

-
摘要: 在人类信息获取过程中, 视听觉扮演着重要角色, 大脑通过整合视听信息, 形成统一、连贯且稳定的知觉体验. 视听多模态学习旨在模拟人类的视听多感官整合能力, 近年来受到研究者的广泛关注. 然而, 该领域在应用场景、任务目标和技术方法上呈现出显著的多样性, 目前尚且缺乏对视听多模态学习领域系统性回顾和分析的综合性中文综述. 基于人类的多感官整合机制在视听认知中的重要性以及不同视听多模态学习任务间的内在关联性, 提出一个统一框架, 将现有研究归纳为三类: 视听增强通过引入音频或视觉信息实现对初始单模态任务的增强效应; 跨模态交互旨在探索视听信息间的相互转换; 视听协作致力于探索视听信息的综合理解方法及其协同效应. 在此基础上, 对该领域中的最新研究进展进行系统性综述和总结. 此外, 深入剖析当前视听多模态学习研究所面临的五大核心共性问题和挑战---视听表征、对齐、转换、融合和共同学习; 并探讨大模型背景下视听多模态学习的发展现状.Abstract: In the process of human information acquisition, audio-visual plays crucial roles, with the brain integrating audio-visual information to form a unified, coherent, and stable perceptual experience. Audio-visual Multi-modal Learning (AVMML) aims to simulate human capacity for audio-visual multi-sensory integration, which has garnered significant attention from researchers in recent years. However, this field exhibits significant diversity in application scenarios, task objectives and technical methodologies. Currently, there is a lack of a comprehensive Chinese survey that systematically reviews and analyzes the field of AVMML. In this paper, we proposes a unified framework based on the importance of human multi-sensory integration mechanisms in audio-visual cognition and the intrinsic relationships among different AVMML tasks. Under our framework, existing AVMML researches can be categorized into three main types: Audio-visual enhancement, which improves the performance of initial uni-modal tasks by incorporating audio or visual information; Cross-modal interaction, which explores the mutual translation between audio and visual information; Audio-visual collaboration, which investigate comprehensive understanding methods and synergistic effects of audio-visual information. Building on this, this paper systematically reviews and summarizes the latest research progress in the AVMML field. Additionally, we provides an in-depth analysis of five core issues and challenges faced by current AVMML research, covering audio-visual representation, alignment, translation, fusion, and co-learning; We also discusses the development state of AVMML in the context of large models.
-

图 2 视听多模态学习文献年度统计分析图
Fig. 2 Annual statistical analysis chart of audio-visual multi-modal learning

图 3 视听多模态学习任务及其分类示意图
Fig. 3 Audio-visual multi-modal learning tasks and the diagram of their classification

图 4 本文结构及其章节安排示意图
Fig. 4 Schematic diagram of the paper structure and chapter organization

图 5 视听增强分类及其任务划分示意图
Fig. 5 Audio-visual enhancement categorization and schematic diagram of its task division
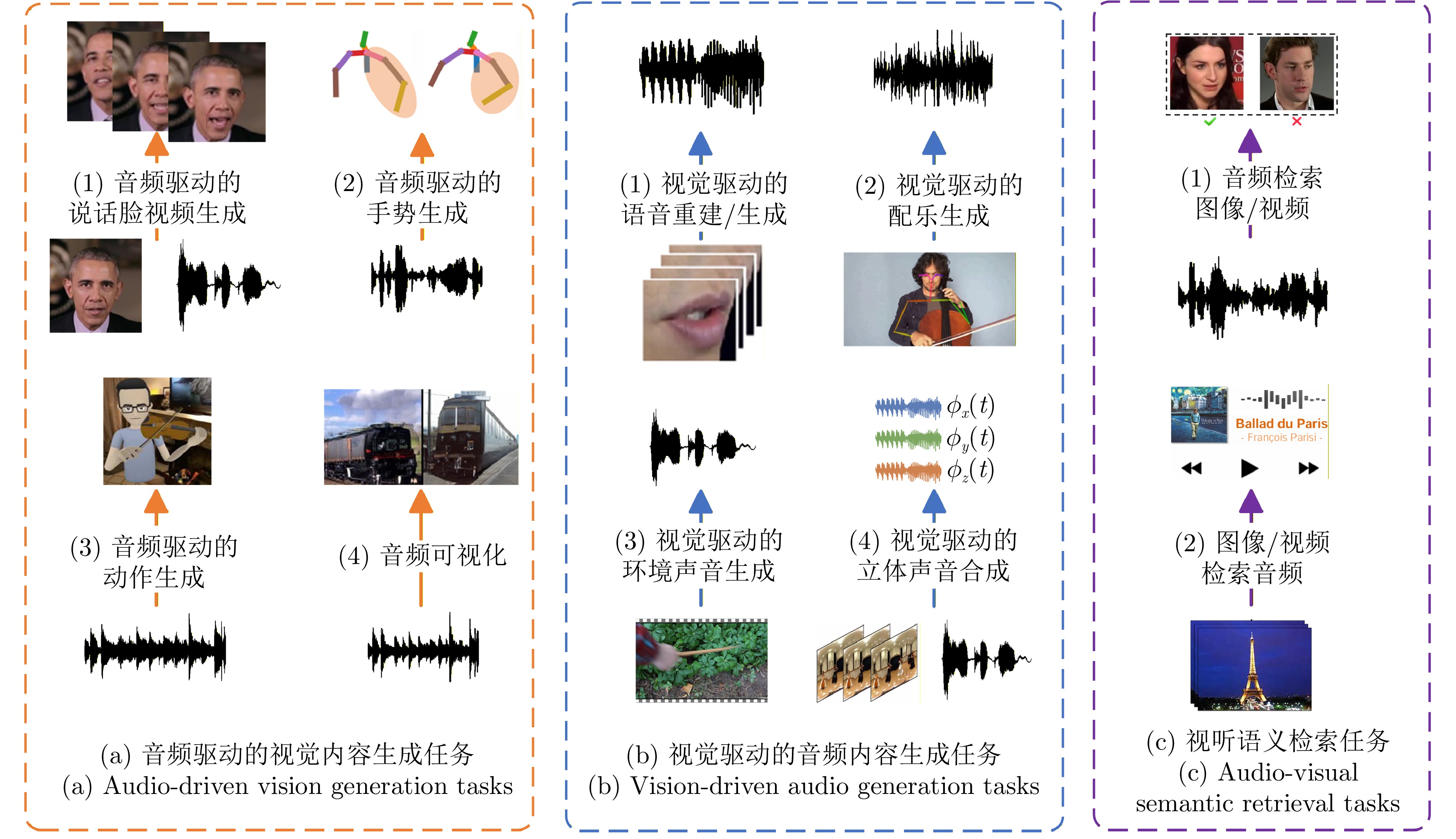
图 6 跨模态交互分类及其任务划分示意图
Fig. 6 Cross-modal interaction learning categorization and the schematic diagram of its task division (a) The schematic diagram of audio-driven vision generation tasks; (b) The schematic diagram of vision-driven audio generation tasks; (c) Audio-visual semantic retrieval tasks

图 7 视听协作分类及其任务划分示意图
Fig. 7 Audio-visual collaboration and schematic diagram of its task division
表 1 视/听单模态学习与视听多模态学习
Table 1 Audio/vision uni-modal learning and audio-visual multi-modal learning
数据处理能力 知识迁移能力 噪声鲁棒能力 计算机视觉/音频处理(CV/AP) 单模态学习 仅能处理图像、视频、
音频单一模态数据知识只能从一种模态中
学习并应用在该模态中容易受到模态自身数据
噪声的影响视听多模态学习 多模态学习 能同时处理图像、视频、
音频多模态数据知识可以从一种模态获取,
也能应用于不同模态各模态数据噪声互不影响,
且信息可相互补充 下载: 导出CSV
下载: 导出CSV
表 2 视听学习任务涉及的核心问题/挑战
Table 2 Core issues/challenges involved in audio-visual learning tasks
分类 子类 视听表征 视听转换 视听对齐 视听融合 视听共同学习 视听增强学习 音频增强的视觉任务 $ \surd $ $ \surd $ $ \surd $ 视觉增强的音频任务 $ \surd $ $ \surd $ $ \surd $ 视听跨模态学习 视听生成任务 $ \surd $ $ \surd $ $ \surd $ 视听检索任务 $ \surd $ $ \surd $ $ \surd $ 视听协作学习 视听实例感知任务 $ \surd $ $ \surd $ $ \surd $ 视听场景理解任务 $ \surd $ $ \surd $ $ \surd $ 视听推理与交互任务 $ \surd $ $ \surd $ $ \surd $ 非传统的视听学习任务 $ \surd $ $ \surd $ $ \surd $ $ \surd $
下载: 导出CSV
-
[1] Treichler D G. Are you missing the boat in training aids. Film and Audio-Visual Communication, 1967, 1(48): 14−30 [2] 文小辉, 刘强, 孙弘进, 等. 多感官线索整合的理论模型. 心理科学进展, 2009, 17(04): 659−666Wen X H, Liu Q, Sun H J, et al. Theoretical models of multisensory integration. Advances in Psychological Science, 2009, 17(04): 659−666 [3] Calvert G A, Brammer M J, Bullmore E T, et al. Response amplification in sensory-specific cortices during cross modal binding. NeuroReport, 1999, 10(12): 2619−2623 doi: 10.1097/00001756-199908200-00033 [4] Zhu H, Luo M D, Wang R, et al. Deep audio-visual learning: A survey. International Journal of Automation and Computing, 2021, 18(3): 351−376 doi: 10.1007/s11633-021-1293-0 [5] Wei Y, Hu D, Tian Y, et al. Learning in audio-visual context: A review, analysis, and new perspective. arXiv preprint arXiv: 2208.09579, 2022. [6] Bedny M. Evidence from blindness for a cognitively pluripotent cortex. Trends in Cognitive Sciences, 2017, 21(9): 637−648 doi: 10.1016/j.tics.2017.06.003 [7] Calvert G A, Bullmore E T, Brammer M J, et al. Activation of auditory cortex during silent lip-reading. Science, 1997, 276(5312): 593−596 doi: 10.1126/science.276.5312.593 [8] Michael G A, Jacquot L, Millot J L, et al. Ambient odors modulate visual attentional capture. Neuroscience Letters, 2003, 352(3): 221−225 doi: 10.1016/j.neulet.2003.08.068 [9] Shannon C E. A mathematical theory of communication. The Bell System Technical Journal, 1948, 27(3): 379−423 doi: 10.1002/j.1538-7305.1948.tb01338.x [10] Sedaghati N, Ardebili S, Ghaffari A. Application of human activity/action recognition: a review. Multimedia Tools and Applications, 2025, 84(56): 33475−33504 doi: 10.1007/s11042-024-20576-2 [11] Liu Y, Tan Y, Lan H. Self-supervised contrastive learning for audio-visual action recognition. In: Proceedings of the International Conference on Image Processing. New York, USA: IEEE, 2023. 1000-1004. [12] Shaikh M B, Chai D, Islam S M S, et al. Maivar-t: Multimodal audio-image and video action recognizer using transformers. In: Proceedings of the European Workshop on Visual Information Processing. New York, USA: IEEE, 2023. 1-6. [13] Shahabinejad M, Kezele I, Nabavi S S, et al. Video action recognition with adaptive zooming using motion residuals. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2023. 1214-1223. [14] Shaikh M B, Chai D, Islam S M S, et al. Multimodal fusion for audio-image and video action recognition. Neural Computing and Applications, 2024, 35(22): 1−15 doi: 10.2139/ssrn.4342070 [15] Gao R, Oh T H, Grauman K, et al. Listen to look: Action recognition by reviewing audio. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2020. 10457-10467. [16] Song L, Huang J B C, Xu C. Audio-visual action prediction with soft-boundary in egocentric videos. In: Proceedings of the International Conference on Computer Vision Workshops. New York, USA: IEEE, 2024. 1-5. [17] Chalk J, Huh J, Kazakos E, Zisserman A, Damen D. TIM: A time interval machine for audio-visual action recognition. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 18153–18163. [18] Wang K, Hatzinakos D. MOMA: Mixture-of-modality-adaptations for transferring knowledge from image models towards efficient audio-visual action recognition. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2024. 8055–8059. [19] Han H, Zheng Q, Luo M, Miao K, et al. Noise-tolerant learning for audio-visual action recognition. IEEE Transactions on Multimedia, 2024, 26(78): 7761−7774 [20] Wang W, Shen J, Guo F, et al. Revisiting video saliency: a large-scale benchmark and a new model. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2018. 4894-4903. [21] 罗霄骁, 康冠兰, 周晓林. McGurk效应的影响因素与神经基础. 心理科学进展, 2018, 26(11): 1935−1951 doi: 10.3724/SP.J.1042.2018.01935Luo X X, Kang G L, Zhou X L. Influencing factors and neural basis of the mcgurk effect. Advances in Psychological Science, 2018, 26(11): 1935−1951 doi: 10.3724/SP.J.1042.2018.01935 [22] Tavakoli H R, Borji A, Rahtu E, et al. Dave: A deep audio-visual embedding for dynamic saliency prediction. arXiv preprint arXiv: 1905.10693, 2019. [23] Min X, Zhai G, Gu K, et al. Fixation prediction through multimodal analysis. ACM Transactions on Multimedia Computing, Communications, and Applications, 2016, 13(1): 1−23 doi: 10.1109/vcip.2015.7457921 [24] Jiang L, Xu M, Liu T, et al. Deepvs: A deep learning based video saliency prediction approach. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2018. 602-617. [25] Jain S, Yarlagadda P, Jyoti S, et al. Vinet: Pushing the limits of visual modality for audio-visual saliency prediction. In: Proceedings of the International Conference on Intelligent Robots and Systems. New York, USA: IEEE, 2021. 3520-3527. [26] Xiong J, Wang G, Zhang P, et al. Casp-net: Rethinking video saliency prediction from an audio-visual consistency perceptual perspective. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 6441-6450. [27] Chang Q, Zhu S. Human vision attention mechanism inspired temporal-spatial feature pyramid for video saliency detection. Cognitive Computation, 2023, 15(3): 856−868 doi: 10.1007/s12559-023-10114-x [28] Xie J, Liu Z, Li G, Song Y. Audio-visual saliency prediction with multisensory perception and integration. Image and Vision Computing, 2024, 143(39): 104955−104968 doi: 10.1016/j.imavis.2024.104955 [29] Chen Z, Zhang K, Cai H, et al. Audio-visual saliency prediction for movie viewing in immersive environments: Dataset and benchmarks. Journal of Visual Communication and Image Representation, 2024, 100(66): 104095−104112 doi: 10.1016/j.jvcir.2024.104095 [30] Zhu D, Zhu K, Ding W, et al. MTCAM: A novel weakly-supervised audio-visual saliency prediction model with multi-modal transformer. IEEE Transactions on Emerging Topics in Computational Intelligence, 2024, 8(2): 1756−1771 doi: 10.1109/TETCI.2024.3358184 [31] Qiao M, Liu Y, Xu M, et al. Joint learning of audio–visual saliency prediction and sound source localization on multi-face videos. International Journal of Computer Vision, 2024, 132(6): 2003−2025 doi: 10.1007/s11263-023-01950-3 [32] Xiong J, Zhang P, You T, Li C, et al. DiffSal: Joint audio and video learning for diffusion saliency prediction. