

-
摘要: 针对小样本学习过程中样本数量不足导致的性能下降问题, 基于原型网络(Prototype network, ProtoNet)的小样本学习方法通过实现查询样本与支持样本原型特征间的距离度量, 从而达到很好的分类性能. 然而, 这种方法直接将支持集样本均值视为类原型, 在一定程度上加剧了对样本数量稀少情况下的敏感性. 针对此问题, 提出了基于自适应原型特征类矫正的小样本学习方法(Few-shot learning based on class rectification via adaptive prototype features, CRAPF), 通过自适应生成原型特征来缓解方法对数据细微变化的过度响应, 并同步实现类边界的精细化调整. 首先, 使用卷积神经网络构建自适应原型特征生成模块, 该模块采用非线性映射获取更为稳健的原型特征, 有助于减弱异常值对原型构建的影响; 然后, 通过对原型生成过程的优化, 提升不同类间原型表示的区分度, 进而强化原型特征对类别表征的整体效能; 最后, 在3个广泛使用的基准数据集上的实验结果显示, 该方法提升了小样本学习任务的表现.Abstract: In response to the performance degradation issue from inadequate sample sizes during few-shot learning, prototypical network (ProtoNet)-based few-shot learning methods achieve commendable classification capabilities by measuring the distance metrics between query sample features and the prototype features of support samples. However, this method directly treats the mean of the support set samples as class prototypes, exacerbating sensitivity to scarcity of samples. To address this issue, we propose a few-shot learning method based on class rectification via adaptive prototype features (CRAPF). This method mitigates the model's over-responsiveness to minor data variations by adaptively generating prototype features and simultaneously achieves fine-tuned adjustments of class boundaries. First, we construct an adaptive prototype feature generation module using convolutional neural networks. This module leverages nonlinear mappings to obtain more robust prototype features, thereby mitigating the impact of outliers on prototype construction. Second, by optimizing the prototype generation process, we enhance the discriminability of prototype representations across different classes, thus strengthening the overall efficacy of prototype features in class representation. Finally, experiments conducted on three extensively utilized benchmark datasets reveal that this method significantly enhances the performance of few-shot learning tasks.
-
无线传感网(Wireless sensor networks, WSNs)由负责感知和传输任务的传感器节点组成, 具有功耗低、成本小、易部署的优势, 被广泛应用于环境监控、工业控制等领域[1-3]. 时间同步是无线传感网的关键技术之一. 无线传感网的许多基础功能, 例如数据融合、传输调度和目标定位等, 都需要节点间的精确时间同步[4-6]. 因此, 对无线传感网中的时间同步技术进行研究和探索具有重要意义.
由于时钟的启动时刻和振荡器的变化特性不同, 传感器节点时钟之间通常存在两方面的偏差. 一方面是时钟的初始相位偏差, 称之为时钟偏移; 另一方面是时钟运行速率的偏差, 称之为时钟漂移. 无线传感网中的节点之间要维持高精度同步, 就需要利用时间同步技术计算相对时钟漂移和偏移. 如果仅对时钟漂移进行估计, 那么只能校正节点之间的时钟速率偏差, 而相位偏差会一直存在, 导致同步无法实现. 反之, 若只估计时钟偏移, 虽然能够校正相位偏差, 但是振荡器的差异会导致同步时间较短, 从而需要频繁地进行重同步. 因此, 为了避免上述情况的出现, 就必须对时钟漂移和偏移参数进行联合估计.
无线传感网时间同步机制的设计所面临的一项重要挑战是: 如何尽可能地减少同步能耗. 由于网络中节点间的同步通常需要传输同步信息, 而同步信息传输所需能耗占据同步能耗的绝大部分. 因此, 一个有效的解决方案是设计以最小化同步信息传输数量为目标的低功耗同步协议. 隐含同步是其中的一个典型协议[7], 它基于无线媒介的广播特性, 利用监听策略隐式地获取同步信息, 可以显著减少同步信息传输数量. 在该机制中, 一个活跃节点(既发送同步信息又接收同步信息)和一个时钟源节点之间执行双向信息交换同步操作, 而一些位于这两个节点重叠通信范围内的节点(称之为隐含节点), 只需监听它们之间的信息交换过程就能实现与时钟源节点的同步. 在此过程中, 隐含节点仅接收了信息, 没有发送任何信息, 大幅度地降低了同步能耗. 文献[7-9]基于隐含同步机制, 在不同的网络场景下, 利用统计信号处理技术设计了多种同步算法, 实现节点之间的高精度低能耗同步. 文献[10-11]则将隐含同步机制与另一种同步机制(校正式同步)相结合, 节点仅以少量的能量就能在估计时钟参数的同时校正自己的本地时钟, 实现实时的同步. 此外, 文献[12]还将隐含同步机制应用到了水下无线传感网中, 提出适用于水下传感器节点的低功耗同步算法.
免时间戳同步是近年来提出的另一种低能耗的同步机制[13-16]. 由于其交互过程无需时间戳, 同步功能可以无缝嵌入现有网络数据流, 从而能够显著减少能耗. 在免时间戳同步中, 首先活跃节点发送不含时间戳的数据包给时钟源节点, 并记录此时的本地时间; 接着时钟源节点接收到数据包后在预定义的响应时间间隔返回不含时间戳的数据包; 最后活跃节点在接收到返回的数据包后记录自己的本地时间, 并通过预定义的响应时间间隔规则估计时钟参数, 与时钟源节点达到同步. 该机制利用接收方对发送方的预定义响应时间来传递同步信息, 避免了专用同步帧的传输. 文献[13]提出一种基于和响应策略的免时间戳同步协议, 其中时钟源节点响应时间和接收时间的和满足特定的规则. 通过在两个不同的时间间隔各返回一个响应数据包, 文献[14]提出一种跟随响应免时间戳同步协议. 但是, 由于跟随响应数据包的存在, 限制了该协议在实际网络中的应用. 为解决上述问题, 文献[15]提出一种基于动态响应的免时间戳同步协议, 利用特定的映射规则, 将连续的两个或多个同步周期的响应时间设置为不同值, 消除了跟随响应数据包的传输. 进一步, 文献[16]提出一种免时间戳交互与单向传输混合的同步机制, 实现了时钟漂移和偏移的联合估计.
将免时间戳同步与隐含同步相结合, 能够联合发挥两种同步机制的低能耗优势, 从而进一步降低无线传感网同步能耗开销. 文献[15]对其进行了初步的研究, 但是, 在基于动态响应的免时间戳同步方法中, 隐含节点只能估计时钟漂移, 不能估计时钟偏移, 从而无法实现隐含节点的完全同步. 因此, 针对此问题, 本文提出了一种在不传递时间戳的情况下, 隐含节点能够联合估计时钟漂移和偏移的低功耗同步协议. 主要贡献如下:
1)提出了一种基于免时间戳交互的隐含同步协议, 隐含节点记录监听到数据包的本地时间戳, 再结合预定义的响应规则就能完成对时钟漂移和偏移的联合估计, 以少量的能耗达到与时钟源节点的完全同步;
2)针对典型的高斯随机时延, 推导了隐含节点时钟漂移和偏移的联合最大似然估计器(Maximum likelihood estimator, MLE), 以及相应的克拉美罗下限(Cramer-Rao lower bound, CRLB);
3)仿真结果表明, 所提估计算法能够有效实现对隐含节点时钟漂移和偏移参数的免时间戳联合估计, 并具有达到CRLB的优良性能.
1. 同步协议描述
本节将对所提的基于免时间戳交互的隐含同步协议进行介绍, 并建立节点的时钟模型.
1.1 交互过程
考虑一个由多个节点构成的无线传感网, 其中节点
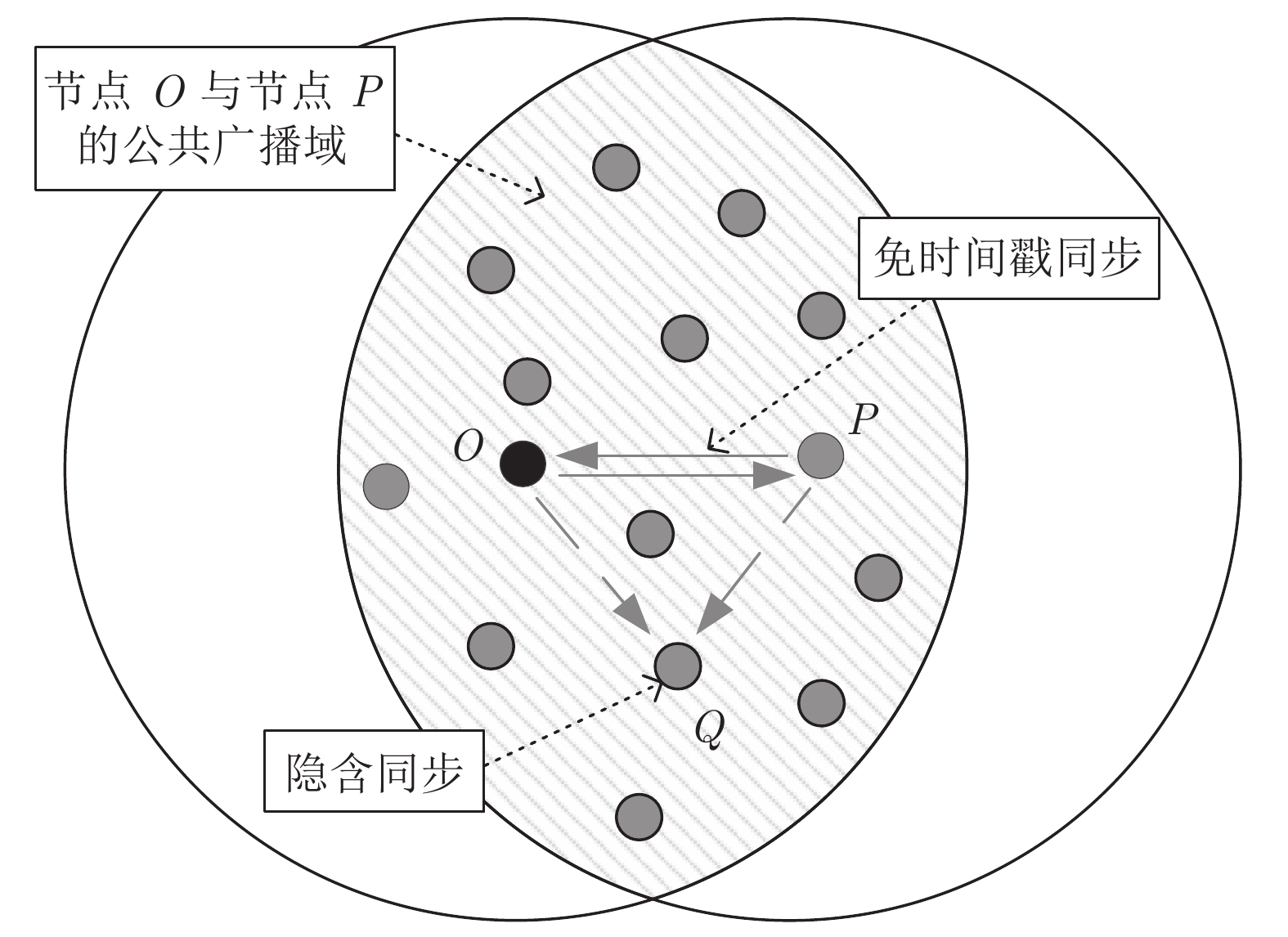
$ O $ 是时钟源节点, 为网络提供参考时间; 节点$ P $ 是活跃节点, 周期性地与时钟源节点$ O $ 进行双向信息交互; 节点$ Q $ 是位于活跃节点$ P $ 与时钟源节点$ O $ 公共广播领域内的隐含节点, 能够监听它们之间的信息交互过程, 如图1所示.当网络同步开始, 活跃节点
