

-
摘要: 针对具有状态约束的离散时间非线性系统, 开发一种知识驱动高效安全评判学习控制算法. 首先, 基于知识迁移技术, 利用历史任务中的先验知识来改善评判学习控制算法在当前目标任务的学习效率. 同时, 构造一类单调递减的衰减函数以避免先验知识影响控制策略的最优性. 其次, 通过设计合适的障碍函数, 成功将具有状态约束的最优调节问题转化为无约束最优调节问题, 进而建立一种安全评判学习控制框架. 利用所提控制算法, 可高效求解一类具有状态约束的非线性系统最优控制问题. 此外, 为提供严谨的理论支持, 给出了所提控制算法的收敛性证明以及控制策略的稳定性判别准则. 最后, 利用两个数值仿真实例验证了所提算法的有效性.Abstract: In this paper, a knowledge-driven efficient safe critic learning control algorithm is developed for discrete-time nonlinear systems subject to state constraints. First, leveraging knowledge transfer techniques, prior knowledge from historical tasks is utilized to enhance the learning efficiency of the critic learning control algorithm in the current target task. Meanwhile, a class of monotonically decreasing decay functions is constructed to avoid the impact of prior knowledge on the optimality of the control strategy. Secondly, by designing an appropriate barrier function, the original state-constrained optimal regulation problem is transformed into an unconstrained one, thereby enabling the development of a safe critic learning control framework. By leveraging the control algorithm, the optimal control problem for a class of nonlinear systems with state constraints can be efficiently solved. Furthermore, to provide rigorous theoretical support, the convergence proof of the control algorithm and the admissibility criterion of the control strategy are presented. Finally, the effectiveness of the proposed algorithm is verified through two numerical simulation examples.
