

-
摘要: 参考多目标跟踪(RMOT)是一项利用语言与视觉模态数据进行目标定位与跟踪的任务, 旨在在视频帧中根据语言提示精准识别并持续跟踪指定目标. 尽管现有RMOT方法在该领域取得了一定进展, 但针对语言表述概念粒度的建模仍较为有限, 导致模型在处理复杂语言描述时存在语义解析不足的问题. 为此, 提出基于语义概念关联的参考多目标跟踪方法(SCATrack), 通过引入共享语义概念(SSC)和语义概念辅助生成(SCG)模块, 以提升模型对语言表述的深层理解能力, 从而增强跟踪任务的持续性与鲁棒性. 具体而言, SSC模块对语言表述进行语义概念划分, 使模型能够有效区分相同语义的不同表达方式, 以及不同语义间的相似表达方式, 从而提升多粒度输入条件下的目标辨别能力. SCG模块则采用特征遮蔽与生成机制, 引导模型学习多粒度语言概念的表征信息, 增强其对复杂语言描述的鲁棒性和辨别能力. 在两个广泛使用的基准数据集上的实验结果表明, 所提出的SCATrack显著提升了RMOT任务的跟踪性能, 验证了方法的有效性与优越性.Abstract: Referring multi-object tracking (RMOT) is a task that jointly leverages language and visual modalities for object localization and tracking, aiming to accurately identify and continuously track specific objects in video frames according to natural language prompts. Although existing RMOT methods have achieved notable progress, their modeling of the conceptual granularity of language expressions remains limited, leading to insufficient semantic parsing when handling complex descriptions. To address this issue, we propose a semantic concept association-based RMOT framework, termed SCATrack. The framework introduces two key modules, namely the sharing semantic concept (SSC) module and the semantic concept auxiliary generation (SCG) module, to enhance the model's capability of deeply understanding language expressions, thereby improving both the continuity and robustness of tracking. Specifically, the SSC module performs semantic concept partitioning over the language expressions, enabling the model to effectively distinguish different expressions conveying the same semantics and similar expressions across distinct semantics, which strengthens object discrimination under multi-granularity input conditions. The SCG module adopts a feature masking and generation mechanism to guide the model in learning representations of multi-granularity language concepts, thereby improving its robustness and discriminative ability in complex language scenarios. Experimental results on two widely used benchmark datasets demonstrate that the proposed SCATrack significantly improves tracking performance in RMOT tasks, validating its effectiveness and superiority.
-
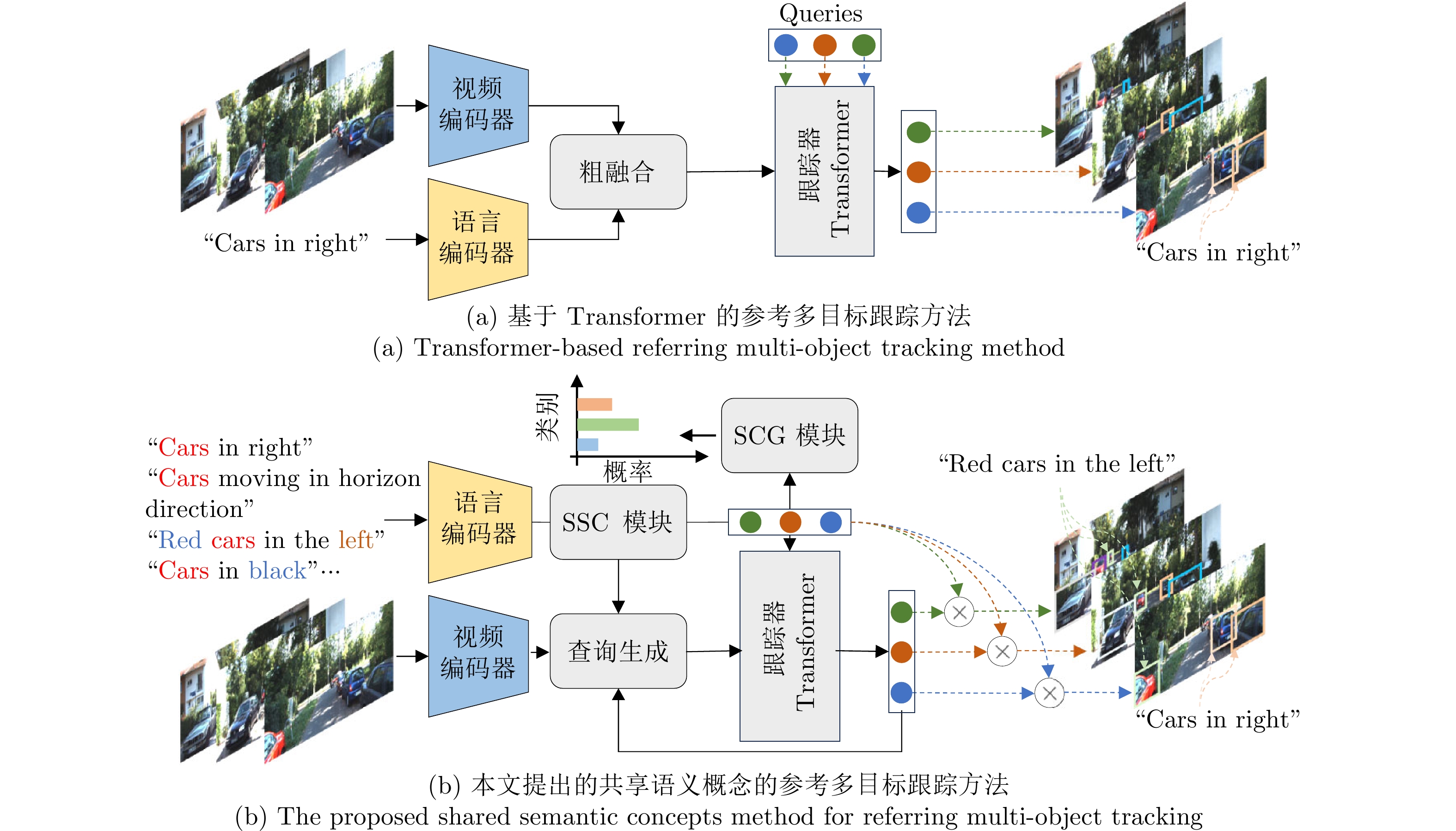
图 1 现有RMOT方法与所提SCATrack方法的示意图
Fig. 1 Illustration of the existing RMOT and the proposed SCATrack methods
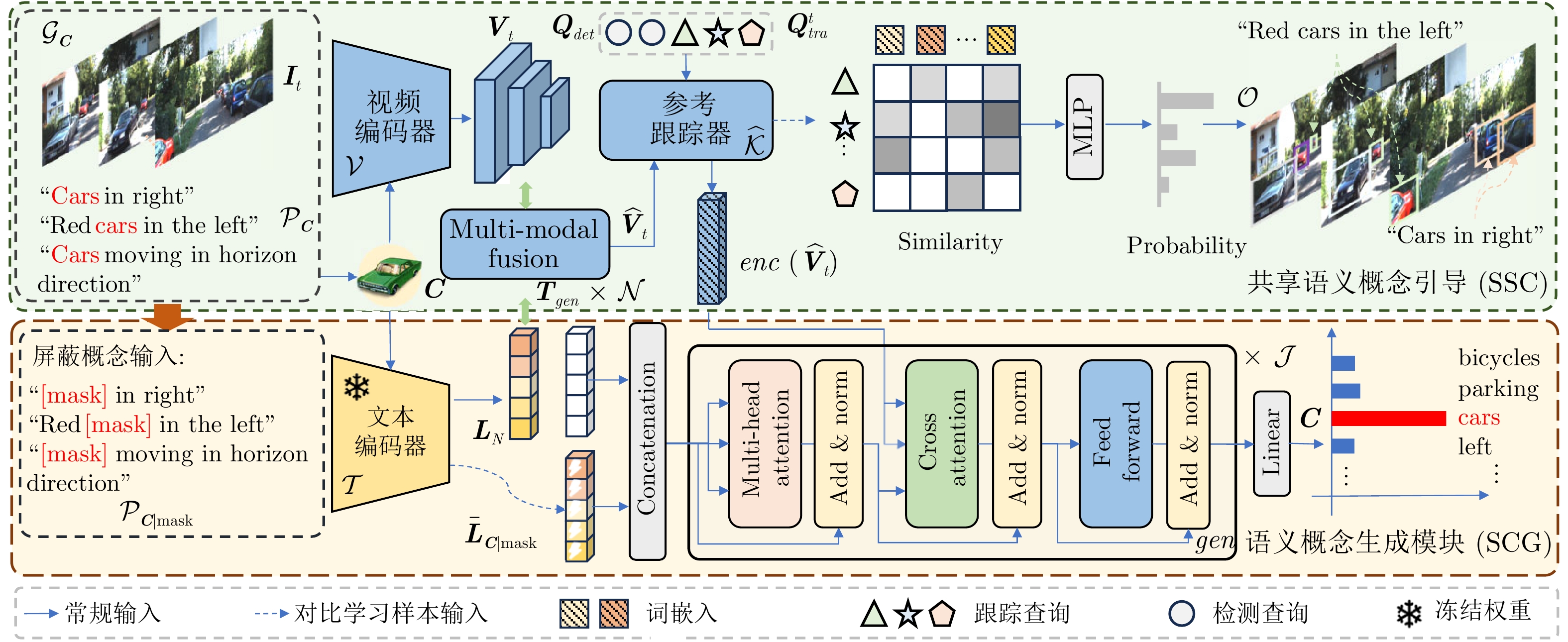
图 2 语义概念关联的参考多目标跟踪算法框架结构
