

Optimal Consensus for Strict-feedback Multi-agent Systems Based on Proportional-integral Regulation
-
摘要: 本文研究了严格反馈多智能体系统的最优一致性问题, 旨在局部信息交互的条件下, 使所有智能体收敛至全局代价函数的最优解. 首先, 针对权重非平衡有向图, 提出一种新的分布式比例积分(Proportional-integral, PI)变量, 将最优一致性问题转化为PI调节问题, 使得经典的控制技术能够通过调节PI变量的方式来处理更加复杂的多智能体系统. 然后, 结合所提出的分布式PI变量和预设性能控制, 设计一类基于PI调节的分布式控制算法, 使得带有死区输入非线性和有界扰动的严格反馈多智能体系统实现近似最优一致性. 最后, 通过仿真实验验证了所设计算法的有效性.Abstract: In this paper, the optimal consensus problem for strict-feedback multi-agent systems is investigated. The goal is to ensure that all agents converge to the optimal solution of the global cost function using only local exchanged information. First, a new type of distributed proportional-integral (PI) variables is proposed for weight-unbalanced directed graphs, transforming the optimal consensus problem into a PI regulation problem. This transformation allows classical control techniques to handle more complicated multi-agent systems by regulating the PI variables. Subsequently, combining the proposed distributed PI variables with prescribed performance control, we design a class of