

Policy Optimization Method for Multi-UAV Cooperative Maritime Navigation Based on Causal Influence Detection
-
摘要: 多无人机协同导航是实现高效海上协同作业的重要技术. 然而, 在广阔且动态未知的海域中, 受限的感知能力与自主决策机制使无人机之间的协作关系复杂, 难以获取全局信息. 近年来, 基于集中训练与分散执行范式的多智能体强化学习在协作行为学习方面取得显著进展, 并被广泛应用于海上协同导航任务. 但由于智能体交互往往仅在特定情境下发生, 如何有效提升协作效率与探索能力仍是关键挑战. 为解决上述问题, 提出一种基于因果影响检测的多智能体近端策略优化方法. 该方法以智能体之间的因果影响为衡量准则, 引入基于协作规则设计的内在奖励机制, 利用因果推断与条件互信息来检测智能体之间在行为上的因果影响, 从而引导其优先探索对全局状态具有正向影响的动作, 强化多智能体间的合作. 实验结果表明, 所提方法表现出显著的性能提升, 尤其在海上搜救任务中展现出更高的协同效率, 验证了方法的有效性.Abstract: Multi-UAV cooperative navigation is a crucial technology for achieving efficient cooperative maritime operations. However, in vast and dynamically unknown maritime environments, limited sensing capabilities and autonomous decision-making mechanism lead to complex cooperation relationships among UAVs, making it difficult to obtain global information. In recent years, multi-agent reinforcement learning under the centralized training and decentralized execution paradigm has achieved remarkable progress in learning cooperative behaviors and has been widely applied to cooperative maritime navigation tasks. Nevertheless, because agent interactions often occur only in specific situations, improving cooperation efficiency and exploration capability remains a major challenge. To address this issue, this paper proposes a causal influence detection for multi-agent proximal policy optimization method. The proposed method uses causal influence among agents as an evaluation metric and introduces an intrinsic reward mechanism designed based on cooperation rules. By leveraging causal inference and conditional mutual information, the