

Intelligent Operational Optimization of Municipal Solid Waste Incineration Process Based on Multi-objective Particle Swarm Algorithm
-
摘要: 城市固废焚烧(Municipal solid waste incineration, MSWI)技术因兼具减量化、无害化、资源化等特点, 已成为治理固废污染的主要方式. 由于城市固废成分复杂, 含水率、热值动态波动, 固废燃烧、余热利用、烟气净化等环节耦合冲突, 实际工业过程难以高效运行. 为此, 本文提出了一种基于多目标粒子群算法的城市固废焚烧过程智能操作优化方法, 以期实现燃烧效率和烟气净化效率的协同优化. 首先, 设计自组织径向基函数(Self-organizing radial basis function, SORBF)神经网络建立运行指标模型, 实现城市固废焚烧过程运行性能的在线评价; 其次, 引入区域拥挤度指标提出了一种改进的多目标粒子群优化算法, 以获取操作变量的Pareto解集; 然后, 利用熵权法确定操作变量最佳设定值, 实现城市固废焚烧过程高效运行; 最后, 通过北京某城市固废焚烧厂的实际运行数据对所提方法进行验证, 实验结果表明基于多目标粒子群算法的智能操作优化方法可以实现燃烧效率与脱硝效率的协同提升.Abstract: Municipal solid waste incineration (MSWI) technology has become the main way to address solid waste pollution due to its characteristics of reduction, harmlessness, and resource utilization. However, it is difficult for actual industries to operate efficiently due to the complex composition of municipal solid waste, dynamic fluctuations in moisture content and calorific value, coupling conflicts in solid waste combustion, waste heat utilization and flue gas purification. To enhance combustion efficiency and flue gas purification efficiency, this paper proposes an intelligent operational optimization method of MSWI process based on multi-objective particle swarm algorithm. First, operational index models are established by designing self-organizing radial basis function (SORBF) neural networks to achieve online evaluation of operational performance in MSWI process. Second, an improved multi-objective particle swarm optimization algorithm is presented by incorporating regional congestion degree index to obtain the Pareto solutions of operating variables. Then, the entropy weight method is employed to determine the optimal set value of operating variables, achieving efficient operation of MSWI process. Finally, the proposed method is verified through actual operational data from a MSWI plant in Beijing, and the experimental results demonstrate that the intelligent operational optimization method based on multi-objective particle swarm algorithm can improve combustion efficiency and reduce nitrogen oxide emissions.
-
稀疏信号恢复具有广泛的应用性和充分的理论支持, 因此成为信号处理领域中的一个重要且受到持续关注的研究课题. 稀疏信号恢复可应用于麦克风阵列信号处理[1-3], 图像处理[4-9], 脑电信号处理[10-11], 雷达信号处理[12-14]等领域. 目前, 有多种稀疏信号恢复算法被提出, 主要包括基于
$ \ell_p $ 范数$ (0<p \leq 1) $ 惩罚项的凸优化算法, 贪婪算法, 贝叶斯方法. 其中, 基于$ \ell_p $ 范数惩罚项的凸优化算法有基追踪去噪(Basis pursuit denoise, BPDN), 欠定系统聚焦求解(Focal underdetermined system solver, FOCUSS)等, 贪婪算法有正交匹配追踪(Orthgornal matching pursuit, OMP), 压缩采样匹配追踪(Compressive sampling matching pursuit, CoSaMP)等, 贝叶斯方法有稀疏贝叶斯学习(Sparse Bayesian learning, SBL)等. 基于$ \ell_p $ 范数惩罚项的凸优化算法在给定合适的正则因子时可以取得比较好的稀疏恢复效果, 但是在实际应用中, 正则化因子的选取通常比较困难, 一般通过经验选取导致对算法环境变化不鲁棒[15]. 贪婪算法在已知源信号的稀疏度的条件下表现良好, 信号恢复效果在源信号稀疏度未知的体条件下变差, 而实际应用中源信号稀疏度很难获得, 限制了该类算法的应用. 贝叶斯算法具有自回归与不确定性估计的特性, 可以自适应学习正则化因子, 并且可以提供具有不确定度的估计结果. 因此, 基于SBL的稀疏信号恢复算法受到越来越多的关注.SBL与其他贝叶斯算法类似, 通过赋予信号稀疏先验分布, 最大化后验分布得到信号的估计. 与其他贝叶斯方法不同的是SBL采取构建多层贝叶斯框架的方式赋予信号中每个元素独立的稀疏分布, 根据稀疏分布的不同, SBL可以分为基于Student-t先验的SBL[16], 基于Laplace先验的SBL[17-18], 基于合成LASSO先验的分布等[19]. SBL最早在文献[16]中提出, 该文献中构建了一种多层贝叶斯框架, 通过赋予信号中每个元素多层共轭先验, 等价赋予信号Student-t稀疏先验. 多层共轭先验的贝叶斯框架的构造使得模型中每层参数可以依次更新. 类似的, 文献[17]提出一种基于Laplace先验的多层贝叶斯框架. 文献[18]中提出一种针对复值信号的自聚焦的基于Laplace先验的多层贝叶斯框架. 文献[19]中提出一种基于合成LASSO先验的多层贝叶斯框架, 赋予信号LASSO先验. 由于LASSO分布缺少共轭先验, 文中采用了高斯接近的方法进行求解. 该文献对应于在文献[20]中提出的一种基于凸优化的自适应LASSO算法.
由于SBL算法在参数更新时需要矩阵求逆运算, 导致计算量很高. 为降低计算复杂度, 文献[21]提出一种基于基选择的快速SBL算法, 文献[17]给出了Lalapce先验下基于基选择的快速算法, 但是该算法无法推广至复值信号模型. 文献[22]提出一种基于最大化证据下界的快速算法, 但是该算法稳定性欠佳, 存在不收敛的情况. 文献[23]提出一种基于近似消息传递(Approximate message passing, AMP)的SBL算法, 并在文献[24]针对相干信号进行进一步改进. 文献[25]提出一种基于空间轮换的SBL算法. 文献[26]在[25]基础上提出一种应用于大数据量的基于标量平均场的SBL算法.
为提高稀疏信号恢复的准确性, 本文开展了基于自适应LASSO先验的SBL算法研究. 在贝叶斯模型构造阶段, 本文中通过构建一种与现有SBL算法不同的多层贝叶斯框架, 赋予信号中每个元素具有独立权重的LASSO先验, 比现有稀疏先验更有效的鼓励稀疏. 根据该多层贝叶斯框架提出一种基于自适应LASSO先验的SBL算法. 为进一步降低提出算法的计算复杂度, 在贝叶斯推断阶段利用空间轮换技术避免矩阵求逆运算, 形成一种快速算法.
本文中使用到的符号总结如下:
$ {\bf{R}} $ 表示实数集合;$ {\bf{C}} $ 表示复数集合;$ \|{\boldsymbol{y}}\|_0 $ 表示向量$ {\boldsymbol{y}} $ 的$ \ell_0 $ 范数, 即向量$ {\boldsymbol{y}} $ 中非零元素的个数;$ \|{\boldsymbol{y}}\|_p\;(0<p\leq1) $ 表示向量$ {\boldsymbol{y}} $ 的$ \ell_p $ 范数, 定义为$\|{\boldsymbol{y}}\|_p = \left(\sum\nolimits_{i = 1}^N|y_i|^p\right)^\tfrac{1}{p}$ , 其中,$ y_i $ 表示向量$ {\boldsymbol{y}} $ 中第$ i $ 个元素,$ |y_i| $ 表示$ y_i $ 的模;$\|{\boldsymbol{y}}\|_2 = \sqrt{{\boldsymbol{y}}^{\rm{H}}{\boldsymbol{y}}}$ 表示向量$ {\boldsymbol{y}} $ 的Euclidean范数, 又称为$ \ell_2 $ 范数, 其中,$ {\boldsymbol{y}}^{\rm{H}} $ 表示向量$ {\boldsymbol{y}} $ 的共轭转置;$ \|{\boldsymbol{y}}\|_F $ 表示向量$ {\boldsymbol{y}} $ 的Frobenius范数;$ {\cal{N}}({\boldsymbol{y}};{\boldsymbol{\mu}},{\boldsymbol{\Sigma}}) $ 表示向量$ {\boldsymbol{y}} $ 服从于期望为$ {\boldsymbol{\mu}} $ 、方差为$ {\boldsymbol{\Sigma}} $ 的高斯分布;$ {\cal{CN}}({\boldsymbol{y}};\bar{{\boldsymbol{\mu}}},\bar{{\boldsymbol{\Sigma}}}) $ 表示向量$ {\boldsymbol{y}} $ 服从于期望为$ \bar{{\boldsymbol{\mu}}} $ 、方差为$ \bar{{\boldsymbol{\Sigma}}} $ 的复高斯分布;$ {\cal{G}}(z;a,b) $ 表示变量$ z $ 服从于形状参数为$ a\;(a>0) $ 、尺度参数为$ b\;(b>0) $ 的Gamma分布, 其函数形式为${\cal{G}}(z;a,b) = \dfrac{b^a}{\varGamma(a)}z^{a-1}{\rm{e}}^{-bz}$ ;$\varGamma(a) = $ $ \displaystyle \int_{0}^{\infty}x^{a-1}{\rm{e}}^{-x}{\rm{d}}x$ 表示Gamma函数;${{K}}_p(z) = \displaystyle \int_{0}^{\infty} $ $ {\rm{e}}^{-z\cosh z} \cosh pt{\rm{d}}t$ 表示修正Bessel函数, 其中, 当$p = \dfrac{1}{2}$ 时有${{K}}_{\frac{1}{2}}(z) = \sqrt{\dfrac{\pi}{2z}}{\rm{e}}^{-z}$ ;$ \left<z\right> $ 表示变量$ z $ 的期望;$ {\rm{Var}}(z) $ 表示变量$ z $ 的方差.1. 稀疏信号恢复问题描述
稀疏信号恢复问题是指已知测量矩阵
${\boldsymbol{A}}\in $ $ {\bf{R}}^{M\times N}$ , 利用欠采样数据$ {\boldsymbol{x}}\in{\bf{R}}^{M} $ 和稀疏恢复算法估计稀疏信号$ {\boldsymbol{g}}\in{\bf{R}}^{N} $ 的问题. 实值稀疏信号恢复的数学模型表示如下:$$ {\boldsymbol{x}} = {\boldsymbol{A}}{\boldsymbol{g}}+{\boldsymbol{w}} $$ (1) 其中,
$ {\boldsymbol{w}}\in{\bf{R}}^{M} $ 是可加性高斯白噪声. 复值信号模型与实值信号模型的区别在于测量矩阵$ {\boldsymbol{A}}\in{\bf{C}}^{M\times N} $ 是复值矩阵, 测量数据$ {\boldsymbol{x}}\in{\bf{C}}^{M} $ 和稀疏信号$ {\boldsymbol{g}}\in{\bf{C}}^{N} $ 是复值向量,$ {\boldsymbol{w}}\in{\bf{C}}^{M} $ 是复值圆周对称高斯白噪声.由于测量数据
$ {\boldsymbol{x}} $ 是欠采样数据, 即数据维度$ M $ 小于信号维度$ N $ , 因此使用最小二乘算法求解信号$ {\boldsymbol{g}} $ 是一个不适定问题. 然而, Candes等在文献[27]中证明了在已知信号$ {\boldsymbol{g}} $ 是稀疏信号且满足有限等距性质(Restricted isometry property, RIP)条件下, 稀疏信号恢复问题具有唯一解. 为了利用信号的稀疏先验信息, 最直接的方法是添加正则项$ \|{\boldsymbol{g}}\|_0 $ 约束解的范围. 从而将稀疏信号恢复问题转化为如下优化问题:$$ {\cal{L}}({\boldsymbol{g}}) = \arg \min\limits_{{\boldsymbol{g}}}\|{\boldsymbol{x}}- {\boldsymbol{A}}{\boldsymbol{g}}\|_2^2+\zeta\|{\boldsymbol{g}}\|_0 $$ (2) 其中,
$ \zeta $ 是正则化因子. 然而, 凸优化问题 (2)是一个NP-hard问题, 难以进行求解. 常用的求解问题 (2)的方法是将$ \ell_0 $ 范数释放至$ \ell_1 $ 范数, 形成如下凸优化问题:$$ {\cal{L}}({\boldsymbol{g}}) = \arg \min\limits_{{\boldsymbol{g}}}\|{\boldsymbol{x}}- {\boldsymbol{A}}{\boldsymbol{g}}\|_2^2+\zeta\|{\boldsymbol{g}}\|_1 $$ (3) 其中,
$ \|\cdot\|_1 $ 表示$ \ell_1 $ 范数. 凸优化问题 (3)可以通过LASSO算法进行求解, 但是LASSO算法不能一定保证收敛, 为提高算法性能, Zou在文献[20]中对LASSO算法进行了改进, 提出了自适应LASSO算法, 并对该算法的Oracle特性进行了证明1. 自适应LASSO算法求解如下优化问题:$$ {\cal{L}}({\boldsymbol{g}}) = \arg \min\limits_{{\boldsymbol{g}}}\|{\boldsymbol{x}}- {\boldsymbol{A}}{\boldsymbol{g}}\|_2^2+\zeta\sum\limits_{i = 1}^N\omega_i|g_i| $$ (4) 其中,
$ g_i $ 是信号$ {\boldsymbol{g}} $ 中的第$ i $ 个元素,$ \omega_i $ 表示信号元素$ g_i $ 的权重.本文利用稀疏贝叶斯框架构建了基于自适应LASSO先验的SBL算法, 通过构建多层贝叶斯网络赋予信号中每个元素独立信号的LASSO先验, 从而实现贝叶斯框架下的自适应LASSO算法.
2. 贝叶斯模型
在贝叶斯模型中, 所有未知变量都被认为是随机变量, 并根据未知变量的先验信息赋予随机变量不同的分布. 本文中根据信号的稀疏特性赋予未知信号
