

Visual Industrial Defect Detection: A Survey on the Evolution and Synergy From Non-foundation Model to Foundation Model
-
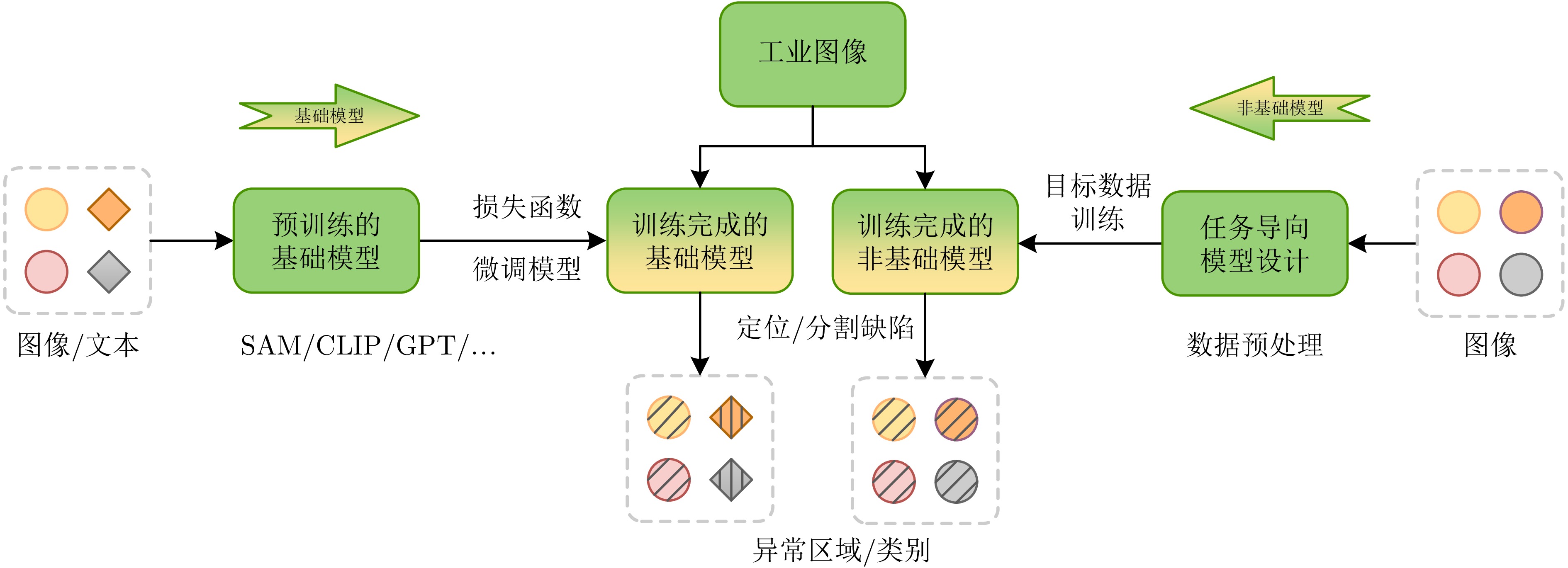
摘要: 随着工业产品日益丰富且精密复杂, 视觉工业缺陷检测技术备受关注. 近年来, 基础模型(FM)凭借其从海量数据中获取的广博先验知识, 在泛化能力及少样本与零样本场景中展现出强大的潜力. 然而, 梳理现有方法可以发现一个值得关注的现象:当前许多先进的FM方法, 其性能的显著提升并非单纯依赖FM的应用, 而是通过将FM强大的通用表征能力与非基础模型(NFM)方法中成熟、高效的任务导向型原理(例如对比学习、知识蒸馏和异常合成)进行战略性融合. 为系统性地分析并揭示这一协同范式, 首先分别对NFM和FM方法进行系统性综述, 并从多维度比较两种方法, 分析各自的优势与局限. 在此基础上, 深入剖析NFM策略如何从其原始架构中解耦出来, 并被重新用于增强基础模型在工业应用中的性能, 同时构建协同机制适配性矩阵. 此外, 进一步探讨该范式在实际场景中的落地局限. 在对比数据的支持下, 分析结果表明, FM的通用知识与NFM的任务特化优势之间存在巨大的协同潜力, 这为未来的研究指明一条有效的借鉴思路.Abstract: As industrial products become increasingly abundant and sophisticated, visual industrial defect detection technology has received much attention. In recent years, foundation model (FM) have demonstrated powerful potential, particularly in generalization as well as in few-shot and zero-shot scenarios, by leveraging broad prior knowledge acquired from vast amounts of data. However, upon reviewing existing methods, a noteworthy phenomenon can be observed: The significant performance improvements of many current advanced FM methods do not rely solely on the application of FM, but rather through the strategic fusion of the FM's powerful general-purpose representation capabilities with mature, efficient, task-specific principles from non-foundation model (NFM) methods, such as contrastive learning, knowledge distillation, and anomaly synthesis. To systematically analyze and reveal this synergistic paradigm, a systematic survey of both NFM and FM methods is first provided, and the two methods are compared from multiple dimensions to analyze their respective advantages and limitations. Building on this, an in-depth analysis is conducted on how NFM strategies can be decoupled from their original architectures and repurposed to enhance the performance of foundation model in industrial applications, while an adaptability matrix for collaborative mechanisms is simultaneously constructed. Furthermore, the practical deployment limitations of this paradigm in real-world scenarios are further explored. Supported by comparative data, the analysis results indicate that there is significant synergistic potential between the general knowledge of FM and the task-specialization advantages of NFM, pointing to an effective direction for future research.
