

-
摘要: 强化学习(Reinforcement learning, RL)通过智能体与环境在线交互来学习最优策略, 近年来已成为解决复杂环境下感知决策问题的重要手段. 然而, 在线收集数据的方式可能会引发安全、时间或成本等问题, 极大限制了强化学习在实际中的应用. 与此同时, 原始数据的维度高且结构复杂, 解决复杂高维数据输入问题也是强化学习面临的一大挑战. 幸运的是, 基于表征学习的离线强化学习能够仅从历史经验数据中学习策略, 而无需与环境产生交互. 它利用表征学习技术将离线数据集中的特征表示为低维向量, 然后利用这些向量来训练离线强化学习模型. 这种数据驱动的方式为实现通用人工智能提供了新契机. 为此, 对近期基于表征学习的离线强化学习方法进行全面综述. 首先给出离线强化学习的形式化描述, 然后从方法、基准数据集、离线策略评估与超参数选择3个层面对现有技术进行归纳整理, 进一步介绍离线强化学习在工业、推荐系统、智能驾驶等领域中的研究动态. 最后, 对全文进行总结, 并探讨基于表征学习的离线强化学习未来所面临的关键挑战与发展趋势, 以期为后续的研究提供有益参考.Abstract: Reinforcement learning (RL), learning an optimal policy through online interaction between an agent and environment, has recently become an important tool to solve perceptual decision-making issues in complex environments. However, the online data collection may raise issues of security, time, or cost, greatly limiting the practical applications of reinforcement learning. Meanwhile, tackling intricate high-dimensional data input problems has also become a significant challenge for reinforcement learning due to the intricate and multifaceted nature of raw data. Fortunately, offline reinforcement learning based on representation learning can learn the policy only from historical experience data without interacting with the environment. It utilizes representation learning techniques to map the features of the offline dataset into low-dimensional vectors, which are subsequently employed to train the offline reinforcement learning model. This data-driven paradigm provides a new opportunity to realize the general artificial intelligence. To this end, this paper comprehensively reviews the recent research on offline reinforcement learning based on representation learning. Firstly, the problem setup of offline reinforcement learning is given. Then, the existing technologies are summarized from three aspects: Methodologies, benchmarks, offline policy evaluation and hyperparameter selection. Moreover, the study trends of offline reinforcement learning in industries, recommendation systems, intelligent driving, and other fields are introduced. Finally, the conclusion is drawn and the key challenges and development trends of offline reinforcement learning based on representation learning in the future are discussed, so as to provide a valuable reference for subsequent study.
-
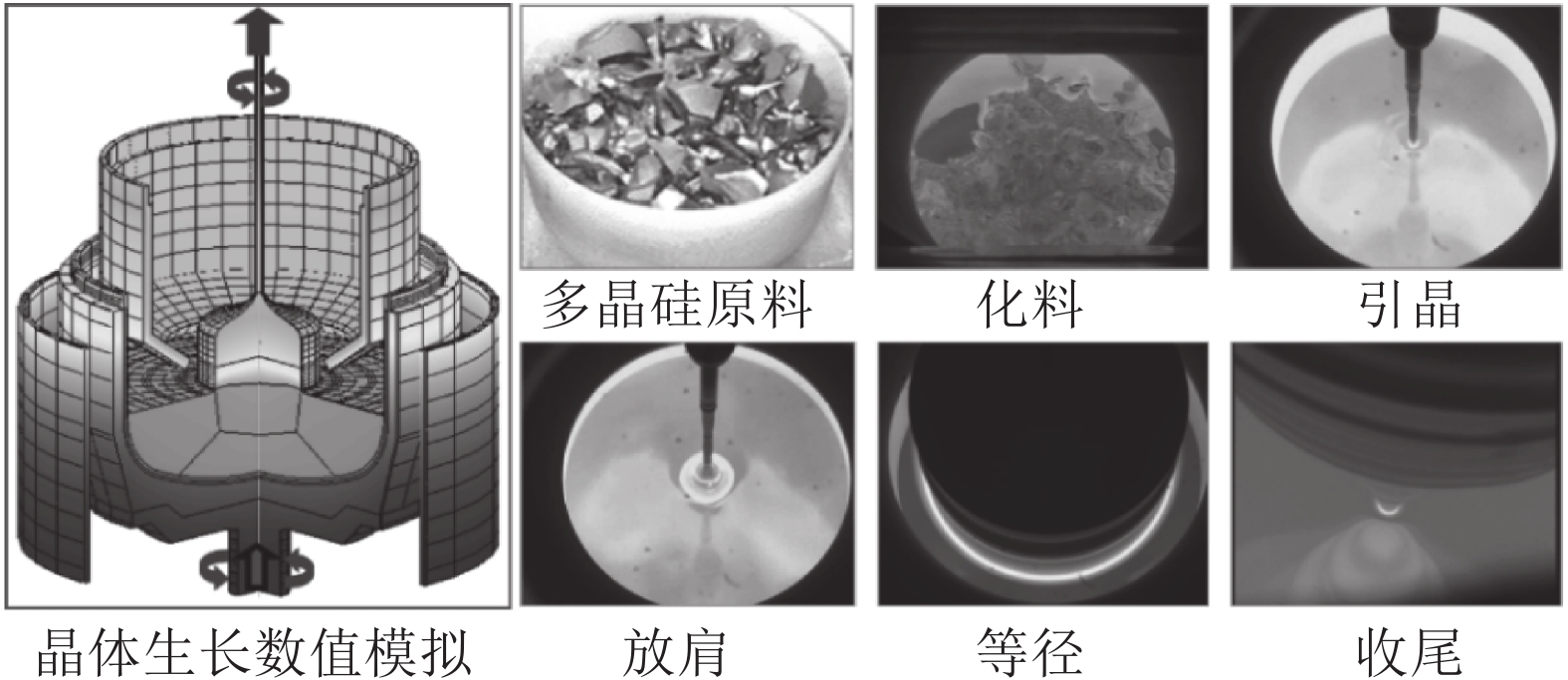
硅是最重要的半导体材料. 据统计, 全球95 %以上的半导体器件和99 %以上的集成电路采用硅单晶作为衬底材料, 因此稳定、高效、高品质的硅单晶生产对信息产业安全可靠发展以及持续技术创新起到至关重要的支撑作用. 直拉法(Czochralski法, Cz法)晶体生长工艺是目前生产大尺寸、电子级硅单晶的主要方法[1-3]. 其原理是将石英坩埚中的多晶硅原料熔化, 并经过引晶、放肩、等径和收尾等一系列步骤, 最终从硅熔体中提拉出圆柱形的硅单晶, 生长工艺流程如图1所示.
Cz法硅单晶生长的主要目的是提拉出的硅单晶具有等直径、杂质少、低缺陷等优点[4-5]. 晶体直径是硅单晶生长过程中一个重要的控制目标, 精准的直径控制不但可以避免晶体内部位错缺陷生成的可能性, 而且能够提高后续加工的晶体利用率. 为此, 研究人员提出了多种晶体直径控制方法并应用于实际生产[6-8]. Zheng等根据Cz法硅单晶生长过程中能量、质量平衡、流体力学和几何方程建立了晶体半径和晶体生长速率的集总参数模型, 并利用工业运行数据验证了模型的有效性[9]. Abdollahi和Dubljevic针对晶体半径和温度提出了分布式参数模型, 该模型能够准确地描述系统动力学行为和晶体内部温度分布状态[10]. Winkler等基于弯月面处晶体半径变化与晶体倾斜角之间的关系, 建立了晶体生长过程的流体力学和几何模型, 避免了热动力学建模的复杂性. 同时, 设计了晶体半径和生长速率的双PID控制系统, 并获得了比较接近实际过程的控制效果[11-12]. Rahmanpour等针对Cz法硅单晶生长过程的非线性和大滞后特性, 设计了基于模型的提拉速度和加热器功率两个协同工作的模型预测控制器(Model predictive control, MPC), 用于控制晶体半径和熔体温度, 并获得了良好的控制性能[13]. 然而, 传统基于模型的控制器设计策略很难应用于实际硅单晶生长过程控制, 且晶体提拉速度的不断变化容易导致硅单晶品质降低. 通常, 影响晶体直径变化的主要操纵变量是加热器功率和晶体提拉速度[14]. 其中, 晶体提拉速度优化调节范围窄, 而且频繁的变化会导致生长界面波动剧烈, 容易产生断晶和缺陷生成的可能性, 而加热器功率对晶体直径的调节是一个缓慢的时延过程, 具有调节范围大、不易导致生长界面波动的优点[3, 15]. 因此, 如何建立加热器功率与晶体直径之间的硅单晶生长过程模型和设计良好的直径控制器是实现硅单晶高品质生长的关键性问题.
机理模型和数据驱动模型是晶体直径控制的两种常用模型. Cz法硅单晶生长过程处于高温、高压、多场耦合的环境中, 机理不明, 且是一个具有大滞后的非线性慢时变动态过程[1], 所以机理模型难以建立且很难实际应用于硅单晶生产过程控制. 然而, 数据驱动控制可以直接利用数据实现复杂工业过程建模和控制, 且已受到学术界的广泛关注[16-17]. 因此, 针对Cz法硅单晶生长过程中复杂的动态特性, 基于数据驱动的晶体直径建模与控制是一种可行途径. 近年来, 随着人工智能技术的迅速发展和普及, 许多机器学习方法和深度学习模型被广泛应用于工业过程建模. 然而, 单一的模型往往难以达到预期的预测效果, 所以研究人员基于“分而治之”原理提出了混合集成建模方法. 相比单一模型, 混合集成建模方法综合了不同模型的优点, 具有令人满意的预测效果[18-20]. 实际硅单晶生长过程中的数据(加热器功率、晶体直径等)包含了大量反映硅单晶生产运行和产品质量等关键参数的潜在信息, 所以采用混合集成建模方法建立硅单晶生长过程的预测模型, 具有无需显式建模晶体生长系统内部状态以及减少建模成本和提高建模精度的优点. 预测控制是工业实践中先进控制的主导技术, 具有处理大滞后、非线性、不确定性的良好能力[21-22]. 因此, 针对具有大滞后、非线性、慢时变动态特性的Cz法硅单晶生长过程, 预测控制方法可以作为晶体直径控制的首选方法. 然而, 复杂的硅单晶生长过程使得优化晶体直径目标函数的求解变得十分困难, 常用的非线性优化方法, 如最速下降法、牛顿法等很难方便实施应用, 且这些方法要求解空间具有凸性, 有的算法还要求目标函数具有二阶或高阶导数. 相比之下, 启发式优化算法对所求解问题的数学模型要求不高, 常被用于复杂目标函数的优化求解[23-24], 如遗传算法(GA)和蚁狮优化(ALO)等. ALO算法是一种无梯度的优化算法[25], 具有可调参数少、求解灵活且易于实现等优点, 非常适合求解目标函数复杂的硅单晶直径预测控制问题.
本文在不依赖Cz法硅单晶生长过程的任何数学模型信息的情况下, 根据“分而治之”原理和工业运行数据提出了一种基于混合集成建模的晶体直径自适应非线性预测控制方法(自适应 Nonlinear model predictive control, 自适应NMPC), 该方法由晶体直径混合集成建模和晶体直径预测控制组成. 其中, 晶体直径混合集成预测模型包括三个模块: 数据分解模块, 预测模型模块, 数据集成模块. 数据分解模块采用WPD将原始的硅单晶生长实验数据分解为若干子序列, 目的在于减少数据中的非平稳性和随机噪声; 预测模型模块通过ELM和LSTM网络分别对近似(低频)子序列和细节(高频)子序列进行晶体直径离线建模; 数据集成模块则利用WPD重构各个子序列晶体直径预测模型的预测结果, 以得到晶体直径的整体预测输出. 另外, 在基于混合集成预测模型的晶体直径自适应NMPC中, 考虑到晶体直径混合集成模型可能存在模型失配问题以及目标函数求解难的问题, 采用了ALO算法在线更新预测模型参数并获取满足约束的最优加热器功率控制量. 最后, 通过工程实验数据仿真验证了所提方法在硅单晶直径预测建模和控制方面的可行性和先进性.
1. 数据驱动晶体直径预测建模
Cz法硅单晶生长过程是一个非线性、大滞后的慢时变动态过程, 单晶炉内的高温、多相、多场耦合环境使得内部反应状态难以检测, 因此晶体生长机理不清, 基于机理模型的硅单晶直径控制难以实施. 为此, 本文以单晶炉制备硅单晶的历史实验数据为基础, 采用如下非线性自回归滑动平均(Nonlinear autoregressive moving average with eXogenous inputs, NARMAX)模型来描述加热器功率与晶体直径之间的关系:
$$\begin{split} y(k) =& {f_{NARMAX}}(u(k - d), \cdots ,u(k - d - {n_u}),\\ &y(k - 1), \cdots ,y(k - {n_y})) \end{split}$$ (1) 其中,
${f_{NARMAX}}( \cdot )$ 为未知的非线性映射函数;$d$ 为加热器功率与晶体直径之间的时滞阶次,${n_u}$ 和${n_y}$ 分别是模型输入输出阶次,$y(k)$ 和$u(k)$ 分别表示$k$ 时刻系统的晶体直径输出和加热器功率控制输入.对于式(1)所表述的Cz法硅单晶生长系统, 本文采用混合集成建模方法建立其模型. 考虑到混合集成建模方法是基于“分而治之”原理, 同时为了综合不同模型的优点, 基于历史加热器功率输入数据和晶体直径输出数据, 我们采用机器学习方法ELM和深度学习方法LSTM建立晶体直径预测模型. 其中, ELM方法具有快速的训练和预测速度[26-27], 能够节省晶体直径建模成本, 而LSTM方法可以学习长期依赖的信息, 能够抓取数据序列中的时间特征, 非常适合处理具有非线性特征的数据序列回归问题[28-29]. 具体的晶体直径混合集成建模流程将在第1.2节给出.
