

-
Abstract: Human visual attention is highly selective. The artificial vision system that imitates this mechanism increases the efficiency, intelligence, and robustness of mobile robots in environment modeling. This paper presents a 3-D modeling method based on visual attention for mobile robots. This method uses the distance-potential gradient as motion contrast and combines the visual features extracted from the scene with a mean shift segment algorithm to detect conspicuous objects in the surrounding environment. This method takes the saliency of objects as priori information, uses Bayes' theorem to fuse sensor modeling and grid priori modeling, and uses the projection method to create and update the 3-D environment modeling. The results of the experiments and performance evaluation illustrate the capabilities of our approach in generating accurate 3-D maps.
-
Key words:
- 3-D Mapping /
- grid model /
- mobile robots /
- visual attention
-
1. Introduction
Environmental mapping has always been one of the most active areas in mobile robotics research for decades. Mobile robots use sensors to perceive the surrounding environment and build environment maps, which provide essential information for the navigation, localization, and path planning of mobile robots.
Many scholars have been dedicated to the environment mapping research of mobile robots to promote their applications in various fields. The primary models of this field include metric models [1], topology models [2], and hybrid models [3], which are used in different environments. Metric models, which include occupancy grids and feature maps, are often applied to small environments, e.g., a room or a small building, and metrical methods are effective in building accurate geometrical models of small-scale environments. A topological map models the world as a collection of nodes, which can be paths or places. Thus, topological maps can describe a large-scale environment easily. However, topological representations lack details such as the structures associated with the nodes and the relationships described as links. Hybrid models combine the strengths of metrical and topological approaches and are suitable for modeling large-scale spaces. These proposed models are used to describe the environment with 2-D maps, which are widely adopted in mobile robots because of their relatively small computation requirements [4]-[6].
Although 2-D maps have the advantages of simplicity and small computation, these maps provide limited information, particularly height information; thus, they are unsuitable for use in complex environments. For example, obstacles above the ground (mobile robots can pass through) are difficult to be described by using 2-D maps (e.g., four-legged tables in a room, hole-type passages, and external components of tunnels). Many researchers have expanded these 2-D representations to 3-D maps [7]-[10], which may be used to safely navigate a complex environment and perform other useful tasks (e.g., local localization).
Point cloud models and voxel based grid models are the major existing 3-D models. For example, the 3-D laser mapping [11] and 3-D RGB-D camera mapping [12]. However, the huge amounts of data have to be processed for the point cloud model. It greatly reduces the efficiency of the system. Also, the point cloud data are easily influenced by noise and cause the accuracy of modeling to deteriorate. Grid maps are widely used in the environment modeling. However, the runtime and accuracy highly depend on the degree of discretization. Environment mapping for mobile robots brings great challenges, especially when robots work in an outdoor environment. For example, uncertainty of the environment, illumination variation, etc., which may deteriorate the accuracy of modeling. This paper uses the saliency based modeling to improve these performances in construction of environment 3-D maps.
Visual attention is the ability of human vision system to rapidly select the most relevant information in the visual field [13]. In computer vision, the advancements obtained by simulating visual attention have accelerated the development of computer models. In some applications of mobile robots such as navigation, simultaneous localization and mapping (SLAM), and local planning, the robots need to model only nearby objects at every moment (we consider these objects as relevant) and not all the objects in the environment. Thus, visual attention models are suitable for mobile robots in modeling the environment. One of the most popular visual saliency models was proposed by Itti et al.[13], namely, the data-driven attention model, which computes the multi-scales feature contrasts of input images (such as intensity, color, and orientation features) by using a difference of Gaussian filter and linearly combines the features conspicuous maps to produce a master saliency map. After nearly 20 years of development, researchers have proposed many computational visual attention models [14], including Bayesian surprise models, task-driven models, etc. These models have been applied in many fields of robotics [15].
Motivated by the advantages of visual attention models, we intend to apply these models to robot environment modeling. In this paper, we first present a visual saliency model that extracts the visual features from the scene and combines the features with the mean shift algorithm by using motion contrasts to detect the saliency of objects. We then adopt a stereo visual method and Bayesian estimation algorithm to construct and update the 3-D grid model of the environment. The evaluated system and the block diagram of the proposed method are shown in Figs. 1 and 2. The dash box in Fig. 2 is used to create the saliency model.
 图 1 The robot system used in our evaluations. (a) Mobile robot platform. (b) Binocular visual system and DM642 image processing card.Fig. 1 The robot system used in our evaluations. (a) Mobile robot platform. (b) Binocular visual system and DM642 image processing card.
图 1 The robot system used in our evaluations. (a) Mobile robot platform. (b) Binocular visual system and DM642 image processing card.Fig. 1 The robot system used in our evaluations. (a) Mobile robot platform. (b) Binocular visual system and DM642 image processing card.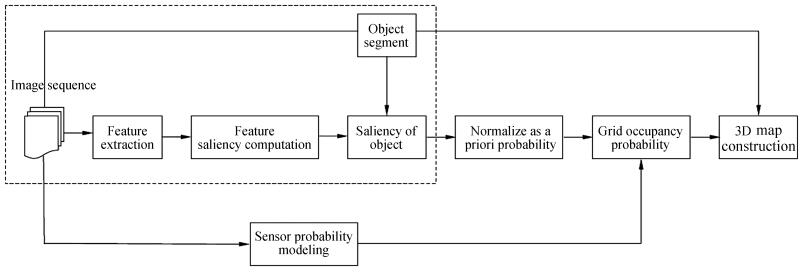 图 2 Schematic overview of the method. The dash box is used for saliency modeling construction, and a 3-D map is generated by using the probability of occupancy.Fig. 2 Schematic overview of the method. The dash box is used for saliency modeling construction, and a 3-D map is generated by using the probability of occupancy.
图 2 Schematic overview of the method. The dash box is used for saliency modeling construction, and a 3-D map is generated by using the probability of occupancy.Fig. 2 Schematic overview of the method. The dash box is used for saliency modeling construction, and a 3-D map is generated by using the probability of occupancy.The remainder of this paper is organized as follows. Section 2 provides an overview of related works. Section 3 describes the proposed visual saliency models. Section 4 explains the construction of the 3-D environment. Section 5 provides some experiments to verify the effectiveness of our proposed method. Finally, Section 5 concludes.
2. Related Work
Attention-driven visual saliency allows humans to focus on conspicuous objects. By utilizing this visual attention mechanism, mobile robots can be made to adapt to complex environments. Currently, visual saliency models are used in many fields of mobile robots, such as visual simultaneous localization and mapping (VSLAM), environment modeling, conspicuous object detection, and local localization [15].
