

Distributed Operating Performance Assessment of Dynamic Industrial Processes Based on Slow Feature Analysis
-
摘要: 现代工业过程通常具有规模大、流程长和工序多的特点, 导致传统的集中式建模方法会淹没过程的局部变化信息, 从而无法及时识别早期的非优运行状态. 此外, 闭环控制的广泛应用使得过程变量普遍存在时序相关性. 针对以上问题, 提出一种基于慢特征分析(Slow feature analysis, SFA)的分布式动态工业过程运行状态评价方法. 首先, 结合动态时间规整(Dynamic time warping, DTW)和K-medoids聚类算法对过程进行分解; 然后, 对每一变量子块建立相应的动态慢特征分析(Dynamic slow feature analysis, DSFA)模型; 最后, 利用贝叶斯推理获得全局的综合评价指标. 通过在数值案例和金湿法冶金过程的仿真应用, 验证了该方法的有效性.
-
关键词:
- 分布式模型 /
- 运行状态评价 /
- 慢特征分析 /
- 动态时间规整 /
- K-medoids聚类
Abstract: The modern industrial processes are generally characterized by large scale, long processes and multiple procedures. In this case, the traditional centralized model may submerge the local change information of the processes, thus failing to identify the early non-optimal operation status in time. In addition, the wide application of closed-loop control brings the universal existence of temporal correlations of process variables. In view of the above problem, a distributed operating performance assessment scheme of dynamic industrial