

-
摘要: 基于视觉的人体动作质量评价利用计算机视觉相关技术自动分析个体运动完成情况, 并为其提供相应的动作质量评价结果. 这已成为运动科学和人工智能交叉领域的一个热点研究问题, 在竞技体育、运动员选材、健身锻炼、运动康复等领域具有深远的理论研究意义和很强的实用价值. 本文将从数据获取及标注、动作特征表示、动作质量评价3个方面对涉及到的技术进行回顾分析, 对相关方法进行分类, 并比较分析不同方法在AQA-7、JIGSAWS、EPIC-Skills 2018三个数据集上的性能. 最后讨论未来可能的研究方向.Abstract: Vision-based motion quality assessment utilizes computer vision techniques to analyze the quality of individual movement behavior automatically and provide the corresponding assessments of movement quality. It has gradually become the hot issue at the intersection of the sport science and artificial intelligence, and has widely used in the fields of sporting events, athlete selection, fitness and rehabilitation. This article conducts a retrospective analysis of the involved technologies from three aspects: Data acquisition and annotation, motion feature representation, and motion quality assessment. It categorizes and compares various mainstream methods on three datasets: AQA-7, JIGSAWS, and EPIC-Skills 2018. Finally, potential future research directions are discussed.
-
Key words:
- Motion quality /
- assessment /
- computer vision /
- data acquisition /
- feature representation /
- loss function
-
在信息爆炸的"互联网+"新时代, 随着网络时代的发展, 人类的注意力开始变短, "碎片化"学习成为人类的主要学习模式, 而在线网络课程由于其"微课"的教学模式, 时间的相对自由性, 成本相对比较低等优点迅速受到广大学者的喜爱[1-4].伴随着普通学生、成年人、工作者越来越多地进行在线网络学习, 许多机构也采用网络课程模式对其员工进行培训, 但是不同于传统的培训, 在线网络学习难以被管控, 机构无法得到员工的培训效果, 因此, 即使意识到这种学习的重要性, 许多企业也不知道如何"培育"它.这是因为在线网络课程目前仍处于完善阶段, 其本身存在一些缺陷, 由于时间的自由和目前的无人监督模式, 学生的学习效率难以得到保障, 学生很可能因为自律性不够或课程的枯燥而出现不专心的情况[5].针对这种情况, 有必要对学习者的学习状态进行分析和评估, 以监督学生的学习状态, 给相关机构提供测评依据, 也反馈给在线授课者, 帮助教育者提高授课质量[6].
目前在已有的研究成果中很难找到针对MOOC (Massive open online course)授课过程中学生的行为检测, 虽然在其他应用背景下的人体行为检测已经有了很多, 但是针对MOOC授课过程中的学生这一特定目标, 对其行为进行检测对提升MOOC的教育教学还是有不容小觑的意义.为了获取学生的专注度, 首先要做的就是获得学生的行为信息, 考虑到学生登录慕课时, 所使用的电脑、平板和手机等设备一般都带有摄像头, 如果能够利用摄像头来实时记录学生的学习状态, 就可以根据获取到的视频对学生的行为进行分析, 以得到学生的学习专注度.目前国内外的学者在行为识别领域上已经取得了一系列成果, Jaouedi等为了更好地使机器人服务于残疾人, 他们对残疾人与智能机器人交流中的手势、步行速率等信息进行了分析, 之后使用卡尔曼滤波方法对移动的人体进行跟踪, 最后采用"最近邻居法"对所得到的行为信息进行处理, 以给出人体的行为决策[7]; 而Xiao等对人机交互中的头部运动进行了行为分析研究, 他们提出了以数据为基础来识别头部运动模式的方法, 先将人体头部运动按照时间进行分段, 再用线性预测特征参数法来建立运动模型, 之后用高斯混合模型对运动类型进行融合推理, 得出头部运动所代表的特定行为, 例如接受、赞赏、责备、反对等[8]; Tsai等为了检测公共场所人类吸烟饮酒等非法行为, 他们将相机安装在工作场所的某一固定位置, 然后提取三个主要特征:脸与手的接触时间特征、烟雾特征和手持物体特征, 最后根据"决策树"来判断是否有人在公共场所从事了吸烟饮酒等非法行为[9].
虽然目前对人体行为的检测已经取得了较多成果, 并且可以实现人体的跟踪问题[7-11], 但是利用学生听课过程中的视频来"判定学生在线网络学习中的专注度"这一方面的研究还比较空缺[12].针对慕课这一新的应用环境, 我们分析摄像头获取的学生行为信息, 建立人体的"四维特征信息模型", 根据各个特征的变化范围对每个焦元进行基本概率赋值, 最后采用D-S方法融合时空域中的概率值, 判断出学生的人体信息, 最后给出学生对某一门慕课课程学习效果的初步评价.
该分析系统可以用图 1来表示.
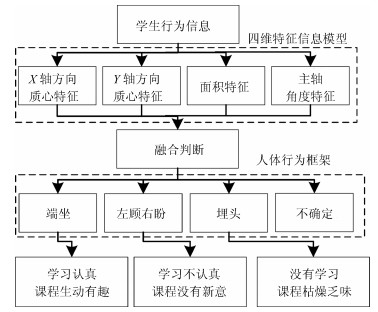 图 1 慕课授课过程中学生专注度自动检测与判定系统Fig. 1 Automatic detection system on student focus during MOOC teaching
图 1 慕课授课过程中学生专注度自动检测与判定系统Fig. 1 Automatic detection system on student focus during MOOC teaching论文的主要工作组成共分为以下内容:第1节, 提取人体轮廓, 并建立学生"四维特征信息模型"; 第2节, 搭建人体行为框架, 并对其进行基本概率赋值, 之后采用D-S方法对其进行融合, 最后给出学生的行为状态; 第3节, 采用多种状态的视频信息对以上算法进行了实验验证, 并将D-S理论与贝叶斯理论进行对比, 来证明D-S理论融合的有效性; 第4节, 总结和展望.
1. 慕课授课过程中学生行为模型的建立
1.1 慕课授课过程中学生人体检测
慕课授课过程中的运动人体检测任务是将人体从视频序列中分割出来, 因此, 能否准确地提取出人体轮廓就显得尤为重要[13-15].
本文采用的是背景减除法提取目标人体[16], 由于实验地点相对单一, 我们使用无学生的背景图片作为背景模型, 将视频中当前帧图像与背景图像进行差分运算, 如果像素点灰度值差别很大, 则为目标人体, 如果差值在一定阈值范围内, 则为背景像素点; 得到的差值图像采用最大类间方差法找到合适的二值化阈值; 再对二值化后的图像提取出最大连通域, 消除背景的干扰, 最后我们还使用基于逆合成孔径雷达(Inverse synthetic aperture radar, ISAR)图像目标形状提取的数学形态学方法对检测到的前景目标进行后处理[17], 以平滑连接目标人体的边缘, 使提取出的人体轮廓更加完整.
1.2 建立"四维特征信息模型"
提取人体轮廓后, 还需进一步提取出图像的主要特征信息, 才能进行特征信息融合与听课专注度的决策推理.根据学生在学习时可能出现的行为状态, 例如认真学习时的端坐状态, 有点疲惫时的斜坐状态, 非常困倦时可能会出现趴在桌子上睡觉的状态等, 为了能全面且准确地描述这些人体的行为信息, 我们从人体轮廓中提取了4个行为特征信息, 将其定义为人体"四维特征信息模型", 其具体内容为:
$$ \left\{ \begin{aligned} &\text{人体$x$轴质心特征:}~X=\frac{M_{10}}{M_{00}}\\ &\text{人体$y$轴质心特征:}~Y=\frac{M_{01}}{M_{00}} \\ &\text{面积特征标记矩阵:}\\ &\qquad STATS=regionprops(L, \ properties)\\ &\text{人体主轴特征:}~\theta=atan2(2b, a-c+sqrt) \end{aligned} \right. $$ (1) 其中, $regionprops$和$atan2$分别为Matlab中度量图像区域属性和四象限反正切函数.我们通过判断学生人体$x$轴质心特征, 人体$y$轴质心特征和人体主轴特征是否偏离原点位置来判定其是否处于端坐状态, 如果处于端坐状态, 则记录端坐时的面积特征, 并将端坐时的四维特征作为基准, 当学生四维特征信息出现变化时, 再去判断其处于哪种状态.从目标提取中, 我们得到了最大连通域, 然后使用基于空间分布特征的多连通域融合算法来计算四维特征信息中的人体的质心位置, 人体的面积和人体主轴信息[18].
1) 人体质心特征($X, Y$)
对于质心, 可以认为得到的二值图像或者灰度图像是一个二维的密度分布函数.对于一个二维连续函数$f(x, y)$, 其零阶矩$M_{00}$和一阶矩$M_{10}$、$M_{01}$分别为
$$ \begin{split} M_{00}&=\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}f(x, y){\rm d}x{\rm d}y\\ M_{10}&=\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}xf(x, y){\rm d}x{\rm d}y\\ M_{01}&=\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}yf(x, y){\rm d}x{\rm d}y\\ \end{split} $$ (2) 则得到人体的质心为:
$$ X=\frac{M_{10}}{M_{00}}, \quad Y=\frac{M_{01}}{M_{00}} $$ (3) 其中, ($X, Y$)为目标人体的质心坐标.
2) 学生人体主轴方向变化特征$\theta$
对中心矩进行归一化操作:
$$ \mu_{pq}=N_{pq}=\frac{M_{pq}}{M_{00}^r}, \quad r=\frac{p+q}{2}+1 $$ (4) 然后利用:
$$ f(x)=\begin{cases} a = \dfrac{\mu_{20}}{\mu_{00}}\\[3mm] b = \dfrac{\mu_{11}}{\mu_{00}}\\[3mm] c = \dfrac{\mu_{02}}{\mu_{00}} \end{cases} $$ (5) 得到
$$ \begin{cases} sqrt=\sqrt{4b^2-(a-c)^2}\\ \theta=atan2(2b, a-c+sqrt) \end{cases} $$ (6) 其中, $\theta$是学生人体主轴方向与垂直方向的夹角, 以作为人体主轴变化特征.
3) 面积特征$S$
将得到的连通域进行标记, 而标记的方法有很多种, 有的算法可以一次遍历图像完成标记, 有的则需要2次或更多次遍历图像, 这样也就造成了不同的算法效率的差异.