Extracting useful landmarks is one of the main tasks of VSLAM. Frintrop et al. [16] presented a method of selecting landmarks on the basis of attention-driven mechanisms that favor salient regions. The feature vectors of salient regions are considered landmarks, and their results have shown that their method facilitates the easy detection, matching, and tracing of landmarks compared with standard detectors such as Harris-Laplacians and scale-invariant feature transform (SIFT) key points. Newman et al. [17] used the entropy of the saliency field as landmarks and applied it to the loop-closing task. However, the features extracted with the saliency model are distinct and sparse and are unsuitable for environment mapping.
Ouerhani et al. [18] adopted a multi-scale saliency-based model of visual attention to automatically acquire robust visual landmarks and constructed a topological map of the navigation environment. Einhorn et al. [19] applied attention-driven saliency models to 3-D environment modeling and mainly focus on the feature selection of image areas where the obstacle situation is unclear and a detailed scene reconstruction is necessary. Roberts et al. [20] presented an approach of tree mapping in unstructured outdoor environments for vision-based autonomous aerial robots. The visual attention models they used target the saliency of nearby trees and ignore innocuous objects that are far away from the robots. This approach is related to our work; however, the motion parallax was used to describe the saliency in these models and the camera rotation was to be estimated.
Compared with 2-D maps, 3-D maps can provide detailed information and are suitable for mobile robot applications, such as local localization and navigation. Three-dimensional grid maps are one of the most used metric approaches because of their simplicity and suitability for all types of sensors. Souza et al. [7] used a grid occupancy probability method to construct the 3-D environment of mobile robots. They used stereo vision to interpret the depth of image pixels and deduce a sensorial uncertainty model related to the disparity to correct the 3-D maps; however, the cost of computation was expensive. By using the data acquired by laser range finders, Hähnel et al. [8] combined robot pose estimation with an algorithm to approximate environments by using flat surfaces to reconstruct the 3-D environment. Given the large data and to accelerate the computation, they used the split-and-merge technique to extract the lines out of the individual 2-D range scans; however, their method requires expensive laser sensors. Pirker et al. [9] presented a fast and accurate 3-D environment modeling method. They used depth image pyramids to accelerate the computation time and a weighted interpolation scheme between neighboring pyramids layers to boost the model accuracy. The algorithm is real time but is implemented on the GPU. Kim et al. [10] proposed a framework of building continuous occupancy maps. They used a coarse-to-fine clustering method and applied Gaussian processes to each local cluster to reduce the high-computational complexity. The experiment results with real 3-D data in large-scale environments show the feasibility of this method.
Most saliency models compute primitive feature contrasts such as intensity, orientation, color, and others (e.g., edge gradient) to generate saliency, and these models are widely used for robots in landmark selection, and object tracking or location. However, these models are unsuitable for environment mapping. Our system uses motion contrasts to construct the saliency model, which is conducive for mapping close and conspicuous objects in the applications of robots such as navigation and VSLAM. In 3-D mapping, we approximate the saliency value as a priori information on the occupancy of the cell. This scheme avoids the need to train the grid occupancy maps created previously. Many objects exist in the visual scene of robots, and the selective mapping and priori information approximation of 3-D cells significantly improve the efficiency of system mapping and reduce interferences such as illumination changes.
3. Visual Saliency Modeling
Cameras capture more detailed information in every moment than range finders, such as laser scanners. However, not all objects in the environment have an effect on mobile robots. For example, in the application of mobile robots such as navigation, only some nearby obstacles hinder the motion of mobile robots and objects that are far from the mobile robots have a minimal effect at times. If we only model the objects that have considerable effects on mobile robots in every moment, the entire system will be simplified. Visual saliency modeling (VSM) makes the robots focus on conspicuous objects. If the conspicuous objects are defined as nearby objects, environment modeling will be easily constructed.
In the visual scene of mobile robots, only some objects in the environment affect the robots in a moment, e.g., objects that hinder the motion of mobile robots. Thus, the saliency model needs to highlight these conspicuous obstacles in the robot environment. Here, we use the distance between an obstacle and the mobile robot as the main parameters of saliency. The entire structure of the saliency model is shown in Fig. 2 in the dashed box.
In the navigation of mobile robots, the scene captured by the visual system of the robots is always dynamic. Many previous works have focused on the detection of feature contrasts to trigger human vision nerves. This type of detection is usually referred to as the "stimuli-driven" mechanism. To detect nearby objects, we use a distance-potential function $\phi$ related to the distance r, i.e.,
$ \begin{equation} \label{eq1} \phi =\frac{1}{2}k_p \left( {\frac{1}{r}-\frac{1}{r_0 }} \right)^2. \end{equation} $
(1) Equation (1) shows that a smaller distance $r$ leads to a larger distance-potential $\phi$ . We define the distance-potential gradient of obstacles $s$ as follows:
$ \begin{equation} \label{eq2} s=\frac{d\phi }{dt}=-k_p \left( {\frac{1}{r}-\frac{1}{r_0 }} \right)\frac{1}{r^2}\frac{dr}{dt}. \end{equation} $
(2) Assume that the center coordinate of the mobile robot is $p(x, y, z)$ and that $p_i (x_i, y_i, z_i )$ is the point on the static obstacle. We can then obtain the following:
$ r=\sqrt {(x_i-x)^2+(y_i-y)^2+(z_i-z)^2} . $
By substituting $r$ in (2) and not considering the motion of the robot along the $z$ -axis (moves in a flat terrain), we obtain the following:
$ \begin{equation} \label{eq3} s=-k_p \left( {\frac{1}{r}-\frac{1}{r_0 }} \right)\frac{1}{r^3}\left[{\left( {x_i-x} \right)v_x +\left( {y_i-y} \right)v_y } \right]. \end{equation} $
(3) We model the motion contrast with (2) and consider the influence of the position of $p_i (x_i, y_i )$ . Thereafter, the saliency of $p_i$ can be defined as follows:
$ \begin{equation} \label{eq4} {\rm sal} (p_i )=k_p k_d \left( {\frac{1}{r}-\frac{1}{r_0 }} \right)\frac{1}{r^3}\left[{\left( {x-x_i } \right)v_x +\left( {y-y_i } \right)v_y } \right] \end{equation} $
(4) where $k_p$ is a normalization term and $r_0$ is the critical distance related to the speed of the mobile robot. $r_0$ can be obtained by experiments, and we determined that $r_0 =0.85$ in our experiments. $v_x$ and $v_y$ are the horizontal and vertical speeds of the mobile robot, respectively. The saliency of $p_i$ exhibits a higher value when the mobile robot moves closer to the obstacles with faster speed.
