

-
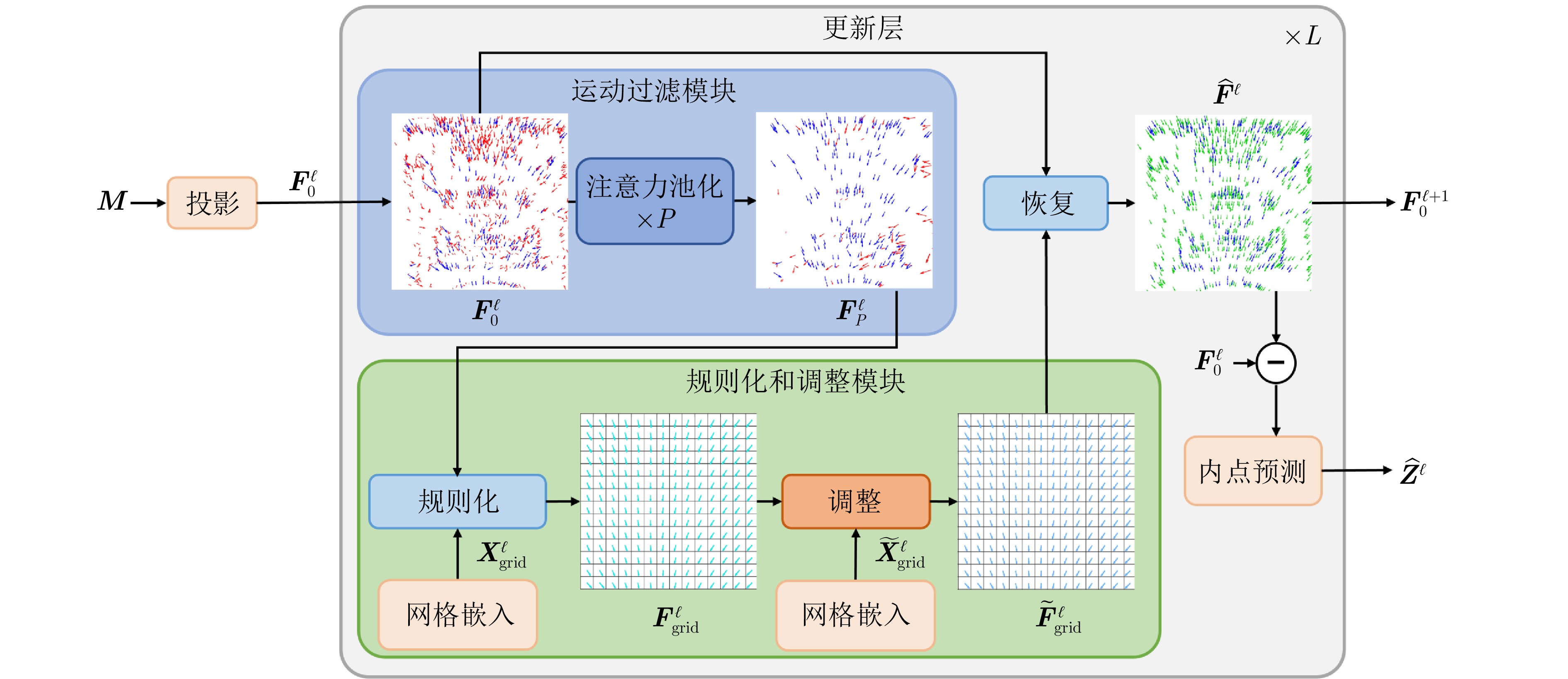
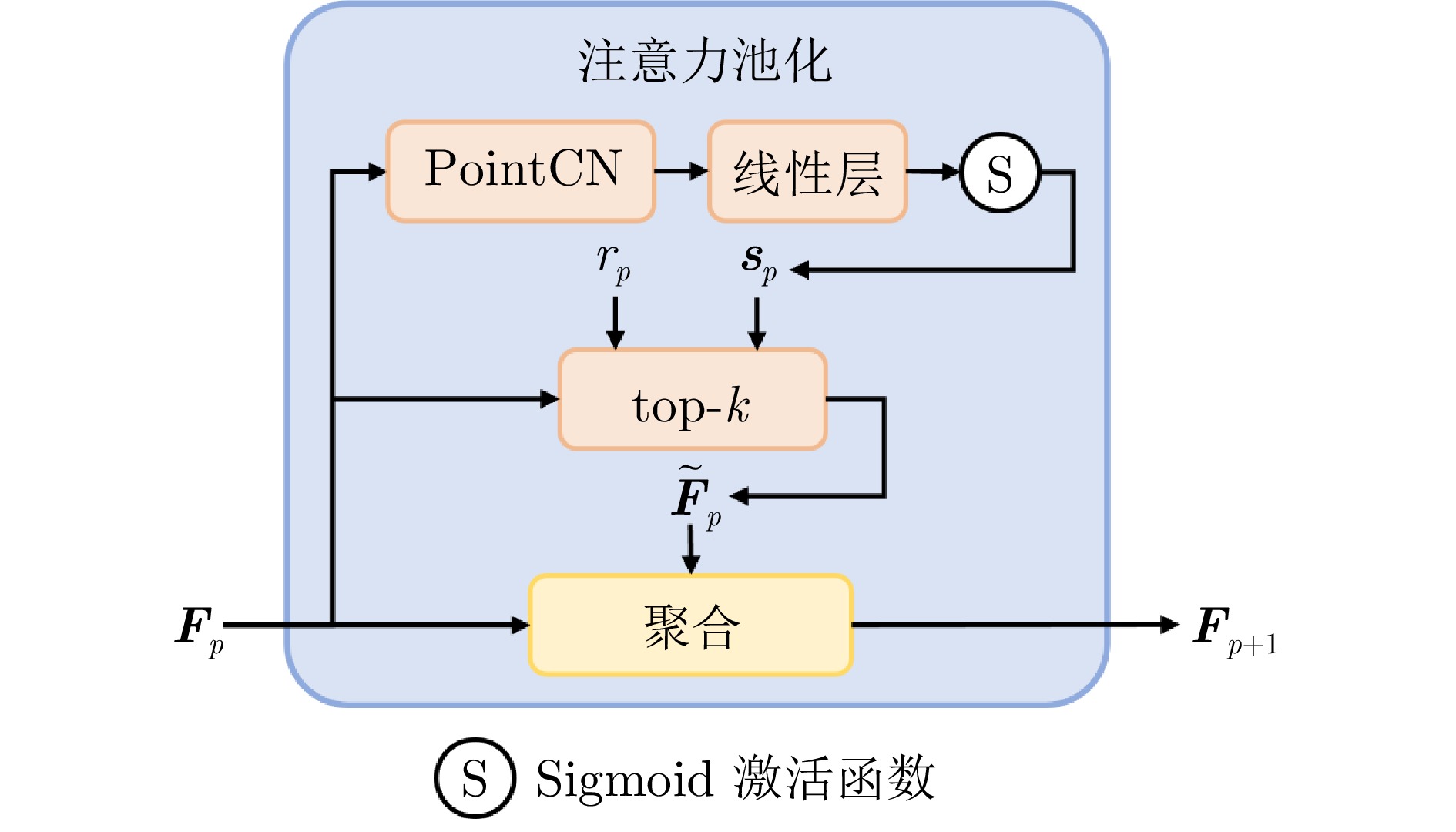
摘要: 由现有的特征提取器建立的图像特征点匹配集合通常包含大量离群点, 这严重影响特征匹配的有效性和依赖匹配结果的下游任务的性能. 最近提出的几种离群点去除方法通过估计运动场来利用匹配对的运动一致性, 并使用卷积神经网络(CNN)来减少离群点造成的污染, 以捕获上下文. 然而, CNN在捕捉全局上下文方面存在固有缺陷, 其感受野的固定性与局部性导致模型难以自适应地整合远距离信息, 从而制约相关方法的性能. 与这些使用卷积神经网络直接估计运动场的方法不同, 本文尝试在不使用CNN的情况下估计高质量的运动场. 因此, 提出基于运动过滤和调整的网络, 以减轻在捕捉上下文时离群点的影响. 具体而言, 首先, 设计一个运动过滤模块, 以迭代地去除离群点并捕获上下文. 然后, 设计一个规则化和调整模块, 该模块先估计初始运动场, 接着通过利用额外的位置信息对其进行调整, 使其更加准确. 在离群点去除和相对姿态估计任务中, 利用室内和室外数据集评估所提出方法的性能. 实验结果表明, 与现有多种方法相比, 所提方法展现出更优的性能.Abstract: The image point correspondences established by off-the-shelf feature extractors usually contain a large number of outliers, which severely affects the effectiveness of feature matching and the performance of downstream tasks reliant on the matching results. Several recently proposed outlier removal methods leverage the motion consistency of correspondences by estimating a motion field and employ convolutional neural network (CNN) to reduce contamination from outliers to capture context. However, CNN inherently suffers from limitations in capturing global context, as the fixed and localized nature of their receptive fields makes it difficult for models to adaptively integrate long-range information, thereby constraining the performance of related methods. Departing from these methods that directly estimate motion fields using CNN, this paper explores estimating a high-quality motion field without reliance on CNN. To this end, a motion filtering and adjustment network (MFANet) is proposed to mitigate the impact of outliers during context capture. Specifically, a motion-filtering block is first designed to iteratively remove outliers and capture contextual