

-
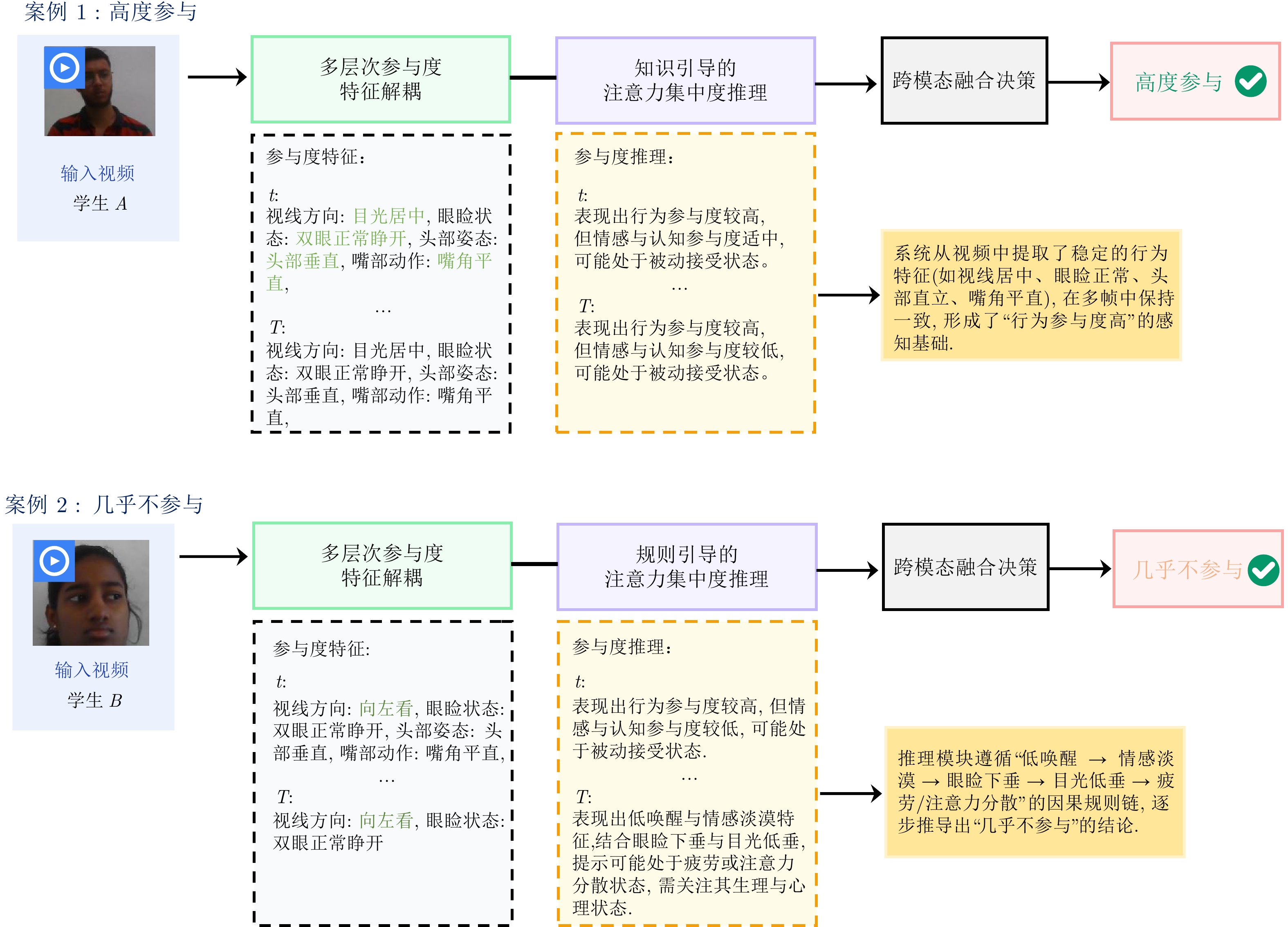
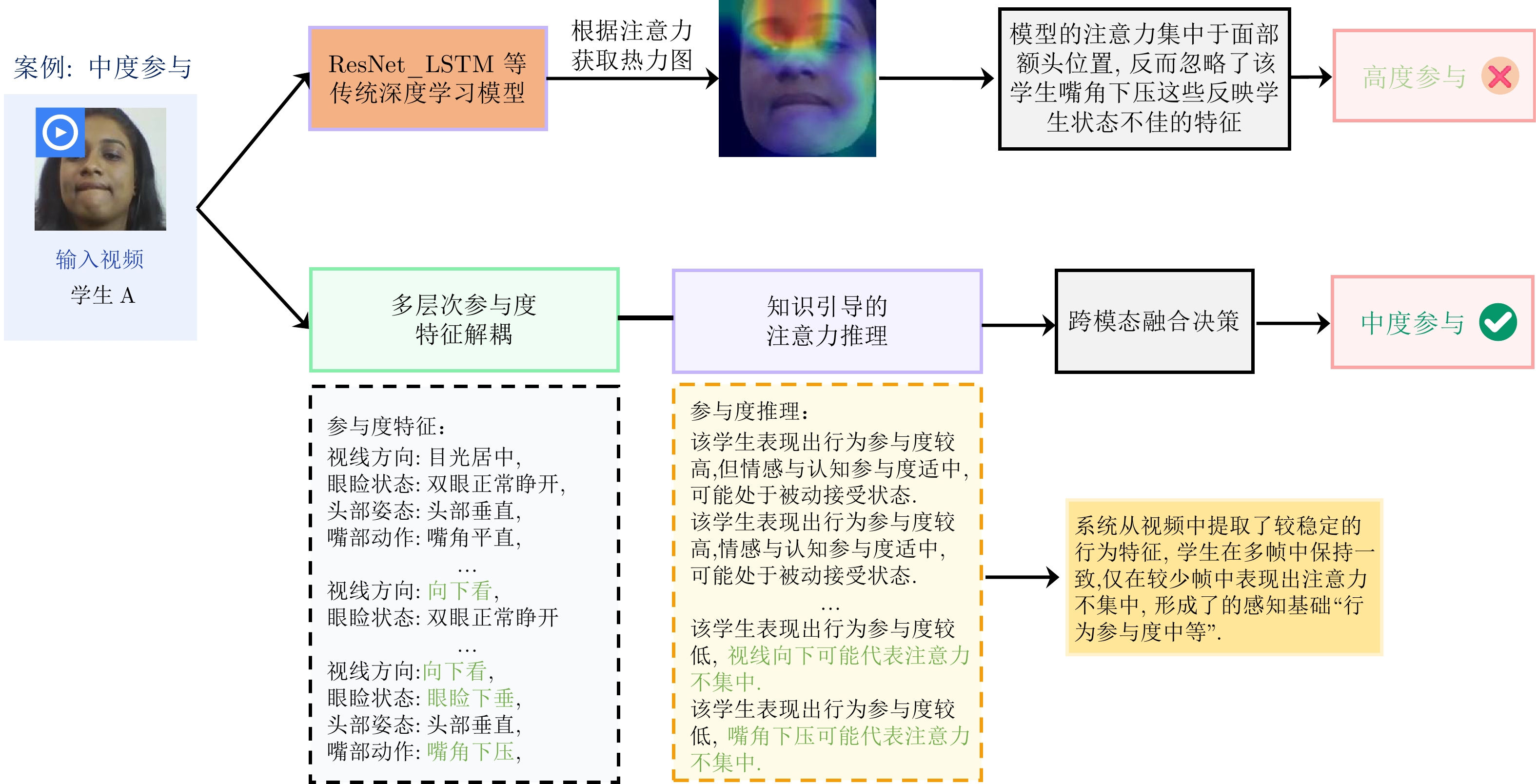
摘要: 随着在线教育的普及, 学生参与度预测(SEP)已成为评估教学效能的核心任务. 尽管视觉语言模型(VLMs)在通用多模态表征学习中表现卓越, 但直接迁移至SEP领域时, 受限于对细粒度面部微表情及特定教学语境下宏观情绪的感知瓶颈, 难以实现视觉特征与高层语义标签的精准对齐. 为此, 提出基于VLMs的多模态学生参与度预测方法VLM-SEP. 该方法先进行多层次参与度特征解耦, 从面部表情与动作姿态中提取结构化参与度特征; 再引入知识引导的注意力集中度推理, 建立离散视觉特征与参与度状态语言描述的显式映射; 最后通过跨模态融合决策, 结合视觉与文本信息实现参与度精准判别. 在三个公开数据集上的实验结果表明, 该方法有效提升了VLMs在SEP领域的适配性, 为学生参与度预测提供可解释解决方案.Abstract: With the widespread adoption of online education, student engagement prediction (SEP) has emerged as a core task in evaluating teaching effectiveness. Although vision-language models (VLMs) have demonstrated exceptional performance in general multimodal representation learning, their direct transfer to the SEP domain is hindered by perceptual bottlenecks regarding fine-grained facial micro-expressions and macro-emotions within specific pedagogical contexts. Consequently, it remains challenging to achieve a precise alignment between visual features and high-level semantic labels. To address this issue, we propose VLM-SEP, a multimodal student engagement prediction method based on VLMs. Specifically, this method first performs multi-level engagement feature decoupling to extract structured engagement features from facial expressions and body postures; Subsequently, it introduces knowledge-guided attention concentration reasoning to establish an explicit mapping between discrete visual features and linguistic descriptions of engagement states; Finally, through cross-modal fusion decision-making, it integrates visual and textual information to achieve accurate engagement assessment. Experimental results on three public datasets demonstrate that the proposed method effectively enhances the adaptability of VLMs in the SEP domain, offering an interpretable solution for student engagement prediction.