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 27273–27283. [33] Khan M A, Menouar H, Hamila R. Revisiting crowd counting: State-of-the-art, trends, and future perspectives. Image and Vision Computing, 2023, 129(22): 104597−104610 [34] Hu D, Mou L C, Wang Q, et al. Ambient sound helps: Audiovisual crowd counting in extreme conditions. In: Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops. New York, USA: IEEE, 2020. 1-4. [35] Zou Y, Min W, Zhao H, et al. A novel framework for crowd counting using video and audio. Computers and Electrical Engineering, 2023, 109(22): 108754−108766 doi: 10.1016/j.compeleceng.2023.108754 [36] Hu R, Mo Q, Xie Y, et al. Avmsn: An audio-visual two stream crowd counting framework under low-quality conditions. IEEE Access, 2021, 9(12): 80500−80510 [37] Sajid U, Chen X, Sajid H, et al. Audio-visual transformer based crowd counting. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2023. 2249-2259. [38] Hu D, Li X, Mou L, et al. Cross-task transfer for geotagged audiovisual aerial scene recognition. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2020. 68-84. [39] Heidler K, Mou L, Hu D, et al. Self-supervised audiovisual representation learning for remote sensing data. International Journal of Applied Earth Observation and Geoinformation, 2023, 116(2): 103130−103140 [40] Sun X, Gao J, Yuan Y. Alignment and fusion using distinct sensor data for multimodal aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62(102): 1−11 [41] Han F, Yu T, Zhang L, et al. SlotFusion: Object-centric audiovisual feature fusion with slot attention for remote sensing scene recognition. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2025. 1–5. [42] Khanal S, Xing E, Sastry S, et al. PSM: Learning probabilistic embeddings for multi-scale zero-shot soundscape mapping. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2024. 1361–1369. [43] Corley I, Robinson C, Dodhia R, et al. Revisiting pre-trained remote sensing model benchmarks: Resizing and normalization matters. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 3162–3172. [44] Liu X, Yu Y, Li X, et al. Mcl: Multimodal contrastive learning for deepfake detection. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 34(4): 2803−2813 doi: 10.1109/tcsvt.2023.3312738 [45] Rana M S, Nobi M N, Murali B, et al. Deepfake detection: a systematic literature review. IEEE access, 2022, 10(15): 25494−25513 [46] Hashmi A, Shahzad S A, Lin C W, et al. Avtenet: Audio-visual transformer-based ensemble network exploiting multiple experts for video deepfake detection. arXiv preprint arXiv: 2310.13103, 2023. [47] Zhang Y, Lin W, Xu J. Joint audio-visual attention with contrastive learning for more general deepfake detection. ACM Transactions on Multimedia Computing, Communications, and Applications, 2024, 20(5): 1−23 doi: 10.1145/3625100 [48] Wang R, Ye D, Tang L, et al. AVT $.{2}$-DWF: Improving deepfake detection with audio-visual fusion and dynamic weighting strategies. IEEE Signal Processing Letters, 2024, 1(31): 1960−1964 doi: 10.1109/lsp.2024.3433596 [49] Wang Y, Wu X, Zhang J, et al. Building robust video-level deepfake detection via audio-visual local-global interactions. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2024. 11370–11376. [50] Liu W, She T, Liu J, et al. Lips are lying: Spotting the temporal inconsistency between audio and visual in lip-syncing deepfakes. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2024. 91131–91155. [51] Astrid M, Ghorbel E, Aouada D. Audio-visual deepfake detection with local temporal inconsistencies. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2025. 1–5. [52] Koutlis C, Papadopoulos S. DiMoDif: Discourse modality-information differentiation for audio-visual deepfake detection and localization. arXiv preprint arXiv: 2411.10193. 2024. [53] Shahzad S A, Hashmi A, Peng Y T, et al. Av lip-sync+: Leveraging av-hubert to exploit multimodal inconsistency for video deepfake detection. arXiv preprint arXiv: 2311.02733, 2023. [54] Chugh K, Gupta P, Dhall A, et al. Not made for each other-audio-visual dissonance-based deepfake detection and localization. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2020. 439-447. [55] Zou H, Shen M, Hu Y, et al. Cross-modality and within-modality regularization for audio-visual deepfake detection. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2024. 4900–4904. [56] Bekheet A A, Ghoneim A, Khoriba G. A comprehensive comparative analysis of deepfake detection techniques in visual, audio, and audio-visual domains. In: Proceedings of the Intelligent Methods, Systems, and Applications. New York, USA: IEEE, 2024. 122–129. [57] Nie F, Ni J, Zhang J, Zhang B, Zhang W. FRADE: Forgery-aware audio-distilled multimodal learning for deepfake detection. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2024. 6297–6306. [58] Zhao H, Zhou W, Chen D, et al. Audio-visual contrastive pre-train for face forgery detection. ACM Transactions on Multimedia Computing, Communications, and Applications, 2024, 21(2): 1−16 doi: 10.1145/3651311 [59] Liang Y, Yu M, Li G, et al. SpeechForensics: Audio-visual speech representation learning for face forgery detection. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2024. 86124–86144. [60] Oorloff T, Koppisetti S, Bonettini N, Solanki D, Colman B, Yacoob Y, Shahriyari A, Bharaj G. AVFF: Audio-visual feature fusion for video deepfake detection. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 27102–27112. [61] Li X, Liu Z, Chen C, et al. Zero-shot fake video detection by audio-visual consistency. arXiv preprint arXiv: 2406.07854. 2024. [62] Muppalla S, Jia S, Lyu S. Integrating audio-visual features for multimodal deepfake detection. In: Proceedings of the MIT Undergraduate Research Technology Conference. New York, USA: IEEE, 2023. 1-5. [63] Yang W, Zhou X, Chen Z, et al. Avoid-df: Audio-visual joint learning for detecting deepfake. IEEE Transactions on Information Forensics and Security, 2023, 18(22): 2015−2029 doi: 10.1109/tifs.2023.3262148 [64] Yu C, Chen P, Tian J, et al. Modality-agnostic audio-visual deepfake detection. arXiv preprint arXiv: 2307.14491, 2023. [65] 李金新, 黄志勇, 李文斌, 周登文. 基于多层次特征融合的图像超分辨率重建. 自动化学报, 2023, 49(1): 161−171 doi: 10.16383/j.aas.c200585Li J X, Huang Z Y, Li W B, Zhou D W. Image super-resolution based on multi-hierarchical features fusion network. Acta Automatica Sinica, 2023, 49(1): 161−171 doi: 10.16383/j.aas.c200585 [66] Sanguineti V, Thakur S, Morerio P, et al. Audio-visual inpainting: reconstructing missing visual information with sound. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2023. 1-5. [67] Lu Y, Wang Z, Liu M, et al. Learning spatial temporal implicit neural representations for event-guided video super-resolution. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 1557-1567. [68] Chen Y, Zhao P, Qi M, et al. Audio matters in video super-resolution by implicit semantic guidance. IEEE Transactions on Multimedia, 2022, 24(12): 4128−4142 doi: 10.1109/tmm.2022.3152941 [69] Xiao J, Jiang X, Zheng N, et al. Online video super resolution with convolutional kernel bypass grafts. IEEE Transactions on Multimedia, 2023, 25(12): 8972−8987 doi: 10.1109/tmm.2023.3243615 [70] Chakraborty C, Talukdar P H. Issues and limitations of hmm in speech processing: a survey. International Journal of Computer Applications, 2016, 141(7): 8875−8887 doi: 10.5120/ijca2016909693 [71] Fang H, Frintrop S, Gerkmann T. Uncertainty-driven hybrid fusion for audio-visual phoneme recognition. In: Proceedings of the ITG Conference on Speech Communication. Braunschweig, Germany: VDE VERLAG GMBH, 2023. 255-259. [72] Richter J, Liebold J, Gerkamnn T. Continuous phoneme recognition based on audio-visual modality fusion. In: Proceedings of the International Joint Conference on Neural Networks. Piscataway, USA: IEEE, 2022. 1-8. [73] Biswas A, Sahu P K, Bhowmick A, et al. Vidtimit audio visual phoneme recognition using aam visual features and human auditory motivated acoustic wavelet features. In: Proceedings of the International Conference on Recent Trends in Information Technology. New York, USA: IEEE, 2015. 428-433. [74] Hu Y, Li R, Chen C, et al. Hearing lips in noise: Universal viseme-phoneme mapping and transfer for robust audio-visual speech recognition. arXiv preprint arXiv: 2306.10563. 2023. [75] Kim M, Yeo J, Park S J, et al. Efficient training for multilingual visual speech recognition: Pre-training with discretized visual speech representation. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2024. 1311–1320. [76] Pai L T, Wang Y, Yan B, et al. An effective contextualized automatic speech recognition approach leveraging self-supervised phoneme features. In: Proceedings of the Asia Pacific Signal and Information Processing Association Annual Summit and Conference. New York, USA: IEEE, 2024. 1–6. [77] Vincent E, Virtanen T, Gannot S. Audio Source Separation and Speech Enhancement. John Wiley & Sons, 2018. 110-234. [78] Li G, Deng J, Geng M, et al. Audio-visual end to-end multi-channel speech separation, dereverberation and recognition. The IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31(11): 2707−2723 doi: 10.1109/icassp43922.2022.9747237 [79] Tan R, Ray A, Burns A, et al. Language-guided audio-visual source separation via trimodal consistency. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 10575-10584. [80] Gao R, Grauman K. Visualvoice: Audio-visual speech separation with cross-modal consistency. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2021. 15490-15500. [81] Yoshinaga T, Tanaka K, Morishima S. Audio visual speech enhancement with selective off screen speech extraction. In: Proceedings of the European Signal Processing Conference. New York, USA: IEEE, 2023. 595-599. [82] Pan Z, Wichern G, Masuyama Y, et al. Scenario-aware audio-visual tf-gridnet for target speech extraction. In: Proceedings of the Automatic Speech Recognition and Understanding Workshops. New York, USA: IEEE, 2023. 