

-
摘要: 无人机因其高度的灵活性, 在临地安防、灾后救援、地质勘测、农业植保等领域发挥着重要作用, 因此受到越来越多的关注. 定位导航作为无人机中的关键技术, 对于无人机能否顺利执行任务至关重要. 当前主要的定位导航算法包括全球导航卫星系统、惯性定位以及景象匹配定位导航等. 首先, 景象匹配定位导航方法利用计算机视觉技术, 对无人机飞行时采集的航空影像进行数字化特征编码; 随后, 通过构建相似性度量与检索模型, 将航空影像特征与预先获取的遥感地图库特征进行相似性度量, 从而完成景象匹配; 最后, 根据无人机航空影像与遥感卫星地图的匹配结果, 获取相应的地理位置信息, 并将其更新为无人机的定位结果. 景象匹配定位导航方法摆脱了定位系统对定位信号的依赖, 实现了无人机飞行定位的自主化. 鉴于此, 以景象匹配算法中的特征提取方式为线索, 分别针对基于模板匹配、基于手工特征以及基于度量学习的景象匹配, 梳理其发展过程, 并总结景象匹配定位导航方法中的关键问题. 最后, 针对景象匹配算法的发展现状, 总结无人机景象匹配定位方法中亟待解决的问题.Abstract: Drones play an important role in vicinagearth security, post-disaster rescue, geological survey, agricultural plant protection, and other fields due to their high flexibility, and they receive increasing attention. As a key technology in drones, positioning and navigation are crucial for whether the drone can successfully perform tasks. Currently, the main positioning and navigation algorithms include the global navigation satellite system, inertial positioning, and scene matching positioning and navigation. Among them, the scene matching positioning and navigation method uses computer vision technology to encode the digital features of aerial images collected during the flight of drones. Then, by constructing a similarity measurement and retrieval model, it measures the similarity between the aerial image features and the pre-obtained remote sensing map library features to complete the scene matching. Finally, based on the matching results of drone aerial images and remote sensing satellite maps, it obtains the corresponding geographic position information and updates it as the positioning result of the drone. The scene matching positioning and navigation method eliminates the dependence of the positioning system on positioning signals and realizes the autonomy of drone flight positioning. This paper follows the feature extraction methods in the scene matching algorithm and outlines the development process of scene matching based on template matching, manual feature-based, and metric learning-based approaches while summarizing the key problems in the positioning and navigation methods of scene matching. Finally, this paper summarizes the urgent problems that need to be solved in drone scene matching localization methods based on the current development status of scene matching algorithms.
-
Key words:
- Vicinagearth security /
- drone /
- visual geo-localization /
- scene matching /
- metric learning /
- multi-view changes
-
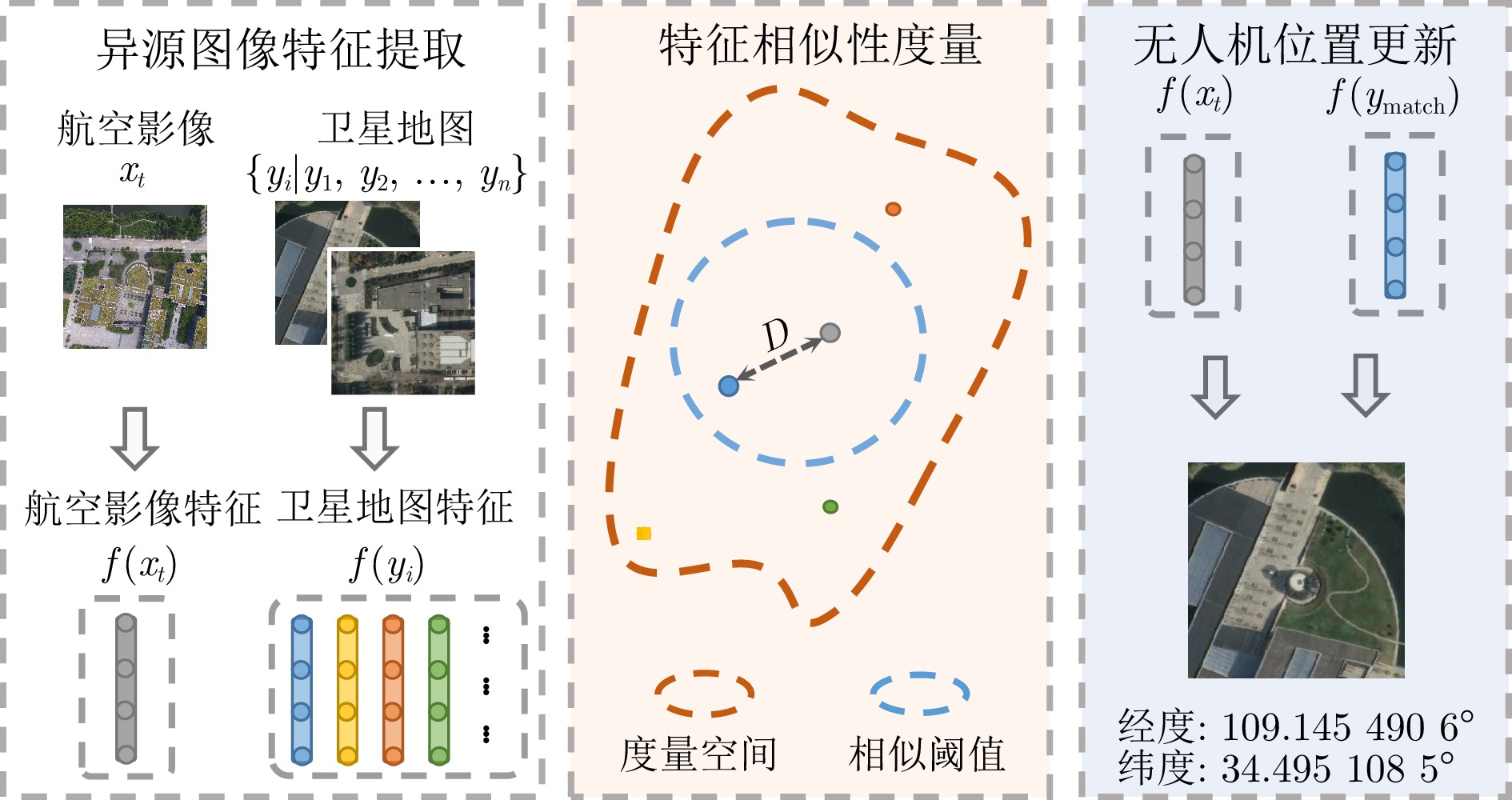
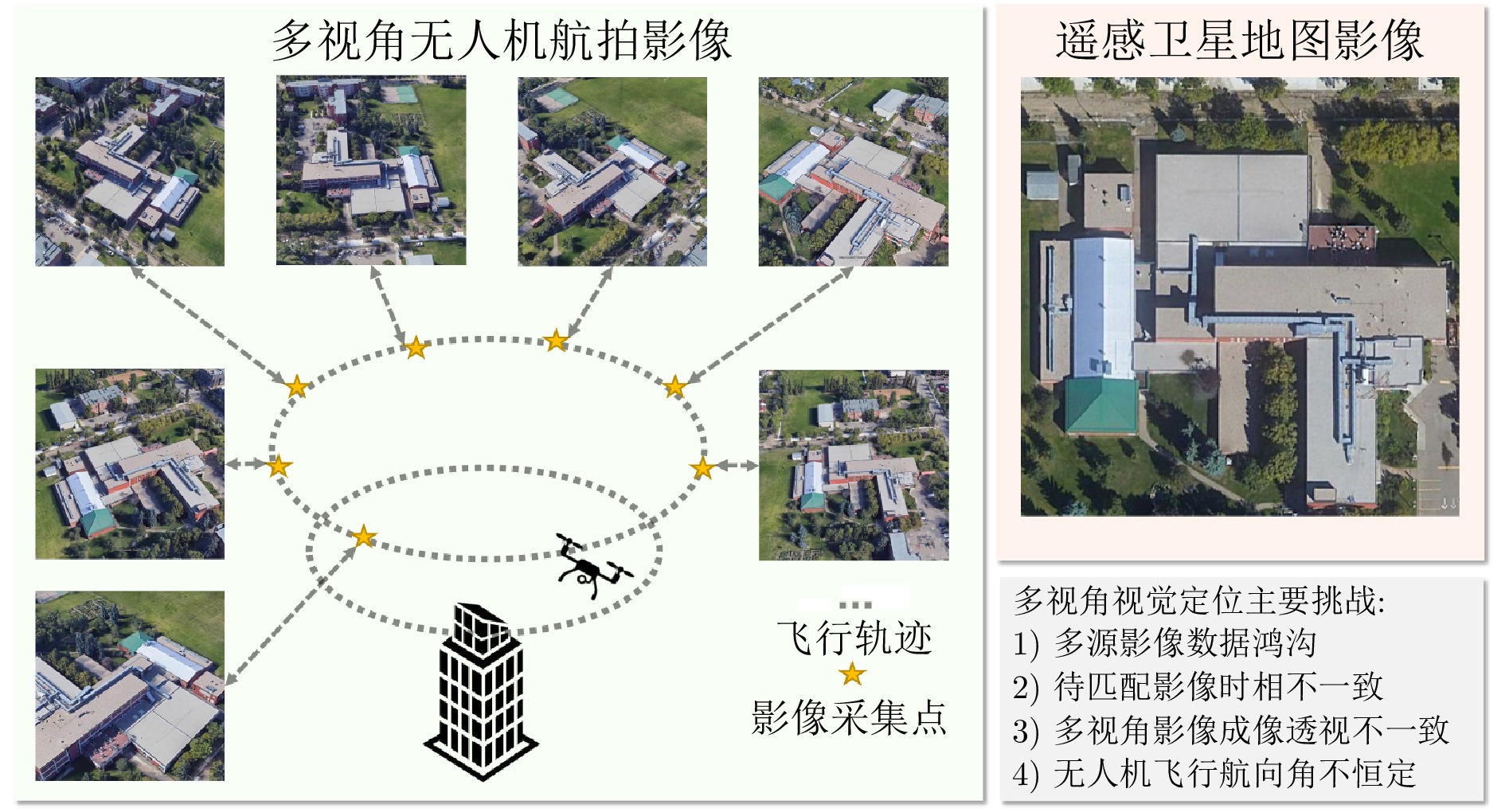
图 1 无人机景象匹配定位算法流程图
Fig. 1 Flow chart of drone scene matching geo-localization algorithm
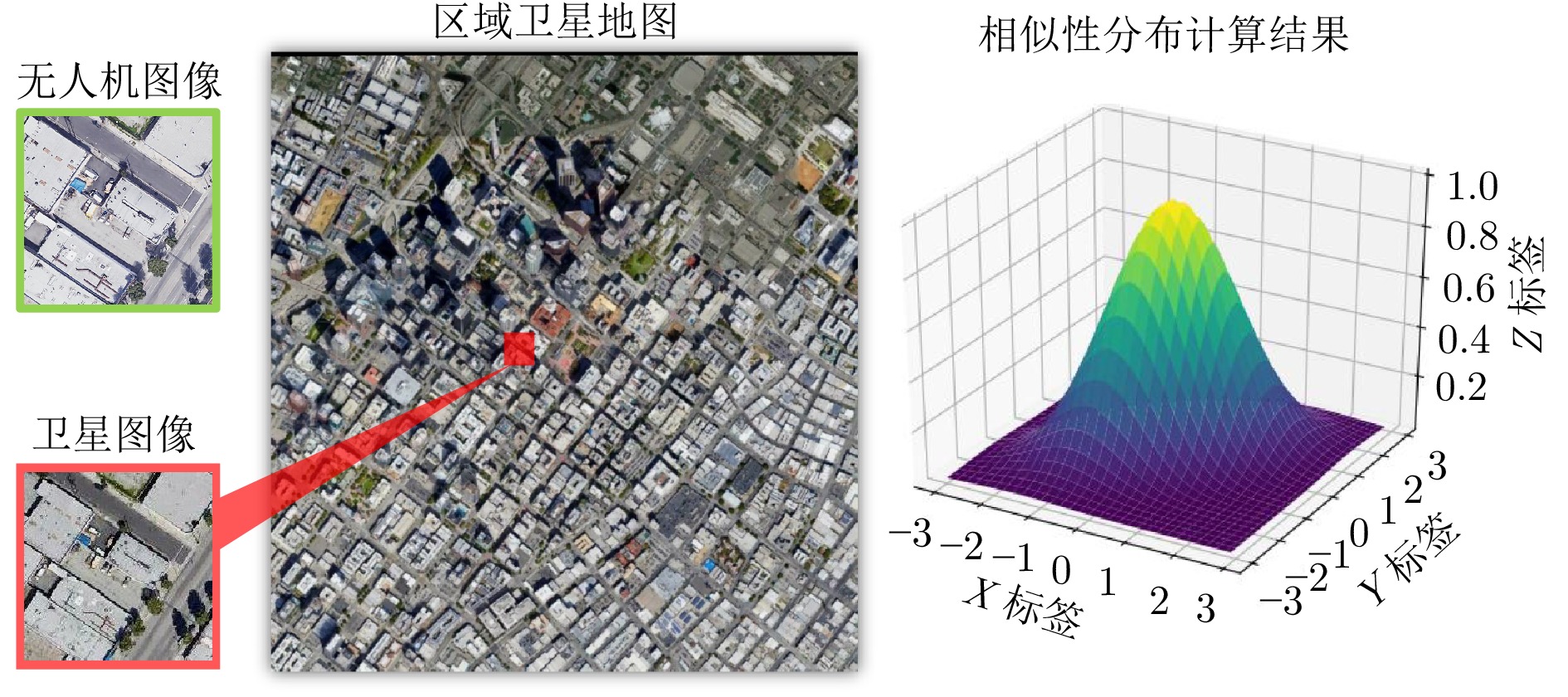
图 2 基于模板匹配的定位算法示意图
Fig. 2 Schematic diagram of location algorithm based on template matching
表 1 定位算法对比结果
Table 1 Comparison results of localization algorithms
分类 方法 精度 抗干扰性 实时性 发展现状 相对定位 INS 短时精度高 强 强 较为成熟 绝对定位 GPS 较高 弱 强 成熟 绝对定位 SMS 较低 强 强 亟待研究  下载: 导出CSV
下载: 导出CSV
表 2 代表性方法汇总
Table 2 Summary of representative methods
方法 算法分类 实现方式 地图数据来源 无人机数据来源 航拍影像尺寸(像素) Loeckx等[16] 模板匹配 NCC 谷歌地图 真实拍摄 — Yol等[18] 模板匹配 MI 谷歌地图 真实拍摄 — Fan等[19] 模板匹配 NCC 谷歌地图 谷歌地球 — Levin等[20] 模板匹配 CC DEM数据 DEM 数据 — Lin等[55] 模板匹配 MI 谷歌地图 谷歌地球 720$ \times $480 Huang等[56] 模板匹配 MI 谷歌地图 真实拍摄 640$ \times $480 Wan等[57] 模板匹配 PC 卫星数据 真实拍摄 3 648$ \times $2 736 Patel[58] 模板匹配 NID 谷歌地图 真实拍摄 560$ \times $315 Shan等[23] 特征点法 HOG 谷歌地图 真实拍摄 850$ \times $500 Masselli等[27] 特征点法 ORB 谷歌地图 真实拍摄 640$ \times $480 Chiu等[30] 特征点法 2D-3D点 DARPA 真实拍摄 — Mantelli等[31] 特征点法 abBREIF 谷歌地图 真实拍摄 — Shan等[33] 特征点法 MSD+ LSS 谷歌地图 真实拍摄 — Woo等[34] 特征点法 角点 谷歌地图 真实拍摄 — Pluckter等[59] 特征点法 ORB 谷歌地图 真实拍摄 — Pan等[61] 特征点法 SIFT 谷歌地图 真实拍摄 586$ \times $452 Couturier等[81] 特征点法 ORB — 真实拍摄 — Couturier等[82] 特征点法 SURF — 真实拍摄 1 920$ \times $1 080 Goforth等[42] 深度学习 VGG16 谷歌地图 真实拍摄 4 608$ \times $2 592 Amer等[44] 深度学习 VGG16 谷歌地图 Bing地图 500$ \times $500 Nassar等[48] 深度学习 U-Net 谷歌地图+Bing地图 谷歌地球 — Marcu等[60] 深度学习 MSMT OpenStreetMap — 1 500$ \times $1 500 Schleiss[52] 深度学习 cGAN+SSD — 真实拍摄 — Zheng等[64] 深度学习 ResNet 谷歌地图 谷歌地球 512$ \times $512 Workman等[65] 深度学习 — 谷歌地图 谷歌街景/Flickr — Hays等[66] 深度学习 — 网络爬取 Flickr — Weyand等[62] 深度学习 LSTM 谷歌地图 谷歌地球 — Wu等[63] 深度学习 Lucas-Kanade 真实拍摄 仿真数据 5 632$ \times $5 376 Li等[96] 深度学习 channel attention 真实拍摄 真实拍摄 — Kinnari等[97] 深度学习 正交投影 谷歌地图 真实拍摄 4 800$ \times $2 987 Wen等[98] 深度学习 SiamRPN 谷歌地图 真实拍摄 — Wang等[78] 深度学习 LPN 谷歌地图 谷歌地球 512$ \times $512 Dai等[99] 深度学习 FSRA 谷歌地图 谷歌地球 512$ \times $512 Tian等[100] 深度学习 PCL 谷歌地图 谷歌地球 512$ \times $512 Zhu等[101] 深度学习 SUES-200 谷歌地图 真实拍摄 512$ \times $512
下载: 导出CSV
-
[1] 李学龙. 临地安防. 中国计算机学会通讯, 2022, 18(11): 44−52Li Xue-Long. Vicinagearth security. Communications of the CCF, 2022, 18(11): 44−52 [2] 陈杰, 方浩, 曾宪琳. 面向高危行业的无人平台智能化发展. 中国科学: 信息科学, 2021, 51(9): 1397−1410 doi: 10.1360/SSI-2021-0154Chen Jie, Fang Hao, Zeng Xian-Lin. On the intelligent development of unmanned platforms in high-risk industries. Scientia Sinica Informationis, 2021, 51(9): 1397−1410 doi: 10.1360/SSI-2021-0154 [3] 中国民用航空局, 国家发展改革委员会, 交通运输部. “十四五”民用航空发展规划 [Online], available: https://www.gov.cn/zhengce/zhengceku/2022-01/07/5667003/files/d12ea75169374a15a742116f7082df85.pdf, 2024-12-31)Civil Aviation Administration of China, National Development and Reform Commission, Ministry of Transport. Civil aviation development during the 14th Five Year Plan period exhibition planning [Online], available: https://www.gov.cn/zhengce/zhengceku/2022-01/07/5667003/files/d12ea75169374a15a742116f7082df85.pdf, December 31, 2024 [4] 赵春晖, 周昳慧, 林钊, 胡劲文, 潘泉. 无人机景象匹配视觉导航技术综述. 中国科学: 信息科学, 2019, 49(5): 507−519 doi: 10.1360/N112018-00316Zhao Chun-Hui, Zhou Yi-Hui, Lin Zhao, Hu Jin-Wen, Pan Quan. Review of scene matching visual navigation for unmanned aerial vehicles. Scientia Sinica Informationis, 2019, 49(5): 507−519 doi: 10.1360/N112018-00316 [5] Huang G Q. Visual-inertial navigation: A concise review. In: Proceedings of the International Conference on Robotics and Automation (ICRA). Montreal, Canada: IEEE, 2019. 9572−9582 [6] Shen L, Stopher P R. Review of GPS travel survey and GPS data-processing methods. Transport Reviews, 2014, 34(3): 316−334 doi: 10.1080/01441647.2014.903530 [7] Couturier A, Akhloufi M A. A review on absolute visual localization for UAV. Robotics and Autonomous Systems, 2021, 135: Article No. 103666 doi: 10.1016/j.robot.2020.103666 [8] Ma J Y, Jiang X Y, Fan A X, Jiang J J, Yan J C. Image matching from handcrafted to deep features: A survey. International Journal of Computer Vision, 2021, 129(1): 23−79 doi: 10.1007/s11263-020-01359-2 [9] Zitová B, Flusser J. Image registration methods: A survey. Image and Vision Computing, 2003, 21(11): 977−1000 doi: 10.1016/S0262-8856(03)00137-9 [10] Le Moigne J, Campbell W J, Cromp R F. An automated parallel image registration technique based on the correlation of wavelet features. IEEE Transactions on Geoscience and Remote Sensing, 2002, 40(8): 1849−1864 doi: 10.1109/TGRS.2002.802501 [11] Pan W H, Wei S D, Lai S H. Efficient NCC-based image matching in Walsh-Hadamard domain. In: Proceedings of the 10th European Conference on Computer Vision. Marseille, France: Springer, 2008. 