

Study on Hydraulic Support Alignment Strategy Based on Multi-agent Cooperative Game
-
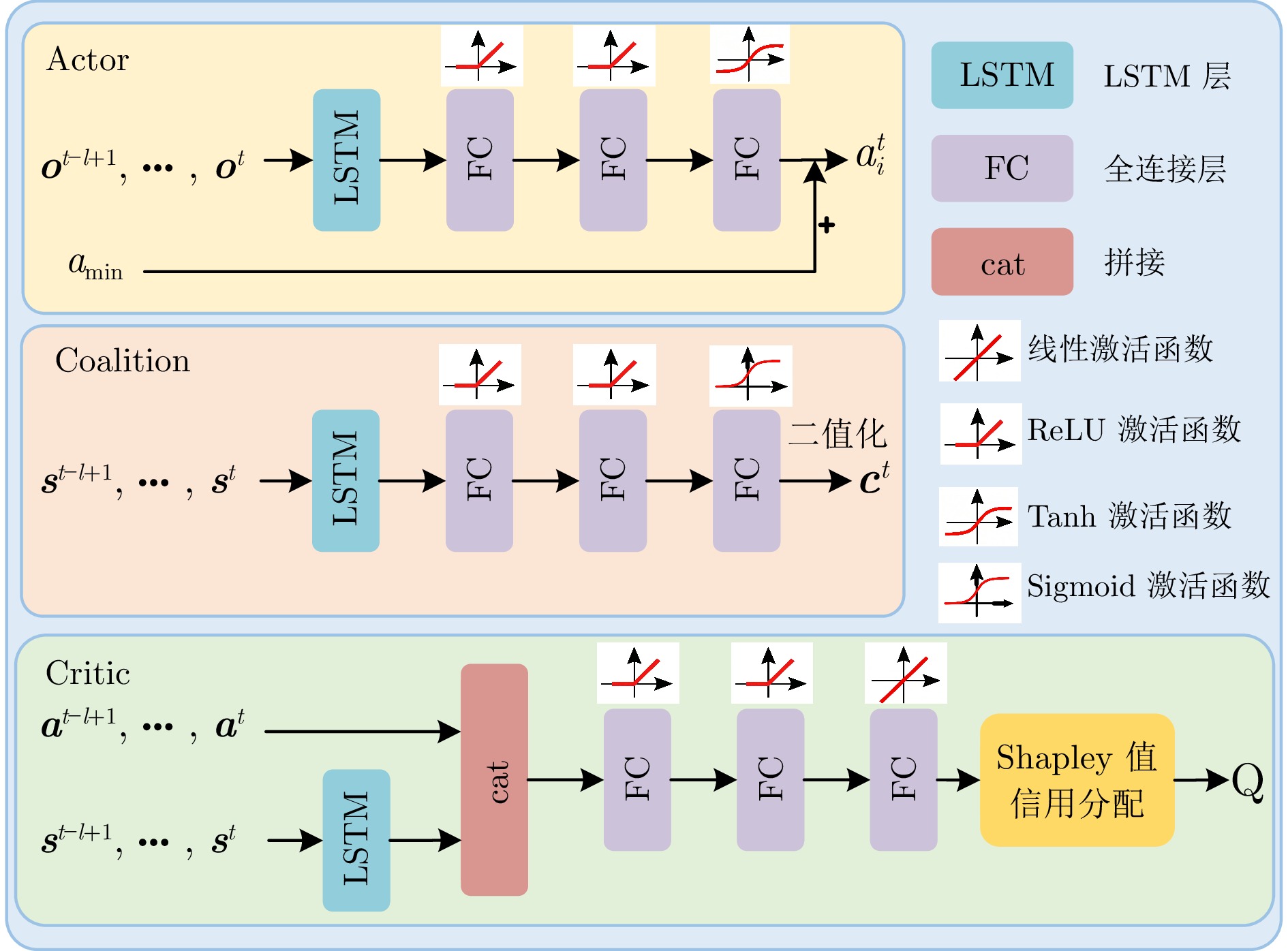
摘要: 综采工作面液压支架群调直过程中, 支架群间的强耦合关系与液压缸摩擦−滑移非线性构成典型的“耦合−非线性”双重复杂性, 使传统控制方法难以有效建模. 现有多智能体强化学习方法能实现并行决策, 但面临全局奖励无法精确归因至各支架动作、仅依赖观测状态难以捕获支架群姿态的时序演化规律等问题, 阻碍策略的有效收敛. 为此, 提出融合合作博弈与长短期记忆网络(LSTM)的多智能体强化学习算法CG-LSTM-MATD3. 该算法基于去中心化部分可观测马尔科夫决策过程对液压支架调直过程建模, 引入Shapley值实现各液压支架边际贡献的合理归因, 并设计Coalition网络通过联盟生成降低计算复杂度. 其次, 在Actor、Critic以及Coalition网络中嵌入LSTM模块, 通过对状态序列等信息的记忆, 使模型能够捕获状态的时序依赖关系, 增强对环境动态特性和真实状态的感知能力. 实验结果表明, 该算法在七支架任务中直线度相对基线算法提升80.59%, 消融实验进一步证明了合作博弈机制与LSTM模块的有效性.Abstract: During the alignment of hydraulic support clusters in fully mechanized mining faces, the strong coupling between support clusters and the friction-slip nonlinearity of hydraulic cylinders create a typical “coupling-nonlinearity” dual complexity, making it difficult for traditional control methods to model the system effectively. Existing multi-agent reinforcement learning methods can achieve parallel decision-making, while they face challenges such as the inability to precisely attribute global rewards to each support action, and the difficulty of capturing the temporal evolution of the support cluster's posture based solely on observed states, which hinder effective policy convergence. To address these problems, this paper proposes the multi-agent reinforcement learning algorithm CG-LSTM-MATD3, which integrates cooperative games with long short-term memory networks (LSTM). This algorithm models the hydraulic support alignment process based on a decentralized partially observable Markov decision process, introduces Shapley values to reasonably attribute the marginal contributions of each hydraulic support, and designs a Coalition network to reduce computational complexity through coalition formation. Furthermore, LSTM modules are embedded in the Actor, Critic, and Coalition networks. By storing information such as state sequences, the model can capture temporal dependencies among states, thereby enhancing its ability to perceive the dynamic characteristics of the environment and the true state. Experimental results show that the algorithm achieves an 80.59% improvement in linearity compared to the baseline algorithm in the seven-support task. Ablation experiments further validate the effectiveness of the cooperative game mechanism and the LSTM modules.
-
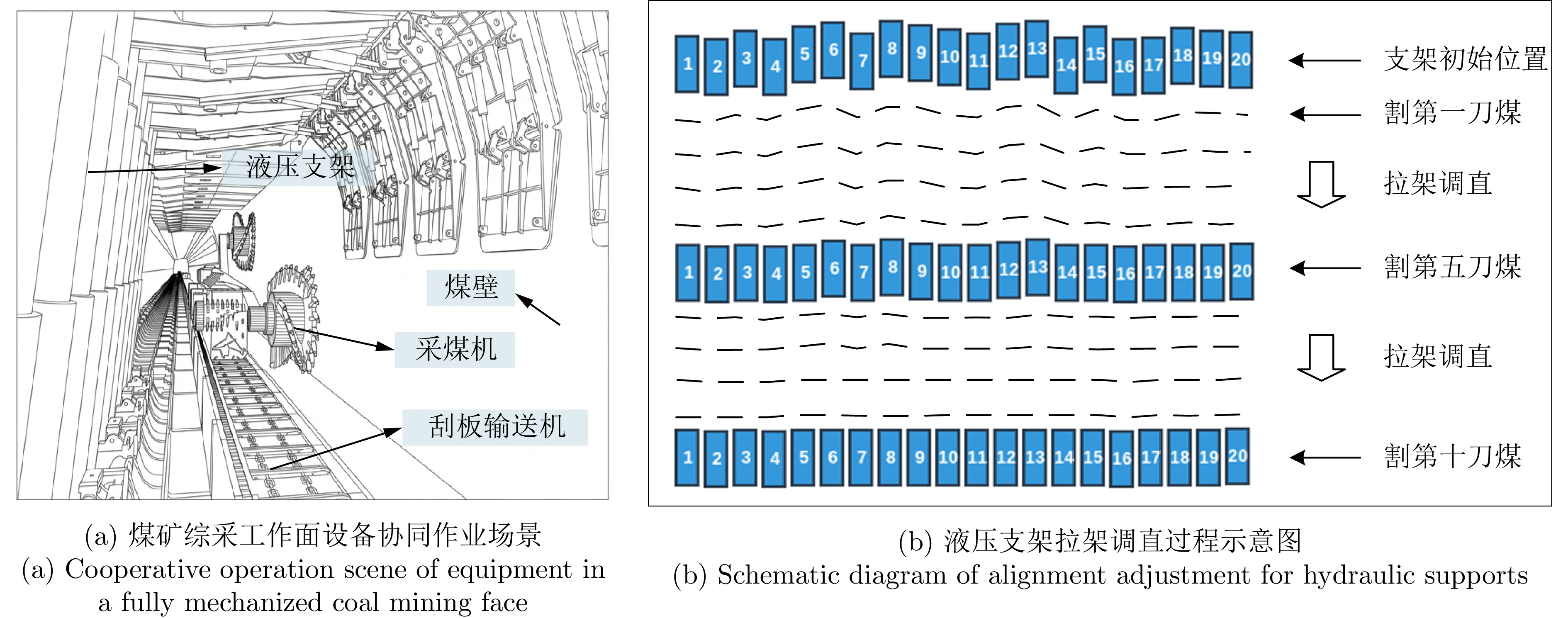
图 1 煤矿综采工作面液压支架协同作业
Fig. 1 Cooperative operation of hydraulic supports in fully mechanized coal mining face
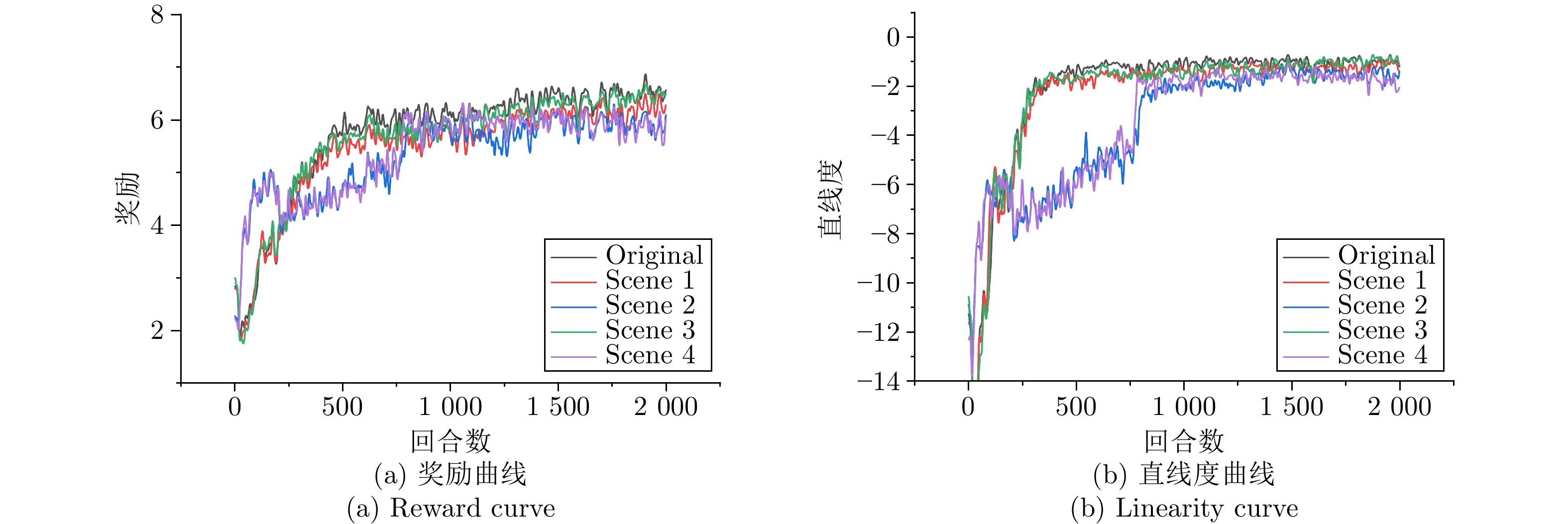
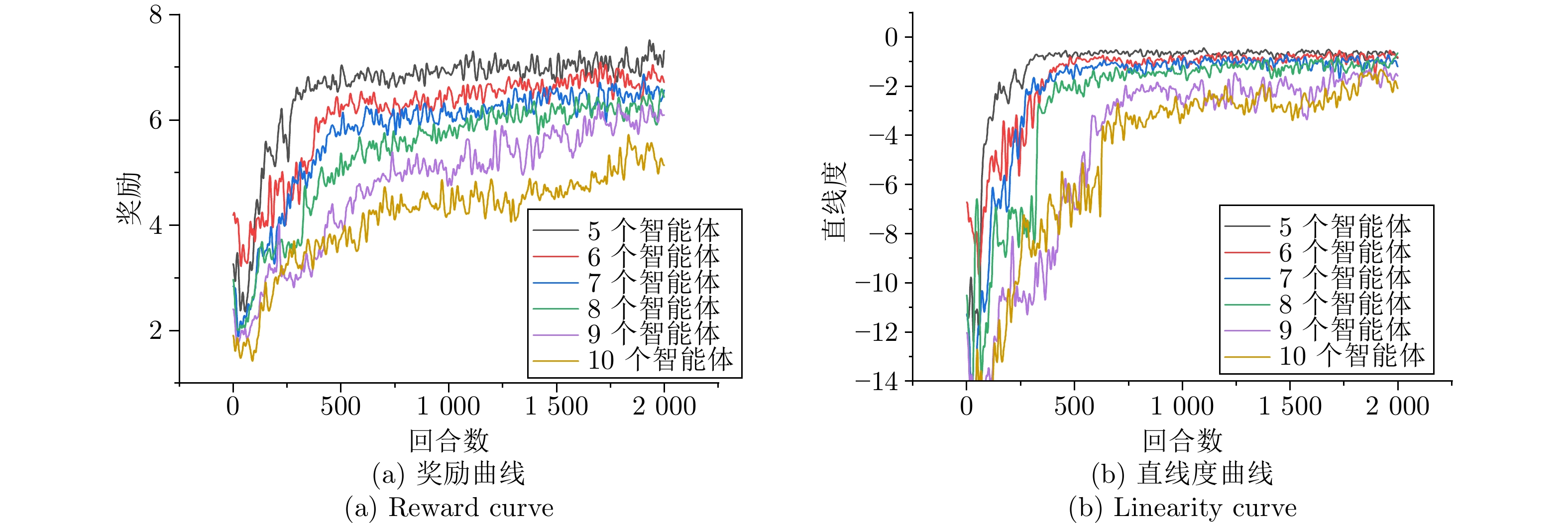
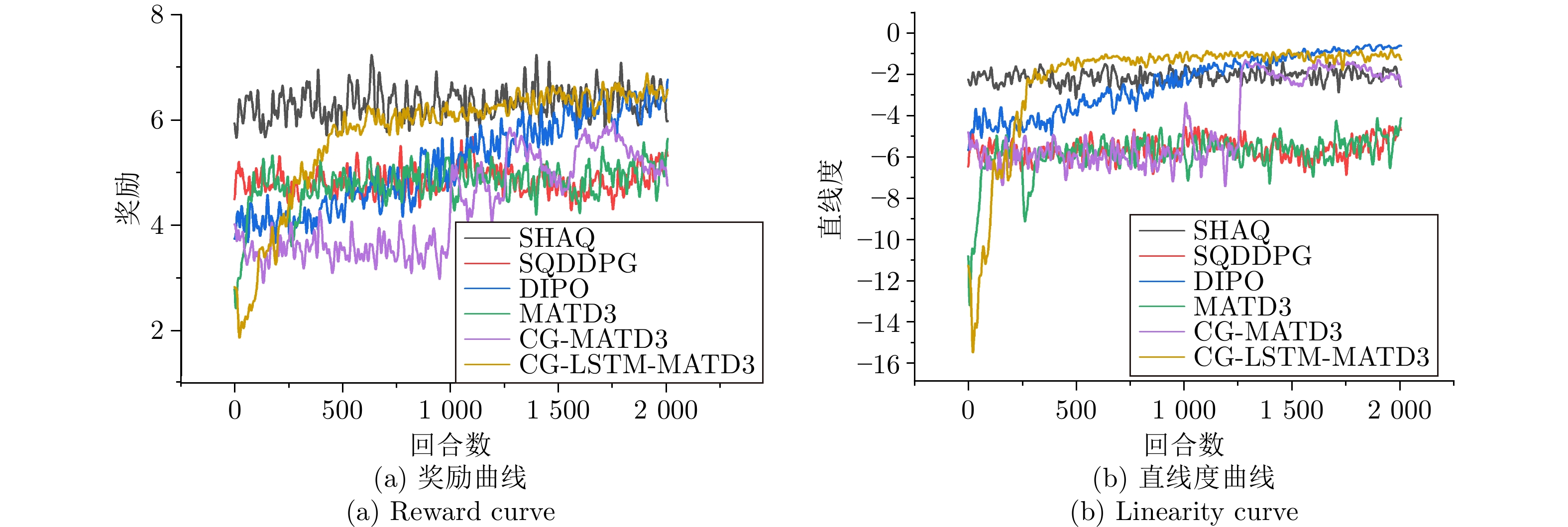
图 9 不同噪声场景下七个智能体的性能曲线
Fig. 9 Performance curves of 7 agents under different noise scenes
表 1 算法超参数设置
Table 1 Algorithm hyperparameter setting
参数 Actor
学习率Critic
学习率联盟
学习率折扣
因子软更新
参数步数 训练
总回合经验池
容量批容量 动作梯度
步数扩散推理
时间步动作
学习率Actor、Critic
梯度裁剪范数动作梯度