1-8. [83] Chen J, Zhang R, Lian D, et al. Iquery: Instruments as queries for audio-visual sound separation. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 14675-14686. [84] Chatterjee M, Le Roux J, Ahuja N, et al. Visual scene graphs for audio source separation. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2021. 1204-1213. [85] Ye Y, Yang W, Tian Y. Lavss: Location-guided audio-visual spatial audio separation. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2024. 5508-5519. [86] Pan T, Liu J, Wang B, Tang J, Wu G. RAVSS: Robust audio-visual speech separation in multi-speaker scenarios with missing visual cues. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2024. 4748–4756. [87] Li K, Xie F, Chen H, Yuan K, Hu X. An audio-visual speech separation model inspired by cortico-thalamo-cortical circuits. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(10): 6637−6651 doi: 10.1109/TPAMI.2024.3384034 [88] Liu Y, Deng Y, Wei Y. A two-stage audio-visual speech separation method without visual signals for testing and tuples loss with dynamic margin. IEEE Journal of Selected Topics in Signal Processing, 2024, 3(18): 459−472 doi: 10.1109/jstsp.2024.3427424 [89] Pian W, Nan Y, Deng S, Mo S, Guo Y, Tian Y. Continual audio-visual sound separation. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2024. 76058–76079. [90] Kalkhorani V A, Kumar A, Tan K, Xu B, Wang D. Audiovisual speaker separation with full-and sub-band modeling in the time-frequency domain. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2024. 12001–12005. [91] Fan C, Xiang W, Tao J, et al. Cross-modal knowledge distillation with multi-stage adaptive feature fusion for speech separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2025, 1(33): 935−948 doi: 10.1109/taslpro.2025.3533359 [92] Boll S. Suppression of acoustic noise in speech using spectral subtraction. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2020. 7314-7318. [93] Isik Y, Roux J L, Chen Z, et al. Single-channel multi speaker separation using deep clustering. In: Proceedings of the Annual Conference of the International Speech Communication Association. Dublin, Ireland: ISCA, 2016. 545-549. [94] Zhu Z, Yang H, Tang M, et al. Real-timeaudio-visual end to-end speech enhancement. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2023. 1-5. [95] Balasubramanian S, Rajavel R, Kar A. Ideal ratio mask estimation based on cochleagram for audio-visual monaural speech enhancement. Applied Acoustics, 2023, 211(11): 109524−109535 doi: 10.1016/j.apacoust.2023.109524 [96] Li Y, Zhang X. Lip landmark-based audio-visual speech enhancement with multimodal feature fusion network. Neurocomputing, 2023, 549(12): 126432−126444 doi: 10.2139/ssrn.4342062 [97] Hussain T, Dashtipour K, Tsao Y, Hussain A. Audio-visual speech enhancement in noisy environments via emotion-based contextual cues. arXiv preprint arXiv: 2402.16394. 2024. [98] Zheng R C, Ai Y, Ling Z H. Incorporating ultrasound tongue images for audio-visual speech enhancement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32(29): 1430−1444 doi: 10.21437/interspeech.2023-780 [99] Gogate M, Dashtipour K, Hussain A. Robust real-time audio-visual speech enhancement based on DNN and GAN. IEEE Transactions on Artificial Intelligence, 2024, 567(46): 1−10 doi: 10.1109/tai.2024.3366141 [100] Chen H, Mira R, Petridis S, Pantic M. RT-LA-Voce: Real-time low-SNR audio-visual speech enhancement. arXiv preprint arXiv: 2407.07825. 2024. [101] Jung C, Lee S, Kim J-H, Chung J S. FlowAVSE: Efficient audio-visual speech enhancement with conditional flow matching. arXiv preprint arXiv: 2406.09286. 2024. [102] Passos L A, Papa J P, Del Ser J, et al. Multimodal audio visual information fusion using canonical-correlated graph neural network for energy-efficient speech enhancement. Information Fusion, 2023, 90(22): 1−11 [103] Morrone G, Michelsanti D, Tan Z H, et al. Audio-visual speech inpainting with deep learning. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2021. 6653-6657. [104] Chen H, Wang Q, Du J, et al. Optimizing audio-visual speech enhancement using multi-level distortion measures for audio-visual speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32(46): 2508−2521 doi: 10.1109/taslp.2024.3393732 [105] Chen S, Kirton-Wingate J, Doctor F, Arshad U, Dashtipour K, Gogate M, Halim Z, Al-Dubai A, Arslan T, Hussain A. Context-aware audio-visual speech enhancement based on neuro-fuzzy modelling and user preference learning. IEEE Transactions on Fuzzy Systems, 2024, 10(32): 5400−5412 doi: 10.1109/tfuzz.2024.3435050 [106] Ahlawat H, Aggarwal N, Gupta D. Automatic Speech Recognition: A survey of deep learning techniques and approaches. International Journal of Cognitive Computing in Engineering, 2025, 6(4): 201−237 doi: 10.1016/j.ijcce.2024.12.007 [107] Hong J, Kim M, Choi J, et al. Watch or listen: Robust audio-visual speech recognition with visual corruption modeling and reliability scoring. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 18783-18794. [108] Wang X, Mi J, Li B, Zhao Y, Meng J. CATNet: Cross-modal fusion for audio-visual speech recognition. Pattern Recognition Letters, 2024, 178(45): 216−222 doi: 10.1016/j.patrec.2024.01.002 [109] Wang H, Guo P, Zhou P, Xie L. MLCA-AVSR: Multi-layer cross attention fusion based audio-visual speech recognition. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2024. 8150–8154. [110] Wang J, Qian X, Li H. Predict-and-update network: Audio-visual speech recognition inspired by human speech perception. The IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 1(67): 11−22 doi: 10.1109/taslp.2024.3507575 [111] Ma P, Haliassos A, Fernandez-Lopez A, et al. Auto-avsr: Audio-visual speech recognition with automatic labels. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2023. 1-5. [112] Yeo J H, Kim M, Choi J, et al. Akvsr: Audio knowledge empowered visual speech recognition by compressing audio knowledge of a pretrained model. IEEE Transactions on Multimedia, 2024, 26(12): 6462−6474 doi: 10.1109/tmm.2024.3352388 [113] Lian J, Baevski A, Hsu W N, et al. Av-data2vec: Self-supervised learning of audio-visual speech representations with contextualized target representations. In: Proceedings of the Automatic Speech Recognition and Understanding Workshop. New York, USA: IEEE, 2023. 1-8. [114] Dai Y, Chen H, Du J, Wang R, Chen S, Wang H, Lee C-H. A study of dropout-induced modality bias on robustness to missing video frames for audio-visual speech recognition. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 27445–27455. [115] Rouditchenko A, Gong Y, Thomas S, et al. Whisper-Flamingo: Integrating visual features into Whisper for audio-visual speech recognition and translation. arXiv preprint arXiv: 2406.10082. 2024. [116] Wang J, Pan Z, Zhang M, Tan R T, Li H. Restoring speaking lips from occlusion for audio-visual speech recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2024. 19144–19152. [117] Li J, Li C, Wu Y, Qian Y. Unified cross-modal attention: robust audio-visual speech recognition and beyond. The IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32(78): 1941−1953 [118] Fu D, Cheng X, Yang X, Wang H, Zhao Z, Jin T. Boosting speech recognition robustness to modality-distortion with contrast-augmented prompts. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2024. 3838–3847. [119] Burchi M, Puvvada K C, Balam J, et al. Multilingual audio-visual speech recognition with hybrid CTC/RNN-T fast conformer. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2024. 10211–10215. [120] Kabir M M, Mridha M F, Shin J, et al. A survey of speaker recognition: Fundamental theories, recognition methods and opportunities. IEEE Access, 2021, 9(2): 79236−79263 doi: 10.1109/access.2021.3084299 [121] Chelali F Z. Bimodal fusion of visual and speech data for audiovisual speaker recognition in noisy environment. International Journal of Information Technology, 2023, 15(6): 3135−3145 doi: 10.1007/s41870-023-01291-x [122] Tang X, Li Z. Audio-guided video-based face recognition. IEEE Transactions on Circuits and Systems for Video Technology, 2009, 19(7): 955−964 doi: 10.1109/TCSVT.2009.2022694 [123] Gong D, Li N, Li Z, et al. Multi-feature subspace analysis for audio-vidoe based multi-modal person recognition. In: Proceedings of the International Conference on Information Science and Technology. New York, USA: IEEE, 2014. 776-779. [124] Tao R, Lee K A, Shi Z, et al. Speaker recognition with two-step multi-modal deep cleansing. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2023. 1-5. [125] Gebru I D, Ba S, Li X, et al. Audio-visual speaker diarization based on spatiotemporal bayesian fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(5): 1086−1099 doi: 10.1109/tpami.2017.2648793 [126] Lin Y, Cheng M, Zhang F, Gao Y, Zhang S, Li M. VoxBlink2: A 100k+ speaker recognition corpus and the open-set speaker-identification benchmark. arXiv preprint arXiv: 2407.11510. 2024. [127] Clarke J, Gotoh Y, Goetze S. Speaker embedding informed audiovisual active speaker detection for egocentric recordings. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2025. 1–5. [128] Tao R, Qian X, Jiang Y, et al. Audio-visual target speaker extraction with selective auditory attention. The IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2025, 1(33): 797−811 doi: 10.1109/taslpro.2025.3527766 [129] 李韩超, 沈成泽, 刘新国. 带虚拟边约束的面部表情基生成方法. 计算机学报, 2023, 46(11): 2453−2462 doi: 10.11897/SP.J.1016.2023.02453Li H C, Shen C Z, Liu X G. A method for generating facial expressions with virtual edgeconstraints. Chinese Journal of Computers, 2023, 46(11): 2453−2462 doi: 10.11897/SP.J.1016.2023.02453 [130] Agarwal M, Mukhopadhyay R, Namboodiri V P, et al. Audio-visual face reenactment. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2023. 5178-5187. [131] Wang S, Li L, Ding Y, et al. One-shot talking face generation from single-speaker audio-visual correlation learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2022. 