-
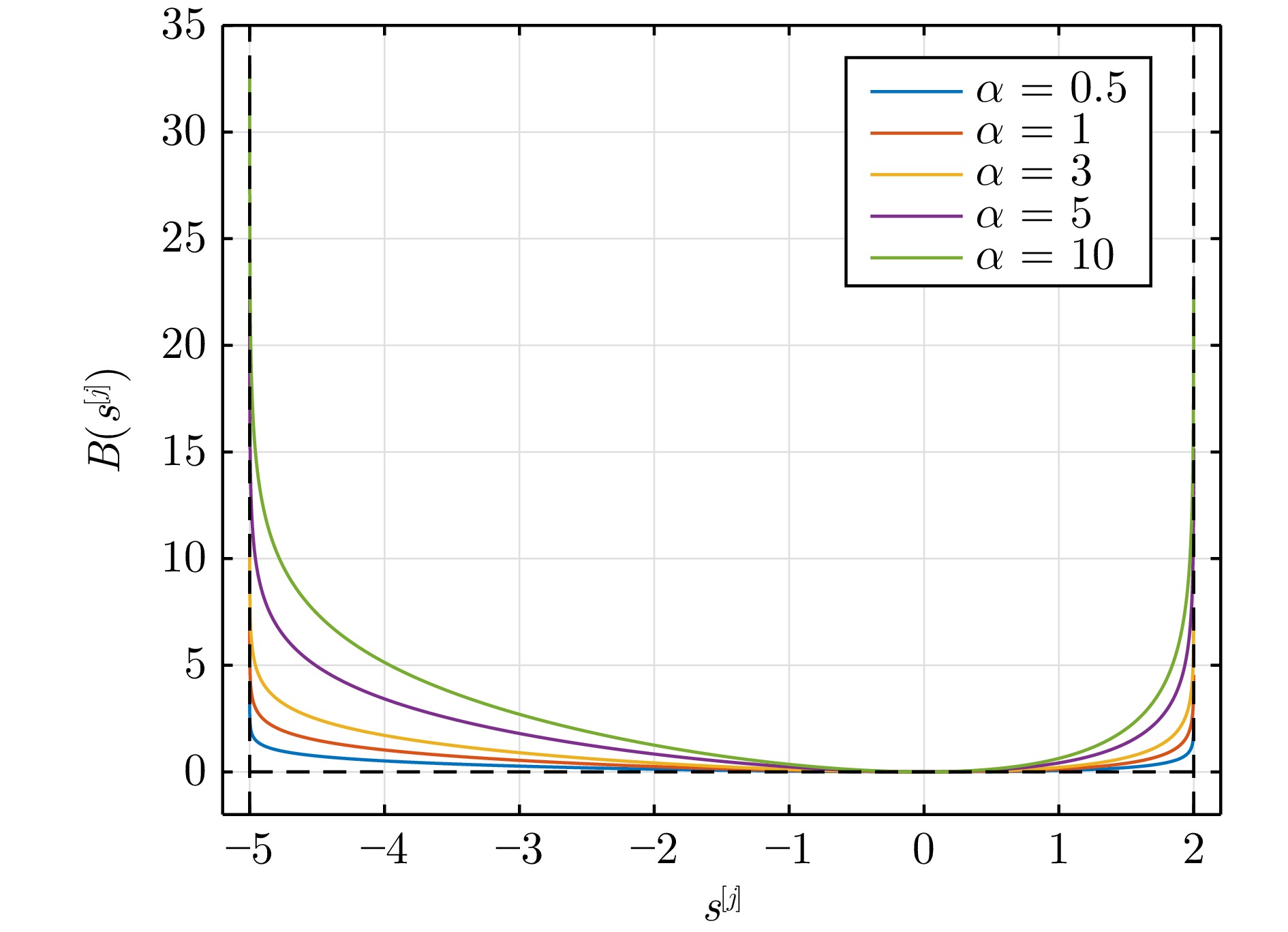
图 1 $ B({s^{[j]}}) $在不同安全系数下的轨迹
Fig. 1 Trajectories of $ B({s^{[j]}}) $ under different safety coefficients
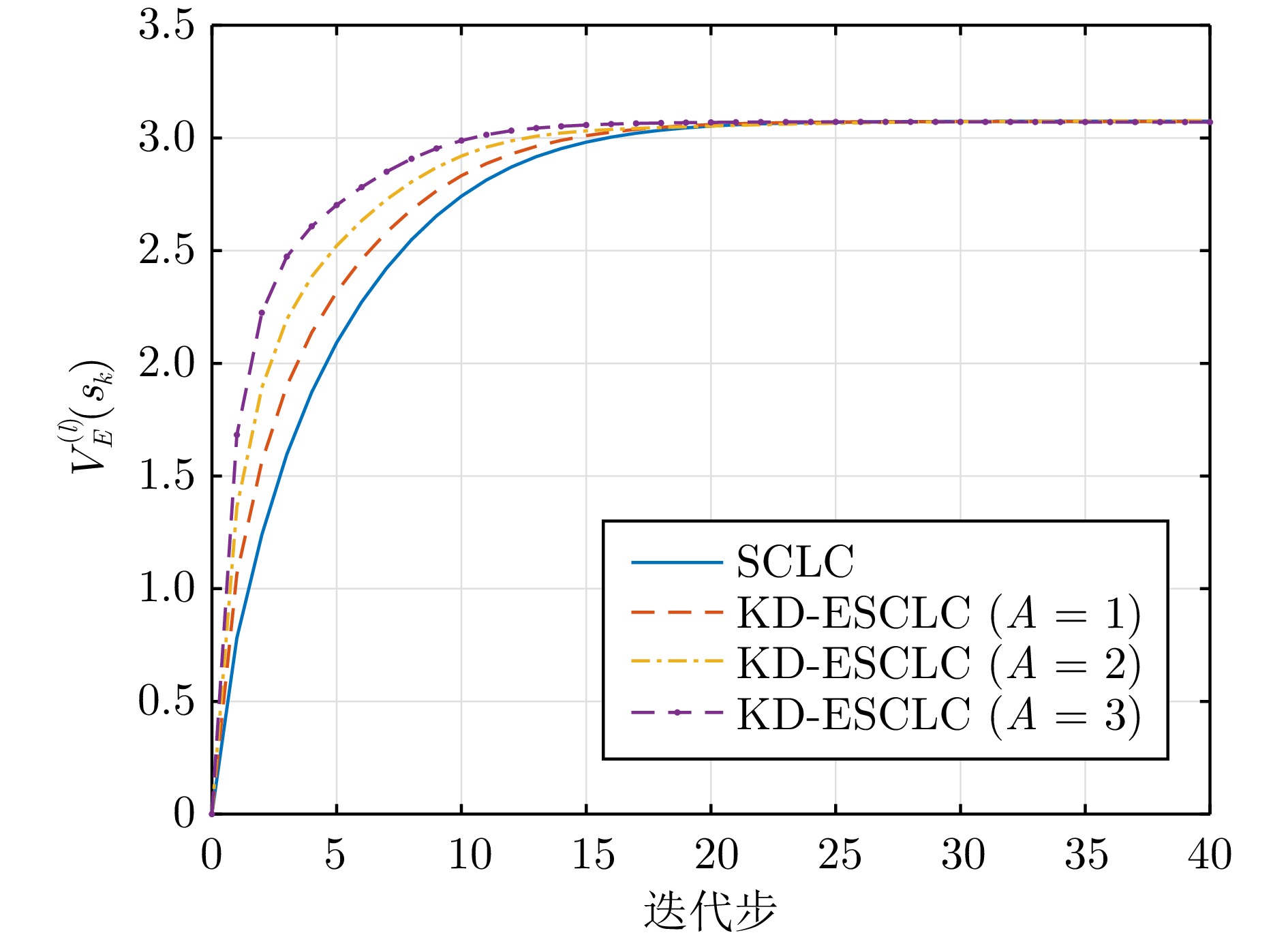
图 3 不同$ A $值下的迭代值函数收敛轨迹(例1)
Fig. 3 Convergence trajectories of the iterative value function under different $ A $ values (Example 1)
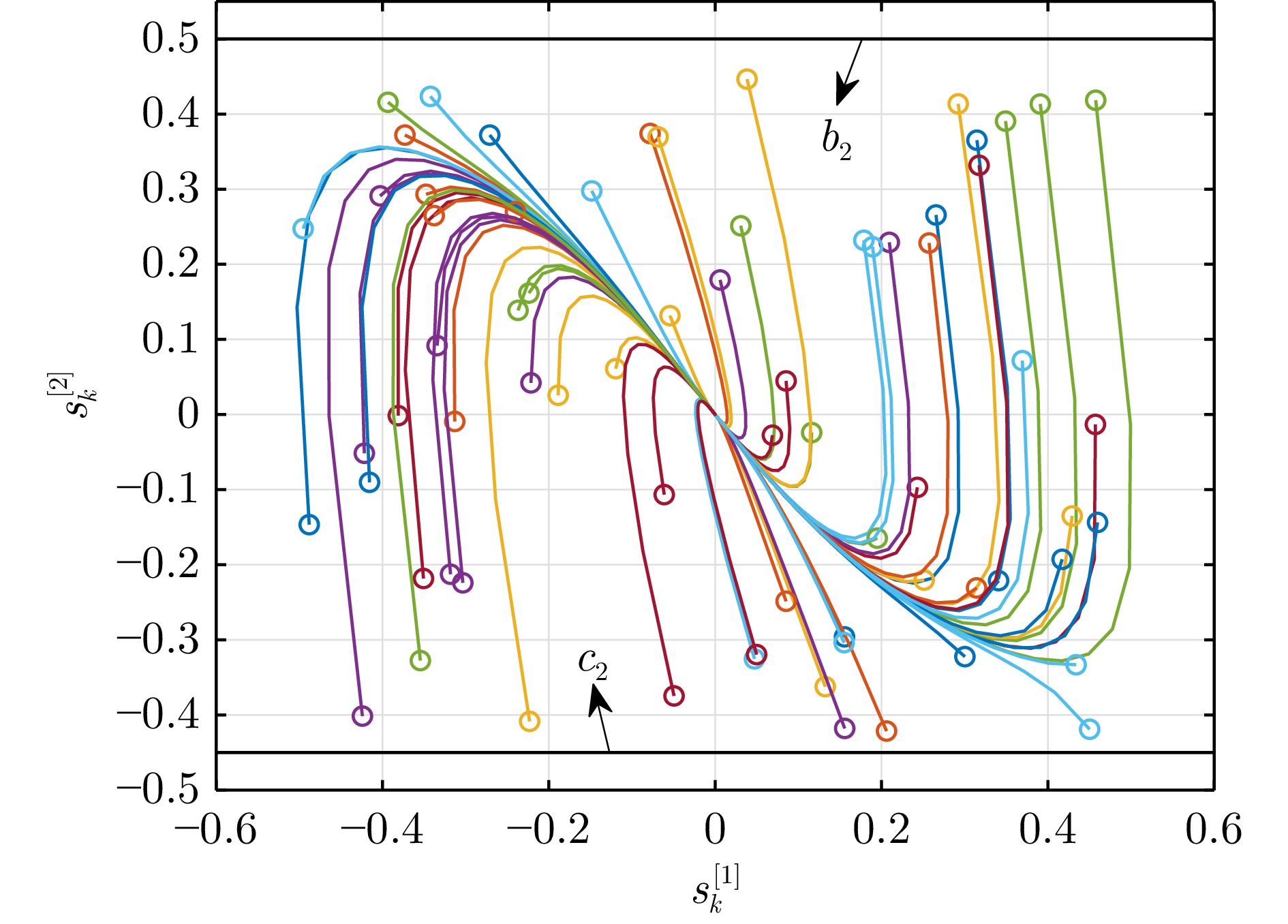
图 4 KD-ESCLC算法下的系统状态轨迹(例1)
Fig. 4 Trajectories of the system states under the KD-ESCLC algorithm (Example 1)
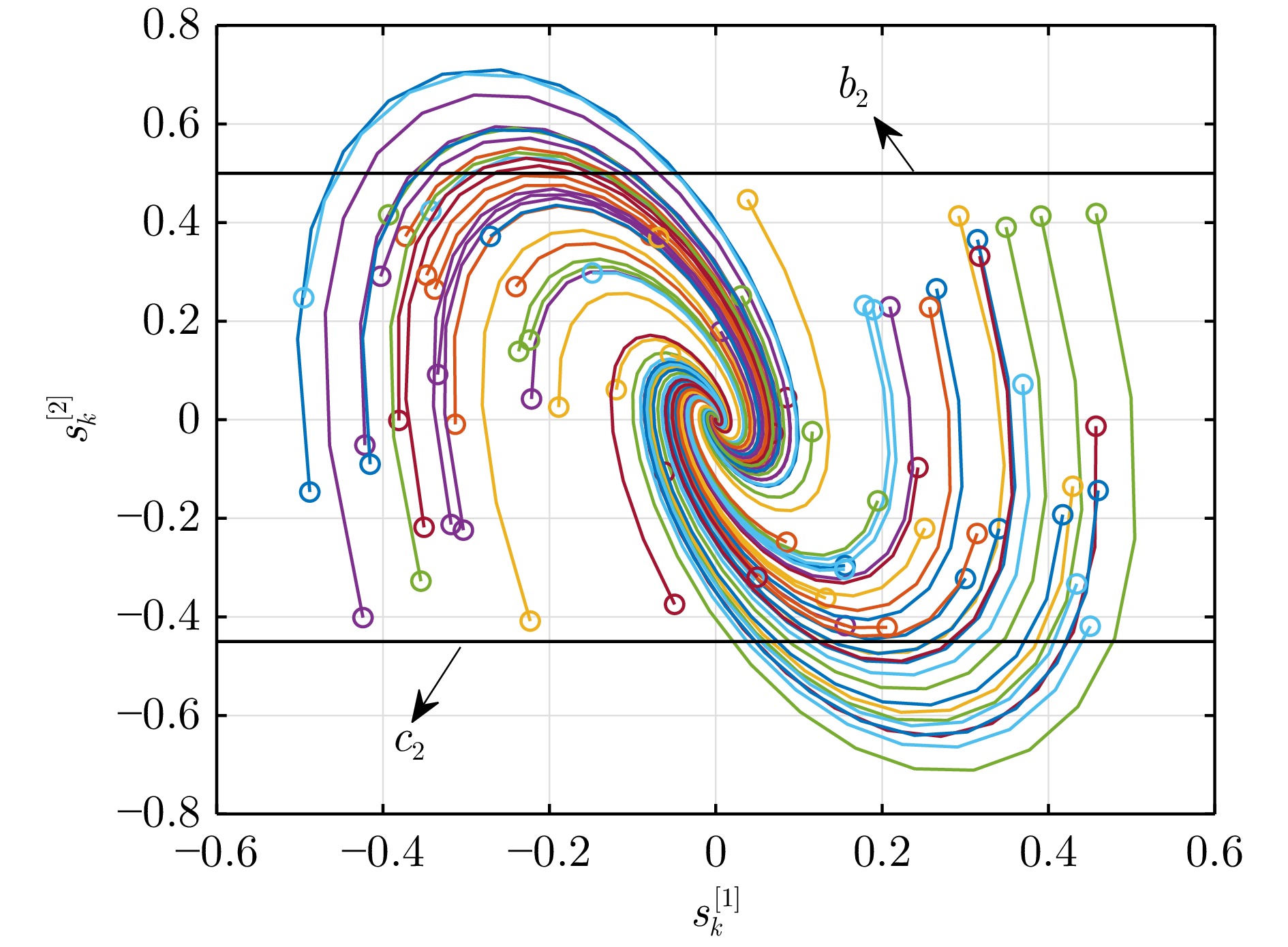
图 5 常规CLC算法下的系统状态轨迹(例1)
Fig. 5 Trajectories of the system states under the conventional CLC algorithm (Example 1)
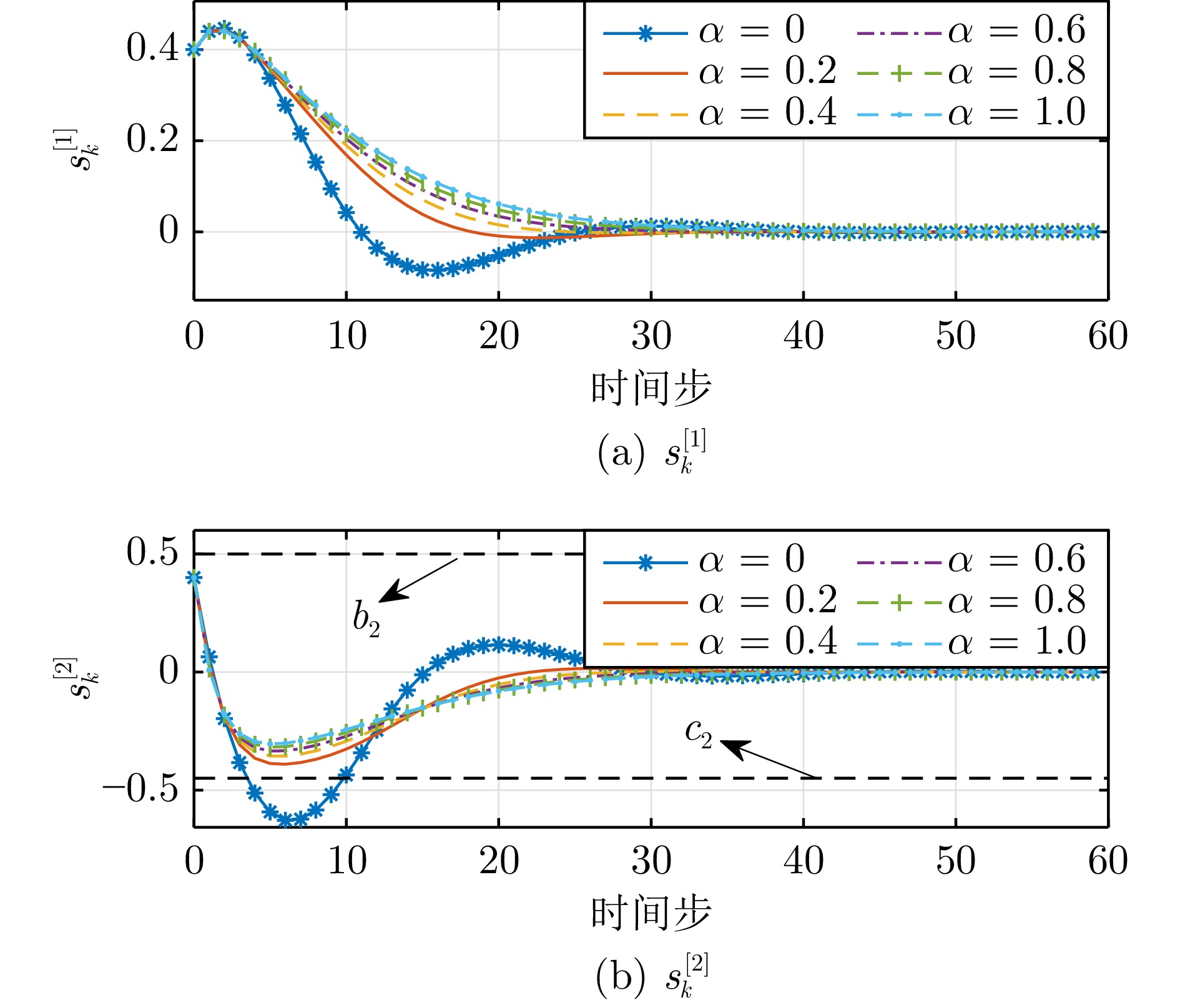
图 6 不同安全系数$ \alpha $下的系统状态轨迹(例1)
Fig. 6 Trajectories of the system states under different safety coefficients $ \alpha $ (Example 1)
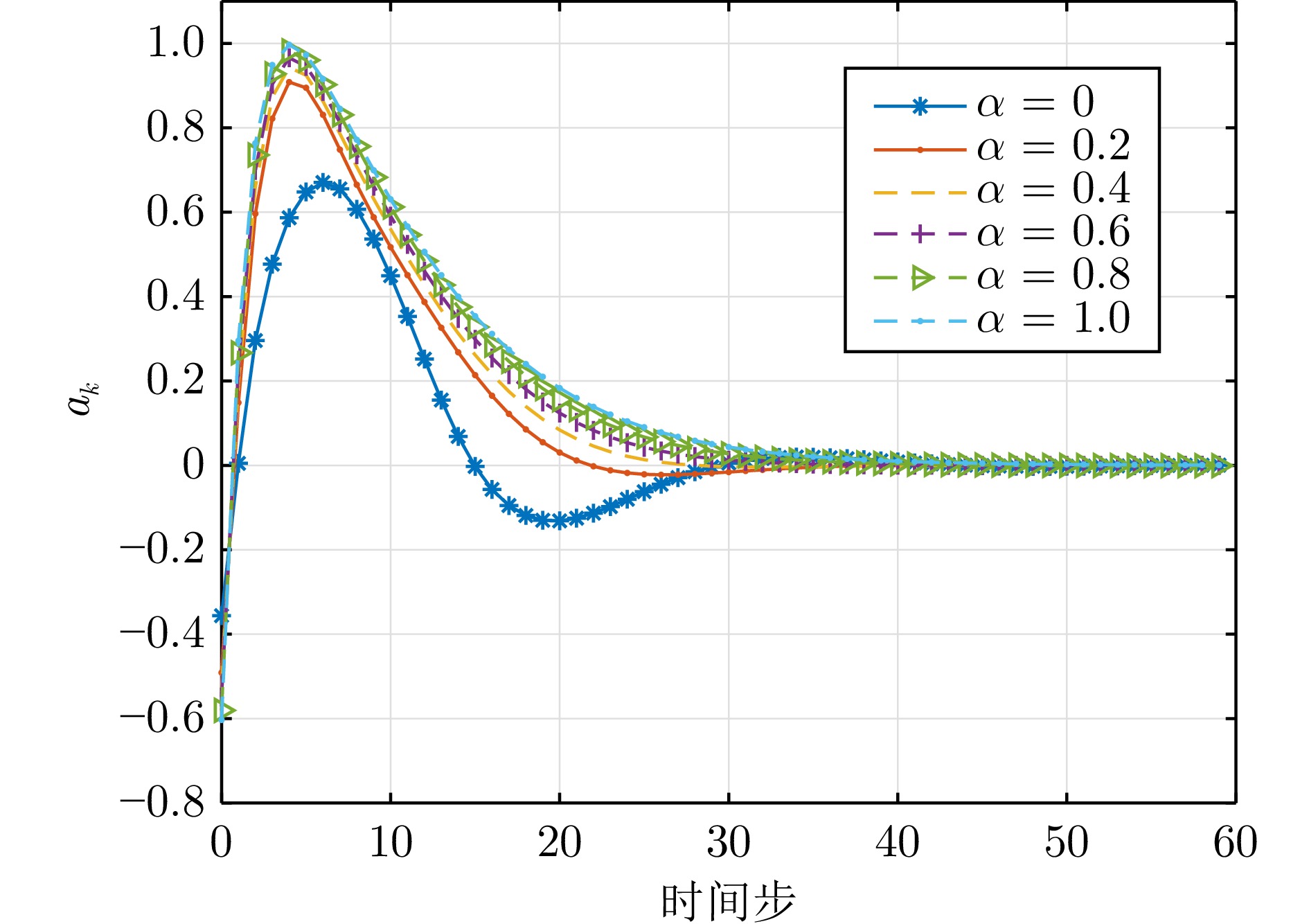
图 7 不同安全系数$ \alpha $下的控制输入轨迹(例1)
Fig. 7 Trajectories of the control input under different safety coefficients $ \alpha $ (Example 1)
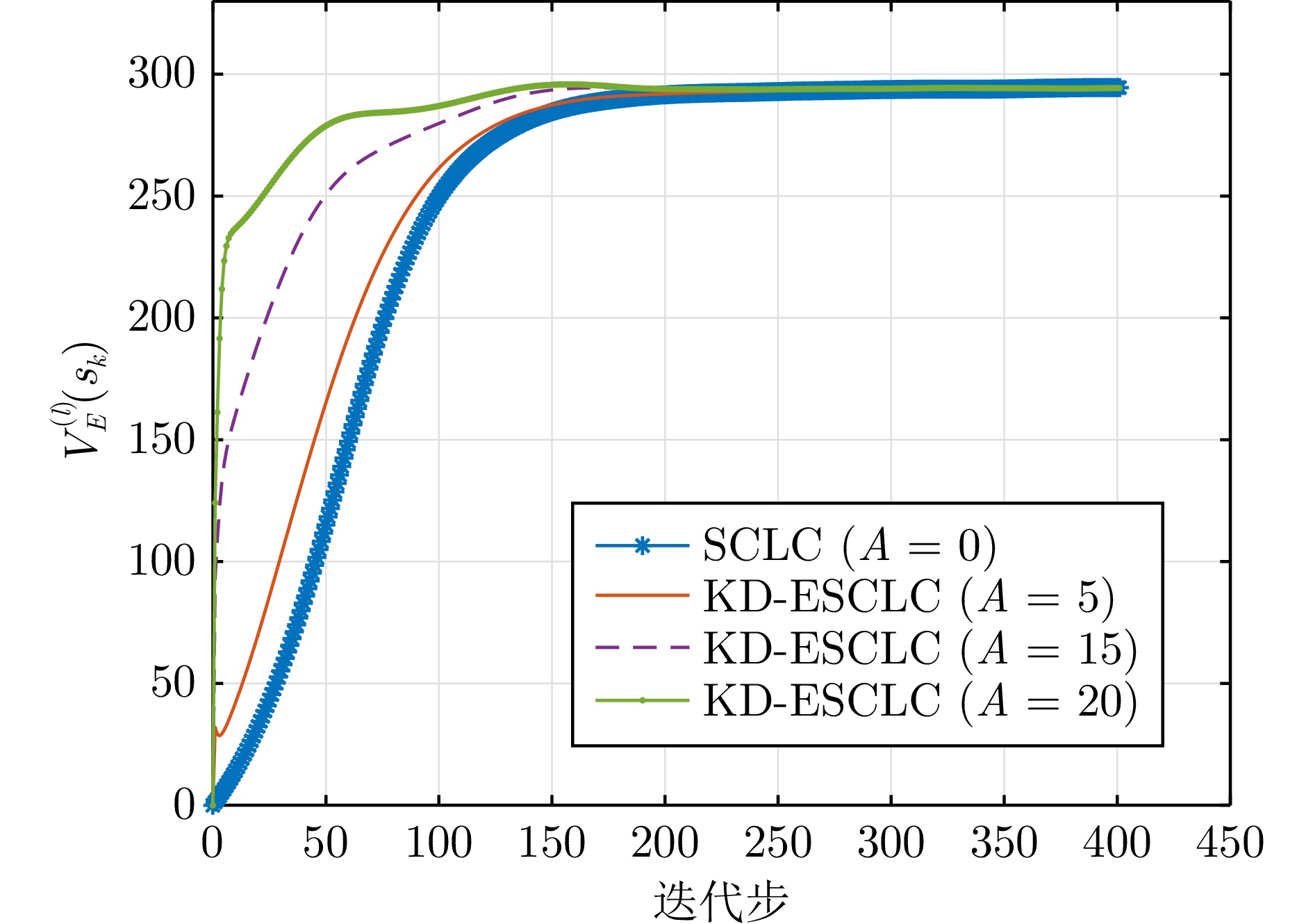
图 9 不同$ A $值下的迭代值函数收敛轨迹(例2)
Fig. 9 Convergence trajectories of the iterative value function under different $ A $ values (Example 2)
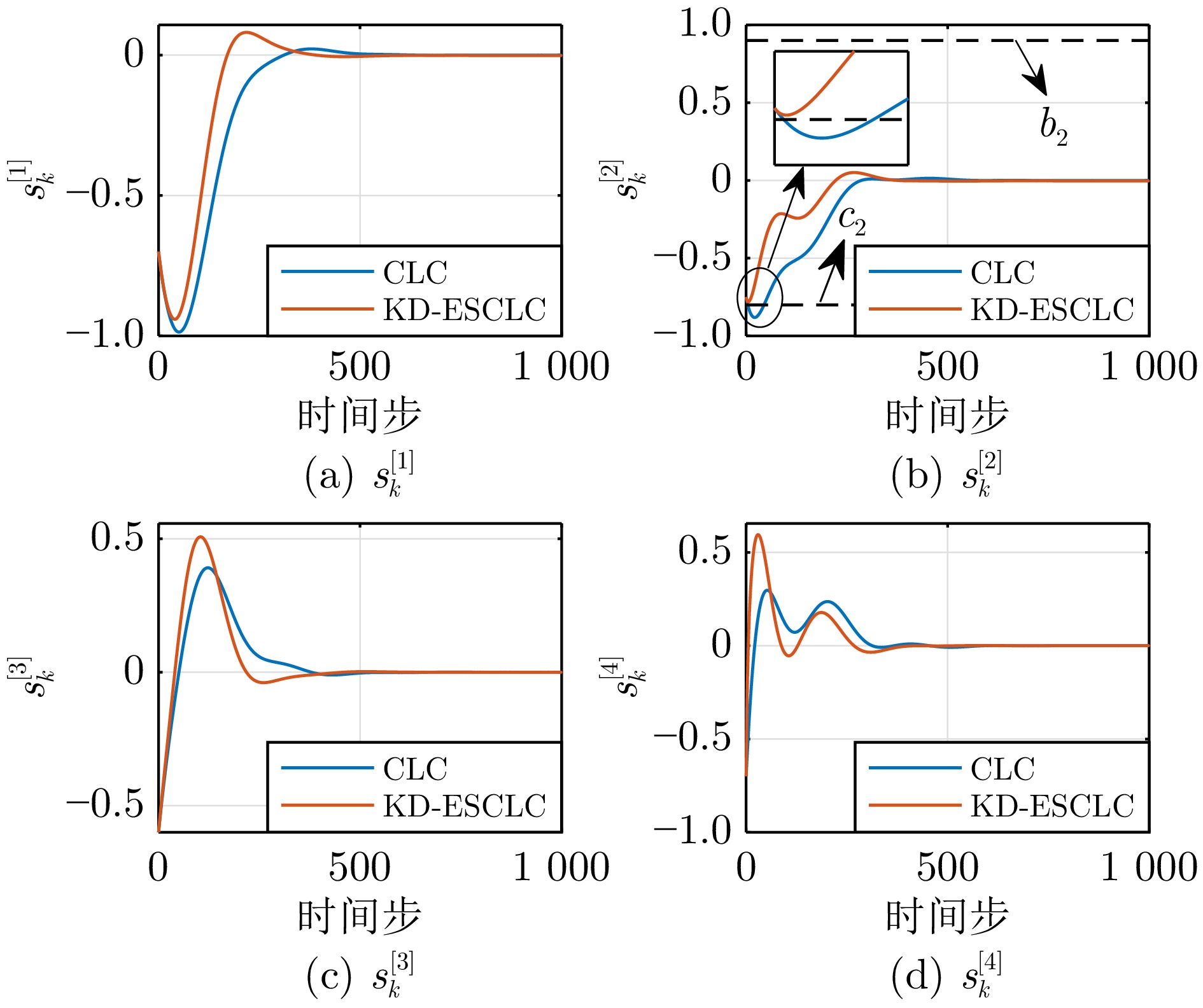
图 10 不同控制算法下的状态轨迹(例2)
Fig. 10 Trajectories of the system states under different control algorithms (Example 2)