method detects behavioral causal influence among agents, guiding them to preferentially explore actions that positively affect the global state and thus enhancing inter-agent cooperation. Experimental results demonstrate that the proposed method achieves significant performance improvements, especially in maritime search and rescue tasks, where it exhibits higher cooperation efficiency, validating the effectiveness of the method.
-
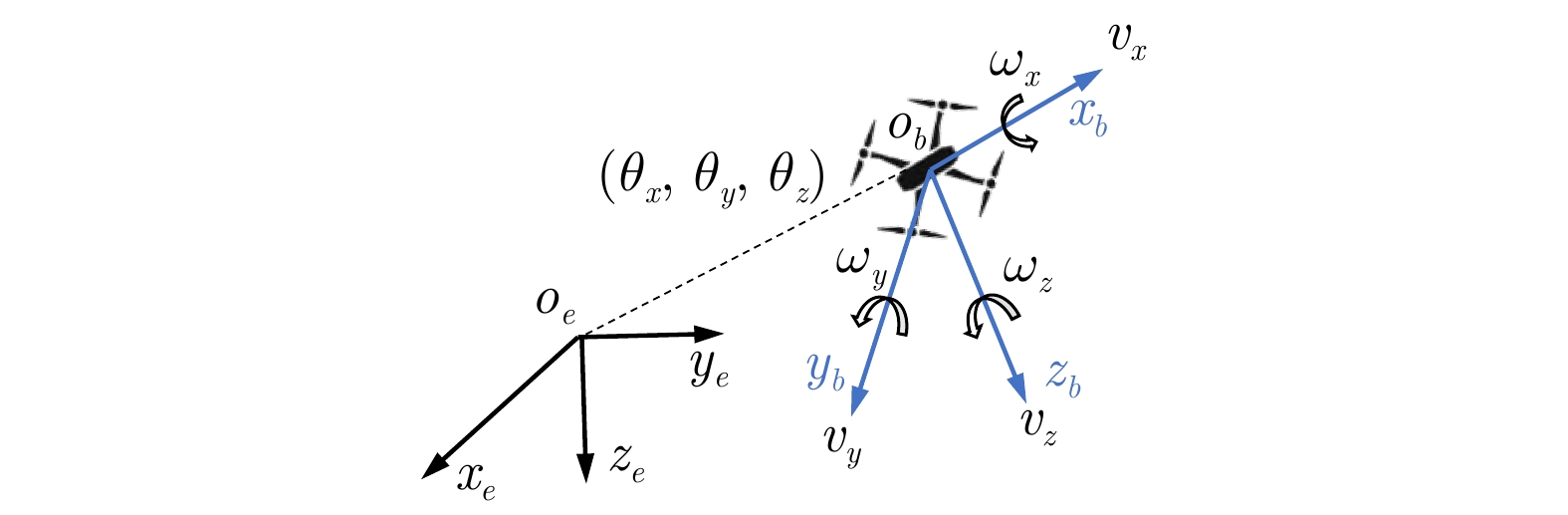
图 2 无人机的机体固定坐标系和惯性坐标系
Fig. 2 The body-fixed coordinate system and inertial coordinate system of UAV
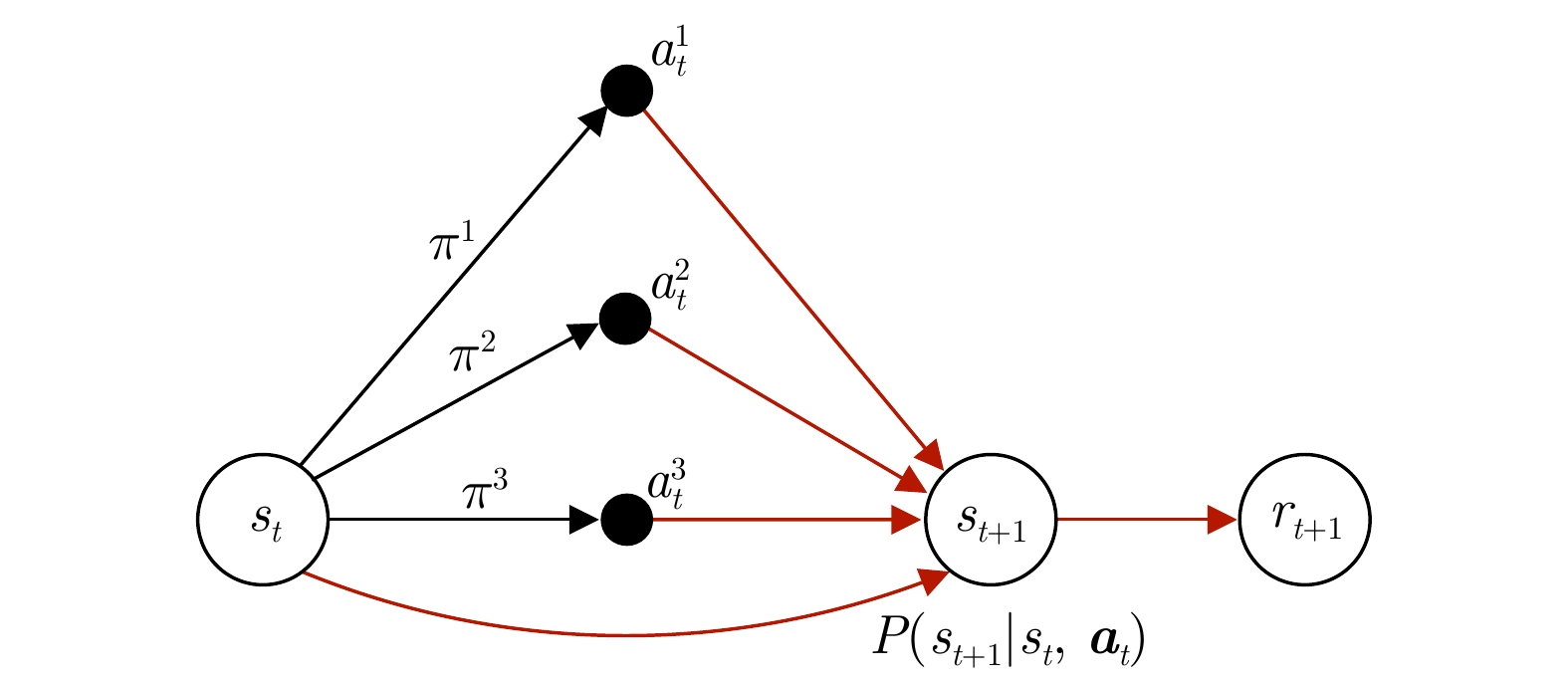
图 3 具有3个智能体的单步状态转移因果图模型
Fig. 3 The causal graphic model of one-step state transition with three agents
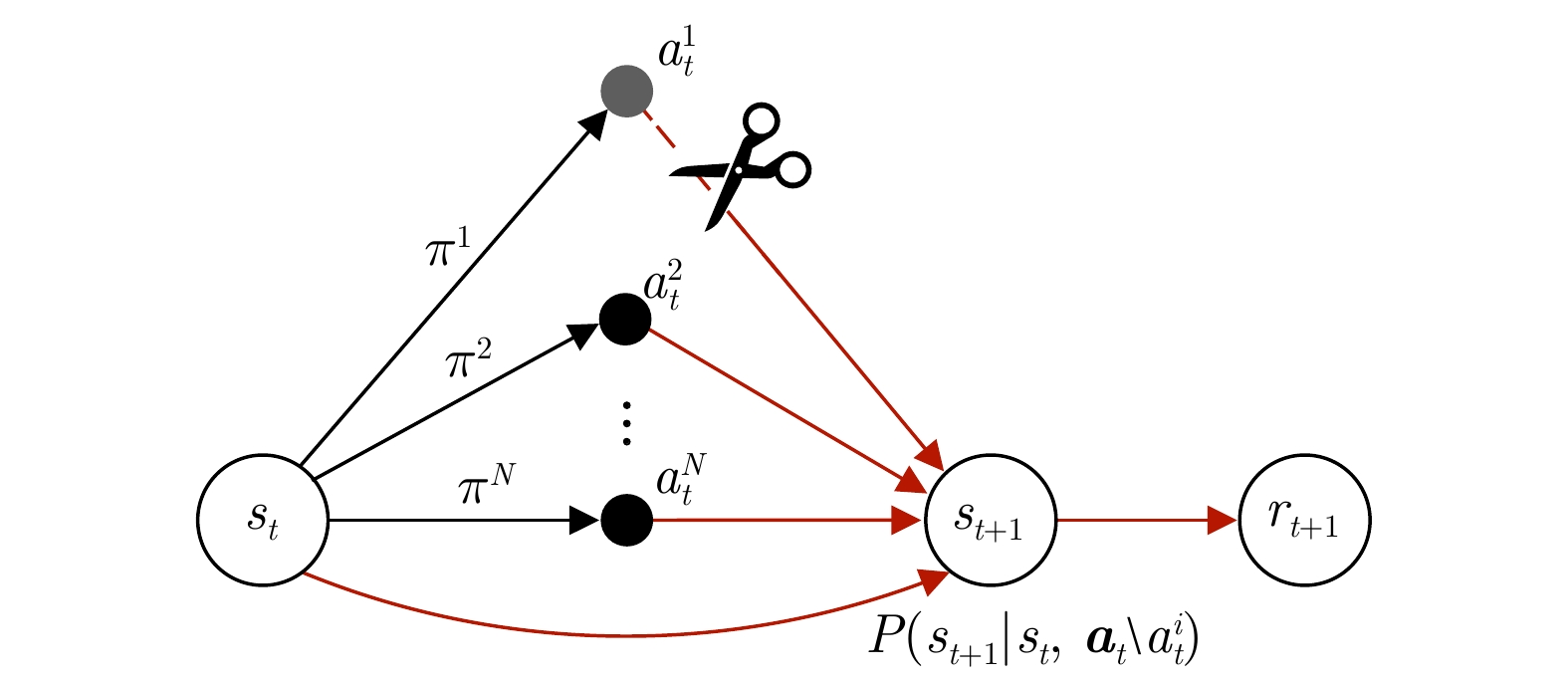
图 4 不考虑智能体$i$动作的因果图模型
Fig. 4 The causal graphic model without considering the action of agent $i$
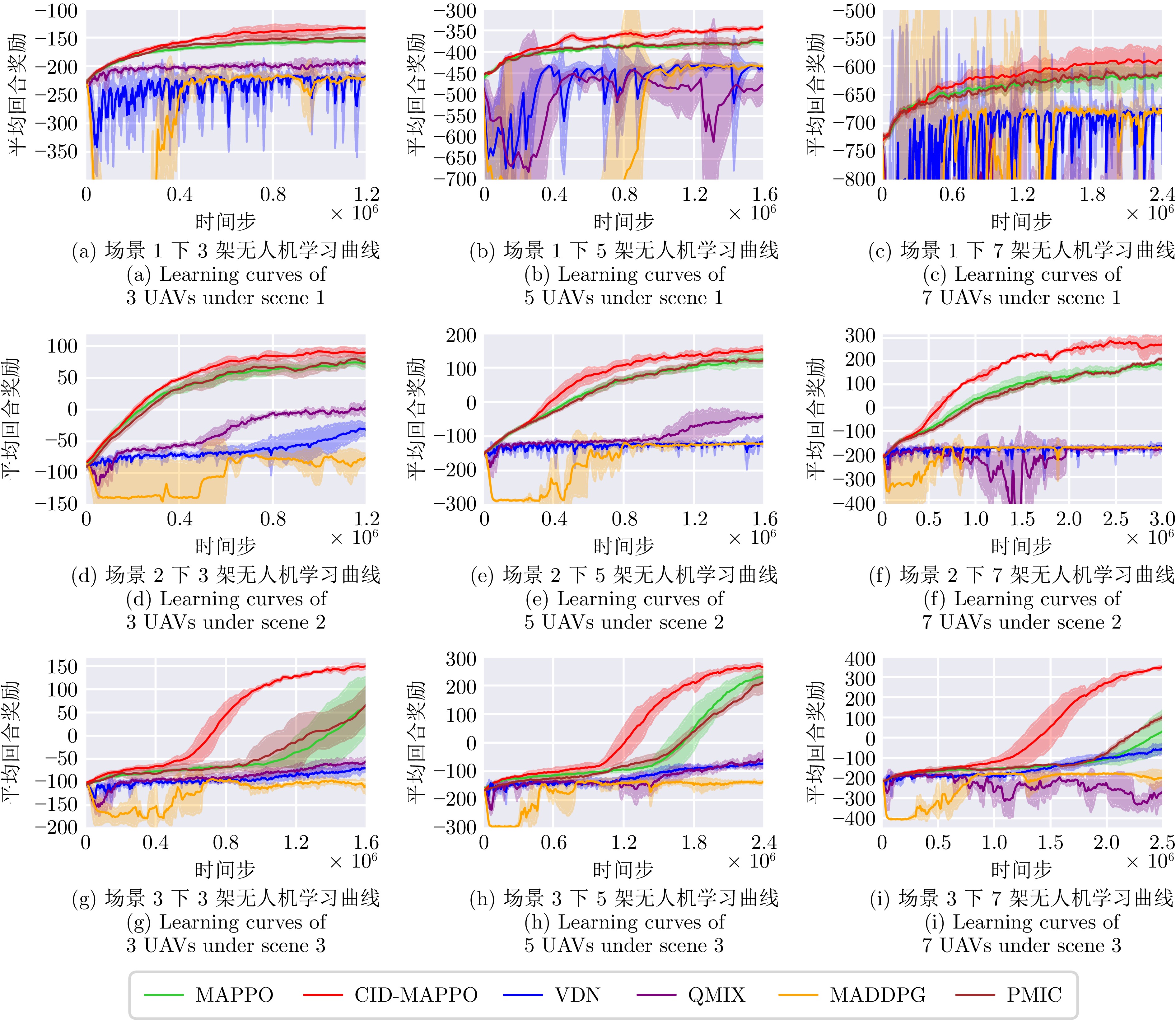
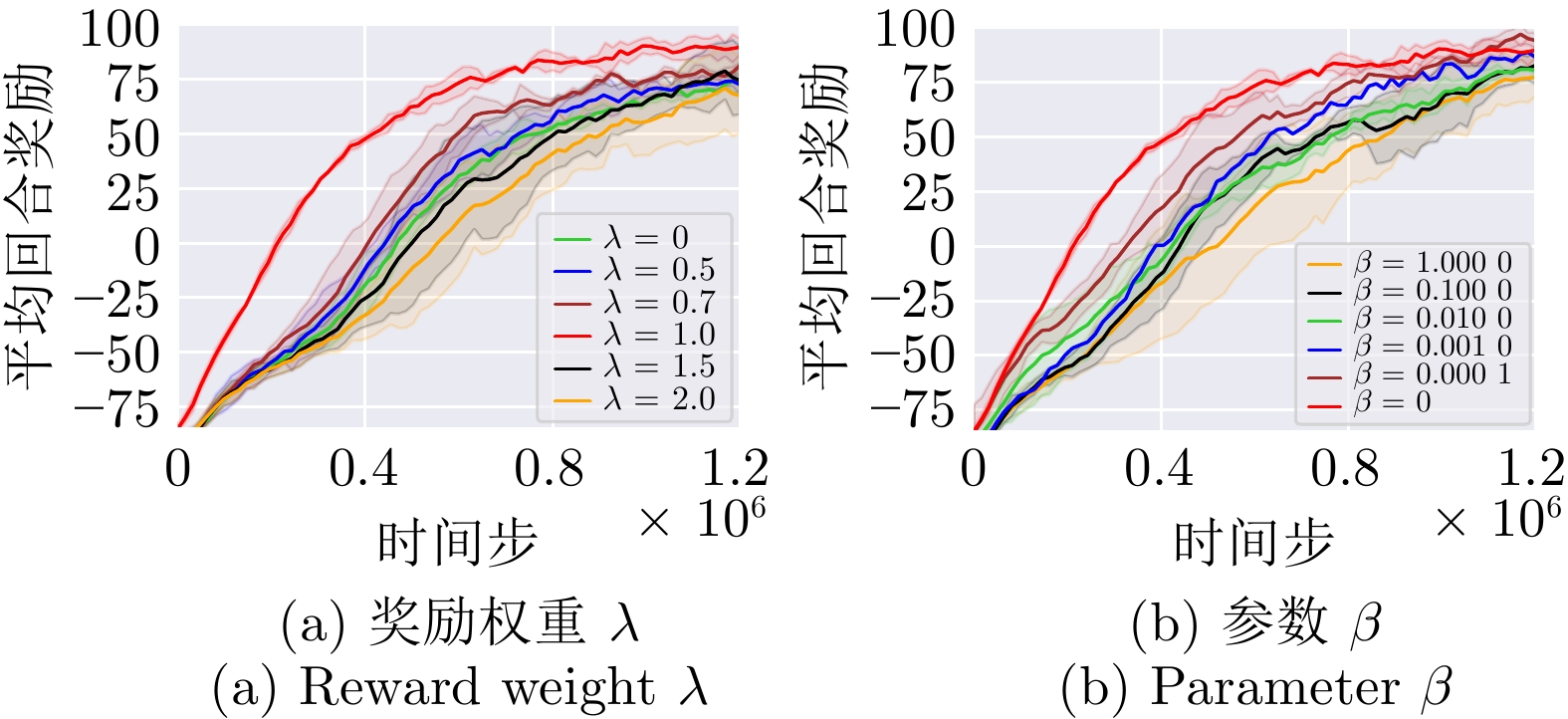
图 8 不同场景下各算法学习曲线
Fig. 8 Learning curves of different algorithms under various scenarios
表 1 数学符号说明
Table 1 Explanation of mathematical symbols
数学符号 符号说明 $ \mathcal{I}=\{1,\; 2,\; \cdots,\; N\} $ 无人机集合 $ s_t $ 时刻 $ t $ 的系统状态 $ o_t^i $ 无人机 $ i $ 在时刻 $ t $ 的局部观测 $ a_t^i $ 无人机 $ i $ 在时刻 $ t $ 的动作 $ \pi^i $ 无人机 $ i $ 的策略 $ \boldsymbol{a}_t=[a_t^1,\; \cdots,\; a_t^N] $ 联合动作 $ \boldsymbol{a}_t \setminus a_t^i $ 去除无人机 $ i $ 动作后的联合动作 $ P(s_{t+1} | s_t,\; \boldsymbol{a}_t) $ 状态转移概率 $ \gamma $ 折扣因子 $ C^i(s_t,\; s_{t+1}) $ 无人机 $ i $ 的因果影响度量 $ D_\mathrm{KL}(\cdot \| \cdot) $ KL散度 $ \beta $ $ \beta {\text{-}} $VAE正则系数 $ r^i_t $ 无人机 $ i $ 在时刻 $ t $ 的奖励 $ r^i_{\mathrm{cid},\; t} $ 无人机 $ i $ 在时刻 $ t $ 的因果内在奖励 $ \lambda $ 内在奖励权重  下载: 导出CSV