$ {\boldsymbol{g}} $ 自适应LASSO先验分布$ p({\boldsymbol{g}}|{\boldsymbol{\eta}}) $ , 并且假设测量数据$ {\boldsymbol{x}} $ 是一个条件概率为$ p({\boldsymbol{x}}|{\boldsymbol{g}},\rho) $ 的随机过程. 其中,$ \rho $ 表示噪声的精度, 即噪声方差的倒数. 下面将对该多层贝叶斯框架进行具体的描述.2.1 观测模型
假定实值模型中观测噪声
$ {\boldsymbol{w}} $ 是方差为$ \rho^{-1} $ 的高斯白噪声, 复值模型中观测噪声$ {\boldsymbol{w}} $ 是方差为$ \rho^{-1} $ 的圆周共轭复高斯白噪声, 则实值模型和复值模型中测量数据$ {\boldsymbol{x}} $ 的条件概率表示如下:$$ \begin{split} &p({\boldsymbol{x}}|{\boldsymbol{g}},\rho,\varsigma) = \frac{\rho^{\tfrac{M}{\varsigma}}}{(\varsigma\pi)^{\tfrac{M}{\varsigma}}}{\rm{e}}^{-\frac{\rho}{\varsigma}({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})^{{\rm{H}}}({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})}=\\ &\left\{ \begin{aligned} &{\cal{N}}({\boldsymbol{x}};{\boldsymbol{A}}{\boldsymbol{g}},\rho^{-1}{\boldsymbol{I}}_M), & \varsigma = 2\\ &{\cal{CN}}({\boldsymbol{x}};{\boldsymbol{A}}{\boldsymbol{g}},\rho^{-1}{\boldsymbol{I}}_M), & \varsigma = 1 \end{aligned} \right. \end{split} $$ (5) 其中,
$ \varsigma = 2 $ 对应于实值模型,$ \varsigma = 1 $ 对应于复值模型. 为更新噪声精度$ \rho $ , 假设$ \rho $ 服从于如下Gamma分布:$$ p(\rho|c,d) = {\cal{G}}(c,d) $$ (6) 其中,
$ c $ 和$ d $ 是预设的模型参数, 且$ c>0 $ 是Gamma分布的形状参数,$ d>0 $ 是Gamma分布的尺度参数. 在变量$ \rho $ 服从于Gamma分布 (6)的假定下, 变量的均值和方差分别表示为$\dfrac{c}{d}$ 和$\dfrac{c}{d^2}$ .2.2 信号模型
类似于其它SBL算法, 未知信号
$ {\boldsymbol{g}} $ 的自适应LASSO先验$ p({\boldsymbol{g}}|{\boldsymbol{\eta}}) $ 通过多层共轭先验的形式实现. 首先, 使用零均值的多维高斯分布对信号进行如下建模:$$ p({\boldsymbol{g}}|{\boldsymbol{\varLambda}}) = \frac{1}{(\varsigma\pi)^{\frac{N}{\varsigma}}|{\boldsymbol{\varLambda}}|}{\rm{e}}^{-\frac{1}{\varsigma}{\boldsymbol{g}}^{{\rm{H}}}{\boldsymbol{\varLambda}}^{-1}{\boldsymbol{g}}} = \prod\limits_{i = 1}^{N}\frac{1}{(\varsigma\pi\lambda_i)^{\frac{1}{\varsigma}}}{\rm{e}}^{-\frac{{g_i}^{{\rm{H}}}{g_i}}{\varsigma\lambda_i}} $$ (7) 其中,
${\boldsymbol{\varLambda}} = {\rm{diag}}\{{\boldsymbol{\lambda}}\}$ 表示多维高斯分布的协方差矩阵,$ {\boldsymbol{\lambda}} = [\lambda_1,\lambda_2,\cdots,\lambda_N]^{\rm{T}} $ 表示信号的方差向量且$ \lambda_i>0 $ ,$ {\rm{diag}}\{\cdot\} $ 表示对角矩阵操作. 对于变量$ {\boldsymbol{\lambda}} $ , 假设其服从于如下独立的Gamma分布:$$ p({\boldsymbol{\lambda}}|{\boldsymbol{\eta}}) = \prod\limits_{i = 1}^{N}{\cal{G}}\left(\lambda_i;\frac{1}{2}+2^{1-\varsigma},\frac{\eta_i^2}{2^{3-\varsigma}}\right) $$ (8) 其中,
$ {\boldsymbol{\eta}} = [\eta_1,\eta_2,\cdots,\eta_N]^{\rm{T}} $ 表示变量的向量且$ \eta_i> $ $ 0 $ . 根据式 (7)和 (8), 变量$ {\boldsymbol{g}} $ 关于变量$ {\boldsymbol{\eta}} $ 的边缘分布可以通过对变量$ {\boldsymbol{\lambda}} $ 积分获得, 表示如下:$$ p({\boldsymbol{g}}|{\boldsymbol{\eta}}) = \int p({\boldsymbol{g}}|{\boldsymbol{\varLambda}})p({\boldsymbol{\lambda}}|{\boldsymbol{\eta}}){\rm{d}}{\boldsymbol{\lambda}} = \prod\limits_{i = 1}^N\frac{\eta_i^{2^{2-\varsigma}}}{2\pi^{\varsigma-1}}{\rm{e}}^{-\eta_i|g_i|} $$ (9) 即, 前两层贝叶斯先验 (7)和 (8)等价与赋予信号
$ {\boldsymbol{g}} $ 一种LASSO先验, 其中,$ \eta_i $ 对应于式 (4)中的权重$ w_i $ . 为了自适应调节LASSO先验的权重, 对非负变量$ {\boldsymbol{\eta}} $ 赋予如下Gamma分布:$$ p({\boldsymbol{\eta}}|{\boldsymbol{a}},{\boldsymbol{b}}) = \prod\limits_{i = 1}^{N}{\cal{G}}(\eta_i;a_i,b_i) $$ (10) 其中,
$ a_i>0 $ 和$ b_i>0 $ 为预设的模型参数.根据式 (9)和 (10), 变量
$ {\boldsymbol{g}} $ 关于$ {\boldsymbol{a}} $ 和$ {\boldsymbol{b}} $ 的边缘分布可通过对变量$ {\boldsymbol{\eta}} $ 的积分获得, 结果如下:$$ \begin{split} &p({\boldsymbol{g}}|{\boldsymbol{a}},{\boldsymbol{b}}) = \int p({\boldsymbol{g}}|{\boldsymbol{\eta}})p({\boldsymbol{\eta}}|{\boldsymbol{a}},{\boldsymbol{b}}){\rm{d}}{\boldsymbol{\eta}}=\\ &\qquad\prod\limits_{i = 1}^{N}\frac{b_i^{a_i}\varGamma\left(a_i+2^{2-\varsigma}\right)}{2\pi^{\varsigma-1}\varGamma(a_i)}\left(b_i+|g_i|\right)^{-\left(a_i+2^{2-\varsigma}\right)} \end{split} $$ (11) 其中,
$\varGamma(\cdot)$ 表示Gamma函数. 实际上, 根据式 (11), 本文提出的贝叶斯框架最终赋予信号$ {\boldsymbol{g}} $ 一种Student-t先验. 其中, Student-t分布是一种具有长拖尾特性的分布, 可以表达信号的稀疏特性[16]. 基于自适应LASSO先验的SBL模型由式 (5), (7), (8), (10)构成. 该模型的因子图如图1所示. 图中节点函数总结如下:$$ f_i^g = p(g_i|\lambda_i) \tag{12a}$$ $$ f_i^{\lambda} = p(\lambda_i|\eta_i) \tag{12b}$$ $$ f_i^{\eta} = p(\eta_i|a_i,b_i) \tag{12c}$$ $$ f^x = p({\boldsymbol{x}}|{\boldsymbol{g}},\rho) \tag{12d} $$ $$ f^{\rho} = p(\rho|\boldsymbol{a},\boldsymbol{b})\tag{12e} $$  图 1 基于自适应LASSO先验的SBL框架的因子图Fig. 1 The factor graph of the proposed SBL framework using adaptive LASSO priors
图 1 基于自适应LASSO先验的SBL框架的因子图Fig. 1 The factor graph of the proposed SBL framework using adaptive LASSO priors2.3 基于自适应LASSO先验SBL算法的稀疏恢复原理分析
SBL算法本质是一种鲁棒的最大后验估计方法[2,16]. 一般通过I型或II型估计器稀疏求解[28]. 本文采用I型估计器对提出的基于自适应LASSO先验SBL算法进行分析. I型估计器为最大化后验分布[28]:
$$ \begin{split} \tilde{{\boldsymbol{g}}} =\;& \arg\max\limits_{{\boldsymbol{g}}} p({\boldsymbol{g}}|{\boldsymbol{x}})=\\ &\arg\max\limits_{{\boldsymbol{g}}}\ln \int \int p({\boldsymbol{x}}|{\boldsymbol{g}})p({\boldsymbol{g}}|{\boldsymbol{\lambda}})p({\boldsymbol{\lambda}}|{\boldsymbol{\eta}})p({\boldsymbol{\eta}}){\rm{d}}{\boldsymbol{\lambda}}{\rm{d}}{\boldsymbol{\eta}}=\\ &\arg\max\limits_{{\boldsymbol{g}}}\ln \int p({\boldsymbol{x}}|{\boldsymbol{g}})p({\boldsymbol{g}}|{\boldsymbol{\eta}})p({\boldsymbol{\eta}}){\rm{d}}{\boldsymbol{\eta}}\\[-13pt] \end{split} $$ (13) 其中,
$ \tilde{{\boldsymbol{g}}} $ 为信号$ {\boldsymbol{g}} $ 的估计.在SBL算法中, 通过迭代的方式对参数进行更新, 对于每一次迭代需要使用上一次迭代的参数. 即在每一步迭代中等价于如下优化问题:
$$ \begin{split} {\boldsymbol{g}}^{\rm{new}} =\;& \arg \max\limits_{{\boldsymbol{g}}} \ln p({\boldsymbol{x}}|{\boldsymbol{g}},\rho)+\\ & \int \ln(p({\boldsymbol{g}}|{\boldsymbol{\eta}})) p({\boldsymbol{\eta}}|{\boldsymbol{g}}^{\rm{old}},{\boldsymbol{a}},{\boldsymbol{b}}){\rm{d}}{\boldsymbol{\eta}} \end{split} $$ (14) 其中,
$ {\boldsymbol{g}}^{\rm{new}} $ 和$ {\boldsymbol{g}}^{\rm{old}} $ 分别是本次迭代和上一次迭代中$ {\boldsymbol{g}} $ 的估计. 根据式 (9), 式 (14)可写为如下形式:$$ \begin{split} {\boldsymbol{g}}^{\rm{new}} = \;& \arg \max\limits_{{\boldsymbol{g}}}p({\boldsymbol{x}}|{\boldsymbol{g}},\rho)-\\ &\sum\limits_{i = 1}^{N}\int\eta_i|g_i|p(\eta_i|{g}_i^{\rm{old}},a_i,b_i){\rm{d}}\eta_i \end{split} $$ (15) 由Laplace分布和Gamma分布的共轭性质可得, 变量
$ {\boldsymbol{\eta}} $ 服从于如下Gamma分布:$$ p({\boldsymbol{\eta}}) = \prod\limits_{i = 1}^{N}{\cal{G}}\left(a_i+2^{2-\varsigma}, b_i+\left|g_i^{\rm{old}}\right|\right) $$ (16) 其中,
$ \eta_i $ 的期望表示为$\dfrac{a_i+2^{2-\varsigma}}{b_i+\left|g_i^{\rm{old}}\right|}$ . 根据式 (5)和式 (14), 式 (15)等价于$$ {\boldsymbol{g}}^{\rm{new}} = \arg \min\limits_{{\boldsymbol{g}}}\|{\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}}\|_2^2+\zeta\sum\limits_{i = 1}^{N}w_i|g_i| $$ (17) 其中,
$\zeta = \dfrac{\varsigma}{\rho}$ ,$w_i = \dfrac{a_i+2^{2-\varsigma}}{b_i+\left|g_i^{\rm{old}}\right|}$ .比较式 (17)和式 (4)可知, 本文提出的基于自适应LASSO先验的SBL算法对应于自适应LASSO算法. 自适应LASSO算法需要预定义回归系数
$ \zeta $ , 但本文中算法具有自回归特性, 可自适应选择合适的回归系数, 并且SBL算法具有不确定估计特性, 估计结果在统计意义上优于自适应LASSO算法. 根据文献[20], 自适应LASSO算法是对LASSO算法的改进, 稀疏恢复性能优于LASSO算法. 又根据文献[17], 基于Laplace先验的SBL算法对应于LASSO算法, 并且性能优于基于Student-t算法. 文献[19]提出的基于合成LASSO先验的SBL算法对应于自适应LASSO算法, 但是由于采用高斯接近的方法进行参数更新, 导致在测量数少或者SNR低时存在无法进行高斯拟合的情况. 本文提出的基于自适应LASSO先验的SBL算法通过多层贝叶斯框架的方式构造自适应LASSO先验, 避免了无法拟合的情况. 通过以上分析可知, 本文提出的基于基于自适应LASSO先验的SBL算法性能优于现有算法.为更直观的表现本文提出的算法所提供的稀疏恢复特性, 我们绘制了实值模型下不同算法的稀疏先验的代价函数的二位等高线图, 结果见图2. 复值信号模型与实值信号模型的结果类似, 此处不再重复讨论. 图中BPDN是文献[29]提出的算法, FastSBL是文献[21]提出的基于Student-t先验的SBL算法, FastLap-SBL是文献[17]提出基于Laplace先验的SBL算法, aLASSO-SBL是本文提出的基于自适应LASSO先验的SBL算法. 其中, BPDN和FastLap-SBL的先验与参数无关; FastSBL和aLASSO-SBL算法的参数设置相同, 都为
$ a = 1 $ ,$ b = 0.1 $ . 根据文献[16]、文献[30]和文献[19], 如果先验具有长拖尾特性并且概率分布在零点处越“尖锐”则越鼓励稀疏, 反映到二维等高线图上为越靠近坐标轴, 越鼓励稀疏. 观察图2, 自适应LASSO先验的二维等高线图相比于其他先验更靠近坐标轴. 由图中可知, 本文提出的算法比其他算法有更好的稀疏恢复性.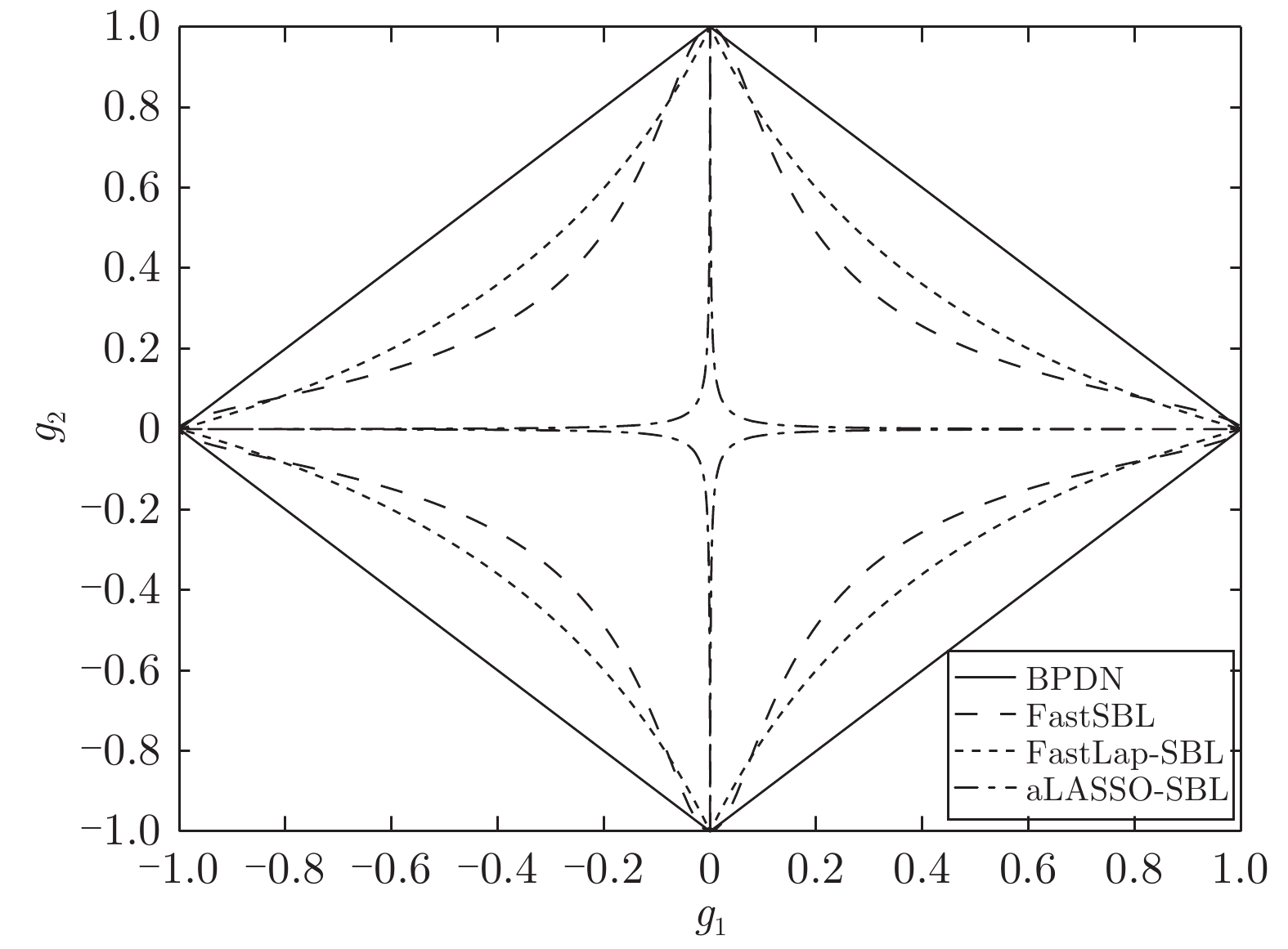 图 2 四种算法的稀疏先验代价函数二维等高线图Fig. 2 Two dimensional contour plots of cost functions of different sparse priors
