

DeepRail: Automatic Visual Detection System for Railway Surface Defect Using Bayesian CNN and Attention Network
-
摘要: 面向复杂多样的钢轨场景, 本文扩展了最先进的深度学习语义分割框架DeepLab v3+ 到一个新的轻量级、可伸缩性的贝叶斯版本DeeperLab, 实现表面缺陷的概率分割. 具体地, Dropout被融入改进的Xception网络, 使得从后验分布中生成蒙特卡罗样本; 其次, 提出多尺度多速率的空洞空间金字塔池化(Atrous spatial pyramid pooling, ASPP)模块, 提取任意分辨率下的密集特征图谱; 更简单有效的解码器细化目标的边界, 计算Softmax概率的均值和方差作为分割预测和不确定性. 为解决类别不平衡问题, 基于在线前景 − 背景挖掘思想, 提出损失注意力网络(Loss attention network, LAN)定位缺陷以计算惩罚系数, 从而补偿和抑制DeeperLab的前景与背景损失, 实现辅助监督训练. 实验结果表明本文算法具有91.46 %分割精度和0.18 s/帧的运行速度, 相比其他方法更加快速鲁棒.Abstract: This paper extends the state-of-the-art deep learning framework DeepLab v3+ to a light-weighted and scalable Bayesian version DeeperLab for the defect detection on complex and diverse rail surface. Specifically, Dropout is incorporated into the improved Xception network for Monte Carlo sampling from posterior distribution. Atrous spatial pyramid pooling (ASPP) module is utilized to extract the dense features at multiple scales and rates. Furthermore, a simpler and efficient decoder is proposed to improve the defect edges, and outputs the mean and variance of Softmax probability as segmentation and uncertainty. To solve class imbalance problem, we present the loss attention network (LAN) to perform auxiliary