

Autonomous Planning and Processing Framework for Complex Tasks Based on Large Language Models
-
摘要: 随着深度学习和自然语言处理技术的进步, 大语言模型(Large language models, LLMs)展现出巨大潜力. 尽管如此, 它们在处理复杂任务时仍存在局限性, 特别是在任务需要结合规划及外部工具调用的场合. 面向这一挑战, 提出国内首个以军事游戏为背景的中文的复杂任务规划与执行数据集(Complex task planning and execution dataset, CTPaE), 以及一个基于LLMs的自主复杂任务规划 (Complex task planning, CTP) 处理框架AutoPlan. 该框架可以对复杂任务进行自主规划得到元任务序列, 并使用递进式ReAct提示 (Progressive ReAct prompting,PRP) 方法对已规划的元任务逐步执行. 该框架的有效性通过在CTPaE上的实验及与其他经典算法的比较分析得到了验证. 项目地址:
https://github.com/LDLINGLINGLING/AutoPlan .Abstract: With the advancement of deep learning and natural language processing technologies, large language models (LLMs) have shown significant potential. Despite their power, they still face limitations when dealing with complex tasks, especially when the tasks require integrative planning and the invocation of external tools. In response to this challenge, this paper proposes the first domestic dataset for complex task planning and execution with a military game context, the Chinese complex task planning and execution dataset (CTPaE), and a new framework for autonomous complex task planning (CTP) using LLMs named AutoPlan. The framework is capable of autonomously planning complex tasks to generate a sequence of meta-tasks, and employs a progressive ReAct prompting (PRP) method to gradually execute the planned meta-tasks. The effectiveness of the framework has been validated through experiments on the CTPaE and comparative analysis with other classic algorithms. The link of project:https://github.com/LDLINGLINGLING/AutoPlan .-