我们使用$bwlabel$和$regionprops$算子对连通域进行操作. $bwlabel$算子是二值图像中的标签连接组件, 式(7)返回一个标签矩阵, 其中变量$n$表示的是指定的连接方向数量, 而$num$表示的是在图像$BW$中发现的连接对象的数量.
$$ \label{equ_bwla} [L, num]=bwlabel(BW, n) $$ (7) 而regionprops算子是一个度量图像区域属性的函数, 式(8)返回的是标签矩阵$L$中每个标记区域的特征值.
$$ STATS=regionprops(L, properties) $$ (8) 在得到的标记矩阵STATS中, 不同的数字代表着不同的区域, 面积标记矩阵如式(9)所示, 然后累加最大域中的值就可以得到人体面积特征$S$.
$$ \begin{bmatrix} 1 & 1 &1 & 1 &1 & 1 &1 \\ 1 & 1 &1 & 1 &1 & 1 &1 \\ 1 & 1 &1 & 1 &1 & 1 &1 \\ 1 & 1 &1 & 1 &1 & 1 &1 \\ 1 & 1 &1 & 1 &1 & 1 &1 \\ 0 & 1 &1 & 1 &1 & 1 &1 \\ 0 & 0 &0 & 0 &0 & 0 &0 \\ 0 & 0 &0 & 0 &0 & 0 &0 \\ 0 & 0 &0 & 0 &0 & 0 &0 \\ 0 & 0 &0 & 0 &0 & 0 &0 \\ 0 & 0 &0 & 0 &0 & 0 &0 \end{bmatrix} $$ (9) 2. 基于改进D-S方法的学生注意力模型分析与决策
随着网络时代的到来, 人们生活中信息的形式、数量、复杂度都大大增加, 因此对信息处理的及时性、准确性的要求也越来越高.数据融合是指通过对多个同质或异质传感器获得的数据进行有机结合, 最后给出检测结果.其实信息融合存在于我们生活中的方方面面, 例如人类将各种感觉器官(眼、耳、鼻)所探测到的(图像、声音、气味)信息与先验知识进行综合, 得出对周围的环境综合判断, 以决定接下来的行动[19].本文在信息融合时选用改进的D-S算法来处理得到的信息, 先获取人体四维特征信息, 之后采用"基本概率赋值法"对每个焦元进行概率赋值, 最后对特征信息进行融合, 从而计算出学生人体行为框架中每个状态的概率分配[20].
2.1 人体行为框架的建立及基本概率赋值
根据学生在线网络学习时可能出现的行为状态, 结合专家经验和理论常识, 我们将人体识别框架设定为$\Omega=\{$左顾右盼, 埋头, 端坐, 不确定$\}$ 4种行为状态, 分别用$h_1$, $h_2$, $h_3$和$U$来表示, 3种人体行为如图 3所示.
接下来为每一个证据体进行概率赋值, 基本概率赋值是相关领域专家依据自身经验和已有知识对整个识别框架中不同证据进行不同归纳判断而得到的, 其中含有很强的个人主观性, 所以不同专家对于同一个证据不可能给出完全一样的基本概率分配, 有时差别会很大.
在本文中我们将人体的$X$轴质心变化, $Y$轴质心变化, 面积变化和角度变化作为4个独立的证据体: $M=\{X, Y, S, \theta\}$, 用$X, Y, S, \theta$分别表示当前时刻目标人体的$X$轴坐标值, $Y$轴坐标值, 面积和主轴角度, 当人体行为出现变化时, 为了定性地给4个证据体赋值, 我们在每个证据体的曲线中分别选择两个阈值, 分别计算4个证据体($X, Y, S, \theta$)每条曲线在阈值外和阈值内所占的百分比, 像图 4所示的那样, 再使用式(10) $\sim$式(14), 就可以得到人体辨识框架中每一部分的基本概率赋值.
当人体处于端坐状态时, 4个证据体的数值基本保持不变; 当人体左顾右盼时, 人体的质心坐标和方向会不断发生变化; 当人埋头时, 人体的$Y$轴质心坐标会发生变化, 同时人体的面积也会显著减小.结合学生在授课时的行为状态, 本文提出一种新的基本概率赋值方法-四维基本概率赋值法, 该方法不仅充分利用了4种证据体所包含的信息, 也在很大程度上提高了D-S决策的准确率, 同时又避免了分析单一证据所得结果的不完整性和片面性.
四维基本概率赋值法公式如下所示, 其中用$X_{threshold1}$和$X_{threshold2}$分别表示$X$轴质心变化的上下阈值, $Y, S, \theta$的上下阈值依次类推, $S_{threshold3}$为一个很小的值, 代表学生不在画面中时人体的面积, 为防止光照, 背景等因素的干扰, 这里不设定为0, 而设定为一个很小的值.
$$ \label{equ_prob1}\left\{ \begin{aligned} &\text{若}\quad X > X_{threshold1} \text{或}\ X < X_{threshold2}, \\ &\quad \text{左顾右盼的次数+1}\\ &\text{否则}, \quad \text{埋头的次数+0.5}, \quad \text{端坐的次数+0.5} \end{aligned} \right. $$ (10) $$ \left\{ \begin{aligned} &\text{若}\quad Y > Y_{threshold1} \text {或} \ Y < Y_{threshold2}, \\ &\quad \text{埋头次数+1} \\ &\text{否则}, \quad \text{左顾右盼次数+0.5}, \quad \text{端坐的次数+0.5} \end{aligned} \right. $$ (11) $$ \left\{ \begin{aligned} &\text{若}\quad S > S_{threshold1} \text {或} \ S < S_{threshold2}, \\ &\quad \text{埋头次数+1}\\ &\text{否则}, \quad \text{左顾右盼次数+0.5}\quad \text{端坐次数+0.5} \end{aligned} \right. $$ (12) $$ \label{equ_prob2} \left\{ \begin{aligned} &\text{若}\quad \theta>\theta_{threshold1} \text {或} \ \theta < \theta_{threshold2}, \\ &\quad \text{左顾右盼次数+0.5}, \quad \text{埋头次数+0.5}\\ &\text{否则}, \quad \text{端坐次数+1} \end{aligned} \right. $$ (13) $$ \left\{ \begin{aligned} &\text{若}\ (X > X_{threshold1} \text {或} \ X < X_{threshold2}) \\ & \text{且} ~(Y > Y_{threshold1} \text {或} \ Y < Y_{threshold2})\\ & \text{且} ~(S > S_{threshold1} \text {或} \ S < S_{threshold2})\\ & \text{且} ~(\theta > \theta_{threshold1} \text{或}\ \theta < \theta_{threshold2})\\ & \text{或} ~(S < S_{threshold3}), \\ & \text{不确定次数+1} \\ \end{aligned} \right. $$ (14) 2.2 D-S人体信息融合模型
D-S证据理论是关于证据和可能性推理的理论, 它主要处理证据加权和证据支持度问题, 并且利用可能性推理来实现证据的组合.随着信息融合的发展, 我们融合的对象不再局限于传感器获取的数据和信息, 而是可拓广到各种方法, 专家经验甚至思想等.
我们将从实验中得到的学生的学习视频一共分为$n$个部分, 针对实验过程中收集到的4个证据体$ \{X, Y, S, \theta\}$, 首先计算当前帧中每个证据体的概率值, 即判断4个证据体的变化是否有超出设定的阈值, 得到每一帧中每个证据体对每种行为框架(端坐、左顾右盼、埋头和不确定)的概率分配值, 在实验中$m(h_{1jk}), m(h_{2jk}), m(h_{3jk}), m(h_{4jk})$分别表示$X$轴质心坐标变化, $Y$轴质心坐标变化, 面积变化以及角度变化4个证据体的值, $j$表示第$j$个人体框架($1\leq j\leq m$), $k$表示第$k$个周期($1\leq k\leq n$).
然后将每个证据体对每种框架的概率值进行空间域上的融合, 即每个周期中传感器之间的融合.在这里是指融合4个证据体对每种行为框架概率值, 就可以得到在每个周期中4种人体框架的概率值, 如式(15)所示:
$$ \begin{split} &m(h_{jk})=\\ &\frac{1}{K}\sum\limits_{h_{1jk}\cap \cdots \cap h_{4jk}=h_{jk}}m(h_{1jk})m(h_{2jk})m(h_{3jk})m(h_{4jk}) \end{split} $$ (15) 其中, $K$是归一化因子.
$${\small \begin{split} K&=\sum\limits_{h_{1jk}\cap \cdots \cap h_{4jk}\neq \emptyset}m(h_{1jk})m(h_{2jk})m(h_{3jk})m(h_{4jk})=\\ &1-\sum\limits_{h_{1jk}\cap \cdots \cap h_{4jk} =\emptyset}m(h_{1jk})m(h_{2jk})m(h_{3jk})m(h_{4jk}) \end{split}} $$ (16) 最后将各个时间段内4种框架的概率值进行时间域上的融合, 即进行周期之间的融合, 得到最后的时空融合结果.也就得到了最终的4种坐姿的概率分配$m(k)$, 经过比较大小就可以判断出在这个时间段中人体的坐姿情况, 计算过程如式(17)所示:
$$ \begin{split} &m(h_j)=m(h_{j1})\oplus m(h_{j2})\oplus \cdots \oplus m(h_{jk})=\\ &\qquad\frac{1}{K}\sum\limits_{h_{j1}\cap h_{j2}\cap \cdots \cap h_{jn}=h_j}m(h_{j1})m(h_{j2})\cdots m(h_{jn}) \end{split} $$ (17) 同理, $K$是归一化因子.
在本文中取$m=4, n=3$, 最后得到的融合结果是学生在听课这一段时间中的行为评价结果, 可以用该结果作为学生学习状态评价的一个初步依据.
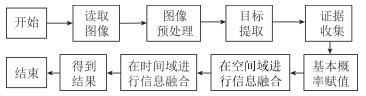
智能教室中学生行为分析与推理决策模型的实验流程图如图 5所示.
3. 实验结果和分析
在实验中, 我们使用笔记本电脑的摄像头对学生的行为进行录像跟踪, 之后对视频进行图像处理得到4个证据体的关键信息, 然后使用D-S证据理论对信息融合后决策.实验中的电脑使用Inter Core i7 4720处理器和8 GB内存, 摄像头参数为:尺寸大小640 $\times$ 480, 采样频率为30 fps, 使用的软件环境为MATLAB 2016a.
首先我们对三种典型的行为进行了实验, 并且将实验中得到的视频按照上面所说的方法分为三部分, 先在每一部分进行空间域的融合, 得到的结果再进行时间域的融合以获得最终的结果.