范数比例MATD3 $ 3\times10^{-4} $ $ 3\times10^{-4} $ — 0.99 $ 5\times10^{-3} $ 10 2000 10000 256 — — — — — CG-MATD3 $ 3\times10^{-4} $ $ 3\times10^{-4} $ $ 3\times10^{-4} $ 0.99 $ 5\times10^{-3} $ 10 2000 10000 256 — — — — — CG-LSTM-MATD3 $3\times10^{-4} $ $ 3\times10^{-4} $ $ 3\times10^{-4} $ 0.99 $ 5\times10^{-3} $ 10 2000 10000 256 — — — — — DIPO $3\times10^{-4} $ $3\times10^{-4} $ — 0.99 $ 5\times10^{-3} $ 10 2000 10000 256 4 4 0.04 1.0 0.1  下载: 导出CSV
下载: 导出CSV
表 2 不同场景下的奖励与直线度数值
Table 2 Reward and linearity values under different scenes
场景 说明 奖励 直线度 Original 无干扰 6.476 $ - $1.028 Scene 1 液压支架偏斜 6.180 $ - $1.188 Scene 2 传感器噪声 5.930 $ - $1.534 Scene 3 煤层起伏 6.416 $ - $0.985 Scene 4 混合噪声干扰 5.895 $ - $1.683
下载: 导出CSV
表 3 LSTM与经验回放模块互补性分析
Table 3 Complementary analysis of LSTM and experience replay modules
MATD3算法配置 收敛回合数 平均直线度 直线度提升 平均奖励 奖励提升 经验回放 未收敛至最优 $ - $5.301 — 5.001 — LSTM+顺序采样 530 $ - $1.795 66.14% 5.548 10.94% LSTM+经验回放 350 $ - $1.497 71.76% 6.320 26.37%
下载: 导出CSV
表 4 消融实验
Table 4 Ablation experiment
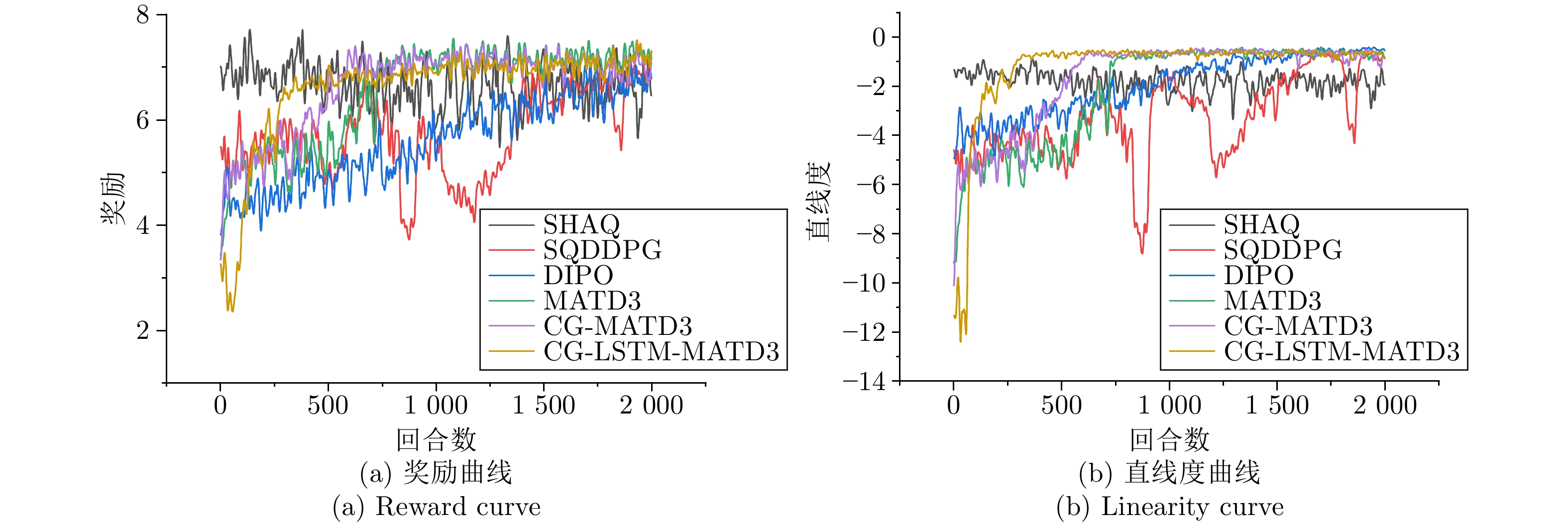
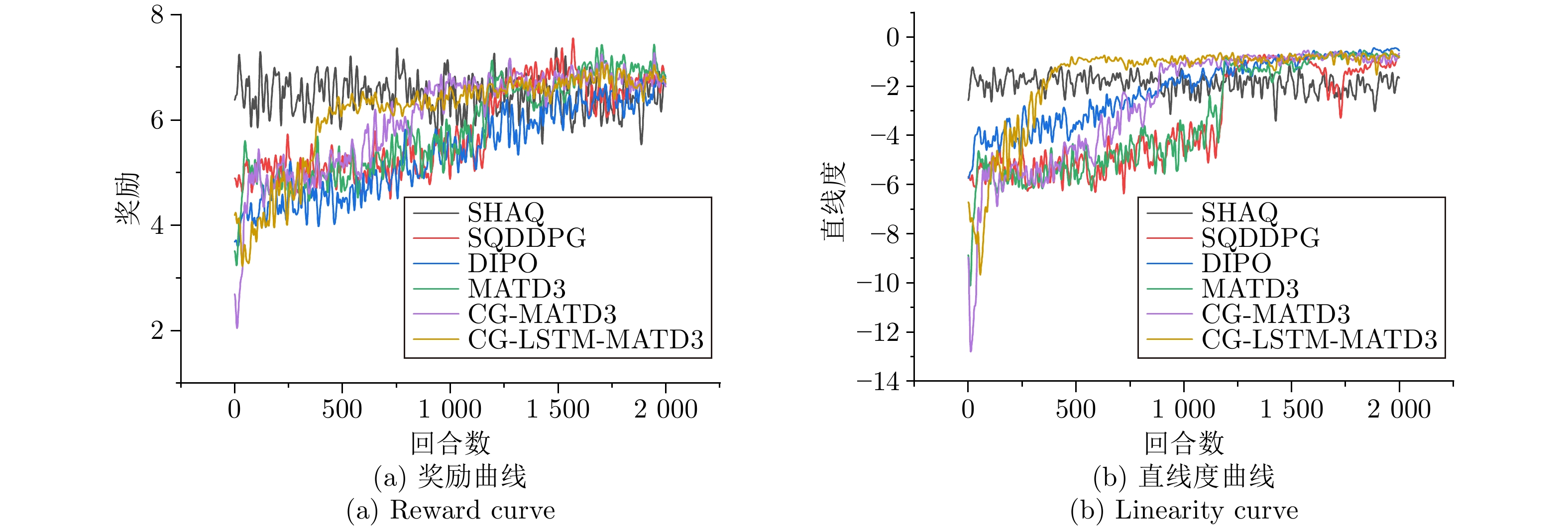
CG LSTM 直线度 奖励 运行时间(ms) GPU占用(MB) 模型参数量(KB) Avg Std 提升 Avg Std 提升 MATD3 $ \times $ $ \times $ $ - $5.301 1.71 — 5.001 0.89 — 6.88 7.71 344.9 LSTM-MATD3 $ \times $ $ \checkmark $ $ - $1.497 1.61 71.76% 6.320 0.47 26.37% 9.34 17.42 363.7 CG-MATD3 $ \checkmark $ $ \times $ $ - $1.675 0.54 68.40% 5.428 0.53 8.54% 9.34 8.37 357.1 CG-LSTM-MATD3 $ \checkmark $ $ \checkmark $ $ - $1.029 0.43 80.59% 6.477 0.44 29.51% 9.34 19.73 378.9
下载: 导出CSV
-