$ P $ 与时钟源节点$ O $ 之间进行免时间戳同步, 隐含节点$ Q $ 监听两节点的交互信息进行隐含同步. 具体的同步过程如图2所示, 以第$ j $ 轮通信过程为例, 详细步骤如下.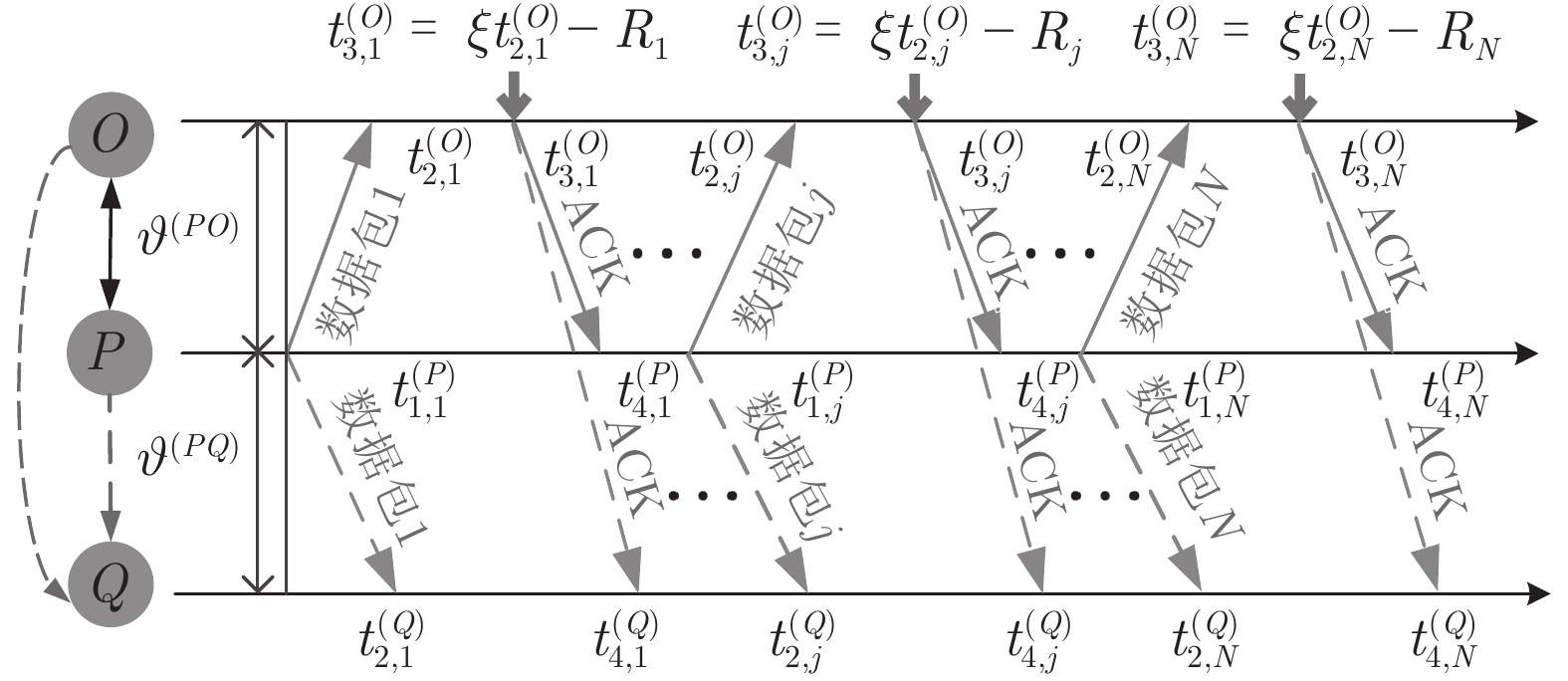 图 2 节点
图 2 节点$Q$ 监听节点$O$ 与节点$P$ 之间的$N$ 轮免时间戳交互Fig. 2 The$N$ rounds of timestamp-free exchange between node$O$ and$P$ with node$Q$ overhearing them1)活跃节点
$ P $ 在本地时间为$ t_{1,j}^{\left( P \right)} $ 时刻发送不含时间戳信息的数据包给时钟源节点$ O $ .2)时钟源节点
$ O $ 接收到该数据包时, 记录本地时间为$ t_{2,j}^{\left( O \right)} $ . 接着等待一段时间, 在$ t_{3,j}^{\left( O \right)} $ 时刻返回一个不含时间戳的确认帧(Acknowledgement, ACK)给节点$ P $ . 这里$ t_{3,j}^{\left( O \right)} = \xi t_{2,j}^{\left( O \right)}-{{R}_{j}} $ , 其中$ \xi $ 是一个大于1且接近于1的已知常数,$ {{R}_{j}} $ 是一个等待间隔补偿.3)活跃节点
$ P $ 接收到来自时钟源节点$ O $ 的ACK时, 记录本地时间为$ t_{4,j}^{\left( P \right)} $ .4)隐含节点
$ Q $ 监听到来自活跃节点$ P $ 的数据包和时钟源节点$ O $ 的ACK时, 分别记录本地时间为$ t_{2,j}^{\left( Q \right)} $ 和$ t_{4,j}^{\left( Q \right)} $ .5)经过
$ N $ 轮的同步过程之后, 隐含节点$ Q $ 获得了一系列观测信息$ \left\{ t_{2,j}^{\left( Q \right)},t_{4,j}^{\left( Q \right)},{{R}_{j}} \right\}_{j = 1}^{N} $ . 至此, 隐含节点$ Q $ 可以利用该观测信息估计相对于时钟源节点$ O $ 的时钟漂移和偏移.在上述过程中, 活跃节点
$ P $ 与时钟源节点$ O $ 之间进行免时间戳同步, 隐含节点$ Q $ 监听它们之间的成对信息. 因此, 节点$ Q $ 只接收了信息, 节省了由发送报文产生的能耗.根据免时间戳同步的现有研究可知[16], 隐含节点
$ Q $ 若要估计相对于时钟源节点$ O $ 的时钟漂移与偏移, 除了记录接收数据包和ACK的本地时间戳之外, 还需要获取$ t_{2,j}^{\left( O \right)} $ (用于估计时钟偏移)和$ t_{3,j}^{\left( O \right)}- t_{2,j}^{\left( O \right)} $ (用于估计时钟漂移). 针对此, 本文通过预设时钟源节点返回ACK的时间$ t_{3,j}^{\left( O \right)} $ 同时获取$ t_{2,j}^{\left( O \right)} $ 和$ t_{3,j}^{\left( O \right)}-t_{2,j}^{\left( O \right)} $ . 变换步骤2)中的关系式可得:$$ \begin{equation} {R_j} = \left( {\xi - 1} \right)t_{2,j}^{\left( O \right)} - \left( {t_{3,j}^{\left( O \right)} - t_{2,j}^{\left( O \right)}} \right) \end{equation} $$ (1) 从式(1)中可以看出, 由于
$ \xi $ 大于1且接近于1, 因此$ t_{3,j}^{\left( O \right)}-t_{2,j}^{\left( O \right)} $ 的信息和部分$ t_{2,j}^{\left( O \right)} $ 的信息(即$ \left( \xi -1 \right)t_{2,j}^{\left( O \right)} $ )可以被嵌入到$ {{R}_{j}} $ 中.$ {{R}_{j}} $ 在本文中被定义为$ {{R}_{j}} = \left( \xi -1 \right)\left( j-1 \right)T $ , 其中$ T $ 是活跃节点$ P $ 与时钟源节点$ O $ 的固定交互周期. 隐含节点$ Q $ 在每轮监听过程中, 可以根据该定义式计算$ {{R}_{j}} $ , 从而隐含地获取到$ t_{3,j}^{\left( O \right)}-t_{2,j}^{\left( O \right)} $ 和部分$ t_{2,j}^{\left( O \right)} $ . 因此, 从获取同步信息的角度来看, 隐含节点$ Q $ 能够估计出两个同步参数(具体推导过程见第2节).$ {{R}_{j}} $ 的作用除了嵌入同步信息之外, 另一个作用是补偿时钟源节点$ O $ 的响应时间(因此称之为等待间隔补偿). 因为$ t_{2,j}^{\left( O \right)} $ 会随着交互次数的增多而不断增长, 如果没有$ {{R}_{j}} $ , 那么$ t_{3,j}^{\left( O \right)} = \xi t_{2,j}^{\left( O \right)} $ , 响应时间$ t_{3,j}^{\left( O \right)}- t_{2,j}^{\left( O \right)} = \left( \xi -1 \right)t_{2,j}^{\left( O \right)} $ 会逐渐增长, 最终会影响网络的正常运行. 此外, 设置$ \xi $ 为一个大于1且接近于1的常数有两个原因: 1)$ \xi $ 大于1可以保留部分$ t_{2,j}^{\left( O \right)} $ ; 2)$ \xi $ 接近于1可以确保响应时间合理, 因为$t_{3,j}^{\left( O \right)}- t_{2,j}^{\left( O \right)} = \left( \xi -1 \right)\left[ t_{2,j}^{\left( O \right)}-\left( j-1 \right)T \right]$ .1.2 时钟模型
网络中每个传感器节点的时钟相对于理想时间都存在时钟漂移和偏移. 其时钟模型可以表示为:
$$ \begin{equation} C\left( {{t_0}} \right) = \left( {1 + \alpha } \right){t_0} + \vartheta \end{equation} $$ (2) 其中,
$ C\left( {{t}_{0}} \right) $ 和$ {{t}_{0}} $ 分别表示节点的本地时间和理想时间,$ \alpha $ 和$ \vartheta $ 分别表示时钟漂移和偏移.同步信息在传输过程中会经历多种时延, 这些时延可分为固定时延和随机时延[17]. 其中固定时延包括传输时间、接收时间、传播时间, 随机时延包括发送时间、接收处理时间和信道访问时间. 一般情况下, 固定时延被假设为一个常数, 而随机时延则会根据不同的网络场景被建模为服从不同分布的随机变量. 例如, 延迟是由许多独立的随机过程相互叠加时, 根据中心极限定理, 随机时延可以被建模为高斯分布[18]. 此外, 该随机时延模型已被实验证明是合理的[19]. 因此, 在本文中, 假设固定时延是已知常数, 随机时延是独立同分布的高斯分布, 其均值为0, 方差为
$ {{\sigma }^{2}} $ .根据时钟模型式(2), 时钟源节点
$ O $ 在$ j $ 轮同步信息交换过程中, 本地时间戳$ t_{2,j}^{\left( O \right)} $ 可以表示为:$$ \begin{split} t_{2,j}^{\left( O \right)} = \;&\left( {1 + {\alpha ^{\left( {PO} \right)}}} \right)\times\\ &\left( {t_{1,j}^{\left( P \right)} + {d^{\left( {PO} \right)}} + \omega _j^{\left( {PO} \right)}} \right) + {\vartheta ^{\left( {PO} \right)}}{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} \end{split} $$ (3) 其中,
$ {{\alpha }^{\left( PO \right)}} $ 和$ {{\vartheta }^{\left( PO \right)}} $ 分别表示节点$ P $ 相对节点$ O $ 的时钟漂移和偏移,$ {{d}^{\left( PO \right)}} $ 和$ \omega _{j}^{\left( PO \right)} $ 分别表示信息从节点$ P $ 传输到节点$ O $ 过程中的固定时延和随机时延.同样地, 时钟源节点
$ O $ 在$ j $ 轮交互过程中返回ACK的时间戳$ t_{3,j}^{\left( O \right)} $ 可以表示为:$$ \begin{split} t_{3,j}^{\left( O \right)} =\; & \left( {1 + {\alpha ^{\left( {QO} \right)}}} \right)\times\\ &\left( {t_{4,j}^{\left( Q \right)} - {d^{\left( {OQ} \right)}} - \omega _j^{\left( {OQ} \right)}} \right) + {\vartheta ^{\left( {QO} \right)}} \end{split} $$ (4) 其中,