-

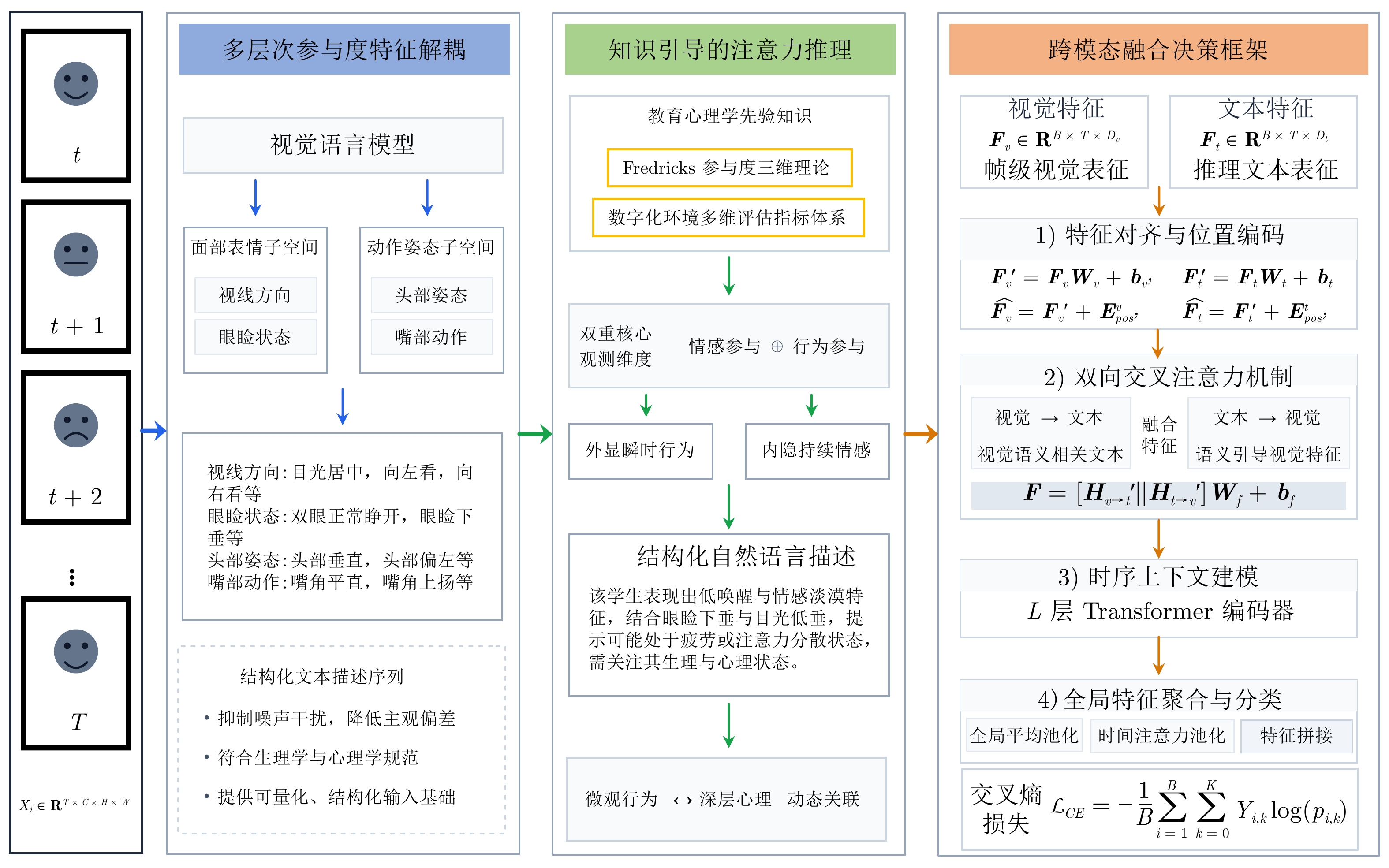
图 2 多层次参与度特征解耦模块的提示词
Fig. 2 Prompt for multi-level engagement feature decoupling module

图 4 特征解耦前后样本分布对比
Fig. 4 Comparison of sample distributions before and after feature decoupling
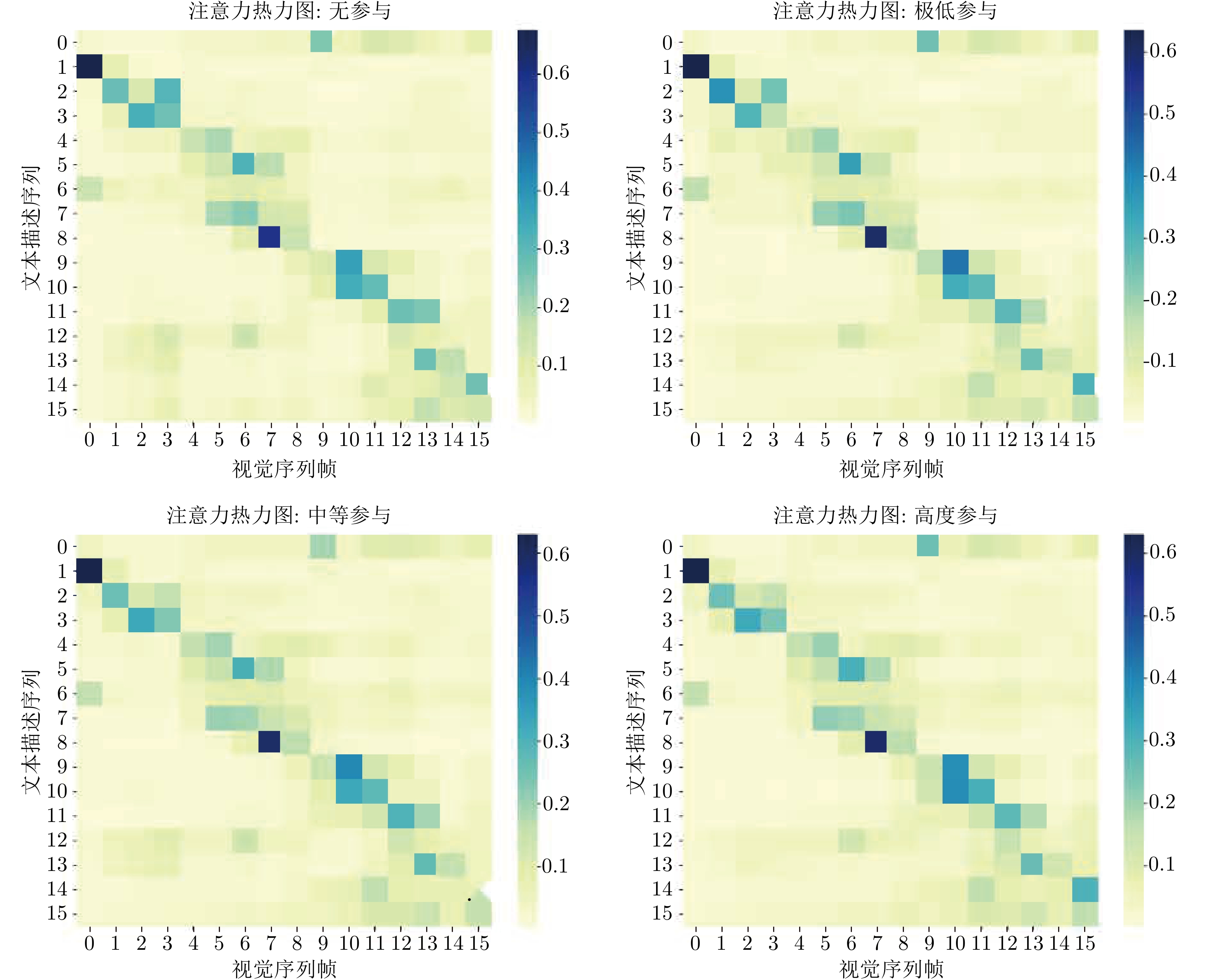
图 5 文本特征与视频特征的时序相关性热力图
Fig. 5 Temporal correlation heatmap between text and video features
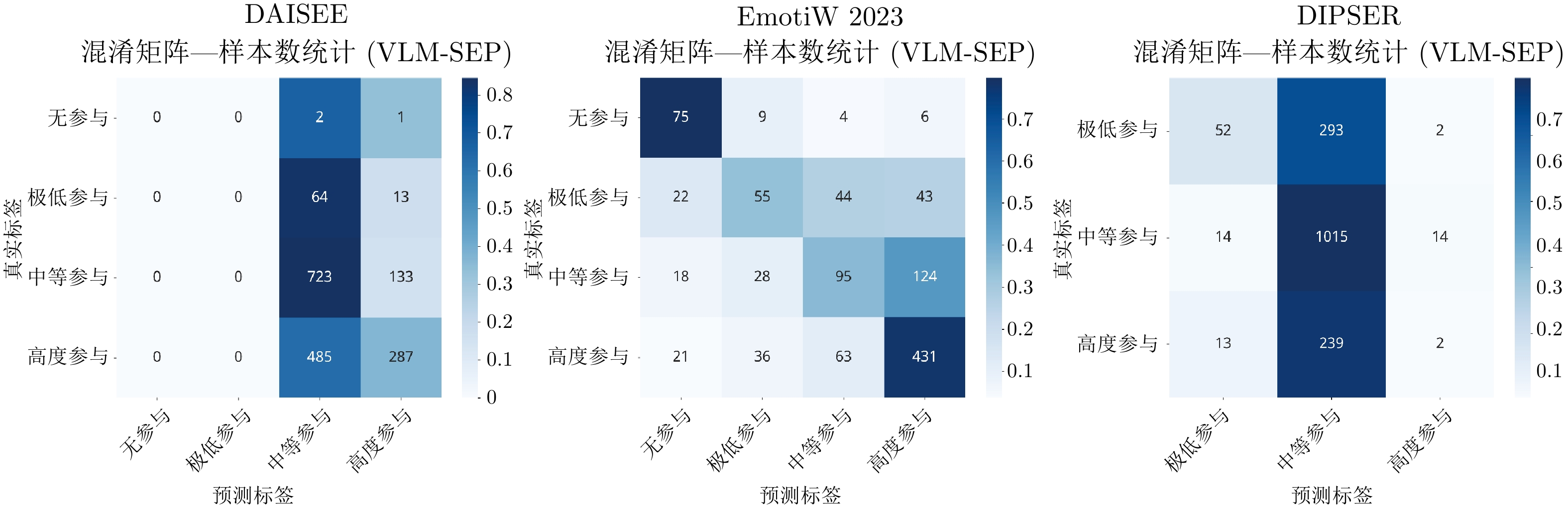
图 6 VLM-SEP方法在三个数据集上的混淆矩阵
Fig. 6 Confusion matrices of the VLM-SEP method on the three datasets
表 1 数据集分布表
Table 1 Dataset distribution table
数据集 训练集 验证集 测试集 总计 DAISEE 5 466 1 712 1 708 8 886 EmotiW2023 5 443 1 427 1 074 7 944 DIPSER 5 560 1 470 1 644 8 674  下载: 导出CSV
下载: 导出CSV
表 2 在三个学生数据集上VLM-SEP与传统方法的准确率对比(%)
Table 2 Accuracy comparison between VLM-SEP and traditional methods on three student datasets (%)
模型 输入 DAISEE EmotiW2023 DIPSER Video InceptionNet 视频帧 $ 53.98 \pm 0.30 $ $ 52.05 \pm 0.30 $ $ 63.63 \pm 0.20 $ C3D + LSTM 视频帧 $ 57.08 \pm 0.20 $ $ 51.44 \pm 0.20 $ $ 63.44 \pm 0.25 $ ResNet + LSTM 视频帧 $ 57.62 \pm 0.15 $ $ 54.05 \pm 0.15 $ $ 64.11 \pm 0.30 $ Swin-Transformer 视频帧 $ 55.62 \pm 0.30 $ $ 52.52 \pm 0.30 $ $ 63.44 \pm 0.20 $ ViViT 视频帧 $ 57.03 \pm 0.25 $ $ 54.17 \pm 0.25 $ $ 63.99 \pm 0.30 $ EfficientNet + LSTM 视频帧 $ 56.98 \pm 0.25 $ $ 58.13 \pm 0.25 $ $ 63.56 \pm 0.20 $ EfficientNet + Bi-LSTM 视频帧 $ 57.33 \pm 0.25 $ $ 58.87 \pm 0.35 $ $\underline{64.54 \pm 0.20 }$ FANN 视频帧 $ 58.08 \pm 0.30 $ $ 57.91 \pm 0.40 $ $ 64.17 \pm 0.20 $ VisioPhysioENet 视频帧 + 生理信号 $ 56.64 \pm 0.10 $ $ 51.30 \pm 0.20 $ — MGAFR 视频帧 + 文本 $\underline{58.36 \pm 0.10 }$ $\underline{59.39\pm 0.10} $ — MIST 视频帧 + 文本 $ 57.22 \pm 0.20 $ $ 57.86 \pm 0.20 $ — Video-LLaVA (7B) 视频帧 + 文本 $ 49.97 \pm 0.00 $ $ 29.73 \pm 0.00 $ $ 48.24 \pm 0.00 $ LLaVa-Next (7B) 视频帧 + 文本 $ 45.17 \pm 0.00 $ $ 24.67 \pm 0.00 $ $ 21.11 \pm 0.00 $ Qwen3-VL (8B) 视频帧 + 文本 $ 50.24 \pm 0.00 $ $ 51.30 \pm 0.00 $ $ 55.23 \pm 0.00 $ VLM-SEP 视频帧 + 文本 59.01$ \pm $0.20 61.08$ \pm $0.10 65.82$ \pm $0.20