supervision for DeeperLab training. Experimental results show that the proposed algorithm is more accurate and robust than other methods with 91.46 % precision and 0.18 s/frame speed.1) Engineering, Zhengzhou University of Light Industry, Zhengzhou 4500002) 收稿日期 2019-03-07 录用日期 2019-08-08 Manuscript received March 7, 2019; accepted August 8, 2019 国家自然科学基金 (61573134, 61733004), 湖南省科技计划项目 (2017XK2102, 2018GK2022, 2018JJ3079) 资助 Supported by National Natural Science Foundation of China (61573134, 61733004) and Hunan Key Project of Research and Development Plan (2017XK2102, 2018GK2022, 2018JJ3079) 本文责任编委 阳春华 Recommended by Associate Editor YANG Chun-Hua 1. 湖南大学电气与信息工程学院 长沙 410082 2. 湖南大学机器人视觉感知与控制技术国家工程实验室 长沙 410082 3. 长沙理工大学电气与信息工程学院 长沙 410114 4. 郑州轻工业大学电气与信息工程学院 郑州 450000 1. College of Electrical and Information Engineering, Hunan University, Changsha 410082 2. National Engineering Laboratory of Robot Vision Perception and Control Technology, Hunan University, Changsha 410082 3. College of Electrical and Information Engineering, Changsha University of Science and Technology, Changsha 410114 4. College of Electrical and Information
-
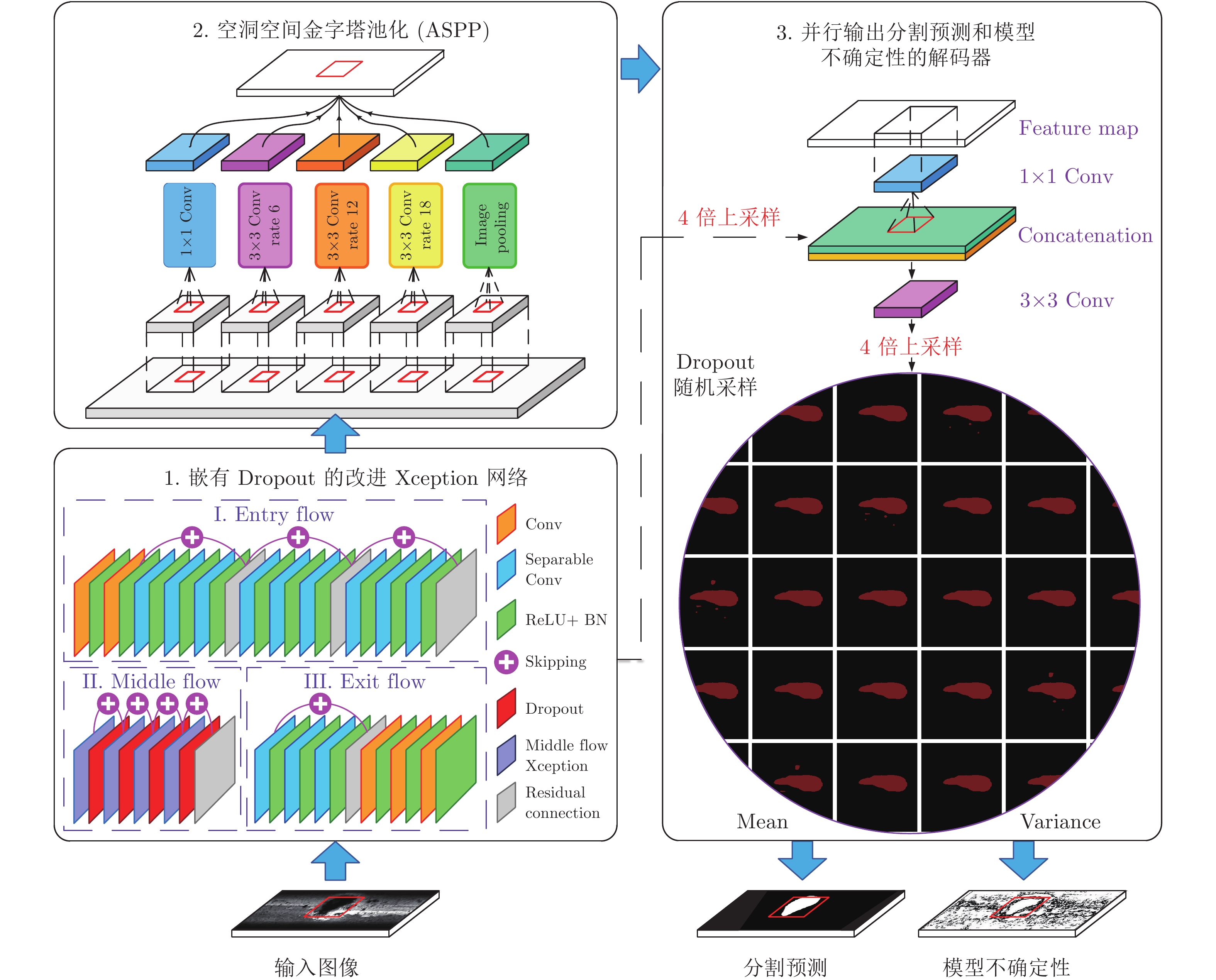
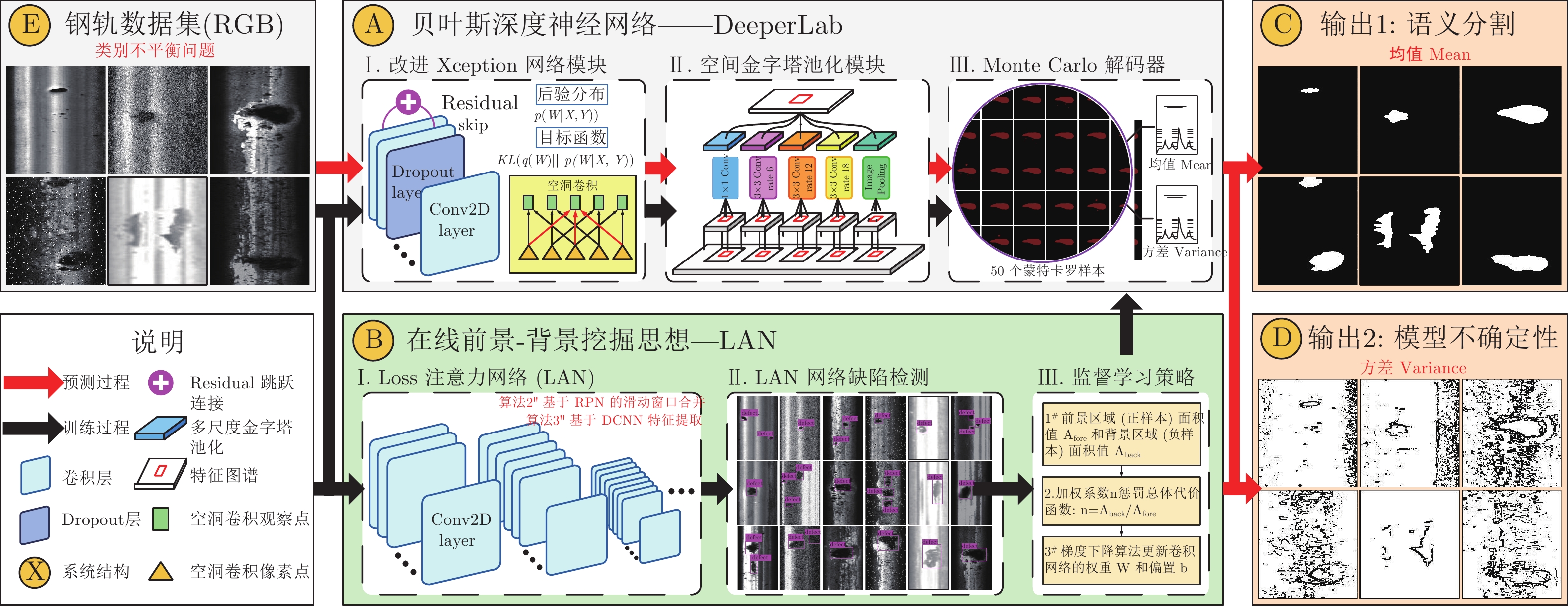
图 3 贝叶斯网络DeeperLab的编码器 − 解码器架构
