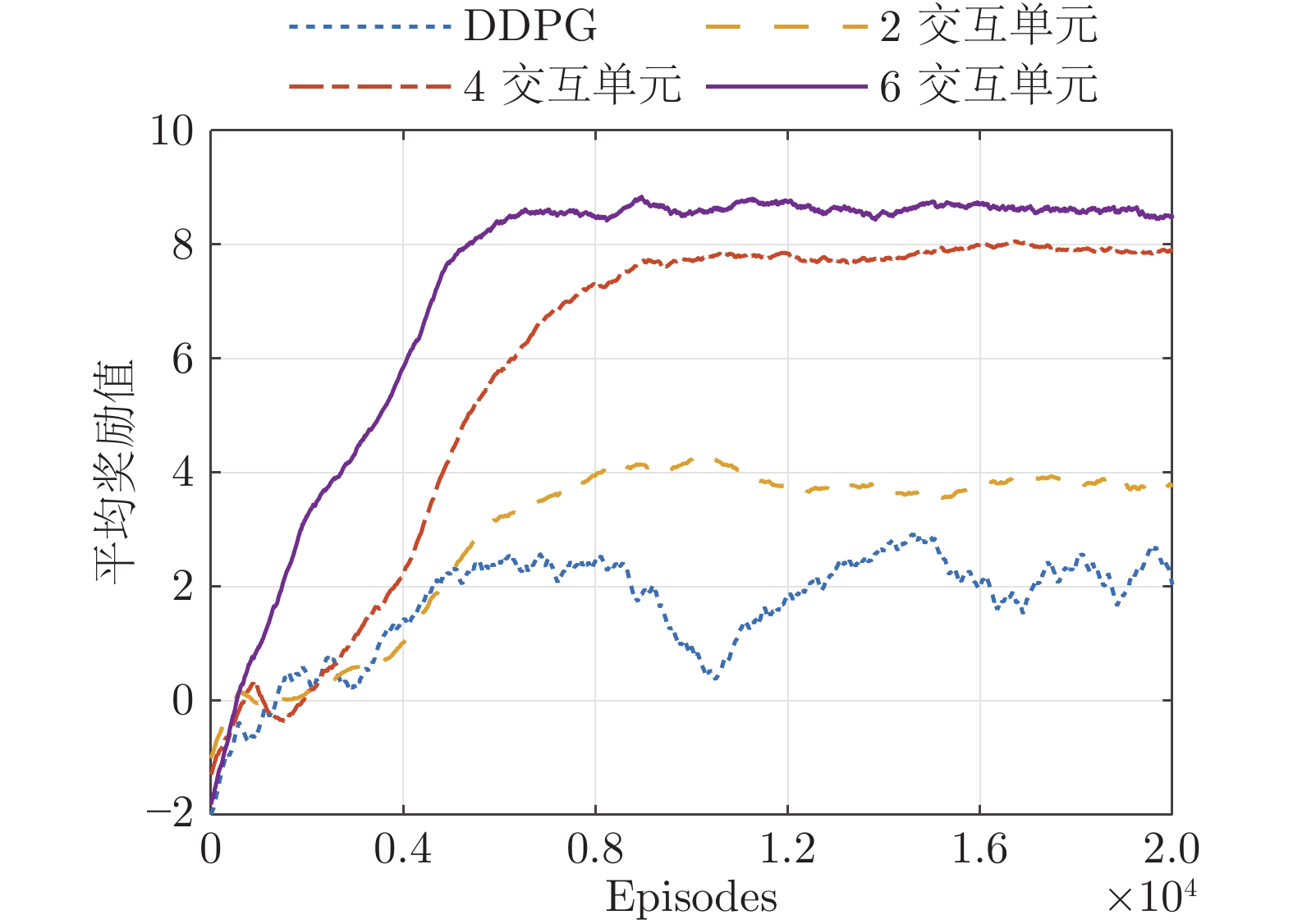
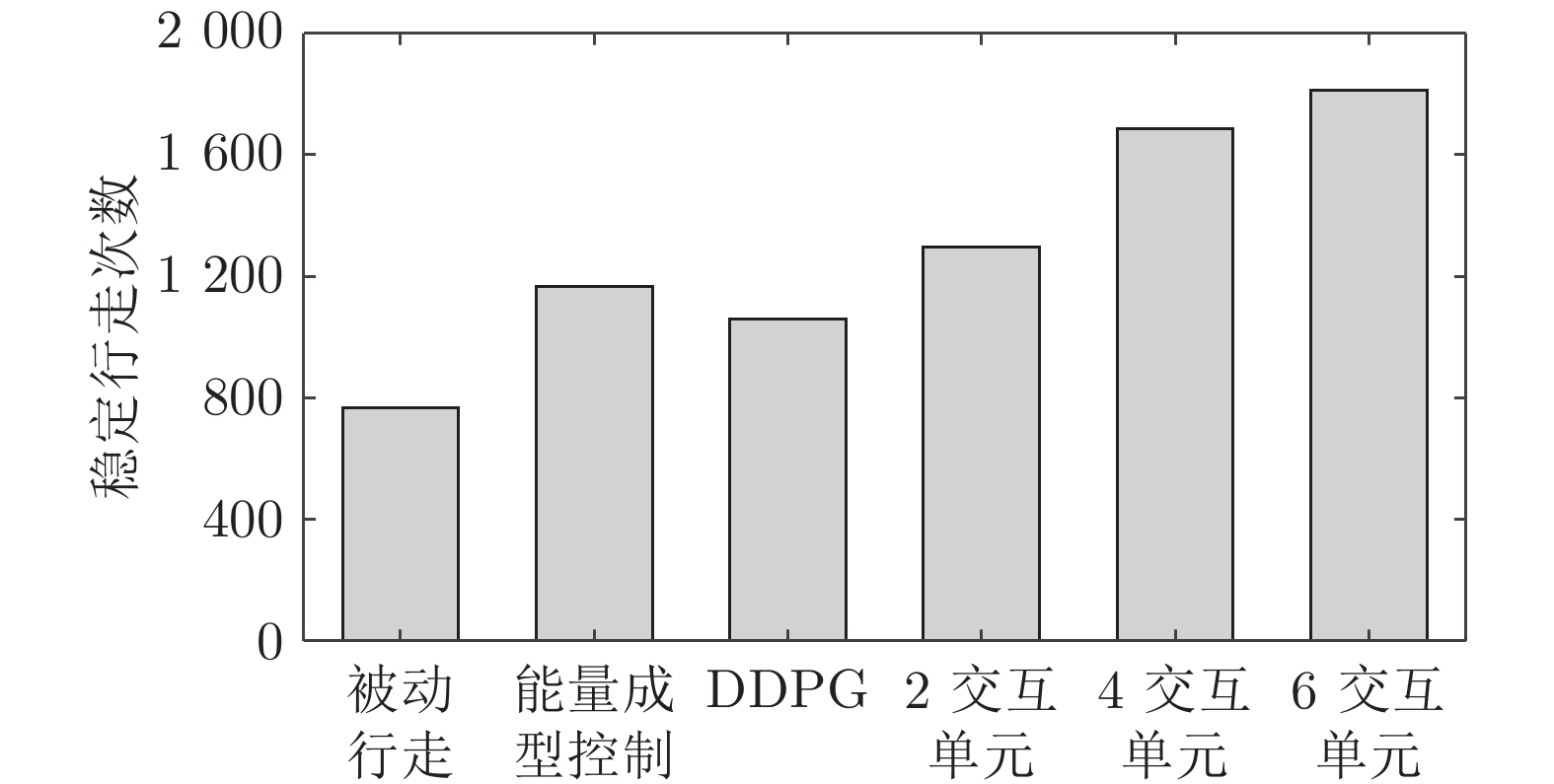
