

Research on Fused Magnesium Furnace Working Condition Recognition Method Based on Deep Convolutional Stochastic Configuration Networks
-
摘要: 为解决电熔镁炉工况识别模型泛化能力和可解释性弱的缺陷, 提出一种基于深层卷积随机配置网络(Deep convolutional stochastic configuration networks, DCSCN)的可解释性电熔镁炉异常工况识别方法. 首先, 基于监督学习机制生成具有物理含义的高斯差分卷积核, 采用增量式方法构建深层卷积神经网络(Deep convolutional neural network, DCNN), 确保识别误差逐级收敛, 避免反向传播算法迭代寻优卷积核参数的过程. 定义通道特征图独立系数获取电熔镁炉特征类激活映射图的可视化结果, 定义可解释性可信度评测指标, 自适应调节深层卷积随机配置网络层级, 对不可信样本进行再认知以获取最优工况识别结果. 实验结果表明, 所提方法较其他方法具有更优的识别精度和可解释性.
-
关键词:
- 电熔镁炉 /
- 深层卷积随机配置网络 /
- 高斯差分卷积核 /
- 类激活映射图 /
- 可解释性
Abstract: In order to solve the defects of generalization ability and weak interpretability of fused magnesium furnace working condition recognition model, an interpretable fused magnesium furnace abnormal working condition recognition method based on deep convolutional stochastic configuration networks (DCSCN) is proposed in this paper. Firstly, based on the supervised learning mechanism to generate Gaussian differential convolution kernel with physical meaning, an incremental method is used to construct a deep convolutional neural network (DCNN) to ensure that the recognition error converges step by step, and to avoid the process that back propagation algorithm iteratively finds the optimal convolutional kernel parameters. This paper defines channel feature map independent coefficients to obtain visualization results of fused magnesium furnace feature class activation mapping map, defines interpretable credibility measure to adaptively adjust deep convolutional stochastic configuration network layers, and recognizes untrustworthy samples to obtain optimal working condition recognition results. The experimental results show that the proposed method in this paper has better recognition accuracy and interpretability than other methods. -