Fig. 3 Encoder-decoder architecture of the proposed DeeperLab

图 6 不同钢轨场景下LAN网络对不同尺度表面缺陷的检测结果
Fig. 6 LAN detection results of different scaled defects in various rail scenes

图 8 本文方法和其他方法在不同钢轨样本的测试结果
Fig. 8 Results of the proposed method and other methods on various rail samples
表 1 本文方法和其他方法在不同钢轨样本的定量结果
Table 1 Quantitative results of our method and other methods in various rail samples
图像 指标/方法 FCN[32] Unet[34] SegNet[35] PSPNet[36] 之前工作[29] DeepLab v3+[25] Mask RCNN[23] 本文方法 样本 1 MCR (%) 2.25 11.28 1.87 1.12 4.71 1.33 0.94 1.01 RI (%) 97.65 80.87 98.33 98.57 92.46 98.39 98.65 99.60 PSNR (dB) 19.18 28.93 21.09 25.56 24.33 21.46 29.07 32.78 Jacc (%) 31.86 41.67 41.92 64.06 58.35 44.15 81.55 91.09 VI (pixel) 0.20 0.91 0.16 0.12 0.50 0.14 0.11 0.08 样本 2 MCR (%) 1.69 29.72 1.58 1.35 3.43 2.40 2.27 2.49 RI (%) 98.19 53.90 98.31 98.65 96.63 98.42 98.36 98.61 PSNR (dB) 19.37 23.50 19.97 21.49 20.01 24.76 24.53 26.07 Jacc (%) 57.60 27.43 61.19 69.01 59.23 81.84 78.72 85.99 VI (pixel) 0.16 2.24 0.17 0.13 0.31 0.17 0.17 0.15 样本 3 MCR (%) 6.79 31.77 8.95 3.24 14.78 7.91 6.73 6.85 RI (%) 89.00 57.92 93.65 95.35 82.54 95.79 96.40 97.63 PSNR (dB) 12.12 16.95 15.40 15.81 11.41 18.29 19.89 23.37 Jacc (%) 46.47 38.81 64.76 66.97 39.73 78.69 81.00 91.99 VI (pixel) 0.52 2.65 0.44 0.31 