

-
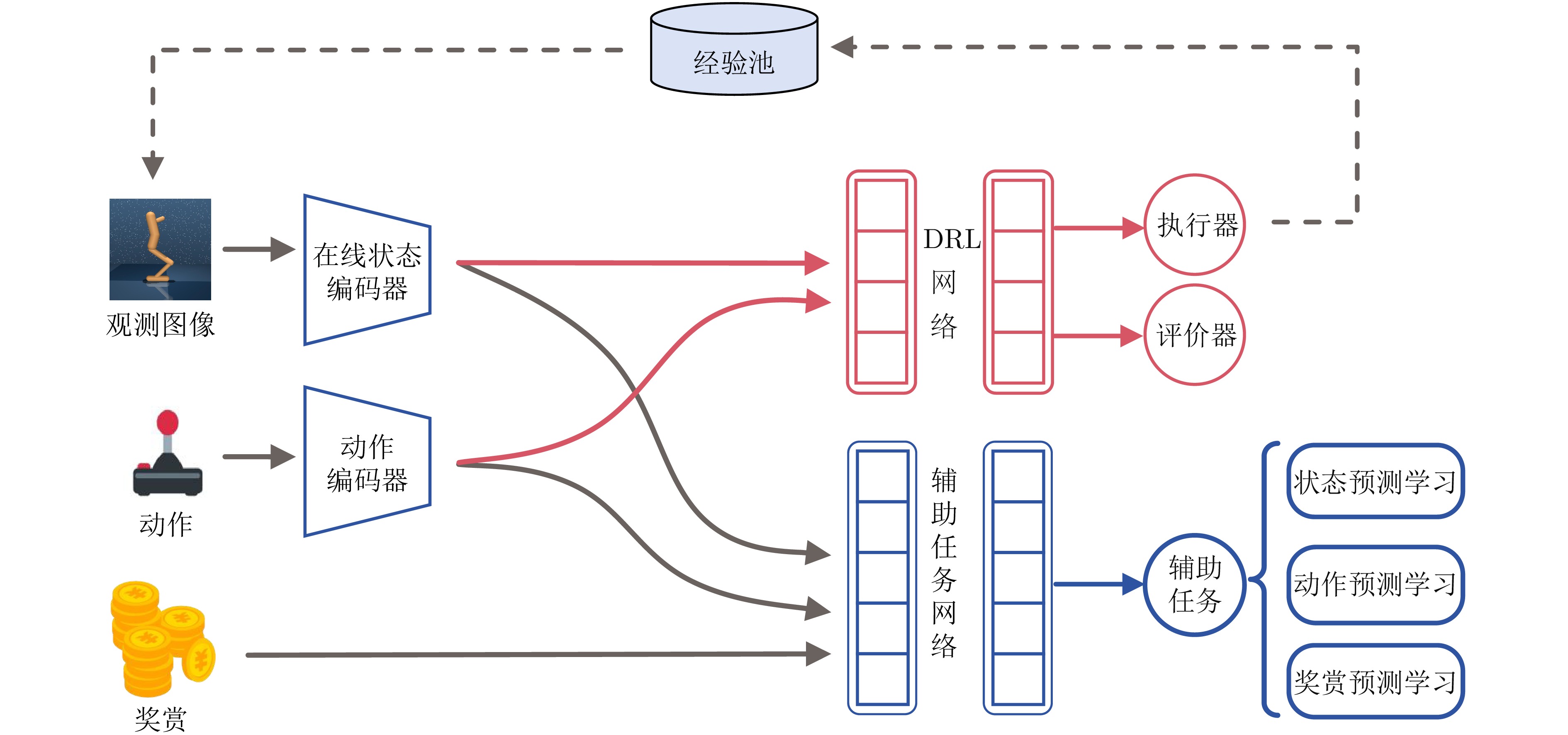
摘要: 为了提升具有高维动作空间的复杂连续控制任务的性能和样本效率, 提出一种基于Transformer的状态−动作−奖赏预测表征学习框架(Transformer-based state-action-reward prediction representation learning framework, TSAR). 具体来说, TSAR提出一种基于Transformer的融合状态−动作−奖赏信息的序列预测任务. 该预测任务采用随机掩码技术对序列数据进行预处理, 通过最大化掩码序列的预测状态特征与实际目标状态特征间的互信息, 同时学习状态与动作表征. 为进一步强化状态和动作表征与强化学习(Reinforcement learning, RL)策略的相关性, TSAR引入动作预测学习和奖赏预测学习作为附加的学习约束以指导状态和动作表征学习. TSAR同时将状态表征和动作表征显式地纳入到强化学习策略的优化中, 显著提高了表征对策略学习的促进作用. 实验结果表明, 在DMControl的9个具有挑战性的困难环境中, TSAR的性能和样本效率超越了现有最先进的方法.
