

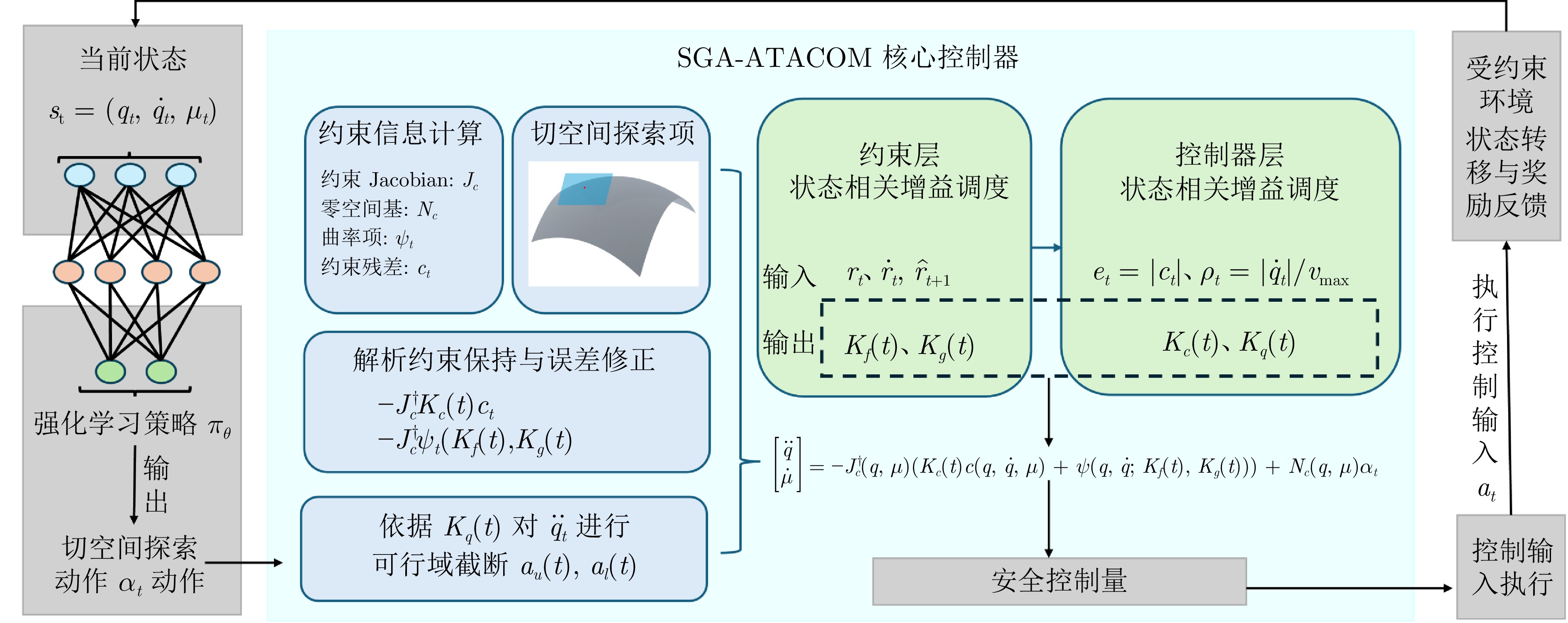
Adaptive Manifold Constrained Reinforcement Learning for Dynamic Balance Between Safety and Performance
-
摘要: 在机器人走向实际场景的过程中, 如何在严格满足安全约束的同时兼顾学习探索效率, 已成为制约智能机器人实用化的重要挑战.现有安全学习方法依赖固定控制增益参数的设计范式, 难以在训练过程中动态平衡探索效率与约束满足, 易导致过度保守或约束保持不足.为此, 提出一种面向安全-性能动态平衡的状态相关增益调度自适应 ATACOM 方法, 简称 SGA-ATACOM. 在保持 ATACOM 原有的约束流形切空间探索、解析约束保持和误差修正控制结构不变的基础上, 构建约束层与控制器层的双层在线调度机制. 其中, 约束层依据当前约束状态、变化趋势及短时预测结果, 自适应调节可行性约束参数; 控制器层结合约束残差与速度风险指标, 在线更新误差修正增益和速度可行域增益, 从而实现在风险指标较高时增强约束回拉与速度保护、在风险指标较低时释放更有效的探索空间的自适应协调. 为验证所提方法的有效性, 分别在 CircularMotion 任务和 Planar Air Hockey 机械臂任务上, 结合不同强化学习算法开展仿真实验. 实验结果表明, 该算法在不同任务场景和不同强化学习算法下均表现出良好的通用性, 能够在维持较低约束违反的同时取得更优的安全−性能平衡.消融实验进一步验证了约束层调度与控制器层调度的互补作用. 该算法为受约束强化学习中的安全−性能协同优化提供了一种具有几何可解释性和结构保持性的改进方案.Abstract: In the deployment of robots to real-world scenarios, how to achieve a balance between strict safety constraint satisfaction and learning exploration efficiency has become a critical challenge restricting the practical application of intelligent robotic systems. Existing safe learning methods generally rely on fixed control-gain design paradigms, making it difficult to dynamically balance exploration efficiency and constraint satisfaction during training, which may lead to overly conservative behavior or insufficient constraint maintenance. To address this issue, this paper proposes a state-dependent gain-scheduled adaptive ATACOM method for dynamic safety-performance balancing, termed SGA-ATACOM. Without altering the original ATACOM structure of tangent-space exploration on the constraint manifold, analytical constraint enforcement, and error-correction control, a two-layer online scheduling mechanism consisting of a constraint layer and a controller layer is developed. Specifically, the constraint layer adaptively adjusts the viability-constraint parameters according to the current constraint state, its variation trend, and short-term prediction results, while the controller layer updates the error-correction gain and the velocity-feasibility gain online based on the constraint residual and velocity-risk indicators. In this way, stronger constraint recovery and velocity protection are activated when the risk level is high, whereas more effective exploration space is released when the risk level is low. Simulation experiments are conducted on the CircularMotion task and the Planar Air Hockey manipulator task using different reinforcement learning algorithms. The results show that the method exhibits good generality across different task scenarios and reinforcement learning algorithms, and achieves a better safety-performance trade-off while maintaining low constraint violations. Ablation studies further verify the complementary roles of the constraint-layer scheduling and controller-layer scheduling mechanisms. Overall, the proposed method provides a geometrically interpretable and structure-preserving improvement for coordinated safety-performance optimization in constrained reinforcement learning.