distributed control algorithms based on PI regulation. These algorithms are used to achieve approximate optimal consensus for strict-feedback multi-agent systems with dead-zone input nonlinearity and bounded disturbances. Finally, the effectiveness of the designed algorithms is verified through a simulation experiment.
-
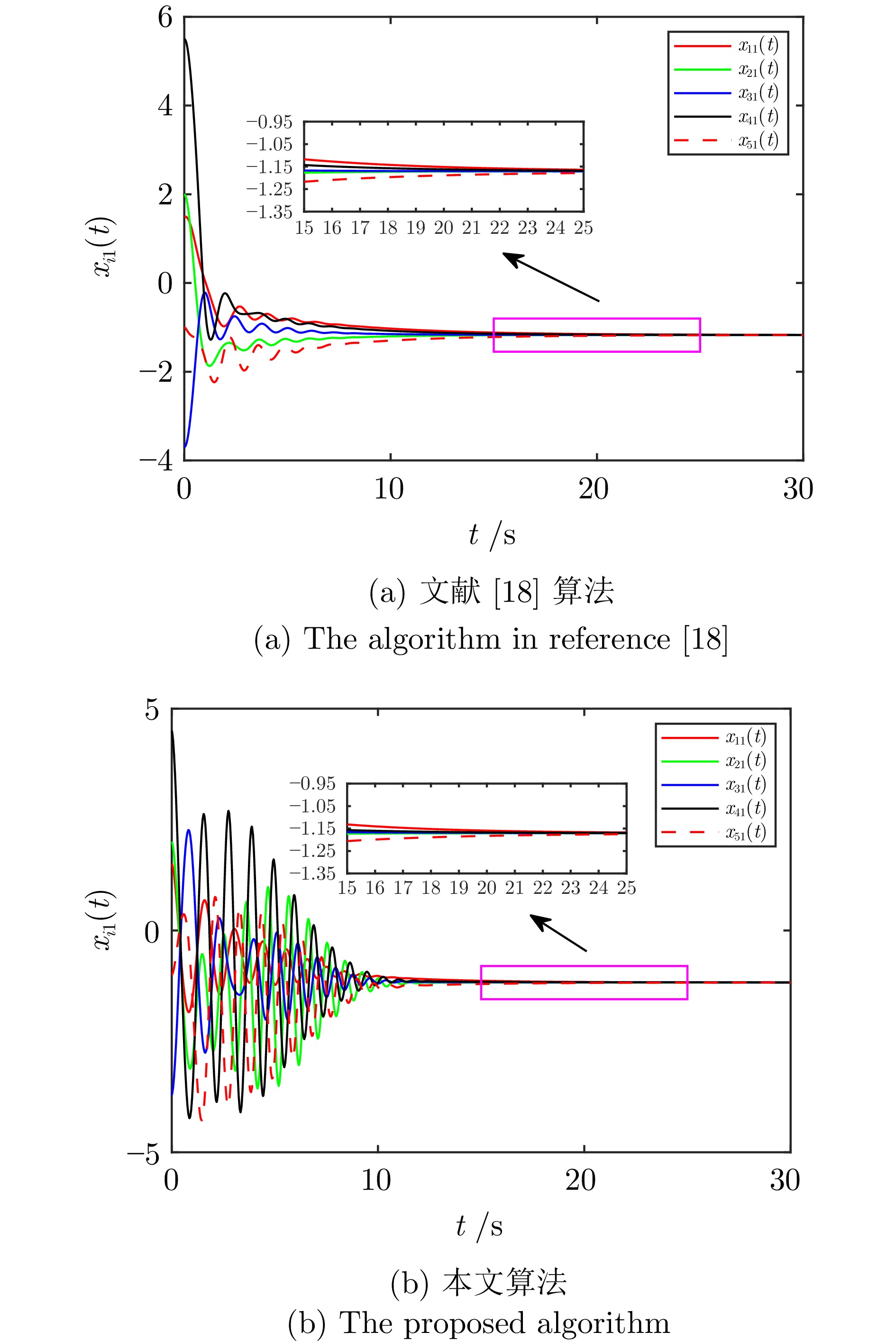
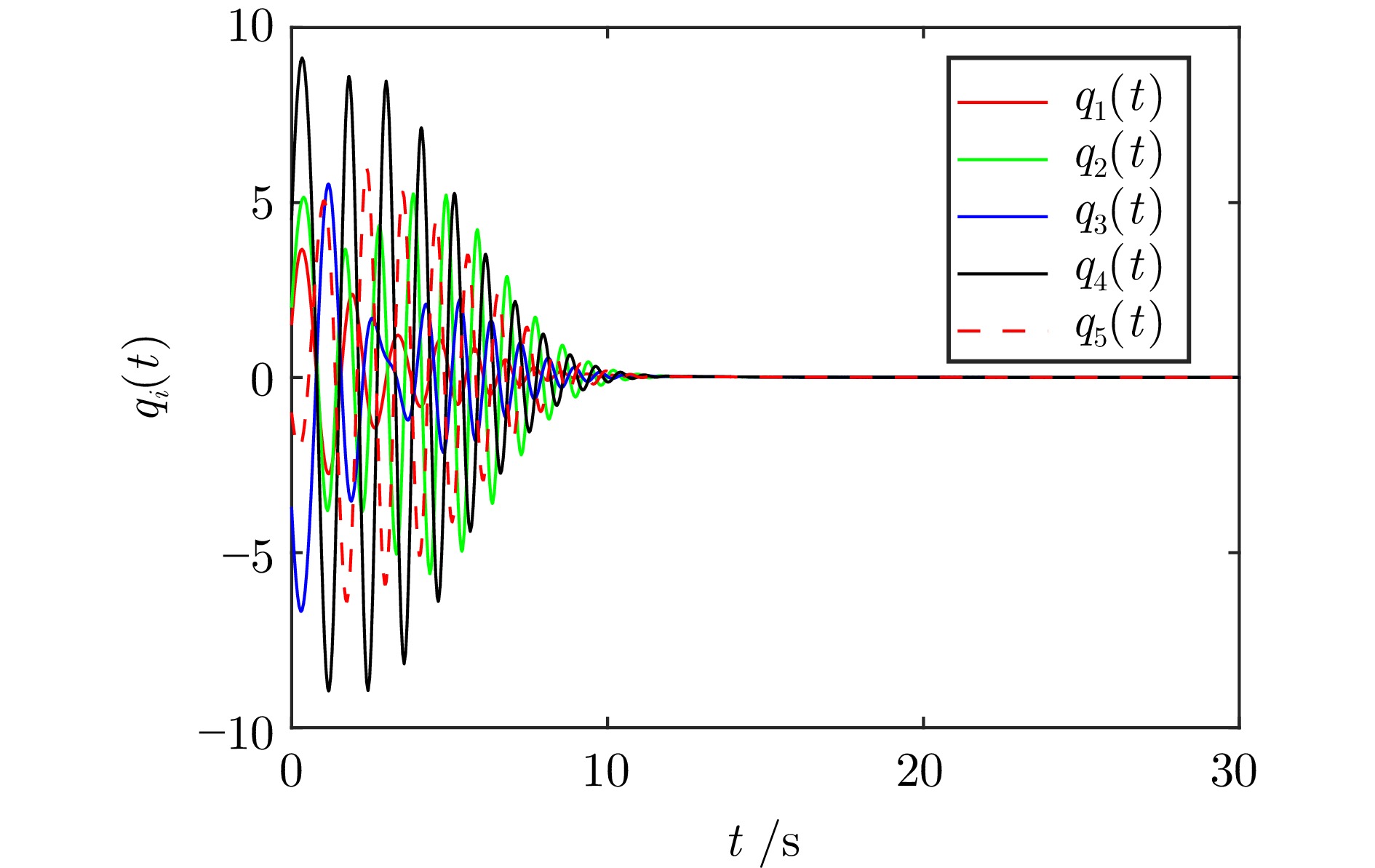
图 2 不同算法下状态变量$ x_{i1}(t) $的轨迹
Fig. 2 The trajectories of the state variables $ x_{i1}(t)$ under different algorithms
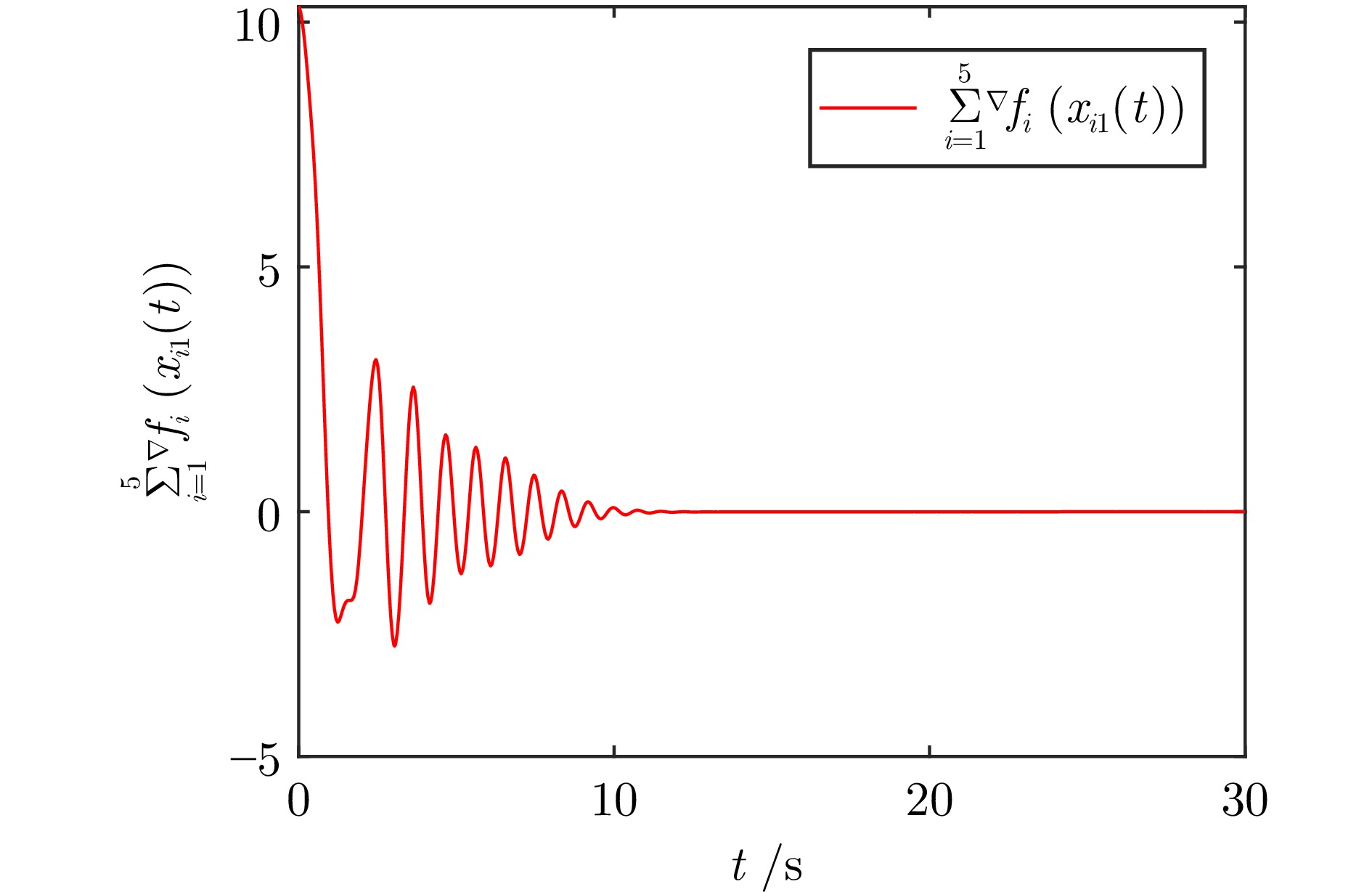
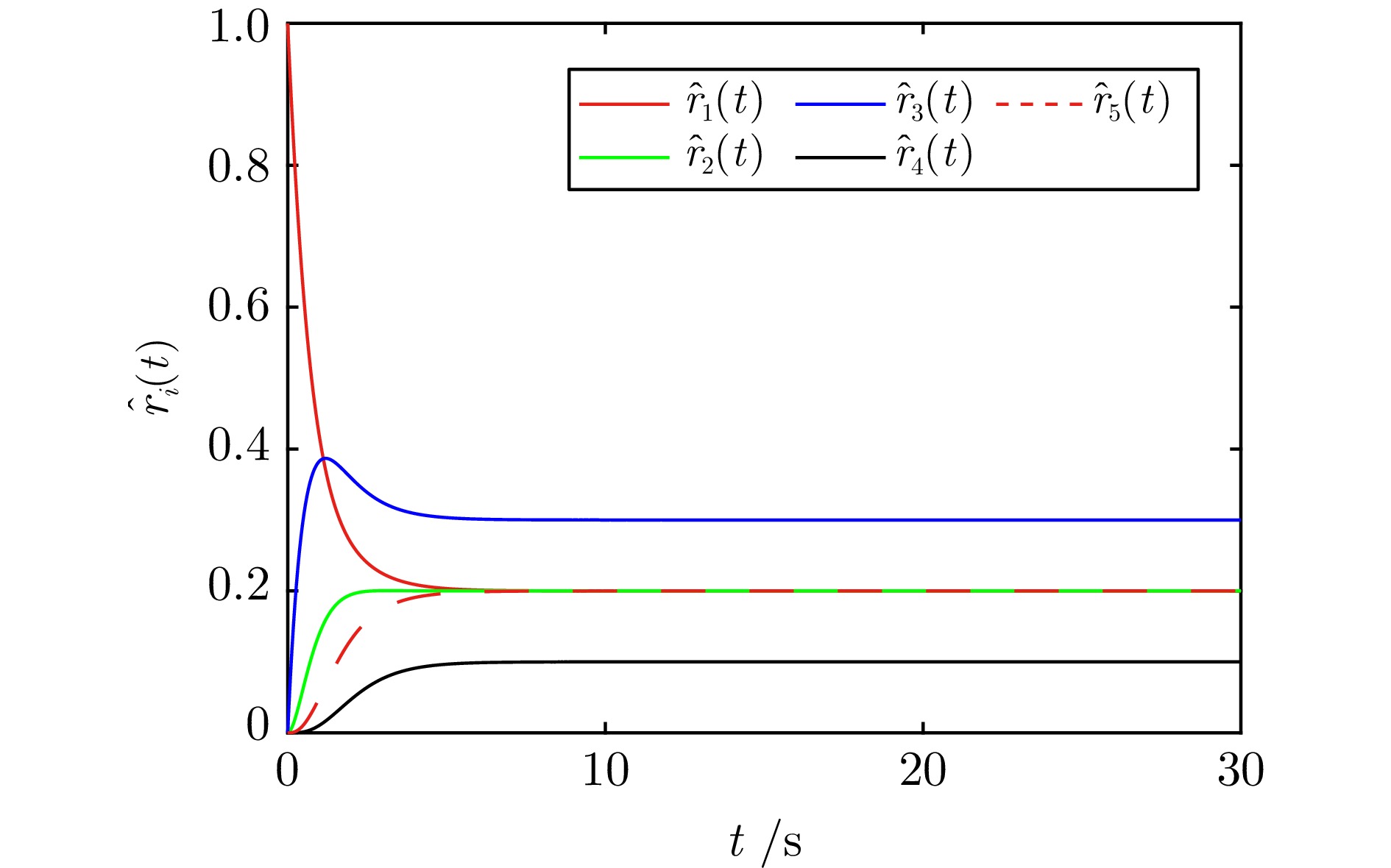
图 5 全局代价函数梯度$\sum_{i = 1}^{5}\nabla f_i(x_{i1}(t))$的轨迹
Fig. 5 The trajectory of global cost function gradient $\sum_{i = 1}^{5}\nabla f_i(x_{i1}(t))$
-
[1] Dougherty S, Guay M. An extremum-seeking controller for distributed optimization over sensor networks. IEEE Transactions on Automatic Control, 2017, 62(2): 928−933 doi: 10.1109/TAC.2016.2566806 [2] Chang T H, Nedic A, Scaglione A. Distributed constrained optimization by consensus-based primal-dual perturbation method. IEEE Transactions