图 1 基于深层卷积随机配置网络的可解释电熔镁炉工况识别模型结构图
Fig. 1 Structure of interpretable fused magnesium furnace working condition recognition model based on deep convolutional stochastic configuration networks
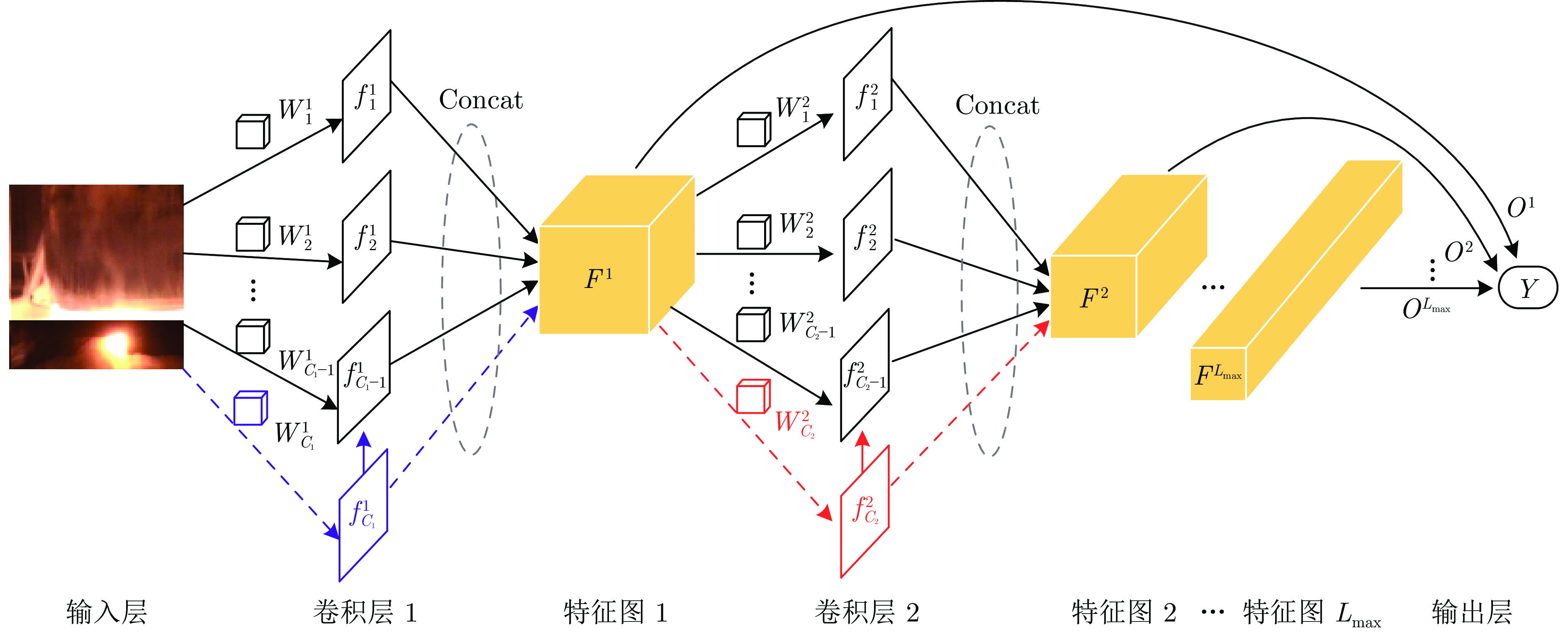
图 2 深层卷积随机配置网络结构图
Fig. 2 Deep convolutional stochastic configuration networks structure diagram
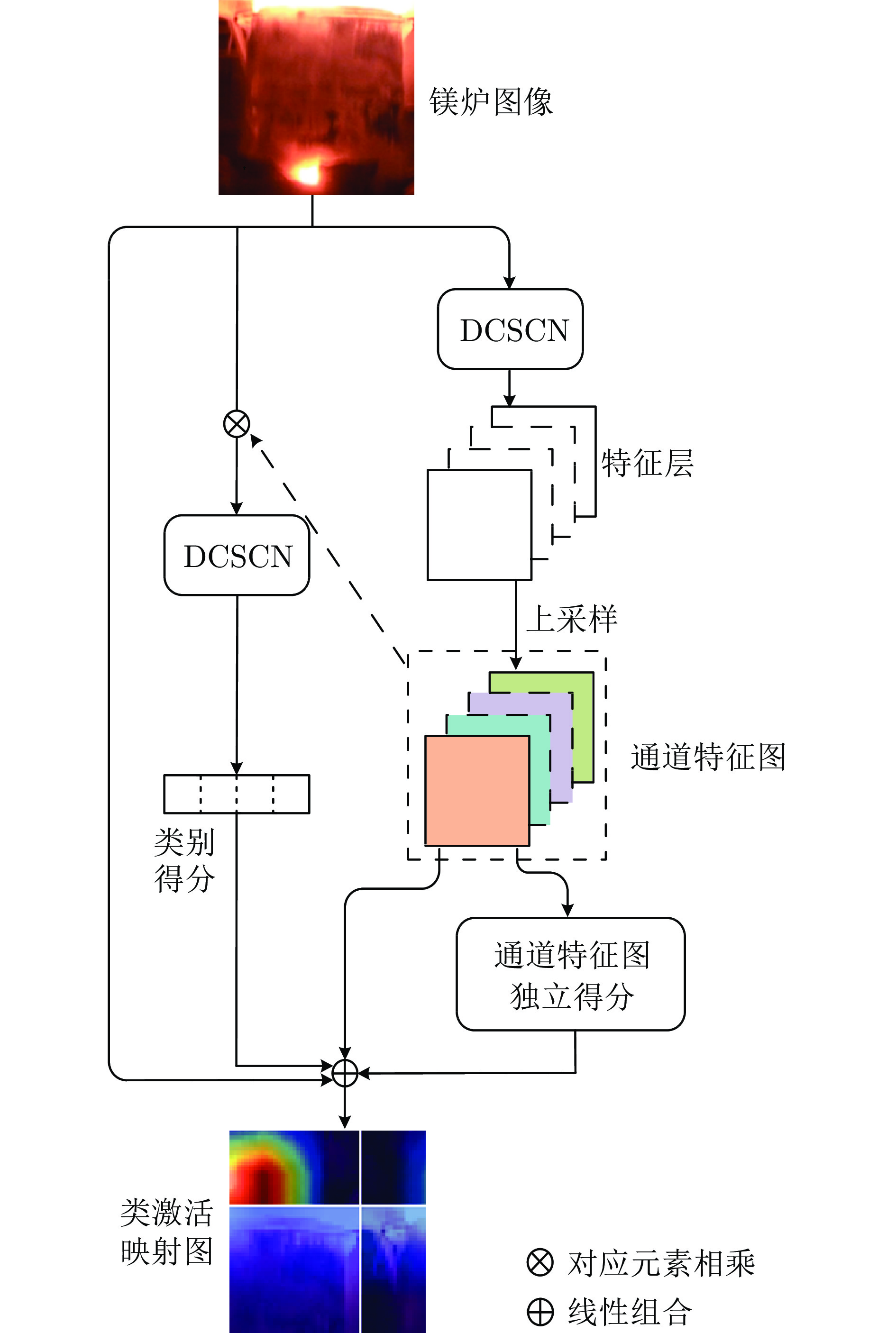
图 3 基于特征图独立性得分的类激活映射示意图
Fig. 3 Schematic diagram of the class activation mapping based on feature map independence scores

图 5 欠烧工况图像数据增强后的结果
Fig. 5 Results after image data enhancement for underburning conditions

图 6 过热工况图像数据增强后的结果
Fig. 6 Results after image data enhancement for superheated operating conditions

图 7 异常排气工况图像数据增强后的结果
Fig. 7 Results after image data enhancement for abnormal exhaust conditions
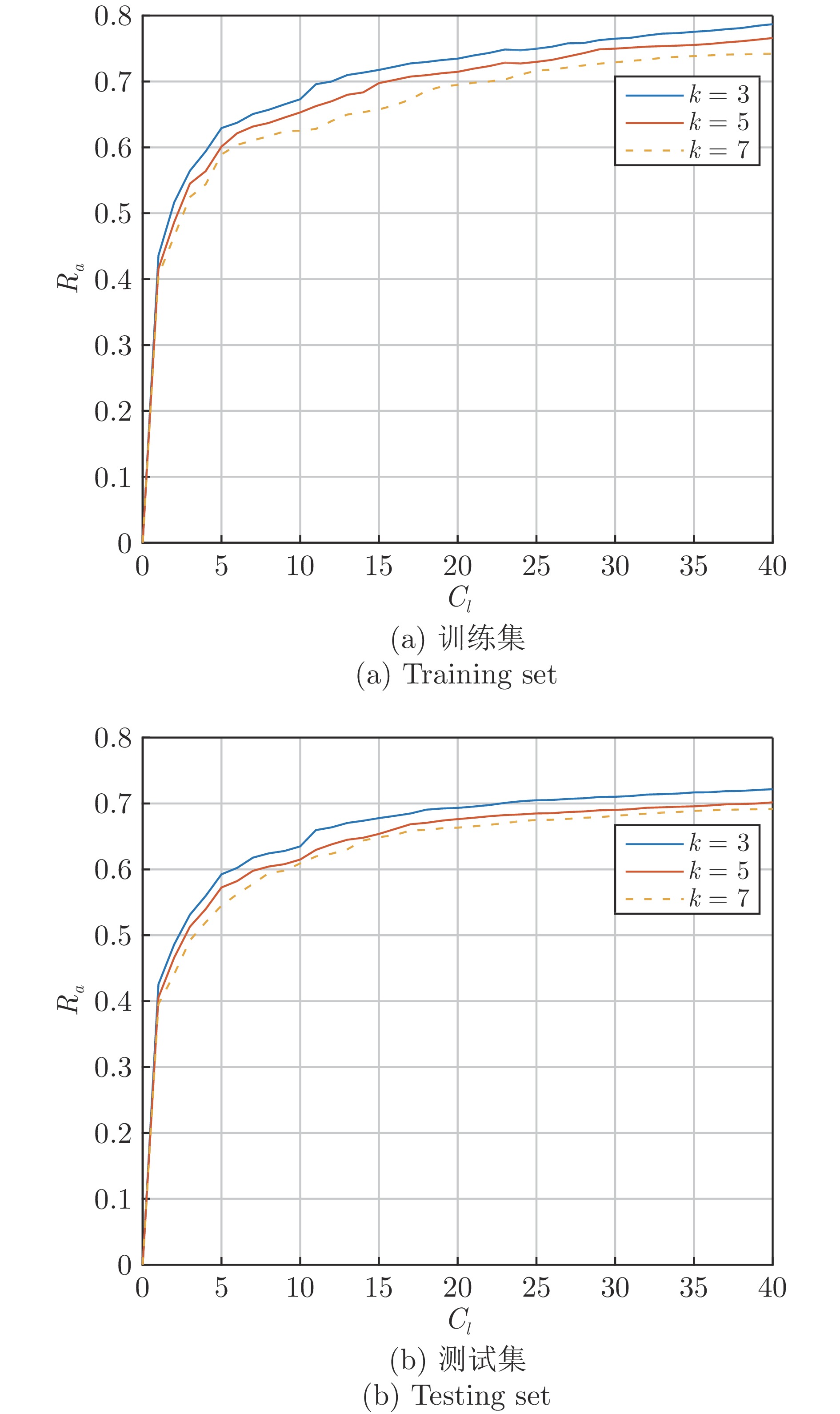
图 8 不同卷积核大小条件下的识别精度曲线
Fig. 8 Recognition accuracy curves under different convolutional kernel sizes

图 9 强化学习训练过程的平均奖励曲线
Fig. 9 Average reward curves for training process of reinforcement learning methods

图 11 本文方法与基于强化学习的类激活映射图对比
Fig. 11 Comparison of the method proposed in this paper with the class activation mapping maps based on reinforcement learning

图 12 本文方法与基于强化学习的可信识别样本比例变化曲线
Fig. 12 The proportion change curves of trusted recognition samples based on reinforcement learning and the method proposed in this paper
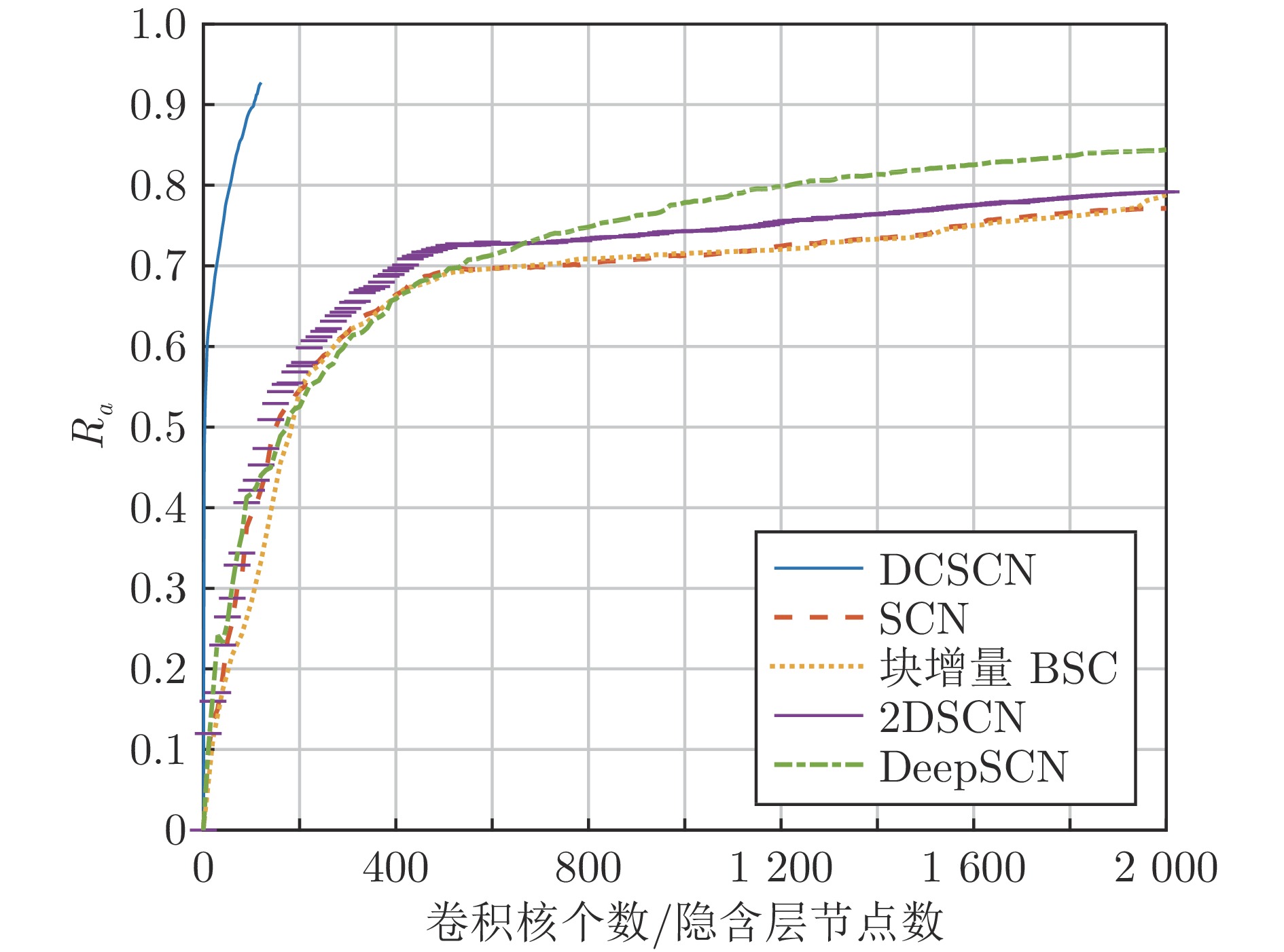
图 13 不同网络模型的训练样本识别精度曲线
Fig. 13 Recognition accuracy curves of training samples for different network models