2531-2539. [132] Jang Y, Rho K, Woo J, et al. That’s what i said: fully controllable talking face generation. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2023. 3827-3836. [133] Park S J, Kim M, Hong J, et al. Synctalkface: Talking face generation with precise lip-syncing via audio-lip memory. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2022. 2062-2070. [134] Wang G, Zhang P, Xie L, et al. Attention-based lip audio visual synthesis for talking face generation in the wild. arXiv preprint arXiv: 2203.03984, 2022. [135] Zhang J, Liu Y, Li X, et al. Talking face generation driven by time-frequency domain features of speech audio. Displays, 2023, 80(1): 102558−102570 [136] Liu S, Wang H. Talking face generation via facial anatomy. ACM Transactions on Multimedia Computing, Communications, and Applications, 2023, 19(3): 1−19 doi: 10.1145/3571746 [137] Yaman D, Eyiokur F I, Bärmann L, Akti S, Ekenel H K, Waibel A. Audio-Visual Speech Representation Expert for Enhanced Talking Face Video Generation and Evaluation. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 6003–6013. [138] Jang Y, Kim J-H, Ahn J, et al. Faces that speak: Jointly synthesising talking face and speech from text. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 8818–8828. [139] Xu S, Chen G, Guo Y-X, et al. VASA-1: Lifelike audio-driven talking faces generated in real time. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2024. 660–684. [140] Zhang Z, Zhang J, Mai W. VPT: Video Portraits Transformer for realistic talking face generation. Neural Networks, 2025, 184(26): 107122−107134 doi: 10.1016/j.neunet.2025.107122 [141] Nyatsanga S, Kucherenko T, Ahuja C, et al. A comprehensive review of data-driven co-speech gesture generation. Computer Graphics Forum, 2023, 42(2): 569−596 [142] Cassell J, Vilhjálmsson H H, Bickmore T. BEAT: the behavior expression animation toolkit. In: Proceedings of the annual conference on Computer graphics and interactive techniques. New York, USA: ACM, 2001. 477-486. [143] Neff M, Kipp M, Albrecht I, et al. Gesture modeling and animation based on a probabilistic re-creation of speaker style. ACM Transactions on Graphics, 2008, 27(1): 1−24 doi: 10.1145/1330511.1330516 [144] Ferstl Y, McDonnell R. Investigating the use of recurrent motion modelling for speech gesture generation. In: Proceedings of the International Conference on Intelligent Virtual Agents. New York, USA: ACM, 2018. 93-98. [145] Liang Y, Feng Q, Zhu L, et al. Seeg: Semantic energized co-speech gesture generation. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2022. 10473-10482. [146] Hasegawa D, Kaneko N, Shirakawa S, et al. Evaluation of speech-to-gesture generation using bi-directional lstm network. In: Proceedings of the International Conference on Intelligent Virtual Agents. New York, USA: ACM, 2018. 79-86. [147] Yoon Y, Cha B, Lee J H, et al. Speech gesture generation from the trimodal context of text, audio, and speaker identity. ACM Transactions on Graphics, 2020, 39(6): 1−16 doi: 10.1145/3414685.3417838 [148] Qi X, Liu C, Li L, Hou J, Xin H, Yu X. EmotionGesture: Audio-driven diverse emotional co-speech 3D gesture generation. IEEE Transactions on Multimedia, 2024, 26(10): 10420−10430 doi: 10.1109/tmm.2024.3407692 [149] Liu P, Zhang P, Kim H, Garrido P, Shapiro A, Olszewski K. Contextual Gesture: Co-speech gesture video generation through context-aware gesture representation. arXiv preprint arXiv: 2502.07239. 2025. [150] Gao Z, Li Y, Wu S, Cao Y, Duan H, Zhai G. GES-QA: A multidimensional quality assessment dataset for audio-to-3D gesture generation. arXiv preprint arXiv: 2508.12020. 2025. [151] Liu H, Zhu Z, Becherini G, et al. EMAGE: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 1144–1154. [152] Chen J, Huan Y, Shi R, et al. Audio-driven Gesture Generation via Deviation Feature in the Latent Space. arXiv preprint arXiv: 2503.21616. 2025. [153] Lee M, Lee K, Park J. Music similarity-based approach to generating dance motion sequence. Multimedia Tools and Applications, 2013, 62(3): 895−912 doi: 10.1007/s11042-012-1288-5 [154] Huang Y, Zhang J, Liu S, et al. Genre-conditioned long-term 3d dance generation driven by music. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2022. 4858-4862. [155] Wang T, Li L, Lin K, etal. Disco: Disentangledcontrol for realistic human dance generation. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 9326-9336. [156] Tseng J, Castellon R, Liu K. Edge: Editable dance generation from music. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 448-458. [157] Yang Z, Wen Y H, Chen S Y, et al. Keyframe control of music-driven 3d dance generation. IEEE Transactions on Visualization and Computer Graphics, 2023, 12(2): 112−124 [158] Siyao L, Yu W, Gu T, et al. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(12): 14192−14207 [159] Yin W, Yin H, Baraka K, et al. Dance style transfer with cross-modal transformer. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2023. 5058-5067. [160] Habibie I, Xu W, Mehta D, et al. Learning speech-driven 3d conversational gestures from video. In: Proceedings of the International Conference on Intelligent Virtual Agents. New York, USA: ACM, 2021. 101-108. [161] Yi H, Liang H, Liu Y, et al. Generating holistic 3d human motion from speech. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 469-480. [162] Zhu H, Li Y, Zhu F, et al. Let’s play music: Audio driven performance video generation. In: Proceedings of the International Conference on Pattern Recognition. New York, USA: IEEE, 2021. 3574-3581. [163] Xu S, Dou Z, Shi M, Pan L, Ho L, Wang J, Liu Y, Lin C, Ma Y, Wang W, et al. MOSPA: Human motion generation driven by spatial audio. arXiv preprint arXiv: 2507.11949. 2025. [164] Zhang Z, Wang Y, Mao W, et al. Motion Anything: Any to Motion Generation. arXiv preprint arXiv: 2503.06955. 2025. [165] Zhang M, Jin D, Gu C, et al. Large motion model for unified multi-modal motion generation. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2024. 397–421. [166] Him J Y, Kim J, Kim J K. S2i-bird: Sound-to-image generation of bird species using generative adversarial networks. In: Proceedings of the International Conference on Pattern Recognition. New York, USA: IEEE, 2021. 2226-2232. [167] Song C, Zhang Y, Peng W, et al. Audioviewer: Learning to visualize sounds. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2023. 2206-2216. [168] Sung-Bin K, Senocak A, Ha H, et al. Sound to visual scene generation by audio-to-visual latent alignment. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 6430-6440. [169] Lee S H, Roh W, Byeon W, et al. Sound-guided semantic image manipulation. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2022. 3377-3386. [170] Zhuang Y, Kang Y, Fei T, Bian M, Du Y. From hearing to seeing: Linking auditory and visual place perceptions with soundscape-to-image generative artificial intelligence. Computers, Environment and Urban Systems, 2024, 110(587): 102122−102134 doi: 10.1016/j.compenvurbsys.2024.102122 [171] Ephrat A, Peleg S. Vid2speech: speech reconstruction from silent video. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2017. 5095-5099. [172] Kumar Y, Aggarwal M, Nawal P, et al. Harnessing ai for speech reconstruction using multi-view silent video feed. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2018. 1976-1983. [173] Dong Z, Xu Y, Abel A, et al. Lip2speech: lightweight multi-speaker speech reconstruction with gabor features. Applied Sciences, 2024, 14(2): 798−813 doi: 10.3390/app14020798 [174] Kefalas T, Panagakis Y, Pantic M. Audio-visual video-to speech synthesis with synthesized input audio. arXiv preprint arXiv: 2307.16584, 2023. [175] Hong J, Kim M, Ro Y M. Visagesyntalk: Unseen speaker visage video-to-speech feature synthesis via selection. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2022. 452-468. [176] Kameoka H, Tanaka K, Puche A V, et al. Crossmodal voice conversion. arXiv preprint arXiv: 1904.04540, 2019. [177] Weng S E, Shuai H H. Zero-shot face-based voice conversion: bottleneck-free speech disentanglement in the real-world scenario. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2023. 13718-13726. [178] Wang D, Yang S, Su D, et al. Vcvts: Multi-speaker video-to-speech synthesis via cross-modal knowledge transfer from voice conversion. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2022. 7252-7256. [179] Lu H H, Weng S E, Yen Y F, et al. Face-based voice conversion: Learning the voice behind a face. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2021. 496-505. [180] Mira R, Vougioukas K, Ma P, et al. End-to-end video to-speech synthesis using generative adversarial networks. IEEE Transactions on Cybernetics, 2022, 53(6): 3454−3466 [181] Chen X, Wang Y, Wu X, et al. Exploiting audio-visual features with pretrained av-hubert for multi-modal dysarthric speech reconstruction. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2024. 12341–12345. [182] Pham L K, Tran T V T, Pham M T, Nguyen V. RESOUND: Speech Reconstruction from Silent Videos via Acoustic-Semantic Decomposed Modeling. arXiv preprint arXiv: 2505.22024. 2025. [183] Rong Y, Liu L. Seeing your speech style: A novel zero-shot identity-disentanglement face-based voice conversion. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 25092–25100. [184] Zhu Y, Olszewski K, Wu Y, et al. Quantized gan for complex music generation from dance videos. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2022. 182-199. [185] Su K, Li J Y, Huang Q, Kuzmin D, Lee J, Donahue C, et al. V2meow: Meowing to the visual beat via video-to-music generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2024. 4952–4960. [186] Liu X, Tu T, Ma Y, Chua T-S. Extending Visual Dynamics for Video-to-Music Generation. arXiv preprint arXiv: 2504.07594. 2025. [187] Lin Y-B, Tian Y, Yang L, Bertasius G, Wang H. Vmas: Video-to-music generation via semantic alignment in web music videos. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2025. 