

-
摘要: 低光照图像增强旨在提高在低光照环境下所采集图像的视觉质量. 然而, 现有的低光照图像增强方法难以在计算效率与增强性能之间达到很好的平衡, 为此, 提出一种基于Retinex先验引导的低光照图像快速增强方法, 将Retinex模型与Gamma校正相结合, 快速输出具有对比度高、视觉效果好和低噪声的图像. 为获取具有良好光照的图像以引导确定与输入图像尺寸大小一致的Gamma校正图, 提出基于Retinex模型的先验图像生成方法. 针对所提先验图像生成方法在极低光照区域中存在颜色失真的问题, 提出一种基于融合的Gamma校正图估计方法, 采用反正切变换恢复极低光照区域的颜色和对比度, 以提升Gamma校正图在极低光照区域的增强性能. 为抑制输出图像的噪声, 考虑到完全平滑的Gamma校正图不会平滑细节纹理的特点, 提出基于域变换递归滤波的Gamma校正图优化方法, 降低输出图像噪声的同时保持颜色和对比度. 实验结果表明, 所提方法不仅在主客观图像质量评价上优于现有大多数主流算法, 而且在计算效率上具有十分显著的优势.Abstract: Low light image enhancement aims to improve the visual quality of images captured in low light environment. However, existing low light image enhancement methods are difficult to achieve a good balance between computational efficiency and enhancement performance. Therefore, a fast low light image enhancement method guided by Retinex prior is proposed. The Retinex model is combined with Gamma correction to quickly output images with high contrast, good visual effects and low noise. To obtain images with good illumination and guide the determination of Gamma correction map with the same size as the input image, a prior image generation method based on Retinex model is proposed. To solve the problem of color distortion in extremely low illumination areas, a fusion-based Gamma correction map estimation method is proposed, which uses arctangent transform to restore the color and contrast of extremely low illumination areas to improve the enhancement performance of Gamma correction map in extremely low illumination areas. To suppress the noise of the output image, considering that the completely smooth Gamma correction map cannot smooth the detail texture, an optimization method of Gamma correction map based on domain transform recursive filtering is proposed, which can reduce the noise and preserve the color and contrast of the output image. The experimental results show that the proposed method not only outperforms most of the existing mainstream algorithms in subjective and objective image quality evaluation, but also has significant advantages in computational efficiency.
-
Key words:
- Low light image enhancement /
- Gamma correction map /
- Retinex model /
- noise suppression
-
煤、石油、天然气等传统能源日渐枯竭, 可再生能源的利用逐渐得到各个国家的重视. 风力发电和光伏发电是目前应用最为广泛的可再生能源发电技术[1]. 然而, 风能和光伏能源固有的随机和间歇性特点会对电网的稳定运行和电能质量带来不利影响. 为了解决上述问题, 微电网作为集成分布式电源的解决方案, 已成为当前电力行业的研究热点[2-3]. 微电网是由分布式发电单元(微源)、储能装置、相关负荷、电力电子转换接口和通信网络组成的小型发配电系统. 目前, 现有微电网工程主要以交流微电网形式存在, 以匹配传统交流电网和交流用电设备[4]. 随着直流可再生能源和直流负载日益增多, 通过直流母线相连组成直流微电网, 不仅可以降低交流/直流功率转换的功率损耗, 还无需考虑频率控制和无功功率问题.
电压平衡和负荷分配(负载共享)是直流微电网的两个基本控制任务[5]. 电压平衡能够确保母线所连接负载的正常工作, 负荷分配可以防止任一微源的过度出力. 直流微电网的母线电压能够反映系统的功率平衡, 通过控制微电网的母线电压平衡, 即可控制各微源、储能装置及负载间的功率平衡, 从而维持微电网的稳定运行[6]. 微电网实现微源间负荷的合理分配是微电网协调控制的重要目标. 文献[7-9]通过不同方法对负荷分配及电压平衡进行研究, 然而, 这两个基本控制任务是相互竞争的, 在实现母线电压平衡的同时需要保证负荷公平分配. 为了实现这一控制目标, 集中式控制、分散式控制以及分布式控制方法得到了广泛的应用[10]. 集中式控制需要获取全局的状态信息, 对通信系统具有高度的依赖性, 一旦某个子系统出现故障, 将会导致整个系统无法正常运行, 降低了系统运行的可靠性[11]. 与集中控制相比, 分散控制仅需局部信息就地控制, 不会因为个别单元的故障影响其余单元. 但由于缺少各单元之间的通信联系, 很难进行系统层级的优化调节, 往往达不到期望的效果. 而分布式控制可以结合两者的优点, 利用局部通信获取反应全局状态的有效信息, 从系统层面协调控制各分布式发电单元[12]. 因此急需一种基于分布式控制策略的下垂控制器从系统层面解决微电网的电压平衡和负荷分配问题, 下面对相关文献进行综述.
