

-
摘要: 显著性检测是近年来国内外计算机视觉领域研究的热点问题,在图像压缩、目标识别与跟踪、场景分类等领域具有广泛的应用.针对大多显著性检测方法只针对单个目标且鲁棒性不强这一问题,本文提出一种基于深度特征的显著性检测方法.首先,在多个尺度上对输入图像进行超像素分割,利用目标先验知识对预显著区域进行提取和优化.然后,采用卷积神经网络提取预选目标区域的深度特征.对高维深度特征进行主成分分析并计算显著性值.最后,提出一种改进的加权多层元胞自动机方法,对多尺度分割显著图进行融合优化,得到最终显著图.在公开标准数据集SED2和HKU_IS的实验表明,与现有经典显著性检测方法相比,本文方法对多显著目标检测更准确.Abstract: Saliency detection has been a hot topic in the field of computer vision in recent years, and has been widely applied in image compression, scene recognition and understanding, target tracking and other applications. Most saliency detection methods are only for a single target and their robustness is not good enough. For this problem, a saliency detection method based on deep feature is proposed. Firstly, the image is over-segmentated with multiple-scales, and the prior knowledge is used to extract and optimize pre-salient regions. Then, the deep features of pre-salient regions are extracted with deep convolution neural networks. The principal component analysis is used to reduce the dimension of deep feature, and the saliency value is calculated. Finally, a weighted multi-layer cellular automata is proposed, and the final saliency map is obtained by fusing the multi-scale segmentation saliency maps with the automata. Experiments on standard datasets SED2 and HKU_IS show that the proposed method is more effective compared with other saliency detection methods.
-
Key words:
- Saliency detection /
- convolutional neural networks /
- over-segmentation /
- deep feature /
- cellular automata
1) 本文责任编委 贾云得 -
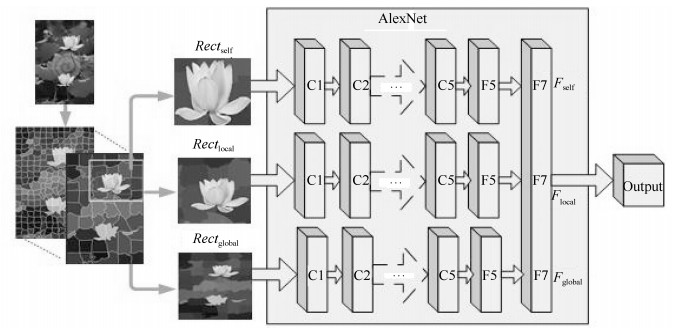
图 3 基于卷积神经网络的深度特征提取架构图
Fig. 3 Deep features extraction based on convolutional neural network
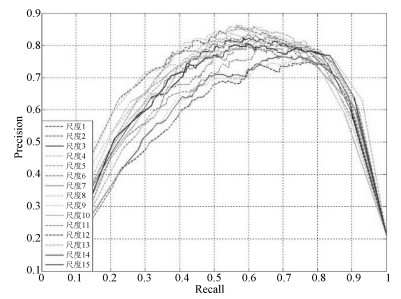
图 4 不同分割尺度下显著性检测的PR曲线图
Fig. 4 Precision-Recall curves of saliency detection in different segmentation scales
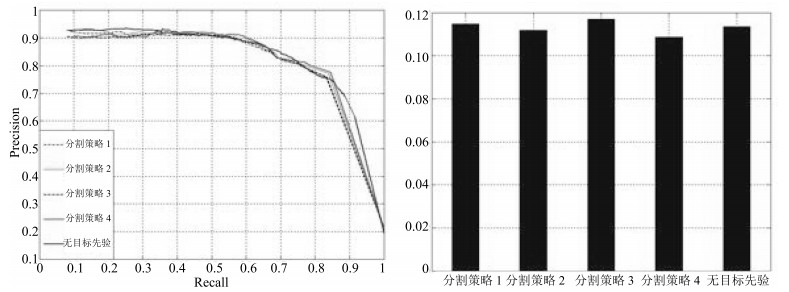
图 5 不同分割策略下显著性检测的PR曲线图以及MAE柱状图
Fig. 5 Precision-recall curves and MAE histogram in different segmentation strategies
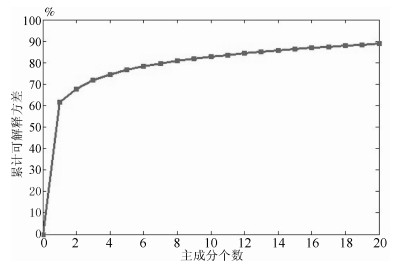
图 6 主成分个数与累计可解释方差关系图
Fig. 6 The relationship between the number of principal component and percentage explained variance

图 7 不同融合方法的PR曲线与MAE柱状图
Fig. 7 Precision-Recall curves and MAE histogram of different fusion methods
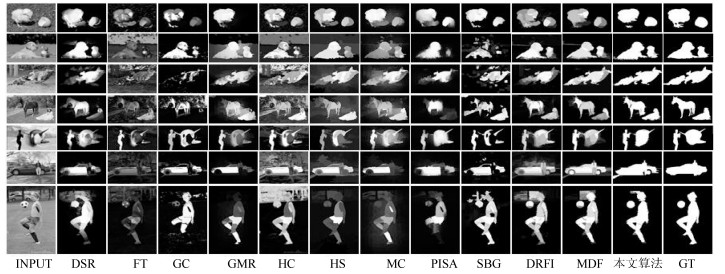
图 9 不同算法在具有不同类别目标的数据集HKU IS上的视觉显著图
Fig. 9 Saliency maps of different algorithms on dataset HKU IS with different classes of objects
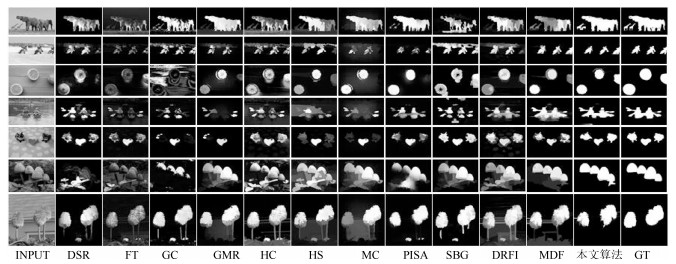
图 10 不同算法在具有多个目标的数据集HKU IS上的视觉显著图
Fig. 10 Saliency maps of different algorithms on dataset HKU IS with different multiple objects

图 11 不同算法在数据集SED2上的PR曲线图和F-measure柱状图
Fig. 11 PR curves and F-measure histogram of different algorithms on dataset SED2