1.04 0.35 0.35 0.24 样本 4 MCR (%) 4.66 45.13 10.85 4.45 14.95 11.25 8.43 8.51 RI (%) 94.41 44.64 92.49 13.62 84.56 91.29 95.16 96.10 PSNR (dB) 14.93 16.94 14.15 15.98 19.97 14.96 19.80 21.53 Jacc (%) 64.13 31.80 60.45 67.33 83.72 64.04 82.88 88.98 VI (pixel) 0.44 3.67 0.61 0.47 1.16 0.68 0.49 0.42 样本 5 MCR (%) 7.83 23.93 7.61 12.30 13.98 14.07 11.98 12.21 RI (%) 89.42 76.97 89.73 92.63 91.11 89.75 91.80 95.91 PSNR (dB) 12.34 19.27 12.53 16.67 16.36 13.42 15.80 19.98 Jacc (%) 59.42 70.08 61.14 76.56 76.15 65.02 71.83 89.84 VI (pixel) 0.68 2.09 0.66 0.81 1.00 0.66 0.79 0.51 样本 6 MCR (%) 9.00 17.68 8.64 8.31 14.30 9.54 6.60 7.35 RI (%) 94.33 79.14 95.12 94.87 84.60 93.16 98.00 97.44 PSNR (dB) 16.11 20.54 16.56 17.70 12.45 15.80 22.38 22.64 Jacc (%) 69.14 59.89 71.84 74.68 49.52 67.57 89.78 91.15 VI (pixel) 0.45 1.62 0.40 0.47 0.98 0.53 0.28 0.26  下载: 导出CSV
下载: 导出CSV
表 2 不同贝叶斯变体的性能(%)
Table 2 Performance of difierent Bayesian variants (%)
概率变体 加权平均法 蒙特卡罗采样法 Jacc Dice Jacc Dice 无 Dropout 68.36 68.95 − − 编码器 55.24 56.71 64.60 66.07 解码器 61.78 61.34 63.92 65.88 编−解码器 58.62 60.12 60.57 62.49 输入流 75.44 76.21 82.65 80.33 中间流 83.12 80.69 90.43 91.52 输出流 68.50 67.33 77.21 78.06
下载: 导出CSV
表 3 综合性能的消融研究
Table 3 Ablation experiment of comprehensive performance
方法 Pixel Jacc.