information. Then, a regularization and adjustment block is designed to estimate an initial motion field, which is then refined for greater accuracy by incorporating additional positional information. The performance of MFANet is evaluated on both indoor and outdoor datasets for the tasks of outlier removal and relative pose estimation. Experimental results demonstrate that MFANet achieves superior performance compared to several existing methods.
-
Key words:
- computer vision /
- outlier removal /
- motion filtering /
- regularization /
- adjustment
-
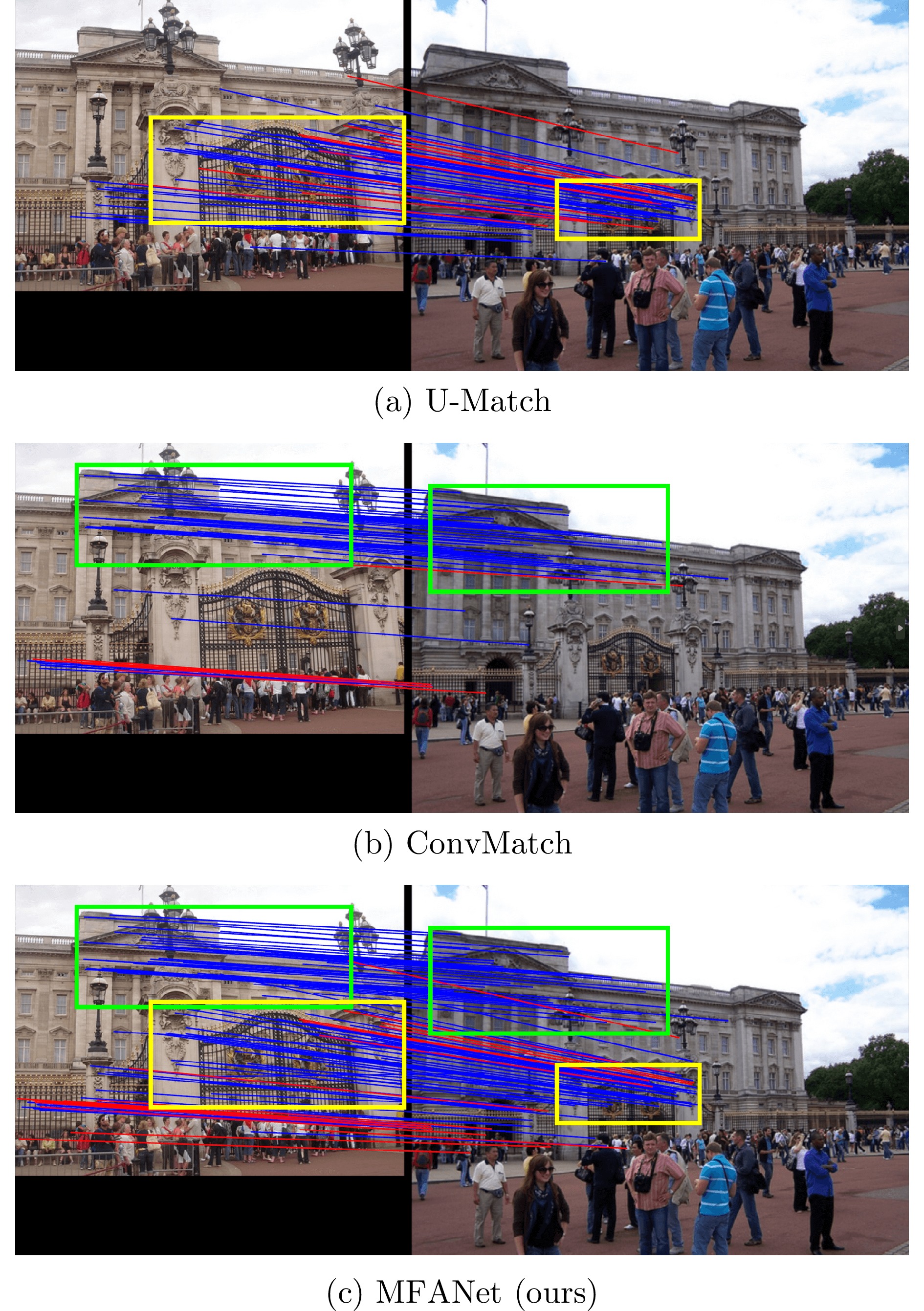
图 1 通过U-Match、ConvMatch和MFANet建立的匹配对(内点和离群点分别用蓝色和红色线标记)
Fig. 1 Matching pairs established by U-Match, ConvMatch, and MFANet (Inliers and outliers are marked with blue and red lines, respectively)
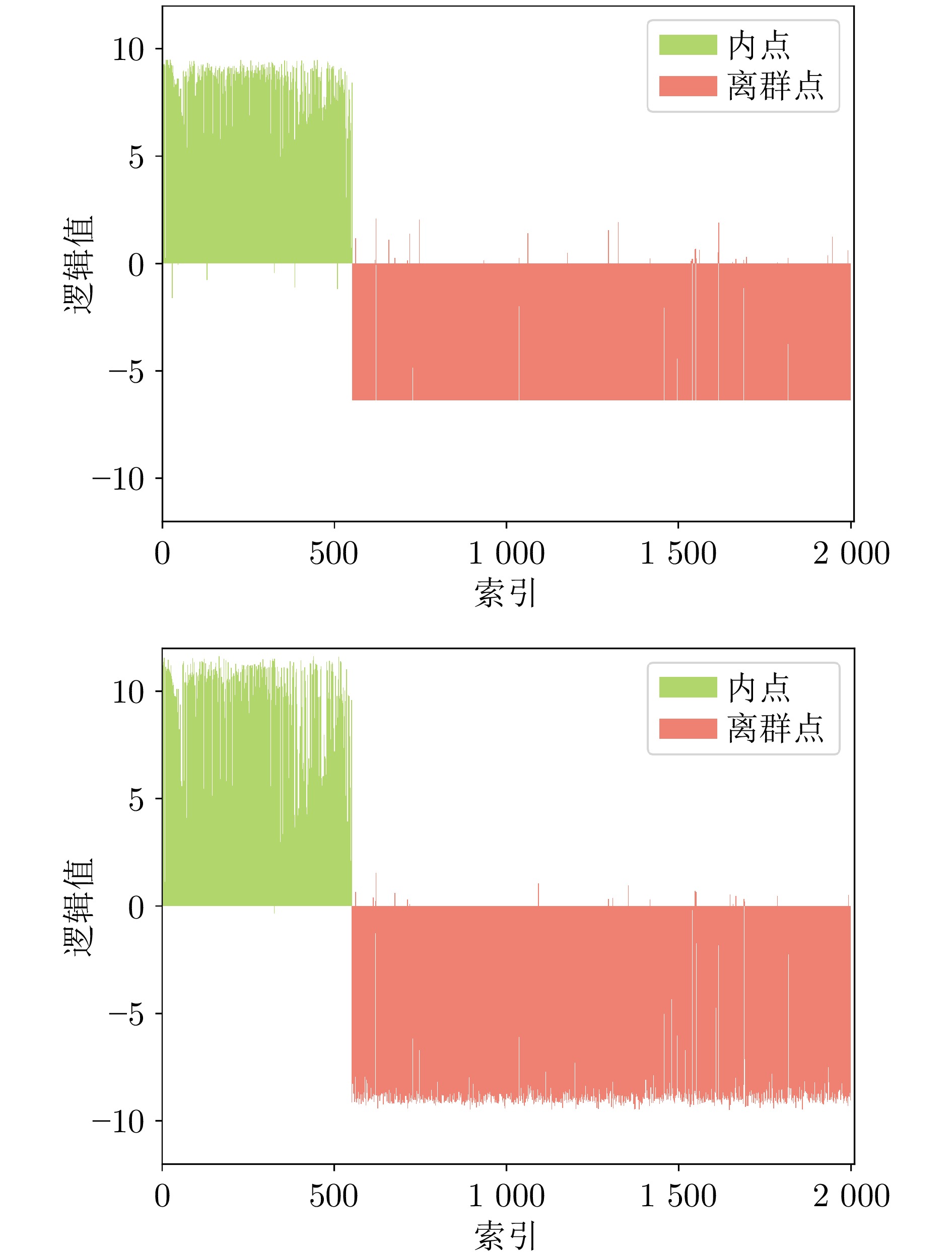
图 4 ConvMatch (上)和所提出的MFANet (下)预测的逻辑值对比
Fig. 4 Comparisons of logical values predicted by ConvMatch (top) and the proposed MFANet (bottom)
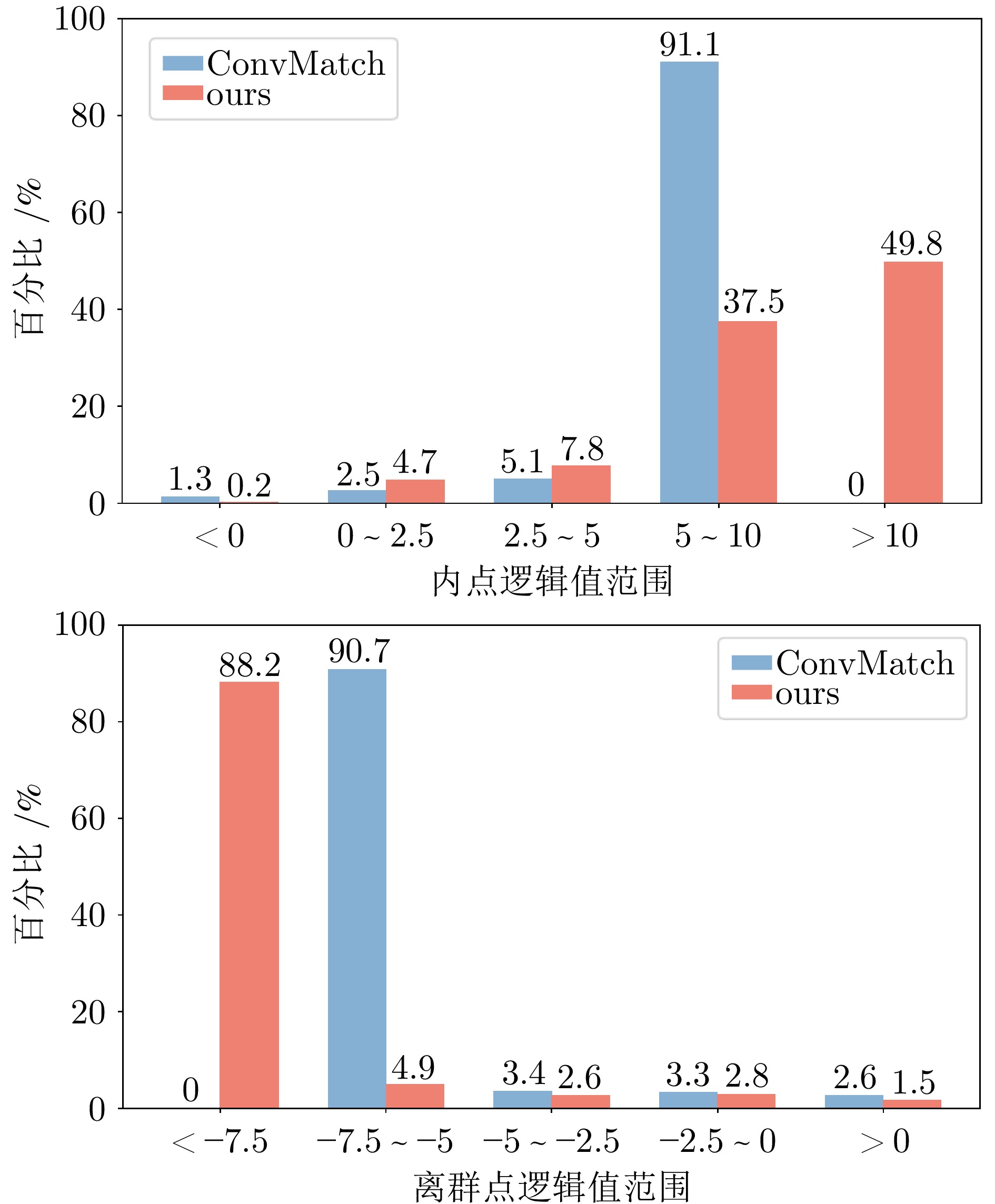
图 5 ConvMatch和所提出的MFANet预测的内点逻辑值(上)和离群点逻辑值(下)对比
Fig. 5 Comparisons of logical values of inliers (top) and outliers (bottom) predicted by ConvMatch and the proposed MFANet
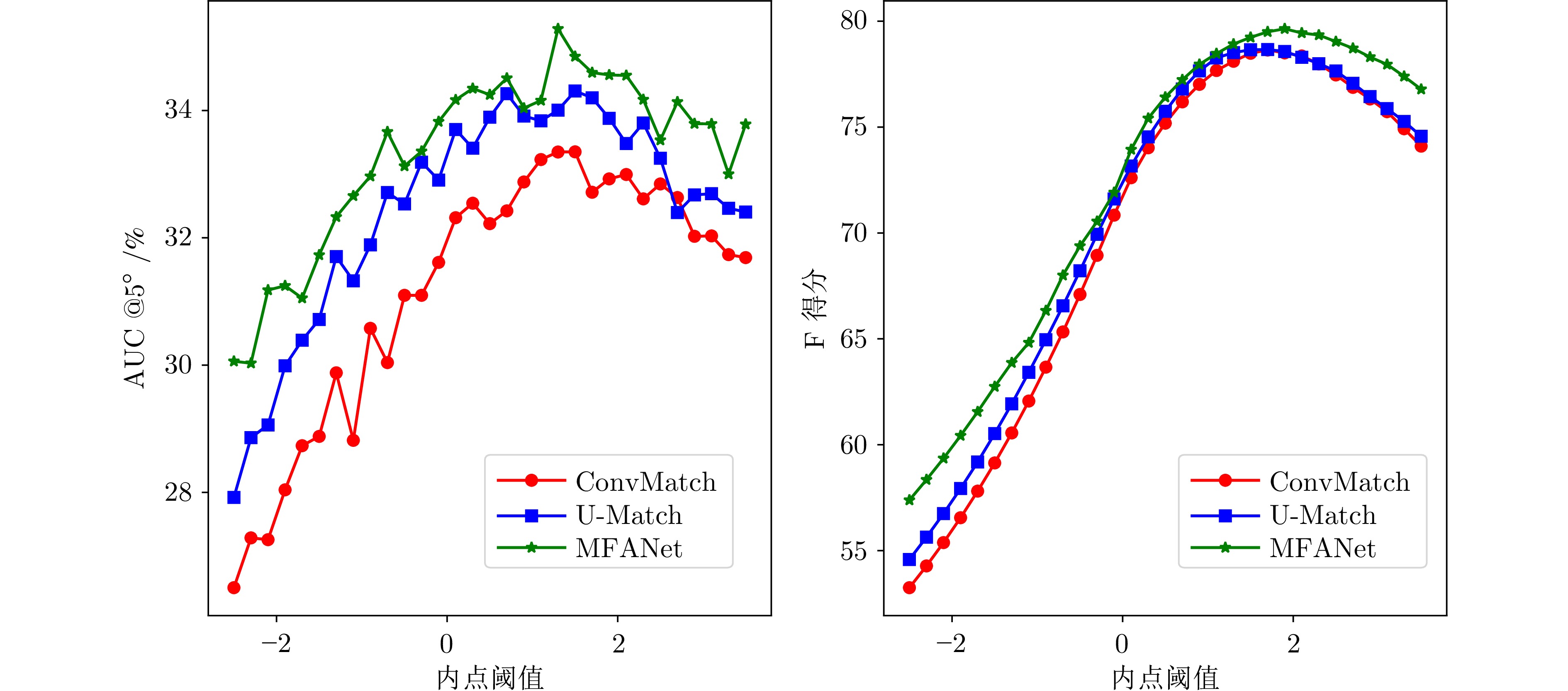
图 6 MFANet、ConvMatch以及U-Match在不同内点阈值下的性能对比
Fig. 6 Performance comparisons of MFANet, ConvMatch, and U-Match at different inlier thresholds

图 7 U-Match、ConvMatch和所提出的MFANet的可视化结果
Fig. 7 Visualization results of U-Match, ConvMatch, and the proposed MFANet
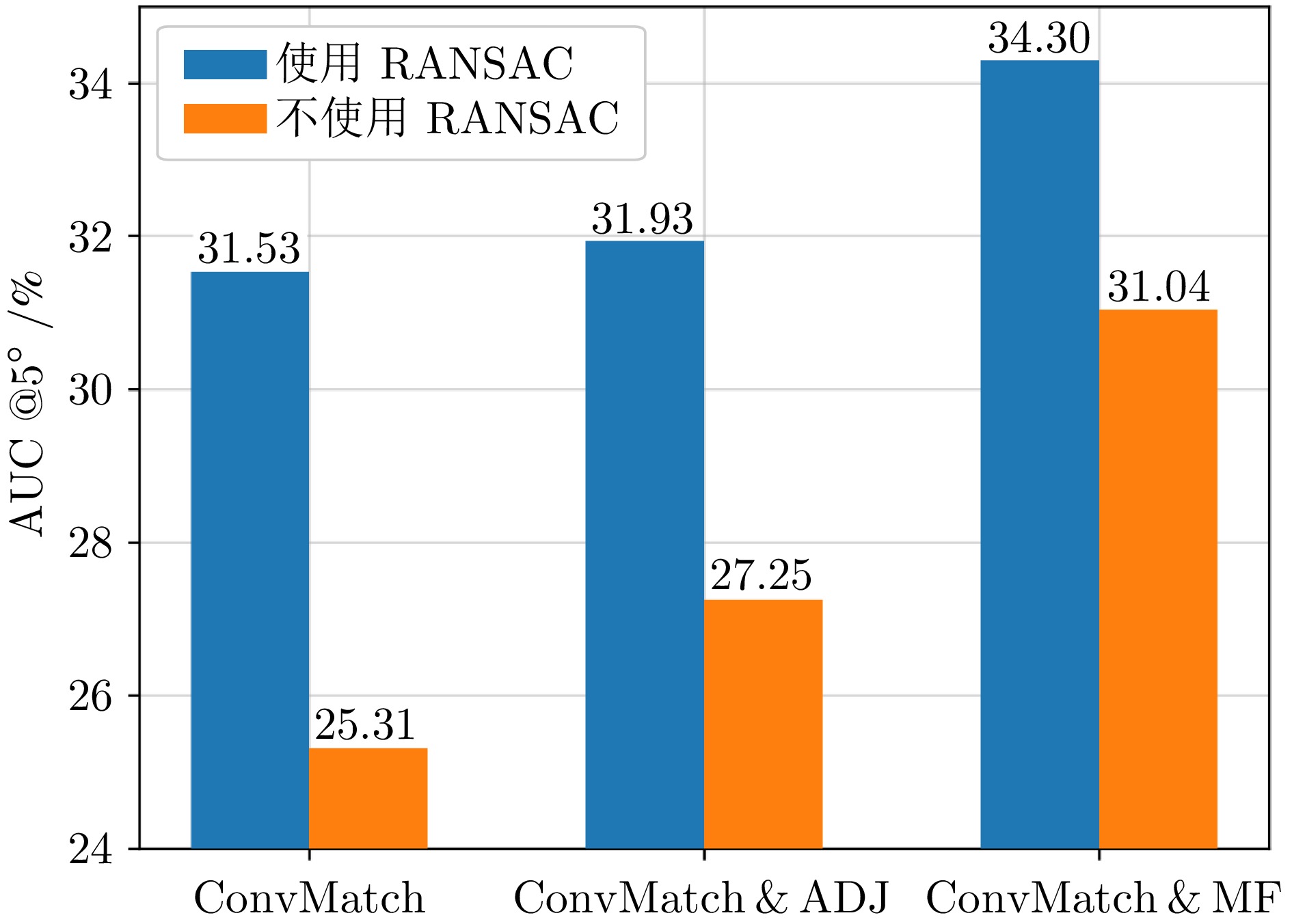
图 8 MF和ADJ集成在ConvMatch上的效果
Fig. 8 Performance of ConvMatch with integrated MF and ADJ modules
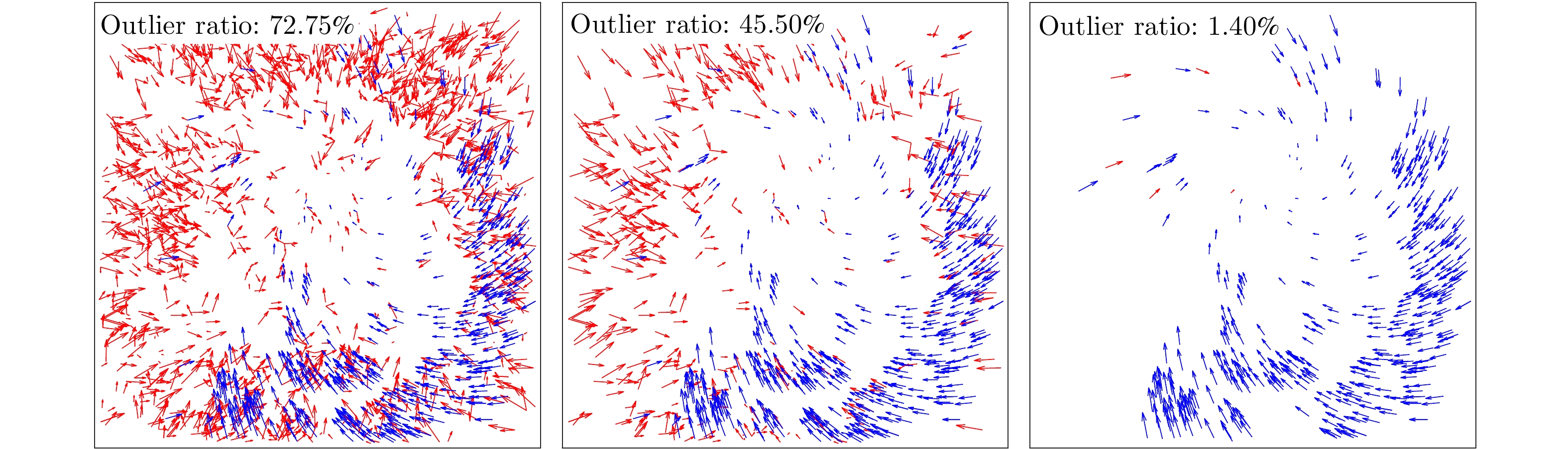
图 9 初始运动向量集合(左)、使用1个注意力池化层(中)、使用2个注意力池化层(右)的过滤结果