下载: 导出CSV
表 2 实验超参数设置
Table 2 Experimental hyper-parameters setting
参数名称 取值 学习率$ \alpha $ 0.000 5 VAE模块学习率$ \alpha_\mathrm{vae} $ 0.000 5 折扣因子$ \gamma $ 0.99 裁剪系数$ \varepsilon $ 0.2 激活函数 ReLU 批量数据大小 1 024 经验回放池$ \mathcal{D} $大小 3 200 奖励权重$ \lambda $ 1.0 VAE参数$ \beta $ 0 蒙特卡洛采样数$ K $ 128 actor网络全连接层节点数 [64, 64, 64] actor网络RNN隐层节点数 64 critic网络全连接层节点数 [64, 64] critic网络RNN隐层节点数 64 $ \beta {\text{-}}$VAE编码器隐层节点数 (状态编码) [256, 128, 64] $ \beta {\text{-}}$VAE编码器隐层节点数 (动作编码) [64, 128] $ \beta {\text{-}} $VAE解码器隐层节点数 [64, 128, 256]
下载: 导出CSV
表 3 各算法在不同实验配置下的累积回报统计结果
Table 3 Statistical results of cumulative rewards for different algorithms under various experimental configurations
场景 CID-MAPPO MAPPO VDN QMIX MADDPG PMIC 场景1下3架无人机 −131.89 ± 22.66 −155.67 ± 15.71 −225.21 ± 39.60 −194.05 ± 5.96 −225.02 ± 9.64 −147.94 ± 17.65 场景1下5架无人机 −342.43 ± 26.52 −377.48 ± 16.83 −442.86 ± 11.65 −548.82 ± 116.16 −425.96 ± 6.70 −371.49 ± 17.98 场景1下7架无人机 −590.88 ± 43.33 −616.58 ± 35.03 −673.14 ± 211.54 −916.50 ± 239.70 −673.55 ± 28.43 −610.09 ± 26.67 场景2下3架无人机 89.79 ± 10.45 65.35 ± 12.62 −43.16 ± 16.48 7.42 ± 32.91 −75.18 ± 29.76 74.46 ± 18.73 场景2下5架无人机 156.93 ± 16.15 128.10 ± 15.49 −117.25 ± 23.16 −49.41 ± 29.84 −120.12 ± 33.18 125.02 ± 21.03 场景2下7架无人机 259.88 ± 41.40 194.71 ± 23.77 −176.29 ± 26.21 −180.94 ± 31.54 −173.93 ± 24.84 228.79 ± 16.97 场景3下3架无人机 149.63 ± 12.43 71.39 ± 63.32 −73.31 ± 14.59 −55.00 ± 21.38 −106.13 ± 33.02 89.83 ± 48.67 场景3下5架无人机 279.15 ± 11.32 232.04 ± 23.27 −70.00 ± 29.73 55.69 ± 35.57 −141.55 ± 14.94 209.06 ± 28.05 场景3下7架无人机 332.24 ± 12.04 92.45 ± 41.34 −58.83 ± 35.12 −276.00 ± 76.42 −197.56 ± 27.56 115.33 ± 34.52