on Automatic Control, 2014, 59(6): 1524−1538 doi: 10.1109/TAC.2014.2308612 [3] Jaleel H, Shamma J S. Distributed optimization for robot networks: From real-time convex optimization to game-theoretic self-organization. Proceedings of the IEEE, 2020, 108(11): 1953−1967 doi: 10.1109/JPROC.2020.3028295 [4] 杨涛, 柴天佑. 分布式协同优化的研究现状与展望. 中国科学: 技术科学, 2020, 50(11): 1414−1425 doi: 10.1360/SST-2020-0040Yang Tao, Chai Tian-You. Research status and prospects of distributed collaborative optimization. Scientia Sinica Technologica, 2020, 50(11): 1414−1425 doi: 10.1360/SST-2020-0040 [5] Yang T, Yi X L, Wu J F, Yuan Y, Wu D, Meng Z Y, et al. A survey of distributed optimization. Annual Reviews in Control, 2019, 47: 278−305 doi: 10.1016/j.arcontrol.2019.05.006 [6] 杨涛, 徐磊, 易新蕾, 张圣军, 陈蕊娟, 李渝哲. 基于事件触发的分布式优化算法. 自动化学报, 2022, 48(1): 133−143Yang Tao, Xu Lei, Yi Xin-Lei, Zhang Sheng-Jun, Chen Rui-Juan, Li Yu-Zhe. Event-triggered distributed optimization algorithms. Acta Automatica Sinica, 2022, 48(1): 133−143 [7] 朱文博, 王庆领. 基于梯度估计的多智能体系统有限时间分布式优化. 