$k_d $ in (4) is defined as the directional deviation of $p_i$ relative to the mobile robot (Fig. 3). We take as follows:
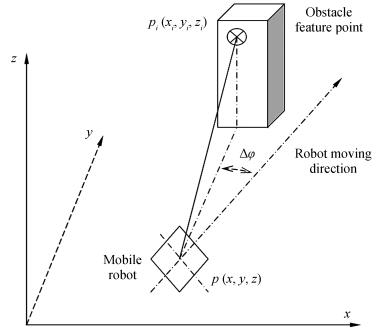 图 3 The relation of $\Delta \varphi$ , $p$ ( $x$ , $y$ , $z$ ), and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ), where $p$ ( $x$ , $y$ , $z$ ) is the center of the robot and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ) is the feature point on the objects.Fig. 3 The relation of $\Delta \varphi$ , $p$ ( $x$ , $y$ , $z$ ), and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ), where $p$ ( $x$ , $y$ , $z$ ) is the center of the robot and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ) is the feature point on the objects.
图 3 The relation of $\Delta \varphi$ , $p$ ( $x$ , $y$ , $z$ ), and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ), where $p$ ( $x$ , $y$ , $z$ ) is the center of the robot and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ) is the feature point on the objects.Fig. 3 The relation of $\Delta \varphi$ , $p$ ( $x$ , $y$ , $z$ ), and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ), where $p$ ( $x$ , $y$ , $z$ ) is the center of the robot and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ) is the feature point on the objects.$ \begin{equation} \label{eq5} \Delta \varphi _i =\tan ^{-1}\left( {\frac{v_y }{v_x }} \right)-\tan ^{-1}\left( {\frac{y_i -y}{x_i -x}} \right). \end{equation} $
(5) Equation (5) shows that point $p_i$ is located in front of the mobile robot when $\Delta \varphi =0$ . We normalize (5) as $k_d$ between $(-\pi, \pi )$ , then
$ \begin{equation} \label{eq6} k_d =\left\{ {{\begin{array}{*{20}c} {1-\dfrac{\Delta \varphi _i }{\pi }}, \hfill \\ 1, \hfill \\ {1+\dfrac{\Delta \varphi _i }{\pi }}, \hfill \\ \end{array} }} \right.{\begin{array}{*{20}c} \hfill \\ \hfill \\ \hfill \\ \end{array} }{\begin{array}{*{20}c} \hfill \\ \hfill \\ \hfill \\ \end{array} }{\begin{array}{*{20}c} {\Delta \varphi >0} \hfill \\ {\Delta \varphi =0} \hfill \\ {\Delta \varphi <0} \hfill \\ \end{array} }. \end{equation} $
(6) The motion saliency of points on obstacles can be calculated by using (4), and the result shows higher saliency when the mobile robot moves closer to the front obstacles.
In (4) and (6), the position of points on objects can be acquired from the point cloud data obtained by using the stereo system. To reduce computational complexity, we use visual features such as SURF [21] or SIFT [22] to calculate the saliency of points. These features are widely used in the fields of image registration, matching, and object recognition because of their exceptional invariance performance in translation, rotation, scaling, lighting, and noise. The $v=(v_x, v_y )$ of the mobile robot can be obtained by using the output of the encoders coupled to the motors.
Our target is to acquire the saliency of an object. Here, we use the conspicuous features to segment the objects. We first adopt the mean shift algorithm [23] to segment the objects and then use the conspicuous features to merge the segmented regions to generate the conspicuous objects. The mean shift algorithm is a robust feature-space analysis approach that can be applied to deal with discontinuity, preserving smoothing, and image segmentation problems. The algorithm uses an adaptive gradient ascent method to decompose an image into homogeneous tiles, and the mean shift procedure is not computationally expensive. The conspicuous objects acquired with the method will be applied to environment modeling.
4. Environment Modeling
We use volumetric models [24] (3-D occupancy grid modeling) to construct the environment of mobile robots. The volumetric models adopt the occupancy of each independent cell to describe the position distribution of obstacles in the environment. These models have been extensively used in robotics because of their simplicity and suitability for various types of sensors. To reduce the uncertainty of mapping introduced by sensor noise, we use the probability of occupancy to model the environment of mobile robots.
We suppose that the robotic environment workspace W is discreted into equally sized voxels $v_{i}$ with edge $\delta $ , and any edge of any voxel is assumed to be aligned with one of the axes of a global coordinate's frame [24]. We define the occupancy state of obstacle voxel $v_{i}$ as an independent random variable, and $p (v_{i})$ denotes the occupancy probability of the voxel occupied by an obstacle. The entire environment of mobile robots can be described as a probabilistic 3-D map, and the mobile robot uses the sensors to perceive the environment and acquires the data to update the map in the process of moving. Here, we apply Bayes' theorem [25] to update the probabilistic map. If we use $m$ to denote the measurement state, we obtain the following:
$ \begin{equation} \label{eq7} p (v_i^t \vert m_i^t )=\frac{1}{\alpha }p(m_i^t \vert v_i^t )p(v_i^t \vert m_i^{t-1} ) \end{equation} $
(7) where $t$ is the current time and $t-$ 1 is the last time. $\alpha $ is a normalization term and is related to the sensor model and is related to the priori information of voxel occupancy probability.
4.1 Sensor Modeling
Our mobile robot is equipped with a binocular stereo visual system, and the 3-D positions of points in the map coordinate frame can be calculated by using the robot pose and point disparity [26]. The error of position increases with distance because of the uncertainty of sensors. Reference [27] indicated that the error was proportional to the square of the distance:
$ \begin{equation} \label{eq8} \Delta z=\frac{z^2}{Bf}\Delta d \end{equation} $
(8) where $z$ is the depth of the feature points, and $\Delta z$ , $\Delta d$ are the depth error and disparity error respectively. $B$ is the stereo baseline, and $f$ is the focal length. In general, $\Delta d\approx 0.5$ . Assuming that the measurement error can be modeled by a Gaussian distribution, can be written as follows:
$ \begin{equation} \label{eq9} p (m_i^t \vert v_i^t )=\frac{k_m }{\Delta r\sqrt {2\pi } }\exp \left[{-\frac{1}{2}\left( {\frac{r_i-\bar {r}}{\Delta r}} \right)^2} \right] \end{equation} $
(9) where $\bar {r}=(\sum_{i=1}^N {r_i })/N$ , , $N$ is the number of features, $r$ denotes the measured distance of features, and $k_{m}$ is the normalization factor.
4.2 Grid Priori Modeling
A priori information about the occupancy of the cell can be obtained by training the grid occupancy maps created previously [25]; however, this procedure requires a large computation. Our proposed saliency model highlights nearby conspicuous objects in the robot environment and not all the objects. If we approximate the priori information with the feature saliency, it will reduce the cost of the computation. In (7), $p (v_i^t \vert m_i^{t-1} )$ is related to the priori information. To reduce the cost of the computation, we approximate the priori information with the feature saliency. Feature saliency describes the conspicuousness of feature points on obstacles. These points become larger when the mobile robot moves closer to the front feature points; hence, the occupancy probability of voxels contained in these feature points is similarly large. To make this approximation, we take $p (v_i^t \vert m_i^{t-1} )$ as follows:
$ \begin{equation} \label{eq10} p (v_i^t \vert m_i^{t-1} )=\left\{ {{\begin{array}{*{20}c} {\zeta _i }, \hfill \\ {0.5}, \hfill \\ \end{array} }} \right.{\begin{array}{*{20}c} \hfill \\ \hfill \\ \end{array} }{\begin{array}{*{20}c} {z\le 3} \hfill \\ {z>3} \hfill \\ \end{array} } \end{equation} $
(10) where $\zeta _i={\rm sal} (p_i )$ .