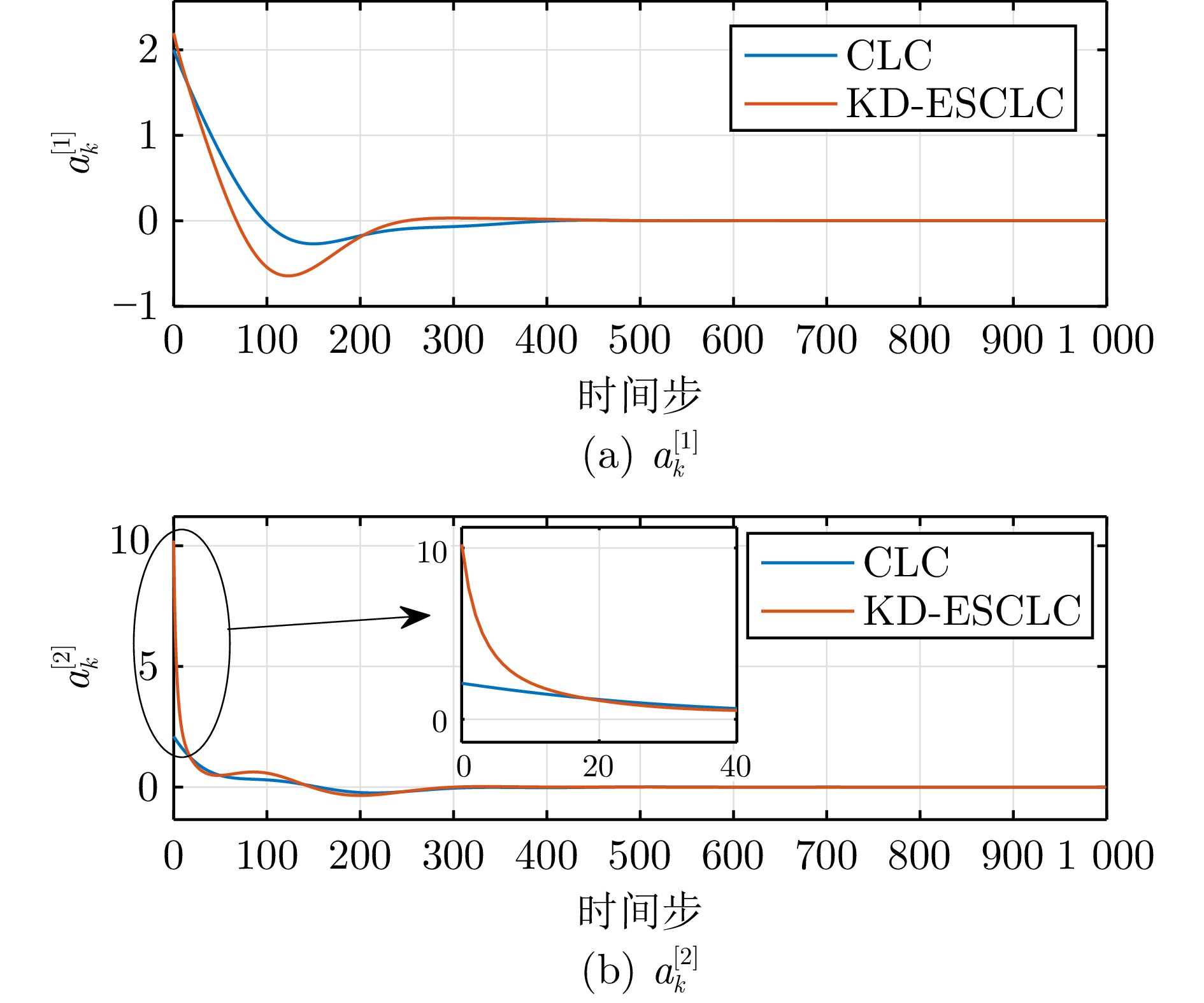
图 11 不同控制算法下的控制输入轨迹(例2)
Fig. 11 Trajectories of the control inputs under different control algorithms (Example 2)
表 1 KD-ESCLC算法的设计参数
Table 1 Design parameters of the KD-ESCLC algorithm
参数 $ Q $ $ R $ $ \alpha $ $ A $ $ q $ $ l_{\rm{max}} $ $ \psi $ 例1 $ I_{2} $ $ 1 $ $ 1 $ $ 2 $ $ 0.2 $ $ 40 $ $ 0.8 $ 例2 $ I_{4} $ $ I_{2} $ $ 2 $ $ 10 $ $ 0.1 $ $ 400 $ $ 0.6 $  下载: 导出CSV
下载: 导出CSV
表 2 神经网络的训练参数
Table 2 Training parameters of neural networks
参数 $ {h_m} $ $ {h_c} $ $ {h_a} $ $ {G_m} $ $ {G_c} $ $ {G_a} $ 例1 $ 20 $ $ 30 $ $ 15 $ $ 10^{-6} $ $ 10^{-8} $ $ 10^{-6} $ 例2 $ 30 $ $ 40 $ $ 20 $ $ 10^{-7} $ $ 10^{-9} $ $ 10^{-7} $
下载: 导出CSV
-
[1] Wang D, Gao N, Liu D, Li J, Lewis F. Recent progress in reinforcement learning and adaptive dynamic programming for advanced control applications. IEEE/CAA Journal of Automatica Sinica, 2024, 11(1): 18−36 doi: 10.1109/JAS.2023.123843 [2] Zhao M, Wang D, Qiao J, Ha M, Ren J. Advanced value iteration for discrete-time intelligent critic control: A survey. Artificial Intelligence Review, 2023, 56: 12315−12346 doi: 10.1007/s10462-023-10497-1 [3] 王鼎, 王将宇, 乔俊飞. 融合自适应评判的随机系统数据驱动策略优化. 自动化学报, 2024, 50(5): 980−990Wang Ding, Wang Jiang-Yu, Qiao Jun-Fei. Data-driven policy optimization for stochastic systems involving adaptive critic. Acta Automatica Sinica, 2024, 50(5): 980−990 [4] Heydari A. Stability analysis of optimal adaptive control using value iteration with approximation errors. IEEE Transactions on Automatic Control, 2018, 63(9): 3119−3126 doi: 10.1109/TAC.2018.2790260 [5] 王鼎, 刘奥, 乔俊飞. 