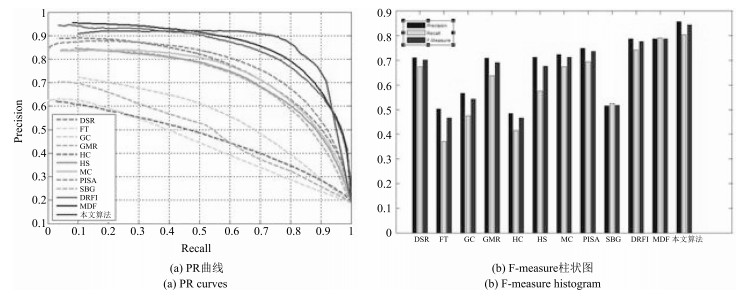
图 12 不同算法在数据集HKU IS上的PR曲线图和F-measure柱状图
Fig. 12 PR curves and F-measure histogram of different algorithms on dataset HKU_IS

图 13 不同算法在数据集SED2和HKU_IS上的MAE柱状图
Fig. 13 The MAE histogram of different algorithms on dataset of SED2 and HKU_IS
表 1 不同分割策略下平均每幅图像检测时间
Table 1 The average detection time for each image in different segmentation strategies
方法 时间(s) 分割策略1 2.70017 分割策略2 2.33585 分割策略3 2.52179 分割策略4 2.31023 无目标先验 4.52449  下载: 导出CSV
下载: 导出CSV
表 2 平均检测时间对比表
Table 2 Table of contrast result in running times
方法 DSR FT GC GM HS MC SBG DRFI MDF 本文算法 代码类型 MATLAB C++ C++ MATLAB C++ MATLAB MATLAB MATLAB MATLAB MATLAB 时间(s) 3.534 0.023 0.095 0.252 0.492 0.146 3.882 12.135 15.032 2.31
下载: 导出CSV
-
[1] Rothenstein A L, Tsotsos J K. Attention links sensing to recognition. Image and Vision Computing, 2008, 26(1):114-126 doi: 10.1016/j.imavis.2005.08.011 [2] Shao J, Gao J, Yang J. Synergetic object recognition based on visual attention saliency map. In:Proceedings of the 2006 IEEE International Conference on Information Acquisition. Weihai, China:IEEE, 2006. 660-665 http://www.wanfangdata.com.cn/details/detail.do?_type=conference&id=WFHYXW172394 [3] Forssen P E, Meger D, Lai K, Helmer S, Little J J, Lowe D G. Informed visual search:Combining attention and object recognition. In:Proceedings of the 2008 IEEE International Conference on Robotics and Automation. Pasadena, CA, USA:IEEE, 2008. 935-942 https://ieeexplore.ieee.org/document/4543325/ [4] Nakano H, Okuma S, Yano Y. A study on fast object recognition based on selective visual attention system. In:Proceedings of the 2008 IEEE International Conference on Systems, Man and Cybernetics. Singapore:IEEE, 2008. 2116-2121 https://ieeexplore.ieee.org/document/4811604 [5] Borji A, Cheng M M, Jiang H, Li J. Salient object detection:a benchmark. IEEE Transactions on Image Processing, 2015, 24(12):5706-5722 doi: 10.1109/TIP.2015.2487833 [6] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11):1254-1259 doi: 10.1109/34.730558 [7] Hou X D, Zhang L Q. Saliency detection:a spectral residual approach. In:Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, MN, USA:IEEE, 2007. 1-8 https://ieeexplore.ieee.org/document/4270292 [8] Guo C L, Zhang L M. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. IEEE Transactions on Image Processing, 2010, 19(1):185-198 doi: 10.1109/TIP.2009.2030969 [9] Li J, Levine M D, An X J, Xu X, He H G. Visual saliency based on scale-space analysis in the frequency domain. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(4):996-1010 doi: 10.1109/TPAMI.2012.147 [10] Cheng M M, Mitra N J, Huang X L, Torr P H S, Hu S M. Global contrast based salient region detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3):569-582 doi: 10.1109/TPAMI.2014.2345401 [11] Shen X H, Wu Y. A unified approach to salient object detection via low rank matrix recovery. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA:IEEE, 2012. 853-860 https://ieeexplore.ieee.org/document/6247758 [12] Yang C, Zhang L H, Lu H C, Ruan X, Yang M H. Saliency detection via graph-based manifold ranking. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 3166-3173 https://ieeexplore.ieee.org/document/6619251 [13] Cheng M M, Warrell J, Lin W Y, Zheng S, Vineet V, Crook N. Efficient salient region detection with soft image abstraction. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia:IEEE, 2013. 1529-1536 https://ieeexplore.ieee.org/document/6751300 [14] Li X H, Lu H C, Zhang L H, Ruan X, Yang M H. Saliency detection via dense and sparse reconstruction. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia:IEEE, 2013. 2976-2983 [15] 杨赛, 赵春霞, 徐威.一种基于词袋模型的新的显著性目标检测方法.自动化学报, 2016, 42(8):1259-1273 http://d.old.wanfangdata.com.cn/Periodical/zdhxb201608013Yang Sai, Zhao Chun-Xia, Xu Wei. A novel salient object detection method using bag-of-features. Acta Automatica Sinica, 2016, 42(8):1259-1273 http://d.old.wanfangdata.com.cn/Periodical/zdhxb201608013 [16] Jiang H Z, Wang J D, Yuan Z J, Wu Y, Zheng N N, Li S P. Salient object detection:a discriminative regional feature integration approach. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 2083-2090 doi: 10.1007%2Fs11263-016-0977-3 [17] 李岳云, 许悦雷, 马时平, 史鹤欢.深度卷积神经网络的显著性检测.中国图象图形学报, 2016, 21(1):53-59 http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a201601007Li Yue-Yun, Xu Yue-Lei, Ma Shi-Ping, Shi He-Huan. Saliency detection based on deep convolutional neural network. Journal of Image and Graphics, 2016, 21(1):53-59 http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a201601007 [18] Li G B, Yu Y Z. Visual saliency based on multiscale deep features. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015. 5455-5463 http://www.oalib.com/paper/4072276 [19] Hu Y, Liang Z, Chi Z R, Fu H. A combined convolutional neural network and potential region-of-interest model for saliency detection. In:Proceedings of 2015 the 11th IEEE International Conference on Natural Computation. Zhangjiajie, China:IEEE, 2015. 154-158 https://ieeexplore.ieee.org/document/7377982/?arnumber=7377982 [20] 刘志伟, 周东傲, 林嘉宇.基于图像显著性检测的图像分割.