Fig. 2 Semantic concept association for referring multi-object tracking framework

图 3 SCATrack与现有RMOT方法在Refer-KITTI上的定性比较
Fig. 3 Qualitative comparison of the proposed SCATrack with existing RMOT methods on Refer-KITTI

图 4 SCATrack与现有RMOT方法在Refer-BDD上的定性比较
Fig. 4 Qualitative comparison of the proposed SCATrack with existing RMOT methods on Refer-BDD

图 5 SCATrack在Refer-KITTI上的更多定性结果
Fig. 5 More qualitative results of the proposed SCATrack on Refer-KITTI

图 6 SCATrack在Refer-BDD上的更多定性结果
Fig. 6 More qualitative results of the proposed SCATrack on Refer-BDD
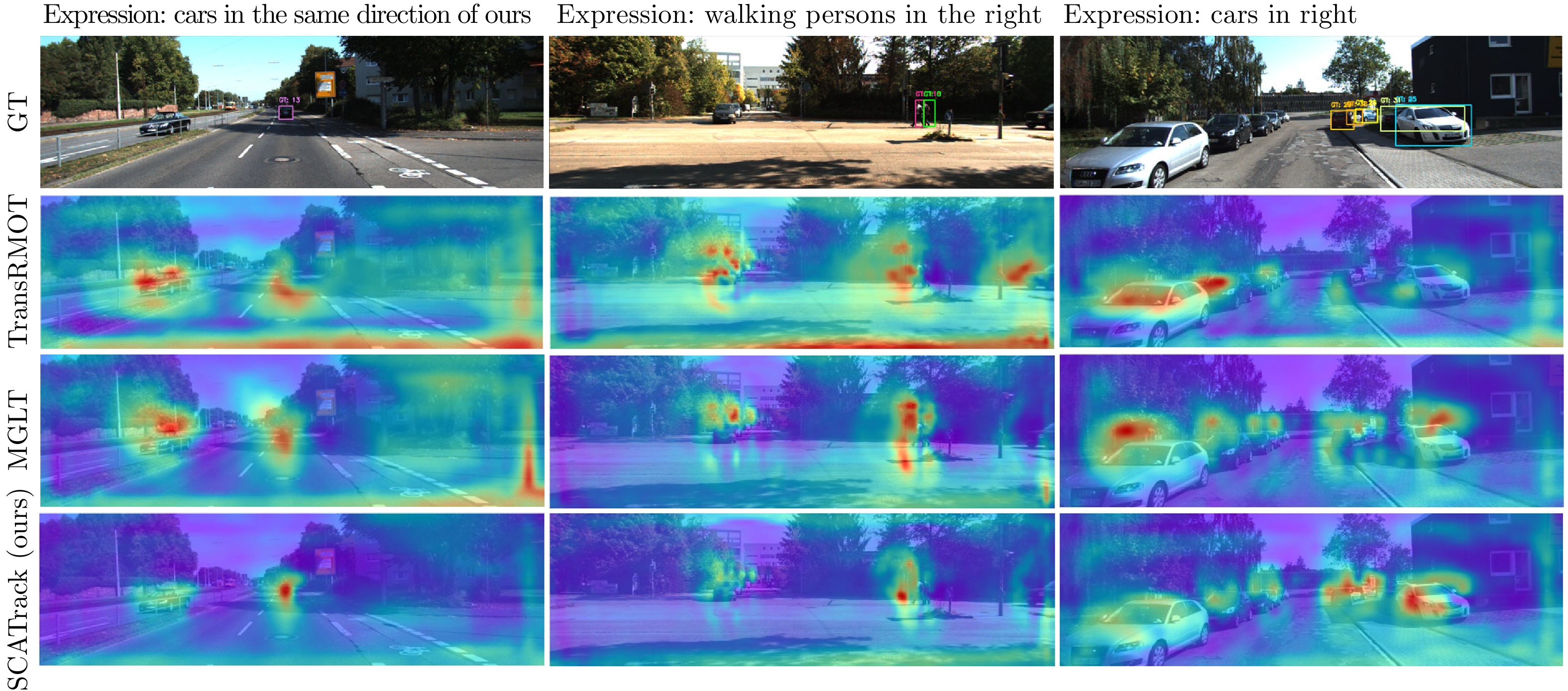
图 7 SCATrack与现有RMOT方法的编码器最后一层热力图在Refer-KITTI上的比较
Fig. 7 Comparison of the SCATrack with the existing RMOT method's encoder last layer heat map on Refer-KITTI
表 1 SCATrack与现有RMOT方法在Refer-KITTI上的定量结果
Table 1 Quantification of the proposed SCATrack with existing RMOT methods on Refer-KITTI
方法 特征提取网络 检测器 HOTA$\uparrow$ DetA$\uparrow$ AssA$\uparrow$ MOTA$\uparrow$ IDF1$\uparrow$ IDS$\downarrow$ DeepSORT[26] ${}_{\rm{ICIP17}}$ — FairMOT 25.59 19.76 34.31 — — — FairMOT[48] ${}_{\rm{IJCV21}}$ DLA-34 CenterNet 23.46 14.84 40.15 0.80 26.18 3376 ByteTrack[49] ${}_{\rm{ECCV22}}$ — FairMOT 24.95 15.50 43.11 — — — CSTrack[50] ${}_{\rm{TIP22}}$ DarkNet-53 YOLOv5 27.91 20.65 39.00 — — — TransTrack[27] ${}_{\rm{arXiv20}}$ ResNet-50 Deformable-DETR 32.77 23.31 45.71 — — — TrackFormer[14] ${}_{\rm{CVPR22}}$ ResNet-50 Deformable-DETR 33.26 25.44 45.87 — — — DeepRMOT[3] ${}_{\rm{ICASSP24}}$ ResNet-50 Deformable-DETR 39.55 30.12 53.23 — — — EchoTrack[6] ${}_{\rm{TITS24}}$ ResNet-50 Deformable-DETR 39.47 31.19 51.56 — — — TransRMOT[2] ${}_{\rm{CVPR23}}$ ResNet-50 Deformable-DETR 46.56 37.97 57.33 24.68 53.85 3144 iKUN[5] ${}_{\rm{CVPR24}}$ ResNet-50 Deformable-DETR 48.84 35.74 66.80 12.26 54.05 — MLS-Track[29] ${}_{\rm{arXiv24}}$ ResNet-50 Deformable-DETR 49.05 40.03 60.25 — — — MGLT MOTRv2[31] ${}_{\rm{TIM25}}$ ResNet-50 YOLOX+DAB-D-DETR 47.75 35.11 65.08 8.36 53.39 2948 MGLT CO-MOT[31] ${}_{\rm{TIM25}}$ ResNet-50 Deformable-DETR 49.25 37.09 65.50 21.13 55.91 2442 SCATrack${}_{\rm{MOTRv2}}$ (ours) ResNet-50 YOLOX+DAB-D-DETR $\underline{49.98}_{ {+ 2.23}}$ $37.57_{ {+ 2.46}}$ $\underline{66.68}_{ {+ 1.60}}$ $13.08_{ {+ 4.72}}$ $\underline{56.66}_{ {+ 3.27}}$ $2\;985_{+ 37}$ SCATrack CO-MOT (ours) ResNet-50 Deformable-DETR ${\bf{50.33}}_{ {+ 1.08}}$ $\underline{38.53}_{ {+ 1.44}}$ $65.84_{ {+ 0.34}}$ $\underline{23.86}_{ {+ 2.73}}$ ${\bf{57.10}}_{ {+ 1.19}}$ $\underline{2\;700}_{+ 258}$  下载: 导出CSV