-
Key words:
- industrial defect detection /
- few-shot learning /
- foundation model /
- non-foundation model
-

图 4 主流工业缺陷检测数据集与典型缺陷样本示例
Fig. 4 Mainstream industrial defect detection datasets and typical defect sample examples
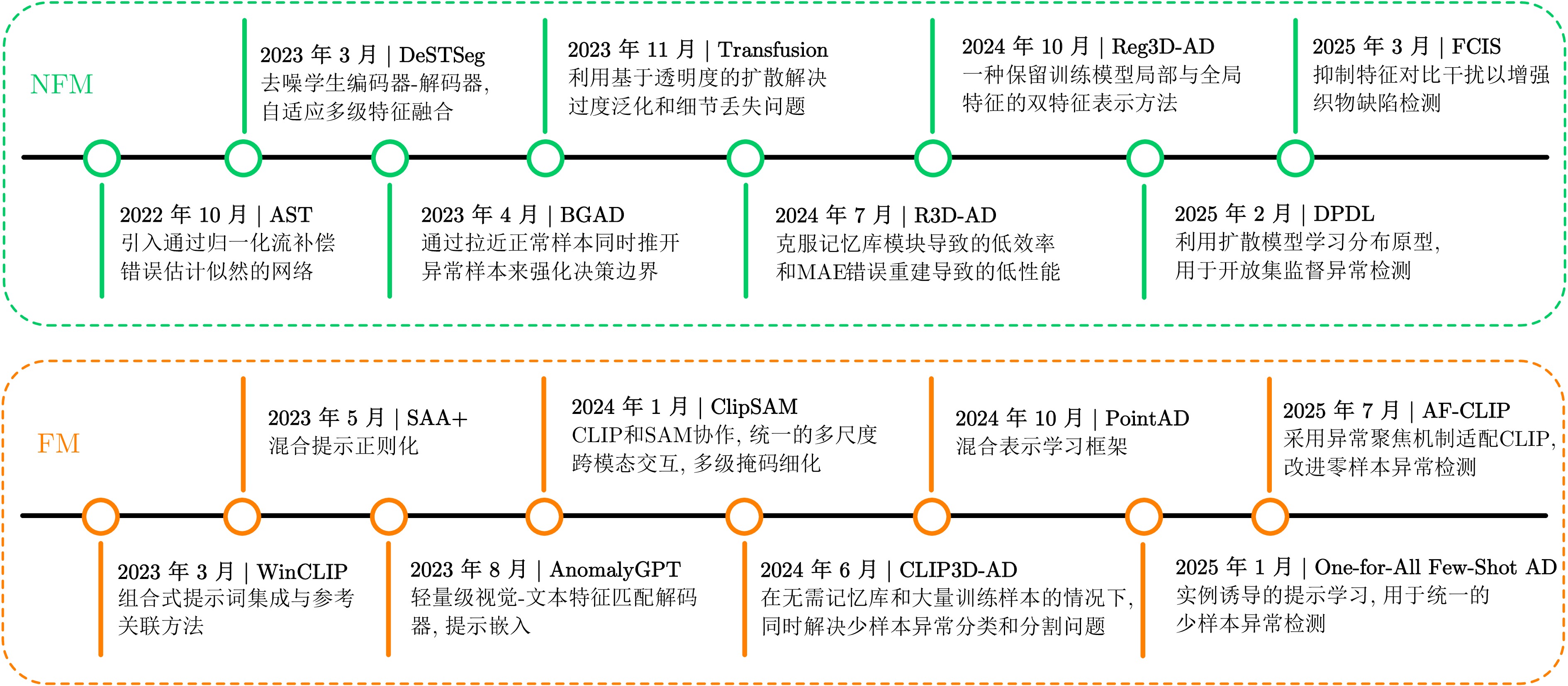
图 5 NFM与FM模型发展中的代表性方法
Fig. 5 Representative methods along the development of NFM and FM mdoel
表 1 主流工业检测数据集、核心挑战与典型应用场景汇总
Table 1 Summary of mainstream industrial datasets, core challenges and typical application scenarios
 下载: 导出CSV
下载: 导出CSV
表 2 多维度评测体系
Table 2 Multi-dimensional evaluation framework
评测维度 场景/任务 推荐指标 缺陷感知 2D分类 I-AUROC、F1-max 2D分割 P-AUROC、PRO 3D检测 3D-PRO、Chamfer 逻辑异常 Acc.、Conf. Matrix 工业部署 实时产线 FPS、Latency 边缘设备 Params、Memory 场景适应 少样本 Performance Gain 域迁移 Domain Adapt. Acc.
下载: 导出CSV
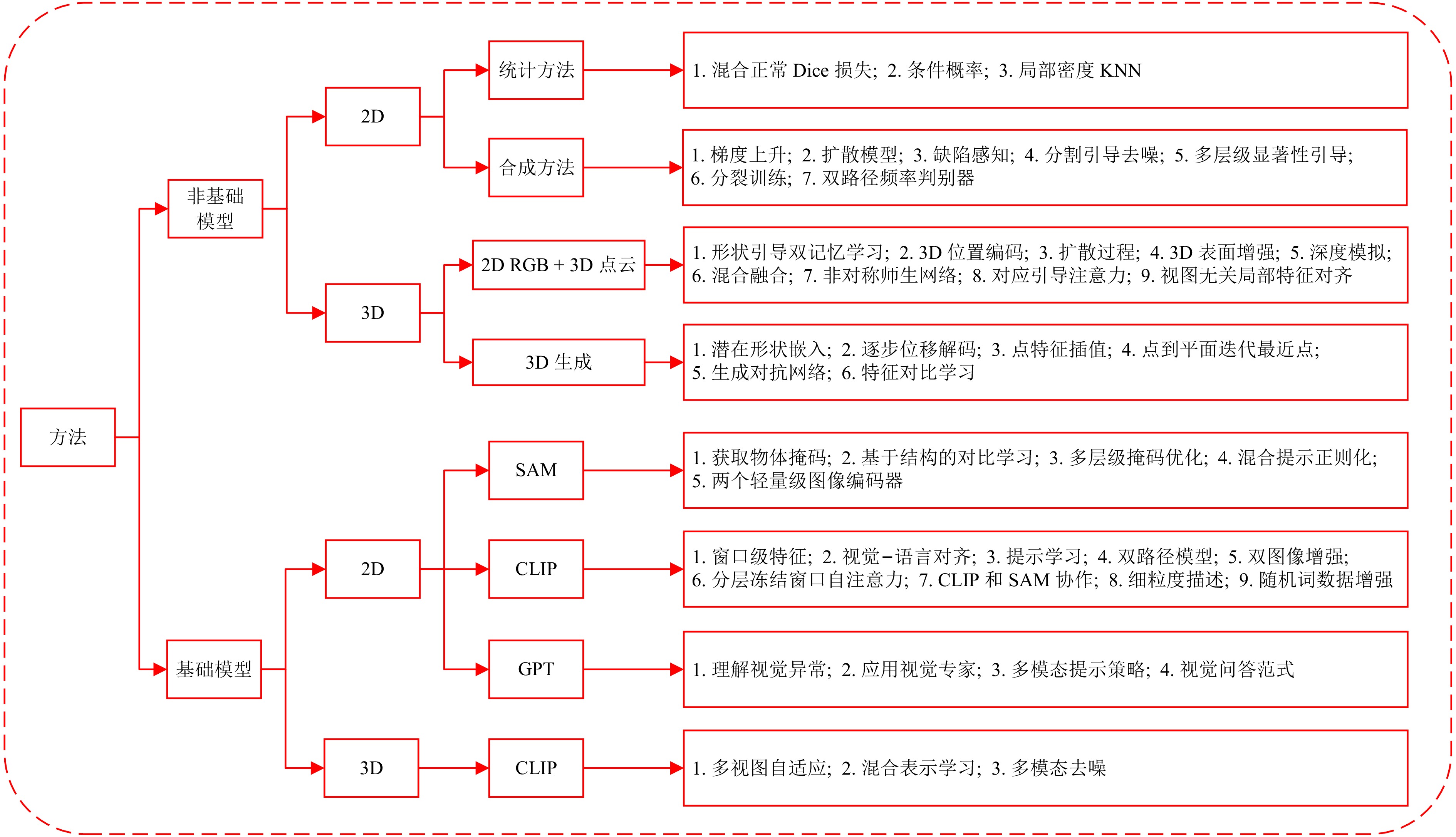
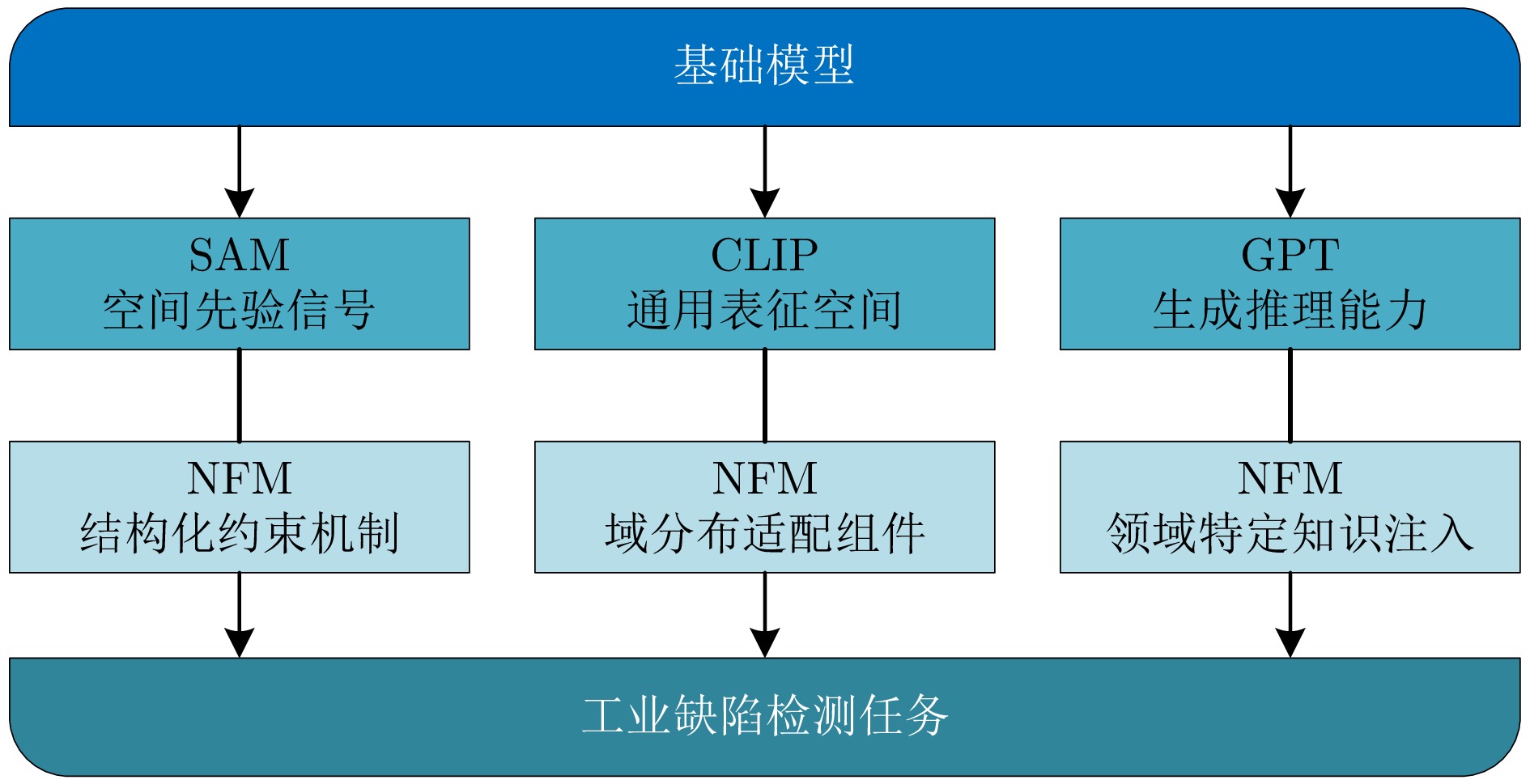
表 3 不同NFM与FM方法的简要总结与概览
Table 3 A brief summary and overview of different NFM and FM methods
类别 子类别 方法 描述 发表平台 性能 数据集 非基础模型方法 2D统计 SOFS[45] 引入异常先验图和混合正常Dice损失 IEEE TII 2025 93.3 MVTec AD PNI[46] 利用位置和邻域信息 ICCV 2023 99.6 REB[47] 减少领域和局部密度偏差 KBS 2024 99.5 BGAD[48] 通过拉近正常样本同时推开异常样本来强化决策边界 CVPR 2023 99.3 COAD[49] 通过受控的过拟合增强模型对异常的敏感性 ICLR 2025 99.9 2D合成 GLASS[50] 基于高斯噪声和梯度上升的异常合成 ECCV 2024 99.9 AdaBLDM[51] 具有特征编辑功能的潜在扩散模型 ARXIV 2024 - RealNet[52] 强度可控的扩散异常合成 CVPR 2024 99.6 CAGEN[53] 文本引导的可控异常生成 ICASSP 2024 97.7 AnomalyXFusion[54] 用于增强样本保真度的多模态异常合成 ARXIV 2024 99.2 AnomalyDiffusion[55] 空间异常嵌入, 自适应注意力重加权机制 AAAI 2024 99.2 DFMGAN[56] 在StyleGAN2中使用缺陷感知残差块 AAAI 2023 - DeSTSeg[57] 去噪学生编码器-解码器, 自适应多级特征融合 CVPR 2023 98.6 CutSwap[58] 利用显著性指导以纳入语义线索 SIVP 2023 98.0 Split Training[59] 缓解过拟合问题的拆分训练策略 AAAI 2024 98.3 DFD[60] 具有双路径频率判别器的频域分析 KBS 2024 93.3 PBAS[61] 利用正常样本特征的紧凑分布指导特征级异常合成的方向 IEEE TCSVT 2024 99.8 2D RGB + 3D点云 Shape-Guided[62] 用于颜色和形状异常定位的协同专家模型 ICML 2023 94.7 MVTec3D-AD CPMF[63] 结合手工PCD描述符和预训练的2D神经网络 Pattern Recognition 2023 92.9 Back to the Feature[64] 具有PatchCore的手工3D表示 CVPR 2023 97.8 TransFusion[65] 利用基于透明度的扩散解决过度泛化和细节丢失问题 ECCV 2024 98.2 3DSR[66] 深度感知离散自动编码器和模拟深度生成过程 WACV 2024 97.8 M3DM[103] 一种混合融合方案, 以减少多模态特征间的干扰并鼓励特征交互 CVPR 2023 94.5 AST[67] 引入网络以补偿归一化流错误估计的似然性 WACV 2023 93.7 3D生成 R3D-AD[68] 克服记忆库模块导致的低效和MAE不正确重建导致的低性能 ECCV 2024 73.4 Real 3D-AD Reg 3D-AD[104] 一种双特征表示方法, 以保留训练原型的局部和全局特征 NeurIPS 2023 70.4 Real 3D-AD PointCore[69] 降低推理中的计算成本和错配干扰 ARXIV 2024 82.9 Real 3D-AD Uni-3DAD[70] 对无模型工业产品具有显著的适应性 Expert Syst. Appl. 2025 - MVTec 3D-AD Group3AD[71] 通过组级别特征对比学习提高3D异常检测的分辨率和准确性 ACM MM 2024 75.1 Real 3D-AD 基础模型方法 基于2D SAM ClipSAM[21] 具有多级提示的分层掩码细化 Neurocomputing 2025 92.3 MVTec AD UCAD[20] 使用SAM的基于结构的对比学习 AAAI 2024 93.0 SAM-LAD[19] 使用SAM获取查询和参考图像的对象掩码, 并提取对象特征进行匹配 KBS 2025 98.4 SAA+[18] 混合提示正则化 IEEE T-CYB 2025 - STLM[17] 利用SAM作为教师指导学生网络 ACM TOMM 2025 98.3 SPT[22] 调整SAM以更好地理解图像中不同区域间关系 AAAI 2025 - 基于2D CLIP WinCLIP[23] 组合式提示集成, 参考关联方法 CVPR 2023 93.1 AnoCLIP[110] 局部感知视觉令牌, 领域感知提示, 测试时自适应方法 ARXIV 2024 - AnomalyCLIP[24] 对象无关的文本提示模板, 全局异常损失函数 ICLR 2024 - AdaCLIP[25] 混合(静态和动态)可学习提示, 混合语义融合模块 ECCV 2024 - VCP-CLIP[26] 视觉上下文提示模型 ECCV 2024 - 基础模型方法 基于2D CLIP SimCLIP[27] 多层次视觉适配器, 隐式提示学习, 先验感知优化算法 ACM MM 2024 95.3 MVTec AD CLIP-AD[28] 文本提示分布, 通过线性层促进对齐 IJCAI 2024 - CLIP-FSAC[29] 两阶段训练策略, 视觉驱动的文本特征, 融合-文本匹配任务 IJCAI 2024 95.5 ClipSAM[21] CLIP与SAM协作, 统一的多尺度跨模态交互, 多级掩码细化 Neurocomputing 2025 - SOWA[30] 层次化冻结窗口自注意力, 双重可学习提示 ACM MM 2024 - SAA+[18] 混合提示, 领域专家知识和目标图像上下文 IEEE T-CYB 2025 – APRIL-GAN[31] 采用状态和模板集成组合, 基于记忆库的方法 ARXIV 2023 92.0 PromptAD[32] 提示学习, 语义串联, 显式异常边界 CVPR 2024 94.6 FiLo[33] 细粒度描述, 可学习向量, 位置增强的高质量定位方法 ACM MM 2024 - Dual-Image Enhanced CLIP[34] 双图像特征增强, 使用伪异常合成的测试时自适应 ARXIV 2024 - 基于2D GPT AnomalyGPT[35] 轻量级且基于视觉-文本特征匹配的解码器, 提示嵌入 AAAI 2024 94.1 Myriad[38] 应用视觉专家, 视觉专家分词器 ARXIV 2023 94.1 ALFA[39] 运行时提示自适应策略, 细粒度对齐器 ACM MM 2024 94.5 GPT-4V-AD[40] 视觉问答范式, 颗粒化区域划分, 提示设计, Text2Segmentation方法 IJCAI 2024 - Customizable-VLM[37] 通过提示将专家知识作为外部记忆集成, 以增强基础模型 IEEE CSCWD 2025 82.9 LogiCode[41] 使用LLM提取图像逻辑并生成代码以进行逻辑异常检测 IEEE TASE 2025 - 基于3D CLIP CLIP3D-AD[42] 无需记忆库和大量训练样本, 解决少样本异常分类和分割 ACM MM 2024 - MVTec3D-AD PointAD[43] 混合表示学习框架 NeurIPS 2024 97.2 M3DM-NR[44] 使用疑似异常图实现去噪 IEEE TPAMI 2025 94.5
下载: 导出CSV
表 4 基础模型增强方法及其在MVTec AD上的性能比较(%)
Table 4 Comparison of foundation model enhancement methods and their performance on MVTec AD (%)
FM FM方法 增强方法 与NFM方法的联系 性能(MVTec) 指标 基线 增强后 提升 SAM UCAD 由高保真SAM掩码引导的对比学习 对比学习(BGAD、Group3AD): 利用对比学习框架, 使用SAM掩码定义正负样本 p_AUROC I_AUROC 69.3
18.393.0
45.6↑23.7