控制理论与应用, 2023, 40(4): 615−623Zhu Wen-Bo, Wang Qing-Ling. Gradient estimations based distributed finite-time optimization for multiagent systems. Control Theory & Applications, 2023, 40(4): 615−623 [8] Nedic A, Ozdaglar A. Distributed subgradient methods for multi-agent optimization. IEEE Transactions on Automatic Control, 2009, 54(1): 48−61 doi: 10.1109/TAC.2008.2009515 [9] Shi W, Ling Q, Wu G, Yin W. EXTRA: An exact first-order algorithm for decentralized consensus optimization. SIAM Journal on Optimization, 2015a, 25(2): 944−966 doi: 10.1137/14096668X [10] Gharesifard B, Cortes J. Distributed continuous-time convex optimization on weight-balanced digraphs. IEEE Transactions on Automatic Control, 2014, 59(3): 781−786 doi: 10.1109/TAC.2013.2278132 [11] Kia S S, Cortes J, Martinez S. Distributed convex optimization via continuous-time coordination algorithms with discrete-time communication. Automatica, 2015, 55: 254−264 doi: 10.1016/j.automatica.2015.03.001 [12] Wang X H, Hong Y G, Ji H B. Distributed optimization for a class of nonlinear multiagent systems with disturbance rejection. IEEE Transactions on Cybernetics, 2016, 46(7): 