We define the occupancy probability of a grid as 0.5 in (10) because the uncertainty of the sensors quickly increases with distance when the depth measured is over 3 m, i.e., it is an unknown state. We also approximate the probability by using the saliency value of the feature points.
4.3 Obstacles Occlusion
Three-dimensional grid modeling uses a space occupancy grid to describe the environment. In this section, we only discuss the static environment. We define obstacles as the static objects aboveground, such as the indoor wall, table, outdoor tree, and pillar.
Our mobile robot is equipped with stereo vision. However, considering the installation's height restriction and that the mobile robot always detects objects from one side, occlusion will occur. Furthermore, identifying the grid occupancy state of entire object in maps will be difficult. We use the method of projection to calculate the occupancy range of the objects in the maps, and this method is shown in Fig. 4.
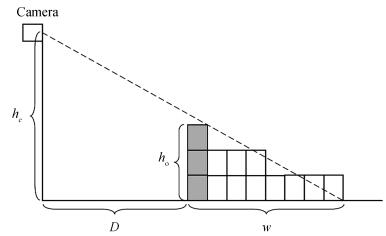 图 4 Occupancy grid maps creation when objects produce visual occlusion. We use the projection method to calculate the objects occupancy width w.Fig. 4 Occupancy grid maps creation when objects produce visual occlusion. We use the projection method to calculate the objects occupancy width w.
图 4 Occupancy grid maps creation when objects produce visual occlusion. We use the projection method to calculate the objects occupancy width w.Fig. 4 Occupancy grid maps creation when objects produce visual occlusion. We use the projection method to calculate the objects occupancy width w.Fig. 4 is a side view of object projection. The shadow is an object that is divided into grid cells, and the others are the grid cells after projection. Suppose that the object occupancy width in a map is $w$ , the following can be expressed:
$ \begin{equation} \label{eq11} w=\left\{ {{\begin{array}{*{20}c} {\dfrac{h_o D}{h_c -h_o }}, \hfill \\ \infty, \hfill \\ \end{array} }} \right.{\begin{array}{*{20}c} \hfill & {h_c >h_o } \hfill \\ \hfill & {h_c \le h_o } \hfill \\ \end{array} } \end{equation} $
(11) where $h_c $ is the installation height of the cameras, $h_{o}$ is the object height, and $D$ is the distance from the object to camera. If $h_c \le h_o $ , the back of the objects cannot be detected. We then define $w=\infty $ . The length of objects can be obtained by using the mean shift segmentation algorithm [23], and its positions can be calculated by the stereo visual method.
4.4 Grid Update
In mapping, the mobile robot must update the grid occupancy in time by using its visual system. The robot perceives the environment, obtains data, and calculates by using (7), (9), and (10). When the mobile robot finds the matching feature points (we only consider the features matching in the consecutive two images), the final updating can be conducted as follows:
$ \begin{equation} \label{eq12} p (v_i^t \vert m_i^t )={\rm min}\left[{p (v_i^t \vert m_i^t ), p (v_i^{t-1} \vert m_i^{t-1} )} \right] \end{equation} $
(12) where $p (v_i^t \vert m_i^t )$ and are the grid occupancies of the matching feature points in consecutive two images and min $[\cdot]$ is the obtained minimum. We used the projection method to calculate the grid occupancy of objects in the maps; hence, the occupancy range after projection may be larger than actual size of the objects. When a mobile robot moves from one position to another, the direction of the projection changes and we use (12) to correct these changes (Fig. 5). $A$ and $B$ are the two positions that the mobile robot passes in order, the arrows are the directions of the projection, and the shadows are the increasing area after projection. We use (12) to update the mobile robot moving from $A$ to $B$ , and the occupancy range of the objects decreases to be close to its actual size.
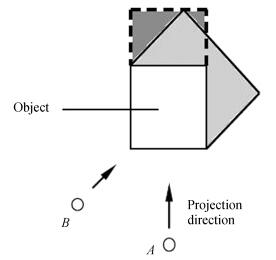 图 5 Overhead view of occupancy grid updating. The updated results using (12) will be close to the size of objects when robot moves from $A$ to $B$ . The shadows are the occupancy fields of occlusion.Fig. 5 Overhead view of occupancy grid updating. The updated results using (12) will be close to the size of objects when robot moves from $A$ to $B$ . The shadows are the occupancy fields of occlusion.
图 5 Overhead view of occupancy grid updating. The updated results using (12) will be close to the size of objects when robot moves from $A$ to $B$ . The shadows are the occupancy fields of occlusion.Fig. 5 Overhead view of occupancy grid updating. The updated results using (12) will be close to the size of objects when robot moves from $A$ to $B$ . The shadows are the occupancy fields of occlusion.To decrease the mismatching features and remove the useless features, we add the following constraints to extract the matching features according to [8]:
1) All the points in $Z=\pm 0.01$ are removed, where $Z$ is the height of feature points, thus implying that all feature points on the ground are discarded.
2) All the matching points that do not meet the condition are removed as $\vert Z_1 -Z_2 \vert \le \delta _3 $ , where $Z_1 $ and $Z_2 $ are the heights of matching feature points, and we obtain $\delta _3 =0.05$ in our experiments.
In the grid maps, we use the distance--potential gradient based on feature keypoints to calculate the saliency value of keypoints on nearby objects of the robot, and use these feature keypoints to describe the grid occupancy of the obstacles. However, when the number of these points is insufficient to describe the entire occupancy state of obstacles, these obstacles have to be segmented. We first use the mean shift algorithm [23] to segment the scenes scanned by cameras, and then combine these feature keypoints using similarity of features to segment these objects, and apply the stereo visual algorithm [26] to determine the positions of these objects.
5. Experiment Results and Analysis
To verify the ability of the proposed method to construct the environment model, we perform a series of experiments containing VSM and indoor and outdoor environment mapping, and carry out some performance evaluation tests in different conditions. The whole 3-D map is constructed as the robot moving forward, and we use the method of keypoints matching in consecutive frames to avoid previously visited areas being re-mapped.