Key words:
- Large language models (LLMs) /
- tool-use /
- multi-hop reasoning /
- deep learning
-
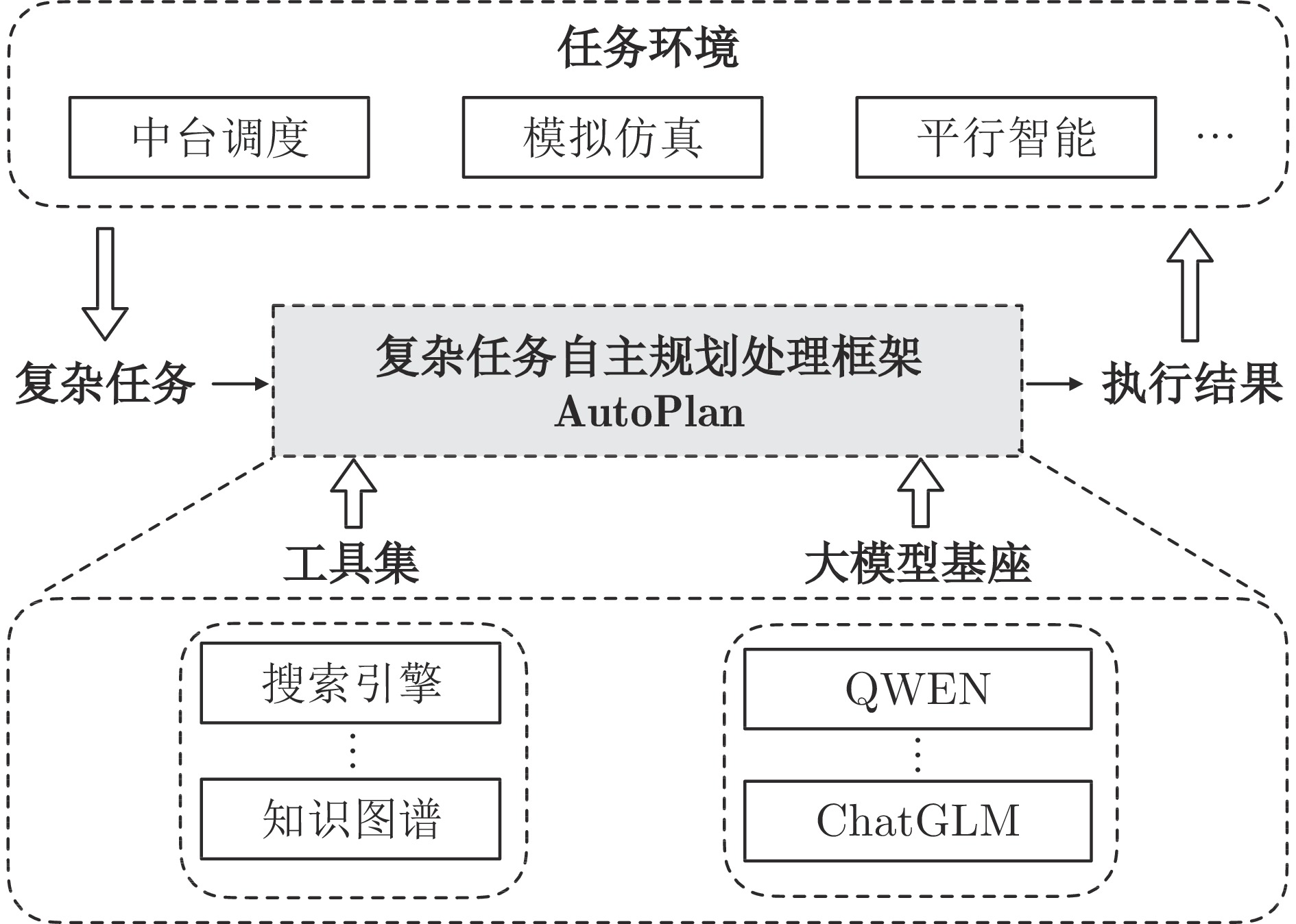
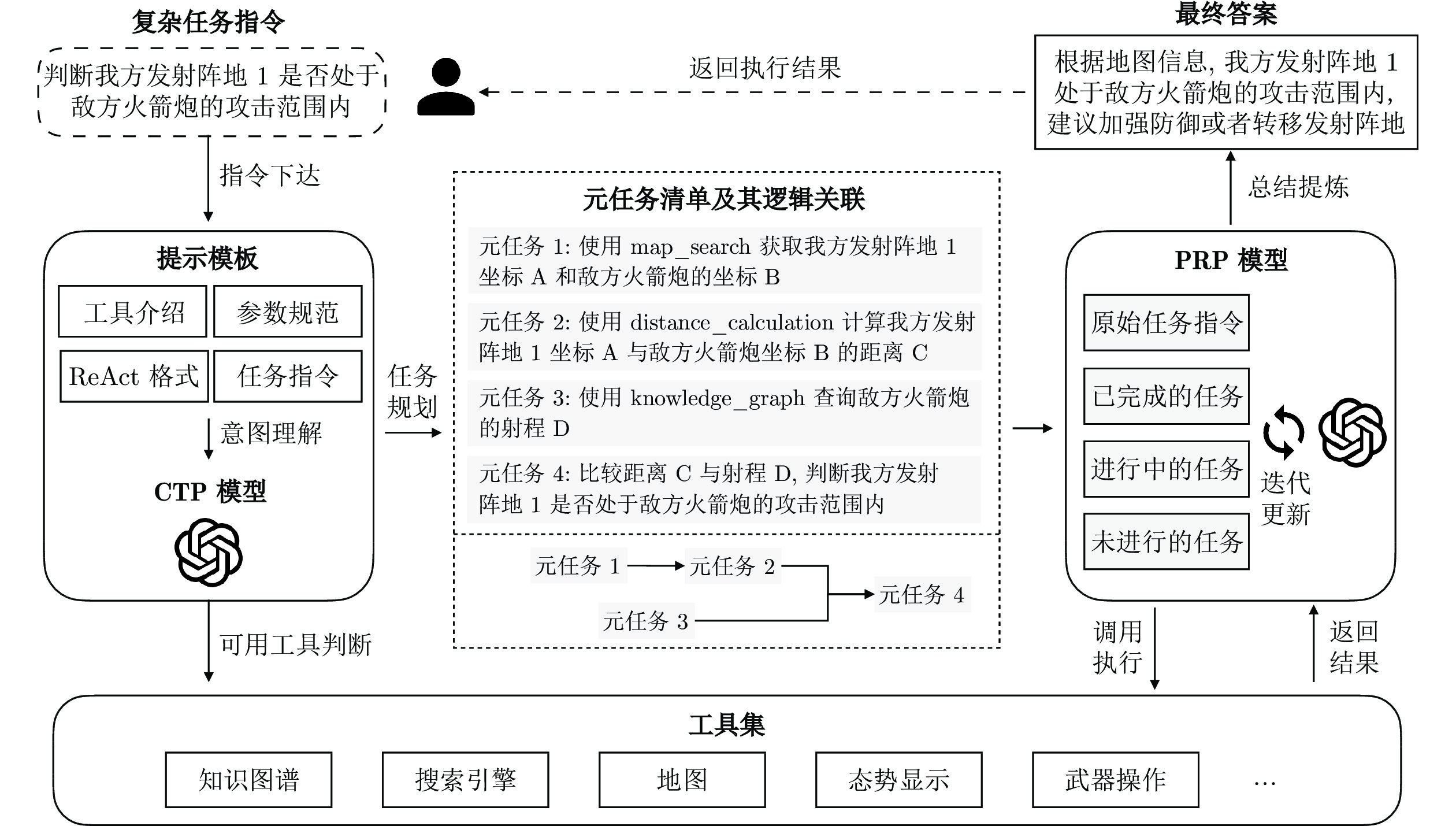
图 1 复杂任务处理框架AutoPlan示意图
Fig. 1 Diagram of AutoPlan framework for complex task processing
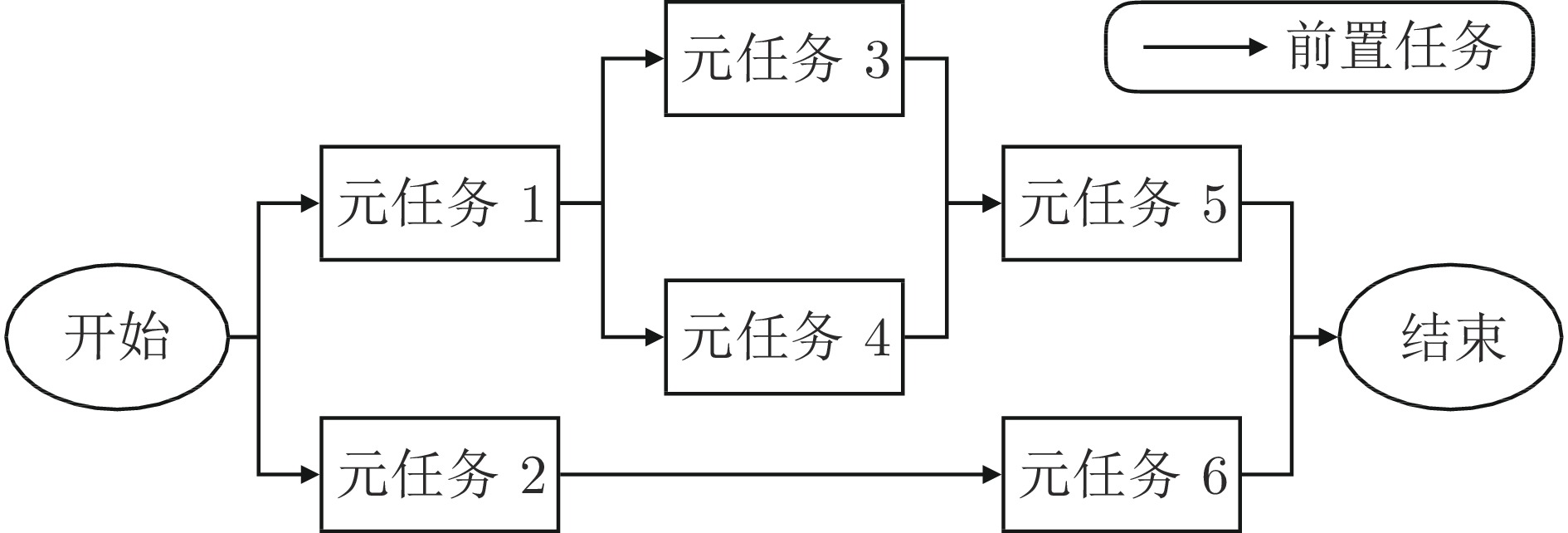
图 2 元任务之间的逻辑关系示意图
Fig. 2 Diagram illustrating the logical relationships between meta-tasks
表 1 元任务的属性
Table 1 Properties of meta-tasks
任务属性 符号表示 属性描述 所在位置 $ s_{i} $ 在序列中的逻辑关系 工具需求 $ a_{i} $ 执行该任务的工具需求 参数配置 $ p_{i} $ 调用工具时的参数配置 运行结果 $ r_{i} $ 该任务的运行结果  下载: 导出CSV
下载: 导出CSV
表 2 CTPaE涉及的工具名称和功能介绍
Table 2 The name and function introduction of the tools involved in the CTPaE
工具名称 功能 google_search 通用搜索引擎, 可访问互联网、查询信息等 military_information_search 军事搜索引擎, 可访问军事内部网络、查询情报等 address_book 获取如电话、邮箱、地址等个人信息 email 发送和接收邮件 image_gen 根据输入的文本生成图像 situation_display 输入目标位置坐标和显示范围、当前敌我双方的战场态势图像, 并生成图片 calendar 获取当前时间和日期 map_search 可以查询地图上所有单位位置信息的工具, 返回所有敌军的位置信息 knowledge_graph 通过武器装备知识图谱获取各类武器装备的信息 math_formulation 可以通过Python的eval(·)函数计算出输入的字符串表达式结果并返回 weapon_launch 武器发射按钮是可以启动指定武器打击指定目标位置的工具 distance_calculation 可以计算给定目标单位之间的距离
下载: 导出CSV
表 3 与相关方法在CTPaE上的性能比较
Table 3 Performance comparison with related methods on the CTPaE