下垂控制已在直流微电网的控制中得到广泛应用. 文献[13]采用传统下垂控制对直流母线电压进行调整, 但该下垂方法会导致电流共享差, 同时还会导致直流母线电压下降. 为此文献[14]提出一种适用于直流微电网并联变换器的下垂指数控制算法. 通过在线计算虚拟电阻来合理调节负载分配, 有效降低了循环电流. 虽然下垂控制减少了对通信系统的依赖, 保证了该控制方法的可靠性, 但控制器只检测本单元的直流母线电压, 使得工作模式只由母线电压决定. 与下垂控制相比, 分层控制对负荷分配和电压平衡的控制更加全面, 该控制方法进一步提高了系统的可靠性. 文献[15]提出了一种基于分布式算法的直流微电网自适应下垂控制策略, 以达到均流和调压的目的. 但算法的稳定性和收敛速度会受到通讯延时和测量误差的影响. 文献[16]提出一种电压电流的双补偿分布式二次控制方法来解决线缆阻抗造成的负荷分配失衡问题. 但前提条件是线缆阻抗较小, 否则将无法保证输出电流的精度. 为提高微源电压平衡和负载共享精度, 文献[17]提出了一种改进的分布式二次控制方案, 该方案同时采用移压和调坡方法, 在减小电压偏差的同时, 提高负载共享精度, 文献[18]通过引入直流母线电压二次协调控制来实现电压恢复和电流的精确分配. 文献[19]提出了一种新的分布式控制策略来实现负荷分配和电压平衡. 通过在有限时间内达到所需的流形, 保证微电网加权平均电压与加权平均参考电压相同的前提下, 实现比例电流共享.
上述文献虽然提出了多种实现负载共享或电压平衡的方法, 但并没有在系统层面通过设计下垂控制器实现负载共享和电压平衡之间的最优平衡. 本文给出一种新的基于分布式策略的下垂控制器设计方法, 能够在统一的框架下实现直流微电网负载共享和电压平衡. 具体贡献总结如下:
1)将直流微电网的负载共享和电压平衡问题转化为多目标优化问题, 其性能指标与微源的容量密切相关且能在负载共享和电压平衡之间实现权衡. 通过最优化该性能指标求得同时实现负载共享和电压平衡的最优解, 即集中式控制策略, 并通过设计的下垂控制器实现微电网的电压平衡和负荷分配.
2)给出一种能够降低通信负担的分布式控制策略, 通过理论分析证明了该分布式策略能够指数收敛到多目标优化问题的最优解. 与集中式策略相比, 该分布式控制策略能在不增加系统复杂度的情况下, 降低系统的通信负担, 提高微电网的灵活性和稳定性.
1. 直流微电网建模
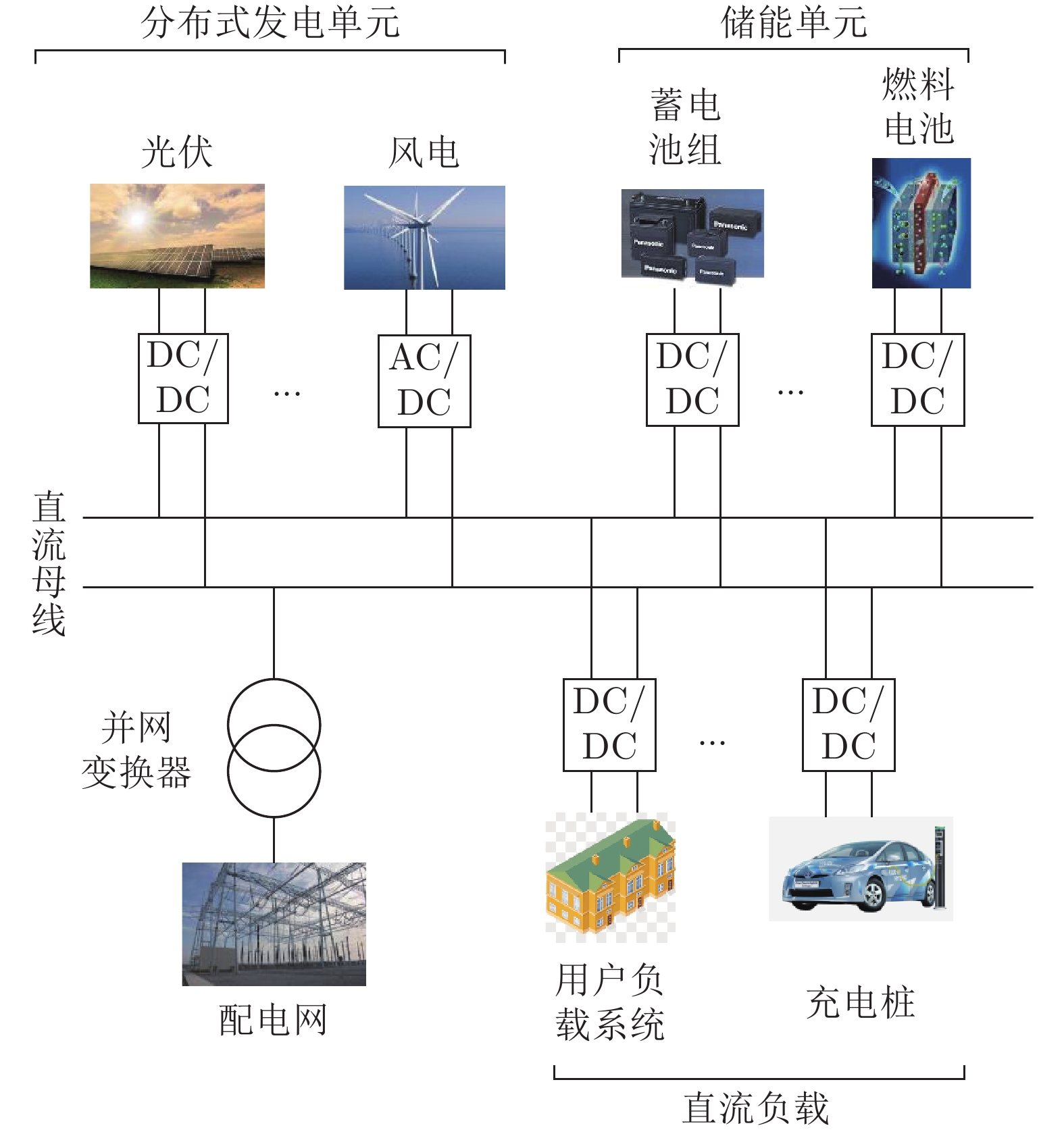
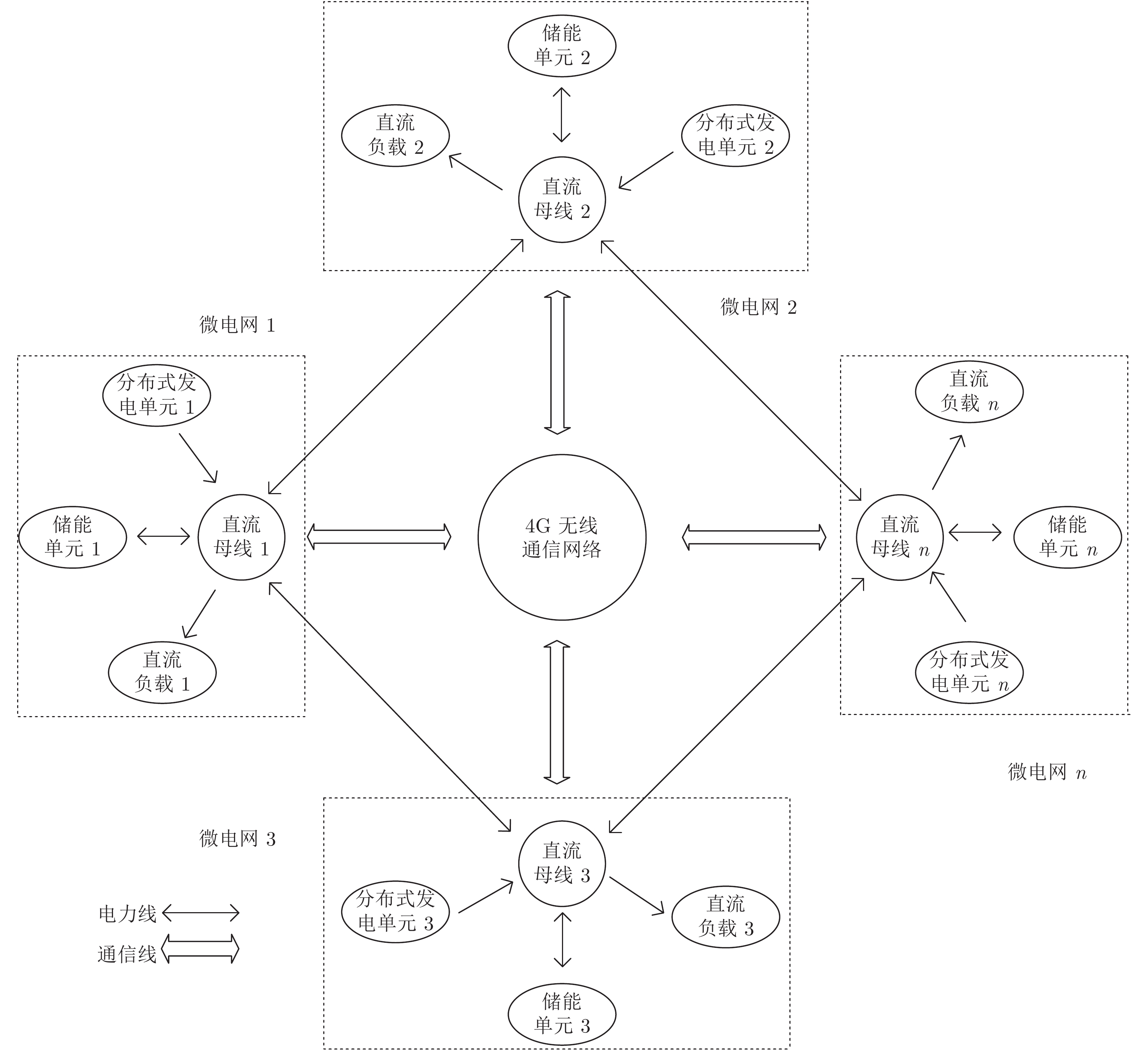
图1给出了用户级直流微电网的典型结构. 从图中可以看出, 直流微电网主要由微源, 储能单元, 负载单元、并网变换器及无线通信网络组成.
分布式发电单元主要有风力和光伏等可再生能源构成, 可采用下垂控制和最大功率跟踪控制两种运行模式; 储能单元具有平衡功率的作用, 同时承担着电源和负载的角色, 在用电低谷时段可以作为负荷储存电能, 在用电高峰时段又将电能回馈到微电网; 并网变换器作为微电网与配电网的接口维持直流母线稳定, 并根据各单元发出能量以及负载吸收能量情况工作于逆变或整流状态. 本文研究的是多用户级微电网通过直流传输线互联所构成的系统级微电网, 如图2所示.
为满足实际生活生产所需, 将多个用户级直流微电网两两互联构成系统级微电网. 用户级微电网通过使用通信网络进行信息交换, 以此实现信息共享, 提高了系统级微电网的可伸缩性和扩展性.
1.1 用户级微电网模型
本文假设分布式电源采用下垂控制模式, 储能单元和负荷具有恒流特性. 根据文献[12]可知, 采用电压−电流下垂控制的变换器稳态运行时, 输出端等效为一个理想电压源和电阻的串联. 最大功率控制变换器输出模型[20] 可等效为电流为
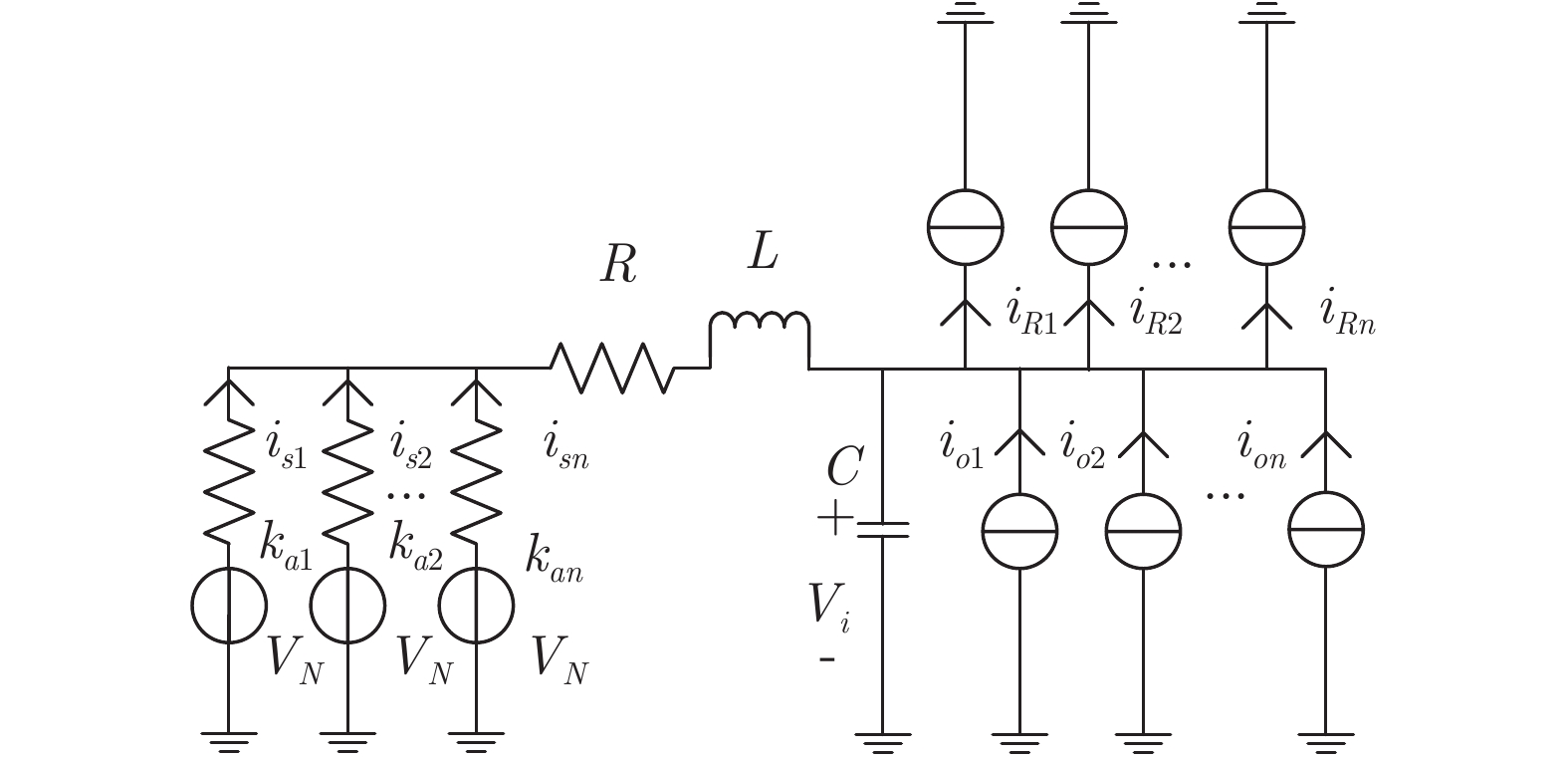
$ I_o $ 的电流源. 恒功率负载电路可等效为电流为$ I_R $ 的电流源. 假设因此, 用户级微电网$ i $ 的等效电路模型如图3所示.图3中,
$ V_N $ 为变换器空载输出电压,$ V_i $ 为母线电压;$ i_{si} $ 为变换器输出电流即电源输出电流,$ i_{oi} $ 为储能单元的输出电流,$ i_{Ri} $ 为恒功率负载的电流;$ k_{ai} $ 为下垂系数;$ L $ 、$ R $ 、$ C $ 为母线阻抗及滤波电容的等效模型. 当微电网达到稳态运行时, 电感$ L $ 和电容$ C $ 可以忽略不计. 一般情况下, 用户级微电网的母线较短, 可以忽略母线电阻$ R $ (若不忽略母线电阻的影响, 只需将下垂系数进行修正即可). 因此母线电压及电流可以表示为$$ V_i = V_N -k_i I_{si} $$ (1) $$ I_{si} = I_{Ri} -I_{oi} \hspace{5pt}$$ (2) 其中
$$\begin{split} &k_i = 1/\displaystyle\sum\limits_{j = 1}^n {\dfrac{1}{k_{aj} }} \\ &I_{si} = i_{s1} +i_{s2} +\cdots +i_{sn}\end{split} \hspace{10pt}$$ $$ I_{Ri} = i_{R1} +i_{R2} +\cdots +i_{Rn} $$ $$ I_{oi} = i_{o1} +i_{o2} +\cdots +i_{on} \hspace{10pt}$$ 1.2 系统级微电网模型
如图2所示, 该系统级微电网由
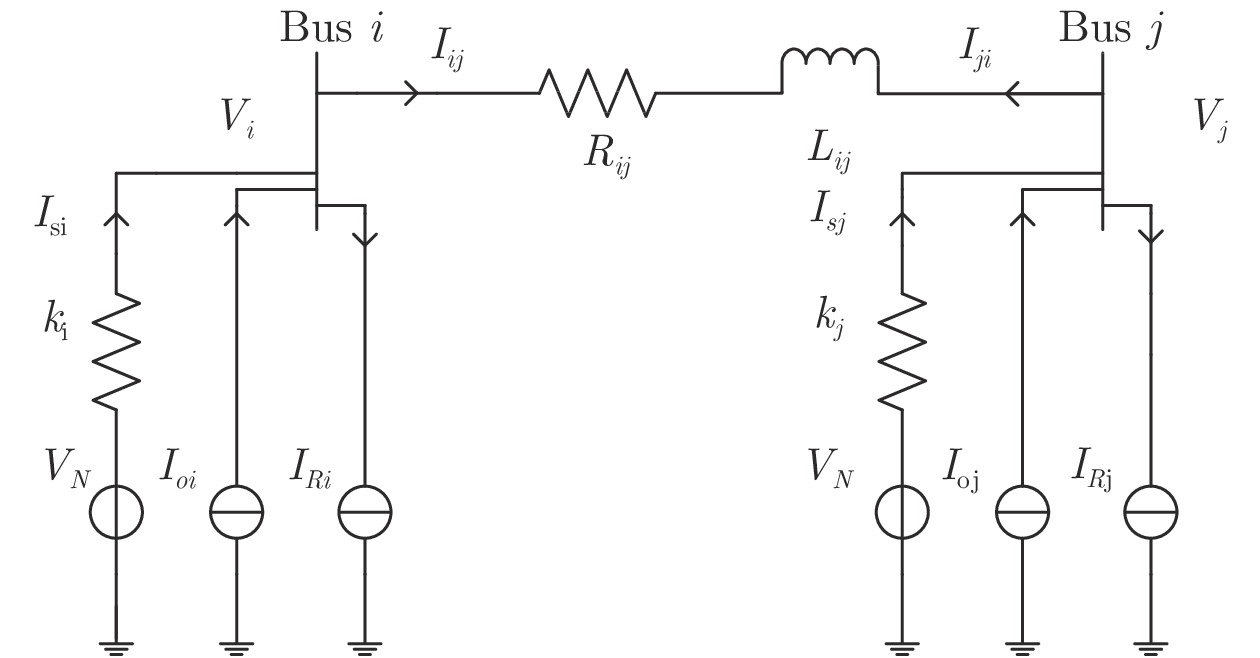
$ n $ 个用户级微电网互联构成. 从图论的角度分析, 可以将每个用户级微电网看做节点, 用户级微电网之间的直流传输线看做边, 因此可将直流微电网建模为无向连通图$ \vartheta = (\nu, \varepsilon ) $ , 其中,$ \nu { = \{}1,2,\cdot \cdot \cdot, {{n}\}} $ 是非空节点集合,$ \varepsilon \subseteq v\times v $ 是边的集合.$ \varepsilon _{ij} = (i,j)\in \varepsilon $ 代表节点$ i $ 和$ j $ 通过直流传输线连接, 对应直流传输线的阻抗为$ R_{ij} >0 $ 、$ L_{ij} >0 $ , 节点$ j $ 称之为$ i $ 的邻居节点,$N_i = \left\{ {j\left| {\varepsilon _{ij} \in \varepsilon } \right.} \right\}$ 是$ i $ 邻居节点的集合.$ A = [\omega _{ij} ]\in $ ${\bf R}^{n\times n}$ 为图的加权邻接矩阵用来描述节点与边之间关系, 当$ \varepsilon _{ij} \in \varepsilon $ 时,$ \omega _{ij} = \dfrac{1}{R_{ij} } $ ; 否则,$ \omega _{ij} = 0 $ . 图$ \vartheta $ 的度矩阵${{D}} = {\rm diag}\{\varpi _1, \varpi _2, \cdot \cdot \cdot, \varpi _n \}$ , 其对角元素$ \varpi _i = $ $ \displaystyle\sum\nolimits_{j\in N_i } {\omega _{ij} } $ , 因此, 图$ \vartheta $ 的拉普拉斯矩阵为$Y = $ $ D-A$ ,$ Y = Y^{\rm T} $ . 此外, 假设每一个节点都可以与其邻居节点相互通信, 即该系统级微电网的通信拓扑与物理拓扑相同.下面只给出节点