表 1 基于强化学习的漏诊率、误诊率和精度对比 (%)
Table 1 Comparison of missed diagnosis rate, misdiagnosis rate and accuracy based on reinforcement learning (%)
模型 训练集 测试集 漏诊率 误诊率 精度 漏诊率 误诊率 精度 单层 本文方法 7.61 ± 0.189 9.15 ± 0.331 83.24 ± 0.195 9.95 ± 0.216 10.30 ± 0.231 79.75 ± 0.108 强化学习 9.08 ± 0.082 10.14 ± 0.354 80.76 ± 0.228 10.51 ± 0.172 12.81 ± 0.390 76.68 ± 0.305 三层 本文方法 5.31 ± 0.239 1.96 ± 0.165 92.73 ± 0.166 5.24 ± 0.245 2.45 ± 0.203 92.31 ± 0.283 强化学习 7.36 ± 0.361 2.58 ± 0.313 90.06 ± 0.313 6.57 ± 0.361 3.61 ± 0.313 89.82 ± 0.329  下载: 导出CSV
下载: 导出CSV
表 2 消融实验结果 (%)
Table 2 Results of ablation experiments (%)
模型 训练集 测试集 漏诊率 误诊率 精度 漏诊率 误诊率 精度 本文方法 5.31 ± 0.239 1.96 ± 0.165 92.73 ± 0.166 5.24 ± 0.245 2.45 ± 0.203 92.31 ± 0.283 未加入可解释性模块 5.57 ± 0.232 2.51 ± 0.223 91.92 ± 0.278 7.29 ± 0.173 1.59 ± 0.181 91.12 ± 0.347 未加入高斯卷积核 4.29 ± 0.274 4.51 ± 0.391 91.20 ± 0.264 3.45 ± 0.255 2.50 ± 0.329 90.54 ± 0.231 未加入可解释性模块以及高斯卷积核 6.02 ± 0.183 4.25 ± 0.231 89.73 ± 0.325 4.13 ± 0.242 6.73 ± 0.228 89.14 ± 0.179
下载: 导出CSV
表 3 不同高斯噪声的实验结果 (%)
Table 3 Experimental results with different Gaussian noises (%)
模型 训练集 测试集 漏诊率 误诊率 精度 漏诊率 误诊率 精度 本文方法($\eta=0.3$) 5.31 ± 0.239 1.96 ± 0.165 92.73 ± 0.166 5.24 ± 0.245 2.45 ± 0.203 92.31 ± 0.283 $\eta=0.6$模型 6.92 ± 0.232 2.21 ± 0.223 90.87 ± 0.206 7.19 ± 0.173 2.52 ± 0.181 90.29 ± 0.347 $\eta=0.9$模型 8.31 ± 0.423 2.29 ± 0.248 89.40 ± 0.297 7.45 ± 0.382 7.01 ± 0.274 85.54 ± 0.288
下载: 导出CSV
表 4 不同模型的测试样本漏诊率、误诊率和精度对比 (%)
Table 4 Comparison of missed diagnosis rate, misdiagnosis rate and accuracy of test samples with different models (%)