$ {{\alpha }^{\left( QO \right)}} $ 和$ {{\vartheta }^{\left( QO \right)}} $ 分别表示节点$ Q $ 相对节点$ O $ 的时钟漂移和偏移,$ {{d}^{\left( OQ \right)}} $ 和$ \omega _{j}^{\left( OQ \right)} $ 分别表示信息从节点$ O $ 传输到节点$ Q $ 过程中的固定时延和随机时延.隐含节点
$ Q $ 在$ j $ 轮同步过程中监听到来自节点$ P $ 的数据包时的时间戳$ t_{2,j}^{\left( Q \right)} $ 可以表示为:$$ \begin{split} t_{2,j}^{\left( Q \right)} = \;& \left( {1 + {\alpha ^{\left( {PQ} \right)}}} \right)\times\\ &\left( {t_{1,j}^{\left( P \right)} + {d^{\left( {PQ} \right)}} + \omega _j^{\left( {PQ} \right)}} \right) + {\vartheta ^{\left( {PQ} \right)}} \end{split} $$ (5) 其中,
$ {{\alpha }^{\left( PQ \right)}} $ 和$ {{\vartheta }^{\left( PQ \right)}} $ 分别表示节点$ P $ 相对节点$ Q $ 的时钟漂移和偏移,$ {{d}^{\left( PQ \right)}} $ 和$ \omega _{j}^{\left( PQ \right)} $ 分别表示信息从节点$ P $ 传输到节点$ Q $ 过程中的固定时延和随机时延.2. 参数估计
基于上述的时间戳表达式, 本节将推导隐含节点时钟漂移和偏移的联合MLE以及相应的CRLB.
2.1 联合MLE
在实际无线传感网中,
$ {{\alpha }^{\left( PO \right)}} $ 、$ {{\alpha }^{\left( QO \right)}} $ 、$ {{\alpha }^{\left( PQ \right)}} $ 都非常小且接近于0, 导致累计的时钟偏移${{\alpha }^{\left( PO \right)}}\times \left( {{d}^{\left( PO \right)}} + \omega _{j}^{\left( PO \right)} \right)$ ,${{\alpha }^{\left( QO \right)}} \left( {{d}^{\left( OQ \right)}} + \omega _{j}^{\left( OQ\right)} \right)$ ,${{\alpha }^{\left( PQ \right)}} \Big( {{d}^{(PQ)}}+ \omega _{j}^{\left( PQ \right)} \Big)$ 相对较小. 因此, 为了简化推导, 忽略式(3)$ \sim $ 式(5)中的累计时钟偏移, 则第1节中的时间戳表达式可以分别重写为:$$ \begin{equation} t_{2,j}^{\left( O \right)} = {\alpha ^{\left( {PO} \right)}}t_{1,j}^{\left( P \right)} + t_{1,j}^{\left( P \right)} + {d^{\left( {PO} \right)}} + \omega _j^{\left( {PO} \right)} + {\vartheta ^{\left( {PO} \right)}} \end{equation} $$ (6) $$ \begin{equation} t_{3,j}^{\left( O \right)} = {\alpha ^{\left( {QO} \right)}}t_{4,j}^{\left( Q \right)} + t_{4,j}^{\left( Q \right)} - {d^{\left( {OQ} \right)}} - \omega _j^{\left( {OQ} \right)} + {\vartheta ^{\left( {QO} \right)}} \end{equation} $$ (7) $$ \begin{equation} t_{2,j}^{\left( Q \right)} = {\alpha ^{\left( {PQ} \right)}}t_{1,j}^{\left( P \right)} + t_{1,j}^{\left( P \right)} + {d^{\left( {PQ} \right)}} + \omega _j^{\left( {PQ} \right)} + {\vartheta ^{\left( {PQ} \right)}} \end{equation} $$ (8) 由于
$ t_{3,j}^{\left( O \right)} = \xi t_{2,j}^{\left( O \right)}-{{R}_{j}} $ , 将式(6)和式(7)代入可得:$$ \begin{split} {R_j} = \;&\xi t_{1,j}^{\left( P \right)}{\alpha ^{\left( {PO} \right)}} - t_{4,j}^{\left( Q \right)}{\alpha ^{\left( {QO} \right)}} + \xi t_{1,j}^{\left( P \right)}{\kern 1pt} -\\ &t_{4,j}^{\left( Q \right)} + {d^{\left( {OQ} \right)}} + \xi {d^{\left( {PO} \right)}} - {\vartheta ^{\left( {QO} \right)}}{\kern 1pt}+\\ &\xi {\vartheta ^{\left( {PO} \right)}} + \omega _j^{\left( {OQ} \right)} + \xi \omega _j^{\left( {PO} \right)} \end{split} $$ (9) 注意到, 式(9)中包含
$ {{\alpha }^{\left( PO \right)}} $ ,$ {{\alpha }^{\left( QO \right)}} $ ,$ {{\vartheta }^{\left( PO \right)}} $ ,$ {{\vartheta }^{\left( QO \right)}} $ 4个时钟参数, 而节点$ Q $ 要与节点$ O $ 达到时间同步, 只需估计$ {{\alpha }^{\left( QO \right)}} $ 和$ {{\vartheta }^{\left( QO \right)}} $ . 为了消除$ {{\alpha }^{\left( PO \right)}} $ 和$ {{\vartheta }^{\left( PO \right)}} $ 这2个无关参数, 将式(9)减去$ \xi $ 倍的式(8)可得:$$ \begin{split} {R_j} - \xi t_{2,j}^{\left( Q \right)} =\; &\xi t_{1,j}^{\left( P \right)}{\alpha ^{\left( {PO} \right)}} - \xi t_{1,j}^{\left( P \right)}{\alpha ^{\left( {PQ} \right)}} - t_{4,j}^{\left( Q \right)}{\alpha ^{\left( {QO} \right)}}-\\ &t_{4,j}^{\left( Q \right)} + {d^{\left( {OQ} \right)}} + \xi {d^{\left( {PO} \right)}} - \xi {d^{\left( {PQ} \right)}} -\\ &{\vartheta ^{\left( {QO} \right)}} + \xi {\vartheta ^{\left( {PO} \right)}} - \xi {\vartheta ^{\left( {PQ} \right)}} +\\ &\omega _j^{\left( {OQ} \right)} + \xi \omega _j^{\left( {PO} \right)} - \xi \omega _j^{\left( {PQ} \right)}\\[-12pt] \end{split} $$ (10) 根据3个节点之间时钟漂移和偏移的关系:
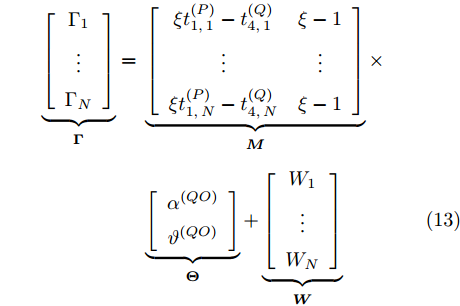
$ {{\alpha }^{\left( QO \right)}} = {{\alpha }^{\left( PO \right)}}-{{\alpha }^{\left( PQ \right)}} $ ,$ {{\vartheta }^{\left( QO \right)}} = {{\vartheta }^{\left( PO \right)}}-{{\vartheta }^{\left( PQ \right)}} $ , 可得系统的同步通式为:$$ \begin{split} {R_j} &- \xi t_{2,j}^{\left( Q \right)} + t_{4,j}^{\left( Q \right)} - {d^{\left( {OQ} \right)}} - \xi {d^{\left( {PO} \right)}} + \xi {d^{\left( {PQ} \right)}} = \\ &\left( {\xi t_{1,j}^{\left( P \right)} - t_{4,j}^{\left( Q \right)}} \right){\alpha ^{\left( {QO} \right)}} + \left( {\xi - 1} \right){\vartheta ^{\left( {QO} \right)}} +\\ &\;\,\omega _j^{\left( {OQ} \right)} + \xi \omega _j^{\left( {PO} \right)} - \xi \omega _j^{\left( {PQ} \right)} \\[-12pt]\end{split} $$ (11) 令