3.1 学生端坐状态实验
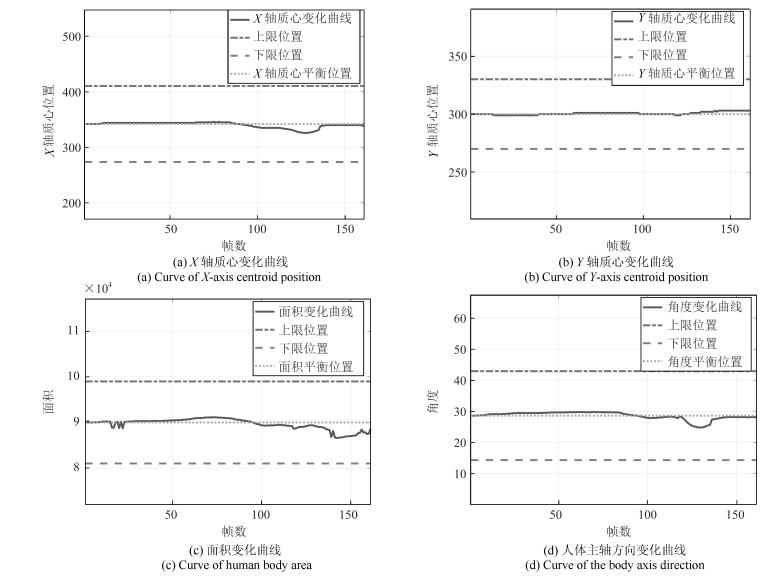
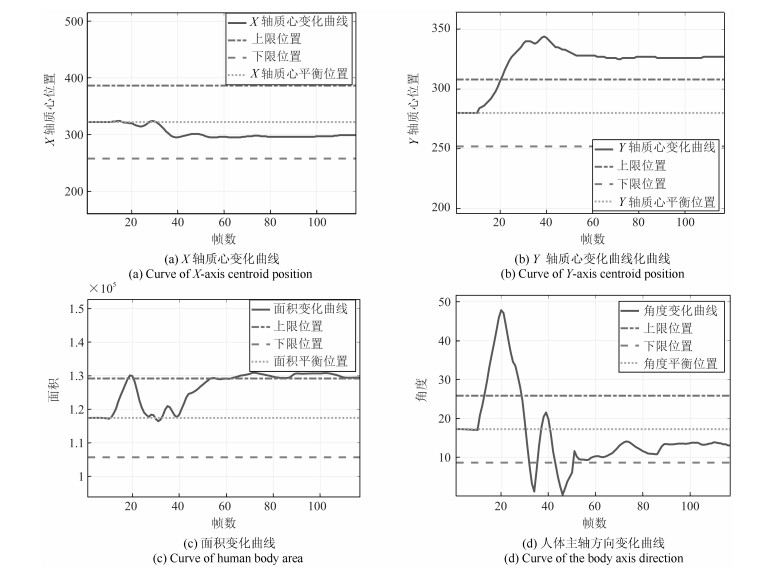
在这个实验中, 我们模拟了学生专心学习的场景, 学生大部分时间处于端坐状态, 我们得到视频中的关键帧如图 6所示.同时得到实验的4条曲线如图 7.
计算每一部分的基本概率赋值我们可以得到表 1, 其中$m(h_{ijk})$代表第$i$个证据体($X$轴质心特征, $Y$轴质心特征, 面积特征, 角度特征)在第$k$个周期($k=1, 2, 3$)对第$j$个人体识别框架(左顾右盼、埋头、端坐和不确定)的基本概率赋值.将表 1中学生端坐时各个阶段每个证据体对每种人体行为框架的基本概率值进行空间域的融合可以得到表 2, 即得到了三个周期中每种人体行为框架的概率值.
表 1 端坐时的基本概率赋值Table 1 The probability distributions when sit up$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0 0.4444 0.4444 0.1112 $m(h_{1j2})$ 0 0.4528 0.4528 0.0944 $m(h_{1j3})$ 0 0.4528 0.4528 0.0944 $m(h_{2j1})$ 0.4444 0 0.4444 0.1112 $m(h_{2j2})$ 0.4528 0 0.4528 0.0944 $m(h_{2j3})$ 0.4528 0 0.4528 0.0944 $m(h_{3j1})$ 0.4444 0 0.4444 0.1112 $m(h_{3j2})$ 0.4528 0 0.4528 0.0944 $m(h_{3j3})$ 0.4528 0 0.4528 0.0944 $m(h_{4j1})$ 0 0 0.8888 0.1112 $m(h_{4j2})$ 0 0 0.9056 0.0944 $m(h_{4j3})$ 0 0 0.9056 0.0944 表 2 空间域融合后的结果Table 2 The results of fusion in the spatial domain$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.0191 0.0036 0.9773 0 $m(h_{j2})$ 0.0142 0.0023 0.9834 0 $m(h_{j3})$ 0.0142 0.0023 0.9834 0 之后将表 2中三个周期每个证据体的概率值进行时间域上的融合, 即进行周期之间的融合, 得到$m(h_1)=4.1001\times10^{-6}, m(h_2)=2.1133\times10^{-8}, m(h_3)=0.9999, m(U)=4.7766\times10^{-24}$, 已知$m(h_3)>m(h_1)>m(h_2)>m(U)$, 所以最终的决策结果是$h_3$.即学生在这段时间基本处于端坐状态, 这和我们的认知是符合的.也说明课程相对比较轻松有趣, 学生学习比较认真, 授课者需要继续保持这种授课模式, 相关机构可以认为员工在线培训比较成功.
为了验证"四维特征信息模型"提取的有效性, 在本次实验中我们还做了三组对比实验.实验1采用$X$轴质心变化和$Y$轴质心变化二维特征来判断学生的专注度, 它作为本实验的$baseline$; 实验2采用$X$轴质心变化, $Y$轴质心变化和面积变化来判断学生在这段时间的学习行为; 实验3采用本文提出的"四维特征信息模型"对学生的行为进行判断.实验结果如表 3所示.
表 3 多维特征信息融合结果对比Table 3 Comparison of multi-dimensional feature information fusion results实验方法 实验结果 $m(h_{1})$ $m(h_{2})$ $m(h_{3})$ $m(U)$ $X+Y(baseline)$ 0.0042 0.0042 0.9916 0 $X+Y+S$ 0.0042 0 0.9958 0 $X+Y+S+\theta$ 0 0 0.9999 0 从实验结果可以看出, 采用"四维特征信息模型"可以有效提高结果的准确率, 减少其他状态的干扰, 使结果更具有信服力.
3.2 学生左顾右盼状态实验
在这个实验中, 学生一直在左顾右盼, 我们得到视频中的关键帧如图 8所示.
我们同时得到学生人体特征变化的四条曲线如图 9.
和端坐时一样, 计算每一部分的基本概率赋值我们可以得到该实验的基本概率赋值如表 4.
表 4 左顾右盼状态的基本概率赋值Table 4 The probability distributions when look around$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0 0.4442 0.4442 0.1116 $m(h_{1j2})$ 0.6271 0.1394 0.1394 0.0942 $m(h_{1j3})$ 0.9058 0 0 0.0942 $m(h_{2j1})$ 0.4442 0 0.4442 0.1116 $m(h_{2j2})$ 0.4529 0 0.4529 0.0942 $m(h_{2j3})$ 0.0784 0.7490 0.0784 0.0942 $m(h_{3j1})$ 0.4442 0 0.4442 0.1116 $m(h_{3j2})$ 0.4529 0 0.4529 0.0942 $m(h_{3j3})$ 0.4529 0 0.4529 0.0942 $m(h_{4j1})$ 0.0261 0.0261 0.8361 0.1116 $m(h_{4j2})$ 0.3135 0.3135 0.2787 0.0942 $m(h_{4j3})$ 0.4529 0.4529 0 0.0942 同理, 将表 4中学生左顾右盼时的基本概率值进行空间域的融合可以得到表 5.
表 5 空间域融合后的结果Table 5 The results of fusion in the spatial domain$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.0249 0.0047 0.9704 0 $m(h_{j2})$ 0.7743 0.0047 0.2210 0 $m(h_{j3})$ 0.9228 0.0681 0.0091 0 之后进行时间域上的融合, 得到$m(h_1)=0.9013, m(h_2)=7.7065\times 10^{-5}, m(h_3)= 0.0987, m(U)=4.4837\times 10^{-21}$, 已知$m(h_1)>m(h_3)>m(h_2)>m(U)$, 所以最终的决策结果是$h_1$, 即学生在这段时间经常左右摇晃, 可以认为学生学习不认真, 可能是这节慕课课程没有太大的吸引力, 有点枯燥乏燥, 授课者应注意改善授课质量, 也可能是因为学生学习态度不认真, 培训机构可以提醒相应员工经过后期检查决定该员工是否需要重新学习, 以取得良好的学习效果.
3.3 学生埋头状态实验
在这个实验中, 学生处于埋头状态, 我们得到视频中的关键帧如图 10所示.我们得到实验的四条曲线如图 11所示.
计算每一部分的基本概率赋值我们可以得到该实验的基本概率赋值如表 6.
表 6 埋头时的基本概率赋值Table 6 The probability distributions when head drop$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0 0.4500 0.4500 0.1000 $m(h_{1j2})$ 0 0.4500 0.4500 0.1000 $m(h_{1j3})$ 0 0.4500 0.4500 0.1000 $m(h_{2j1})$ 0.2308 0.4385 0.2308 0.1000 $m(h_{2j2})$ 0 0.9000 0 0.1000 $m(h_{2j3})$ 0 0.9000 0 0.1000 $m(h_{3j1})$ 0.4269 0.0462 0.4269 0.1000 $m(h_{3j2})$ 0.2308 0.4385 0.2308 0.1000 $m(h_{3j3})$ 0 0.9000 0 0.1000 $m(h_{4j1})$ 0.2308 0.2308 0.4385 0.1000 $m(h_{4j2})$ 0.0923 0.0923 0.7154 0.1000 $m(h_{4j3})$ 0 0 0.9000 0.1000 将表 6中学生埋头时的基本概率值进行空间域的融合可以得到表 7.
表 7 空间域融合后的结果Table 7 The results of fusion in the spatial domain$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.0658 0.2048 0.7294 0 $m(h_{j2})$ 0.0020 0.8131 0.1848 0 $m(h_{j3})$ 0 0.9221 0.0778 0 之后进行时间域上的融合, 得到$m(h_1)=3.8405\times10^{-8}, m(h_2)=0.9360, m(h_3)= 0.0640, $$m(U)=7.0128\times 10^{-21}$, 已知$m(h_2)>m(h_3)>$ $m(h_1)>m(U)$, 所以最终的决策结果是$h_2$.即学生在这段时间大部分处于埋头状态, 可以推测学生在这段时间并没有听课, 而是爬在桌子上, 可能学生这段时间比较疲惫, 也可能这节慕课课程太枯燥乏味, 慕课平台应着重审核该课程是否符合慕课上线标准, 如果该学生属于个例, 培训机构应要求该学生重新学习这门课程, 以达到培训的目的.