↑27.3SAA+ 使用专家知识和图像上下文的混合提示正则化 知识驱动: 将领域专家先验知识编码到混合提示中以指导基础模型 F_p
F_r30.95
29.1734.85
34.07↑3.9
↑4.9STLM SAM引导的双流轻量级架构 学生−教师架构(AST、DeSTSeg)/知识重建(R3D-AD): 一个流基于学生−教师架构生成判别性特征; 另一个流重建无异常图像 p_AUROC
I_AUROC- 98.26
99.05- CLIP AnoCLIP 使用合成噪声扰动的测试时自适应 异常合成(GLASS、CAGEN): 合成数据用于轻量级适配器的在线优化 p_AUROC
I_AUROC88.9
-90.6
-↑1.7
-Dual-Image
Enhanced CLIP使用合成异常的测试时自适应 异常合成: 类似于AnoCLIP p_AUROC
I_AUROC85.3
91.692.8
93.2↑7.5
↑1.6SimCLIP 多级视觉适配器与隐式提示学习 适配器/提示学习(SimCLIP): 插入轻量级模块对齐工业纹理与预训练分布的域差异 p_AUROC
I_AUROC- 95.6
95.3- WinCLIP 组合式提示集成与参考关联方法 记忆库机制(PatchCore): 引入外部记忆库存储正常特征以辅助少样本决策 p_AUROC
I_AUROC85.1
91.895.2
93.1↑10.1
↑1.3APRIL-GAN 线性适配层与记忆库结合 记忆库机制/对比学习: 结合分布存储与线性层以优化少样本下的稳定性 p_AUROC
I_AUROC- 95.1
92.0- GPT AnomalyGPT 在模拟数据上训练, 结合特征匹配解码器和提示学习器 异常合成(AnomalyXFusion): 通过生成大量"异常图像-文本描述"数据对来训练LVLM, 实现视觉−语言对齐 p_AUROC
I_AUROC- 93.1
97.4- Myriad 由专业"视觉专家"引导的LoRA自适应 学生−教师知识蒸馏(AST): 专业的检测器作"教师", 生成异常图以指导LMM (学生)的注意力 Accuracy 92.0 94.2 ↑2.2 Customizable-VLM 多模态提示策略 知识驱动: 将专家知识编码到提示中 I_AUROC - 82.9 -
下载: 导出CSV
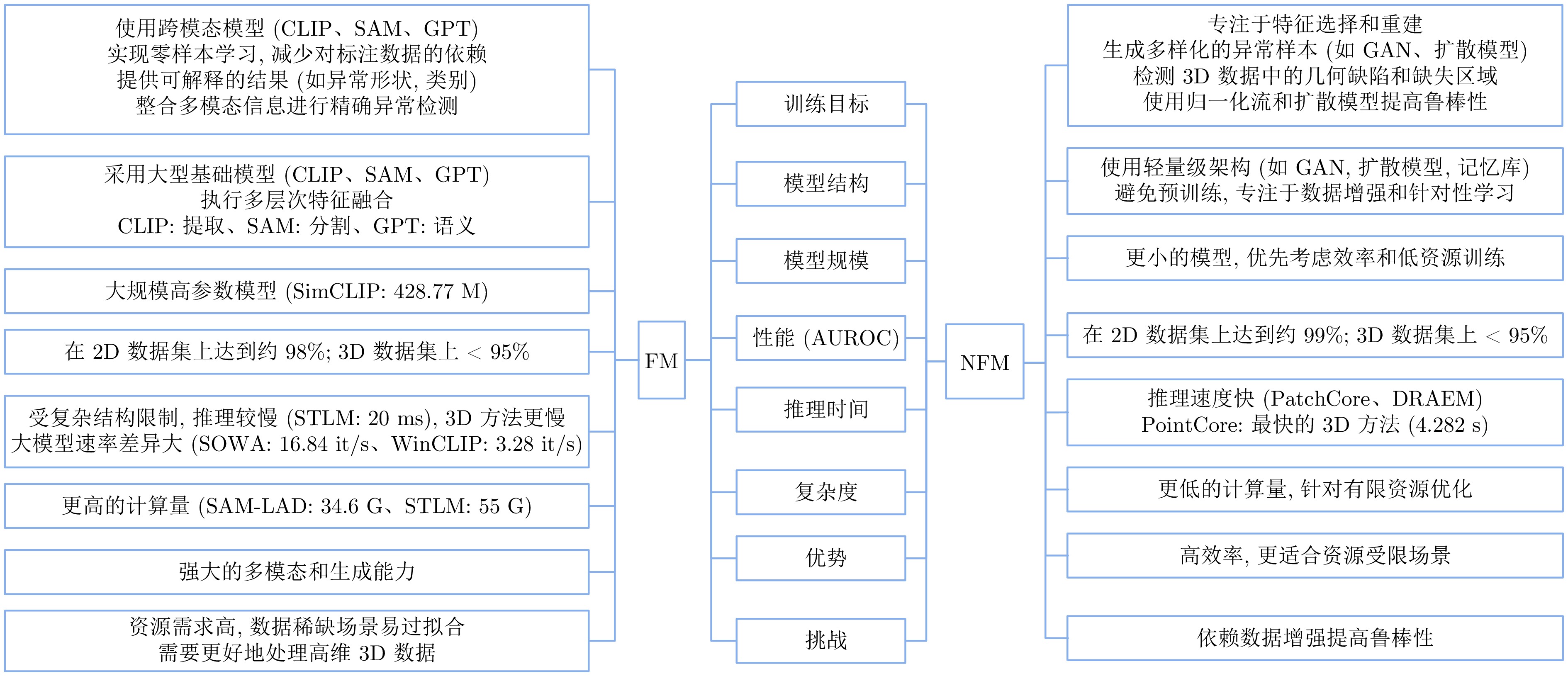
表 5 FM面临挑战与NFM协同机制适配性矩阵
Table 5 Adaptability matrix of FM facing challenges and NFM collaborative mechanisms
FM类型 主要局限/挑战 适用场景/缺陷类型 推荐NFM协同机制 协同原理简述 代表性方法 SAM 缺乏语义感知
(不识“缺陷”类别)语义/对象级缺陷
(如异物、组件缺失)知识驱动/提示工程 将专家知识(如“划痕”)编码为提示, 引导SAM聚焦特定异常语义 SAA+[18]
ClipSAM[21]特征判别性不足
(仅基于边缘分割)微小纹理/隐蔽缺陷
(如微划痕、同色疵点)对比学习 利用掩码构造结构化正负样本, 强化特征空间对微小差异的敏感度 UCAD[20] CLIP 定位精度低
(分割分辨率差)像素级表面缺陷
(需高精度定位)异常合成 生成伪异常微调适配器, 强制模型学习像素级边界 AnoCLIP[110]
Dual-Image[34]域分布差异
(自然与工业)复杂工业纹理
(强背景干扰)适配器/提示学习 插入轻量级模块对齐特征空间, 弥合自然图像与工业纹理鸿沟 SimCLIP[27]
AdaCLIP[25]样本极少
(需分布参考)多品种小批量
(少样本/零样本)记忆库机制 引入外部记忆库存储正常分布, 辅助少样本下的决策稳定性 WinCLIP[23]
APRIL-GAN[31]GPT/LVLM 缺乏领域知识
(描述不专业)逻辑/因果异常
(需推理诊断)知识驱动/上下文学习 注入专家示例与多模态提示, 激活模型的逻辑推理与泛化能力 Customizable-VLM[37]
AnomalyGPT[35]推理开销大
(难以实时)在线实时检测
(高FPS需求)知识蒸馏 大模型作为"教师"生成伪标签, 指导轻量级"学生"网络学习 STLM[17]
Myriad[38]
下载: 导出CSV
-
[1] Pang G, Shen C, Cao L, Hengel A V D. Deep learning for anomaly detection: A review. ACM Computing Surveys, 2021, 54(2): 38 [2] Bergmann P, Löwe S, Fauser M, Sattlegger D, Steger C. Improving unsupervised defect segmentation by applying structural similarity to autoencoders. arXiv: 1807.02011, 2018. [3] Gong D, Liu L, Le V, Saha B, Mansour M R, Venkatesh S, et al. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 1705-1714. [4] Liu Y, Zhuang C, Lu F. Unsupervised two-stage anomaly detection. arXiv: 2103.11671, 2021. [5] Deng H, Li X. Anomaly detection via reverse distillation from one-class embedding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 9727-9736. [6] Liu Z, Zhou Y, Xu Y, Wang Z. SimpleNet: A simple network for image anomaly detection and localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 20402-20411. [7] Liang Y, Hu Z, Huang J, Di D, Su A, Fan L. ToCoAD: Two-stage contrastive learning for industrial anomaly detection. IEEE Transactions on Instrumentation and Measurement, 2025, 74: 1−13 doi: 10.1109/tim.2025.3545987 [8] Hu H, Wang X, Zhang Y, Chen Q, Guan Q. A comprehensive survey on contrastive learning. Neurocomputing, 2024, 584: 128645 [9] Bergmann P, Fauser M, Sattlegger D, Steger C. MVTec AD — A comprehensive real-world dataset for unsupervised anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 9584-9592. [10] Zou Y, Jeong J, Pemula L, Zhang D, Dabeer O. Spot-the-difference self-supervised pre-training for anomaly detection and segmentation. In: Proceedings of the European Conference on Computer Vision. Berlin, Germany: Springer, 2022. 392-408. [11] Wang C, Zhu W, Gao B B, Gan Z, Zhang J, Gu Z, et al. Real-IAD: A real-world multi-view dataset for benchmarking versatile industrial anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2024. 22883-22892. [12] Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the International Conference on Machine Learning (ICML). Virtual Event: PMLR, 2021. 8748-8763. [13] Zhu D, Chen J, Shen X, Li X, Elhoseiny M. MiniGPT-4: Enhancing vision-language understanding with advanced large language models. arXiv: 2304.10592, 2023. [14] Yang Z, Li L, Lin K, Wang J, Lin C C, Liu Z, et al. The dawn of LMMs: Preliminary explorations with GPT-4V(ision). arXiv: 2309.17421, 2023. [15] Kirillov A, Mintun E, Ravi N, Mao H, Rolland C, Gustafson L, et al. Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 4015-4026. [16] Rani A, Ortiz-Arroyo D, Durdevic P. Advancements in point cloud-based 3D defect detection and classification for industrial systems: A comprehensive survey. arXiv: 2402.12923, 2024. [17] Li C, Qi L, Geng X. A SAM-guided two-stream lightweight model for anomaly detection. ACM Transactions on Multimedia Computing, Communications and Applications, 2025, 21(2): 1−23 [18] Cao Y, Xu X, Sun C, Cheng Y, Du Z, Gao L, et al. Personalizing vision-language models with hybrid prompts for zero-shot anomaly detection. IEEE Transactions on Cybernetics, 2025, DOI: 10.1109/TCYB.2025.10884560. [19] Peng Y, Lin X, Ma N, Du J, Liu C, Liu C, et al. SAM-LAD: Segment anything model meets zero-shot logic anomaly detection. Knowledge-Based Systems, 2025, 310: 112634 doi: 10.1016/j.knosys.2025.113176 [20] Liu J, Wu K, Nie Q, Chen Y, Gao B B, Liu Y, et al. Unsupervised continual anomaly detection with contrastively-learned prompt. In: Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024, 38(4): 3639-3647. [21] Li S, Cao J, Ye P, Ding Y, Tu C, Chen T. Enhancing zero-shot anomaly detection: CLIP-SAM collaboration with cascaded prompts. Neurocomputing, 2025, 615: 128682 doi: 10.1007/978-981-97-8490-5_4 [22] Yang H Y, Chen H, Wang A, Chen K, Lin Z, Tang Y, et al. Promptable anomaly segmentation with sam through self-perception tuning. In: Proceedings of the AAAI Conference on Artificial Intelligence. Philadelphia, USA: AAAI Press, 2025. [23] Jeong J, Zou Y, Kim T, Zhang D, Ravichandran A, Dabeer O. WinClip: Zero-/few-shot anomaly classification and segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 19606-19616. [24] Zhou Q, Pang G, Tian Y, He S, Chen J. Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection. In: Proceedings of the International Conference on Learning Representations. Vienna, Austria: OpenReview, 2024. [25] Cao Y, Zhang J, Frittoli L, Cheng Y, Shen W, Boracchi G. AdaCLIP: Adapting CLIP with hybrid learnable prompts for zero-shot anomaly detection. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: Springer, 2025. 55-72. [26] Qu Z, Tao X, Prasad M, Shen F, Zhang Z, Gong X, et al. Vcp-clip: A visual context prompting model for zero-shot anomaly segmentation. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: Springer, 2024. [27] Deng C, Xu H, Chen X, Xu H, Tu X, Ding X, et al. SimCLIP: Refining image-text alignment with simple prompts for zero-/few-shot anomaly detection. In: Proceedings of the 32nd ACM International Conference on Multimedia. Melbourne, Australia: ACM, 2024. 1761-1770. [28] Chen X, Zhang J, Tian G, He H, Zhang W, Wang Y, et al. CLIP-AD: A language-guided staged dual-path model for zero-shot anomaly detection. In: Proceedings of the International Joint Conference on Artificial Intelligence. Jeju, South Korea: ijcai.org, 2024. 17-33. [29] Zuo Z, Wu Y, Li B, Dong J, Zhou Y, Zhou L, et al. CLIP-FSAC: Boosting CLIP for few-shot anomaly classification with synthetic anomalies. In: Proceedings of the 33rd International Joint Conference on Artificial Intelligence. Jeju, South Korea: ijcai.org, 2024. 1834-1842. [30] Hu Z, Zhang Z. Sowa: Adapting hierarchical frozen window self-attention to visual-language models for better anomaly detection. In: Proceedings of the 32nd ACM International Conference on Multimedia. Melbourne, Australia: ACM, 2024. [31] Chen X, Han Y, Zhang J. APRIL-GAN: A zero-/few-shot anomaly classification and segmentation method. arXiv: 2305.17382, 2023. [32] Li X, Zhang Z, Tan X, Chen C, Qu Y, Xie Y, et al. PromptAD: Learning prompts with only normal samples for few-shot anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2024. 16838-16848. [33] Gu Z, Zhu B, Zhu G, Chen Y, Li H, Tang M, et al. Filo: Zero-shot anomaly detection by fine-grained description and high-quality localization. In: Proceedings of the 32nd ACM International Conference on Multimedia. Melbourne, Australia: ACM, 2024. 2041-2049. [34] Zhang Z, Deng H, Bao J, Li X. Dual-image enhanced CLIP for zero-shot anomaly detection. arXiv: 2405.04782, 2024. [35] Gu Z, Zhu B, Zhu G, Chen Y, Tang M, Wang J. AnomalyGPT: Detecting industrial anomalies using large vision-language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024, 38(3): 1932-1940. [36] Cao Y, Xu X, Sun C, Huang X, Shen W. Towards generic anomaly detection and understanding: Large-scale visual-linguistic model (GPT-4V) takes the lead. arXiv: 2311.02782, 2023. [37] Xu X, Cao Y, Chen Y, Shen W, Huang X. Customizing visual-language foundation models for multi-modal anomaly detection and reasoning. In: Proceedings of the IEEE 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD). Winnipeg, Canada: IEEE, 2025. [38] Li Y, Wang H, Yuan S, Liu M, Zhao D, Guo Y, et al. Myriad: Large multimodal model by applying vision experts for industrial anomaly detection. arXiv: 2310.19070, 2023. [39] Zhu J, Cai S, Deng F, Ooi B C, Wu J. Do LLMs understand visual anomalies? Uncovering LLM's capabilities in zero-shot anomaly detection. In: Proceedings of the 32nd ACM International Conference on Multimedia. Melbourne, Australia: ACM, 2024. 