$ i $ 和$ j $ 的互联结构, 如图4所示. 在节点$ i $ 中, 分布式电源、储能单元和直流负载通过直流母线$ i $ 连接在了一起, 对应的电流分别为$ I_{si} $ 、$ I_{oi} $ 、$ I_{Ri} $ , 方向如图所示. 母线$ i $ 的电压为$ V_i $ , 母线$ i $ 和$ j $ 通过直流传输线相连接, 对应传输线电流为$ I_{ij} $ . 根据基尔霍夫电流定律可知, 节点$ i $ 处注入电流$ I_{si} $ 、$ I_{oi} $ 之和等于流出量$ I_{Ri} $ 、$ I_{ij} $ 之和, 即$I_{si} +I_{oi} = $ $ I_{Ri} +\displaystyle\sum\nolimits_{j\in N_i } {I_{ij} } $ . 令$ I_{ci} = I_{Ri} -I_{oi} $ , 则$I_{si} = I_{ci} + $ $ \displaystyle\sum\nolimits_{j\in N_i } {I_{ij} } $ . 类似文献[10], 可以假设电感$ L_{ij} $ 足够小, 使得$L_{ij} \dfrac{{\rm d}I_{ij} }{{\rm d}t} = 0$ , 则可以得到$I_{ij} = \dfrac{V_i -V_j }{R_{ij} }$ 或$I_{ji} =$ $ \dfrac{V_j -V_i }{R_{ji} } $ . 又因为直流传输线的电阻$ R_{ij} = R_{ji} $ , 因此可得$ I_{ij} = -I_{ji} $ . 由以上分析可知母线$ i $ 处的电流关系式为$ I_{si} = I_{ci} +\displaystyle\sum\nolimits_{j\in N_i } {\dfrac{V_i -V_j }{R_{ij} }} $ , 定义向量${\boldsymbol \delta }= [1,1,\cdots , $ $1]^{\rm T}, $ $ {\boldsymbol k} = {\rm{diag}}\left\{ {k_1, k_2, \cdot \cdot \cdot, k_n } \right\}, $ ${{\boldsymbol{I}}_{\boldsymbol{c}}} =[I_{c1}, I_{c2}, \cdot \cdot \cdot, I_{cn} ]^{\rm T},$ $ {\boldsymbol{V}}=[V_1, V_2, \cdot \cdot \cdot, V_n ]^{\rm T}, $ $ {{\boldsymbol{I}}_{\boldsymbol{s}}} =[I_{s1}, I_{s2}, \cdot \cdot \cdot, I_{sn} ]^{\rm T}. $ 将$ n $ 个节点的等式联立可得系统级微电网模型,$$ I_s = YV+I_c $$ (3) $$ V = \delta V_N -kI_s $$ (4) 若定义
${{\boldsymbol{I'}}_{\boldsymbol{s}}} = {\rm diag}\{I_{s1}, I_{s2}, \cdot \cdot \cdot, I_{sn}\}$ ,$ {\boldsymbol{{k'}}} = \left[ k_1, \right.$ $\left. k_2, \cdot \cdot \cdot,k_n \right] $ , 则式(4)变为$ V = \delta V_N -I'_s k' $ , 可求得$$ k' = I_s^{'-1} (\delta V_N -V) $$ (5) 即可以通过微源输出电流
$ I_s $ 和母线电压$ V $ 设计所需要的下垂系数, 这是本文的所要解决的基本问题之一.2. 本文的控制目标
负荷分配和电压平衡是直流微电网的两个基本控制任务. 这两个控制任务是相互竞争的, 很难同时实现比例负荷分配和理想母线电压分布.
2.1 电压平衡
一般情况下, 为了保证微电网的电压平衡, 需要调节各节点电压使其接近额定值, 即:
$$ \mathop {\lim }\limits_{t\to \infty } \left| {V_i (t)-V_i^{ref} } \right|\to \tau,\quad i\in \nu $$ (6) $ V_i^{ref} $ 是节点的额定电压值,$ \tau $ 是足够小的常数.可以看出当母线电压
$ V = V^{ref} $ 时, 母线电压达到最优分布. 但实际情况还要受到分布式电源输出电流的限制, 只能调节母线电压$ V $ 尽可能地接近额定电压$ V^{ref} $ . 在对输出电流没有限制的情况下, 母线电压可以达到最优分布, 求得母线输出电流$ I_s = I_c +YV^{ref} $ , 从而计算出满足电压平衡的下垂系数$ k $ . 进一步分析可知, 下垂系数与母线额定电压$ V^{ref} $ 和电源输出电流$ I_s $ 紧密相关, 通过额定电压$ V^{ref} $ 和电流$ I_s $ 可确定唯一的下垂系数$ k $ . 由于未考虑负荷分配的影响, 电源的出力受到较大影响. 这种情况具有较大的局限性, 只满足于特定情形.2.2 比例负荷分配
首先给出比例负荷分配条件, 即所有的微源出力满足以下条件:
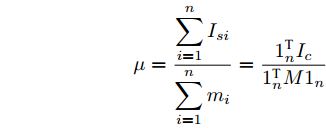
$$ \frac{I_{si} }{m_i } = \frac{I_{sj} }{m_j } = \mu, \quad i,j\in v $$ (7) 其中,
$ m_i >0 $ 和$ m_j >0 $ 分别代表与微源$ i $ 和$ j $ 额定容量有关的比例系数,$ \mu >0 $ 称为微源的负载率. 由式(3)可知$ 1_n^{\rm T} I_s = 1_n^{\rm T} I_c $ . 则由式(7)可得:$$ \mu = \frac{\displaystyle\sum\limits_{i = 1}^n {I_{si} } }{\displaystyle\sum\limits_{i = 1}^n {m_i} } = \frac{1_n^{\rm T} I_c }{1_n^{\rm T} M1_n } $$ 因此, 在不考虑电压平衡的情况下, 要实现比例负荷分配需要满足
$I_s = \mu M^{-1}\delta,\ M={\rm diag}\{m_i\}$ . 由于拉普拉斯矩阵$ Y $ 的秩小于$ n $ , 则非齐次线性方程组$ YV = I_s -I_c $ 有无穷组解. 由式(5)可知对应的下垂系数为无穷个. 但通过对第2.1节内容的分析可知这无穷组解很难实现母线电压最优分布, 只能挑选出一组最优解. 因此, 只考虑比例负荷分配的情况, 对母线电压平衡具有较大影响, 具有很大的局限性.2.3 负荷分配和电压平衡的权衡