下载: 导出CSV
表 2 SCATrack与现有RMOT方法在Refer-BDD上的定量结果
Table 2 Quantification of the proposed SCATrack with existing RMOT methods on Refer-BDD
方法 特征提取网络 检测器 HOTA$\uparrow$ DetA $\uparrow$ AssA $\uparrow$ MOTA $\uparrow$ IDF1 $\uparrow$ IDS $\downarrow$ TransRMOT[2] ${}_{\rm{CVPR23}}$ ResNet-50 Deformable-DETR 34.79 26.22 47.56 — — — EchoTrack[6] ${}_{\rm{TITS24}}$ ResNet-50 Deformable-DETR 38.00 28.57 51.24 — — — MOTRv2[10] ${}_{\rm{CVPR23}}$ ResNet-50 YOLOX+DAB-D-DETR 36.49 23.64 56.88 −1.05 37.38 17670 CO-MOT[17] ${}_{\rm{arXiv23}}$ ResNet-50 Deformable-DETR 37.32 25.53 55.09 10.57 40.56 14432 MGLT MOTR[31]${}_{\rm{TIM25}}$ ResNet-50 Deformable-DETR 38.69 27.06 55.76 $\underline{13.97}$ 41.85 13846 MGLT MOTRv2[31]${}_{\rm{TIM25}}$ ResNet-50 YOLOX+DAB-D-DETR 38.40 26.48 56.23 0.69 41.01 14804 MGLT CO-MOT[31]${}_{\rm{TIM25}}$ ResNet-50 Deformable-DETR 40.26 28.44 57.58 11.68 44.41 $\underline{12\;935}$ SCATrack ${}_{\rm{MOTRv2}}$ (ours) ResNet-50 YOLOX+DAB-D-DETR $\underline{40.49}_{ {+ 2.09}}$ $\underline{28.68}_{ {+ 2.20}}$ $\underline{57.73}_{ {+ 1.50}}$ $4.15_{ {+3.46}}$ $\underline{44.65}_{ {+ 3.64}}$ $13\;613_{ {- 1\;191}}$ SCATrack CO-MOT (ours) ResNet-50 Deformable-DETR ${\bf{41.27}}_{ {+ 1.01}}$ ${\bf{29.11}}_{ {+ 0.67}}$ ${\bf{59.21}}_{ {+ 1.63}}$ ${\bf{14.24}}_{ {+2.56}}$ ${\bf{45.46}}_{ {+ 1.05}}$ ${\bf{12\;458}}_{ {- 477}}$
下载: 导出CSV
表 3 不同组件组合模型性能对比
Table 3 Performance comparison of different component combination models
设置 HOTA$\uparrow$ DetA$\uparrow$ AssA$\uparrow$ MOTA$\uparrow$ IDF1$\uparrow$ IDS$\downarrow$ Acc (%)$\uparrow$ 基线 49.25 37.09 65.50 21.13 55.91 2442 — w. SSC 49.42 37.43 65.35 20.79 56.19 2574 — w. SCG 49.81 38.01 65.37 18.81 56.42 2862 53.78 SCATrack (ours) ${\bf{50.33}}$ ${\bf{38.53}}$ ${\bf{65.84}}$ ${\bf{23.86}}$ ${\bf{57.10}}$ 2700 54.60
下载: 导出CSV
表 4 模型效率分析
Table 4 Model efficiency analysis
方法 阶段 Params. (M) FLOPs (G) FPS 训练/推理时间 基线 训练 82.84 338.24 — $33$小时$29$分钟 推理 82.84 338.17 10.56 $2$小时$24$分钟 SCATrack (ours) 训练 116.98 340.05 — $38$小时$17$分钟 推理 82.84 338.17 10.56 $2$小时$24$分钟
下载: 导出CSV
表 5 SCG中不同屏蔽方式模型性能对比
Table 5 Comparison of the model performance of the proposed SCG with different shielding methods