3.4 复杂状态实验1
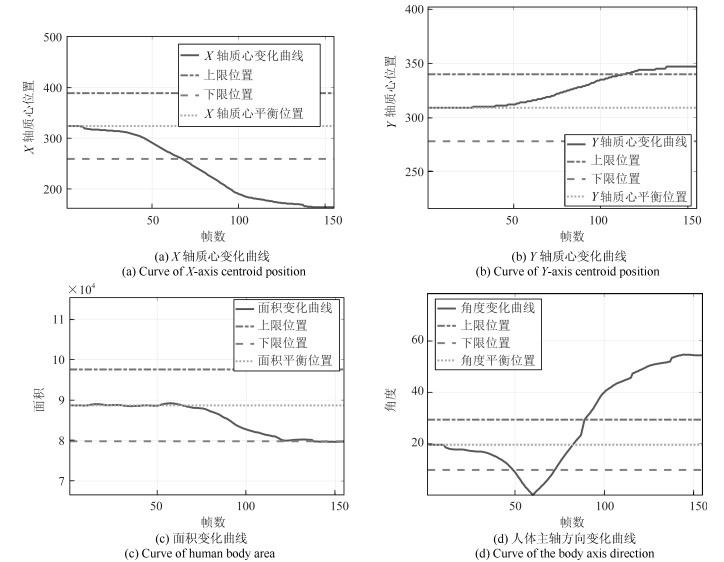
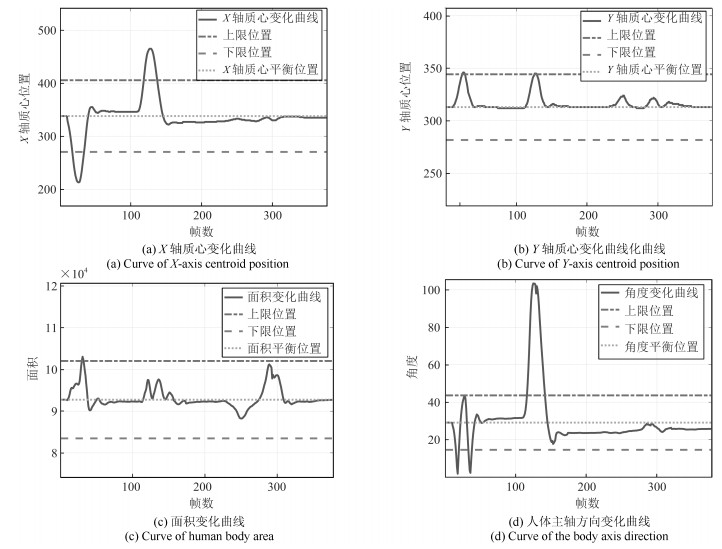
在这个实验中, 我们模拟了学生处于正常学习时的状态, 在这段时间里, 学生一共左顾右盼了2次, 埋头了2次, 但基本上是处于端坐的学习状态.实验中的关键帧序列如图 12所示, 我们同样获得曲线图如图 13.
计算每一部分的基本概率赋值我们可以得到该实验的基本概率赋值如表 8.
表 8 证据体的基本概率赋值(复杂状态实验1)Table 8 Basic probability distribution of evidence bodies (Complex condition 1)$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0.1719 0.3617 0.3617 0.1048 $m(h_{1j2})$ 0.0859 0.4082 0.4082 0.0976 $m(h_{1j3})$ 0 0 0.4512 0.0976 $m(h_{2j1})$ 0.4333 0.0286 0.4333 0.1048 $m(h_{2j2})$ 0.4405 0.0215 0.4405 0.0976 $m(h_{2j3})$ 0.4512 0 0.4512 0.0976 $m(h_{3j1})$ 0.4369 0.0215 0.4369 0.1048 $m(h_{3j2})$ 0.4515 0 0.4512 0.0976 $m(h_{3j3})$ 0.4512 0.0430 0.4512 0.0976 $m(h_{4j1})$ 0.0645 0.0645 0.7663 0.1048 $m(h_{4j2})$ 0.0573 0.0573 0.7878 0.0976 $m(h_{4j3})$ 0 0 0.9024 0.0976 将表 8中学生各个状态的基本概率值进行空间域上的融合后, 可以得到表 9.
表 9 空间域融合后的结果(复杂状态实验1)Table 9 Results of fusion in the spatial domain (Complex condition 1)$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.1003 0.0087 0.8910 0 $m(h_{j2})$ 0.0567 0.0056 0.9377 0 $m(h_{j3})$ 0.0151 0.0026 0.9823 0 之后进行时间域上的融合, 得到$m(h_1)=1.0477\times 10^{-4}, m(h_2)=1.5324\times 10^{-7}, m(h_3)= 0.9999, m(U)=1.6917\times 10^{-23}$, 已知$m(h_3)>m(h_1)>m(h_2)>m(U)$, 所以最终的决策结果是$h_3$.本次实验模拟了学生处于真实状态下的学习情况, 学习时间比较长, 里面包括了左顾右盼、埋头、端坐等各种姿态, 最终结论学生处于端坐状态, 即在这段时间内学生虽然有几次走神情况, 但基本上在专心学习, 可以得出学生在这段时间学习比较认真的结论.
3.5 复杂状态实验2
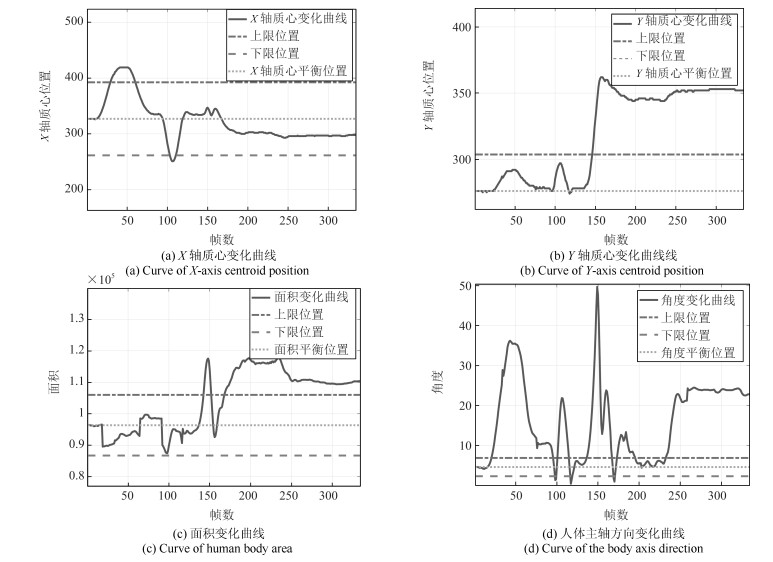
在这个实验中, 我们模拟了学习时的另一种情况, 在这段时间里, 学生长时间的处于埋头的情况, 并且有时身体处于倾斜状态.实验的关键帧序列如图 14所示, 我们同样获得曲线图如图 15.
计算每一部分的基本概率赋值可以得到该实验的基本概率赋值如表 10.将表 10中学生各个状态的基本概率值进行空间域上的融合后, 得到表 11.
表 10 证据体的基本概率赋值(复杂状态实验2)Table 10 Basic probability distribution of evidence bodies (Complex condition 2)$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0.3027 0.2951 0.2951 0.1027 $m(h_{1j2})$ 0 0.4487 0.4487 0.1027 $m(h_{1j3})$ 0 0.4527 0.4527 0.0946 $m(h_{2j1})$ 0.4487 0 0.4487 0.1027 $m(h_{2j2})$ 0.1415 0.6144 0.1455 0.1027 $m(h_{2j3})$ 0 0.9054 0 0.0946 $m(h_{3j1})$ 0.4487 0 0.4487 0.1027 $m(h_{3j2})$ 0.1900 0.5174 0.1900 0.1027 $m(h_{3j3})$ 0 0.9054 0 0.0946 $m(h_{4j1})$ 0.3557 0.3557 0.1859 0.1027 $m(h_{4j2})$ 0.2425 0.2425 0.4123 0.1027 $m(h_{4j3})$ 0.4123 0.4123 0.0808 0.0946 表 11 空间域融合后的结果(复杂状态实验2)Table 11 Results of fusion in the spatial domain (Complex condition 2)$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.6109 0.0162 0.3728 0 $m(h_{j2})$ 0.0164 0.7998 0.1837 0 $m(h_{j3})$ 0.0001 0.9973 0.0026 0 再进行时间域上的融合, 得到$m(h_1)=8.3532\times 10^{-5}, m(h_2)=0.9863, m(h_3)= 0.0136, m(U)=1.0782\times 10^{-21}$, 已知$m(h_2)>m(h_3)>m(h_1)>m(U)$, 所以最终的决策结果是$h_2$.本次复杂实验2模拟了学生处于疲劳状态下的学习情况, 里面包括了左顾右盼、埋头、端坐等各种姿态, 最终结论是学生处于埋头状态.即学生在这段时间虽然有学习的时候, 但总体来看, 大部分时间处于埋头状态, 所以认定该学生没有认真学习.
3.6 与基于贝叶斯方法的行为分析与推理决策的比较
贝叶斯方法由英国学者贝叶斯(T. Bayes 1701 $\sim$ 1761)提出的贝叶斯公式发展而来.贝叶斯公式在形式上是对条件概率的定义和全概率公式的一个简单的归纳和推理.设$A$为样本空间$\Omega$中的一个事件, $B_1, B_2, \cdots, B_n$ ($n$为有限或无穷)是样本空间$\Omega$中的一个完备事件群, 且有${\rm P}(B_i)>0~(i=1, 2, \cdots, n)$, ${\rm P}(A)>0$, 则事件$A$的全概率公式可写为式(18).
$$ {\rm P}(A)={\rm P}\left(\sum\limits_{i=1}^nAB_i\right)=\sum\limits_{i=1}^n{\rm P}(A|B_i){\rm P}(B_i) $$ (18) 在全概率公式的条件下, 按照条件概率, 贝叶斯公式可以表示为式(19)
$$ {\rm P}(B_i|A)=\frac{{\rm P}(A|B_i){\rm P}(B_i)}{{\rm P}(A)}=\frac{{\rm P}(A|B_i){\rm P}(B_i)}{\sum\limits_{i=1}^n{\rm P}(A|B_i){\rm P}(B_i)} $$ (19) 3.6.1 对比实验1
在这个实验中, 我们使用第3.4节, 也就是复杂状态实验1的实验数据.
先验概率是指缺乏某个事实的情况下描述一个变量.在这里的先验概率是指在不知道视频中学生$X, Y, S, \theta$变化量的情况下, 而根据专家经验估计学生出现左顾右盼、埋头和端坐的概率.通过观察视频中的学生状态并和多位有经验的教师分析讨论, 我们设定: ${\rm P}(h_1^*)=0.2, {\rm P}(h_2^*)=0.1, {\rm P}(h_3^*)=0.7$.
似然函数是指在已知某些观测所得到的结果时, 对有关事物性质的参数进行估计, 即在给定输出$h$时, 关于参数$M$的似然函数${\rm P}(M|h)$, 它(在数值上)等于已知观察结果$h$前提下给定参数$M$的发生的条件概率.例如抛10次硬币都为正面朝上的概率, 那硬币正反面对称(也就是正反面概率均为0.5的概率)的似然程度是多少.在本文中我们有4个证据体$M~(X$、$Y$、面积$S$、角度$\theta$), 人体框架中有三个状态$h$ (左顾右盼、埋头、端坐), 根据理论常识结合多次实验我们发现, 当左顾右盼($h_1$)时, $X$轴质心和角度一定会发生较大的变化, 所以这里我们赋予${\rm P}(X|h_1)=0.4$和${\rm P}(\theta|h_1)=0.45$较大的概率, 而$Y$轴方向上的质心和学生的面积可能不会太大的变化, 所以我们设定${\rm P}(Y|h_1)=0.1$和${\rm P}(S|h_1)=0.05$.同样的道理, 我们设定:
$$ \begin{align}&{\rm P}(X|h_2)=0.05, {\rm P}(Y|h_2)=0.55 \\&{\rm P}(S|h_2)=0.35, {\rm P}(\theta|h_2)=0.05\\&{\rm P}(X|h_3)=0.25, {\rm P}(Y|h_3)=0.25 \\&{\rm P}(S|h_3)=0.25, {\rm P}(\theta|h_3)=0.25\end{align} $$ 后验概率是指考虑了一个事实之后的条件概率, 它通过贝叶斯公式, 用先验概率和似然函数计算出来.根据以上的分析, 并根据贝叶斯公式(19), 那么后验概率为:
$$ \begin{align} &{\rm P}(h_1|X)=\frac{{\rm P}(X|h_1){\rm P}(h_1^*)}{\sum\limits_{i=1}^3{\rm P}(X|h_i){\rm P}(h_i^*)}=0.3077 \\&{\rm P}(h_1|Y)=0.0800, \ {\rm P}(h_1|S)=0.0455\\&{\rm P}(h_1|\theta)=0.3333 \end{align} $$ 同理得到:
$$ \begin{align}&{\rm P}(h_2|X)=0.0192, \ {\rm P}(h_2|Y)=0.22\\& {\rm P}(h_2|S)=0.1591, \ {\rm P}(h_2|\theta)=0.0185 \\&{\rm P}(h_3|X)=0.6731, \ {\rm P}(h_3|Y)=0.7000\\&{\rm P}(h_3|S)=0.7954, \ {\rm P}(h_3|\theta)=0.6482\end{align} $$ 从复杂状态实验1的实验数据中, 结合式(10) $\sim$ (14), 我们可以得到, 在这段时间内, $X$轴质心变化的帧数为36, $Y$轴质心变化的帧数为7, 面积变化的帧数为3, 角度变化的帧数为35.所以${\rm P}(X)=0.4444, {\rm P}(Y)=0.0864, {\rm P}(S)=0.0370, {\rm P}(a)=0.4321$.
