

Construction and Evaluation of Multi-agent Automated Penetration Testing Framework Based on Large Language Models
-
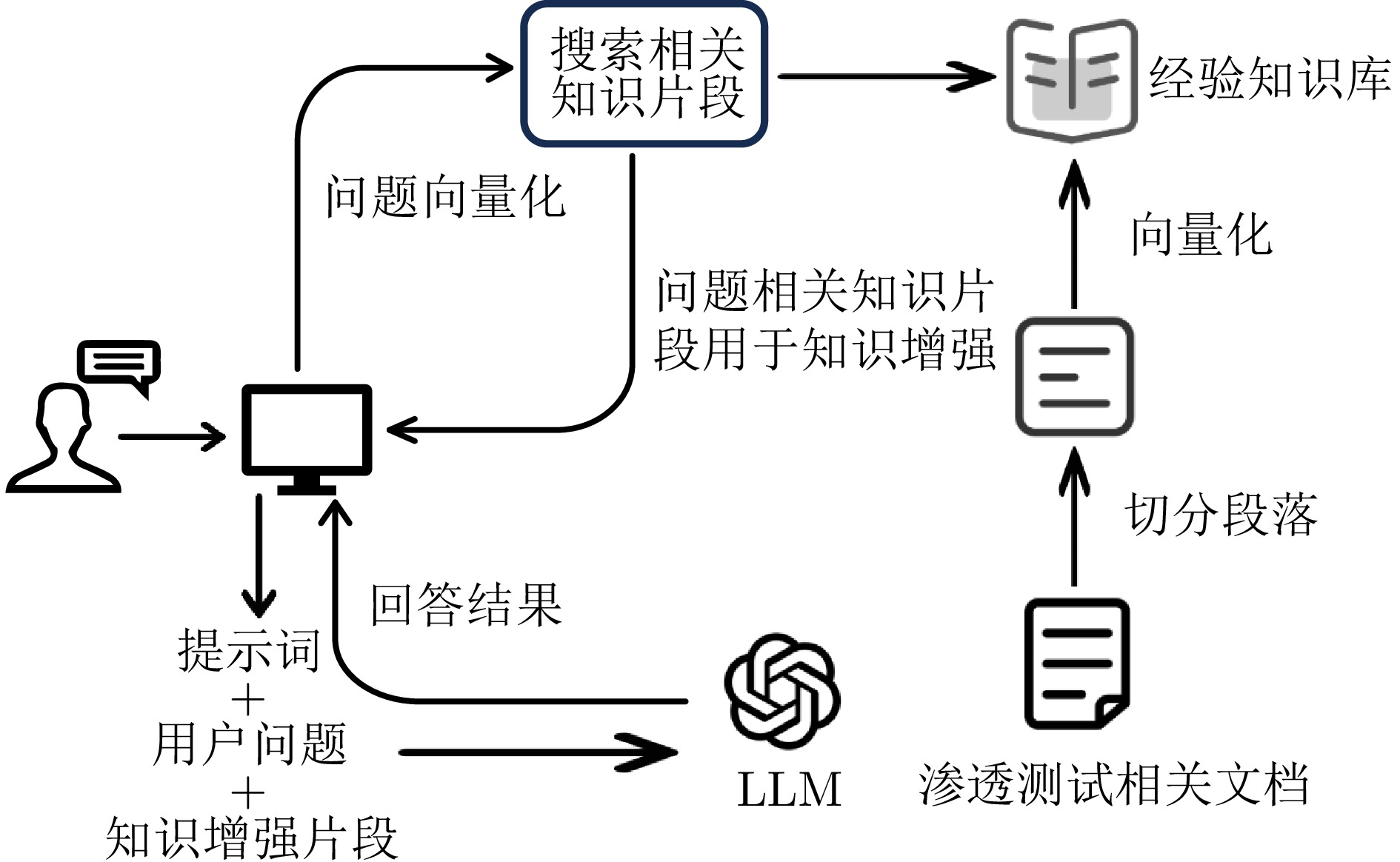
摘要: 渗透测试作为一种主动的安全评估手段, 在保障网络安全中发挥着至关重要的作用. 传统的渗透测试通常高度依赖专家经验和人工操作, 测试过程复杂且耗时. 基于大语言模型的渗透测试智能体能够在测试环境中生成和调整策略, 相较于传统的方式, 具备更强的创新性和适应性. 在大语言模型辅助渗透测试的过程中, 存在因测试路径偏移、大语言模型“幻觉”问题而导致渗透测试任务中断或失败的情况. 基于此, 提出一个基于大语言模型的多智能体渗透测试框架LangPentest, 旨在通过自然语言处理技术提高攻击策略的自动生成和执行能力, 框架采用了大语言模型驱动的程序框架(LangChain)和检索增强生成技术, 提高LangPentest性能并降低大语言模型在应用渗透测试方面的“幻觉”问题. 框架由任务生成、任务执行、经验管理和任务调整四部分模块组成, 对基准目标测试后, 基于Claude 3.5 Sonnet模型的框架任务成功率最高; 且与AutoGPT和PentestGPT相比, 本框架在任务成功率方面具有明显优势, 在任务完成和整体性能方面证明了LangPentest的可行性和有效性.Abstract: Penetration testing, as an active security assessment approach, plays a vital role in guaranteeing network security. Conventional penetration testing typically relies heavily on expert experience and manual operations, resulting in a complex and time-consuming testing process. The penetration testing agent based on large language models is capable of generating and adjusting strategies within the testing environment. Compared with traditional methods, it demonstrates stronger innovativeness and adaptability. During the process of large language model assisted penetration testing, there exist situations where the penetration testing tasks are interrupted or fail due to test path deviations and the “hallucination” issue of large language models. Based on this, a multi-agent penetration testing framework based on large language