In our experiments, the mobile robot we used is as shown in Fig. 1, and the ground is a plane. The mobile robot is equipped with a stereo camera pair, and the installation height of the cameras is $h_c =370$ mm. This value is used to compute the locations of the visual features of the environment. The computing hardware of the mobile robot includes a DM642 card with 600 MHz and an Intel Core i3 CPU with 2.40 GHz. The first installation is used for binocular stereo visual computation and feature extraction, whereas the other computational tasks are done by the Core i3 CPU, and these installations exchange data through network. $A_{\rm L}$ and are defined as the internal parameters of the left and right cameras, respectively, after calibration, and are given by the following:
$ A_{\rm L} =\left[{{\begin{array}{*{20}ccccc} {1015.6} \hfill & ~~\!~~0 \hfill & {357.7} \hfill \\ ~~\!~~0 \hfill & {1073.5} \hfill & {264.3} \hfill \\ ~~\!~~0 \hfill & ~~\!~~0 \hfill & ~~\!~~1 \hfill \\ \end{array} }} \right] $
$ A_{\rm R} =\left[{{\begin{array}{*{20}ccccc} {1037.0} \hfill & ~~\!~~0 \hfill & {339.0} \hfill \\ ~~\!~~0 \hfill & {1099.2} \hfill & {289.2} \hfill \\ ~~\!~~0 \hfill & ~~\!~~0 \hfill & ~~\!~~1 \hfill \\ \end{array} }} \right]. $
The rotation matrix $R_{0}$ and translation matrix $T_{0}$ are given as follows:
$ R_0 =\left[{{\begin{array}{*{20}cccccc} ~~\!~~1 \hfill & {-0.0059} \hfill & ~~{0.0060} \hfill \\ ~~{0.0062} \hfill & ~~{0.9987} \hfill & {-0.0503} \hfill \\ {-0.0057} \hfill & ~~{0.0503} \hfill & ~~{0.9987} \hfill \\ \end{array} }} \right] $
$ T_0 =\left[{{\begin{array}{*{20}c} {-111.191} \hfill & {-1.395} \hfill & {6.279} \hfill \\ \end{array} }} \right]~~~~~ $
where $A_{\rm L}$ , $A_{\rm R}$ , $R_{0}$ , and $T_{0}$ will be used in stereo visual computation. In our experiments, the speed of the mobile robot is limited to $v\le 0.5$ m/s.
5.1 Visual Saliency Modeling Experiments
In the saliency modeling experiments, we use the visual features to construct the saliency maps. However, the number of features extracted from some objects may be not enough to show the saliency of these objects. Hence we first adopt the mean shift algorithm [23] to segment the objects, and then merge the segmented regions with these features to acquire the saliency of the objects. If the surface textures of the larger objects show a significant difference and are far apart from each other, the saliency may be different, as shown in Fig. 6.
 图 6 An example of a saliency map. (a) Conspicuous objects. Parts 1 and 3 are of the same object; however, because of the differences in texture and distance, the object was segmented into two parts. (b) Indoor corridor and conspicuous SURF features.Fig. 6 An example of a saliency map. (a) Conspicuous objects. Parts 1 and 3 are of the same object; however, because of the differences in texture and distance, the object was segmented into two parts. (b) Indoor corridor and conspicuous SURF features.
图 6 An example of a saliency map. (a) Conspicuous objects. Parts 1 and 3 are of the same object; however, because of the differences in texture and distance, the object was segmented into two parts. (b) Indoor corridor and conspicuous SURF features.Fig. 6 An example of a saliency map. (a) Conspicuous objects. Parts 1 and 3 are of the same object; however, because of the differences in texture and distance, the object was segmented into two parts. (b) Indoor corridor and conspicuous SURF features.Fig. 6(a) is a constructed visual saliency map with the conspicuous SURF features, and it is obtained by using (4) and (6) combined with the mean shift algorithm. In Fig. 6, the SURF features on ground have been removed. There are eight conspicuous regions in this figure, and first has the highest saliency and eighth has the least. In Region 1, the features are nearest to the mobile robot and have the smallest deviation relative to the moving direction of the robot. In Region 2, the features have smaller deviation, however, these are farther from the robot compared with Region 1. Hence the saliency in Region 2 is lower than Region 1. Regions 7 and 8 have a larger deviation and are far away from the robot, thus their saliency is the lowest. In right of Fig. 6(b) is the conspicuous SURF features map, and the saliencies of features are different.
We first performed the 3-D grid modeling experiments in an indoor environment with a size of approximately 5.0 m $\times $ 6.5 m. The size of the grid is 0.1 m $\times $ 0.1 m $\times $ 0.1 m, and the grid modeling is mainly focused on conspicuous objects. The number of conspicuous visual features on the objects is inadequate, thus the objects contour formed by the voxels based on the features may not describe the actual occupancy situation of the objects in the environment, as shown in left portion of Fig. 7. The features are part of the map constructed by the SURF features (some closer features are combined together). In this figure, many grids show discontinuity because of the uneven distribution of features. To improve this situation, we first adopted the stereo visual method [26] to acquire the location of the objects with these features, and combined the mean shift segmentation algorithm and projection method to calculate the occupancy range of the objects in the map, as shown in Fig. 7(b) . The discontinuous grids are significantly reduced compared with Fig. 7(a) . Fig. 8 is an indoor corridor (see the left of Fig. 6(b)) 3-D grid map constructed by using our method, where the dashed line and arrow describe the path and moving direction of mobile robot, respectively.
 图 7 A part of 3-D occupancy grid map. (a) The map is created using SURF features, and many grids show discontinuity. (b) The map is created by combining the conspicuous SURF features with the mean shift algorithm, and the discontinuity is reduced significantly.Fig. 7 A part of 3-D occupancy grid map. (a) The map is created using SURF features, and many grids show discontinuity. (b) The map is created by combining the conspicuous SURF features with the mean shift algorithm, and the discontinuity is reduced significantly.
图 7 A part of 3-D occupancy grid map. (a) The map is created using SURF features, and many grids show discontinuity. (b) The map is created by combining the conspicuous SURF features with the mean shift algorithm, and the discontinuity is reduced significantly.Fig. 7 A part of 3-D occupancy grid map. (a) The map is created using SURF features, and many grids show discontinuity. (b) The map is created by combining the conspicuous SURF features with the mean shift algorithm, and the discontinuity is reduced significantly.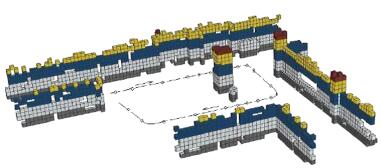 图 8 Indoor corridor 3-D map with 1 dm $^3$ voxel size. The dash line and arrow are the trajectory and moving direction of mobile robot, respectively, and the small circles are the places used to evaluate the performance.Fig. 8 Indoor corridor 3-D map with 1 dm $^3$ voxel size. The dash line and arrow are the trajectory and moving direction of mobile robot, respectively, and the small circles are the places used to evaluate the performance.