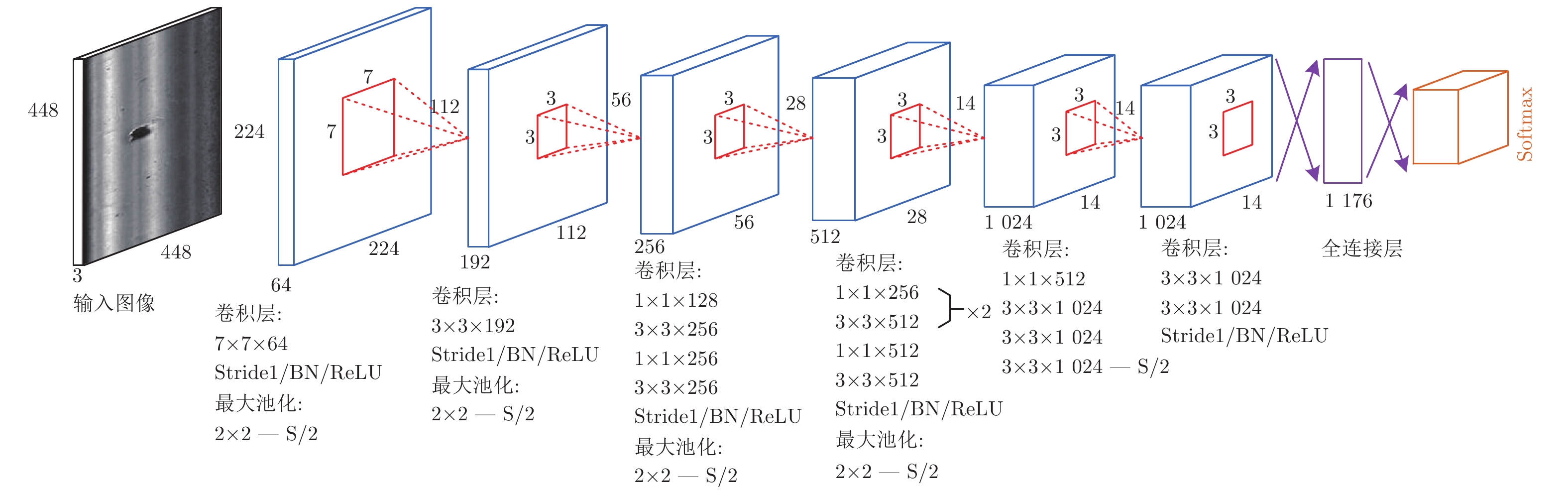
(%)运行时间 (ms) 模型成本(MB) 训练成本(GB) 60 × 40 250 × 160 500 × 300 MobileNet (β = 16) 77.17 19.91 53.10 133.49 23 3.82 ResNet50 (β = 16) 77.80 40.55 141.92 336.36 274 4.43 ResNet101 (β = 16) 78.45 66.37 181.80 431.42 477 6.99 Xception34 (β = 16) 81.66 46.64 149.13 352.70 288 3.97 Xception34 + DA (β = 16) 83.25 − − − − 3.95 Xception65 + DA (β = 16) 88.73 79.64 159.29 517.70 439 4.20 Xception65 + DA + MC (β = 16) 91.46 90.26 180.53 586.73 − 5.56
下载: 导出CSV
-
[1] 贺振东, 王耀南, 毛建旭, 印峰. 基于反向P-M扩散的钢轨表面缺陷视觉检测. 自动化学报, 2014, 40(8): 1667−16791 He Zhen-Dong, Wang Yao-Nan, Mao Jian-Xu, Yin Feng. Research on inverse P-M diffusion-based rail surface defect detection. Acta Automatica Sinica, 2014, 40(8): 1667−1679 [2] 2 He Z D, Wang Y N, Yin F, Liu J. Surface defect detection for high-speed rails using an inverse PM diffusion model. Sensor Review, 2016, 36(1): 86−97 doi: 10.1108/SR-03-2015-0039 [3] 3 Resendiz E, Hart J M, Ahuja N. Automated visual inspection of railroad tracks. IEEE Transactions on Intelligent Transportation Systems, 2013, 14(2): 751−760 doi: 10.1109/TITS.2012.2236555 [4] 孙次锁, 张玉华. 基于智能识别与周期检测的钢轨伤损自动预警方法研究. 铁道学报, 2018, 40(11): 140−146 doi: 10.3969/j.issn.1001-8360.2018.11.0204 Sun Ci-Suo, Zhang Yu-Hua. Research on automatic early warning method for rail flaw based on intelligent identification and periodic detection. Journal of the China Railway Society, 2018, 40(11): 140−146 doi: 10.3969/j.issn.1001-8360.2018.11.020 [5] 5 Liang B, Iwnicki S, Ball A, Young A E. Adaptive noise cancelling and time-frequency techniques for rail surface defect detection. Mechanical Systems and Signal Processing, 2015, 54−55: 41−51 [6] 6 Gibert X, Patel V M, Chellappa R. Deep multitask learning for railway track inspection. IEEE Transactions on Intelligent transportation systems, 2017, 18(1): 153−164 doi: 10.1109/TITS.2016.2568758 [7] Giben X, Patel V M, Chellappa R. Material classification and semantic segmentation of railway track images with deep convolutional neural networks. In: Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Québec, Canada: IEEE, 2015: 621−625 [8] Faghih-Roohi S, Hajizadeh S, Núñez A, Babuska R. Deep convolutional neural networks for detection of rail surface defects. In: Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), IEEE, 2016: 2584−2589 [9] Masci J, Meier U, Ciresan D, et al. Steel defect classification with max-pooling convolutional neural networks. In: Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), IEEE, 2012: 1−6 [10] 10 Chen J W, Liu Z Y, Wang H R, Núñez A, Han Z W. Automatic defect detection of fasteners on the catenary