models, namely LangPentest, is proposed, aiming to enhance the automatic generation and execution of attack strategies through natural language processing techniques. The framework employs a large language model driven program framework (LangChain) and retrieval-augmented generation technology to improve the performance of LangPentest and mitigate the “hallucination” problem of large language models in the application of penetration testing. The framework is composed of four modules: Task generation, task execution, experience management, and task adjustment. After benchmark target testing, the framework based on the Claude 3.5 Sonnet model achieves the highest task success rate. In comparison with AutoGPT and PentestGPT, this framework exhibits a distinct advantage in terms of task success rate, and proves the feasibility and effectiveness of LangPentest in task completion and overall performance.
-
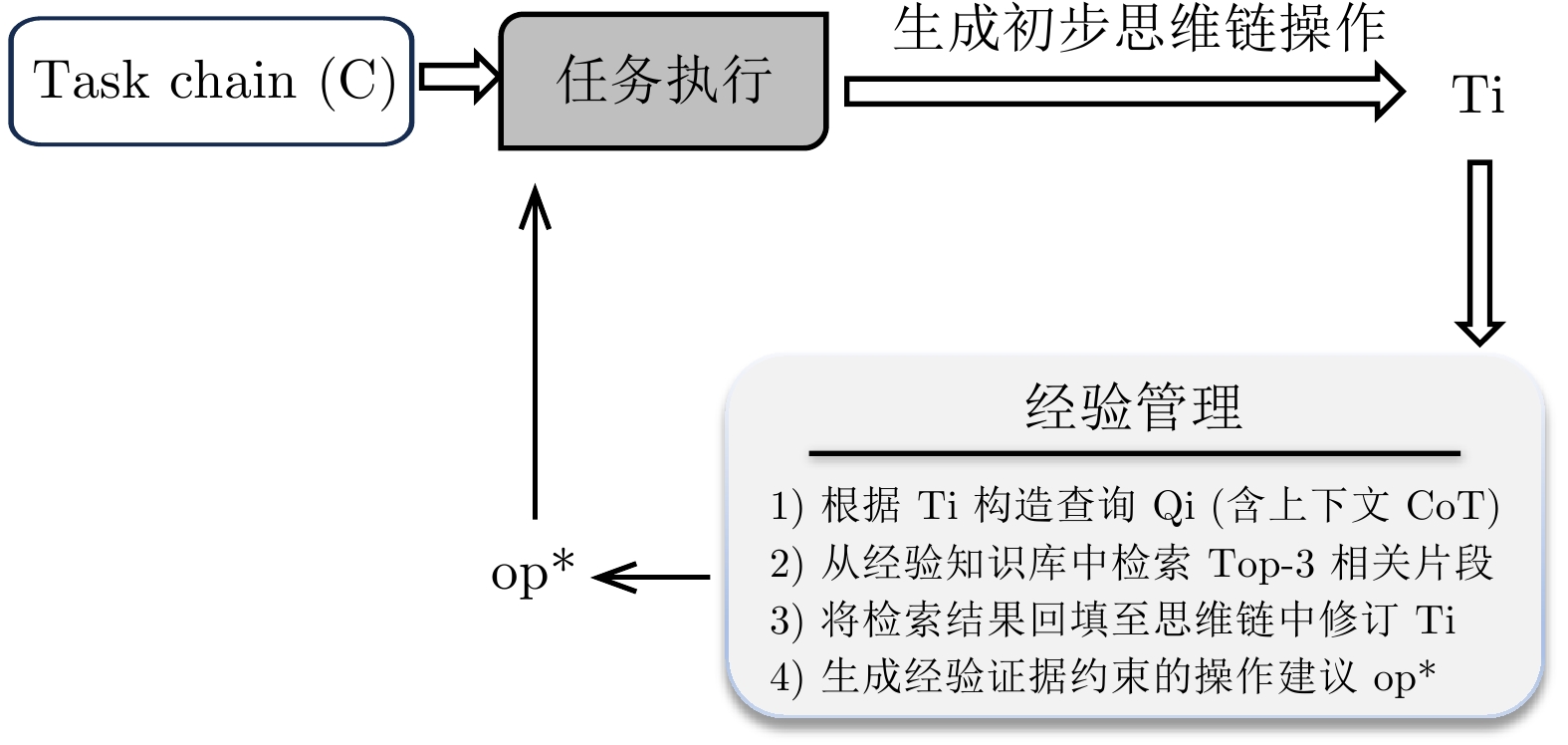
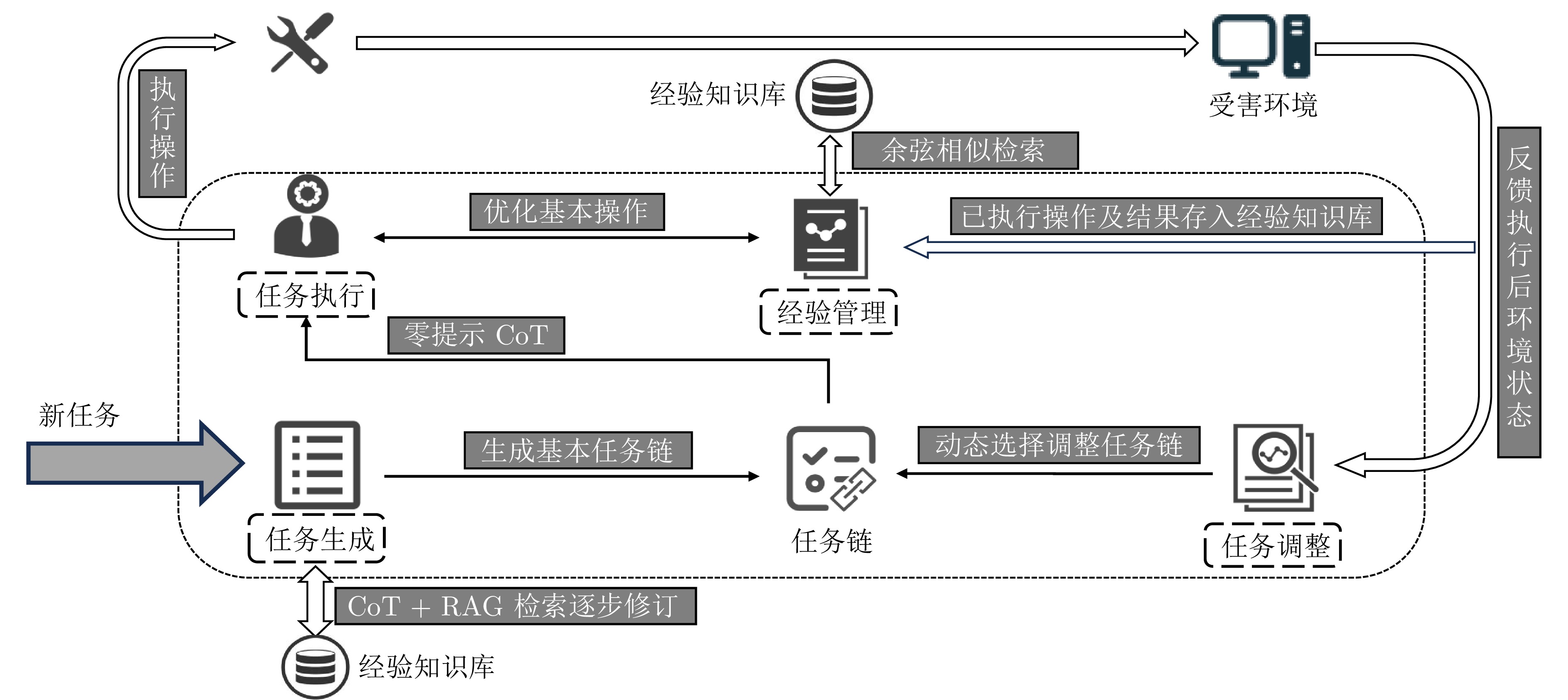
图 4 LangPentest任务执行与经验优化流程
Fig. 4 Task execution and experience optimization process in LangPentest
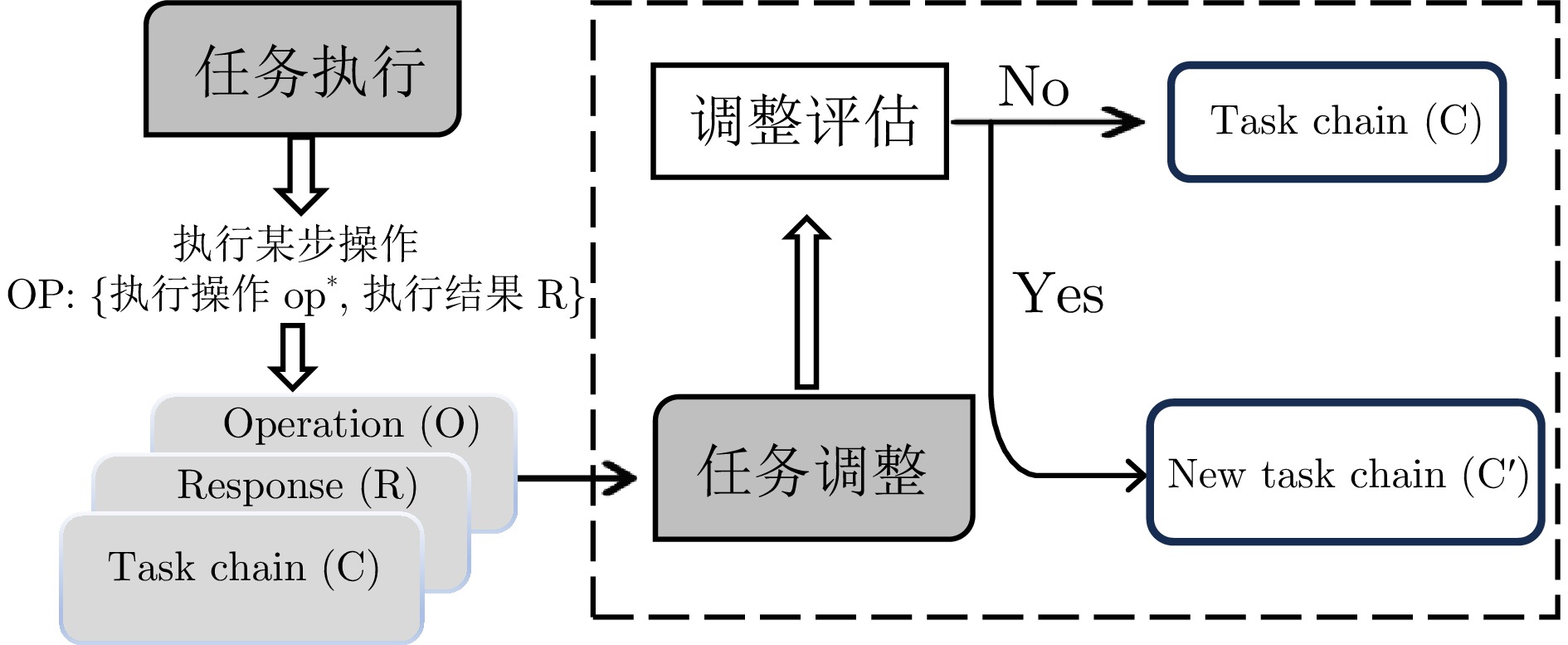
图 7 LangPentest任务调整与任务链修正流程
Fig. 7 Task adjustment and task-chain revision process in LangPentest
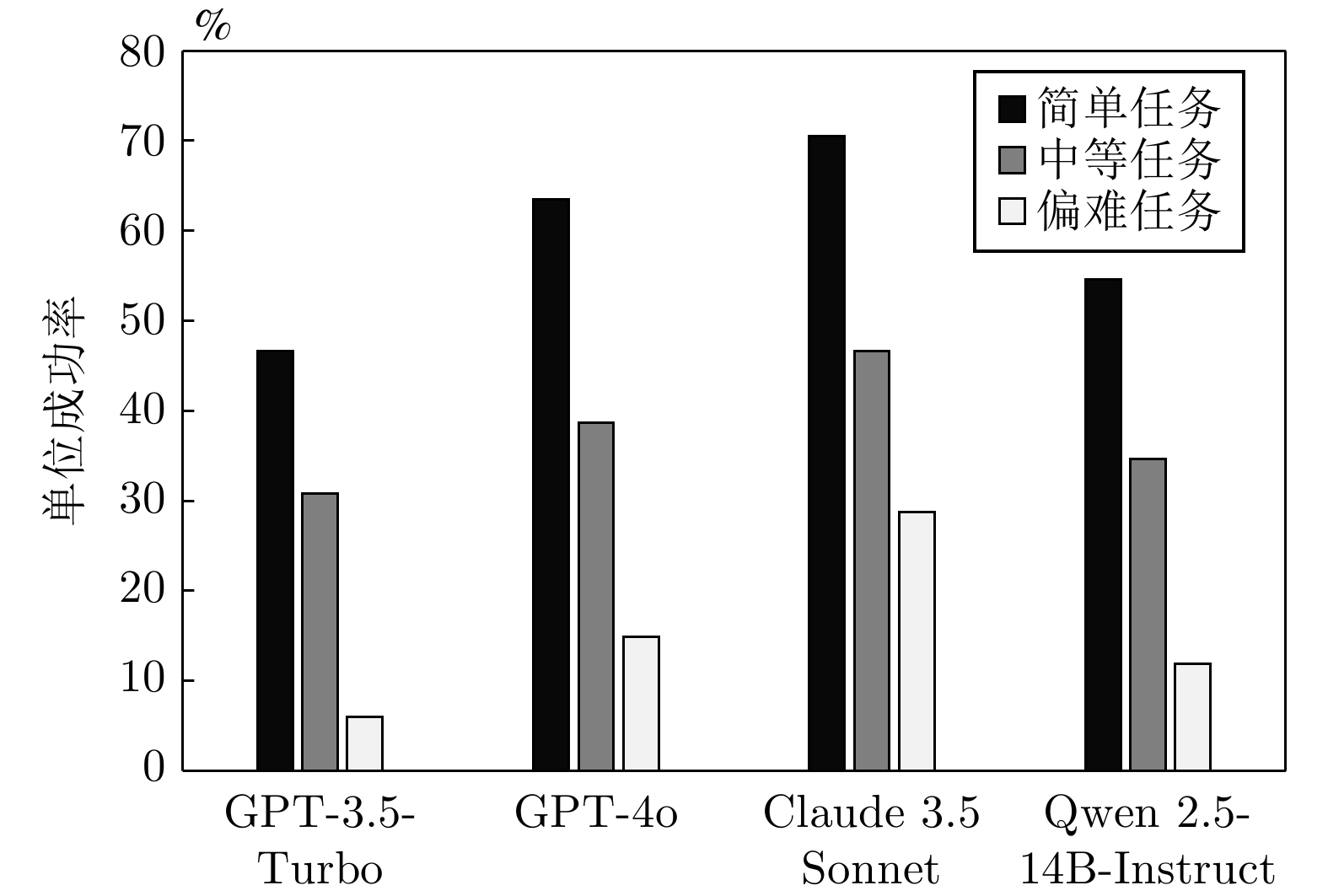
表 1 单主机单任务列表
Table 1 Single host single-task list
任务 描述 难度 文件操作 文件操作(如上传、写入、读取)的验证或利用 简单 脚本执行 在目标主机上运行自定义脚本以实现特定攻击目标 中等 远程代码执行 在目标主机上执行未经授权的代码 偏难 权限提升 利用漏洞获取更高的用户访问权限 中等 信息泄露 提取系统中敏感信息, 如配置文件和日志 中等 身份验证绕过 利用漏洞绕过目标主机或应用的身份验证机制 中等 未授权访问 利用系统或服务的配置缺陷, 绕过认证机制, 获取未授权的访问权限 偏难 路径穿越 利用路径解析漏洞访问目标主机的敏感文件 中等 SQL注入 向应用程序的SQL查询中注入恶意代码, 获取或篡改数据 简单 XML实体注入 利用XML解析器处理实体的漏洞, 读取文件导致信息泄露 中等  下载: 导出CSV