图 2 四种算法的稀疏先验代价函数二维等高线图Fig. 2 Two dimensional contour plots of cost functions of different sparse priors另外, 我们绘制了不同参数下自适应LASSO先验的代价函数等高线图, 如图3所示, 在参数
$ a $ 固定为$ 1 $ 的条件下, 参数$ b $ 越接近于$ 0 $ , 二维等高线越靠近坐标轴, 即算法提供的解越稀疏. 基于以上分析, 相比于其它算法, 本文提出的算法在理论上可以提供最稀疏的解, 从而得到更精确的稀疏信号恢复性能. 图 3 本算法在不同参数下稀疏先验代价函数二维等高线图Fig. 3 Two dimensional contour plots of cost functions of the proposed sparse priors versus hyperparameters
图 3 本算法在不同参数下稀疏先验代价函数二维等高线图Fig. 3 Two dimensional contour plots of cost functions of the proposed sparse priors versus hyperparameters3. 变元贝叶斯推断
在本文提出的贝叶斯模型中, 所有隐藏变量的集合表示为
$ {\boldsymbol{\Theta}} = \{{\boldsymbol{g}},{\boldsymbol{\lambda}},{\boldsymbol{\eta}},\rho\} $ . 根据图1表示的贝叶斯模型, 联合概率密度表示如下:$$ p({\boldsymbol{x}},{\boldsymbol{\Theta}}) = p({\boldsymbol{x}}|{\boldsymbol{g}},\rho)p({\boldsymbol{g}}|{\boldsymbol{\eta}})p({\boldsymbol{\eta}})p(\rho) $$ (18) 后验分布的闭合形式
$ p({\boldsymbol{\Theta}}|{\boldsymbol{x}}) $ 需要计算边缘分布密度函数$ p({\boldsymbol{x}}) $ , 但是$ p({\boldsymbol{x}}) $ 难以求得, 因此本文采用变元贝叶斯推断的方法进行参数更新. 变元贝叶斯推断使用因子化变量分布对实际后验分布进行近似. 隐藏变量的因子化变量分布表示如下:$$ q({\boldsymbol{\Theta}}) = q({\boldsymbol{g}})q({\boldsymbol{\lambda}})q({\boldsymbol{\eta}})q(\rho) $$ (19) 其中,
$ q({\boldsymbol{\Theta}}) $ 是实际后验$ p({\boldsymbol{\Theta}}|{\boldsymbol{x}}) $ 的近似. 然后, 通过最小化实际后验分布$ p({\boldsymbol{\Theta}}|{\boldsymbol{x}}) $ 与近似分布$ q({\boldsymbol{\Theta}}) $ 的KL散度(Kullback-Leibler, KL)对参数进行更新, 该过程等价于最大化如下目标函数:$$ {\cal{L}}({\boldsymbol{\Theta}}) = {\rm{E}}_{q({\boldsymbol{\Theta}})}[\ln p({\boldsymbol{\Theta}}|{\boldsymbol{x}})]-{\rm{E}}_{q({\boldsymbol{\Theta}})}[\ln q({\boldsymbol{\Theta}})] $$ (20) 其中,
$ {\rm{E}}_q[\cdot] $ 表示在$ q $ 分布下的求参数期望的算子, 即$ {\rm{E}}_{q(x)}[p(x)] = \int q(x)p(x){\rm{d}}x $ .如图1所示, 本文提出的模型中所有节点的先验和似然函数都存在共轭指数分布族, 因此变元贝叶斯推断表示如下[31-32]:
$$ \ln q({\boldsymbol{\theta}}_k) = {\rm{E}}_{q({\boldsymbol{\Theta}}\backslash{\theta_{k}})}[\ln p({\boldsymbol{x}},{\boldsymbol{\Theta}})]+{{C}} $$ (21) 其中,
$ {\boldsymbol{\theta}}_k $ 表示隐藏变量集合$ {\boldsymbol{\Theta}} $ 中第$ k $ 个变量, 例如$ {\boldsymbol{\theta}}_1 $ 表示变量$ {\boldsymbol{g}} $ ,$ {\boldsymbol{\Theta}}\backslash{{\boldsymbol{\theta}}_{k}} $ 表示集合$ {\boldsymbol{\Theta}} $ 中去除第$ k $ 个变量$ {\boldsymbol{\theta}}_k $ 的集合,${{C}}$ 表示常数.3.1 参数更新
根据式 (18), 对数形式的联合分布表示如下:
$$ \begin{split} \ln p({\boldsymbol{x}},&{\boldsymbol{\Theta}}) = \frac{M}{\varsigma}\ln\rho-\frac{\rho}{\varsigma}({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})^{{\rm{H}}}({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})+\\ &\sum\limits_{i = 1}^N\frac{1}{\varsigma}\ln\lambda_i^{-1}-\frac{1}{\varsigma}{\boldsymbol{g}}^{\rm{H}}{\boldsymbol{\varLambda}}^{-1}{\boldsymbol{g}}+\\ &\sum\limits_{i = 1}^N(1+2^{2-\varsigma})\ln\eta_i+(-\frac{1}{2}+2^{1-\varsigma})\times\\ &\ln\lambda_i-\frac{\eta_i^2}{2^{3-\varsigma}}\lambda_i+\sum\limits_{i = 1}^N(a_i-1)\ln\eta_i-\\ &b_i\eta_i+(c-1)\ln\rho-b\rho+{{C}} \end{split} $$ (22) 然后, 参数可根据式 (21)和 (22)更新, 下面给出具体更新规则.
参数
$ {\boldsymbol{g}} $ 的更新: 根据式 (21), 实际后验分布$ p({\boldsymbol{g}}|{\boldsymbol{x}}) $ 的变元近似分布的对数形式为$$ \begin{split} \ln q({\boldsymbol{g}}) = \;&-\frac{1}{\varsigma}{\boldsymbol{g}}^{{\rm{H}}}\big(\left\langle\rho\right\rangle{\boldsymbol{A}}^{{\rm{H}}}{\boldsymbol{A}}+\left\langle{\boldsymbol{\varLambda}}^{-1}\right\rangle\big){\boldsymbol{g}}-\\ &\frac{\left\langle\rho\right\rangle}{\varsigma}{\boldsymbol{x}}^{{\rm{H}}}{\boldsymbol{A}}{\boldsymbol{g}}- \frac{\left\langle\rho\right\rangle}{\varsigma}{\boldsymbol{g}}^{{\rm{H}}}{\boldsymbol{A}}^{{\rm{H}}}{\boldsymbol{x}}+{{c}}_g \end{split} $$ (23) 其中,
$\left\langle \cdot\right\rangle$ 表示参数的期望,${{c}}_g$ 表示更新参数$ {\boldsymbol{g}} $ 时的常量. 由式 (23)可知,$ q({\boldsymbol{g}}) $ 可以使用多维高斯分布表示, 其期望和方差表示如下:$$ {\boldsymbol{\mu}} = \left\langle\rho\right\rangle{\boldsymbol{\Sigma}}{\boldsymbol{A}}^{{\rm{H}}}{\boldsymbol{x}} \tag{24a}$$ $$ \qquad\begin{split} {\boldsymbol{\Sigma}} =\;& \big(\left\langle\rho\right\rangle{\boldsymbol{A}}^{{\rm{H}}}{\boldsymbol{A}}+\left\langle{\boldsymbol{\varLambda}}^{-1}\right\rangle\big)^{-1}= \\ & \left\langle{\boldsymbol{\varLambda}}\right\rangle-\left\langle{\boldsymbol{\varLambda}}\right\rangle{\boldsymbol{A}}^{{\rm{H}}}\big(\left\langle\rho\right\rangle^{-1}{\boldsymbol{I}}_M+\\ &{\boldsymbol{A}}\left\langle{\boldsymbol{\varLambda}}\right\rangle{\boldsymbol{A}}^{{\rm{H}}}\big)^{-1}{\boldsymbol{A}}\left\langle{\boldsymbol{\varLambda}}\right\rangle\end{split}\tag{24b} $$ 其中,
${\boldsymbol{I}}_M$ 表示维度为$ M $ 的单位矩阵. 式 (24b)的推导使用了Woodbury引理[33], 目的是降低矩阵求逆的计算量. 其中, Woodbury引理见附录A.参数
$ {\boldsymbol{\lambda}} $ 的更新: 变量$ {\boldsymbol{\lambda}} $ 的对数近似后验为:$$ \ln q(\lambda_i) = -\frac{1}{2}\ln\lambda_i-\lambda_i^{-1}\left<g_i^{{\rm{H}}}g_i\right>-\frac{\left<\eta_i^2\right>}{2^{3-\varsigma}}\lambda_i+{{c}}_{\lambda_i} $$ (25) 其中,
$ {c}_{\lambda_i} $ 表示更新$ \lambda_i $ 时的常数,$\left < g_i^{{\rm{H}}}g_i\right > = \mu_i^{{\rm{H}}}\mu_i+ $ $ \{{\boldsymbol{\Sigma}}\}_{ii}$ ,$ \left<\eta_i^2\right> = \left<\eta_i\right>^2+{\rm{Var}}(\eta_i) $ ,$ \mu_i $ 是$ {\boldsymbol{\mu}} $ 的第$ i $ 个元素,$ \{{\boldsymbol{\Sigma}}\}_{ii} $ 是协方差矩阵$ {\boldsymbol{\Sigma}} $ 的第$ i $ 个对角线元素,$ {\rm{Var}}(\eta_i) $ 是$ \eta_i $ 的方差. 根据式 (25), 使用Gamma分布无法对实际分布$ p({\boldsymbol{\lambda}}) $ 进行近似, 因此本文采用广义逆高斯分布对实际分布$ p({\boldsymbol{\lambda}}) $ 进行近似. 对应的参数表示如下:$$ p = \frac{1}{2},\; \bar{a}_i = \frac{\left<\eta_i^2\right>}{2^{2-\varsigma}},\;\bar{b}_i = 2\left<g_i^{{\rm{H}}}g_i\right> $$ (26) 变量
$ \lambda_i $ 的估计如下:$$ \left<\lambda_i\right> = \frac{\sqrt{\bar{b}_i}{{K}}_{\frac{3}{2}}(\sqrt{\bar{a}_i\bar{b}_i})}{\sqrt{\bar{a}_i}{{K}}_{\frac{1}{2}}(\sqrt{\bar{a}_i\bar{b}_i})} = \frac{\sqrt{\bar{b}_i}}{\sqrt{\bar{a}_i}}+\frac{1}{\bar{a}_i} \tag{27a} $$ $$ \left<\lambda_i^{-1}\right> = \frac{\sqrt{\bar{a}_i}{{K}}_{\frac{3}{2}}(\sqrt{\bar{a}_i\bar{b}_i})}{\sqrt{\bar{b}_i}{{K}}_{\frac{1}{2}}(\sqrt{\bar{a}_i\bar{b}_i})}-\frac{2p}{\bar{b}_i} = \frac{\sqrt{\bar{a}_i}}{\sqrt{\bar{b}_i}}\tag{27b} $$ 参数
$ {\boldsymbol{\eta}} $ 的更新: 根据式 (21), 变量$ \eta_i $ 的对数近似分布表示为:$$ \begin{split} &\ln q(\eta_i) = {\rm{E}}_{q({\boldsymbol{\Theta}}\backslash\eta_i)}\big[\ln \big(p({\boldsymbol{x}}|{\boldsymbol{\eta}})p({\boldsymbol{\eta}}|{\boldsymbol{a}},{\boldsymbol{b}})\big)\big]+{{c}}_{\eta_i0}=\\ & \qquad(a_i+2^{2-\varsigma}-1)\ln\eta_i-(\left<|g_i|\right>+b_i)\eta_i+{{c}}_{\eta_i}\\[-10pt] \end{split} $$ (28) 其中,
$ {\boldsymbol{\Theta}}\backslash\eta_i $ 表示去除变量$ \eta_i $ 之后隐藏变量的集合,${{c}}_{\eta_i0}$ 和${{c}}_{\eta_i}$ 是更新参数$ \eta_i $ 时的常量. 因此, 根据式 (28), 变量$ \eta_i $ 的近似分布为Gamma分布, 对应参数如下:$$ \tilde{a}_i = a_i+2^{2-\varsigma},\; \tilde{b}_i = \left<|g_i|\right>+b_i $$ (29) 因此, 参数
$ \eta_i $ 的更新如下:$$ \left<\eta_i\right> = \frac{\tilde{a}_i}{\tilde{b}_i} \tag{30a} $$ $$ {\rm{Var}}(\eta_i) = \frac{\tilde{a}_i}{\tilde{b}_i^2} \tag{30b} $$ 参数
$ \rho $ 的更新: 根据式 (21)和式 (22), 变量$ \rho $ 的对数近似分布表示如下:$$ \begin{split} \ln q(\rho) =\;& \bigg(c+\frac{M}{\varsigma}-1\bigg)\ln\rho-\\ &\bigg(\frac{1}{\varsigma}\left<({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})^{{\rm{H}}}({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})\right>+d\bigg)\rho+{{c}}_{\rho} \end{split} $$ (31) 其中,
${{c}}_{\rho}$ 表示参数$ \rho $ 更新时的常量. 根据式 (31), 变量$ \rho $ 的近似分布为Gamma分布, 对应参数如下:$$ \tilde{c} = c+\frac{M}{\varsigma},\; \tilde{d} = \frac{1}{\varsigma}\left<({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})^{{\rm{H}}}({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})\right>+d $$ (32) 其中,