再根据全概率公式, 本次实验中左顾右盼的概率为:
$$ \begin{align} {\rm P}(h_1)= &\sum\limits_{j=1}^4{\rm P}(h_1|M_j){\rm P}(M_j)=\\ &\sum\limits_{j=1}^4{\rm P}(h_1|M_{j})\sum\limits_{i=1}^3{\rm P}(M_j|h_i){\rm P}(h_i^*)=\\ &\sum\limits_{j=1}^4\sum\limits_{i=1}^3{\rm P}(h_1|M_j){\rm P}(M_j|h_i){\rm P}(h_i^*)=\\ &0.2894 \end{align} $$ 其中, ${\rm P}(M_j)$表示的是4个证据体($X$轴质心坐标、$Y$轴质心坐标、面积和角度)发生变化的概率.
同样的方法, 我们可以得到埋头的概率为:
$$ \begin{split} {\rm P}(h_2)=\sum\limits_{j=1}^4{\rm P}(h_2|M_j){\rm P}(M_j)=0.0415 \end{split} $$ 端坐的概率为:
$$ \begin{split} {\rm P}(h_3)=\sum\limits_{j=1}^4{\rm P}(h_3|M_j){\rm P}(M_j)=0.6692 \end{split} $$ 根据上面得到的概率值, 我们可以得到这段时间学生处于端坐状态, 可以推测其学习比较认真.
为了证明不同的先验概率对最后决策结果的影响, 这里加入另一组先验概率下的决策推断.设定${\rm P}(h_1^{*})=0.3, {\rm P}(h_2^{*})=0.1, {\rm P}(h_3^{*})=0.6$.最终得出的${\rm P}(h_1)=0.3805, {\rm P}(h_2)=0.0534, {\rm P}(h_3)=0.5662$.从结果可以看出不同的先验概率, 虽然会影响最终的概率值, 但不会影响最终的决策结果.
3.6.2 对比实验2
在这个实验中, 我们使用第3.5节也就是复杂状态实验2的实验数据.根据专家经验估计并通过观察视频中的学生状态并和多位有经验的教师分析讨论, 我们设定先验概率为${\rm P}(h_1^{*})=0.2, {\rm P}(h_2^{*})=0.65, {\rm P}(h_3^{*})=0.15$.由于在抛硬币时, 不管第几次抛, 何时抛, 硬币正反面对称(也就是正反面概率均为0.5的概率)的似然程度是不变的, 所以本次实验的似然函数仍采用对比实验1中的值.
有了先验概率和似然函数, 根据贝叶斯公式, 那么后验概率为:
$$ \begin{align} &{\rm P}(h_1|X)=0.5333, {\rm P}(h_1|Y)=0.0482\\ &{\rm P}(h_1|S)=0.0364, {\rm P}(h_1|A)=0.5625\\ &{\rm P}(h_2|X)=0.2167, {\rm P}(h_2|Y)=0.8614 \\ \;\;\\ &{\rm P}(h_2|S)=0.8273, {\rm P}(h_2|A)=0.2031\\ &{\rm P}(h_3|X)=0.2500, {\rm P}(h_3|Y)=0.0904\\ &{\rm P}(h_3|S)=0.1364, {\rm P}(h_3|A)=0.2344 \end{align} $$ 通过实验数据我们得到:
$$ \begin{split} &{\rm P}(X)=0.0583, {\rm P}(Y)=0.2883\\ &{\rm P}(S)=0.2699, {\rm P}(A)=0.3834 \end{split} $$ 最后根据全概率公式, 得到:
$$ \begin{split} &{\rm P}(h_1)=0.2705, {\rm P}(h_2)=0.5622\\ &{\rm P}(h_3)=0.1673 \end{split} $$ 在表 12中我们比较了使用D-S证据理论和贝叶斯方法得到的结果, 可以发现和使用贝叶斯方法相比, 使用D-S理论可以降低推理过程中的不确定性, 同时使用D-S方法得到的结果也与我们的认知更为相符.
表 12 D-S推理方法和贝叶斯推理方法的对比Table 12 Comparison of D-S inference and the Bayesian inference methods对比实验 理论方法 $h_1$ $h_2$ $h_3$ $U$ 对比实验1 D-S理论 0.0001 0 0.9999 0 贝叶斯方法 0.2894 0.0415 0.6692 - 对比实验2 D-S理论 0.0001 0.9863 0.0136 0 贝叶斯方法 0.2705 0.5622 0.1673 - 从表 12中的数据我们可以看出, D-S理论方法比贝叶斯方法具有更高的决策支持.在对比实验1中, D-S理论得出的结果相对于贝叶斯理论方法提高了$\frac{0.9999-0.6692}{0.6692}\times100 \%=49.42\, \%$的决策支持; 而在对比实验2中, 相对于贝叶斯方法, D-S理论更是提高了$\frac{0.9863-0.5622}{0.5622}\times100\, \%=75.44\, \%$的决策支持, 贝叶斯方法过多地依赖于先验概率和经验常识, 使用D-S理论可以更好地处理得到的人体信息, 并完成决策推理工作.与贝叶斯方法的对比实验表明, 使用D-S理论可以大幅度降低决策中的不确定性, 同时得到的决策结果也与我们的认知更加符合.
4. 结论
为了解决在线课程授课过程中, 缺乏对于学生学习情况的跟踪与教学效果评估问题, 本文依据视频信息对学生注意力进行建模, 并提出了一种评判学生听课专心程度的行为自动分析算法.该算法能够有效跟踪学生的学习状态, 提取学生的行为特征参数, 并对这些参数进行D-S融合判决, 以获得学生的听课专注度.经过多次实验的结果表明, 本文采用的方法能够有效评判学生在授课期间的专心程度, 对每一种行为的识别率可以达到$95\, \%$以上.在融合决策中, 与贝叶斯推理方法相比, 采用D-S融合评判的准确度更高.
本文还存在着分类的种类较为简单, 不能完全概括网络在线授课中学生的学习状态的不足.对此, 可以扩充人体行为的分类方式, 尝试加入模糊隶属度函数, 在多种分类的情况下, 对人体的行为进行分析和判断, 得到更为完备的人体辨识框架.这也是本研究后续的工作方向.
-

图 1 文中总结的不同方法及其解决的主要问题
Fig. 1 Different methods summarized in this article and the main issues they address
表 1 基于视觉的动作质量评价方法不同阶段的主要任务及存在的问题
Table 1 Main tasks and existing challenges in different stages of vision-based motion quality assessment
阶段 主要任务 存在的问题 动作数据获取 通过视觉传感器来收集和记录与动作相关的数据(RGB、深度图、骨架序列) 如何根据不同的应用场景选择适用的数据模态? 如何确保专家的评分质量? 动作特征表示 综合利用静态图像和人体动作等多方面信息, 设计具有区分性的特征向量以描述人体的运动过程 如何根据动作质量评价任务本身的特性学习具有强鉴别性的动作特征, 以有效地抽取和表示不同运动者在执行相同动作时的细微差异? 动作质量评价 设计特征映射方式, 将提取的特征与相应的评分、评级或排序评价目标关联起来 如何在设计损失函数时考虑标注不确定性(如不同专家的评分差异)、同一动作之间的评分差异等问题?  下载: 导出CSV
下载: 导出CSV
表 2 主流的动作质量评价数据集总览
Table 2 Brief overview of mainstream motion quality assessment dataset
数据集 动作类别 样本数(受试者人数) 标注类别 应用场景 数据模态 发表年份 Heian Shodan[25] 1 14 评级标注 健身锻炼 3D骨架 2003 FINA09 Dive[26] 1 68 评分标注 体育赛事 RGB视频 2010 MIT-Dive[8] 1 159 评分标注、反馈标注 体育赛事 RGB视频 2014 MIT-Skate[8] 1 150 评分标注 体育赛事 RGB视频 2014 SPHERE-Staircase2014[10] 1 48 评级标注 运动康复 3D骨架 2014 JIGSAWS[9] 3 103 评级标注 技能训练 RGB视频、运动学数据 2014 SPHERE-Walking2015[16] 1 40 评级标注 运动康复 3D骨架 2016 SPHERE-SitStand2015[16] 1 109 评级标注 运动康复 3D骨架 2016 LAM Exercise Dataset[23] 5 125 评级标注 运动康复 3D骨架 2016 First-Person Basketball[27] 1 48 排序标注 健身锻炼 RGB视频 2017 UNLV-Dive[28] 1 370 评分标注 体育赛事 RGB视频 2017 UNLV-Vault[28] 1 176 评分标注 体育赛事 RGB视频 2017 UI-PRMD[20] 10 100 评级标注 运动康复 3D骨架 2018 EPIC-Skills 2018[24] 4 216 排序标注 技能训练 RGB视频 2018 Infant Grasp[29] 1 94 排序标注 技能训练 RGB视频 2019 AQA-7[30] 7 1189 评分标注 体育赛事 RGB视频 2019 MTL-AQA[31] 1 1412 评分标注 体育赛事 RGB视频 2019 FSD-10[32] 10 1484 评分标注 体育赛事 RGB视频 2019 BEST 2019[32] 5 500 排序标注 技能训练 RGB视频 2019 KIMORE[22] 5 78 评分标注 运动康复 RGB、深度视频、3D骨架 2019 Fis-V[33] 1 500 评分标注 体育赛事 RGB视频 2020 TASD-2(SyncDiving-3m)[34] 1 238 评分标注 体育赛事 RGB视频 2020 TASD-2(SyncDiving-10m)[34] 1 368 评分标注 体育赛事 RGB视频 2020 RG[35] 4 1000 评分标注 体育赛事 RGB视频 2020 QMAR[36] 6 38 评级标注 运动康复 RGB视频 2020 PISA[37] 1 992 评级标注 技能训练 RGB视频、音频 2021 FR-FS[38] 1 417 评分标注 体育赛事 RGB视频 2021 SMART[39] 8 640 评分标注 体育赛事、健身锻炼 RGB视频 2021 Fitness-AQA[40] 3 1000 反馈标注 健身锻炼 RGB视频 2022 Finediving[41] 1 3000 评分标注 体育赛事 RGB视频 2022 LOGO[42] 1 200 评分标注 体育赛事 RGB视频 2023 RFSJ[43] 23 1304 评分标注 体育赛事 RGB视频 2023 FineFS[44] 2 1167 评分标注 体育赛事 RGB视频、骨架数据 2023 AGF-Olympics[45] 1 500 评分标注 体育赛事 RGB视频、骨架数据 2024
下载: 导出CSV
表 3 两类动作特征表示方法优缺点对比
Table 3 Advantage and disadvantage comparison for two types of motion feature methods
下载: 导出CSV
表 4 基于RGB信息的深度动作特征方法优缺点对比
Table 4 Advantage and disadvantage comparison for RGB-based deep motion feature methods
方法分类 优点 缺点 基于卷积神经网络的动作特征
表示方法[12, 24, 28, 30−33, 48, 54, 59]简单易实现 无法充分捕捉动作特征的复杂性 基于孪生网络的动作特征
表示方法[24, 62−64]便于建模动作之间的细微差异 计算复杂度较高, 需要构建有效的样本对 基于时序分割的动作特征
表示方法[44, 48, 59, 65−68]降低噪声干扰, 更好地捕获动作的细节和变化 额外的分割标注信息, 片段划分不准确对性能影响较大 基于注意力机制的动作特征表示
方法[29, 32−35, 38, 41, 43−44, 68−72]自适应性好, 对重要特征的捕获能力强, 可解释性较好 计算复杂度高、内存消耗大
下载: 导出CSV
表 5 基于骨架序列的深度动作特征方法优缺点对比
Table 5 Advantage and disadvantage comparison for skeleton-based deep motion feature methods
下载: 导出CSV
表 6 在体育评分数据集AQA-7上的不同方法性能对比
Table 6 Performance comparison of different methods on sports scoring dataset AQA-7
方法 Diving Gym Vault Skiing Snowboard Sync. 3m Sync. 10m AQA-7 传统/深度 发表年份 Pose+DCT+SVR[8] 0.5300 0.1000 — — — — — 传统 2014 C3D+SVR[28] 0.7902 0.6824 0.5209 0.4006 0.5937 0.9120 0.6937 深度 2017 C3D+LSTM[28] 0.6047 0.5636 0.4593 0.5029 0.7912 0.6927 0.6165 深度 2017 Li 等[11] 0.8009 0.7028 — — — — — 深度 2018 S3D[59] — 0.8600 — — — — — 深度 2018 All-action C3D+LSTM[30] 0.6177 0.6746 0.4955 0.3648 0.8410 0.7343 0.6478 深度 2019 C3D-AVG-MTL[30] 0.8808 — — — — — — 深度 2019 JRG[49] 0.7630 0.7358 0.6006 0.5405 0.9013 0.9254 0.7849 深度 2019 USDL[12] 0.8099 0.7570 0.6538 0.7109 0.9166 0.8878 0.8102 深度 2020 AIM[36] 0.7419 0.7296 0.5890 0.4960 0.9298 0.9043 0.7789 深度 2020 DML[62] 0.6900 0.4400 — — — — — 深度 2021 CoRe[63] 0.8824 0.7746 0.7115 0.6624 0.9442 0.9078 0.8401 深度 2021 Lei 等[69] 0.8649 0.7858 — — — — — 深度 2021 EAGLE-EYE[98] 0.8331 0.7411 0.6635 0.6447 0.9143 0.9158 0.8140 深度 2021 TSA-Net[38] 0.8379 0.8004 0.6657 0.6962 0.9493 0.9334 0.8476 深度 2021 Adaptive[97] 0.8306 0.7593 0.7208 0.6940 0.9588 0.9298 0.8500 深度 2022 PCLN[64] 0.8697 0.8759 0.7754 0.5778 0.9629 0.9541 0.8795 深度 2022 TPT[70] 0.8969 0.8043 0.7336 0.6965 0.9456 0.9545 0.8715 深度 2022
下载: 导出CSV
表 7 JIGSAWS数据集上的不同方法性能对比
Table 7 Performance comparison of different methods on JIGSAWS
方法 数据模态 评价方法 技能水平
划分交叉验证方法 评测指标 SU KT NP 发表年份 k-NN[110] 动作特征 GRS 两类 LOSO Accuracy 0.897 — 0.821 2018 LOUO Accuracy 0.719 — 0.729 2018 LR[110] 动作特征 GRS 两类 LOSO Accuracy 0.899 — 0.823 2018 LOUO Accuracy 0.744 — 0.702 2018 SVM[110] 动作特征 GRS 两类 LOSO Accuracy 0.754 — 0.754 2018 LOUO Accuracy 0.798 — 0.779 2018 SMT[111] 动作特征 Self-proclaimed 三类 LOSO Accuracy 0.990 0.996 0.999 2018 LOUO Accuracy 0.353 0.323 0.571 2018 DCT[111] 动作特征 Self-proclaimed 三类 LOSO Accuracy 1.000 0.997 0.999 2018 LOUO Accuracy 0.647 0.548 0.357 2018 DFT[111] 动作特征 Self-proclaimed 三类 LOSO Accuracy 1.000 0.999 0.999 2018 LOUO Accuracy 0.647 0.516 0.464 2018 ApEn[111] 动作特征 Self-proclaimed 三类 LOSO Accuracy 1.000 0.999 1.000 2018 LOUO Accuracy 0.882 0.774 0.857 2018 CNN[102] 动作特征 Self-proclaimed 三类 LOSO Accuracy 0.934 0.898 0.849 2018 CNN[102] 动作特征 GRS 三类 LOSO Accuracy 0.925 0.954 0.913 2018 CNN[105] 动作特征 Self-proclaimed 三类 LOSO Micro F1 1.000 0.921 1.000 2018 Macro F1 1.000 0.932 1.000 2018 Forestier 等[112] 动作特征 GRS 三类 LOSO Micro F1 0.897 0.611 0.963 2018 Macro F1 0.867 0.533 0.958 2018 S3D[59] 视频数据 GRS 三类 LOSO SRC 0.680 0.640 0.570 2018 LOUO SRC 0.030 0.140 0.350 2018 FCN[99] 动作特征 Self-proclaimed 三类 LOSO Micro F1 1.000 0.921 1.000 2019 Macro F1 1.000 0.932 1.000 2019 3D ConvNet (RGB)[103] 视频数据 Self-proclaimed 三类 LOSO Accuracy 1.000 0.958 0.964 2019 3D ConvNet (OF)[103] 视频数据 Self-proclaimed 三类 LOSO Accuracy 1.000 0.951 1.000 2019 JRG[49] 视频数据 GRS 三类 LOUO SRC 0.350 0.190 0.670 2019 USDL[12] 视频数据 GRS 三类 4-fold cross validation SRC 0.710 0.710 0.690 2020 AIM[34] 视频数据