1155–1165. [188] Wang B, Zhuo L, Wang Z, Bao C, Wu C, Nie X, et al. Multimodal music generation with explicit bridges and retrieval augmentation. arXiv preprint arXiv: 2412.09428. 2024. [189] Tian Z, Liu Z, Yuan R, Pan J, Liu Q, Tan X, et al. Vidmuse: A simple video-to-music generation framework with long-short-term modeling. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2025. 18782–18793. [190] Owens A, Isola P, McDermott J, et al. Visually indicated sounds. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2016. 2405-2413. [191] Zhou Y, Wang Z, Fang C, et al. Visual to sound: Generating natural sound for videos in the wild. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2018. 3550-3558. [192] Du Y, Chen Z, Salamon J, et al. Conditional generation of audio from video via foley analogies. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 2426-2436. [193] Iashin V, Rahtu E. Taming visually guided sound generation. In: Proceedings of the British Machine Vision Conference. London, UK: BMVA, 2021. 1-15. [194] Sheffer R, Adi Y. I hear your true colors: Image guided audio generation. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2023. 1-5. [195] Chen P, Zhang Y, Tan M, et al. Generating visually aligned sound from videos. IEEE Transactions on Image Processing, 2020, 29(21): 8292−8302 doi: 10.1109/tip.2020.3009820 [196] Liu H, Wang J, Luo K, et al. ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing. arXiv preprint arXiv: 2506.21448. 2025. [197] Jeong Y, Kim Y, Chun S, Lee J. Read, watch and scream! sound generation from text and video. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 17590–17598. [198] Xie Z, Yu S, He Q, Li M. Sonicvisionlm: Playing sound with vision language models. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2024. 26866–26875. [199] Chen Z, Geng D, Owens A. Images that sound: Composing images and sounds on a single canvas. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2024. 37: 85045–85073. [200] Hawley M L, Litovsky R Y, Culling J F. The benefit of binaural hearing in a cocktail party: Effect of location and type of interferer. The Journal of the Acoustical Society of America, 2004, 115(2): 833−843 doi: 10.1121/1.1639908 [201] 王睿琦, 程皓楠, 叶龙. 分层特征编解码驱动的视觉引导立体声生成方法. 软件学报, 2024, 35(5): 2165−2175 doi: 10.13328/j.cnki.jos.007027Wang R Q, Cheng H N, Ye L. Visual-guided binaural audio generation method based on hierarchical feature encoding and decoding. Ruan Jian Xue Bao/Journal of Software, 2024, 35(5): 2165−2175 doi: 10.13328/j.cnki.jos.007027 [202] Cheng C I, Wakefield G H. Introduction to head-related transfer functions (hrtfs): representations of hrtfs in time, frequency, and space. Journal of the Audio Engineering Society, 1999, 49(4): 5026−5035 [203] Lin Y, Lee D D. Bayesian regularization and nonnegative deconvolution for room impulse response estimation. IEEE Transactions on Signal Processing, 2006, 54(3): 839−847 doi: 10.1109/TSP.2005.863030 [204] Morgado P, Nvasconcelos N, Langlois T, et al. Self-supervised generation of spatial audio for 360 video. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2018. 11235-11247. [205] Parida K K, Srivastava S, Sharma G. Beyond mono to binaural: Generating binaural audio from mono audio with depth and cross modal attention. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2022. 3347-3356. [206] Li Z, Zhao B, Yuan Y. Cross-modal generative model for visual-guided binaural stereo generation. Knowledge-based Systems, 2024, 296(2): 111814−111826 doi: 10.1016/j.knosys.2024.111814 [207] Chen M, Shlizerman E. AV-Cloud: Spatial Audio Rendering Through Audio-Visual Cloud Splatting. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2024. 141021–141044. [208] Xie S, Zhu H, He T, Li X, Chen Z. Sonic4D: Spatial Audio Generation for Immersive 4D Scene Exploration. arXiv preprint arXiv: 2506.15759. 2025. [209] Marinoni C, Gramaccioni R F, Shimada K, Shibuya T, Mitsufuji Y, Comminiello D. StereoSync: Spatially-Aware Stereo Audio Generation from Video. arXiv preprint arXiv: 2510.05828. 2025. [210] Li X, Zhuo F, Luo D, Chen J, Kang S, Wu Z, et al. Generating stereophonic music with single-stage language models. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2024. 1471–1475. [211] Kim J, Yun H, Kim G. Visage: Video-to-spatial audio generation. arXiv preprint arXiv: 2506.12199. 2025. [212] Nagrani A, Albanie S, Zisserman A. Seeing voices and hearing faces: Cross-modal biometric matching. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2018. 8427-8436. [213] Fang Z, Liu Z, Hung C C, et al. Learning coordinated emotion representation between voice and face. Applied Intelligence, 2023, 53(11): 14470−14492 doi: 10.1007/s10489-022-04216-6 [214] Zeng D, Yu Y, Oyama K. Audio-visual embedding for cross-modal music video retrieval through supervised deep cca. In: Proceedings of the International Symposium on Multimedia. New York, USA: IEEE, 2018. 143-150. [215] Guo M, Zhou C, Liu J. Jointly learning of visual and auditory: a new approach for rs image and audio cross modal retrieval. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019, 12(11): 4644−4654 doi: 10.1109/JSTARS.2019.2949220 [216] Chen G, Zhang D, Liu T, et al. Self-lifting: A novel framework for unsupervised voice-face association learning. In: Proceedings of the International Conference on Multimedia Retrieval. New York USA: ACM, 2022. 527-535. [217] Oncescu A-M, Henriques J F, Zisserman A, Albanie S, Koepke A S. A sound approach: Using large language models to generate audio descriptions for egocentric text-audio retrieval. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2024. 7300–7304. [218] Lin J, Liu D, Chen X, Qu X, Yang X, Zhu J, Zhang S, Dong J. Audio Does Matter: Importance-Aware Multi-Granularity Fusion for Video Moment Retrieval. arXiv preprint arXiv: 2508.04273. 2025. [219] Li X, Hu D, Lu X. Image2song: Song retrieval via bridging image content and lyric words. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2017. 5649-5658. [220] Hong S, Im W, Yang H S. Cbvmr: content-based video music retrieval using soft intra-modal structure constraint. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2023. 7056-7064. [221] Nakatsuka T, Hamasaki M, Goto M. Content-based music-image retrieval using self-and cross-modal feature embedding memory. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2024. 2174-2184. [222] Cheng X, Zhu Z, Li H, et al. Ssvmr: Saliency-based self training for video-music retrieval. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2023. 100-105. [223] Era Y, Togo R, Maeda K, et al. Video-music retrieval with fine-grained cross-modal alignment. In: Proceedings of the International Conference on Image Processing. New York, USA: IEEE, 2023. 2005-2009. [224] McKee D, Salamon J, Sivic J, et al. Language guided music recommendation for video via prompt analogies. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 14784-14793. [225] Chen Y, Du C, Zi Y, Xiong S, Lu X. Scale-aware adaptive refinement and cross interaction for remote sensing audio-visual cross-modal retrieval. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62(90): 1−12 [226] Huang J, Chen Y, Xiong S, Lu X. Cross-modal remote sensing image–audio retrieval with adaptive learning for aligning correlation. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62(89): 1−13 [227] Wu P, Su W, He X, Wang P, Zhang Y. VarCMP: Adapting Cross-Modal Pre-Training Models for Video Anomaly Retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 8423–8431. [228] Tian Y, Shi J, Li B, et al. Audio-visual event localization in unconstrained videos. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2018. 247-263. [229] Xuan H, Zhang Z, Chen S, et al. Cross-modal attention network for temporal inconsistent audio-visual event localization. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2020. 34(01): 279-286. [230] Mahmud T, Marculescu D. Ave-clip: Audioclip-based multi-window temporal transformer for audio visual event localization. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2023. 5158-5167. [231] Bao P, Yang W, Ng B P, et al. Cross-modal label contrastive learning for unsupervised audio visual event localization. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2023. 215-222. [232] Zhou Z, Zhou J, Qian W, et al. Dense audio-visual event localization under cross-modal consistency and multi-temporal granularity collaboration. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 39: 10905-10913. [233] Sun C, Chen M, Zhu C, et al. Listen with seeing: Cross-modal contrastive learning for audio-visual event localization. IEEE Transactions on Multimedia, 2025, 39(27): 2650−2665 doi: 10.1109/tmm.2025.3535359 [234] Liu L, Li S, Zhu Y. Audio-Visual Semantic Graph Network for Audio-Visual Event Localization. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2025. 23957-23966. [235] Zhang P, Wang J, Wan M, et al. Multi-Relation Learning Network for audio-visual event localization. Knowledge-based Systems, 2025, 310(67): 112925−112937 doi: 10.1016/j.knosys.2024.112925 [236] Lin Y B, Tseng H Y, Lee H Y, et al. Exploring cross-video and cross-modality signals for weakly supervised audio-visual video parsing. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2021. 11449-11461. [237] Fan Y, Wu Y, Du B, et al. Revisit weakly supervised audio-visual video parsing from the language perspective. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2023. 11642-11654. [238] Fu J, Gao J, Bao B K, et al. Multimodal imbalance aware gradient modulation for weakly-supervised audio visual video parsing. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 30(12): 1−12 [239] Geng T, Wang T, Duan J, et al. Dense-localizing audio-visual events in untrimmed videos: A large scale benchmark and baseline. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 22942-22951. [240] Yu J, Cheng Y, Zhao R W, et al. Mm-pyramid: Multimodal pyramid attentional network for audio-visual event localization and video parsing. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2022. 6241-6249. [241] Lai Y H, Ebbers J, Wang Y C F, et al. UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2025. 13561-13570. [242] Gao Y, Sun X, Lv G, et al. Reinforced Label Denoising for Weakly-Supervised Audio-Visual Video Parsing. In: Proceedings of the International Conference on Computational Visual Media. Cham, Switzerland: Springer Nature, 2025. 107-124. [243] Gao J, Chen M, Xu C. Learning probabilistic presence-absence evidence for weakly-supervised audio-visual event perception. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 6(47): 4787−4802 doi: 10.1109/cvpr52729.2023.01805 [244] Zhao P, Zhou J, Zhao Y, et al. Multimodal class-aware semantic enhancement network for audio-visual video parsing. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 10448-10456. [245] Senocak A, Oh T H, Kim J, et al. Learning to localize sound source in visual scenes. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2018. 4358-4366. [246] Xuan H, Wu Z, Yang J, et al. A proposal-based paradigm for self-supervised sound source localization in videos. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2022. 1029-1038. [247] Liu J, Ju C, Xie W, et al. Exploiting transformation invariance and equivariance for self-supervised sound localisation. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2022. 3742-3753. [248] Qian R, Hu D, Dinkel H, et al. Multiple sound sources localization from coarse to fine. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2020. 292-308. [249] Mo S, Tian Y. Audio-visual grouping network for sound localization from mixtures. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 10565-10574. [250] Ryu H, Kim S, Chung J S, et al. Seeing Speech and Sound: Distinguishing and Locating Audio Sources in Visual Scenes. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2025. 13540-13549. [251] Senocak A, Ryu H, Kim J, et al. Soundsource localization is all about cross-modal alignment. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2023. 7777-7787. [252] Senocak A, Ryu H, Kim J, et al. Toward Interactive Sound Source Localization: Better Align Sight and Sound!. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 9(47): 7643−7659 [253] Kim I, Song Y, Park J, et al. Improving Sound Source Localization with Joint Slot Attention on Image and Audio. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2025. 3121-3130. [254] Liu T, Zhang P, Xiong J, et al. Less Means More: Single Stream Audio-Visual Sound Source Localization via Shared-Parameter Network. The IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2025, 15(56): 1−13 doi: 10.1109/taslpro.2025.3619850 [255] Zhou J, Shen X, Wang J, et al. Audio-visual segmentation with semantics. International Journal of Computer Vision, 2025, 133(4): 1644−1664 doi: 10.1007/s11263-024-02261-x [256] Mo S, Raj B. Weakly-supervised audio-visual segmentation. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2023. 11325-11337. [257] Bhosale S, Yang H, Kanojia D, et al. Leveraging foundation models for unsupervised audio-visual segmentation. arXiv preprint arXiv: 2309.06728, 2023. [258] Liu J, Wang Y, Ju C, et al. Annotation-free audio-visual segmentation. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2024. 5604-5614. [259] Chen T, Tan Z, Gong T, et al. Bootstrapping audio visual segmentation by strengthening audio cues. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 35(3): 2398−2409 doi: 10.1109/tcsvt.2024.3486344/mm1 [260] Mao Y, Zhang J, Xiang M, et al. Multimodal variational auto-encoder based audio-visual segmentation. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2023. 954-965. [261] Liu C, Li P, Yang L, et al. Robust Audio-Visual Segmentation via Audio-Guided Visual Convergent Alignment. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2025. 28922-28931. [262] Bhosale S, Yang H, Kanojia D, et al. Unsupervised audio-visual segmentation with modality alignment. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 15567-15575. [263] Zhu Y, Li K, Yang Z. Exploiting EfficientSAM and Temporal Coherence for Audio-Visual Segmentation. IEEE Transactions on Multimedia, 2025, 1(89): 2999−3008 doi: 10.1109/tmm.2025.3557637 [264] Xuan H, Liu T, Dong W, et al. X-STA: Cross-Modal Spatial-Temporal Alignment Network for Unified Audio-Visual Segmentation. IEEE Signal Processing Letters, 2025, 1(32): 2883−2887 doi: 10.1109/lsp.2025.3586552 [265] Lei Y, Cao H. Audio-visual emotion recognition with preference learning based on intended and multi-modal perceived labels. IEEE Transactions on Automatic Control, 2023, 14(4): 2954−2969 doi: 10.1109/taffc.2023.3234777 [266] Goncalves L, Leem S G, Lin W C, et al. Versatile audio-visual learning for emotion recognition. IEEE Transactions on Automatic Control, 2024, 16(1): 306−318 doi: 10.1109/taffc.2024.3433386 [267] Hsu J H, Wu C H. Applying segment-level attention on bi-modal transformer encoder for audio-visual emotion recognition. IEEE Transactions on Automatic Control, 2023, 14(4): 3231−3243 doi: 10.1109/taffc.2023.3258900 [268] Mocanu B, Tapu R, Zaharia T. Multimodal emotion recognition using cross modal audio-video fusion with attention and deep metric learning. Image and Vision Computing, 2023, 133(2): 104676−104688 doi: 10.1016/j.imavis.2023.104676 [269] Praveen R G, Cardinal P, Granger E. Audio-visual fusion for emotion recognition in the valence-arousal space using joint cross-attention. IEEE Transactions on Biometrics, Behavior, and Identity Science, 2023, 14(4): 2954−2969 doi: 10.1109/tbiom.2022.3233083 [270] Rajasekhar G P, Alam J, Charton E. United we stand, divided we fall: Handling weak complementarity for audio-visual emotion recognition in valence-arousal space. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2025. 5741-5751. [271] Pan B, Hirota K, Jia Z, et al. Multimodal emotion recognition based on feature selection and extreme learning machine in video clips. Journal of Ambient Intelligence and Humanized Computing, 2023, 14(3): 1903−1917 doi: 10.1007/s12652-021-03407-2 [272] Shi T, Ge X, Jose J M, et al. Detail-enhanced intra-and inter-modal interaction for audio-visual emotion recognition. In: Proceedings of the International Conference on Pattern Recognition. New York, USA: IEEE, 2024. 451-465. [273] Ding S Y, Tang T B, Lu C K. Lightweight Spatio-Temporal Convolutional Neural Network for Audio-Visual Emotion Recognition. IEEE Transactions on Automatic Control, 2025, 1(89): 1−14 doi: 10.1109/taffc.2025.3566773/mm1 [274] Sharafi M, Yazdchi M, Rasti J. Audio-visual emotion recognition using k-means clustering and spatio-temporal cnn. In: Proceedings of the International Conference on Pattern Recognition and Image Analysis. New York, USA: IEEE, 2023. 1-6. [275] Wang A, Fang Z, Jiang X, et al. Depth estimation of multi-modal scene based on multi-scale modulation. In: Proceedings of the International Conference on Image Processing. New York, USA: IEEE, 2023. 2795-2799. [276] Gao R, Chen C, Al-Halah Z, et al. Visualechoes: Spatial image representation learning through echolocation. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2020. 658-676. [277] Liu X, Hornauer S, Moutarde F, et al. AVS-Net: Audio-Visual Scale Net for Self-supervised Monocular Metric Depth Estimation. arXiv preprint arXiv: 2412.01637, 2024. [278] Karaoguz C, Weisswange T H, Rodemann T, et al. Reward-based learning of optimal cue integration in audio and visual depth estimation. In: Proceedings of the International Conference on Advanced Robotics. New York, USA: IEEE, 2011. 389-395. [279] Zhang C, Tian K, Ni B, et al. Stereo depth estimation with echoes. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2022. 496-513. [280] Sun W, Qiu L. Visual Timing For Sound Source Depth Estimation in the Wild. In: Proceedings of the International Conference on Intelligent Robots and Systems. New York, USA: IEEE, 2024. 12348-12355. [281] Parida K K, Srivastava S, Sharma G. Beyond image to depth: Improving depth prediction using echoes. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2021. 8268-8277. [282] Liang S, Huang C, Tian Y, et al. Av-nerf: Learning neural fields for real-world audio-visual scene synthesis. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2023. 37472-37490. [283] Purushwalkam S, Gari S V A, Ithapu V K, et al. Audio visual floorplan reconstruction. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2021. 1183-1192. [284] Wilson J, Rewkowski N, Lin M C, et al. Echo reconstruction: Audio-augmented 3d scene reconstruction. arXiv preprint arXiv: 2110.02405, 2021. [285] Kim H, Remaggi L, Jackson P J B, et al. 3d room geometry reconstruction using audio-visual sensors. In: Proceedings of the International Conference on 3D Vision. New York, USA: IEEE, 2017. 621-629. [286] Alawadh M. 3D Audio-Visual Indoor Scene Reconstruction and Completion for Virtual Reality from a Single Image[Ph.D. dissertation]. University of Southampton, UK, 2025. [287] Konno T, Nishida K, Itoyama K, et al. Audio-visual 3D reconstruction framework for dynamic scenes. In: Proceedings of the International Symposium on System Integration. New York, USA: IEEE, 2020. 802-807. [288] Younes A, Honerkamp D, Welschehold T, et al. Catch me if you hear me: audio-visual navigation in complex unmapped environments with moving sounds. IEEE Robotics and Automation Letters, 2023, 8(2): 928−935 doi: 10.1109/LRA.2023.3234766 [289] Shi Z, Zhang L, Li L, et al. Towards Audio-Visual Navigation in Noisy Environments: A Large-Scale Benchmark Dataset and an Architecture Considering Multiple Sound-Sources. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 14673-14680. [290] Wang H, Wang Y, Zhong F, et al. Learning semantic-agnostic and spatial-aware representation for generalizable visual-audio navigation. IEEE Robotics and Automation Letters, 2023, 8(6): 3900−3907 doi: 10.1109/LRA.2023.3272518 [291] Huang C, Mees O, Zeng A, et al. Audio visual language maps for robot navigation. In: Proceedings of the International Symposium on Experimental Robotics. Cham, Switzerland: Springer Nature, 2023. 