${{\Gamma }_{j}} ={{R}_{j}}\;-\;\xi t_{2,j}^{\left( Q \right)}\;+\;t_{4,j}^{\left( Q \right)}-{{d}^{\left( OQ \right)}}-\xi {{d}^{\left( PO \right)}}+ \xi {{d}^{\left( PQ \right)}}$ ,$ {{W}_{j}} = \omega _{j}^{\left( OQ \right)}+\xi \omega _{j}^{\left( PO \right)}-\xi \omega _{j}^{\left( PQ \right)} $ . 同步通式(11)可以简写为:$${\Gamma _j} = \left( {\xi t_{1,j}^{\left( P \right)} - t_{4,j}^{\left( Q \right)}} \right){\alpha ^{\left( {QO} \right)}} +\left( {\xi - 1} \right){\vartheta ^{\left( {QO} \right)}} + {W_j} $$ (12) 经观察发现, 式(12)还包含节点
$ P $ 的本地时间戳$ t_{1,j}^{\left( P \right)} $ , 节点$ Q $ 无法直接获取. 但是, 由于数据周期性发送,$ T = t_{1,j}^{\left( P \right)}-t_{1,j-1}^{\left( P \right)} $ , 隐含节点$ Q $ 可以根据$ t_{1,j}^{\left( P \right)} = \left( j-1 \right)T $ 计算得到$ t_{1,j}^{\left( P \right)} $ . 此外, 隐含节点$ Q $ 监听了$ N $ 轮的免时间戳交互, 可以获得$ N $ 个同步通式. 为了能够实现高精度的同步, 需利用$ N $ 个同步通式估计时钟漂移和偏移. 将所有的同步通式写成矩阵形式:$$ \begin{equation} \begin{split} \underbrace {\left[ {\begin{array}{*{20}{c}} {{\Gamma _1}}\\ \vdots \\ {{\Gamma _N}} \end{array}} \right]}_{ \buildrel \over {\boldsymbol{\Gamma}}} =\;& \underbrace {\left[ {\begin{array}{*{20}{c}} {\xi t_{1,1}^{\left( P \right)} - t_{4,1}^{\left( Q \right)}}&{\xi - 1}\\ \vdots & \vdots \\ {\xi t_{1,N}^{\left( P \right)} - t_{4,N}^{\left( Q \right)}}&{\xi - 1} \end{array}} \right]}_{ \buildrel \over {\boldsymbol{M}}}\times\\ &\underbrace {\left[ {\begin{array}{*{20}{c}} {{\alpha ^{\left( {QO} \right)}}}\\ {{\vartheta ^{\left( {QO} \right)}}} \end{array}} \right]}_{ \buildrel \over {\boldsymbol{\Theta }}} + \underbrace {\left[ {\begin{array}{*{20}{c}} {{W_1}}\\ \vdots \\ {{W_N}} \end{array}} \right]}_{ \buildrel \over {\boldsymbol{W}}} \end{split} \end{equation} $$ (13) 最大似然估计是一种能够简便地实现复杂估计问题求解的估计方法, 其是利用已知的观测数据, 反推最大概率产生该观测信息的参数值. 无线传感网中的时间同步就是通过观测的同步信息计算时钟参数. 此外, 在式(13)中,
$ \boldsymbol{\Gamma } $ 是由已知观测数据构成的矢量矩阵;$ \boldsymbol{M} $ 是秩为2的观测矩阵;$ \boldsymbol{\Theta } $ 是包含2个待估时钟参数的矢量, 并且与$ \boldsymbol{\Gamma } $ 呈线性关系;$ \boldsymbol{W} $ 是均值为0, 方差为$ \left( 1+2{{\xi }^{2}} \right){{\sigma }^{2}}\mathbf{1} $ 的高斯噪声矢量, 其中$ \mathbf{1} $ 是单位矩阵, 满足线性模型的最大似然估计定理. 因此, 根据文献[20]中的定理7.5, 时钟参数矢量$ \boldsymbol{\Theta } $ 的MLE为:$$ \begin{equation} {\boldsymbol{\Theta }} = {\left( {{{\boldsymbol{M}}^{\rm{H}}}{\boldsymbol{M}}} \right)^{ - 1}}{{\boldsymbol{M}}^{\rm{H}}}{\boldsymbol{\Gamma }} \end{equation} $$ (14) 将式(14)进行数学运算, 节点
$ Q $ 时钟漂移和偏移的最大似然估计器分别表示为:$$ \begin{equation} \begin{split} \left[ {\begin{array}{*{20}{c}} {{{\hat \alpha }^{\left( {QO} \right)}}}\\ {{{\hat \vartheta }^{\left( {QO} \right)}}} \end{array}} \right] =\;& \frac{1}{{\left( {\xi - 1} \right)\left( {N\displaystyle \sum\limits_{j = 1}^N {G_j^2 - {{\left( {\sum\limits_{j = 1}^N {{G_j}} } \right)}^2}} } \right)}}\times\\ &\left[ {\begin{array}{*{20}{c}} {\left( {\xi - 1} \right)\displaystyle \sum\limits_{j = 1}^N {{\Gamma _j}\left( {N{G_j} - \sum\limits_{j = 1}^N {{G_j}} } \right)} }\\ {\displaystyle \sum\limits_{j = 1}^N {{\Gamma _j}\left( {\displaystyle \sum\limits_{j = 1}^N {G_j^2} - {G_j}\displaystyle \sum\limits_{j = 1}^N {{G_j}} } \right)} } \end{array}} \right] \end{split} \end{equation} $$ (15) 其中,
$ {G_j} = \xi t_{1,j}^{\left( P \right)} - t_{4,j}^{\left( Q \right)} $ .所以, 利用估计器(15), 隐含节点
$ Q $ 可以估计自身的时钟漂移和偏移, 达到与时钟源节点$ O $ 的同步. 与现有的免时间戳同步与隐含同步相结合的同步机制相比, 本文所提的同步机制完成了对隐含节点完整时钟参数(时钟漂移和偏移)的估计, 实现了与时钟源节点的完全时间同步.2.2 克拉美罗下限(CRLB)
CRLB是衡量无偏估计器性能的一个理论标准[20], 无偏估计量的方差只能无限逼近或等于CRLB, 而不会小于CRLB, 当两者相等时, 表示估计器性能达到最优. 由于它容易被确定, 常被用来评估无偏估计器性能的好坏, 判断估计器性能是否达到了最优. 为了评估所提联合MLE的性能, 本节推导矢量参数
$\boldsymbol{\Theta } = {{\left[ {{\alpha }^{\left( QO \right)}} \;\; {{\vartheta }^{\left( QO \right)}} \ \right]}^{\rm{T}}}$ 的CRLB. 首先需要计算$ 2\times 2 $ 的费希尔信息矩阵, 然后再求其逆矩阵可分别得到$ {{\alpha }^{\left( QO \right)}} $ 和$ {{\vartheta }^{\left( QO \right)}} $ 的CRLB.由式(12)可得
$ \left( {{\alpha }^{\left( QO \right)}}, {{\vartheta }^{\left( QO \right)}} \right) $ 的对数似然函数如下:$$ \begin{split} &\ln L\left( {{\alpha ^{\left( {QO} \right)}},{\vartheta ^{\left( {QO} \right)}}} \right) = N\ln \frac{1}{\sigma{\sqrt {2\pi \left( {1 + 2{\xi ^2}} \right)} }}-\\ &\qquad\frac{{\displaystyle \sum\limits_{j = 1}^N {{{\left[ {{\Gamma _j} - {G_j}{\alpha ^{\left( {QO} \right)}} + \left( {\xi - 1} \right){\vartheta ^{\left( {QO} \right)}}} \right]}^2}} }}{{2\left( {1 + 2{\xi ^2}} \right){\sigma ^2}}} \end{split} $$ (16) 进一步, 似然函数分别对