方法 规模 (B) 评价指标(%) TSR TCR PT ST ReAct 1.8 7.99 30.30 39.23 34.50 14 37.37 90.00 60.57 48.99 72 39.24 76.40 68.33 60.04 TPTU 1.8 0.60 18.80 33.07 24.92 14 36.13 87.30 60.19 48.30 72 39.84 76.80 68.14 59.96 AutoPlan 1.8 18.70 45.70 91.11 48.15 14 52.30 94.70 90.81 79.24 72 87.02 99.90 99.34 97.09
下载: 导出CSV
表 4 不同任务规划方法性能比较
Table 4 Performance comparison of different task planning methods
方法 规模 (B) 评价指标(%) TSR TCR PT ST 不进行规划 1.8 7.99 30.30 39.23 34.50 14 37.37 90.00 60.57 48.99 72 39.24 76.40 68.33 60.04 TPTU 1.8 0.60 18.80 33.07 24.92 14 36.13 87.30 60.19 48.30 72 39.84 76.80 68.14 59.96 CTP 1.8 7.27 30.20 39.23 34.50 14 37.54 89.90 60.63 49.02 72 39.48 76.90 68.01 59.82 人工规划 1.8 8.17 43.38 39.24 34.50 14 47.70 92.05 83.54 72.21 72 61.69 97.60 86.78 80.75
下载: 导出CSV
表 5 不同任务执行策略性能比较
Table 5 Performance comparison of different task execution strategies
任务规划方法 任务执行方法 规模 (B) 评价指标(%) TSR TCR PT ST 人工规划 ReAct 1.8 8.17 43.38 39.24 34.50 14 47.70 92.05 83.54 72.21 72 61.69 97.60 86.78 80.75 PRP 1.8 18.39 (+10.22) 45.60 (+2.22) 91.15 (+51.91) 48.28 (+13.78) 14 53.29 (+5.59) 94.70 (+2.65) 91.07 (+7.53) 79.44 (+7.23) 72 86.43 (+24.74) 99.90 (+2.30) 99.47 (+12.69) 97.89 (+17.14) CTP ReAct 1.8 7.27 30.20 39.23 34.50 14 37.54 89.90 60.63 49.02 72 39.48 76.90 68.01 59.82 PRP 1.8 18.70 (+11.43) 45.70 (+15.50) 91.11 (+51.88) 48.15 (+13.65) 14 52.30 (+14.76) 94.70 (+4.80) 90.81 (+30.18) 79.24 (+30.22) 72 87.02 (+47.54) 99.90 (+23.00) 99.34 (+31.33) 97.09 (+37.27)
