

Object Image Annotation Based on Formal Concept Analysis and Semantic Association Rules
-
摘要: 基于目标的图像标注一直是图像处理和计算机视觉领域中一个重要的研究问题.图像目标的多尺度性、多形变性使得图像标注十分困难.目标分割和目标识别是目标图像标注任务中两大关键问题.本文提出一种基于形式概念分析(Formal concept analysis, FCA)和语义关联规则的目标图像标注方法, 针对目标建议算法生成图像块中存在的高度重叠问题, 借鉴形式概念分析中概念格的思想, 按照图像块的共性将其归成几个图像簇挖掘图像类别模式, 利用类别概率分布判决和平坦度判决分别去除目标噪声块和背景噪声块, 最终得到目标语义簇; 针对语义目标判别问题, 首先对有效图像簇进行特征融合形成共性特征描述, 通过分类器进行类别判决, 生成初始目标图像标注, 然后利用图像语义标注词挖掘语义关联规则, 进行图像标注的语义补充, 以避免挖掘类别模式时丢失较小的语义目标.实验表明, 本文提出的图像标注算法既能保证语义标注的准确性, 又能保证语义标注的完整性, 具有较好的图像标注性能.Abstract: Object-based image annotation has always been an important research issue in the field of image processing and computer vision. Image annotation is very difficult because of the multi-scale and variability of the objects. Object-based image annotation has two key issues: object segmentation and object recognition. This paper proposed an object image annotation method based on formal concept analysis (FCA) and semantic association rules. Aiming at the high overlap problem of image blocks for objectness proposal generation algorithm, the idea of concept lattice in formal concept analysis was used to classify the image blocks into several image clusters according to the commonality of image blocks and mine the image category pattern. After removing the object-noise block and the background-noise block by the category probability distribution decision and the flatness decision, respectively, the final semantic object clusters are obtained. In addition, aiming at the discrimination problem of semantic objects, we firstly got common feature descriptions by fusing features of image clusters, and generated the initial object image annotation through the classifier. The semantic association rules were then mined through the semantic image annotations to perform the semantic complement of image annotations to avoid missing smaller semantic objects when mining category patterns. Experimental results show that the proposed image annotation algorithm not only ensures the precision of semantic annotation, but also ensures the integrity of semantic annotation. It has the better performance of image annotation.
-
Key words:
- Image annotation /
- formal concept analysis (FCA) /
- semantic association rules /
- common features /
- feature fusion
1) 本文责任编委 黄庆明 -

图 4 目标图像簇和背景图像簇的平坦度对比
Fig. 4 Flatness comparison of object image clusters and background image clusters

图 5 基于类别模式和特征融合的图像标注
Fig. 5 Image annotation based on category pattern and feature fusion