1655−1666 doi: 10.1109/TCYB.2015.2453167 [13] Wang D, Wang Z, Wen C Y. Distributed optimal consensus control for a class of uncertain nonlinear multiagent networks with disturbance rejection using adaptive technique. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2021, 51(7): 4389−4399 doi: 10.1109/TSMC.2019.2933005 [14] Liu T F, Qin Z Y, Hong Y G, Jiang Z P. Distributed optimization of nonlinear multiagent systems: A small-gain approach. IEEE Transactions on Automatic Control, 2022, 67(2): 676−691 doi: 10.1109/TAC.2021.3053549 [15] Tang Y T, Deng Z H, Hong Y G. Optimal output consensus of high-order multiagent systems with embedded technique. IEEE Transactions on Cybernetics, 2019, 49(5): 1768−1779 doi: 10.1109/TCYB.2018.2813431 [16] Tang Y T, Wang X H. Optimal output consensus for nonlinear multiagent systems with both static and dynamic uncertainties. IEEE Transactions on Automatic Control, 2021, 66(4): 1733−1740 doi: 10.1109/TAC.2020.2996978 [17] Wang Q L, Wu W Q. A distributed finite-time optimization algorithm for directed networks of continuous-time agents. International Journal of Robust and Nonlinear Control, 2024, 34(6): 4032−4050 doi: 10.1002/rnc.7176 [18] Zhang J, Liu L, Ji H B. Optimal output consensus of second-order uncertain nonlinear systems on weight-unbalanced directed networks. International Journal of Robust and Nonlinear Control, 2022, 32(8): 4878−4898 doi: 10.1002/rnc.6059 [19] Gkesoulis A K, Psillakis H E, Lagos A R. Optimal consensus via OCPI regulation for unknown pure-feedback agents with disturbances and state delays. IEEE Transactions on Automatic Control, 2022, 67(8): 4338−4345 doi: 10.1109/TAC.2022.3179218 [20] 时侠圣, 杨涛, 林志赟, 王雪松. 基于连续时间的二阶多智能体分布式资源分配算法. 自动化学报, 2021, 47(8): 2050−2060Shi Xia-Sheng, Yang Tao, Lin Zhi-Yun, Wang Xue-Song. Distributed resource allocation algorithm for second-order multi-agent systems in continuous-time. Acta Automatica Sinica, 2021, 47(8): 2050−2060 [21] 杨正全, 杨秀伟, 陈增强. 非平衡有向网络下带约束的连续时间分布式优化算法设计. 控制理论与应用, 2023, 40(6): 1053−1060Yang Zheng-Quan, Yang Xiu-Wei, Chen Zeng-Qiang. Continuous time with constraints in general directed networks distributed optimization algorithm design. Control Theory & Applications, 2023, 40(6): 1053−1060 [22] 刘奕葶, 马铭莙, 付俊. 