从以上分析可以看出, 实现电压平衡的同时很难实现负荷的比例分配, 反之亦然. 为了解决上面两种方案的局限性, 需要在负荷分配和电压平衡之间实现适当的权衡, 使其在直流微电网的控制中达到资源分配的合理性. 因此, 本文在文献[5]的基础上引入以下多目标优化问题:
$$ \begin{split} \mathop {\min }\limits_{V_i I_{si} } J =\;& \frac{a}{2}\sum\limits_{i = 1}^n {\left( {\frac{I_{si} }{m_i }-\mu } \right)} ^2 +\\ &\frac{b}{2}\sum\limits_{i = 1}^n {m_i (V_i } -V^{ref})^2 \end{split} $$ (8) 约束条件: 式(3)
其中,
$ a>0 $ 和$ b>0 $ 满足$ a+b = 1 $ 为权衡系数, 用于调整负荷分配和电压平衡的比重, 确保二者之间的平衡. 在实际应用中, 可以根据微电网的整体性能要求改变$ a $ 和$ b $ 的数值. 从式(8)可以看出, 性能指标$ J $ 包含两项: 第一项是电流项, 用于处理负荷分配问题, 由系数$ a $ 调整其比重; 第二项是电压项, 用于处理电压平衡问题, 由权重系数$ b $ 调整其比重. 因此, 通过对性能指标$ J $ 进行优化, 可以实现负荷分配和电压稳定的权衡. 与文献[5]相比, 电压项增加了一个权重系数$ m_i $ , 也就是说本文采用的是加权平方和. 此处选择与微源容量相关的$ m_i $ 作为加权系数可以减小大容量微源的相关偏差, 一般来说, 大容量的微源对电网电压的维持作用更大.综上所述, 本文的研究目标是根据已建立的直流微电网模型, 构建一种新的分布式控制策略能够在负荷分配和电压平衡之间实现适当的权衡. 最后通过设计下垂系数实现系统级微电网的电压平衡和负荷分配.
3. 多目标优化问题求解
经过上一节的分析, 可以将微电网的电压平衡和负荷分配问题转化为多目标优化问题. 首先求解式(8)得到一组能够实现式电压平衡和负荷分配的最优下垂系数. 然后通过构建一种新的分布式控制策略实现式(8)的多目标优化问题, 解决系统级微电网的电压平衡和负荷分配问题.
3.1 集中式控制策略
定理 1. 基于多目标优化问题求解, 实现控制目标(6)和(7)的系统级微电网的最优下垂系数设计如下:
$$ k^\ast = {\rm diag}\{I_s^{'-1} (\delta V_N-V^\ast)\} $$ (9) 其中,
$I'_s\; =\; {\rm diag}\{YV^\ast +I_c \}, $ $V^\ast \;=\; (aYMMY+ $ $ bM^{-1})^{-1}(bM^{-1}V^{ref}-$ $ aYM(MI_c -\mu \delta)) $ 为母线电压的最优值.证明.
将式(8)中的性能指标改写为矩阵形式:
$$ \begin{split} J =\;& \frac{a}{2}(MI_s -\mu \delta )^{\rm T}(MI_s -\mu \delta ) +\\ & \frac{b}{2}(V-V^{ref})^{\rm T}M^{-1}(V-V^{ref}) \end{split} $$ (10) 将约束条件式(3)代入上式,
$$ \begin{split} J =\;& \frac{a}{2}(M(YV+I_c )-\mu \delta )^{\rm T}(M(YV+I_c )-\mu \delta ) +\\ & \frac{b}{2}(V-V^{ref})^{\rm T}M^{-1}(V-V^{ref}) \\[-12pt] \end{split} $$ (11) 对上式求偏导可得:
$$ \begin{split} \frac{\partial J}{\partial V} =\;& (aYMMY+bM^{-1})V +\\& aYM(MI_c -\mu \delta )-bM^{-1}V^{ref} \end{split} $$ (12) 由于对角矩阵
$ M>0 $ , 因此矩阵$ aYMMY+ $ $bM^{-1} $ 为正定矩阵. 令$ \dfrac{\partial J}{\partial V}=0 $ , 可求得最优母线电压$ V^\ast $ , 将$ V^\ast $ 代入式(3)可得最优电流解$ I_s^\ast $ .多目标优化问题(8)的全局最优解为(
$ I_s ^\ast $ ,$ V_{bus}^\ast ) $ , 将得到的最优解代入式(5)可以设计出实现控制目标的最优下垂系数(9). □从定理1中可以看出最优下垂系数与权衡系数
$ a $ 和$ b $ 密切相关, 通过调整参数$ a $ 和$ b $ , 可以得到不同情况下的最优下垂系数, 这间接反映了下垂系数可以对负荷分配和电压平衡进行权衡. 尤其, 当$ a=0 $ 时表示不考虑比例负荷分配的影响实现理想的电压平衡; 当$ b=0 $ 时表示不考虑电压平衡的影响实现比例负荷分配.3.2 分布式控制策略
上一节基于多目标优化问题求解设计出实现负荷分配和电压平衡的最优下垂系数. 从定理1中可以看出, 该下垂系数的设计需要获取所有母线电压信息, 而母线电压的计算是通过一个能够获取微电网全局信息的集中式控制策略实现的. 在实际应用中, 这一要求通常不能满足, 尤其是在分布式目标大规模渗透的情况下, 使用一个中央控制器与所有发电机和负载进行通信, 这对于微电网来说是昂贵的, 有时是不切实际的. 而分布式控制方案可以通过与邻居节点的信息交换实现全局最优. 因此, 本节提出一种新的求解母线电压的分布式控制策略, 如下所示:
$$ \dot {V}_i (t) = r_1 a\varphi _i (t)-r_2 bm_i \left( {V_i -V_i^{ref} } \right) \hspace{40pt}$$ (13) $$ \dot {\varphi }_i (t) = -\frac{r_1 }{r_2 }\varphi _i (t)-\sum\limits_{j\in N_i } {\frac{1}{R_{ij} }} \left(\frac{\Delta I_{si} (t)}{m_i }-\frac{\Delta I_{sj} (t)}{m_j }\right) $$ (14) 其中,
$ \Delta I_{si} (t)=\dfrac{I_{si} (t)}{m_i }-\mu $ ,$ \varphi _i (t) $ 为辅助变量,$ r_1 >0 $ 和$ r_2 >0 $ 为控制器增益.可以看出分布式控制策略(13)和(14)是通过获取邻居节点的信息实现的. 很明显, 节点
$ i $ 的控制更新只依赖于其自身的电压信息和相邻节点的电流信号. 在这个方案中, 节点的辅助变量$ \varphi _i (t) $ 用来估计当前节点的电流负载率和理想负载率$ \mu $ 之间的偏差. 接下来给出分布式策略(13)和(14)指数收敛到母线电压最优解的结论, 见如下定理:定理 2. 给定控制器增益