-
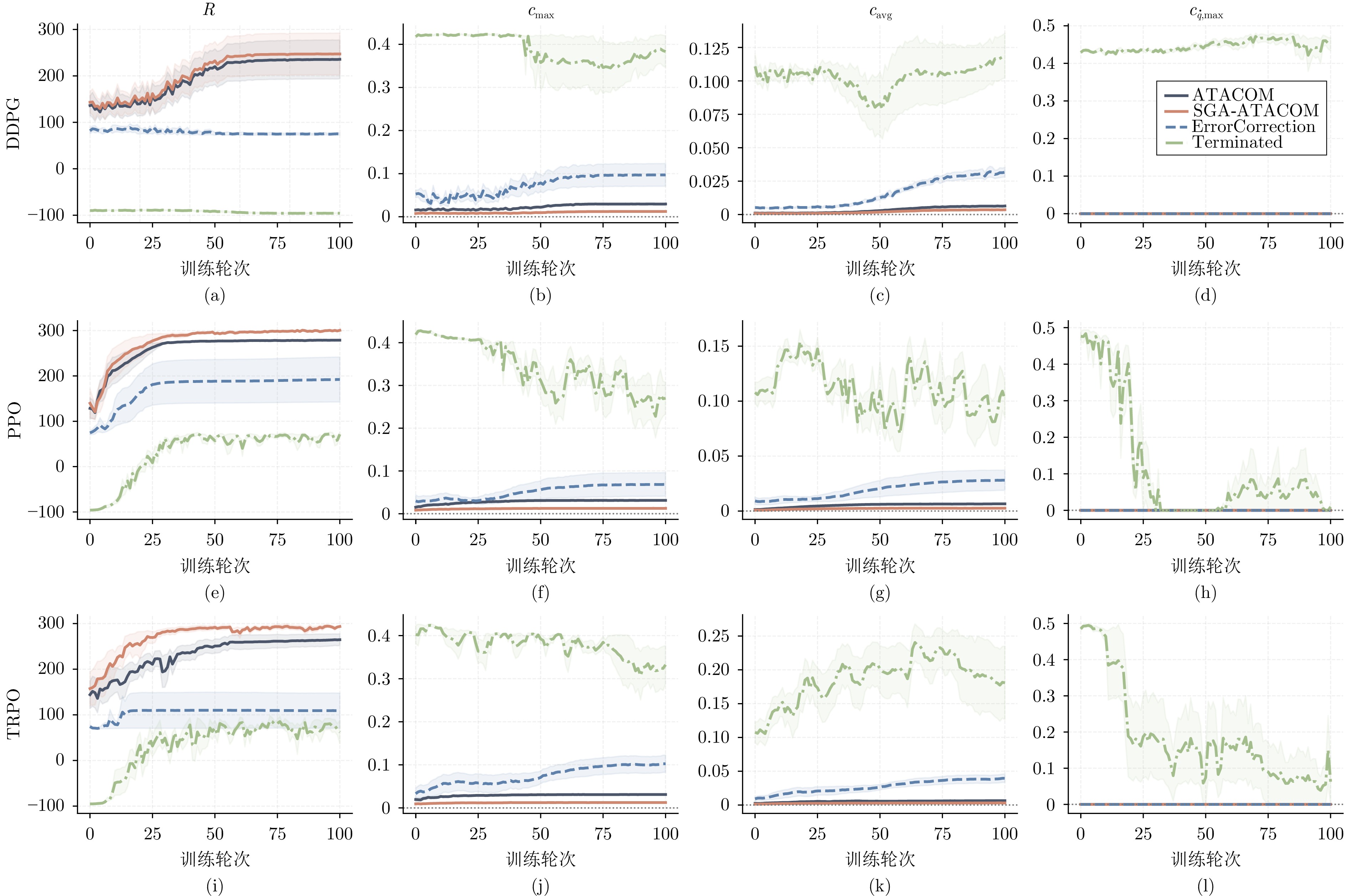
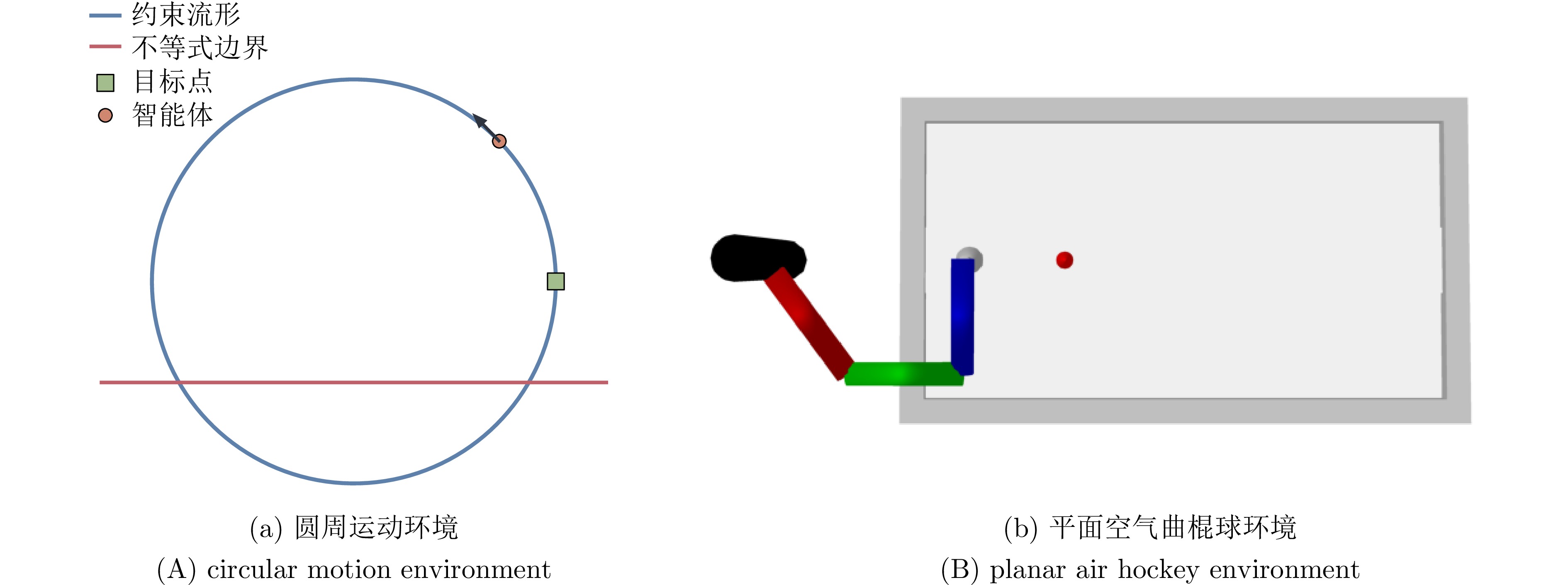
图 3 CircularMotion环境下不同方法的性能与约束对比
Fig. 3 Comparison of performance and constraints of different methods in the CircularMotion environment
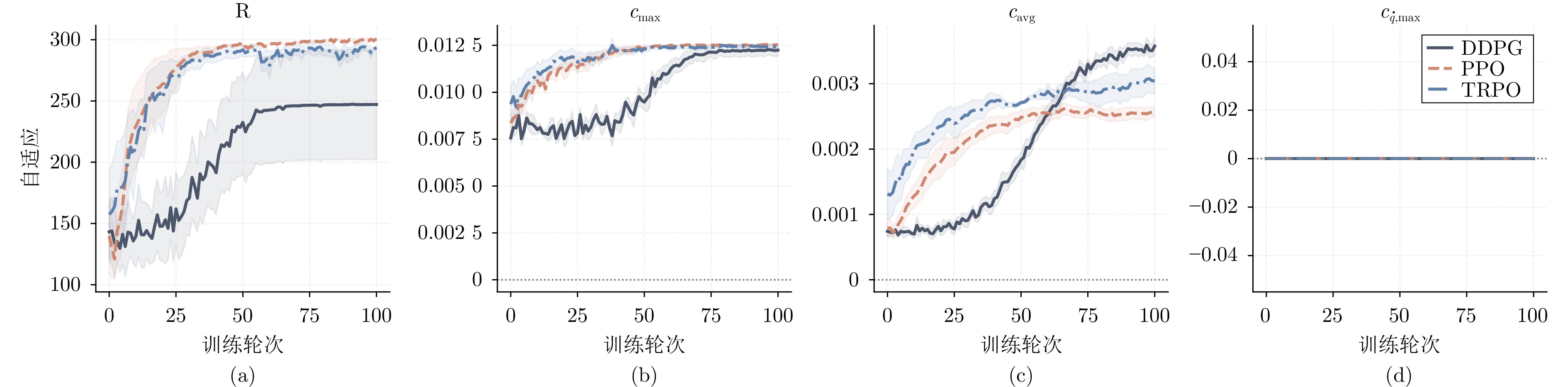
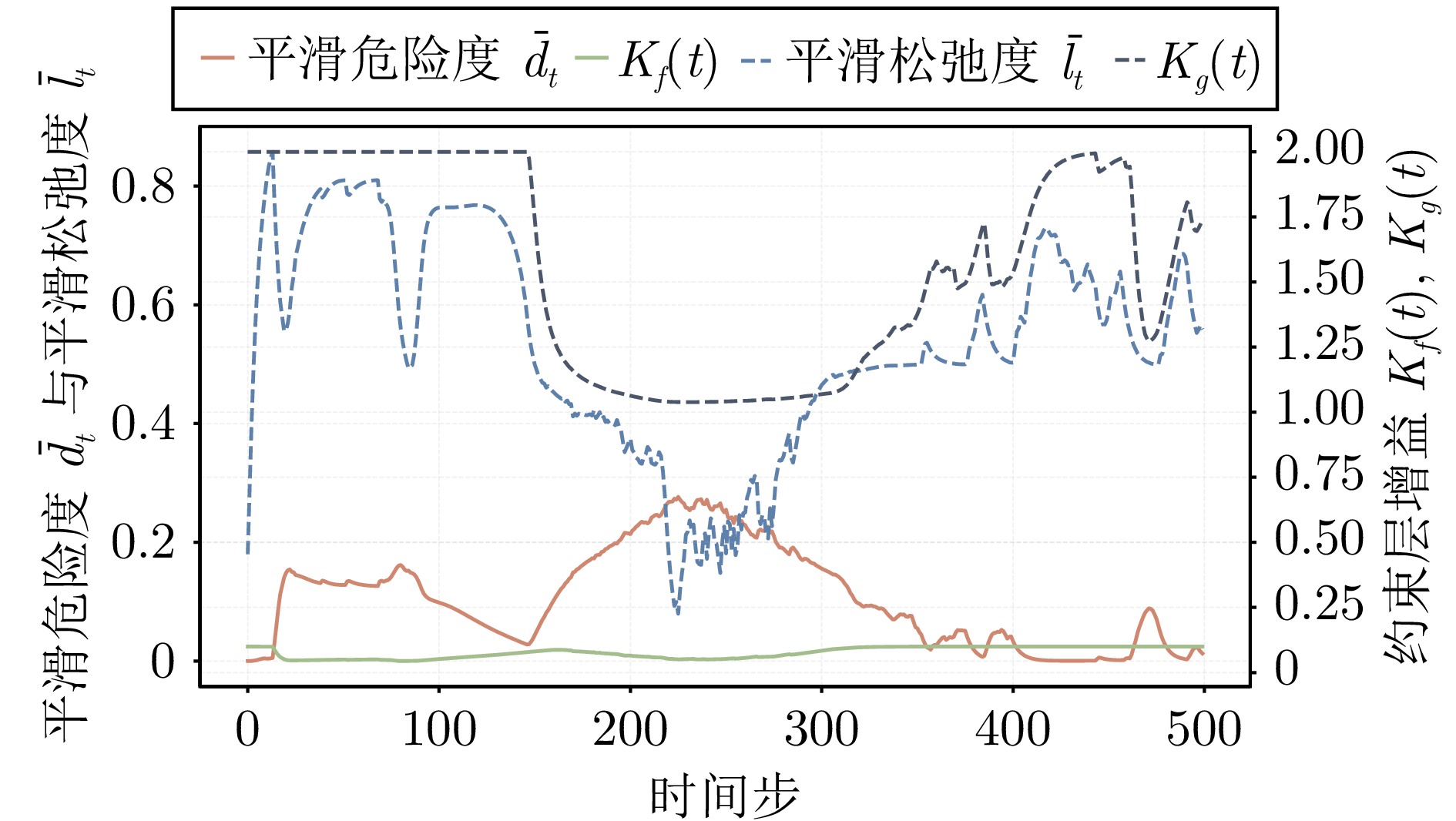
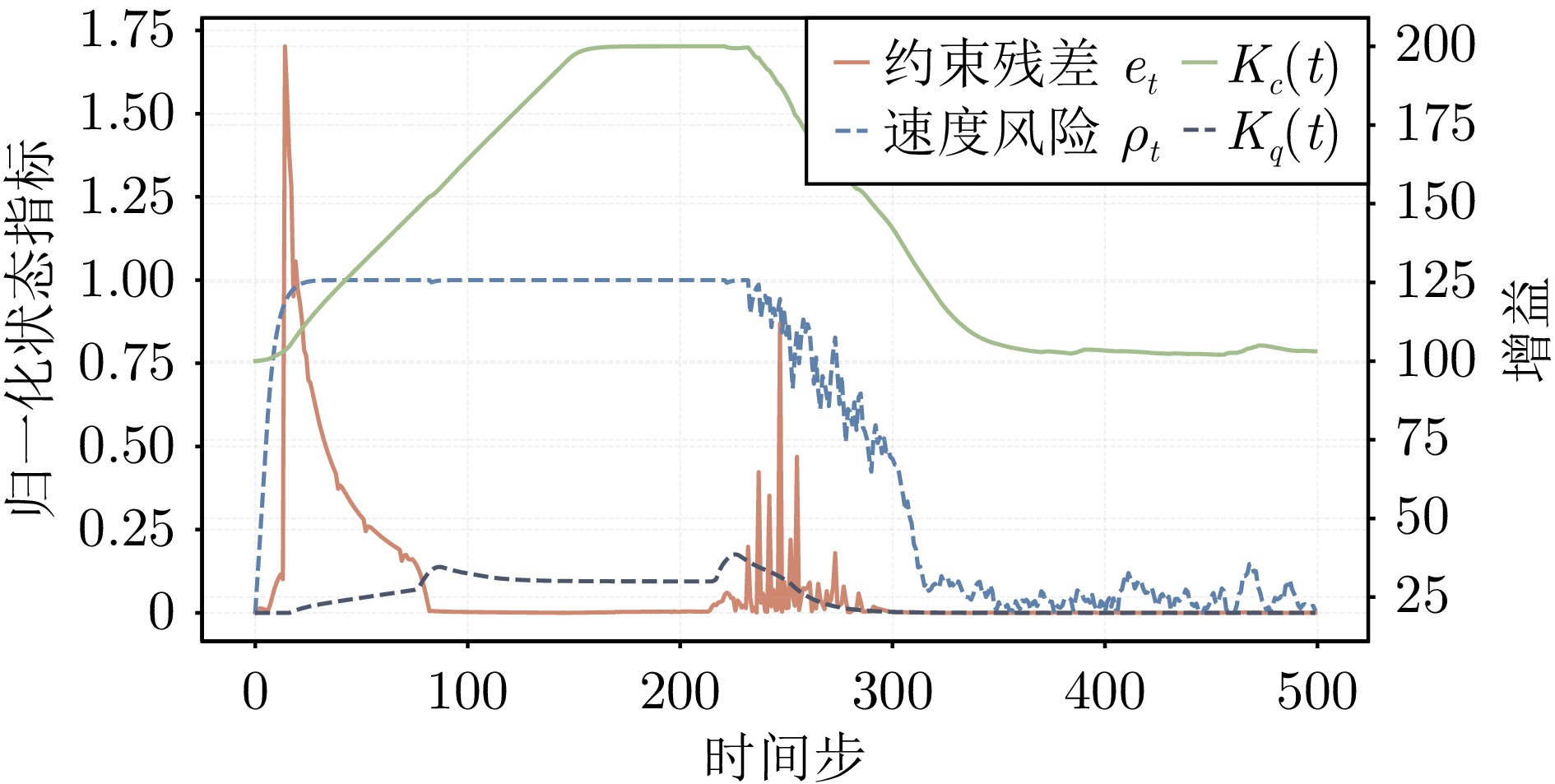
图 4 CircularMotion环境下SGA-ATACOM在不同强化学习算法上的训练曲线对比
Fig. 4 Training curves of SGA-ATACOM under different reinforcement learning algorithms in the CircularMotion environment
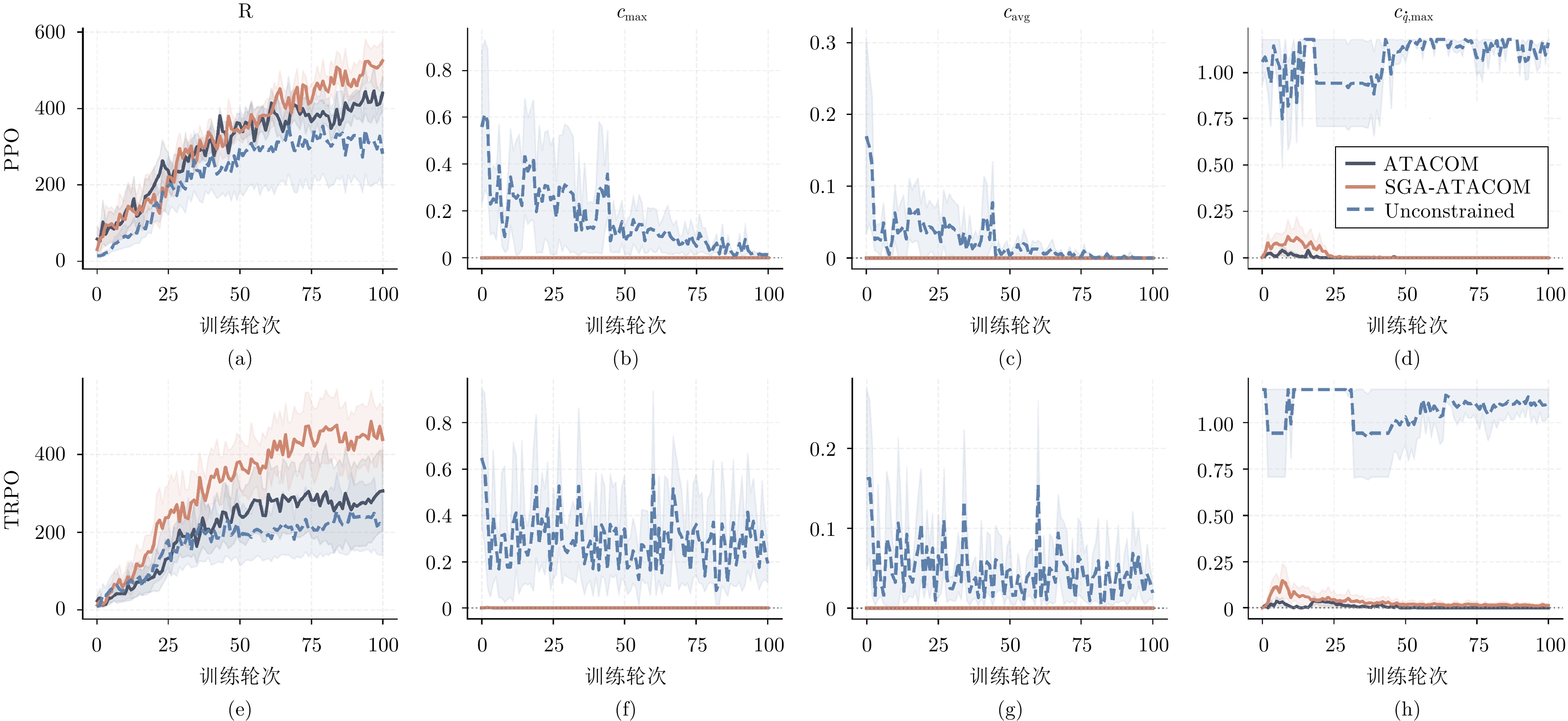
图 5 Planar Air Hockey环境下不同方法的性能与约束对比
Fig. 5 Performance and constraint comparison of different methods in the Planar Air Hockey environment
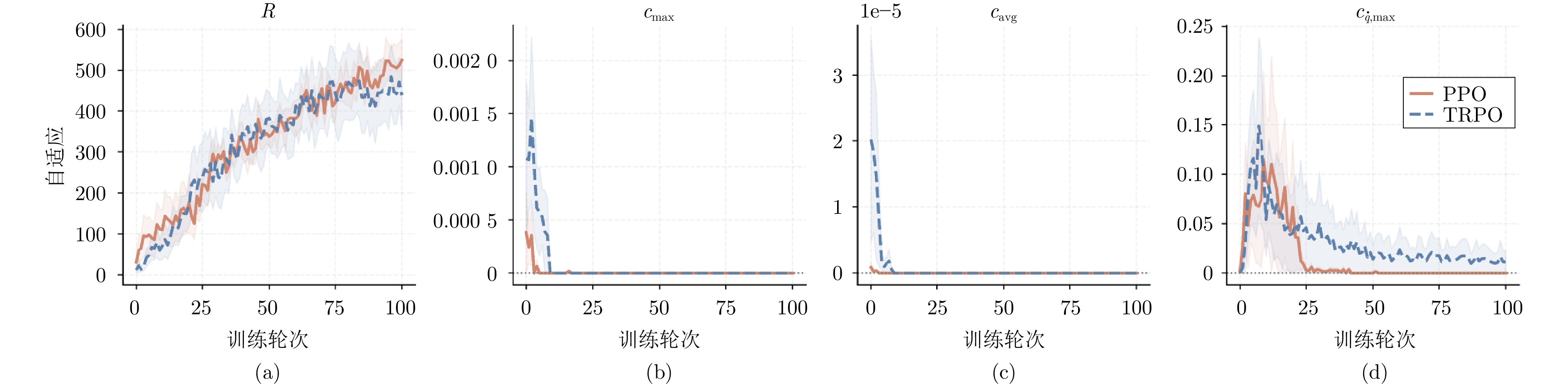
图 6 Planar Air Hockey环境下SGA-ATACOM在不同强化学习算法上的训练曲线对比
Fig. 6 Comparison of training curves of SGA-ATACOM on different reinforcement learning algorithms in the Planar Air Hockey environment
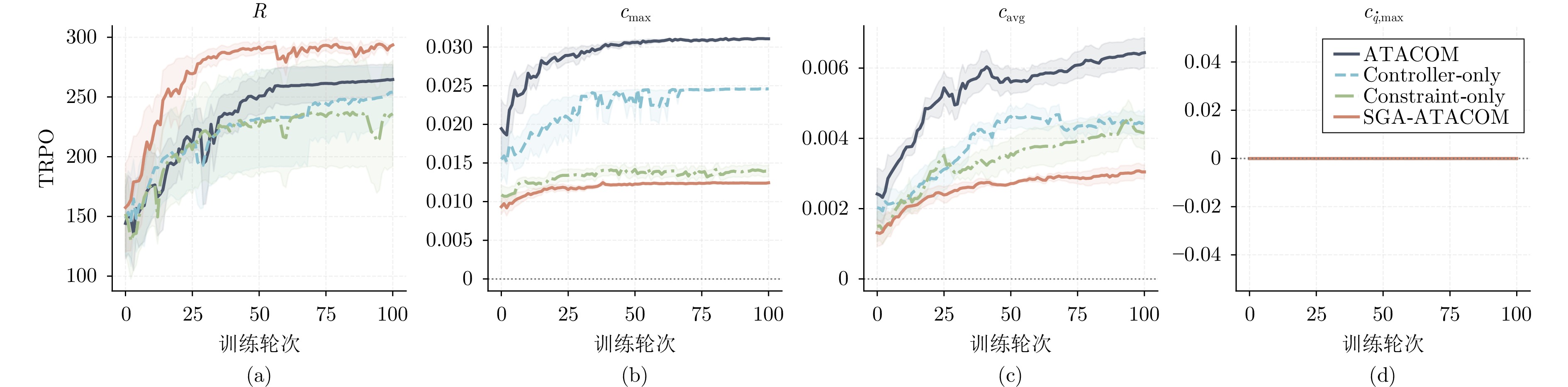
图 7 CircularMotion环境下SGA-ATACOM的消融实验结果
Fig. 7 Ablation results of SGA-ATACOM in the CircularMotion environment
表 1 SGA-ATACOM 的关键方法超参数
Table 1 Key method hyperparameters of SGA-ATACOM
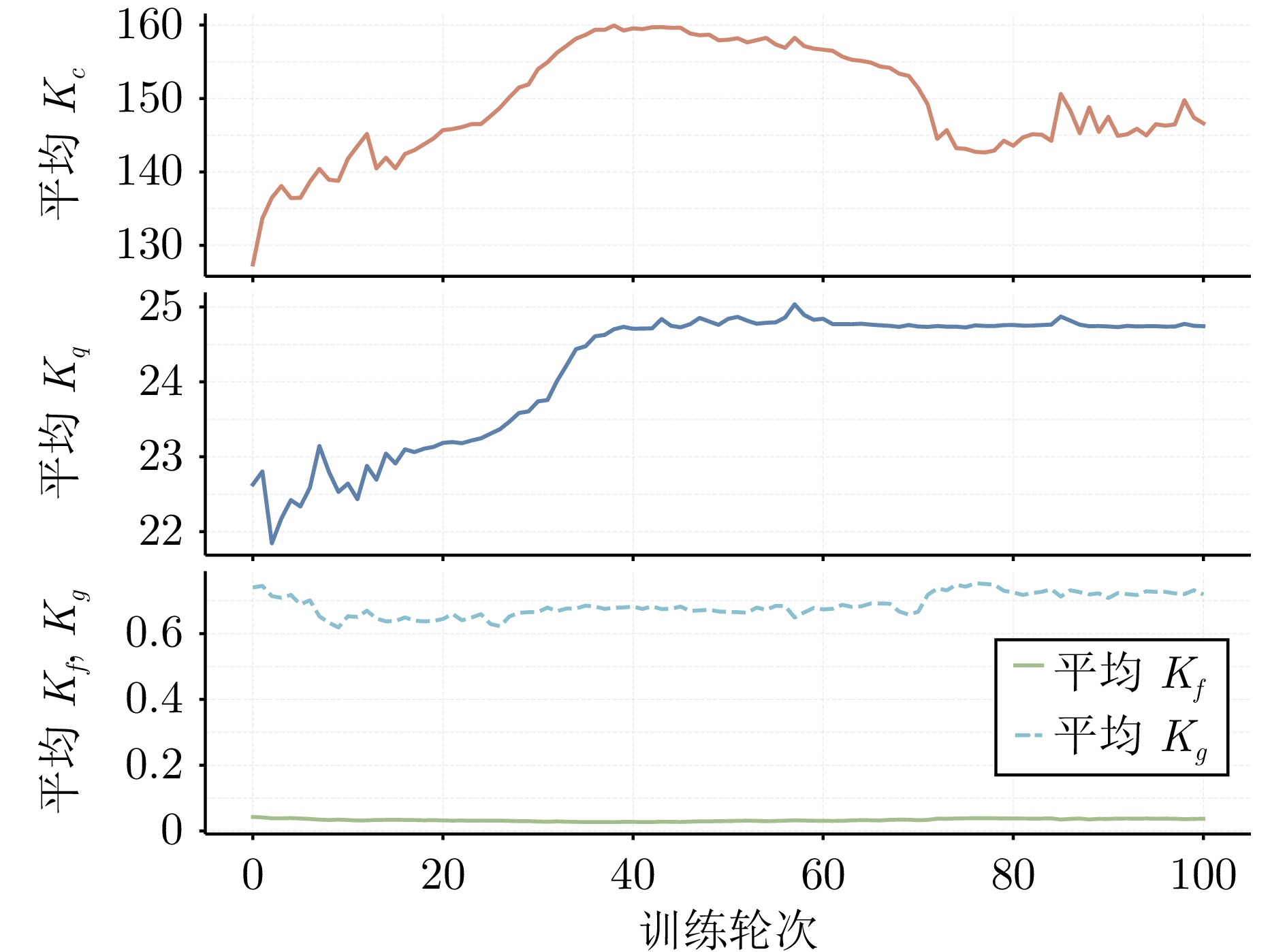