48-57. [40] Zhang J, He H, Chen X, Xue Z, Wang Y, Wang C, et al. GPT-4V-AD: Exploring grounding potential of VQA-oriented GPT-4V for zero-shot anomaly detection. In: Proceedings of the International Joint Conference on Artificial Intelligence. Jeju, South Korea: ijcai.org, 2024. 3-16. [41] Zhang Y, Cao Y, Xu X, Shen W. LogiCode: An LLM-driven framework for logical anomaly detection. IEEE Transactions on Automation Science and Engineering, 2024, DOI: 10.1109/TASE.2024.3468464. [42] Zuo Z, Dong J, Wu Y, Qu Y, Wu Z. Clip3d-ad: Extending clip for 3d few-shot anomaly detection with multi-view images generation. In: Proceedings of the 32nd ACM International Conference on Multimedia. Melbourne, Australia: ACM, 2024. [43] Zhou Q, Yan J, He S, Meng W, Chen J. Pointad: Comprehending 3d anomalies from points and pixels for zero-shot 3d anomaly detection. In: Proceedings of the Annual Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates, Inc., 2024. [44] Wang C, Zhu H, Peng J, Wang Y, Yi R, Wu Y, et al. M3DM-NR: RGB-3D noisy-resistant industrial anomaly detection via multimodal denoising. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(11): 11091585 [45] Zhang Z, Niu C, Zhao Z, Zhang X, Chen X. Small object few-shot segmentation for vision-based industrial inspection. IEEE Transactions on Industrial Informatics, 2025, 21(3): 10908360 [46] Bae J, Lee J H, Kim S. PNI: Industrial anomaly detection using position and neighborhood information. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 6350-6360. [47] Lyu S, Mo D, Wong W K. REB: Reducing biases in representation for industrial anomaly detection. Knowledge-Based Systems, 2024, 290: 111563 doi: 10.1016/j.knosys.2024.111563 [48] Yao X, Li R, Zhang J, Sun J, Zhang C. Explicit boundary guided semi-push-pull contrastive learning for supervised anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 24490-24499. [49] Qian L, Zhu B, Chen Y, Tang M, Wang J. Friend or foe? Harnessing controllable overfitting for anomaly detection. In: Proceedings of the International Conference on Learning Representations. Singapore: OpenReview, 2025. [50] Chen Q, Luo H, Lv C, Zhang Z. A unified anomaly synthesis strategy with gradient ascent for industrial anomaly detection and localization. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: Springer, 2025. 37-54. [51] Li H, Zhang Z, Chen H, Wu L, Li B, Liu D, et al. A novel approach to industrial defect generation through blended latent diffusion model with online adaptation. arXiv: 2402.19330, 2024. [52] Zhang X, Xu M, Zhou X. RealNet: A feature selection network with realistic synthetic anomaly for anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2024. 16699-16708. [53] Jiang B, Xie Y, Li J, Li N, Jiang Y, Xia S T. CAGEN: Controllable anomaly generator using diffusion model. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Seoul, South Korea: IEEE, 2024. 3110-3114. [54] Hu J, Huang Y, Lu Y, Xie G, Jiang G, Zheng Y, et al. AnomalyXfusion: Multi-modal anomaly synthesis with diffusion. arXiv: 2404.19444, 2024. [55] Hu T, Zhang J, Yi R, Du Y, Chen X, Liu L, et al. AnomalyDiffusion: Few-shot anomaly image generation with diffusion model. In: Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024, 38(8): 8526-8534. [56] Duan Y, Hong Y, Niu L, Zhang L. Few-shot defect image generation via defect-aware feature manipulation. In: Proceedings of the AAAI Conference on Artificial Intelligence. Washington, DC, USA: AAAI Press, 2023, 37(1): 571-578. [57] Zhang X, Li S, Li X, Huang P, Shan J, Chen T. DestSeg: Segmentation guided denoising student-teacher for anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 3914-3923. [58] Qin J, Gu C, Yu J, Zhang C. Multilevel saliency-guided self-supervised learning for image anomaly detection. Signal, Image and Video Processing, 2023, 18: 6339−6351 doi: 