下载: 导出CSV
-
[1] 卢经纬, 郭超, 戴星原, 缪青海, 王兴霞, 杨静, 等. 问答ChatGPT之后: 超大预训练模型的机遇和挑战. 自动化学报, 2023, 49(4): 705−717Lu Jing-Wei, Guo Chao, Dai Xing-Yuan, Miao Qing-Hai, Wang Xing-Xia, Yang Jing, et al. The ChatGPT after: Opportunities and challenges of very large scale pre-trained models. Acta Automatica Sinica, 2023, 49(4): 705−717 [2] Zhao W X, Zhou K, Li J Y, Tang T Y, Wang X L, Hou Y P, et al. A survey of large language models. arXiv preprint arXiv: 2303.18223, 2023. [3] Dong Q X, Li L, Dai D M, Zheng C, Wu Z Y, Chang B B, et al. A survey for in-context learning. arXiv preprint arXiv: 2301.00234, 2023. [4] Wei J, Wang X Z, Schuurmans D, Bosma M, Ichter B, Xia F, et al. Chain-of-thought prompting elicits reasoning in large language models. arXiv preprint arXiv: 2201.11903, 2023. [5] Cui J X, Li Z J, Yan Y, Chen B H, Yuan L. ChatLaw: Open-source legal large language model with integrated external knowledge bases. arXiv preprint arXiv: 2306.16092, 2023. [6] Nakano R, Hilton J, Balaji S, Wu J, Ouyang L, Kim C, et al. WebGPT: Browser-assisted question-answering with human feedback. arXiv preprint arXiv: 2112.09332, 2022. [7] Schick T, Dwivedi-Yu J, Dessì R, Raileanu R, Lomeli M, Zettlemoyer L, et al. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv: 2302.04761, 2023. [8] Ruan J Q, Chen Y H, Zhang B, Xu Z W, Bao T P, Du G Q, et al. TPTU: Task planning and tool usage of large language model-based AI agents. arXiv preprint arXiv: 2308.03427, 2023. [9] Patel A, Bhattamishra S, Goyal N. Are NLP models really able to solve simple math word problems? arXiv preprint arXiv: 2103.07191, 2021. [10] Wang F Y. New control paradigm for industry 5.0: From big models to foundation control and management. IEEE/CAA Journal of Automatica Sinica, 2023, 10(8): 1643−1646 [11] Wang X X, Yang J, Wang Y T, Miao Q H, Wang F Y, Zhao A J, et al. Steps toward industry 5.0: Building “6S” parallel industries with cyber-physical-social intelligence. IEEE/CAA Journal of Automatica Sinica, 2023, 10(8): 1692−1703 doi: 10.1109/JAS.2023.123753 [12] Song C H, Wu J M, Washington C, Sadler B M, Chao W L, Su Y. LLM-Planner: Few-shot grounded planning for embodied agents with large language models. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2013. 2998−3009 [13] 阳东升, 卢经纬, 李强, 王飞跃. 超大预训练模型在指挥控制领域的应用与挑战. 指挥与控制学报, 2023, 9(2): 146−155Yang Dong-Sheng, Lu Jing-Wei, Li Qiang, Wang Fei-Yue. Issues and challenges of ChatGPT-like large scale pre-trained model for command and control. Journal of Command and Control, 2023, 9(2): 146−155 [14] Wang F Y. Parallel intelligence in metaverses: Welcome to Hanoi! IEEE Intelligent Systems, 2022, 37(1): 16−20 [15] Gao L Y, Madaan A, Zhou S Y, Alon U, Liu P F, Yang Y M, et al. PAL: Program-aided language models. In: Proceedings of the 40th International Conference on Machine Learning. Hawaii, USA: PMLR, 2023. 