模块 参数 CircularMotion Planar Air Hockey 约束层 基线 $ K_f/K_g $ $ 0.1 / 2.0 $ $ 0.5 / 1.0 $ 调节范围 $ [k_{\min},\; k_{\max}] $ $ [0.35,\; 1.0] / [0.40,\; 1.0] $ $ [0.45,\; 1.0] / [0.50,\; 1.0] $ adaptation_rate $ 0.25 / 0.30 $ $ 0.18 / 0.16 $ danger_gain / relax_gain $ 4.0,\; 0.05 / 3.0,\; 0.05 $ $ 2.5,\; 0.04 / 2.0,\; 0.05 $ 控制器层 基线 $ K_c/K_q $ $ 100 / 20 $ $ 240 / 2a_{\max}/v_{\max} $ 最大放缩系数 $ 2.0 / 2.0 $ $ 1.8 / 1.8 $ adaptation_rate / decay_ratio $ 0.15,\; 0.35 / 0.20,\; 0.35 $ $ 0.12,\; 0.35 / 0.16,\; 0.30 $ trigger / gain / EMA $ 0.85,\; 1.5,\; 0.20 / 0.18 $ $ 0.88,\; 1.2,\; 0.18 / 0.18 $  下载: 导出CSV
下载: 导出CSV
表 2 CircularMotion 环境下不同方法的定量结果
Table 2 Quantitative results of different methods in the CircularMotion environment
算法 方法 $ R $ $ c_{\mathrm{avg}} $ $ c_{\max} $ $ c_{\dot{q},\;\max} $ DDPG ATACOM $ 235.7015 $ $ 0.006402 $ $ 0.031223 $ $ 0 $ SGA-ATACOM $ 247.1787 $ $ 0.003576 $ $ 0.012514 $ $ 0 $ 误差修正 $ 74.95398 $ $ 0.031649 $ $ 0.140175 $ $ 0 $ 终止机制 $ -95.7393 $ $ 0.118951 $ $ 0.428035 $ $ 0.498038 $ PPO ATACOM $ 278.9282 $ $ 0.006523 $ $ 0.031222 $ $ 0 $ SGA-ATACOM $ 300.6381 $ $ 0.002561 $ $ 0.012518 $ $ 0 $ 误差修正 $ 192.1773 $ $ 0.028069 $ $ 0.139112 $ $ 0 $ 终止机制 $ 71.2089 $ $ 0.101304 $ $ 0.401823 $ $ 0.046248 $ TRPO ATACOM $ 264.6153 $ $ 0.006437 $ $ 0.031204 $ $ 0 $ SGA-ATACOM $ 293.5804 $ $ 0.003045 $ $ 0.012515 $ $ 0 $ 误差修正 $ 109.1742 $ $ 0.039597 $ $ 0.135171 $ $ 0 $ 终止机制 $ 62.17836 $ $ 0.180728 $ $ 0.405737 $ $ 0.313938 $
下载: 导出CSV
表 3 Planar Air Hockey 环境下不同方法的定量结果
