

-
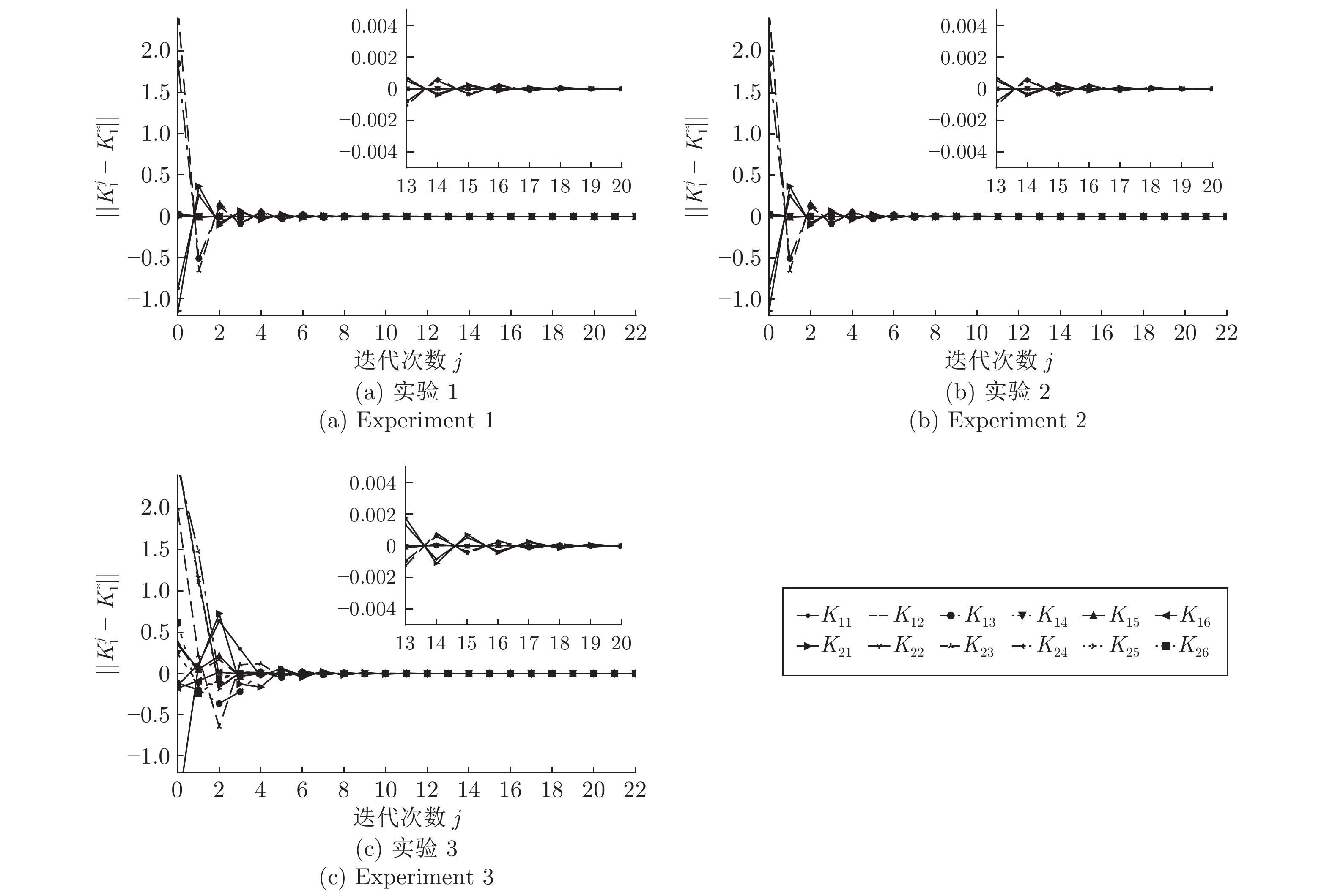
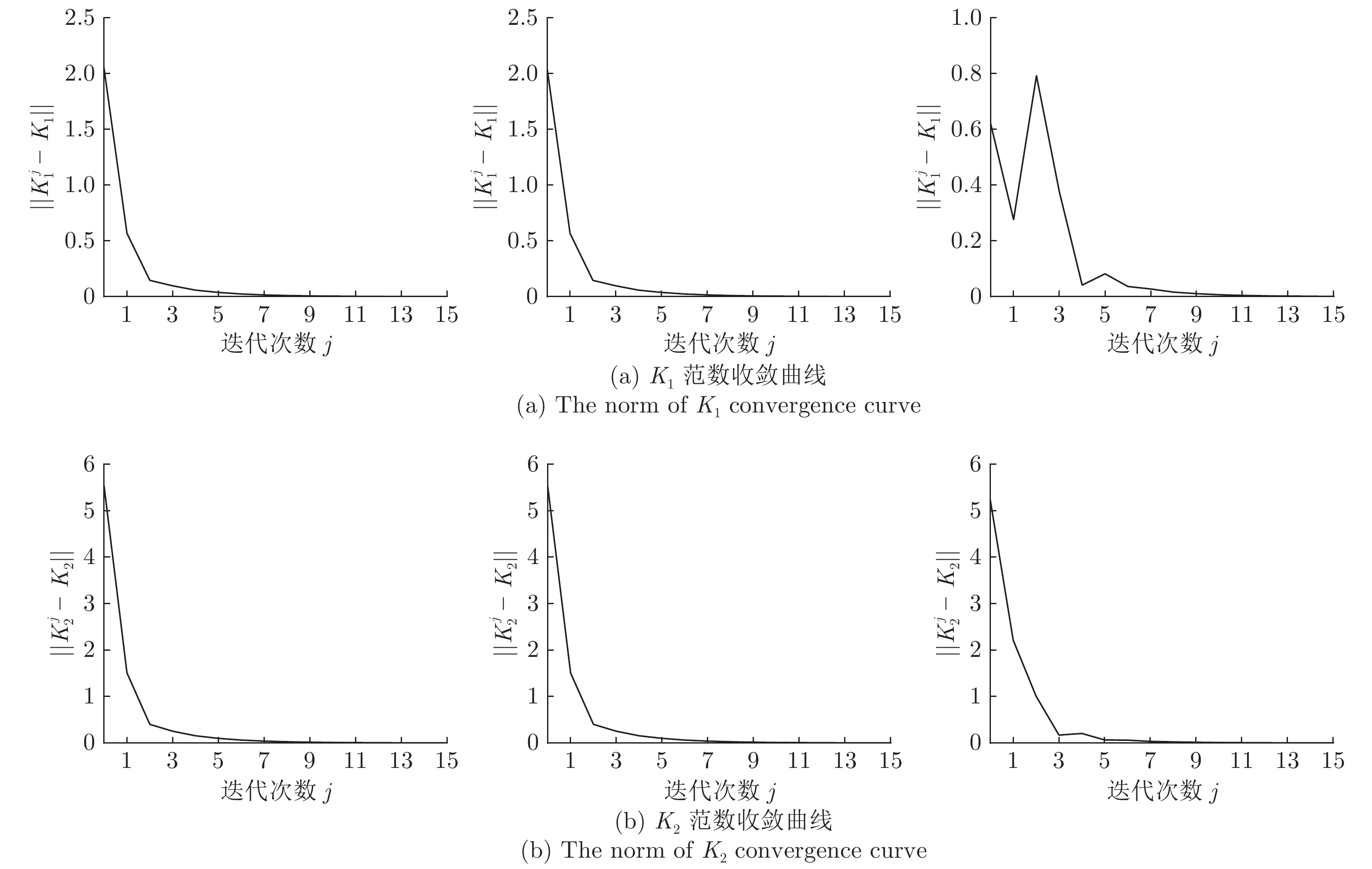
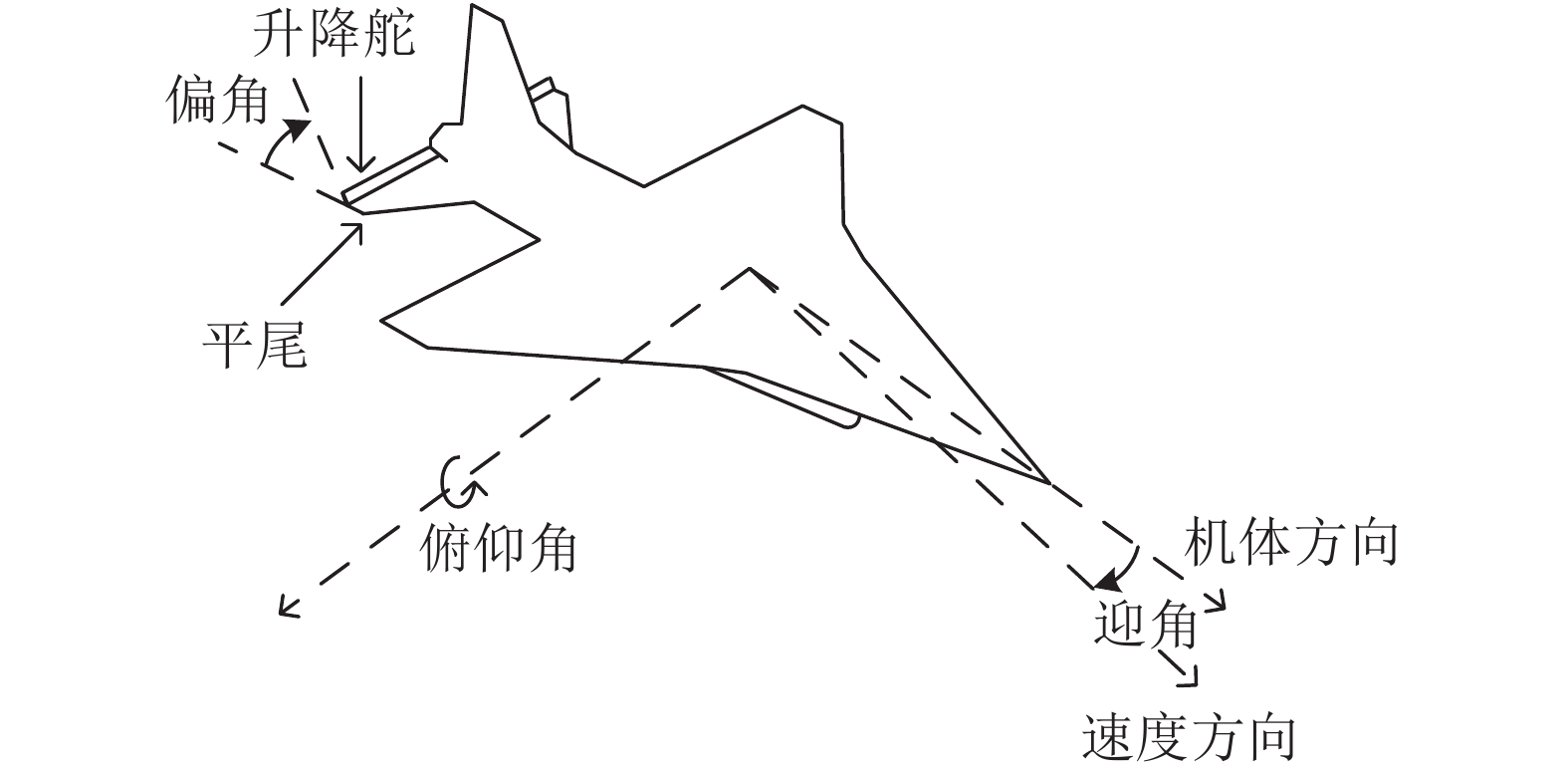
摘要: 针对模型未知的线性离散系统在扰动存在条件下的调节控制问题, 提出了一种基于Off-policy的输入输出数据反馈的H∞控制方法. 本文从状态反馈在线学习算法出发, 针对系统运行过程中状态数据难以测得的问题, 通过引入增广数据向量将状态反馈策略迭代在线学习算法转化为输入输出数据反馈在线学习算法. 更进一步, 通过引入辅助项的方法将输入输出数据反馈策略迭代在线学习算法转化为无模型输入输出数据反馈Off-policy学习算法. 该算法利用历史输入输出数据实现最优输出反馈策略的学习, 同时克服了On-policy算法需要频繁与实际环境进行交互这一缺点. 除此之外, 与On-policy算法相比, Off-policy学习算法具有克服学习噪声的影响, 使学习结果收敛于理论最优值这一优点. 最终, 通过仿真实验验证了学习算法的收敛性.
