

Large-scale Episodic Multi-agent Reinforcement Learning With Exponential Graph Information Communication
-
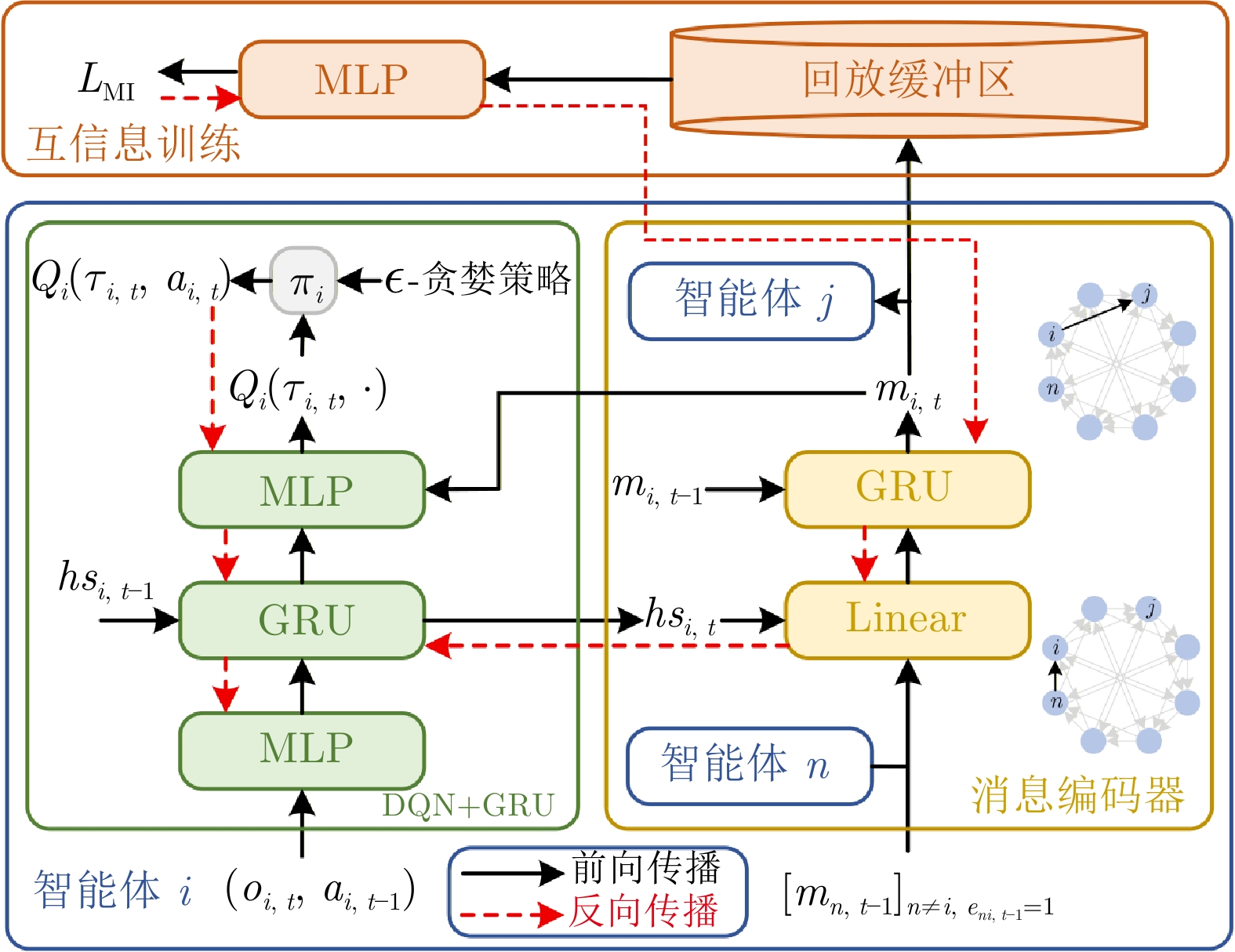
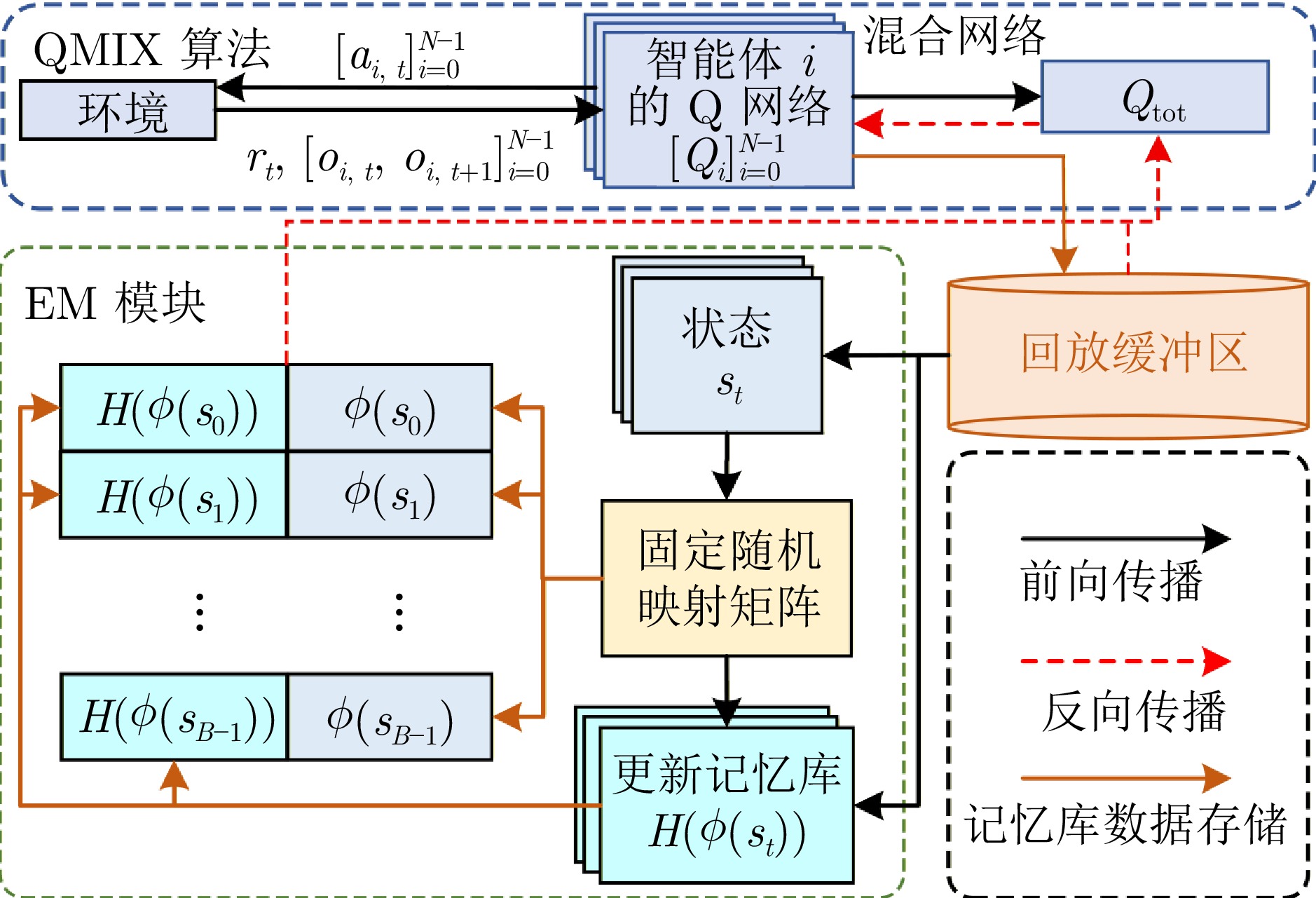
摘要: 多智能体强化学习(MARL)在协同任务中展现出卓越的性能. 然而, 在具有复杂交互关系的大规模多智能体系统(MAS)中, 传统的MARL算法由于缺乏高效的通信机制, 性能往往受到限制. 为提升MARL在大规模MAS中的性能, 本文提出一种具有指数图信息通信的情境MARL算法(EMAGIC). 首先, 设计基于单点指数图的通信拓扑结构, 每个智能体在每个时间步仅与一个智能体进行通信, 消息通过循环通信链路传递给所有智能体. 其次, 构建图信息通信机制, 利用门控循环单元编码多个时间步的消息, 并通过最大化同一时间步不同智能体间消息的互信息来优化消息的编码特征. 最后, 构建独立情境记忆(EM)模块, 建立平均回报与全局状态的对应关系以构建记忆库, 利用EM目标与个体价值均值的误差来构建损失函数. 在多个大规模多智能体环境中的实验结果表明, EMAGIC始终优于最先进的MARL基线方法.Abstract: Multi-agent reinforcement learning (MARL) demonstrates excellent performance in cooperative tasks. However, in large-scale multi-agent systems (MAS) with complex interaction relationships, traditional MARL algorithms perform poorly due to the lack of efficient communication mechanisms. To enhance the performance of MARL in large-scale MAS, this paper proposes an episodic MARL algorithm with exponential graph information communication (EMAGIC). First, this paper designs a one-peer exponential graph-based communication topology, where each agent communicates with only one other agent at each time step and transmits messages to all agents through a cyclic communication link. Second, this paper constructs a graph information communication mechanism that uses a gated recurrent unit to encode messages across multiple time steps and optimizes the