Table 3 Quantitative results of different methods in the Planar Air Hockey environment
算法 方法 $ R $ $ c_{\mathrm{avg}} $ $ c_{\max} $ $ c_{\dot{q},\;\max} $ PPO ATACOM $ 440.1124 $ $ 0 $ $ 0 $ $ 0 $ SGA-ATACOM $ 525.2286 $ $ 0 $ $ 0 $ $ 0 $ 无约束方法 $ 280.524 $ $ 0.000182 $ $ 0.033132 $ $ 1.178097 $ TRPO ATACOM $ 306.4537 $ $ 0 $ $ 0 $ $ 0 $ SGA-ATACOM $ 438.2295 $ $ 0 $ $ 0 $ $ 0.055845 $ 无约束方法 $ 215.1846 $ $ 0.019395 $ $ 0.37453 $ $ 1.178097 $
下载: 导出CSV
表 4 CircularMotion 环境下消融实验的定量结果
Table 4 Quantitative results of ablation experiments in CircularMotion environment
方法 $ R $ $ c_{\mathrm{avg}} $ $ c_{\max} $ $ c_{\dot{q},\;\max} $ ATACOM $ 264.615\,3 $ $ 0.006\,437 $ $ 0.031\,204 $ $ 0 $ 仅控制器层调度 $ 254.084\,3 $ $ 0.004\,486 $ $ 0.024\,616 $ $ 0 $ 仅约束层调度 $ 235.940\,3 $ $ 0.004\,151 $ $ 0.015\,066 $ $ 0 $ SGA-ATACOM $ 293.580\,4 $ $ 0.003\,045 $ $ 0.012\,515 $ $ 0 $
下载: 导出CSV
-
[1] Gu S, Yang L, Du Y, et al. A review of safe reinforcement learning: Methods, theories, and applications. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 11216−11235 doi: 10.1109/TPAMI.2024.3457538 [2] Lee J, Schroth L, Klemm V, et al. Exploring constrained reinforcement learning algorithms for quadrupedal locomotion[C]//2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024: 11132−11138 [3] Keyumarsi S, Atman M W S, Gusrialdi A. LiDAR-based online control barrier function synthesis for safe navigation in unknown environments. IEEE Robotics and Automation Letters, 2023, 9(2): 1043−1050 doi: 10.1109/lra.2023.3339059 [4] 周毅, 张浩, 施孟佶, 等. 