

-
摘要: 鸟瞰视图表征基于统一的空间坐标系, 能够实现多传感器时空对齐与特征融合, 在自动驾驶领域三维目标检测任务中展现出显著优势. 首先, 阐述BEV表征的优势以及常用自动驾驶3D目标检测数据集与评价指标. 其次, 不同于现有综述文献的输入模态特性或模态特征融合的分析视角, 基于BEV表征, 从其稠密程度切入, 分别从稀疏表示、稠密表示、稀疏−稠密混合表示角度系统梳理现有研究工作, 指出现有方法在时空消耗与表征完备性之间的权衡困境. 最后, 从全天候鲁棒感知、相机参数无关的自适应几何建模、自动驾驶开放世界检测等角度, 指出实现低成本、高精度自动驾驶BEV目标检测的研究趋势, 希望为从事BEV感知研究的学者提供启发, 推动自动驾驶技术的发展.Abstract: Bird's-eye-view (BEV) representation, based on a unified spatial coordinate system, enables multi-sensor spatiotemporal alignment and feature fusion, demonstrating significant advantages in 3D object detection tasks for autonomous driving. Firstly, this paper elaborates on the benefits of BEV representation, and introduces commonly used autonomous driving datasets and evaluation metrics for 3D object detection. Differing from existing review literature that focus on input modality characteristics or modality feature fusion, this study systematically organizes current research works by using BEV representation density as the perspective, categorizing approaches into sparse representations, dense representations and hybrid sparse-dense representations. This study reveals the inherent trade-off dilemma between temporal and spatial overhead and representation completeness in existing methods. Finally, this study outlines future research trends toward low-cost and high-precision BEV object detection in autonomous driving, including but not limited to all-weather robust perception, camera-parameter-independent adaptive geometric modeling, and autonomous driving open-world object detection. These proposed research directions aim to inspire BEV perception researchers and accelerate technological breakthroughs in autonomous driving systems.
-
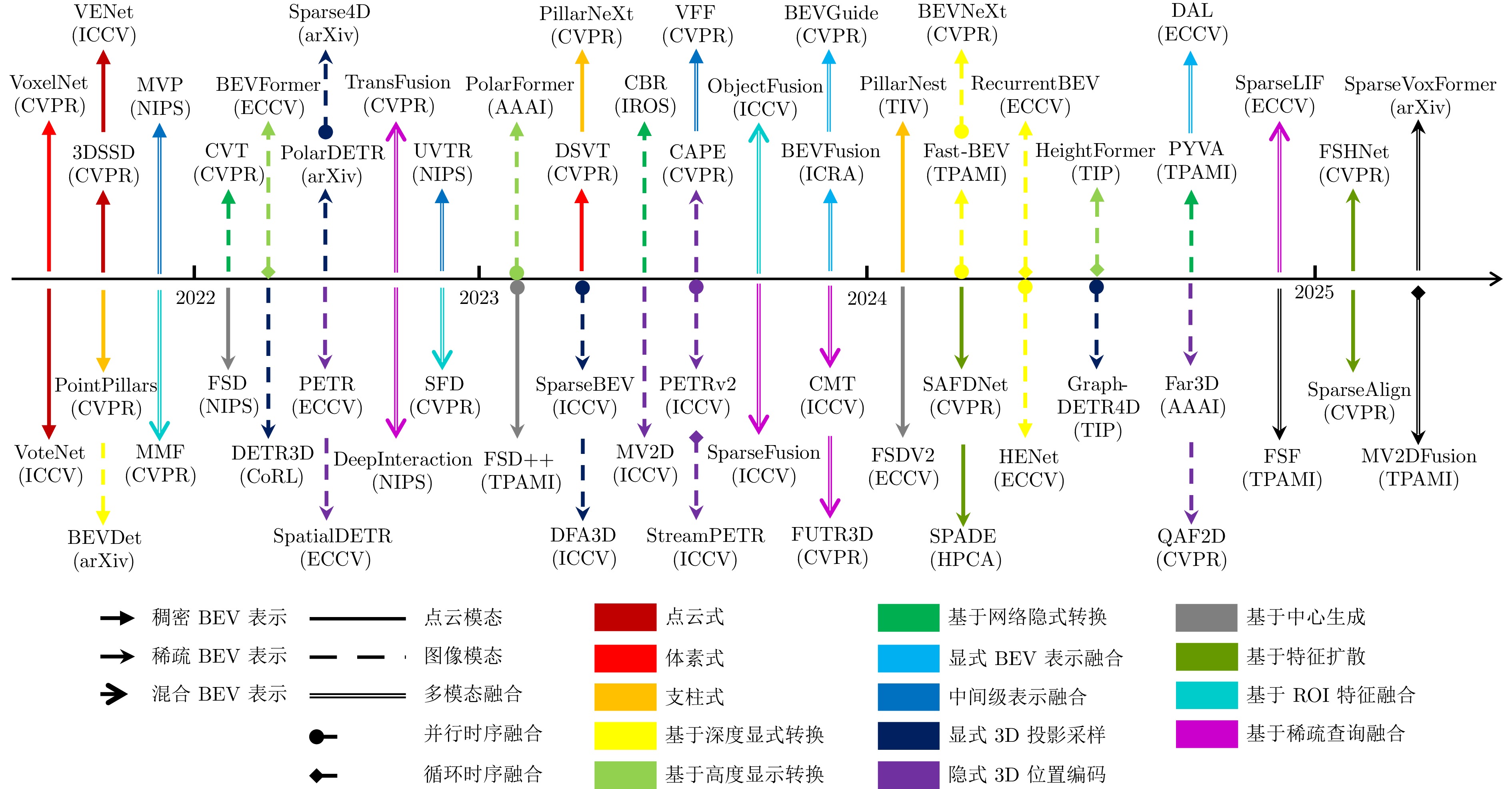
图 2 代表性BEV目标检测方法时间线概览
Fig. 2 Timeline overview of representative BEV object detection methods

图 3 BEV目标检测中典型的输入数据可视化示意图
Fig. 3 Schematic diagram of visualizing typical input data in BEV object detection
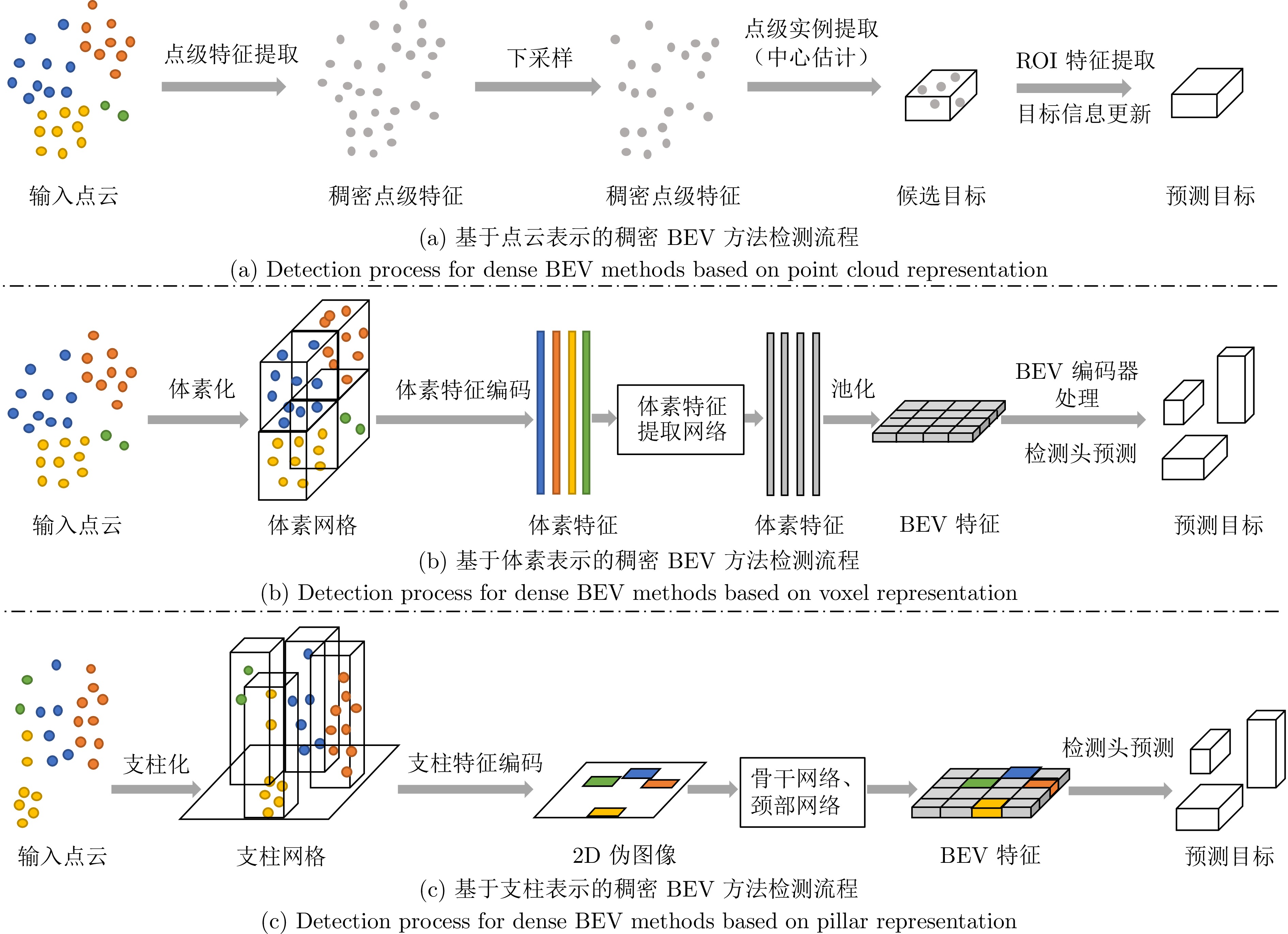
图 4 点云稠密BEV检测流程对比
Fig. 4 Comparison of dense BEV detection processes based on point clouds
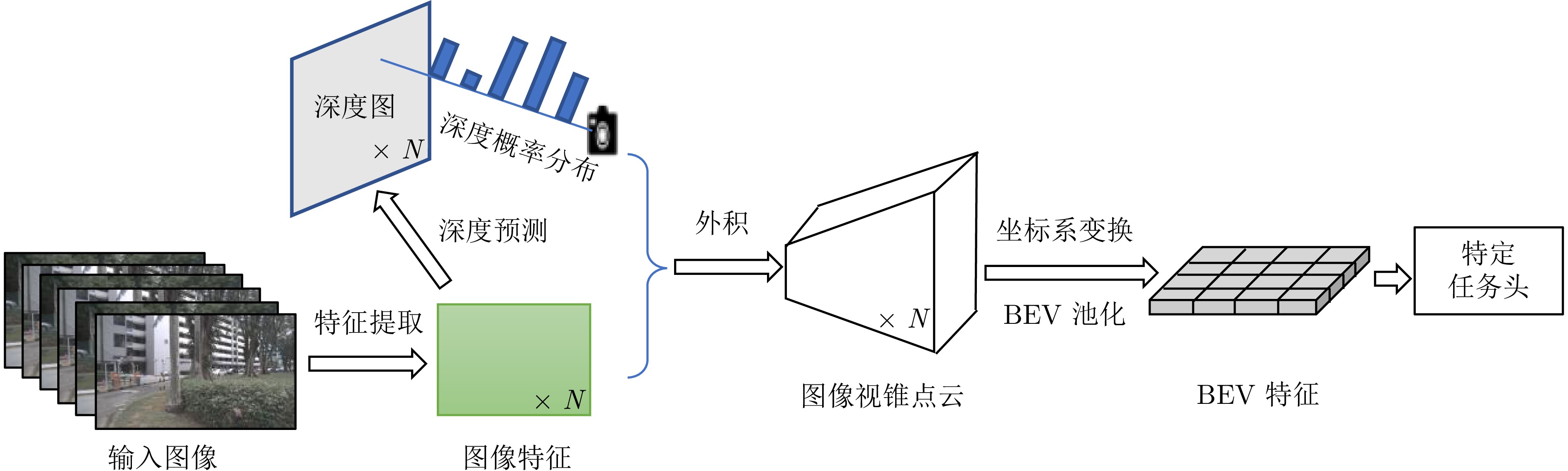
图 6 图像稠密BEV方法中基于深度显式转换的检测框架
Fig. 6 Detection framework of depth explicit transformation-based dense BEV methods in image modality
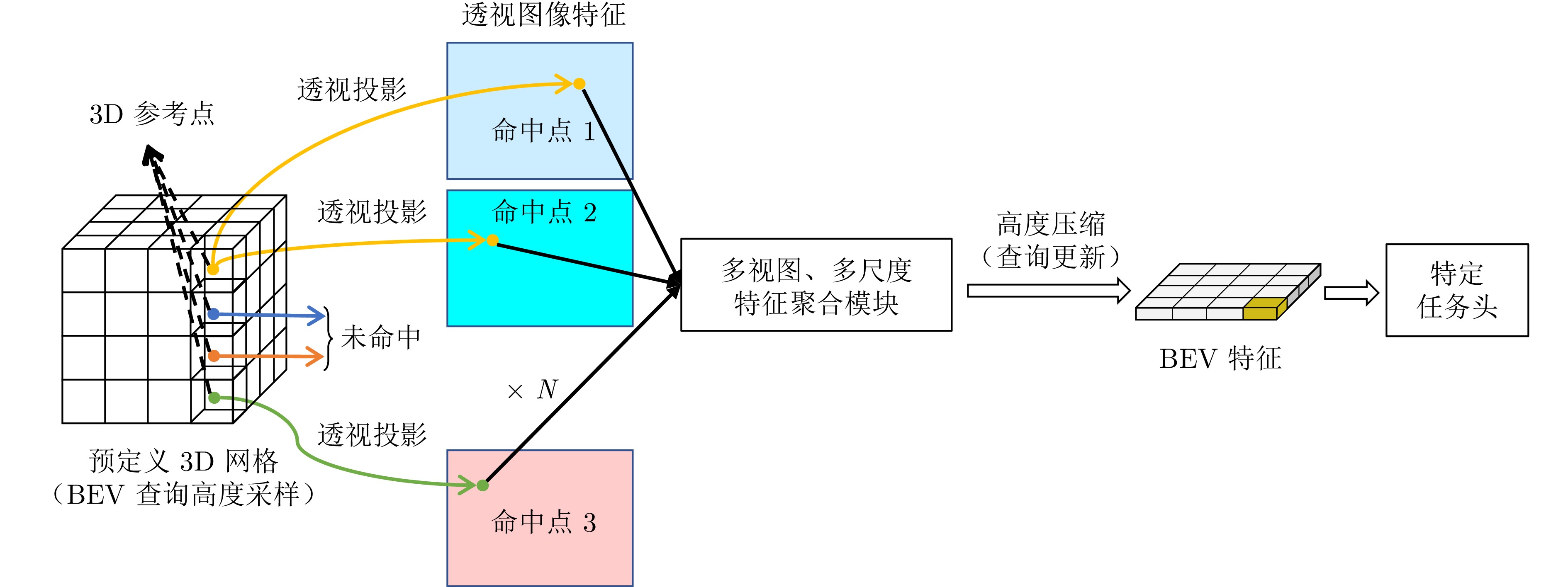
图 7 图像稠密BEV方法中基于高度显式转换的检测框架
Fig. 7 Detection framework of height explicit transformation-based dense BEV methods in image modality
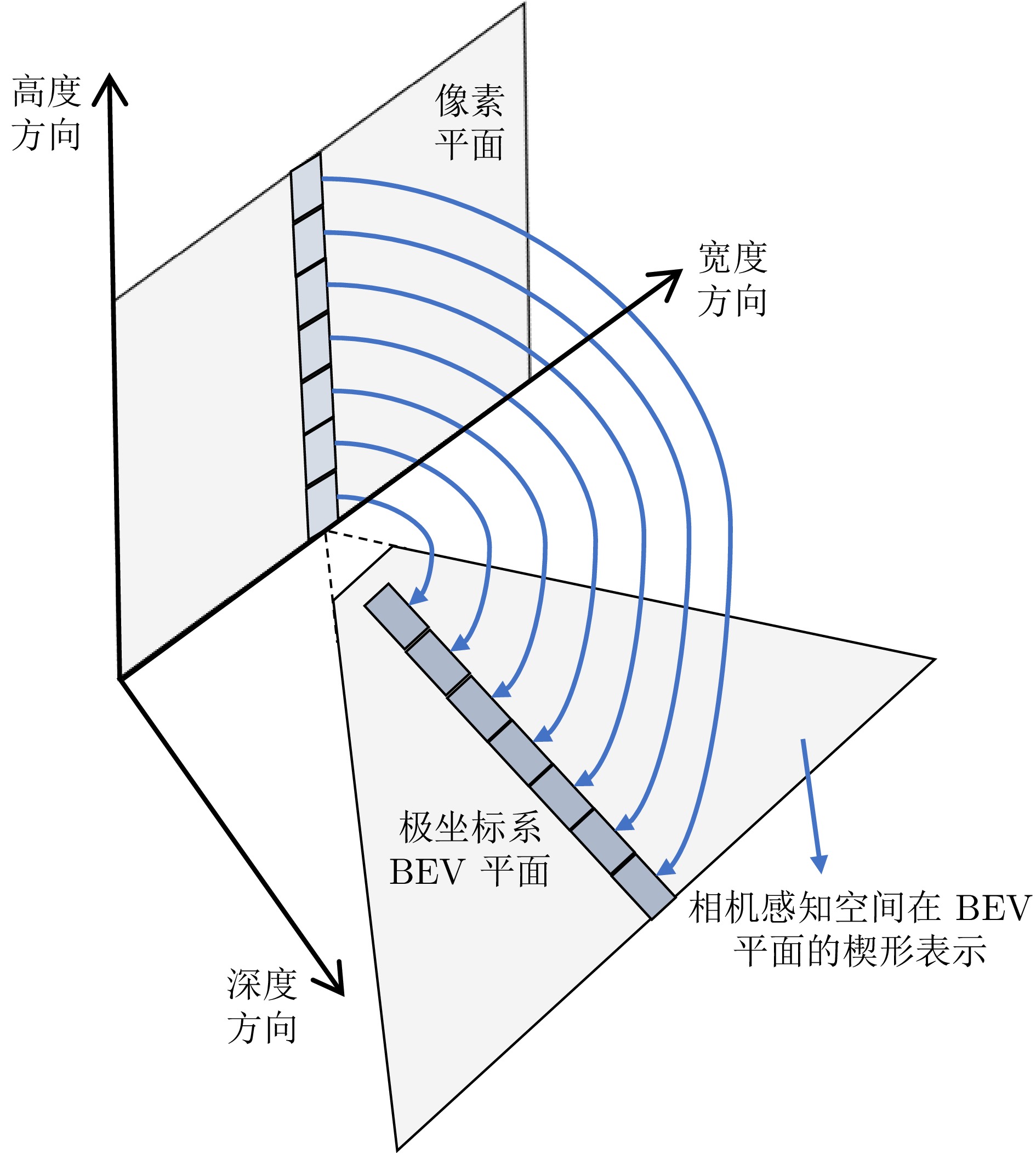
图 8 图像特征列在极坐标系下的表示
Fig. 8 Representation of image feature columns in polar coordinate system
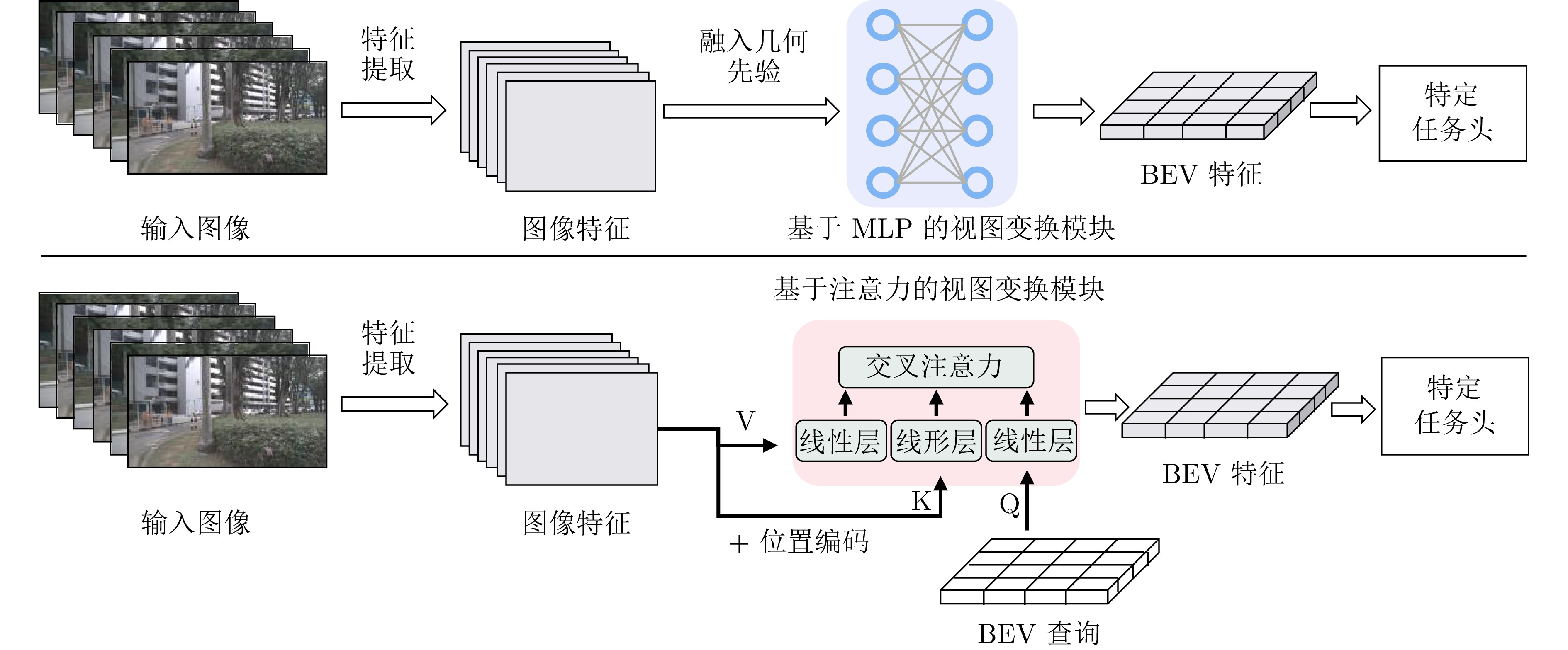
图 9 图像稠密BEV方法中基于网络隐式转换的检测框架
Fig. 9 Detection framework of network-based implicit transformation in image dense BEV methods
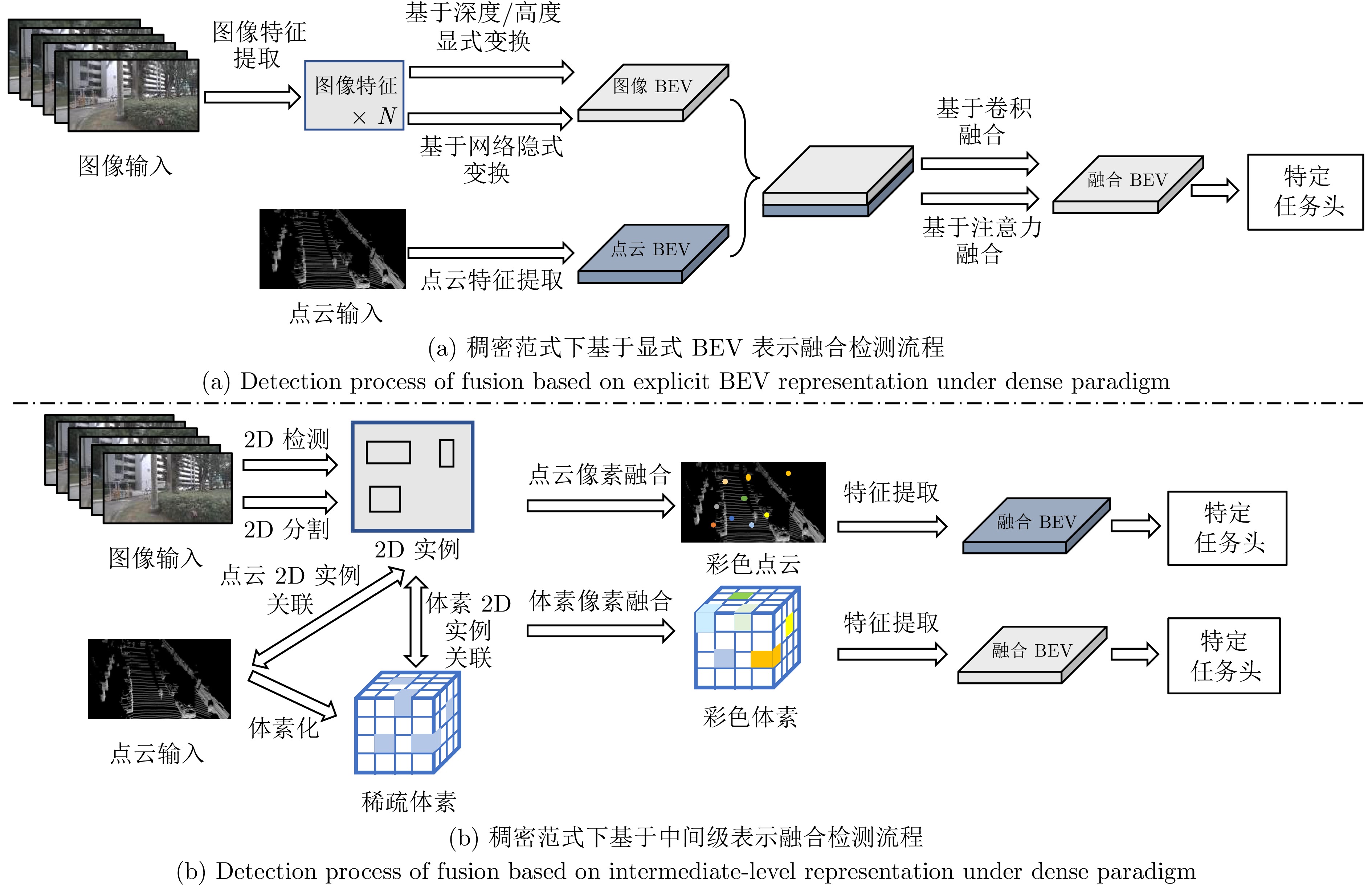
图 10 稠密范式下两类多模态融合BEV检测流程对比
Fig. 10 Comparison of two types of multi-modal fusion BEV detection processes under dense paradigm
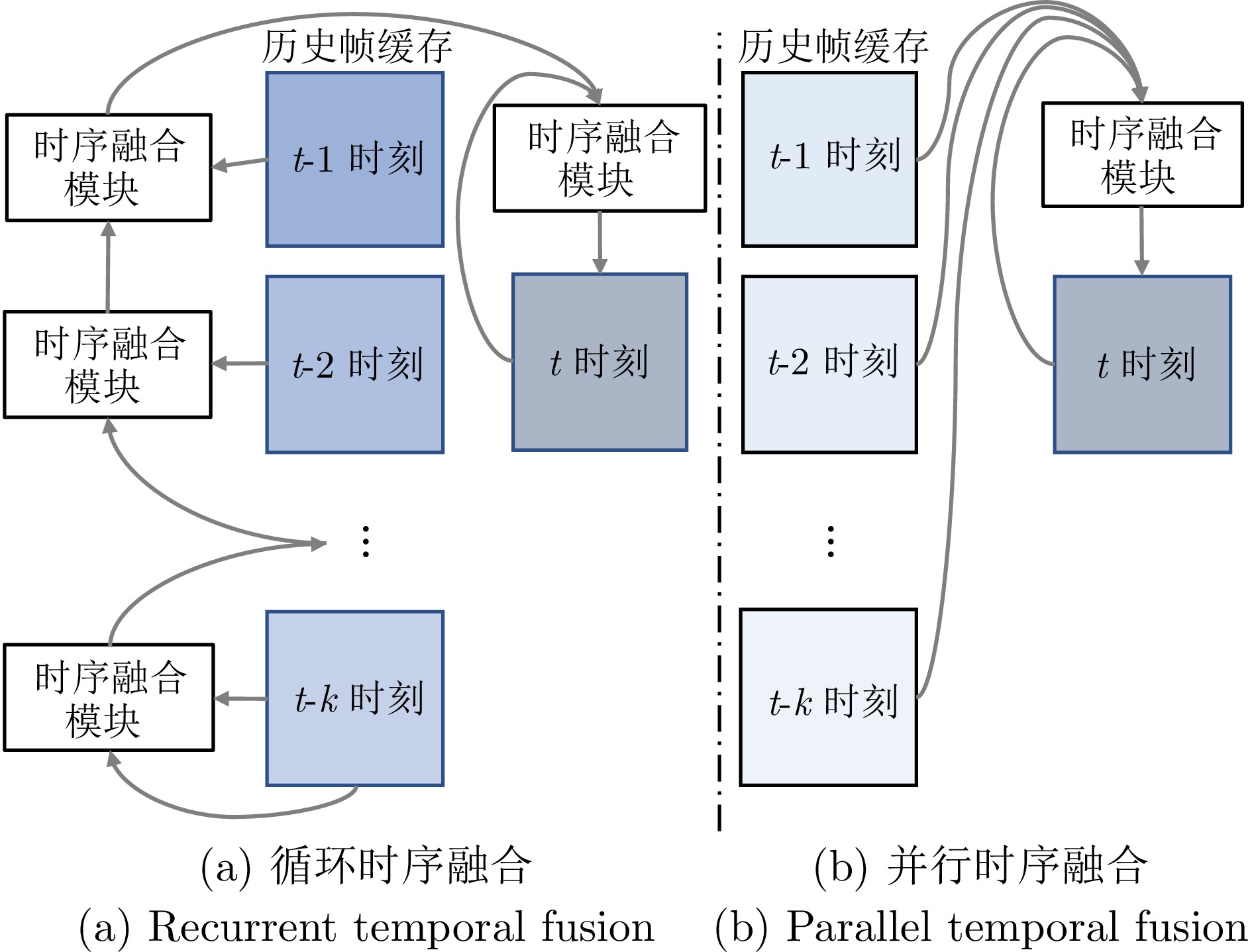
图 11 两类稠密时序融合技术框架对比
Fig. 11 Comparison of two types of dense temporal fusion technology frameworks
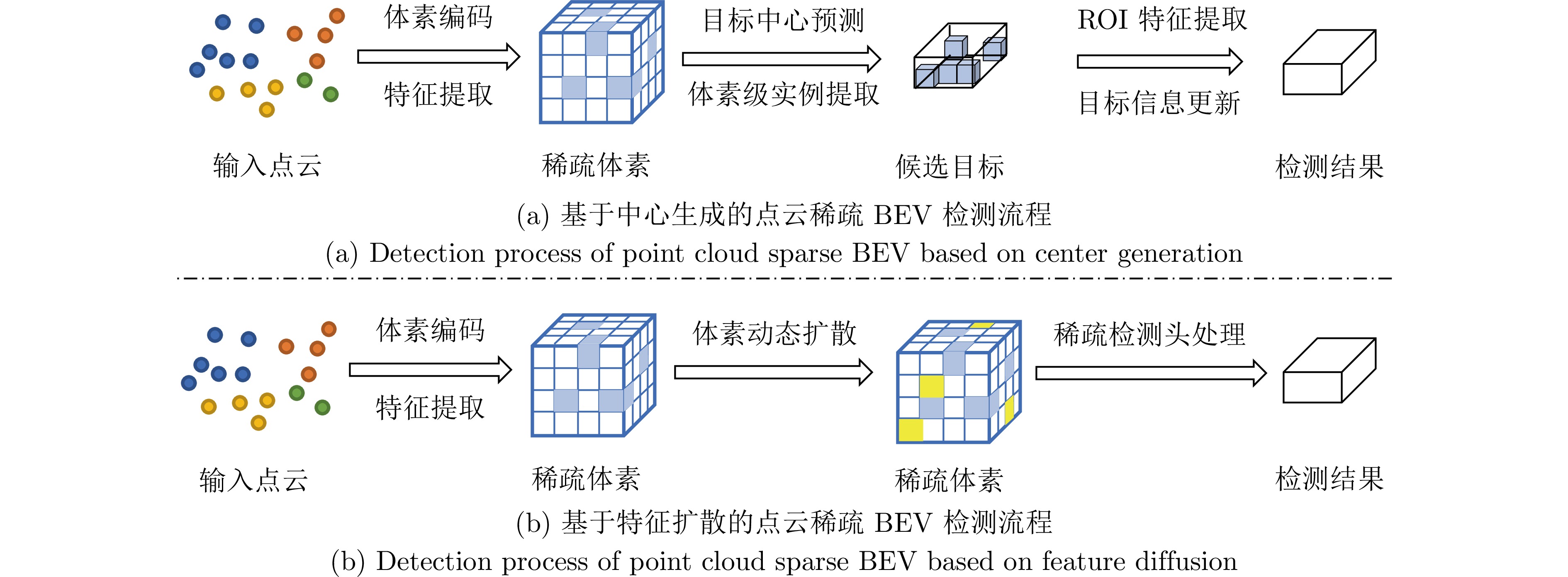
图 12 点云稀疏BEV方法检测流程示意图
Fig. 12 Schematic diagram of detection process for sparse BEV methods based on point clouds
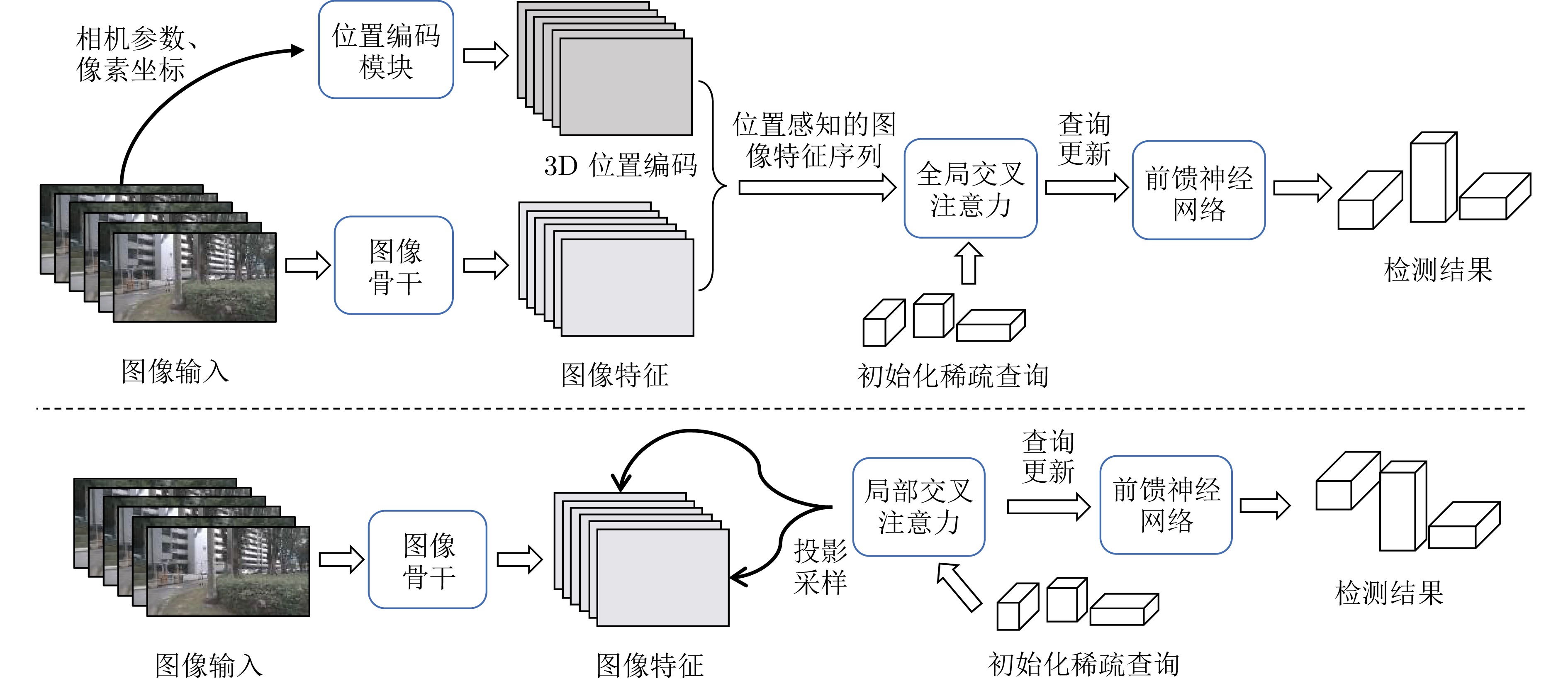
图 13 两类图像稀疏BEV方法检测流程示意图
Fig. 13 Schematic diagram of detection process for two types of image-based sparse BEV methods
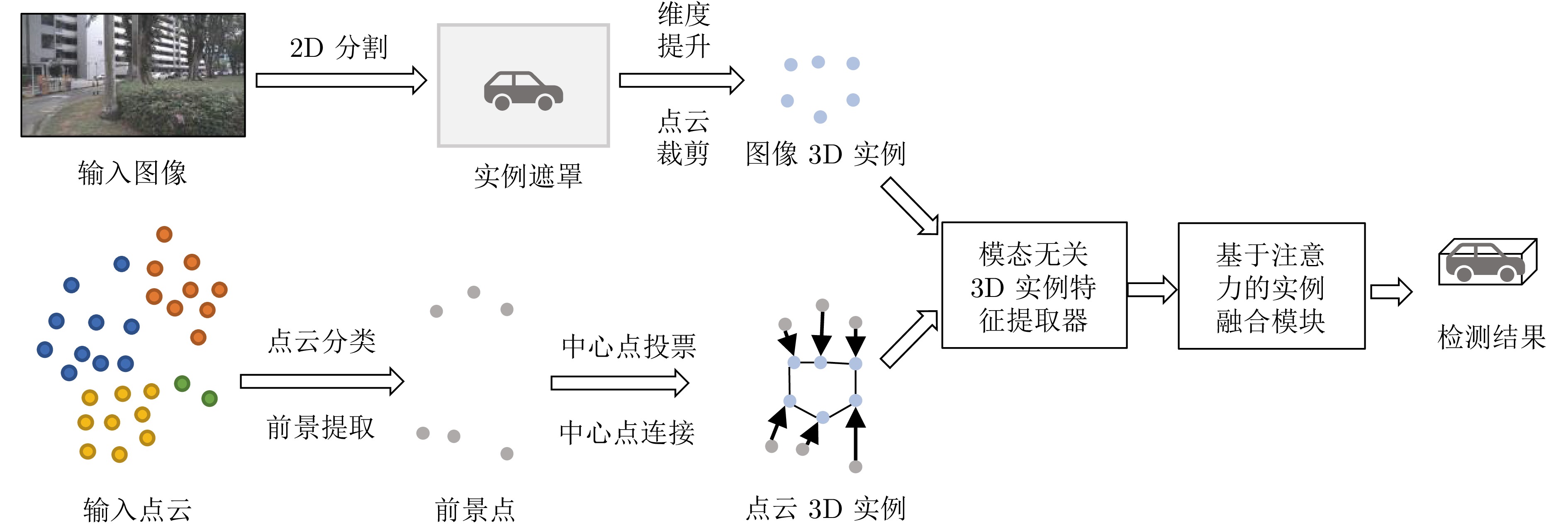
图 14 典型多模态融合稀疏BEV检测方法FSF
Fig. 14 Typical multi-modal fusion sparse BEV detection method: FSF
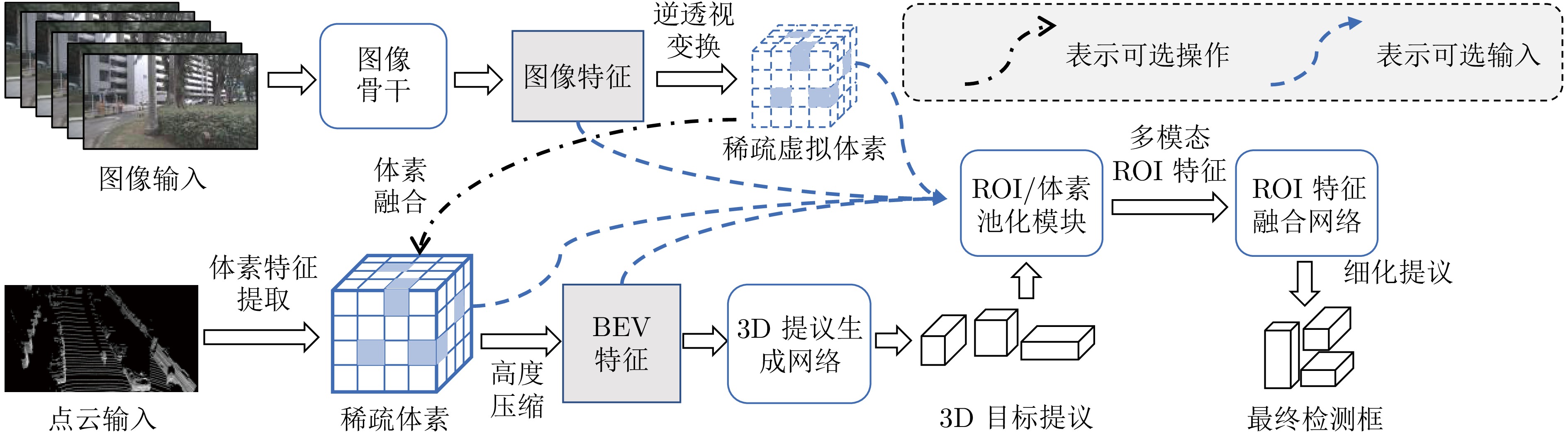
图 15 稀疏−稠密混合BEV表示范式中基于ROI特征融合的检测框架
Fig. 15 Detection framework based on ROI feature fusion under the sparse-dense hybrid BEV representation paradigm
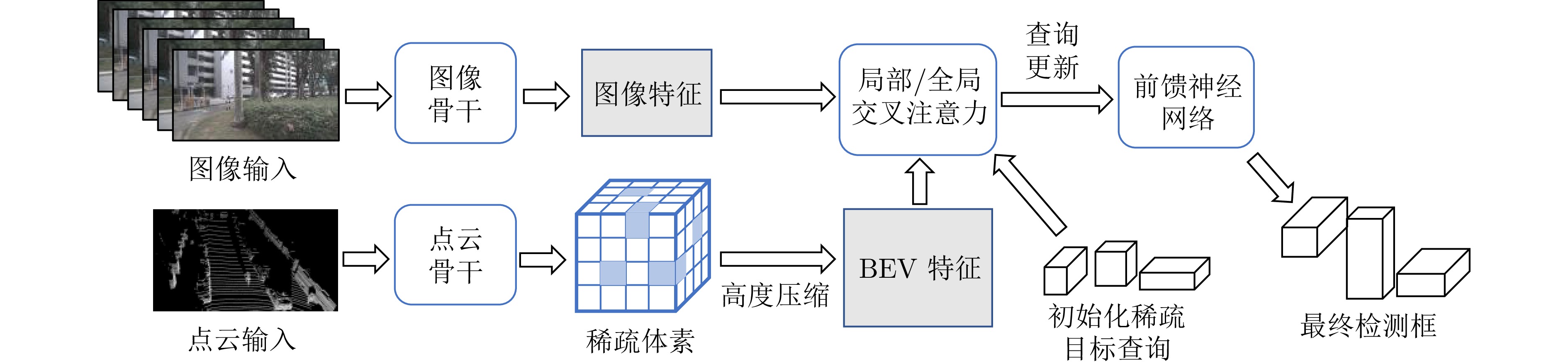
图 16 稀疏−稠密混合BEV表示范式中基于稀疏查询融合的检测框架
Fig. 16 Detection framework based on sparse query fusion under the sparse-dense hybrid BEV representation paradigm
表 1 常用传感器比较
Table 1 Comparison of common sensors
名称 优点 缺点 相机 颜色纹理丰富; 帧率高; 成本较低; 部署简单 不可测量速度; 无深度信息; 受天气因素影响 激光雷达 高精度3D位置、分辨率较高 速度测量精度低; 抗干扰能力弱; 对物体材质敏感; 造价高 毫米波雷达 距离、速度测量精度较高; 不受光照和天气影响 分辨率较低; 缺乏高度信息 4D毫米波雷达 距离、速度测量精度高; 不受光照和恶劣天气影响; 有高度维度 成本高; 分辨率低于激光雷达  下载: 导出CSV
下载: 导出CSV
表 2 常见多模态自动驾驶数据集
Table 2 Common multi-modal autonomous driving datasets
名称 年份 点云数 图像数 类别数 标注帧数 3D边界框数 优缺点说明 KITTI[7] 2012 $1.5\times10^4$ $1.50\times10^4$ 8 $1.50\times10^4$ $2.00\times10^5$ 优点: 标定精准, 适合快速开发验证. 缺点: 规模小、场景单一, 仅含前视图图像, 不利于BEV任务 ApolloScape[11] 2018 $8.0\times10^4$ $1.44\times10^5$ 25 $1.44\times10^5$ $7.00\times10^4$ 优点: 像素级语义标注, 车道级检测支持较好. 缺点: 无360度传感器覆盖, 3D标注有限 KAIST[12] 2018 $8.9\times10^3$ $8.90\times10^3$ 3 $8.90\times10^3$ 0 优点: 包含热成像图像数据, 适配夜间/低光场景任务. 缺点: 类别少、规模小、无3D目标框标注, 难以支撑完整检测任务 A*3D[13] 2019 $3.9\times10^4$ $3.90\times10^4$ 7 $3.90\times10^4$ $2.30\times10^5$ 优点: 包含挑战性场景, 采集车行驶速度快, 适合动态建模. 缺点: 仅含前视视角图像, 标注频率低, 不利于时序建模 A2D2[14] 2019 - - 14 $1.20\times10^4$ - 优点: 360度环视图像数据, 车辆总线信息可辅助BEV任务. 缺点: 标注帧少、缺乏点云数据, 场景单一且缺乏多模态信息 Argoverse[15] 2019 $4.4\times10^4$ $4.90\times10^5$ 15 $2.20\times10^4$ $9.93\times10^5$ 优点: 含高精度地图与大量轨迹数据, 时序建模支持较好. 缺点: 无毫米波雷达数据, 缺乏专用BEV检测基准 H3D[16] 2019 $2.7\times10^4$ $8.30\times10^4$ 8 $2.70\times10^4$ $1.10\times10^6$ 优点: 目标密度高, 标注密集, 适配城市内感知任务. 缺点: 类别少、传感器多样性差, 覆盖范围有限 Lyft L5[17] 2019 $4.6\times10^4$ $3.23\times10^5$ 9 $4.60\times10^4$ $1.30\times10^6$ 优点: 规模较大、传感器多样, 含高清航拍与语义地图, 适配BEV建模. 缺点: 类别相对少, 侧重预测/规划任务 Nuscenes[8] 2019 $4.0\times10^5$ $1.40\times10^6$ 23 $4.00\times10^4$ $1.40\times10^6$ 优点: 传感器多样、标注信息丰富、360度覆盖, 适配多模态BEV任务. 缺点: 类别不平衡严重, 部分驾驶场景挑战性不足 Waymo[9] 2019 $2.0\times10^5$ $1.00\times10^6$ 4 $2.00\times10^5$ $1.20\times10^7$ 优点: 点云密度高且精度较好, 标注规模大, 360度覆盖, 广泛用作BEV基准. 缺点: 类别少、无语义地图 KITTI-360[18] 2020 $1.0\times10^5$ $3.20\times10^5$ 19 $8.00\times10^4$ $6.80\times10^4$ 优点: 相较于KITTI扩展鱼眼镜头, 覆盖范围更广, 更适配BEV感知. 缺点: 场景数及标注数量较少, 更适合小规模实验 ONCE[19] 2021 $1.0\times10^6$ $7.00\times10^6$ 5 $1.50\times10^4$ $4.17\times10^5$ 优点: 场景多样、规模大, 相机覆盖范围广, 适配BEV任务. 缺点: 类别少、标注帧偏少, 更适用于半/自监督或预训练 K-Radar[10] 2022 $3.5\times10^4$ $1.40\times10^5$ 5 $3.50\times10^4$ $9.33\times10^4$ 优点: 包含原始4D雷达张量, 传感器信息丰富、覆盖角度广, 适合全天候感知. 缺点: 数据总量大、存储成本较高、类别较少 TJ4DRadSet[20] 2022 $4.0\times10^4$ $4.00\times10^4$ 8 $7.76\times10^3$ - 优点: 以4D雷达为主导, 可用于多模态与全天候感知任务. 缺点: 点云稀疏、类别少、规模有限 Dual Radar[21] 2024 $5.0\times10^4$ $5.00\times10^4$ 6 $1.00\times10^4$ $1.03\times10^5$ 优点: 双4D雷达数据, 可对比不同雷达点云性能差异, 场景覆盖全面. 缺点: 类别少、规模有限、传感器覆盖范围较小 注: “-”表示无统计数据