基于有向图的分布式连续时间非光滑耦合约束凸优化分析. 自动化学报, 2024, 50(1): 66−75Liu Yi-Ting, Ma Ming-Jun, Fu Jun. Distributed continuous-time non-smooth convex optimization analysis with coupled constraints over directed graphs. Acta Automatica Sinica, 2024, 50(1): 66−75 [23] Zhu Y N, Yu W W, Wen G H, Ren W. Continuous-time coordination algorithm for distributed convex optimization over weight-unbalanced directed networks. IEEE Transactions on Circuits and Systems II: Express Briefs, 2019, 66(7): 1202−1206 [24] Li Z H, Ding Z T, Sun J Y, Li Z K. Distributed adaptive convex optimization on directed graphs via continuous-time algorithms. IEEE Transactions on Automatic Control, 2018, 63(5): 1434−1441 doi: 10.1109/TAC.2017.2750103 [25] Psillakis H E. PI consensus error transformation for adaptive cooperative control of nonlinear multi-agent systems. Journal of the Franklin Institute-Engineering and Applied Mathematics, 2019, 356(18): 11581−11604 doi: 10.1016/j.jfranklin.2019.09.024 [26] Khalil H K. Nonlinear Systems. New Jersey: Prentice Hall, 2002. [27] Theodorakopoulos A, Rovithakis G A. Guaranteeing preselected tracking quality for uncertain strict-feedback systems with deadzone input nonlinearity and disturbances via low-complexity control. Automatica, 2015, 54: 135−145 doi: 10.1016/j.automatica.2015.01.038 [28] Bechlioulis C P, Rovithakis G A. A low-complexity global approximation-free control scheme with prescribed performance for unknown pure feedback systems. Automatica, 2014, 50(4): 1217−1226 doi: 10.1016/j.automatica.2014.02.020 [29] 张晋熙, 柴天佑, 王良勇. 时延非线性系统无模型预设性能控制. 自动化学报, 2024, 50(5): 939−948Zhang Jin-Xi, Chai Tian-You, Wang Liang-Yong. Model-free prescribed performance control of time-delay nonlinear systems. Acta Automatica Sinica, 2024, 50(5): 939−948 [30] Na J. Adaptive prescribed performance control of nonlinear systems with unknown dead zone. International Journal of Adaptive Control and Signal Processing, 2013, 27(5): 426−446 doi: 10.1002/acs.2322 -

 下载:
下载:
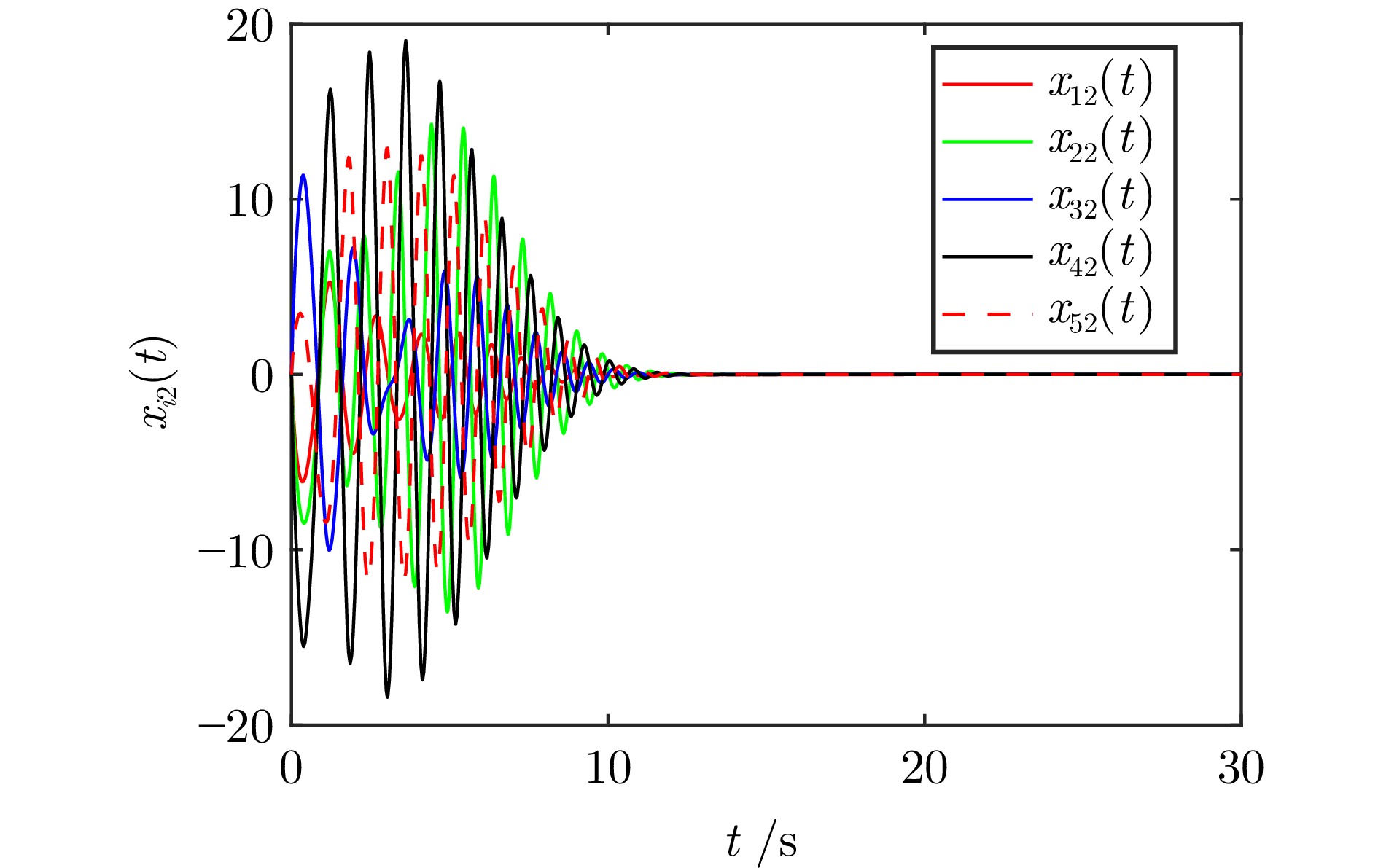
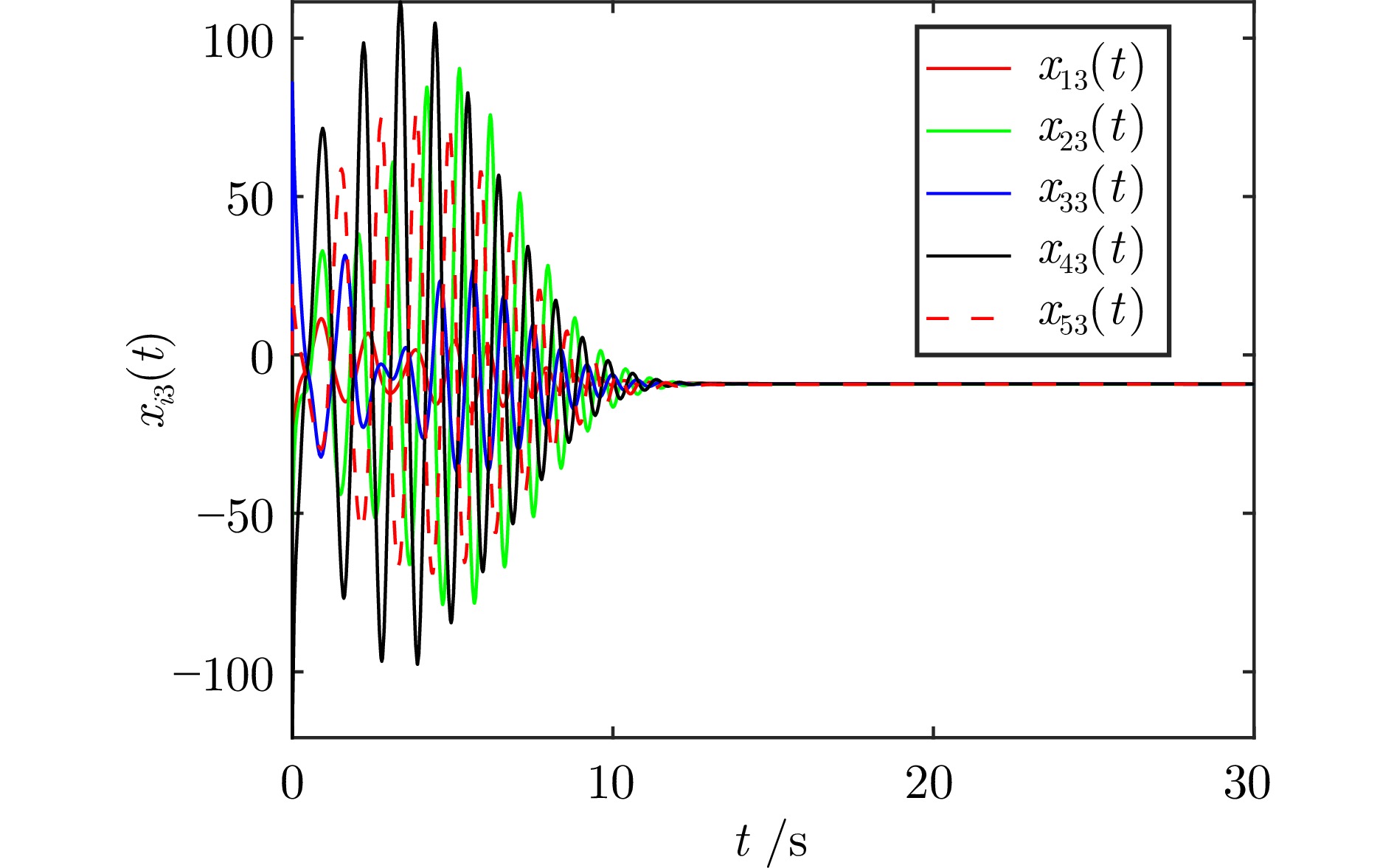

图(7)
计量
- 文章访问数: 639
- HTML全文浏览量: 3200
- PDF下载量: 219
- 被引次数: 0