$ \left<({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})^{{\rm{H}}}({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})\right> $ 的表示如下:$$ \begin{split} \left<({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})^{{\rm{H}}}({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{g}})\right> =\;& \left|({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{\mu}})^{{\rm{H}}}({\boldsymbol{x}}-{\boldsymbol{A}}{\boldsymbol{\mu}})\right|+\\ &{\rm{tr}}\left({\boldsymbol{A}}^{{\rm{H}}}{\boldsymbol{\Sigma}}{\boldsymbol{A}}\right) \end{split} $$ 其中,
$ {\rm{tr}}(\cdot) $ 表示矩阵的迹. 因此, 参数$ \rho $ 的更新规则为:$$ \left<\rho\right> = \frac{\tilde{c}}{\tilde{d}} $$ (33) 上述为本文提出的基于自适应LASSO先验的SBL算法所有参数的更新规则, 以下将该算法简称为aLASSO-SBL. 为清晰描述算法, 将参数更新流程总结如算法1所示.
算法1. aLASSO-SBL算法伪代码
输入: 输入测量数据
$ {\boldsymbol{x}} $ , 测量矩阵$ {\boldsymbol{A}} $ ; 设置终止条件: 最大迭代次数$ {I_{\max}} $ 和相邻迭代最大允许误差$ e_{\max} $ .输出: 稀疏信号
$ {\boldsymbol{g}} $ 的期望$ {\boldsymbol{\mu}} $ 和方差$ {\boldsymbol{\Sigma}} $ .初始化参数
$ {\boldsymbol{g}} $ 的期望$ {\boldsymbol{\mu}} $ 和方差$ {\boldsymbol{\Sigma}} $ 以及参数$ {\boldsymbol{\lambda}} $ ,$ {\boldsymbol{\eta}} $ ,$ \rho $ ; 初始化模型参数$ {\boldsymbol{a}},{\boldsymbol{b}},c,d $ , 模型参数均设为接近于零的常数, 例如$ 10^{-6} $ . 初始化迭代次数$ i = 0 $ , 迭代误差$ e = 1 $ .While
$ i<I_{\max} $ and$ e>e_{\max} $ do更新迭代次数
$ i = i+1 $ ;更新中间变量
$ {\boldsymbol{\mu}}^{{\rm{old}}} = {\boldsymbol{\mu}} $ ;更新参数
$ {\boldsymbol{\mu}} = \left<\rho\right>{\boldsymbol{\Sigma}}{\boldsymbol{A}}^{{\rm{H}}}{\boldsymbol{x}} $ ;更新参数
${\boldsymbol{\Sigma}} = \left\langle {\boldsymbol{\varLambda}}\right\rangle -\left\langle {\boldsymbol{\varLambda}}\right\rangle{\boldsymbol{A}}^{{\rm{H}}}\big(\left\langle \rho\right\rangle^{-1}{\boldsymbol{I}}_M+ {\boldsymbol{A}}\left\langle {\boldsymbol{\varLambda}}\right\rangle{\boldsymbol{A}}^{{\rm{H}}}\big)^{-1} $ $ {\boldsymbol{A}}\left\langle {\boldsymbol{\varLambda}} \right\rangle$ ;For
$ i = 1:N $ do更新参数
$\left < \lambda_i\right > = \frac{\sqrt{\bar{b}_i}}{\sqrt{\bar{a}_i}}+\frac{1}{\bar{a}_i}$ ;更新参数
$\left < \lambda_i^{-1}\right > = \frac{\sqrt{\bar{a}_i}}{\sqrt{\bar{b}_i}}$ ;更新参数
$ \left<\eta_i\right> = \frac{\tilde{a}_i}{\tilde{b}_i} $ ;更新参数
$ {\rm{Var}}(\eta_i) = \frac{\tilde{a}_i}{\tilde{b}_i^2} $ ;End For
更新参数
$ \left<\rho\right> = \frac{\tilde{c}}{\tilde{d}} $ ;计算迭代误差
$ e = \frac{\|{\boldsymbol{\mu}}-{\boldsymbol{\mu}}^{{\rm{old}}}\|_1}{\|{\boldsymbol{\mu}}\|_1} $ .End While
3.2 快速算法
根据参数更新规则, 算法的主要计算量在于更新参数
$ {\boldsymbol{g}} $ 的协方差矩阵$ {\boldsymbol{\Sigma}} $ . 为进一步降低算法计算量, 本文采用空间轮换方法对参数$ {\boldsymbol{g}} $ 进行更新. 在$ {\boldsymbol{g}} $ 中元素相互独立的假设下, 根据式 (21), 变量$ g_i $ 的对数近似分布表示如下:$$ \begin{split} \ln q(g_i) = \;&{\rm{E}}_{q({\boldsymbol{\Theta}}\backslash g_i)}\big[\ln\big(p({\boldsymbol{x}}|{\boldsymbol{g}},\rho)p({\boldsymbol{g}}|{\boldsymbol{\lambda}})\big)\big]+{{c}}_{g_i0}=\\ &-\frac{1}{\varsigma}\Big( \left\langle\rho\right\rangle({\boldsymbol{x}}-{\boldsymbol{A}}_{\bar{i}} \left\langle{\boldsymbol{g}}_{\bar{i}}\right\rangle-{\boldsymbol{a}}_ig_i)^{{\rm{H}}}\times\\ &({\boldsymbol{x}}-{\boldsymbol{A}}_{\bar{i}} \left\langle{\boldsymbol{g}}_{\bar{i}}\right\rangle-{\boldsymbol{a}}_ig_i)+g_i^{{\rm{H}}} \left\langle\lambda_i^{-1}\right\rangle g_i\Big)+{{c}}_{g_i1} \end{split} $$ (34) 令
$ \tilde{{\boldsymbol{x}}}_i = {\boldsymbol{x}}-{\boldsymbol{A}}_{\bar{i}}\left<{\boldsymbol{g}}_{\bar{i}}\right> $ , 并代入式 (34)则有$$ \begin{split} \ln q(g_i) =\;& -\frac{1}{\varsigma}\Big(g_i^{{\rm{H}}}\big(\left\langle\rho\right\rangle{\boldsymbol{a}}_i^{{\rm{H}}}{\boldsymbol{a}}_i+\left\langle\lambda_i^{-1}\right\rangle\big)g_i+\\ &\left\langle\rho\right\rangle\tilde{{\boldsymbol{x}}}_i^{{\rm{H}}}{\boldsymbol{a}}_ig_i+\left\langle\rho\right\rangle g_i^{\rm{H}}{\boldsymbol{a}}_i^{\rm{H}}\tilde{{\boldsymbol{x}}}_i\Big)+{{c}}_{g_i2} \end{split} $$ (35) 其中,
$ {\boldsymbol{a}}_i $ 是测量矩阵$ {\boldsymbol{A}} $ 的第$ i $ 列向量,$ {\boldsymbol{A}}_{\bar{i}} $ 是测量矩阵$ {\boldsymbol{A}} $ 去除$ {\boldsymbol{a}}_i $ 后的矩阵,${{c}}_{g_i0}$ ,${{c}}_{g_i1}$ 和${{c}}_{g_i2}$ 是更新参数$ g_i $ 时的常量. 根据式 (35),$ g_i $ 的近似分布为高斯分布, 对应参数表示如下:$$ \mu_i = \left<\rho\right>\sigma_i^2{\boldsymbol{a}}_i^{\rm{H}}\tilde{{\boldsymbol{x}}}_i \tag{36a} $$ $$ \sigma_i^2 = \big(\left<\rho\right>{\boldsymbol{a}}_i^{{\rm{H}}}{\boldsymbol{a}}_i+\left<\lambda_i^{-1}\right>\big)^{-1} \tag{36b} $$ 其中,
$ \mu_i $ 和$ \sigma_i^2 $ 分别表示变量$ g_i $ 的期望和方差. 此时, 变量$ {\boldsymbol{g}} $ 的期望和方差分别表示为${\boldsymbol{\mu}} = [\mu_1, \mu_2,\cdots, $ $ \mu_N]^{\rm{T}}$ 和${\boldsymbol{\Sigma}} = {\rm{diag}}\{{\boldsymbol{\sigma}}^2\}$ , 且$ {\boldsymbol{\sigma}}^2 = [\sigma_1^2,\sigma_2^2,\cdots,\sigma_N^2]^{\rm{T}} $ .快速算法的参数更新流程与第3.1节中aLASSO-SBL算法的区别在于参数
$ {\boldsymbol{g}} $ 的更新, 即使用式(36)替代式(24)进行更新, 其余参数更新规则不变. 快速算法的优势在于更新参数$ {\boldsymbol{g}} $ 的协方差矩阵$ {\boldsymbol{\Sigma}} $ 时避免了矩阵求逆运算, 从而降低计算量, 缺点在于忽略了变量$ {\boldsymbol{g}} $ 不同元素之间的协方差项, 所以在测量矩阵$ {\boldsymbol{A}} $ 的列向量相关的情况下, 快速算法的稀疏信号恢复准确度会降低. 为描述方便, 下文中将快速算法简称为FaLASSO-SBL算法.算法2. FaLASSO-SBL算法伪代码
输入: 输入测量数据
$ {\boldsymbol{x}} $ , 测量矩阵$ {\boldsymbol{A}} $ ; 设置终止条件: 最大迭代次数$ {I_{\max}} $ 和相邻迭代最大允许误差$ e_{\max} $ .输出: 稀疏信号
$ {\boldsymbol{g}} $ 的期望$ {\boldsymbol{\mu}} $ 和方差$ {\boldsymbol{\Sigma}} $ .初始化参数
$ {\boldsymbol{g}} $ 的期望$ {\boldsymbol{\mu}} $ 和方差$ {\boldsymbol{\Sigma}} $ 以及参数$ {\boldsymbol{\lambda}} $ ,$ {\boldsymbol{\eta}} $ ,$ \rho $ ; 初始化模型参数$ {\boldsymbol{a}},{\boldsymbol{b}},c,d $ , 模型参数均设为接近于零的常数, 例如$ 10^{-6} $ ; 初始化迭代次数$ i = 0 $ , 迭代误差$ e = 1 $ .While
$ i<I_{\max} $ and$ e>e_{\max} $ do更新迭代次数
$ i = i+1 $ ;更新中间变量
$ {\boldsymbol{\mu}}^{{\rm{old}}} = {\boldsymbol{\mu}} $ ;For
$ i = 1:N $ do更新参数
$ \mu_i = \left<\rho\right>\sigma_i^2{\boldsymbol{a}}_i^{\rm{H}}\tilde{{\boldsymbol{x}}}_i $ ;更新参数
$ \sigma_i^2 = \big(\left<\rho\right>{\boldsymbol{a}}_i^{{\rm{H}}}{\boldsymbol{a}}_i+\left<\lambda_i^{-1}\right>\big)^{-1} $ ;更新参数
$\left < \lambda_i\right > = \frac{\sqrt{\boldsymbol{\bar{b}_i}}}{\sqrt{\boldsymbol{\bar{a}_i}}}+\frac{1}{\boldsymbol{\bar{a}_i}}$ ;更新参数
$\left < \lambda_i^{-1}\right > = \frac{\sqrt{\boldsymbol{\bar{a}_i}}}{\sqrt{\boldsymbol{\bar{b}_i}}}$ ;更新参数
$\left < \eta_i\right > = \frac{\tilde{\boldsymbol{a}}_i}{\tilde{\boldsymbol{b}}_i}$ ;更新参数
${\rm{Var}}(\eta_i) = \frac{\tilde{\boldsymbol{a}}_i}{\tilde{\boldsymbol{b}}_i^2}$ ;End For
更新参数
$ \left<\rho\right> = \frac{\tilde{c}}{\tilde{d}} $ ;计算迭代误差
$ e = \frac{\|{\boldsymbol{\mu}}-{\boldsymbol{\mu}}^{{\rm{old}}}\|_1}{\|{\boldsymbol{\mu}}\|_1} $ ;End While
3.3 算法计算量分析
本文通过使用算法中的乘法或除法运算数量衡量计算复杂度, 并且在欠定条件
$ M<N )$ 下进行分析. 在aLASSO-SBL算法中, 更新参数$ {\boldsymbol{g}} $ 期望$ {\boldsymbol{\mu}} $ 的计算复杂度为$ {\cal{O}}(MN) $ , 更新参数$ {\boldsymbol{g}} $ 协方差矩阵的计算复杂度为$ {\cal{O}}(MN^2) $ , 更新参数$ \rho $ 的计算复杂度为$ {\cal{O}}(MN) $ . 所以, 算法每次迭代的总计算复杂度为$ {\cal{O}}(MN^2) $ . 对于FaLASSO-SBL算法, 更新参数$ {\boldsymbol{g}} $ 的期望和方差矩阵的计算复杂度都为$ {\cal{O}}(MN) $ , 更新参数$ \rho $ 的计算复杂度为$ {\cal{O}}(MN) $ , 算法每次迭代的总计算复杂度为$ {\cal{O}}(MN) $ . 文献[16]提出的SBL算法的每次迭代的计算复杂为$ {\cal{O}}(MN^2) $ , 文献[18]提出的自回归算法的计算量为$ {\cal{O}}(MN^2) $ , 文献[25]提出的算法计算复杂度为$ {\cal{O}}(MN) $ , 文献[19]提出合成LASSO先验SBL算法的计算复杂度为$ {\cal{O}}(MN^2) $ . 通过分析可知本文提出的aLASSO算法计算复杂度与目前多数SBL算法的计算复杂度处于同一量级, FaLASSO算法的计算复杂度低于多数算法的计算复杂度.4. 仿真实验
本节通过仿真实验验证提出的aLASSO-SBL和FaLASSO-SBL算法的性能. 仿真实验分别针对实值信号模型(
$ \varsigma = 2 $ )和复值信号模型($ \varsigma = 1 $ )开展. 对于实值信号模型, 测量矩阵$ {\boldsymbol{A}} $ 中的元素满足独立同分布的高斯分布, 稀疏信号$ {\boldsymbol{g}} $ 中非零元素服从于独立同分布的高斯分布. 对于复值信号模型, 测量矩阵$ {\boldsymbol{A}} $ 中的元素和稀疏信号$ {\boldsymbol{g}} $ 中的非零元素都服从于独立同分布的复高斯分布. 无噪测量数据通过测量矩阵$ {\boldsymbol{A}} $ 与和稀疏信号$ {\boldsymbol{g}} $ 相乘得到, 即$ {\boldsymbol{A}}{\boldsymbol{g}} $ , 然后对信号添加高斯白噪声, 信噪比(Signal-Noise Ratio, SNR)的定义如下:$$ {\rm{SNR}} = 10\lg\frac{\|{\boldsymbol{A}}{\boldsymbol{g}}\|_2^2}{\|{\boldsymbol{w}}\|_2^2} $$ 各个算法的稀疏恢复准确性通过均方根误差(Root-Mean-Square-Error, RMSE)衡量, 定义如下:
$$ {\rm{RMSE}} = \sqrt{\sum\limits_{j = 1}^J\frac{\|\hat{{\boldsymbol{g}}}_j-{\boldsymbol{g}}_0\|_2^2}{J\|{\boldsymbol{g}}_0\|_2^2}} $$ (37) 其中,
$ \hat{{\boldsymbol{g}}}_j $ 是第$ j $ 次独立实验恢复的信号,$ J $ 是独立实验的总次数,$ {\boldsymbol{g}}_0 $ 是原始信号. 稀疏恢复算法估计的信号的RMSE越低表示算法的准确性越高, 性能越好.本文使用的算法及相应简称总结如下: BPDN为文献[29]提出的基追踪去噪算法, OMP为文献[34]提出的正交基追踪算法, aLASSO为文献[20]提出的自适应LASSO算法, FastSBL为文献[21]提出的快速SBL算法, GAMP-SBL为文献[24]中提出的基于近似消息传递(Approximate Message Passing, AMP)的SBL算法, FastLap-SBL为文献[17]提出的基于Laplace先验的快速SBL算法, MFOCUSS为文献[35]提出的类
$ \ell_p $ 范数优化算法, HSL-SBL为文献[19]提出的合成LASSO先验的SBL算法, aLASSO-SBL和FaLASSO-SBL是本文提出的基于自适应LASSO先验的SBL算法及其快速算法. 其中, aLASSO的正则因子设置为$ 1 $ , MFOCUSS的参数$ p $ 按文中建议设为$ 0.8 $ , FastSBL, Lap-SBL, HSL-SBL, aLASSO-SBL和FaLASSO-SBL的模型参数设置为相同的接近于零的值$ 10^{-6} $ .本文中所有仿真实验使用MATLAB软件实现, 软件版本为R2020a, 操作系统为64位Windows 10. 硬件配置总结如下: 处理器为AMD Ryzen 7 4750U, 物理核心数为8, 主频为1.7 GHz, 内存容量为16 GB.
4.1 仿真实验一
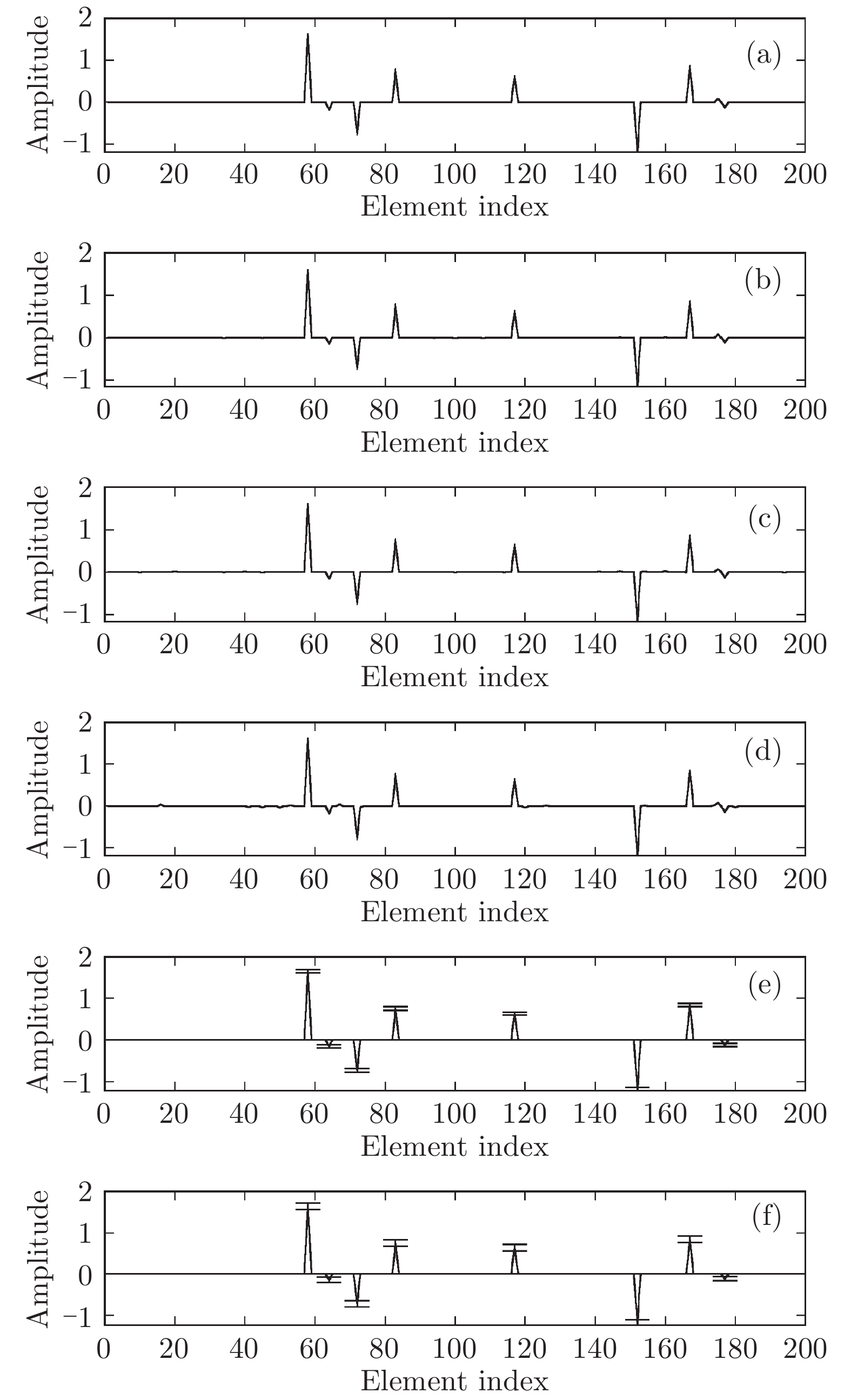
与凸优化和贪婪算法相比, 贝叶斯方法的一个重要特性是可以提供未知信号的后验分布而非点估计结果. 利用后验分布估计参数的优势在于通过协方差矩阵
$ {\boldsymbol{\Sigma}} $ 可以得到参数估计的不确定度, 在统计的角度优于凸优化算法. 本次实验中我们给出实值模型下各个算法对稀疏信号的估计结果. 仿真中测量矩阵的维度为$ 50\times200 $ , 即测量数为$ 50 $ , 信号长度为$ 200 $ , 信号中非零元素的个数设置为$ 10 $ , SNR设置为30 dB. 实验结果如图4所示. 其中, 图4(a)为纯净的稀疏信号; 图4(b)为使用BPDN算法恢复的信号; 图4(c)为使用aLASSO算法恢复的信号; 图4(d)为使用OMP算法恢复的信号; 图4(e)为使用FaLASSO-SBL算法恢复的信号; 图4(f)为使用aLASSO-SBL算法恢复的信号. 由图4可知. 基于凸优化的BPDN和aLASSO算法以及基于贪婪算法的OMP算法仅提供点估计结果, 而本文提出的aLASSO-SBL和FaLASSO-SBL算法与其它贝叶斯算法相同, 可以提供具有不确定度的估计结果. 其中, 图中误差线表示恢复信号的不确定度. 由于FaLASSO-SBL算法忽略协方差项导致对信号方差的估计小于aLASSO-SBL算法估计的方差, 但是协方差项的忽略会导致稀疏信号恢复准确性降低(见仿真实验二, 三和四).4.2 仿真实验二
本次仿真实验研究各个算法稀疏恢复性能与测量数的关系. 对于实值信号模型, 信号长度设置为
$ 200 $ , 非零元素数设置为$ 30 $ , 测量数变化范围为$ 50 $ 到$ 100 $ , 间隔为$ 10 $ . SNR为30 dB. 独立实验次数为$ 200 $ 次. 对于复值信号模型, 测量数变化范围为$ 40 $ 到$ 90 $ , 其它参数设置与实值信号模型相同, 原因是相同维度下, 复值测量数据的信息量大于实值测量数据的信息量, 所以需要更少的测量数. 实值信号模型和复值信号模型的实验结果如图5和图6所示. 表1给出了测量数为$ 80 $ 时实值信号模型和复值信号模型下各算法单次运行的时间. 图 5 实值模型下各算法稀疏恢复准确度与测量数的关系Fig. 5 RMSE of different algorithms with the real-value signal model versus length of measurements
图 5 实值模型下各算法稀疏恢复准确度与测量数的关系Fig. 5 RMSE of different algorithms with the real-value signal model versus length of measurements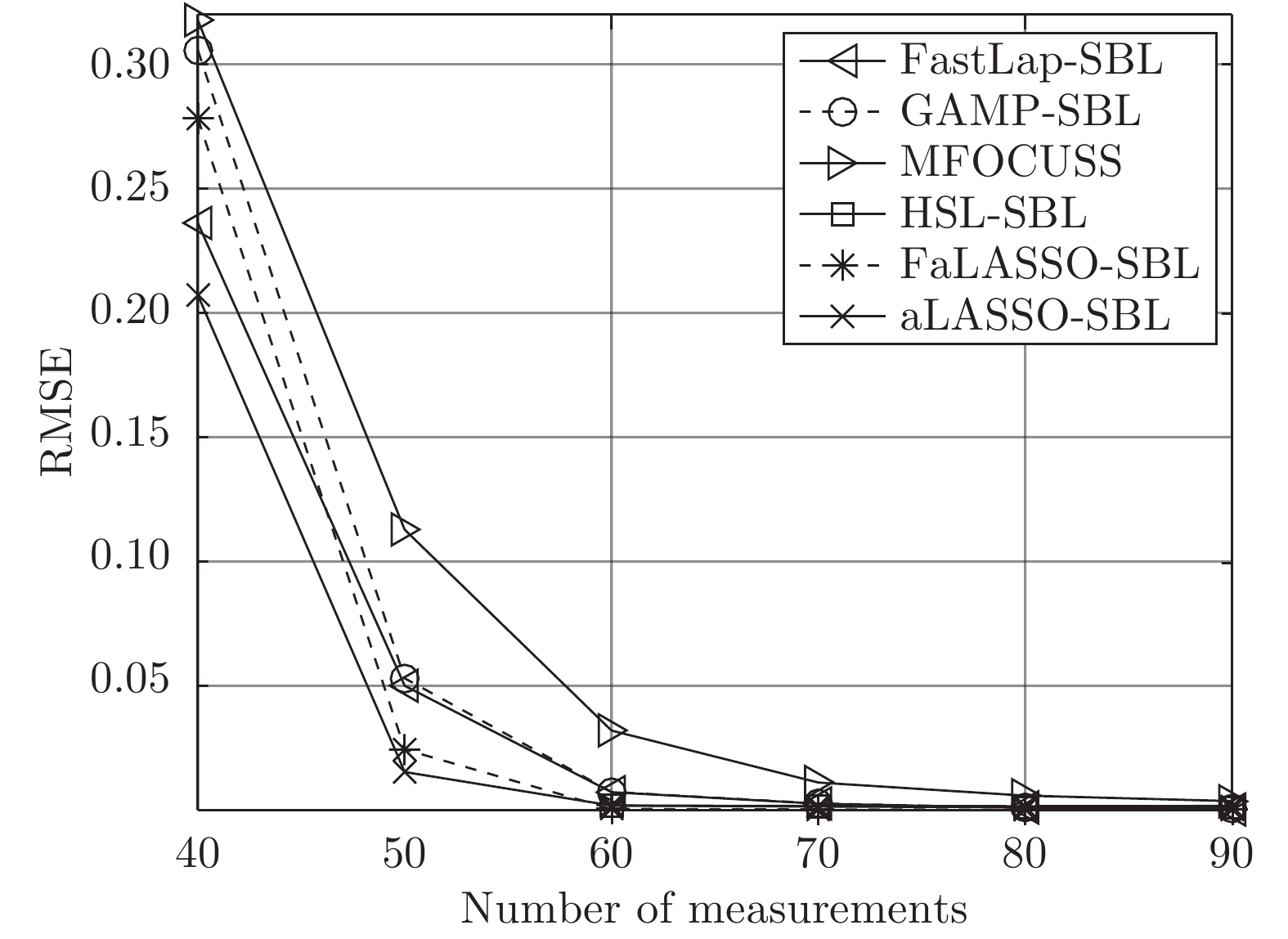 图 6 复值模型下各算法稀疏恢复准确度与测量数的关系Fig. 6 RMSE of different algorithms with the complex-value signal model versus length of measurements表 1 各算法单次运行时间Table 1 Time consumptions of different algorithms
图 6 复值模型下各算法稀疏恢复准确度与测量数的关系Fig. 6 RMSE of different algorithms with the complex-value signal model versus length of measurements表 1 各算法单次运行时间Table 1 Time consumptions of different algorithms实值信号模型 复值信号模型 算法 用时(s) 算法 用时(s) FastLaplace 0.11 FastSBL 1.54 aLASSO 1.94 GAMP-SBL 0.51 FastSBL 0.40 MFOCUSS 0.21 GAMP-SBL 0.07 HSL-SBL 3.16 FaLASSO-SBL 0.26 FaLASSO-SBL 0.74 aLASSO-SBL 0.98 aLASSO-SBL 2.33 由图5可知, 针对实值信号模型, 当测量数
$M = $ $ 50$ 时, 所有算法失效. 当测量数$ M\geq60 $ 时, 本文提出的aLASSO-SBL的稀疏恢复准确性优于其他算法, 特别是在测量数较小($ 60\leq M\leq90 $ )时恢复效果相较于其它算法有明显提升. 快速算法FaLASSO-SBL算法的准确性相比于aLASSO-SBL算法有一定程度的降低, 但是如表1所示, FaLASSO-SBL算法计算时间明显低于aLASSO-SBL算法. 根据图5和表1, FastLap-SBL算法和GAMP-SBL算法的运算速度比本文提出的FaLASSO-SBL算法快, 但是信号恢复的准确度比本文提出的算法低.如图6所示, 对于复值信号模型, 所有算法在测量数
$ 70\leq M\leq90 $ 时稀疏恢复效果较好, 在测量数$ 50\leq M\leq70 $ 时, 本文提出的aLASSO-SBL和FaLASSO-SBL算法相比于其他算法具有更低的RMSE. 在测量数$ M = 40 $ 时, 所有算法的恢复效果很差. 在测量数$ M\geq60 $ 时, HSL-SBL算法与本文提出的算法有相同的稀疏恢复效果, 但是HSL-SBL算法在测量数小于$ 60 $ 时出现不收敛的情况, 所以无法显示其在$ M< 60 $ 时的结果. 相比HSL-SBL算法, 本文提出的算法稳定性较高. 根据图6和表1, 对于复值信号模型, MFOCUSS算法和GAMP-SBL算法的计算速度比本文提出的FaLASSO-SBL算法速度快, 但信号恢复的准确率低于本文提出的算法. 原因是MFOCUSS算法在归一化因子选择不合适时准确性降低; GAMP-SBL是一种基于Student-t先验的快速SBL算法, 其优势在于计算速度快, 但缺点在于其信号恢复的准确率低于基于Student-t先验的SBL算法.为进一步验证本文中提出的aLASSO-SBL算法对高维信号的稀疏恢复性能, 进行如下仿真实验. 对于实值信号模型, 信号长度设置为
$ 2\,000 $ , 非零元素数设置为$ 100 $ , 测量数变化范围为$ 100 $ 到$ 350 $ , 间隔为$ 50 $ . SNR为20 dB. 独立实验次数为$ 200 $ 次. 复值信号模型参数设置与实值信号模型相同. 仿真实验结果如图7和图8所示. 图 7 高维实值信号模型下各算法稀疏恢复准确度与测量数的关系Fig. 7 RMSE of different algorithms with the high-dimensional real-value signal model versus length of measurements
图 7 高维实值信号模型下各算法稀疏恢复准确度与测量数的关系Fig. 7 RMSE of different algorithms with the high-dimensional real-value signal model versus length of measurements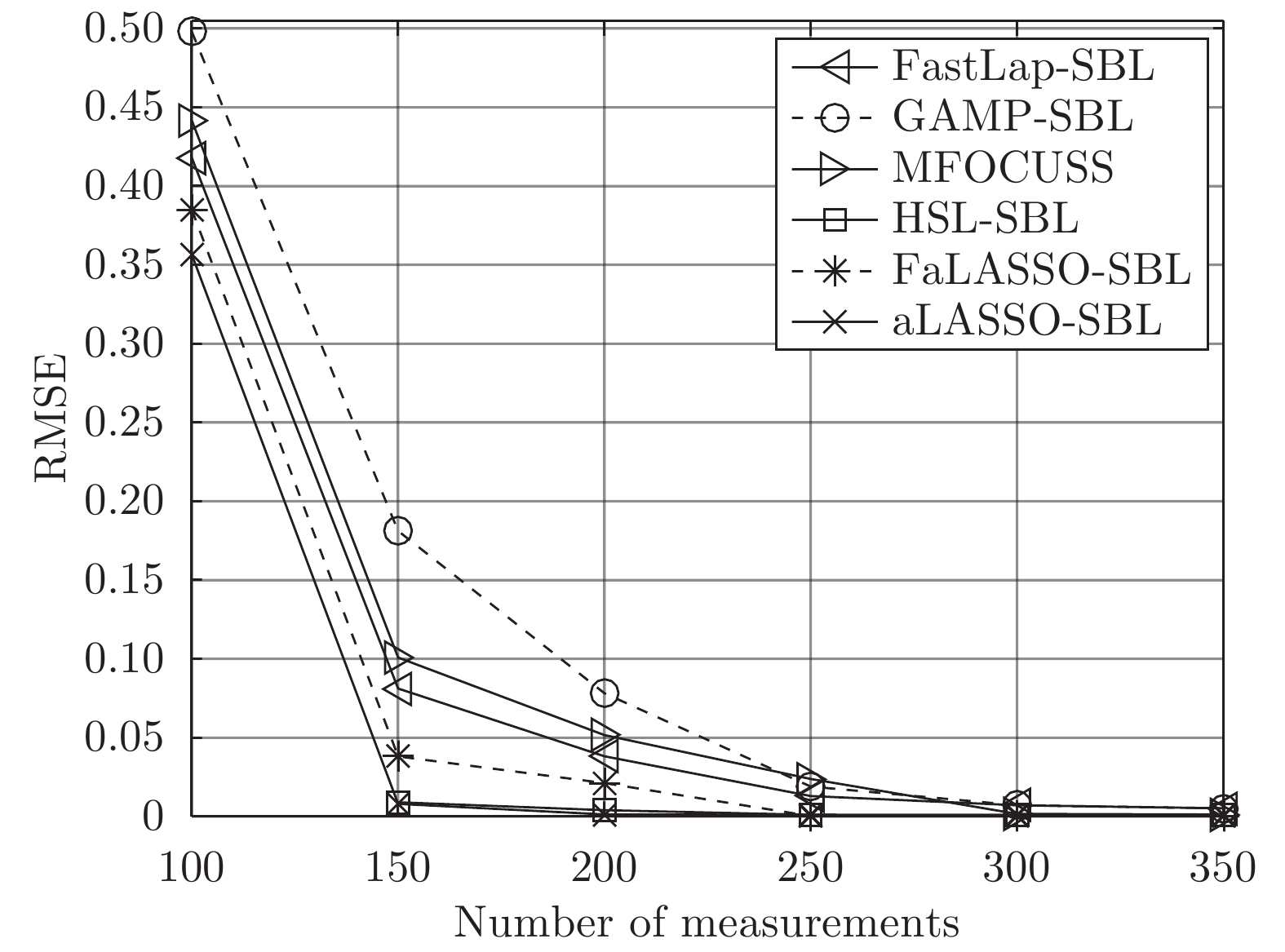 图 8 高维复值信号模型下各算法稀疏恢复准确度与测量数的关系Fig. 8 RMSE of different algorithms with the high-dimensional complex-value signal model versus length of measurements
图 8 高维复值信号模型下各算法稀疏恢复准确度与测量数的关系Fig. 8 RMSE of different algorithms with the high-dimensional complex-value signal model versus length of measurements图7为高维信号实值模型下各算法稀疏恢复准确度与测量数的关系. 由图7可知, 本文提出的aLASSO-SBL算法的稀疏信号恢复准确性优于现有稀疏恢复算法. 本文FaLASSO-SBL算法的准确性比aLASSO-SBL算法有所降低, 但在测量数
$ M\geq150 $ 时高于其他算法. 图8为高维信号复值模型下各算法稀疏恢复准确度与测量数的关系. 由图8可知, HSL-SBL算法在$ M\geq 150 $ 时与本文提出的aLASSO-SBL算法的稀疏信号恢复准确度相同并且高于其它算法, 但是当$ M<150 $ 时失效. 本文FaLASSO-SBL算法的准确性比aLASSO-SBL算法略低, 但在$ M\geq 150 $ 时高于除aLASSO-SBL算法和HSL-SBL算法之外的其它算法, 但计算量低于aLASSO-SBL算法和HSL-SBL算法.表2给出了高维信号实值模型和复值模型在测量长度为200时单次运行需要的时间. 与表1相比可知, 信号维度增加会导致计算量的增加. 结合表2、图7和图8可知, 对于高维信号, 本文中提出的aLASSO-SBL算法的稀疏信号恢复准确性高于现有算法, 但是在信号维度增高时计算量会显著增加; 本文中提出的FaLASSO-SBL算法稀疏恢复准确性略低于aLASSO-SBL算法, 但运算速度明显高于aLASSO-SBL算法.
表 2 恢复高维信号时各算法单次运行时间Table 2 Time consumptions of different algorithms when the dimension of signal is high实值信号模型 复值信号模型 算法 用时(s) 算法 用时(s) FastLaplace 0.83 FastSBL 6.95 aLASSO 5.71 GAMP-SBL 2.17 FastSBL 3.40 MFOCUSS 2.86 GAMP-SBL 0.69 HSL-SBL 15.73 FaLASSO-SBL 1.06 FaLASSO-SBL 4.61 aLASSO-SBL 8.38 aLASSO-SBL 17.41 4.3 仿真实验三
本次仿真实验研究各个算法稀疏恢复性能和稀疏度的关系. 对于实值信号模型, 测量矩阵的维度设置为
$ 100\times200 $ , 即测量数为$ 100 $ , 信号长度为$ 200 $ 信号中非零元素个数变化范围为$ 10 $ 到$ 50 $ , 间隔为$ 10 $ . SNR设置为30 dB. 独立实验次数为$ 200 $ . 对于复值信号模型, 信号中非零元度的个数变化范围设置为$ 20 $ 到$ 70 $ , 其他参数设置与实值模型设置相同. 针对实值信号模型和复值信号模型的稀疏恢复结果如图9和图10所示.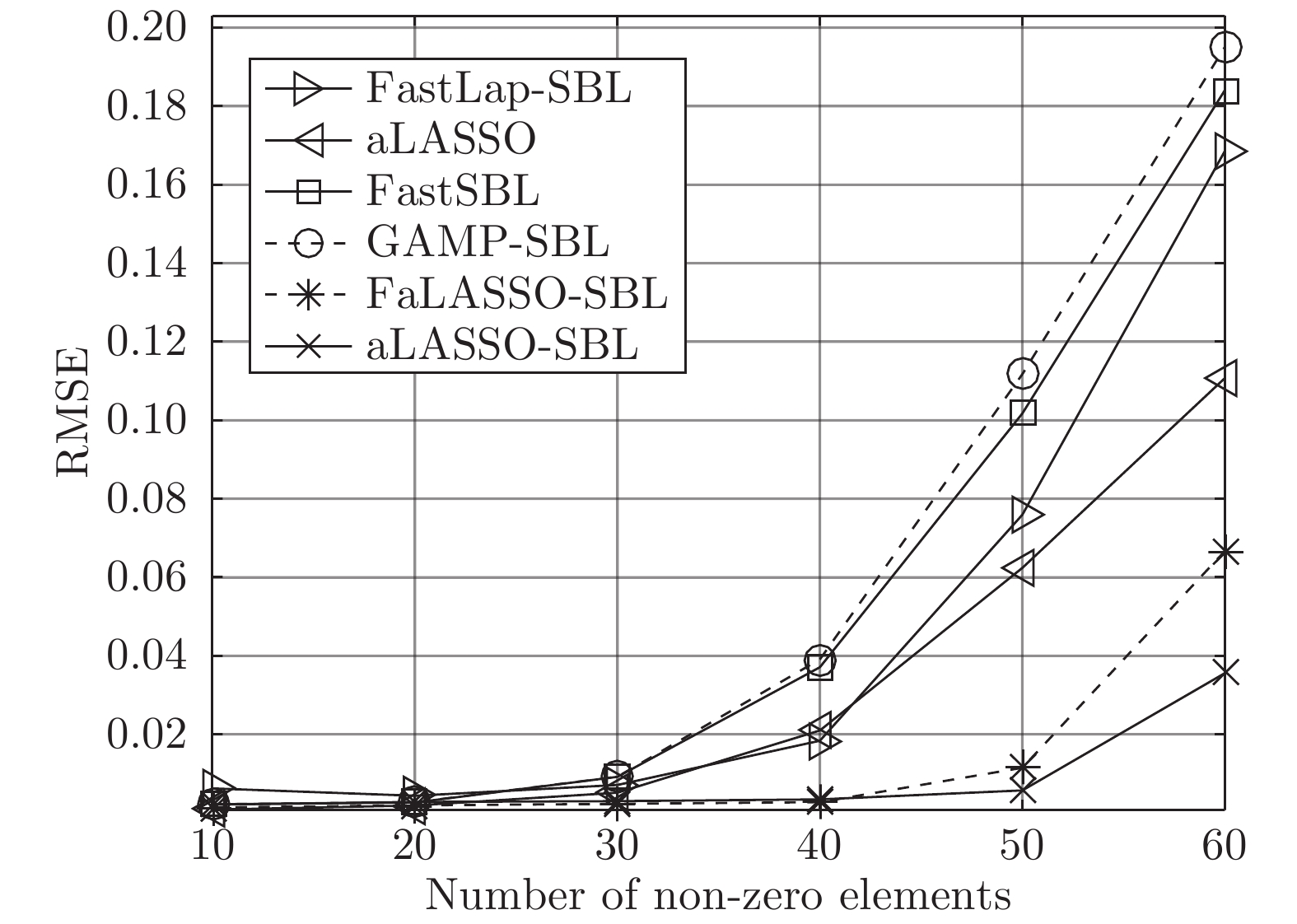 图 9 实值模型下各算法稀疏恢复准确度与稀疏度的关系Fig. 9 RMSE of different algorithms with the real-value signal model versus number of non-zero elements
图 9 实值模型下各算法稀疏恢复准确度与稀疏度的关系Fig. 9 RMSE of different algorithms with the real-value signal model versus number of non-zero elements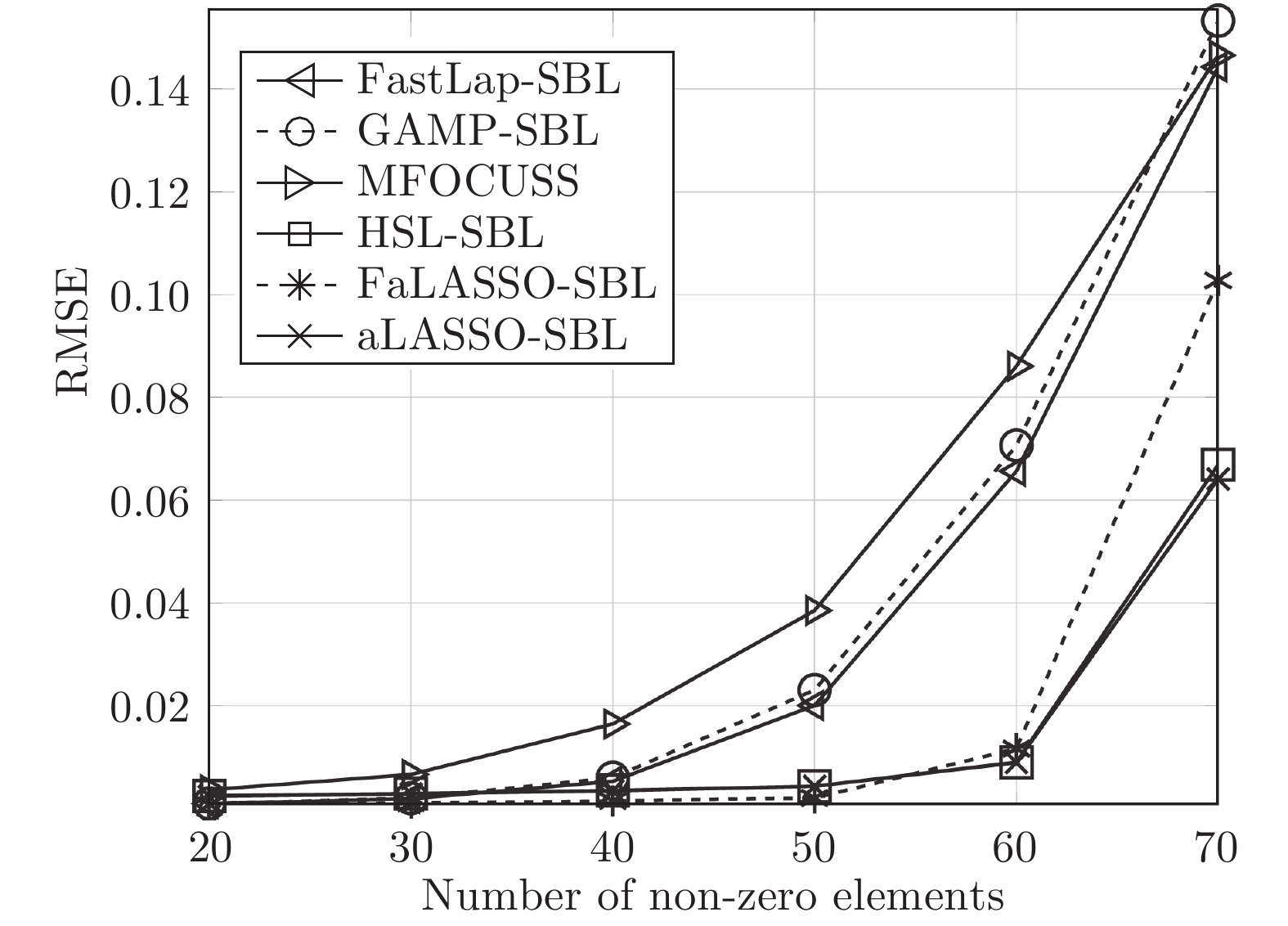 图 10 复值模型下各算法稀疏恢复准确度与稀疏度的关系Fig. 10 RMSE of different algorithms with the complex-value signal model versus number of non-zero elements
图 10 复值模型下各算法稀疏恢复准确度与稀疏度的关系Fig. 10 RMSE of different algorithms with the complex-value signal model versus number of non-zero elements根据图9可知, 针对实值信号模型, 所有算法在稀疏度高的条件下, 即信号中非零元素个数
$ 10\leq K\leq 30 $ 时稀疏恢复效果较好, 在稀疏度低的条件下($ 30\leq K\leq 60 $ ), FaLASSO-SBL和aLASSO-SBL的RMSE明显低于其它算法, 即本文提出的算法对信号稀疏度的鲁棒性比其它常用算法更强.如图10所示, 针对复值信号模型, MFOCUSS算法的恢复效果比贝叶斯算法的恢复效果差. 比较贝叶斯算法, HSL-SBL与aLASSO-SBL算法的恢复效果处于相同水平, 优于其它算法, FaLASSO-SBL算法作为aLASSO-SBL的快速算法, 在信号非零元素个数增加到一定程度
$ (K\geq60 )$ 时稀疏信号恢复的准确性有所下降.与仿真二相同, 为了进一步验证本文提出的算法对高维稀疏信号的恢复性能, 进行如下仿真实验. 对于实值信号模型, 信号长度设置为
$ 2\,000 $ , 测量数设置为$ 200 $ , 信号中非零元素数目变化范围为$ 20 $ 到$ 120 $ , 间隔为$ 20 $ . SNR为20 dB. 独立实验次数为$ 200 $ 次. 对于复值信号模型, 信号中非零元素数目变化范围为$ 20 $ 到$ 160 $ , 间隔为$ 20 $ , 其它参数设置与实值信号模型相同. 仿真实验结果如图11和图12所示. 图 11 高维实值信号模型下各算法稀疏恢复准确度与稀疏度的关系Fig. 11 RMSE of different algorithms with the high-dimensional real-value signal model versus number of non-zero elements
图 11 高维实值信号模型下各算法稀疏恢复准确度与稀疏度的关系Fig. 11 RMSE of different algorithms with the high-dimensional real-value signal model versus number of non-zero elements 图 12 高维复值信号模型下各算法稀疏恢复准确度与稀疏度的关系Fig. 12 RMSE of different algorithms with the high-dimensional complex-value signal model versus number of non-zero elements