动作特征GRS 三类 LOUO SRC 0.450 0.610 0.340 2020 MTL-VF (ResNet)[113] 视频数据 GRS 三类 LOSO SRC 0.790 0.630 0.730 2020 LOUO SRC 0.680 0.720 0.480 2020 MTL-VF (C3D)[113] 视频数据 GRS 三类 LOSO SRC 0.770 0.890 0.750 2020 LOUO SRC 0.690 0.830 0.860 2020 CoRe[63] 视频数据 GRS 三类 4-fold cross validation SRC 0.840 0.860 0.860 2021 VTPE[106] 视频数据
动作特征GRS 三类 LOUO SRC 0.450 0.590 0.650 2021 4-fold cross validation SRC 0.830 0.820 0.760 2021 ViSA[107] 视频数据 GRS 三类 LOSO SRC 0.840 0.920 0.930 2022 LOUO SRC 0.720 0.760 0.900 2022 4-fold cross validation SRC 0.790 0.840 0.860 2022 Gao 等[108] 视频数据
动作特征GRS 三类 LOUO SRC 0.600 0.690 0.660 2023 4-fold cross validation SRC 0.830 0.950 0.830 2023 Contra-Sformer[109] 视频数据 GRS 三类 LOSO SRC 0.860 0.890 0.710 2023 LOUO SRC 0.650 0.690 0.710 2023
下载: 导出CSV
表 8 在EPIC-Skills 2018上的不同方法性能对比
Table 8 Performance comparison of different methods on EPIC-Skills 2018
下载: 导出CSV
-
[1] 朱煜, 赵江坤, 王逸宁, 郑兵兵. 基于深度学习的人体行为识别算法综述. 自动化学报, 2016, 42(6): 848−857Zhu Yu, Zhao Jiang-Kun, Wang Yi-Ning, Zheng Bing-Bing. A review of human action recognition based on deep learning. Acta Automatica Sinica, 2016, 42(6): 848−857 [2] Lei Q, Du J X, Zhang H B, Ye S, Chen D S. A survey of vision-based human action evaluation methods. Sensors, 2019, 19(19): Article No. 4129 doi: 10.3390/s19194129 [3] Ahad M A R, Antar A D, Shahid O. Vision-based action understanding for assistive healthcare: A short review. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. Long Beach, USA: IEEE, 2019. 1−11 [4] Voulodimos A, Doulamis N, Doulamis A, Protopapadakis E. Deep learning for computer vision: A brief review. Computational Intelligence and Neuroscience, 2018, 2018(1): Article No. 7068349 [5] 郑太雄, 黄帅, 李永福, 冯明驰. 基于视觉的三维重建关键技术研究综述. 自动化学报, 2020, 46(4): 631−652Zheng Tai-Xiong, Huang Shuai, Li Yong-Fu, Feng Ming-Chi. Key techniques for vision based 3D reconstruction: A review. Acta Automatica Sinica, 2020, 46(4): 631−652 [6] 林景栋, 吴欣怡, 柴毅, 尹宏鹏. 卷积神经网络结构优化综述. 自动化学报, 2020, 46(1): 24−37Lin Jing-Dong, Wu Xin-Yi, Chai Yi, Yin Hong-Peng. Structure optimization of convolutional neural networks: A survey. Acta Automatica Sinica, 2020, 46(1): 24−37 [7] 张重生, 陈杰, 李岐龙, 邓斌权, 王杰, 陈承功. 深度对比学习综述. 自动化学报, 2023, 49(1): 15−39Zhang Chong-Sheng, Chen Jie, Li Qi-Long, Deng Bin-Quan, Wang Jie, Chen Cheng-Gong. Deep contrastive learning: A survey. Acta Automatica Sinica, 2023, 49(1): 15−39 [8] Pirsiavash H, Vondrick C, Torralba A. Assessing the quality of actions. In: Proceedings of the 13th European Conference on Computer Vision (ECCV 2014). Zurich, Switzerland: Springer, 2014. 556−571 [9] Gao Y, Vedula S S, Reiley C E, Ahmidi N, Varadarajan B, Lin H C, et al. JHU-ISI gesture and skill assessment working set (JIGSAWS): A surgical activity dataset for human motion modeling. In: Proceedings of the Modeling and Monitoring of Computer Assisted Interventions (M2CAI)-MICCAI Workshop. 2014. [10] Paiement A, Tao L L, Hannuna S, Camplani M, Damen D, Mirmehdi M. Online quality assessment of human movement from skeleton data. In: Proceedings of the British Machine Vision Conference. Nottingham, UK: 2014. 153−166 [11] Li Y J, Chai X J, Chen X L. End-to-end learning for action quality assessment. In: Proceedings of the 19th Pacific-Rim Conference on Multimedia, Advances in Multimedia Information Processing (PCM 2018). Hefei, China: Springer, 2018. 125−134 [12] Tang Y S, Ni Z L, Zhou J H, Zhang D Y, Lu J W, Wu Y, et al. Uncertainty-aware score distribution learning for action quality assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 9839−9848 [13] Xu J L, Yin S B, Zhao G H, Wang Z S, Peng Y X. FineParser: A fine-grained spatio-temporal action parser for human-centric action quality assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 14628−14637 [14] Morgulev E, Azar O H, Lidor R. Sports analytics and the big-data era. International Journal of Data Science and Analytics, 2018, 5(4): 213−222 doi: 10.1007/s41060-017-0093-7 [15] Butepage J, Black M J, Kragic D, Kjellström H. Deep representation learning for human motion prediction and classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 1591−1599 [16] Tao L L, Paiement A, Damen D, Mirmehdi M, Hannuna S, Camplani M, et al. A comparative study of pose representation and dynamics modelling for online motion quality assessment. Computer Vision and Image Understanding, 2016, 148: 136−152 doi: 10.1016/j.cviu.2015.11.016 [17] Khalid S, Goldenberg M, Grantcharov T, Taati B, Rudzicz F. Evaluation of deep learning models for identifying surgical actions and measuring performance. JAMA Network Open, 2020, 3(3): Article No. e201664 doi: 10.1001/jamanetworkopen.2020.1664 [18] Qiu Y H, Wang J P, Jin Z, Chen H H, Zhang M L, Guo L Q. Pose-guided matching based on deep learning for assessing quality of action on rehabilitation training. Biomedical Signal Processing and Control, 2022, 72: Article No. 103323 doi: 10.1016/j.bspc.2021.103323 [19] Niewiadomski R, Kolykhalova K, Piana S, Alborno P, Volpe G, Camurri A. Analysis of movement quality in full-body physical activities. ACM Transactions on Interactive Intelligent Systems (TiiS), 2019, 9(1): Article No. 1 [20] Vakanski A, Jun H P, Paul D, Baker R. A data set of human body movements for physical rehabilitation exercises. Data, 2018, 3(1): Article No. 2 doi: 10.3390/data3010002 [21] Alexiadis D S, Kelly P, Daras P, O'Connor N E, Boubekeur T, Moussa M B. Evaluating a dancer's performance using Kinect-based skeleton tracking. In: Proceedings of the 19th ACM International Conference on Multimedia. Scottsdale, USA: ACM, 2011. 659−662 [22] Capecci M, Ceravolo M G, Ferracuti F, Iarlori S, MonteriùA, Romeo L, et al. The KIMORE dataset: Kinematic assessment of movement and clinical scores for remote monitoring of physical rehabilitation. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2019, 27(7): 1436−1448 doi: 10.1109/TNSRE.2019.2923060 [23] Parmar P, Morris B T. Measuring the quality of exercises. In: Proceedings of the 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Orlando, USA: IEEE, 2016. 2241−2244 [24] Doughty H, Damen D, Mayol-Cuevas W. Who's better? Who's best? Pairwise deep ranking for skill determination. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 6057−6066 [25] Ilg W, Mezger J, Giese M. Estimation of skill levels in sports based on hierarchical spatio-temporal correspondences. In: Proceedings of the 25th DAGM Symposium on Pattern Recognition. Springer, 2003. 523−531 [26] Wnuk K, Soatto S. Analyzing diving: A dataset for judging action quality. In: Proceedings of the Asian 2010 International Workshops on Computer Vision (ACCV 2010 Workshops). Queenstown, New Zealand: Springer, 2010. 266−276 [27] Bertasius G, Park H S, Yu S X, Shi J B. Am I a baller? Basketball performance assessment from first-person videos. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2196−2204 [28] Parmar P, Morris B T. Learning to score Olympic events. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, USA: IEEE, 2017. 76−84 [29] Li Z Q, Huang Y F, Cai M J, Sato Y. Manipulation-skill assessment from videos with spatial attention network. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). Seoul, Korea: IEEE, 2019. 4385−4395 [30] Parmar P, Morris B. Action quality assessment across multiple actions. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV). Waikoloa Village, USA: IEEE, 2019. 1468−1476 [31] Parmar P, Morris B T. What and how well you performed? A multitask learning approach to action quality assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 304−313 [32] Doughty H, Mayol-Cuevas W, Damen D. The pros and cons: Rank-aware temporal attention for skill determination in long videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 7854−7863 [33] Xu C M, Fu Y W, Zhang B, Chen Z T, Jiang Y G, Xue X Y. Learning to score figure skating sport videos. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(12): 4578−4590 doi: 10.1109/TCSVT.2019.2927118 [34] Gao J B, Zheng W S, Pan J H, Gao C Y, Wang Y W, Zeng W, et al. An asymmetric modeling for action assessment. In: Proceedings of the 16th European Conference on Computer Vision (ECCV 2020). Glasgow, UK: Springer, 2020. 