下载: 导出CSV
表 2 不同框架在典型单任务类型下的对比
Table 2 Comparison of different frameworks on typical single-task types
单任务类型 模型 成功/总次数 AutoGPT 2/5 文件上传 PentestGPT 3/5 LangPentest 4/5 AutoGPT 0/5 权限提升 PentestGPT 2/5 LangPentest 3/5 AutoGPT 0/5 XML实体注入 PentestGPT 1/5 LangPentest 1/5 AutoGPT 1/5 身份验证 PentestGPT 3/5 LangPentest 4/5 AutoGPT 0/5 Apache Log4j2 PentestGPT 1/5 LangPentest 2/5
下载: 导出CSV
表 3 LangPentest在不同任务下的成本
Table 3 Cost of LangPentest under different tasks
任务 GPT-3.5-Turbo (USD) GPT-4o (USD) Claude 3.5 Sonnet (USD) 任意文件写入 0.54 0.62 0.68 特权升级 0.68 0.68 0.73 脚本执行 0.71 0.78 0.67 本地权限提升 0.45 0.41 0.54 SQL注入 0.86 0.89 0.87 目录遍历 1.71 1.82 1.92 XML实体注入 3.24 3.42 3.61 文件上传 1.43 1.65 1.87
下载: 导出CSV
表 4 多任务成功率及交互轮次
Table 4 Multi-task success rate and interaction rounds
经验管理 任务调整 交互轮次 成功率(%) 禁用 禁用 29 42 启用 禁用 33 65 禁用 启用 27 48 启用 启用 31 78
下载: 导出CSV
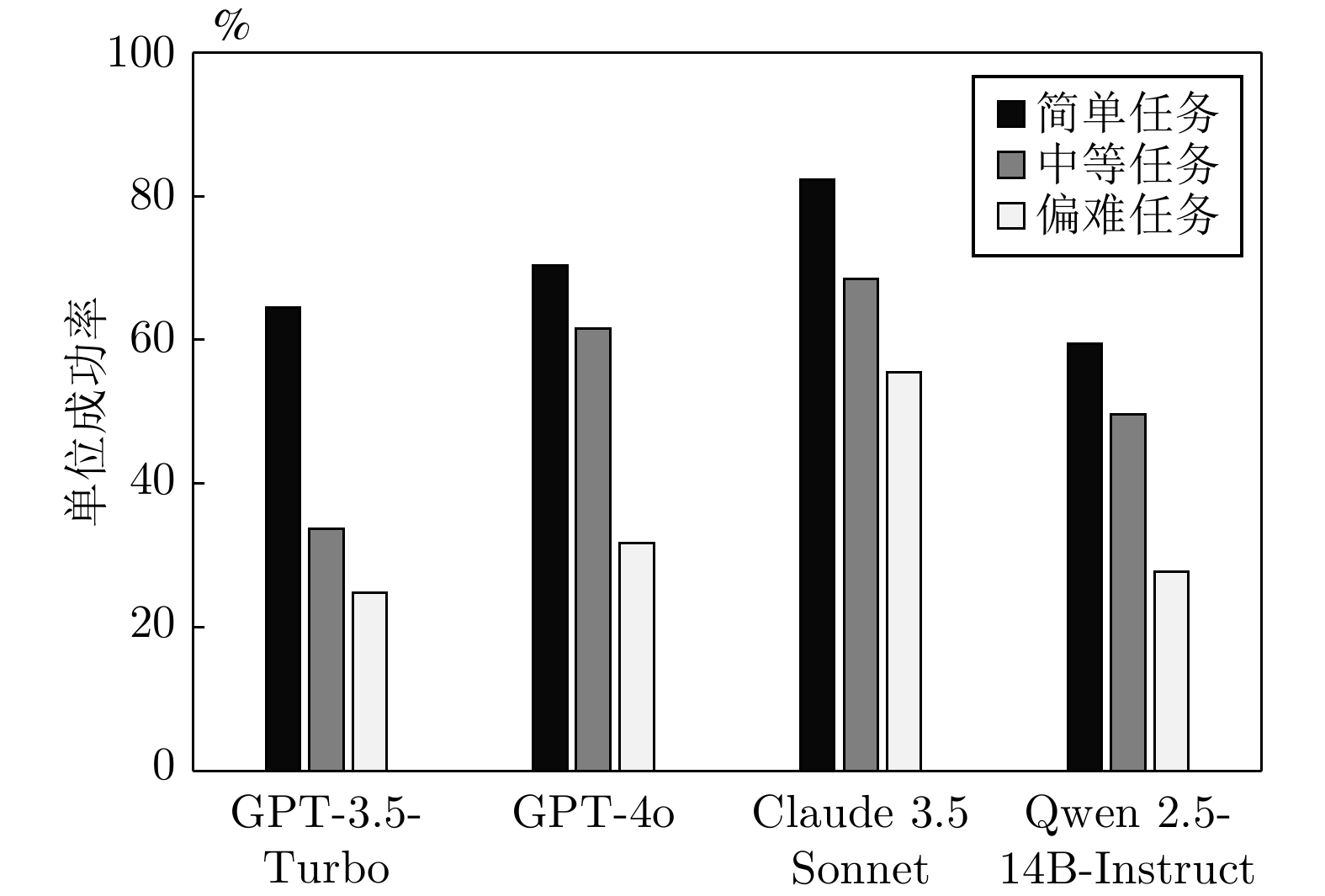
表 5 单任务成功率及交互轮次
Table 5 Single-task success rate and interaction rounds
经验管理 任务调整 交互轮次 成功率(%) 禁用 禁用 13 64 启用 禁用 12 73 禁用 启用 13 66 启用 启用 9 86
下载: 导出CSV
表 6 失败统计表
Table 6 Failure statistics table
失败类型 典型现象 数量 证据绑定不足 召回片段相关但未严格引用 7 环境前置条件/依赖缺失 权限/端口/依赖报错 10 长上下文/记忆衰减 遗忘前置发现 8 任务调整触发保守 连续弱失败未改路 5
下载: 导出CSV
-