$ {{\alpha }^{\left( QO \right)}} $ 和$ {{\vartheta }^{\left( QO \right)}} $ 求二阶导可得:$$ \begin{equation} \frac{{{\partial ^2}\ln L}}{{\partial {{\left( {{\alpha ^{\left( {QO} \right)}}} \right)}^2}}} = - \frac{1}{{\left( {1 + 2{\xi ^2}} \right){\sigma ^2}}}\sum\limits_{j = 1}^N {G_j^2} \end{equation} $$ (17) $$ \begin{equation} \frac{{{\partial ^2}\ln L}}{{\partial {{\left( {{\vartheta ^{\left( {QO} \right)}}} \right)}^2}}} = - \frac{{N{{\left( {\xi - 1} \right)}^2}}}{{\left( {1 + 2{\xi ^2}} \right){\sigma ^2}}} \end{equation} $$ (18) $$ \begin{equation} \frac{{{\partial ^2}\ln L}}{{\partial {\alpha ^{\left( {QO} \right)}}{\vartheta ^{\left( {QO} \right)}}}} = - \frac{{ {\xi - 1} }}{{\left( {1 + 2{\xi ^2}} \right){\sigma ^2}}}\sum\limits_{j = 1}^N {{G_j}} \end{equation} $$ (19) 再对式(17) ~ 式(19)求负期望可得费希尔信息矩阵如下:
$$ \begin{split} &{\bf{FIM}}\left( \lambda \right)=\\ & \left[ {\begin{array}{*{20}{c}} { - {\rm{E}} \left[ {\dfrac{{{\partial ^2}\ln L}}{{\partial {{\left( {{\alpha ^{\left( {QO} \right)}}} \right)}^2}}}} \right]}&{ - {\rm{E}} \left[ {\dfrac{{{\partial ^2}\ln L}}{{\partial {\alpha ^{\left( {QO} \right)}}{\vartheta ^{\left( {QO} \right)}}}}} \right]}\\ { - {\rm{E}} \left[ {\dfrac{{{\partial ^2}\ln L}}{{\partial {\alpha ^{\left( {QO} \right)}}{\vartheta ^{\left( {QO} \right)}}}}} \right]}&{ - {\rm{E}} \left[ {\dfrac{{{\partial ^2}\ln L}}{{\partial {{\left( {{\vartheta ^{\left( {QO} \right)}}} \right)}^2}}}} \right]} \end{array}} \right]=\;\;\;\;\\ & \dfrac{{\left[ {\begin{array}{*{20}{c}} {\displaystyle\sum\limits_{j = 1}^N {G_j^2} }&{\left( {\xi - 1} \right)\displaystyle\sum\limits_{j = 1}^N {{G_j}} }\\ {\left( {\xi - 1} \right)\displaystyle\sum\limits_{j = 1}^N {{G_j}} }&{N{{\left( {\xi - 1} \right)}^2}} \end{array}} \right]}}{{\left( {1 + 2{\xi ^2}} \right){\sigma ^2}}}\\[-25pt] \end{split} $$ (20) 最后, 求得费希尔信息矩阵的逆矩阵为:
$$ \begin{aligned} &{\bf{FI}}{{\bf{M}}^{ - 1}}\left( \lambda \right) = \\ &\frac{{\left( {1 + 2{\xi ^2}} \right){\sigma ^2}\left[ {\begin{array}{*{20}{c}} {N{{\left( {\xi - 1} \right)}^2}}&{ - \left( {\xi - 1} \right)\displaystyle\sum\limits_{j = 1}^N {{G_j}} }\\ { - \left( {\xi - 1} \right)\displaystyle\sum\limits_{j = 1}^N {{G_j}} }&{\displaystyle\sum\limits_{j = 1}^N {G_j^2} } \end{array}} \right]}}{{{{\left( {\xi - 1} \right)}^2}\left[ {N\displaystyle\sum\limits_{j = 1}^N {G_j^2} - {{\left( {\displaystyle\sum\limits_{j = 1}^N {{G_j}} } \right)}^2}} \right]}} \end{aligned} $$ (21) 费希尔信息矩阵的逆矩阵的对角元素即为相应参数的CRLB[20]. 因此, 时钟漂移
$ {{\alpha }^{\left( QO \right)}} $ 和时钟偏移$ {{\vartheta }^{\left( QO \right)}} $ 的CRLB分别表示为:$$ \begin{equation} {\mathop{\rm var}} \left( {{{\hat \alpha }^{\left( {QO} \right)}}} \right) \ge \frac{{N\left( {1 + 2{\xi ^2}} \right){\sigma ^2}}}{{N\displaystyle\sum\limits_{j = 1}^N {G_j^2} - {{\left( {\displaystyle\sum\limits_{j = 1}^N {{G_j}} } \right)}^2}}} \end{equation} $$ (22) $$ {\mathop{\rm var}} \left( {{{\hat \vartheta }^{\left( {QO} \right)}}} \right) \ge \\ \frac{{\left( {1 + 2{\xi ^2}} \right){\sigma ^2}\displaystyle\sum\limits_{j = 1}^N {G_j^2} }}{{{{\left( {\xi - 1} \right)}^2}\left[ {N\displaystyle\sum\limits_{j = 1}^N {G_j^2} - {{\left( {\displaystyle\sum\limits_{j = 1}^N {{G_j}} } \right)}^2}} \right]}} $$ (23) 3. 仿真验证与对比分析
本节基于MATLAB仿真平台, 验证所提隐含节点的联合最大似然估计器的有效性. 同时, 在估计性能、能量开销、计算数量三个方面, 将所提同步机制与现有的相关同步机制进行了对比.
3.1 仿真验证
在无线传感网中, 固定时延和同步周期通常是ms量级, 而对于典型的石英晶体振荡器, 时钟漂移的数量级通常为
$ {{10}^{-6}}\; $ s. 从而可以得出, 时钟漂移大约是时钟偏移和固定时延的$ {{10}^{-3}} $ 倍. 因此, 在仿真验证中, 将活跃节点$ P $ 相对于时钟源节点$ O $ 、活跃节点$ P $ 相对于隐含节点$ Q $ 的时钟漂移和偏移分别设置为:$ {{\alpha }^{( PO )}} = 0.003 $ ,$ {{\alpha }^{( PQ )}} = 0.001 $ ,$ {{\vartheta }^{( PO )}} = [ -5,5 ] $ ,$ {{\vartheta }^{( PQ )}} = [ -2.5,2.5 ] $ . 隐含节点$ Q $ 相对于时钟源节点$ O $ 的时钟漂移$ {{\alpha }^{( QO )}} $ 和偏移$ {{\vartheta }^{( QO )}} $ 可由它们之间的关系得出. 此外, 节点$ P $ 发送数据包的周期$ T $ 设置为80 ms, 高斯随机时延的标准差设置为$ \sigma = 0.2 $ , 信息传输链路中的固定时延取值范围分别设置为:$ {{d}^{( PO )}} = [ 3,13 ] $ ,${{d}^{( OP )}} = [ 0,10 ]$ ,${{d}^{( PQ )}} = [ 3,13 ]$ ,${{d}^{( OQ )}} = [ 0,10 ]$ , 节点$ O $ 在每轮同步过程中计算ACK响应时间$ t_{3,j}^{( O )} $ 的系数$ \xi = 1.4 $ . 在估计理论中, 通常选择均方误差(Mean square error, MSE)作为估计性能标准, 因此这里采用MSE来衡量所提时钟漂移$ {{\alpha }^{( QO )}} $ 和偏移$ {{\vartheta }^{( QO )}} $ 估计器的性能. 为了使仿真结果更加可靠, 在所有的仿真图中, 每个样本点的值都是10000次仿真运行后的平均值.图3为隐含节点