图 12 高维复值信号模型下各算法稀疏恢复准确度与稀疏度的关系Fig. 12 RMSE of different algorithms with the high-dimensional complex-value signal model versus number of non-zero elements图11为高维信号实值模型下的稀疏恢复准确度与稀疏度之间的关系. 如图所示, 本文提出的aLASSO-SBL算法的稀疏恢复准确度高于现有算法, 本文提出的FaLASSO-SBL算法准确度在非零元素个数为
$ 20 $ 到$ 100 $ 的范围内与aLASSO-SBL算法接近, 但是在非零元素个数增加到$ 120 $ 时准确性低于FaLASSO-SBL算法. 图12为高维信号复值模型下的稀疏恢复准确度与稀疏度之间的关系. 观察图12, HSL-SBL算法和本文提出的aLASSO-SBL算法在非零元素数目为$ 20 $ 到$ 120 $ 范围内的稀疏恢复准确性优于现有算法, 但是HSL-SBL算法在非零元素数目大于$ 120 $ 时失效. 本文提出的FaLASSO算法稀疏恢复准确性优于除aLASSO-SBL算法和HSL-SBL算法之外的其它算法, 但计算复杂度低于aLASSO-SBL算法和HSL-SBL算法.4.4 仿真实验四
本次仿真实验研究各个算法稀疏恢复性能和信噪比的关系. 对于实值信号模型, 测量矩阵的维度设置为
$ 100\times200 $ , 即测量数为$ 100 $ , 信号长度为$ 200 $ . 信号中非零元素个数设置为$ 50 $ . SNR变化范围为10 dB到30 dB, 间隔为5 dB. 独立实验次数为$ 200 $ 次. 复值信号模型参数设置与实值信号模型相同. 对于实值信号模型和复值信号模型的稀疏信号恢复结果分别如图13和图14所示. 图 13 实值模型下各算法稀疏恢复准确度与信噪比的关系Fig. 13 RMSE of different algorithms versus SNR with the real-value signal model
图 13 实值模型下各算法稀疏恢复准确度与信噪比的关系Fig. 13 RMSE of different algorithms versus SNR with the real-value signal model 图 14 复值模型下各算法稀疏恢复准确度与信噪比的关系Fig. 14 RMSE of different algorithms versus SNR with the complex-value signal model
图 14 复值模型下各算法稀疏恢复准确度与信噪比的关系Fig. 14 RMSE of different algorithms versus SNR with the complex-value signal model由图13可知, 当SNR小于20 dB时, 所有算法失效, 即信号几乎不能被恢复. 当SNR大于20 dB时, 所有算法的稀疏恢复准确性随SNR的提高而提高. 其中, 本文提出的aLASSO-SBL和FaLASSO-SBL算法在SNR大于20 dB时恢复效果优于其他算法.
如图14所示, 对于复值信号模型, 当SNR低于15 dB时, 所有算法恢复效果比较差, HSL-SBL在SNR为10 dB的情况下出现不收敛的情况. 当SNR大于15 dB时, 所有算法的RMSE随SNR的增加而降低, 而本文提出的aLASSO-SBL和FaLASSO-SBL算法恢复信号的RMSE比其它算法低.
与仿真二和仿真三相同, 为验证本文提出算法对高维信号的恢复性能, 进行如下实验. 对于实值信号模型, 信号长度设置为2000, 测量数设置为200, 非零元素数设置为100. SNR变化范围为15到35, 间隔为5 dB. 独立实验次数为200次. 对于复值信号模型, SNR变化范围为10到30, 其它参数设置与实值信号模型相同.
图15为高维实值信号模型下各算法稀疏恢复准确度与信噪比的关系. 观察图15, 所有算法的恢复准确度随着SNR的增大而提高, 本文提出的aLASSO-SBL算法和FaLASSO-SBL算法在SNR为20 dB到35 dB的范围内恢复的准确率优于现有算法.
 图 15 高维实值信号模型下各算法稀疏恢复准确度与信噪比的关系Fig. 15 RMSE of different algorithms versus SNR with the high-dimensional real-value signal model
图 15 高维实值信号模型下各算法稀疏恢复准确度与信噪比的关系Fig. 15 RMSE of different algorithms versus SNR with the high-dimensional real-value signal model图16为高维实值信号模型下各算法稀疏恢复准确度与信噪比的关系. 观察图16, HSL-SBL算法、aLASSO-SBL算法和FaLASSO-SBL算法在SNR为20 dB到30 dB的范围内恢复的准确率优于现有算法, 但是HSL-SBL算法在SNR低于20 dB时失效.
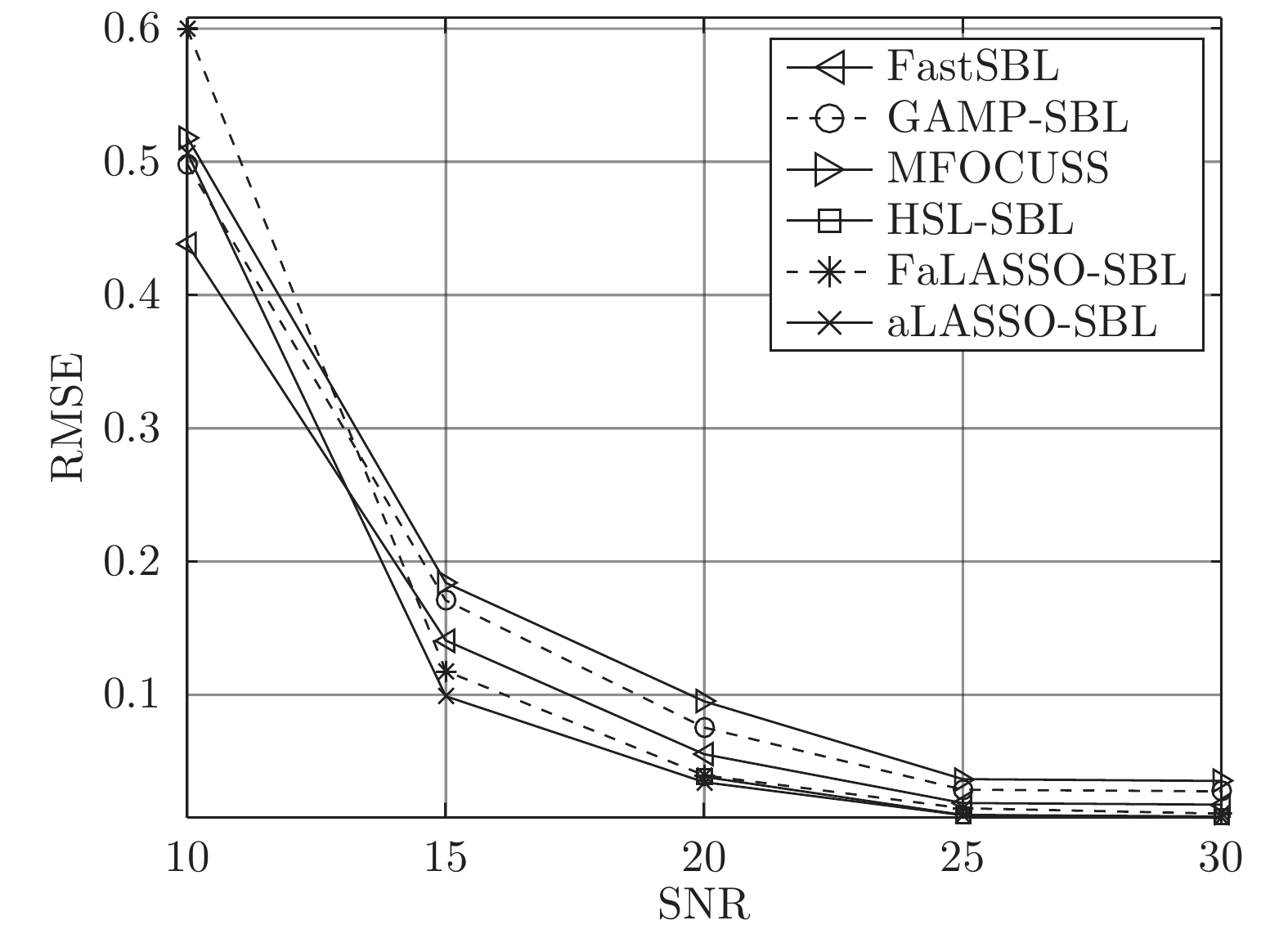 图 16 高维复值信号模型下各算法稀疏恢复准确度与信噪比的关系Fig. 16 RMSE of different algorithms versus SNR with the high-dimensional complex-value signal model
图 16 高维复值信号模型下各算法稀疏恢复准确度与信噪比的关系Fig. 16 RMSE of different algorithms versus SNR with the high-dimensional complex-value signal model4.5 单快拍条件下波达方向估计实验验证
波达方向(Direction of arrival, DOA)估计是稀疏恢复的应用之一. 通过预定义网格构建测量信号的空间中的过完备表达模型, 将DOA估计问题可转换为稀疏信号恢复问题[15]. 其中, 恢复的信号的非零元素对应的位置代表信号源的到达角. 使用单个快拍的测量数据进行DOA估计的方法称为单快拍DOA估计. 本小节将结合单快拍DOA估计验证提出的算法的性能.
本小节中使用的所有算法总结如下: SS-ESPRIT算法为文献[36]中提出的针对单快拍条件下DOA估计的空间平滑ESPRIT算法; L1-SR算法为文献[37]中提出的基于
$ \ell_1 $ 范数的单快拍DOA估计算法; SURE-IR算法为文献[38]中提出的超分辨算法; OGSBL为文献[39]提出的基于SBL的离网格DOA估计算法; HSL-SBL为文献[19]中提出的基于合成LASSO先验的SBL算法; aLASSO-SBL算法和FaLASSO-SBL算法为本文中提出的算法. 其中, HSL-SBL算法、aLASSO-SBL算法和FaLASSO-SBL算法需采用文献[39]中的离网格方法对估计的方位角进行提纯.假设使用均匀线性阵列接收信号, 阵元间隔为
$\dfrac{\gamma}{2}$ , 其中$ \gamma $ 为波长. 目标平面为阵列前$ -60^\circ $ 到$ 60^\circ $ 的扇形区域, 即所有信号源位于该扇形区域中. 仿真中信号源个数$ K $ 设置为$ 10 $ , 每次实验, 信号源的方位角、幅度和相位随机生成, 根据信号源的方位角确定阵列响应, 然后根据阵列响应生成纯净的测量数据, 最后对测量数据添加噪声得到带噪测量数据$ {\boldsymbol{x}} $ . 对目标平面进行均匀网格化, 网格间隔为$ 0.5^\circ $ , 即网格数为$ N = 241 $ . 根据预定义网格构建阵列流型矩阵$ {\boldsymbol{A}} $ . 在生成以上数据后, 由测量数据$ {\boldsymbol{x}} $ 和流型矩阵$ {\boldsymbol{A}} $ 使用DOA估计算法进行DOA估计. 假设信号源的实际方位角为$ {\boldsymbol{\theta}} = [\theta_1,\theta_2,\cdots,\theta_K]^{\rm{T}} $ , 估计得到的方位角为$ \tilde{{\boldsymbol{\theta}}} = [\tilde{\theta}_1,\tilde{\theta}_2,\cdots,\tilde{\theta}_K]^{\rm{T}} $ , 使用RMSE对DOA估计的准确度进行衡量, 定义如下:$$ e = \sqrt{\frac{1}{KN_{{\rm{MC}}}}\sum\limits_{i = 1}^{N_{{\rm{MC}}}}\|\tilde{{\boldsymbol{\theta}}}_i-{\boldsymbol{\theta}}_i\|_{\cal{F}}^2} $$ (38) 其中,
$ N_{MC} $ 表示Monte-Carlo实验的次数, 设置为200;$ {\boldsymbol{\theta}}_i $ 表示第$ i $ 次Monte-Carlo实验的声源实际方位角;$ \tilde{{\boldsymbol{\theta}}}_i $ 表示第$ i $ 次Monte-Carlo实验的估计的声源方位角. 本次仿真分别测试各个算法在不同测量数(阵元数)和不同SNR下的DOA估计准确性. 结果分别如图17和图18所示.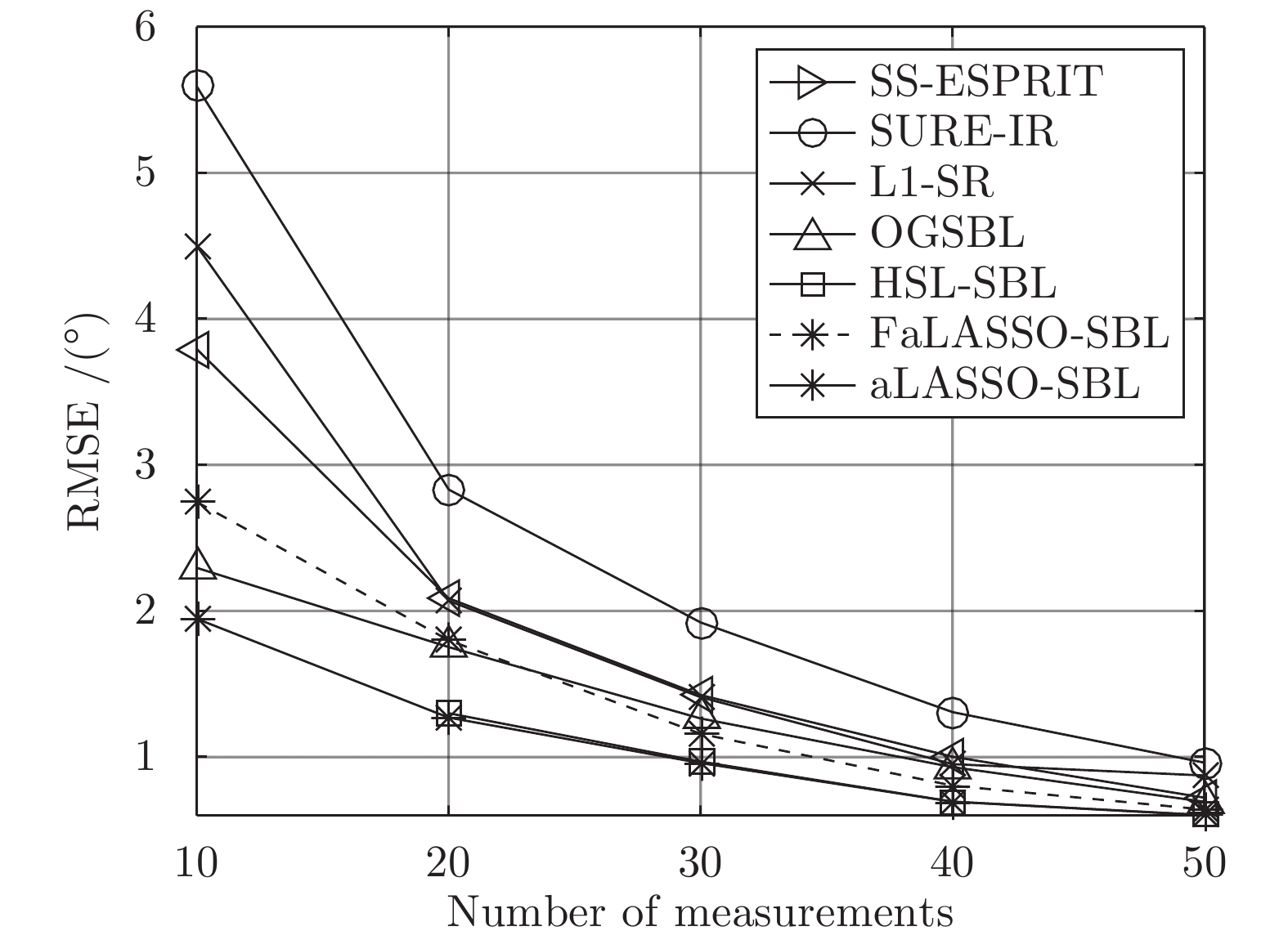 图 17 DOA估计的准确度与测量数的关系Fig. 17 RMSE of DOA estimation using different algorithms versus number of measurements
图 17 DOA估计的准确度与测量数的关系Fig. 17 RMSE of DOA estimation using different algorithms versus number of measurements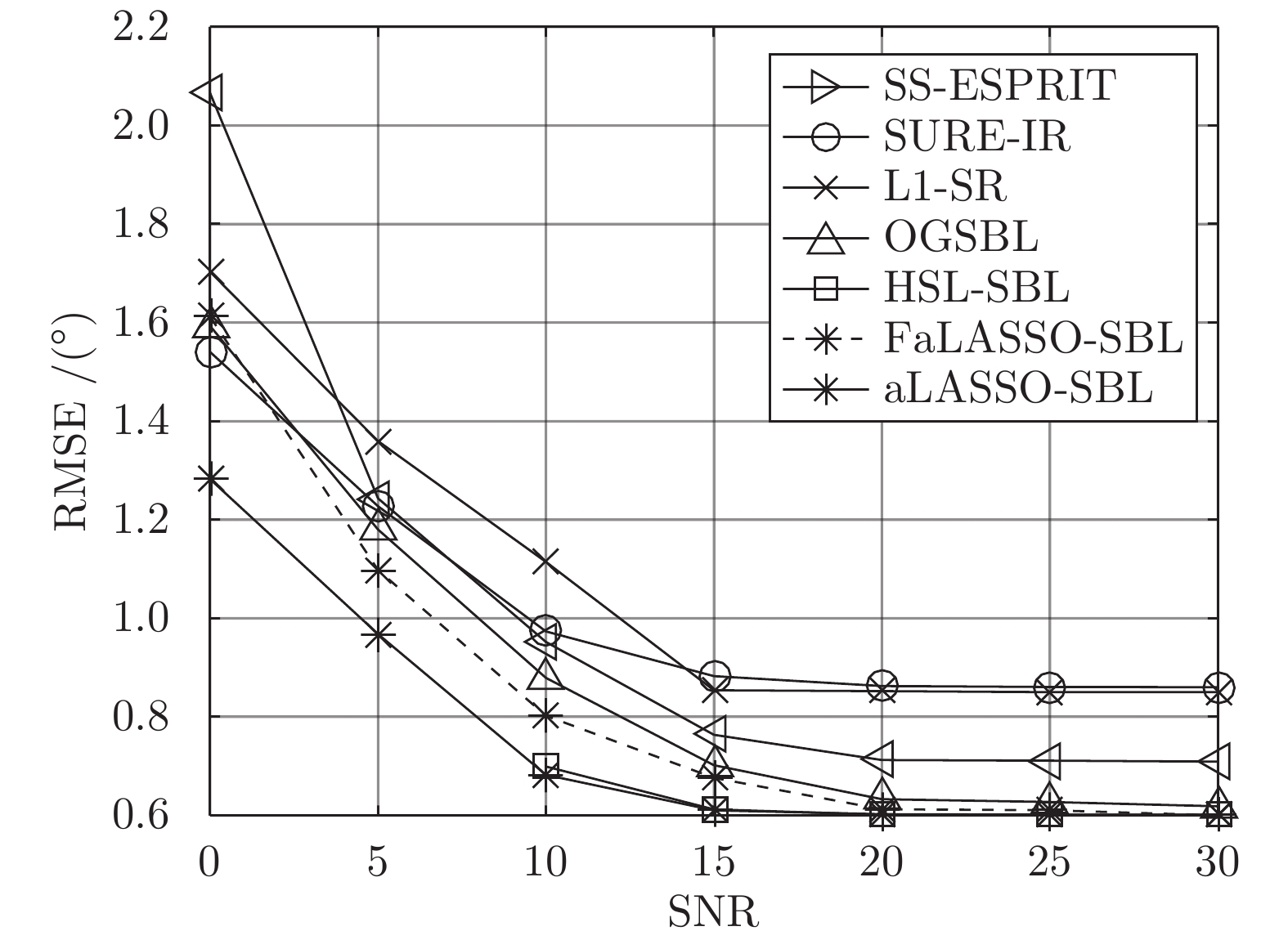 图 18 DOA估计准确度与信噪比的关系Fig. 18 RMSE of DOA estimation using different algorithms versus SNR
图 18 DOA估计准确度与信噪比的关系Fig. 18 RMSE of DOA estimation using different algorithms versus SNR图17为不同测量数下DOA估计准确度的结果. 其中, SNR设置为20 dB. 如图所示, HSL-SBL算法和本文中提出的aLASSO-SBL算法在测量数为
$ 20 $ 到$ 50 $ 的范围内DOA估计准确性优于其余算法, 但是HSL-SBL算法在测量数小于$ 20 $ 时失效. 与HSL-SBL算法和aLASSO-SBL算法相比, FaLASSO-SBL算法的准确性有所下降, 原因是阵列流形矩阵中的列向量在测量数小的情况下相关性较高[15], 导致FaLASSO-SBL算法性能下降. 但是当测量数增大$ M\geq 30 $ 时, 本文提出的FaLASSO算法准确性优于OGSBL算法、L-SR算法和SURE-IR算法.图18为不同SNR下DOA估计准确度的结果. 其中, 测量数设置为
$ 50 $ . 如图所示, HSL-SBL算法和本文中提出的aLASSO-SBL算法在SNR为$ 10 $ 到$ 30 $ 的范围内的DOA估计准确性优于其余算法, 但是HSL-SBL算法在SNR小于$ 10 $ 时失效. 与HSL-SBL算法和aLASSO-SBL算法相比, FaLASSO-SBL算法的准确性有所下降.表3给出了SNR为20 dB, 测量数为
$ 50 $ 时各单快拍DOA估计算法单次运行时间. 结合图17和图18可知, 相比于HSL-SBL算法, 本文提出aLASSO-SBL算法在不增加计算量的前提下提高了算法的稳定性, 在小测量数或低信噪比的情况下性能优于HSL-SBL算法. 而本文提出的FaLASSO-SBL算法在运算速度方面具有优势.表 3 单快拍DOA估计实验各算法单次运行时间Table 3 Time consumptions of different algorithms for single snapshot DOA estimation算法 用时(s) 算法 用时(s) SS-ESPRIT 0.37 HSL-SBL 0.85 SURE-IR 1.64 FaLASSO-SBL 0.47 L1-SR 0.91 aLASSO-SBL 0.83 OGSBL 0.69 4.6 仿真结果分析总结
下面对实验结果进行总结. 通过图5、图6、图7和图8可知, 在相同测量数下, 本文提出aLASSO-SBL和FaLASSO-SBL算法稀疏恢复准确性优于现有算法. 另外, 比较表1和表2, 当信号维度增加时, 本文提出aLASSO-SBL算法的计算量会明显提高, 本文提出的FaLASSO-SBL算法对高维信号进行恢复时, 在计算量方面比aLASSO-SBL算法有明显优势. 根据图9、图10、图11和图12可知, aLASSO-SBL和FaLASSO-SBL算法鲁棒于信号的稀疏度, 即在稀疏度比较低的情况下仍然可以精确的恢复出信号. 根据图13、图14、图15和图16可知, 本文提出的LASSO-SBL和FaLASSO-SBL算法的在高SNR的条件下信号恢复准确性比其它常用算法高.
对于单快拍DOA估计而言, 由于单快拍DOA估计中阵列流型矩阵的列向量具有在测量数较少时相关性较高, 所以导致FaLASSO-SBL算法在小测量数时(
$ M\leq 20 $ )性能下降. 根据图17和图18可知, 当测量数较大时, 本文提出的aLASSO-SBL算法和FaLASSO-SBL算法的单快拍DOA估计准确性优于现有单快拍DOA估计算法, 结合表3可知, 本文提出的FaLASSO算法降低了aLASSO-SBL算法计算量. 综上所述, 当测量矩阵$ {\boldsymbol{A}} $ 的列向量不相关时, aLASSO-SBL算法的稀疏恢复准确度优于现有算法, FaLASSO-SBL算法的准确度略低于aLASSO-SBL算法但是计算量明显低于aLASSO-SBL算法; 当测量矩阵$ {\boldsymbol{A}} $ 的列向量相关时, FaLASSO-SBL算法的稀疏恢复准确度有明显下降. 对于单快拍DOA估计而言, 在测量数大的情况下FaLASSO-SBL算法准确性和运算速度优于现有算法.5. 结 论
针对稀疏信号恢复问题, 本文提出了两种SBL算法, 即aLASSO-SBL算法和FaLASSO-SBL算法. 其中, FaLASSO-SBL算法是aLASSO-SBL算法的快速算法. 具体的创新点为: 1) 提出一种多层先验的稀疏贝叶斯框架用于稀疏贝叶斯模型构建, 赋予信号中元素独立的LASSO先验. 通过分析, 自适应LASSO先验比现有稀疏先验更有效的鼓励稀疏. 根据构建的稀疏恢复模型提出了aLASSO-SBL算法. 2) 在贝叶斯推断阶段, 利用空间轮换方法避免矩阵求逆运算, 进一步降低了算法的计算复杂度, 使参数更新快速高效. 从而提出了FaLASSO-SBL算法. 本文提出的算法的稀疏恢复性能通过仿真实验进行了验证, 结果表明本文提出基于自适应LASSO先验的SBL算法比现有算法具有更高的稀疏恢复准确度; 本文提出的快算法的准确度略低于基于自适应LASSO先验的SBL算法, 但计算复杂度明显降低. 对于单快拍DOA估计而言, 在测量数大的情况下FaLASSO-SBL算法准确性和运算速度优于现有算法.
附录A
Woodbury引理. 如果矩阵
$ {\boldsymbol{A}} $ 、矩阵$ {\boldsymbol{C}} $ 和矩阵${\boldsymbol{C}}^{-1}+ $ $ {\boldsymbol{V}}{\boldsymbol{A}}^{-1}{\boldsymbol{U}}$ 是非奇异矩阵, 则有以下恒等式:$$ \begin{split} &({\boldsymbol{A}}+{\boldsymbol{U}}{\boldsymbol{C}}{\boldsymbol{V}})^{-1} = \\ &\quad{\boldsymbol{A}}^{-1}-{\boldsymbol{A}}^{-1}{\boldsymbol{U}}\left({\boldsymbol{C}}^{-1}+{\boldsymbol{V}}{\boldsymbol{A}}^{-1}{\boldsymbol{U}}\right)^{-1}{\boldsymbol{V}}{\boldsymbol{A}}^{-1} \end{split}\tag{A1} $$ 其中, 矩阵
$ {\boldsymbol{A}} $ 、矩阵$ {\boldsymbol{C}} $ 、矩阵$ {\boldsymbol{U}} $ 和矩阵$ {\boldsymbol{V}} $ 为维度合适的矩阵. -