下载: 导出CSV
-
[1] Chang Y Y, John A, Hsiung P A. Maritime UAV patrol tasks based on YOLOv4 object detection. In: Proceedings of the 2022 International Conference on Computational Science and Computational Intelligence. Las Vegas, USA: IEEE, 2022. 1484–1490 [2] Xu P F, Fang Y, Jiang Q Y, Lu H F, Li G X, Zhou H. Design and research of a water quality monitoring system for aquaculture using UAV integrated with 3D GIS. Advances in Transdisciplinary Engineering, DOI: 10.3233/atde241331 [3] Sendner F. An energy-autonomous UAV swarm concept to support sea-rescue and maritime patrol missions in the Mediterranean Sea. Aircraft Engineering and Aerospace Technology, 2022, 94(1): 112−123 doi: 10.1108/AEAT-12-2020-0316 [4] Nomikos N, Gkonis P K, Bithas P S, Trakadas P. A survey on UAV-aided maritime communications: Deployment considerations, applications, and future challenges. IEEE Open Journal of the Communications Society, 2022, 4: 56−78 doi: 10.1109/ojcoms.2022.3225590 [5] Liu H D, Long X L, Li Y, Yan J J, Li M Y, Chen C, et al. Adaptive multi-UAV cooperative path planning based on novel rotation artificial potential fields. Knowledge-Based Systems, 2025, 317: Article No. 113429 doi: 10.1016/j.knosys.2025.113429 [6] Zhao H M, Gu M X, Qiu S P, Zhao A, Deng W. Dynamic path planning for space-time optimization cooperative tasks of multiple unmanned aerial vehicles in uncertain environment. IEEE Transactions on Consumer Electronics, 2025, 71(3): 7673−7682 doi: 10.1109/TCE.2025.3593383 [7] Hu W J, Yu Y, Liu S M, She C Y, Guo L, Vucetic B. Multi-UAV coverage path planning: A distributed online cooperation method. IEEE