计算机工程与科学, 2016, 38(1):144-147 doi: 10.3969/j.issn.1007-130X.2016.01.024Liu Zhi-Wei, Zhou Dong-Ao, Lin Jia-Yu. Image segmentation based on saliency detection. Computer Engineering & Science, 2016, 38(1):144-147 doi: 10.3969/j.issn.1007-130X.2016.01.024 [21] Li D R, Zhang G F, Wu Z C, Yi L N. An edge embedded marker-based watershed algorithm for high spatial resolution remote sensing image segmentation. IEEE Transactions on Image Processing, 2010, 19(10):2781-2787 doi: 10.1109/TIP.2010.2049528 [22] Liu Y J, Yu C C, Yu M J, He Y. Manifold SLIC:a fast method to compute content-sensitive superpixels. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, Nevada, USA:IEEE, 2016. 651-659 https://ieeexplore.ieee.org/document/7780446 [23] 郭丽丽, 丁世飞.深度学习研究进展.计算机科学, 2015, 42(5):28-33). http://d.old.wanfangdata.com.cn/Periodical/ranj201902029Guo Li-Li, Ding Shi-Fei. Research progress on deep learning. Computer Science, 2014, 42(5):28-33 http://d.old.wanfangdata.com.cn/Periodical/ranj201902029 [24] Shahid N, Perraudin N, Kalofolias V, Puy G, Vandergheynst P. Fast robust PCA on graphs. IEEE Journal of Selected Topics in Signal Processing, 2016, 10(4):740-756 doi: 10.1109/JSTSP.2016.2555239 [25] Qin Y, Lu H C, Xu Y Q, Wang H. Saliency detection via cellular automata. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015. 110-119 [26] 曲延云, 郑南宁, 李翠华, 袁泽剑, 叶聪颖.基于支持向量机的显著性建筑物检测.计算机研究与发展, 2007, 44(1):141-147 http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz200701020Qu Yan-Yun, Zheng Nan-Ning, Li Cui-Hua, Yuan Ze-Jian, Ye Cong-Ying. Salient building detection based on SVM. Journal of Computer Research and Development, 2007, 44(1):141-147 http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz200701020 [27] Shen NM, Li J, Zhou PY, Huo Y, Zhuang Y. BSFCoS:block and sparse principal component analysis based fast co-saliency detection method. International Journal of Pattern Recognition and Artificial Intelligence, 2016, 30(1):Article No.1655003 http://d.old.wanfangdata.com.cn/Periodical/jsjkx201508062 [28] Achanta R, Hemami S, Estrada F, Susstrunk S. Frequency-tuned salient region detection. In:Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA:IEEE, 2009. 1597-1604 https://ieeexplore.ieee.org/document/5206596 [29] Yan Q, Xu L, Shi J P, Jia J Y. Hierarchical saliency detection. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 1155-1162 https://ieeexplore.ieee.org/document/6618997 [30] Shi K Y, Wang K Z, Lu J B, Lin L. PISA:pixelwise image saliency by aggregating complementary appearance contrast measures with spatial priors. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 2115-2122 [31] Chakraborty S, Mitra P. A dense subgraph based algorithm for compact salient image region detection. Computer Vision and Image Understanding, 2016, 145:1-14 doi: 10.1016/j.cviu.2015.12.005 -

 下载:
下载:




计量
- 文章访问数: 5105
- HTML全文浏览量: 1344
- PDF下载量: 357
- 被引次数: 0