方法 HOTA$\uparrow$ DetA$\uparrow$ AssA$\uparrow$ MOTA$\uparrow$ IDF1$\uparrow$ IDS$\downarrow$ Acc (%)$\uparrow$ 固定“#” ${\bf{50.33}}$ ${\bf{38.53}}$ 65.84 23.86 ${\bf{57.10}}$ ${\bf{2\,700}}$ 54.60 随机字符 49.47 36.76 ${\bf{66.74}}$ 19.46 55.94 2956 53.78 0值填充 49.39 38.38 63.66 ${\bf{25.04}}$ 55.78 2992 54.05
下载: 导出CSV
表 6 SCG中不同可学习词嵌入设置模型性能对比
Table 6 Performance comparison of different learnable word embedding setup models for the proposed SCG
设置 HOTA$\uparrow$ DetA$\uparrow$ AssA$\uparrow$ MOTA$\uparrow$ IDF1$\uparrow$ IDS$\downarrow$ Acc (%)$\uparrow$ none 49.35 37.85 64.42 23.31 55.83 2706 53.65 1 ${\bf{50.33}}$ ${\bf{38.53}}$ 65.84 ${\bf{23.86}}$ ${\bf{57.10}}$ ${\bf{2\,700}}$ 54.60 2 49.79 37.64 ${\bf{65.91}}$ 18.67 55.68 2786 54.28
下载: 导出CSV
表 7 不同$\gamma_{gen}$设置模型性能对比
Table 7 Performance comparison of models with different $\gamma_{gen}$ values
$\gamma_{gen}$ HOTA$\uparrow$ DetA$\uparrow$ AssA$\uparrow$ MOTA$\uparrow$ IDF1$\uparrow$ IDS$\downarrow$ 0.02 49.70 37.15 ${\bf{66.66}}$ 20.18 56.28 2959 0.1 ${\bf{50.33}}$ ${\bf{38.53}}$ 65.84 23.86 ${\bf{57.10}}$ 2700 0.5 47.49 35.79 63.11 24.54 55.13 2190 1 46.96 35.12 62.86 ${\bf{24.55}}$ 54.66 ${\bf{2\,160}}$
下载: 导出CSV
表 8 不同${\cal{J}}$值下模型的性能对比
Table 8 Comparison of model performance for different ${\cal{J}}$ values
${\cal{J}}$ HOTA$\uparrow$ DetA$\uparrow$ AssA$\uparrow$ MOTA$\uparrow$ IDF1$\uparrow$ IDS$\downarrow$ 1 49.67 37.13 66.60 25.49 56.26 3018 2 ${\bf{50.33}}$ 38.53 65.84 23.86 ${\bf{57.10}}$ ${\bf{2\,700}}$ 3 49.81 ${\bf{39.11}}$ 63.54 ${\bf{27.28}}$ 56.52 2922 4 49.86 37.50 ${\bf{66.92}}$ 19.86 56.65 3022
下载: 导出CSV
表 9 不同${\cal{N}}$设置模型性能对比
Table 9 Comparison of model performance with different ${\cal{N}}$ settings
${\cal{N}}$ HOTA$\uparrow$ DetA$\uparrow$ AssA$\uparrow$ MOTA$\uparrow$ IDF1$\uparrow$ IDS$\downarrow$ 1 47.53 35.55 63.63 ${\bf{24.90}}$ 55.11 ${\bf{2\,406}}$ 2 48.26 37.51 62.21 23.24 54.25 2840 3 48.95 37.21 64.50 19.91 55.10 2681 4 49.16 37.03 65.34 19.86 55.49 2633 5 ${\bf{50.33}}$ ${\bf{38.53}}$ ${\bf{65.84}}$ 23.86 ${\bf{57.10}}$ 2700 6 49.96 38.11 65.58 22.32 55.91 2530
下载: 导出CSV
表 10 不同$\delta$设置模型性能对比
Table 10 Comparison of model performance with different $\delta$ settings
$\delta$ HOTA$\uparrow$ DetA$\uparrow$ AssA$\uparrow$ MOTA$\uparrow$ IDF1$\uparrow$ IDS$\downarrow$ 0.2 48.54 35.23 ${\bf{66.95}}$ 1.12 53.57 3916 0.3 49.66 37.03 66.71 12.36 55.54 3412 0.4 50.27 38.07 66.48 19.29 56.65 3043 0.5 ${\bf{50.33}}$ ${\bf{38.53}}$ 65.84 23.86 ${\bf{57.10}}$ 2700 0.6 49.64 38.09 64.78 26.34 56.57 2361 0.7 47.81 36.26 63.10 ${\bf{26.60}}$ 54.54 2 035
