

A Survey on Parameter-efficient Fine-tuning of Large Models: Techniques, Trends, and Challenges
-
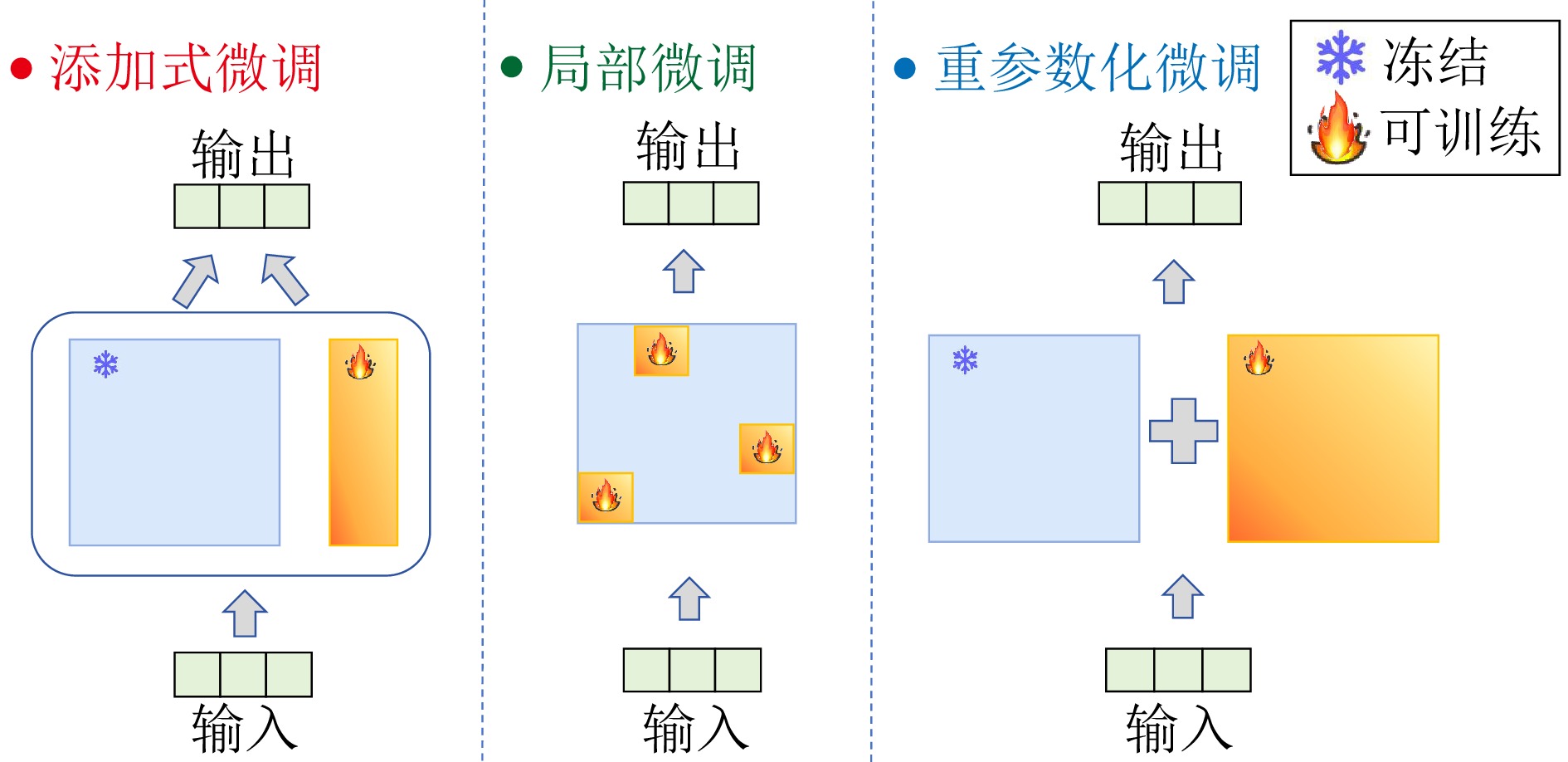
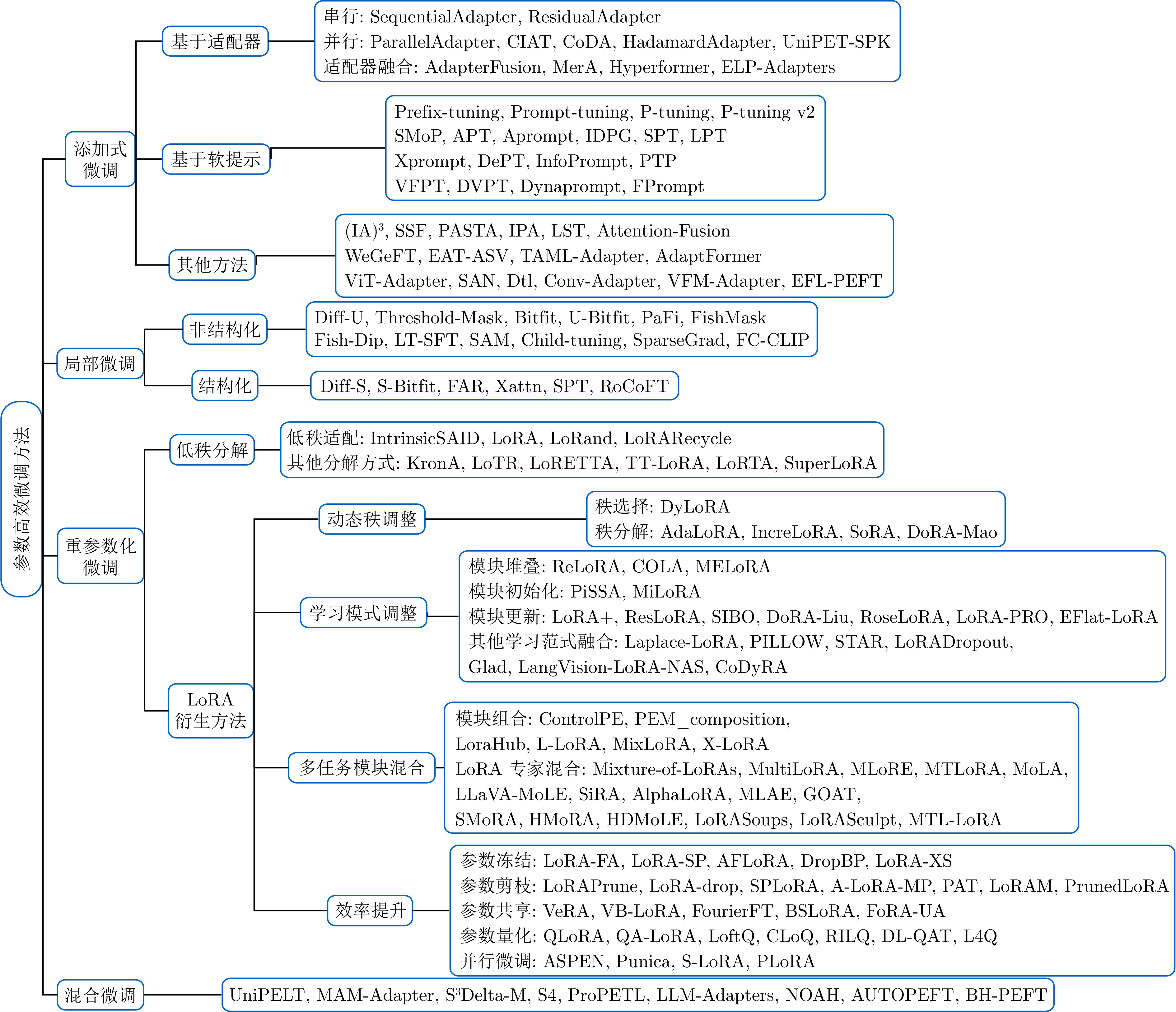
摘要: 大规模预训练模型已经在自然语言处理等领域展现出强大的能力. 为更好地适配下游任务, 微调预训练模型是一个常用的方法. 然而, 大模型的全参数微调面临计算成本高昂、存储需求巨大等严峻挑战. 参数高效微调(PEFT)作为解决这些问题的关键技术范式, 仅引入或选择极少量可训练参数, 在显著降低计算和存储开销的同时, 有效保持模型的能力. 该综述系统梳理PEFT领域的主流方法体系、关键技术进展与发展趋势. 首先, 将现有方法归纳为四大范式: 添加式、局部式、重参数化式以及融合式, 并深入剖析各类方法的核心机理、性能特征、应用场景及策略优势. 进而, 重点探讨PEFT的技术演进, 从技术变化中分析出现该发展的内在本质规律, 总结出PEFT 方法从单一方法创新向存储、计算、性能三元权衡, 以及自动化、智能化、软硬件协同等统一框架发展的技术趋势. 更进一步, 该综述对各类PEFT中的代表性方法进行系统性的定量比较, 在统一的模型与数据集上评估其性能与参数效率. 此外, 本综述还涵盖PEFT 技术在视觉、语音及跨模态模型等领域的拓展应用, 展现其广泛的适用性. 最后, 总结并探讨未来研究方向, 以推动更高效、更适应多样化任务的大型模型微调技术的发展.Abstract: Large-scale pre-trained models have demonstrated remarkable capabilities in fields such as natural language processing. Fine-tuning these models is a common approach to adapt them to downstream tasks. However, full fine-tuning of large models faces severe challenges, including high computational costs and substantial storage requirements. Parameter-efficient fine-tuning (PEFT) has emerged as a key technical paradigm to address these issues by introducing or selecting a minimal number of trainable parameters, significantly reducing computation and storage overhead while effectively preserving the core capabilities of models. This paper provides a systematic review of the mainstream methodologies, key technological advances, and development trends within the PEFT field. First, we categorize existing methods into four major paradigms: Additive, selective, reparameterized, and hybrid fine-tuning, offering an in-depth analysis of their core mechanisms, performance characteristics, application scenarios, and strategic advantages. Furthermore, we focus on the technical evolution of PEFT, analyzing the intrinsic principles behind its development. We summarize a clear technical trajectory: The field is moving from isolated method innovations toward a sophisticated tri-balance of storage, computation, and performance, and further advancing into unified frameworks emphasizing automation, intelligence, and hardware-software co-design. Furthermore, we conduct a systematic quantitative comparison of representative methods from various PEFT categories, evaluating their performance and parameter efficiency on uniform models and datasets. In addition, this survey also covers the extended applications of PEFT technology in fields such as vision, speech, and cross-modal models, demonstrating its broad applicability. Finally, we discuss promising future research directions to facilitate the development of more efficient and adaptable fine-tuning techniques for large-scale models across diverse tasks.