模型 漏诊率 误诊率 精度 SCN 14.21 ± 0.228 14.21 ± 0.228 76.14 ± 0.215 块增量BSC 12.58 ± 0.285 10.57 ± 0.153 76.85 ± 0.233 2DSCN 6.49 ± 0.263 15.52 ± 0.303 77.99 ± 0.353 DeepSCN 9.04 ± 0.285 7.32 ± 0.075 83.64 ± 0.209 CNN 6.82 ± 0.376 5.46 ± 0.167 87.72 ± 0.231 贝叶斯网络[6] 5.36 ± 0.268 4.72 ± 0.252 89.92 ± 0.256 CNN+LSTM[8] 6.91 ± 0.201 3.52 ± 0.184 89.57 ± 0.337 本文方法 5.24 ± 0.245 2.45 ± 0.203 92.31 ± 0.283
下载: 导出CSV
表 5 不同识别模型的综合性能对比
Table 5 Comprehensive performance comparison of different recognition models
下载: 导出CSV
表 6 太阳能电池板数据集实验结果对比 (%)
Table 6 Comparison of experimental results for solar panel dataset (%)
模型 漏诊率 误诊率 精度 单层 本文方法 7.31$\pm$0.187 7.86$\pm$0.259 84.83$\pm$0.245 未加入可解释性模块 9.87$\pm$0.252 6.94$\pm$0.243 83.19$\pm$0.279 三层 本文方法 3.45$\pm$0.213 3.51$\pm$0.169 93.04$\pm$0.323 未加入可解释性模块 4.13$\pm$0.192 4.22$\pm$0.257 91.65$\pm$0.236
下载: 导出CSV
-
[1] 卢绍文, 温乙鑫. 基于图像与电流特征的电熔镁炉欠烧工况半监督分类方法. 自动化学报, 2021, 47(4): 891-902Lu Shao-Wen, Wen Yi-Xin. Semi-supervised classification of semi-molten working condition of fused magnesium furnace based on image and current features. Acta Automatica Sinica, 2021, 47(4): 891-902 [2] 刘强, 孔德志, 郎自强. 基于多级动态主元分析的电熔镁炉异常工况诊断. 自动化学报, 2021, 47(11): 2570-2577Liu Qiang, Kong De-Zhi, Lang Zi-Qiang. Multi-level dynamic principal component analysis for abnormality diagnosis of fused magnesia furnaces. Acta Automatica Sinica, 2021, 47(11): 2570-2577 [3] Wu Z W, Wu Y J, Chai T Y, Sun J. Data-driven abnormal condition identification and self-healing control system for fused magnesium furnace. IEEE Transactions on Industrial Electronics, 2015, 62(3): 1703-1715 doi: 10.1109/TIE.2014.2349479 [4] 吴志伟. 嵌入式电熔镁炉智能控制系统研究 [博士学位论文], 东北大学, 中国, 2015.Wu Zhi-Wei. Embedded Intelligent Control System for Fused Magnesium Furnace [Ph.D. dissertation], Northeastern University, China, 2015. [5] 李荟, 王福利, 李鸿儒. 