Transactions on Vehicular Technology, 2023, 72(9): 11727−11740 doi: 10.1109/TVT.2023.3266817 [8] Sil M, Rakshit P, Chatterjee S, Ghosh R A, Chowdhury A. Multi-UAV cooperative path-planning in complex terrain: A multi-objective optimization approach. IETE Journal of Research, 2025, 71(8): Article No. 2606 doi: 10.1080/03772063.2025.2497515 [9] Sun W M, Hao M R. A survey of cooperative path planning for multiple UAVs. In: Proceedings of the 2021 International Conference on Autonomous Unmanned Systems. Singapore: Springer, 2021. 189–196 [10] Liu W, Cai W Z, Jiang K, Cheng G R, Wang Y D, Wang J W, et al. Xuance: A comprehensive and unified deep reinforcement learning library. arXiv preprint arXiv: 2312.16248, 2023. [11] Alexandros T, Georgios D. A comprehensive survey on the applications of swarm intelligence and bio-inspired evolutionary strategies. Machine Learning Paradigms: Advances in Deep Learning-based Technological Applications, DOI: 10.1007/978-3-030-49724-8_15 [12] Dario F, Claudio M. Bio-inspired Artificial Intelligence: Theories, Methods, and Technologies. Cambridge: MIT press, 2008. [13] Haldorai A, Kandaswamy U. A bio-inspired swarm intelligence technique for social aware cognitive radio handovers. Computers & Electrical Engineering, 2018, 71: 925−937 doi: 10.1016/j.compeleceng.2017.09.016 [14] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301−1312 doi: 10.16383/j.aas.c200159Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301−1312 doi: 10.16383/j.aas.c200159 [15] 罗彪, 胡天萌, 周育豪, 黄廷文, 阳春华, 桂卫华. 多智能体强化学习控制与决策研究综述. 