-
表 1 PEFT方法分类对比
Table 1 Comparison of PEFT method classification
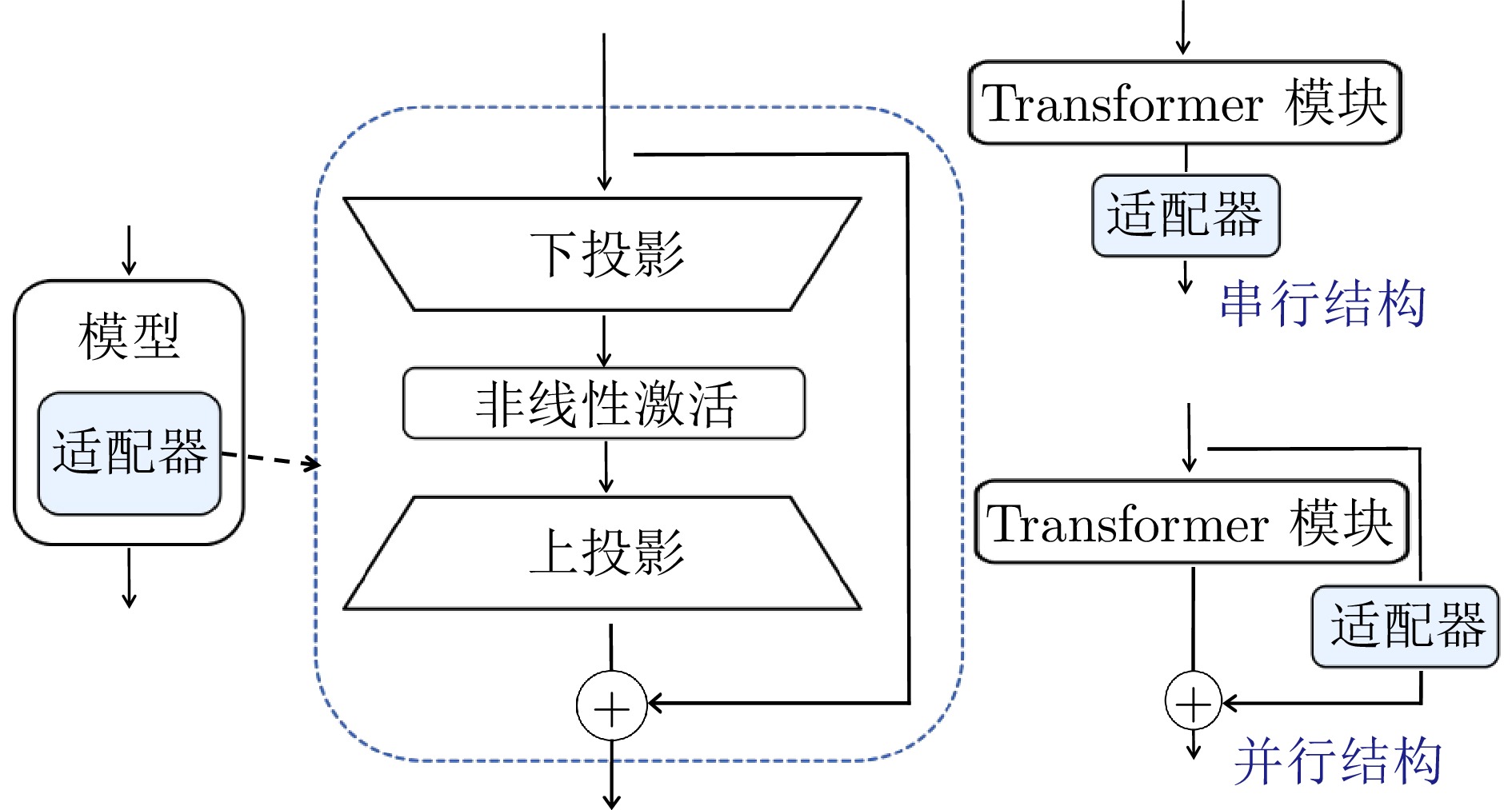
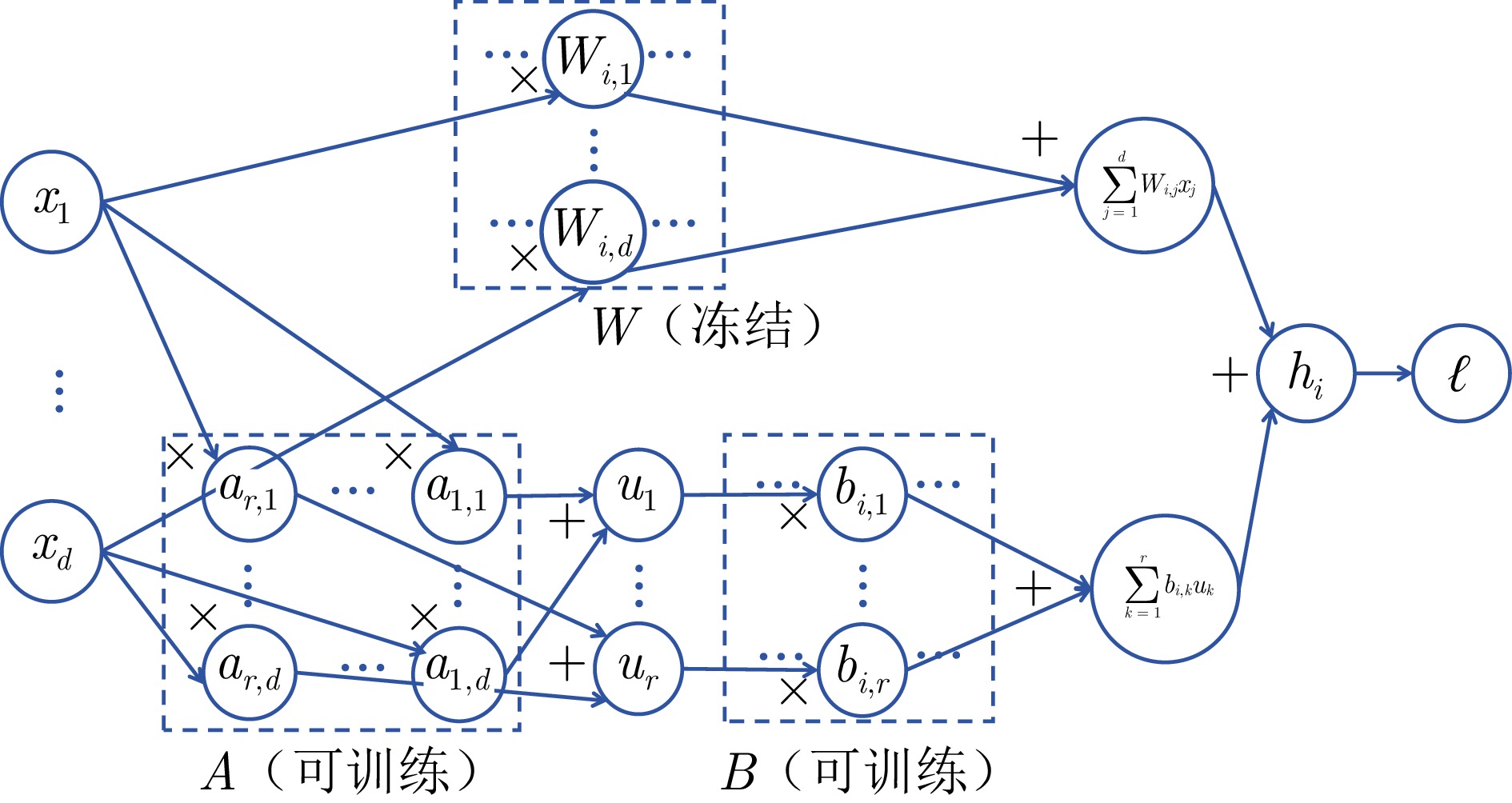
方法类别 核心思想 分类依据 参数可合并 推理延迟 典型代表方法 添加式 引入全新的可训练单元(模块/参数/前缀等), 与原始主干并行或串联工作 是否在原始模型结构外增加新的可训练计算单元到原计算图; 训练与推理均依赖该新增单元 否 低到高 Sequential Adapter, Prefix-tuning, Prompt-tuning, (IA)3 局部 激活或选择模型的一部分进行更新 是否修改网络结构, 是否通过门控、掩码或选择机制来动态决定使用模型的哪些部分; 计算图基本不变 是 低或无 Diff, Bitfit, PaFi 重参数化 对原始参数进行低秩或结构性变换, 训练后可与原模型合并 是否通过一个参数化的变换(如矩阵分解、张量分解)来间接更新权重, 且推理时能还原为原始架构 是 低或无 LoRA, LoRTA, LoraHub, MultiLoRA, LoRAPrune, QLoRA 融合 结合上述多种策略以发挥各自优势 是否明确地融合了两种及以上不同类别的PEFT技术 视情况而定 视情况而定 UniPELT, MAM-Adapter, AUTOPEFT  下载: 导出CSV
下载: 导出CSV
表 2 PEFT代表性方法在RoBERTa-Large模型上的性能对比
Table 2 Performance comparison of representative PEFT methods on RoBERTa-Large model
类别 方法 作用位置 推理延迟 可训练参数(%) 数据集(%) 平均值(%) SST-2 MRPC CoLA QNLI RTE - 全量微调 所有参数 无 100 96.1 90.2 68.0 94.2 86.0 87.1 添加式 Prefix-Tuning 注意力 有 0.11 95.6 86.8 59.1 94.6 74.8 82.2 Prompt-Tuning 输入 有 0.30 94.6 73.0 61.1 89.1 60.3 75.6 Sequential Adapter 前馈层 有 4.72 96.0 89.2 65.4 94.5 84.1 85.8 (IA)3 注意力、前馈 无 0.34 94.6 86.5 61.1 94.2 91.2 85.5 局部 BitFit 注意力 无 0.41 96.1 90.9 68.0 94.5 87.7 87.4 Child-tuningD - 无 0.10 95.1 90.7 63.1 93.1 86.3 85.7 SparseGrad 前馈 无 47.32 96.8 90.5 63.2 93.3 64.7 81.7 RoCoFT1row 注意力、前馈 无 0.06 96.6 90.0 65.7 94.2 85.3 86.4 RoCoFT3row 注意力、前馈 无 0.18 96.7 91.1 67.4 94.9 87.8 87.6 RoCoFT1col 注意力、前馈 无 0.06 96.6 89.1 64.9 94.1 85.7 86.1 RoCoFT3col 注意力、前馈 无 0.18 96.7 89.9 67.2 94.8 87.8 87.3 重参数化 LoRA 注意力 无 0.24 96.2 90.2 68.2 94.8 85.2 86.9 LoRA-FA 注意力 无 1.10 96.0 90.0 68.0 94.4 86.1 86.9 AdaLoRA 注意力 无 0.24 95.0 90.4 66.9 94.6 84.5 86.3 PiSSA 注意力 无 0.24 95.5 86.9 61.1 92.1 56.8 78.5 FourierFT 注意力 无 0.01 96.0 90.9 67.1 94.4 87.4 87.2 VeRA 注意力、前馈 无 0.02 96.1 90.9 68.0 94.4 85.9 87.1 RoseLoRA 注意力、前馈 无 0.02 95.2 90.2 69.2 94.7 89.2 87.7 LoRA-PRO 注意力 无 0.24 95.9 90.9 66.7 93.0 60.5 81.4 LoRA-dropout 注意力 无 0.12 96.2 89.9 68.5 94.9 88.8 87.7 WeGeFT 注意力 无 0.02 95.0 75.7 64.0 93.7 53.6 76.4 EFlat-LoRA 注意力 无 0.24 96.3 90.3 68.0 94.8 89.3 87.7 LoRETTA 注意力 无 0.04 96.2 90.5 69.5 94.1 53.0 80.7 FoRA-UA 注意力 无 0.01 96.6 91.2 69.0 93.9 86.9 87.5 融合 MAM-Adapter - 有 12.30 95.8 90.1 67.3 94.3 86.6 86.8 ProPETL-Adapter 注意力、前馈 有 1.50 96.3 89.7 65.6 95.2 88.9 87.1 ProPETL-Prefix 注意力 有 7.60 96.2 90.0 62.2 94.7 79.7 84.6 ProPETL-LoRA 注意力 无 1.20 95.9 89.1 61.9 94.9 83.6 85.1
下载: 导出CSV
-
[1] Junyi Li, Tianyi Tang, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. Pre-trained language models for text generation: A survey. ACM Computing Surveys, 2024, 56(9): 1−39 [2] Xiao Xia, Dan Zhang, Zibo Liao, Zhenyu Hou, Tianrui Sun, Jing Li, Ling Fu, and Yuxiao Dong. Scenegenagent: Precise industrial scene generation with coding agent. arXiv preprint arXiv: 2410.21909, 2024. [3] Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. Multilingual machine translation with large language models: Empirical results and analysis. arXiv preprint arXiv: 2304.04675, 2023. [4] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 2023, 36: 46595−46623 [5] Jin K Kim, Michael Chua, Mandy Rickard, and Armando Lorenzo. Chatgpt and large language model (llm) chatbots: The current state of acceptability and a proposal for guidelines on utilization in academic medicine. Journal of Pediatric Urology, 2023, 19(5): 598−604 doi: 10.1016/j.jpurol.2023.05.018 [6] Jia-Ji Wang. The power of ai-assisted diagnosis. EAI Endorsed Transactions on e-Learning, 8(4), 2022. [7] Som S Biswas. Role of chat gpt in public health. Annals of biomedical engineering, 2023, 51(5): 868−869 [8] Haitao Li, Junjie Chen, Jingli Yang, Qingyao Ai, Wei Jia, Youfeng Liu, Kai Lin, Yueyue Wu, Guozhi Yuan, Yiran Hu, et al. Legalagentbench: Evaluating llm agents in legal domain. arXiv preprint arXiv: 2412.17259, 2024. [9] Frank Xing. Designing heterogeneous llm agents for financial sentiment analysis. ACM Transactions on Management Information Systems, 2025, 16(1): 1−24 [10] Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey. arXiv preprint arXiv: 2403.14608, 2024. [11] Demi Guo, Alexander M Rush, and Yoon Kim. Parameter-efficient transfer learning with diff pruning. arXiv preprint arXiv: 2012.07463, 2020. [12] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. International Conference on Learning Representations, 2022, 1(2): 3 [13] Vladislav Lialin, Vijeta Deshpande, and Anna Rumshisky. Scaling down to scale up: A guide to parameter-efficient fine-tuning. arXiv preprint arXiv: 2303.15647, 2023. [14] Danilo Vucetic, Mohammadreza Tayaranian, Maryam Ziaeefard, James J Clark, Brett H Meyer, and Warren J Gross. Efficient fine-tuning of bert models on the edge. In 2022 IEEE International Symposium on Circuits and Systems (ISCAS), pages 1838-1842. IEEE, 2022. [15] Zihao Fu, Haoran Yang, Anthony Man-Cho So, Wai Lam, Lidong Bing, and Nigel Collier. On the effectiveness of parameter-efficient fine-tuning. In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 12799-12807, 2023. [16] Luping Wang, Sheng Chen, Linnan Jiang, Shu Pan, Runze Cai, Sen Yang, and Fei Yang. Parameter-efficient fine-tuning in large models: A survey of methodologies. arXiv preprint arXiv: 2410.19878, 2024. [17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017. [18] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171-4186, 2019. [19] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv: 2303.08774, 2023. [20] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv: 2206.07682, 2022. [21] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 2022, 35: 27730−27744 [22] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv: 1707.06347, 2017. [23] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 2023, 36: 53728−53741 [24] Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Ren Lu, Thomas Mesnard, Johan Ferret, Colton Bishop, Ethan Hall, Victor Carbune, and Abhinav Rastogi. Rlaif: Scaling reinforcement learning from human feedback with ai feedback. 2023. [25] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018. [26] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 2019, 1(8): 9 [27] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 2020, 33: 1877−1901 [28] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv: 2302.13971, 2023. [29] Raja Vavekanand and Kira Sam. Llama 3.1: An in-depth analysis of the next-generation large language model. Preprint, July, 2024. [30] Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv: 2401.02954, 2024. [31] Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv: 2405.04434, 2024. [32] Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv: 2412.19437, 2024. [33] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv: 2501.12948, 2025. [34] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv: 2309.16609, 2023. [35] An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv: 2505.09388, 2025. [36] Imtiaz Ahmed, Sadman Islam, Partha Protim Datta, Imran Kabir, Naseef Ur Rahman Chowdhury, and Ahshanul Haque. Qwen 2.5: A comprehensive review of the leading resource-efficient llm with potentioal to surpass all competitors. Authorea Preprints, 2025. [37] Loredana Caruccio, Stefano Cirillo, Giuseppe Polese, Giandomenico Solimando, Shanmugam Sundaramurthy, and Genoveffa Tortora. Claude 2.0 large language model: Tackling a real-world classification problem with a new iterative prompt engineering approach. Intelligent Systems with Applications, 2024, 21: 200336 doi: 