[1] El Kafhali S, El Mir I, Hanini M. Security threats, defense mechanisms, challenges, and future directions in cloud computing. Archives of Computational Methods in Engineering, 2022, 29(1): 223−246 doi: 10.1007/s11831-021-09573-y [2] Pfleeger C P, Pfleeger S L, Theofanos M F. A methodology for penetration testing. Computers & Security, 1989, 8(7): 613−620 doi: 10.1016/0167-4048(89)90054-0 [3] Denis M, Zena C, Hayajneh T. Penetration testing: Concepts, attack methods, and defense strategies. In: Proceedings of the IEEE Long Island Systems, Applications and Technology Conference (LISAT). Farmingdale, USA: IEEE, 2016. 1−6 [4] Stefinko Y, Piskozub A, Banakh R. Manual and automated penetration testing. Benefits and drawbacks. Modern tendency. In: Proceedings of the 13th International Conference on Modern Problems of Radio Engineering, Telecommunications and Computer Science (TCSET). Lviv, Ukraine: IEEE, 2016. 488−491 [5] Kojima T, Gu S S, Reid M, Matsuo Y, Iwasawa Y. Large language models are zero-shot reasoners. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 1613 [6] Talebirad Y, Nadiri A. Multi-agent collaboration: Harnessing the power of intelligent LLM agents. arXiv preprint arXiv: 2306.03314, 2023. [7] Wu Q Y, Bansal G, Zhang J Y, Wu Y R, Li B B, Zhu E K, et al. AutoGen: Enabling next-gen LLM applications via multi-agent conversations. In: Proceedings of the 1st Conference on Language Modeling. Philadelphia, USA: 2024. [8] He J D, Treude C, Lo D. LLM-based multi-agent systems for software engineering: Literature review, vision, and the road ahead. ACM Transactions on Software Engineering and Methodology, 2025, 34(5): Article No. 124 doi: 