下载: 导出CSV
-
[1] Ma Y X, Wang T, Bai X Y, Yang H T, Hou Y N, Wang Y M, et al. Vision-centric bev perception: a survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 10978−10997 doi: 10.1109/TPAMI.2024.3449912 [2] Qian R, Lai X, Li X R. 3D object detection for autonomous driving: a survey. Pattern Recognition, 2022, 130: 108796−108812 doi: 10.1016/j.patcog.2022.108796 [3] Mao J G, Shi S S, Wang X G, Li H S. 3D object detection for autonomous driving: a comprehensive survey. International Journal of Computer Vision, 2023, 131(8): 1909−1963 doi: 10.1007/s11263-023-01790-1 [4] Wang L, Zhang X Y, Song Z Y, Bi J F, Zhang G X, Wei H Y, et al. Multi-modal 3d object detection in autonomous driving: a survey and taxonomy. IEEE Transactions on Intelligent Vehicles, 2023, 8(7): 3781−3798 doi: 10.1109/TIV.2023.3264658 [5] 张新钰, 卢毅果, 高鑫, 黄雨宁, 刘华平, 王云鹏, 等. 面向智能网联汽车的车路协同感知技术及发展趋势. 自动化学报, 2025, 51(2): 233−248 doi: 10.16383/j.aas.c230575Zhang Xin-Yu, Lu Yi-Guo, Gao Xin, Huang Yu-Ning, Liu Hua-Ping, Wang Yun-Peng, et al. Vehicle-road collaborative perception technology and development trend for intelligent connected vehicles. Acta Automatica Sinica, 2025, 51(2): 233−248 doi: 10.16383/j.aas.c230575 [6] 沈甜雨, 陶子锐, 王亚东, 张庭祯, 刘宇航, 王兴霞, 等. 具身智能研究的关键问题: 自主感知、行动与进化. 自动化学报, 2025, 51(1): 43−71 doi: 10.16383/j.aas.c240364Shen Tian-Yu, Tao Zi-Rui, Wang Ya-Dong, Zhang Ting-Zhen, Liu Yu-Hang, Wang Xing-Xia, et al. Key problems of embodied intelligence research: autonomous perception, action, and evolution. Acta Automatica Sinica, 2025, 51(1): 43−71 doi: 10.16383/j.aas.c240364 [7] Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving? the kitti vision benchmark suite. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Providence, USA: IEEE, 2012. 3354-3361 [8] Caesar H, Bankiti V, Lang A H, Vora S, Liong V E, Xu Q, et al. Nuscenes: a multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 11621-11631 [9] Sun P, Kretzschmar H, Dotiwalla X, Chouard A, Patnaik V, Tsui P, et al. Scalability in perception for autonomous driving: waymo open dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 2446-2454 [10] Paek D H, Kong S H, Wijaya2 K T. K-Radar: 4D Radar Object Detection for Autonomous Driving in Various Weather Conditions. In: Proceedings of the Advances in Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2022. 3819-3829 [11] Huang X Y, Cheng X J, Geng Q C, Cao B B, Zhou D F, Wang P, et al. The apolloscape dataset for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. Salt Lake City, USA: IEEE, 2018. 954-960 [12] Choi Y, Kim N, Hwang S, Park K, Yoon J S, An K, et al. Kaist multi-spectral day/night data set for autonomous and assisted driving. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(3): 934−948 doi: 10.1109/TITS.2018.2791533 [13] Pham Q H, Sevestre P, Pahwa R S, Zhan H J, Pang C H, Chen Y D, et al. A*3d dataset: towards autonomous driving in challenging environments. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Paris, France: IEEE, 2020. 2267-2273 [14] Geyer J, Kassahun Y, Mahmudi M, Ricou X, Durgesh R, Chung A S, et al. A2d2: audi autonomous driving dataset. arXiv preprint arXiv: 2004.06320, 2020 [15] Chang M F, Lambert J, Sangkloy P, Singh J, Bak S, Hartnett A, et al. Argoverse: 3d tracking and forecasting with rich maps. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 8748-8757 [16] Patil A, Malla S, Gang H M, Chen Y T. The h3d dataset for full-surround 3d multi-object detection and tracking in crowded urban scenes. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Montreal, Canada: IEEE, 2019. 9552-9557 [17] Houston J, Zuidhof G, Bergamini L, Ye Y W, Chen L, Jain A, et al. One thousand and one hours: self-driving motion prediction dataset. In: Proceedings of the Conference on Robot Learning. Cambridge, USA: PMLR, 2020. 409-418 [18] Liao Y Y, Xie J, Geiger A. KITTI-360: a novel dataset and benchmarks for urban scene understanding in 2d and 3d. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(3): 3292−3310 doi: 10.1109/tpami.2022.3179507 [19] Mao J G, Niu M Z, Jiang C H, Liang H X, Chen J H, Liang X D, et al. One million scenes for autonomous driving: once dataset. arXiv preprint arXiv: 2106.11037, 2021 [20] Zheng L Q, Ma Z X, Zhu X C, Tan B, Li S, Long K, et al. TJ4DRadSet: A 4D radar dataset for autonomous driving. In: Proceedings of the IEEE International Intelligent Transportation Systems Conference (ITSC). Macau, China: IEEE, 2022. 493-498 [21] Zhang X Y, Wang L, Chen J, Chen F, Yang G Q, Wang Y C, et al. Dual radar: A multi-modal dataset with dual 4d radar for autononous driving. Scientific data, 2025, 12(1): 439−451 doi: 10.1038/s41597-025-04698-2 [22] Everingham M, Van Gool L, Williams C K, Winn J, Zisserman A. The pascal visual object classes (voc) challenge. International Journal of Computer Vision, 2010, 88: 303−338 doi: 10.1007/s11263-009-0275-4 [23] Qi C R, Su H, Mo K C, Guibas L J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 652-660 [24] Qi C R, Yi L, Su H, Guibas L J. Pointnet++: deep hierarchical feature learning on point sets in a metric space. In: Proceedings of the Advances in Neural Information Processing Systems. Long Beach, USA: Curran Associates, 2017. 5099-5108 [25] Shi W J, Rajkumar R. Point-gnn: graph neural network for 3d object detection in a point cloud. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 1711-1719 [26] Zhang Y F, Hu Q Y, Xu G Q, Ma Y X, Wan J W, Guo Y L. Not all points are equal: learning highly efficient point-based detectors for 3d lidar point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 18953-18962 [27] Yang Z T, Sun Y, Liu S, Jia J Y. 3Dssd: point-based 3d single stage object detector. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 11040-11048 [28] Qi C R, Litany O, He K M, Guibas L J. Deep hough voting for 3d object detection in point clouds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, South Korea: IEEE, 2019. 9277-9286 [29] Xie Q, Lai Y K, Wu J, Wang Z T, Zhang Y M, Xu K, et al. Mlcvnet: multi-level context votenet for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 10447-10456 [30] Xie Q, Lai Y K, Wu J, Wang Z T, Lu D N, Wei M Q, et al. Venet: voting enhancement network for 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Virtual Event: IEEE, 2021. 