10764−10799 [16] Parisi A, Zhao Y, Fiedel N. TALM: Tool augmented language models. arXiv preprint arXiv: 2205.12255, 2022. [17] Qin Y J, Liang S H, Ye Y N, Zhu K L, Yan L, Lu Y X, et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIS. arXiv preprint arXiv: 2307.16789, 2023. [18] 杨静, 王晓, 王雨桐, 刘忠民, 李小双, 王飞跃. 平行智能与CPSS: 三十年发展的回顾与展望. 自动化学报, 2023, 49(3): 614−634Yang Jing, Wang Xiao, Wang Yu-Tong, Liu Zhong-Min, Li Xiao-Shuang, Wang Fei-Yue. Parallel intelligence and CPSS in 30 years: An ACP approach. Acta Automatica Sinica, 2023, 49(3): 614−634 [19] Wu W S, Yang W Y, Li J J, Zhao Y, Zhu Z Q, Chen B, et al. Autonomous crowdsensing: Operating and organizing crowdsensing for sensing automation. IEEE Transactions on Intelligent Vehicles, DOI: 10.1109/TIV.2024.3355508 [20] Wang Y T, Wang X, Wang X X, Yang J, Kwan O, Li L X, et al. The ChatGPT after: Building knowledge factories for knowledge workers with knowledge automation. IEEE/CAA Journal of Automatica Sinica, 2023, 10(11): 2041−2044 doi: 10.1109/JAS.2023.123966 [21] Paranjape B, Lundberg S, Singh S, Hajishirzi H, Zettlemoyer L, Ribeiro M T. ART: Automatic multi-step reasoning and tool-use for large language models. arXiv preprint arXiv: 2303.09014, 2023. [22] Wang B, Li G, Li Y. Enabling conversational interaction with mobile UI using large language models. In: Proceedings of the CHI Conference on Human Factors in Computing Systems. Hamburg, Germany: ACM, 2023. 