1.1 晶体直径预测模型结构辨识
在硅单晶生长过程控制中, 建立准确的晶体直径预测模型是实现其控制的基础[3]. 为了准确辨识式(1)中的时滞
$d,$ 本文提出了一种基于互相关函数的时滞优化估计方法, 其中互相关系数的估计如下式:$${\hat \phi _{uy}}(d) = \frac{1}{n}\sum\limits_{i = 1}^n {\left| {\dfrac{({u_{i - d}} - {\mu _u})({y_i} - {\mu _y})}{{s_u}{s_y}}} \right|} $$ (2) 其中,
$u$ 和$y$ 可以分别表示历史的加热器功率数据序列和晶体直径数据序列,${\mu _u}$ 、${\mu _y}$ 和${s_u}$ 、${s_y}$ 分别是加热器功率和晶体直径数据的均值和标准差.根据互相关系数式(2), 可以将时滞估计问题转化为如下的优化问题:
$$\left\{ {\begin{array}{*{20}{l}} \mathop {\max }\limits_d g(y,u) = f(y,u(i - d))\\ {\rm s.t}.\;{\rm{ }}{d_{\min }} \le d \le {d_{\max }} \end{array}} \right.$$ (3) 其中,
$f( \cdot )$ 表示互相关系数${\hat \phi _{uy}}(d).$ ${d_{\min }}$ 为时滞阶次的下界,${d_{\max }}$ 为时滞阶次的上界.基于上述时滞优化问题式(3), 本文采用ALO算法进行时滞阶次寻优, 并将式(3)作为待优化的适应度函数, 从而确定式(1)中的时滞阶次
$d$ .在辨识获得时滞阶次
$d$ 的前提下, 本文提出了一种基于Lipschitz商准则[30]和模型拟合优度[31]的晶体直径模型阶次辨识方法. 所提辨识方法不仅可以保证模型估计精度, 而且无需模型阶次的先验知识, 不需要经历复杂优化过程且容易实现. 针对式(1), 将其写成更一般的形式, 如下$$y = {f_{NARMAX}}({x_1},{x_2}, \cdots ,{x_m})$$ (4) 其中,
$m$ 是变量个数且$m = {n_u} + {n_{y }}+ 1.$ $ X = [ {x_1},$ ${x_2}, \cdots ,{x_m} ] \rm ^T$ 表示${f_{NARMAX}}( \cdot )$ 的输入向量, 即历史的加热器功率与晶体直径数据.定义Lipschitz商如下
$${q_{i,j}} = \frac{{\left| {y(i) - y(j)} \right|}}{{\left| {x(i) - x(j)} \right|}},i \ne j$$ (5) 其中,
$\left| {x(i) - x(j)} \right|$ 表示两个输入向量之间的距离, 而$\left| {y(i) - y(j)} \right|$ 则表示晶体直径输出${f_{NARMAX}}(x(i))$ 与${f_{NARMAX}}(x(j))$ 之间的距离. 将Lipschitz商式(5)展开可得$$q_{i,j}^{(m)} = \frac{{\left| {y(i) - y(j)} \right|}}{{\sqrt {{{({x_1}(i) - {x_1}(j))}^2} + \cdots + {{({x_m}(i) - {x_m}(j))}^2}} }}$$ (6) 其中,
$q_{i,j}^{(m)}$ 的上标$m$ 表示式(3)中的变量个数. 根据参考文献[32]可知,$q_{i,j}^{(m)}$ 可以被用来表示非线性系统的输入是否遗漏了必要变量或者加入了多余变量. 当一个必要的输入变量${x_m}$ 被遗漏时, Lipschitz商$q_{i,j}^{(m - 1)}$ 将会远远大于$q_{i,j}^{(m)},$ 甚至表现为无穷大. 相反地, 当一个多余变量${x_{m + 1}}$ 被加入时, Lipschitz商$q_{i,j}^{(m{\rm{ + }}1)}$ 将会略小于或者大于$q_{i,j}^{(m)},$ 差别不会很明显. 为了减小噪声对辨识结果的影响, 本文采用指标式(7)来选择晶体直径模型${f_{NARMAX}}( \cdot )$ 中的变量个数, 即$${q^{(m)}} = {\left( {\prod\limits_{i = 1}^p {\sqrt m {q^m}(i)} } \right)^{\frac{1}{p}}}$$ (7) 其中,
${q^m}(i)$ 是所有的Lipschitz商$q_{i,j}^{(m)}$ 中第$i{\rm{ - }}th$ 的最大值, 而$p$ 是一个正数, 通常满足$p \in \left[ {0.01N,0.02N} \right].$ 然后, 定义停止准则评价指标$\Gamma (m + 1,m)$ 如下:$$\Gamma (m + 1,m) = \frac{{\left| {{q^{(m + 1)}} - {q^{(m)}}} \right|}}{{\max (1,\left| {{q^{(m)}}} \right|)}} < \varepsilon $$ (8) 其中, 本文将阈值
$\varepsilon $ 取为0.01. 通过Lipschitz商准则, 可以很准确地得到最佳变量个数$m$ , 再结合晶体直径模型拟合优度式(9), 将拟合优度最高值确定为最优晶体直径模型阶次组合, 从而实现对晶体直径系统式(1)的输入输出阶次辨识.$${\rm{Fit}} = 100\; {\text{%}} \times \left( {1 - \frac{{\left\| {y - \hat y} \right\|}}{{\left\| y \right\|}}} \right)$$ (9) 其中,
$y$ 是晶体直径实际值,$\hat y$ 是ELM网络的晶体直径预测值.1.2 基于WPD-ELM-LSTM的混合集成预测模型
针对硅单晶生长过程机理建模难问题, 采用数据驱动建模方法可以直接使用传感器获取的测量数据, 而无需显式建模晶体生长系统内部的状态, 减少了晶体直径建模成本和时间. 混合集成建模方法是基于“分而治之”原理, 利用多个子模型进行预测建模, 从而在预测中产生协同效应, 克服了单一模型预测性能不佳的缺点. 因此, 本文提出了一种新颖的WPD-ELM-LSTM混合集成建模方法, 并将其应用于硅单晶直径建模, 整体的建模框架, 如图2所示.
 图 2 基于WPD-ELM-LSTM的混合集成建模框架Fig. 2 Hybrid integrated modeling framework based on WPD-ELM-LSTM
图 2 基于WPD-ELM-LSTM的混合集成建模框架Fig. 2 Hybrid integrated modeling framework based on WPD-ELM-LSTM晶体直径混合集成建模过程主要包括两个阶段. 在第一阶段, 由于单晶炉内复杂的生长环境, 各种不确定性因素导致采集的晶体直径数据呈现出非平稳、非线性的特征, 所以本文选用应用广泛且可靠的WPD信号分解方法, 将原始晶体直径数据序列分解成不同的低频和高频平稳信号, 目的在于减少非平稳性、非线性特征以及满足基于“分而治之”原理对不同频率信号进行预测建模的需求. 通常, 低频子序列和高频子序列分别被称为近似子序列和细节子序列. 与低频分量相比, 高频分量具有较大的随机性, 包含了不确定性的随机噪声, 因此本文去除了最高频子序列, 从而减少了随机噪声对预测性能的影响. 在第二阶段, 首先将获得的子序列划分为训练集和测试集; 其次, 由于近似子序列包含了原始晶体直径数据固有的本征信息, 所以我们采用建模速度快和泛化能力强的ELM进行预测建模; 细节子序列是一个高频的非线性信号序列, 为了更准确地捕获晶体直径数据序列中的时间特征信息, 我们使用了具有时间记忆功能的LSTM网络进行预测建模. 然而, ELM和LSTM网络的隐含节点个数对预测性能有较大的影响, 为了得到最佳的晶体直径预测效果, 采用ALO算法进行隐含节点个数寻优, 并将晶体直径预测值与实际值之间的均方根误差作为待优化的适应度函数, 从而获取最优节点个数. 最后, 通过WPD重构所有子序列预测模型的预测结果, 以得到晶体直径的整体预测输出. 与传统单一预测建模方法相比, 混合集成建模方法能够捕捉原始数据的内在特征, 学习历史数据之间的相互依赖关系, 从而有效地提高整体预测能力.
2. 晶体直径自适应非线性预测控制
等径阶段的晶体直径控制是Cz法硅单晶生长过程的核心, 精准的直径控制, 一方面有利于减小生长界面的热应力波动, 避免位错缺陷生成的可能性, 另一方面可以提高后续晶体加工利用率[33]. 目前, 在Cz法硅单晶实际生产线上, 普遍采用的是PID控制. 然而, 非线性、时变性和大滞后特性的存在, 不但使得传统的PID控制难以实现精确的直径跟踪控制和约束处理, 而且容易降低晶体生长系统的可靠性. 因此, 为了提高硅单晶直径控制性能, 所提自适应非线性预测控制方法能够很好地解决这些潜在的问题.
2.1 晶体直径预测控制结构
晶体直径预测控制的控制性能依赖于所建混合集成预测模型的预测性能, 当被控晶体生长系统参数发生变化时, 会存在模型失配问题, 此时如果仍采用原始晶体直径预测模型的非线性预测控制器, 会导致晶体直径控制性能变差甚至不稳定, 甚至引发晶体生长失败. 因此, 为了使晶体直径预测控制系统仍能达到控制目标要求, 本文提出了一种基于ALO算法优化求解的自适应NMPC方法, 并通过ALO算法调整晶体直径混合集成预测模型的参数, 使其与晶体生长过程保持一致. 基于WPD-ELM-LSTM的晶体直径自适应NMPC结构, 如图3所示, 主要包括: 期望晶体直径参考轨迹、晶体直径WPD-ELM-LSTM预测模型、模型参数自适应更新、基于ALO算法的滚动优化、反馈校正等几个部分.
