

A Distributed Multi-Agent Path Coordination Method Based on Multimodal Feature Fusion and Local Perception Reasoning
-
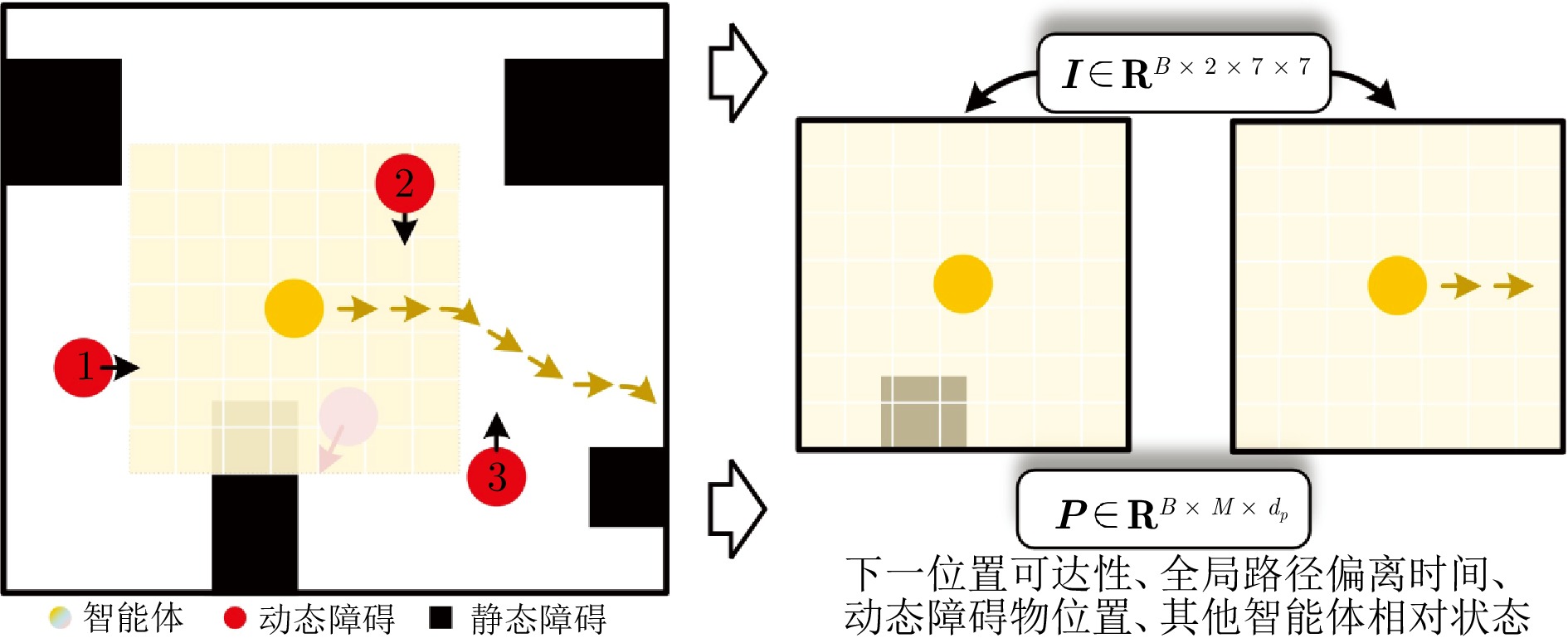
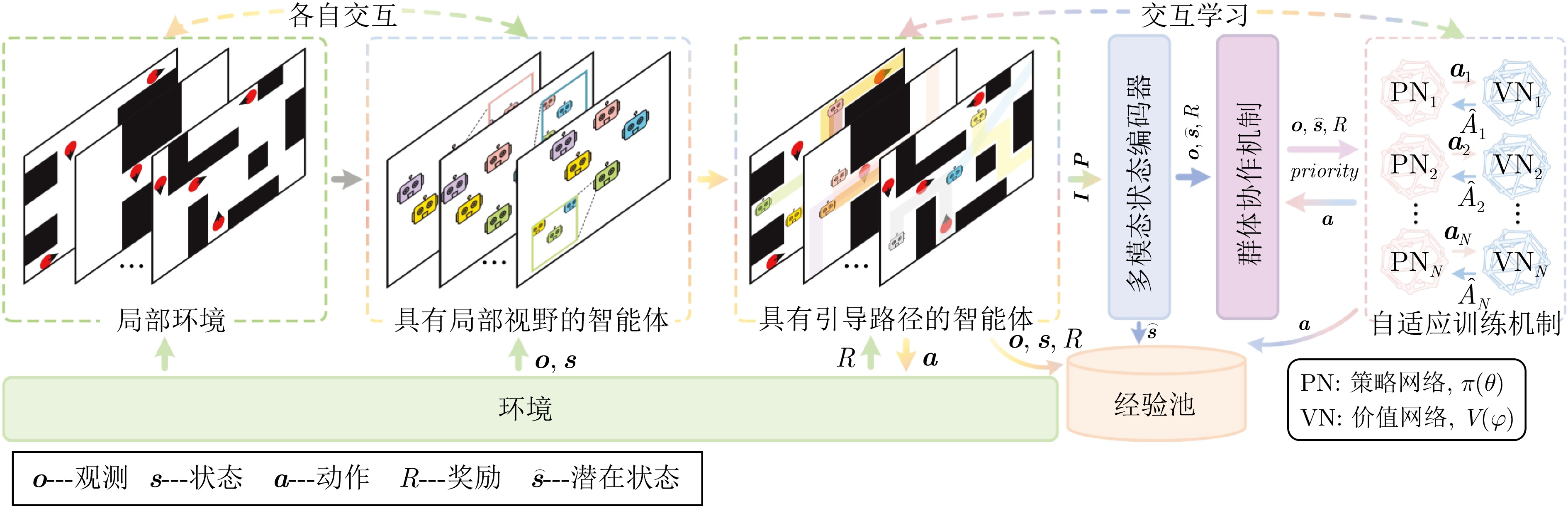
摘要: 在部分可观测且动态变化的环境中, 深度强化学习(DRL) 为多智能体路径规划提供具备自学习、泛化与动态适应能力的分布式求解途径. 然而, DRL 在该问题中仍存在协调性不足与局部近视两个挑战: 智能体间的隐式交互易引发冲突, 仅依赖局部观测的反应式避障又导致路径冗长与全局目标偏离. 为此, 提出一种基于多模态特征融合与局部感知推理的分布式路径协作方法——LYRA. 该方法在分布式DRL 框架下构建从感知到决策的学习体系, 使智能体能依托局部观测实现推理与隐式让行. 多模态状态编码器融合局部碰撞线索与全局路径语义, 平衡即时避障与长期导航目标; 奖励引导的路径学习策略保证局部决策与全局任务一致; 群体协作机制通过隐式优先级推理化解局部冲突; 自适应学习率机制动态调节策略更新以提升训练稳定性. 实验结果表明, LYRA 在任务成功率和安全性上较基线方法有大幅提升, 在不同环境复杂度下保持良好泛化性, 为实现高效鲁棒的分布式多智能体路径规划提供了新范式.Abstract: In partially observable and dynamically changing environments, deep reinforcement learning (DRL) offers a distributed solution for multi-agent path finding (MAPF) with self-learning capability, generalization, and dynamic adaptability. Nevertheless, DRL-based MAPF still suffers from insufficient coordination and local myopia: Implicit agent interactions easily cause conflicts, while reactive collision avoidance relying solely on local observations often leads to elongated paths and deviations from global objectives. To address these challenges, we propose local yielding and reasoning for agents (LYRA), a distributed path coordination method based on multi-modal feature fusion and local perceptual reasoning. LYRA constructs an end-to-end learning framework from perception to decision-making under distributed DRL, enabling agents to perform reasoning and implicit yielding using only local observations. A multi-modal state encoder integrates local collision cues with global path semantics to balance immediate avoidance and long-term navigation goals. A reward-guided path learning strategy aligns local decisions with global tasks, while a collective coordination mechanism resolves local conflicts through implicit priority reasoning. In addition, an adaptive learning rate mechanism dynamically adjusts strategy updates to improve training stability. Experiments show that LYRA improves task success rate and safety by approximately 35 % and 25 %, respectively, over baselines, while maintaining strong generalization across environments of varying complexity. These results suggest a new paradigm for efficient and robust distributed multi-agent path planning.