图 6 目标建议算法生成的图像局部框
Fig. 6 Local blocks generated by the objectness proposal generation algorithm
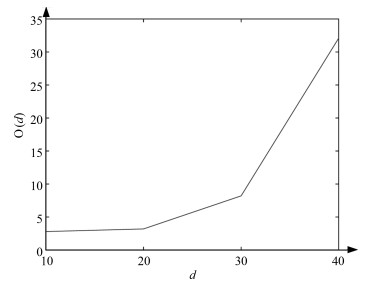
图 8 $d$与算法时间复杂度O${(d)}$的关系
Fig. 8 The relationship between $d$ and time complexity O${(d)}$
表 1 CNN特征稀疏二值化分类效果对比
分类精度 CNN$-$10 CNN$-$20 CNN$-$30 CNN$-$40 CNN$-$50 CNN Accuracy 0.81 0.88 0.86 0.89 0.93 0.93  下载: 导出CSV
下载: 导出CSV
表 5 参数${\beta}$对实验性能的影响
Table 5 Performance on parameter ${\beta}$
${\beta}$ 2 3 4 5 6 7 8 Silhouette 0.16 0.232 0.33 0.63 0.662 0.72 0.761 ${Mc(\beta)}$ 6 5.4 5.1 4.9 4.2 3.4 2.8
下载: 导出CSV
表 6 ${supp}_{\min}$对实验性能的影响
Table 6 Performance on parameter ${supp}_{ \min}$
${supp}_{ \min}$ $2\times10^{-4}$ $1\times10^{-3}$ $2\times10^{-3}$ $3\times10^{-3}$ $4\times10^{-3}$ O$({ supp}_{ \min})$ 2.04 0.57 0.31 0.19 0.16 ${N}({ supp}_{ \min})$ 281 135 96 75 73
下载: 导出CSV
表 7 ${conf}_{\min}$对实验性能的影响
Table 7 Performance on parameter ${conf}_{ \min}$
${conf}_{ \min}$ 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 ${N}({conf}_{ \min})$ 122 87 71 55 37 16 10 5 ${P}({conf}_{ \min})$ 0.46 0.54 0.62 0.72 0.84 0.86 0.94 0.98
下载: 导出CSV
表 8 三种聚类算法的比较
Table 8 Comparison of three clustering algorithms
PMC $k$-means AP ${o}({ ct})$ 3.20 1.58 1.31 Silhouette 0.68 0.33 0.39
下载: 导出CSV
表 9 VOC 2007数据集中部分语义关联规则
Table 9 Partial semantic association rules in the VOC 2007 data set
存在语义 bicycle diningtable bicycle, bus bottle, chair pottedplant, bottle 关联语义 persion chair person diningtable person 相关度 0.68 0.70 0.92 0.67 0.70
下载: 导出CSV
表 10 三种特征融合方式对比
Table 10 Comparison of three feature fusion methods
${P}$ ${R}$ ${F}$ 最大值融合 0.59 0.61 0.60 均值融合 0.64 0.58 0.61 组合融合 0.72 0.56 0.63
下载: 导出CSV
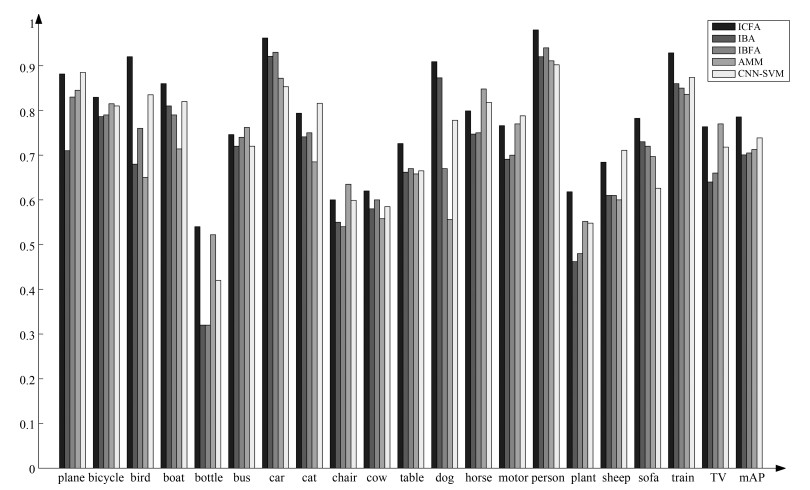
表 11 标注实验结果比对
Table 11 Comparison of annotation results
${P}$ ${R}$ ${F}$ O${(t)}$ IBA 0.44 0.72 0.55 10.94 IBFA 0.46 0.75 0.57 11.46 ICFA 0.72 0.56 0.63 10.51 ICFA + SC 0.72 0.62 0.67 11.74
下载: 导出CSV
-
[1] Duygulu P, Barnard K, Freitas J F G D, Forsyth D A. Object Recognition as Machine Translation:Learning a Lexicon for a Fixed Image Vocabulary. Berlin: Springer, 2002. 97-112 [2] Qu S, Xi Y, Ding S. Visual attention based on long-short term memory model for image caption generation. In: Proceedings of the 2017 the Chinese Control and Decision Conference. Chongqing, China: IEEE, 2017. 4789-4794 [3] Lin T Y, Dollar P, Girshick R, He K, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE Computer Society, 2017. 2117-2125 [4] Ren S, He K, Girshick R, Sun J. Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149 doi: 10.5555/2969239.2969250 [5] Wang J, Yang Y, Mao J, Huang Z H. CNN-RNN: a unified framework for multi-label image classification. In: Proceedings of Computer Vision and Pattern Recognition. Las Vegas, Nevada, USA: IEEE, 2016. avXiv: 1604.04573 [6] Tang J, Li H, Qi G J, Chua T S. Image annotation by graph-based inference with integrated multiple single instance representations. IEEE Transactions on Multimedia, 2010, 12(2): 131-141 doi: 10.1109/TMM.2009.2037373 [7] Wu B, Jia F, Liu W, Ghanem B, Lyu S. Multi-label learning with missing labels using mixed dependency graphs. International Journal of Computer Vision, 2018, 126(8): 875-896 doi: 10.1007/s11263-018-1085-3 [8] Kong X, Wu Z, Li L J, Zhang R, Yu P S, Wu H, et al. Large-scale multi-label learning with incomplete label assignments. ArXiv preprint, 2014 [9] Jin C, Jin S W. Image distance metric learning based on neighborhood sets for automatic image annotation. Journal of Visual Communication & Image Representation, 2016, 34(C): 167-175 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=3bb87385164eec73ad990f117c7224fa [10] Chen Y, Zhu L, Yuille A, Zhang H. Unsupervised learning of probabilistic object models (POMs) for object classification, segmentation, and recognition using knowledge propagation. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2009, 31(10): 1747-1761 https://www.ncbi.nlm.nih.gov/pubmed/19696447 [11] Yang C, Dong M. Region-based image annotation using asymmetrical support vector machine-based multi-instance learning. In: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2006. 17-22 [12] Uijlings J R R, van de Sande K E A, Gevers T, Smeulders A W M. Selective search for object recognition. International Journal of Computer Vision, 2013, 104(2): 154-171 doi: 10.1007/s11263-013-0620-5 [13] Cheng M M, Zhang Z, Lin W Y, Torr P. Bing: binarized normed gradients for objectness estimation at 300 fps. In: Proceedings of the Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 3286-3293 [14] Felzenszwalb P F, Mcallester D A, Ramanan D. A discriminatively trained, multiscale, deformable part model. In: Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2008). Anchorage, Alaska, USA: IEEE, 2008. 24-26 [15] Moran S, Lavrenko V. A sparse kernel relevance model for automatic image annotation. International Journal of Multimedia Information Retrieval, 2014, 3(4): 209-229 doi: 10.1007/s13735-014-0063-y [16] Wille R. Restructuring lattice theory: an approach based on hierarchies of concepts. Orderd Sets D Reidel, 1982, 83: 314-339 doi: 10.1007%2F978-94-009-7798-3_15 [17] Thomas, J. Cook, K. A visual analytics agenda. IEEE Transactions on Computer Graphics and Applications, 2006, 26(1): 12-19 http://d.old.wanfangdata.com.cn/OAPaper/oai_doaj-articles_8e2e1226ca7727d15769e97e76f9ebce [18] Tsoumakas G, Katakis I, Vlahavas I. Mining Multi-Label Data. US: Springer, 2010: 667-685 [19] Yang J, Yang F, Wang G, Li M. Multi-channel and multi-scale mid-level image representation for scene classification. Journal of Electronic Imaging, 2017, 26(2): 023018 doi: 10.1117/1.JEI.26.2.023018 [20] Girish K, Premraj V, Ordonez V, Dhar S, Li S, Choi Y. Baby talk: understanding and generating simple image descriptions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2891-2903 doi: 10.1109/TPAMI.2012.162 [21] Jia X, Shen L, Zhou X, Yu S. Deep convolutional neural network based HEp-2 cell classification. In: Proceedings of International Conference on Pattern Recognition. Cancun, Mexico: IEEE, 2017 [22] Rajkomar A, Lingam S, Taylor A G, Blum M, Mongan J. High-throughput classification of radiographs using deep convolutional neural networks. Journal of Digital Imaging, 2017, 30(1): 95-101 doi: 10.1007/s10278-016-9914-9 [23] Bai C, Huang L, Pan X, Zheng J, Chen S. Optimization of deep convolutional neural network for large scale image retrieval. Neurocomputing, 2018: S0925231218304648 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=5b44c6a8f6eed1303e3763295c7b3d61 [24] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2014, 115(3): 211-252 http://d.old.wanfangdata.com.cn/NSTLHY/NSTL_HYCC0214533907/ [25] Smirnov E A, Timoshenko D M, Andrianov S N. Comparison of regularization methods for imageNet classification with deep convolutional neural networks. AASRI Procedia, 2014, 6: 89-94 doi: 10.1016/j.aasri.2014.05.013 [26] Razavian A S, Azizpour H, Sullivan J, Carlsson S. CNN features off-the-shelf: an astounding baseline for recognition. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Workshops, 2014: 512-519 [27] Pang J, Huang J, Qin L, Zhang W, Qing L, Huang Q. Rotative maximal pattern: a local coloring descriptor for object classification and recognition. Information Sciences, 2017, 405 https://www.sciencedirect.com/science/article/pii/S0020025517306527 [28] Chen Q, Song Z, Dong J, Huang Z, Hua Y, Yan S. Contextualizing Object Detection and Classification. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado USA: IEEE Computer Society, 2011. 1585-1592 [29] Lu X, Chen Y, Li X. Hierarchical recurrent neural hashing for image retrieval with hierarchical convolutional features. IEEE Transactions on Image Processing, 2018, 1(27): 106-120 https://ieeexplore.ieee.org/document/8048518 -






计量
- 文章访问数: 4433
- HTML全文浏览量: 5506
- PDF下载量: 178
- 被引次数: 0