连续时间系统混合迭代鲁棒自适应评判控制. 自动化学报, 2026, 52(1): 137−147Wang Ding, Liu Ao, Qiao Jun-Fei. Robust adaptive critic control with hybrid iteration for continuous-time systems. Acta Automatica Sinica, 2026, 52(1): 137−147 [6] Wang D, Hu L, Zhao M, Qiao J. Adaptive critic for event-triggered unknown nonlinear optimal tracking design with wastewater treatment applications. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(9): 6276−6288 doi: 10.1109/TNNLS.2021.3135405 [7] Liu D, Xue S, Zhao B, Luo B, Wei Q. Adaptive dynamic programming for control: A survey and recent advances. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2021, 51(1): 142−160 doi: 10.1109/TSMC.2020.3042876 [8] Wang D, Zhao M, Ha M, Qiao J. Stability and admissibility analysis for zero-sum games under general value iteration formulation. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(11): 8707−8718 doi: 10.1109/tnnls.2022.3152268 [9] Fu J, Wen G, Yu X. Safe consensus tracking with guaranteed full state and input constraints: A control barrier function-based approach. IEEE Transactions on Automatic Control, 2023, 68(12): 8075−8081 doi: 10.1109/tac.2023.3283697 [10] 王鼎, 赵明明, 刘德荣, 乔俊飞, 宋世杰. 数据驱动自适应评判控制研究进展. 