10.1145/3712003 [9] Tran K T, Dao D, Nguyen M D, Pham Q V, O'Sullivan B, Nguyen H D. Multi-agent collaboration mechanisms: A survey of LLMs. arXiv preprint arXiv: 2501.06322, 2025. [10] Kong H, Hu D, Ge J G, Li L X, Li T, Wu B Z. VulnBot: Autonomous penetration testing for a multi-agent collaborative framework. arXiv preprint arXiv: 2501.13411, 2025. [11] Shen X M, Wang L Z, Li Z Y, Chen Y, Zhao W C, Sun D W, et al. PentestAgent: Incorporating LLM agents to automated penetration testing. In: Proceedings of the 20th ACM Asia Conference on Computer and Communications Security. Hanoi, Vietnam: ACM, 2025. 375−391 [12] Happe A, Cito J. Getting pwn'd by AI: Penetration testing with large language models. In: Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. San Francisco, USA: ACM, 2023. 2082−2086 [13] Ji Z W, Lee N, Frieske R, Yu T Z, Su D, Xu Y, et al. Survey of hallucination in natural language generation. ACM Computing Surveys, 2023, 55(12): Article No. 248 [14] Dziri N, Milton S, Yu M, Zaiane O, Reddy S. On the origin of hallucinations in conversational models: Is it the datasets or the models? In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle, USA: ACL, 2022. 5271−5285 [15] CVE Program. CVE.TM program mission [Online], available: https://www.cve.org, December 25, 2025 [16] Wang Z H, Liu A J, Lin H W, Li J Q, Ma X J, Liang Y T. RAT: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation. arXiv preprint arXiv: 2403.05313, 2024. [17] Lewis P, Perez E, Piktus A, Petroni