222−238 [35] Zeng L A, Hong F T, Zheng W S, Yu Q Z, Zeng W, Wang Y W, et al. Hybrid dynamic-static context-aware attention network for action assessment in long videos. In: Proceedings of the 28th ACM International Conference on Multimedia. Seattle, USA: ACM, 2020. 2526−2534 [36] Sardari F, Paiement A, Hannuna S, Mirmehdi M. VI-Net——View-invariant quality of human movement assessment. Sensors, 2020, 20(18): Article No. 5258 doi: 10.3390/s20185258 [37] Parmar P, Reddy J, Morris B. Piano skills assessment. In: Proceedings of the 23rd International Workshop on Multimedia Signal Processing (MMSP). Tampere, Finland: IEEE, 2021. 1−5 [38] Wang S L, Yang D K, Zhai P, Chen C X, Zhang L H. TSA-Net: Tube self-attention network for action quality assessment. In: Proceedings of the 29th ACM International Conference on Multimedia. Virtual Event: ACM, 2021. 4902−4910 [39] Chen X, Pang A Q, Yang W, Ma Y X, Xu L, Yu J Y. SportsCap: Monocular 3D human motion capture and fine-grained understanding in challenging sports videos. International Journal of Computer Vision, 2021, 129(10): 2846−2864 doi: 10.1007/s11263-021-01486-4 [40] Parmar P, Gharat A, Rhodin H. Domain knowledge-informed self-supervised representations for workout form assessment. In: Proceedings of the 17th European Conference on Computer Vision (ECCV 2022). Tel Aviv, Israel: Springer, 2022. 105−123 [41] Xu J L, Rao Y M, Yu X M, Chen G Y, Zhou J, Lu J W. FineDiving: A fine-grained dataset for procedure-aware action quality assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 2939−2948 [42] Zhang S Y, Dai W X, Wang S J, Shen X W, Lu J W, Zhou J, et al. LOGO: A long-form video dataset for group action quality assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 2405−2414 [43] Liu Y C, Cheng X N, Ikenaga T. A figure skating jumping dataset for replay-guided action quality assessment. In: Proceedings of the 31st ACM International Conference on Multimedia. Ottawa, Canada: ACM, 2023. 2437−2445 [44] Ji Y L, Ye L F, Huang H L, Mao L J, Zhou Y, Gao L L. Localization-assisted uncertainty score disentanglement network for action quality assessment. In: Proceedings of the 31st ACM International Conference on Multimedia. Ottawa, Canada: ACM, 2023. 8590−8597 [45] Zahan S, Hassan G M, Mian A. Learning sparse temporal video mapping for action quality assessment in floor gymnastics. IEEE Transactions on Instrumentation and Measurement, 2024, 73: Article No. 5020311 [46] Ahmidi N, Tao L L, Sefati S, Gao Y X, Lea C, Haro B, et al. A dataset and benchmarks for segmentation and recognition of gestures in robotic surgery. IEEE Transactions on Biomedical Engineering, 2017, 64(9): 2025−2041 doi: 10.1109/TBME.2016.2647680 [47] Liao Y L, Vakanski A, Xian M. A deep learning framework for assessing physical rehabilitation exercises. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2020, 28(2): 468−477 doi: 10.1109/TNSRE.2020.2966249 [48] Li Y J, Chai X J, Chen X L. ScoringNet: Learning key fragment for action quality assessment with ranking loss in skilled sports. In: Proceedings of the 14th Asian Conference on Computer Vision (ACCV 2018). Perth, Australia: Springer, 2018. 149−164 [49] Pan J H, Gao J B, Zheng W S. Action assessment by joint relation graphs. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 6330−6339 [50] Lei Q, Zhang H B, Du J X, Hsiao T, Chen C C. Learning effective skeletal representations on RGB video for fine-grained human action quality assessment. Electronics, 2020, 9(4): Article No. 568 doi: 10.3390/electronics9040568 [51] Gordon A S. Automated video assessment of human performance. In: Proceedings of the AI-ED-World Conference on Artificial Intelligence in Education. Washington, USA: AACE Press, 1995. 541−546 [52] Venkataraman V, Vlachos I, Turaga P. Dynamical regularity for action analysis. In: Proceedings of the British Machine Vision Conference. Swansea, UK: BMVA Press, 2015. 67−78 [53] Zia A, Sharma Y, Bettadapura V, Sarin E L, Ploetz T, Clements M A, et al. Automated video-based assessment of surgical skills for training and evaluation in medical schools. International Journal of Computer Assisted Radiology and Surgery, 2016, 11(9): 1623−1636 doi: 10.1007/s11548-016-1468-2 [54] Parmar P. On Action Quality Assessment [Ph.D. dissertation], University of Nevada, USA, 2019. [55] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, US: ACM, 2014. 568−576 [56] Tran D, Bourdev L, Fergus R, Torresani L, Paluri M. Learning spatiotemporal features with 3D convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4489−4497 [57] Carreira J, Zisserman A. Quo Vadis, action recognition? A new model and the kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 4724−4733 [58] Qiu Z F, Yao T, Mei T. Learning spatio-temporal representation with pseudo-3D residual networks. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 5534−5542 [59] Xiang X, Tian Y, Reiter A, Hager G D, Tran T D. S3D: Stacking segmental P3D for action quality assessment. In: Proceedings of the IEEE International Conference on Image Processing (ICIP). Athens, Greece: IEEE, 2018. 928−932 [60] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico: ICLR, 2016. 928−932 [61] Bromley J, Bentz J W, Bottou L, Guyon I, Lecun Y, Moor C, et al. Signature verification using a "siamese" time delay neural network. International Journal of Pattern Recognition and Artificial Intelligence, 1993, 7(4): 669−688 doi: 10.1142/S0218001493000339 [62] Jain H, Harit G, Sharma A. Action quality assessment using siamese network-based deep metric learning. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(6): 2260−2273 doi: 10.1109/TCSVT.2020.3017727 [63] Yu X M, Rao Y M, Zhao W L, Lu J W, Zhou J. Group-aware contrastive regression for action quality assessment. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 7899−7908 [64] Li M Z, Zhang H B, Lei Q, Fan Z W, Liu J H, Du J X. Pairwise contrastive learning network for action quality assessment. In: Proceedings of the 17th European Conference on Computer Vision (ECCV 2022). Tel Aviv, Israel: Springer, 2022. 457−473 [65] Dong L J, Zhang H B, Shi Q H Y, Lei Q, Du J X, Gao S C. Learning and fusing multiple hidden substages for action quality assessment. Knowledge-Based Systems, 2021, 229: Article No. 107388 doi: 10.1016/j.knosys.2021.107388 [66] Lea C, Flynn M D, Vidal R, Reiter A, Hager G D. Temporal convolutional networks for action segmentation and detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 1003−1012 [67] Liu L X, Zhai P J, Zheng D L, Fang Y. Multi-stage action quality assessment method. In: Proceedings of the 4th International Conference on Control, Robotics and Intelligent System. Guangzhou, China: ACM, 2023. 116−122 [68] Gedamu K, Ji Y L, Yang Y, Shao J, Shen H T. Fine-grained spatio-temporal parsing network for action quality assessment. IEEE Transactions on Image Processing, 2023, 32: 6386−6400 doi: 10.1109/TIP.2023.3331212 [69] Lei Q, Zhang H B, Du J X. Temporal attention learning for action quality assessment in sports video. Signal, Image and Video Processing, 2021, 15(7): 1575−1583 doi: 10.1007/s11760-021-01890-w [70] Bai Y, Zhou D S, Zhang S Y, Wang J, Ding E R, Guan Y, et al. Action quality assessment with temporal parsing transformer. In: Proceedings of the 17th European Conference on Computer Vision (ECCV 2022). Tel Aviv, Israel: Springer, 2022. 422−438 [71] Xu A, Zeng L A, Zheng W S. Likert scoring with grade decoupling for long-term action assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 3222−3231 [72] Du Z X, He D, Wang X, Wang Q. Learning semantics-guided representations for scoring figure skating. IEEE Transactions on Multimedia, 2024, 26: 4987−4997 doi: 10.1109/TMM.2023.3328180 [73] Yan S J, Xiong Y J, Lin D H. Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 7444−7452 [74] Gao X, Hu W, Tang J X, Liu J Y, Guo Z M. Optimized skeleton-based action recognition via sparsified graph regression. In: Proceedings of the ACM International Conference on Multimedia. Nice, France: ACM, 2019. 