[1] 张德生, 周杰, 任怀伟, 冯银辉, 韩会军, 巩师鑫. 超大采高工作面装备群智能协同控制关键技术. 煤炭技术, 2025, 44(10): 1−5 doi: 10.13301/j.cnki.ct.2025.10.001Zhang De-Sheng, Zhou Jie, Ren Huai-Wei, Feng Yin-Hui, Han Hui-Jun, Gong Shi-Xin. Key technologies for intelligent collaborative control of equipment group in super high mining face. Coal Technology, 2025, 44(10): 1−5 doi: 10.13301/j.cnki.ct.2025.10.001 [2] Murphy K. Reinforcement learning: An overview. arXiv preprint arXiv: 2412.05265, 2024. [3] 罗开成, 高阳, 杨艺, 常亚军, 袁瑞甫. 基于均值偏差奖赏函数的放煤口控制策略研究. 煤炭工程, 2022, 54(9): 105−111Luo Kai-Cheng, Gao Yang, Yang Yi, Chang Ya-Jun, Yuan Rui-Fu. Control strategy of drawing opening based on mean deviation reward function. Coal Engineering, 2022, 54(9): 105−111 [4] 杨艺, 李庆元, 李化敏, 李东印, 杨延麟, 费树岷. 基于批量式强化学习的群组放煤智能决策研究. 煤炭科学技术, 2022, 50(10): 188−197Yang Yi, Li Qing-Yuan, Li Hua-Min, Li Dong-Yin, Yang Yan-Lin, Fei Shu-Min. Research on intelligent decision-making of group drawing based on batch reinforcement learning. Coal Science and Technology, 2022, 50(10): 188−197 [5] 杨艺, 王圣文, 崔科飞, 费树岷. 基于模糊深度Q网络的放煤智能决策方法. 工矿自动化, 2023, 49(4): 78−85 doi: 10.13272/j.issn.1671-251x.2022090068Yang Yi, Wang Sheng-Wen, Cui Ke-Fei, Fei Shu-Min. Intelligent drawing decision method based on fuzzy deep Q-network. Industry and Mine Automation, 2023, 49(4): 78−85 doi: 10.13272/j.issn.1671-251x.2022090068 [6] 杨艺, 孙英杰, 常亚军, 刘斌斌, 王科平. 基于链式基站坐标融合的采煤机定位方法. 