图 1 城市固废焚烧过程智能操作优化方法框架
Fig. 1 The framework for intelligent operational optimization method of municipal solid waste incineration process

图 14 不同算法对 NOx排放的优化结果
Fig. 14 Optimization results of NOx emissions using different algorithms
表 1 实验数据基本信息
Table 1 Basic information of experimental data
变量名称 取值范围 单位 炉排速度 30.05 ~ 30.08 % 一次风入口流量 47698.32 ~63444.03 m3/h 一次风出口压力 1988.02 ~3189.73 Pa 二次风入口流量 4924.86 ~5124.70 m3/h NOx排放浓度 79.21 ~ 231.27 mg/m3 CO排放浓度 0.39 ~ 7.38 mg/m3 CO2排放浓度 4.80 ~ 6.55 mg/m3  下载: 导出CSV
下载: 导出CSV
表 2 不同指标模型精度
Table 2 Accuracy of different index models
方法 NOx指标模型 CO指标模型 CO2指标模型 RMSE MAPE (%) RMSE MAPE (%) RMSE MAPE (%) LSSVR 11.2729 7.0716 0.6281 17.8164 0.1970 2.6587 Kriging 10.3483 6.1612 0.5376 15.5635 0.1967 2.5834 RBF 11.6462 7.3384 0.5595 16.5597 0.1908 2.4366 SORBF 9.3939 5.5603 0.5368 15.4444 0.1866 2.2523
下载: 导出CSV
表 3 不同算法优化结果均值比较
Table 3 Comparison of mean optimization results using different algorithms
不同优化算法 NOx排放(mg/m3) 燃烧效率(%) 实际运行 133.840 2 79.274 0 NSGA-II 123.567 4 84.460 1 MOPSO 121.792 7 83.122 0 MOPSO-CD 119.997 0 84.890 7 MOPSO-RC 113.462 5 85.299 0
下载: 导出CSV
-
[1] Maalouf A, Mavropoulos A, El-Fadel M. Global municipal solid waste infrastructure: Delivery and forecast of uncontrolled disposal. Waste Management & Research, 2020, 38(9): 1028−1036 [2] 汤健, 夏恒, 余文, 乔俊飞. 城市固废焚烧过程智能优化控制研究现状与展望. 自动化学报, 2023, 49(10): 2019−2059Tang Jian, Xia Heng, Yu Wen, Qiao Jun-Fei. Research status and prospects of intelligent optimization control for municipal solid waste incineration process. Acta Automatica Sinica, 2023, 49(10): 2019−2059 [3] Frey H H, Peters B, Hunsinger H, Vehlow J. Characterization of municipal solid waste combustion in a grate furnace. Waste Management, 2003, 23(8): 689−701 doi: 10.1016/S0956-053X(02)00070-3 [4] Shin D, Choi S. The combustion of simulated waste particles in a fixed bed. Combustion and Flame, 2000, 121(1−2): 167−180 doi: 10.1016/S0010-2180(99)00124-8 [5] Yang Y B, Goh Y R, Zakaria R, Nasserzadeh V, Swithenbank J. Mathematical modelling of MSW incineration on a travelling bed. Waste Management, 2002, 22(4): 369−380 doi: 10.1016/S0956-053X(02)00019-3 [6] Liang Z, Ma X. Mathematical modeling of MSW combustion and SNCR in a full-scale municipal incinerator and effects of grate speed and oxygen-enriched atmospheres on operating conditions. Waste Management, 2010, 30(12): 2520−2529 doi: 10.1016/j.wasman.2010.05.006 [7] Xia Z, Li J, Wu T, Chen C, Zhang X. CFD simulation of MSW combustion and SNCR in a commercial incinerator. Waste Management, 2014, 34(9): 1609−1618 doi: 10.1016/j.wasman.2014.04.015 [8] Hu Z, Jiang E, Ma X. Numerical simulation on operating parameters of SNCR process in a municipal solid waste incinerator. Fuel, 2019, 245: 160−173 doi: 10.1016/j.fuel.2019.02.071 [9] Yang X, Liao Y, Ma X, Zhou J. Effects of air supply optimization on NOx reduction in a structurally modified municipal solid waste incinerator. Applied Thermal Engineering, 2022, 201: Article No. 117706 doi: 10.1016/j.applthermaleng.2021.117706 [10] Huai X L, Xu W L, Qu Z Y, Li Z G, Zhang F P, Xiang G M, et al. Numerical simulation of municipal solid waste combustion in a novel two-stage reciprocating incinerator. Waste Management, 2008, 28(1): 15−29 doi: 10.1016/j.wasman.2006.11.010 [11] Han H, Liu Y, Hou Y, Qiao J. Multi-modal multi-objective particle swarm optimization with self-adjusting strategy. Information Sciences, 2023, 629: 580−598 doi: 10.1016/j.ins.2023.02.019 [12] Zhou P, Wang X, Chai T. Multiobjective operation optimization of wastewater treatment process based on reinforcement self-learning and knowledge guidance. IEEE Transactions on Cybernetics, 2023, 53(11): 6896−6909 doi: 10.1109/TCYB.2022.3164476 [13] 丁进良, 陈佳鑫, 马欣然. 基于自适应差分进化的常压塔轻质油产量多目标优化. 控制与决策, 2020, 35(3): 604−612Ding Jin-Liang, Chen Jia-Xin, Ma Xin-Ran. Multi-objective optimization of light oil production in atmospheric distillation column based on self-adaptive differential evolution. Control and Decision, 2020, 35(3): 604−612 [14] 阳春华, 孙备, 李勇刚, 黄科科, 桂卫华. 复杂生产流程协同优化与智能控制. 自动化学报, 2023, 49(3): 528−539Yang Chun-Hua, Sun Bei, Li Yong-Gang, Huang Ke-Ke, Gui Wei-Hua. Cooperative optimization and intelligent control of complex production processes. Acta Automatica Sinica, 2023, 49(3): 528−539 [15] Huang W, Mohammad M. Development, exergoeconomic assessment and optimization of a novel municipal solid waste-incineration and solar thermal energy based integrated power plant: An effort to improve the performance of the power plant. Process Safety and Environmental Protection, 2023, 172: 562−578 doi: 10.1016/j.psep.2023.02.016 [16] Costa M, Indrizzi V, Massarotti N, Mauro A. Modeling and optimization of an incinerator plant for the reduction of the environmental impact. International Journal of Numerical Methods for Heat & Fluid Flow, 2015, 25(6): 1463−1487 [17] Pan M, Chen X, Li X. Multi-objective analysis and optimization of cascade supercritical CO2 cycle and organic Rankine cycle systems for waste-to-energy power plant. Applied Thermal Engineering, 2022, 214: Article No. 118882 doi: 10.1016/j.applthermaleng.2022.118882 [18] Özahi E, Tozlu A, Abuşoğlu A. Thermoeconomic multi-objective optimization of an organic Rankine cycle (ORC) adapted to an existing solid waste power plant. Energy Conversion and Management, 2018, 168: 308−319 doi: 10.1016/j.enconman.2018.04.103 [19] Mayanti B, Songok J, Helo P. Multi-objective optimization to improve energy, economic and, environmental life cycle assessment in waste-to-energy plant. Waste Management, 2021, 127: 147−157 doi: 10.1016/j.wasman.2021.04.042 [20] Tang Z, Zhang Z. The multi-objective optimization of combustion system operations based on deep data-driven models. Energy, 2019, 182: 37−47 doi: 10.1016/j.energy.2019.06.051 [21] Chai T, Zhang J, Yang T. Demand forecasting of the fused magnesia smelting process with system identification and deep learning. IEEE Transactions on Industrial Informatics, 2021, 17(12): 8387−8396 doi: 10.1109/TII.2021.3065930 [22] Anderson S R, Kadirkamanathan V, Chipperfield A, Sharifi V, Swithenbank J. Multi-objective optimization of operational variables in a waste incineration plant. Computers & Chemical Engineering, 2005, 29(5): 1121−1130 [23] 崔莺莺, 蒙西, 乔俊飞. 城市固废焚烧过程风量智能优化设定方法. 控制与决策, 2023, 38(2): 318−326Cui Ying-Ying, Meng Xi, Qiao Jun-Fei. The intelligent optimization setting method of air flow for municipal solid wastes incineration process. Control and Decision, 2023, 38(2): 318−326 [24] Sun J, Meng X, Qiao J. Data-driven optimal control for municipal solid waste incineration process. IEEE Transactions on Industrial Informatics, 2023, 19(12): 11444−11454 doi: 10.1109/TII.2023.3246467 [25] 孙剑, 蒙西, 乔俊飞. 城市固废焚烧过程烟气含氧量自适应预测控制. 自动化学报, 2023, 49(11): 2338−2349Sun Jian, Meng Xi, Qiao Jun-Fei. Adaptive predictive control of oxygen content in flue gas for municipal solid waste incineration process. Acta Automatica Sinica, 2023, 49(11): 2338−2349 [26] 白良成. 生活垃圾焚烧处理工程技术. 北京: 中国建筑工业出版社. 2021Bai Liang-Cheng. Engineering Technology for Incineration Treatment of Municipal Solid Waste. Beijing: China Architecture & Building Press, 2021. [27] Meng X, Rozycki P, Qiao J, Wilamowski B. Nonlinear system modeling using RBF networks for industrial application. IEEE Transactions on Industrial Informatics, 2017, 14(3): 931−940 [28] Qiao J, Zhou J, Meng X. A multitask learning model for the prediction of NOx emissions in municipal solid waste incineration processes. IEEE Transactions on Instrumentation and Measurement, 2022, 72: 1−14 [29] Zhou W, Li X, Yi J, He H. A novel UKF-RBF method based on adaptive noise factor for fault diagnosis in pumping unit. IEEE Transactions on Industrial Informatics, 2018, 15(3): 1415−1424 [30] Yao F, Zhao J, Li X, Mao L, Qu K. RBF neural network based virtual synchronous generator control with improved frequency stability. IEEE Transactions on Industrial Informatics, 2020, 17(6): 4014−4024 [31] Liu W, Wang Z, Yuan Y, Zeng N, Hone K, Liu X. A novel sigmoid-function-based adaptive weighted particle swarm optimizer. IEEE Transactions on Cybernetics, 2019, 51(2): 1085−1093 [32] Smola A, Schölkopf B. A tutorial on support vector regression. Statistics and Computing, 2004, 14(3): 199−222 doi: 10.1023/B:STCO.0000035301.49549.88 [33] Sacks J, Welch W J, Mitchell T J, Wynn H P. Design and analysis of computer experiments. Statistical Seience, 1989, 4(4): 409−423 -