468−480 [12] Liu H Z, Guo B L, Feng Z Z. Pseudo-log-polar Fourier transform for image registration. IEEE Signal Processing Letters, 2006, 13(1): 17−20 doi: 10.1109/LSP.2005.860549 [13] Cain S C, Hayat M M, Armstrong E E. Projection-based image registration in the presence of fixed-pattern noise. IEEE Transactions on Image Processing, 2001, 10(12): 1860−1872 doi: 10.1109/83.974571 [14] van Dalen G J, Magree D P, Johnson E N. Absolute localization using image alignment and particle filtering. In: Proceedings of the AIAA Guidance, Navigation, and Control Conference. San Diego, USA: AIAA, 2016. Article No. 647van Dalen G J, Magree D P, Johnson E N. Absolute localization using image alignment and particle filtering. In: Proceedings of the AIAA Guidance, Navigation, and Control Conference. San Diego, USA: AIAA, 2016. Article No. 647 [15] Klein S, Staring M, Pluim J P W. Evaluation of optimization methods for nonrigid medical image registration using mutual information and B-splines. IEEE Transactions on Image Processing, 2007, 16(12): 2879−2890 doi: 10.1109/TIP.2007.909412 [16] Loeckx D, Slagmolen P, Maes F, Vandermeulen D, Suetens P. Nonrigid image registration using conditional mutual information. IEEE Transactions on Medical Imaging, 2010, 29(1): 19−29 doi: 10.1109/TMI.2009.2021843 [17] Viola P A, Wells W M. Alignment by maximization of mutual information. International Journal of Computer Vision, 1997, 24(2): 137−154 doi: 10.1023/A:1007958904918 [18] Yol A, Delabarre B, Dame A, Dartois J E, Marchand E. Vision-based absolute localization for unmanned aerial vehicles. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Chicago, USA: IEEE, 2014. 3429−3434 [19] Fan B J, Du Y K, Zhu L L, Tang Y D. The registration of UAV down-looking aerial images to satellite images with image entropy and edges. In: Proceedings of the 3rd International Conference on Intelligent Robotics and Applications. Shanghai, China: Springer, 2010. 609−617 [20] Levin E, Kupiec S A, Forrester T, DeBacker T A, Jannson T P. GIS-based UAV real-time path planning and navigation. In: Proceedings of the SPIE 4708, Sensors, and Command, Control, Communications, and Intelligence (C3I) Technologies for Homeland Defense and Law Enforcement. Orlando, USA: SPIE, 2002. 296−303 [21] Lowe D G. Object recognition from local scale-invariant features. In: Proceedings of the 17th IEEE International Conference on Computer Vision. Kerkyra, Greece: IEEE, 1999. 1150−1157 [22] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2): 91−110 doi: 10.1023/B:VISI.0000029664.99615.94 [23] Shan M, Wang F, Lin F, Gao Z, Tang Y Z, Chen B M. Google map aided visual navigation for UAVs in GPS-denied environment. In: Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO). Zhuhai, China: IEEE, 2015. 114−119 [24] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). San Diego, USA: IEEE, 2005. 886−893 [25] Sun D Q, Roth S, Black M J. Secrets of optical flow estimation and their principles. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 2432−2439 [26] Rublee E, Rabaud V, Konolige K, Bradski G. ORB: An efficient alternative to SIFT or SURF. In: Proceedings of the International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 2564−2571 [27] Masselli A, Hanten R, Zell A. Localization of unmanned aerial vehicles using terrain classification from aerial images. In: Proceedings of the 13th International Conference IAS-13. Cham, Germany: Springer, 2016. 831−842 [28] Alcantarilla P F, Nuevo J, Bartoli A. Fast explicit diffusion for accelerated features in nonlinear scale spaces. In: Proceedings of the British Machine Vision Conference. Bristol, UK: BMVA, 2013. 