

Data-driven Nonlinear Near-optimal Regulation Based on Iterative Neural Dynamic Programming
-
摘要: 利用数据驱动控制思想,建立一种设计离散时间非线性系统近似最优调节器的迭代神经动态规划方法.提出针对离散时间一般非线性系统的迭代自适应动态规划算法并且证明其收敛性与最优性.通过构建三种神经网络,给出全局二次启发式动态规划技术及其详细的实现过程,其中执行网络是在神经动态规划的框架下进行训练.这种新颖的结构可以近似代价函数及其导函数,同时在不依赖系统动态的情况下自适应地学习近似最优控制律.值得注意的是,这在降低对于控制矩阵或者其神经网络表示的要求方面,明显地改进了迭代自适应动态规划算法的现有结果,能够促进复杂非线性系统基于数据的优化与控制设计的发展.通过两个仿真实验,验证本文提出的数据驱动最优调节方法的有效性.Abstract: An iterative neural dynamic programming approach is established to design the near optimal regulator of discrete-time nonlinear systems using the data-driven control formulation. An iterative adaptive dynamic programming algorithm for discrete-time general nonlinear systems is developed and proved to guarantee the property of convergence and optimality. Then, a globalized dual heuristic programming technique is developed with detailed implementation by constructing three neural networks, where the action network is trained under the framework of neural dynamic programming. This novel architecture can approximate the cost function with its derivative, and simultaneously, adaptively learn the near-optimal control law without depending on the system dynamics. It is significant to observe that it greatly improves the existing results of iterative adaptive dynamic programming algorithm, in terms of reducing the requirement of control matrix or its neural network expression, which promotes the development of data-based optimization and control design for complex nonlinear systems. Two simulation experiments are described to illustrate the effectiveness of the data-driven optimal regulation method.1) 本文责任编委 侯忠生
-
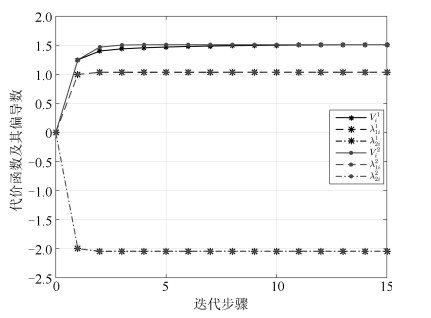
图 4 代价函数及其偏导数的收敛过程
Fig. 4 The convergence process of the cost function and its derivative