下载: 导出CSV
-
[1] Li Z Y, Tao R, Gavves E, Snoek C G M, Smeulders A W M. Tracking by natural language specification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 6495−6503 [2] Wu D M, Han W C, Wang T C, Dong X P, Zhang X Y, Shen J B. Referring multi-object tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 14633−14642 [3] He W Y, Jian Y J, Lu Y, Wang H Z. Visual-linguistic representation learning with deep cross-modality fusion for referring multi-object tracking. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Seoul, Korea: IEEE, 2024. 6310−6314 [4] Wu J N, Jiang Y, Sun P Z, Yuan Z H, Luo P. Language as queries for referring video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 4964−4974 [5] Du Y H, Lei C, Zhao Z C, Su F. iKUN: Speak to trackers without retraining. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 19135−19144 [6] Lin J C, Chen J J, Peng K Y, He X, Li Z Y, Stiefelhagen R, et al. EchoTrack: Auditory referring multi-object tracking for autonomous driving. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(11): 18964−18977 doi: 10.1109/TITS.2024.3437645 [7] Zeng F G, Dong B, Zhang Y, Wang T C, Zhang X Y, Wei Y C. MOTR: End-to-end multiple-object tracking with transformer. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 659−675 [8] 张虹芸, 陈辉, 张文旭. 扩展目标跟踪中基于深度强化学习的传感器管理方法. 自动化学报, 2024, 50(7): 1417−1431Zhang Hong-Yun, Chen Hui, Zhang Wen-Xu. Sensor management method based on deep reinforcement learning in extended target tracking. Acta Automatica Sinica, 2024, 50(7): 1417−1431 [9] Gao R P, Wang L M. MeMOTR: Long-term memory-augmented transformer for multi-object tracking. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 9867−9876 [10] Zhang Y, Wang T C, Zhang X Y. MOTRv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 22056−22065 [11] 安志勇, 梁顺楷, 李博, 赵峰, 窦全胜, 相忠良. 一种新的分段式细粒度正则化的鲁棒跟踪算法. 自动化学报, 2023, 49(5): 1116−1130An Zhi-Yong, Liang Shun-Kai, Li Bo, Zhao Feng, Dou Quan-Sheng, Xiang Zhong-Liang. Robust visual tracking with a novel segmented fine-grained regularization. Acta Automatica Sinica, 2023, 49(5): 1116−1130 [12] 张鹏, 雷为民, 赵新蕾, 董力嘉, 林兆楠, 景庆阳. 跨摄像头多目标跟踪方法综述. 