电熔镁炉熔炼过程异常工况识别及自愈控制方法. 自动化学报, 2020, 46(7): 1411-1419Li Hui, Wang Fu-Li, Li Hong-Ru. Abnormal condition identification and self-Healing control scheme for the electro-fused magnesia smelting process. Acta Automatica Sinica, 2020, 46(7): 1411-1419 [6] 闫浩, 王福利, 孙钰沣, 何大阔. 基于贝叶斯网络参数迁移学习的电熔镁炉异常工况识别. 自动化学报, 2021, 47(1): 197-208Yan Hao, Wang Fu-Li, Sun Yu-Feng, HE Da-Kuo. Abnormal condition identification based on bayesian network parameter transfer learning for the electro-fused magnesia. Acta Automatica Sinica, 2021, 47(1): 197-208 [7] Lu S W, Wen Y X. Semi-supervised condition monitoring and visualization of fused magnesium furnace. IEEE Transactions on Automation Science and Engineering, 2022, 19(4): 3471-3482 doi: 10.1109/TASE.2021.3124015 [8] 吴高昌, 刘强, 柴天佑, 秦泗钊. 基于时序图像深度学习的电熔镁炉异常工况诊断. 自动化学报, 2019, 45(8): 1475-1485Wu Gao-Chang, Liu Qiang, Chai Tian-You, Qin Si-Zhao. Abnormal condition diagnosis through deep learning of image sequences for fused magnesium furnaces. Acta Automatica Sinica, 2019, 45(8): 1475-1485 [9] Lu S W, Gao H R. Deep learning based fusion of RGB and infrared images for the detection of abnormal condition of fused magnesium furnace. In: Proceedings of the IEEE 15th International Conference on Control and Automation (ICCA). Edinburgh, UK: IEEE, 2019. 987−993 [10] Bu K Q, Liu Y, Wang F L. Operating performance assessment based on multi-source heterogeneous information with deep learning for smelting process of electro-fused magnesium furnace. ISA Transactions, 2022, 128: 357-371 doi: 10.1016/j.isatra.2021.10.024 [11] 卢绍文, 王克栋, 吴志伟, 李鹏琦, 郭章. 