工矿自动化, 2025, 51(5): 49−56Yang Yi, Sun Ying-Jie, Chang Ya-Jun, Liu Bin-Bin, Wang Ke-Ping. Shearer positioning method based on chain base station coordinate fusion. Industry and Mine Automation, 2025, 51(5): 49−56 [7] Luo B, Liu D, Wu H N, Huang T, Yang C, Gui W. Recent advances on off-policy reinforcement learning for optimization control. IEEE Transactions on Cybernetics, DOI: 10.1109/TCYB.2026.3683384 [8] Yang Y, Dai Y, Wang T, Qian W. Hydraulic-supports alignment by TD3 with segmented experience pool. Neural Processing Letters, 2025, 57: Article No. 35 doi: 10.1007/s11063-025-11744-y [9] 郭雷, 梁成庆. 基于MATD3算法的多智能体避碰控制. 计算技术与自动化, 2024, 43(1): 9−15Guo Lei, Liang Cheng-Qing. Multi-agent collision avoidance control based on MATD3 algorithm. Computing Technology and Automation, 2024, 43(1): 9−15 [10] Shen G C, Wang Y. Review on Dec-POMDP model for MARL algorithms. In: Proceedings of the Smart Communications, Intelligent Algorithms and Interactive Methods. Singapore: Springer, 2022. 29−35 [11] Alvarez-Mozos M, Macho-Stadler I, Perez-Castrillo D. Sequential creation of surplus and the Shapley value. Games and Economic Behavior, 2026, 155: 149−166 doi: 10.1016/j.geb.2025.09.007 [12] Neuman E, Tuschmann S. Stochastic graphon games with interventions. arXiv preprint arXiv: 2507.00561, 2025. [13] Krichen M, Mihoub A. Long short-term memory networks: A comprehensive survey. AI, 2025, 6(9): Article No. 215 doi: 10.3390/ai6090215 [14] 白晋铭, 王然风, 付翔. 基于架间行走机器人的液压支架直线度测量方法. 