10.1016/j.iswa.2024.200336 [38] Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv: 2312.11805, 2023. [39] Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. Olmo: Accelerating the science of language models. arXiv preprint arXiv: 2402.00838, 2024. [40] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748-8763. PMLR, 2021. [41] Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv: 2303.15389, 2023. [42] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv: 2001.08361, 2020. [43] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv: 2203.15556, 2022. [44] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv: 1804.07461, 2018. [45] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv: 1809.02789, 2018. [46] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432-7439, 2020. [47] Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv: 1904.09728, 2019. [48] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv: 1905.07830, 2019. [49] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv: 1905.10044, 2019. [50] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 2021, 64(9): 99−106 doi: 10.1145/3474381 [51] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv: 1803.05457, 2018. [52] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset. arXiv preprint arXiv: 1705.06950, 2017. [53] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740-755. Springer, 2014. [54] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 633-641, 2017. [55] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 2010, 88(2): 303−338 doi: 10.1007/s11263-009-0275-4 [56] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International conference on machine learning, pages 2790-2799. PMLR, 2019. [57] Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. arXiv preprint arXiv: 2005.00247, 2020. [58] Zhaojiang Lin, Andrea Madotto, and Pascale Fung. Exploring versatile generative language model via parameter-efficient transfer learning. arXiv preprint arXiv: 2004.03829, 2020. [59] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning. arXiv preprint arXiv: 2110.04366, 2021. [60] Yaoming Zhu, Jiangtao Feng, Chengqi Zhao, Mingxuan Wang, and Lei Li. Counter-interference adapter for multilingual machine translation. arXiv preprint arXiv: 2104.08154, 2021. [61] Tao Lei, Junwen Bai, Siddhartha Brahma, Joshua Ainslie, Kenton Lee, Yanqi Zhou, Nan Du, Vincent Zhao, Yuexin Wu, Bo Li, et al. Conditional adapters: Parameter-efficient transfer learning with fast inference. Advances in Neural Information Processing Systems, 2023, 36: 8152−8172 [62] Yuyan Chen, Qiang Fu, Ge Fan, Lun Du, Jian-Guang Lou, Shi Han, Dongmei Zhang, Zhixu Li, and Yanghua Xiao. Hadamard adapter: An extreme parameter-efficient adapter tuning method for pre-trained language models. In Proceedings of the 32nd ACM international conference on information and knowledge management, pages 276-285, 2023. [63] Shwai He, Run-Ze Fan, Liang Ding, Li Shen, Tianyi Zhou, and Dacheng Tao. Mera: Merging pretrained adapters for few-shot learning. arXiv preprint arXiv: 2308.15982, 2023. [64] Rabeeh Karimi Mahabadi, Sebastian Ruder, Mostafa Dehghani, and James Henderson. Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks. arXiv preprint arXiv: 2106.04489, 2021. [65] Nakamasa Inoue, Shinta Otake, Takumi Hirose, Masanari Ohi, and Rei Kawakami. Elp-adapters: Parameter efficient adapter tuning for various speech processing tasks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024. [66] Aleksandar Petrov, Philip HS Torr, and Adel Bibi. When do prompting and prefix-tuning work? a theory of capabilities and limitations. arXiv preprint arXiv: 2310.19698, 2023. [67] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv: 2101.00190, 2021. [68] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv: 2104.08691, 2021. [69] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. Gpt understands, too. AI Open, 2024, 5: 208−215 doi: 10.1016/j.aiopen.2023.08.012 [70] Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv: 2110.07602, 2021. [71] Joon-Young Choi, Junho Kim, Jun-Hyung Park, Wing-Lam Mok, and SangKeun Lee. Smop: Towards efficient and effective prompt tuning with sparse mixture-of-prompts. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14306-14316, 2023. [72] Zhen-Ru Zhang, Chuanqi Tan, Haiyang Xu, Chengyu Wang, Jun Huang, and Songfang Huang. Towards adaptive prefix tuning for parameter-efficient language model fine-tuning. arXiv preprint arXiv: 2305.15212, 2023. [73] Qifan Wang, Yuning Mao, Jingang Wang, Hanchao Yu, Shaoliang Nie, Sinong Wang, Fuli Feng, Lifu Huang, Xiaojun Quan, Zenglin Xu, et al. Aprompt: Attention prompt tuning for efficient adaptation of pre-trained language models. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 9147-9160, 2023. [74] Zhuofeng Wu, Sinong Wang, Jiatao Gu, Rui Hou, Yuxiao Dong, VG Vydiswaran, and Hao Ma. Idpg: An instance-dependent prompt generation method. arXiv preprint arXiv: 2204.04497, 2022. [75] Wei Zhu and Ming Tan. Spt: Learning to selectively insert prompts for better prompt tuning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11862-11878, 2023. [76] Xiangyang Liu, Tianxiang Sun, Xuanjing Huang, and Xipeng Qiu. Late prompt tuning: A late prompt could be better than many prompts. arXiv preprint arXiv: 2210.11292, 2022. [77] Fang Ma, Chen Zhang, Lei Ren, Jingang Wang, Qifan Wang, Wei Wu, Xiaojun Quan, and Dawei Song. Xprompt: Exploring the extreme of prompt tuning. arXiv preprint arXiv: 2210.04457, 2022. [78] Zhengxiang Shi and Aldo Lipani. Dept: Decomposed prompt tuning for parameter-efficient fine-tuning. arXiv preprint arXiv: 2309.05173, 2023. [79] Junda Wu, Tong Yu, Rui Wang, Zhao Song, Ruiyi Zhang, Handong Zhao, Chaochao Lu, Shuai Li, and Ricardo Henao. Infoprompt: Information-theoretic soft prompt tuning for natural language understanding. Advances in Neural Information Processing Systems, 2023, 36: 61060−61084 [80] Lichang Chen. Ptp: Boosting stability and performance of prompt tuning with perturbation-based regularizer. Master's thesis, University of Pittsburgh, 2023. [81] Runjia Zeng, Cheng Han, Qifan Wang, Chunshu Wu, Tong Geng, Lifu Huangg, Ying Nian Wu, and Dongfang Liu. Visual fourier prompt tuning. Advances in Neural Information Processing Systems, 2024, 37: 5552−5585 [82] Along He, Yanlin Wu, Zhihong Wang, Tao Li, and Huazhu Fu. Dvpt: Dynamic visual prompt tuning of large pre-trained models for medical image analysis. Neural Networks, 2025, 185: 107168 doi: 10.1016/j.neunet.2025.107168 [83] Zehao Xiao, Shilin Yan, Jack Hong, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiayi Shen, Qi Wang, and Cees GM Snoek. Dynaprompt: Dynamic test-time prompt tuning. arXiv preprint arXiv: 2501.16404, 2025. [84] Zhengpin Li, Minhua Lin, Jian Wang, and Suhang Wang. Fairness-aware prompt tuning for graph neural networks. In Proceedings of the ACM on Web Conference 2025, pages 3586-3597, 2025. [85] Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Advances in Neural Information Processing Systems, 2022, 35: 1950−1965 doi: 10.52202/068431-0142 [86] Dongze Lian, Daquan Zhou, Jiashi Feng, and Xinchao Wang. Scaling & shifting your features: A new baseline for efficient model tuning. Advances in Neural Information Processing Systems, 2022, 35: 109−123 doi: 10.52202/068431-0009 [87] Xiaocong Yang, James Y Huang, Wenxuan Zhou, and Muhao Chen. Parameter-efficient tuning with special token adaptation. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 865-872, 2023. [88] Ximing Lu, Faeze Brahman, Peter West, Jaehun Jung, Khyathi Chandu, Abhilasha Ravichander, Prithviraj Ammanabrolu, Liwei Jiang, Sahana Ramnath, Nouha Dziri, et al. Inference-time policy adapters (ipa): Tailoring extreme-scale lms without fine-tuning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6863-6883, 2023. [89] Yi Lin Sung, Jaemin Cho, and Mohit Bansal. Lst: Ladder side-tuning for parameter and memory efficient transfer learning. Advances in Neural Information Processing Systems, 2022, 35: 12991−13005 doi: 10.52202/068431-0944 [90] Jin Cao, Chandana Satya Prakash, and Wael Hamza. Attention fusion: a light yet efficient late fusion mechanism for task adaptation in nlu. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 857-866, 2022. [91] Chinmay Savadikar, Xi Song, and Tianfu Wu. Wegeft: Weight-generative fine-tuning for multi-faceted efficient adaptation of large models. In Forty-second International Conference on Machine Learning. [92] Mufan Sang and John HL Hansen. Unipet-spk: A unified framework for parameter-efficient tuning of pre-training speech models for robust speaker verification. IEEE Transactions on Audio, Speech and Language Processing, 2025. [93] Mufan Sang and John HL Hansen. Efficient adapter tuning of pre-trained speech models for automatic speaker verification. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12131-12135. IEEE, 2024. [94] Yunpeng Liu, Xukui Yang, Jiayi Zhang, Yangli Xi, and Dan Qu. Taml-adapter: Enhancing adapter tuning through task-agnostic meta-learning for low-resource automatic speech recognition. IEEE Signal Processing Letters, 2025. [95] Mengjie Zhao, Tao Lin, Fei Mi, Martin Jaggi, and Hinrich Schütze. Masking as an efficient alternative to finetuning for pretrained language models. arXiv preprint arXiv: 2004.12406, 2020. [96] Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv preprint arXiv: 2106.10199, 2021. [97] Neal G Lawton, Anoop Kumar, Govind Thattai, Aram Galstyan, and Greg Ver Steeg. Neural architecture search for parameter-efficient fine-tuning of large pre-trained language models. In The 61st Annual Meeting Of The Association For Computational Linguistics, 2023. [98] Baohao Liao, Yan Meng, and Christof Monz. Parameter-efficient fine-tuning without introducing new latency. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4242-4260, 2023. [99] Yi Lin Sung, Varun Nair, and Colin A Raffel. Training neural networks with fixed sparse masks. Advances in Neural Information Processing Systems, 2021, 34: 24193−24205 [100] Sarkar Snigdha Sarathi Das, Haoran Ranran Zhang, Peng Shi, Wenpeng Yin, and Rui Zhang. Unified low-resource sequence labeling by sample-aware dynamic sparse finetuning. In The 2023 Conference on Empirical Methods in Natural Language Processing. [101] Alan Ansell, Edoardo Maria Ponti, Anna Korhonen, and Ivan Vulić. Composable sparse fine-tuning for cross-lingual transfer. arXiv preprint arXiv: 2110.07560, 2021. [102] Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations, 2018. [103] Eran Malach, Gilad Yehudai, Shai Shalev-Schwartz, and Ohad Shamir. Proving the lottery ticket hypothesis: Pruning is all you need. In International Conference on Machine Learning, pages 6682-6691. PMLR, 2020. [104] Runxin Xu, Fuli Luo, Zhiyuan Zhang, Chuanqi Tan, Baobao Chang, Songfang Huang, and Fei Huang. Raise a child in large language model: Towards effective and generalizable fine-tuning. arXiv preprint arXiv: 2109.05687, 2021. [105] Viktoriia A Chekalina, Anna Rudenko, Gleb Mezentsev, Aleksandr Mikhalev, Alexander Panchenko, and Ivan Oseledets. Sparsegrad: A selective method for efficient fine-tuning of mlp layers. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 14929-14939, 2024. [106] Mozhdeh Gheini, Xiang Ren, and Jonathan May. Cross-attention is all you need: Adapting pretrained transformers for machine translation. arXiv preprint arXiv: 2104.08771, 2021. [107] Haoyu He, Jianfei Cai, Jing Zhang, Dacheng Tao, and Bohan Zhuang. Sensitivity-aware visual parameter-efficient fine-tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11825-11835, 2023. [108] Md Kowsher, Tara Esmaeilbeig, Chun-Nam Yu, Chen Chen, Mojtaba Soltanalian, and Niloofar Yousefi. Rocoft: Efficient finetuning of large language models with row-column updates. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 26659-26678, 2025. [109] Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv preprint arXiv: 2012.13255, 2020. [110] Sadhika Malladi, Alexander Wettig, Dingli Yu, Danqi Chen, and Sanjeev Arora. A kernel-based view of language model fine-tuning. In International Conference on Machine Learning, pages 23610-23641. PMLR, 2023. [111] Yuchen Zeng and Kangwook Lee. The expressive power of low-rank adaptation. arXiv preprint arXiv: 2310.17513, 2023. [112] Uijeong Jang, Jason D Lee, and Ernest K Ryu. Lora training in the ntk regime has no spurious local minima. arXiv preprint arXiv: 2402.11867, 2024. [113] Jiacheng Zhu, Kristjan Greenewald, Kimia Nadjahi, Haitz Sáez De Ocáriz Borde, Rickard Brüel Gabrielsson, Leshem Choshen, Marzyeh Ghassemi, Mikhail Yurochkin, and Justin Solomon. Asymmetry in low-rank adapters of foundation models. arXiv preprint arXiv: 2402.16842, 2024. [114] Ali Edalati, Marzieh Tahaei, Ivan Kobyzev, Vahid Partovi Nia, James J Clark, and Mehdi Rezagholizadeh. Krona: Parameter-efficient tuning with kronecker adapter. In Enhancing LLM Performance: Efficacy, Fine-Tuning, and Inference Techniques, pages 49-65. Springer, 2025. [115] Yifan Yang, Jiajun Zhou, Ngai Wong, and Zheng Zhang. Loretta: Low-rank economic tensor-train adaptation for ultra-low-parameter fine-tuning of large language models. arXiv preprint arXiv: 2402.11417, 2024. [116] Ivan V Oseledets. Tensor-train decomposition. SIAM Journal on Scientific Computing, 2011, 33(5): 2295−2317 doi: 10.1137/090752286 [117] Daniel Bershatsky, Daria Cherniuk, Talgat Daulbaev, Aleksandr Mikhalev, and Ivan Oseledets. Lotr: Low tensor rank weight adaptation. arXiv preprint arXiv: 2402.01376, 2024. [118] Xiangyu Chen, Jing Liu, Ye Wang, Pu Perry Wang, Matthew Brand, Guanghui Wang, and Toshiaki Koike-Akino. Superlora: Parameter-efficient unified adaptation of multi-layer attention modules. arXiv preprint arXiv: 2403.11887, 2024. [119] Afia Anjum, Maksim E Eren, Ismael Boureima, Boian Alexandrov, and Manish Bhattarai. Tensor train low-rank approximation (tt-lora): Democratizing ai with accelerated llms. In 2024 International Conference on Machine Learning and Applications (ICMLA), pages 583-590. IEEE, 2024. [120] Ignacio Hounie, Charilaos Kanatsoulis, Arnuv Tandon, and Alejandro Ribeiro. Lorta: Low rank tensor adaptation of large language models. arXiv preprint arXiv: 2410.04060, 2024. [121] Yupeng Chang, Yi Chang, and Yuan Wu. Bias-aware low-rank adaptation: Mitigating catastrophic inheritance of large language models. arXiv e-prints, pages arXiv–2408, 2024. [122] Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, et al. Lora learns less and forgets less. arXiv preprint arXiv: 2405.09673, 2024. [123] Mojtaba Valipour, Mehdi Rezagholizadeh, Ivan Kobyzev, and Ali Ghodsi. Dylora: Parameter efficient tuning of pre-trained models using dynamic search-free low-rank adaptation. arXiv preprint arXiv: 2210.07558, 2022. [124] Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv: 2303.10512, 2023. [125] Feiyu