计算机学报, 2024, 47(2): 287−309Zhang Peng, Lei Wei-Min, Zhao Xin-Lei, Dong Li-Jia, Lin Zhao-Nan, Jing Qing-Yang. A survey on multi-target multi-camera tracking methods. Chinese Journal of Computers, 2024, 47(2): 287−309 [13] Nijhawan S S, Hoshikawa L, Irie A, Yoshimura M, Otsuka J, Ohashi T. Efficient joint detection and multiple object tracking with spatially aware transformer. arXiv preprint arXiv: 2211.05654, 2022. [14] Meinhardt T, Kirillov A, Leal-Taixé L, Feichtenhofer C. TrackFormer: Multi-object tracking with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: 2022. 8834−8844 [15] Ge Z, Liu S T, Wang F, Li Z M, Sun J. YOLOX: Exceeding YOLO series in 2021. arXiv preprint arXiv: 2107.08430, 2021. [16] Gao R P, Qi J, Wang L M. Multiple object tracking as ID prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. [17] Yan F, Luo W X, Zhong Y J, Gan Y Y, Ma L. Bridging the gap between end-to-end and non-end-to-end multi-object tracking. arXiv preprint arXiv: 2305.12724, 2023. [18] Zhang Y F, Wang X G, Ye X Q, Zhang W, Lu J C, Tan X, et al. ByteTrackV2: 2D and 3D multi-object tracking by associating every detection box. arXiv preprint arXiv: 2303.15334, 2023. [19] Cao J K, Pang J M, Weng X S, Khirodkar R, Kitani K. Observation-centric SORT: Rethinking SORT for robust multi-object tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 9686−9696 [20] Yang M Z, Han G X, Yan B, Zhang W H, Qi J Q, Lu H C, et al. Hybrid-SORT: Weak cues matter for online multi-object tracking. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024. 6504−6512 [21] 卢锦, 马令坤, 吕春玲, 章为川, Sun Chang-Ming. 基于代价参考粒子滤波器组的多目标检测前跟踪算法. 自动化学报, 2024, 50(4): 851−861Lu Jin, Ma Ling-Kun, Lv Chun-Ling, Zhang Wei-Chuan, Sun Chang-Ming. A multi-target track-before-detect algorithm based on cost-reference particle filter bank. Acta Automatica Sinica, 2024, 50(4): 851−861 [22] Feng Q, Ablavsky V, Bai Q X, Sclaroff S. Siamese natural language tracker: Tracking by natural language descriptions with Siamese trackers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 5847−5856 [23] Li Y H, Yu J, Cai Z P, Pan Y W. Cross-modal target retrieval for tracking by natural language. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). New Orleans, USA: IEEE, 2022. 4931−4940 [24] Guo M Z, Zhang Z P, Fan H, Jing L P. Divert more attention to vision-language tracking. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 321 [25] Ma D, Wu X Q. Tracking by natural language specification with long short-term context decoupling. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 13966−13975 [26] Wojke N, Bewley A, Paulus D. Simple online and realtime tracking with a deep association metric. In: Proceedings of the IEEE International Conference on Image Processing (ICIP). Beijing, China: IEEE, 2017. [27] Sun P Z, Cao J K, Jiang Y, Zhang R F, Xie E Z, Yuan Z H, et al. TransTrack: Multiple object tracking with transformer. arXiv preprint arXiv: 2012.15460, 2020.Sun P Z, Cao J K, Jiang Y, Zhang R F, Xie E Z, Yuan Z H, et al. TransTrack: Multiple object tracking with transformer. arXiv preprint arXiv: 2012.15460, 2020. [28] Nguyen P, Quach K G, Kitani K, Luu K. Type-to-track: Retrieve any object via prompt-based tracking. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 142 [29] Ma Z L, Yang S, Cui Z, Zhao Z C, Su F, Liu D L, et al. MLS-track: Multilevel semantic interaction in RMOT. arXiv preprint arXiv: 2404.12031, 2024. [30] Chen S J, Yu E, Tao W B. Cross-view referring multi-object tracking. In: Proceedings of the 39th AAAI Conference on Artificial Intelligence. Philadelphia, USA: AAAI Press, 2025. [31] Chen J J, Lin J C, Zhong G J, Yao Y, Li Z Y. Multigranularity localization transformer with collaborative understanding for referring multiobject tracking. IEEE Transactions on Instrumentation and Measurement, 2025, 74: Article No. 5004613 [32] Ma C F, Jiang Y, Wen X, Yuan Z H, Qi X J. CoDet: Co-occurrence guided region-word alignment for open-vocabulary object detection. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 3113 [33] Honnibal M, Johnson M. An improved non-monotonic transition system for dependency parsing. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal: ACL, 2015. 1373−1378 [34] Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 213−229 [35] Devlin J, Chang M W, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, USA: ACL, 2019. 4171−4186 [36] Liu C, Ding H H, Zhang Y L, Jiang X D. Multi-modal mutual attention and iterative interaction for referring image segmentation. IEEE Transactions on Image Processing, 2023, 32: 3054−3065 doi: 10.1109/TIP.2023.3277791 [37] Chng Y X, Zheng H, Han Y Z, Qiu X C, Huang G. Mask grounding for referring image segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 26573−26583 [38] Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021. 