自动化学报, 2025, 51(6): 1170−1190Wang Ding, Zhao Ming-Ming, Liu De-Rong, Qiao Jun-Fei, Song Shi-Jie. Research advances on data-driven adaptive critic control. Acta Automatica Sinica, 2025, 51(6): 1170−1190 [11] 王鼎, 赵慧玲, 李鑫. 基于多目标粒子群优化的污水处理系统自适应评判控制. 工程科学学报, 2024, 46(5): 908−917Wang Ding, Zhao Hui-Ling, Li Xin. Adaptive critic control for wastewater treatment systems based on multiobjective particle swarm optimization. Chinese Journal of Engineering, 2024, 46(5): 908−917 [12] Shen H, Yu X, Yan H, Park J H, Wang J. Robust fixed-time sliding mode attitude control for a 2-DOF helicopter subject to input saturation and prescribed performance. IEEE Transactions on Transportation Electrification, 2025, 11(1): 1223−1233 doi: 10.1109/TTE.2024.3402316 [13] Liang L, Zhao B, Zhou J, Zhang Z. Impact angle controlled integrated guidance and control with input and state constraints. International Journal of Control, 2024, 97(4): 796−810 doi: 10.1080/00207179.2023.2175408 [14] Zhu L, Huang D, Li X, Wang Q. Cooperative operation control of virtual coupling high-speed trains with input saturation and full-state constraints. IEEE Transactions on Automation Science and Engineering, 2024, 21(3): 3497−3510 doi: 10.1109/TASE.2023.3280188 [15] Castroviejo-Fernandez M, Leung J, Kolmanovsky I. Robust reference governor for input-constrained model predictive control to enforce state constraints at low computational cost. International Journal