F, Karpukhin V, Goyal N, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 793 [18] Sarker K U, Yunus F, Deraman A. Penetration taxonomy: A systematic review on the penetration process, framework, standards, tools, and scoring methods. Sustainability, 2023, 15(13): Article No. 10471 doi: 10.3390/su151310471 [19] Nmap.org. Get Nmap 7.99 here [Online], available: https://nmap.org, December 25, 2025 [20] Greenbone Networks. OPENVAS by Greenbone [Online], available: https://www.openvas.org, December 25, 2025 [21] Rapid7. Metasploit [Online], available: https://www.metasploit.com, December 25, 2025 [22] Hu Z G, Beuran R, Tan Y S. Automated penetration testing using deep reinforcement learning. In: Proceedings of the IEEE European Symposium on Security and Privacy Workshops (EuroS&PW). Genoa, Italy: IEEE, 2020. 2−10 [23] Zhang K Q, Yang Z R, Başar T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. Handbook of Reinforcement Learning and Control. Cham: Springer, 2021. 321−384 [24] Takaesu I. Deep Exploit [Online], available: https://github.com/13o-bbr-bbq/machine_learning_security/blob/master/DeepExploit/README.md, December 25, 2025 [25] Moreno A C, Hernandez-Suarez A, Sanchez-Perez G, Toscano-Medina L K, Perez-Meana H, Portillo-Portillo J, et al. Analysis of autonomous penetration testing through reinforcement learning and recommender systems. Sensors, 2025, 25(1): Article No. 211 doi: 10.3390/s25010211 [26] 高文龙, 周天阳, 赵子恒, 朱俊虎. 基于深度强化学习的网络攻击路径规划方法. 