自动化学报, 2025, 51(3): 510−539 doi: 10.16383/j.aas.c240392Luo Biao, Hu Tian-Meng, Zhou Yu-Hao, Huang Ting-Wen, Yang Chun-Hua, Gui Wei-Hua. Survey on multi-agent reinforcement learning for control and decision-making. Acta Automatica Sinica, 2025, 51(3): 510−539 doi: 10.16383/j.aas.c240392 [16] 陈凯, 雷一辰, 李琰泽, 方国宇, 胡子卓, 杨明实, 等. 基于改进MADDPG的多目标航迹规划方法. 北京航空航天大学学报, DOI: 10.13700/j.bh.1001-5965.2025.0636Chen Kai, Lei Yi-Chen, Li Yan-Ze, Fang Guo-Yu, Hu Zi-Zhuo, Yang Ming-Shi, et al. Multi-object trajectory planning method based on improved MADDPG. Journal of Beijing University of Aeronautics and Astronautics, DOI: 10.13700/j.bh.1001-5965.2025.0636 [17] Sunehag P, Lever G, Gruslys A, Czarnecki W M, Zambaldi V, Jaderberg M, et al. Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv: 1706.05296, 2017. [18] Rashid T, Samvelyan M, de Witt C S, Farquhar G, Foerster J, Whiteson S. Monotonic value function factorisation for deep multi-agent reinforcement learning. Journal of Machine Learning Research, 2020, 21(178): 1−51 [19] Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I. Multi-agent actor-critic for mixed cooperative competitive environments. Advances in Neural Information Processing Systems, DOI: 10.48550/arXiv.1706.02275 [20] Yu C, Velu A, Vinitsky E, Gao J X, Wang Y, Bayen A, et al. The surprising effectiveness of PPO in cooperative multi-agent games. Advances in Neural Information Processing Systems, 2022, 35: 24611−24624 doi: 10.52202/068431-1787 [21] Foerster J, Farquhar G, Afouras T, Nardelli N, Whiteson S. Counterfactual multi-agent policy gradients. In: Proceedings of the 2018 AAAI Conference on Artificial Intelligence. Louisiana, USA: AAAI Press, 2018. 