基于深度卷积网络的电熔镁炉欠烧工况在线识别. 控制与决策, 2019, 34(7): 1537-1544Lu Shao-Wen, Wang Ke-Dong, Wu Zhi-Wei, Li Peng-Qi, Guo Zhang. Online detection of semi-molten of fused magnesium furnace based ondeep convolutional neural network. Control and Decision, 2019, 34(7): 1537-1544 [12] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of the 13th European Conference on Computer Vision (ECCV). Zurich, Switzerland: Springer, 2014. 818−833 [13] Samek W, Binder A, Montavon G, Lapuschkin S, Müller K R. Evaluating the visualization of what a deep neural network has learned. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(11): 2660-2673 doi: 10.1109/TNNLS.2016.2599820 [14] Larsen A B L, Sonderby S K, Larochelle H, Winther O. Autoencoding beyond pixels using a learned similarity metric. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: PMLR, 2016. 1558−1566 [15] Zhang Q S, Wu Y N, Zhu S C. Interpretable convolutional neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8827−8836 [16] Pham H, Guan M, Zoph B, Le Q, Dean J. Efficient neural architecture search via parameters sharing. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 4095−4104 [17] Ding Z X, Chen Y R, Li N N, Zhao D B, Sun Z Q, Chen C L P. BNAS: Efficient neural architecture search using broad scalable architecture. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(9): 5004-5018 doi: 10.1109/TNNLS.2021.3067028 [18] Alvarez J M, Salzmann M. Learning the number of neurons in deep networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc., 2016. 2270−2278 [19] Kawaguchi K. Deep learning without poor local minima. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc., 2016. 