-
Key words:
- multi-agent path finding /
- deep reinforcement learning /
- partial observability /
- multi-modal /
- inference /
- coordination
1)1 1项目演示视频见: https://github.com/HuoLinL/LYRA.2)2 2实物演示视频见: https://github.com/HuoLinL/LYRA. -

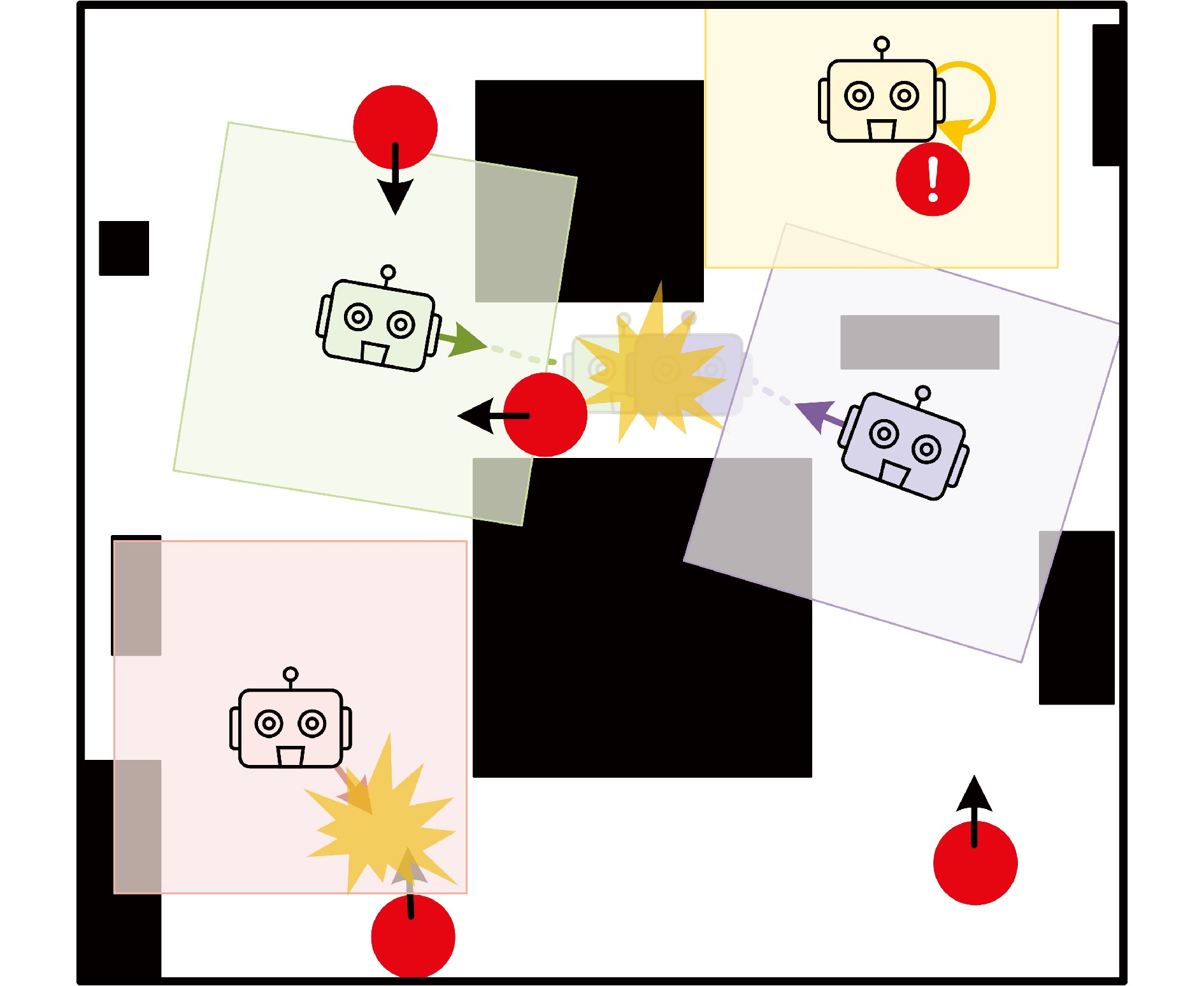
图 7 稀疏奖励机制示意图(黑、红、灰、蓝、橙色分别代表静态障碍、动态障碍、全局引导路径、目标点与智能体)
Fig. 7 Schematic diagram of the sparse reward mechanism (the black, red, grey, blue, and orange cells represent static obstacles, dynamic obstacles, global guidance, goals, and agents, respectively)
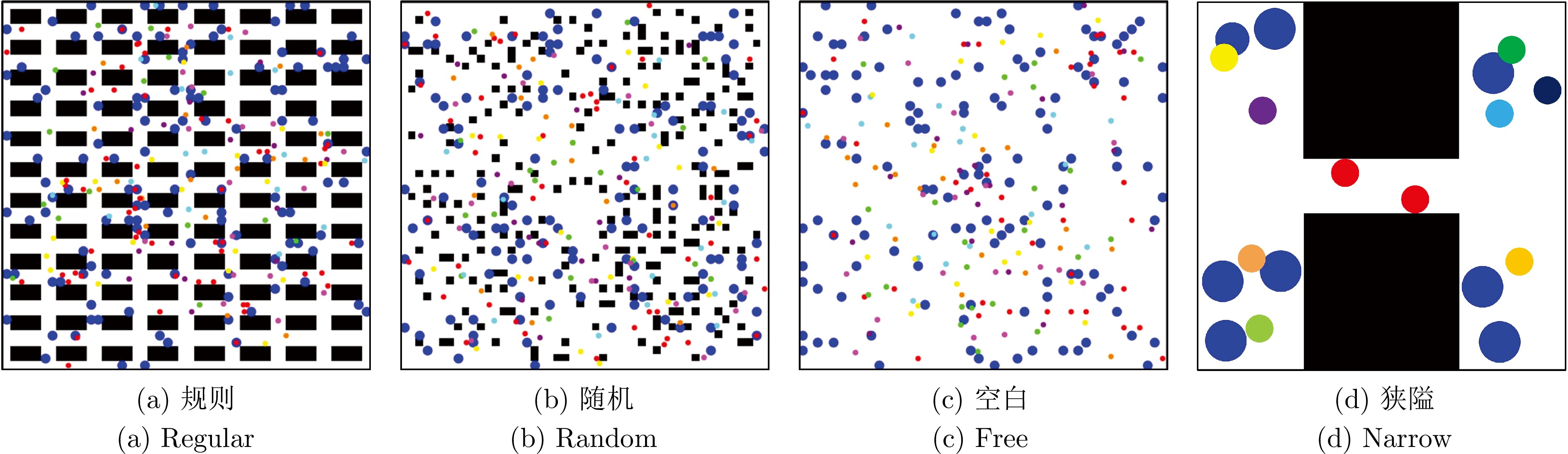
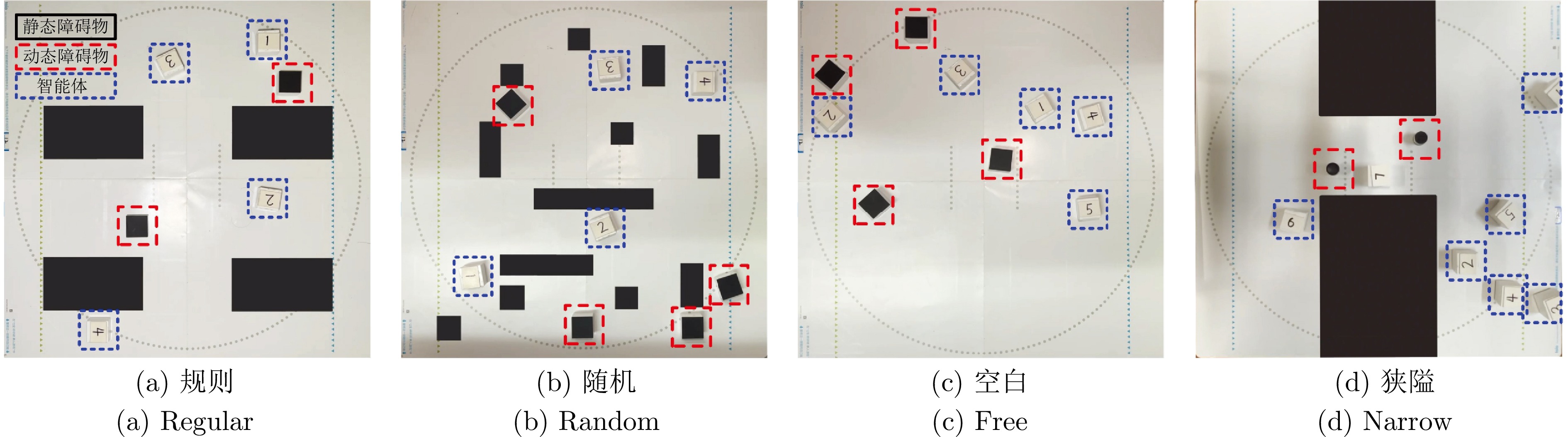
图 8 MAPF实验环境示意图(黑色、红色、蓝色及其他颜色分别代表静态障碍、动态障碍、目标点与智能体)
Fig. 8 Schematic diagram of the MAPF experimental environment (the black, red, blue, and other color cells represent the static obstacle, the dynamic obstacle, the goals and the agents, respectively)
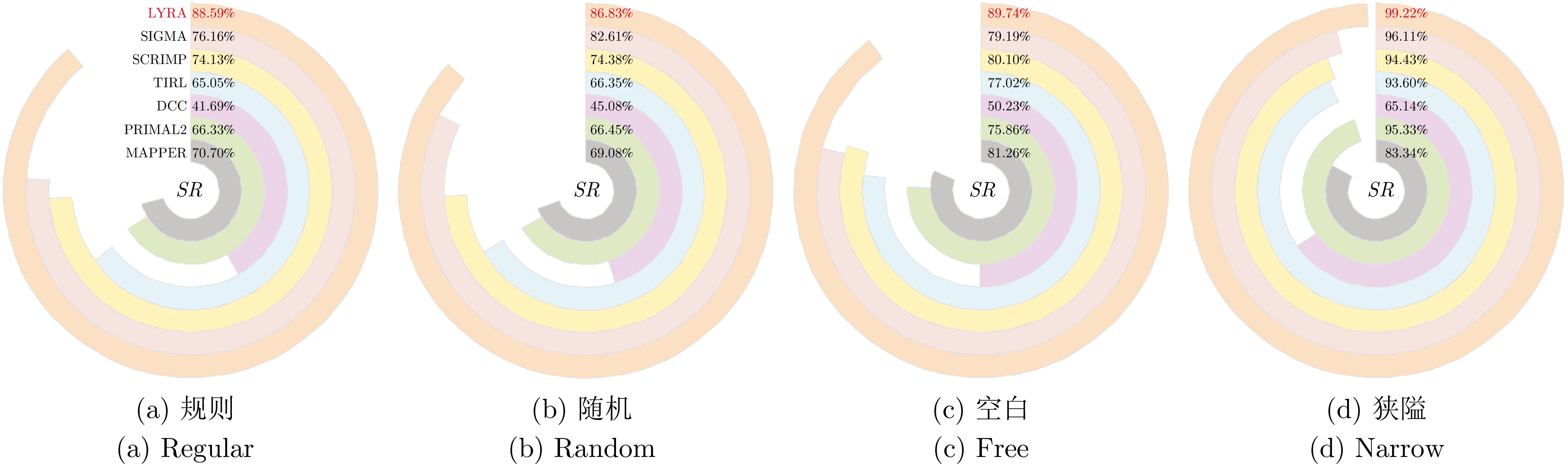
图 9 不同MAPF环境的算法成功率对比
Fig. 9 Comparison of success rates of algorithms in different MAPF environments
表 1 超参数设置
Table 1 Hyperparameter settings
超参数 取值 折扣因子$ \gamma $ 0.95 策略网络初始学习率$ lr_{0,\;\pi} $ 1×10−5 价值网络初始学习率$ lr_{0,\;v} $ 5×10−5 衰减速率$ \lambda $ 0.10 调制幅度系数$ A $ 0.10 经验缓冲区分段长度$ L $ 20 批大小$ B $ 512 观测视野$ \mathit{FOV} $ $ 7 \times 7 $ 优化器类型 Adam 隐藏层维度 128 智能体ID更新频率 每轮更新 裁剪系数$ \varepsilon $ 0.15 策略网络最终学习率$ lr_{K,\;\pi} $ 3×10−7 价值网络最终学习率$ lr_{K,\;v} $ 1×10−7 初始熵权重$ \beta_0 $ 5×10−3 周期系数$ C $ 10.0 最小批量minibatch 1 训练轮数$ K $ 600 最大可见邻居数$ M $ 8 Adam参数$ (\rho_1,\; \rho_2,\; \rho_3) $ (0.9, 0.999, 1×10−8) 激活函数 ReLU 动态障碍更新频率 每轮更新  下载: 导出CSV
下载: 导出CSV
表 2 三种地图(规则、随机、空白)中的路径质量对比
Table 2 Comparison of path quality in three maps (regular, random, and free)
智能体数量 指标 MAPPER PRIMAL2 DCC TIRL SCRIMP SIGMA LYRA 16 $ SR $ 0.8704 0.8353 0.6333 0.8052 0.8479 0.9722 0.9831 $ C_{{\rm{act}}} $ 32.8703 32.7627 29.5958 33.8917 33.4555 35.7576 30.0737 $ T_{{\rm{avg}}} $ (s) 32.8947 32.7668 29.7577 34.0307 33.8156 36.6788 36.9454 32 $ SR $ 0.8080 0.7794 0.5483 0.7640 0.8128 0.8826 0.9727 $ C_{{\rm{act}}} $ 32.8446 32.8876 27.7264 34.6483 35.5310 32.5537 30.2058 $ T_{{\rm{avg}}} $ (s) 32.8822 32.8954 27.9363 34.8102 36.1857 33.9869 36.6436 64 $ SR $ 0.7158 0.6693 0.4090 0.6761 0.7494 0.7432 0.9238 $ C_{{\rm{act}}} $ 33.7400 30.2338 25.2589 