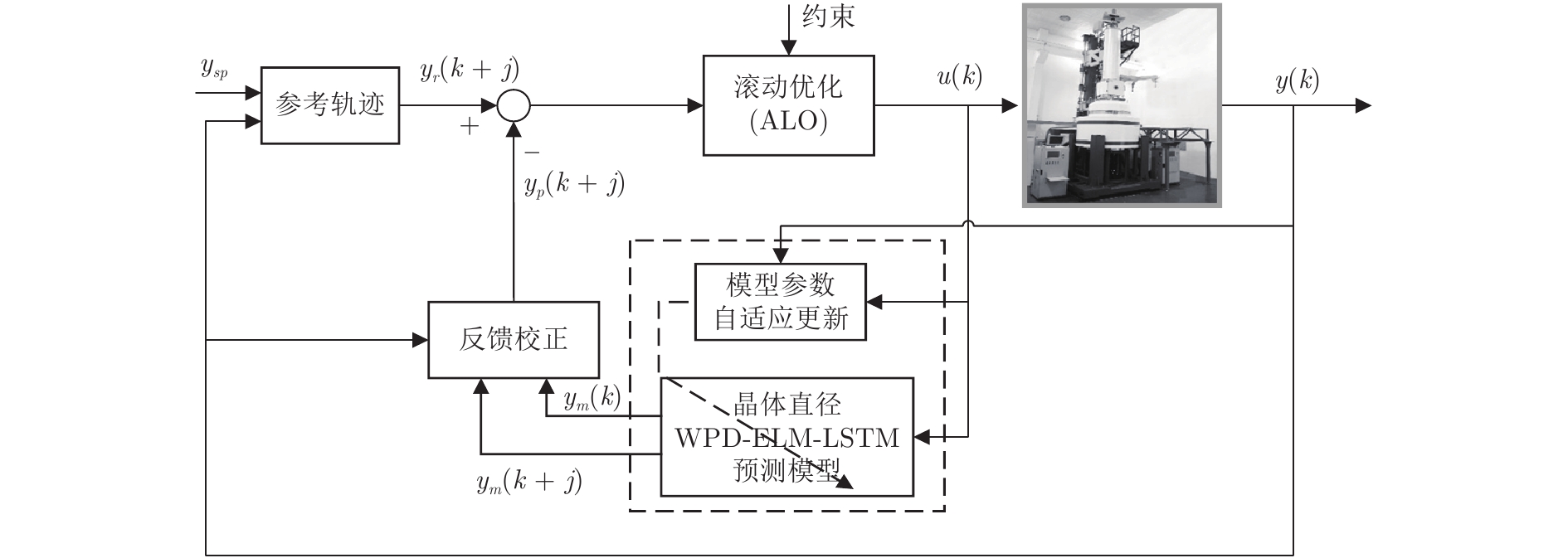 图 3 基于WPD-ELM-LSTM的晶体直径自适应NMPC结构Fig. 3 Crystal diameter adaptive NMPC structure based on WPD-ELM-LSTM
图 3 基于WPD-ELM-LSTM的晶体直径自适应NMPC结构Fig. 3 Crystal diameter adaptive NMPC structure based on WPD-ELM-LSTM晶体直径WPD-ELM-LSTM预测模型: 根据式(1)所描述的晶体直径非线性系统, 建立其相应的WPD-ELM-LSTM混合集成预测模型. 预测模型的训练输入数据集由历史加热器功率和晶体直径数据组成, 即
$X = \{ u(k - d), \cdots ,u(k - d - {n_u}),$ $y(k), \cdots , y(k - {n_y})\},$ 输出数据集为历史晶体直径$Y = \left\{ {y(k)} \right\},$ 晶体直径系统的时滞阶次$d$ 、模型阶次${n_u}$ 和${n_y}$ 可由第1.1节所提模型辨识方法确定. 晶体直径WPD-ELM-LSTM预测模型可由第1.2节所提的建模方法建立. 所建立的晶体直径混合集成预测模型的目的是为求解晶体直径预测控制优化问题提供可靠的基础.根据建立的晶体直径混合集成预测模型, 从
$k$ 时刻起利用系统的当前信息和未来的加热器功率控制输入, 可以预测出未来的晶体直径预测值${y_m}$ , 然后经过在线反馈校正为滚动优化问题提供所需的未来晶体直径控制预测输出${y_p}$ .基于ALO算法的滚动优化: 本文所设计的晶体直径非线性预测控制是一种有限时域内的滚动优化过程. 定义
$k$ 时刻的加热器功率控制输入信号为$U = {\left[ {u(k),u(k + 1), \cdots ,u(k + N - 1)} \right]\rm^T}.$ 在采样时刻$k,$ 优化式(10)所示的性能指标.$$\left\{ \begin{array}{*{20}{l}} \min {\rm{ }}J(u) = \displaystyle\sum\limits_{j = 1}^{{N_p}} {{{\left[ {{y_r}(k + j) - {y_p}(k + j)} \right]}^2} + } \\ \qquad\qquad {\rm{ }}\displaystyle\sum\limits_{j = 1}^{{N_c}} {r{{\left[ {\Delta u(k + j - 1)} \right]}^2}} \\ {\rm{s}}{\rm{.t}}{\rm{. }}\;\Delta {u_{\min }} \le \Delta u \le \Delta {u_{\max }},\\ \qquad{u_{\min }} \le u \le {u_{\max }} \end{array} \right.$$ (10) 其中,
${N_p}$ 为预测时域,${N_c}$ 为控制时域,${N_p} \geqslant {N_c}$ ,$r$ 为控制权系数.$\Delta u(k) = u(k) - u(k - 1)$ ;${y_p}(k + j)$ 是第$j$ 步晶体直径混合集成预测模型的预测输出;${y_r}(k + j)$ 是第$j$ 步晶体直径参考输出, 其由式(11)所示的参考轨迹给出.晶体直径自适应NMPC的核心是式(10)所示非线性约束优化问题, 由于建立的WPD-ELM-LSTM混合集成预测模型相对复杂, 难以采用传统优化算法进行求解. 而ALO算法是一种模拟蚁狮与蚂蚁之间狩猎行为及相互作用机制的全局优化搜索方法, 具有潜在的并行性和鲁棒性. 此外, ALO算法是一种无梯度的算法, 它把优化问题看作一个黑盒, 很容易应用于实际复杂工业优化问题的求解, 算法的具体实现过程, 可以参考文献[25]. 本文正是基于ALO算法的优点, 通过求解晶体直径预测控制性能指标函数式(10), 获得一组最优的加热器功率控制序列U, 但仅对硅单晶生长系统施加第一个控制量
${u^ * }(k).$ 参考轨迹: 针对上述晶体直径自适应非线性预测控制过程, 为了把当前晶体生长系统输出的晶体直径
$y(k)$ 平滑地过渡到真实设定值$y_{sp},$ 定义${y_r}(k + j)$ 为第 j 步的晶体直径参考输出, 即$$\left\{ {\begin{array}{*{20}{l}} {{y_r}(k) = y(k)}\\ {{y_r}(k + j) = \eta {y_r}(k + j - 1) + (1 - \eta ){y_{{{sp}}}}} \end{array}} \right.$$ (11) 其中,
$ \eta \; (0 < \eta < 1)$ 为柔化系数, 用以调整系统的鲁棒性和收敛性.反馈校正: 为了克服所建立的晶体直径混合集成预测模型与晶体生长被控系统之间的模型失配和外部干扰对控制系统的影响, 通过反馈校正对晶体直径预测输出补偿, 即
$$\left\{ {\begin{array}{*{20}{l}} e(k) = y(k) - {y_m}(k)\\ {y_p}(k + j) = {y_m}(k + j) + h \times e(k) \end{array}} \right.$$ (12) 其中,
$h$ 为补偿系数,${y_m}$ 是晶体直径混合集成预测模型WPD-ELM-LSTM的预测输出,${y_p}$ 是经过反馈校正的晶体直径预测输出.2.2 模型参数自适应更新
Cz法硅单晶生长过程存在各种不确定性因素(熔体对流、氩气流动等), 使得所建立的晶体直径混合集成预测模型难免与实际系统存在偏差. 另外, 当实际晶体生长过程的结构参数发生变化造成模型失配时, 会导致晶体直径预测模型的输出和实际输出之间的误差增大, 因而难以获得满意的晶体直径预测控制性能. 为此, 进一步引入模型参数自适应估计方法[34], 通过最小化晶体直径混合预测模型输出和实际输出之间的误差, 在线调整预测模型WPD-ELM-LSTM的参数集. 考虑到近似子序列的ELM预测模型包含着晶体直径固有的本征信息, 且方便在线实施模型参数估计, 所以本文主要调整ELM网络的输入权值
$W$ 和偏置 b, 以保证晶体直径混合集成预测模型的准确性. WPD–ELM–LSTM模型参数估计的性能指标, 如式(13)所示:$$\left\{ {\begin{array}{*{20}{l}} {\mathop {\min {\rm{ }}}\limits_\theta {J_\theta } = {{\left[ {y(k) - {{\hat y}_\theta }(k)} \right]}^2} + \psi \displaystyle\sum\limits_{m = 1}^{{n_\theta }} {{{\left( {\Delta {\theta _m}(k)} \right)}^2}} }\\ {\rm{s}}{\rm{.t}}{\rm{. }}\;{{\hat y}_\theta }(k) = {{\hat y}_{{\theta _{ELM}}}}(k) + {{\hat y}_{LSTM}}(k)\\ \quad\;\; {\rm{ }}\Delta {\theta _m}(k) = {\theta _m}(k) - {\theta _m}(k - 1) \end{array}} \right.$$ (13) 其中,
$\theta $ 为ELM网络中的参数$\left\{ {W,b} \right\},$ $y(k)$ 和${\hat y_\theta }(k)$ 分别表示$k$ 时刻晶体直径系统的实际输出值和晶体直径预测模型WPD–ELM–LSTM的预测值;$\psi\; (\psi > 0)$ 为参数变量权系数,${n_\theta }$ 表示模型参数个数;${\hat y_{{\theta _{ELM}}}}(k)$ 和${\hat y_{LSTM}}(k)$ 分别表示晶体直径近似子序列和细节子序列的预测值.针对上述混合集成预测模型参数估计问题, 本文将模型参数估计性能指标函数式(13)作为ALO算法优化的适应度函数, 当满足迭代终止条件时, 即可求得当前
$k$ 时刻自适应调整后的WPD-ELM-LSTM预测模型参数值.2.3 实现步骤
基于WPD-ELM-LSTM混合集成预测模型的晶体直径自适应NMPC算法的实现步骤如下:
1) 设定合适的控制参数包括预测时域
${N_p}$ 、控制时域${N_c}$ 、柔化系数$\eta $ 、补偿系数$h$ 、控制加权系数$r$ 、参数变量权系数$\psi $ 以及ALO算法的种群个数$Num,$ 最大迭代次数$Ma{x_{iter}};$ 2) 离线训练晶体直径混合集成预测模型WPD-ELM-LSTM;
3) 设定晶体直径的期望值
${y_{sp}},$ 并按式(11)得到晶体直径参考轨迹${y_r};$ 4) 计算晶体直径混合集成预测模型的预测输出值
${y_m}(k)$ 以及实际系统直径输出值$y(k);$ 5) 根据ALO算法求解式(13) 非线性优化问题, 以得到最优参数集
$\hat \theta ,$ 从而更新晶体直径预测模型WPD–ELM–LSTM;6) 利用当前时刻晶体直径预测误差
$e(k)$ 和未来时刻晶体直径预测值${y_m}(k + j),$ 经在线反馈校正式(12)得到晶体直径预测输出${y_p}(k + j);$ 7) 基于ALO算法滚动优化求解晶体直径预测控制性能指标式(10), 并获得一组最优的加热器功率控制量序列
$U(k);$ 8) 将最优加热器功率控制序列的第1个控制量
${u^ * }(k)$ 作用于当前硅单晶生长系统;9) 返回步骤4), 不断进行迭代求解.
3. 工业数据实验与分析
为了验证本文所提方法在实际Cz法硅单晶生长控制过程中的有效性, 本文以晶体生长设备及系统集成国家地方联合工程研究中心的TDR-150型号的单晶炉为实验平台, 图4是Cz法单晶炉生长设备及直径测量系统[35]. 从图4可知, 硅单晶是由多晶硅原料在高温、磁场等作用下经过一系列晶体生长工艺步骤所获得. 晶体直径的动态变化是通过CCD相机进行实时监测. 实验数据采集过程来源于8英寸硅单晶生长实验, 实验条件分别为: 多晶硅原料为180 kg, 炉压为20 Torr, 磁场强度为2 000高斯, 晶体旋转速度为10 r/min, 坩埚旋转速度为10 r/min, 氩气流速为100 L/min.
 图 4 Cz法硅单晶生长过程和晶体直径测量系统Fig. 4 Cz silicon single crystal growth process and crystal diameter measurement system
图 4 Cz法硅单晶生长过程和晶体直径测量系统Fig. 4 Cz silicon single crystal growth process and crystal diameter measurement system3.1 模型建立
基于上述TDR-150单晶炉拉制8英寸硅单晶现场数据库收集到的2017年2月26日至2017年3月2日的历史实验数据进行预测建模和直径控制. 由于硅单晶等径阶段的晶体生长控制不仅影响后期晶体加工的利用率, 还决定了硅单晶品质的好坏, 所以本文主要利用硅单晶等径阶段的晶体直径和加热器功率的历史测量数据, 整个硅单晶等径阶段总共历时27小时左右, 采样时间为2 s. 考虑到后续晶体直径建模的计算量, 我们从等径阶段某个时刻起间隔5个数据点连续选取5 000组实验数据, 该数据集的数据记录时间间隔为10 s, 原始实验数据如图5所示. 选取前3 800组作为训练数据集, 后1 200组作为测试数据集, 用于验证模型拟合效果. 表1是实验数据集的统计描述, 包括总样本数, 平均值(Mean), 最大值(Max), 最小值(Min)和标准差(Std).
表 1 原始实验数据集的统计特性Table 1 Statistical characteristics of the raw experimental data set数据集 数量 Mean Max Min Std 晶体直径 (mm) 总样本 5 000 208.92 212.57 206.16 0.66 训练集 3 800 208.92 212.57 206.16 0.72 测试集 1 200 208.92 209.83 208.06 0.41 加热器功率 (kW) 总样本 5 000 70.52 72.51 68.37 0.80 训练集 3 800 70.20 72.32 68.37 0.59 测试集 1 200 71.56 72.51 70.44 0.40 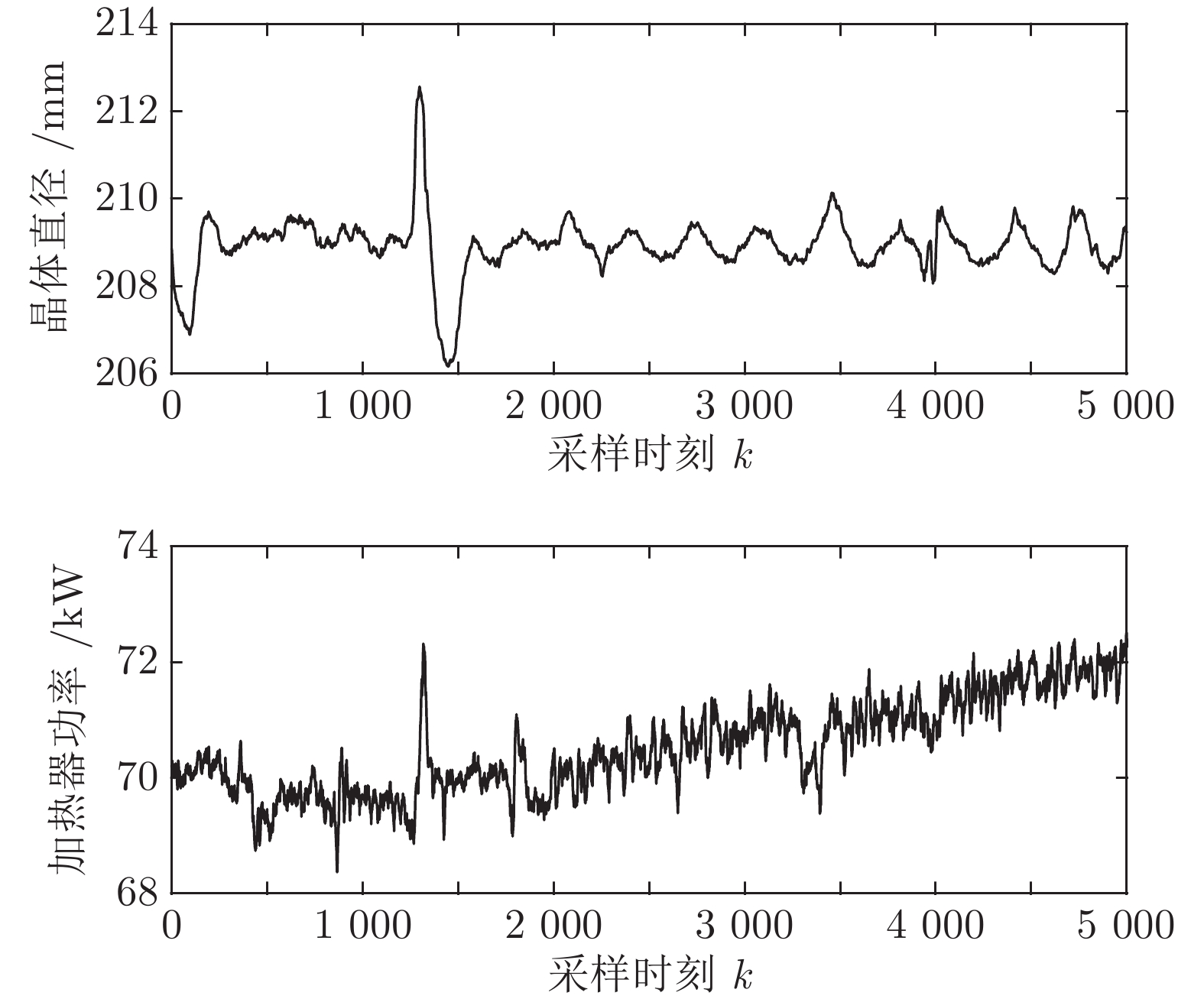 图 5 原始晶体直径与加热器功率实验数据Fig. 5 Experimental data of raw crystal diameter and heater power
图 5 原始晶体直径与加热器功率实验数据Fig. 5 Experimental data of raw crystal diameter and heater power基于上述等径阶段的历史实验数据, 并考虑到所提混合集成模型的复杂度和计算量, 采用WPD信号分解方法对晶体直径原始数据进行2层分解, 图6是分解之后的不同子序列结果.