Fig. 9 Filtering results: Initial motion vector set (left), one attention pooling layer (middle), and two attention pooling layers (right)
表 1 在YFCC100M数据集上基于RANSAC的相机姿态估计比较结果(%)
Table 1 Comparative results of RANSAC-based camera pose estimation on the YFCC100M dataset (%)
方法 AUC $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ RANSAC 3.63 9.00 18.32 GMS 12.12 22.78 35.27 LPM 15.18 27.30 40.93 OANet 28.07 46.22 62.99 CLNet 31.26 51.50 69.11 MS2 DGNet 31.01 50.80 68.38 PGFNet 30.59 49.28 66.07 U-Match 33.54 52.41 68.96 ConvMatch 31.53 51.07 68.11 LCT 30.99 50.65 68.09 CHCANet 30.36 49.94 67.48 ours 34.43 54.05 70.46  下载: 导出CSV
下载: 导出CSV
表 2 在YFCC100M数据集上且未采用RANSAC的相机姿态估计比较结果(%)
Table 2 Comparative results of camera pose estimation without using RANSAC on the YFCC100M dataset (%)
方法 AUC $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ OANet 15.94 35.90 57.05 CLNet 24.56 44.64 63.58 MS2 DGNet 18.59 40.48 62.63 PGFNet 20.85 42.21 62.19 U-Match 30.86 52.05 69.65 ConvMatch 25.31 47.26 66.53 LCT 20.79 42.16 63.00 CHCANet 20.80 42.60 63.31 ours 31.26 53.37 71.06
下载: 导出CSV
表 3 在SUN3D数据集上基于RANSAC的相机姿态估计比较结果(%)
Table 3 Comparative results of RANSAC-based camera pose estimation on the SUN3D dataset (%)
方法 AUC $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ RANSAC 0.96 3.29 8.66 GMS 3.60 9.02 17.68 LPM 4.82 12.30 23.62 OANet 6.81 17.14 32.46 MS2 DGNet 7.18 17.91 33.72 PGFNet 6.80 17.22 32.53 U-Match 7.11 17.82 33.66 ConvMatch 7.03 18.12 34.22 LCT 7.38 18.57 34.77 CHCANet 7.22 17.78 33.38 ours 7.40 18.61 34.76
下载: 导出CSV
表 4 在SUN3D数据集上且未采用RANSAC的相机姿态估计比较结果(%)
Table 4 Comparative results of camera pose estimation without using RANSAC on the SUN3D dataset (%)