下载: 导出CSV
表 3 消融实验
Table 3 Ablation study
消融模块 DAISEE EmotiW2023 DIPSER 准确率(%) F1分数 平均绝对误差 准确率(%) F1分数 平均绝对误差 准确率(%) F1分数 平均绝对误差 仅视觉 57.96 0.533 0 0.430 9 59.78 0.585 7 0.563 3 64.90 0.611 6 0.402 7 仅文本 53.04 0.515 9 0.485 4 60.43 0.537 7 0.533 5 63.44 0.492 5 0.365 6 简单融合 58.72 0.546 0 0.422 7 59.78 0.566 8 0.544 7 65.70 0.635 0 0.376 5 无知识引导模块 56.79 0.525 9 0.441 5 60.04 0.580 1 0.499 1 65.15 0.550 3 0.357 1 单向视觉引导文本 58.08 0.547 2 0.430 9 61.92 0.596 9 0.496 3 64.78 0.531 9 0.366 8 单向文本引导视觉 57.73 0.479 2 0.445 6 60.15 0.584 4 0.522 3 65.39 0.626 1 0.389 9 完整模型(VLM-SEP) 59.01 0.555 4 0.418 6 61.08 0.597 0 0.533 5 65.82 0.610 8 0.374 7
下载: 导出CSV
-
[1] 肖建力, 黄星宇, 姜飞. 智慧教育中的大语言模型综述. 智能系统学报, 2025, 20(5): 1054−1070 doi: 10.11992/tis.202406040Xiao Jian-Li, Huang Xing-Yu, Jiang Fei. A review of large language models in intelligent education. CAAI Transactions on Intelligent Systems, 2025, 20(5): 1054−1070 doi: 10.11992/tis.202406040 [2] Doherty K, Doherty G. Engagement in HCI: Conception, theory and measurement. ACM Computing Surveys, 2018, 51(5): 1−39 [3] D'Mello S K. Improving Student Engagement in and With Digital Learning Technologies. Cham: Springer, 2021. 79–104 [4] Wei Y T, Wang J X, Yang H H, Shi Y H, Zhou G W, Li X. Research on the influence of students' engagement in blended synchronous learning. In: Proceedings of the 2023 International Symposium on Educational Technology. Hong Kong, China: IEEE, 2023. 37–41 [5] Fredricks J A, Blumenfeld P C, Paris A H. School engagement: Potential of the concept, state of the evidence. Review of Educational Research, 2004, 74(1): 59−109 doi: 10.3102/00346543074001059 [6] Fredricks J A, Filsecker M, Lawson M A. Student engagement, context, and adjustment: Addressing