从图6中可以明显看出, 近似子序列具有晶体直径原始数据的固有本征信息特征, 代表了晶体直径数据序列的整体趋势, 而细节子序列具有高频的非线性特征反映了晶体直径数据局部波动趋势. 由于高频分量具有较大的随机性, 通常包含了不确定性的测量噪声, 所以为了保证晶体直径预测模型的准确性, 本文将具有最高频的细节子序列3移除, 利用剩余的子序列进行预测建模.
根据晶体生长过程的先验知识, 滞后时间
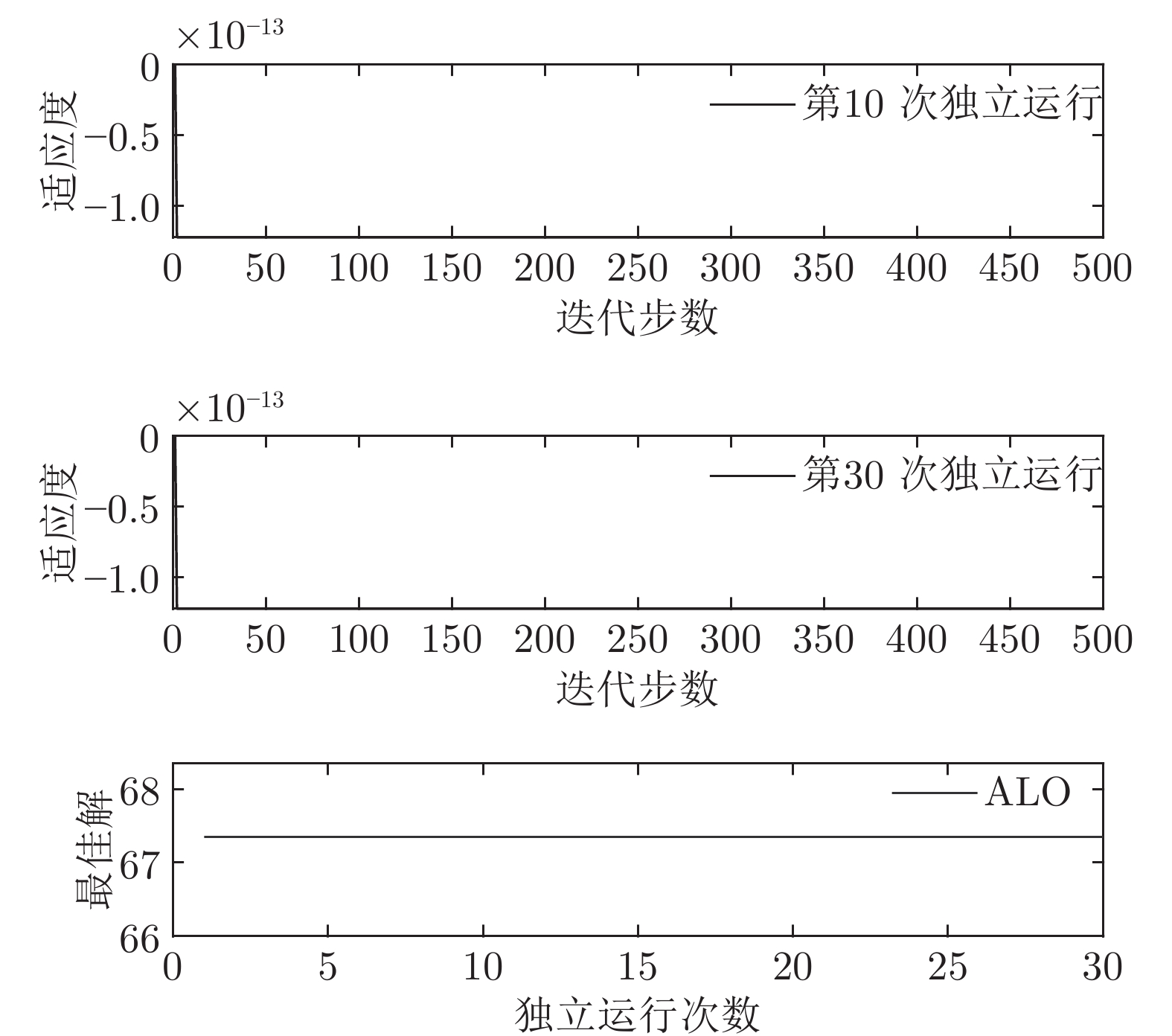
$t$ 一般在5 min ~ 25 min. 采用本文所提出的模型结构辨识方法, 首先对晶体直径模型式(1)中的时滞阶次进行辨识. ALO算法的参数设置为: 种群数$Num = 30,$ 最大迭代次数$Ma{x_{iter}} = 500,$ 时滞阶次$d$ 范围为$30\sim 150. $ 由于ALO算法的初始种群位置是随机生成的, 为了说明所提时滞辨识方法的准确性和可靠性, 图7是30次独立运行后的时滞阶次寻优结果. 可知, 30次独立寻优的时滞阶次未发生明显变化, 说明了所辨识的时滞是准确且可靠的, 同时也说明了ALO算法具有很强的全局搜索能力. 通过四舍五入原则确定时滞
$d = 67,$ 即滞后时间$t = 670\;\rm s,$ 约为11.17 min.然后, 针对式(1)中的模型输入输出阶次, 假设最高阶次为5, 采用所提模型阶次辨识方法, 初步得到表2中基于Lipschitz商准则的不同输入变量个数的评价指标值
$\Gamma $ . 根据停止准则评价指标$\Gamma (m + $ $1,m),$ 可以确定最佳的输入变量个数为$m = {n_u} + $ $ {n_y} + 1 = 5,$ 即${n_u} + {n_y} = 4.$ 最后, 根据模型拟合优度方法可以得到不同阶次组合下的拟合优度值, 如表3所示. 依据最优拟合优度值可以确定输入阶次${n_u} = 1,$ 输出阶次${n_y} = 3.$ 表 2 基于Lipschitz商准则的输入变量个数辨识结果Table 2 Identification results of the number of input variables based on Lipschitz quotient criterion$\Gamma (m + 1,m)$ $\Gamma (4,3)$ $\Gamma (5,4)$ $\Gamma (6,5)$ $\Gamma (7,6)$ $\Gamma (8,7)$ $\Gamma (9,8)$ $\Gamma (10,9)$ $\Gamma (11,10)$ 指标值 0.0145 0.0105 0.0088 0.0071 0.0141 0.0071 0.0033 0.0003 表 3 不同阶次组合的模型拟合优度结果Table 3 Goodness-of-fit of the models with different order combinations不同阶次组合$({n_u},{n_y})$ (1,3) (2,2) (3,1) 模型拟合优度值Fit 99.9132 99.9085 99.9090 3.2 预测性能
为了验证本文所提的晶体直径混合集成预测模型WPD-ELM-LSTM的有效性, 采用三种常用的统计标准来评估直径预测性能, 如表4所示.
表 4 模型性能评价指标Table 4 Model performance evaluation index指标 定义 公式 MAE 平均绝对值误差 ${\rm MAE} = \dfrac{1}{N}\displaystyle\sum\limits_{i = 1}^N {\left| {f(i) - \hat f(i)} \right|} $ MAPE 平均绝对百分
比误差${\rm MAPE} = \dfrac{1}{N}\displaystyle\sum\limits_{i = 1}^N {\left| {\frac{ {f(i) - \hat f(i)} }{ {f(i)} } } \right|} \times 100{\rm{\% } }$ RMSE 均方根误差 ${\rm RMSE} = \sqrt {\dfrac{1}{N}\displaystyle\sum\limits_{i = 1}^N { { {(f(i) - \hat f(i))}^2} } } $ 表5是不同晶体直径预测方法的参数设置. 图8是所提建模方法与ELM、LSTM、WPD-ELM和WPD-LSTM方法的晶体直径预测效果以及相应的预测性能评价指标对比. 为了准确评价所提预测建模方法的有效性, 表6中比较了不同预测模型的预测性能指标. 本文所有的仿真环境配置如下: 系统Windows 10, 内存16 GB, 处理器Intel(R) Core(TM) i5-4590, 仿真软件MATLAB 2018b.
表 5 不同预测方法的参数设置Table 5 Parameter setting of different prediction methods预测方法 参数设置 ELM 20 个隐含节点数, 激活函数 sigmoid LSTM 200 个隐含节点数, 学习率 0.005, 训练轮次 200 WPD-ELM 20 个隐含节点数, 激活函数 sigmoid WPD-LSTM 200 个隐含节点数, 学习率 0.005, 训练轮次 200 WPD-ELM-LSTM ELM: 27 个隐含节点数, 激活函数 sigmoid; LSTM: 185 个隐含节点数, 学习率 0.005, 训练轮次 200 表 6 不同预测模型的晶体直径预测指标Table 6 Prediction index of crystal diameter based on different prediction models模型 MAE (mm) MAPE (%) RMSE (mm) ELM 0.0197 0.0094 0.0258 LSTM 0.0878 0.0420 0.1131 WPD-ELM 0.0172 0.0082 0.0228 WPD-LSTM 0.0431 0.0206 0.0627 WPD-ELM-LSTM 0.0096 0.0046 0.0125  图 8 不同建模方法的晶体直径预测效果及评价指标对比Fig. 8 Comparison of prediction effect and evaluation index of crystal diameter by different modeling methods
图 8 不同建模方法的晶体直径预测效果及评价指标对比Fig. 8 Comparison of prediction effect and evaluation index of crystal diameter by different modeling methods根据图8所示, 所提的混合集成预测模型WPD-ELM-LSTM的晶体直径预测准确性优于其他预测模型(ELM、LSTM、WPD-ELM和WPD-LSTM). 在表6中, 与其他预测模型相比, 所提晶体直径预测模型的MAE指标分别降低了51.27 %, 89.07 %, 44.19 %和77.73 %; MAPE指标下降了51.06 %, 89.05 %, 43.90 %和77.67 %; RMSE指标减少了51.55 %, 88.95 %, 45.18 %和80.06 %. 此外, 所提混合集成预测模型WPD-ELM-LSTM的晶体直径预测值与实际值有更多的相似性, 这是因为混合集成预测模型在预测过程中产生了协同效应, 提高了整体预测结果的准确性. 总之, 所提晶体直径混合集成预测模型WPD-ELM-LSTM提高了单一ELM或LSTM模型的晶体直径预测性能, 从而显示了强大的“分解–集成”框架的学习预测能力.
为了描述上述不同晶体直径预测模型在模型训练阶段的计算量, 表7是不同晶体直径预测模型的训练计算时间, 即离线建模时间. 可以看出集成模型WPD-ELM和WPD-LSTM的训练计算时间分别高于各自单一模型ELM和LSTM, 而在单一模型中ELM的训练计算时间小于LSTM, 从而说明了ELM具有快速训练模型的优点. 正是基于ELM的建模优点, 所以所提WPD-ELM-LSTM的训练计算时间有所减少. 总之, 由于集成模型是由多个子模型进行建模, 必然会牺牲一定的建模时间. 然而在实际应用中晶体直径离线建模的计算量很少被优先考虑. 另一方面, 随着硬件计算能力的提高以及并行计算技术的应用, 所提混合集成建模方法的计算量将会有所减少.