1−11 [29] Leutenegger S, Chli M, Siegwart R Y. BRISK: Binary robust invariant scalable keypoints. In: Proceedings of the International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 2548−2555 [30] Chiu H P, Das A, Miller P, Samarasekera S, Kumar R. Precise vision-aided aerial navigation. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Chicago, USA: IEEE, 2014. 688−695 [31] Mantelli M, Pittol D, Neuland R, Ribacki A, Maffei R, Jorge V, et al. A novel measurement model based on abBRIEF for global localization of a UAV over satellite images. Robotics and Autonomous Systems, 2019, 112: 304−319 doi: 10.1016/j.robot.2018.12.006 [32] Wei Q L, Yang Z S, Su H Z, Wang L J. Monte Carlo-based reinforcement learning control for unmanned aerial vehicle systems. Neurocomputing, 2022, 507: 282−291Wei Q L, Yang Z S, Su H Z, Wang L J. Monte Carlo-based reinforcement learning control for unmanned aerial vehicle systems. Neurocomputing, 2022, 507: 282−291 [33] Shan M, Charan A. Google map referenced UAV navigation via simultaneous feature detection and description. In: Proceedings of the IEEE International Conferenceon on Robotics and Biomimetics (ROBIO). 2015. 114−119Shan M, Charan A. Google map referenced UAV navigation via simultaneous feature detection and description. In: Proceedings of the IEEE International Conferenceon on Robotics and Biomimetics (ROBIO). 2015. 114−119 [34] Woo J, Son K, Li T, Kim G, Kweon I S. Vision-based UAV navigation in mountain area. In: Proceedings of the MVA. Tokyo, Japan: MVA, 2007. 236−239 [35] Han X F, Leung T, Jia Y Q, Sukthankar R, Berg A C. MatchNet: Unifying feature and metric learning for patch-based matching. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 3279−3286 [36] Chang J, Lan Z H, Cheng C M, Wei Y C. Data uncertainty learning in face recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 5709−5718 [37] Tian Y X, Deng X Q, Zhu Y, Newsam S. Cross-time and orientation-invariant overhead image geolocalization using deep local features. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV). Snowmass, USA: IEEE, 2020. 2501−2509 [38] Nassar A, Amer K, ElHakim R, ElHelw M. A deep CNN-based framework for enhanced aerial imagery registration with applications to UAV geolocalization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Salt Lake City, USA: IEEE, 2018. 1594−1604 [39] Noh H, Araujo A, Sim J, Weyand T, Han B. Large-scale image retrieval with attentive deep local features. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 3476−3485 [40] Teichmann M, Araujo A, Zhu M L, Sim J. Detect-to-retrieve: Efficient regional aggregation for image search. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 5104−5113 [41] Hinzmann T, Siegwart R. Deep UAV localization with reference view rendering. arXiv preprint arXiv: 2008.04619, 2020.Hinzmann T, Siegwart R. Deep UAV localization with reference view rendering. arXiv preprint arXiv: 2008.04619, 2020. [42] Goforth H, Lucey S. GPS-denied UAV localization using pre-existing satellite imagery. In: Proceedings of the International Conference on Robotics and Automation (ICRA). Montreal, Canada: IEEE, 2019. 2974−2980 [43] Kinnari J, Verdoja F, Kyrki V. Season-invariant GNSS-denied visual localization for UAVs. IEEE Robotics and Automation Letters, 2022, 7(4): 10232−10239 doi: 10.1109/LRA.2022.3191038 [44] Amer K, Samy M, ElHakim R, Shaker M, ElHelw M. Convolutional neural network-based deep urban signatures with application to drone localization. In: Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW). Venice, Italy: IEEE, 2017. 