encoded features of the messages by maximizing the mutual information between messages of different agents at the same time step. Finally, this paper builds an independent episodic memory (EM) module to establish the correspondence between average returns and global states for constructing a memory bank, and constructs the loss function by using the error between the EM target and the mean of individual values. Experimental results in multiple large-scale multi-agent environments show that EMAGIC consistently outperforms advanced MARL baseline methods.
-
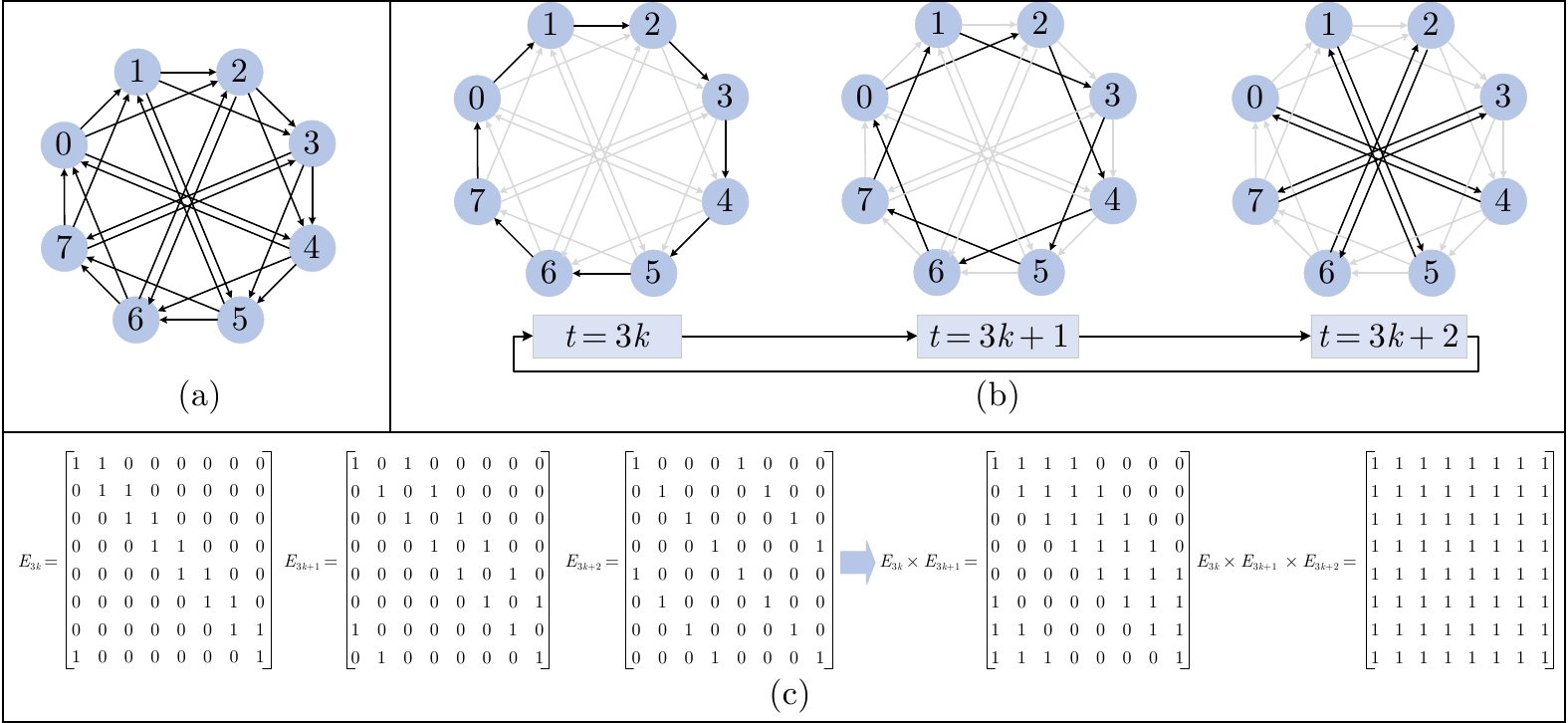
图 2 包含$ 8 $个智能体的基于指数图的通信拓扑((a)基于静态指数图的拓扑结构; (b)基于单点指数图的通信拓扑结构; (c)单点指数图单周期的布尔逻辑矩阵及矩阵相乘结果)
Fig. 2 Exponential graph-based communication topology with 8 agents ((a) Static exponential graph-based topology structure; (b) One-peer exponential graph-based communication topology structure; (c) Boolean logic matrix and matrix multiplication result of one-peer exponential graph in one cycle)
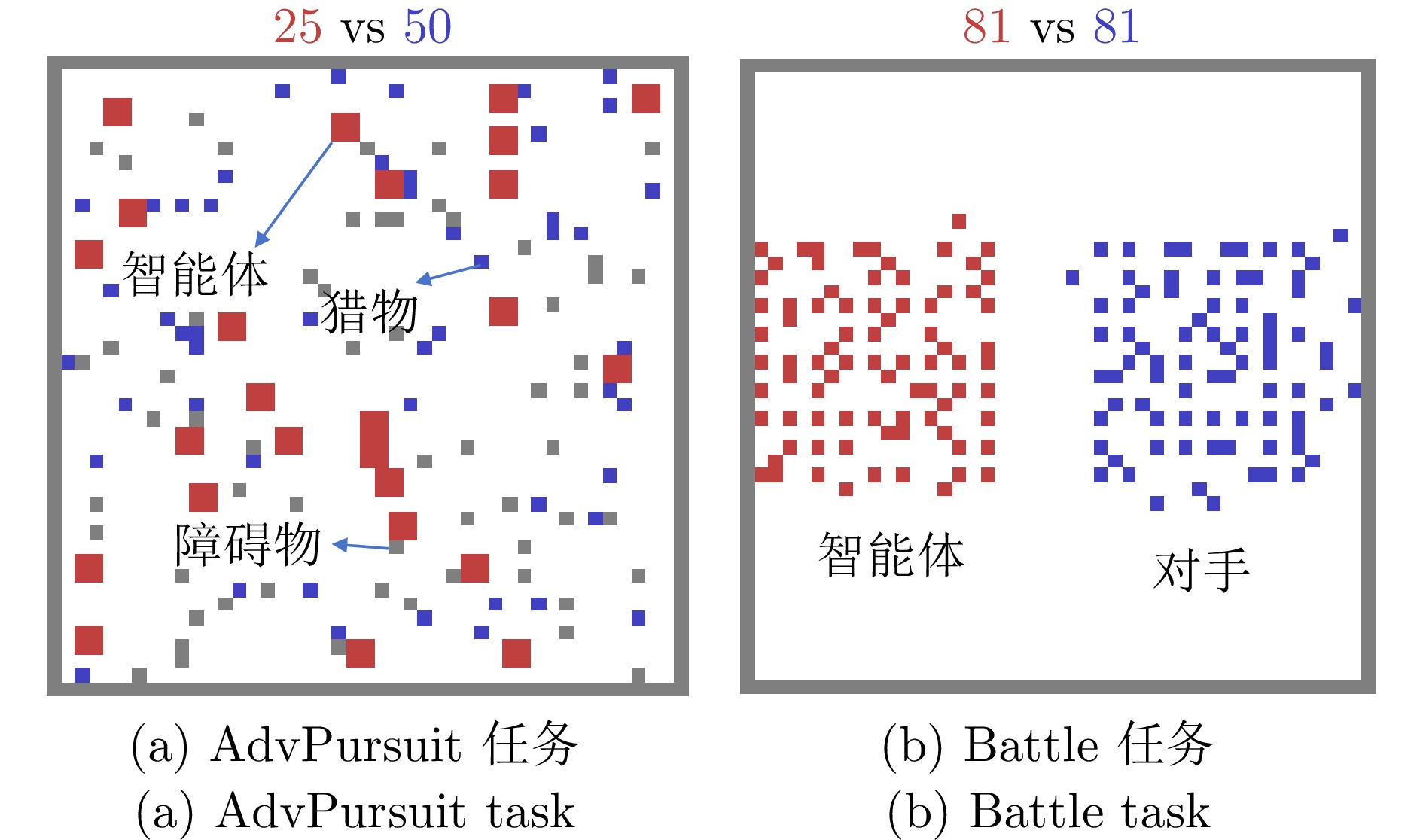
图 4 MAgent环境下两个任务的示意图
Fig. 4 Schematic diagrams of two tasks in the MAgent environment
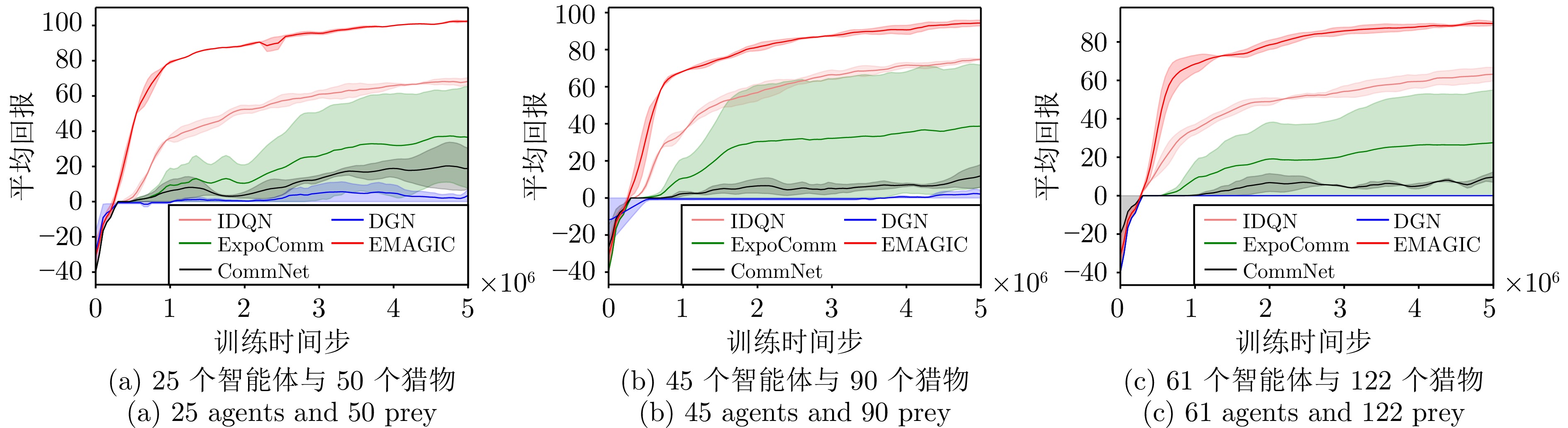
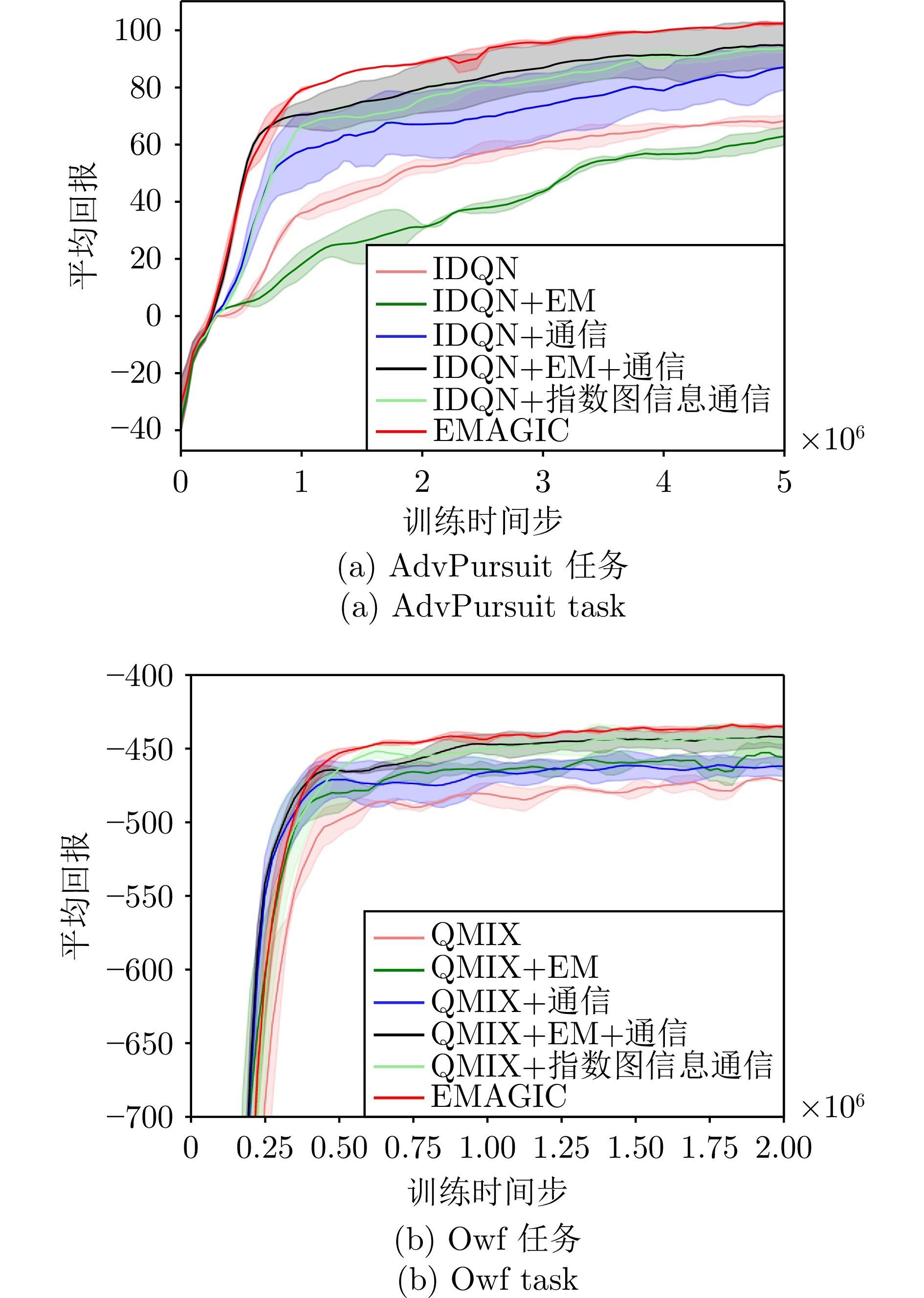
图 6 MAgent环境下AdvPursuit任务中的对比实验
Fig. 6 Comparative experiments on AdvPursuit tasks in the MAgent environment
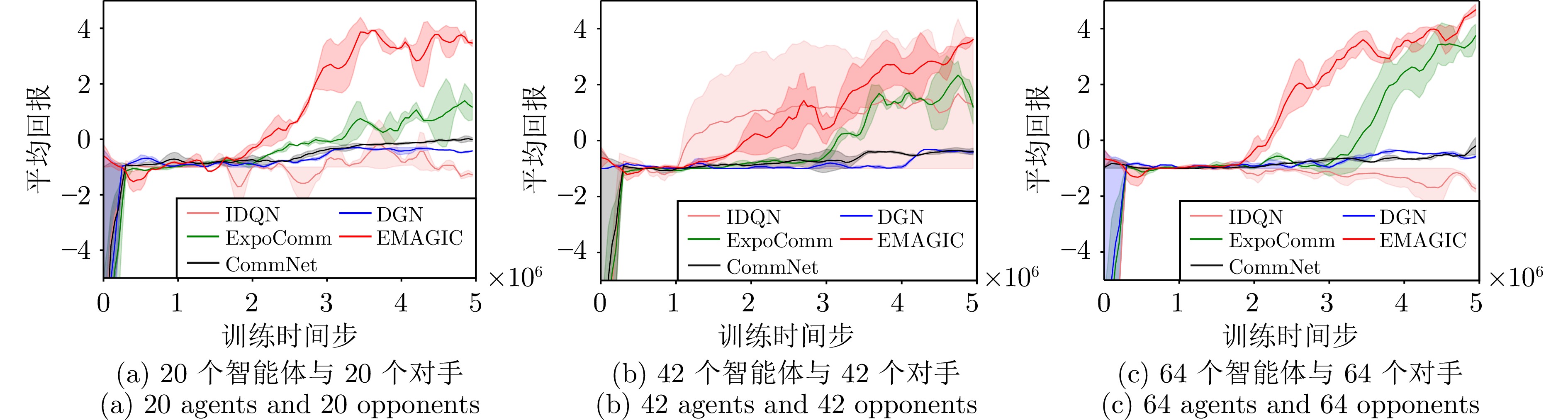
图 7 MAgent环境下Battle任务中的对比实验
Fig. 7 Comparative experiments on Battle tasks in the MAgent environment