表 7 不同晶体直径预测模型的训练计算时间Table 7 Training calculation time of different crystal diameter prediction models预测模型 训练计算时间 (s) ELM 0.0828 LSTM 304.4786 WPD-ELM 0.2752 WPD-LSTM 972.6920 WPD-ELM-LSTM 601.1670 3.3 控制测试
为了验证本文所提晶体直径混合集成预测模型WPD-ELM-LSTM和ALO优化求解方法在晶体直径自适应NMPC过程中的有效性. 选取预测时域
${N_p}$ 为5, 控制时域${N_c}$ 为3, 柔化系数$\eta $ 为0.2, 控制加权系数$r$ 为0.3, 补偿系数$h$ 为0.5, 控制量约束$\Delta {u_{\min }} = - 2,$ $\Delta {u_{\max }} = - 2,$ ${u_{\min }} = 69,$ ${u_{\max }} = 73,$ 控制量$u$ 的单位是kW. WPD-ELM-LSTM模型参数估计器的优化参数变量权系数$\psi = 0.03.$ ALO的参数设置为种群个数$Num = 30,$ 最大迭代次数$Ma{x_{iter}} = 300.$ 根据晶体生长工艺要求, 晶体生长控制目标为: 晶体直径$y$ 变化范围207 mm ~ 210 mm 加热器功率$u$ 变化范围69 kW ~ 73 kW. 由于实际硅单晶生长过程中会存在很多不确定性干扰因素, 为了模拟检测系统在测量过程中所产生的随机误差, 同时为了验证所提控制方法的鲁棒性, 所以本文在单晶炉系统的输出中加入均值为0, 方差0.01的高斯随机噪声, 用以模拟传感器数据采集混入的高斯噪声.首先, 测试所提混合集成建模方法下晶体直径自适应NMPC的跟踪性能, 选取晶体直径的初始设定值
${y_{sp}}$ 为208.5 mm, 在采样时刻150时改变晶体直径设定值${y_{sp}}$ 为209 mm, 得到晶体直径的设定值跟踪曲线, 如图9所示. 在外部干扰的情况下, 所提自适应NMPC方法和常规NMPC方法的晶体直径控制输出均在直径设定点附近轻微波动、超调较小, 且各自的加热器功率控制变量也在约束的范围之内. 然而, 在直径跟踪精度和快速性方面, 所提基于混合集成预测模型WPD-ELM-LSTM的晶体直径自适应NMPC控制性能优于常规NMPC, 而且加热器功率控制变量的抖动幅度相对较小. 因此, 自适应NMPC方法更适合硅单晶生长过程中的晶体直径控制.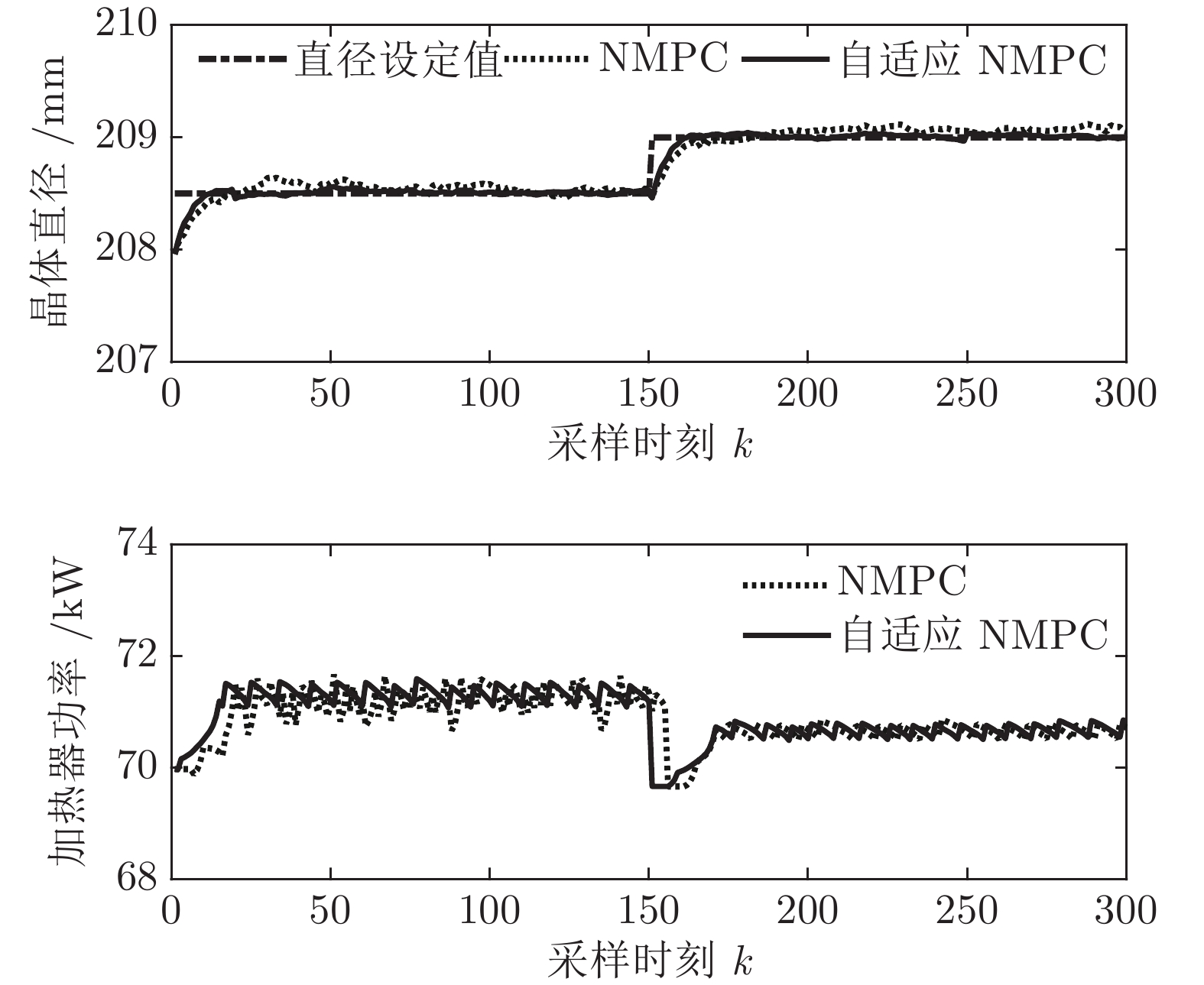 图 9 自适应NMPC和常规NMPC的晶体直径设定值跟踪效果Fig. 9 Crystal diameter setpoint tracking effect of adaptive NMPC and conventional NMPC
图 9 自适应NMPC和常规NMPC的晶体直径设定值跟踪效果Fig. 9 Crystal diameter setpoint tracking effect of adaptive NMPC and conventional NMPC然后, 验证所提晶体直径自适应NMPC在ALO优化求解下的晶体直径控制性能指标
$J$ 收敛性、WPD-ELM-LSTM预测模型参数估计性能指标${J_\theta }$ 收敛性以及晶体直径预测控制的实时性. 根据上述图9晶体直径设定值跟踪仿真结果, 可以得到晶体直径自适应NMPC在单步计算过程中的控制性能指标$J$ 和模型参数估计的性能指标${J_\theta }$ 收敛曲线, 如图10所示. 从中可以看出, 晶体直径控制性能指标$J$ 基本在160次迭代以后, 进入稳定收敛状态, 而晶体直径预测模型参数估计的性能指标${J_\theta }$ 在第150次迭代以后, 也能够满足稳定收敛. 因此, 采用ALO算法求解自适应NMPC可以实现晶体直径的有效控制. 此外, 为了比较晶体直径自适应NMPC在直径设定值跟踪控制中的实时性, 表8是不同预测模型下晶体直径预测控制计算时间, 即平均控制量更新时间. 从表8中可以看出, 所提混合集成预测模型WPD-ELM-LSTM的自适应NMPC计算时间高于单一模型的计算时间, 这主要是由所建混合集成模型的复杂性导致. 另外, 基于混合集成预测模型WPD-ELM-LSTM的自适应NMPC计算时间高于常规NMPC, 这主要是因为模型参数自适应更新过程比较耗时. 然而, 硅单晶生长是一个缓慢的时变动态过程, 通过加热器功率调节晶体直径存在较大的滞后时间(5 min ~ 25 min), 且实际应用中对控制系统的实时性要求不高, 所以7.3113 s的平均控制量更新时间是可以接受的. 另外, 随着硬件计算能力的提高, 所提控制方法的计算时间将会有所减少.表 8 基于不同预测模型的晶体直径预测控制计算时间Table 8 Calculation time of crystal diameter predictive control based on different prediction models预测模型 平均控制量更新时间 (s) ELM (常规NMPC) 0.4512 LSTM (常规NMPC) 0.4899 WPD-ELM-LSTM (常规NMPC) 0.6841 WPD-ELM-LSTM (自适应NMPC) 7.3113 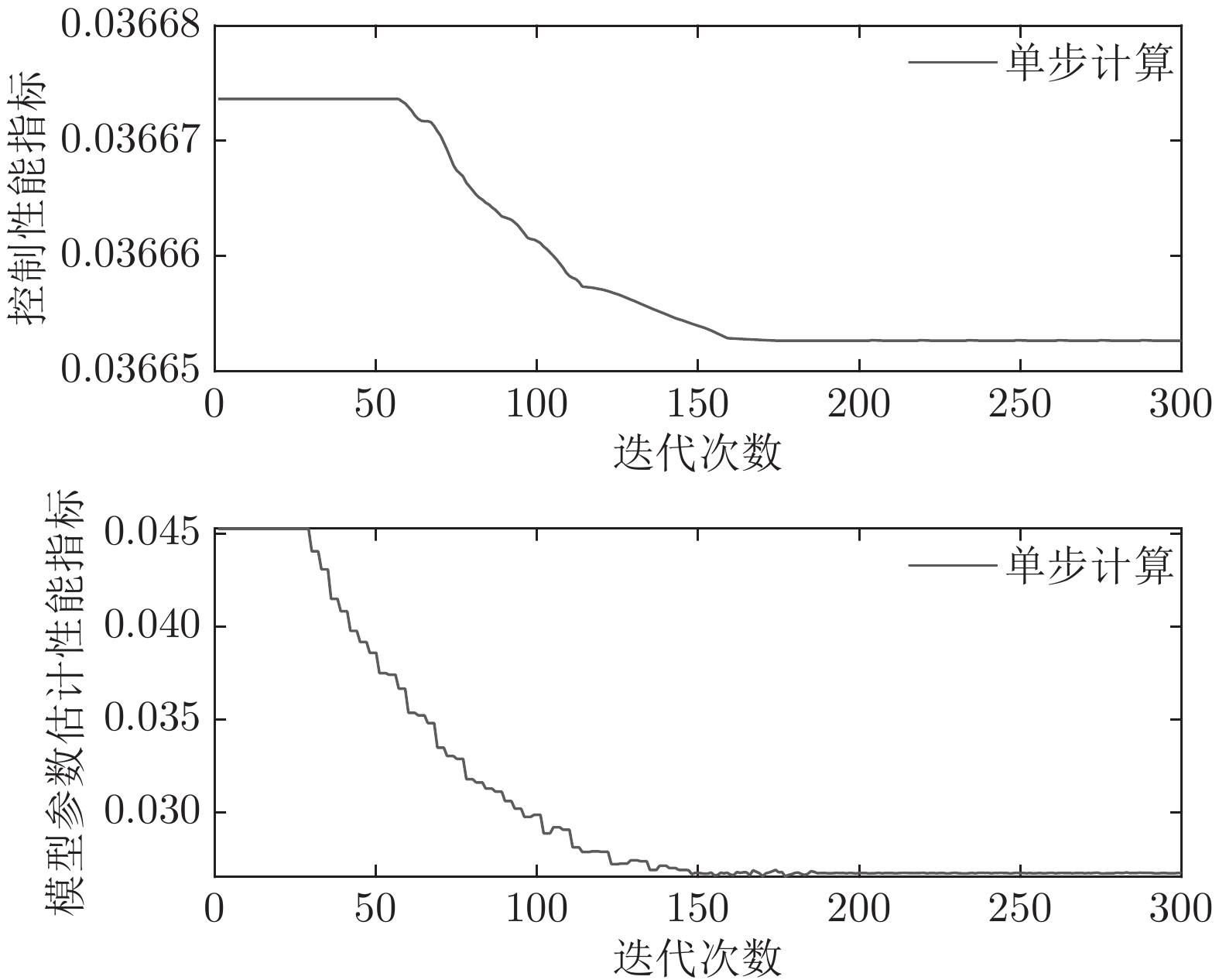 图 10 晶体直径控制性能指标和模型参数估计性能指标收敛曲线Fig. 10 Convergence curve of crystal diameter control performance index and model parameter estimation performance index