Zhang, Liangzhi Li, Junhao Chen, Zhouqiang Jiang, Bowen Wang, and Yiming Qian. Increlora: Incremental parameter allocation method for parameter-efficient fine-tuning. arXiv preprint arXiv: 2308.12043, 2023. [126] Ning Ding, Xingtai Lv, Qiaosen Wang, Yulin Chen, Bowen Zhou, Zhiyuan Liu, and Maosong Sun. Sparse low-rank adaptation of pre-trained language models. arXiv preprint arXiv: 2311.11696, 2023. [127] Yulong Mao, Kaiyu Huang, Changhao Guan, Ganglin Bao, Fengran Mo, and Jinan Xu. Dora: Enhancing parameter-efficient fine-tuning with dynamic rank distribution. arXiv preprint arXiv: 2405.17357, 2024. [128] Vladislav Lialin, Namrata Shivagunde, Sherin Muckatira, and Anna Rumshisky. Relora: High-rank training through low-rank updates. arXiv preprint arXiv: 2307.05695, 2023. [129] Wenhan Xia, Chengwei Qin, and Elad Hazan. Chain of lora: Efficient fine-tuning of language models via residual learning. arXiv preprint arXiv: 2401.04151, 2024. [130] Pengjie Ren, Chengshun Shi, Shiguang Wu, Mengqi Zhang, Zhaochun Ren, Maarten de Rijke, Zhumin Chen, and Jiahuan Pei. Melora: Mini-ensemble low-rank adapters for parameter-efficient fine-tuning. arXiv preprint arXiv: 2402.17263, 2024. [131] Soufiane Hayou, Nikhil Ghosh, and Bin Yu. The impact of initialization on lora finetuning dynamics. Advances in Neural Information Processing Systems, 2024, 37: 117015−117040 doi: 10.52202/079017-3715 [132] Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models. Advances in Neural Information Processing Systems, 2024, 37: 121038−121072 doi: 10.52202/079017-3846 [133] Hanqing Wang, Yixia Li, Shuo Wang, Guanhua Chen, and Yun Chen. Milora: Harnessing minor singular components for parameter-efficient llm finetuning. arXiv preprint arXiv: 2406.09044, 2024. [134] Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models. arXiv preprint arXiv: 2402.12354, 2024. [135] Shuhua Shi, Shaohan Huang, Minghui Song, Zhoujun Li, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. Reslora: Identity residual mapping in low-rank adaption. arXiv preprint arXiv: 2402.18039, 2024. [136] Zhihao Wen, Jie Zhang, and Yuan Fang. Sibo: A simple booster for parameter-efficient fine-tuning. arXiv preprint arXiv: 2402.11896, 2024. [137] Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. In Forty-first International Conference on Machine Learning, 2024. [138] Haoyu Wang, Tianci Liu, Ruirui Li, Monica Xiao Cheng, Tuo Zhao, and Jing Gao. Roselora: Row and column-wise sparse low-rank adaptation of pre-trained language model for knowledge editing and fine-tuning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 996-1008, 2024. [139] Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, and Tieniu Tan. Lora-pro: Are low-rank adapters properly optimized? In International Conference on Learning Representations, 2025. [140] Jiaxin Deng, Qingcheng Zhu, Junbiao Pang, Linlin Yang, Zhongqian Fu, and Baochang Zhang. Eflat-lora: Efficiently seeking flat minima for better generalization in fine-tuning large language models and beyond. arXiv preprint arXiv: 2508.00522, 2025. [141] Adam X Yang, Maxime Robeyns, Xi Wang, and Laurence Aitchison. Bayesian low-rank adaptation for large language models. arXiv preprint arXiv: 2308.13111, 2023. [142] Zhenting Qi, Xiaoyu Tan, Shaojie Shi, Chao Qu, Yinghui Xu, and Yuan Qi. Pillow: enhancing efficient instruction fine-tuning via prompt matching. arXiv preprint arXiv: 2312.05621, 2023. [143] Linhai Zhang, Jialong Wu, Deyu Zhou, and Guoqiang Xu. Star: Constraint lora with dynamic active learning for data-efficient fine-tuning of large language models. arXiv preprint arXiv: 2403.01165, 2024. [144] Yang Lin, Xinyu Ma, Xu Chu, Yujie Jin, Zhibang Yang, and Yasha Wang. Lora dropout as a sparsity regularizer for overfitting reduction. Knowledge-Based Systems, 2025page 114241 [145] Jingjing Zheng, Wanglong Lu, Yiming Dong, Chaojie Ji, Yankai Cao, and Zhouchen Lin. Adamss: Adaptive multi-subspace approach for parameter-efficient fine-tuning. Advances in Neural Information Processing Systems, 2025. [146] Xi Wang, Laurence Aitchison, and Maja Rudolph. Lora ensembles for large language model fine-tuning. arXiv preprint arXiv: 2310.00035, 2023. [147] Ziyu Zhao, Leilei Gan, Guoyin Wang, Wangchunshu Zhou, Hongxia Yang, Kun Kuang, and Fei Wu. Loraretriever: Input-aware lora retrieval and composition for mixed tasks in the wild. arXiv preprint arXiv: 2402.09997, 2024. [148] Yuhan Sun, Mukai Li, Yixin Cao, Kun Wang, Wenxiao Wang, Xingyu Zeng, and Rui Zhao. To be or not to be? an exploration of continuously controllable prompt engineering. arXiv preprint arXiv: 2311.09773, 2023. [149] Jinghan Zhang, Junteng Liu, Junxian He, et al. Composing parameter-efficient modules with arithmetic operation. Advances in Neural Information Processing Systems, 2023, 36: 12589−12610 doi: 10.52202/075280-0552 [150] Chengsong Huang, Qian Liu, Bill Yuchen Lin, Tianyu Pang, Chao Du, and Min Lin. Lorahub: Efficient cross-task generalization via dynamic lora composition. arXiv preprint arXiv: 2307.13269, 2023. [151] Jialin Liu, Antoine Moreau, Mike Preuss, Jeremy Rapin, Baptiste Roziere, Fabien Teytaud, and Olivier Teytaud. Versatile black-box optimization. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference, pages 620-628, 2020. [152] Anke Tang, Li Shen, Yong Luo, Yibing Zhan, Han Hu, Bo Du, Yixin Chen, and Dacheng Tao. Parameter efficient multi-task model fusion with partial linearization. arXiv preprint arXiv: 2310.04742, 2023. [153] Ying Shen, Zhiyang Xu, Qifan Wang, Yu Cheng, Wenpeng Yin, and Lifu Huang. Multimodal instruction tuning with conditional mixture of lora. arXiv preprint arXiv: 2402.15896, 2024. [154] Eric L Buehler and Markus J Buehler. X-lora: Mixture of low-rank adapter experts, a flexible framework for large language models with applications in protein mechanics and molecular design. APL Machine Learning, 2(2), 2024. [155] Wenfeng Feng, Chuzhan Hao, Yuewei Zhang, Yu Han, and Hao Wang. Mixture-of-loras: An efficient multitask tuning method for large language models. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 11371-11380, 2024. [156] Yiming Wang, Yu Lin, Xiaodong Zeng, and Guannan Zhang. Multilora: Democratizing lora for better multi-task learning. arXiv preprint arXiv: 2311.11501, 2023. [157] Yuqi Yang, Peng-Tao Jiang, Qibin Hou, Hao Zhang, Jinwei Chen, and Bo Li. Multi-task dense prediction via mixture of low-rank experts. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 27927-27937, 2024. [158] Ahmed Agiza, Marina Neseem, and Sherief Reda. Mtlora: Low-rank adaptation approach for efficient multi-task learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16196-16205, 2024. [159] Chongyang Gao, Kezhen Chen, Jinmeng Rao, Baochen Sun, Ruibo Liu, Daiyi Peng, Yawen Zhang, Xiaoyuan Guo, Jie Yang, and VS Subrahmanian. Higher layers need more lora experts. arXiv preprint arXiv: 2402.08562, 2024. [160] Shaoxiang Chen, Zequn Jie, and Lin Ma. Llava-mole: Sparse mixture of lora experts for mitigating data conflicts in instruction finetuning mllms. arXiv preprint arXiv: 2401.16160, 2024. [161] Yun Zhu, Nevan Wichers, Chu-Cheng Lin, Xinyi Wang, Tianlong Chen, Lei Shu, Han Lu, Canoee Liu, Liangchen Luo, Jindong Chen, et al. Sira: Sparse mixture of low rank adaptation. arXiv preprint arXiv: 2311.09179, 2023. [162] Peijun Qing, Chongyang Gao, Yefan Zhou, Xingjian Diao, Yaoqing Yang, and Soroush Vosoughi. Alphalora: Assigning lora experts based on layer training quality. arXiv preprint arXiv: 2410.10054, 2024. [163] Junjie Wang, Guangjing Yang, Wentao Chen, Huahui Yi, Xiaohu Wu, and Qicheng Lao. Mlae: Masked lora experts for parameter-efficient fine-tuning. arXiv preprint arXiv: 2405.18897, 2: 29-30, 2024. [164] Chenghao Fan, Zhenyi Lu, Sichen Liu, Chengfeng Gu, Xiaoye Qu, Wei Wei, and Yu Cheng. Make lora great again: Boosting lora with adaptive singular values and mixture-of-experts optimization alignment. arXiv preprint arXiv: 2502.16894, 2025. [165] Ziyu Zhao, Yixiao Zhou, Zhi Zhang, Didi Zhu, Tao Shen, Zexi Li, Jinluan Yang, Xuwu Wang, Jing Su, Kun Kuang, et al. Each rank could be an expert: Single-ranked mixture of experts lora for multi-task learning. arXiv preprint arXiv: 2501.15103, 2025. [166] Mengqi Liao, Wei Chen, Junfeng Shen, Shengnan Guo, and Huaiyu Wan. Hmora: Making llms more effective with hierarchical mixture of lora experts. In International Conference on Learning Representations, 2025. [167] Bingshen Mu, Kun Wei, Pengcheng Guo, and Lei Xie. Mixture of lora experts with multi-modal and multi-granularity llm generative error correction for accented speech recognition. IEEE Transactions on Audio, Speech and Language Processing, 2025. [168] Akshara Prabhakar, Yuanzhi Li, Karthik Narasimhan, Sham Kakade, Eran Malach, and Samy Jelassi. Lora soups: Merging loras for practical skill composition tasks. In Proceedings of the 31st International Conference on Computational Linguistics: Industry Track, pages 644-655, 2025. [169] Jian Liang, Wenke Huang, Guancheng Wan, Qu Yang, and Mang Ye. Lorasculpt: Sculpting lora for harmonizing general and specialized knowledge in multimodal large language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 26170-26180, 2025. [170] Yaming Yang, Dilxat Muhtar, Yelong Shen, Yuefeng Zhan, Jianfeng Liu, Yujing Wang, Hao Sun, Weiwei Deng, Feng Sun, Qi Zhang, et al. Mtl-lora: Low-rank adaptation for multi-task learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22010-22018, 2025. [171] Longteng Zhang, Lin Zhang, Shaohuai Shi, Xiaowen Chu, and Bo Li. Lora-fa: Memory-efficient low-rank adaptation for large language models fine-tuning. arXiv preprint arXiv: 2308.03303, 2023. [172] Yichao Wu, Yafei Xiang, Shuning Huo, Yulu Gong, and Penghao Liang. Lora-sp: streamlined partial parameter adaptation for resource efficient fine-tuning of large language models. In Third International Conference on Algorithms, Microchips, and Network Applications (AMNA 2024), volume 13171, pages 488-496. SPIE, 2024. [173] Zeyu Liu, Souvik Kundu, Anni Li, Junrui Wan, Lianghao Jiang, and Peter Anthony Beerel. Aflora: Adaptive freezing of low rank adaptation in parameter efficient fine-tuning of large models. arXiv preprint arXiv: 2403.13269, 2024. [174] Sunghyeon Woo, Baeseong Park, Byeongwook Kim, Minjung Jo, Se Jung Kwon, Dongsuk Jeon, and Dongsoo Lee. Dropbp: Accelerating fine-tuning of large language models by dropping backward propagation. Advances in Neural Information Processing Systems, 2024, 37: 20170−20197 doi: 10.52202/079017-0637 [175] Klaudia Bałazy, Mohammadreza Banaei, Karl Aberer, and Jacek Tabor. Lora-xs: Low-rank adaptation with extremely small number of parameters. arXiv preprint arXiv: 2405.17604, 2024. [176] Mingyang Zhang, Hao Chen, Chunhua Shen, Zhen Yang, Linlin Ou, Xinyi Yu, and Bohan Zhuang. Loraprune: Structured pruning meets low-rank parameter-efficient fine-tuning. arXiv preprint arXiv: 2305.18403, 2023. [177] Hongyun Zhou, Xiangyu Lu, Wang Xu, Conghui Zhu, Tiejun Zhao, and Muyun Yang. Lora-drop: Efficient lora parameter pruning based on output evaluation. In Proceedings of the 31st International Conference on Computational Linguistics, pages 5530-5543, 2025. [178] Shuang Ao, Yi Dong, Jinwei Hu, and Sarvapali Ramchurn. Safe pruning lora: Robust distance-guided pruning for safety alignment in adaptation of llms. arXiv preprint arXiv: 2506.18931, 2025. [179] Ryota Miyano and Yuki Arase. Adaptive lora merge with parameter pruning for low-resource generation. arXiv preprint arXiv: 2505.24174, 2025. [180] Yijiang Liu, Huanrui Yang, Youxin Chen, Rongyu Zhang, Miao Wang, Yuan Du, and Li Du. Pat: Pruning-aware tuning for large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24686-24695, 2025. [181] Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Yang You, Guiming Xie, Xuejian Gong, and Kunlong Zhou. Train small, infer large: Memory-efficient lora training for large language models. arXiv preprint arXiv: 2502.13533, 2025. [182] Xin Yu, Cong Xie, Ziyu Zhao, Tiantian Fan, Lingzhou Xue, and Zhi Zhang. Prunedlora: Robust gradient-based structured pruning for low-rank adaptation in fine-tuning. arXiv preprint arXiv: 2510.00192, 2025. [183] Dawid J Kopiczko, Tijmen Blankevoort, and Yuki M Asano. Vera: Vector-based random matrix adaptation. arXiv preprint arXiv: 2310.11454, 2023. [184] Yang Li, Shaobo Han, and Shihao Ji. Vb-lora: Extreme parameter efficient fine-tuning with vector banks. Advances in Neural Information Processing Systems, 2024, 37: 16724−16751 doi: 10.52202/079017-0533 [185] Ziqi Gao, Qichao Wang, Aochuan Chen, Zijing Liu, Bingzhe Wu, Liang Chen, and Jia Li. Parameter-efficient fine-tuning with discrete fourier transform. arXiv preprint arXiv: 2405.03003, 2024. [186] Yuhua Zhou, Ruifeng Li, Changhai Zhou, Fei Yang, and Aimin Pan. Bslora: Enhancing the parameter efficiency of lora with intra-layer and inter-layer sharing. In Forty-second International Conference on Machine Learning, 2025. [187] Jinman Zhao, Xueyan Zhang, Jiaru Li, Jingcheng Niu, Yulan Hu, Erxue Min, and Gerald Penn. Tiny budgets, big gains: Parameter placement strategy in parameter super-efficient fine-tuning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6326-6344, 2025. [188] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 2023, 36: 10088−10115 doi: 10.52202/075280-0441 [189] Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhengsu Chen, Xiaopeng Zhang, and Qi Tian. Qa-lora: Quantization-aware low-rank adaptation of large language models. arXiv preprint arXiv: 2309.14717, 2023. [190] Yixiao Li, Yifan Yu, Chen Liang, Pengcheng He, Nikos Karampatziakis, Weizhu Chen, and Tuo Zhao. Loftq: Lora-fine-tuning-aware quantization for large language models. arXiv preprint arXiv: 2310.08659, 2023. [191] Yanxia Deng, Aozhong Zhang, Naigang Wang, Selcuk Gurses, Zi Yang, and Penghang Yin. Cloq: Enhancing fine-tuning of quantized llms via calibrated lora initialization. arXiv preprint arXiv: 2501.18475, 2025. [192] Geonho Lee, Janghwan Lee, Sukjin Hong, Minsoo Kim, Euijai Ahn, Du-Seong Chang, and Jungwook Choi. Rilq: Rank-insensitive lora-based quantization error compensation for boosting 2-bit large language model accuracy. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 18091-18100, 2025. [193] Wenjin Ke, Zhe Li, Dong Li, Lu Tian, and Emad Barsoum. Dl-qat: Weight-decomposed low-rank quantization-aware training for large language models. arXiv preprint arXiv: 2504.09223, 2025. [194] Hyesung Jeon, Yulhwa Kim, and Jae-Joon Kim. L4q: parameter efficient quantization-aware fine-tuning on large language models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2002-2024, 2025. [195] Zhengmao Ye, Dengchun Li, Jingqi Tian, Tingfeng Lan, Jie Zuo, Lei Duan, Hui Lu, Yexi Jiang, Jian Sha, Ke Zhang, et al. Aspen: High-throughput lora fine-tuning of large language models with a single gpu. CoRR, 2023. [196] Lequn Chen, Zihao Ye, Yongji Wu, Danyang Zhuo, Luis Ceze, and Arvind Krishnamurthy. Punica: Multi-tenant lora serving. Proceedings of Machine Learning and Systems, 2024, 6: 1−13 [197] Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, et al. S-lora: Serving thousands of concurrent lora adapters. arXiv preprint arXiv: 2311.03285, 2023. [198] Minghao Yan, Zhuang Wang, Zhen Jia, Shivaram Venkataraman, and Yida Wang. Plora: Efficient lora hyperparameter tuning for large models. arXiv preprint arXiv: 2508.02932, 2025. [199] Yuning Mao, Lambert Mathias, Rui Hou, Amjad Almahairi, Hao Ma, Jiawei Han, Wen-tau Yih, and Madian Khabsa. Unipelt: A unified framework for parameter-efficient language model tuning. arXiv preprint arXiv: 2110.07577, 2021. [200] Shengding Hu, Zhen Zhang, Ning Ding, Yadao Wang, Yasheng Wang, Zhiyuan Liu, and Maosong Sun. Sparse structure search for delta tuning. Advances in Neural Information Processing Systems, 2022. [201] Jiaao Chen, Aston Zhang, Xingjian Shi, Mu Li, Alex Smola, and Diyi Yang. Parameter-efficient fine-tuning design spaces. arXiv preprint arXiv: 2301.01821, 2023. [202] Guangtao Zeng, Peiyuan Zhang, and Wei Lu. One network, many masks: Towards more parameter-efficient transfer learning. arXiv preprint arXiv: 2305.17682, 2023. [203] Zhiqiang Hu, Lei Wang, Yihuai Lan, Wanyu Xu, Ee-Peng Lim, Lidong Bing, Xing Xu, Soujanya Poria, and Roy Ka-Wei Lee. Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. arXiv preprint arXiv: 2304.01933, 2023. [204] Yuanhan Zhang, Kaiyang Zhou, and Ziwei Liu. Neural prompt search. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. [205] Han Zhou, Xingchen Wan, Ivan Vulić, and Anna Korhonen. Autopeft: Automatic configuration search for parameter-efficient fine-tuning. Transactions of the Association for Computational Linguistics, 2024, 12: 525−542 doi: 10.1162/tacl_a_00662 [206] Yidong Chai, Yang Liu, Yonghang Zhou, Jiaheng Xie, and Daniel Dajun Zeng. A bayesian hybrid parameter-efficient fine-tuning method for large language models. arXiv preprint arXiv: 2508.02711, 2025. [207] Lingling Xu, Haoran Xie, Si-Zhao Joe Qin, Xiaohui Tao, and Fu Lee Wang. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment. arXiv preprint arXiv: 2312.12148, 2023. [208] Luping Wang, Sheng Chen, Linnan Jiang, Shu Pan, Runze Cai, Sen Yang, and Fei Yang. Parameter-efficient fine-tuning in large language models: a survey of methodologies. Artificial Intelligence Review, 2025, 58(8): 227 doi: 10.1007/s10462-025-11236-4 [209] Lingchen Meng, Hengduo Li, Bor-Chun Chen, Shiyi Lan, Zuxuan Wu, Yu-Gang Jiang, and Ser-Nam Lim. Adavit: Adaptive vision transformers for efficient image recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12309-12318, 2022. [210] Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adaptformer: Adapting vision transformers for scalable visual recognition. Advances in Neural Information Processing Systems, 2022, 35: 16664−16678 [211] Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong Lu, Jifeng Dai, and Yu Qiao. Vision transformer adapter for dense predictions. In International Conference on Learning Representations, 2023. [212] Mengde Xu, Zheng Zhang, Fangyun Wei, Han Hu, and Xiang Bai. Side adapter network for open-vocabulary semantic segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2945-2954, 2023. [213] Minghao Fu, Ke Zhu, and Jianxin Wu. Dtl: Disentangled transfer learning for visual recognition. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 12082-12090, 2024. [214] Hao Chen, Ran Tao, Han Zhang, Yidong Wang, Xiang Li, Wei Ye, Jindong Wang, Guosheng Hu, and Marios Savvides. Conv-adapter: Exploring parameter efficient transfer learning for convnets. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1551-1561, 2024. [215] Zheng Chen, Yu Zeng, Zehui Chen, Hongzhi Gao, Lin Chen, Jiaming Liu, and Feng Zhao. Vfm-adapter: Adapting visual foundation models for dense prediction with dynamic hybrid operation mapping. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 2385-2393, 2025. [216] Deep Pandey, Spandan Pyakurel, and Qi Yu. Be confident in what you know: Bayesian parameter efficient fine-tuning of vision foundation models. Advances in Neural Information Processing Systems, 2024, 37: 44814−44844 doi: 10.52202/079017-1424 [217] Qihang Yu, Ju He, Xueqing Deng, Xiaohui Shen, and Liang-Chieh Chen. Convolutions die hard: Open-vocabulary segmentation with single frozen convolutional clip. Advances in Neural Information Processing Systems, 2023, 36: 32215−32234 [218] Dongshuo Yin, Yiran Yang, Zhechao Wang, Hongfeng Yu, Kaiwen Wei, and Xian Sun. 1% vs 100%: Parameter-efficient low rank adapter for dense predictions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20116-20126, 2023. [219] Zixuan Hu, Yongxian Wei, Li Shen, Chun Yuan, and Dacheng Tao. Lora recycle: Unlocking tuning-free few-shot adaptability in visual foundation models by recycling pre-tuned loras. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 25026-25037, 2025. [220] Zheda Mai, Ping Zhang, Cheng-Hao Tu, Hong-You Chen, Quang-Huy Nguyen, Li Zhang, and Wei-Lun Chao. Lessons and insights from a unifying study of parameter-efficient fine-tuning (peft) in visual recognition. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14845-14857, 2025. [221] Tiantian Feng and Shrikanth Narayanan. Peft-ser: On the use of parameter efficient transfer learning approaches for speech emotion recognition using pre-trained speech models. In 2023 11th International Conference on Affective Computing and Intelligent Interaction (ACⅡ), pages 1-8. IEEE, 2023. [222] Tzu-Han Lin, How-Shing Wang, Hao-Yung Weng, Kuang-Chen Peng, Zih-Ching Chen, and Hung-yi Lee. Peft for speech: Unveiling optimal placement, merging strategies, and ensemble techniques. In 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), pages 705-709. IEEE, 2024. [223] Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 2022, 16(6): 1505−1518 doi: 10.1109/JSTSP.2022.3188113 [224] Mohamed Nabih Ali, Daniele Falavigna, and Alessio Brutti. Efl-peft: A communication efficient federated learning framework using peft sparsification for asr. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1-5. IEEE, 2025. [225] Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, and Helen Meng. Large language model can transcribe speech in multi-talker scenarios with versatile instructions. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1-5. IEEE, 2025. [226] Tzu-Quan Lin, Wei-Ping Huang, Hao Tang, and Hung-yi Lee. Speech-ft: Merging pre-trained and fine-tuned speech representation models for cross-task generalization. arXiv preprint arXiv: 2502.12672, 2025. [227] Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM transactions on audio, speech, and language processing, 2021, 29: 3451−3460 doi: 10.1109/TASLP.2021.3122291 [228] Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 2020, 33: 12449−12460 [229] Shaoshi Ling and Yuzong Liu. Decoar 2.0: Deep contextualized acoustic representations with vector quantization. arXiv preprint arXiv: 2012.06659, 2020. [230] Zhisheng Zhong, Chengyao Wang, Yuqi Liu, Senqiao Yang, Longxiang Tang, Yuechen Zhang, Jingyao Li, Tianyuan Qu, Yanwei Li, Yukang Chen, et al. Lyra: An efficient and speech-centric framework for omni-cognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3694-3704, 2025. [231] Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Diana Marculescu. Open-vocabulary semantic segmentation with mask-adapted clip. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7061-7070, 2023. [232] Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters. International Journal of Computer Vision, 2024, 132(2): 581−595 doi: 10.1007/s11263-023-01891-x [233] Liqi Yan, Cheng Han, Zenglin Xu, Dongfang Liu, and Qifan Wang. Prompt learns prompt: Exploring knowledge-aware generative prompt collaboration for video captioning. In IJCAI, pages 1622-1630, 2023. [234] Lingxiao Yang, Ru-Yuan Zhang, Yanchen Wang, and Xiaohua Xie. Mma: Multi-modal adapter for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23826-23837, 2024. [235] Zehuan Huang, Yuan-Chen Guo, Haoran Wang, Ran Yi, Lizhuang Ma, Yan-Pei Cao, and Lu Sheng. Mv-adapter: Multi-view consistent image generation made easy. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16377-16387, 2025. [236] Fengdi Li. Mh-peft: Mitigating hallucinations in large vision-language models through the peft method. In Proceedings of the 2025 2nd International Conference on Generative Artificial Intelligence and Information Security, pages 137-142, 2025. [237] Zhengqin Xu, Zelin Peng, Xiaokang Yang, and Wei Shen. Fate: Feature-adapted parameter tuning for vision-language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9014-9022, 2025. [238] Yi Zhang, Yi-Xuan Deng, Meng-Hao Guo, and Shi-Min Hu. Adaptive parameter selection for tuning vision-language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4280-4290, 2025. [239] Matteo Farina, Massimiliano Mancini, Giovanni Iacca, and Elisa Ricci. Rethinking few-shot adaptation of vision-language models in two stages. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 29989-29998, 2025. [240] Maxime Zanella and Ismail Ben Ayed. Low-rank few-shot adaptation of vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1593-1603, 2024. [241] Ricardo Ornelas, Alton Chao, Shyam Gupta, Edmund Chao, and Ross Greer. Improving event-phase captions in multi-view urban traffic videos via prompt-aware lora tuning of vision language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1821-1827, 2025. [242] Haodong Lu, Chongyang Zhao, Jason Xue, Lina Yao, Kristen Moore, and Dong Gong. Adaptive rank, reduced forgetting: Knowledge retention in continual learning vision-language models with dynamic rank-selective lora. arXiv preprint arXiv: 2412.01004, 2024. [243] Krishna Teja Chitty-Venkata, Murali Emani, and Venkatram Vishwanath. Langvision-lora-nas: Neural architecture search for variable lora rank in vision language models. In 2025 IEEE International Conference on Image Processing (ICIP), pages 1330-1335. IEEE, 2025. [244] Yuqi Peng, Pengfei Wang, Jianzhuang Liu, and Shifeng Chen. Glad: Generalizable tuning for vision-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4310-4320, 2025. [245] Thong Nguyen, Xiaobao Wu, Xinshuai Dong, Khoi M Le, Zhiyuan Hu, Cong-Duy Nguyen, See-Kiong Ng, and Anh Tuan Luu. Read-pvla: recurrent adapter with partial video-language alignment for parameter-efficient transfer learning in low-resource video-language modeling. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18824-18832, 2024. [246] Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, et al. Vla-adapter: An effective paradigm for tiny-scale vision-language-action model. arXiv preprint arXiv: 2509.09372, 2025. [247] Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv: 2510.10274, 2025. [248] Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success. arXiv preprint arXiv: 2502.19645, 2025. [249] Yeachan Kim, Junho Kim, Wing-Lam Mok, Jun-Hyung Park, and SangKeun Lee. Client-customized adaptation for parameter-efficient federated learning. In Findings of the Association for Computational Linguistics: ACL 2023, pages 1159-1172, 2023. [250] Dongqi Cai, Yaozong Wu, Shangguang Wang, and Mengwei Xu. Fedadapter: Efficient federated learning for mobile nlp. In Proceedings of the ACM Turing Award Celebration Conference-China 2023, pages 27-28, 2023. [251] Haokun Chen, Yao Zhang, Denis Krompass, Jindong Gu, and Volker Tresp. Feddat: An approach for foundation model finetuning in multi-modal heterogeneous federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 11285-11293, 2024. [252] Baochen Xiong, Xiaoshan Yang, Yaguang Song, Yaowei Wang, and Changsheng Xu. Pilot: Building the federated multimodal instruction tuning framework. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 21716-21724, 2025. [253] Pramit Saha, Divyanshu Mishra, Felix Wagner, Konstantinos Kamnitsas, and J Alison Noble. Fedpia–permuting and integrating adapters leveraging wasserstein barycenters for finetuning foundation models in multi-modal federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 20228-20236, 2025. [254] Rui Wang, Tong Yu, Ruiyi Zhang, Sungchul Kim, Ryan Rossi, Handong Zhao, Junda Wu, Subrata Mitra, Lina Yao, and Ricardo Henao. Personalized federated learning for text classification with gradient-free prompt tuning. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 4597-4612, 2024. [255] Fu-En Yang, Chien-Yi Wang, and Yu-Chiang Frank Wang. Efficient model personalization in federated learning via client-specific prompt generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19159-19168, 2023. [256] Hongming Piao, Yichen Wu, Dapeng Wu, and Ying Wei. Federated continual learning via prompt-based dual knowledge transfer. In Forty-first International Conference on Machine Learning, 2024. [257] Sikai Bai, Jie Zhang, Song Guo, Shuaicheng Li, Jingcai Guo, Jun Hou, Tao Han, and Xiaocheng Lu. Diprompt: Disentangled prompt tuning for multiple latent domain generalization in federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27284-27293, 2024. [258] Yue Tan, Guodong Long, Jie Ma, Lu Liu, Tianyi Zhou, and Jing Jiang. Federated learning from pre-trained models: A contrastive learning approach. Advances in Neural Information Processing Systems, 2022, 35: 19332−19344 doi: 10.52202/068431-1405 [259] Zhuo Zhang, Yuanhang Yang, Yong Dai, Qifan Wang, Yue Yu, Lizhen Qu, and Zenglin Xu. Fedpetuning: When federated learning meets the parameter-efficient tuning methods of pre-trained language models. In Annual Meeting of the Association of Computational Linguistics 2023, pages 9963-9977. Association for Computational Linguistics (ACL), 2023. [260] Shangchao Su, Bin Li, and Xiangyang Xue. Fedra: A random allocation strategy for federated tuning to unleash the power of heterogeneous clients. In European Conference on Computer Vision, pages 342-358. Springer, 2024. [261] Guodong Long, Tao Shen, Jing Jiang, Michael Blumenstein, et al. Dual-personalizing adapter for federated foundation models. Advances in Neural Information Processing Systems, 2024, 37: 39409−39433 doi: 10.52202/079017-1245 [262] Sajjad Ghiasvand, Yifan Yang, Zhiyu Xue, Mahnoosh Alizadeh, Zheng Zhang, and Ramtin Pedarsani. Communication-efficient and tensorized federated fine-tuning of large language models. In Findings of the Association for Computational Linguistics: ACL 2025, pages 24192-24207, 2025. [263] Jieming Bian, Lei Wang, Letian Zhang, and Jie Xu. Lora-fair: Federated lora fine-tuning with aggregation and initialization refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3737-3746, 2025. -

 下载:
下载:

计量
- 文章访问数: 1183
- HTML全文浏览量: 2459
- 被引次数: 0