definitional, measurement, and methodological issues. Learning and Instruction, 2016, 43: 1−4 doi: 10.1016/j.learninstruc.2016.02.002 [7] Li T, Zhu A. How online classroom interaction tool change the teaching and learning mode under the traditional computer-assisted instruction? In: Proceedings of the International Conference on Computer Science and Educational Informatization. Kunming, China: IEEE, 2019. 25–29 [8] Smith J, Schreder K. Are they paying attention, or are they shoe-shopping? Evidence from online learning. International Journal of Multidisciplinary Perspectives in Higher Education, 2020, 5(1): 200−209 [9] 莫元娇. 基于跨分支注意力学习的课堂学生参与度预测方法. 工业控制计算机, 2025, 38(1): 118−120 doi: 10.3969/j.issn.1001-182X.2025.01.045Mo Yuan-Jiao. Classroom student engagement prediction method based on cross-branch attention learning. Industrial Control Computer, 2025, 38(1): 118−120 doi: 10.3969/j.issn.1001-182X.2025.01.045 [10] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 770–778 [11] Geng L, Xu M, Wei Z Q, Zhou X Z. Learning deep spatiotemporal feature for engagement recognition of online courses. In: Proceedings of the Symposium Series on Computational Intelligence. Xiamen, China: IEEE, 2019. 442–447 [12] 沃焱, 梁籍云, 韩国强. 基于度量学习的跨模态人脸检索方法. 华南理工大学学报(自然科学版), 2022, 50(6): 1−9Wo Yan, Liang Ji-Yun, Han Guo-Qiang. Cross-modal face retrieval method based on metric learning. Journal of South China University of Technology (Natural Science Edition), 2022, 50(6): 1−9 [13] Zhang H, Xiao X F, Huang T, Liu S Y, Xia Y, Li J. A novel end-to-end network for automatic student engagement recognition. In: Proceedings of the 9th International Conference on Electronics Information and Emergency Communication. Beijing, China: IEEE, 2019. 