-
关键词:
- H∞ 控制 /
- 强化学习 /
- Off-policy /
- 数据驱动
Abstract: This paper proposes an H∞ control method based on input and output data feedback and off-policy iteration for linear discrete-time systems with unknown model in the presence of disturbances. Aiming at the problem that it is difficult to measure the state data during the operation of the system, this paper considers the knowledge of the state feedback policy iteration (PI) algorithm and transforms the online state feedback learning algorithm into the online input-output data feedback learning algorithm by introducing augmented data vector. Furthermore, the online input-output data feedback learning algorithm is transformed into a model-free input-output data feedback off-policy learning algorithm by introducing auxiliary items. This algorithm uses historical input and output data to realize the optimal output feedback learning strategy, and overcomes the shortcoming of the on-policy algorithm that needs frequent interaction with the environment. In addition, compared with the on-policy algorithm, off-policy has the advantage of overcoming the influence of learning noise and converging to the theoretical optimal value. Finally, the convergence of this algorithm is verified by simulation experiments.-
Key words:
- H∞ control /
- reinforcement learning /
- off-policy /
- data-driven
-
[1] Zames G. Feedback and optimal sensitivity: model reference transformations, multiplicative seminorms, and approximate inverses. IEEE Transactions on Automatic Control, 1981, 26(2): 301-320 doi: 10.1109/TAC.1981.1102603 [2] Basar T, Bernhard P. H∞ Optimal Control and Related Minimax Design Problems: A Dynamic Game Approach. Boston, MA, USA: Birkhauser. 1995. [3] Alberto Isidori, Lin Wei. Global L2-gain design for a class of nonlinear systems. Systems & Control Letters, 1998, 34: 295-302 [4] Alberto Isidori, Wei Kang. H-infinity control via measurement feedback for affine nonlinear system. IEEE Transactions on Automatic Control, 1995, 40(3): 466-472 doi: 10.1109/9.376058 [5] Jacobson D H. On values and strategies for infinite-time linear quadratic games. IEEE Transactions on Automatic Control, 1977, 22(3): 490-491 doi: 10.1109/TAC.1977.1101515 [6] Lewis F L, Vrabie D L, Syrmos V L. Optimal Control (3rd Edition). New York: Wiley & Sons Inc, 2012. [7] 刘强, 卓洁, 郎自强, 秦泗钊. 数据驱动的工业过程运行监控与自优化研究展望. 自动化学报, 2018, 44(11): 1944-1956Liu Qiang, Zhuo Jie, Lang Zi-Qiang, Qin S. Joe. Perspectives on data-driven operation monitoring and selfoptimization of industrial processes. Acta Automatica Sinica, 2018, 44(11): 1944-1956 [8] 侯钟生, 许建新. 数据驱动控制理论及方法的回顾和展望. 自动化学报, 2009, 35(6): 650-667Hou Zhong-Sheng, Xu Jian-Xin. On data-driven control theory: the state of the art and perspective. Acta Automatica Sinica, 2009, 35(6): 650-667 [9] Howard R. Dynamic Programming and Markov Processes [Ph.D. dissertation], Massachusetts Institute of Technology, 1960. [10] Frank L Lewis, Draguna Vrabie, Kyriakos G. Vamvoudakis, Reinforcement learning and feedback control using natural decision methods to design optimal adaptive controllers. IEEE Control Systems Magazine, 2012, 32(6): 76-105 doi: 10.1109/MCS.2012.2214134 [11] Wang Fei-Yue, Zhang Hua-Guang, Liu De-Rong. Adaptive dynamic programming: an introduction. IEEE Computational Intelligence Magazine, 2009, 4(2): 39-47 doi: 10.1109/MCI.2009.932261 [12] 池荣虎, 侯忠生, 黄彪. 间歇过程最优迭代学习控制的发展: 从基于模型到数据驱动. 自动化学报, 2017, 43(6): 917-932Chi Rong-Hu, Hou Zhong-Sheng, Huang Biao. Optimal iterative learning control of batch processes: from modelbased to data-driven. Acta Automatica Sinica, 2017, 43(6): 917-932 [13] Kenji Doya. Reinforcement learning in continuous-time and space. Neural Computationm 2000, 12(1): 219-45 doi: 10.1162/089976600300015961 [14] 吴倩, 范家璐, 姜艺, 柴天佑. 