

A Frequency-guided Sparse Fusion Algorithm for Multispectral Object Detection in Complex Environments
-
摘要:
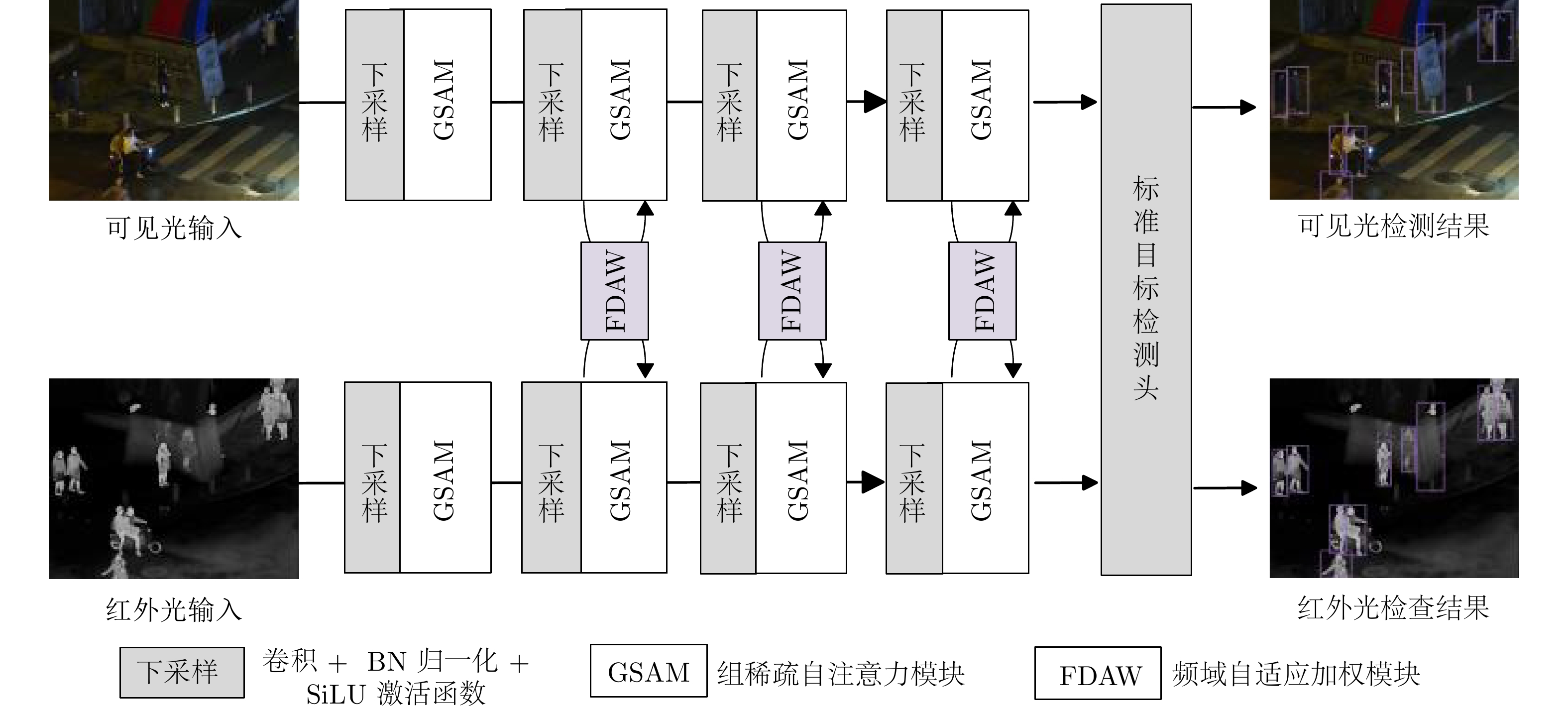
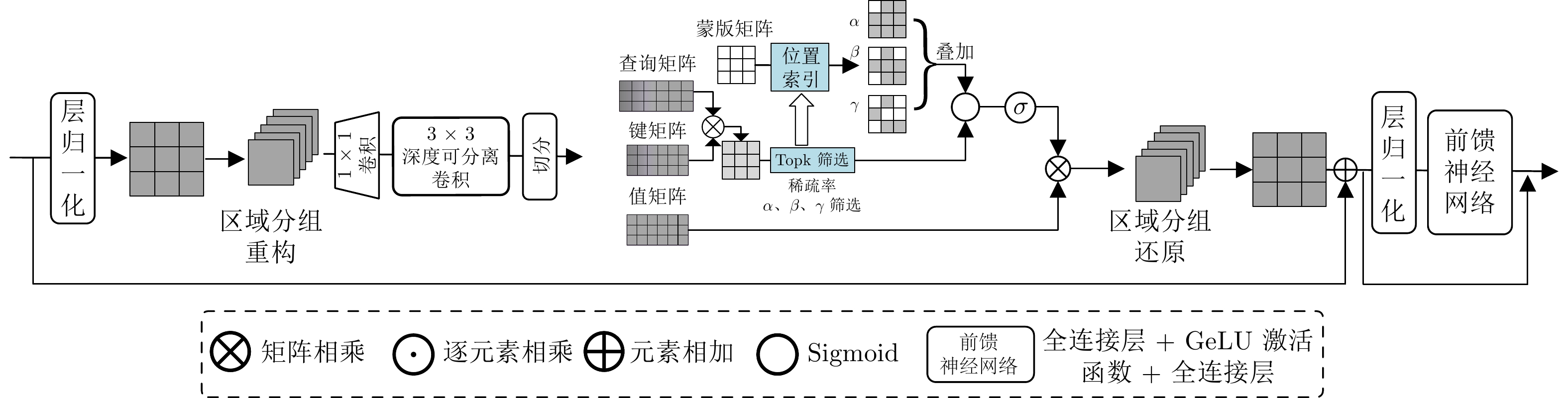
随着多光谱感知与智能视觉技术的发展, 如何在复杂环境中实现稳定而精确的目标检测已成为自动化视觉检测领域的重要研究方向. 针对传统单模态可见光目标检测在夜间、大雾及低照度等复杂环境中性能下降的问题, 提出一种基于频域特征细化导向的多光谱稀疏融合目标检测方法. 该方法利用共享权重的双分支编码器分别提取可见光与红外光特征, 并通过组稀疏自注意力模块实现跨模态长距离特征筛选, 以抑制冗余信息、增强显著特征表达. 同时, 设计频域自适应加权模块, 在频域空间中进行多光谱特征解耦与自适应融合, 实现不同光谱模态间的高效语义交互与动态权重分配. 该方法可在端到端框架下实现跨模态特征的高精度对齐与融合, 有效提升模型的检测精度与鲁棒性. 在M3FD、KAIST和FLIR三个公开数据集上分别取得83.5%, 76.2%和81.6%的mAP50结果, 显著优于现有多光谱目标检测算法, 验证了所提方法在复杂场景下的优越性能和泛化能力.
Abstract:With the development of multispectral perception and intelligent vision technologies, achieving reliable and accurate object detection in complex environments has become a critical research focus in automatic vision detection. To address the performance degradation problem of traditional unimodal visible-light object detection in complex environments such as darkness, dense fog, and low illumination, this paper proposes a multispectral sparse fusion object detection method guided by frequency-domain feature refinement. The proposed method employs a dual-branch encoder with shared weights to extract features from visible and infrared modalities. A group sparse self-attention module is designed to perform cross-modal long-range feature selection, suppress redundant information, and enhance salient feature representation. Furthermore, a frequency-domain adaptive weighting module is developed to decouple and adaptively fuse multispectral features in the frequency domain, achieving efficient semantic interaction and dynamic weighting allocation across different spectral modalities. Under an end-to-end architecture, this method realizes high-precision cross-modal feature alignment and fusion, significantly improving detection accuracy and robustness. The proposed method achieved mAP50 results of 83.5%, 76.2%, and 81.6% on the M3FD, KAIST and FLIR public datasets, respectively. These results significantly outperform those of existing multispectral object detection algorithms, and demonstrate the superior performance and generalization capability of the proposed method in complex scenes.