8748−8763Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021. 8748−8763 [39] Lin T Y, Goyal P, Girshick R, He K M, Dollár P. Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2999−3007 [40] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [41] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 740−755 [42] Zhu X Z, Su W J, Lu L W, Li B, Wang X G, Dai J F. Deformable DETR: Deformable transformers for end-to-end object detection. In: Proceedings of the 9th International Conference on Learning Representations. OpenReview.net, 2021.Zhu X Z, Su W J, Lu L W, Li B, Wang X G, Dai J F. Deformable DETR: Deformable transformers for end-to-end object detection. In: Proceedings of the 9th International Conference on Learning Representations. OpenReview.net, 2021. [43] Loshchilov I, Hutter F. Decoupled weight decay regularization. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: OpenReview.net, 2019. [44] Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 3354−3361 [45] Luiten J, Ošep A, Dendorfer P, Torr P, Geiger A, Leal-Taixé L, et al. HOTA: A higher order metric for evaluating multi-object tracking. International Journal of Computer Vision, 2021, 129(2): 548−578 doi: 10.1007/s11263-020-01375-2 [46] Bernardin K, Stiefelhagen R. Evaluating multiple object tracking performance: The CLEAR MOT metrics. EURASIP Journal on Image and Video Processing, 2008, 2008(1): Article No. 246309 [47] Ristani E, Solera F, Zou R, Cucchiara R, Tomasi C. Performance measures and a data set for multi-target, multi-camera tracking. In: Proceedings of the European Conference on Computer Vision. Amsterdam, Netherlands: Springer, 2016. 17−35 [48] Zhang Y F, Wang C Y, Wang X G, Zeng W J, Liu W Y. FairMOT: On the fairness of detection and re-identification in multiple object tracking. International Journal of Computer Vision, 2021, 129(11): 3069−3087 doi: 10.1007/s11263-021-01513-4 [49] Zhang Y F, Sun P Z, Jiang Y, Yu D D, Weng F C, Yuan Z H, et al. ByteTrack: Multi-object tracking by associating every detection box. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 1−21 [50] Liang C, Zhang Z P, Zhou X, Li B, Zhu S Y, Hu W M. Rethinking the competition between detection and ReID in multiobject tracking. IEEE Transactions on Image Processing, 2022, 31: 3182−3196 doi: 10.1109/TIP.2022.3165376 -

 下载:
下载:

计量
- 文章访问数: 952
- HTML全文浏览量: 855
- PDF下载量: 225
- 被引次数: 0