未知环境中基于控制障碍函数的机器人安全控制研究综述. 电子科技大学学报, 2025, 54(01): 29−38 doi: 10.12178/1001-0548.2023296ZHOU Y, ZHANG H, SHI M J, et al. A review of research on robot safety control based on control barrier functions in unknown environments. Journal of University of Electronic Science and Technology of China, 2025, 54(01): 29−38 doi: 10.12178/1001-0548.2023296 [5] K?nighofer B, Bloem R, Jansen N, et al. Shields for safe reinforcement learning. Communications of the ACM, 2025, 68(11): 80−90 doi: 10.1145/3715958 [6] Dawood M, Shokry A, Bennewitz M. A dynamic safety shield for safe and efficient reinforcement learning of navigation tasks[J]. arXiv preprint arXiv: 2412.04153, 2024 [7] 董明泽, 温庄磊, 陈锡爱, 等. 安全凸空间与深度强化学习结合的机器人导航方法. 兵工学报, 2024, 45(12): 4372−4382 doi: 10.12382/bgxb.2023.0982DONG Mingze, WEN Zhuanglei, CHEN Xiai, et al. Research on Robot Navigation Method Integrating Safe Convex Space and Deep Reinforcement Learning. Journal of China Ordnance, 2024, 45(12): 4372−4382 doi: 10.12382/bgxb.2023.0982 [8] Liu P, Tateo D, Ammar H B, et al. Robot reinforcement learning on the constraint manifold[C]//Conference on Robot Learning. PMLR, 2022: 1357-1366 [9] 张昌昕, 张兴龙, 徐昕, 等. 安全强化学习及其在机器人系统中的应用综述. 