方法 AUC $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ OANet 5.92 16.90 34.33 MS2 DGNet 6.31 17.76 35.78 PGFNet 5.60 16.35 33.46 U-Match 8.05 20.81 38.71 ConvMatch 8.39 21.75 40.01 LCT 5.83 16.52 33.42 CHCANet 6.93 18.65 36.48 ours 9.15 22.91 41.06
下载: 导出CSV
表 5 在YFCC100M数据集上进行相机姿态估计时, 使用/不使用RANSAC两种情况下的比较结果(%)
Table 5 Comparative results of camera pose estimation with and without using RANSAC on the YFCC100M dataset (%)
方法 mAP $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ RANSAC 9.08/— 14.28/— 22.80/— GMS 26.30/— 34.59/— 40.43/— LPM 28.78/— 37.55/— 47.47/— OANet 52.35/39.23 62.10/53.76 72.08/67.63 CLNet 58.60/42.98 68.99/53.13 78.98/63.47 MS2 DGNet 57.25/45.03 68.10/59.90 77.97/73.99 PGFNet 55.23/47.95 65.49/61.03 75.16/72.98 U-Match 59.70/60.33 69.43/71.09 78.41/80.28 ConvMatch 58.58/57.05 68.44/68.79 78.04/78.79 LCT 57.48/47.43 67.43/60.91 77.29/74.04 CHCANet 56.53/46.92 67.31/61.06 77.41/74.16 ours 61.65/62.03 71.26/72.98 80.06/81.87
下载: 导出CSV
表 6 在 SUN3D 数据集上进行相机姿态估计时, 使用/不使用 RANSAC 两种情况下的比较结果(%)
Table 6 Comparative results of camera pose estimation with and without using RANSAC on the SUN3D dataset (%)
方法 mAP $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ RANSAC 2.86/— 5.61/— 11.22/— GMS 10.58/— 16.63/— 21.59/— LPM 12.16/— 19.08/— 28.93/— OANet 17.34/16.35 26.67/35.70 39.54/42.19 CLNet 17.70/9.96 27.61/18.56 40.99/31.70 MS2 DGNet 17.98/17.35 27.66/28.71 40.98/43.99 PGFNet 17.44/15.49 26.70/26.27 39.57/41.41 U-Match 18.01/21.40 27.85/32.68 41.13/47.12 ConvMatch 18.74/22.66 28.77/34.53 42.12/49.04 LCT 17.31/16.04 27.08/26.62 40.05/41.26 CHCANet 17.33/17.80 27.16/28.88 40.37/43.41 ours 19.31/23.68 29.12/35.34 42.31/49.69
下载: 导出CSV
表 7 在YFCC100M数据集上使用不同特征提取算法的比较结果(%)
Table 7 Comparative results of various feature extraction methods on the YFCC100M dataset (%)