-
关键词:
- 深度强化学习 /
- 表征学习 /
- 自监督对比学习 /
- Transformer
Abstract: To enhance the performance and sample efficiency of complex continuous control tasks with high-dimensional action spaces, this paper introduces a Transformer-based state-action-reward prediction representation learning framework (TSAR). Specifically, TSAR proposes a sequence prediction task integrating state-action-reward information using the Transformer architecture. This prediction task employs random masking techniques for preprocessing sequence data and seeks to maximize the mutual information between predicted features of masked sequences and actual target state features, thus concurrently learning state representation and action representation. To further strengthen the relevance of state representation and action representation to reinforcement learning (RL) strategies, TSAR incorporates an action prediction model and a reward prediction model as additional learning constraints to guide the learning of state and action representations. TSAR explicitly incorporates state representation and action representation into the optimization of reinforcement learning strategies, significantly enhancing the facilitative role of representations in policy learning. Experimental results demonstrate that, across nine challenging and difficult environments in DMControl, the performance and sample efficiency of TSAR exceed those of existing state-of-the-art methods. -
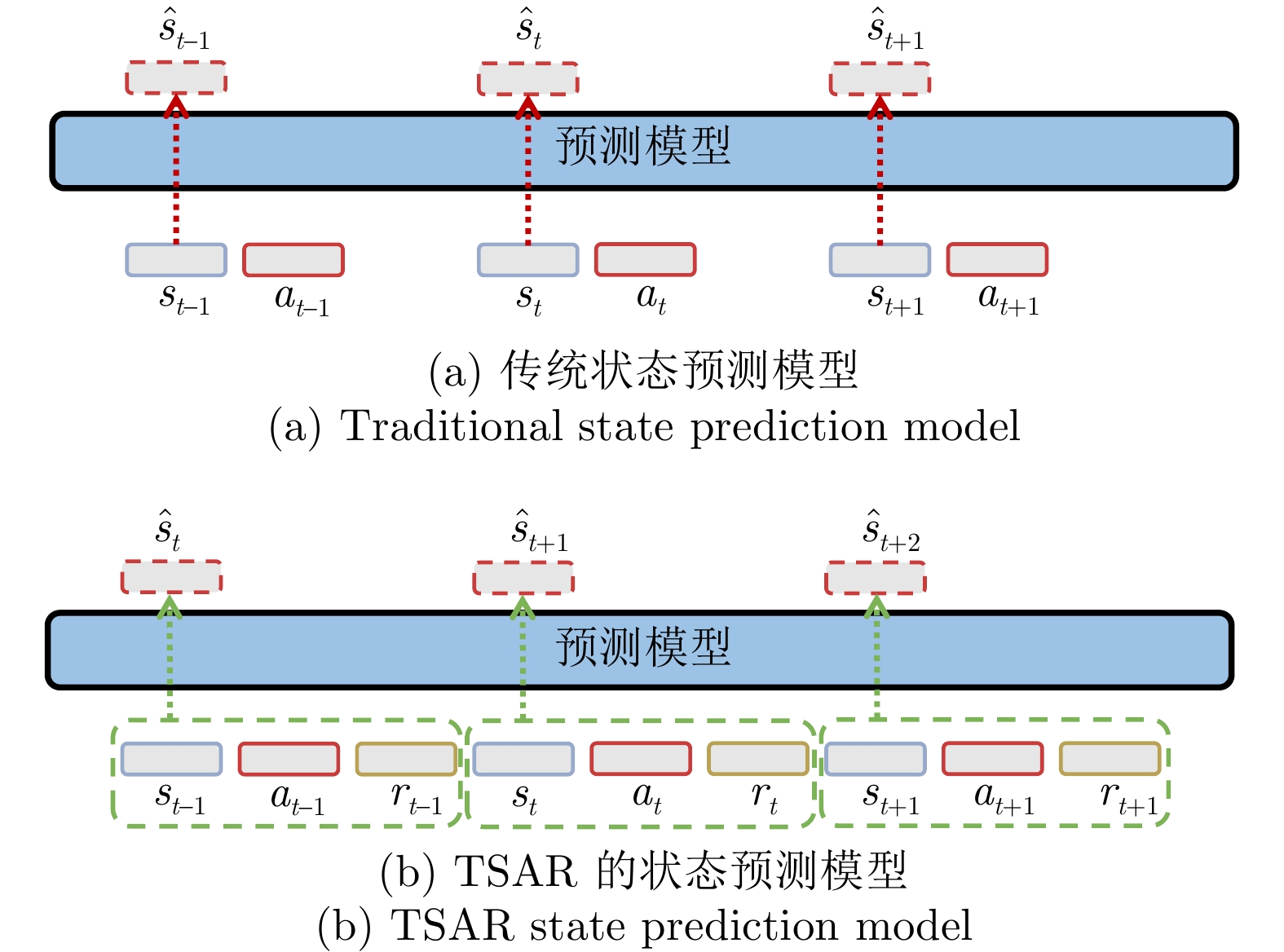
图 1 传统状态预测模型和TSAR的状态预测模型
Fig. 1 Traditional stale prediction model and TSAR stale prediction model
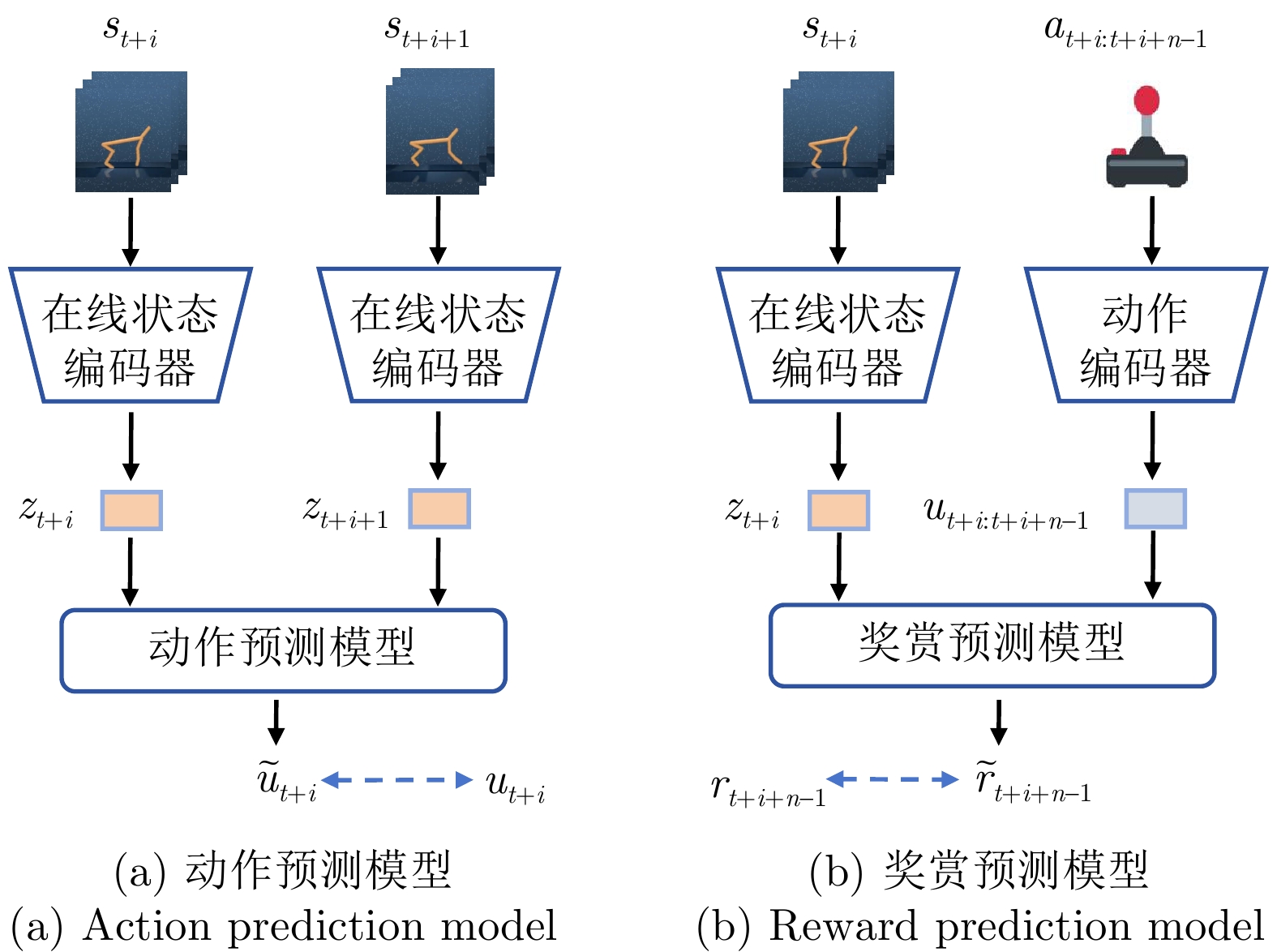
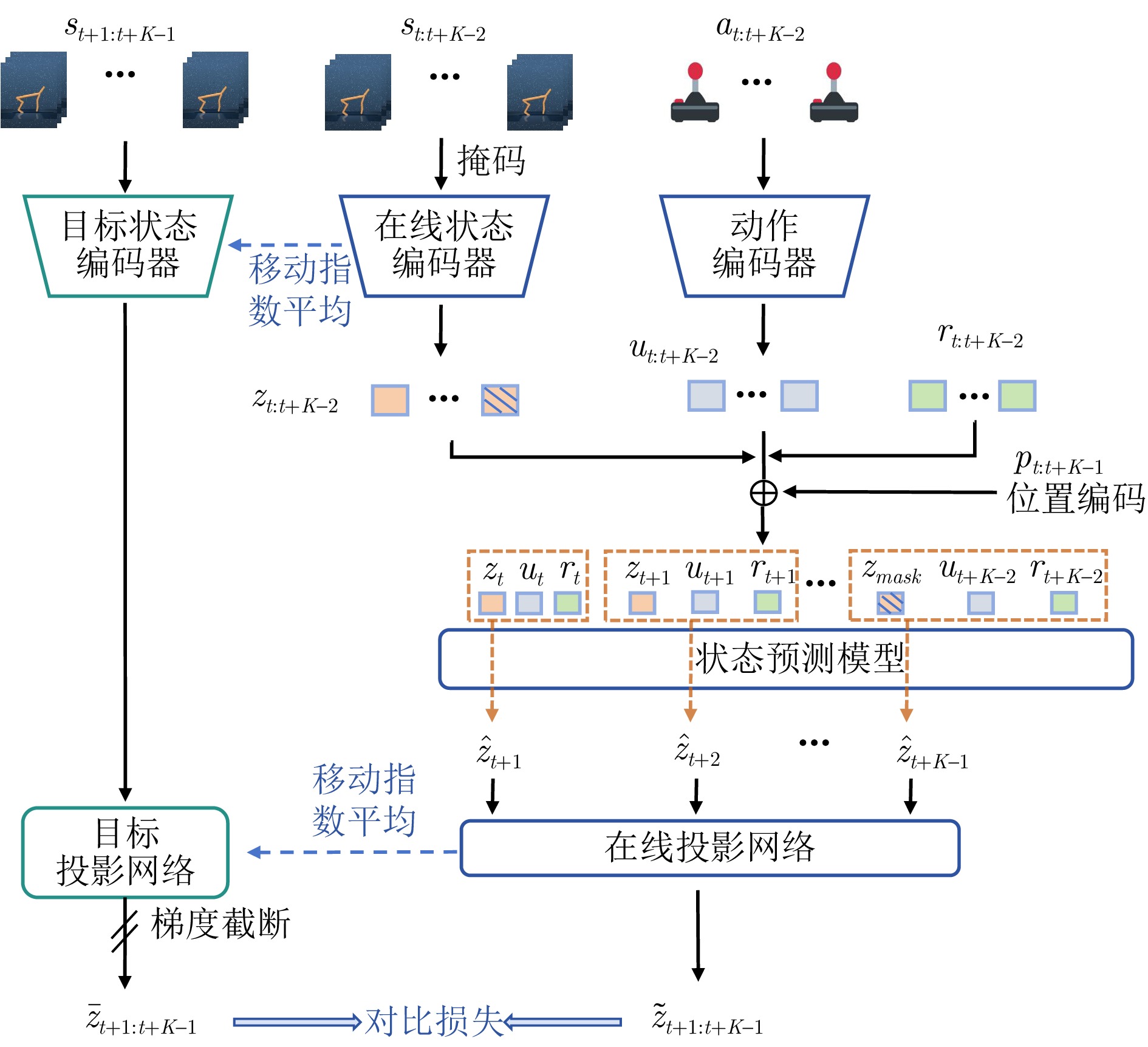
图 4 动作预测学习和奖赏预测学习框架
Fig. 4 The framework of action prediction learning and reward prediction learning
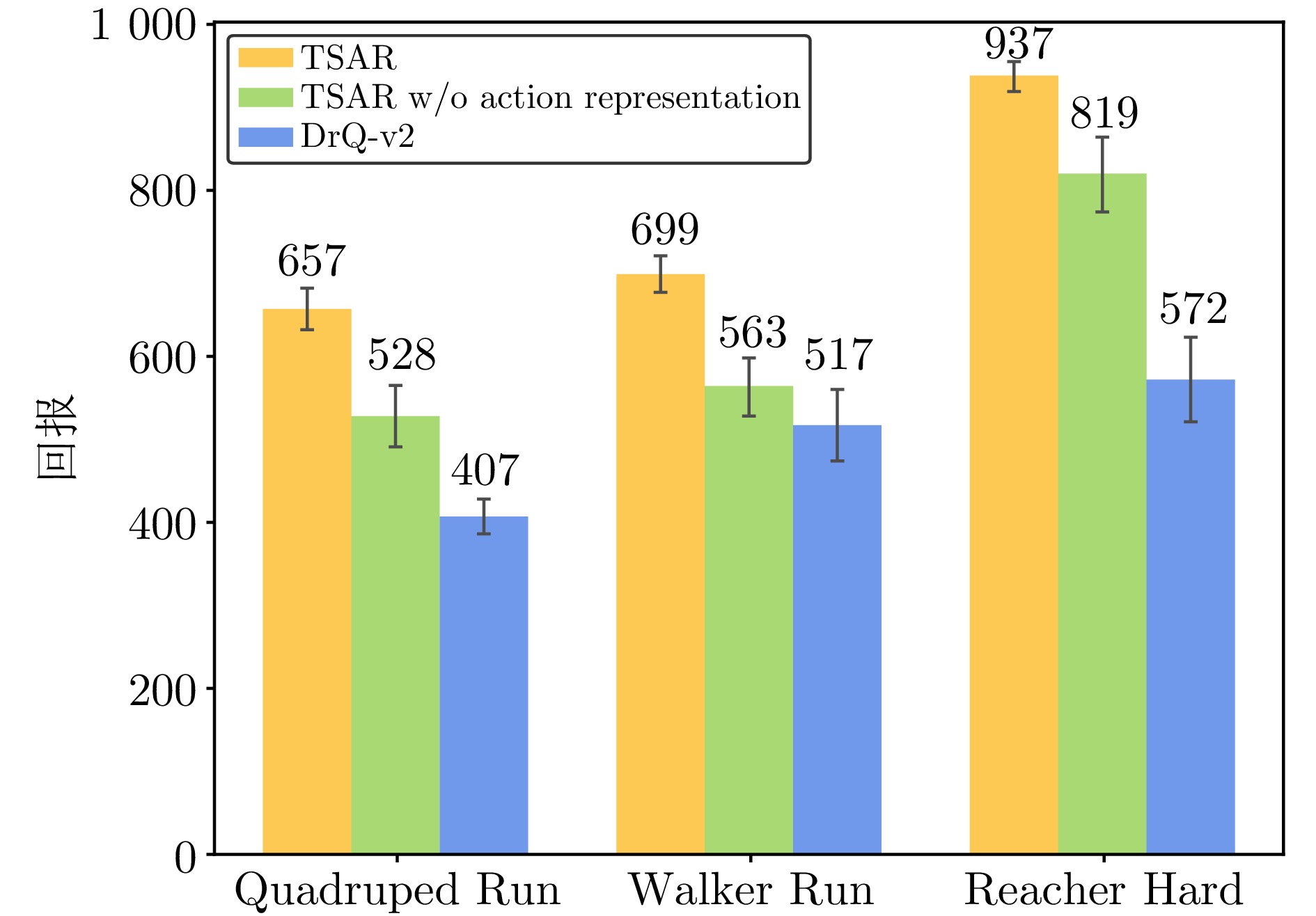
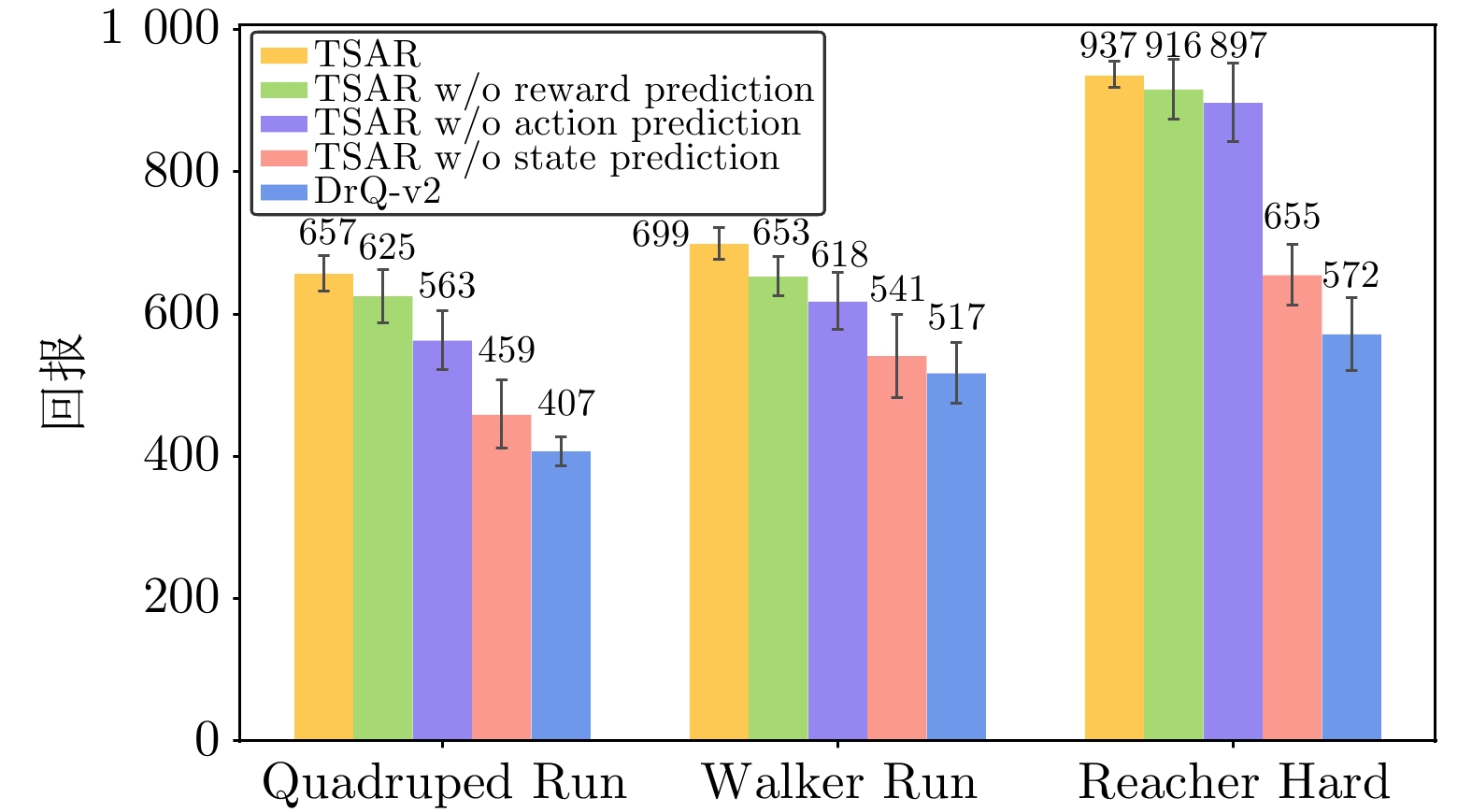
图 8 RL策略学习中动作表征的消融实验
Fig. 8 Ablation study of action representation in RL policy learning
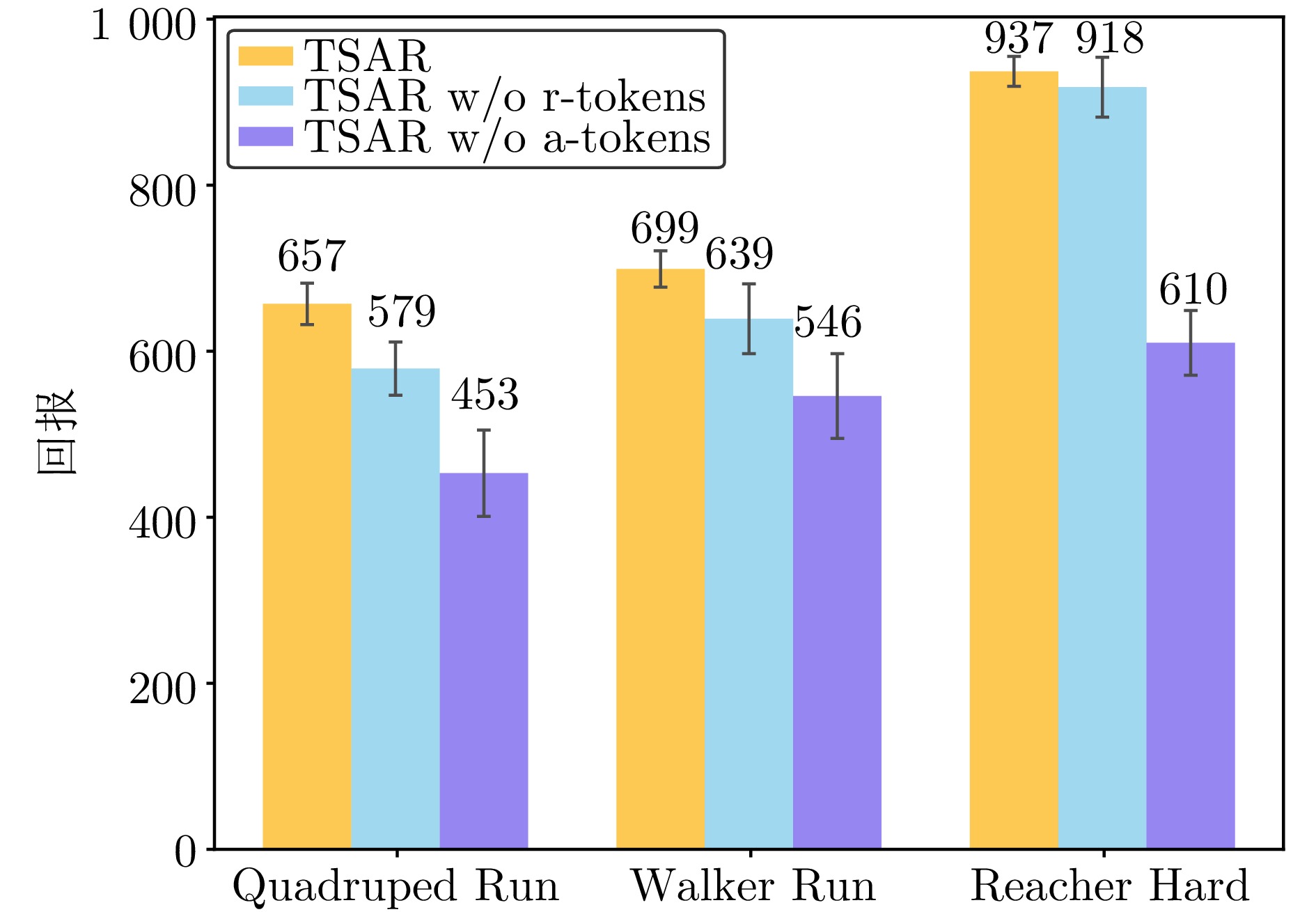
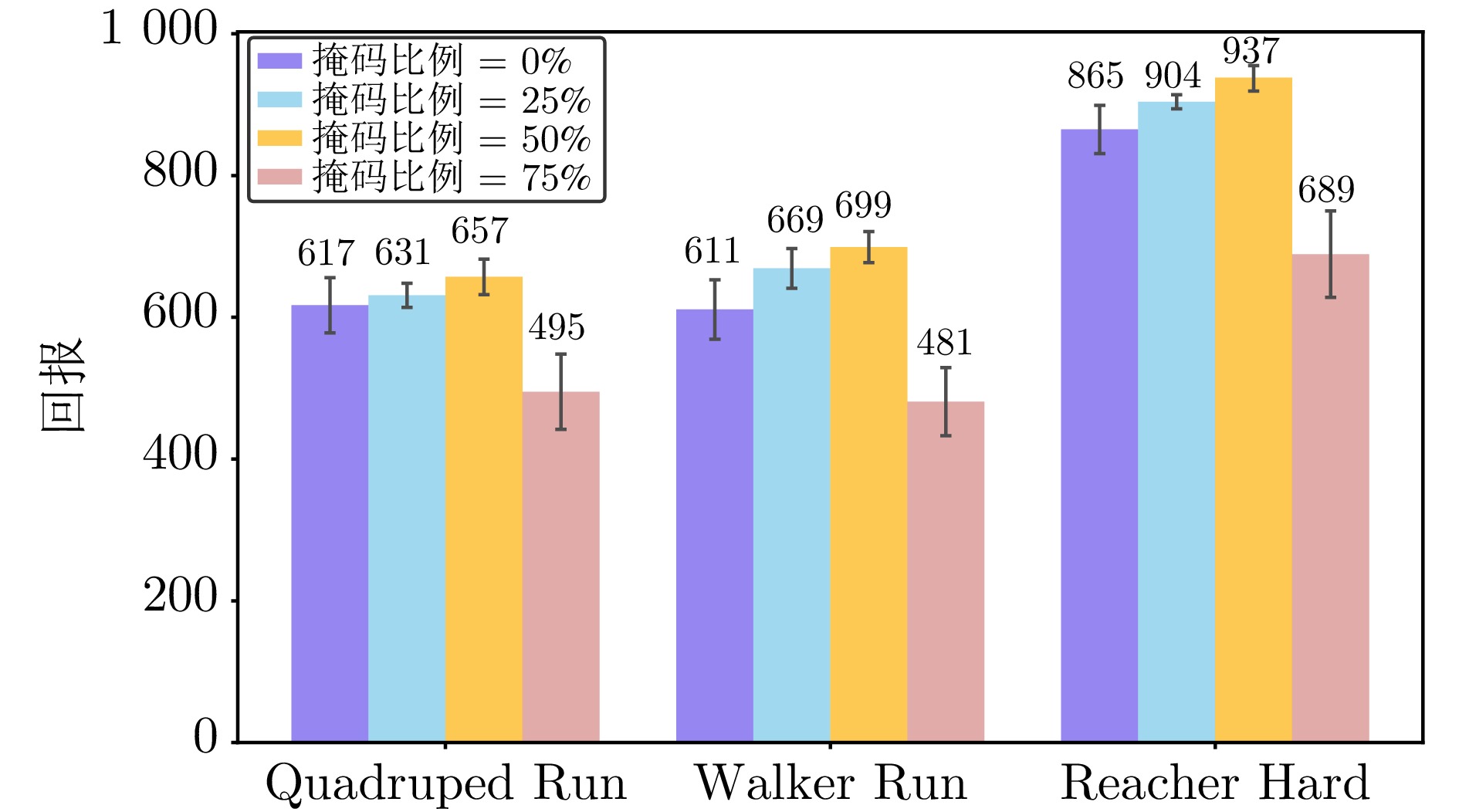
图 9 状态预测模型输入词符的消融实验
Fig. 9 Ablation study on the input tokens of the state prediction model