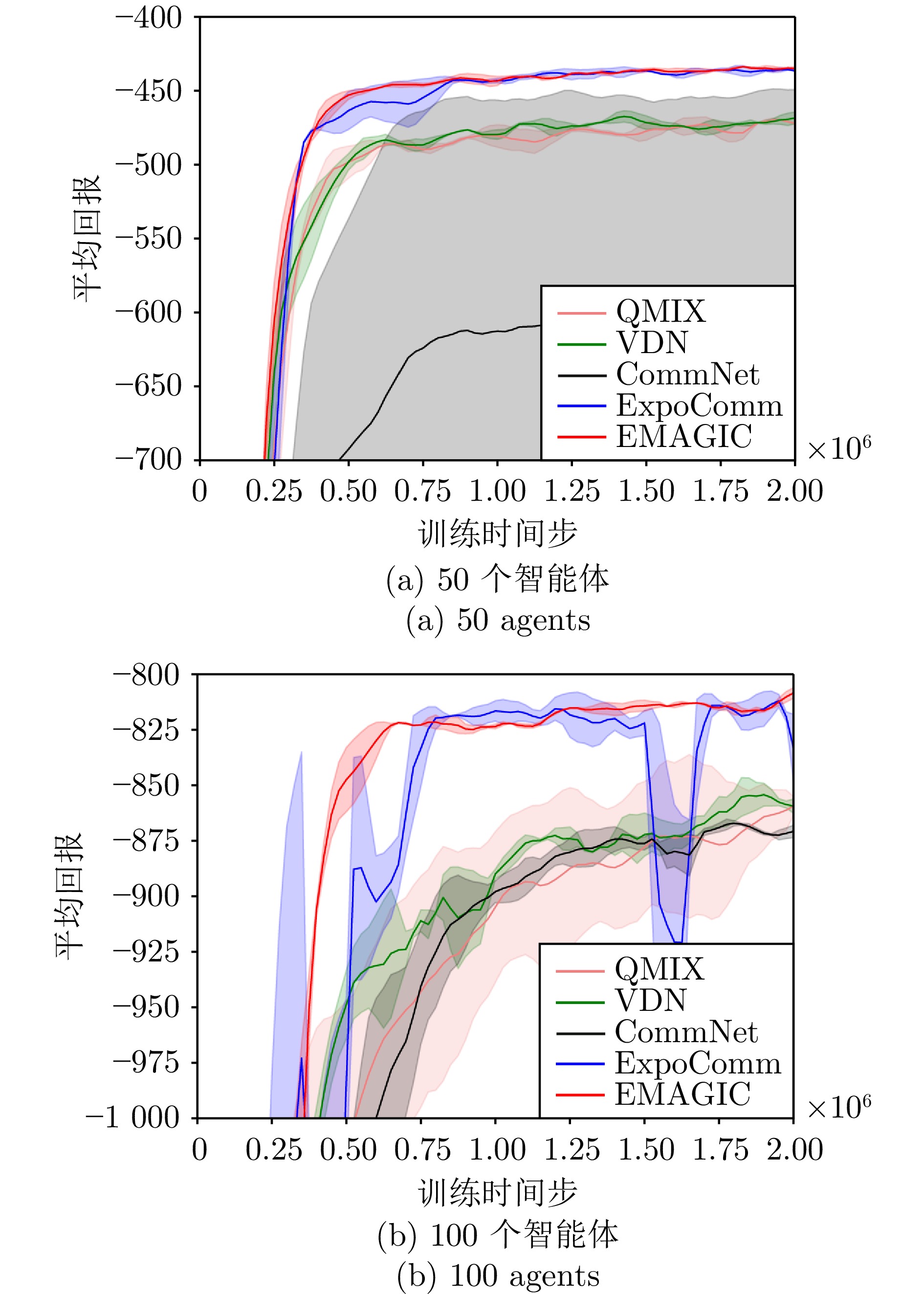
图 8 IMP环境下Owf任务中的对比实验
Fig. 8 Comparative experiments on Owf tasks in the IMP environment
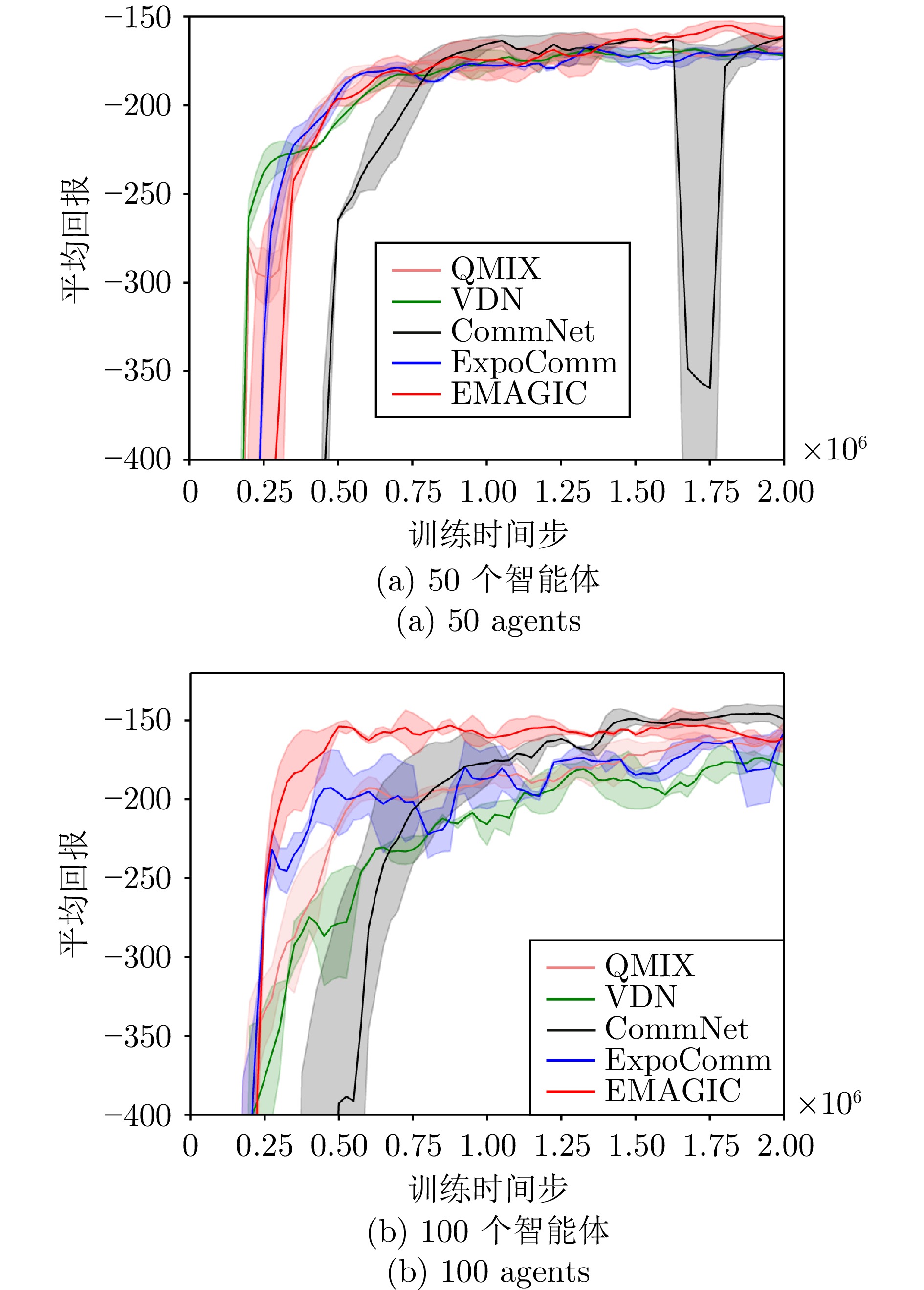
图 10 IMP环境下kn任务中的对比实验
Fig. 10 Comparative experiments on kn tasks in the IMP environment
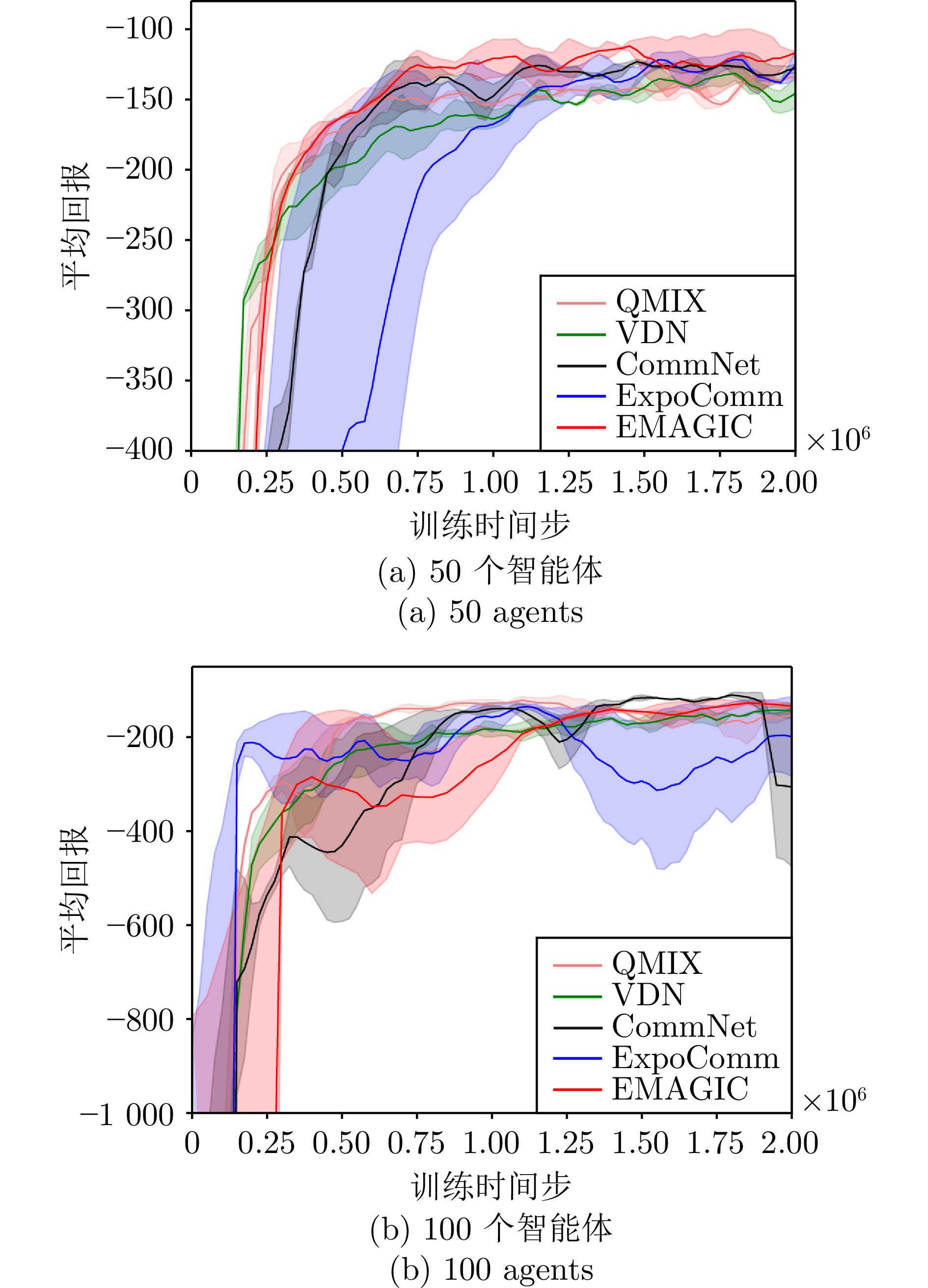
图 9 IMP环境下Ckn任务中的对比实验
Fig. 9 Comparative experiments on Ckn tasks in the IMP environment
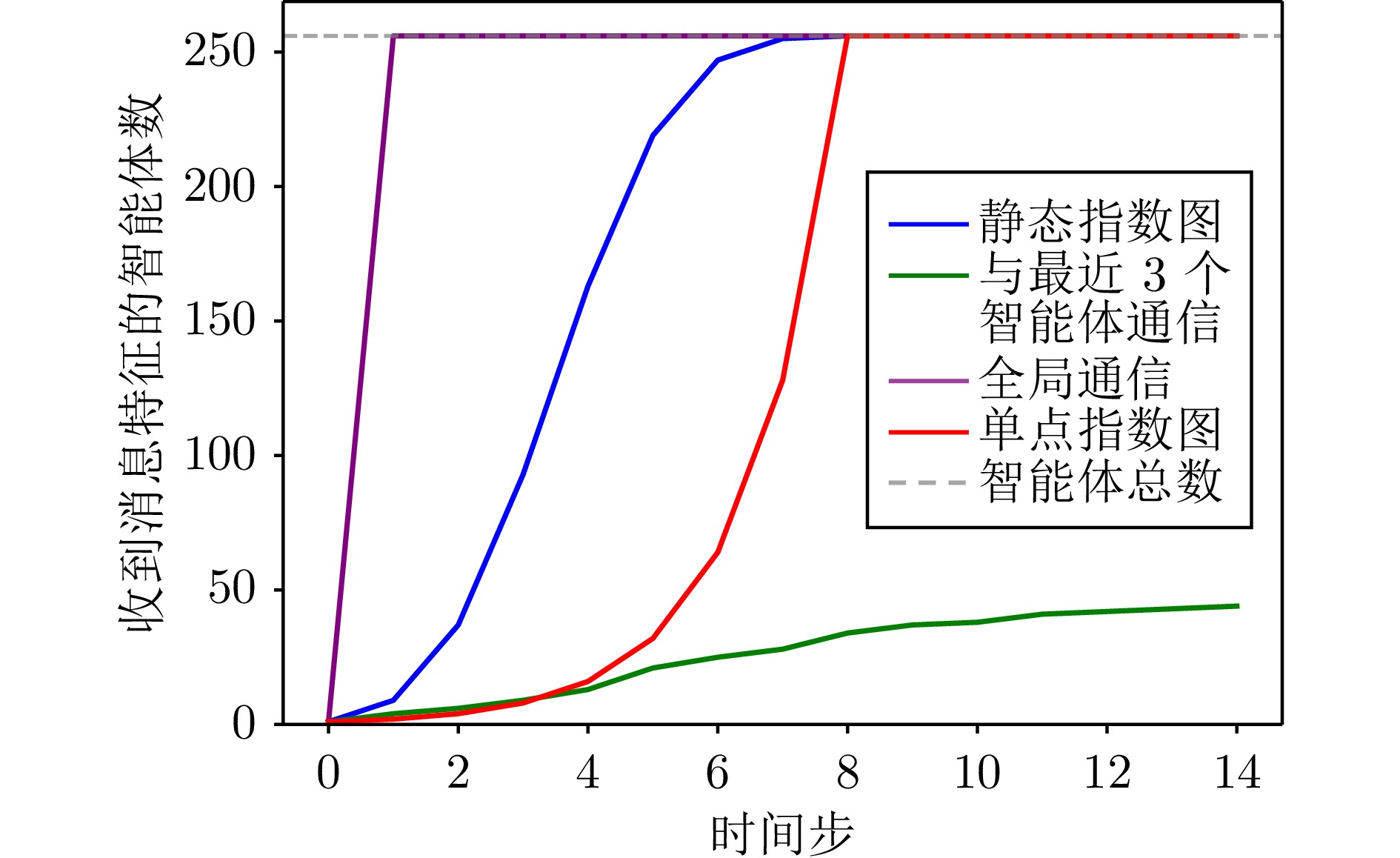
图 11 几种通信拓扑的消息传播速度比较
Fig. 11 Message propagation speed comparison among several communication topologies
表 1 EMAGIC的重要超参数
Table 1 Important hyperparameters of EMAGIC
消息特征维度$ D $ $ \alpha $ $ \beta $ 记忆库大小$ B $ 嵌入特征维度$ d $ $ 64 $ $ 0.1 $ $ 0.1 $ $ 1\times 10^6 $ $ 4 $  下载: 导出CSV
下载: 导出CSV
表 2 EMC和EMAGIC在IMP环境下收敛后的平均回报值
Table 2 Converged average return values of EMC and EMAGIC in the IMP environment
算法 Owf任务 Ckn任务 kn任务 50个智能体 100个智能体 50个智能体 100个智能体 50个智能体 100个智能体 EMC −2892.53 −5785.06 −1155.38 −1743.98 −2047.55 −1788.10 EMAGIC −432.77 −801.71 −119.79 −117.66 −168.93 −165.59
下载: 导出CSV
表 3 几种通信拓扑的通信成本对比, 后$ 3 $种通信拓扑分别对应ExpoComm、DGN和CommNet
Table 3 Comparison of communication costs of several communication topologies, where the latter $ 3 $ communication topologies correspond to ExpoComm, DGN, and CommNet, respectively
下载: 导出CSV
-