586−594 [20] Pao Y H, Park G H, Sobajic D J. Learning and generalization characteristics of the random vector functional-link net. Neurocomputing, 1994, 6(2): 163-180 doi: 10.1016/0925-2312(94)90053-1 [21] Wang D H, Li M. Stochastic configuration networks: Fundamentals and algorithms. IEEE Transactions on Cybernetics, 2017, 47(10): 3466-3479 doi: 10.1109/TCYB.2017.2734043 [22] Li M, Wang D H. 2-D stochastic configuration networks for image data analytics. IEEE Transactions on Cybernetics, 2021, 51(1): 359-372 doi: 10.1109/TCYB.2019.2925883 [23] Wang D H, Li M. Deep stochastic configuration networks with universal approximation property. In: Proceedings of the International Joint Conference on Neural Networks (IJCNN). Rio de Janeiro, Brazil: IEEE, 2018. 1−8 [24] Pratama M, Wang D H. Deep stacked stochastic configuration networks for lifelong learning of non-stationary data streams. Information Sciences, 2019, 495: 150-174 doi: 10.1016/j.ins.2019.04.055 [25] Li W T, Zhang Q, Wang D H, Sun W, Li Q Y. Stochastic configuration networks for self-blast state recognition of glass insulators with adaptive depth and multi-scale representation. Information Sciences, 2022, 604: 61-79 doi: 10.1016/j.ins.2022.04.061 [26] Li W T, Deng Y L, Ding M S, Wang D H, Sun W, Li Q Y. Industrial data classification using stochastic configuration networks with self-attention learning features. Neural Computing and Applications, 2022, 34: 22047-22069 doi: 10.1007/s00521-022-07657-9 [27] Peng S Y, Ding L J, Li W T, Sun W, Li Q Y. Research on intelligent recognition method for self-blast state of glass insulator based on mixed data augmentation. High