特征 方法 AUC $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ SIFT OANet 28.07/15.94 46.22/35.90 62.99/57.05 PGFNet 30.59/20.85 49.28/42.21 66.07/62.19 U-Match 33.54/30.86 52.41/52.05 68.96/69.65 ConvMatch 31.53/25.31 51.07/47.26 68.11/66.53 ours 34.43/31.26 54.05/53.37 70.46/71.06 RootSIFT OANet 29.74/17.69 48.77/38.18 65.62/59.05 PGFNet 31.25/22.78 50.72/44.76 67.47/64.21 U-Match 33.28/27.86 52.84/49.41 69.46/67.96 ConvMatch 33.16/27.49 52.49/49.23 68.97/68.03 ours 35.25/32.31 54.54/54.33 70.93/71.71
下载: 导出CSV
表 8 在YFCC100M和SUN3D数据集上的离群点去除结果(%)
Table 8 Outlier removal results on the YFCC100M and SUN3D datasets (%)
方法 数据集 YFCC100M SUN3D Pr R F Pr R F OANet 57.54 86.64 66.94 46.91 83.69 60.12 MS2 DGNet 59.91 87.30 71.06 47.69 84.29 60.92 PGFNet 58.11 87.38 69.80 47.35 84.32 57.05 U-Match 60.28 90.61 72.40 47.59 85.59 61.17 ConvMatch 60.03 89.19 71.76 47.55 84.60 60.88 LCT 59.18 87.65 70.65 48.40 83.84 61.37 CHCANet 59.88 87.07 70.96 46.63 84.66 60.14 ours 60.97 90.72 72.93 48.02 85.19 61.42 ours (−2) 43.14 97.91 59.89 27.40 96.96 42.73 ours (−1) 49.43 95.90 65.24 36.31 93.12 52.25 ours (1) 72.89 84.59 78.31 60.32 76.90 67.61 ours (2) 82.02 77.66 79.78 66.01 66.82 66.41 注: 括号中的值表示用于分类网络预测的逻辑值的内点阈值(未标注时默认为0). 当匹配对对应的逻辑值大于该阈值时, 判定该匹配对为内点; 反之, 判 定为离群点.
下载: 导出CSV
表 9 在YFCC100M和SUN3D数据集上的离群点去除结果(%)
Table 9 Outlier removal results on the YFCC100M and SUN3D datasets (%)
方法 数据集 YFCC100M SUN3D Pr R F Pr R F OANet 68.04 68.41 68.22 57.66 63.11 60.26 MS2 DGNet 71.71 73.44 72.56 58.22 63.25 60.63 PGFNet 71.00 72.26 71.62 57.84 64.00 60.76 U-Match 74.02 75.75 74.88 58.95 64.81 61.74 ConvMatch 73.12 74.35 73.73 59.48 65.43 62.31 LCT 71.61 73.33 72.46 57.95 63.69 60.68 CHCANet 72.05 72.93 72.49 58.43 63.86 61.02 ours 75.20 77.38 76.27 59.63 65.48 62.42 注: 本表使用网络预测的本质矩阵计算匹配对的极线距离, 并以极线距离及指定的内点阈值来预测内点.