[1] Peng Z, Wu G H, Luo B, Wang L. Multi-UAV cooperative pursuit strategy with limited visual field in urban airspace: A multi-agent reinforcement learning approach. IEEE/CAA Journal of Automatica Sinica, 2025, 12(7): 1350−1367 doi: 10.1109/JAS.2024.124965 [2] 施伟, 冯旸赫, 程光权, 黄红蓝, 黄金才, 刘忠, 等. 基于深度强化学习的多机协同空战方法研究. 自动化学报, 2021, 47(7): 1610−1623 doi: 10.16383/j.aas.c201059Shi Wei, Feng Yang-He, Cheng Guang-Quan, Huang Hong-Lan, Huang Jin-Cai, Liu Zhong, et al. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(7): 1610−1623 doi: 10.16383/j.aas.c201059 [3] Ou W, Luo B, Xu X D, Feng Y, Zhao Y Q. Reinforcement learned multiagent cooperative navigation in hybrid environment with relational graph learning. IEEE Transactions on Artificial Intelligence, 2025, 6(1): 25−36 doi: 10.1109/TAI.2024.3443783 [4] 罗彪, 胡天萌, 周育豪, 黄廷文, 阳春华, 桂卫华. 多智能体强化学习控制与决策研究综述. 自动化学报, 2025, 51(3): 510−539Luo Biao, Hu Tian-Meng, Zhou Yu-Hao, Huang Ting-Wen, Yang Chun-Hua, Gui Wei-Hua. Survey on multi-agent reinforcement learning for control and decision-making. Acta Automatica Sinica, 2025, 51(3): 510−539 [5] Sunehag P, Lever G, Gruslys A, Czarnecki W M, Zambaldi V, Jaderberg M, et al. Value-decomposition networks for cooperative multi-agent learning based on team reward. In: Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems. Stockholm, Sweden: International Foundation for Autonomous Agents and Multiagent Systems, 2018. 2085−2087 [6] Rashid T, Samvelyan M, de Witt C S, Farquhar G, Foerster J, Whiteson S. Monotonic value function factorisation for deep multi-agent reinforcement learning. The Journal of Machine Learning Research, 2020, 21(1): Article