Voltage, 2023, 8(4): 668-681 doi: 10.1049/hve2.12296 [28] Zhang Q, Li W T, Li H, Wang J P. Self-blast state detection of glass insulators based on stochastic configuration networks and a feedback transfer learning mechanism. Information Sciences, 2020, 522: 259-274 doi: 10.1016/j.ins.2020.02.058 [29] Li W T, Tao H, Li H, Chen K Q, Wang J P. Greengage grading using stochastic configuration networks and a semi-supervised feedback mechanism. Information Sciences, 2019, 488: 1-12 doi: 10.1016/j.ins.2019.02.041 [30] Li W T, Chen K Q, Wang D H. Industrial image classification using a randomized neural-net ensemble and feedback mechanism. Neurocomputing, 2016, 173: 708-714 doi: 10.1016/j.neucom.2015.08.019 [31] He Y, Ding Y H, Liu P, Zhu L C, Zhang H W, Yang Y. Learning filter pruning criteria for deep convolutional neural networks acceleration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 2006−2015 [32] Sutton R S, Barto A G. Reinforcement Learning: An Introduction. Cambridge: MIT Press, 1998. [33] Dai W, Li D P, Zhou P, Chai T Y. Stochastic configuration networks with block increments for data modeling in process industries. Information Sciences, 2019, 484: 367-386 doi: 10.1016/j.ins.2019.01.062 [34] LeCun Y. LeNet-5, convolutional neural networks [Online], available: http://yann.lecun.com/exdb/lenet, January 11, 2024 [35] Deitsch S, Christlein V, Berger S, Buerhop-Lutz C, Maier A, Gallwitz F, et al. Automatic classification of defective photovoltaic module cells in electroluminescence images. Solar Energy, 2019, 185: 455-468 doi: 10.1016/j.solener.2019.02.067 -

 下载:
下载:



计量
- 文章访问数: 610
- HTML全文浏览量: 459
- PDF下载量: 239
- 被引次数: 0