下载: 导出CSV
表 10 在YFCC100M上不同方法的效率与资源消耗比较结果
Table 10 Comparative results of the efficiency and resource consumption of different methods on YFCC100M
方法 参数量(M) 推理时间(ms) 训练时间(h) FLOPs (G) PGFNet 2.99 52.3 43 3.28 U-Match 7.76 52.1 52 7.48 ConvMatch 7.49 34.6 40 7.57 ours 5.57 51.1 65 9.73
下载: 导出CSV
表 11 在MegaDepth-1500数据集上且使用RANSAC的相机姿态估计比较结果(%)
Table 11 Comparative results of camera pose estimation with RANSAC on the MegaDepth-1500 dataset (%)
方法 AUC @5° @10° @20° ConvMatch 40.40 56.78 70.59 LCT 39.35 56.23 70.41 CHCANet 40.79 57.61 71.61 ours 41.89 58.28 72.12
下载: 导出CSV
表 12 在Sintel数据集上光流端点误差的比较结果(像素)
Table 12 Comparative results of optical flow endpoint error on the Sintel dataset (pixel)
方法 clean final PWCNet 2.55 3.93 PWC + ours 2.42 3.84
下载: 导出CSV
表 13 在YFCC100M数据集上使用特征提取算法LIFT的比较结果(不使用RANSAC) (%)
Table 13 Comparative results of the LIFT feature extraction method on the YFCC100M dataset (without RANSAC) (%)
方法 AUC @5° @10° @20° OANet 11.42 28.85 50.26 PGFNet 14.69 33.68 54.50 U-Match 18.85 38.80 59.38 ConvMatch 17.75 38.57 59.86 ours 22.48 43.79 64.07
下载: 导出CSV
表 14 MFANet在YFCC100M上的消融实验结果
Table 14 Ablation experiment results of MFANet on the YFCC100M dataset
MF REG ADJ UPS AUC $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ $ \checkmark$ 30.43/21.88 48.88/42.16 65.94/61.65 $ \checkmark$ $ \checkmark$ 29.90/22.42 48.72/42.85 65.99/62.55 $ \checkmark$ 33.18/27.40 52.65/49.56 69.30/68.22 $ \checkmark$ $ \checkmark$ 34.31/30.23 53.59/51.94 69.99/69.97 $ \checkmark$ $ \checkmark$ $ \checkmark$ 34.22/31.03 53.31/52.29 69.68/69.83 $ \checkmark$ $ \checkmark$ $ \checkmark$ 34.43/31.26 54.05/53.37 70.46/71.06 注: 本表展示了不同角度误差范围下使用/不使用RANSAC作为后处 理步骤的比较结果.