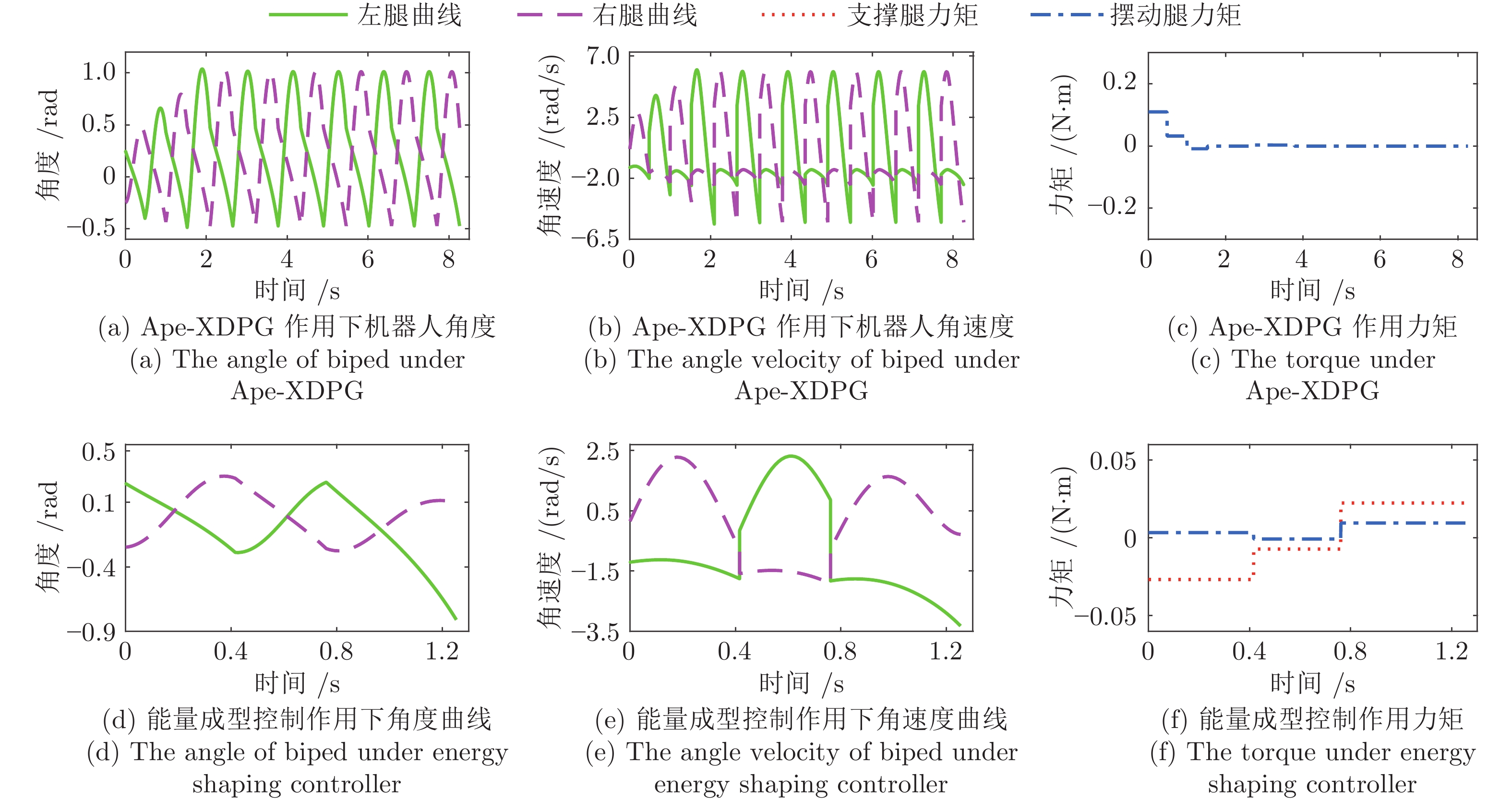
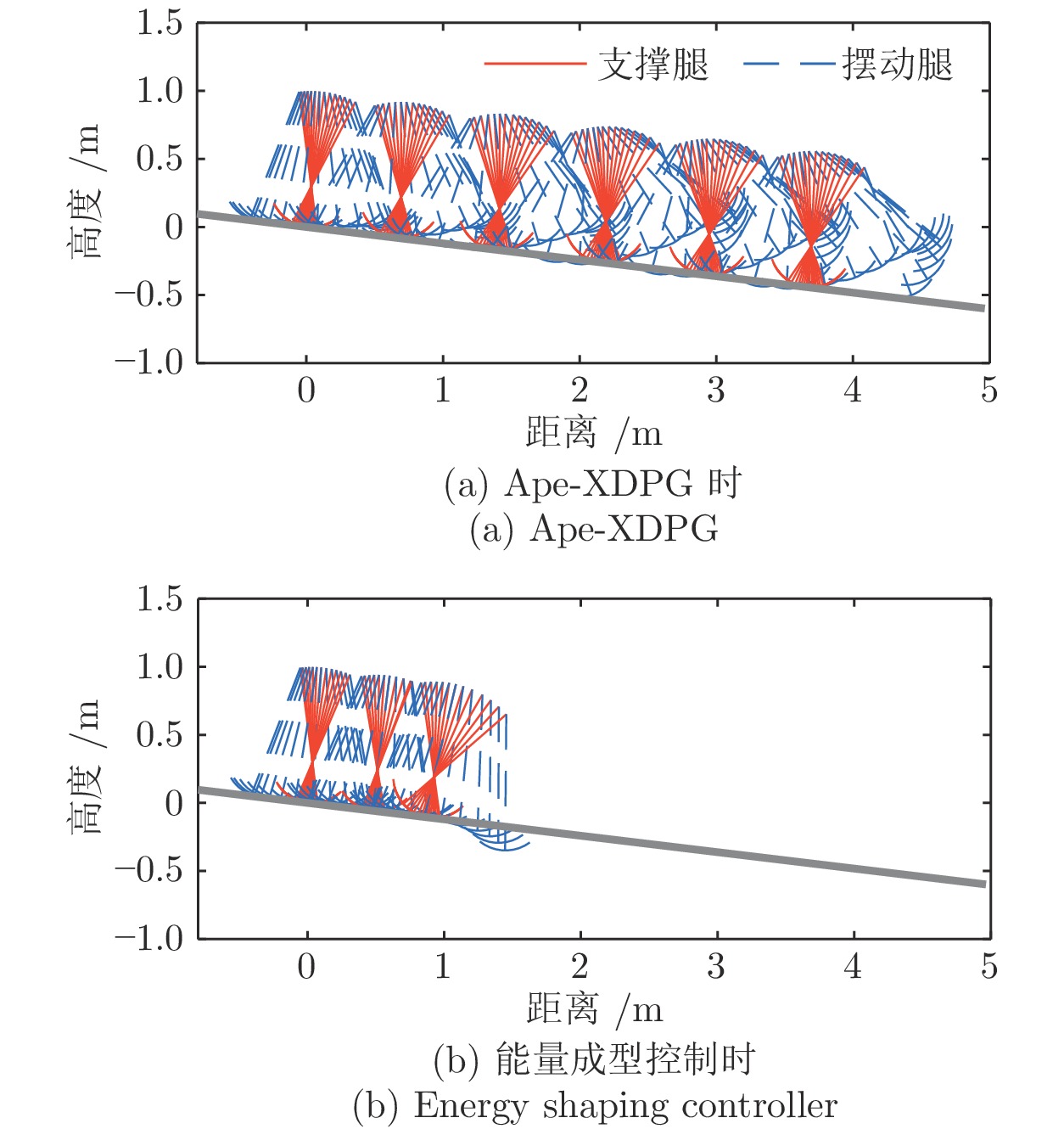
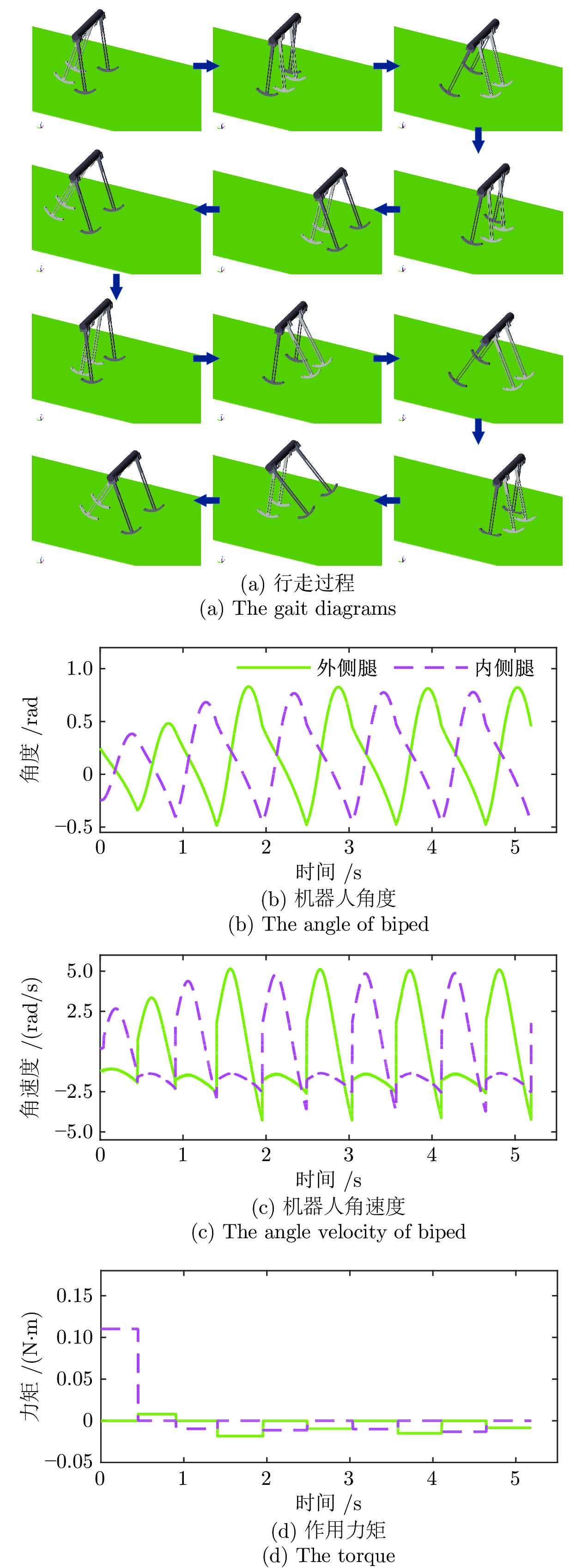
为提高准被动双足机器人斜坡步行稳定性, 本文提出了一种基于深度强化学习的准被动双足机器人步态控制方法. 通过分析准被动双足机器人的混合动力学模型与稳定行走过程, 建立了状态空间、动作空间、episode过程与奖励函数. 在利用基于DDPG改进的Ape-X DPG算法持续学习后, 准被动双足机器人能在较大斜坡范围内实现稳定行走. 仿真实验表明, Ape-X DPG无论是学习能力还是收敛速度均优于基于PER的DDPG. 同时, 相较于能量成型控制, 使用Ape-X DPG的准被动双足机器人步态收敛更迅速、步态收敛域更大, 证明Ape-X DPG可有效提高准被动双足机器人的步行稳定性.