10.1007/s11760-024-03320-z [59] Lin J, Yan Y. A comprehensive augmentation framework for anomaly detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024, 38(8): 8742-8749. [60] Bai Y, Zhang J, Chen Z, Dong Y, Cao Y, Tian G. Dual-path frequency discriminators for few-shot anomaly detection. Knowledge-Based Systems, 2024, 302: 112397 doi: 10.1016/j.knosys.2024.112397 [61] Chen Q, Luo H, Gao H, Lv C, Zhang Z. Progressive boundary guided anomaly synthesis for industrial anomaly detection. IEEE Transactions on Circuits and Systems for Video Technology, 2025, 35(2): 1193−1208 doi: 10.1109/TCSVT.2024.3479887 [62] Chu Y M, Liu C, Hsieh T I, Chen H T, Liu T L. Shape-guided dual-memory learning for 3D anomaly detection. In: Proceedings of the International Conference on Machine Learning (ICML). Honolulu, USA: PMLR, 2023. 6185-6194. [63] Cao Y, Xu X, Shen W. Complementary pseudo multimodal feature for point cloud anomaly detection. Pattern Recognition, 2024, 156: 110761 doi: 10.1016/j.patcog.2024.110761 [64] Horwitz E, Hoshen Y. Back to the feature: Classical 3D features are (almost) all you need for 3D anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 2968-2977. [65] Fučka M, Zavrtanik V, Skočaj D. TransFusion—A transparency-based diffusion model for anomaly detection. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: Springer, 2025. 91-108. [66] Zavrtanik V, Kristan M, Skočaj D. Cheating depth: Enhancing 3D surface anomaly detection via depth simulation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Waikoloa, USA: IEEE, 2024. 2153-2161. [67] Rudolph M, Wehrbein T, Rosenhahn B, Wandt B. Asymmetric student-teacher networks for industrial anomaly detection. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Waikoloa, USA: IEEE, 2023. 2592-2602. [68] Zhou Z, Wang L, Fang N, Wang Z, Qiu L, Zhang S. R3D-AD: Reconstruction via diffusion for 3D anomaly detection. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: Springer, 2025. 91-107. [69] Zhao B, Xiong Q, Zhang X, Guo J, Liu Q, Xing X, et al. PointCore: Efficient unsupervised point cloud anomaly detector using local-global features. arXiv: 2403.01804, 2024. [70] Liu J, Mou S, Gaw N, Wang Y. Uni-3DAD: GAN-inversion aided universal 3D anomaly detection on model-free products. Expert Systems with Applications, 2025, 265: 125862 doi: 10.1016/j.eswa.2025.126665 [71] Zhu H, Xie G, Hou C, Dai T, Gao C, Wang J, et al. Towards high-resolution 3D anomaly detection via group-level feature contrastive learning. In: Proceedings of the 32nd ACM International Conference on Multimedia. Melbourne, Australia: ACM, 2024. 4680-4689. [72] Zavrtanik V, Kristan M, Skočaj D. DRÆM—A discriminatively trained reconstruction embedding for surface anomaly detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 8310-8319. [73] Al-Fakih A, Koeshidayatullah A, Mukerji T, Kaka S I. Enhanced anomaly detection in well log data through the application of ensemble GANs. arXiv: 2411.19875, 2024. [74] Bhosale A, Mukherjee S, Banerjee B, Cuzzolin F. Anomaly detection using diffusion-based methods. arXiv: 2412.07539, 2024. [75] Kim S, Lee S Y, Bu F, Kang S, Kim K, Yoo J, et al. Rethinking reconstruction-based graph-level anomaly detection: Limitations and a simple remedy. arXiv: 2410.20366, 2024. [76] Yao H, Liu M, Yin Z, Yan Z, Hong X, Zuo W. GLAD: Towards better reconstruction with global and local adaptive diffusion models for unsupervised anomaly detection. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: Springer, 2025. 1-17. [77] Zade H R, Zare H, Parsa M G, Davardoust H, Bagheri M S. DCOR: Anomaly detection in attributed networks via dual contrastive learning reconstruction. arXiv: 2412.16788, 2024. [78] Patra S, Taieb S B. Revisiting deep feature reconstruction for logical and structural industrial anomaly detection. arXiv: 2410.16255, 2024. [79] Lee K, Kim M, Jun Y, Woo S S. GDFlow: Anomaly detection with NCDE-based normalizing flow for advanced driver assistance system. arXiv: 2409.05346, 2024. [80] Zhou Y, Xu X, Sun Z, Song J, Cichocki A, Shen H T. VQ-Flow: Taming normalizing flows for multi-class anomaly detection via hierarchical vector quantization. arXiv: 2409.00942, 2024. [81] Liu X, Xing F, Zhuo J, Stone M, Prince J L, El Fakhri G, et al. Speech motion anomaly detection via cross-modal translation of 4D motion fields from tagged MRI. In: Proceedings of the Medical Imaging 2024: Image Processing. Bellingham, USA: SPIE, 2024, 12926: 129262W. [82] Tu Y, Zhang B, Liu L, Li Y, Zhang J, Wang Y, et al. Self-supervised feature adaptation for 3D industrial anomaly detection. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: Springer, 2025. 75-91. [83] Li J, Wang X, Zhao H, Zhong Y. Learning a cross-modality anomaly detector for remote sensing imagery. IEEE Transactions on Image Processing, 2024, 33: 3225−3240 [84] Arav R, Wittich D, Rottensteiner F. Evaluating saliency scores in point clouds of natural environments by learning surface anomalies. arXiv: 2408.14421, 2024. [85] Ye J, Zhao W, Yang X, Cheng G, Huang K. PO3AD: Predicting point offsets toward better 3D point cloud anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2025. [86] Hao S, Fu W, Chen X, Jin C, Zhou J, Yu S, et al. Network anomaly traffic detection via multi-view feature fusion. arXiv: 2409.08020, 2024. [87] Dai A, Chang A X, Savva M, Halber M, Funkhouser T, Nießner M. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2432-2443. [88] Uy M A, Pham Q H, Hua B S, Nguyen T, Yeung S K. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 1588-1597. [89] Zhou Q, He S, Liu H, Chen T, Chen J. Pull & push: Leveraging differential knowledge distillation for efficient unsupervised anomaly detection and localization. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(5): 2176−2189 doi: 10.1109/TCSVT.2022.3218587 [90] Chen Z, Luo X, Wang W, Zhao Z, Su F, Men A. Filter or compensate: Towards invariant representation from distribution shift for anomaly detection. arXiv: 2412.10115, 2024. [91] Liu X, Wang J, Leng B, Zhang S. Unlocking the potential of reverse distillation for anomaly detection. arXiv: 2412.07579, 2024. [92] Liu H, Xu X, Li E, Zhang S, Li X. Anomaly detection with representative neighbors. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(6): 2831−2841 doi: 10.1109/TNNLS.2021.3109898 [93] Zhou J, Wu Y. Outlier-probability-based feature adaptation for robust unsupervised anomaly detection on contaminated training data. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(10): 10023−10035 doi: 10.1109/TCSVT.2024.3408034 [94] Xing P, Li Z. Visual anomaly detection via partition memory bank module and error estimation. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(8): 3596−3607 doi: 10.1109/TCSVT.2023.3237562 [95] Zhang F, Zhu H, Cen Y, Kan S, Zhang L, Vadakkepat P, et al. Low-shot unsupervised visual anomaly detection via sparse feature representation. IEEE Transactions on Neural Networks and Learning Systems, 2024, DOI: 10.1109/TNNLS.2024.3420818. [96] Zhou Y, Song X, Zhang Y, Liu F, Zhu C, Liu L. Feature encoding with autoencoders for weakly supervised anomaly detection. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(6): 2454−2465 doi: 10.1109/TNNLS.2021.3086137 [97] Ramírez Rivera A, Khan A, Bekkouch I E I, Sheikh T S. Anomaly detection based on zero-shot outlier synthesis and hierarchical feature distillation. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(1): 281−291 doi: 10.1109/TNNLS.2020.3027667 [98] Liang Y, Li X, Huang X, Zhang Z, Yao Y. An automated data mining framework using autoencoders for feature extraction and dimensionality reduction. arXiv: 2412.02211, 2024. [99] Chen J, Wang C, Hong Y, Mi R, Zhang L J, Wu Y, et al. A survey on anomaly detection with few-shot learning. In: Proceedings of the International Conference on Cognitive Computing. Berlin, Germany: Springer, 2024. 34-50. [100] Bergmann P, Jin X, Sattlegger D, Steger C. The MVTec 3D-AD dataset for unsupervised 3D anomaly detection and localization. In: Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISAPP). Virtual Event: SCITEPRESS, 2022. 202-213. [101] Yu J, Zheng Y, Wang X, Li W, Wu Y, Zhao R, et al. FastFlow: Unsupervised anomaly detection and localization via 2D normalizing flows. arXiv: 2111.07677, 2021. [102] Roth K, Pemula L, Zepeda J, Schölkopf B, Brox T, Gehler P. Towards total recall in industrial anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 14298-14308. [103] Wang Y, Peng J, Zhang J, Yi R, Wang Y, Wang C. Multimodal industrial anomaly detection via hybrid fusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 8032-8041. [104] Liu J, Xie G, Chen R, Li X, Wang J, Liu Y, et al. Real3D-AD: A dataset of point cloud anomaly detection. Advances in Neural Information Processing Systems, 2023, 36: 30402−30415 