3712-3721 [31] Zhou Y, Tuzel O. Voxelnet: end-to-end learning for point cloud based 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 4490-4499 [32] Ren S Q, He K M, Girshick R, Sun J. Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(6): 1137−1149 doi: 10.1109/tpami.2016.2577031 [33] Yan Y, Mao Y X, Li B. Second: sparsely embedded convolutional detection. Sensors, 2018, 18(10): Article No. 3337 doi: 10.3390/s18103337 [34] He C H, Zeng H, Huang J Q, Hua X S, Zhang L. Structure aware single-stage 3d object detection from point cloud. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 11873-11882 [35] Fan L, Pang Z Q, Zhang T Y, Wang Y X, Zhao H, Wang F, et al. Embracing single stride 3d object detector with sparse transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 8458-8468 [36] Shi S S, Guo C X, Jiang L, Wang Z, Shi J P, Wang X G, et al. Pv-rcnn: point-voxel feature set abstraction for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 10529-10538 [37] Shi S S, Jiang L, Deng J J, Wang Z, Guo C X, Shi J P, et al. Pv-rcnn++: point-voxel feature set abstraction with local vector representation for 3d object detection. International Journal of Computer Vision, 2023, 131(2): 531−551 doi: 10.1007/s11263-022-01710-9 [38] Deng J J, Shi S S, Li P W, Zhou W G, Zhang Y Y, Li H Q. Voxel r-cnn: towards high performance voxel-based 3d object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. Virtual Event: AAAI, 2021. 1201-1209 [39] Neubeck A, Van G L. Efficient non-maximum suppression. In: Proceedings of the 18th International Conference on Pattern Recognition. Hong Kong, China: IEEE, 2006. 850-855 [40] Yin T W, Zhou X Y, Krahenbuhl P. Center-based 3d object detection and tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 11784-11793 [41] Zhou X Y, Wang D Q, Krahenbuhl P. Objects as points. arXiv preprint arXiv: 1904.07850, 2019 [42] Ma R Q, Chen C, Yang B S, Li D R, Wang H P, Cong Y Z, et al. Cg-ssd: corner guided single stage 3d object detection from lidar point cloud. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 191: 33−48 doi: 10.1016/j.isprsjprs.2022.07.006 [43] Ge R Z, Ding Z Z, Hu Y H, Wang Y, Chen S J, Huang L, et al. Afdet: anchor free one stage 3d object detection. arXiv preprint arXiv: 2006.12671, 2020 [44] Hu Y H, Ding Z Z, Ge R Z, Shao W X, Huang L, Li K, et al. Afdetv2: rethinking the necessity of the second stage for object detection from point clouds. In: Proceedings of the AAAI Conference on Artificial Intelligence. Virtual Event: AAAI, 2022. 969-979 [45] Wang Y, Solomon J M. Object dgcnn: 3d object detection using dynamic graphs. In: Proceedings of the Advances in Neural Information Processing Systems. Virtual Event: Curran Associates, 2021. 20745-20758 [46] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the Advances in Neural Information Processing Systems. Long Beach, USA: Curran Associates, 2017. 5998-6008 [47] Mao J G, Xue Y J, Niu M Z, Bai H Y, Feng J S, Liang X D, et al. Voxel transformer for 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Virtual Event: IEEE, 2021. 3164-3173 [48] He C H, Li R H, Li S, Zhang L. Voxel set transformer: a set-to-set approach to 3d object detection from point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 8417-8427 [49] Wang H Y, Shi C, Shi S S, Lei M, Wang S, He D, et al. Dsvt: dynamic sparse voxel transformer with rotated sets. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 13520-13529 [50] Li J N, Dong S C, Ding L H, Xu T F. Mssvt++: mixed-scale sparse voxel transformer with center voting for 3d object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 46(5): 3736−3752 [51] He C H, Li R H, Zhang G W, Zhang L. Scatterformer: efficient voxel transformer with scattered linear attention. In: Proceedings of the European Conference on Computer Vision (ECCV). Milan, Italy: Springer, 2024. 74-92 [52] Lang A H, Vora S, Caesar H, Zhou L B, Yang J, Beijbom O. Pointpillars: fast encoders for object detection from point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 12697-12705 [53] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y, et al. Ssd: single shot multibox detector. In: Proceedings of the European Conference on Computer Vision (ECCV). Amsterdam, The Netherlands: Springer, 2016. 21-37 [54] Wang Y, Fathi A, Kundu A, Ross D A, Pantofaru C, Funkhouser T, et al. Pillar-based object detection for autonomous driving. In: Proceedings of the European Conference on Computer Vision (ECCV). Virtual Event: Springer, 2020. 18-34 [55] Zhou S F, Yuan Z H, Yang D W, Zhao Z Y, Hu X, Shi Y G, et al. Information entropy guided height-aware histogram for quantization-friendly pillar feature encoder. arXiv preprint arXiv: 2405.18734, 2024 [56] Li X S, Wang C L, Wang S M, Zeng Z, Liu J. Pillarnext: improving the 3d detector by introducing voxel2pillar feature encoding and extracting multi-scale features. arXiv preprint arXiv: 2405.09828, 2024 [57] Wang C, Liu Z W. Cafi-pillars: infusing geometry priors for pillar-based 3d detectors through centroid-aware feature interaction. IEEE Transactions on Intelligent Vehicles, 2023, 9(1): 2399−2408 doi: 10.1109/tiv.2023.3323377 [58] Guo D B, Yang G H, Wang C H. Pillarnet++: pillar-based 3d object detection with multi-attention. IEEE Sensors Journal, 2023, 23(22): 27733−27743 doi: 10.1109/JSEN.2023.3323368 [59] Li J Y, Luo C X, Yang X D. Pillarnext: rethinking network designs for 3d object detection in lidar point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 17567-17576 [60] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770-778 [61] Chen L C, Papandreou G, Kokkinos I, Murphy K, Yuille A L. Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(4): 834−848 doi: 10.1109/tpami.2017.2699184 [62] Wang J, Lan S Y, Gao M F, Davis L S. Infofocus: 3d object detection for autonomous driving with dynamic information modeling. In: Proceedings of the European Conference on Computer Vision (ECCV). Virtual Event: Springer, 2020. 