表 1 9个困难环境的基本信息
Table 1 The fundamental information of nine challenging environments
环境 动作空间维度 难易程度 Quadruped Walk 12 困难 Quadruped Run 12 困难 Reach Duplo 9 困难 Walker Run 6 困难 Cheetah Run 6 困难 Hopper Hop 4 困难 Finger Turn Hard 2 困难 Reacher Hard 2 困难 Acrobot Swingup 1 困难  下载: 导出CSV
下载: 导出CSV
表 2 TSAR额外的超参数
Table 2 Additional hyperparameters for TSAR
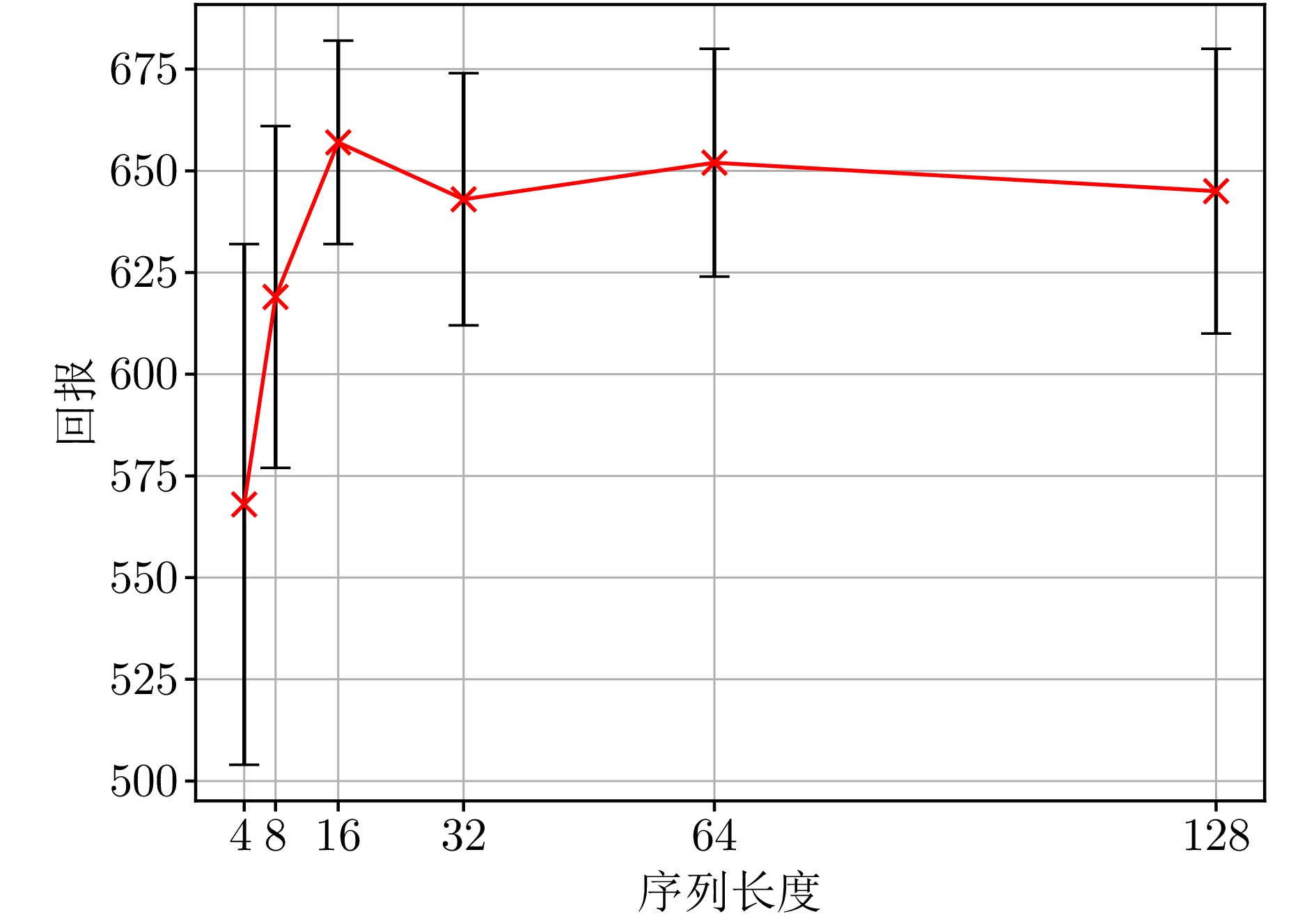
超参数 含义 值 $ \lambda_1 $ 状态预测损失权重 1 $ \lambda_2 $ 动作预测损失权重 1 $ \lambda_3 $ 奖赏预测损失权重 1 batch_size 训练批次大小 256 mask_ratio 掩码比例 50% $ K $ 序列长度 16 $ L $ 注意力层数 2 2: Hopper Hop $ n $ 奖赏预测步长 Reacher Hard 1: 其他 $ \tau $ EMA衰减率 0.95
下载: 导出CSV
表 3 TSAR和对比算法在100万步长时的得分
Table 3 Scores achieved by TSAR and comparison algorithms at 1 M time steps
环境 TSAR (本文) TACO[16] DrQ-v2[22] CURL[8] Dreamer-v3[44] TD-MPC[27] Quadruped Run 657±25 541±38 407±21 181±14 331±42 397±37 Hopper Hop 293±41 261±52 189±35 152±34 369±21 195±18 Walker Run 699±22 637±11 517±43 387±24 765±32 600±28 Quadruped Walk 837±23 793±8 680±52 123±11 353±27 435±16 Cheetah Run 835±32 821±48 691±42 657±35 728±32 565±61 Finger Turn Hard 636±24 632±75 220±21 215±17 810±58 400±113 Acrobot Swingup 318±19 241±21 128±8 5±1 210±12 224±20 Reacher Hard 937±18 883±63 572±51 400±29 499±51 485±31 Reach Duplo 247±11 234±21 206±32 8±1 119±30 117±12 平均性能 606.6 560.3 226.4 236.4 464.9 379.8 中位性能 657 632 179 181 369 400 注: 加粗字体表示在不同环境下各算法的最优结果.