信息安全学报, 2022, 7(5): 65−78 doi: 10.19363/J.cnki.cn10-1380/tn.2022.09.06Gao Wen-Long, Zhou Tian-Yang, Zhao Zi-Heng, Zhu Jun-Hu. Network attack path planning method based on deep reinforcement learning. Journal of Cyber Security, 2022, 7(5): 65−78 doi: 10.19363/J.cnki.cn10-1380/tn.2022.09.06 [27] OpenAI. GPT-3.5 [Online], available: https://platform.openai.com/docs/models, December 25, 2025 [28] OpenAI. GPT-4 [Online], available: https://platform.openai.com/docs/models, December 25, 2025 [29] Deng G L, Liu Y, Mayoral-Vilches V, Liu P, Li Y K, Xu Y, et al. PentestGPT: Evaluating and harnessing large language models for automated penetration testing. In: Proceedings of the 33rd USENIX Security Symposium (USENIX Security 24). Philadelphia, USA: USENIX Association, 2024. Article No. 48 [30] Xu J C, Stokes J W, McDonald G, Bai X S, Marshall D, Wang S Y, et al. AutoAttacker: A large language model guided system to implement automatic cyber-attacks. arXiv preprint arXiv: 2403.01038, 2024. [31] Muzsai L, Imolai D, Lukács A. HackSynth: LLM agent and evaluation framework for autonomous penetration testing. arXiv preprint arXiv: 2412.01778, 2024. [32] NIST. NVD: National vulnerability database [Online], available: https://nvd.nist.gov, December 25, 2025 [33] OSV. A distributed vulnerability database for Open Source [Online], available: https://osv.dev, December 25, 2025 [34] Vulhub. Vulhub [Online], available: https://vulhub.org, December 25, 2025 [35] National Institute of Standards and Technology (NIST). Common vulnerability scoring