of Control, 2025, 98(5): 1111−1124 doi: 10.1080/00207179.2024.2382316 [16] Wiltz A, Chen F, Dimarogonas D. Parallelized robust distributed model predictive control in the presence of coupled state constraints. Automatica, 2025, 171: Article No. 111952 doi: 10.1016/j.automatica.2024.111952 [17] Keusch R, Loeliger H, Geyer T. Long-horizon direct model predictive control for power converters with state constraints. IEEE Transactions on Control Systems Technology, 2024, 32(2): 340−350 doi: 10.1109/TCST.2023.3310203 [18] Zhang H, Lin Y, Han S, Wang S, Lv K. Off-policy conservative distributional reinforcement learning with safety constraints. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2025, 55(3): 2033−2045 doi: 10.1109/TSMC.2024.3516377 [19] Kim D, Oh S. Efficient off-policy safe reinforcement learning using trust region conditional value at risk. IEEE Robotics and Automation Letters, 2022, 7(3): 7644−7651 doi: 10.1109/LRA.2022.3184793 [20] Kim D, Oh S. TRC: Trust region conditional value at risk for safe reinforcement learning. IEEE Robotics and Automation Letters, 2022, 7(2): 2621−2628 doi: 10.1109/LRA.2022.3141829 [21] Li B, Wen S, Yan Z, Wen G, Huang T. A survey on the control lyapunov function and control barrier function for nonlinear-affine control systems. IEEE/CAA Journal of Automatica Sinica, 2023, 10(3): 584−602 doi: 10.1109/JAS.2023.123075 [22] Farzan S, Azimi V, Hu