图 8 Indoor corridor 3-D map with 1 dm $^3$ voxel size. The dash line and arrow are the trajectory and moving direction of mobile robot, respectively, and the small circles are the places used to evaluate the performance.Fig. 8 Indoor corridor 3-D map with 1 dm $^3$ voxel size. The dash line and arrow are the trajectory and moving direction of mobile robot, respectively, and the small circles are the places used to evaluate the performance.Fig. 9 is an outdoor 3-D grid map created with conspicuous SURF features, and the size of scene is approximately 30.5 m $\times $ 10 m. Some conspicuous objects are marked in map, such as trunks, pillars, cars, stone columns, and signboards, as shown in Fig. 9. Object 1 is a tree, and the positions of the tree leaves vary because of the effect of the wind, thus we limited the height of objects in the map as $h\!\!<$ 1.5 m, producing trunks with no leaves in the created map. The dashed line and arrow are the path and moving direction of mobile robot, respectively. The colors of the voxels indicate the heights in Figs. 8 and 9, such as gray: 0.1-0.2 m, white: 0.3-0.6 m, blue: 0.7-0.9 m, yellow: 1.0-1.2 m, red: 1.3-1.4 m.
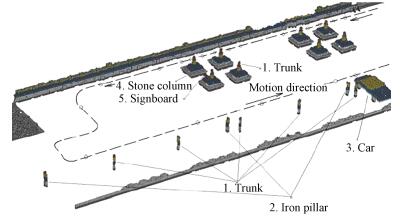 图 9 Outdoor 3-D map with 1 dm3 voxel size, where the dashed line and arrow are the trajectory and moving direction of mobile robot, respectively, and the little circles are the places used to evaluate the performance.Fig. 9 Outdoor 3-D map with 1 dm3 voxel size, where the dashed line and arrow are the trajectory and moving direction of mobile robot, respectively, and the little circles are the places used to evaluate the performance.
图 9 Outdoor 3-D map with 1 dm3 voxel size, where the dashed line and arrow are the trajectory and moving direction of mobile robot, respectively, and the little circles are the places used to evaluate the performance.Fig. 9 Outdoor 3-D map with 1 dm3 voxel size, where the dashed line and arrow are the trajectory and moving direction of mobile robot, respectively, and the little circles are the places used to evaluate the performance.5.2 Performance Evaluation
In our method, we use the visual features to construct 3-D environment modeling, and the feature type is one of the most influential choices for accuracy and runtime performance. We use SIFT, SURF, and Harris-Laplace to evaluate our method in indoor and outdoor environments. Twenty places (see the circles in Figs. 8 and 9) are carefully selected to evaluate the performance. The plots in Fig. 10 show the processing time comparison per frame in indoor and outdoor environments, whereas Fig. 11 shows the mapping accuracy in these places. It is very difficult to evaluate all the mapping errors. We select 10 conspicuous feature points in specified locations (as shown in Figs. 8 and 9 and compute their mapping error. The comparison results clearly show that outdoor modeling requires more time and provides lower mapping accuracy than indoor modeling. More saliency features are extracted and some features easily become unstable because of the effect of light outdoors, particularly for the Harris-Laplace. In contrast, SIFT provides the highest accuracy (median is approximately 0.07 m), however, the processing time is also highest, and Harris-Laplace is the opposite. SURF offers a tradeoff choice for a robot with limited computational resources or applications that require real-time performance.
Illumination changes may make the visual features become unstable, and the shadows of objects cast by light may change. These factors will cause false objects to occur in mapping, and reduce mapping accuracy. In our experiments, we evaluated the robust performance of the proposed method by the effects of light in an indoor environment. We control four lamps mounted on the ceiling to simulate illumination changes. In mapping, we use methods of VO (visual odometry) and SLAM to evaluate mapping accuracy, and the results are shown in Fig. 12. Results of experiments show that mapping accuracy deteriorates because of illumination, particularly the mapping error obtained using point clouds subsampling (PCS) (see the dash lines in Fig. 12). The solid lines are the results of our method, and it shows that the error reduces relatively little by the effects of light and shows good robust performance. This may be explained by the fact that the method of VSM gives priority to the closer objects when the robot is mapping the environment.
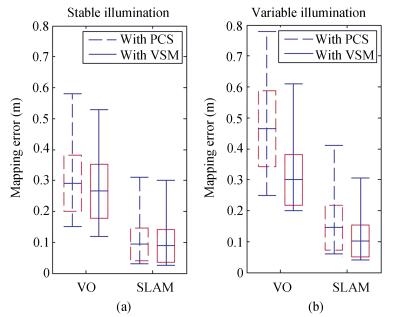 图 12 Evaluation of mapping accuracy under (a) stable illumination and (b) varying illumination. The results are obtained with SURF and the mapping error increases under varying illumination, however, VSM slightly increases.Fig. 12 Evaluation of mapping accuracy under (a) stable illumination and (b) varying illumination. The results are obtained with SURF and the mapping error increases under varying illumination, however, VSM slightly increases.
图 12 Evaluation of mapping accuracy under (a) stable illumination and (b) varying illumination. The results are obtained with SURF and the mapping error increases under varying illumination, however, VSM slightly increases.Fig. 12 Evaluation of mapping accuracy under (a) stable illumination and (b) varying illumination. The results are obtained with SURF and the mapping error increases under varying illumination, however, VSM slightly increases.For the runtime, we compared our approach with some of the discussed approaches such as occupancy grid mapping (OGM) and occupancy mapping with pyramid (OMP) [9]. The experiments are performed in an indoor corridor shown in Fig. 6. The size of grid is 0.1 m 0.1 m $\times $ 0.1 m, and each moving distance of the mobile robot is approximately 8 m. The evaluation results are shown in Fig. 13. VSM significantly reduces mapping time, and OGM requires more time. For VSM, the mapping objects are the higher conspicuous objects, whereas other methods need to map all the objects scanned by the cameras. Hence this feature significantly improves the efficiency of mapping of VSM.
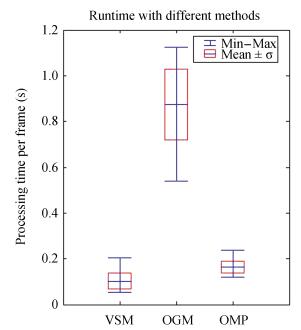 图 13 Evaluation of runtime with VSM, OGM, and OMP. The results are obtained indoors, and the size of the grid is 0.1 m $\times$ 0.1 m $\times$ 0.1 m.Fig. 13 Evaluation of runtime with VSM, OGM, and OMP. The results are obtained indoors, and the size of the grid is 0.1 m $\times$ 0.1 m $\times$ 0.1 m.