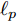

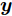
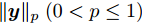
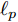
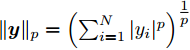
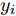

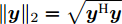
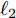
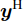
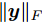
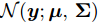
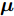
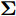
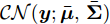
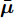

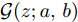
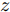
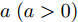
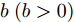
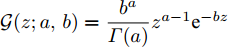
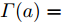
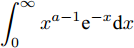
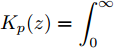
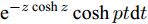
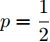
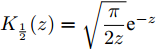
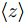
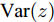
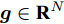
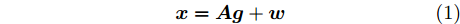
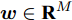
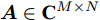
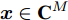
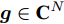
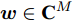
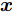
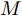
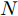
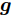
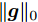
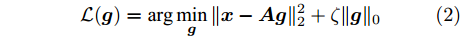
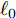
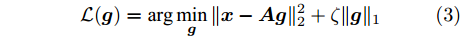
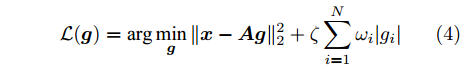
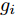
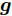

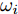
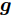
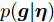
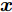
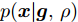
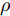
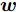
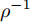
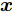
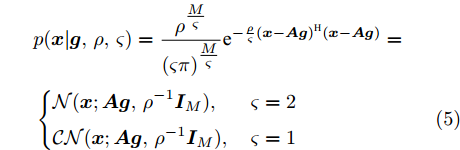
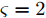

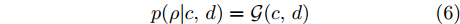
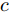
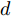
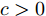
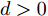
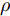

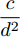
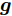
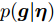
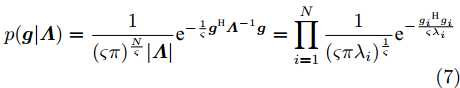
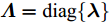
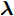
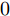
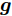
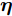
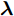
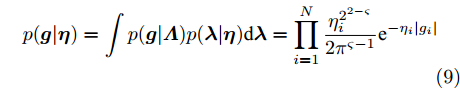
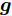
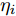
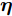
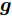
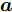
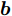
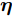
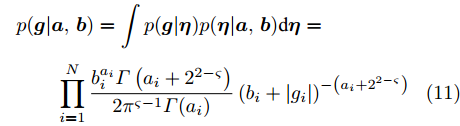
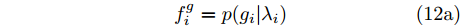
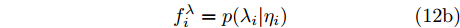
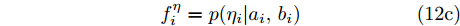
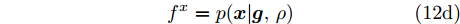

 下载:
下载:
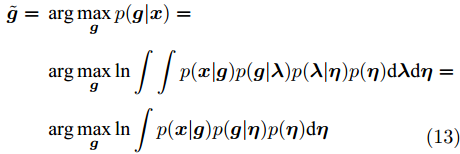
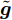
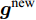
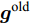
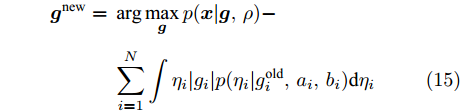
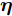
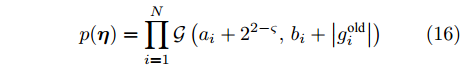
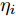
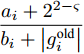
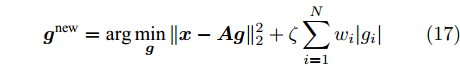

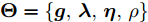
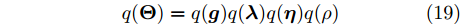

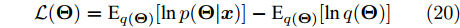
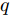
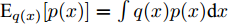
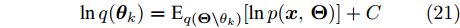
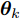

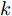
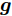
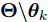
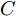
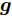
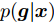
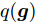

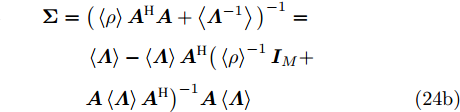
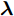
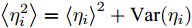
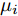
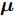

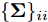
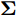
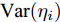
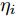
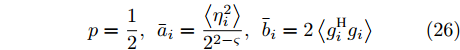
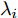
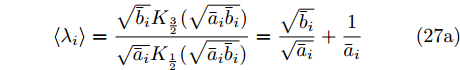
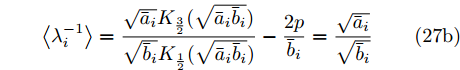
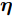
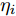
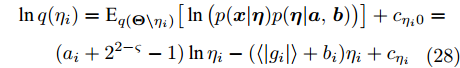
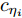
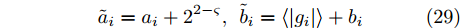
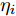
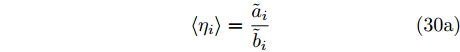
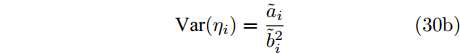
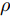
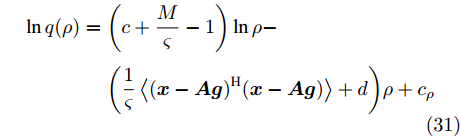
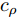
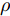
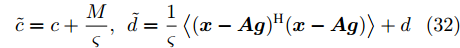
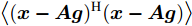
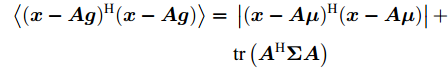
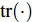
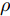
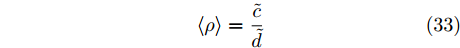
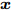
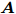


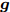
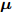
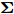
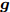
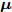
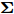
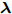
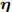
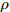
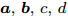
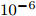


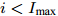
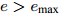
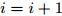
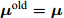
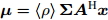
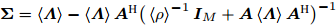
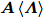
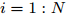
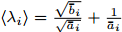
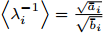
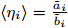
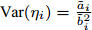
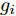
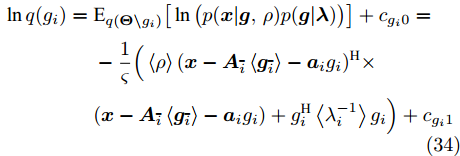
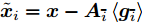
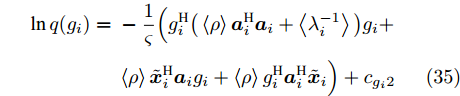
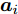
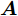

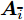
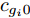
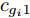
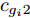
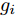
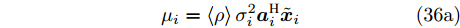
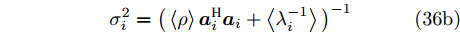
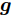
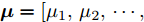
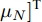
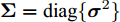
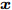
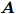


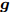
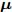
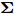
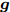
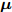
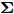


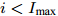
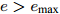
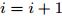
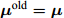
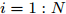
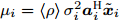
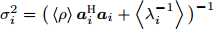
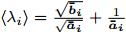
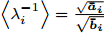
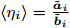
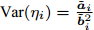
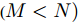
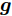
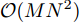
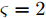

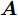
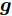
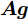
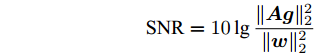

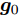
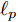
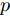
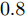
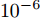
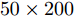
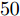
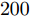
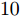
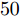
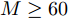
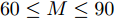

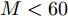
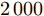
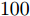
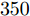
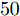
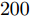
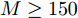
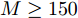
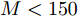
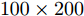
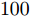
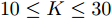
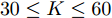
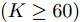
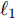

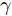
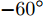
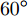
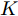
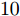
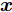
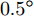
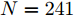
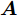
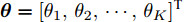
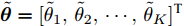
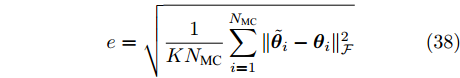
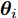

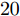
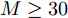
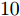
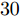
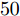
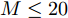
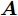
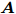
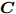
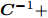
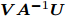
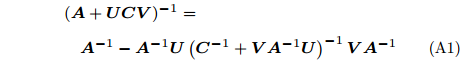













计量
- 文章访问数: 484
- HTML全文浏览量: 225
- PDF下载量: 120
- 被引次数: 0