2138−2145 [45] Google map [Online], available: https://cloud.google.com/mapplatform/, December 31, 2020Google map [Online], available: https://cloud.google.com/mapplatform/, December 31, 2020 [46] Bing map [Online], available: https://www.bing.com/map, December 31, 2020Bing map [Online], available: https://www.bing.com/map, December 31, 2020 [47] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [48] Nassar A, Lefèvre S, Wegner J. Simultaneous multi-view instance detection with learned geometric soft-constraints. In: Proceedingsof the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, South Korea: 2019. 6558−6567Nassar A, Lefèvre S, Wegner J. Simultaneous multi-view instance detection with learned geometric soft-constraints. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, South Korea: 2019. 6558−6567 [49] Nassar A, ElHelw M. Aerial imagery registration using deep learning for UAV geolocalization. Deep Learning in Computer Vision: Principles and Applications. Boca Raton: CRC Press, 2020. 183−210 [50] Fischler M A, Bolles R C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM, 1981, 24(6): 381−395 doi: 10.1145/358669.358692 [51] Ronneberger O, Fischer P, Brox T. U-Net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich, Germany: Springer, 2015. 234−241 [52] Schleiss M. Translating aerial images into street-map-like representations for visual self-localization of UAVs. In: Proceedings of the XLII-2/W13, The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences. Austria: 2019. 575−580Schleiss M. Translating aerial images into street-map-like representations for visual self-localization of UAVs. In: Proceedings of the XLII-2/W13, The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences. Austria: 2019. 575−580 [53] Isola P, Zhu J Y, Zhou T H, Efros A A. Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 5967−5976 [54] OpenStreetMap [Online], available: https://www.openstreetmap.org/, December 31, 2020OpenStreetMap [Online], available: https://www.openstreetmap.org/, December 31, 2020 [55] Lin Y P, Medioni G. Map-enhanced UAV image sequence registration and synchronization of multiple image sequences. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, USA: IEEE, 2007. 1−7 [56] Huang S M, Huang C C, Chou C C. Image registration among UAV image sequence and Google satellite image under quality mismatch. In: Proceedings of the 12th International Conference on ITS Telecommunications. Taipei, China: IEEE, 2012. 311−315 [57] Wan X, Liu J G, Yan H S, Morgan G L K. Illumination-invariant image matching for autonomous UAV localisation based on optical sensing. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 119: 198−213 doi: 10.1016/j.isprsjprs.2016.05.016 [58] Patel B. Visual Localization for UAVs in Outdoor GPS-denied Environments [Master thesis], University of Toronto, Canada, 2019. [59] Pluckter K, Scherer S. Precision UAV landing in unstructured environments. In: Proceedings of the International Symposium on Experimental Robotics. Cham, Germany: Springer, 2020. 177−187 [60] Marcu A, Costea D, Slusanschi E, Leordeanu M. A multi-stage multi-task neural network for aerial scene interpretation and geolocalization. arXiv preprint arXiv: 1804.01322, 2018.Marcu A, Costea D, Slusanschi E, Leordeanu M. A multi-stage multi-task neural network for aerial scene interpretation and geolocalization. arXiv preprint arXiv: 1804.01322, 2018. [61] Pan A N, Yang Y. Remote sensing images registration with different viewpoints. In: Proceedings of the International Conference on Audio, Language and Image Processing (ICALIP). Shanghai, China: IEEE, 2016. 699−704 [62] Weyand T, Kostrikov I, Philbin J. PlaNet-photo geolocation with convolutional neural networks. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 37−55 [63] Wu S B, Du C, Chen H, Jing N. Coarse-to-fine UAV image geo-localization using multi-stage Lucas-Kanade networks. In: Proceedings of the 2nd Information Communication Technologies Conference (ICTC). Nanjing, China: IEEE, 2021. 220−224 [64] Zheng Z D, Wei Y C, Yang Y. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. In: Proceedings of the 28th ACM International Conference on Multimedia. Seattle, USA: ACM, 2020. 1395−1403 [65] Workman S, Souvenir R, Jacobs N. Wide-area image geolocalization with aerial reference imagery. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 3961−3969 [66] Hays J, Efros A A. IM2GPS: Estimating geographic information from a single image. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, USA: IEEE, 2008. 1−8 [67] Yang H L, Lu X F, Zhu Y Y. Cross-view geo-localization with evolving transformer. arXiv preprint arXiv: 2107.00842, 2021.Yang H L, Lu X F, Zhu Y Y. Cross-view geo-localization with evolving transformer. arXiv preprint arXiv: 2107.00842, 2021. [68] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X H, Unterthiner T, et al. An image is worth 16×16 words: Transformers for image recognition at scale. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: ICLR, 2021.Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X H, Unterthiner T, et al. An image is worth 16×16 words: Transformers for image recognition at scale. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: ICLR, 2021. [69] Shi Y J, Liu L, Yu X, Li H D. Spatial-aware feature aggregation for cross-view image based geo-localization. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: ACM, 2019. Article No. 905 [70] Liu L, Li H D. Lending orientation to neural networks for cross-view geo-localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 5617−5626 [71] Hu S Y, Chang X J. Multi-view drone-based geo-localization via style and spatial alignment. arXiv preprint arXiv: 2006.13681, 2020.Hu S Y, Chang X J. Multi-view drone-based geo-localization via style and spatial alignment. arXiv preprint arXiv: 2006.13681, 2020. [72] Jin Y, Li C N, Li Y D, Peng P X, Giannopoulos G A. Model latent views with multi-center metric learning for vehicle re-identification. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(3): 1919−1931 doi: 10.1109/TITS.2020.3042558 [73] Sun B, Liu G C, Yuan Y. F3-Net: Multiview scene matching for drone-based geo-localization. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: Article No. 5610611 [74] Ding L R, Zhou J, Meng L X, Long Z Y. A practical cross-view image matching method between UAV and satellite for UAV-based geo-localization. Remote Sensing, 2021, 13(1): Article No. 47 [75] Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: ACM, 2017. 214−223 [76] Chan E R, Monteiro M, Kellnhofer P, Wu J J, Wetzstein G. pi-GAN: Periodic implicit generative adversarial networks for 3D-aware image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 5795−5805 [77] Shi Y J, Yu X, Liu L, Zhang T, Li H D. Optimal feature transport for cross-view image geo-localization. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 11990−11997 [78] Wang T Y, Zheng Z D, Yan C G, Zhang J Y, Sun Y Q, Zheng B L, et al. Each part matters: Local patterns facilitate cross-view geo-localization. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(2): 867−879 doi: 10.1109/TCSVT.2021.3061265 [79] 司书斌, 赵大伟, 徐婉莹, 张勇刚, 戴斌. 视觉−惯性导航定位技术研究进展. 