工矿自动化, 2019, 45(1): 45−51Bai Jin-Ming, Wang Ran-Feng, Fu Xiang. Straightness measurement method of hydraulic support based on walking robot between supports. Industry and Mine Automation, 2019, 45(1): 45−51 [15] 张旭辉, 王冬曼, 杨文娟. 基于视觉测量的液压支架位姿检测方法. 工矿自动化, 2019, 45(3): 56−60 doi: 10.13272/j.issn.1671-251x.2018090039Zhang Xu-Hui, Wang Dong-Man, Yang Wen-Juan. Position and posture detection method of hydraulic support based on visual measurement. Industry and Mine Automation, 2019, 45(3): 56−60 doi: 10.13272/j.issn.1671-251x.2018090039 [16] 张树楠, 曹现刚, 崔亚仲, 罗璇, 张国祯. 基于多传感器的液压支架直线度测量方法研究. 煤矿机械, 2020, 41(4): 56−59 doi: 10.13436/j.mkjx.202004019Zhang Shu-Nan, Cao Xian-Gang, Cui Ya-Zhong, Luo Xuan, Zhang Guo-Zhen. Research on straightness measurement method of hydraulic support based on multi-sensor. Coal Mine Machinery, 2020, 41(4): 56−59 doi: 10.13436/j.mkjx.202004019 [17] 王宇卓, 常宗旭, 高飞, 廉自生. 液压支架的调直方法研究. 机电工程, 2021, 38(5): 645−649 doi: 10.3969/j.issn.1001-4551.2021.05.020Wang Yu-Zhuo, Chang Zong-Xu, Gao Fei, Lian Zi-Sheng. Research on alignment method of hydraulic support. Journal of Mechanical & Electrical Engineering, 2021, 38(5): 645−649 doi: 10.3969/j.issn.1001-4551.2021.05.020 [18] 宋单阳, 卢春贵, 陶心雅, 杨金衡, 王培恩, 郑文强. 基于最大熵卡尔曼滤波算法的液压支架调直方法. 工矿自动化, 2022, 48(11): 119−124Song Dan-Yang, Lu Chun-Gui, Tao Xin-Ya, Yang Jin-Heng, Wang Pei-En, Zheng Wen-Qiang. Hydraulic support alignment method based on maximum entropy Kalman filter algorithm. Industry and Mine Automation, 2022, 48(11): 119−124 [19] 胡波, 廉自生. 基于支持向量机和遗传算法的液压支架调直系统研究. 