No. 178 [7] Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6382−6393 [8] Ackermann J, Gabler V, Osa T, Sugiyama M. Reducing overestimation bias in multi-agent domains using double centralized critics. arXiv preprint arXiv: 1910.01465, 2019. [9] Yu C, Velu A, Vinitsky E, Gao J X, Wang Y, Bayen A, et al. The surprising effectiveness of PPO in cooperative multi-agent games. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 1787 [10] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529−533 doi: 10.1038/nature14236 [11] Li X R, Wang X L, Bai C J, Zhang J. Exponential topology-enabled scalable communication in multi-agent reinforcement learning. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. 1−25 [12] Zheng L L, Chen J R, Wang J H, He J M, Hu Y J, Chen Y F, et al. Episodic multi-agent reinforcement learning with curiosity-driven exploration. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 287 [13] Ma X, Li W J. State-based episodic memory for multi-agent reinforcement learning. Machine Learning, 2023, 112(12): 5163−5190 doi: 10.1007/s10994-023-06365-2 [14] Blundell C, Uria B, Pritzel A, Li Y Z, Ruderman A, Leibo J Z, et al. Model-free episodic control. arXiv preprint arXiv: 1606.04460, 2016. [15] Pritzel A, Uria B, Srinivasan S, Badia A P, Vinyals O, Hassabis D, et al. Neural episodic control. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: JMLR.org, 2017. 