中国图象图形学报, 2021, 26(6): 1470−1482 doi: 10.11834/jig.200863Si Shu-Bin, Zhao Da-Wei, Xu Wan-Ying, Zhang Yong-Gang, Dai Bin. Review on visual-inertial navigation and positioning technology. Journal of Image and Graphics, 2021, 26(6): 1470−1482 doi: 10.11834/jig.200863 [80] Castañeda N, Lamy-Perbal S. An improved shoe-mounted inertial navigation system. In: Proceedings of the International Conference on Indoor Positioning and Indoor Navigation. Zurich, Switzerland: IEEE, 2010. 1−6 [81] Couturier A, Akhloufi M A. Relative visual localization (RVL) for UAV navigation. In: Proceedings of the SPIE 10642, Degraded Environments: Sensing, Processing, and Display. Orlando, USA: SPIE, 2018. Article No. 106420O [82] Couturier A, Akhloufi M. Conditional probabilistic relative visual localization for unmanned aerial vehicles. In: Proceedings of the IEEE Canadian Conference on Electrical and Computer Engineering (CCECE). London, Canada: IEEE, 2020. 1−4 [83] Carlone L, Karaman S. Attention and anticipation in fast visual-inertial navigation. IEEE Transactions on Robotics, 2019, 35(1): 1−20 doi: 10.1109/TRO.2018.2872402 [84] Tan C W, Park S. Design of accelerometer-based inertial navigation systems. IEEE Transactions on Instrumentation and Measurement, 2005, 54(6): 2520−2530 doi: 10.1109/TIM.2005.858129 [85] Zhao C H, Wang R Z, Zhang T W, Pan Q. Visual odometry and scene matching integrated navigation system in UAV. In: Proceedings of the 17th International Conference on Information Fusion (FUSION). Salamanca, Spain: IEEE, 2014. 1−6 [86] Li Y J, Pan Q, Zhao C H, Yang F. Scene matching based EKF-SLAM visual navigation. In: Proceedings of the 31st Chinese Control Conference. Hefei, China: IEEE, 2012. 5094−5099 [87] Liu P D, Heng L, Sattler T, Geiger A, Pollefeys M. Direct visual odometry for a fisheye-stereo camera. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Vancouver, Canada: IEEE, 2017. 1746−1752 [88] Babu B W, Kim S, Yan Z X, Ren L. σ-DVO: Sensor noise model meets dense visual odometry. In: Proceedings of the IEEE International Symposium on Mixed and Augmented Reality (ISMAR). Merida, Mexico: IEEE, 2016. 18−26 [89] Buczko M, Willert V. How to distinguish inliers from outliers in visual odometry for high-speed automotive applications. In: Proceedings of the IEEE Intelligent Vehicles Symposium (IV). Gothenburg, Sweden: IEEE, 2016. 478−483 [90] Steinbrücker F, Sturm J, Cremers D. Real-time visual odometry from dense RGB-D images. In: Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops). Barcelona, Spain: IEEE, 2011. 719−722 [91] Koide K, Yokozuka M, Oishi S, Banno A. Globally consistent 3D LiDAR mapping with GPU-accelerated GICP matching cost factors. IEEE Robotics and Automation Letters, 2021, 6(4): 8591−8598 doi: 10.1109/LRA.2021.3113043 [92] Hesch J A, Kottas D G, Bowman S L, Roumeliotis S I. Consistency analysis and improvement of vision-aided inertial navigation. IEEE Transactions on Robotics, 2014, 30(1): 158−176 doi: 10.1109/TRO.2013.2277549 [93] 朱启举, 樊振辉, 梅春波, 杨鹏翔, 卢宝峰, 杨朝明. 基于景象匹配的低精度MEMS航向修正与组合算法. 中国惯性技术学报, 2023, 31(9): 870−875Zhu Qi-Ju, Fan Zhen-Hui, Mei Chun-Bo, Yang Peng-Xiang, Lu Bao-Feng, Yang Chao-Ming. Heading correction and combination algorithm for MEMS with low accuracy based on scene matching. Journal of Chinese Inertial Technology, 2023, 31(9): 870−875 [94] Yin X C, Wang X W, Du X G, Chen Q J. Scale recovery for monocular visual odometry using depth estimated with deep convolutional neural fields. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 5871−5879 [95] Ye W C, Lan X Y, Chen S, Ming Y H, Yu X Y, Bao H J, et al. PVO: Panoptic visual odometry. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, Canada: IEEE, 2023. 