342–345 [14] Liao J C, Liang Y, Pan J H. Deep facial spatiotemporal network for engagement prediction in online learning. Applied Intelligence, 2021, 51(10): 6609−6621 doi: 10.1007/s10489-020-02139-8 [15] Liu Z, Kong W Z, Peng X, Yang Z K, Liu S, Liu S Q, et al. Dual-feature-embeddings-based semisupervised learning for cognitive engagement classification in online course discussions. Knowledge-Based Systems, 2023, 259: Article No. 110053 doi: 10.1016/j.knosys.2022.110053 [16] Huang T, Mei Y S, Zhang H, Liu S Y, Yang H L. Fine-grained engagement recognition in online learning environment. In: Proceedings of the 9th International Conference on Electronics Information and Emergency Communication. Beijing, China: IEEE, 2019. 338–341 [17] Singh M, Hoque X, Zeng D H, Wang Y N, Ikeda K, Dhall A. Do I have your attention: A large scale engagement prediction dataset and baselines. In: Proceedings of the 25th ACM International Conference on Multimodal Interaction. New York, USA: ACM, 2023. 174–182 [18] Vedernikov A, Kumar P, Chen H Y, Seppänen T, Li X B. TCCT-Net: Two-stream network architecture for fast and efficient engagement estimation via behavioral feature signals. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2024. 4723–4732 [19] Deng Y Y, Bian J T, Wu S S, Lai J H, Xie X H. Multiplex graph aggregation and feature refinement for unsupervised incomplete multimodal emotion recognition. Information Fusion, 2025, 114: Article No. 102711 doi: 10.1016/j.inffus.2024.102711 [20] Singh A, Verma N, Goyal K, Singh A, Kumar P, Li X B. VisioPhysioENet: Multimodal engagement detection using visual and physiological signals. arXiv preprint arXiv: 2409.16126, 2024. [21] Boitel E, Mohasseb A, Haig E. MIST: Multimodal emotion recognition using DeBERTa for text, Semi-CNN for speech, ResNet-50 for facial, and 3D-CNN for motion analysis. Expert Systems With Applications, 2025, 270: Article No. 126236 doi: 10.1016/j.eswa.2024.126236 [22] Liu Y H, Kuang Z Y, Zhang H Y, Li C, Li