图 10 晶体直径控制性能指标和模型参数估计性能指标收敛曲线Fig. 10 Convergence curve of crystal diameter control performance index and model parameter estimation performance index最后, 由于硅单晶生长系统是一个慢时变动态过程, 且具有大滞后特点, 因此为了进一步验证所提控制方法的应用性能以及在时滞变化情况下的稳定性, 本文将晶体生长工业中常规PID控制方法与本文方法进行对比. 设置晶体直径的期望指标
${y_{sp}}$ 为209 mm, 补偿系数$h$ 为0.3, WPD-ELM-LSTM模型参数估计器的优化参数变量的权系数$\psi = 0.01,$ 其他晶体直径控制参数与上述设置相同; PID控制参数设置为${k_p} = 0.26,$ ${k_i} = 0.01,$ ${k_d} = 0.1.$ 图11是原始时滞阶次下的所提控制方法与常规PID晶体直径控制结果对比. 图12是时滞阶次$d$ 增大20 %和时滞阶次减少20 %的晶体直径控制结果.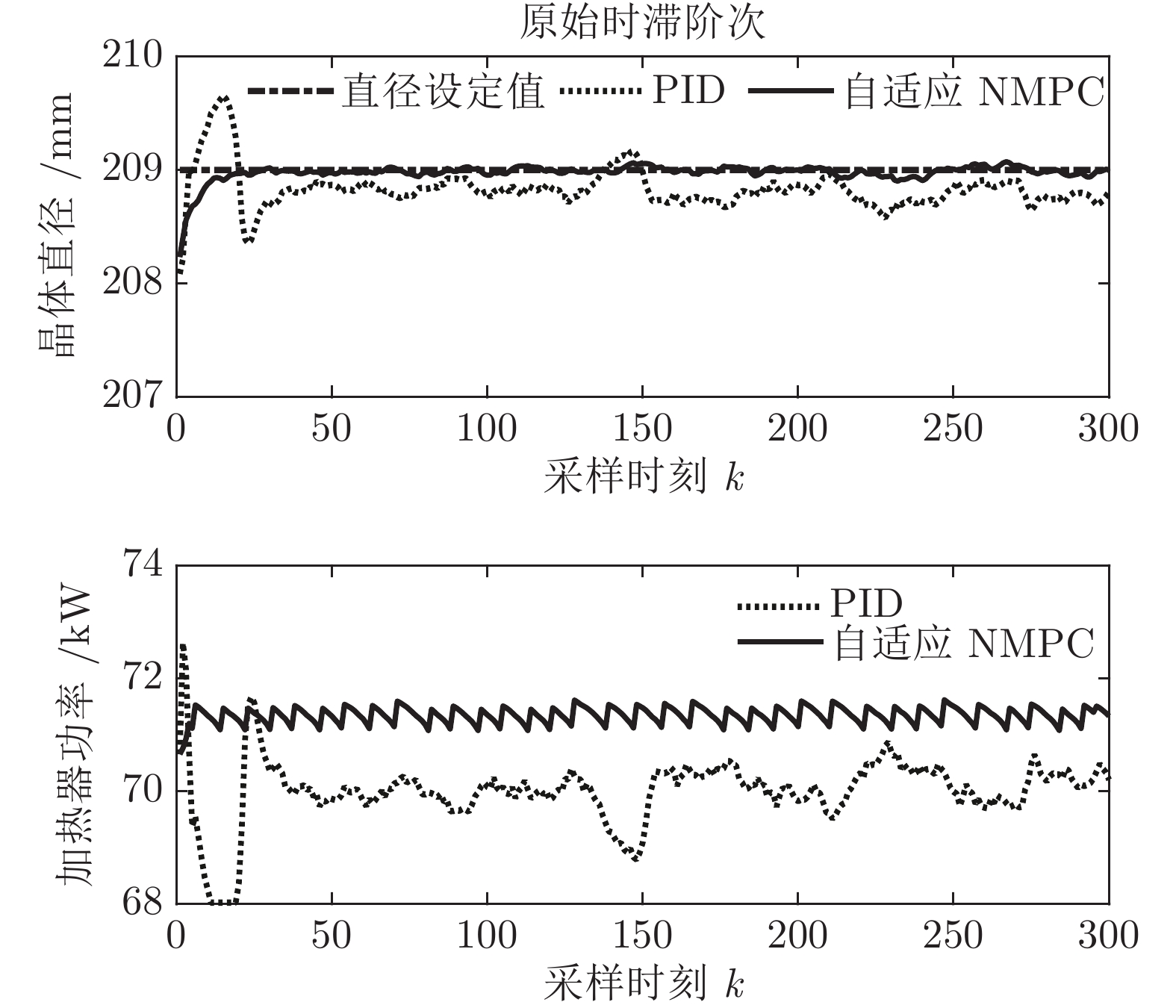 图 11 所提自适应NMPC与常规PID的晶体直径控制结果Fig. 11 The crystal diameter control results of the proposed adaptive NMPC and conventional PID
图 11 所提自适应NMPC与常规PID的晶体直径控制结果Fig. 11 The crystal diameter control results of the proposed adaptive NMPC and conventional PID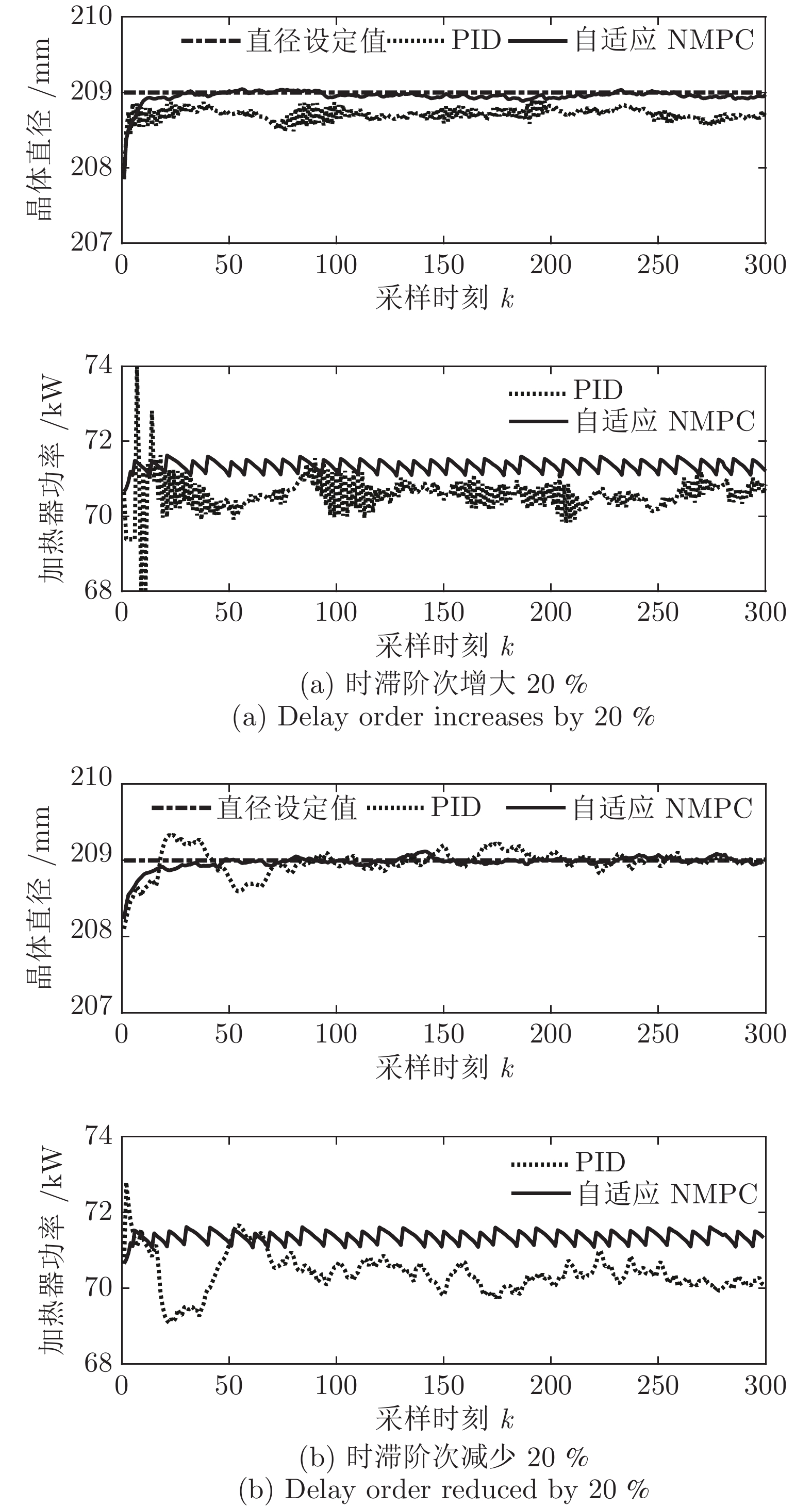 图 12 时滞阶次变化时所提自适应NMPC与常规PID的晶体直径控制结果Fig. 12 Crystal diameter control results of adaptive NMPC and conventional PID for delay order variation
图 12 时滞阶次变化时所提自适应NMPC与常规PID的晶体直径控制结果Fig. 12 Crystal diameter control results of adaptive NMPC and conventional PID for delay order variation从图11可知, 所提控制方法和PID控制均能获得有效的晶体直径控制效果. 然而, 与常规PID方法相比, 所提控制方法的直径设定值跟踪和干扰抑制性能更好, 并且具有更好的动态跟踪和稳态性能. 另外, 在图12中, 当时滞阶次
$d$ 发生变化时, 所提控制方法均能达到满意的晶体直径控制性能, 更好地显示了其具有更强的鲁棒性. 然而, 对于常规PID控制方法而言, 当时滞阶次d增大20 %时, 晶体直径控制难以较好地跟踪直径设定值, 始终存在较大的控制误差, 出现晶体直径控制效果抖振现象; 当时滞阶次d减小20 %时, 晶体直径跟踪控制能够逐渐收敛到直径设定值附近, 且受时滞阶次变化影响较小. 因此, 对于此类具有大滞后、慢时变动态特性的Cz法硅单晶生长过程, 常规PID控制难免有其局限性, 而所提控制方法具有明显的晶体直径控制优点, 即准确、稳定的在线控制性能.4. 结论
Cz法硅单晶生长过程的晶体直径控制一直是晶体生长领域研究的热点和难点. 针对这一问题, 本文提出了一种基于混合集成预测模型WPD-ELM-LSTM的晶体直径自适应NMPC方法. 通过基于互相关函数的时滞优化估计方法和基于Lipschitz商准则与模型拟合优度的模型阶次辨识方法, 准确的辨识了晶体直径模型结构, 并在“分而治之”原理下构建了数据驱动的晶体直径混合集成模型, 为晶体直径预测控制提供了精确的预测模型. 同时, 为了解决晶体直径混合集成模型失配问题以及目标函数难以求解问题, 采用ALO算法设计了晶体直径自适应NMPC求解策略. 基于实际硅单晶生长实验数据的晶体直径建模与控制仿真实验表明, 所提混合集成预测模型WPD-ELM-LSTM比常规ELM、LSTM、WPD-ELM和WPD-LSTM模型表现出更好的晶体直径预测性能和泛化能力. 另外, 基于混合集成模型的硅单晶直径自适应NMPC算法不仅可以实现晶体直径的精准控制, 而且能够有效抑制外部扰动和时滞变化的影响, 具有良好的控制性能以及工程应用前景.