图 13 Evaluation of runtime with VSM, OGM, and OMP. The results are obtained indoors, and the size of the grid is 0.1 m $\times$ 0.1 m $\times$ 0.1 m.Fig. 13 Evaluation of runtime with VSM, OGM, and OMP. The results are obtained indoors, and the size of the grid is 0.1 m $\times$ 0.1 m $\times$ 0.1 m.6. Conclusion
In this paper, we presented a method of 3-D grid modeling based on visual attention. VSM makes the front objects (that are closer to the mobile robots) exhibit larger conspicuousness. This can be beneficial for mobile robots to model the closer objects with higher priority, thus avoiding the modeling of all the objects at every moment, reducing computing time in updating the map of the environment. In the constructed method of VSM, we define the distance-potential gradient as the motion contrast, and combine the visual features with the mean shift segmentation algorithm to determine the saliency of the objects. To create the 3-D environment maps, we use stereo visual method to calculate the positions of conspicuous visual features and objects, and combine Bayes' theorem with the sensors modeling, grid priori modeling, and projection method to update the occupancy probability of the grids. Finally, a series of experiments that include saliency modeling, indoor and outdoor grid modeling, and performance tests are adopted to evaluate the presented method.
-
Fig. 1 The robot system used in our evaluations. (a) Mobile robot platform. (b) Binocular visual system and DM642 image processing card.
Fig. 2 Schematic overview of the method. The dash box is used for saliency modeling construction, and a 3-D map is generated by using the probability of occupancy.
Fig. 3 The relation of $\Delta \varphi$ , $p$ ( $x$ , $y$ , $z$ ), and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ), where $p$ ( $x$ , $y$ , $z$ ) is the center of the robot and $p_i$ ( $x_i$ , $y_i$ , $z_i$ ) is the feature point on the objects.
Fig. 4 Occupancy grid maps creation when objects produce visual occlusion. We use the projection method to calculate the objects occupancy width w.
Fig. 5 Overhead view of occupancy grid updating. The updated results using (12) will be close to the size of objects when robot moves from $A$ to $B$ . The shadows are the occupancy fields of occlusion.
Fig. 6 An example of a saliency map. (a) Conspicuous objects. Parts 1 and 3 are of the same object; however, because of the differences in texture and distance, the object was segmented into two parts. (b) Indoor corridor and conspicuous SURF features.
Fig. 7 A part of 3-D occupancy grid map. (a) The map is created using SURF features, and many grids show discontinuity. (b) The map is created by combining the conspicuous SURF features with the mean shift algorithm, and the discontinuity is reduced significantly.
Fig. 8 Indoor corridor 3-D map with 1 dm $^3$ voxel size. The dash line and arrow are the trajectory and moving direction of mobile robot, respectively, and the small circles are the places used to evaluate the performance.
Fig. 9 Outdoor 3-D map with 1 dm3 voxel size, where the dashed line and arrow are the trajectory and moving direction of mobile robot, respectively, and the little circles are the places used to evaluate the performance.
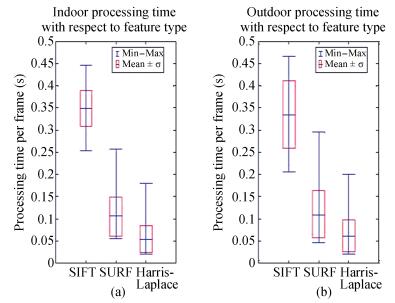
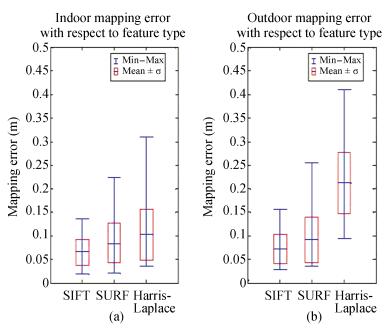
Fig. 12 Evaluation of mapping accuracy under (a) stable illumination and (b) varying illumination. The results are obtained with SURF and the mapping error increases under varying illumination, however, VSM slightly increases.
-
[1] T. K. Lee, S. H. Baek, Y. H. Choi, and S. Y. Oh, "Smooth coverage path planning and control of mobile robots based on high-resolution grid map representation, " Robot. Auton. Syst. , vol. 59, no. 10, pp. 801-812, Oct. 2011. http://www.researchgate.net/publication/220142222_Smooth_coverage_path_planning_and_control_of_mobile_robots_based_on_high-resolution_grid_map_representation [2] H. T. Cheng, H. P. Chen, and Y. Liu, "Topological indoor localization and navigation for autonomous mobile robot, " IEEE Trans. Automat. Sci. Eng. , vol. 12, no. 2, pp. 729-738, Apr. 2015. https://www.researchgate.net/publication/274573448_Topological_Indoor_Localization_and_Navigation_for_Autonomous_Mobile_Robot [3] I. J. Cox and J. J. Leonard, "Modeling a dynamic environment using a Bayesian multiple hypothesis approach, " Artif. Intell. , vol. 66, no. 2, pp. 311-344, Apr. 1994. https://www.researchgate.net/publication/223080507_Modeling_a_dynamic_environment_using_a_Bayesian_multiple_hypothesis_approach?ev=auth_pub [4] B. H. Guo and Z. H. Li, "Dynamic environment modeling of mobile robots based on visual saliency, " Control Theory Appl. , vol. 30, no. 7, pp. 821-827, Jul. 2013. http://en.cnki.com.cn/Article_en/CJFDTotal-KZLY201307006.htm [5] R. Sim and J. J. Little, "Autonomous vision-based exploration and mapping using hybrid maps and Rao-Blackwellised particle filters, " in Proc. 2006 IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Beijing, China, 2006, pp. 2082-2089. https://www.researchgate.net/publication/224685128_Autonomous_vision-based_exploration_and_mapping_using_hybrid_maps_and_Rao-Blackwellised_particle_filters [6] Y. N. Wang, Y. M. Yang, X. F. Yuan, Y. Zuo, Y. L. Zhou, F. Yin, and L. Tan, "Autonomous mobile robot navigation system designed in dynamic environment based on transferable belief model, " Measurement, vol. 44, no. 8, pp. 1389-1405, Oct. 2011. http://www.researchgate.net/publication/251542234_Autonomous_mobile_robot_navigation_system_designed_in_dynamic_environment_based_on_transferable_belief_model [7] A. A. S. Souza, R. Maia, and L. M. G. Gonçalves, "3-D probabilistic occupancy grid to robotic mapping with stereo vision, " in Current Advancements in Stereo Vision, A. Bhatti, Ed. Croacia: INTECH, 2012, pp. 181-198. [8] D. Hähnel, W. Burgard, and S. Thrun, "Learning compact 3-D