2827−2836 [16] Zhao Y Y, Wang Z Y, Zhu C X, Wang S H. Efficient dialogue complementary policy learning via deep Q-network policy and episodic memory policy. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Punta Cana, Dominican Republic: ACL, 2021. 4311−4323 [17] Peng K X, Li P Y, Hao J Y. Enhancing graph-based coordination with evolutionary algorithms for episodic multi-agent reinforcement learning. In: Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems. Detroit, USA: International Foundation for Autonomous Agents and Multiagent Systems, 2025. 1623−1631 [18] 李艺春, 刘泽娇, 洪艺天, 王继超, 王健瑞, 李毅, 等. 基于多智能体强化学习的博弈综述. 自动化学报, 2025, 51(3): 540−558 doi: 10.16383/j.aas.c240478Li Yi-Chun, Liu Ze-Jiao, Hong Yi-Tian, Wang Ji-Chao, Wang Jian-Rui, Li Yi, et al. Multi-agent reinforcement learning based game: A survey. Acta Automatica Sinica, 2025, 51(3): 540−558 doi: 10.16383/j.aas.c240478 [19] Chai J J, Zhu Y H, Zhao D B. NVIF: Neighboring variational information flow for cooperative large-scale multiagent reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(12): 17829−17841 doi: 10.1109/TNNLS.2023.3309608 [20] Li X S, Li J C, Shi H B, Hwang K S. A decentralized communication framework based on dual-level recurrence for multiagent reinforcement learning. IEEE Transactions on Cognitive and Developmental Systems, 2024, 16(2): 640−649 doi: 10.1109/TCDS.2023.3281878 [21] Sukhbaatar S, Szlam A, Fergus R. Learning multiagent communication with backpropagation. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc., 2016. 2252−2260 [22] Chu T S, Wang J, Codecà L, Li Z J. Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(3): 1086−1095 doi: 10.1109/TITS.2019.2901791 [23] Jiang J C, Dun C, Huang T J, Lu Z Q. Graph convolutional reinforcement learning. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: OpenReview.net, 2020. 1−13 [24] Agarwal A, Kumar S, Sycara K, Lewis M. Learning transferable cooperative behavior in multi-agent teams. In: Proceedings of the 19th International Conference on Autonomous Agents and Multiagent Systems. Auckland, New Zealand: International Foundation for Autonomous Agents and Multiagent Systems, 2020. 1741−1743 [25] Nayak S, Choi K, Ding W Q, Dolan S, Gopalakrishnan K, Balakrishnan H. Scalable multi-agent reinforcement learning through intelligent information aggregation. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: PMLR, 2023. 25817−25833 [26] Lo Y L, Sengupta B, Foerster J N, Noukhovitch M. Learning multi-agent communication with contrastive learning. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: OpenReview.net, 2024. 1−18 [27] Ying B C, Yuan K, Chen Y M, Hu H B, Pan P, Yin W T. Exponential graph is provably efficient for decentralized deep training. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 1071 [28] Song J M, Ermon S. Understanding the limitations of variational mutual information estimators. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: OpenReview.net, 2020. 