1−17 [23] Li H X, Su J R, Chen Y T, Li Q, Zhang Z X. SheetCopilot: Bringing software productivity to the next level through large language models. arXiv preprint arXiv: 2305.19308, 2023. [24] Chen Z P, Zhou K, Zhang B C, Gong Z, Zhao W X, Wen J R. ChatCoT: Tool-augmented chain-of-thought reasoning on chat-based large language models. arXiv preprint arXiv: 2305.14323, 2023. [25] Patil S G, Zhang T J, Wang X, Gonzalez J E. Gorilla: Large language model connected with massive APIs. arXiv preprint arXiv: 2305.15334, 2023. [26] Hao S B, Liu T Y, Wang Z, Hu Z T. ToolkenGPT: Augmenting frozen language models with massive tools via tool embeddings. arXiv preprint arXiv: 2305.11554, 2024. [27] Shen Y L, Song K T, Tan X, Li D S, Lu W M, Zhuang Y T, et al. HuggingGPT: Solving AI tasks with ChatGPT and its friends in hugging face. arXiv preprint arXiv: 2303.17580, 2023. [28] Bai J Z, Bai S, Chu Y F, Cui Z Y, Dang K, Deng X D, et al. QWEN technical report. arXiv preprint arXiv: 2309.16609, 2023. [29] Yao S Y, Zhao J, Yu D, Du N, Shafran I, Narasimhan K, et al. ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv: 2210.03629, 2023. [30] Wang Y Z, Kordi Y, Mishra S, Liu A, Smith N A, Khashabi D, et al. Self-instruct: Aligning language models with self-generated instructions. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Toronto, Canada: ACL, 2023. 