Abstract:In order to improve the walking stability on slope of the quasi-passive biped robot, in this paper, we proposed a gait control method for quasi-passive biped robot based on deep reinforcement learning. By analyzing the hybrid dynamics model and the stable walking process of the quasi-passive biped robot establishing the state space, action space, episode process and reward function. After learning by Ape-X DPG algorithm based on DDPG improvement, quasi-passive biped robot can achieve stable walking in a larger slope range. In the simulation, Ape-X DPG is better than DDPG + PER in both learning ability and convergence speed. Meanwhile, compared with energy shaping controller, the gait convergence of quasi-passive biped robot using Ape-X DPG is more rapid and the basins of attraction is larger, which proves that Ape-X DPG can effectively improve the walking stability of quasi-passive biped robot.
-
表 1 机器人符号及无量纲参数
Table 1 Symbols and dimensionless default values of biped parameters
参数 符号 数值 腿长 I 1 腿部质心 m1 1 髋关节质心 m2 2 足半径 r 0.3 腿部质心与圆弧足中心距离 I1 0.55 髋关节与圆弧足中心距离 I2 0.7 髋关节到腿部质心距离 c 0.15 腿部转动惯量 J1 0.01 重力加速度 g 9.8  下载: 导出CSV
下载: 导出CSV
表 2 扰动函数N分配与学习耗时
Table 2 Noise function N settings and learning time
算法 高斯扰动 O-U 扰动 网络参数扰动[39] 耗时 DDPG 0 1 0 6.4 h 2 交互单元 1 1 0 4.2 h 4 交互单元 2 1 1 4.2 h 6 交互单元 2 2 2 4.3 h
下载: 导出CSV
表 3 机器人初始状态
Table 3 The initial states of the biped
状态 $\theta_1$ (rad) $\dot\theta_1$ (rad/s) $\dot\theta_2$ (rad/s) $\phi$ a 0.37149 −1.24226 2.97253 0.078 b 0.24678 −1.20521 0.15476 0.121
下载: 导出CSV
-
[1] 田彦涛, 孙中波, 李宏扬, 王静. 动态双足机器人的控制与优化研究进展. 自动化学报, 2016, 42(8): 1142-1157Tian Yan-Tao, Sun Zhong-Bo, Li Hong-Yang, Wang Jing. A review of optimal and control strategies for dynamic walking bipedal robots. Acta Automatica Sinica, 2016, 42(8): 1142-1157 [2] Chin C S, Lin W P. Robust genetic algorithm and fuzzy inference mechanism embedded in a sliding-mode controller for an uncertain underwater robot. IEEE/ASME Transactions on Mechatronics, 2018, 23(2): 655-666 doi: 10.1109/TMECH.2018.2806389 [3] Wang Y, Wang S, Wei Q P, Tan M, Zhou C, Yu J Z. Development of an underwater manipulator and its free-floating autonomous operation. IEEE/ASME Transactions on Mechatronics, 2016, 21(2): 815-824 doi: 10.1109/TMECH.2015.2494068 [4] Wang Y, Wang S, Tan M, Zhou C, Wei Q P. Real-time dynamic Dubins-Helix method for 3-D trajectory smoothing. IEEE Transactions on Control Systems Technology, 2015, 23(2): 730-736 doi: 10.1109/TCST.2014.2325904 [5] Wang Y, Wang S, Tan M. Path generation of autonomous approach to a moving ship for unmanned vehicles. IEEE Transactions on Industrial Electronics, 2015, 62(9): 5619-5629 doi: 10.1109/TIE.2015.2405904 [6] Ma K Y, Chirarattananon P, Wood R J. Design and fabrication of an insect-scale flying robot for control autonomy. In: Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Hamburg, Germany: IEEE, 2015. 1558−1564 [7] McGeer T. Passive dynamic walking. The International Journal of Robotics Research, 1990, 9(2): 62-82 doi: 10.1177/027836499000900206 [8] Bhounsule P A, Cortell J, Ruina A. Design and control of Ranger: An energy-efficient, dynamic walking robot. In: Proceedings of the 15th International Conference on Climbing and Walking Robots and the Support Technologies for Mobile Machines. Baltimore, MD, USA, 2012. 