405-420 [63] Shen Y, Zhang Y Z, Wu Y M, Wang Z Y, Yang L H, Coleman S, et al. Bsh-det3d: improving 3d object detection with bev shape heatmap. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Detroit, USA: IEEE, 2023. 5730-5737 [64] Huang Z C, Zheng Z J, Zhao J W, Hu H F, Wang Z X, Chen D H. Psa-det3d: pillar set abstraction for 3d object detection. Pattern Recognition Letters, 2023, 168: 138−145 doi: 10.1016/j.patrec.2023.03.016 [65] Zhou S F, Zhang X Y, Chu X X, Zhang B, Zhao Z Y, Lu X B, et al. Fastpillars: a deployment-friendly pillar-based 3d detector. IEEE Transactions on Circuits and Systems for Video Technology, DOI: https://doi.org/ 10.1109/TPAMI.2025.3609348 [66] Mao W X, Wang T C, Zhang D K, Yan J J, Yoshie O. Pillarnest: embracing backbone scaling and pretraining for pillar-based 3d object detection. IEEE Transactions on Intelligent Vehiclese, DOI: 10.1109/TIV.2024.3386576 [67] Liu Z, Mao H Z, Wu C Y, Feichtenhofer C, Darrell T, Xie S N. A convnet for the 2020s. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 11976-11986 [68] Philion J, Fidler S. Lift, splat, shoot: encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In: Proceedings of the European Conference on Computer Vision (ECCV). Virtual Event: Springer, 2020. 194-210 [69] Huang J J, Huang G, Zhu Z, Ye Y, Du D L. Bevdet: high-performance multi-camera 3d object detection in bird-eye-view. arXiv preprint arXiv: 2112.11790, 2021 [70] Xie E Z, Yu Z D, Zhou D Q, Philion J, Anandkumar A, Fidler S, et al. M2bev: multi-camera joint 3d detection and segmentation with unified birds-eye view representation. arXiv preprint arXiv: 2204.05088, 2022 [71] Huang B, Li Y G, Xie E Z, Liang F, Wang L Y, Shen M Z, et al. Fast-bev: Towards real-time on-vehicle bird's-eye view perception. arXiv preprint arXiv: 2301.07870, 2023 [72] Li Y G, Huang B, Chen Z R, Cui Y F, Liang F, Shen M Z, et al. Fast-bev: A fast and strong bird's-eye view perception baseline. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 8665−8679 doi: 10.1109/TPAMI.2024.3414835 [73] Huang J J, Huang G. Bevpoolv2: a cutting-edge implementation of bevdet toward deployment. arXiv preprint arXiv: 2211.17111, 2022 [74] Li Y X, Han Q, Yu M Y, Jiang Y X, Yeo C K, Li Y H, et al. Towards efficient 3d object detection in bird's-eye-space for autonomous driving: a convolutional-only approach. In: Proceedings of the IEEE 26th International Conference on Intelligent Transportation Systems. Bilbao, Spain: IEEE, 2023. 2170-2177 [75] Li Y H, Ge Z, Yu G Y, Yang J R, Wang Z R, Shi Y K, et al. Bevdepth: acquisition of reliable depth for multi-view 3d object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. Washington D.C., USA: AAAI, 2023. 1477-1485 [76] Li Y H, Bao H, Ge Z, Yang J R, Sun J J, Li Z M. Bevstereo: enhancing depth estimation in multi-view 3d object detection with temporal stereo. In: Proceedings of the AAAI Conference on Artificial Intelligence. Washington D.C., USA: AAAI, 2023. 1486-1494 [77] Li Y H, Yang J R, Sun J J, Bao H, Ge Z, Xiao L. Bevstereo++: accurate depth estimation in multi-view 3d object detection via dynamic temporal stereo. arXiv preprint arXiv: 2304.04185, 2023 [78] Li Z X, Lan S Y, Alvarez J M, Wu Z X. Bevnext: reviving dense bev frameworks for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 20113-20123 [79] Man Y Z, Gui L Y, Wang Y X. Dualcross: cross-modality cross-domain adaptation for monocular bev perception. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Detroit, USA: IEEE, 2023. 10910-10917 [80] Chen Z H, Li Z Y, Zhang S Q, Fang L J, Jiang Q H, Zhao F. Bevdistill: cross-modal bev distillation for multi-view 3d object detection. arXiv preprint arXiv: 2211.09386, 2022 [81] Zhou S C, Liu W Z, Hu C, Zhou S C, Ma C. Unidistill: a universal cross-modality knowledge distillation framework for 3d object detection in bird's-eye view. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 5116-5125 [82] Wang Z Y, Li D W, Luo C X, Xie C H, Yang X D. Distillbev: boosting multi-camera 3d object detection with cross-modal knowledge distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 8637-8646 [83] Zhao H M, Zhang Q M, Zhao S S, Chen Z, Zhang J, Tao D C. Simdistill: simulated multi-modal distillation for bev 3d object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2024. 7460-7468 [84] Jiang Z, Zhang J Q, Zhang Y, Liu Q J, Hu Z H, Wang B H, et al. Fsd-bev: foreground self-distillation for multi-view 3d object detection. In: Proceedings of the European Conference on Computer Vision (ECCV). Milan, Italy: Springer, 2024. 110-126 [85] Zhang J Q, Zhang Y N, Qi Y L, Fu Z H, Liu Q J, Wang Y H. Geobev: Learning geometric bev representation for multi-view 3d object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. Philadelphia, USA: AAAI, 2025. 9960-9968 [86] Xu S Q, Li F, Huang P X, Song Z Y, Yang Z X. TiGDistill-BEV: Multi-view BEV 3D object detection via target inner-geometry learning distillation. IEEE Transactions on Circuits and Systems for Video Technology, DOI: https://doi.org/ 10.1109/TCSVT.2025.3596322 [87] Alhamwi A, Vandeportaele B, Piat J. Real time vision system for obstacle detection and localization on fpga. In: Proceedings of the Computer Vision Systems: 10th International Conference. Copenhagen, Denmark: Springer, 2015. 80-90 [88] Kim Y, Kum D. Deep learning based vehicle position and orientation estimation via inverse perspective mapping image. In: Proceedings of the IEEE Intelligent Vehicles Symposium. Paris, France: IEEE, 2019. 317-323 [89] Reiher L, Lampe B, Eckstein L. A sim2real deep learning approach for the transformation of images from multiple vehicle-mounted cameras to a semantically segmented image in bird's eye view. In: Proceedings of the IEEE 23rd International Conference on Intelligent Transportation Systems. Rhodes, Greece: IEEE, 2020. 1-7 [90] Roddick T, Kendall A, Cipolla R. Orthographic feature transform for monocular 3d object detection. arXiv preprint arXiv: 1811.08188, 2018 [91] Li Z Q, Wang W H, Li H Y, Xie E Z, Sima C H, Lu T, et al. BEVFormer: learning bird's-eye-view representation from lidar-camera via spatiotemporal transformers. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(3): 2020−2036 doi: 10.1109/TPAMI.2024.3515454 [92] Yang C Y, Chen Y T, Tian H, Tao C X, Zhu X Z, Zhang Z X, et al. Bevformer v2: adapting modern image backbones to bird's-eye-view recognition via perspective supervision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 17830-17839 [93] Zhu X Z, Su W J, Lu L W, Li B, Wang X G, Dai J F. Deformable detr: deformable transformers for end-to-end object detection. arXiv preprint arXiv: 2010.04159, 2020 [94] Chen S Y, Cheng T H, Wang X G, Meng W M, Zhang Q, Liu W Y. Efficient and robust 2d-to-bev representation learning via geometry-guided kernel transformer. arXiv preprint arXiv: 2206.04584, 2022 [95] Wu Y M, Li R X, Qin Z Q, Zhao X H, Li X. Heightformer: explicit height modeling without extra data for camera-only 3d object detection in bird's eye view. IEEE Transactions on Image Processing, 2024, 34: 689−700 doi: 10.1109/tip.2024.3427701 [96] Cai H X, Zhang Z Y, Zhou Z Y, Li Z Y, Ding W B, Zhao J H. Bevfusion4d: learning lidar-camera fusion under bird's-eye-view via cross-modality guidance and temporal aggregation. arXiv preprint arXiv: 2303.17099, 2023 [97] Man Y Z, Gui L Y, Wang Y X. Bev-guided multi-modality fusion for driving perception. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 21960-21969 [98] Chen Y L, Yu Z D, Chen Y K, Lan S Y, Anandkumar A, Jia J Y, et al. Focalformer3d: focusing on hard instance for 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 8394-8405 [99] Gunn J, Lenyk Z, Sharma A, Donati A, Buburuzan A, Redford J, et al. Lift-attend-splat: bird's-eye-view camera-lidar fusion using transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 4526-4536 [100] Wang S M, Caesar H, Nan L L, Kooij J F P. Unibev: multi-modal 3d object detection with uniform bev encoders for robustness against missing sensor modalities. In: Proceedings of the IEEE Intelligent Vehicles Symposium. Jeju Island, South Korea: IEEE, 2024. 2776-2783 [101] Yin J B, Shen J B, Chen R N, Li W, Yang R G, Frossard P, et al. Is-fusion: instance-scene collaborative fusion for multimodal 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 14905-14915 [102] Saha A, Mendez O, Russell C, Bowden R. Translating images into maps. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Philadelphia, USA: IEEE, 2022. 9200-9206 [103] Jiang Y Q, Zhang L, Miao Z W, Zhu X T, Gao J, Hu W M, et al. Polarformer: multi-camera 3d object detection with polar transformer. In: Proceedings of the AAAI Conference on Artificial Intelligence. Washington D.C., USA: AAAI, 2023. 1042-1050 [104] Yang H T, Bai X Y, Zhu X G, Ma Y X. One training for multiple deployments: polar-based adaptive bev perception for autonomous driving. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). London, UK: IEEE, 2023. 5602-5609 [105] Zhao J W, Jiang Q X, Li X D, Luo J F. Focus on bev: self-calibrated cycle view transformation for monocular birds-eye-view segmentation. arXiv preprint arXiv: 2410.15932, 2024 [106] Pan B W, Sun J K, Leung H Y T, Andonian A, Zhou B L. Cross-view semantic segmentation for sensing surroundings. IEEE Robotics and Automation Letters, 2020, 5(3): 4867−4873 doi: 10.1109/LRA.2020.3004325 [107] Li Q, Wang Y, Wang Y L, Zhao H. Hdmapnet: an online hd map construction and evaluation framework. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Philadelphia, USA: IEEE, 2022. 4628-4634 [108] Roddick T, Cipolla R. Predicting semantic map representations from images using pyramid occupancy networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 11138-11147 [109] Chitta K, Prakash A, Geiger A. Neat: neural attention fields for end-to-end autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Virtual Event: IEEE, 2021. 15793-15803 [110] Yang W X, Li Q, Liu W X, Yu Y L, Ma Y X, He S F, et al. Projecting your view attentively: monocular road scene layout estimation via cross-view transformation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 15536-15545 [111] Liu W X, Li Q, Yang W X, Cai J X, Yu Y L, Ma Y X, et al. Monocular bev perception of road scenes via front-to-top view projection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(9): 6109−6125 doi: 10.1109/TPAMI.2024.3377812 [112] Fan S Q, Wang Z, Huo X L, Wang Y, Liu J J. Calibration-free bev representation for infrastructure perception. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Detroit, USA: IEEE, 2023. 9008-9013 [113] Zhou B, Krahenbuhl P. Cross-view transformers for real-time map-view semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 13760-13769 [114] Bartoccioni F, Zablocki E, Bursuc A, Perez P, Cord M, Alahari K. Lara: latents and rays for multi-camera bird's-eye-view semantic segmentation. In: Proceedings of the Conference on Robot Learning. Auckland, New Zealand: PMLR, 2022. 1663-1672 [115] Peng L, Chen Z R, Fu Z J, Liang P P, Cheng E K. Bevsegformer: bird's eye view semantic segmentation from arbitrary camera rigs. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Waikoloa, USA: IEEE, 2023. 5935-5943 [116] Liu Z J, Tang H T, Amini A, Yang X Y, Mao H Z, Rus D L, et al. Bevfusion: multi-task multi-sensor fusion with unified bird's-eye view representation. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). London, UK: IEEE, 2023. 2774-2781 [117] Huang J J, Ye Y, Liang Z J, Shan Y, Du D L. Detecting as labeling: rethinking lidar-camera fusion in 3d object detection. In: Proceedings of the European Conference on Computer Vision (ECCV). Milan, Italy: Springer, 2024. 439-455 [118] Fu J H, Gao C, Wang Z T, Yang L R, Wang X F, Mu B P, et al. Eliminating cross-modal conflicts in bev space for lidar-camera 3d object detection. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Yokohama, Japan: IEEE, 2024. 16381-16387 [119] Zhu X Z, Xiong Y W, Dai J F, Yuan L, Wei Y C. Deep feature flow for video recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 2349-2358 [120] Li X T, You A S, Zhu Z, Zhao H L, Yang M K, Yang K Y, et al. Semantic flow for fast and accurate scene parsing. In: Proceedings of the European Conference on Computer Vision (ECCV). Virtual Event: Springer, 2020. 