601−610 [75] Patrona F, Chatzitofis A, Zarpalas D, Daras P. Motion analysis: Action detection, recognition and evaluation based on motion capture data. Pattern Recognition, 2018, 76: 612−622 doi: 10.1016/j.patcog.2017.12.007 [76] Microsoft Development Team. Azure Kinect body tracking joints [Online], available: https://learn.microsoft.com/en-us/previous-versions/azure/kinect-dk/body-joints, December 12, 2024 [77] Yang Y, Ramanan D. Articulated pose estimation with flexible mixtures-of-parts. In: Proceedings of the CVPR 2011. Colorado Springs, USA: IEEE, 2011. 1385−1392 [78] Felzenszwalb P F, Girshick R B, McAllester D, Ramanan D. Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627−1645 doi: 10.1109/TPAMI.2009.167 [79] Tian Y, Sukthankar R, Shah M. Spatiotemporal deformable part models for action detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Portland, USA: IEEE, 2013. 2642−2649 [80] Cao Z, Simon T, Wei S E, Sheikh Y. Realtime multi-person 2D pose estimation using part affinity fields. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 7291−7299 [81] Fang H S, Xie S Q, Tai Y W, Lu C W. RMPE: Regional multi-person pose estimation. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2353−2362 [82] He K, Gkioxari G, DollÁR P, Girshick R. Mask R-CNN. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2980−2988 [83] Shotton J, Fitzgibbon A, Cook M, Sharp T, Finocchio M, Moore R, et al. Real-time human pose recognition in parts from single depth images. In: Proceedings of the CVPR 2011. Colorado Springs, USA: IEEE, 2011. 1297−1304 [84] Rhodin H, Meyer F, Spörri J, Müller E, Constantin V, Fua P, et al. Learning monocular 3D human pose estimation from multi-view images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 8437−8446 [85] Dong J T, Jiang W, Huang Q X, Bao H J, Zhou X W. Fast and robust multi-person 3D pose estimation from multiple views. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 7784−7793 [86] Celiktutan O, Akgul C B, Wolf C, Sankur B. Graph-based analysis of physical exercise actions. In: Proceedings of the 1st ACM International Workshop on Multimedia Indexing and Information Retrieval for Healthcare. Barcelona, Spain: ACM, 2013. 23−32 [87] Liu J, Wang G, Hu P, Duan L Y, Kot A C. Global context-aware attention LSTM networks for 3D action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 3671−3680 [88] Lee I, Kim D, Kang S, Lee S. Ensemble deep learning for skeleton-based action recognition using temporal sliding LSTM networks. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 1012−1020 [89] Li C, Zhong Q Y, Xie D, Pu S L. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden: AAAI Press, 2018. 786−792 [90] Li Y S, Xia R J, Liu X, Huang Q H. Learning shape-motion representations from geometric algebra spatio-temporal model for skeleton-based action recognition. In: Proceedings of the IEEE International Conference on Multimedia and Expo (ICME). Shanghai, China: IEEE, 2019. 1066−1071 [91] Li M S, Chen S H, Chen X, Zhang Y, Wang Y F, Tian Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 3590−3598 [92] Shi L, Zhang Y F, Cheng J, Lu H Q. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 12018−12027 [93] Yu B X B, Liu Y, Chan K C C. Skeleton-based detection of abnormalities in human actions using graph convolutional networks. In: Proceedings of the 2nd International Conference on Transdisciplinary AI (TransAI). Irvine, USA: IEEE, 2020. 131−137 [94] Chowdhury S H, Al Amin M, Rahman A K M M, Amin M A, Ali A A. Assessment of rehabilitation exercises from depth sensor data. In: Proceedings of the 24th International Conference on Computer and Information Technology. Dhaka, Bangladesh: IEEE, 2021. 1−7 [95] Deb S, Islam M F, Rahman S, Rahman S. Graph convolutional networks for assessment of physical rehabilitation exercises. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2022, 30: 410−419 doi: 10.1109/TNSRE.2022.3150392 [96] Li H Y, Lei Q, Zhang H B, Du J X, Gao S C. Skeleton-based deep pose feature learning for action quality assessment on figure skating videos. Journal of Visual Communication and Image Representation, 2022, 89: Article No. 103625 doi: 10.1016/j.jvcir.2022.103625 [97] Pan J H, Gao J B, Zheng W S. Adaptive action assessment. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(12): 8779−8795 doi: 10.1109/TPAMI.2021.3126534 [98] Nekoui M, Cruz F O T, Cheng L. Eagle-eye: Extreme-pose action grader using detail bird's-eye view. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Waikoloa, USA: IEEE, 2021. 394−402 [99] Fawaz H I, Forestier G, Weber J, Idoumghar L, Muller P A. Accurate and interpretable evaluation of surgical skills from kinematic data using fully convolutional neural networks. International Journal of Computer Assisted Radiology and Surgery, 2019, 14(9): 1611−1617 doi: 10.1007/s11548-019-02039-4 [100] Roditakis K, Makris A, Argyros A. Towards improved and interpretable action quality assessment with self-supervised alignment. In: Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference. Corfu, Greece: IEEE, 2021. 507−513 [101] Li M Z, Zhang H B, Dong L J, Lei Q, Du J X. Gaussian guided frame sequence encoder network for action quality assessment. Complex & Intelligent Systems, 2023, 9(2): 1963−1974 [102] Wang Z, Fey A M. Deep learning with convolutional neural network for objective skill evaluation in robot-assisted surgery. International Journal of Computer Assisted Radiology and Surgery, 2018, 13(12): 1959−1970 doi: 10.1007/s11548-018-1860-1 [103] Funke I, Mees S T, Weitz J, Speidel S. Video-based surgical skill assessment using 3D convolutional neural networks. International Journal of Computer Assisted Radiology and Surgery, 2019, 14(7): 1217−1225 doi: 10.1007/s11548-019-01995-1 [104] Wang Z, Fey A M. SATR-DL: Improving surgical skill assessment and task recognition in robot-assisted surgery with deep neural networks. In: Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Honolulu, USA: IEEE, 2018. 1793−1796 [105] Fawaz H I, Forestier G, Weber J, Idoumghar L, Muller P A. Evaluating surgical skills from kinematic data using convolutional neural networks. In: Proceedings of the 21st International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2018). Granada, Spain: Springer, 2018. 214−221 [106] Liu D C, Li Q Y, Jiang T T, Wang Y Z, Miao R L, Shan F, et al. Towards unified surgical skill assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 9517−9526 [107] Li Z Q, Gu L, Wang W M, Nakamura R, Sato Y. Surgical skill assessment via video semantic aggregation. In: Proceedings of the 25th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2022). Singapore: Springer, 2022. 410−420 [108] Gao J B, Pan J H, Zhang S J, Zheng W S. Automatic modelling for interactive action assessment. International Journal of Computer Vision, 2023, 131(3): 659−679 doi: 10.1007/s11263-022-01695-5 [109] Anastasiou D, Jin Y M, Stoyanov D, Mazomenos E. Keep your eye on the best: Contrastive regression transformer for skill assessment in robotic surgery. IEEE Robotics and Automation Letters, 2023, 8(3): 1755−1762 doi: 10.1109/LRA.2023.3242466 [110] Fard M J, Ameri S, Ellis R D, Chinnam R B, Pandya A K, Klein M D. Automated robot-assisted surgical skill evaluation: Predictive analytics approach. The International Journal of Medical Robotics and Computer Assisted Surgery, 2018, 14(1): Article No. e1850 [111] Zia A, Essa I. Automated surgical skill assessment in RMIS training. International Journal of Computer Assisted Radiology and Surgery, 2018, 13(5): 731−739 doi: 10.1007/s11548-018-1735-5 [112] Forestier G, Petitjean F, Senin P, Despinoy F, Huaulmé A, Fawaz H I, et al. Surgical motion analysis using discriminative interpretable patterns. Artificial Intelligence in Medicine, 2018, 91: 3−11 doi: 10.1016/j.artmed.2018.08.002 [113] Wang T Y, Wang Y J, Li M. Towards accurate and interpretable surgical skill assessment: A video-based method incorporating recognized surgical gestures and skill levels. In: Proceedings of the 23rd International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2020). Lima, Peru: Springer, 2020. 668−678 [114] Okamoto L, Parmar P. Hierarchical NeuroSymbolic approach for comprehensive and explainable action quality assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, USA: IEEE, 2024. 3204−3213 -

 下载:
下载:











计量
- 文章访问数: 516
- HTML全文浏览量: 282
- PDF下载量: 100
- 被引次数: 0