441−448 [9] Kurz M J, Stergiou N. An artificial neural network that utilizes hip joint actuations to control bifurcations and chaos in a passive dynamic bipedal walking model. Biological Cybernetics, 2005, 93(3): 213-221 doi: 10.1007/s00422-005-0579-6 [10] Sun C Y, He W, Ge W L, Chang C. Adaptive neural network control of biped robots. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2017, 47(2): 315-326 [11] Sugimoto Y, Osuka K. Walking control of quasi passive dynamic walking robot "Quartet III" based on continuous delayed feedback control. In: Proceedings of the 2004 IEEE International Conference on Robotics and Biomimetics. Shenyang, China: IEEE, 2004. 606−611 [12] 刘德君, 田彦涛, 张雷. 双足欠驱动机器人能量成型控制. 机械工程学报, 2012, 48(23): 16-22 doi: 10.3901/JME.2012.23.016Liu De-Jun, Tian Yan-Tao, Zhang Lei. Energy shaping control of under-actuated biped robot. Journal of Mechanical Engineering, 2012, 48(23): 16-22 doi: 10.3901/JME.2012.23.016 [13] Spong M W, Holm J K, Lee D. Passivity-based control of bipedal locomotion. IEEE Robotics & Automation Magazine, 2007, 14(2): 30-40 [14] 刘乃军, 鲁涛, 蔡莹皓, 王硕. 机器人操作技能学习方法综述. 自动化学报, 2019, 45(3): 458-470Liu Nai-Jun, Lu Tao, Cai Ying-Hao, Wang Shuo. A review of robot manipulation skills learning methods. Acta Automatica Sinica, 2019, 45(3): 458-470 [15] Tedrake R, Zhang T W, Seung H S. Stochastic policy gradient reinforcement learning on a simple 3D biped. In: Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Sendai, Japan: IEEE, 2004. 2849−2854 [16] Hitomi K, Shibata T, Nakamura Y, Ishii S. Reinforcement learning for quasi-passive dynamic walking of an unstable biped robot. Robotics and Autonomous Systems, 2006, 54(12): 982-988 doi: 10.1016/j.robot.2006.05.014 [17] Ueno T, Nakamura Y, Takuma T, Shibata T, Hosoda K, Ishii S. Fast and stable learning of quasi-passive dynamic walking by an unstable biped robot based on off-policy natural actor-critic. In: Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems. Beijing, China: IEEE, 2006. 5226−5231 [18] 刘全, 翟建伟, 章宗长, 钟珊, 周倩, 章鹏, 等. 深度强化学习综述. 计算机学报, 2018, 41(1): 1-27 doi: 10.11897/SP.J.1016.2019.00001Liu Quan, Zhai Jian-Wei, Zhang Zong-Zhang, Zhong Shan, Zhou Qian, et al. A survey on deep reinforcement learning. Chinese Journal of Computers, 2018, 41(1): 1-27 doi: 10.11897/SP.J.1016.2019.00001 [19] Kendall A, Hawke J, Janz D, Mazur P, Reda D, Allen J M, et al. Learning to drive in a day [Online], available: https://arxiv.org/abs/1807.00412, July 1, 2018 [20] 王云鹏, 郭戈. 基于深度强化学习的有轨电车信号优先控制. 自动化学报, 2019, 45(12): 2366-2377Wang Yun-Peng, Guo Ge. Signal priority control for trams using deep reinforcement learning. Acta Automatica Sinica, 2019, 45(12): 2366-2377 [21] 张一珂, 张鹏远, 颜永红. 基于对抗训练策略的语言模型数据增强技术. 自动化学报, 2018, 44(5): 891-900Zhang Yi-Ke, Zhang Peng-Yuan, Yan Yong-Hong. Data augmentation for language models via adversarial training. Acta Automatica Sinica, 2018, 44(5): 891-900 [22] Andreas J, Rohrbach M, Darrell T, Klein D. Learning to compose neural networks for question answering. In: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego, California, USA: Association for Computational Linguistics, 2016. 1545−1554 [23] Zhang X X, Lapata M. Sentence simplification with deep reinforcement learning. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark: Association for Computational Linguistics, 2017. 584−594 [24] 赵玉婷, 韩宝玲, 罗庆生. 基于deep Q-network双足机器人非平整地面行走稳定性控制方法. 