9579−9589 [96] Li C, Liu G C, Yuan Y. A multi-source image matching network for UAV visual location. In: Proceedings of the IEEE International Conference on Image Processing (ICIP). Bordeaux, France: IEEE, 2022. 1651−1655 [97] Kinnari J, Renzulli R, Verdoja F, Kyrki V. LSVL: Large-scale season-invariant visual localization for UAVs. Robotics and Autonomous Systems, 2023, 168: Article No. 104497 doi: 10.1016/j.robot.2023.104497 [98] Wen K L, Chu J, Chen J Y, Chen Y, Cai J P. M-O SiamRPN with weight adaptive joint MIoU for UAV visual localization. Remote Sensing, 2022, 14(18): Article No. 4467 doi: 10.3390/rs14184467 [99] Dai M, Hu J H, Zhuang J D, Zheng E H. A transformer-based feature segmentation and region alignment method for UAV-view geo-localization. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(7): 4376−4389 doi: 10.1109/TCSVT.2021.3135013 [100] Tian X Y, Shao J, Ouyang D Q, Shen H T. UAV-satellite view synthesis for cross-view geo-localization. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(7): 4804−4815 doi: 10.1109/TCSVT.2021.3121987 [101] Zhu R Z, Yin L, Yang M Z, Wu F, Yang Y C, Hu W B. SUES-200: A multi-height multi-scene cross-view image benchmark across drone and satellite. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(9): 4825−4839 doi: 10.1109/TCSVT.2023.3249204 [102] Lang C B, Cheng G, Tu B F, Han J W. Global rectification and decoupled registration for few-shot segmentation in remote sensing imagery. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: Article No. 5617211 [103] Zhang B, Wu Y F, Zhao B Y, Chanussot J, Hong D F, Yao J, et al. Progress and challenges in intelligent remote sensing satellite systems. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 1814−1822 doi: 10.1109/JSTARS.2022.3148139 [104] Zhang Z Y, Zheng L L, Piao Y, Tao S P, Xu W, Gao T, et al. Blind remote sensing image deblurring using local binary pattern prior. Remote Sensing, 2022, 14(5): Article No. 1276 doi: 10.3390/rs14051276 [105] Guo J T, Zhang Z R, Mao Y C, Liu S J, Zhu W C, Yang T H. Automatic extraction of discontinuity traces from 3D rock mass point clouds considering the influence of light shadows and color change. Remote Sensing, 2022, 14(21): Article No. 5314 doi: 10.3390/rs14215314 [106] Yao Y X, Zhang Y J, Wan Y, Liu X Y, Yan X H, Li J Y. Multi-modal remote sensing image matching considering co-occurrence filter. IEEE Transactions on Image Processing, 2022, 31: 2584−2597 doi: 10.1109/TIP.2022.3157450 [107] Deng J, Dong W, Socher R, Li L J, Li K, Li F F. ImageNet: A large-scale hierarchical image database. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2009. 248−255 [108] Wang C H, Huang K Y, Yao Y, Chen J C, Shuai H H, Cheng W H. Lightweight deep learning: An overview. IEEE Consumer Electronics Magazine, 2024, 13(4): 51−64 doi: 10.1109/MCE.2022.3181759 [109] Jiang C, Zhao D B, Zhang Q Z, Liu W K. A multi-GNSS/IMU data fusion algorithm based on the mixed norms for land vehicle applications. Remote Sensing, 2023, 15(9): Article No. 2439 doi: 10.3390/rs15092439 [110] Bappy A M R A, Asfak-Ur-Rafi M, Islam M S, Sajjad A, Imran K N. Design and Development of Unmanned Aerial Vehicle (Drone) for Civil Applications. Dhaka: BRAC University Press, 2015. [111] Alberts I L, Mercolli L, Pyka T, Prenosil G, Shi K Y, Rominger A, et al. Large language models (LLM) and ChatGPT: What will the impact on nuclear medicine be? European Journal of Nuclear Medicine and Molecular Imaging, 2023, 50(6): 1549−1552 doi: 10.1007/s00259-023-06172-w -

 下载:
下载:

计量
- 文章访问数: 4206
- HTML全文浏览量: 2362
- PDF下载量: 472
- 被引次数: 0