-

图 1 基于表征学习的离线强化学习总体框架
Fig. 1 The overall framework of offline reinforcement learning based on representation learning

图 2 基于动作表征的离线强化学习框架
Fig. 2 The framework of offline reinforcement learning based on action representation

图 3 基于状态表征的离线强化学习框架
Fig. 3 The framework of offline reinforcement learning based on state representation

图 4 基于状态−动作对表征的离线强化学习框架
Fig. 4 The framework of offline reinforcement learning based on state-action pairs representation

图 5 基于轨迹表征的离线强化学习框架
Fig. 5 The framework of offline reinforcement learning based on trajectory representation

图 6 基于任务(环境)表征的离线强化学习框架
Fig. 6 The framework of offline reinforcement learning based on task (environment) representation
表 1 基于表征学习的离线强化学习方法对比
Table 1 Comparison of offline reinforcement learning based on representation learning
表征对象 参考文献 表征网络架构 环境建模方式 应用场景 特点 缺点 动作表征 [15−21] VAE 无模型 机器人控制、导航 状态条件下生成动作, 将目标
策略限制在行为策略范围内,
缓解分布偏移不适用于离散动作空间 [22−23] 流模型 [24−25] 扩散模型 状态表征 [26−27] VAE 无模型 基于视觉的机器人控制 压缩高维观测状态, 减少
冗余信息, 提高泛化能力限定于图像(像素)输入 [28] VAE 基于模型 [29] GAN 基于模型 [30] 编码器架构 基于模型 [31−32] 编码器架构 无模型 状态−动作
对表征[33] 自编码器 基于模型 基于视觉的机器人控制、
游戏、自动驾驶学习状态−动作联合表征,
捕捉两者交互关系,
指导后续决策任务限定于图像(像素)输入 [34] VAE 基于模型 [35−36] 编码器架构 无模型 [37−38] 编码器架构 基于模型 轨迹表征 [39−44] Transformer 序列模型 机器人控制、导航、游戏 将强化学习视为条件序列建模
问题, 用于预测未来轨迹序列轨迹生成速度慢,
调优成本高[45−47] 扩散模型 任务表征 [48−49] 编码器架构 无模型 机器人控制、导航 借助元学习思想, 使智能体
快速适应新任务泛化能力依赖于任务或
环境之间的相似性环境表征 [50−51] 编码器架构 基于模型  下载: 导出CSV
下载: 导出CSV
表 2 离线强化学习基准数据集对比
Table 2 Comparison of benchmarking datasets for offline reinforcement learning
名称 领域 应用领域 数据集特性 RL Unplugged DeepMind控制套件 机器人连续控制 连续域, 探索难度由易到难 DeepMind运动套件 模拟啮齿动物的运动 连续域, 探索难度大 Atari 2600 视频游戏 离散域, 探索难度适中 真实世界强化学习套件 机器人连续控制 连续域, 探索难度由易到难 D4RL Maze2D 导航 非马尔科夫策略, 不定向与多任务数据 MiniGrid-FourRooms 导航, Maze2D的离散模拟 非马尔科夫策略, 不定向与多任务数据 AntMaze 导航 非马尔科夫策略, 稀疏奖励, 不定向与多任务数据 Gym-MuJoCo 机器人连续控制 次优数据, 狭窄数据分布 Adroit 机器人操作 非表示性策略, 狭窄数据分布, 稀疏奖励, 现实领域 Flow 交通流量控制管理 非表示性策略, 现实领域 FrankaKitchen 厨房机器人操作 不定向与多任务数据, 现实领域 CARLA 自动驾驶车道跟踪与导航 部分可观测性, 非表示性策略, 不定向与多任务数据, 现实领域 NeoRL Gym-MuJoCo 机器人连续控制 保守且数据量有限 工业基准 工业控制任务 高维连续状态和动作空间, 高随机性 FinRL 股票交易市场 高维连续状态和动作空间, 高随机性 CityLearn 不同类型建筑的储能控制 高维连续状态和动作空间, 高随机性 SalesPromotion 商品促销 由人工操作员与真实用户提供的数据
下载: 导出CSV
表 3 基于表征学习的离线强化学习应用综述
Table 3 Summarization of the applications for offline reinforcement learning based on representation learning
应用领域 文献 表征对象 表征网络架构 环境建模方式 所解决的实际问题 策略学习方法 工业 [68] 任务表征 编码器架构 无模型 工业连接器插入 从离线数据中元学习自适应策略 [104] 任务表征 编码器架构 无模型 工业连接器插入 利用域对抗神经网络的域不变性和变分信息瓶颈的
域特定信息流控制来实现策略泛化[67] 轨迹表征 Transformer 序列模型 工业芯片布局 采用因果自注意力掩码并通过自回归
输入标记来预测动作推荐系统 [57] 动作表征 VAE 基于模型 快速适应冷启动用户 利用逆强化学习从少量交互中恢复出
用户策略与奖励[60] 状态表征 编码器架构 基于模型 数据稀疏性 利用群体偏好注入的因果用户模型训练策略 [61] 状态表征 编码器架构 无模型 离线交互推荐 利用保守的Q函数来估计策略 智能驾驶 [58] 动作表征 VAE 无模型 交叉口生态驾驶控制 利用VAE生成动作 [69] 环境表征 VAE 基于模型 长视域任务 利用VAE生成动作 医疗 [63] 状态−动作对表征 编码器架构 基于模型 个性化诊断 使用在线模型预测控制方法选择策略 能源管理 [59] 动作表征 VAE 无模型 油电混动汽车能源利用效率 利用VAE生成动作 量化交易 [70] 环境表征 编码器架构 无模型 最优交易执行的过拟合问题 利用时序差分误差或策略梯度法来学习策略
下载: 导出CSV
-
[1] Sutton R S, Barto A G. Reinforcement Learning: An Introduction (Second edition). Cambridge: The MIT Press, 2018. [2] 孙悦雯, 柳文章, 孙长银. 基于因果建模的强化学习控制: 现状及展望. 自动化学报, 2023, 49(3): 661−677Sun Yue-Wen, Liu Wen-Zhang, Sun Chang-Yin. Causality in reinforcement learning control: The state of the art and prospects. Acta Automatica Sinica, 2023, 49(3): 661−677 [3] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den Driessche G, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587): 484−489 doi: 10.1038/nature16961 [4] Schrittwieser J, Antonoglou I, Hubert T, Simonyan K, Sifre L, Schmitt S, et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 2020, 588(7839): 604−609 doi: 10.1038/s41586-020-03051-4 [5] Senior A W, Evans R, Jumper J, Kirkpatrick J, Sifre L, Green T, et al. Improved protein structure prediction using potentials from deep learning. Nature, 2020, 577(7792): 706−710 doi: 10.1038/s41586-019-1923-7 [6] Li Y J, Choi D, Chung J, Kushman N, Schrittwieser J, Leblond R, et al. Competition-level code generation with AlphaCode. Science, 2022, 378(6624): 1092−1097 doi: 10.1126/science.abq1158 [7] Degrave J, Felici F, Buchli J, Neunert M, Tracey B, Carpanese F, et al. Magnetic control of tokamak plasmas through deep reinforcement learning. Nature, 2022, 602(7897): 414−419 doi: 10.1038/s41586-021-04301-9 [8] Fawzi A, Balog M, Huang A, Hubert T, Romera-Paredes B, Barekatain M, et al. Discovering faster matrix multiplication algorithms with reinforcement learning. Nature, 2022, 610(7930): 47−53 doi: 10.1038/s41586-022-05172-4 [9] Fang X, Zhang Q C, Gao Y F, Zhao D B. Offline reinforcement learning for autonomous driving with real world driving data. In: Proceedings of the 25th IEEE International Conference on Intelligent Transportation Systems (ITSC). Macao, China: IEEE, 2022. 3417−3422 [10] 刘健, 顾扬, 程玉虎, 王雪松. 基于多智能体强化学习的乳腺癌致病基因预测. 自动化学报, 2022, 48(5): 1246−1258Liu Jian, Gu Yang, Cheng Yu-Hu, Wang Xue-Song. Prediction of breast cancer pathogenic genes based on multi-agent reinforcement learning. Acta Automatica Sinica, 2022, 48(5): 1246−1258 [11] Levine S, Kumar A, Tucker G, Fu J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv: 2005.01643, 2020. [12] Prudencio R F, Maximo M R O A, Colombini E L. A survey on offline reinforcement learning: Taxonomy, review, and open problems. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2023.3250269 [13] 程玉虎, 黄龙阳, 侯棣元, 张佳志, 陈俊龙, 王雪松. 广义行为正则化离线Actor-Critic. 计算机学报, 2023, 46(4): 843−855 doi: 10.11897/SP.J.1016.2023.00843Cheng Yu-Hu, Huang Long-Yang, Hou Di-Yuan, Zhang Jia-Zhi, Chen Jun-Long, Wang Xue-Song. Generalized offline actor-critic with behavior regularization. Chinese Journal of Computers, 2023, 46(4): 843−855 doi: 10.11897/SP.J.1016.2023.00843 [14] 顾扬, 程玉虎, 王雪松. 基于优先采样模型的离线强化学习. 自动化学报, 2024, 50(1): 143−153Gu Yang, Cheng Yu-Hu, Wang Xue-Song. Offline reinforcement learning based on prioritized sampling model. Acta Automatica Sinica, 2024, 50(1): 143−153 [15] Fujimoto S, Meger D, Precup D. Off-policy deep reinforcement learning without exploration. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 2052−2062 [16] He Q, Hou X W, Liu Y. POPO: Pessimistic offline policy optimization. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Singapore: IEEE, 2022. 4008−4012 [17] Wu J L, Wu H X, Qiu Z H, Wang J M, Long M S. Supported policy optimization for offline reinforcement learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 2268 [18] Lyu J F, Ma X T, Li X, Lu Z Q. Mildly conservative Q-learning for offline reinforcement learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 125 [19] Rezaeifar S, Dadashi R, Vieillard N, Hussenot L, Bachem O, Pietquin O, et al. Offline reinforcement learning as anti-exploration. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI Press, 2022. 8106−8114 [20] Zhou W X, Bajracharya S, Held D. PLAS: Latent action space for offline reinforcement learning. In: Proceedings of the 4th Conference on Robot Learning. Cambridge, USA: PMLR, 2020. 1719−1735 [21] Chen X, Ghadirzadeh A, Yu T H, Wang J H, Gao A, Li W Z, et al. LAPO: Latent-variable advantage-weighted policy optimization for offline reinforcement learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 2674 [22] Akimov D, Kurenkov V, Nikulin A, Tarasov D, Kolesnikov S. Let offline RL flow: Training conservative agents in the latent space of normalizing flows. In: Proceedings of Offline Reinforcement Learning Workshop at Neural Information Processing Systems. New Orleans, USA: OpenReview.net, 2022. [23] Yang Y Q, Hu H, Li W Z, Li S Y, Yang J, Zhao Q C, et al. Flow to control: Offline reinforcement learning with lossless primitive discovery. In: Proceedings of the 37th AAAI Conference on Artificial Intelligence. Washington, USA: AAAI Press, 2023. 10843−10851 [24] Wang Z D, Hunt J J, Zhou M Y. Diffusion policies as an expressive policy class for offline reinforcement learning. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: OpenReview.net, 2023. [25] Chen H Y, Lu C, Ying C Y, Su H, Zhu J. Offline reinforcement learning via high-fidelity generative behavior modeling. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: OpenReview.net, 2023. [26] Zhang H C, Shao J Z, Jiang Y H, He S C, Zhang G W, Ji X Y. State deviation correction for offline reinforcement learning. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI Press, 2022. 9022−9030 [27] Weissenbacher M, Sinha S, Garg A, Kawahara Y. Koopman Q-learning: Offline reinforcement learning via symmetries of dynamics. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 23645−23667 [28] Rafailov R, Yu T H, Rajeswaran A, Finn C. Offline reinforcement learning from images with latent space models. In: Proceedings of the 3rd Annual Conference on Learning for Dynamics and Control. Zurich, Switzerland: PMLR, 2021. 1154−1168 [29] Cho D, Shim D, Kim H J. S2P: State-conditioned image synthesis for data augmentation in offline reinforcement learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 838 [30] Gieselmann R, Pokorny F T. An expansive latent planner for long-horizon visual offline reinforcement learning. In: Proceedings of the RSS 2023 Workshop on Learning for Task and Motion Planning. Daegu, South Korea: OpenReview.net, 2023. [31] Zang H Y, Li X, Yu J, Liu C, Islam R, Combes R T D, et al. Behavior prior representation learning for offline reinforcement learning. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: OpenReview.net, 2023. [32] Mazoure B, Kostrikov I, Nachum O, Tompson J. Improving zero-shot generalization in offline reinforcement learning using generalized similarity functions. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 1819 [33] Kim B, Oh M H. Model-based offline reinforcement learning with count-based conservatism. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: PMLR, 2023. 16728−16746 [34] Tennenholtz G, Mannor S. Uncertainty estimation using riemannian model dynamics for offline reinforcement learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 1381 [35] Ada S E, Oztop E, Ugur E. Diffusion policies for out-of-distribution generalization in offline reinforcement learning. IEEE Robotics and Automation Letters, 2024, 9(4): 3116−3123 doi: 10.1109/LRA.2024.3363530 [36] Kumar A, Agarwal R, Ma T Y, Courville A C, Tucker G, Levine S. DR3: Value-based deep reinforcement learning requires explicit regularization. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2022. [37] Lee B J, Lee J, Kim K E. Representation balancing offline model-based reinforcement learning. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2021. [38] Chang J D, Wang K W, Kallus N, Sun W. Learning bellman complete representations for offline policy evaluation. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 2938−2971 [39] Chen L L, Lu K, Rajeswaran A, Lee K, Grover A, Laskin M, et al. Decision transformer: Reinforcement learning via sequence modeling. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates, Inc., 2021. 15084−15097 [40] Janner M, Li Q Y, Levine S. Offline reinforcement learning as one big sequence modeling problem. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates, Inc., 2021. 1273−1286 [41] Furuta H, Matsuo Y, Gu S S. Generalized decision transformer for offline hindsight information matching. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2022. [42] Liu Z X, Guo Z J, Yao Y H, Cen Z P, Yu W H, Zhang T N, et al. Constrained decision transformer for offline safe reinforcement learning. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: JMLR.org, 2023. Article No. 893 [43] Wang Y Q, Xu M D, Shi L X, Chi Y J. A trajectory is worth three sentences: Multimodal transformer for offline reinforcement learning. In: Proceedings of the 39th Conference on Uncertainty in Artificial Intelligence. Pittsburgh, USA: JMLR.org, 2023. Article No. 208 [44] Zeng Z L, Zhang C, Wang S J, Sun C. Goal-conditioned predictive coding for offline reinforcement learning. arXiv preprint arXiv: 2307.03406, 2023. [45] Janner M, Du Y L, Tenenbaum J B, Levine S. Planning with diffusion for flexible behavior synthesis. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 9902−9915 [46] Ajay A, Du Y L, Gupta A, Tenenbaum J B, Jaakkola T S, Agrawal P. Is conditional generative modeling all you need for decision making? In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: OpenReview.net, 2023. [47] Liang Z X, Mu Y, Ding M Y, Ni F, Tomizuka M, Luo P. AdaptDiffuser: Diffusion models as adaptive self-evolving planners. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: JMLR.org, 2023. Article No. 854 [48] Yuan H Q, Lu Z Q. Robust task representations for offline meta-reinforcement learning via contrastive learning. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 25747−25759 [49] Zhao C Y, Zhou Z H, Liu B. On context distribution shift in task representation learning for online meta RL. In: Proceedings of the 19th Advanced Intelligent Computing Technology and Applications. Zhengzhou, China: Springer, 2023. 614−628 [50] Chen X H, Yu Y, Li Q Y, Luo F M, Qin Z W, Shang W J, et al. Offline model-based adaptable policy learning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates, Inc., 2021. 8432−8443 [51] Sang T, Tang H Y, Ma Y, Hao J Y, Zheng Y, Meng Z P, et al. PAnDR: Fast adaptation to new environments from offline experiences via decoupling policy and environment representations. In: Proceedings of the 31st International Joint Conference on Artificial Intelligence. Vienna, Austria: IJCAI, 2022. 3416−3422 [52] Lou X Z, Yin Q Y, Zhang J G, Yu C, He Z F, Cheng N J, et al. Offline reinforcement learning with representations for actions. Information Sciences, 2022, 610: 746−758 doi: 10.1016/j.ins.2022.08.019 [53] Kingma D P, Welling M. Auto-encoding variational Bayes. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, Canada: ICLR, 2014. [54] Mark M S, Ghadirzadeh A, Chen X, Finn C. Fine-tuning offline policies with optimistic action selection. In: Proceedings of NeurIPS Workshop on Deep Reinforcement Learning. Virtual Event: OpenReview.net, 2022. [55] 张博玮, 郑建飞, 胡昌华, 裴洪, 董青. 基于流模型的缺失数据生成方法在剩余寿命预测中的应用. 