

-
摘要: 考古出土的青铜器铭文是非常宝贵的文字材料,准确、快速地了解其释义和字形演变源流对考古学、历史学和语言学研究均有重要意义.青铜器铭文的辨识需要综合文字的形、音、义进行研究,其中第一步也是最重要的一步就是分析文字的形体特征.本文提出一种基于两阶段特征映射的神经网络模型来提取每个文字的形体特征,最后对比目前已知的文字研究成果,如《古文字类编》、《说文解字》,得出识别的结果.通过定性和定量的实验分析,我们发现本文提出的方法可达到较高的识别精度.特别地,在前10个预测类别中(Top-10)准确率达到了94.2%,大幅缩小了考古研究者的搜索推测空间,提高了青铜铭文识别的效率和准确性.Abstract: Bronze inscriptions from archaeology are very valuable text materials. Accurate and rapid understanding of their meaning and shape evolution is important for archeology, history and linguistics. It is necessary to combine characters shape, phonology and meaning for recognition of bronze inscription, wherein the first and also the most important step is to analyze shapes of bronze inscriptions. In this paper, we present a bronze inscription analysis method based on convolutional neural network (CNN) with two-phase feature mapping. We first extract the bronze inscriptions by image acquisition, and then, by comparing with the currently known character research results, e.g., "Ancient Chinese Character Type Series" and "Shuo Wen Jie Zi", we obtain the recognition results. Through qualitative and quantitative experimental analyses, we find that the proposed method achieves high recognition accuracy. Specifically, we achieve 94.2% accuracy for the Top-10, greatly reducing the space of archaeological search and improving the efficiency and accuracy of bronze inscription recognition.1) 本文责任编委 刘成林
-

图 1 "保"字的各种演化变体(包括甲骨文、青铜器铭文、篆书等)
Fig. 1 Various evolutionary shapes of character "保" (including oracle-bone, bronze inscription, seal character, etc.)

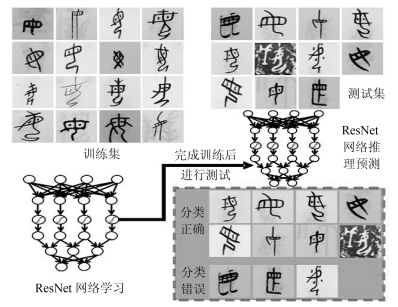
图 7 基于18层ResNet的古文字识别模型示意
Fig. 7 Pipeline of ancient character recognition based on 18-level ResNet
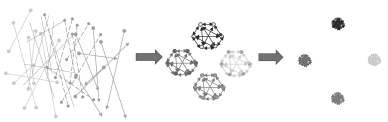
图 8 两阶段映射示意(第一个Loss有能力把杂乱的原始数据聚类得比较好; 第二个Loss进一步聚类数据)
Fig. 8 Demonstration of two-stage mapping (The first loss has the ability to originally cluster the messy raw data and the second further clusters the data.)