计算机应用, 2018, 38(9): 2459-2463Zhao Yu-Ting, Han Bao-Ling, Luo Qing-Sheng. Walking stability control method based on deep Q-network for biped robot on uneven ground. Journal of Computer Applications, 2018, 38(9): 2459-2463 [25] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 doi: 10.1038/nature14236 [26] Kumar A, Paul N, Omkar S N. Bipedal walking robot using deep deterministic policy gradient. In: Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence. Bengaluru, India: IEEE, 2018. [27] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning [Online], available: https://arxiv.org/abs/1509.02971, September 9, 2015 [28] Song D R, Yang C Y, McGreavy C, Li Z B. Recurrent deterministic policy gradient method for bipedal locomotion on rough terrain challenge. In: Proceedings of the 15th International Conference on Control, Automation, Robotics and Vision. Singapore: IEEE, 2018. 311−318 [29] Todorov E, Erez T, Tassa Y. MuJoCo: A physics engine for model-based control. In: Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. Vilamoura-Algarve, Portugal: IEEE. 2012. 5026−5033 [30] Palanisamy P. Hands-On intelligent agents with openai gym: Your guide to developing AI agents using deep reinforcement learning. Birmingham, UK: Packt Publishing Ltd., 2018. [31] Schaul T, Quan J, Antonoglou I, Silver D. Prioritized experience replay. In: Proceedings of the International Conference on Learning Representations 2016. San Juan, Puerto Rico, 2016. 322−355 [32] Horgan D, Quan J, Budden D, Barth-Maron G, Hessel M, van Hasselt H, et al. Distributed prioritized experience replay. In: Proceedings of the International Conference on Learning Representations 2018. Vancouver, Canada, 2018. [33] Zhao J, Wu X G, Zang X Z, Yang J H. Analysis of period doubling bifurcation and chaos mirror of biped passive dynamic robot gait. Chinese Science Bulletin, 2012, 57(14): 1743-1750 doi: 10.1007/s11434-012-5113-3 [34] Silver D, Lever G, Heess N, Degris T, Wierstra D, Riedmiller M. Deterministic policy gradient algorithms. In: Proceedings of the 31st International Conference on International Conference on Machine Learning. Beijing, China, 2014. I-387−I-395 [35] Sutton R S, Barto A G. Reinforcement Learning: An Introduction. Cambridge: MIT Press, 1998. [36] Zhao J, Wu X G, Zhu Y H, Li G. The improved passive dynamic model with high stability. In: Proceedings of the 2009 International Conference on Mechatronics and Automation. Changchun, China: IEEE, 2009. 4687−4692 [37] Abadi M, Barham P, Chen J M, Chen Z F, Davis A, Dean J, et al. TensorFlow: A system for large-scale machine learning. In: Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation. Savannah, USA: USENIX Association, 2016. 265−283 [38] Kingma D P, Ba J. Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference for Learning Representations. San Diego, USA, 2015. [39] Plappert M, Houthooft R, Dhariwal P, Sidor S, Chen R Y, Chen X, et al. Parameter space noise for exploration [Online], available: https://arxiv.org/abs/1706.01905, June 6, 2017 [40] Schwab A L, Wisse M. Basin of attraction of the simplest walking model. In: Proceedings of the ASME 2001 Design Engineering Technical Conferences and Computers and Information in Engineering Conference. Pittsburgh, Pennsylvania: ASME, 2001. 531−539 -

 下载:
下载:







计量
- 文章访问数: 7071
- HTML全文浏览量: 3023
- PDF下载量: 870
- 被引次数: 0