控制理论与应用, 2023, 40(12): 2090−2103 doi: 10.7641/CTA.2023.30247ZHANG Changxin, ZHANG Xinglong, XU Xin, et al. Safe reinforcement learning and its applications in robotics: A survey. Control Theory & Applications, 2023, 40(12): 2090−2103 doi: 10.7641/CTA.2023.30247 [10] Altman E.Constrained Markov Decision Processes[M]. CRC Press: 2021-11-15 [11] Achiam J, Held D, Tamar A, et al. Constrained policy optimization[C]//International conference on machine learning. PMLR, 2017: 22-31 [12] Liu Y, Ding J, Liu X. Ipo: Interior-point policy optimization under constraints[C]//Proceedings of the AAAI conference on artificial intelligence. 2020, 34(04): 4940-4947 [13] Tessler C, Mankowitz D J, Mannor S. Reward constrained policy optimization[J]. arXiv preprint arXiv: 1805.11074, 2018 [14] Stooke A, Achiam J, Abbeel P. Responsive safety in reinforcement learning by pid lagrangian methods[C]//International Conference on Machine Learning. PMLR, 2020: 9133-9143 [15] Ding D, Wei X, Yang Z, et al. Provably efficient safe exploration via primal-dual policy optimization[C]//International conference on artificial intelligence and statistics. PMLR, 2021: 3304−3312 [16] Chow Y, Nachum O, Duenez-Guzman E, et al. A lyapunov-based approach to safe reinforcement learning[J]. Advances in neural information processing systems, 2018, 31 [17] 陈谋, 刘伟, 张鹏. 性能约束下的四旋翼无人机协同吊挂系统分布式避碰跟踪控制. 