2974–2982 [22] Rashid T, Samvelyan M, de Witt C S, Farquhar G, Foerster J, Whiteson S. Maritime search and rescue based on group mobile computing for unmanned aerial vehicles and unmanned surface vehicles. IEEE Transactions on Industrial Informatics, 2020, 16(12): 7700−7708 doi: 10.1109/TII.2020.2974047 [23] Lei C J, Wu S H, Yang Y, Xue J Y, Zhang Q Y. Maritime search and rescue leveraging heterogeneous units: A multi agent reinforcement learning approach. In: Proceedings of the 12th IEEE/CIC International Conference on Communications. Dalian, China: IEEE, 2018. 1–6 [24] Lei C J, Wu S H, Yang Y, Xue J Y, Zhang Q Y. Joint trajectory and communication optimization for heterogeneous vehicles in maritime sar: Multi-agent reinforcement learning. IEEE Transactions on Vehicular Technology, 2024, 73(9): 12328−12344 doi: 10.1109/TVT.2024.3388499 [25] Wu X, Yan Q Z, Wang J C, Zhou Y H, Huang Q L, Jiang C H. Dynamic task allocation for UAV swarms in maritime rescue scenarios based on PG-MAPPO. IEEE Internet of Things Journal, 2025, 12(18): 38073−38087 doi: 10.1109/JIOT.2025.3584767 [26] Luo Q Y, Luan T H, Shi W S, Fan P Z. Deep reinforcement learning based computation offloading and trajectory planning for multi-UAV cooperative target search. IEEE Journal on Selected Areas in Communications, 2022, 41(2): 504−520 doi: 10.23919/ccc64809.2025.11179539 [27] Hou Y K, Zhao J, Zhang R Q, Cheng X, Yang L Q. UAV swarm cooperative target search: A multi-agent reinforcement learning approach. IEEE Transactions on Intelligent Vehicles, 2022, 9(1): 568−578 [28] Panait L, Luke S. Cooperative multi-agent learning: The state of the art. Autonomous Agents and Multi-Agent Systems, 2005, 11(3): 