图 11 "子"、"吉"、"名" 3个字的甲骨文、金文和鸟文的对比
Fig. 11 The comparison of oracle-bone, bronze inscriptions and bird-writing for character "子", "吉" and "名"
表 1 测试集的识别准确率
Table 1 Recognition accuracy in the testing dataset
分类器结果对比 Top-1 Top-3 Top-5 Top-8 Top-10 基准分类器 57.1% 73.7% 85.8% 89.6% 92.7% 分类器Ⅰ 57.7% 74.9% 86.2% 90.5% 93.6% 分类器Ⅱ 58.3% 76.1% 87.1% 91.4% 94.2%  下载: 导出CSV
下载: 导出CSV
-
[1] 马承源.中国古代青铜器.第2版.上海:上海人民出版社, 2016. 9-41Ma Cheng-Yuan. Ancient Chinese Bronzes (Second Edition). Shanghai:Shanghai Renmin Press, 2016. 9-41 [2] 李学勤.古文字学初阶.第2版.北京: 中华书局, 2006. 9-46Li Xue-Qin. Primary Chinese Paleography (Second Edition). Beijing: Zhonghua Book Company, 2006. 9-46 [3] 高明.中国古文字学通论.北京:北京大学出版社, 1996. 56-170Gao Ming. General Theory of Chinese Paleography. Beijing:Beijing University Press, 1996. 56-170 [4] 高明, 涂白奎.古文字类编.上海:上海古籍出版社, 2014. 1-1427Gao Ming, Tu Bai-Kui. Ancient Chinese Character Type Series. Shanghai:Shanghai Classics Publishing House, 2014. 1-1427 [5] 张亚初.殷周金文集成引得.北京: 中华书局, 2001. 1-225Zhang Ya-Chu. Shang and Zhou Dynasties Bronze Inscriptions Integration Index. Beijing: Zhonghua Book Company, 2001. 1-225 [6] 周新伦, 李锋, 华星城, 韦剑.甲骨文计算机识别方法研究.复旦学报(自然科学版), 1996, 35(5):481-486 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=QK199600072768Zhou Xin-Lun, Li Feng, Hua Xing-Cheng, Wei Jian. A method of Jia Gu Wen recognition based on a two-level classification. Journal of Fudan University (Natural Science), 1996, 35(5):481-486 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=QK199600072768 [7] 李峰, 周新伦.甲骨文自动识别的图论方法.电子科学学刊, 1996, 18(S1):41-47 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=QK199600067408Li Feng, Zhou Xin-Lun. Recohnition of Jia Gu Wen based on graph theory. Journal of Electronics & Information Technology, 1996, 18(S1):41-47 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=QK199600067408 [8] 顾绍通.基于拓扑配准的甲骨文字形识别方法.计算机与数字工程, 2016, 44(10):2001-2006 doi: 10.3969/j.issn.1672-9722.2016.10.029Gu Shao-Tong. Identification of oracle-bone script fonts based on topological registration. Computer & Digital Engineering, 2016, 44(10):2001-2006 doi: 10.3969/j.issn.1672-9722.2016.10.029 [9] 吕肖庆, 李沫楠, 蔡凯伟, 王晓, 唐英敏.一种基于图形识别的甲骨文分类方法.北京信息科技大学学报, 2010, 25(S2):92-96 http://d.old.wanfangdata.com.cn/Conference/7452730Lv Xiao-Qing, Li Mo-Nan, Cai Kai-Wei, Wang Xiao, Tang Ying-Min. A graphic-based method for Chinese oracle-bone classification. Journal of Beijing Information Science & Technology University, 2010, 25(S2):92-96 http://d.old.wanfangdata.com.cn/Conference/7452730 [10] 王嘉梅, 文永华, 李燕青, 高雅莉.基于图像分割的古彝文字识别系统研究.云南民族大学学报(自然科学版), 2008, 17(1):76-79 doi: 10.3969/j.issn.1672-8513.2008.01.019Wang Jia-Mei, Wen Yong-Hua, Li Yan-Qing, Gao Ya-Li. The recognition system of old-Yi character based on the image segmentation. Journal of Yunnan Nationalities University (Natural Sciences Edition), 2008, 17(1):76-79 doi: 10.3969/j.issn.1672-8513.2008.01.019 [11] 孙华.基于多特征融合SVM的古汉字图像识别研究[硕士学位论文], 中南大学, 中国, 2010 http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y1721380Sun Hua. Study of Ancient Chinese Character based on Multi-feature SVM Image Recognition Method[Master thesis], Central South University, China, 2010 http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y1721380 [12] 孙莹莹.基于混合核LS-SVM的古汉字图像识别[硕士学位论文], 安徽大学, 中国, 2015 http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y2805808Sun Ying-Ying. Recognition of Ancient Chinese Characters Based on Hybrid Kernel LS-SVM[Master thesis], Anhui University, China, 2015 http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y2805808 [13] Krizhevsky K, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: ACM, 2012. 1097-1105 [14] Deng J, Dong W, Socher R, Li L J, Li K, Li F F. ImageNet: a large-scale hierarchical image database. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2009. 248-255 [15] Cao C S, Liu X M, Yang Y, Yu Y N, Wang J, Wang Z L, et al. Look and think twice: capturing top-down visual attention with feedback convolutional neural networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2956-2964 [16] Zhang X Y, Bengio Y, Liu C L. Online and offline handwritten Chinese character recognition:a comprehensive study and new benchmark. Pattern Recognition, 2017, 61:348-360 doi: 10.1016/j.patcog.2016.08.005 [17] Wu Y C, Yin F, Liu C L. Improving handwritten Chinese text recognition using neural network language models and convolutional neural network shape models. Pattern Recognition, 2017, 65:251-264 doi: 10.1016/j.patcog.2016.12.026 [18] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 818-833 [19] Zhou B L, Khosla A, Lapedriza A, Oliva A, Torralba A. Object detectors emerge in deep scene CNNs. In: Proceedings of the 2015 International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [20] Simonyan K, Zisserman A. Very deep convolutional networks for large-Scale image recognition. In: Proceedings of the 2015 International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [21] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1-9 [22] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770-778 [23] Mnih V, Heess N, Graves A, Kavukcuoglu K. Recurrent models of visual attention. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: ACM, 2014. 2204-2212 -

 下载:
下载:






计量
- 文章访问数: 3362
- HTML全文浏览量: 1346
- PDF下载量: 1349
- 被引次数: 0