1−18 [29] van den Oord A, Li Y Z, Vinyals O. Representation learning with contrastive predictive coding. arXiv preprint arXiv: 1807.03748, 2018. [30] Nguyen X, Wainwright M J, Jordan M I. Estimating divergence functionals and the likelihood ratio by convex risk minimization. IEEE Transactions on Information Theory, 2010, 56(11): 5847−5861 doi: 10.1109/TIT.2010.2068870 [31] Belghazi M I, Baratin A, Rajeshwar S, Ozair S, Bengio Y, Courville A, et al. Mutual information neural estimation. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 531−540 [32] Zheng L M, Yang J C, Cai H, Zhou M, Zhang W N, Wang J, et al. MAgent: A many-agent reinforcement learning platform for artificial collective intelligence. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 8222−8223 [33] Chen D, Zhang K X, Wang Y Q, Yin X Y, Li Z J, Filev D. Communication-efficient decentralized multi-agent reinforcement learning for cooperative adaptive cruise control. IEEE Transactions on Intelligent Vehicles, 2024, 9(10): 6436−6449 doi: 10.1109/TIV.2024.3368025 [34] Leroy P, Morato P G, Pisane J, Kolios A, Ernst D. IMP-MARL: A suite of environments for large-scale infrastructure management planning via marl. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 2329 [35] Papoudakis G, Christianos F, Schäfer L, Albrecht S V. Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 113 -

 下载:
下载:


计量
- 文章访问数: 331
- HTML全文浏览量: 114
- PDF下载量: 69
- 被引次数: 0