$r_1$ 和$r_2$ 以及系数$ a $ 和$ b $ , 分布式控制策略(13)和(14)指数收敛于最优解$ V^\ast $ , 其收敛率为$ \rho = \min \left\{ {\dfrac{r_1 }{r_2 },r_2 bm_i, i = 1,\cdots, n} \right\} $ .证明. 令
$ \varphi (t) = \left[ {\varphi _1 (t),\varphi _2 (t),\cdot \cdot \cdot, \varphi _n (t)} \right]^{\rm T} $ , 将分布式控制策略(13)和(14)改写为矩阵形式如下:$$ \dot {V}(t) = r_1 a\varphi (t)-r_2 bM^{-1}(V-V^{ref}) $$ (15) $$ \dot {\varphi }(t) = -\frac{r_1 }{r_2 }\varphi (t)-YM\Delta I_s (t) \hspace{35pt}$$ (16) 假设上式的平衡点为
$ (\bar {V},\bar {\varphi }) $ , 则在该平衡点上有$$ r_1 a\bar {\varphi }-r_2 bM^{-1}(\bar {V}-V^{ref})=0 $$ (17) $$ -\frac{r_1 }{r_2 }\bar {\varphi }-YM\Delta \bar {I}_s =0 \hspace{47pt}$$ (18) 其中,
$ \Delta \bar {I}_s =MI-\mu \delta $ . 由式(17), 可得$\bar {\varphi } = $ $ -\;\dfrac{r_2 }{r_1 }YM\Delta \bar {I}_s,$ 将其代入式(18)得$aYM\Delta \bar {I}_s\; - $ $ bM^{-1}(\bar {V}-V^{ref})=0$ , 结合等式(3)整理后可得最优解$ V^\ast $ . 这表明式分布式控制策略(13)和(14)的平衡点$ \bar {V} $ 与最优解$ V^\ast $ 完全一致.下面给出上述分布式控制策略收敛性得证明. 定义误差变量
$ \tilde {V}(t) = V(t)-\bar {V} $ 和$ \tilde {\varphi }(t) = \varphi (t)-\bar {\varphi } $ , 结合式(15) ~ (18)可得:$$ \dot {\tilde {V}}(t) = r_1 a\tilde {\varphi }(t)-r_2 bM^{-1}\tilde {V}(t) $$ (19) $$ \dot {\tilde {\varphi }}(t) = -\frac{r_1 }{r_2 }\tilde {\varphi }(t) \hspace{60pt}$$ (20) 定义
$ z(t) = [\tilde {V}(t),\tilde {\varphi }(t)] $ , 可得$ \dot {z}(t) = Hz(t) $ , 其中$$ H=\left[ {{\begin{array}{*{20}c} {-r_2 bM^{-1}} & {r_1 aE} \\ 0 & {-\dfrac{r_1 }{r_2 }E} \end{array} }} \right] $$ $ E $ 为对应维数的单位矩阵, 可知误差系统的解为$z(t) = {\rm e}^{Ht}z(0)$ .$ H $ 的特征值为$ -r_2 bm_i, i = 1,\cdots, n $ ,$ -\dfrac{r_1 }{r_2 } $ , 可以看出$ H $ 的所有特征值都小于零, 所以可知$\left\| {z(t)} \right\|\le \left\| {{\rm e}^{Ht}} \right\|\left\| {z(0)} \right\|\le {\rm e}^{-\rho t}\left\| {z(0)} \right\|$ . 结果表明$ t $ 趋近于无穷大时,$ z(t) $ 趋近于0, 收敛率为$ \rho. $ □定理2表明, 通过分布式控制(13)和(14)可以实现全局最优解, 相较于集中控制该分布式控制方案实际应用性更高. 同时, 通过适当的调整控制器增益
$ r_1 $ ,$ r_2 $ 可获得一个较为理想的收敛速度.4. 仿真研究
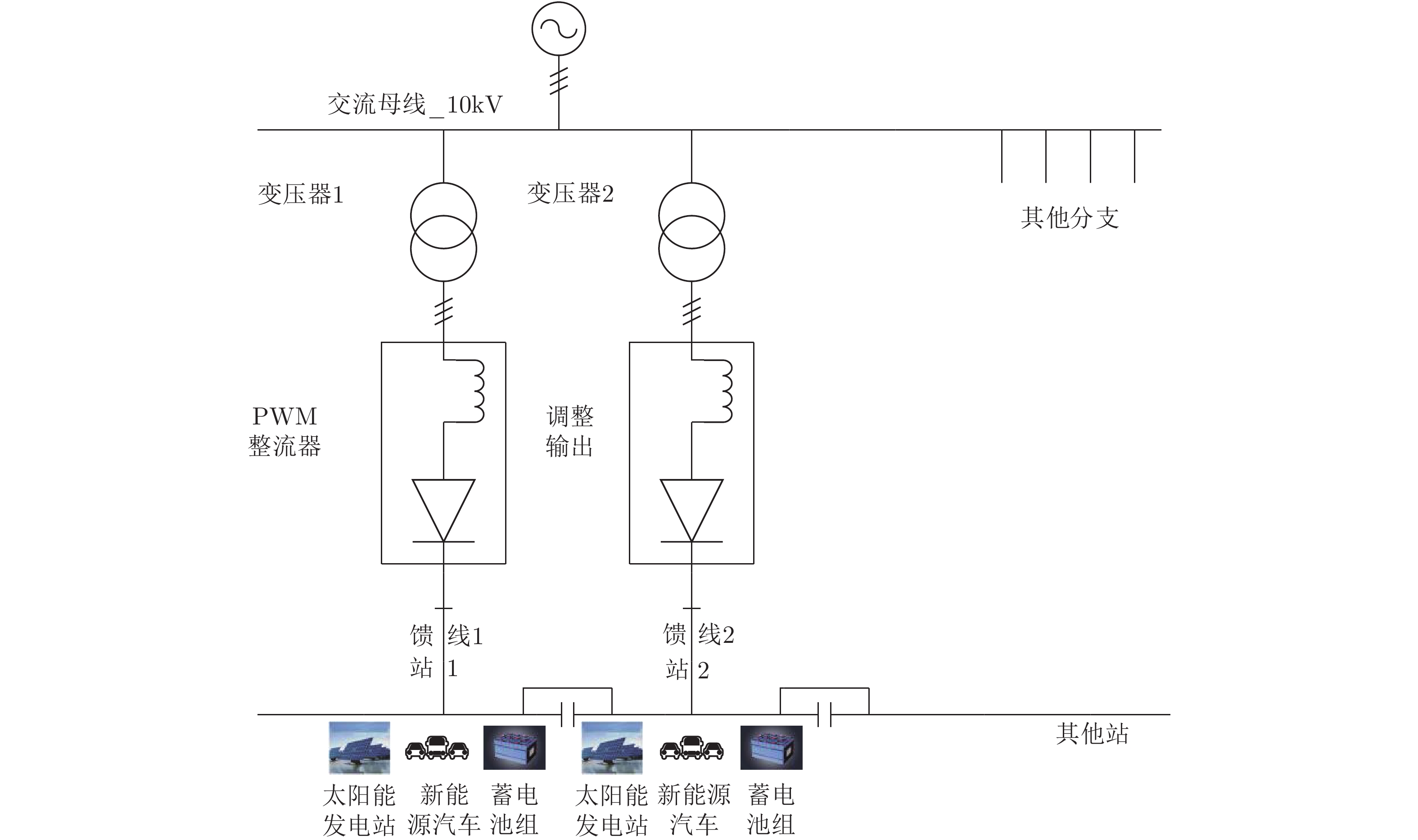
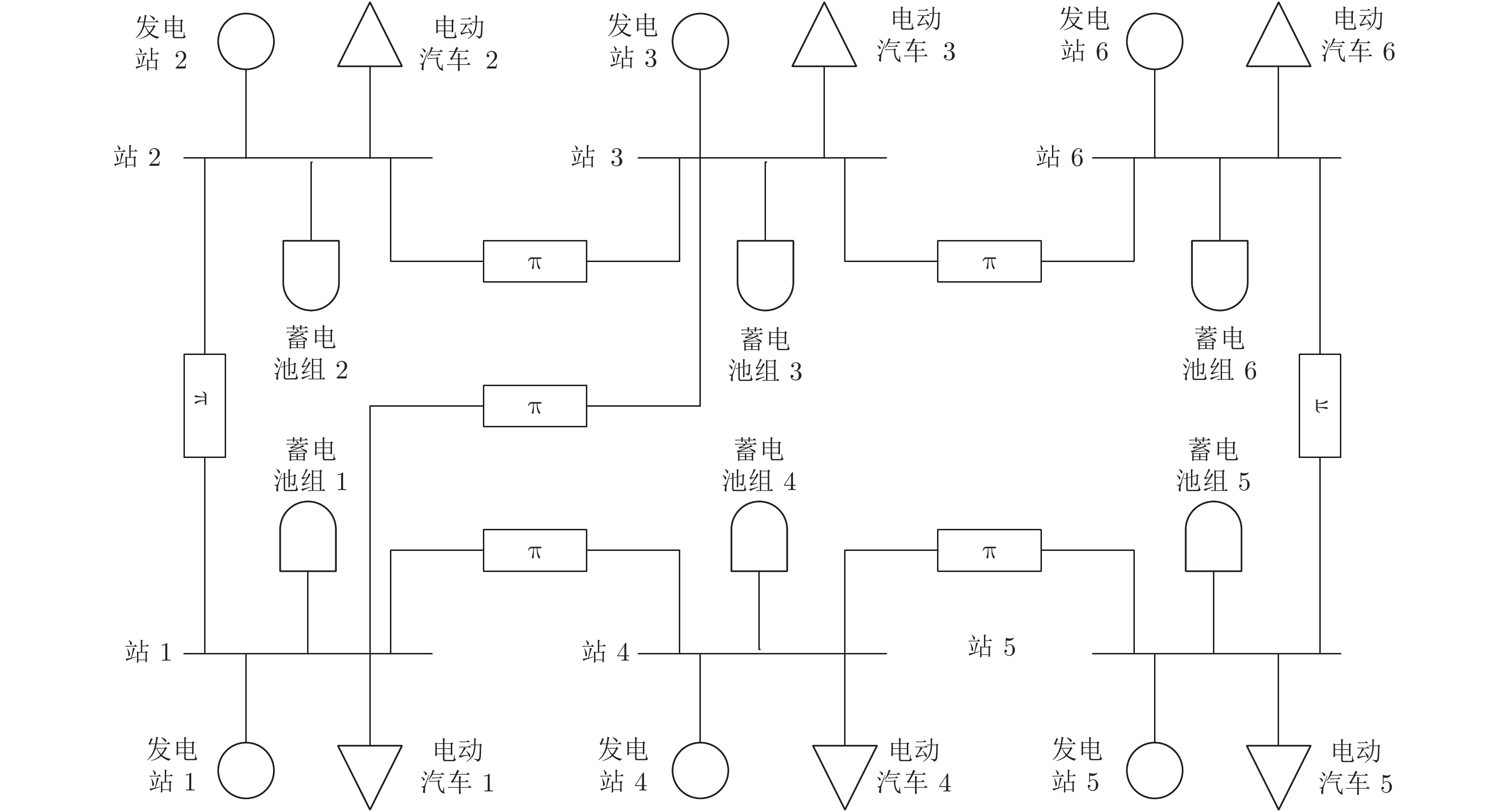
为了验证本文设计的下垂控制器以及分布式策略的有效性, 借助文献[21]的实例, 以新能源电动汽车充换电站网络作为仿真系统. 如图5所示, 新能源汽车充换电站由馈线及太阳能发电站供电. 6个充换电站相互连接组成供电半径约为5公里的供电网络. 每个充换电站都配有独立的太阳能发电系统且可以通过通信网络与相物理连接的充换电站通信. 综上所述, 尽管该内部结构、电路保护、负载条件和储能单元都非常复杂, 但馈线终端的每各站点都可以看作是直流网络的一个节点, 所以该新能源汽车充换电站是一个系统级直流微电网.
类似于文献[5], 采用改进的6母线直流微电网对新能源汽车充换电站进行建模, 如图6所示. 其微源、储能单元、负荷和母线分别代表太阳能发电站和馈线, 蓄电池组, 新能源电动汽车和充换电站站. 所有仿真验证均采用
${ \rm{Matlab}} $ 软件进行, 相关参数来自文献[5], 具体数值如下:节点之间的传输线电阻为
$ R_{12} = R_{21} = 0.40, \; $ $R_{13} = R_{31} = 0.37, \; R_{14} = R_{41} = 0.34, \; R_{23} = R_{32} = 0.38, \; $ $ R_{36} = R_{63} = 0.40,R_{45} = R_{54} = 0.31, \; R_{56} = R_{65} = 0.36 $ . 比例系数分别为:$m_1 = m_2 = 1.50, \; m_3 = m_4 = 1.75, $ $ m_5 = m_6 = 2.00 $ . 节点的额定电压$V_i^{ref} = 380\,{\rm V}$ .负载电流为:
$$ \begin{array}{l} I_{c1} = 721\,{\rm A},I_{c2} = 743\,{\rm A},I_{c3} = 818\,{\rm A}, \\ I_{c4} = 830\,{\rm A},I_{c5} = 921\,{\rm A},I_{c6} = 903\,{\rm A}. \end{array} $$ 初始电压为:
$$ \begin{array}{l} V_1 (0) = 360\,{\rm V},V_2 (0) = 390{\rm V},V_3 (0) = 370{\rm V}, \\ V_4 (0) = 380{\rm V},V_5 (0) = 400{\rm V},V_6 (0) = 350{\rm V}. \end{array} $$ 控制增益设为:
$ r_1 = 3,r_2 = 10 $ .4.1 集中式控制策略
假设权重系数为