自动化学报, 2024, 50(12): 2392−2406 doi: 10.16383/j.aas.c240349Chen Mou, Liu Wei, Zhang Peng. Distributed collision avoidance tracking control for quadrotor cooperative suspension system under performance constraints. Acta Automatica Sinica, 2024, 50(12): 2392−2406 doi: 10.16383/j.aas.c240349 [18] Garcia J, Fernández F. Safe exploration of state and action spaces in reinforcement learning. Journal of Artificial Intelligence Research, 2012, 45: 515−564 [19] Alshiekh M, Bloem R, Ehlers R, et al. Safe reinforcement learning via shielding[C]//Proceedings of the AAAI conference on artificial intelligence. 2018, 32(1 [20] Hans A, Schneega? D, Sch?fer A M, et al. Safe exploration for reinforcement learning[C]//ESANN. 2008: 143-148 [21] 赵静, 裴子楠, 姜斌, 等. 基于深度强化学习的无人机虚拟管道视觉避障. 自动化学报, 2024, 50(11): 2245−2258 doi: 10.16383/j.aas.c230728Zhao Jing, Pei Zi-Nan, Jiang Bin, Lu Ning-Yun, Zhao Fei, Chen Shu-Feng. Virtual tube visual obstacle avoidance for UAV based on deep reinforcement learning. Acta Automatica Sinica, 2024, 50(11): 2245−2258 doi: 10.16383/j.aas.c230728 [22] Dalal G, Dvijotham K, Vecerik M, et al. Safe exploration in continuous action spaces[J]. arXiv preprint arXiv: 1801.08757, 2018 [23] Cheng R, Orosz G, Murray R M, et al. End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks[C]//Proceedings of the AAAI conference on artificial intelligence. 