$ Q $ 相对于时钟源节点$ O $ 的时钟漂移最大似然估计器$ {{\hat{\alpha }}^{\left( QO \right)}} $ 的MSE和CRLB. 从图中可以看出, 时钟漂移最大似然估计器$ {{\hat{\alpha }}^{\left( QO \right)}} $ 的MSE曲线与CRLB曲线基本重合, 表明了其估计性能达到最优, 同时也验证了估计器的有效性. 而且随着观测次数的增加, 所提估计器的估计精度不断提高. 图 3 隐含节点
图 3 隐含节点$Q$ 时钟漂移估计${{\hat{\alpha }}^{\left(QO \right)}}$ 的MSE与CRLBFig. 3 MSE and CRLB of estimated clock skew${{\hat{\alpha }}^{\left(QO \right)}}$ for silent node$Q$ 图4所示为隐含节点
$ Q $ 相对于时钟源节点$ O $ 的时钟偏移最大似然估计器$ {{\hat{\vartheta }}^{\left( QO \right)}} $ 的仿真结果. 在图4中, 时钟偏移最大似然估计器$ {{\hat{\vartheta }}^{\left( QO \right)}} $ 的性能随着观测次数的增加不断提高, 而且MSE曲线与CRLB曲线基本重合, 表明该估计器的性能达到了最优, 同时验证了该估计器的有效性. 值得注意的是, 在仿真中, 系数$ \xi = 1.4 $ , 这表明隐含节点$ Q $ 在通信过程中只是获取到2/5的$ t_{2,j}^{\left( O \right)} $ , 就以此实现了相对于时钟源节点$ O $ 的时钟偏移估计. 此外, 时钟偏移的估计精度是影响同步精度的主要因素. 因为隐含节点$ Q $ 根据估计的时钟漂移与偏移调整本地时间, 减小与时钟源节点$ O $ 的时间偏差, 而时钟漂移的估计精度比时钟偏移的估计精度高出约$ {{10}^{6}} $ 个数量级, 其对同步精度的影响较小, 可以忽略不计. 所以可以利用时钟偏移的估计精度反映节点间的同步精度. 从图4中可以看出, 时钟偏移的估计精度为$ {{10}^{-1}} $ 数量级, 而时钟偏移被设置为数ms, 因此, 所提同步算法可达到数百μs的同步精度.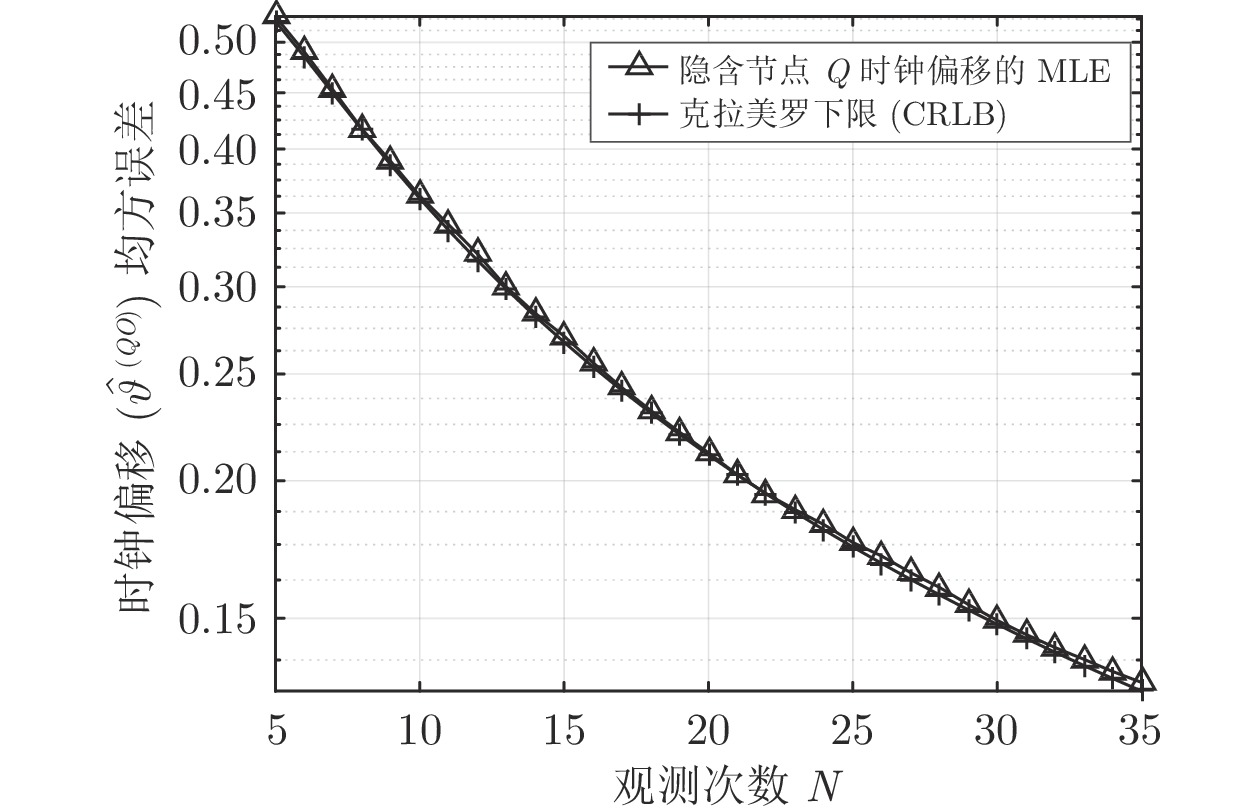 图 4 隐含节点
图 4 隐含节点$Q$ 时钟偏移估计${{\hat{\vartheta }}^{\left(QO \right)}}$ 的MSE与CRLBFig. 4 MSE and CRLB of estimated clock offset${{\hat{\vartheta }}^{\left(QO \right)}}$ for silent node$Q$ 从仿真结果可以看出, 隐含节点
$ Q $ 监听活跃节点$ P $ 和时钟源节点$ O $ 之间的免时间戳同步过程, 通过观测到的数据集$ \left\{ t_{2,j}^{\left( Q \right)},t_{4,j}^{\left( Q \right)}, {{R}_{j}} \right\}_{j = 1}^{N} $ 就可以同时估计相对于节点$ O $ 的时钟漂移和偏移, 达到与节点$ O $ 的同步. 与文献[15]中的基于动态响应的免时间戳的隐含同步方式相比, 所提的免时间戳隐含同步方法继承了现有免时间戳同步和隐含同步的优势, 能够大幅度地减少同步能量消耗, 同时也可以无缝地嵌入到网络数据流之中. 进一步, 隐含节点又能够联合估计相对于时钟源节点的时钟漂移和偏移, 实现隐含节点的完全同步, 弥补了目前两种机制结合使用的不足.3.2 对比分析
首先, 将所提的隐含节点
$ Q $ 的时钟漂移最大似然估计器$ {{\hat{\alpha }}^{\left( QO \right)}} $ 与类似的估计器(文献[15]中的式(26))进行估计性能比较. 为了确保比较的公平性, 在两种估计器的对比仿真中, 各个参数的初始化设置均相同, 文献[15]中两个连续周期内ACK的响应时间间隔设置为$ \left\{ 10,30 \right\} $ . 仿真结果如图3所示, 本文所提的隐含节点$ Q $ 的时钟漂移估计器的性能显著优于文献[15]中的时钟漂移估计器, 而且其估计精度大约高出101 ~ 103个数量级. 其原因是所提同步机制通过预设时钟源节点$ O $ 返回ACK的本地时间, 传递了部分时间戳信息$ \left( \xi -1 \right)t_{2,j}^{\left( O \right)} $ 给隐含节点$ Q $ , 时间戳信息的获取有利于时钟漂移估计精度的提高. 图5所示为不同系数$ \xi $ 下时钟漂移估计器性能对比结果, 其中设置$\xi = \{ 1.2,1.3,1.4, 1.5,1.6 \}$ . 从图中可以看出, 随着系数$ \xi $ 的增大, 所提时钟漂移估计器$ {{\hat{\alpha }}^{\left( QO \right)}} $ 的估计性能不断提高, 表明隐含节点$ Q $ 获取的时间戳信息越多, 时钟漂移的估计效果越好. 同时, 从仿真的角度说明, 相较于文献[15]中无法获取时间戳信息的隐含节点, 所提同步机制的隐含节点由于能够间接地获取部分时间戳信息, 因此其时钟漂移估计器性能更优. 但是, 需要注意的是, 不能为了提高时钟漂移的估计性能无限地增加$ \xi $ , 因为$ \xi $ 的取值必须确保响应时间间隔不会过大, 影响网络的正常运行.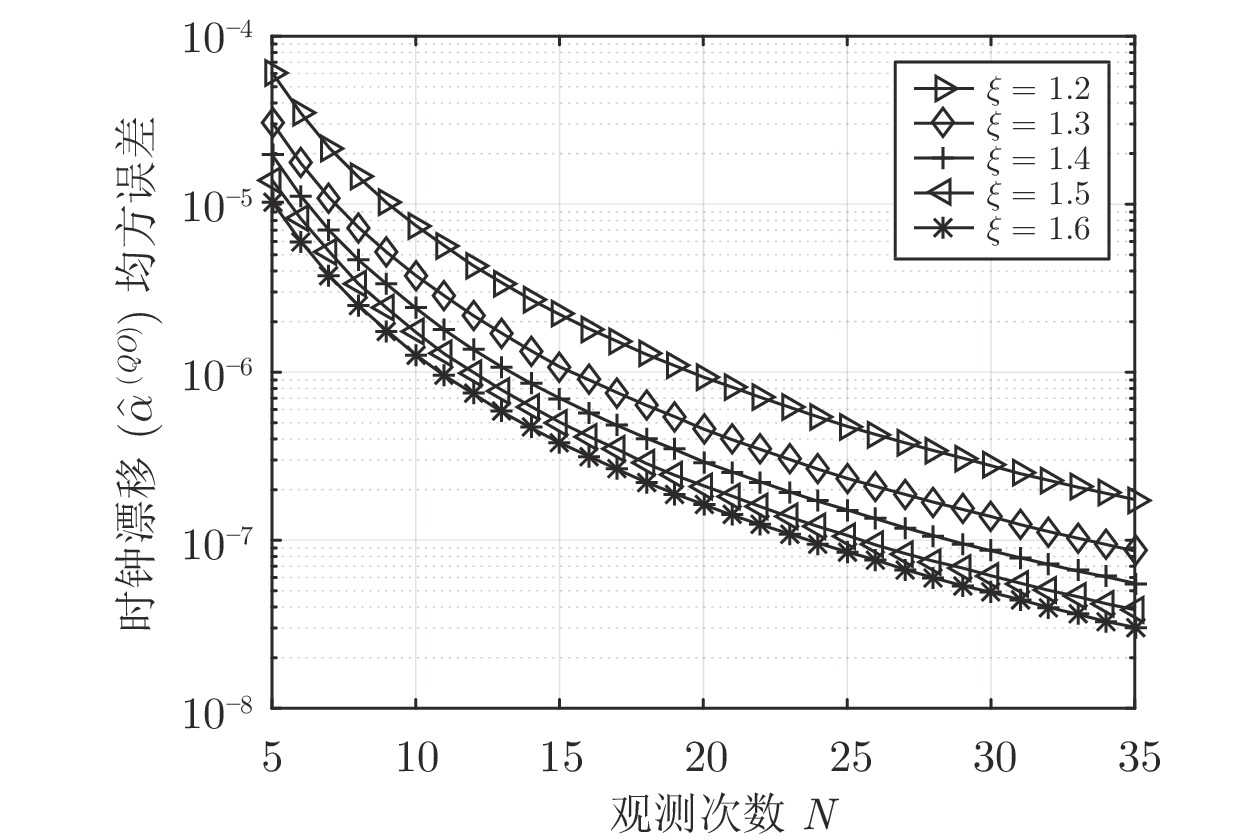 图 5 不同系数
图 5 不同系数$\xi $ 下时钟漂移估计器性能对比结果Fig. 5 The performance comparison results of clock skew estimator under different coefficient$\xi $ 其次, 将所提同步机制与隐含同步机制[7]、基于动态响应的免时间戳同步机制[15]进行信令流程及能耗开销对比. 无线传感网的时间同步依赖于信息交互, 交互流程所导致的能耗开销是影响同步能耗的重要因素. 在隐含同步机制中, 隐含节点监听的是传统的双向信息交互过程, 需要专用的同步帧传递时间戳信息, 同步帧的传输需要消耗额外的能量. 在基于动态响应的免时间戳同步机制中, 待同步节点无需发送时间戳信息, 在普通数据收发中实现同步, 无需消耗额外的能量. 在所提机制中, 隐含节点监听的是时钟源节点和活跃节点的免时间戳交互过程, 不需要专用同步帧, 没有额外的能量开销. 因此, 相较于隐含同步机制, 所提机制避免了网络中专用同步帧传输, 显著减少了能耗. 与免时间戳机制相比, 所提机制能够一次性实现公共广播领域内多个节点的同步, 而免时间戳机制只能实现一个节点的同步, 对于网络整体的能耗而言, 所提机制更具优势.
最后, 分析所提同步算法、隐含同步算法[7]、基于动态响应的免时间戳同步算法[15]以及免时间戳与隐含同步结合算法[15]的计算复杂度, 主要是对算法中加法和减法、乘法和除法计算数量进行比较, 对比结果如表1所示. 从表中可以看出, 4种同步算法时钟参数的计算复杂度均为
$ {\rm{O}}({{N}^{2}}) $ . 而本文算法时钟参数乘除法的计算数量高于隐含同步算法和免时间戳同步算法时钟参数计算数量, 这是因为时钟源节点$ O $ 返回ACK的本地时间中包含系数$ \xi $ , 导致算法中乘除法的数量相对较高. Wang等[16]研究表明, 传输1比特数据超过100米消耗的能量与执行300万条指令所需能量大致相等. 因此, 虽然本文算法的计算数量略高, 但能够在不传输专用同步帧的情况下实现多个节点的同步, 它仍然是一个高能效的同步方案. 相较于文献[15]中的免时间戳与隐含同步结合算法, 本文算法时钟漂移的计算复杂度略低于其时钟漂移计算复杂度, 而且本文算法还可以估计时钟偏移, 实现完整的同步.表 1 本文算法与隐含同步算法、免时间戳同步算法以及免时间戳和隐含同步结合算法的计算数量对比结果Table 1 The comparison results of the number of calculations among proposed algorithm, implicit synchronization algorithm, timestamp-free synchronization algorithm and combination algorithm of timestamp-free and implicit synchronization算法 参数 加减法数量 乘除法数量 本文算法 时钟漂移 $2{N^2} + 14N - 3$ ${N^2} + 11N + 3$ 时钟偏移 $5{N^2} + 13N - 2$ $4{N^2} + 11N + 4$ 隐含同步算法 时钟漂移 $2{N^2} + 12N - 3$ $3N + 3$ 时钟偏移 $5{N^2} + 11N - 3$ ${N^2} + 3N + 3$ 免时间戳同步算法 时钟漂移 ${N^2} + 6N - 2$ $4N + 3$ 免时间戳与隐含同步结合算法 时钟漂移 $4{N^2} + 10N - 1$ $4{N^2} + 12N + 1$ 4. 结论
本文提出了一种能够联合估计免时间戳同步场景中隐含节点的时钟漂移和偏移的同步协议. 在高斯随机时延下, 推导了隐含节点时钟漂移和偏移的最大似然估计器和相应的CRLB. 最后, 通过数值仿真验证了所提估计器的有效性, 并且与现有的相关同步方案在估计性能、能量开销和计算数量三个方面进行了对比, 论证了所提方案低功耗的优势.
-