自动化学报, 2023, 49(1): 185−196Zhang Bo-Wei, Zheng Jian-Fei, Hu Chang-Hua, Pei Hong, Dong Qing. Missing data generation method based on flow model and its application in remaining life prediction. Acta Automatica Sinica, 2023, 49(1): 185−196 [56] Yang L, Zhang Z L, Song Y, Hong S D, Xu R S, Zhao Y, et al. Diffusion models: A comprehensive survey of methods and applications. ACM Computing Surveys, 2023, 56(4): Article No. 105 [57] Wang Y N, Ge Y, Li L, Chen R, Xu T. Offline meta-level model-based reinforcement learning approach for cold-start recommendation. arXiv preprint arXiv: 2012.02476, 2020. [58] 张健, 姜夏, 史晓宇, 程健, 郑岳标. 基于离线强化学习的交叉口生态驾驶控制. 东南大学学报(自然科学版), 2022, 52(4): 762−769 doi: 10.3969/j.issn.1001-0505.2022.04.018Zhang Jian, Jiang Xia, Shi Xiao-Yu, Cheng Jian, Zheng Yue-Biao. Offline reinforcement learning for eco-driving control at signalized intersections. Journal of Southeast University (Natural Science Edition), 2022, 52(4): 762−769 doi: 10.3969/j.issn.1001-0505.2022.04.018 [59] He H W, Niu Z G, Wang Y, Huang R C, Shou Y W. Energy management optimization for connected hybrid electric vehicle using offline reinforcement learning. Journal of Energy Storage, 2023, 72: Article No. 108517 doi: 10.1016/j.est.2023.108517 [60] Nie W Z, Wen X, Liu J, Chen J W, Wu J C, Jin G Q, et al. Knowledge-enhanced causal reinforcement learning model for interactive recommendation. IEEE Transactions on Multimedia, 2024, 26: 1129−1142 doi: 10.1109/TMM.2023.3276505 [61] Zhang R Y, Yu T, Shen Y L, Jin H Z. Text-based interactive recommendation via offline reinforcement learning. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI Press, 2022. 11694−11702 [62] Rigter M, Lacerda B, Hawes N. RAMBO-RL: Robust adversarial model-based offline reinforcement learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. 16082−16097 [63] Agarwal A, Alomar A, Alumootil V, Shah D, Shen D, Xu Z, et al. PerSim: Data-efficient offline reinforcement learning with heterogeneous agents via personalized simulators. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates, Inc., 2021. 18564−18576 [64] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6000−6010 [65] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X H, Unterthiner T, et al. An image is worth 16×16 words: Transformers for image recognition at scale. In: Proceedings of the 9th International Conference on Learning Representations. Vienna, Austria: OpenReview.net, 2021. [66] 王雪松, 王荣荣, 程玉虎. 安全强化学习综述. 自动化学报, 2023, 49(9): 1813−1835Wang Xue-Song, Wang Rong-Rong, Cheng Yu-Hu. Safe reinforcement learning: A survey. Acta Automatica Sinica, 2023, 49(9): 1813−1835 [67] Lai Y, Liu J X, Tang Z T, Wang B, Hao J Y, Luo P. ChiPFormer: Transferable chip placement via offline decision transformer. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: PMLR, 2023. 18346−18364 [68] Zhao T Z, Luo J L, Sushkov O, Pevceviciute R, Heess N, Scholz J, et al. Offline meta-reinforcement learning for industrial insertion. In: Proceedings of International Conference on Robotics and Automation. Philadelphia, USA: IEEE, 2022. 6386−6393 [69] Li Z N, Nie F, Sun Q, Da F, Zhao H. Boosting offline reinforcement learning for autonomous driving with hierarchical latent skills. arXiv preprint arXiv: 2309.13614, 2023. [70] Zhang C H, Duan Y T, Chen X Y, Chen J Y, Li J, Zhao L. Towards generalizable reinforcement learning for trade execution. In: Proceedings of the 32nd International Joint Conference on Artificial Intelligence. Macao, China: IJCAI, 2023. Article No. 553 [71] Gulcehre C, Wang Z Y, Novikov A, Le Paine T, Colmenarejo S G, Zołna K, et al. RL unplugged: A suite of benchmarks for offline reinforcement learning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 608 [72] Fu J, Kumar A, Nachum O, Tucker G, Levine S. D4RL: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv: 2004.07219, 2020. [73] Qin R J, Zhang X Y, Gao S Y, Chen X H, Li Z W, Zhang W N, et al. NeoRL: A near real-world benchmark for offline reinforcement learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 1795 [74] Song H F, Abdolmaleki A, Springenberg J T, Clark A, Soyer H, Rae J W, et al. V-MPO: On-policy maximum a posteriori policy optimization for discrete and continuous control. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: Open Review.net, 2020. [75] Merel J, Hasenclever L, Galashov A, Ahuja A, Pham V, Wayne G, et al. Neural probabilistic motor primitives for humanoid control. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: OpenReview.net, 2019. [76] Merel J, Aldarondo D, Marshall J, Tassa Y, Wayne G, Olveczky B. Deep neuroethology of a virtual rodent. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: OpenReview.net, 2020. [77] Machado M C, Bellemare M G, Talvitie E, Veness J, Hausknecht M, Bowling M. Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents. Journal of Artificial Intelligence Research, 2018, 61: 523−562 doi: 10.1613/jair.5699 [78] Dulac-Arnold G, Levine N, Mankowitz D J, Li J, Paduraru C, Gowal S, et al. An empirical investigation of the challenges of real-world reinforcement learning. arXiv preprint arXiv: 2003.11881, 2020. [79] Abdolmaleki A, Springenberg J T, Tassa Y, Munos R, Heess N, Riedmiller M A. Maximum a posteriori policy optimisation. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: OpenReview.net, 2018. [80] Pomerleau D A. ALVINN: An autonomous land vehicle in a neural network. In: Proceedings of the 1st International Conference on Neural Information Processing Systems. Denver, USA: MIT Press, 1988. 305−313 [81] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529−533 doi: 10.1038/nature14236 [82] Barth-Maron G, Hoffman M W, Budden D, Dabney W, Horgan D, Dhruva T B, et al. Distributed distributional deterministic policy gradients. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: OpenReview.net, 2018. [83] Dabney W, Ostrovski G, Silver D, Munos R. Implicit quantile networks for distributional reinforcement learning. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 1104−1113 [84] Wu Y F, Tucker G, Nachum O. Behavior regularized offline reinforcement learning. arXiv preprint arXiv: 1911.11361, 2019. [85] Siegel N, Springenberg J T, Berkenkamp F, Abdolmaleki A, Neunert M, Lampe T, et al. Keep doing what worked: Behavior modelling priors for offline reinforcement learning. In: Proceedings of International Conference on Learning Representations. Addis Ababa, Ethiopia: OpenReview.net, 2020. [86] Agarwal A, Schuurmans D, Norouzi M. An optimistic perspective on offline reinforcement learning. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: PMLR, 2020. 104−114 [87] Haarnoja T, Zhou A, Abbeel P, Levine S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 1856−1865 [88] Kumar A, Fu J, Soh M, Tucker G, Levine S. Stabilizing off-policy Q-learning via bootstrapping error reduction. In: Proceedings of the International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates, Inc., 2019. 11761−11771 [89] Peng X B, Kumar A, Zhang G, Levine S. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. arXiv preprint arXiv: 1910.00177, 2019. [90] Kumar A, Zhou A, Tucker G, Levine S. Conservative Q-learning for offline reinforcement learning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 100 [91] Nachum O, Dai B, Kostrikov I, Chow Y, Li L H, Schuurmans D. AlgaeDICE: Policy gradient from arbitrary experience. arXiv preprint arXiv: 1912.02074, 2019. [92] Wang Z Y, Novikov A, Żołna K, Springenberg J T, Reed S, Shahriari B, et al. Critic regularized regression. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 651 [93] Matsushima T, Furuta H, Matsuo Y, Nachum O, Gu S X. Deployment-efficient reinforcement learning via model-based offline optimization. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2021. [94] Yu T H, Thomas G, Yu L T, Ermon S, Zou J, Levine S, et al. MOPO: Model-based offline policy optimization. In: Proceedings of the 34th International Conference on Advances in Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 1185 [95] Le H M, Voloshin C, Yue Y S. Batch policy learning under constraints. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 3703−3712 [96] Koller D, Friedman N. Probabilistic Graphical Models: Principles and Techniques. Cambridge: MIT Press, 2009. [97] 王硕汝, 牛温佳, 童恩栋, 陈彤, 李赫, 田蕴哲, 等. 强化学习离线策略评估研究综述. 计算机学报, 2022, 45(9): 1926−1945 doi: 10.11897/SP.J.1016.2022.01926Wang Shuo-Ru, Niu Wen-Jia, Tong En-Dong, Chen Tong, Li He, Tian Yun-Zhe, et al. Research on off-policy evaluation in reinforcement learning: A survey. Chinese Journal of Computers, 2022, 45(9): 1926−1945 doi: 10.11897/SP.J.1016.2022.01926 [98] Fu J, Norouzi M, Nachum O, Tucker G, Wang Z Y, Novikov A, et al. Benchmarks for deep off-policy evaluation. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2021. [99] Schweighofer K, Dinu M, Radler A, Hofmarcher M, Patil V P, Bitto-nemling A, et al. A dataset perspective on offline reinforcement learning. In: Proceedings of the 1st Conference on Lifelong Learning Agents. McGill University, Canada: PMLR, 2022. 470−517 [100] Konyushkova K, Chen Y T, Paine T, Gülçehre C, Paduraru C, Mankowitz D J, et al. Active offline policy selection. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates, Inc., 2021. 24631−24644 [101] Kurenkov V, Kolesnikov S. Showing your offline reinforcement learning work: Online evaluation budget matters. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 11729−11752 [102] Lu C, Ball P J, Parker-Holder J, Osborne M A, Roberts S J. Revisiting design choices in offline model based reinforcement learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2022. [103] Hu H, Yang Y Q, Zhao Q C, Zhang C J. On the role of discount factor in offline reinforcement learning. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 9072−9098 [104] Nair A, Zhu B, Narayanan G, Solowjow E, Levine S. Learning on the job: Self-rewarding offline-to-online finetuning for industrial insertion of novel connectors from vision. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). London, United Kingdom: The IEEE, 2023. 7154−7161 [105] Kostrikov I, Nair A, Levine S. Offline reinforcement learning with implicit Q-learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2022. 期刊类型引用(4)
1. 乔宏霞,杜杭威,李元可,杨安. 氯氧镁水泥混凝土中涂层钢筋的锈蚀劣化模型研究. 建筑结构. 2024(03): 65-70 .  百度学术
百度学术2. 康守强,邢颖怡,王玉静,王庆岩,谢金宝,MIKULOVICH Vladimir Ivanovich. 基于无监督深度模型迁移的滚动轴承寿命预测方法. 自动化学报. 2023(12): 2627-2638 . 本站查看3. 严帅,熊新. 基于KPCA和TCN-Attention的滚动轴承退化趋势预测. 电子测量技术. 2022(15): 28-34 . 百度学术4. 张伟涛,纪晓凡,黄菊,楼顺天. 航发轴承复合故障诊断的循环维纳滤波方法. 西安电子科技大学学报. 2022(06): 139-151 . 百度学术其他类型引用(12)
-

 下载:
下载:
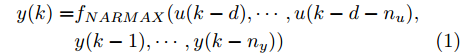
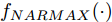
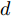
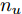
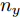
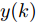
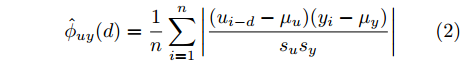
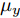
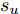
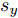
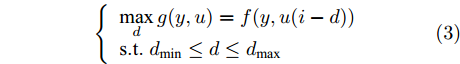
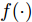
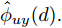


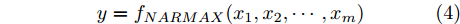

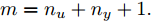
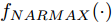
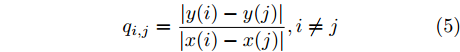
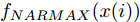
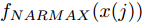
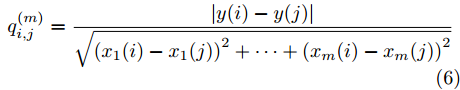
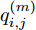

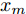
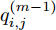
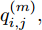
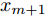
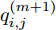
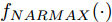
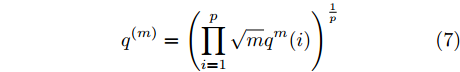
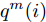
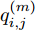
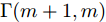
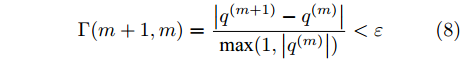


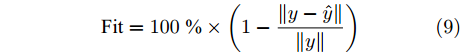
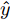
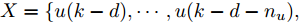
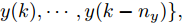
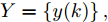
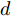
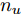
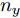
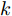
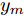
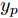
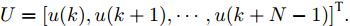
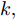
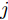
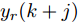
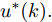
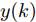
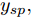
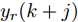
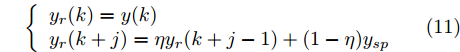
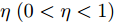
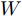
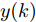
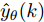
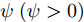
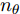
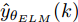
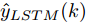
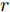
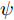
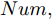
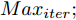
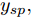
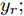
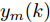
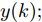
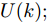
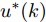
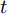
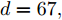
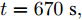
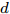
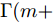
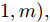
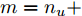
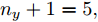
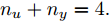
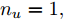
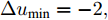
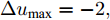
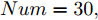



计量
- 文章访问数: 3500
- HTML全文浏览量: 816
- PDF下载量: 477
- 被引次数: 16