$ a = 0.5,b = 0.5 $ , 由定理1求出下垂系数, 母线电压以及微源输出电流的最优解为$$ \begin{split}& k_1^\ast = 0.1042,k_2^\ast = 0.1088,k_3^\ast = 0.0854, \\ &k_4^\ast = 0.0862,k_5^\ast = 0.0710,k_6^\ast = 0.0684. \\ &V_1^\ast = 375.8394, V_2^\ast = 372.1973,V_3^\ast = 379.2690, \\ &V_4^\ast = 379.0309,V_5^\ast = 383.9641,V_6^\ast = 386.4960. \\ &I_{s1}^\ast = 711.4490,I_{s2}^\ast = 715.2852,I_{s3}^\ast = 827.8112, \\ &I_{s4}^\ast = 823.4735,I_{s5}^\ast = 929.8805,I_{s6}^\ast = 928.1005. \end{split} $$ 从计算数据可以看出, 母线电压基本稳定在参考电压附近, 输出电流基本实现了比例分配. 由此说明基于集中式控制策略设计的下垂控制器能够实现负荷共享和电压平衡的权衡.
4.2 分布式控制策略
基于分布式控制方案(13)和(14), 得到下垂系数
$ k $ , 母线电压$ V $ 以及输出电流$ I_s $ 随时间变化的曲线, 如图7所示. 图中可以看出曲线最终都处于平衡状态. 从图中可以看出分布式控制方案(13)和(14)所得的下垂系数$ k $ , 母线电压$ V $ 和输出电流$ I_s $ 的曲线收敛于定理1中的最优解. 因此证明了本文提出的分布式控制策略的有效性.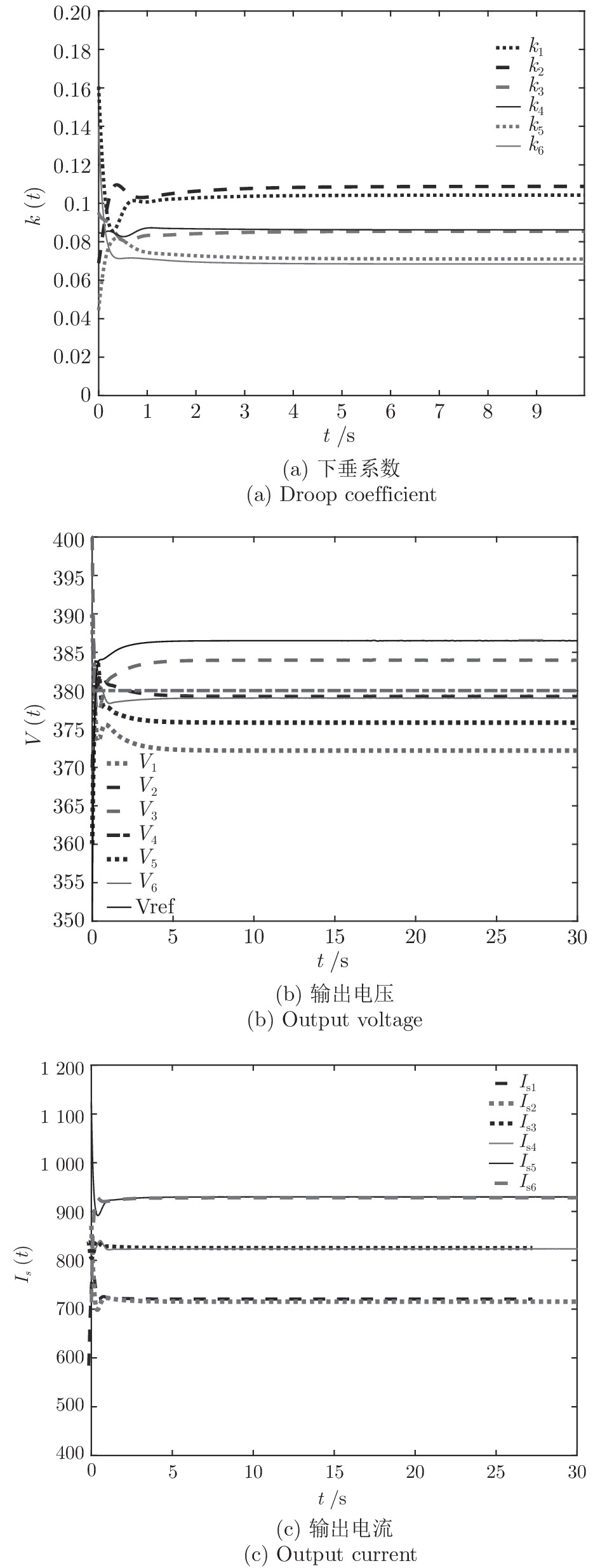 图 7 基于分布式方案的
图 7 基于分布式方案的$k, V, I_s $ 的演化曲线$a = 0.5$ Fig. 7 When$a = 0.5$ , the evolution curve of$k, V, I_s $ based on the distributed scheme4.3 负载共享与电压平衡的权衡
如上所述, 可以通过调整权重系数
$ a $ 实现微电网母线电压平衡和负荷分配的权衡. 这一节我们将通过仿真实例来研究权重系数变化时所提出的基于分布式控制策略的下垂控制器性能. 假设系数$ a $ 和$ b $ 的变化规律如下:1)
$t\in [0\,{\rm s},10\,{\rm s}],a = 0.10,b = 0.90$ 2)
$t\in [10\,{\rm s},20\,{\rm s}],a = 0.50,b = 0.50$ 3)
$t\in [20\,{\rm s},30\,{\rm s}],a = 0.90,b = 0.10$ 下垂系数, 母线电压以及输出电流随时间的变曲线如图8所示. 从图中可以看出, 在
$t = [0\,{\rm s},10\,{\rm s}]$ 时, 电压平衡的性能要优于负荷的比例分配; 而在$t = [20\,{\rm s},30\,{\rm s}]$ 时, 恰巧相反. 在$t = [10\,{\rm s},20\,{\rm s}]$ 时, 系统基本实现了电压平衡和负荷的比例分配, 且具有较好的性能. 因此, 可以根据实际情况通过调整权重系数实现电压平衡和负荷分配的权衡. 需要指出的是母线电压$ V $ 的变化曲线与下垂系数$ k $ 的变化曲线相似, 由此可以确定母线电压$ V $ 受到下垂系数$ k $ 的控制. 图 8
图 8$a = 0.1, 0.5, 0.9$ 的$k, V, I_s/m$ 的演化曲线Fig. 8 When$a = 0.1, 0.5, 0.9$ , the evolution curve of$k, V, I_s/m$ 4.4 负载变化时的性能
由于车辆进出站充电, 每个充换电站的负荷需求会发生频繁的变化. 因此, 通过负载变化对所提的分布式控制策略的性能进行验证. 假设在
$10\,{\rm s}\sim$ $20\,{\rm s}$ 母线2的负载下降30 %, 然后恢复. 当$ a = b = 0.5 $ 时, 下垂系数, 母线电压以及输出电流随时间的变曲线如图9所示. 从图中可以看出, 当负载在$t = 10\,{\rm s}$ 和$t = 20\,{\rm s}$ 发生变化时, 系统能够在下垂控制器的作用下迅速作出响应, 使得母线电压和输出电流作出相应的调整, 最终趋于稳定. 因此本文使用分布式控制策略能够增加系统的鲁棒性. 图 9 负载变化对
图 9 负载变化对$k, V, I_s $ 的影响$a = 0.5$ Fig. 9 When$a = 0.5$ , effect of load change on$k, V, I_s $ 4.5 即插即用的性能
在实际中, 经常出现部分充换电站因维修而停用或新建充换电站的情况, 这就要求新能源汽车充换电站系统具有即插即用的特性. 接下来, 通过充换电站的加入和退出对所提的分布式控制策略的性能进行验证. 假设在
$10\,{\rm s}\sim20\,{\rm s}$ 内独立运行的充换电站7接入系统, 其他时间独立运行. 其参数为$ R_{57} = $ $R_{75} =0.40\,\Omega ,$ $R_{67} \;=\; R_{76} \;=\;0.35\,\Omega,$ $V_7 (0) = 365\,{\rm V},$ $I_{c7} = $ $660\,{\rm A}$ 和$ m_7 = 1.50 $ . 当$ a = b = 0.5 $ 时, 下垂系数, 母线电压以及输出电流随时间的变曲线如图10所示. 从图中可以看出, 当节点7在$t = 10\,{\rm s}$ 和$t = 20\,{\rm s}$ 加入和退出时, 系统能够在下垂控制器的作用下迅速作出响应, 使得母线电压和输出电流作出相应的调整, 最终趋于稳定. 仿真结果表明分布式控制策略(13)和(14)使系统对新节点的接入和退出具有良好的适应性.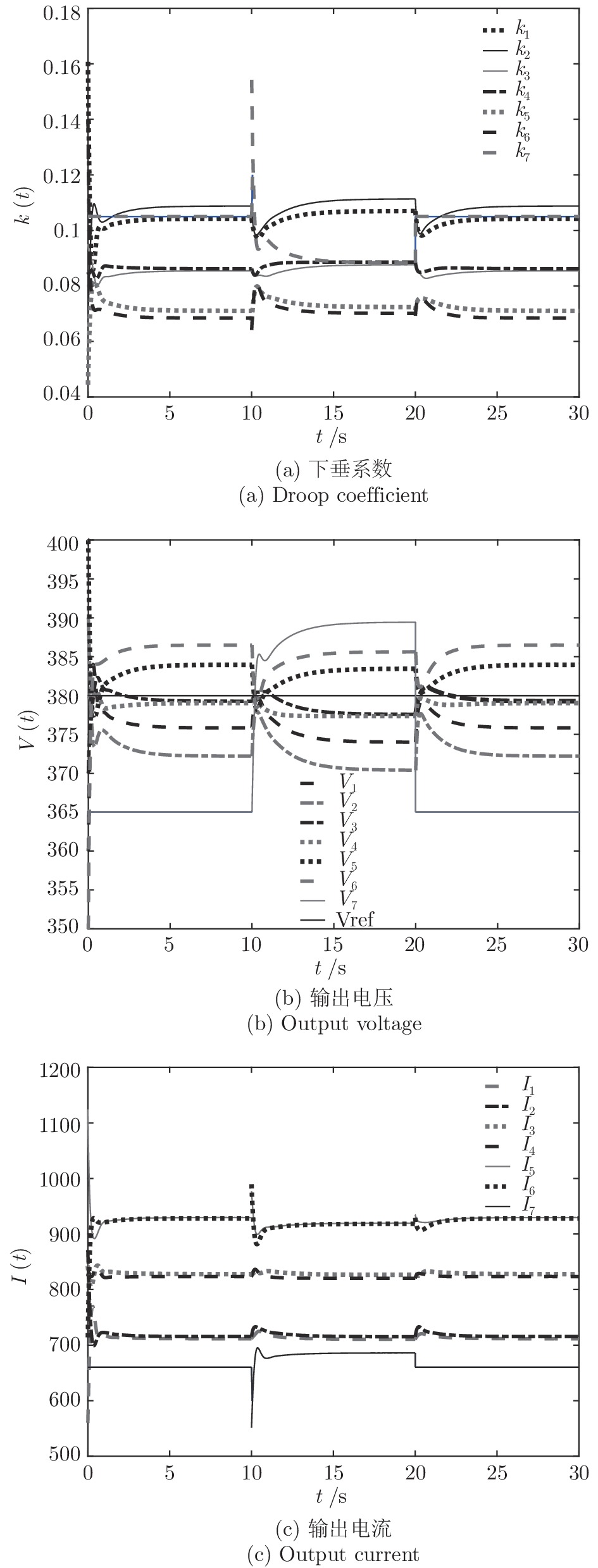 图 10 节点7接入和退出对
图 10 节点7接入和退出对$k, V, I_s $ 的影响$a = 0.5$ Fig. 10 When$a = 0.5$ , influence of node 7 access and exit on$k, V, I_s $ 5. 总结
本文针对直流微电网中的负荷分配和电压平衡问题进行了研究. 分析了没有负荷分配影响时的电压平衡以及没有电压平衡影响时的负荷分配问题, 发现这两种情况具有较大的局限性. 因此将微电网的负荷分配和电压平衡问题转化为一种多目标优化问题, 通过权衡系数来调整电压平衡和负荷分配的比重. 然后给出多目标优化问题的最优解, 通过集中式策略设计的下垂控制器实现微电网的电压平衡和负荷的比例分配. 为了降低系统的通信负担和提高系统的可靠性, 提出一种新的只需与邻居节点交换信息的分布式控制策略. 理论结果表明, 该分布式控制策略与集中式策略具有完全一致的性能. 最后, 基于新能源汽车充换电站系统进行了仿真研究, 通过仿真结果可以看出适当的调节下垂系数可以实现电压平衡和负荷分配的权衡. 同时还表明该控制算法具有较快的收敛速率, 良好的鲁棒特性和即插即用性.
-