775-793 [121] Hu H T, Wang F Y, Su J W, Wang Y N, Hu L F, Fang W Y, et al. Ea-lss: edge-aware lift-splat-shot framework for 3d bev object detection. arXiv preprint arXiv: 2303.17895, 2023 [122] Song Z Y, Yang L, Xu S Q, Liu L, Xu D Y, Jia C Y, et al. Graph-bev: towards robust bev feature alignment for multi-modal 3d object detection. In: Proceedings of the European Conference on Computer Vision (ECCV). Milan, Italy: Springer, 2024. 347-366 [123] Liang T T, Xie H W, Yu K C, Xia Z X, Lin Z W, Wang Y T, et al. Bevfusion: a simple and robust lidar-camera fusion framework. In: Proceedings of the Advances in Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2022. 10421-10434 [124] Zeng Y H, Zhang D, Wang C W, Miao Z W, Liu T, Zhan X, et al. Lift: learning 4d lidar image fusion transformer for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 17172-17181 [125] Li X T, Fan B J, Tian J D, Fan H J. Gafusion: adaptive fusing lidar and camera with multiple guidance for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 21209-21218 [126] Chen M, Yang M C, Zhang Y, Han T, Li X C, Zhao H C, et al. Multi-modal BEV enhancement fusion for 3D object detection in autonomous driving. IEEE Transactions on Intelligent Transportation Systems, 2025, 26(11): 18447−18459 doi: 10.1109/TITS.2025.3589581 [127] Vora S, Lang A H, Helou B, Beijbom O. Pointpainting: sequential fusion for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 4604-4612 [128] Yin T W, Zhou X Y, Krahenbuhl P. Multimodal virtual point 3d detection. In: Proceedings of the Advances in Neural Information Processing Systems. Virtual Event: Curran Associates, 2021. 16494-16507 [129] Xu S Q, Zhou D F, Fang J, Yin J B, Bin Z, Zhang L J. Fusionpainting: multimodal fusion with adaptive attention for 3d object detection. In: Proceedings of the IEEE International Intelligent Transportation Systems Conference (ITSC). Indianapolis, USA: IEEE, 2021. 3047-3054 [130] Zhu H Q, Deng J J, Zhang Y, Ji J M, Mao Q Y, Li H Q, et al. Vpfnet: improving 3d object detection with virtual point based lidar and stereo data fusion. IEEE Transactions on Multimedia, 2022, 25: 5291−5304 doi: 10.1109/tmm.2022.3189778 [131] Mahmoud A, Hu J S, Waslander S L. Dense voxel fusion for 3d object detection. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Waikoloa, USA: IEEE, 2023. 663-672 [132] Chen Y K, Li Y W, Zhang X Y, Sun J, Jia J Y. Focal sparse convolutional networks for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 5428-5437 [133] Chen Y K, Liu J H, Zhang X Y, Qi X J, Jia J Y. Largekernel3d: scaling up kernels in 3d sparse cnns. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 13488-13498 [134] Li Y W, Qi X J, Chen Y K, Wang L W, Li Z M, Sun J, et al. Voxel field fusion for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 1120-1129 [135] Li Y W, Chen Y L, Qi X J, Li Z M, Sun J, Jia J Y. Unifying voxel-based representation with transformer for 3d object detection. In: Proceedings of the Advances in Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2022. 18442-18455 [136] Jiao Y, Jie Z Q, Chen S X, Chen J J, Ma L, Jiang Y G. Msmdfusion: fusing lidar and camera at multiple scales with multi-depth seeds for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 21643-21652 [137] Li Y W, Yu A W, Meng T J, Caine B, Ngiam J, Peng D Y, et al. Deepfusion: lidar-camera deep fusion for multi-modal 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 17182-17191 [138] Chen Z H, Li Z Y, Zhang S Q, Fang L J, Jiang Q H, Zhao F, et al. Autoalign: pixel-instance feature aggregation for multi-modal 3d object detection. arXiv preprint arXiv: 2201.06493, 2022 [139] Chen Z H, Li Z Y, Zhang S Q, Fang L J, Jiang Q H, Zhao F. Deformable feature aggregation for dynamic multi-modal 3d object detection. In: Proceedings of the European Conference on Computer Vision (ECCV). Tel Aviv, Israel: Springer, 2022. 628-644 [140] Li X, Shi B T, Hou Y N, Wu X J, Ma T L, Li Y K, et al. Homogeneous multi-modal feature fusion and interaction for 3d object detection. In: Proceedings of the European Conference on Computer Vision (ECCV). Tel Aviv, Israel: Springer, 2022. 691-707 [141] Wang H Y, Tang H, Shi S S, Li A X, Li Z G, Schiele B, et al. Unitr: a unified and efficient multi-modal transformer for bird's-eye-view representation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 6792-6802 [142] Huang J J, Huang G. Bevdet4d: exploit temporal cues in multi-camera 3d object detection. arXiv preprint arXiv: 2203.17054, 2022 [143] Zhang Y P, Zhu Z, Zheng W Z, Huang J J, Huang G, Zhou J, et al. Beverse: unified perception and prediction in birds-eye-view for vision-centric autonomous driving. arXiv preprint arXiv: 2205.09743, 2022 [144] Hu A, Murez Z, Mohan N, Dudas S, Hawke J, Badrinarayanan V, et al. Fiery: future instance prediction in bird's-eye view from surround monocular cameras. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Virtual Event: IEEE, 2021. 15273-15282 [145] Hu S C, Chen L, Wu P H, Li H Y, Yan J C, Tao D C. St-p3: end-to-end vision-based autonomous driving via spatial-temporal feature learning. In: Proceedings of the European Conference on Computer Vision (ECCV). Tel Aviv, Israel: Springer, 2022. 533-549 [146] Park J, Xu C F, Yang S J, Keutzer K, Kitani K, Tomizuka M, et al. Time will tell: new outlooks and a baseline for temporal multi-view 3d object detection. arXiv preprint arXiv: 2210.02443, 2022 [147] Yao Y, Luo Z X, Li S W, Fang T, Quan L. Mvsnet: depth inference for unstructured multi-view stereo. In: Proceedings of the European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 767-783 [148] Zong Z F, Jiang D Z, Song G L, Xue Z Y, Su J Y, Li H S, et al. Temporal enhanced training of multi-view 3d object detector via historical object prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 3781-3790 [149] Xia Z Y, Lin Z W, Wang X H, Wang Y T, Xing Y, Qi S X, et al. Henet: hybrid encoding for end-to-end multi-task 3d perception from multi-view cameras. In: Proceedings of the European Conference on Computer Vision (ECCV). Milan, Italy: Springer, 2024. 376-392 [150] Qin Z Q, Chen J Y, Chen C, Chen X Z, Li X. Unifusion: unified multi-view fusion transformer for spatial-temporal representation in bird's-eye-view. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 8690-8699 [151] Zaremba W, Sutskever I, Vinyals O. Recurrent neural network regularization. arXiv preprint arXiv: 1409.2329, 2014 [152] Han C R, Yang J R, Sun J J, Ge Z, Dong R P, Zhou H Y, et al. Exploring recurrent long-term temporal fusion for multi-view 3d perception. IEEE Robotics and Automation Letters, 2024, 9(7): 6544−6551 doi: 10.1109/LRA.2024.3401172 [153] Hu C Y, Zheng H, Li K, Xu J Y, Mao W B, Luo M C, et al. Fusionformer: a multi-sensory fusion in bird's-eye-view and temporal consistent transformer for 3d object detection. arXiv preprint arXiv: 2309.05257, 2023 [154] Chang M, Zhang X S, Zhang R, Zhao Z P, He G H, Liu S L. Recurrentbev: a long-term temporal fusion framework for multi-view 3d detection. In: Proceedings of the European Conference on Computer Vision (ECCV). Milan, Italy: Springer, 2024. 131-147 [155] Saini L, Meuter M, Tercan H, Meisen T. AttentiveGRU: Recurrent Spatio-Temporal Modeling for Advanced Radar-Based BEV Object Detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 2415-2424 [156] Chen Y K, Liu J H, Zhang X Y, Qi X J, Jia J Y. Voxelnext: fully sparse voxelnet for 3d object detection and tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 21674-21683 [157] Fan L, Wang F, Wang N Y, Zhang Z X. Fully sparse 3d object detection. In: Proceedings of the Advances in Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2022. 351-363 [158] Fan L, Yang Y X, Wang F, Wang N Y, Zhang Z X. Super sparse 3d object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(10): 12490−12505 doi: 10.1109/TPAMI.2023.3286409 [159] Fan L, Wang F, Wang N Y, Zhang Z X. Fsd v2: improving fully sparse 3d object detection with virtual voxels. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(2): 1279−1292 doi: 10.1109/TPAMI.2024.3502456 [160] Zhang G, Chen J N, Gao G H, Li J M, Liu S, Hu X L. Safdnet: a simple and effective network for fully sparse 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 14477-14486 [161] Yuan Y S, Xia Y, Cremers D, Sester M. SparseAlign: A Fully Sparse Framework for Cooperative Object Detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 22296-22305 [162] Sun P, Tan M X, Wang W Y, Liu C X, Xia F, Leng Z Q, et al. Swformer: sparse window transformer for 3d object detection in point clouds. In: Proceedings of the European Conference on Computer Vision (ECCV). Tel Aviv, Israel: Springer, 2022. 426-442 [163] Liu L, Song Z Y, Xia Q M, Jia F Y, Jia C Y, Yang L, et al. Sparsedet: a simple and effective framework for fully sparse lidar-based 3d object detection. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: Article No. 5707114 doi: 10.1109/tgrs.2024.3468394/v3/review2 [164] Liu S, Cui M, Li B, Liang Q, Hong T, Huang K, et al. FSHNet: Fully Sparse Hybrid Network for 3D Object Detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 8900-8909 [165] Lee M, Park S, Kim H, Yoon M, Lee J, Choi J W, et al. SPADE: Sparse Pillar-based 3D Object Detection Accelerator for Autonomous Driving. In: Proceedings of the 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). Edinburgh, UK: IEEE, 2024. 454-467 [166] Wang T, Zhu X G, Pang J M, Lin D H. Fcos3d: fully convolutional one-stage monocular 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Virtual Event: IEEE, 2021. 913-922 [167] Tian Z, Shen C H, Chen H, He T. Fcos: a simple and strong anchor-free object detector. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(4): 1922−1933 [168] Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. In: Proceedings of the European Conference on Computer Vision (ECCV). Virtual Event: Springer, 2020. 213-229 [169] Wang Y, Guizilini V C, Zhang T Y, Wang Y L, Zhao H, Solomon J. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In: Proceedings of the Conference on Robot Learning. Auckland, New Zealand: PMLR, 2022. 180-191 [170] Chen S Y, Wang X G, Cheng T H, Zhang Q, Huang C, Liu W Y. Polar parametrization for vision-based surround-view 3d detection. arXiv preprint arXiv: 2206.10965, 2022 [171] Lin X W, Lin T W, Pei Z X, Huang L C, Su Z Z. Sparse4d: multi-view 3d object detection with sparse spatial-temporal fusion. arXiv preprint arXiv: 2211.10581, 2022 [172] Lin X W, Lin T W, Pei Z X, Huang L C, Su Z Z. Sparse4d v2: recurrent temporal fusion with sparse model. arXiv preprint arXiv: 2305.14018, 2023 [173] Chen Z H, Li Z Y, Zhang S Q, Fang L J, Jiang Q H, Zhao F. Graph-detr3d: rethinking overlapping regions for multi-view 3d object detection. In: Proceedings of the 30th ACM International Conference on Multimedia. Lisbon, Portugal: ACM, 2022. 5999-6008 [174] Chen Z H, Chen Z, Li Z Y, Zhang S Q, Fang L J, Jiang Q H, et al. Graph-detr4d: spatio-temporal graph modeling for multi-view 3d object detection. IEEE Transactions on Image Processing, 2024, 33: 4488−4500 doi: 10.1109/TIP.2024.3430473 [175] Liu H S, Teng Y, Lu T, Wang H G, Wang L M. Sparsebev: high-performance sparse 3d object detection from multi-camera videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 18580-18590 [176] Li H Y, Zhang H, Zeng Z Y, Liu S L, Li F, Ren T H, et al. Dfa3d: 3d deformable attention for 2d-to-3d feature lifting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 6684-6693 [177] Lin X W, Pei Z X, Lin T W, Huang L C, Su Z Z. Sparse4d v3: advancing end-to-end 3d detection and tracking. arXiv preprint arXiv: 2311.11722, 2023 [178] Xu L Z, Pang S M, Qiu W Z, Wu Z H, Bai X X, Mei K Z, et al. Redundant queries in detr-based 3d detection methods: unnecessary and prunable. arXiv preprint arXiv: 2412.02054, 2024 [179] 田永林, 王雨桐, 王建功, 王晓, 王飞跃. 视觉Transformer研究的关键问题: 现状及展望. 自动化学报, 2022, 48(4): 957−979 doi: 10.16383/j.aas.c220027Tian Yong-Lin, Wang Yu-Tong, Wang Jian-Gong, Wang Xiao, Wang Fei-Yue. Key problems and progress of vision transformers: the state of the art and prospects. Acta Automatica Sinica, 2022, 48(4): 957−979 doi: 10.16383/j.aas.c220027 [180] Liu Y F, Wang T C, Zhang X Y, Sun J. Petr: position embedding transformation for multi-view 3d object detection. In: Proceedings of the European Conference on Computer Vision (ECCV). Tel Aviv, Israel: Springer, 2022. 