下载: 导出CSV
表 15 对运动过滤模块的参数分析
Table 15 Parameter analysis of the motion filtering module
$ P $ $ r $ AUC $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ 0 — 29.90 48.72 65.99 1 0.50 32.96 52.27 69.01 2 0.50 34.43 54.05 70.46 3 0.50 33.94 53.10 69.71 1 0.25 32.82 52.18 68.92 2 0.30 32.28 51.74 68.71 2 0.70 33.06 52.07 68.39 注: 本表展示了使用RANSAC作为后处理步骤的评估结果.
下载: 导出CSV
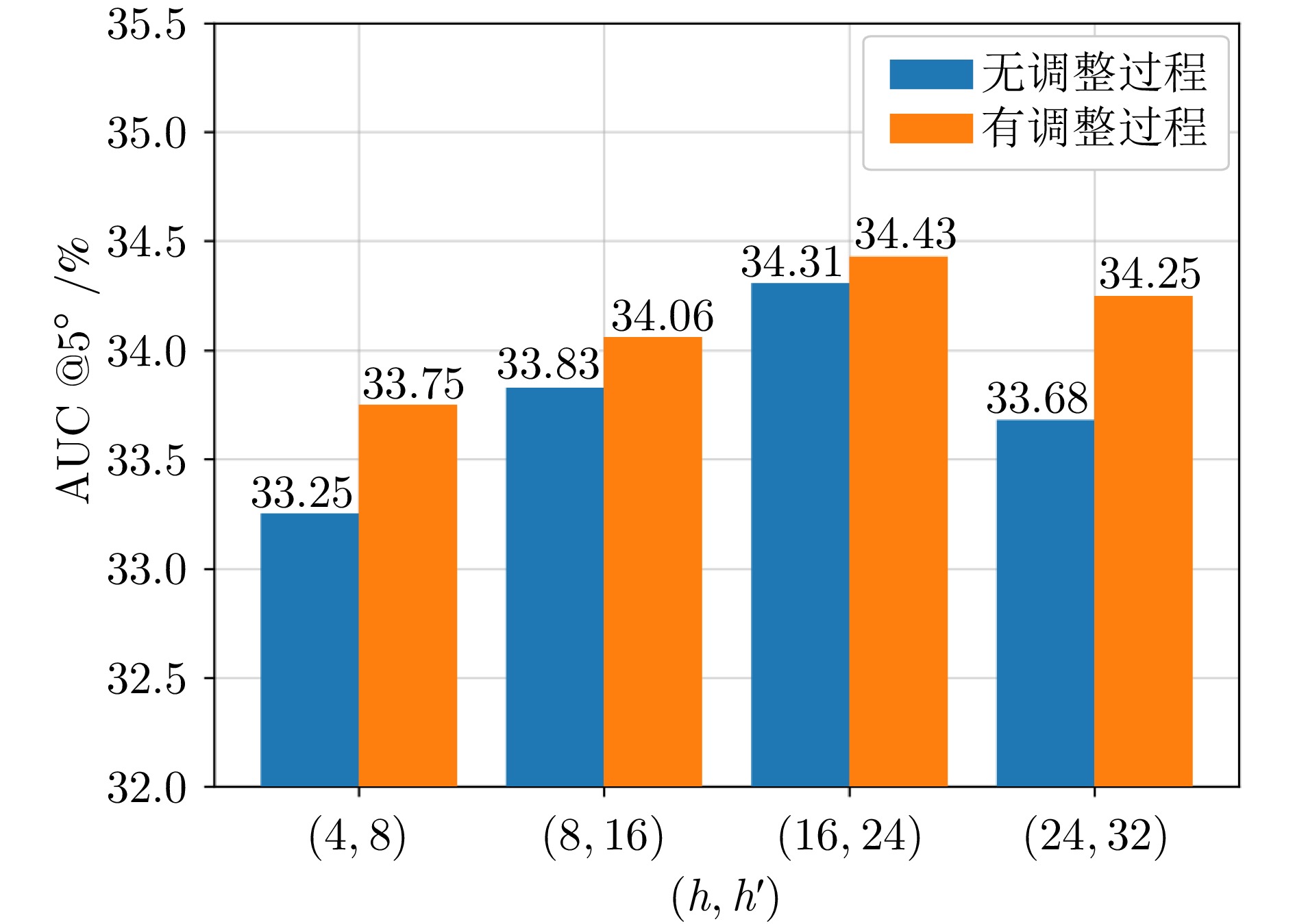
表 16 规则化和调整模块不同超参数组合的比较
Table 16 Comparisons of different hyperparameter combinations for the regularization and adjustment modules
$ h $ $ h' $ 参数量(×106) AUC $ @5^{\circ} $ $ @10^{\circ} $ $ @20^{\circ} $ 16 — 4.51 34.31 53.59 69.99 16 16 5.57 33.67 53.29 70.24 16 24 5.57 34.43 54.05 70.46 24 16 5.57 33.99 53.58 70.37 注: 本表展示了使用RANSAC作为后处理步骤的评估结果.