2019, 33(01): 3387-3395 [24] Koller T, Berkenkamp F, Turchetta M, et al. Learning-based model predictive control for safe exploration[C]//2018 IEEE conference on decision and control (CDC). IEEE, 2018: 6059−6066 [25] Hewing L, Wabersich K P, Menner M, et al. Learning-based model predictive control: Toward safe learning in control. Annual Review of Control, Robotics, and Autonomous Systems, 2020, 3(1): 269−296 doi: 10.1146/annurev-control-090419-075625 [26] Liu P, Bou-Ammar H, Peters J, et al. Safe reinforcement learning on the constraint manifold: Theory and applications[J]. IEEE Transactions on Robotics, 2025 [27] Liu P, Zhang K, Tateo D, et al. Safe reinforcement learning of dynamic high-dimensional robotic tasks: navigation, manipulation, interaction[J]. arXiv preprint arXiv: 2209.13308, 2022 [28] 张楠杰, 陈玉全, 季茂沁, 等. 面向不同粗糙程度地面的四足机器人自适应控制方法. 自动化学报, 2025, 51(07): 1585−1598 doi: 10.16383/j.aas.c240738Zhang Nan-Jie, Chen Yu-Quan, Ji Mao-Qin, Sun Yun-Kang, Wang Bing. Adaptive control method for quadruped robot facing floors of different roughness. Acta Automatica Sinica, 2025, 51(07): 1585−1598 doi: 10.16383/j.aas.c240738 [29] Miki T, Lee J, Hwangbo J, et al. Learning robust perceptive locomotion for quadrupedal robots in the wild. Science robotics, 2022, 7(62): eabk2822 doi: 10.1126/scirobotics.abk2822 -

 下载:
下载:

计量
- 文章访问数: 7
- HTML全文浏览量: 5
- 被引次数: 0