processes based on slow feature analysis (SFA) is proposed. First, the process decomposition is realized by combining dynamic time warping (DTW) and K-medoids clustering algorithms. Second, the corresponding dynamic slow feature analysis (DSFA) model is established for each sub-block. Finally, the overall comprehensive assessment index is obtained through Bayesian inference. The effectiveness of the scheme is verified by numerical examples and gold hydrometallurgy process. -
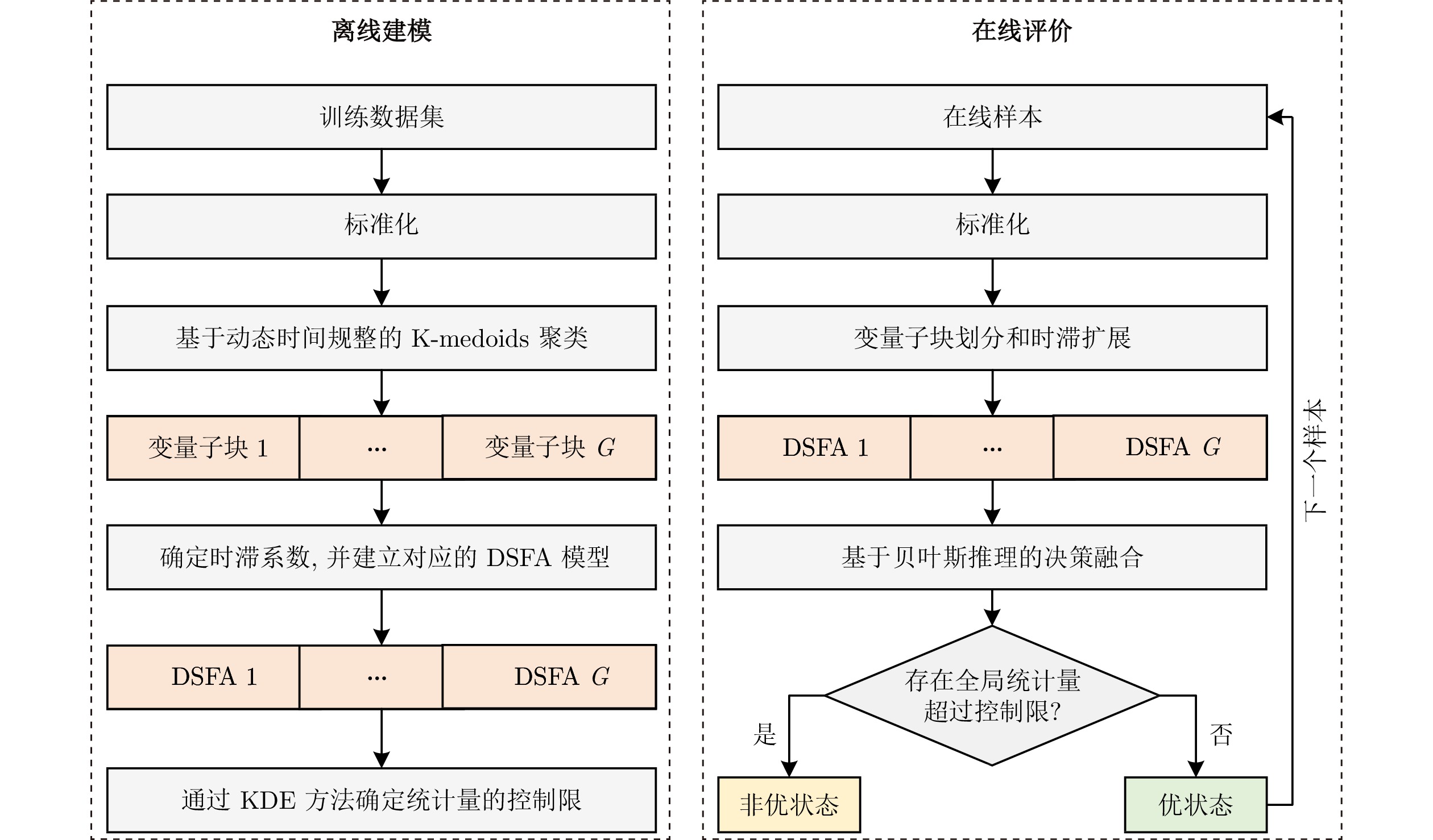
图 1 基于DDSFA的运行状态评价流程图