无线网络环境下数据驱动混合选别浓密过程双率控制方法. 自动化学报, 2019, 45(6): 1128-1141Wu Qian, Fan Jia-Lu, Jiang Yi, Chai Tian-You. Data-driven dual-rate control for mixed separation thickening process in a wireless network environment. Acta Automatica Sinica, 2019, 45(6): 1128-1141 [15] Jiang Yi, Fan Jia-Lu, Chai Tian-You, Li Jin-Na, Frank L Lewis. Data-driven flotation industrial process operational optimal control based on reinforcement learning. IEEE Transactions on Industrial Informatics, 2018, 14(5): 1974-1989 doi: 10.1109/TII.2017.2761852 [16] Jiang Yi, Fan Jia-Lu, Chai Tian-You, Frank L Lewis. Dualrate operational optimal control for flotation industrial process with unknown operational madel. IEEE Transactions on Industrial Electronics, 2019, 66(6): 4587-4599 doi: 10.1109/TIE.2018.2856198 [17] Xue W Q, Fan J L, Lopez V G, Li J N, Jiang Y, Chai T Y, Lewis F L. New methods for optimal operational control of industrial processes using reinforcement learning on multiple time-scales. IEEE Transactions on Industrial Informatics, 2020, 16(5): 3085−3099 [18] Jiang Yi, Fan Jia-Lu, Chai Tian-You, Frank L Lewis, Li Jin-Na. Tracking control for linear discrete-time networked control systems with unknown dynamics and dropout. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(10): 4607-4620 doi: 10.1109/TNNLS.2017.2771459 [19] Jiang Y, Kiumarsi B, Fan J L, Chai T Y, Li J N, Lewis F L. Optimal output regulation of linear discrete-time systems with unknown dynamics using reinforcement learning. IEEE Transactions on Cybernatics, 2020, 50(7): 3147−3156 [20] Luo Biao, Liu De-Rong, Huang Ting-Wen, Wang Ding. Model-Free Optimal Tracking Control via Critic-Only QLearning. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(10): 2134-2142 doi: 10.1109/TNNLS.2016.2585520 [21] Luo Biao, Yang Yin, Liu De-Rong. Adaptive Q-Learning for Data-Based Optimal Output Regulation With Experience Replay. IEEE Transactions on Cybernetics, 2018, 48(12): 3337-3347 doi: 10.1109/TCYB.2018.2821369 [22] Wang D, Ha M M, Qiao J F. Self-learning optimal regulation for discrete-time nonlinear systems under event-driven formulation. IEEE Transactions on Automatic Control, 2020, 65(3): 1272−1279 [23] Wang Ding, He Hai-Bo, Liu De-Rong. Adaptive Critic Nonlinear Robust Control: A Survey. IEEE Transactions on Cybernetics, 2017, 47(10): 3429-3451 doi: 10.1109/TCYB.2017.2712188 [24] Asma A T, Lewis F L, Murad A K. Model-free Q-learning designs for linear discrete-time zero-sum games with application to H-infinity control. Automatica. 2007, 43: 473-481 doi: 10.1016/j.automatica.2006.09.019 [25] Kiumarsi B, Lewis F L, Jiang Z P. H-infinity control of linear discrete-time systems: off-policy reinforcement learning. Automatica, 2017, 37(1): 144-152 [26] Luo Biao, Wu Huai-Ning, Huang Ting-Wen. Off-policy reinforcement learning for H-infinity control design. IEEE Transactions on Cybernetics, 2014, 45(1): 65-67 [27] Li Hong-Liang, Liu De-Rong, Wang Ding. Integral reinforcement learning for linear continuous-time zero-sum games with completely unknown dynamics. IEEE Transactions on Automation Science and Engineering, 2014, 11(3): 706-714 doi: 10.1109/TASE.2014.2300532 [28] John W Brewer. Kronecker products and matrix calculus in system theory. IEEE Transactions on Circuits and Systems, 1978, 25(9): 772-781 doi: 10.1109/TCS.1978.1084534 [29] Kim Jin-Hoon, Frank L Lewis. Model-free H-infinity control design for unknown linear discrete-time systems via Qlearning with LMI. Automatica, 2010, 46(8): 1320-1326 doi: 10.1016/j.automatica.2010.05.002 [30] Stevens B L, Lewis F L, Johnson E N. Aircraft Control and Simulation: Dynamics, Controls Design, and Autonomous Systems, (3rd Edition). New York: Wiley, 2015. 516−529 -

 下载:
下载:

图(3)
计量
- 文章访问数: 1333
- HTML全文浏览量: 312
- PDF下载量: 270
- 被引次数: 0