A P, Rogers J. Adaptive control of wire-borne underactuated brachiating robots using control lyapunov and barrier functions. IEEE Transactions on Control Systems Technology, 2022, 30(6): 2598−2614 doi: 10.1109/TCST.2022.3160058 [23] Zeng D, Jiang Y, Wang Y, Zhang H, Feng Y. Robust adaptive control barrier functions for input-affine systems: Application to uncertain manipulator safety constraints. IEEE Control Systems Letters, 2024, 8: 279−284 doi: 10.1109/LCSYS.2023.3329518 [24] Marvi Z, Kiumarsi B. Safe reinforcement learning: A control barrier function optimization approach. International Journal of Robust and Nonlinear Control, 2021, 31(6): 1923−1940 doi: 10.1002/rnc.5132 [25] Roshanravan S, Shamaghdari S. Integrated fault detection and fault-tolerant optimal tracking control for unknown nonlinear systems with state and input constraints using safe reinforcement learning. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2026, 56(1): 46−58 doi: 10.1109/TSMC.2025.3617850 [26] Zhang L, Xie L, Jiang Y, Li Z, Liu X, Su H. Optimal control for constrained discrete-time nonlinear systems based on safe reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(1): 854−865 doi: 10.1109/TNNLS.2023.3326397 [27] Yazdani N, Moghaddam R, Kiumarsi B, Modares H. A safety-certified policy iteration algorithm for control of constrained nonlinear systems. IEEE Control Systems Letters, 2020, 4(3): 