图 1 固定原型和自适应原型生成示例 (5类5样本)
Fig. 1 Examples of fixed prototype and adaptive prototype generation (5-way-5-shot)

图 5 在不同数据集上自适应原型和预训练模块的性能比较
Fig. 5 Performance comparison of adaptive prototype and pre-training module on different datasets

图 6 应用不同N类K样本设置的性能比较
Fig. 6 Performance comparison using different N-way-K-shot settings
表 1 数据集基本信息
Table 1 Basic information of datasets
数据集 样本数量 训练/验证/测试类别数量 图片尺寸(像素) MiniImageNet 60000 64/16/20 84$ \times $84 CIFAR-FS 60000 64/16/20 32$ \times $32 FC100 60000 60/20/20 32$ \times $32  下载: 导出CSV
下载: 导出CSV
表 2 应用不同网络的实验结果 (%)
Table 2 Experimental results using different networks (%)
网络 数据集 ProtoNet CRAPF ResNet12 MiniImageNet 72.08 77.08 CIFAR-FS 75.68 85.11 FC100 50.96 54.56 ResNet18 MiniImageNet 73.68 74.40 CIFAR-FS 72.83 84.93 FC100 47.50 53.33
下载: 导出CSV
表 3 MiniImageNet数据集上的对比实验结果 (%)
Table 3 Comparative experimental results on the MiniImageNet dataset (%)
方法 网络 5类1样本 5类5样本 TEAM ResNet18 60.07 75.90 TransCNAPS ResNet18 55.60 73.10 MTUNet ResNet18 58.13 75.02 IPN ResNet10 56.18 74.60 ProtoNet* ResNet12 53.42 72.08 TADAM ResNet12 58.50 76.70 SSR ResNet12 68.10 76.90 MDM-Net ResNet12 59.88 76.60 CRAPF* ResNet12 59.38 77.08
下载: 导出CSV
表 4 CIFAR-FS数据集上的对比实验结果 (%)
Table 4 Comparative experimental results on the CIFAR-FS dataset (%)
方法 网络 5类1样本 5类5样本 ProtoNet* ResNet12 56.86 75.68 Shot-Free ResNet12 69.20 84.70 TEAM ResNet12 70.40 80.30 DeepEMD ResNet12 46.50 63.20 DSN ResNet12 72.30 85.10 MTL ResNet12 69.50 84.10 DSMNet ResNet12 60.66 79.26 MTUNet ResNet18 67.43 82.81 CRAPF* ResNet12 72.34 85.11
下载: 导出CSV
表 5 FC100数据集上的对比实验结果 (%)
Table 5 Comparative experimental results on the FC100 dataset (%)
方法 网络 5类1样本 5类5样本 ProtoNet* ResNet12 37.50 50.96 SimpleShot ResNet10 40.13 53.63 Baseline2020 ResNet12 36.82 49.72 TADAM ResNet12 40.10 56.10 CRAPF* ResNet12 40.44 54.56
下载: 导出CSV
-
[1] Jiang H, Diao Z, Shi T, Zhou Y, Wang F, Hu W, et al. A review of deep learning-based multiple-lesion recognition from medical images: Classification, detection and segmentation. Computers in Biology and Medicine, 2023, 157: Article No. 106726 [2] 赵凯琳, 靳小龙, 王元卓. 小样本学习研究综述. 软件学报, 2021, 32(2): 349−369Zhao Kai-Lin, Jin Xiao-Long, Wang Yuan-Zhuo. Survey on few-shot learning. Journal of Software, 2021, 32(2): 349−369 [3] 赵一铭, 王佩瑾, 刁文辉, 孙显, 邓波. 基于通道注意力机制的小样本SAR飞机图像分类方法. 南京大学学报(自然科学版), 2024, 60(3): 464−476Zhao Yi-Ming, Wang Pei-Jin, Diao Wen-Hui, Sun Xian, Deng Bo. Few-shot SAR aircraft image classification method based on channel attention mechanism. Journal of Nanjing University (Natural Science), 2024, 60(3): 464−476 [4] Li F F, Fergus R, Perona P. A Bayesian approach to unsupervised one-shot learning of object categories. In: Proceedings of the IEEE International Conference on Computer Vision. Nice, Franc: IEEE, 2003. 1134−1141 [5] 刘颖, 雷研博, 范九伦, 王富平, 公衍超, 田奇. 基于小样本学习的图像分类技术综述. 自动化学报, 2021, 47(2): 297−315Liu Ying, Lei Yan-Bo, Fan Jiu-Lun, Wang Fu-Ping, Gong Yan-Chao, Tian Qi. Survey on image classification technology based on small sample learning. Acta Automatica Sinica, 2021, 47(2): 297−315 [6] Li X, Yang X, Ma Z, Xue J. Deep metric learning for few-shot image classification: A review of recent developments. Pattern Recognition, 2023, 138: Article No. 109381 [7] Snell J, Swersky K, Zemel R. Prototypical networks for few-shot learning. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: 2017. 4077−4087 [8] Qiang W, Li J, Su B, Fu J, Xiong H, Wen J. Meta attention-generation network for cross-granularity few-shot learning. IEEE International Journal of Computer Vision, 2023, 131(5): 1211−1233 doi: 10.1007/s11263-023-01760-7 [9] Li W, Wang L, Xu J, Huo J, Gao Y, Luo J. Revisiting local descriptor based image-to-class measure for few-shot learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 7260−7268 [10] Xu W, Xu Y, Wang H, Tu Z. Attentional constellation nets for few-shot learning. In: Proceedings of the International Conference on Learning Representations. Vienna, Austria: ICLR, 2021. 1−12 [11] Huang H, Zhang J, Yu L, Zhang J, Wu Q, Xu C. TOAN: Target-oriented alignment network for fine-grained image categorization with few labeled samples. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 32(2): 853−866 [12] Xie J, Long F, Lv J, Wang Q, Li P. Joint distribution matters: Deep Brownian distance covariance for few-shot classification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 7972−7981 [13] Luo X, Wei L, Wen L, Yang J, Xie L, Xu Z, et al. Rectifying the shortcut learning of background for few-shot learning. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: 2021. 13073−13085 [14] Kwon H, Jeong S, Kim S, Sohn K. Dual prototypical contrastive learning for few-shot semantic segmentation. arXiv preprint arXiv: 2111.04982, 2021. [15] Li J, Liu G. Few-shot image classification via contrastive self-supervised learning. arXiv preprint arXiv: 2008.09942, 2020. [16] Sung F, Yang Y, Zhang L, Xiang T, Torr P H, Hospedales T M. Learning to compare: Relation network for few-shot learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1199− 1208 [17] Hao F, He F, Cheng J, Wang L, Cao J, Tao D. Collect and select: Semantic alignment metric learning for few-shot learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 8460−8469 [18] Li W, Xu J, Huo J, Wang L, Gao Y, Luo J. Distribution consistency based covariance metric networks for few-shot learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu, USA: 2019. 8642−8649 [19] Zhu W, Li W, Liao H, Luo J. Temperature network for few-shot learning with distribution-aware large margin metric. Pattern Recognition, 2021, 112: Article No. 109381 [20] Allen K, Shelhamer E, Shin H, Tennbaum J B. Infinite mixture prototypes for few-shot learning. In: Proceedings of the International Conference on Machine Learning. Long Beach, USA: ICML, 2019. 232−241 [21] Liu J, Song L, Qin Y. Prototype rectification for few-shot learning. In: Proceedings of the European Conference Computer Vision. Glasgow, UK: Springer, 2020. 741−756 [22] Li X, Li Y, Zheng Y, Zhu R, Ma Z, Xue J, et al. ReNAP: Relation network with adaptive prototypical learning for few-shot classification. Neurocomputing, 2023, 520: 356−364 doi: 10.1016/j.neucom.2022.11.082 [23] Vinyals O, Blundell C, Lillicrap T, Kavukcuoglu K, Wierstra D. Matching networks for one shot learning. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: 2016. 3637−3645 [24] Bertinetto L, Henriques J, Torr P, Vedaldi A. Meta-learning with differentiable closed-form solvers. In: Proceedings of the International Conference on Learning Representations. New Orleans, USA: ICLR, 2019. 1−13 [25] Oreshkin B, Rodríguez Loópez P, Lacoste A. TADAM: Task dependent adaptive metric for improved few-shot learning. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: 2018. 719−729 [26] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, et al. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115: 211−252 doi: 10.1007/s11263-015-0816-y [27] Ravi S, Larochelle H. Optimization as a model for few-shot learning. In: Proceedings of the International Conference on Learning Representations. San Juan, Puerto Rico: ICLR, 2016. 1−11 [28] Krizhevsky A. Learning Multiple Layers of Features From Tiny Images [Master thesis], Toronto University, Canada, 2009. [29] Bertinetto L, Henriques J F, Valmadre J, Torr P H S, Vedaldi A. Learning feed-forward one-shot learners. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: 2016. 523−531 [30] Qiao L, Shi Y, Li J, Wang Y, Huang T, Tian Y. Transductive episodic-wise adaptive metric for few-shot learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 3603−3612 [31] Bateni P, Barber J, van de meent J W, Wood F. Enhancing few-shot image classification with unlabelled examples. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Waikoloa, USA: IEEE, 2022. 2796−2805 [32] Wang B, Li L, Verma M, Nakashima Y, Kawasaki R, Nagahara H. Match them up: Visually explainable few-shot image classification. Applied Intelligence, 2023, 53: 10956−10977 doi: 10.1007/s10489-022-04072-4 [33] Ji Z, Chai X, Yu Y, Pang Y, Zhang Z. Improved prototypical networks for few-shot learning. Pattern Recognition Letters, 2020, 140: 81−87 doi: 10.1016/j.patrec.2020.07.015 [34] Shen X, Xiao Y, Hu S X, Sbai O, Aubry M. Re-ranking for image retrieval and transductive few-shot classification. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: 2021. 25932−25943 [35] Gao F, Cai L, Yang Z, Song S, Wu C. Multi-distance metric network for few-shot learning. International Journal of Machine Learning and Cybernetics, 2022, 13(9): 2495−2506 doi: 10.1007/s13042-022-01539-1 [36] Ravichandran A, Bhotika R, Soatto S. Few-shot learning with embedded class models and shot-free meta training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 331−339 [37] Zhang C, Cai Y, Lin G, Shen C. DeepEMD: Few-shot image classification with differentiable earth mover's distance and structured classifiers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 12203−12213 [38] Simon C, Koniusz P, Nock R, Harandi M. Adaptive subspaces for few-shot learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 4136−4145 [39] Wang H, Zhao H, Li B. Bridging multi-task learning and meta-learning: Towards efficient training and effective adaptation. In: Proceedings of the International Conference on Machine Learning. Vienna, Austria: ICML, 2021. 10991−11002 [40] Yan L, Li F, Zhang L, Zheng X. Discriminant space metric network for few-shot image classification. Applied Intelligence, 2023, 53: 17444−17459 doi: 10.1007/s10489-022-04413-3 [41] Wang Y, Chao W L, Weinberger K Q, Maaten L. SimpleShot: Revisiting nearest-neighbor classification for few-shot learning. arXiv preprint arXiv: 1911.04623, 2019. [42] Ramprasaath R, Michael C, Abhishek D, Ramakrishna V, Devi P, Dhruv B. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 618−626 [43] Dhillon G S, Chaudhari P, Ravichandran A, Soattoet S. A baseline for few-shot image classification. In: Proceedings of the International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. 1−12 期刊类型引用(3)
1. 井荣枝,王延堂,陈小乐,徐峰. 空间约束下多关节机械臂架末端柔顺控制方法. 机械设计与制造. 2024(11): 122-126 .  百度学术
百度学术2. 甘雨,郭鹏,林立栋. 基于变分贝叶斯推断的DPGMM风电机组异常数据识别研究. 动力工程学报. 2023(07): 885-892 . 百度学术3. 杨怡婷. 两轮自平衡可移动机器人能耗最优运动轨迹规划方法. 兰州文理学院学报(自然科学版). 2022(01): 59-63 . 百度学术其他类型引用(6)
-