models of indoor and outdoor environments with a mobile robot, " Robot. Auton. Syst. , vol. 44, no. 1, pp. 15-27, Jul. 2003. [9] K. Pirker, M. Rüther, H. Bischof, and G. Schweighofer, "Fast and accurate environment modeling using three-dimensional occupancy grids, " in Proc. 2011 IEEE Int. Conf. Computer Vision Workshops, Barcelona, Spain, 2011, pp. 1134-1140. https://www.researchgate.net/publication/221430086_Fast_and_accurate_environment_modeling_using_three-dimensional_occupancy_grids [10] S. Kim and J. Kim, "Occupancy mapping and surface reconstruction using local gaussian processes with Kinect sensors, " IEEE Trans. Cybern. , vol. 43, no. 5, pp. 1335-1346, Oct. 2013. http://www.ncbi.nlm.nih.gov/pubmed/23893758 [11] Y. Zhuang, N. Jiang, H. S. Hu, and F. Yan, "3-D-laser-based scene measurement and place recognition for mobile robots in dynamic indoor environments, " IEEE Trans. Instrum. Meas. , vol. 62, no. 2, pp. 438-450, Feb. 2013. https://www.researchgate.net/publication/260492325_3-D-Laser-Based_Scene_Measurement_and_Place_Recognition_for_Mobile_Robots_in_Dynamic_Indoor_Environments [12] F. Endres, J. Hess, J. Sturm, D. Cremers, and W. Burgard, "3-D mapping with an RGB-D camera, " IEEE Trans. Robot. , vol. 30, no. 1, pp. 177-187, Feb. 2014. https://www.researchgate.net/publication/260520054_3-D_Mapping_With_an_RGB-D_Camera [13] L. Itti, C. Koch, and E. Niebur, "A model of saliency-based visual attention for rapid scene analysis, " IEEE Trans. Pattern Anal. Mach. Intell. , vol. 20, no. 11, pp. 1254-1259, Nov. 1998. http://www.researchgate.net/publication/3192913_A_model_of_saliency-based_visual_attention_for_rapid_scene_analysis [14] A. Kimura, R. Yonetani, and T. Hirayama, "Computational models of human visual attention and their implementations: A survey, " IEICE Trans. Inf. Syst. , vol. E96-D, no. 3, pp. 562-578, Mar. 2013. https://www.researchgate.net/publication/275603606_Computational_Models_of_Human_Visual_Attention_and_Their_Implementations_A_Survey [15] S. Frintrop, E. Rome, and H. I. Christensen, "Computational visual attention systems and their cognitive foundations: A survey, " ACM Trans. Appl. Percept. , vol. 7, no. 1, pp. Article ID: 6, Jan. 2010. https://www.researchgate.net/publication/220244956_Computational_visual_attention_systems_and_their_cognitive_foundations_A_survey?ev=prf_cit [16] S. Frintrop and P. Jensfelt, "Attentional landmarks and active gaze control for visual SLAM, " IEEE Trans. Robot. , vol. 24, no. 5, pp. 1054-1065, Oct. 2008. https://www.researchgate.net/publication/224332109_Attentional_Landmarks_and_Active_Gaze_Control_for_Visual_SLAM?ev=auth_pub [17] P. Newman and K. Ho, "SLAM-loop closing with visually salient features, " in Proc. 2005 IEEE Int. Conf. Robotics and Automation, Barcelona, Spain, 2005, pp. 635-642. https://www.researchgate.net/publication/4210014_SLAM-Loop_Closing_with_Visually_Salient_Features [18] N. Ouerhani, A. Bur, and H. Hügli, "Visual attention-based robot self-localization, " in Proc. 2005 European Conf. Mobile Robotics, Ancona, Italy, 2005, pp. 8-13. https://www.researchgate.net/publication/33682208_Visual_attention-based_robot_self-localization [19] E. Einhorn, C. Schröter, and H. M. Gross, "Attention-driven monocular scene reconstruction for obstacle detection, robot navigation and map building, " Robot. Auton. Syst. , vol. 59, no. 5, pp. 296-309, May 2011. https://www.researchgate.net/publication/228572034_Attention-driven_monocular_scene_reconstruction_for_obstacle_detection_robot_navigation_and_map_building [20] R. Roberts, D. N. Ta, J. Straub, K. Ok, and F. Dellaert, "Saliency detection and model-based tracking: A two part vision system for small robot navigation in forested environment, " in Proc. SPIE 8387, Unmanned Systems Technology XIV, Baltimore, Maryland, USA, vol. 8387, Atricle ID 83870S. https://www.researchgate.net/publication/258716451_Saliency_detection_and_model-based_tracking_a_two_part_vision_system_for_small_robot_navigation_in_forested_environment [21] H. Bay, T. Tuytelaars, and L. Van Gool, "SURF: Speeded up robust features, " in Proc. 9th European Conf. Computer Vision, Graz, Austria, 2006, pp. 404-417. https://www.researchgate.net/publication/221303886_SURF_Speeded_Up_Robust_Features [22] D. G. Lowe, "Distinctive image features from scale-invariant keypoints, " Int. J. Comput. Vis. , vol. 60, no. 2, pp. 91-110, Nov. 2004. [23] D. Comaniciu and P. Meer, "Mean shift: A robust approach toward feature space analysis, " IEEE Trans. Pattern Anal. Mach. Intell. , vol. 24, no. 5, pp. 603-619, May 2002. [24] R. Rocha, J. Dias, and A. Carvalho, "Cooperative multi-robot systems: A study of vision-based 3-D mapping using information theory, " Robot. Auton. Syst. , vol. 53, no. 3-4, pp. 282-311, Dec. 2005. https://www.researchgate.net/publication/4210106_Cooperative_Multi-Robot_Systems_A_study_of_Vision-based_3-D_Mapping_using_Information_Theory [25] S. Thrun, W. Burgard, and D. Fox, Probabilistic Robotics. New York, NY, USA:MIT Press, 2005. [26] A. Murarka, "Building safety maps using vision for safe local mobile robot navigation, " Ph. D. dissertation, Dept. CS, Univ. Texas, Austin, USA, 2009. https://www.researchgate.net/publication/50417504_Building_safety_maps_using_vision_for_safe_local_mobile_robot_navigation [27] S. Hrabar, "An evaluation of stereo and laser-based range sensing for rotorcraft unmanned aerial vehicle obstacle avoidance, " J. Field Robot. , vol. 29, no. 2, pp. 215-239, Mar. -Apr. 2012. https://www.researchgate.net/publication/261847674_An_evaluation_of_stereo_and_laser-based_range_sensing_for_rotorcraft_unmanned_aerial_vehicle_obstacle_avoidance 期刊类型引用(2)
1. 李宗刚,王治平,夏广庆,康会峰. 基于动态避障风险区域的仿生机器鱼路径规划方法. 机器人. 2024(04): 488-502 .  百度学术
百度学术2. 田国会,王晓静,张营. 一种家庭服务机器人的环境语义认知机制. 华中科技大学学报(自然科学版). 2018(12): 18-23 . 百度学术其他类型引用(4)
-

 下载:
下载:
 下载:
下载:
计量
- 文章访问数: 2818
- HTML全文浏览量: 302
- PDF下载量: 770
- 被引次数: 6