support device using deep convolutional neural network. IEEE Transactions on Instrumentation and Measurement, 2018, 67(2): 257−269 doi: 10.1109/TIM.2017.2775345 [11] 11 Liu Z G, Wang L Y, Li C J, Yang G J, Han Z W. A high-precision loose strands diagnosis approach for isoelectric line in high-speed railway. IEEE Transactions on Industrial Informatics, 2018, 14(3): 1067−1077 doi: 10.1109/TII.2017.2774242 [12] 12 Zhong J P, Liu Z T, Han Z W, Han Y, Zhang W X. A CNN-based defect inspection method for catenary split pins in high-speed railway. IEEE Transactions on Instrumentation and Measurement, 2018 [13] 袁静, 章毓晋. 融合梯度差信息的稀疏去噪自编码网络在异常行为检测中的应用. 自动化学报, 2017, 43(4): 604−61013 Yuan Jing, Zhang Yu-Jin. Application of sparse denoising auto encoder network with gradient difference information for abnormal action detection. Acta Automatica Sinica, 2017, 43(4): 604−610 [14] 唐贤伦, 杜一铭, 刘雨微, 李佳歆, 马艺玮. 基于条件深度卷积生成对抗网络的图像识别方法. 自动化学报, 2018, 44(5): 855−86414 Tang Xian-Lun, Du Yi-Ming, Liu Yu-Wei, Li Jia-Xin, Ma Yi-Wei. Image recognition with conditional deep convolutional generative adversarial networks. Acta Automatica Sinica, 2018, 44(5): 855−864 [15] 辛宇, 杨静, 谢志强. 基于标签传播的语义重叠社区发现算法. 自动化学报, 2014, 40(10): 2262−227515 Xin Yu, Yang Jing, Xie Zhi-Qiang. An overlapping semantic community structure detecting algorithm by label propagation. Acta Automatica Sinica, 2014, 40(10): 2262−2275 [16] 16 Denker J S, Lecun Y. Transforming neural-net output levels to probability distributions. Advances in Neural Information Processing Systems, 1991: 853−859 [17] 17 MacKay D J C. A practical Bayesian framework for backpropagation networks. Neural Computation, 1992, 4(3): 448−472 doi: 10.1162/neco.1992.4.3.448 [18] 18 Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 2014, 15(1): 1929−1958 [19] Gal Y, Ghahramani Z. Dropout as a Bayesian approximation: representing model uncertainty in deep learning. In: Proceedings of the 2016 International Conference on Machine Learning, 2016: 1050−1059 [20] 郑文博, 王坤峰, 王飞跃. 基于贝叶斯生成对抗网络的背景消减算法. 自动化学报, 2018, 44(5): 878−89020 Zheng Wen-Bo, Wang Kun-Feng, Wang Fei-Yue. Background subtraction algorithm with Bayesian generative adversarial networks. Acta Automatica Sinica, 2018, 44(5): 878−890 [21] Fu J, Zheng H, Mei T. Look closer to see better: recurrent attention convolutional neural network for fine-grained image recognition. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 4438−4446 [22] Wang F, Jiang M Q, Qian C, Yang S, Li C, Zhang H G, et al. Residual attention network for image classification. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 3156−3164 [23] He K M, Gkioxari G, Dollar P, Girshick R. Mask R-CNN. In: Proceedings of the 2017 IEEE International Conference on Computer Vision, 2017: 2961−2969 [24] 24 Lin H, Shi Z, Zou Z. Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images. IEEE Geoscience and Remote Sensing Letters, 2017, 14(10): 1665−1669 doi: 10.1109/LGRS.2017.2727515 [25] Chen L C, Zhu Y K, Papandreou G, Schroff F, Adam H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV), 2018: 801−818 [26] 韩江洪, 乔晓敏, 卫星, 陆阳. 基于空间卷积神经网络的井下轨道检测方法. 电子测量与仪器学报, 2018, 32(12): 34−4326 Han Jiang-Hong, Qiao Xiao-Min, Wei Xing, Lu Yang. Downhole track detection method based on spatial convolutional neural network. Journal of Electronic Measurement and Instrumentation, 2018, 32(12): 34−43 [27] 时增林, 叶阳东, 吴云鹏, 娄铮铮. 基于序的空间金字塔池化网络的人群计数方法. 自动化学报, 2016, 42(6): 866−87427 Shi Zeng-Lin, Ye Yang-Dong, Wu Yun-Peng, Lou Zheng-Zheng. Crowd counting using rank-based spatial pyramid pooling network. Acta Automatica Sinica, 2016, 42(6): 866−874 [28] Chen L C, Papandreou G, Kokkinos I, Murphy K, Yuille A L. Semantic image segmentation with deep convolutional nets and fully connected CRFs, arXiv preprint arXiv: 1412. 7062, 2014 [29] 张辉, 金侠挺, Wu Q M Jonathan, 贺振东, 王耀南. 基于曲率滤波和改进GMM的钢轨缺陷自动视觉检测方法. 仪器仪表学报, 2018, 39(4): 181−19429 Zhang Hui, Jin Xia-Ting, Wu Q. M. Jonathan, He Zhen-Dong, Wang Yao-Nan. Automatic visual detection method of railway surface defects based on curvature filtering and Improved GMM. Chinese Journal of Scientific Instrument, 2018, 39(4): 181−194 [30] 骆小飞, 徐军, 陈佳梅. 基于逐像素点深度卷积网络分割模型的上皮和间质组织分割. 自动化学报, 2017, 43(11): 2003−201330 Luo Xiao-Fei, Xu Jun, Chen Jia-Mei. A deep convolutional network for pixel-wise segmentation on epithelial and stromal tissues in histologic images. Acta Automatica Sinica, 2017, 43(11): 2003−2013 [31] Chollet F. Xception: deep learning with depthwise separable convolutions. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1251−1258 [32] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3431−3440 [33] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779−788 [34] Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation. In: Proceedings of the 2015 International Conference on Medical image Computing and Computer-assisted Intervention, Springer, Cham, 2015: 234−241 [35] 35 Badrinarayanan V, Kendall A, Cipolla R. Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481−2495 doi: 10.1109/TPAMI.2016.2644615 [36] 36 Zhao H S, Shi J P, Qi X J, Wang X G, Jia J Y. Pyramid scene parsing network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2881−2890 -

 下载:
下载:





计量
- 文章访问数: 4413
- HTML全文浏览量: 1713
- PDF下载量: 677
- 被引次数: 0