图 8 代价函数及其偏导数的收敛过程
Fig. 8 The convergence process of the cost function and its derivative
-
[1] Bellman R E. Dynamic Programming. Princeton, NJ: Princeton University Press, 1957. [2] Werbos P J. Approximate dynamic programming for real-time control and neural modeling. Handbook of Intelligent Control. New York: Van Nostrand Reinhold, 1992. [3] Lewis F L, Vrabie D, Vamvoudakis K G. Reinforcement learning and feedback control: using natural decision methods to design optimal adaptive controllers. IEEE Control Systems, 2012, 32(6): 76-105 doi: 10.1109/MCS.2012.2214134 [4] 张化光, 张欣, 罗艳红, 杨珺.自适应动态规划综述.自动化学报, 2013, 39(4): 303-311 doi: 10.1016/S1874-1029(13)60031-2Zhang Hua-Guang, Zhang Xin, Luo Yan-Hong, Yang Jun. An overview of research on adaptive dynamic programming. Acta Automatica Sinica, 2013, 39(4): 303-311 doi: 10.1016/S1874-1029(13)60031-2 [5] 刘德荣, 李宏亮, 王鼎.基于数据的自学习优化控制:研究进展与展望.自动化学报, 2013, 39(11): 1858-1870 doi: 10.3724/SP.J.1004.2013.01858Liu De-Rong, Li Hong-Liang, Wang Ding. Data-based self-learning optimal control: research progress and prospects. Acta Automatica Sinica, 2013, 39(11): 1858-1870 doi: 10.3724/SP.J.1004.2013.01858 [6] Hou Z S, Wang Z. From model-based control to data-driven control: survey, classification and perspective. Information Sciences, 2013, 235: 3-35 doi: 10.1016/j.ins.2012.07.014 [7] Prokhorov D V, Wunsch D C. Adaptive critic designs. IEEE Transactions on Neural Networks, 1997, 8(5): 997-1007 doi: 10.1109/72.623201 [8] Sutton R S, Barto A G. Reinforcement Learning——An Introduction. Cambridge, MA: MIT Press, 1998. [9] Si J, Wang Y T. Online learning control by association and reinforcement. IEEE Transactions on Neural Networks, 2001, 12(2): 264-276 doi: 10.1109/72.914523 [10] 王飞跃.平行控制:数据驱动的计算控制方法.自动化学报, 2013, 39(4): 293-302 http://www.aas.net.cn/CN/abstract/abstract17915.shtmlWang Fei-Yue. Parallel control: a method for data-driven and computational control. Acta Automatica Sinica, 2013, 39(4): 293-302 http://www.aas.net.cn/CN/abstract/abstract17915.shtml [11] Al-Tamimi A, Lewis F L, Abu-Khalaf M. Discrete-time nonlinear HJB solution using approximate dynamic programming: convergence proof. IEEE Transactions on Systems, Man, Cybernetics, Part B, Cybernetics, 2008, 38(4): 943-949 doi: 10.1109/TSMCB.2008.926614 [12] Zhang H G, Luo Y H, Liu D R. Neural-network-based near-optimal control for a class of discrete-time affine nonlinear systems with control constraints. IEEE Transactions on Neural Networks, 2009, 20(9): 1490-1503 doi: 10.1109/TNN.2009.2027233 [13] Dierks T, Thumati B T, Jagannathan S. Optimal control of unknown affine nonlinear discrete-time systems using offline-trained neural networks with proof of convergence. Neural Networks, 2009, 22(5-6): 851-860 doi: 10.1016/j.neunet.2009.06.014 [14] Wang F Y, Jin N, Liu D R, Wei Q L. Adaptive dynamic programming for finite-horizon optimal control of discrete-time nonlinear systems with ε-error bound. IEEE Transactions on Neural Networks, 2011, 22(1): 24-36 doi: 10.1109/TNN.2010.2076370 [15] Liu D R, Wang D, Zhao D B, Wei Q L, Jin N. Neural-network-based optimal control for a class of unknown discrete-time nonlinear systems using globalized dual heuristic programming. IEEE Transactions on Automation Science and Engineering, 2012, 9(3): 628-634 doi: 10.1109/TASE.2012.2198057 [16] Wang D, Liu D R, Wei Q L, Zhao D B, Jin N. Optimal control of unknown nonaffine nonlinear discrete-time systems based on adaptive dynamic programming. Automatica, 2012, 48(8): 1825-1832 doi: 10.1016/j.automatica.2012.05.049 [17] Zhang H G, Qin C B, Luo Y H. Neural-network-based constrained optimal control scheme for discrete-time switched nonlinear system using dual heuristic programming. IEEE Transactions on Automation Science and Engineering, 2014, 11(3): 839-849 doi: 10.1109/TASE.2014.2303139 [18] Liu D R, Li H L, Wang D. Error bounds of adaptive dynamic programming algorithms for solving undiscounted optimal control problems. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(6): 1323-1334 doi: 10.1109/TNNLS.2015.2402203 [19] Zhong X N, Ni Z, He H B. A theoretical foundation of goal representation heuristic dynamic programming. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(12): 2513-2525 doi: 10.1109/TNNLS.2015.2490698 [20] Heydari A, Balakrishnan S N. Finite-horizon control-constrained nonlinear optimal control using single network adaptive critics. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(1): 145-157 doi: 10.1109/TNNLS.2012.2227339 [21] Jiang Y, Jiang Z P. Robust adaptive dynamic programming and feedback stabilization of nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(5): 882-893 doi: 10.1109/TNNLS.2013.2294968 [22] Na J, Herrmann G. Online adaptive approximate optimal tracking control with simplified dual approximation structure for continuous-time unknown nonlinear systems. IEEE/CAA Journal of Automatica Sinica, 2014, 1(4): 412-422 doi: 10.1109/JAS.2014.7004668 [23] Liu D R, Yang X, Wang D, Wei Q L. Reinforcement-learning-based robust controller design for continuous-time uncertain nonlinear systems subject to input constraints. IEEE Transactions on Cybernetics, 2015, 45(7): 1372-1385 doi: 10.1109/TCYB.2015.2417170 [24] Luo B, Wu H N, Huang T W. Off-policy reinforcement learning for H∞ control design. IEEE Transactions on Cybernetics, 2015, 45(1): 65-76 doi: 10.1109/TCYB.2014.2319577 [25] Mu C X, Ni Z, Sun C Y, He H B. Air-breathing hypersonic vehicle tracking control based on adaptive dynamic programming. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(3): 584-598 doi: 10.1109/TNNLS.2016.2516948 [26] Wang D, Liu D R, Zhang Q C, Zhao D B. Data-based adaptive critic designs for nonlinear robust optimal control with uncertain dynamics. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2016, 46(11): 1544-1555 doi: 10.1109/TSMC.2015.2492941 -

 下载:
下载:





图(9)
计量
- 文章访问数: 3437
- HTML全文浏览量: 389
- PDF下载量: 1896
- 被引次数: 0