煤矿机械, 2014, 35(10): 39−41Hu Bo, Lian Zi-Sheng. Research on hydraulic support alignment system based on support vector machine and genetic algorithm. Coal Mine Machinery, 2014, 35(10): 39−41 [20] 王虹, 尤秀松, 李首滨, 魏文艳. 基于遗传算法与BP神经网络的支架跟机自动化研究. 煤炭科学技术, 2021, 49(1): 272−277 doi: 10.13199/j.cnki.cst.2021.01.024Wang Hong, You Xiu-Song, Li Shou-Bin, Wei Wen-Yan. Research on support following automation based on genetic algorithm and BP neural network. Coal Science and Technology, 2021, 49(1): 272−277 doi: 10.13199/j.cnki.cst.2021.01.024 [21] 李文俊, 周展. 基于惯导系统的综采工作面自动调直技术. 陕西煤炭, 2022, 41(4): 130−133 doi: 10.3969/j.issn.1008-0155.2023.23.018Li Wen-Jun, Zhou Zhan. Automatic alignment technology of fully mechanized working face based on inertial navigation system. Shaanxi Coal, 2022, 41(4): 130−133 doi: 10.3969/j.issn.1008-0155.2023.23.018 [22] 王云飞, 赵继云, 张鹤, 王浩, 张阳. 基于神经网络补偿的液压支架群推移系统直线度控制方法. 煤炭科学技术, 2024, 52(11): 174−185Wang Yun-Fei, Zhao Ji-Yun, Zhang He, Wang Hao, Zhang Yang. Straightness control method of hydraulic support group pushing system based on neural network compensation. Coal Science and Technology, 2024, 52(11): 174−185 [23] 孙铭泽, 王永强, 常亚军, 朱德昇, 李石岩, 杨克虎. 液压支护机器人群组移架一致性分布式协同控制. 煤炭学报, 2024, 49(S2): 1208−1222Sun Ming-Ze, Wang Yong-Qiang, Chang Ya-Jun, Zhu De-Sheng, Li Shi-Yan, Yang Ke-Hu. Distributed cooperative synchronization control of hydraulic support robot group for advancing. Journal of China Coal Society, 2024, 49(S2): 1208−1222 [24] Wang J, Zhang Y, Kim T K, Gu Y. Shapley Q-value: A local reward approach to solve