下载: 导出CSV
-
[1] 张峻宁, 苏群星, 刘鹏远, 朱庆, 张凯. 一种自适应特征地图匹配的改进VSLAM算法. 自动化学报, 2019, 45(3): 553−565Zhang Jun-Ning, Su Qun-Xing, Liu Peng-Yuan, Zhu Qing, Zhang Kai. An improved VSLAM algorithm based on adaptive feature map. Acta Automatica Sinica, 2019, 45(3): 553−565 [2] 李海丰, 刘景泰. 一种优化的消失点估计方法及误差分析. 自动化学报, 2012, 38(2): 213−219 doi: 10.3724/SP.J.1004.2012.00213Li Hai-Feng, Liu Jing-Tai. An optimal vanishing point detection method with error analysis. Acta Automatica Sinica, 2012, 38(2): 213−219 doi: 10.3724/SP.J.1004.2012.00213 [3] Xing X J, Lu Z D, Wang Y Q, Xiao J. Efficient single correspondence voting for point cloud registration. IEEE Transactions on Image Processing, 2024, 33: 2116−2130 doi: 10.1109/TIP.2024.3374120 [4] Peng Z Y, Ma Y, Zhang Y J, Li H, Fan F, Mei X G. Seamless UAV hyperspectral image stitching using optimal seamline detection via graph cuts. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: Article No. 5512213 [5] Lai T T, Sadri A, Lin S Y, Li Z Y, Chen R Q, Wang H Z. Efficient sampling using feature matching and variable minimal structure size. Pattern Recognition, 2023, 137: Article No. 109311 doi: 10.1016/j.patcog.2023.109311 [6] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2): 91−110 doi: 10.1023/B:VISI.0000029664.99615.94 [7] Arandjelović R, Zisserman A. Three things everyone should know to improve object retrieval. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 2911−2918 [8] Lin S Y, Chen X, Xiao G B, Wang H Z, Huang F R, Weng J. Multi-stage network with geometric semantic attention for two-view correspondence learning. IEEE Transactions on Image Processing, 2024, 33: 3031−3046 doi: 10.1109/TIP.2024.3391002 [9] Fischler M A, Bolles R C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM, 1981, 24(6): 381−395 doi: 10.1145/358669.358692 [10] Raguram R, Chum O, Pollefeys M, Matas J, Frahm J M. USAC: A universal framework for random sample consensus. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 2022−2038 doi: 10.1109/TPAMI.2012.257 [11] Barath D, Matas J, Noskova J. MAGSAC: Marginalizing sample consensus. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 10197−10205 [12] Lin S Y, Huang F R, Lai T T, Lai J H, Wang H Z, Weng J. Robust heterogeneous model fitting for multi-source image correspondences. International Journal of Computer Vision, 2024, 132(8): 2907−2928 doi: 10.1007/s11263-024-02023-9 [13] Ma J Y, Zhao J, Jiang J J, Zhou H B, Guo X J. Locality preserving matching. International Journal of Computer Vision, 2019, 127(5): 512−531 doi: 10.1007/s11263-018-1117-z [14] Ma J Y, Zhao J, Tian J W, Yuille A L, Tu Z W. Robust point matching via vector field consensus. IEEE Transactions on Image Processing, 2014, 23(4): 1706−1721 doi: 10.1109/TIP.2014.2307478 [15] Jiang X Y, Ma J Y, Fan A X, Xu H P, Lin G, Lu T, et al. Robust feature matching for remote sensing image registration via linear adaptive filtering. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(2): 1577−1591 doi: 10.1109/TGRS.2020.3001089 [16] Bian J W, Lin W Y, Matsushita Y, Yeung S K, Nguyen T D, Cheng M M. GMS: Grid-based motion statistics for fast, ultra-robust feature correspondence. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 2828−2837 [17] Yi K M, Trulls E, Ono Y, Lepetit V, Salzmann M, Fua P. Learning to find good correspondences. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 2666−2674 [18] Zhang J H, Sun D W, Luo Z X, Yao A B, Zhou L, Shen T W, et al. Learning two-view correspondences and geometry using order-aware network. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 5844−5853 [19] Zhao C, Ge Y X, Zhu F, Zhao R, Li H S, Salzmann M. Progressive correspondence pruning by consensus learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 6444−6453 [20] Liu X, Xiao G B, Chen R Q, Ma J Y. PGFNet: Preference-guided filtering network for two-view correspondence learning. IEEE Transactions on Image Processing, 2023, 32: 1367−1378 doi: 10.1109/TIP.2023.3242598 [21] Liu Y, Liu L J, Lin C, Dong Z, Wang W P. Learnable motion coherence for correspondence pruning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 3236−3245 [22] Ma J Y, Fan A X, Jiang X Y, Xiao G B. Feature matching via motion consistency driven probabilistic graphical model. International Journal of Computer Vision, 2022, 130(9): 2249−2264 doi: 10.1007/s11263-022-01644-2 [23] Zhang S H, Ma J Y. ConvMatch: Rethinking network design for two-view correspondence learning. In: Proceedings of the 37th AAAI Conference on Artificial Intelligence. Washington DC, USA: AAAI, 2023. 3472−3479 [24] Zhang S H, Ma J Y. ConvMatch: Rethinking network design for two-view correspondence learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(5): 2920−2935 doi: 10.1109/TPAMI.2023.3334515 [25] Kang Z, Lai T T, Li Z Y, Wei L F, Chen R Q. PRNet: Parallel reinforcement network for two-view correspondence learning. Knowledge-Based Systems, 2025, 310: Article No. 112978 [26] Li Z Z, Zhang S H, Ma J Y. U-Match: Two-view correspondence learning with hierarchy-aware local context aggregation. In: Proceedings of the 32nd International Joint Conference on Artificial Intelligence. Macao, China: 2023. Article No. 130 [27] Ma J Y, Jiang X Y, Fan A X, Jiang J J, Yan J C. Image matching from handcrafted to deep features: A survey. International Journal of Computer Vision, 2021, 129(1): 23−79 doi: 10.1007/s11263-020-01359-2 [28] Zhao C, Cao Z G, Li C, Li X, Yang J Q. NM-Net: Mining reliable neighbors for robust feature correspondences. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 215−224 [29] Wu T H, Chen K W. LGCNet: Feature enhancement and consistency learning based on local and global coherence network for correspondence selection. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). London, United Kingdom: IEEE, 2023. 6182−6188 [30] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6000−6010 [31] Sun W W, Jiang W, Trulls E, Tagliasacchi A, Yi K M. ACNe: Attentive context normalization for robust permutation-equivariant learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 11283−11292 [32] Ma J Y, Wang Y, Fan A X, Xiao G B, Chen R Q. Correspondence attention transformer: A context-sensitive network for two-view correspondence learning. IEEE Transactions on Multimedia, 2023, 25: 3509−3524 doi: 10.1109/TMM.2022.3162115 [33] Wang G, Chen Y F, Wu B. CHCANet: Two-view correspondence pruning with consensus-guided hierarchical context aggregation. Pattern Recognition, 2025, 161: Article No. 111282 doi: 10.1016/j.patcog.2024.111282 [34] Wang G, Chen Y F. Two-view correspondence learning with local consensus transformer. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(7): 11861−11874 doi: 10.1109/TNNLS.2024.3488197 [35] Hartley R, Zisserman A. Multiple View Geometry in Computer Vision. Cambridge: Cambridge University Press, 2003. [36] Thomee B, Shamma D A, Friedland G, Elizalde B, Ni K, Poland D, et al. YFCC100M: The new data in multimedia research. Communications of the ACM, 2016, 59(2): 64−73 doi: 10.1145/2812802 [37] Xiao J X, Owens A, Torralba A. SUN3D: A database of big spaces reconstructed using SFM and object labels. In: Proceedings of the IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 1625−1632 [38] Li Z Q, Snavely N. MegaDepth: Learning single-view depth prediction from internet photos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 2041−2050 [39] Sun J M, Shen Z H, Wang Y A, Bao H J, Zhou X W. LoFTR: Detector-free local feature matching with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 8918−8927 [40] Butler D J, Wulff J, Stanley G B, Black M J. A naturalistic open source movie for optical flow evaluation. In: Proceedings of the 12th European Conference on Computer Vision. Florence, Italy: Springer, 2012. 611−625 [41] Dai L Y, Liu Y Z, Ma J Y, Wei L F, Lai T T, Yang C C, et al. MS2DG-Net: Progressive correspondence learning via multiple sparse semantics dynamic graph. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 8963−8972 [42] Sun D Q, Yang X D, Liu M Y, Kautz J. PWC-Net: CNNs for optical flow using pyramid, warping, and cost volume. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8934−8943 -

 下载:
下载:

计量
- 文章访问数: 487
- HTML全文浏览量: 323
- PDF下载量: 94
- 被引次数: 0