图 4 先验图像与增强图像之间优势和劣势的可视化
Fig. 4 Visualization of advantages and disadvantages between prior image and enhanced image

图 5 不同$ \alpha $取值下的权重函数曲线
Fig. 5 Weight function curves with different values of $ \alpha $

图 6 室内场景下不同方法的低光照图像增强结果
Fig. 6 Low light image enhancement results of different methods in indoor scene

图 7 室外场景下不同方法的低光照图像增强结果
Fig. 7 Low light image enhancement results of different methods in outdoor scene

图 8 黑夜环境下不同方法的低光照图像增强结果
Fig. 8 Low light image enhancement results of different methods under dark night environment

图 9 针对真实高噪声低光照图像下不同方法的增强结果
Fig. 9 Enhancement results of different methods for real high-noise low light image

图 10 所提方法不同模块的消融研究
Fig. 10 Ablation studies of different modules of the proposed method
表 1 不同方法在不同低光照数据集中的CEIQ值
Table 1 CEIQ values of different methods in different low light datasets
NPEA[34] LIME[8] MF[9] LECARM[35] STAR[36] SCI[16] 所提方法 DCIM 3.399 3.358 3.145 3.109 3.162 3.185 3.063 Fusion 3.405 3.399 3.428 3.405 3.387 3.340 3.358 NPE 3.784 3.478 3.499 3.497 3.484 3.523 3.429 VV 3.485 3.512 3.342 3.321 3.316 3.345 3.258 LIME 3.426 3.490 3.181 3.184 3.046 3.193 2.990 Darkface 3.198 3.246 2.779 2.716 2.438 2.407 2.496 平均值 3.449 3.413 3.229 3.205 3.139 3.165 3.099  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在不同低光照数据集中的LOE值
Table 2 LOE values of different methods in different low light datasets
NPEA[34] LIME[8] MF[9] LECARM[35] STAR[36] SCI[16] 所提方法 DCIM 753.2 857.5 782.2 770.0 590.9 777.6 581.0 Fusion 564.9 803.6 614.2 681.7 527.4 703.1 523.0 NPE 731.2 847.6 750.1 845.2 549.3 849.7 588.1 VV 563.3 799.3 517.3 596.5 369.3 619.8 347.6 LIME 540.9 608.8 661.0 687.4 537.9 678.1 557.1 Darkface 955.8 942.1 883.9 428.6 621.8 458.9 260.8 平均值 684.9 809.9 701.4 668.2 532.7 681.2 476.2
下载: 导出CSV
表 3 不同方法在不同低光照数据集中的NL值
Table 3 NL values of different methods in different low light datasets
NPEA[34] LIME[8] MF[9] LECARM[35] STAR[36] SCI[16] 所提方法 DCIM 1.156 1.707 0.578 0.485 0.491 1.099 0.358 Fusion 0.561 0.715 0.509 0.599 0.597 0.510 0.325 NPE 0.778 0.908 0.690 0.685 0.688 0.623 0.526 VV 0.764 0.836 0.549 0.637 0.663 0.539 0.459 LIME 1.036 1.074 0.872 0.733 0.722 0.744 0.619 Darkface 2.019 2.586 1.585 1.157 1.147 1.084 0.789 平均值 1.052 1.304 0.797 0.716 0.718 0.766 0.512
下载: 导出CSV
表 4 不同方法处理不同图像尺寸的运行时间 (s)
Table 4 Running time for different image sizes processed by different methods (s)
下载: 导出CSV
-
[1] 徐少平, 张贵珍, 林珍玉, 刘婷云, 李崇禧. 一种多图像局部结构化融合的低照度图像增强算法. 自动化学报, 2022, 48(12): 2981−2995Xu Shao-Ping, Zhang Gui-Zhen, Lin Zhen-Yu, Liu Ting-Yun, Li Chong-Xi. A multi-image local structured fusion-based low-light image enhancement algorithm. Acta Automatica Sinica, 2022, 48(12): 2981−2995 [2] 鞠明, 李成, 高山, 穆举国, 毕笃彦. 基于向心自动波交叉皮质模型的非均匀光照图像增强. 自动化学报, 2011, 37(7): 800−810Ju Ming, Li Cheng, Gao Shan, Mu Ju-Guo, Bi Du-Yan. Non uniform-lighting image enhancement based on centripetal autowave intersecting cortical model. Acta Automatica Sinica, 2011, 37(7): 800−810 [3] Kim T, Paik J. Adaptive contrast enhancement using gain-controllable clipped histogram equalization. IEEE Transactions on Consumer Electronics, 2008, 54(4): 1803−1810 doi: 10.1109/TCE.2008.4711238 [4] Arici T, Dikbas S, Altunbasak Y. A histogram modifcation framework and its application for image contrast enhancement. IEEE Transactions on Image Processing, 2009, 18(9): 1921−1935 doi: 10.1109/TIP.2009.2021548 [5] Farid H. Blind inverse gamma correction. IEEE Transactions on Image Processing, 2001, 10(10): 1428−1433 doi: 10.1109/83.951529 [6] Huang S C, Cheng F C, Chiu Y S. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE Transactions on Image Processing, 2013, 22(3): 1032−1041 [7] Land E H, McCann J J. Lightness and Retinex theory. Journal of the Optical Society of America, 1971, 61(1): 1−11 doi: 10.1364/JOSA.61.000001 [8] Guo X J, Li Y, Ling H B. LIME: Low-light image enhancement via illumination map estimation. IEEE Transactions on Image Processing, 2017, 26(2): 982−993 doi: 10.1109/TIP.2016.2639450 [9] Fu X Y, Zeng D L, Huang Y, Liao Y H, Ding X H, Paisley J. A fusion-based enhancing method for weakly illuminated images. Signal Processing, 2016, 129: 82−96 doi: 10.1016/j.sigpro.2016.05.031 [10] Li M D, Liu J Y, Yang W H, Sun X Y, Guo Z M. Structure-revealing low-light image enhancement via robust Retinex model. IEEE Transactions on Image Processing, 2018, 27(6): 2828−2841 doi: 10.1109/TIP.2018.2810539 [11] Li J J, Feng X M, Hua Z. Low-light image enhancement via progressive-recursive network. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(11): 4227−4240 doi: 10.1109/TCSVT.2021.3049940 [12] Lv F F, Li Y, Lu F. Attention guided low-light image enhancement with a large scale low-light simulation dataset. International Journal of Computer Vision, 2021, 129: 2175−2193 doi: 10.1007/s11263-021-01466-8 [13] Lu K, Zhang L H. TBEFN: A two-branch exposure-fusion network for low-light image enhancement. IEEE Transactions on Multimedia, 2021, 23: 4093−4105 [14] Guo C L, Li C Y, Guo J C, Loy C C, Hou J H, Kwong S, et al. Zero-reference deep curve estimation for low-light image enhancement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 1777−1786 [15] Zhao Z J, Xiong B S, Wang L, Ou Q F, Yu L, Kuang F. RetinexDIP: A unified deep framework for low-light image enhancement. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(3): 1076−1088 doi: 10.1109/TCSVT.2021.3073371 [16] Ma L, Ma T Y, Liu R S, Fan X, Luo Z X. Toward fast, flexible, and robust low-light image enhancement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 5627−5636 [17] Xu H T, Zhai G T, Wu X L, Yang X K. Generalized equalization model for image enhancement. IEEE Transactions on Multimedia, 2014, 16(1): 68−82 doi: 10.1109/TMM.2013.2283453 [18] Pisano E D, Zong S Q, Hemminger B M, DeLuca M, Johnston R E. Contrast limited adaptive histogram equalization image processing to improve the detection of simulated spiculations in dense mammograms. Journal of Digital Imaging, 1998, 11: Article No. 193 doi: 10.1007/BF03178082 [19] Rahman S, Rahman M M, Abdullah-Al-Wadud M, Al-Quaderi G D, Shoyaib M. An adaptive gamma correction for image enhancement. EURASIP Journal on Image and Video Processing, 2016, 2016(1): Article No. 35 [20] Yang K F, Li H, Kuang H L, Li C Y, Li Y J. An adaptive method for image dynamic range adjustment. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(3): 640−652 [21] Jeong I, Lee C. An optimization-based approach to gamma correction parameter estimation for low-light image enhancement. Multimedia Tools and Applications, 2021, 80: 18027−18042 doi: 10.1007/s11042-021-10614-8 [22] Jobson D J, Rahman Z, Woodell G A. Properties and performance of a center/surround Retinex. IEEE Transactions on Image Processing, 1997, 6(3): 451−462 [23] Jobson D J, Rahman Z, Woodell G A. A multi-scale Retinex for bridging the gap between color images and the human observation of scenes. IEEE Transactions on Image Processing, 1997, 6(7): 965−976 doi: 10.1109/83.597272 [24] Dabov K, Foi A, Katkovnik V, Egiazarian K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Transactions on Image Processing, 2007, 16(8): 2080−2095 doi: 10.1109/TIP.2007.901238 [25] Fu X Y, Zeng D L, Huang Y, Zhang X P, Ding X H. A weighted variational model for simultaneous reflectance and illumination estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2782−2790 [26] Ren W Q, Liu S F, Ma L, Xu Q Q, Xu X Y, Cao X C, et al. Low-light image enhancement via a deep hybrid network. IEEE Transactions on Image Processing, 2019, 28(9): 4364−4375 doi: 10.1109/TIP.2019.2910412 [27] Lore K G, Akintayo A, Sarkar S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognition, 2017, 61: 650−662 doi: 10.1016/j.patcog.2016.06.008 [28] Lv F F, Lu F, Wu J H, Lim C. MBLLEN: Low-light image/video enhancement using CNNs. In: Proceedings of the 29th British Machine Vision Conference. Newcastle, UK: BMVA, 2018. 