-
Key words:
- object detection /
- cross-spectral /
- feature selection /
- cross-modal feature alignment
-

图 1 大雾场景下的可见光(左上)与红外光(右上)及黑夜场景下的可见光(左下)与红外光(右下)示例图
Fig. 1 Example images of visible light (top-left) and infrared light (top-right) under dense fog scenes, and visible light (bottom-left) and infrared light (bottom-right) under night-time scenes

图 5 不同算法在$ {\rm{M}}^3 $FD数据集上的检测结果图
Fig. 5 Detection results diagram for different algorithms on the $ {\rm{M}}^3 $FD dataset
表 1 不同方法在$ {\rm{M}}^3 $FD数据集上的实验评价结果比较
Table 1 Comparative experimental evaluation results of different methods on the $ {\rm{M}}^3 $FD dataset
$ {\rm{AP}}_{50} $ (%) 架构 方法 巴士 轿车 灯 摩托车 行人 卡车 精度(%) 召回率(%) $ {\rm{mAP}}_{50} $ (%) $ {\rm{mAP}}_{50:95} $ (%) param (M) FPS 单光谱模态 Visible 90.9 88.5 79.6 75.2 67.7 85.3 89.4 73.4 81.2 50.5 1.77 175.4 Infrared 90.7 86.5 57.8 69.5 79.0 83.9 85.1 71.5 77.9 48.2 1.77 175.4 融合检测架构 U2fusion[16] 80.8 86.3 73.8 56.4 73.2 78.2 84.1 70.1 74.8 45.4 — — RFN[27] 79.2 85.7 69.9 53.1 71.4 76.4 88.5 65.1 72.6 44.9 — — Tardal[17] 77.7 85.0 67.1 56.7 73.1 74.4 84.4 65.7 72.3 43.6 — — MFEIF[18] 79.7 84.9 68.2 56.9 72.9 73.5 85.2 65.9 72.7 44.6 — — HALDeR[28] 79.8 86.0 70.8 52.7 71.2 75.4 86.7 66.8 72.7 44.4 — — 端到端架构 Twin-Yolov5-n 89.1 87.8 77.1 66.2 77.0 83.8 85.0 75.1 80.2 47.8 2.84 192.3 Twin-Yolov8-n 89.8 88.6 78.2 67.5 78.3 85.1 85.2 73.0 81.2 49.6 4.28 128.2 DEYOLO[29] 89.3 87.5 77.7 67.8 77.4 85.2 84.0 75.9 80.8 49.3 4.57 188.5 ICAFusion[20] 90.4 87.6 78.5 65.2 77.2 86.0 83.6 76.1 80.8 48.5 5.94 144.9 CFT [19] 90.4 87.9 77.0 70.2 76.6 85.1 87.7 74.3 81.2 48.1 11.2 154 DAMSDet[21] 83.1 92.7 71.1 73.5 73.6 78.6 78.7 83.1 78.8 51.0 78.9 88.5 SuperYOLO[30] 89.1 87.6 74.7 68.9 76.6 83.2 88.2 70.1 80.0 48.0 1.8 212.7 FGSFNet 92.1 89.0 80.5 74.3 79.0 86.1 86.7 77.3 83.5 51.2 7.44 208.3  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在KAIST和FLIR数据集上的实验评价结果比较
Table 2 Comparative of experimental evaluation results for different methods on the KAIST and FLIR datasets
KAIST (单类别: 行人) FLIR (多类别) $ {\rm{AP}}_{50} $ (%) 架构 方法 精度(%) 召回率(%) $ {\rm{AP}}_{50} $ (%) $ {\rm{mAP}}_{50:95} $ (%) 自行车 汽车 行人 精度(%) 召回率(%) $ {\rm{mAP}}_{50} $ (%) $ {\rm{mAP}}_{50:95} $ (%) 单光谱模态 Visible 71.6 54.4 62.0 24.6 68.9 83.5 70.0 80.2 67.6 74.1 34.8 Infrared 75.8 65.4 73.5 32.3 75.8 87.5 81.2 84.5 72.0 81.5 40.6 融合检测架构 U2fusion[16] 65.4 45.9 52.2 21.1 63.1 83.0 71.6 79.4 65.9 72.6 33.8 RFN[27] 59.6 43.7 48.9 18.9 63.1 82.0 71.4 78.7 65.2 72.1 33.4 Tardal[17] 62.4 45.0 50.6 20.6 60.1 81.5 68.5 77.1 63.3 70.0 32.3 MFEIF[18] 62.1 43.8 50.0 20.6 62.9 80.9 69.7 76.0 66.2 71.2 32.8 HALDeR[28] 63.3 45.7 51.6 21.1 62.9 82.1 70.1 79.6 64.9 71.7 32.9 端到端架构 Twin-Yolov5-n 76.7 68.7 74.8 32.8 74.9 87.2 82.0 84.0 74.6 81.4 39.4 Twin-Yolov8-n 78.2 68.0 74.2 32.9 73.8 87.5 81.2 83.0 72.6 80.8 39.7 DEYOLO[29] 74.9 68.2 74.4 31.9 74.5 86.9 82.0 84.7 72.7 81.1 40.0 ICAFusion[20] 75.5 69.1 75.7 33.2 74.8 87.4 81.6 82.2 75.9 81.3 39.6 CFT[19] 77.6 67.2 75.7 32.9 72.9 87.4 82.1 82.9 73.4 80.8 39.2 SuperYOLO[30] 74.3 65.5 71.8 31.5 70.6 86.3 78.3 82.1 69.1 78.4 37.7 FGSFNet 77.6 71.1 76.2 33.8 75.0 87.7 82.1 83.4 75.0 81.6 40.2