F F, Ding X H. PRADA: Prompt-guided representation alignment and dynamic adaption for time series forecasting. Knowledge-Based Systems, 2025, 318: Article No. 113478 doi: 10.1016/j.knosys.2025.113478 [23] Zou X, Li X H, Hu P, Dong M. MrBalance: A framework for enhancing event causality identification in multi-agent debates via role assignment. Knowledge-Based Systems, 2025: Article No. 114470 [24] Qi X Y, Zeng Y, Xie T H, Chen P Y, Jia R X, Mittal P, et al. Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv: 2310.03693, 2023. [25] Heilporn G, Raynault A, Frenette É. Student engagement in a higher education course: A multidimensional scale for different course modalities. Social Sciences & Humanities Open, 2024, 9: Article No. 100794 doi: 10.1016/j.ssaho.2023.100794 [26] Fredricks J A, McColskey W. The measurement of student engagement: A comparative analysis of various methods and student self-report instruments. Handbook of Research on Student Engagement. Boston, MA: Springer US, 2012. 763–782 [27] Blikstein P. Multimodal learning analytics. In: Proceedings of the 3rd International Conference on Learning Analytics and Knowledge. New York, USA: ACM, 2013. 102–106 [28] Yang A, Li A F, Yang B S, Zhang B C, Hui B Y, Zheng B, et al. Qwen3 technical report. arXiv preprint arXiv: 2505.09388, 2025. [29] Gupta A, D'Cunha A, Awasthi K, Balasubramanian V. DAI-SEE: Towards user engagement recognition in the wild. arXiv preprint arXiv: 1609.01885, 2016. [30] Dhall A, Singh M, Goecke R, Gedeon T, Zeng D H, Wang Y N, et al. EmotiW2023: Emotion recognition in the wild challenge. In: Proceedings of the 25th ACM International Conference on Multimodal Interaction. New York, USA: ACM, 2023. 