387−434 doi: 10.1007/s10458-005-2631-2 [29] Liu M H, Zhou M, Zhang W N, Zhuang Y Z, Wang J, Liu W L, et al. Multi-agent interactions modeling with correlated policies. arXiv preprint arXiv: 2001.03415, 2020. [30] Du X, Ye Y T, Zhang P Y, Yang Y N, Chen M S, Wang T. Situation-dependent causal influence-based cooperative multi-agent reinforcement learning. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2024. 17362–17370 [31] Li P Y, Tang H Y, Yang T P, Hao X T, Sang T, Zheng Y, et al. PMIC: Improving multi-agent reinforcement learning with progressive mutual information collaboration. In: Proceedings of the 39th International Conference on Machine Learning. Seoul, South Korea: PMLR, 2022. 12979–12997 [32] Kim W J, Jung W Y, Cho M S, Sung Y C. A variational approach to mutual information-based coordination for multi-agent reinforcement learning. arXiv preprint arXiv: 2303.00451, 2023. [33] Kim W J, Jung W Y, Cho M S, Sung Y C. Signal instructed coordination in cooperative multi-agent reinforcement learning. arXiv preprint arXiv: 1909.04224, 2019. [34] Seitzer M, Schölkopf B, Martius G. Causal influence detection for improving efficiency in reinforcement learning. In: Proceedings of the 2021 Advances in Neural Information Processing Systems. Virtual Event: NeurlPS, 2021. 22905–22918 [35] Higgins I, Matthey L, Pal A, Burgess C, Glorot X, Botvinick M, et al. Beta-VAE: Learning basic visual concepts with a constrained variational framework. In: Proceedings of the 2017 International Conference on Learning Representations. Toulon, France: ICLR, 2017. 60–81 -

 下载:
下载:

计量
- 文章访问数: 284
- HTML全文浏览量: 118
- PDF下载量: 60
- 被引次数: 0