下载: 导出CSV
表 3 稀疏率组合选取研究实验
Table 3 Study on sparsity rate combination selection
稀疏率参数组合 实验结果(%) 实验 50% 67% 75% 80% $ {\rm{mAP}}_{50} $ $ {\rm{mAP}}_{50:95} $ I 0 0 0 1 78.4 46.2 II 0 1 0 1 82.3 49.7 III 1 1 0 1 83.5 51.2 IV 1 1 1 0 83.5 50.2 V 1 1 1 1 81.4 49.1
下载: 导出CSV
表 4 不同融合阶段性能研究
Table 4 performance study at different integration stages
融合策略 精度(%) 召回率(%) $ {\rm{mAP}}_{50} $ (%) $ {\rm{mAP}}_{50:95} $ (%) params (M) 基线 85.0 75.1 81.2 47.7 7.12 早期融合 86.3 71.8 80.1 48.1 7.12 中期融合 86.7 77.3 83.5 51.2 7.44 晚期融合 86.8 75.2 82.5 49.1 7.39
下载: 导出CSV
表 5 消融实验
Table 5 Ablation experiments
实验 组稀疏
自注意力模块频域自适应
加权模块$ {\rm{mAP}}_{50} $ (%) $ {\rm{mAP}}_{50:95} $ (%) params (M) I $ \times $ $ \times $ 80.2 47.8 2.84 II √ $ \times $ 81.2 47.7 7.12 III $ \times $ √ 82.8 49.5 3.20 IV √ √ 83.5 51.2 7.44
下载: 导出CSV
-
[1] Mao J G, Shi S S, Wang X, and Li H S. 3d object detection for autonomous driving: A comprehensive survey. International Journal of Computer Vision, 2023, 131(8): 1909−1963 doi: 10.1007/s11263-023-01790-1 [2] Shi X L and Song A J. Defog yolo for road object detection in foggy weather. The Computer Journal, 2024, 67(11): 3115−3127 [3] Wang J, Yang P, Liu Y S, Shang D, Hui X, Song J H, and Chen X H. Research on improved yolov5 for low-light environment object detection. Electronics, 2023, 12(14): 3089 [4] 闫梦凯, 钱建军, 杨健. 弱对齐的跨光谱人脸检测. 自动化学报, 2023, 49(1): 135−147 doi: 10.16383/j.aas.c210058Meng-Kai Yan, Jian-Jun Qian, and Jian Yang. Weakly aligned cross-spectral face detection. Acta Automatica Sinica, 2023, 49(1): 135−147 doi: 10.16383/j.aas.c210058 [5] 赵兴科, 李明磊, 张弓, 黎宁, 李家松. 基于显著图融合的无人机载热红外图像目标检测方法. 自动化学报, 2021, 47(9): 2120−2131Xin-Ke Zhao, Ming-Lei Li, Gong Zhang, Ning Li, and Jia-Song Li. Object detection method for uav thermal infrared images based on saliency map fusion. Acta Automatica Sinica, 2021, 47(9): 2120−2131 [6] Hu S M, Zhao F, Lu H Z, Deng Y J, Du J M, and Shen X L. Improving yolov7-tiny for infrared and visible light image object detection on drones. Remote Sensing, 2023, 15(13): 3214 [7] Wang P, Wu J S, Fang A Q, Zhu Z X, and Wang C W. Multi-spectral image fusion for moving object detection. Infrared Physics & Technology, 2024, 141: 105489 [8] He X, Tang C, Zou X, and Zhang W. Multispectral object detection via cross-modal conflict-aware learning. In Proceedings of the 31st ACM International Conference on Multimedia, pages 1465–1474, 2023. [9] Girshick R, Donahue J, Darrell T, and Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 580–587, 2014. [10] 张鹏, 雷为民, 赵新蕾, 董力嘉, 林兆楠, 景庆阳. 跨摄像头多目标跟踪方法综述. 计算机学报, 2024, 47(2): 287−309Peng Zhang, Wei-Min Lei, Xin-Lei Zhao, Li-Jia Dong, Zhao-Nan Lin, and Qing-Yang Jing. A survey on multi-target multi-camera tracking methods. Chinese Journal of Computers, 2024, 47(2): 287−309 [11] Redmon J, Divvala S, Girshick R, and Farhadi A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016. [12] Redmon J and Farhadi A. Yolov3: An incremental improvement. arXiv preprint arXiv: 1804.02767, 2018. [13] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, Kaiser L, and Polosukhin I. Attention is all you need. Advances in neural information processing systems, 30, 2017. [14] Dosovitskiy A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv: 2010.11929, 2020. [15] Chen Y T, Shi J H, Ye Z L, Mertz C, Ramanan D, and Kong S. Multimodal object detection via probabilistic ensembling. In European Conference on Computer Vision, pages 139–158. Springer, 2022. [16] Xu H, Ma J, Jiang J J, Guo X J, and Ling H B. U2fusion: A unified unsupervised image fusion network. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020. [17] Liu J Y, Fan X, Huang Z B, Wu G Y, Liu R S, Zhong W, and Luo Z X. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5802–5811, 2022. [18] Liu J Y, Fan X, Jiang J, Liu R S, and Luo Z X. Learning a deep multi-scale feature ensemble and an edge-attention guidance for image fusion. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 32(1): 105−119 [19] Fang Q Y, Han D P, and Wang Z K. Cross-modality fusion transformer for multispectral object detection. arXiv preprint arXiv: 2111.00273, 2021. [20] Shen J F, Chen Y F, Liu Y, Zuo X, Fan H, and Yang W K. Icafusion: Iterative cross-attention guided feature fusion for multispectral object detection. Pattern Recognition, 2024, 145: 109913 [21] Guo J J, Gao C Q, Liu F C, Meng D Y, and Gao X B. Damsdet: Dynamic adaptive multispectral detection transformer with competitive query selection and adaptive feature fusion. In European Conference on Computer Vision, pages 464–481. Springer, 2024. [22] Zhu X, Su W, Lu L, Li B, Wang X, and Dai J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv: 2010.04159, 2020. [23] Guobao Xiao, Zhimin Tang, Hanlin Guo, Jun Yu, and Heng Tao Shen. Fafusion: Learning for infrared and visible image fusion via frequency awareness. IEEE Transactions on Instrumentation and Measurement, 2024, 73: 1−11 [24] Jiayi Ma, Yong Ma, and Chang Li. Infrared and visible image fusion methods and applications: A survey. Information fusion, 2019, 45: 153−178 [25] Hwang S, Park J, Kim N, Choi Y, and Kweon I S. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1037–1045, 2015. [26] Zhang H, Fromont E, Lefevre S, and Avignon B. Multispectral fusion for object detection with cyclic fuse-and-refine blocks. In 2020 IEEE International conference on image processing (ICIP), pages 276–280. IEEE, 2020. [27] Li H, Wu X J, and Kittler J. Rfn-nest: An end-to-end residual fusion network for infrared and visible images. Information Fusion, 2021, 73: 72−86 [28] Liu J Y, Shang J J, Liu R S, and Fan X. Halder: Hierarchical attention-guided learning with detail-refinement for multi-exposure image fusion. In 2021 IEEE International Conference on Multimedia and Expo (ICME), 2021. [29] Chen Y S, Wang B R, Guo X Y, Zhu W B, He J S, Liu X B, and Yuan J. Deyolo: Dual-feature-enhancement yolo for cross-modality object detection. In International Conference on Pattern Recognition, pages 236–252. Springer, 2025. [30] Zhang J Q, Lei J, Xie W Y, Fang Z M, Li Y S, and Du Q. Superyolo: Super resolution assisted object detection in multimodal remote sensing imagery. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 1−15 -

 下载:
下载:




计量
- 文章访问数: 305
- HTML全文浏览量: 305
- 被引次数: 0