35.8568 39.2429 32.9997 30.2854 $ T_{{\rm{avg}}} $ (s) 33.8197 30.2379 25.6223 36.0231 40.5643 35.6018 35.6982 128 $ SR $ 0.5530 0.4977 0.2359 0.5336 0.6380 0.5747 0.8721 $ C_{{\rm{act}}} $ 34.5973 29.1432 21.0439 36.8009 44.7254 32.1888 30.5756 $ T_{{\rm{avg}}} $ (s) 34.7071 29.1453 21.5344 36.9884 47.0501 37.2716 35.1631 注: 加粗字体表示对应指标的最优结果.
下载: 导出CSV
表 3 狭隘地图中的路径质量对比
Table 3 Comparison of path quality in narrow map
智能体数量 指标 MAPPER PRIMAL2 DCC TIRL SCRIMP SIGMA LYRA 2 $ SR $ 0.9430 0.9930 0.8600 0.9980 0.9930 0.9972 0.9936 $ C_{{\rm{act}}} $ 7.2322 7.0081 8.4350 7.8367 9.1934 9.9995 10.4306 $ T_{{\rm{avg}}} $ (s) 7.2492 7.0101 8.4950 7.8537 9.5438 10.0199 11.1547 4 $ SR $ 0.8520 0.9640 0.5962 0.9480 0.9710 0.9923 0.9902 $ C_{{\rm{act}}} $ 7.4988 7.3734 12.0792 8.2521 12.2307 11.9899 10.3881 $ T_{{\rm{avg}}} $ (s) 7.5481 7.3786 12.2738 8.2880 13.1452 12.0885 11.4061 6 $ SR $ 0.8054 0.9421 0.6117 0.9301 0.9361 0.9745 0.9976 $ C_{{\rm{act}}} $ 7.5539 7.5339 5.8033 8.6406 14.1738 16.9993 10.4422 $ T_{{\rm{avg}}} $ (s) 7.5539 7.5339 6.0068 8.6749 15.5160 17.2584 11.8271 8 $ SR $ 0.7330 0.9140 0.5375 0.8680 0.8770 0.8803 0.9988 $ C_{{\rm{act}}} $ 7.7203 8.0230 5.0262 9.2419 15.3615 17.7298 10.5779 $ T_{{\rm{avg}}} $ (s) 7.8199 8.0295 5.1764 9.3007 17.0764 17.8249 12.3714
下载: 导出CSV
表 4 三种地图(规则、随机、空白)中的行为合规性对比(%)
Table 4 Comparison of behavioral compliance in three maps (regular, random, and free) (%)
智能体数量 指标 MAPPER PRIMAL2 DCC TIRL SCRIMP SIGMA LYRA 16 $ CR $ 10.61 14.35 36.64 19.34 15.15 2.78 1.39 $ OOBP $ 2.35 2.12 0.03 0.13 0.07 0.00 0.10 32 $ CR $ 16.02 20.46 45.16 23.31 18.65 11.74 2.54 $ OOBP $ 3.19 1.60 0.01 0.29 0.07 0.00 0.00 64 $ CR $ 24.48 31.60 59.10 32.29 24.90 25.68 7.23 $ OOBP $ 3.94 1.47 0.01 0.10 0.16 0.00 0.20 128 $ CR $ 38.84 49.15 76.42 46.52 35.91 42.53 12.11 $ OOBP $ 5.86 1.08 0.00 0.13 0.29 0.00 0.10
下载: 导出CSV
表 5 狭隘地图中的行为合规性对比(%)
Table 5 Comparison of behavioral compliance in narrow map (%)
智能体数量 指标 MAPPER PRIMAL2 DCC TIRL SCRIMP SIGMA LYRA 2 $ CR $ 3.00 0.60 14.00 0.20 0.30 0.28 0.00 $ OOBP $ 2.70 0.10 2.50 0.00 0.40 0.00 0.00 4 $ CR $ 11.60 2.90 41.38 5.20 2.40 0.77 0.00 $ OOBP $ 3.20 0.70 8.00 0.00 0.50 0.00 0.00 6 $ CR $ 16.07 4.59 38.83 6.99 5.79 2.55 0.00 $ OOBP $ 3.39 1.20 0.00 0.00 0.60 0.00 0.00 8 $ CR $ 22.30 5.80 46.25 13.20 11.60 11.97 0.00 $ OOBP $ 4.40 2.80 0.00 0.00 0.70 0.00 0.00