global reward games. arXiv preprint arXiv: 1907.05707, 2019. [25] Wang J, Zhang Y, Gu Y, Kim T K. SHAQ: Incorporating Shapley value theory into multi-agent Q-learning. arXiv preprint arXiv: 2105.15013, 2021. [26] Li J. Shapley counterfactual credits for multi-agent reinforcement learning. arXiv preprint arXiv: 2106.00285, 2021. [27] Heuillet A, Couthouis F, Diaz-Rodriguez N. Collective explainable AI: Explaining cooperative strategies and agent contribution in multiagent reinforcement learning with Shapley values. IEEE Computational Intelligence Magazine, 2022, 17(1): 59−71 doi: 10.1109/MCI.2021.3129959 [28] Wang J. Shapley value based multi-agent reinforcement learning: Theory, method and its application to energy network. arXiv preprint arXiv: 2402.15324, 2024. [29] Qin H, Zhang W, Tian R. Collaborative control method of transit signal priority based on cooperative game and reinforcement learning. In: Proceedings of the 4th IEEE International Conference on Electronic Technology, Communication and Information (ICETCI). New York, USA: IEEE, 2024. 537−542 [30] Tang C, Pan L, Chen J, Liu Y, Lai J. A game theory-reinforcement learning approach to cooperation for UAVs. IEEE Transactions on Vehicular Technology, 2025, 74(6): 9864−9869 doi: 10.1109/TVT.2025.3539382 [31] Yang L. Policy representation via diffusion probability model for reinforcement learning. arXiv preprint arXiv: 2305.13122, 2023. -

 下载:
下载:

计量
- 文章访问数: 134
- HTML全文浏览量: 76
- PDF下载量: 6
- 被引次数: 0