105-117. [292] Chen C, Al-Halah Z, Grauman K. Semantic audio-visual navigation. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2021. 15516-15525. [293] Chen C, Jain U, Schissler C, et al. Soundspaces: Audio visual navigation in 3d environments. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2020. 17-36. [294] Kondoh H, Kanezaki A. Multi-Goal Audio-Visual Navigation Using Sound Direction Map. In: Proceedings of the International Conference on Intelligent Robots and Systems. New York, USA: IEEE, 2023. 5219-5226. [295] Yu Y, Huang W, Sun F, et al. Sound adversarial audio-visual navigation. arXiv preprint arXiv: 2202.10910, 2022. [296] Liu X, Paul S, Chatterjee M, et al. Caven: An embodied conversational agent for efficient audio-visual navigation in noisy environments. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2024. 3765-3773. [297] 包希港, 周春来, 肖克晶, 等. 视觉问答研究综述. 软件学报, 2021, 32(08): 2522−2544 doi: 10.13328/j.cnki.jos.006215Bao X, Zhou C L, Xiao K J, et al. A review of visual question answering research. Ruan Jian Xue Bao/Journal of Software, 2021, 32(08): 2522−2544 doi: 10.13328/j.cnki.jos.006215 [298] Yang P, Wang X, Duan X, et al. Avqa: A dataset for audio-visual question answering on videos. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2022. 3480-3491. [299] Zhao Y, Xi W, Bai G, et al. Heterogeneous Interactive Graph Network for Audio–Visual Question Answering. Knowledge-based Systems, 2024, 300(56): 112165−112177 [300] Li G, Hou W, Hu D. Progressive spatio-temporal perception for audio-visual question answering. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2023. 7808-7816. [301] Li Z, Zhou J, Zhang J, et al. Patch-level sounding object tracking for audio-visual question answering. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 5075-5083. [302] Li Z, Guo D, Zhou J, et al. Object-aware adaptive-positivity learning for audio-visual question answering. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2024. 3306-3314. [303] Li L, Jin T, Lin W, et al. Multi-granularity relational attention network for audio-visual question answering. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 21(12): 1120−1132 doi: 10.1109/tcsvt.2023.3264524/mm1 [304] Jiang Y, Yin J. Target-aware spatio-temporal reasoning via answering questions in dynamics audio-visual scenarios. arXiv preprint arXiv: 2305.12397, 2023. [305] Ma J, Hu M, Wang P, et al. Look, listen, and answer: Overcoming biases for audio-visual question answering. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2024. 9507-9531. [306] Lao M, Pu N, Liu Y, et al. Coca: Collaborative causal regularization for audio-visual question answering. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2023. 12995-13003. [307] Li G, Du H, Hu D. Boosting audio visual question answering via key semantic-aware cues. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2024. 5997-6005. [308] Pei B, Huang Y, Chen G, et al. Guiding Audio-Visual Question Answering with Collective Question Reasoning. International Journal of Computer Vision, 2025, 1(15): 1−18 doi: 10.1007/s11263-025-02510-7 [309] Alamri H, Cartillier V, Das A, et al. Audio visual scene-aware dialog. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2019. 7558-7567. [310] Heo Y, Kang S, Seo J. Natural-language-driven multimodalrepresentation learning for audio-visual scene aware dialog system. Sensors, 2023, 23(18): 7875−7886 doi: 10.3390/s23187875 [311] Chen Z, Liu H, Wang Y. Dialogmcf: Multimodal context flow for audio visual scene-aware dialog. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 32(12): 753−764 doi: 10.1109/taslp.2023.3284511 [312] Li Z, Li Z, Zhang J, et al. Bridging text and video: A universal multimodal transformer for audio-visual scene-aware dialog. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29(809): 2476−2483 doi: 10.1109/taslp.2021.3065823 [313] Ye M, You Q, Ma F. Qualifier: Question-guided self attentive multimodal fusion network for audio visual scene-aware dialog. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2022. 248-256. [314] Park S J, Kim Y, Rha H, et al. AV-EmoDialog: Chat with Audio-Visual Users Leveraging Emotional Cues. arXiv preprint arXiv: 2412.17292, 2024. [315] Shah A, Geng S, Gao P, et al. Audio-visual scene-aware dialog and reasoning using audio-visual transformers with joint student-teacher learning. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2022. 7732-7736. [316] Ye Q, Yu Z, Liu X. Answering Diverse Questions via Text Attached with Key Audio-Visual Clues. arXiv preprint arXiv: 2403.06679, 2024. [317] 侯静怡, 齐雅昀, 吴心筱, 等. 跨语言知识蒸馏的视频中文字幕生成. 计算机学报, 2021, 44(09): 1907−1921 doi: 10.11897/SP.J.1016.2021.01907Hou J Y, Qi Y Y, Wu X X, et al. Cross-lingual knowledge distillation for chinese video caption. Chinese Journal of Computers, 2021, 44(09): 1907−1921 doi: 10.11897/SP.J.1016.2021.01907 [318] Shen X, Li D, Zhou J, et al. Fine-grained audible video description. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 10585-10596. [319] Xie Z, Yang Y, Yu Y, et al. Exploring Audio-Visual Concepts for Dense Video Captioning. In: Proceedings of the International Conference on Digital Society and Intelligent Systems. New York, USA: IEEE, 2024: 334-338. [320] Cayli O, Liu X, KiliC V, et al. Knowledge distillation for efficient audio-visual video captioning. In: Proceedings of the European Signal Processing Conference. New York, USA: IEEE, 2023. 745-749. [321] Xie Y, Niu J, Zhang Y, et al. Global-shared text representation based multi-stage fusion transformer network for multi-modal dense video captioning. IEEE Transactions on Multimedia, 2023, 26(8): 3164−3179 doi: 10.1109/tmm.2023.3307972 [322] Yang A, Nagrani A, Seo P H, et al. Vid2seq: Large-scale pretraining of a visual language model for dense video captioning. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 10714-10726. [323] Han S, Liu J, Zhang J, et al. Lightweight dense video captioning with cross-modal attention and knowledge enhanced unbiased scene graph. Complex Intelligent Systems, 2023, 9(5): 4995−5012 doi: 10.1007/s40747-023-00998-5 [324] Kim J, Shin J, Kim J. AVCap: Leveraging audio-visual features as text tokens for captioning. arXiv preprint arXiv: 2407.07801, 2024. [325] Shen X, Li D, Zhou J, et al. Fine-grained audible video description. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 10585-10596. [326] Alsuwat M, Al-Shareef S, Alghamdi M. Audio-visual self-supervised representation learning: A survey. Neurocomputing, 2025, 634(129750): 1−20 doi: 10.2139/ssrn.4854552 [327] Arandjelovic R, Zisserman A. Objects that sound. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2018. 435-451. [328] Owens A, Efros A. Audio-visual scene analysis with self-supervised multisensory features. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2018. 631-648. [329] Korbar B, Tran D, Torresani L. Cooperative learning of audio and video models from self supervised synchronization. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2018. 7774-7785. [330] Huang C, Tian Y, Kumar A, et al. Egocentric audio-visual object localization. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 22910-22921. [331] Sun W, Zhang J, Wang J, et al. Learning audio-visual source localization via false negative aware contrastive learning. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2023. 6420-6429. [332] Morgado P, Vasconcelos N, Misra I. Audio-visual instance discrimination with cross-modal agreement. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2021. 12475-12486. [333] Ma S, Zeng Z, Mc Duff D, et al. Active contrastive learning of audio-visual video representations. In: Proceedings of the International Conference on Learning Representations. Vienna, Austria: OpenReview, 2020. 1-19. [334] Xuan H, Xu Y, Chen S, et al. Active contrastive set mining for robust audio-visual instance discrimination. In: Proceedings of the International Joint Conference on Artificial Intelligence. California, USA: IJCAI, 2022. 3643-3649. [335] Xuan H, Wu Z, Yang J, et al. Robust audio-visual contrastive learning for proposal-based self-supervised sound source localization in videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(7): 4896−4907 doi: 10.1109/TPAMI.2024.3363508 [336] Li Z, Zhao B, Yuan Y. Bio-inspired audiovisual multi-representation integration via self-supervised learning. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2023. 3755-3764. [337] Sarkar P, Etemad A. Self-supervised audio-visual representation learning with relaxed cross-modal synchronicity. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2023. 37(8): 9723-9732. [338] Jenni S, Black A, Collomosse J. Audio-visual contrastive learning with temporal self-supervision. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2023. 7996-8004. [339] Zhang J X, Wan G, Gao J, et al. Audio-visual representation learning via knowledge distillation from speech foundation models. Pattern Recognition, 2025, 162(78): 111432 doi: 10.1016/j.patcog.2025.111432 [340] Zhu B, Wang C, Xu K, et al. Learning incremental audio–visual representation for continual multimodal understanding. Knowledge-based Systems, 2024, 304(56): 112513 doi: 10.1016/j.knosys.2024.112513 [341] Zuo Y, Yao H, Zhuang L, et al. Hierarchical augmentation and distillation for class incremental audio-visual video recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(11): 7348−7362 doi: 10.1109/TPAMI.2024.3387946 [342] Cui M, Yue X, Qian X, et al. Audio-Visual Class-Incremental Learning for Fish Feeding intensity Assessment in Aquaculture. arXiv preprint arXiv: 2504.15171, 2025. [343] Mo S, Pian W, Tian Y. Class-incremental grouping network for continual audio-visual learning. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2023. 7788-7798. [344] Pian W, Mo S, Guo Y, et al. Audio-visual class incremental learning. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2023. 7799-7811. [345] Yue X, Zhang X, Chen Y, et al. Mmal: Multi-modal analytic learning for exemplar-free audio-visual class incremental tasks. In: Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2024. 2428-2437. [346] Cui Y, Liu L, Yu Z, et al. Few-Shot Audio-Visual Class-Incremental Learning with Temporal Prompting and Regularization. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 16118-16126. [347] 张鲁宁, 左信, 刘建伟. 零样本学习研究进展. 自动化学报, 2020, 46(1): 1−23 doi: 10.16383/j.aas.c180429Zhang L N, Zuo X, Liu J W. Research and Development on Zero-Shot Learning. Acta Automatica Sinica, 2020, 46(1): 1−23 doi: 10.16383/j.aas.c180429 [348] Parida K, Matiyali N, Guha T, et al. Coordinated joint multi modal embeddings for generalized audio-visual zeroshot classification and retrieval of videos. In: Proceedings of the Winter Conference on Applications of Computer Vision. New York, USA: IEEE, 2020. 3251-3260. [349] Li Y, Luo Y, Du B. Audio-visual generalize zero shot learning based on variational information bottleneck. In: Proceedings of the International Conference on Multimedia and Expo. New York, USA: IEEE, 2023. 450-455. [350] Zheng Q, Hong J, Farazi M. A generative approach to audio-visual generalized zero-shot learning: Combining contrastive anddiscriminativetechniques. In: Proceedings of the International Joint Conference on Neural Networks. Piscataway, USA: IEEE, 2023. 1-8. [351] Mo S, Morgado P. Audio-visual generalized zero-shot learning the easy way. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2024. 377-395. [352] Dong Y, Chen S, Duan B, et al. Object-aware image augmentation for audio-visual zero-shot learning. IEEE Transactions on Emerging Topics in Computational Intelligence, 2024, 1(987): 30−43 doi: 10.1109/tetci.2024.3485624 [353] Li W, Wang P, Xiong R, et al. Spiking tucker fusion transformer for audio-visual zero-shot learning. IEEE Transactions on Image Processing, 2024, 1(33): 4840−4852 doi: 10.1109/icme55011.2023.00080 [354] Yang Z, Li W, Hou J, et al. Multi-modal spiking tensor regression network for audio-visual zero-shot learning. Neurocomputing, 2025, 629(56): 129636−129650 doi: 10.1016/j.neucom.2025.129636 [355] Li W, Ma Z, Deng L J, et al. Modality-fusion spiking transformer network for audio-visual zero-shot learning. In: Proceedings of the International Conference on Multimedia and Expo. New York, USA: IEEE, 2023. 426-431. [356] Zhang K, Zhao K, Tian Y. Temporal–semantic aligning and reasoning transformer for audio-visual zero-shot learning. Mathematics, 2024, 12(14): 2200−2218 doi: 10.3390/math12142200 [357] Li W, Wang P, Wang X, et al. Multi-Timescale Motion-Decoupled Spiking Transformer for Audio-Visual Zero-Shot Learning. IEEE Transactions on Circuits and Systems for Video Technology, 2025, 1(89): 1−14 doi: 10.1109/tcsvt.2025.3574499 [358] Larsen Freeman D. Transfer of learning transformed. Language Learning, 2013, 63(1): 107−129 doi: 10.1111/j.1467-9922.2012.00740.x [359] Hajavi A, Etemad A. Audio representation learning by distilling video as privileged information. IEEE Transactions on Artificial Intelligence, 2023, 5(1): 446−456 doi: 10.1109/tai.2023.3243596 [360] Yun H, Na J, Kim G. Dense 2d-3d indoor prediction with sound via aligned cross-modal distillation. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2023. 7863-7872. [361] Kim J U, Kim S T. Towards robust audio-based vehicle detection via importance-aware audio-visual learning. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2023. 90-95. [362] Chen J, Wang W, Liu S, et al. Omnidirectional information gathering for knowledge transfer-based audio-visual navigation. In: Proceedings of the International Conference on Computer Vision. New York, USA: IEEE, 2023. 10993-11003. [363] Chen M C, Zhang B, Han Z, et al. Test-Time Selective Adaptation for Uni-Modal Distribution Shift in Multi-Modal Data. In: Proceedings of the International Conference on Machine Learning. New Orleans, USA: PMLR, 2025. 1-10. [364] Duan H, Xia Y, Mingze Z, et al. Cross-modal prompts: Adapting large pre-trained models for audio-visual downstream tasks. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2023. 56075-56094. [365] Mo S, Morgado P. A unified audio-visual learning framework for localization, separation, and recognition. In: Proceedings of the International Conference on Machine Learning. New Orleans, USA: PMLR, 2023. 25006-25017. [366] 蔡朝阳, 周黎婧. 认知心理学视角下学习迁移与能力生成研究. 教育进展, 2025, 15(34): 1226Cai C Y, Zhou L Q. Study on Learning Transfer and Ability Generation from the Perspective of Cognitive Psychology. Advances in Education, 2025, 15(34): 1226 [367] 陈光, 郭军. 大语言模型时代的人工智能: 技术内涵, 行业应用与挑战. 北京邮电大学学报, 2024, 47(4): 20−35 doi: 10.13190/j.jbupt.2024-035Chen G, Guo J. Artificial Intelligence in the Era of Large Language Models: Technical Significance, Industry Applications, and Challenges. The Journal of Beijing University of Posts and Telecommunications, 2024, 47(4): 20−35 doi: 10.13190/j.jbupt.2024-035 [368] Peng P, Huang P Y, Li S W, et al. Voicecraft: Zero-shot speech editing and text-to-speech in the wild. arXiv preprint arXiv: 2403.16973, 2024. [369] Andreyev A. Quantization for OpenAI's Whisper Models: A Comparative Analysis. arXiv preprint arXiv: 2503.09905, 2025. [370] Su Y, Bai J, Xu Q, et al. Audio-language models for audio-centric tasks: A survey. arXiv preprint arXiv: 2501.15177, 2025. [371] Jiang F, Lin Z, Bu F, et al. S2s-arena, evaluating speech2speech protocols on instruction following with paralinguistic information. arXiv preprint arXiv: 2503.05085, 2025. [372] He H, Zhang Y, Lin L, et al. Pre-trained video generative models as world simulators. arXiv preprint arXiv: 2502.07825, 2025. [373] Wang Y, Liu X, Pang W, et al. Survey of Video Diffusion Models: Foundations, Implementations, and Applications. arXiv preprint arXiv: 2504.16081, 2025. [374] Zhang Y, Wei Y, Lin X, et al. Videoelevator: Elevating video generation quality with versatile text-to-image diffusion models. In: Proceedings of the AAAI Conference on Artificial Intelligence. California, USA: AAAI, 2025. 39(10): 10266-10274. [375] Wang Y, Deng Y, Zheng Y, et al. Vision transformers for image classification: A comparative survey. Technologies, 2025, 13(1): 32−44 doi: 10.3390/technologies13010032 [376] Yu Z, Ananiadou S. Understanding multimodal llms: the mechanistic interpretability of llava in visual question answering. arXiv preprint arXiv: 2411.10950, 2024. [377] Zhan J, Dai J, Ye J, et al. Anygpt: Unified multimodal llm with discrete sequence modeling. arXiv preprint arXiv: 2402.12226, 2024. [378] Wu S, Fei H, Qu L, et al. Next-gpt: Any-to-any multimodal llm. In: Proceedings of the International Conference on Machine Learning. New Orleans, USA: PMLR, 2024. [379] Chen F, Han M, Zhao H, et al. X-llm: Bootstrapping advanced large language models by treating multi-modalities as foreign languages. arXiv preprint arXiv: 2305.04160, 2023. [380] Fu C, Lin H, Long Z, et al. Vita: Towards open-source interactive omni multimodal llm. arXiv preprint arXiv: 2408.05211, 2024. [381] Zhan J, Dai J, Ye J, et al. Anygpt: Unified multimodal llm with discrete sequence modeling. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2024. 9637-9662. [382] Akbari H, Yuan L, Qian R, et al. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2021. 24206-24221. [383] Lin Y B, Bertasius G. Siamese vision transformers are scalable audio-visual learners. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2024. 303-321. [384] Huang P Y, Sharma V, Xu H, et al. Mavil: Masked audio-video learners. In: Proceedings of the Conference on Neural Information Processing Systems. New Orleans, USA: PMLR, 2023. 20371-20393. [385] Chowdhury S, Nag S, Dasgupta S, et al. Meerkat: Audio-visual large language model for grounding in space and time. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer Nature, 2024. 52-70. [386] Chen K, Gou Y, Huang R, et al. Emova: Empowering language models to see, hear and speak with vivid emotions. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2025. 5455-5466. [387] Sun G, Yu W, Tang C, et al. video-salmonn: Speech-enhanced audio-visual large language models. In: Proceedings of the International Conference on Machine Learning. New Orleans, USA: PMLR, 2024. 47198-47217. [388] Chu Y, Liao L, Zhou Z, et al. Towards multimodal emotional support conversation systems. arXiv preprint arXiv: 2408.03650, 2024. [389] Sun G, Yang Y, Zhuang J, et al. Video-Salmonn-o1: Reasoning-enhanced Audio-visual Large Language Model. In: Proceedings of the International Conference on Machine Learning. New Orleans, USA: PMLR, 2025. 1-10. [390] Cappellazzo U, Kim M, Chen H, et al. Large language models are strong audio-visual speech recognition learners. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing. Piscataway, USA: IEEE, 2025. 1-5. [391] Mao Y, Ge Y, Fan Y, et al. A survey on lora of large language models. Frontiers of Computer Science, 2025, 19(7): 197605 doi: 10.1007/s11704-024-40663-9 [392] Du H, Li G, Zhou C, et al. Crab: A unified audio-visual scene understanding model with explicit cooperation. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2025. 18804-18814. [393] Jin D, Zhou Y, Zhou J, et al. SimToken: A Simple Baseline for Referring Audio-Visual Segmentation. arXiv preprint arXiv: 2509.17537, 2025. [394] Cappellazzo U, Kim M, Petridis S. Adaptive audio-visual speech recognition via matryoshka-based multimodal llms. arXiv preprint arXiv: 2503.06362, 2025. [395] Tang C, Li Y, Yang Y, et al. video-SALMONN 2: Captioning-Enhanced Audio-Visual Large Language Models. arXiv preprint arXiv: 2506.15220, 2025. [396] Huang, G and Lin, W and Liu, L. Content-Aware Efficient Learner for Audio-Visual Emotion Recognition. In: Proceedings of the International Conference on Social Robotics. Cham, Switzerland: Springer Nature, 2024. 31–40. -

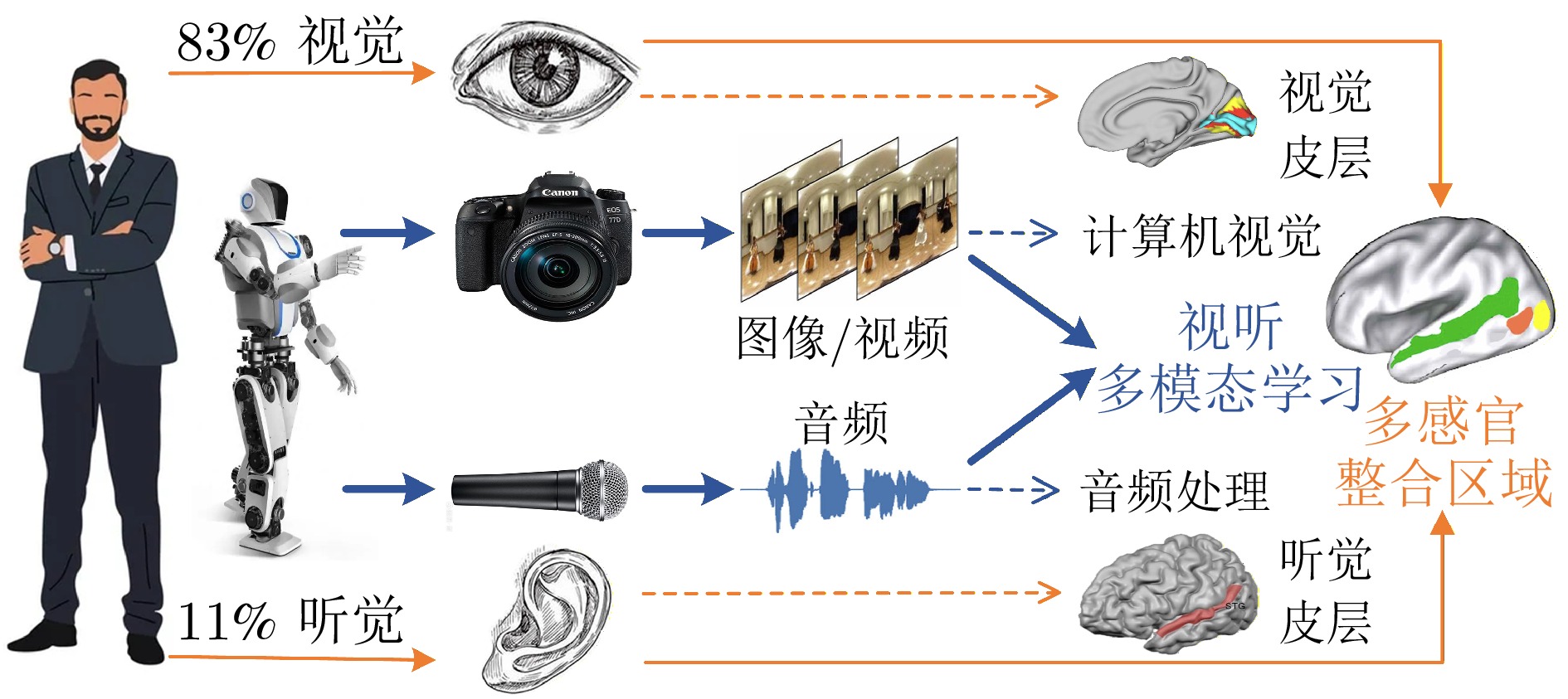
 下载:
下载:


计量
- 文章访问数: 955
- HTML全文浏览量: 1857
- 被引次数: 0