13484−13508 [31] Qin Y J, Cai Z H, Jin D, Yan L, Liang S H, Zhu K L, et al. WebCPM: Interactive web search for Chinese long-form question answering. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Toronto, Canada: ACL, 2023. 8968−8988 [32] Kim G, Baldi P, McAleer S. Language models can solve computer tasks. arXiv preprint arXiv: 2303.17491, 2023. [33] Wu W S, Chang T, Li X M, Yin Q J, Hu Y. Vision-language navigation: A survey and taxonomy. Neural Computing and Applications, 2024, 36(7): 3291−3316 doi: 10.1007/s00521-023-09217-1 [34] Vemprala S, Bonatti R, Bucker A, Kapoor A. ChatGPT for robotics: Design principles and model abilities. arXiv preprint arXiv: 2306.17582, 2023. [35] Driess D, Xia F, Sajjadi M, Lynch C, Chowdhery A, Ichter B, et al. PaLM-E: An embodied multimodal language model. arXiv preprint arXiv: 2303.03378, 2023. [36] Du Z X, Qian Y J, Liu X, Ding M, Qiu J Z, Yang Z L, et al. GLM: General language model pretraining with autoregressive blank infilling. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Dublin, Ireland: ACL, 2023. 320–335 [37] Xiao G X, Tian Y D, Chen B D, Han S, Lewis M. Efficient streaming language models with attention sinks. arXiv preprint arXiv: 2309.17453, 2023. -

 下载:
下载:
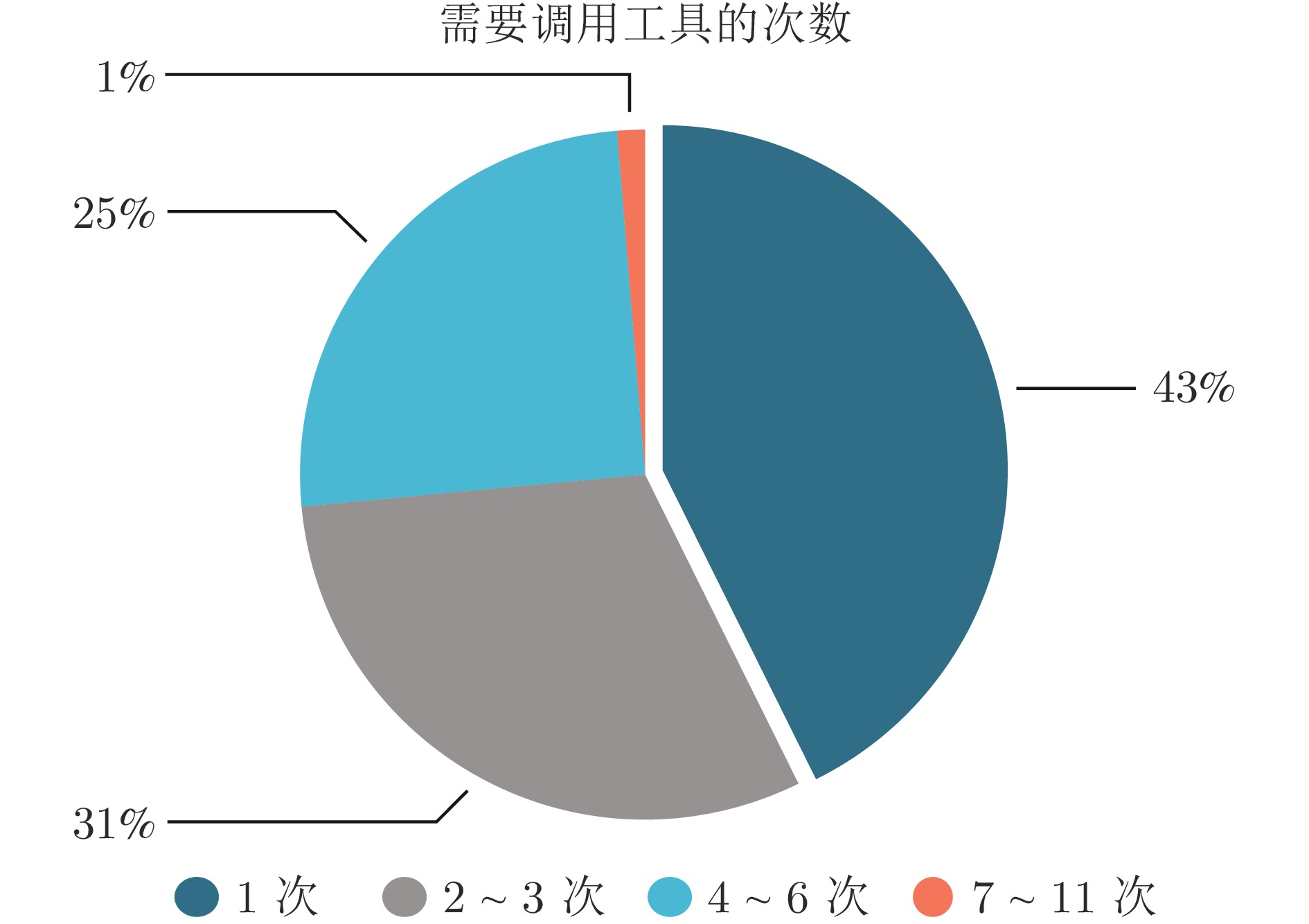
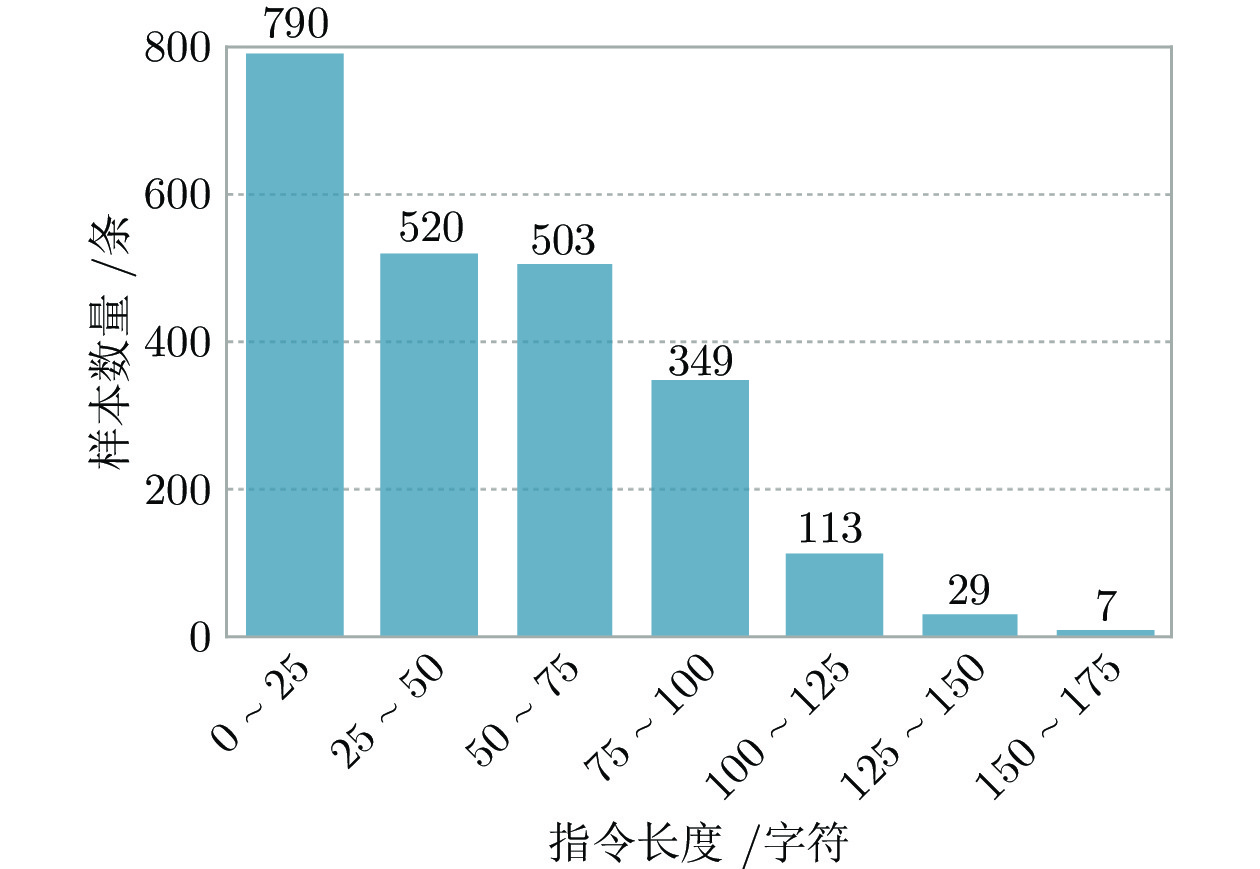

计量
- 文章访问数: 2248
- HTML全文浏览量: 2242
- PDF下载量: 937
- 被引次数: 0