system SIG [Online], available: https://www.first.org/cvss/, December 25, 2025 [36] VulnHub. Virtual machines [Online], available: https://www.vulnhub.com, December 25, 2025 [37] Johnson Z D. Generation, Detection, and Evaluation of Role-Play Based Jailbreak Attacks in Large Language Models [Master thesis], Massachusetts Institute of Technology, USA, 2024. [38] Chu J J, Liu Y G, Yang Z Q, Shen X Y, Backes M, Zhang Y. JailbreakRadar: Comprehensive assessment of jailbreak attacks against LLMs. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: ACL, 2024. 21538−21566 [39] Yu Z Y, Liu X G, Liang S N, Cameron Z, Xiao C W, Zhang N. Don't listen to me: Understanding and exploring jailbreak prompts of large language models. In: Proceedings of the 33rd USENIX Security Symposium (USENIX Security 24). Philadelphia, USA: USENIX Association, 2024. Article No. 262 [40] Yehudai A, Eden L, Li A L, Uziel G, Zhao Y L, Bar-Haim R, et al. Survey on evaluation of LLM-based agents. arXiv preprint arXiv: 2503.16416, 2025. [41] Anthropic. Claude 3.5 Sonnet [Online], available: https://www.anthropic.com/news/claude-3-5-sonnet, December 25, 2025 [42] Qwen. Qwen2.5: A party of foundation models! [Online], available: https://qwenlm.github.io/blog/qwen2.5, December 25, 2025 [43] Significant Gravitas. AutoGPT: An autonomous GPT-4 powered AI agent [Online], available: https://github.com/Significant-Gravitas/AutoGPT, December 25, 2025 -

 下载:
下载:





计量
- 文章访问数: 859
- HTML全文浏览量: 798
- PDF下载量: 115
- 被引次数: 0