746–749 [31] Marquez-Carpintero L, Suescun-Ferrandiz S, Álvarez C L, Fernandez-Herrero J, Viejo D, Roig-Vila R, et al. DIPSER: A dataset for in-person student engagement recognition in the wild. arXiv preprint arXiv: 2502.20209, 2025. [32] Szegedy C, Ioffe S, Vanhoucke V, Alemi A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. San Francisco, CA, USA: AAAI, 2017. 4278–4284 [33] Parmar P, Morris B. Action quality assessment across multiple actions. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Waikoloa Village, HI, USA: IEEE, 2019. 1468–1476 [34] Abedi A, Khan S S. Improving state-of-the-art in detecting student engagement with ResNet and TCN hybrid network. In: Proceedings of the 18th Conference on Robots and Vision. Burnaby, British Columbia, Canada: IEEE, 2021. 151−157 [35] Liu Z, Lin Y T, Cao Y, Hu H, Wei Y X, Zhang Z, et al. Swin Transformer: Hierarchical vision Transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, QC, Canada: IEEE, 2021. 10012–10022 [36] Arnab A, Dehghani M, Heigold G, Sun C, Lučić M, Schmid C. ViViT: A video vision Transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, QC, Canada: IEEE, 2021. 6836–6846 [37] Selim T, Elkabani I, Abdou M A. Students engagement level detection in online e-learning using hybrid EfficientNetB7 together with TCN, LSTM, and Bi-LSTM. IEEE Access, 2022, 10: 99573−99583 doi: 10.1109/ACCESS.2022.3206779 [38] Wang H, Sun H M, Zhang W L, Chen Y X, Jia R S. FANN: A novel frame attention neural network for student engagement recognition in facial video. The Visual Computer, 2025, 41: 6011−6025 doi: 10.1007/s00371-024-03768-7 [39] Lin B, Ye Y, Zhu B, Cui J X, Ning M N, Jin P, et al. Video-LLaVA: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Miami, Florida, USA: ACL, 2024. 5971–5984 [40] Li B, Zhang K C, Zhang H, Guo D, Zhang R R, Li F, et al. LLaVA-NeXT: Stronger LLMs supercharge multimodal capabilities in the wild. arXiv preprint arXiv: 2408.01073, 2024. -

 下载:
下载:

计量
- 文章访问数: 190
- HTML全文浏览量: 207
- 被引次数: 0