下载: 导出CSV
-
[1] 张凯翔, 毛剑琳, 向凤红, 宣志玮. 基于讨价还价博弈机制的B-IHCA* 多机器人路径规划算法. 自动化学报, 2023, 49(7): 1483−1497 doi: 10.16383/j.aas.c220065Zhang Kai-Xiang, Mao Jian-Lin, Xiang Feng-Hong, Xuan Zhi-Wei. B-IHCA*, a bargaining game based multi-agent path finding algorithm. Acta Automatica Sinica, 2023, 49(7): 1483−1497 doi: 10.16383/j.aas.c220065 [2] 李坚强, 蔡俊创, 孙涛, 朱庆灵, 林秋镇. 面向复杂物流配送场景的车辆路径规划多任务辅助进化算法. 自动化学报, 2024, 50(3): 544−559 doi: 10.16383/j.aas.c230043Li Jian-Qiang, Cai Jun-Chuang, Sun Tao, Zhu Qing-Ling, Lin Qiu-Zhen. Multitask-based assisted evolutionary algorithm for vehicle routing problems incomplex logistics distribution scenarios. Acta Automatica Sinica, 2024, 50(3): 544−559 doi: 10.16383/j.aas.c230043 [3] 郝肇铁, 郭斌, 赵凯星, 吴磊, 丁亚三, 李哲涛, 等. 从规则驱动到群智涌现: 多机器人空地协同研究综述. 自动化学报, 2024, 50(10): 1877−1905 doi: 10.16383/j.aas.c230445Hao Zhao-Tie, Guo Bin, Zhao Kai-Xing, Wu Lei, Ding Ya-San, Li Zhe-Tao, et al. From rule-driven to collective intelligence emergence: A review of research on multi-robot air-ground collaboration. Acta Automatica Sinica, 2024, 50(10): 1877−1905 doi: 10.16383/j.aas.c230445 [4] 宣志玮, 毛剑琳, 张凯翔. CBS框架下面向复杂地图的低拓展度A* 算法. 电子学报, 2022, 50(8): 1943−1950 doi: 10.12263/DZXB.20210718Xuan Zhi-Wei, Mao Jian-Lin, Zhang Kai-Xiang. Low-expansion A* algorithm based on CBS framework for complex map. Acta Electronica Sinica, 2022, 50(8): 1943−1950 doi: 10.12263/DZXB.20210718 [5] 钱诚泽, 毛剑琳, 李睿褀, 周雯娜, 龚德正, 张进宝. 基于冲突代价Bayesian权重的改进PBS多智能体路径规划算法. 电子学报, 2025, 53(7): 2358−2371Qian Cheng-Ze, Mao Jian-Lin, Li Rui-Qi, Zhou Wen-Na, Gong De-Zheng, Zhang Jin-Bao. Improved PBS multi-robot path planning algorithm based on conflict cost Bayesian weighting. Acta Electronica Sinica, 2025, 53(7): 2358−2371 [6] Veerapaneni R, Saleem M S, Li J, Likhachev M. Windowed MAPF with completeness guarantees. In: Proceedings of the 39th AAAI Conference on Artificial Intelligence. Philadelphia, USA: AAAI, 2025. 23323−23332 [7] 张书凡, 毛剑琳, 张凯翔, 李睿祺, 李大炎, 王妮娅. 面向不确定性的多机器人路径鲁棒规划研究综述. 控制与决策, 2024, 39(12): 3873−3888 doi: 10.13195/j.kzyjc.2023.1728Zhang Shu-Fan, Mao Jian-Lin, Zhang Kai-Xiang, Li Rui-Qi, Li Da-Yan, Wang Ni-Ya. Survey on robust multi-robot path planning under uncertainty. Control and Decision, 2024, 39(12): 3873−3888 doi: 10.13195/j.kzyjc.2023.1728 [8] Zhu K, Zhang T. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Science and Technology, 2021, 26(5): 674−691 doi: 10.26599/tst.2021.9010012 [9] Wang B, Liu Z, Li Q, Prorok A. Mobile robot path planning in dynamic environments through globally guided reinforcement learning. IEEE Robotics and Automation Letters, 2020, 5(4): 6932−6939 doi: 10.1109/LRA.2020.3026638 [10] Huo L, Mao J, San H, Li R, Zhang S. Deep reinforcement learning of group consciousness for multi-robot pathfinding. Engineering Applications of Artificial Intelligence, 2025, 155: Article No. 110978 doi: 10.1016/j.engappai.2025.110978 [11] Andreychuk A, Yakovlev K, Panov A, Skrynnik A. MAPF-GPT: Imitation learning for multi-agent pathfinding at scale. In: Proceedings of the 39th AAAI Conference on Artificial Intelligence. Philadelphia, USA: AAAI, 2025. 23126−23134 [12] Jin W, Du H, Zhao B, Tian X, Shi B, Yang G. A comprehensive survey on multi-agent cooperative decision-making: Scenarios, approaches, challenges and perspectives. arXiv preprint arXiv: 2503.13415, 2025. [13] Anastassacos N, Hailes S, Musolesi M. Partner selection for the emergence of cooperation in multi-agent systems using reinforcement learning. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 7047−7054 [14] Yu C, Velu A, Vinitsky E, Gao J, Wang Y, Bayen A, et al. The surprising effectiveness of ppo in cooperative multi-agent games. Advances in Neural Information Processing Systems, 2022, 35: 24611−24624 doi: 10.52202/068431-1787 [15] Li Q, Lin W, Liu Z, Prorok A. Message-aware graph attention networks for large-scale multi-robot path planning. IEEE Robotics and Automation Letters, 2021, 6(3): 5533−5540 doi: 10.1109/LRA.2021.3077863 [16] Yao S, Chen G, Pan L, Ma J, Ji J, Chen X. Multi-robot collision avoidance with map-based deep reinforcement learning. In: Proceedings of the 32nd IEEE International Conference on Tools with Artificial Intelligence. Baltimore, USA: IEEE, 2020. 532−539 [17] Alkazzi J M, Okumura K. A comprehensive review on leveraging machine learning for multi-agent path finding. IEEE Access, 2024, 12: 57390−57409 doi: 10.1109/ACCESS.2024.3392305 [18] Yao Z, Wang W. Layeredmapf: A decomposition of MAPF instance to reduce solving costs. arXiv preprint arXiv: 2404. 