doi: 10.52202/075280-1324 [105] Schlegl T, Seeböck P, Waldstein S M, Langs G, Schmidt-Erfurth U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Medical Image Analysis, 2019, 54: 30−44 doi: 10.1016/j.media.2019.01.010 [106] Zhou K, Yang J, Loy C C, Liu Z. Learning to prompt for vision-language models. International Journal of Computer Vision, 2022, 130(9): 2337−2348 doi: 10.1007/s11263-022-01653-1 [107] Zhou K, Yang J, Loy C C, Liu Z. Conditional prompt learning for vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 16816-16825. [108] Fu S, Hamilton M, Brandt L, Feldman A, Zhang Z, Freeman W T. FeatUp: A model-agnostic framework for features at any resolution. arXiv: 2403.10516, 2024. [109] Rombach R, Blattmann A, Lorenz D, Esser P, Ommer B. High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 10674-10685. [110] Deng H, Zhang Z, Bao J, Li X. Bootstrap fine-grained vision-language alignment for unified zero-shot anomaly localization. arXiv: 2308.15939, 2024. [111] Ma B, Liu Y S, Zwicker M, Han Z. Surface reconstruction from point clouds by learning predictive context priors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 6316-6327. [112] Cao Y, Xu X, Liu Z, Shen W. Collaborative discrepancy optimization for reliable image anomaly localization. IEEE Transactions on Industrial Informatics, 2023, 19(11): 10674−10683 doi: 10.1109/TII.2023.3241579 [113] Wan Q, Gao L, Li X, Wen L. Industrial image anomaly localization based on Gaussian clustering of pretrained feature. IEEE Transactions on Industrial Electronics, 2022, 69(6): 6182−6192 doi: 10.1109/TIE.2021.3094452 [114] Liu S, Zeng Z, Ren T, Li F, Zhang H, Yang J, et al. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: Springer, 2025. 38-55. [115] Ross T, Lin T Y, Goyal P, Dollár P, He K. Focal loss for dense object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2980-2988. [116] Milletari F, Navab N, Ahmadi S A. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In: Proceedings of the 4th International Conference on 3D Vision (3DV). Stanford, USA: IEEE, 2016. 565-571. [117] Wang H, Vasu P K A, Faghri F, Vemulapalli R, Farajtabar M, Mehta S, et al. SAM-CLIP: Merging vision foundation models towards semantic and spatial understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2024. 3635-3647. [118] Wang Z, Lu Y, Li Q, Tao X, Guo Y, Gong M, et al. CRIS: CLIP-driven referring image segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 11686-11695. [119] Xing Y, Wang X, Li Y, Huang H, Shi C. Less is more: On the over-globalizing problem in graph transformers. arXiv: 2405.01102, 2024. [120] Sun X, Hu P, Saenko K. DualCoOp: Fast adaptation to multi-label recognition with limited annotations. Advances in Neural Information Processing Systems, 2022, 35: 30569−30582 doi: 10.52202/068431-2216 [121] Ouyang L, Wu J, Jiang X, Almeida D, Wainwright C, Mishkin P, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 2022, 35: 27730−27744 doi: 10.52202/068431-2011 [122] Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M A, Lacroix T, et al. LLaMA: Open and efficient foundation language models. arXiv: 2302.13971, 2023. [123] Zhang R, Guo Z, Zhang W, Li K, Miao X, Cui B, et al. PointCLIP: Point cloud understanding by CLIP. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 8552-8562. [124] Zhou Y, Gu J, Chiang T Y, Xiang F, Su H. Point-SAM: Promptable 3D segmentation model for point clouds. In: Proceedings of the International Conference on Learning Representations. Singapore: ICLR, 2025. [125] Cen J, Zhou Z, Fang J, Yang C, Shen W, Xie L, et al. Segment anything in 3D with radiance fields. International Journal of Computer Vision, 2025, 133(8): 5138−5160 doi: 10.1007/s11263-025-02421-7 [126] Guo Z, Zhang R, Zhu X, Tang Y, Ma X, Han J, et al. Point-Bind & Point-LLM: Aligning point cloud with multi-modality for 3D understanding, generation, and instruction following. arXiv: 2309.00615, 2023. [127] Xu R, Wang X, Wang T, Chen Y, Pang J, Lin D. PointLLM: Empowering large language models to understand point clouds. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: Springer, 2024. [128] Hong Y, Zhen H, Chen P, Zheng S, Du Y, Chen Z, et al. 3D-LLM: Injecting the 3D world into large language models. In: Proceedings of the Annual Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates, Inc., 2023. -

 下载:
下载:

计量
- 文章访问数: 568
- HTML全文浏览量: 1023
- 被引次数: 0