 下载:
下载:

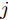


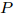
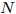


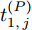


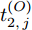
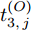
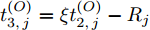
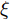
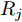
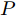

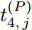
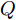
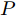

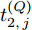
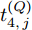
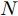


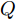

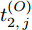
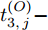
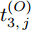
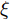
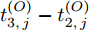
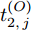
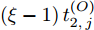
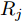
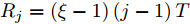
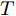
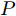

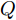
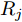

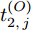
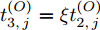
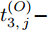
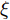
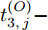
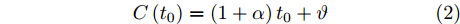
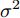

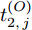
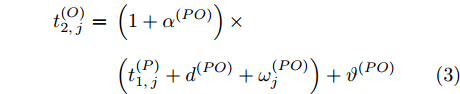
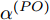
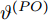
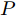

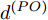
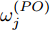

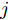
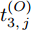
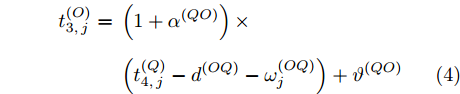
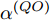
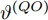
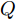

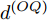
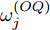
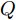
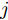
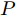
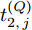
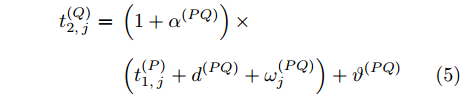
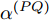
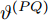
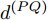
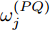
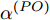
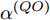
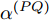
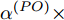
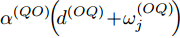
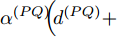
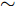
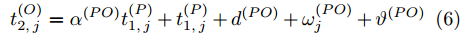
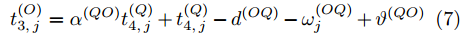
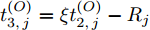
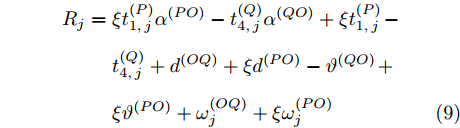
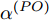
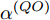
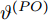
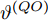
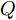

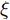
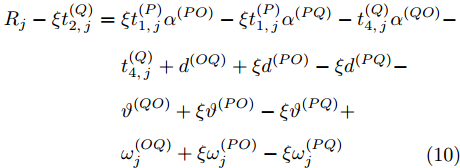
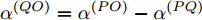
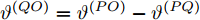
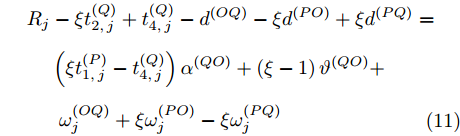
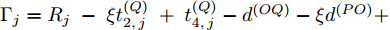
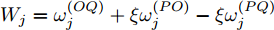
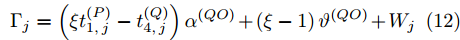
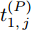
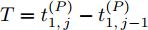
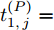

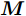

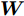
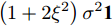
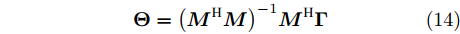
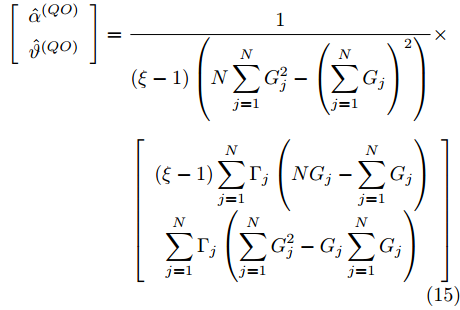
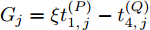
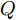

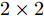
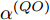
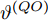
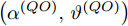
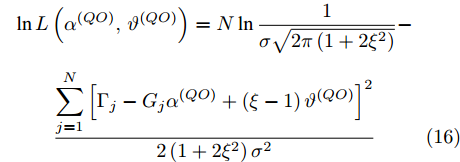
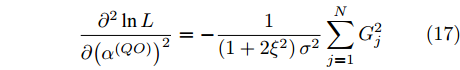
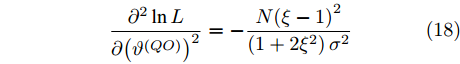
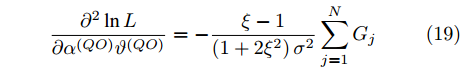
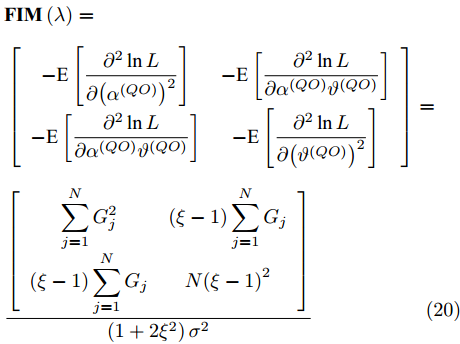
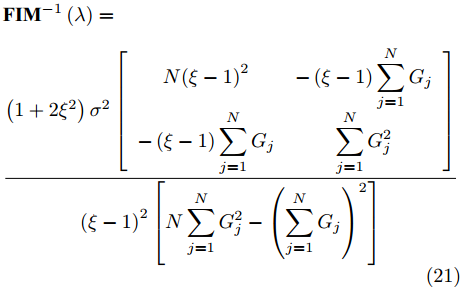
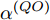
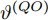
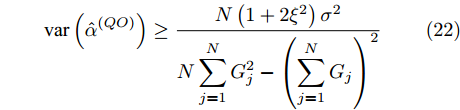
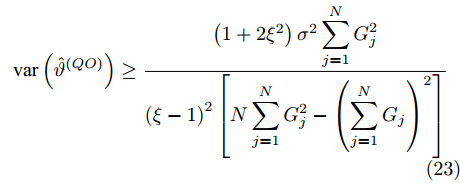
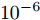
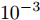


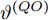
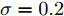
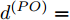

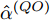

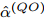


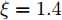
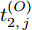
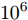
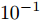

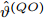
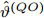


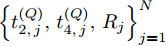
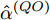
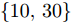

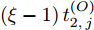







计量
- 文章访问数: 400
- HTML全文浏览量: 198
- PDF下载量: 99
- 被引次数: 9