1−13 [29] Li C Y, Guo J C, Porikli F, Pang Y W. LightenNet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognition Letters, 2018, 104: 15−22 doi: 10.1016/j.patrec.2018.01.010 [30] Jiang Y F, Gong X Y, Liu D, Cheng Y, Fang C, Shen X H, et al. EnlightenGAN: Deep light enhancement without paired supervision. IEEE Transactions on Image Processing, 2021, 30: 2340−2349 doi: 10.1109/TIP.2021.3051462 [31] Fan G D, Fan B, Gan M, Chen G Y, Chen C L P. Multiscale low-light image enhancement network with illumination constraint. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(11): 7403−7417 doi: 10.1109/TCSVT.2022.3186880 [32] Lempitsky V, Vedaldi A, Ulyanov D. Deep image prior. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 9446−9454 [33] Gastal E S L, Oliveira M M. Domain transform for edge-aware image and video processing. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference. Vancouver, Canada: ACM, 2011. 1–12 [34] Wang S H, Zheng J, Hu H M, Li B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Transactions on Image Processing, 2013, 22(9): 3538−3548 doi: 10.1109/TIP.2013.2261309 [35] Ren Y R, Ying Z Q, Li T H, Li G. LECARM: Low-light image enhancement using the camera response model. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(4): 968−981 doi: 10.1109/TCSVT.2018.2828141 [36] Xu J, Hou Y K, Ren D W, Liu L, Zhu F, Yu M Y, et al. STAR: A structure and texture aware Retinex model. IEEE Transactions on Image Processing, 2020, 29: 5022−5037 doi: 10.1109/TIP.2020.2974060 [37] Yang W H, Yuan Y, Ren W Q, Liu J Y, Scheirer W J, Wang Z Y, et al. Advancing image understanding in poor visibility environments: A collective benchmark study. arXiv preprint arXiv: 1904.04474, 2019. [38] Yan J, Li J, Fu X. No-reference quality assessment of contrast-distorted images using contrast enhancement. arXiv preprint arXiv: 1904.08879, 2019. [39] Dong L, Zhou J T, Tang Y Y. Noise level estimation for natural images based on scale-invariant kurtosis and piecewise stationarity. IEEE Transactions on Image Processing, 2017, 26(2): 1017−1030 doi: 10.1109/TIP.2016.2639447 期刊类型引用(5)
1. 韩永明,王新鲁,耿志强,朱群雄,毕帅,张红斌. 基于AMOWOA的区域综合能源系统运行优化调度. 自动化学报. 2024(03): 576-588 .  本站查看
本站查看2. 李远征,张虎,刘江平,赵勇,连义成. 基于电网线路传输安全的电力市场分布式交易模型研究. 自动化学报. 2024(10): 1938-1952 . 本站查看3. 贾晓振,胡江凯,王大鹏,梁晨. 长时间序列格点数据管理平台的设计与实践. 气象科技. 2024(06): 797-806 . 百度学术4. 罗鹏,刘永慧,苏庆堂. 耦合程度加深的电-气综合能源系统的建模及仿真. 控制工程. 2023(11): 2125-2133 . 百度学术5. 张化光,孙宏斌,刘德荣,王剑辉,孙秋野. “分布式信息能源系统”专题特约主编寄语. 中国电机工程学报. 2020(17): 5401-5403 . 百度学术其他类型引用(16)
-

 下载:
下载:
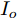
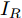

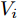
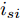
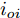
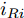
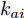
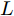
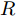
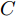
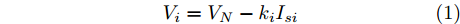
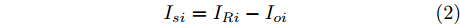
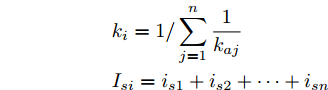
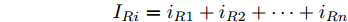
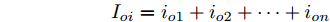
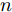
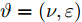
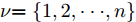
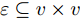

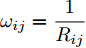
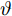
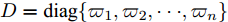
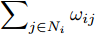


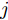
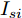
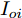
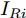
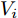
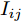
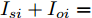
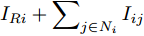
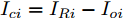
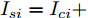
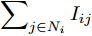
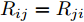
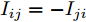
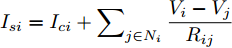
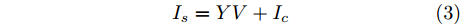
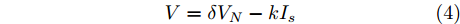
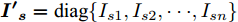
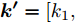
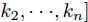
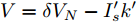
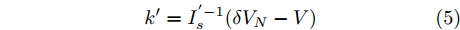
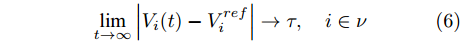

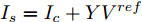
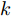
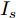
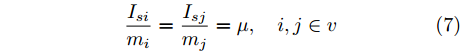

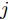
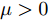
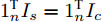
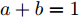
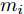
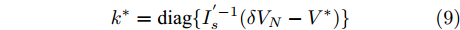
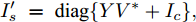
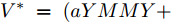
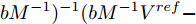
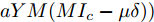
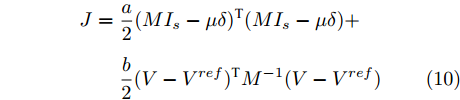
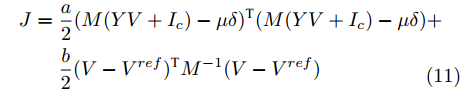
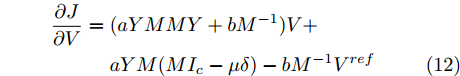
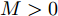
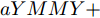
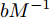
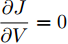
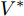
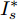
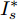
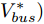
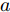
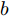

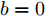
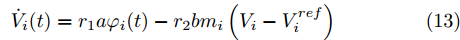
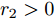

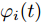
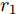
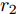
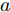
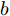
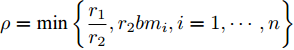
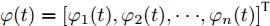
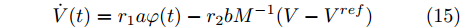
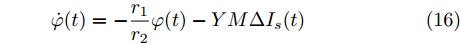
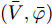
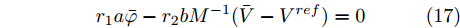
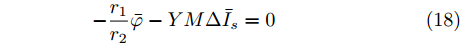
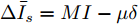
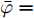
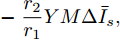
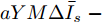
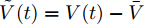
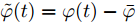
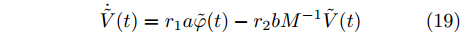
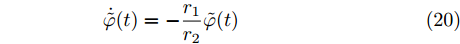
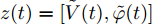
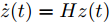
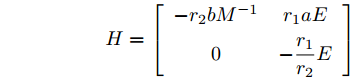

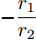
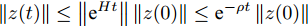
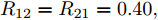
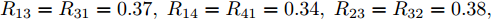
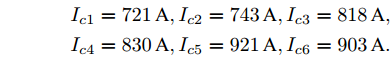
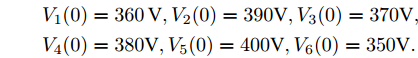
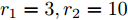
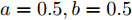

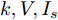
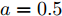

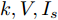
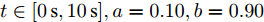
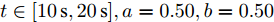
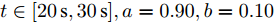


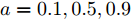
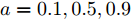
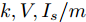
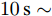
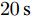
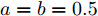
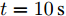
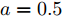
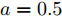
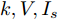
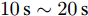
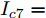
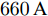

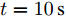
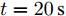
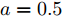
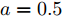



计量
- 文章访问数: 801
- HTML全文浏览量: 435
- PDF下载量: 208
- 被引次数: 21