531-548 [181] Wang S H, Jiang X H, Li Y. Focal-petr: embracing foreground for efficient multi-camera 3d object detection. IEEE Transactions on Intelligent Vehicles, 2023, 9(1): 1481−1489 [182] Liu Y F, Yan J J, Jia F, Li S L, Gao A, Wang T C, et al. Petrv2: a unified framework for 3d perception from multi-camera images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 3262-3272 [183] Wang S H, Liu Y F, Wang T C, Li Y, Zhang X Y. Exploring object-centric temporal modeling for efficient multi-view 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 3621-3631 [184] Chen D, Li J, Guizilini V, Ambrus R A, Gaidon A. Viewpoint equivariance for multi-view 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 9213-9222 [185] Doll S, Schulz R, Schneider L, Benzin V, Enzweiler M, Lensch H P. Spatialdetr: robust scalable transformer-based 3d object detection from multi-view camera images with global cross-sensor attention. In: Proceedings of the European Conference on Computer Vision (ECCV). Tel Aviv, Israel: Springer, 2022. 230-245 [186] Xiong K X, Gong S, Ye X Q, Tan X, Wan J, Ding E R, et al. Cape: camera view position embedding for multi-view 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 21570-21579 [187] Shu C Y, Deng J J, Yu F, Liu Y F. 3Dppe: 3d point positional encoding for transformer-based multi-camera 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 3580-3589 [188] Zhang R R, Qiu H, Wang T, Guo Z Y, Cui Z T, Qiao Y, et al. Monodetr: depth-guided transformer for monocular 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 9155-9166 [189] Tseng C Y, Chen Y R, Lee H Y, Wu T H, Chen W C, Hsu W H. Crossdtr: cross-view and depth-guided transformers for 3d object detection. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). London, UK: IEEE, 2023. 4850-4857 [190] Xie Y M, Jiang H Z, Gkioxari G, Straub J. Pixel-aligned recurrent queries for multi-view 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 18370-18380 [191] Wang Z T, Huang Z H, Fu J H, Wang N Y, Liu S. Object as query: lifting any 2d object detector to 3d detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 3791-3800 [192] Jiang X H, Li S L, Liu Y F, Wang S H, Jia F, Wang T C, et al. Far3d: expanding the horizon for surround-view 3d object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2024. 2561-2569 [193] Ji H X Y, Liang P P, Cheng E K. Enhancing 3d object detection with 2d detection-guided query anchors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 21178-21187 [194] Tang Y, He H, Wang Y, Wu J. Towards efficient multi-modal 3D object detection: Homogeneous sparse fuse network. Expert Systems with Applications, DOI: https://doi.org/ 10.1016/j.eswa.2024.124945 [195] Li Y Y, Fan L, Liu Y, Huang Z H, Chen Y T, Wang N Y, et al. Fully sparse fusion for 3d object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(11): 7217−7231 doi: 10.1109/TPAMI.2024.3392303 [196] Wang Z T, Huang Z H, Gao Y L, Wang N Y, Liu S. MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, DOI: https://doi.org/ 10.1109/TPAMI.2025.3609348 [197] Li Y H, Li H Y, Huang Z H, Chang H, Wang N Y. Sparsefusion: efficient sparse multi-modal fusion framework for long-range 3d perception. arXiv preprint arXiv: 2403.10036, 2024 [198] Son H, He J, Park S I, Min Y, Zhang Y, Yoo B I, et al. SparseVoxFormer: Sparse Voxel-based Transformer for Multi-modal 3D Object Detection. arXiv preprint arXiv: 2503.08092, 2025 [199] Ji H, Ni T, Huang X F, Shi Z, Luo T, Zhan X, et al. Ropetr: Improving temporal camera-only 3d detection by integrating enhanced rotary position embedding. arXiv preprint arXiv: 2504.12643, 2025 [200] Chen X Z, Ma H M, Wan J, Li B, Xia T. Multi-view 3d object detection network for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 1907-1915 [201] Ku J, Mozifian M, Lee J, Harakeh A, Waslander S L. Joint 3d proposal generation and object detection from view aggregation. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Madrid, Spain: IEEE, 2018. 1-8 [202] Cai Q, Pan Y W, Yao T, Ngo C W, Mei T. Objectfusion: multi-modal 3d object detection with object-centric fusion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 18067-18076 [203] Liang M, Yang B, Chen Y, Hu R, Urtasun R. Multi-task multi-sensor fusion for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 7345-7353 [204] Wu X P, Peng L, Yang H H, Xie L, Huang C X, Deng C Q, et al. Sparse fuse dense: towards high quality 3d detection with depth completion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 5418-5427 [205] Pang S, Morris D, Radha H. Clocs: camera-lidar object candidates fusion for 3d object detection. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Las Vegas, USA: IEEE, 2020. 10386-10393 [206] Pang S, Morris D, Radha H. Fast-clocs: fast camera-lidar object candidates fusion for 3d object detection. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Waikoloa, USA: IEEE, 2022. 187-196 [207] Bai X Y, Hu Z Y, Zhu X G, Huang Q Q, Chen Y L, Fu H B, et al. Transfusion: robust lidar-camera fusion for 3d object detection with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 1090-1099 [208] Yan J J, Liu Y F, Sun J J, Jia F, Li S L, Wang T C, et al. Cross modal transformer: towards fast and robust 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 18268-18278 [209] Yang Z Y, Chen J Q, Miao Z W, Li W, Zhu X T, Zhang L. Deepinteraction: 3d object detection via modality interaction. In: Proceedings of the Advances in Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2022. 1992-2005 [210] Yang Z Y, Song N, Li W, Zhu X T, Zhang L, Torr P H S. Deepinteraction++: multi-modality interaction for autonomous driving. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(8): 6749−6763 doi: 10.1109/TPAMI.2025.3565194 [211] Chen X Y, Zhang T Y, Wang Y, Wang Y L, Zhao H. Futr3d: a unified sensor fusion framework for 3d detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 172-181 [212] Zhang H C, Liang L, Zeng P X, Song X, Wang Z. Sparselif: high-performance sparse lidar-camera fusion for 3d object detection. In: Proceedings of the European Conference on Computer Vision (ECCV). Milan, Italy: Springer, 2024. 109-128 [213] Xie Y C, Xu C F, Rakotosaona M J, Rim P, Tombari F, Keutzer K, et al. Sparsefusion: fusing multi-modal sparse representations for multi-sensor 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 17591-17602 -

 下载:
下载:

计量
- 文章访问数: 239
- HTML全文浏览量: 470
- 被引次数: 0