12773, 2024. [19] Omidshafiei S, Pazis J, Amato C, How P J, Vian J. Deep decentralized multi-task multi-agent reinforcement learning under partial observability. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: JMLR. org, 2017. 2681−2690 [20] Wang Y, Xiang B, Huang S, Sartoretti G. Scrimp: Scalable communication for reinforcement-and imitation-learning-based multi-agent pathfinding. In: Proceedings of the International Conference on Intelligent Robots and Systems. Detroit, USA: IEEE, 2023. 9301−9308 [21] Okumura K. LaCAM: Search-based algorithm for quick multi-agent pathfinding. In: Proceedings of the 37th AAAI Conference on Artificial Intelligence. Washington, USA: AAAI, 2023. 11655−11662 [22] Yang Y, Fan M, He C, Wang J, Huang H, Sartoretti G. Attentionbased priority learning for limited time multi-agent path finding. In: Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems. Auckland, New Zealand: IFAAMAS, 2024. 1993−2001 [23] Shi Q, Liu M, Zhang S, Lan X. Reinforcement learning for multi-agent path finding in large-scale warehouses via distributed policy evolution. IEEE Robotics and Automation Letters, 2025, 10(8): 7843−7850 doi: 10.1109/LRA.2025.3579647 [24] Jiang H, Zhang Y, Veerapaneni R, Li J. Scaling lifelong multi-agent path finding to more realistic settings: Research challenges and opportunities. In: Proceedings of the 17th International Symposium on Combinatorial Search. Kananaskis, Canada: AAAI, 2024. 234−242 [25] Wu Z, Yu C, Chen C, Hao J, Zhuo H H. Plan to predict: Learning an uncertainty-foreseeing model for model-based reinforcement learning. Advances in Neural Information Processing Systems, 2022, 35: 15849−15861 doi: 10.52202/068431-1153 [26] Sartoretti G, Kerr J, Shi Y, Wagner G, Kumar T S, Koenig S, et al. PRIMAL: Pathfinding via reinforcement and imitation multiagent learning. IEEE Robotics and Automation Letters, 2019, 4(3): 2378−2385 doi: 10.1109/LRA.2019.2903261 [27] Wang J, Meng M Q H. Real-time decision making and path planning for robotic autonomous luggage trolley collection at airports. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2021, 52(4): 2174−2183 doi: 10.1109/tsmc.2020.3048984 [28] Damani M, Luo Z, Wenzel E, Sartoretti G. PRIMAL2: Pathfinding via reinforcement and imitation multi-agent learning-lifelong. IEEE Robotics and Automation Letters, 2021, 6(2): 2666−2673 doi: 10.1109/LRA.2021.3062803 [29] Abreu N. Efficient deep learning for multi agent pathfinding. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI, 2022. 13122−13123 [30] Ma Z, Luo Y, Ma H. Distributed heuristic multi-agent path finding with communication. In: Proceedings of the IEEE International Conference on Robotics and Automation. Xi'an, China: IEEE, 2021. 8699−8705 [31] Yan Z, Wu C. Neural neighborhood search for multi-agent path finding. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: IEEE, 2024. [32] Ma Z, Luo Y, Pan J. Learning selective communication for multiagent path finding. IEEE Robotics and Automation Letters, 2021, 7(2): 1455−1462 doi: 10.1109/lra.2021.3139145 [33] Lin Q, Ma H. Sacha: Soft actor-critic with heuristic-based attention for partially observable multi-agent path finding. IEEE Robotics and Automation Letters, 2023, 8(8): 5100−5107 doi: 10.1109/LRA.2023.3292004 [34] Liu Z, Chen B, Zhou H, Koushik G, Hebert M, Zhao D. MAPPER: Multi-agent path planning with evolutionary reinforcement learning in mixed dynamic environments. In: Proceedings of the International Conference on Intelligent Robots and Systems. Las Vegas, USA: IEEE, 2020. 11748−11754 [35] He C, Duhan T, Tulsyan P, Kim P, Sartoretti G. Social behavior as a key to learning-based multi-agent pathfinding dilemmas. Artificial Intelligence, 2025, 348: Article No. 104397 doi: 10.1016/j.artint.2025.104397 [36] He C, Yang T, Duhan T, Wang Y, Sartoretti G. ALPHA: Attentionbased long-horizon pathfinding in highly-structured areas. In: Proceedings of the International Conference on Robotics and Automation. Yokohama, Japan: IEEE, 2024. 14576−14582 [37] Chen L, Wang Y, Miao Z, Mo Y, Feng M, Zhou Z, et al. Transformer-based imitative reinforcement learning for multirobot path planning. IEEE Transactions on Industrial Informatics, 2023, 19(10): 10233−10243 doi: 10.1109/TII.2023.3240585 [38] Gao J, Li Y, Li X, Yan K, Lin K, Wu X. A review of graphbased multi-agent pathfinding solvers: From classical to beyond classical. Knowledge-Based Systems, 2024, 283: Article No. 111121 doi: 10.1016/j.knosys.2023.111121 [39] Hu S, Shen L, Zhang Y, Chen Y, Tao D. On transforming reinforcement learning with transformers: The development trajectory. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 8580−8599 doi: 10.1109/TPAMI.2024.3408271 [40] Shen B, Chen Z, Cheema M A, Harabor D D, Stuckey P J. Tracking progress in multi-agent path finding. arXiv preprint arXiv: 2305.08446, 2023. [41] Pham P, Bera A. Optimizing crowd-aware multi-agent path finding through local communication with graph neural networks. arXiv preprint arXiv: 2309.10275, 2023. [42] Chen Z, Harabor D, Li J, Stuckey P J. Traffic flow optimisation for lifelong multi-agent path finding. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2024. 20674−20682 [43] Tang H, Berto F, Park J. Ensembling prioritized hybrid policies for multi-agent pathfinding. In: Proceedings of the International Conference on Intelligent Robots and Systems. Abu Dhabi, United Arab Emirates: IEEE, 2024. 8047−8054 [44] Phan T, Phan T, Koenig S. Generative curricula for multi-agent path finding via unsupervised and reinforcement learning. Journal of Artificial Intelligence Research, 2025, 82: 2471−2534 doi: 10.1613/jair.1.17403 [45] Korolyuk V S, Brodi S, Turbin A. Semi-Markov processes and their applications. Journal of Soviet Mathematics, 1975, 4(3): 244−280 doi: 10.1007/BF01097184 [46] Hart P E, Nilsson N J, Raphael B. A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Science and Cybernetics, 1968, 4(2): 100−107 doi: 10.1109/TSSC.1968.300136 [47] Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, et al. Playing atari with deep reinforcement learning. arXiv preprint arXiv: 1312.5602, 2013. [48] Smith L N. Cyclical learning rates for training neural networks. In: Proceedings of the Winter Conference on Applications of Computer Vision. Santa Rosa, USA: IEEE, 2017. 464−472 [49] Stern R, Sturtevant N, Felner A, Koenig S, Ma H, Walker T, et al. Multi-agent pathfinding: Definitions, variants, and benchmarks. In: Proceedings of the 12th Conference on International Symposium on Combinatorial Search. Napa, USA: AAAI, 2019. 151−158 [50] Liao S, Xia W, Cao Y, Dai W, He C, Wu W, et al. SIGMA: Sheaf-informed geometric multiagent pathfinding. In: Proceedings of the International Conference on Robotics and Automation. Atlanta, USA: IEEE, 2025. 1−7 -

 下载:
下载:

计量
- 文章访问数: 460
- HTML全文浏览量: 339
- PDF下载量: 30
- 被引次数: 0