686−691 doi: 10.1109/LCSYS.2020.2990632 [28] Wang D, Wang J, Zhao M, Xin P, Qiao J. Adaptive multi-step evaluation design with stability guarantee for discrete-time optimal learning control. IEEE/CAA Journal of Automatica Sinica, 2023, 10(9): 1797 doi: 10.1109/JAS.2023.123684 [29] Zhao M, Wang D, Song S, Qiao J. Accelerated value iteration-based safe Q-learning for data-driven optimal tracking control. IEEE Transactions on Cybernetics, 2025, 55(7): 3511−3524 doi: 10.1109/TCYB.2025.3562172 [30] Luo B, Liu D, Huang T, Liu J. Output tracking control based on adaptive dynamic programming with multistep policy evaluation. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 49(10): 2155−2165 doi: 10.1109/TSMC.2017.2771516 [31] Wang D, Li X, Wang H, Qiao J. Safe optimal tracking control via multi-step critic learning for unknown nonlinear systems. IEEE Transactions on Automation Science and Engineering, 2025, 22: 23379−23392 doi: 10.1109/TASE.2025.3626784 [32] Ha M, Wang D, Liu D. Novel discounted adaptive critic control designs with accelerated learning formulation. IEEE Transactions on Cybernetics, 2024, 54(5): 3003−3016 doi: 10.1109/TCYB.2022.3233593 [33] Gao X, Si J, Huang H. Reinforcement learning control with knowledge shaping. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(3): 3156−3167 doi: 10.1109/TNNLS.2023.3243631 -

 下载:
下载:

计量
- 文章访问数: 113
- HTML全文浏览量: 64
- 被引次数: 0