下载: 导出CSV
表 4 与不同表征学习目标的对比
Table 4 Comparison with other representation learning objectives
环境 TSAR (本文) TACO[16] M-CURL[11] SPR[10] ATC[39] DrQ-v2[22] Quadruped Run 657±25 541±38 536±45 448±79 432±54 407±21 Hopper Hop 293±41 261±52 248±61 154±10 112±98 192±41 Walker Run 699±22 637±21 623±39 560±71 502±171 517±43 Quadruped Walk 837±23 793±8 767±29 701±25 718±27 680±52 Cheetah Run 835±32 821±48 794±61 725±49 710±51 691±42 Finger Turn Hard 636±24 632±75 624±102 573±88 526±95 220±21 Acrobot Swingup 318±19 241±21 234±22 198±21 206±61 210±12 Reacher Hard 937±18 883±63 865±72 711±92 863±12 572±51 Reach Duplo 247±11 234±21 229±34 217±25 219±27 206±32 平均性能 606.6 560.3 546.7 476.3 475.4 226.4 中位性能 657 632 623 560 502 179
下载: 导出CSV
表 5 状态预测准确性对比
Table 5 Comparison of state prediction accuracy
环境 TSAR (本文) TACO[16] M-CURL[11] 误差 性能 误差 性能 误差 性能 Quadruped Run 0.097 657±25 0.157 541±38 0.124 536±45 Walker Run 0.081 699±22 0.145 637±21 0.111 623±39 Hopper Hop 0.206 293±41 0.267 261±52 0.245 248±61 Reacher Hard 0.052 937±18 0.142 883±63 0.107 865±72 Acrobot Swingup 0.063 318±19 0.101 241±21 0.082 234±22
下载: 导出CSV
-
[1] Shao K, Zhu Y H, Zhao D B. StarCraft micromanagement with reinforcement learning and curriculum transfer learning. IEEE Transactions on Emerging Topics in Computational Intelligence, 2019, 3(1): 73−84 doi: 10.1109/TETCI.2018.2823329 [2] Hu G Z, Li H R, Liu S S, Zhu Y H, Zhao D B. NeuronsMAE: A novel multi-agent reinforcement learning environment for cooperative and competitive multi-robot tasks. In: Proceedings of the International Joint Conference on Neural Networks (IJCNN). Gold Coast, Australia: IEEE, 2023. 1−8 [3] Wang J J, Zhang Q C, Zhao D B. Highway lane change decision-making via attention-based deep reinforcement learning. IEEE/CAA Journal of Automatica Sinica, 2022, 9(3): 567−569 doi: 10.1109/JAS.2021.1004395 [4] Yarats D, Kostrikov I, Fergus R. Image augmentation is all you need: Regularizing deep reinforcement learning from pixels. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2021. [5] Liu M S, Zhu Y H, Chen Y R, Zhao D B. Enhancing reinforcement learning via Transformer-based state predictive representations. IEEE Transactions on Artificial Intelligence, 2014, 5(9): 4364−4375 [6] Liu M S, Li L T, Hao S, Zhu Y H, Zhao D B. Soft contrastive learning with Q-irrelevance abstraction for reinforcement learning. IEEE Transactions on Cognitive and Developmental Systems, 2023, 15(3): 1463−1473 doi: 10.1109/TCDS.2022.3218940 [7] Chen L L, Lu K, Rajeswaran A, Lee K, Grover A, Laskin M, et al. Decision Transformer: Reinforcement learning via sequence modeling. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 1156 [8] Laskin M, Srinivas A, Abbeel P. CURL: Contrastive unsupervised representations for reinforcement learning. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: JMLR.org, 2020. Article No. 523 [9] van den Oord A, Li Y Z, Vinyals O. Representation learning with contrastive predictive coding. arXiv preprint arXiv: 1807.03748, 2021. [10] Schwarzer M, Anand A, Goel R, Hjelm R D, Courville A C, Bachman P. Data-efficient reinforcement learning with self-predictive representations. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2021. [11] Zhu J H, Xia Y C, Wu L J, Deng J J, Zhou W G, Qin T, et al. Masked contrastive representation learning for reinforcement learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 3421−3433 [12] Yu T, Zhang Z Z, Lan C L, Lu Y, Chen Z B. Mask-based latent reconstruction for reinforcement learning. In: Proceedings of the 36th Conference on Neural Information Processing Systems. New Orleans, LA, USA: NeurIPS, 2022. 25117−25131 [13] Ye W R, Liu S H, Kurutach T, Abbeel P, Gao Y. Mastering Atari games with limited data. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 1951 [14] Kim M, Rho K, Kim Y D, Jung K. Action-driven contrastive representation for reinforcement learning. PLoS One, 2022, 17(3): Article No. e0265456 doi: 10.1371/journal.pone.0265456 [15] Fujimoto S, Chang W D, Smith E J, Gu S S, Precup D, Meger D. For SALE: State-action representation learning for deep reinforcement learning. In: Proceedings of the 37th Conference on Neural Information Processing Systems. New Orleans, LA, USA: NeurIPS, 2023. 61573−61624 [16] Zheng R J, Wang X Y, Sun Y C, Ma S, Zhao J Y, Xu H Z, et al. TACO: Temporal latent action-driven contrastive loss for visual reinforcement learning. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, LA, USA: Curran Associates Inc., 2024. Article No. 2092 [17] Zhang A, Mcallister R, Calandra R, Gal Y, Levine S. Learning invariant representations for reinforcement learning without reconstruction. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: Open-Review.net, 2021. [18] Chai J J, Li W F, Zhu Y H, Zhao D B, Ma Z, Sun K W, et al. UNMAS: Multiagent reinforcement learning for unshaped cooperative scenarios. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(4): 2093−2104 doi: 10.1109/TNNLS.2021.3105869 [19] Hansen N, Su H, Wang X L. Stabilizing deep Q-learning with ConvNets and vision transformers under data augmentation. In: Proceedings of the Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 281 [20] Gelada C, Kumar S, Buckman J, Nachum O, Bellemare M G. DeepMDP: Learning continuous latent space models for representation learning. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, California, USA: PMLR, 2019. 2170−2179 [21] Lee A X, Nagabandi A, Abbeel P, Levine S. Stochastic latent actor-critic: Deep reinforcement learning with a latent variable model. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, BC, Canada: Curran Associates Inc., 2020. Article No. 63 [22] Yarats D, Fergus R, Lazaric A, Pinto L. Mastering visual continuous control: Improved data-augmented reinforcement learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2022. 941−950 [23] Park S, Levine S. Predictable MDP abstraction for unsupervised model-based RL. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, HI, USA: PMLR, 2023. 27246−27268 [24] Yarats D, Fergus R, Lazaric A, Pinto L. Reinforcement learning with prototypical representations. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021. 11920−11931 [25] Yarats D, Zhang A, Kostrikov I, Amos B, Pineau J, Fergus R. Improving sample efficiency in model-free reinforcement learning from images. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI, 2021. 10674−10681 [26] Schwarzer M, Rajkumar N, Noukhovitch M, Anand A, Charlin L, Hjelm D, et al. Pretraining representations for data-efficient reinforcement learning. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 971 [27] Hansen N A, Su H, Wang X L. Temporal difference learning for model predictive control. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, MD, USA: PMLR, 2022. 8387−8406 [28] Hansen N, Wang X L. Generalization in reinforcement learning by soft data augmentation. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Xi'an, China: IEEE, 2021. 13611−13617 [29] Ma Y J, Sodhani S, Jayaraman D, Bastani O, Kumar V, Zhang A. VIP: Towards universal visual reward and representation via value-implicit pre-training. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: OpenReview.net, 2023. [30] Parisi S, Rajeswaran A, Purushwalkam S, Gupta A. The unsurprising effectiveness of pre-trained vision models for control. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, MD, USA: PMLR, 2022. 17359−17371 [31] Hua P, Chen Y B, Xu H Z. Simple emergent action representations from multi-task policy training. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: OpenReview.net, 2023. [32] Chandak Y, Theocharous G, Kostas J, Jordan S, Thomas P. Learning action representations for reinforcement learning. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, California, USA: PMLR, 2019. 941−950 [33] Allshire A, Martín-Martín R, Lin C, Manuel S, Savarese S, Garg A. LASER: Learning a latent action space for efficient reinforcement learning. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Xi'an, China: IEEE, 2021. 6650−6656 [34] Eysenbach B, Zhang T J, Levine S, Salakhutdinov R. Contrastive learning as goal-conditioned reinforcement learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, LA, USA: NeurIPS, 2022. Article No. 2580 [35] Grill J B, Strub F, Altché F, Tallec C, Richemond P H, Buchatskaya E, et al. Bootstrap your own latent: A new approach to self-supervised learning. In: Proceedings of the 34th Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2020. 21271−21284 [36] Mazoure B, Tachet Des Combes R, Doan T L, Bachman P, Hjelm R D. Deep reinforcement and InfoMax learning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, BC, Canada: Curran Associates Inc., 2020. Article No. 311 [37] Rakelly K, Gupta A, Florensa C, Levine S. Which mutual-information representation learning objectives are sufficient for control? In: Proceedings of the 35th Conference on Neural Information Processing Systems. Virtual Event: NeurIPS, 2021. 26345−26357 [38] Anand A, Racah E, Ozair S, Bengio Y, Côté M A, Hjelm R D. Unsupervised state representation learning in Atari. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, BC, Canada: Curran Associates Inc., 2019. Article No. 787 [39] Stooke A, Lee K, Abbeel P, Laskin M. Decoupling representation learning from reinforcement learning. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021. 9870−9879 [40] Zhu Y H, Zhao D B. Online minimax Q network learning for two-player zero-sum Markov games. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(3): 1228−1241 doi: 10.1109/TNNLS.2020.3041469 [41] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2012. 1097−1105 [42] Haynes D, Corns S, Venayagamoorthy G K. An exponential moving average algorithm. In: Proceedings of the IEEE Congress on Evolutionary Computation. Brisbane, QLD, Australia: IEEE, 2012. 1−8 [43] Li N N, Chen Y R, Li W F, Ding Z X, Zhao D B, Nie S. BViT: Broad attention-based vision Transformer. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(9): 12772−12783 doi: 10.1109/TNNLS.2023.3264730 [44] Shakya A K, Pillai G, Chakrabarty S. Reinforcement learning algorithms: A brief survey. Expert Systems With Applications, 2023, 231: Article No. 120495 doi: 10.1016/j.eswa.2023.120495 -



计量
- 文章访问数: 116
- HTML全文浏览量: 40
- PDF下载量: 28
- 被引次数: 0