Fig. 1 Flow diagram of DDSFA-based operating performance assessment
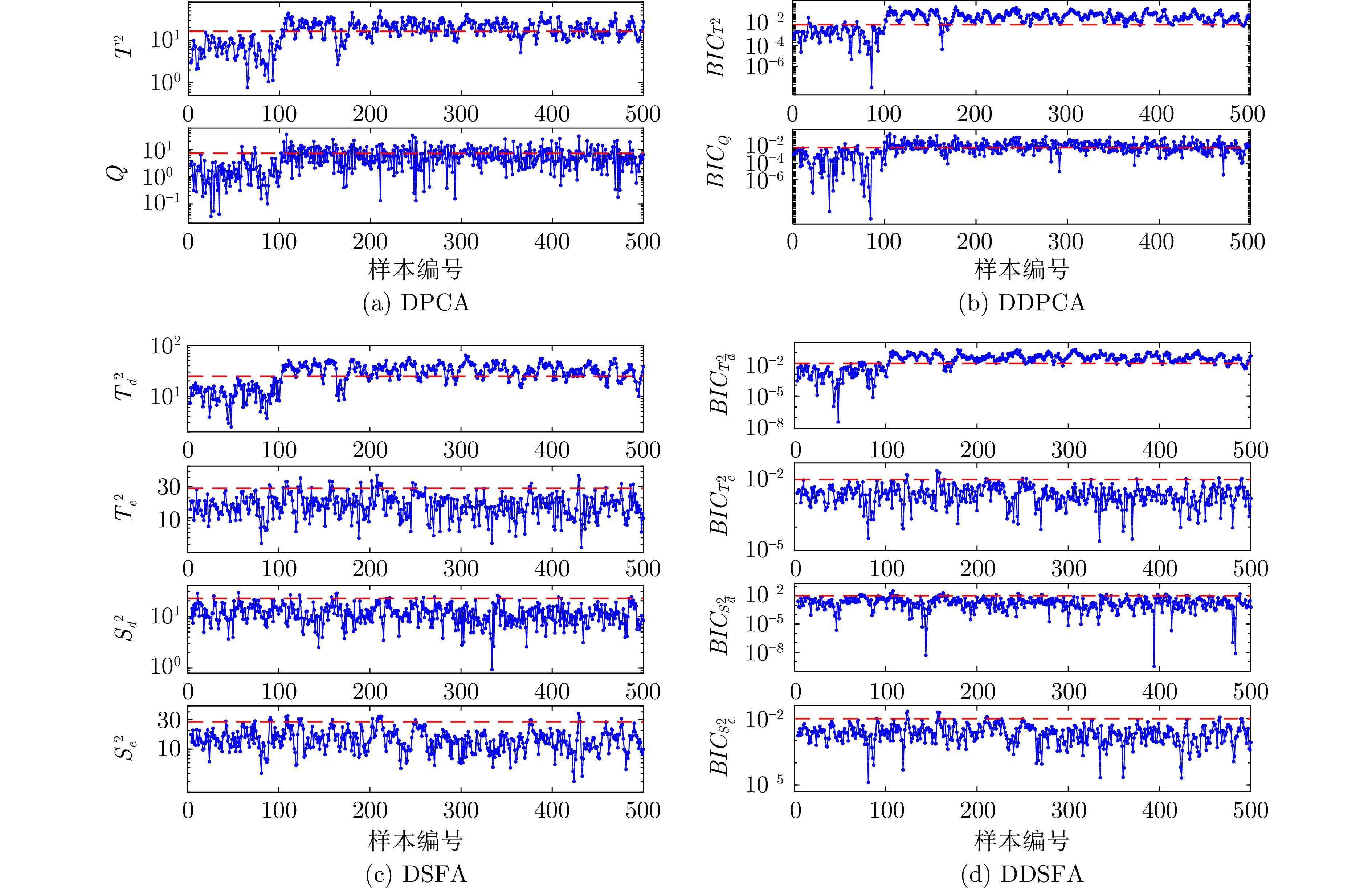
图 2 数值仿真算例中, 案例1的运行状态评价结果
Fig. 2 The operating performance assessment result of case 1 in the numerical example
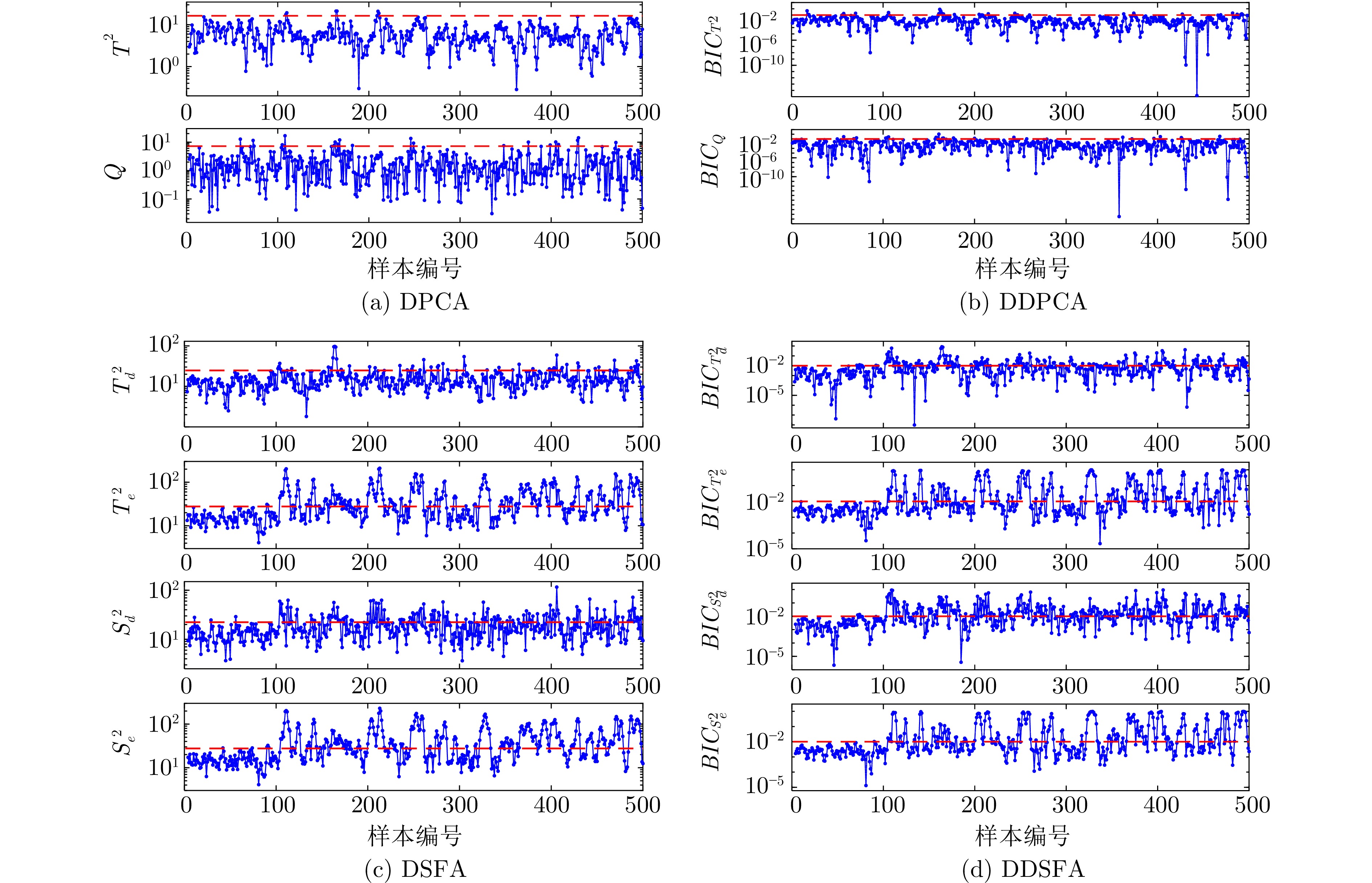
图 3 数值仿真算例中, 案例2的运行状态评价结果
Fig. 3 The operating performance assessment result of case 2 in the numerical example
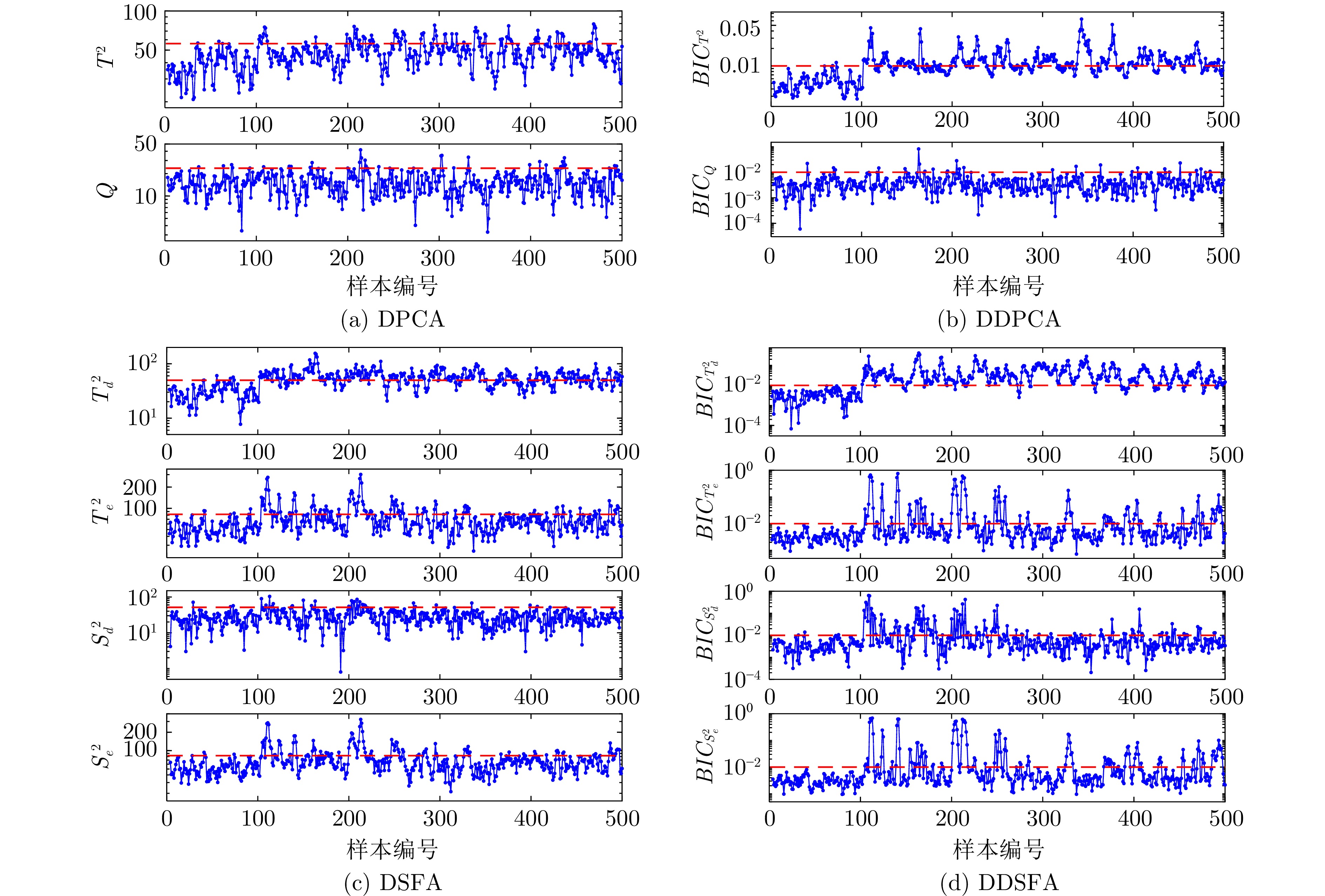
图 5 金湿法冶金过程中, 案例3的运行状态评价结果
Fig. 5 The operating performance assessment result of case 3 in gold hydrometallurgy process
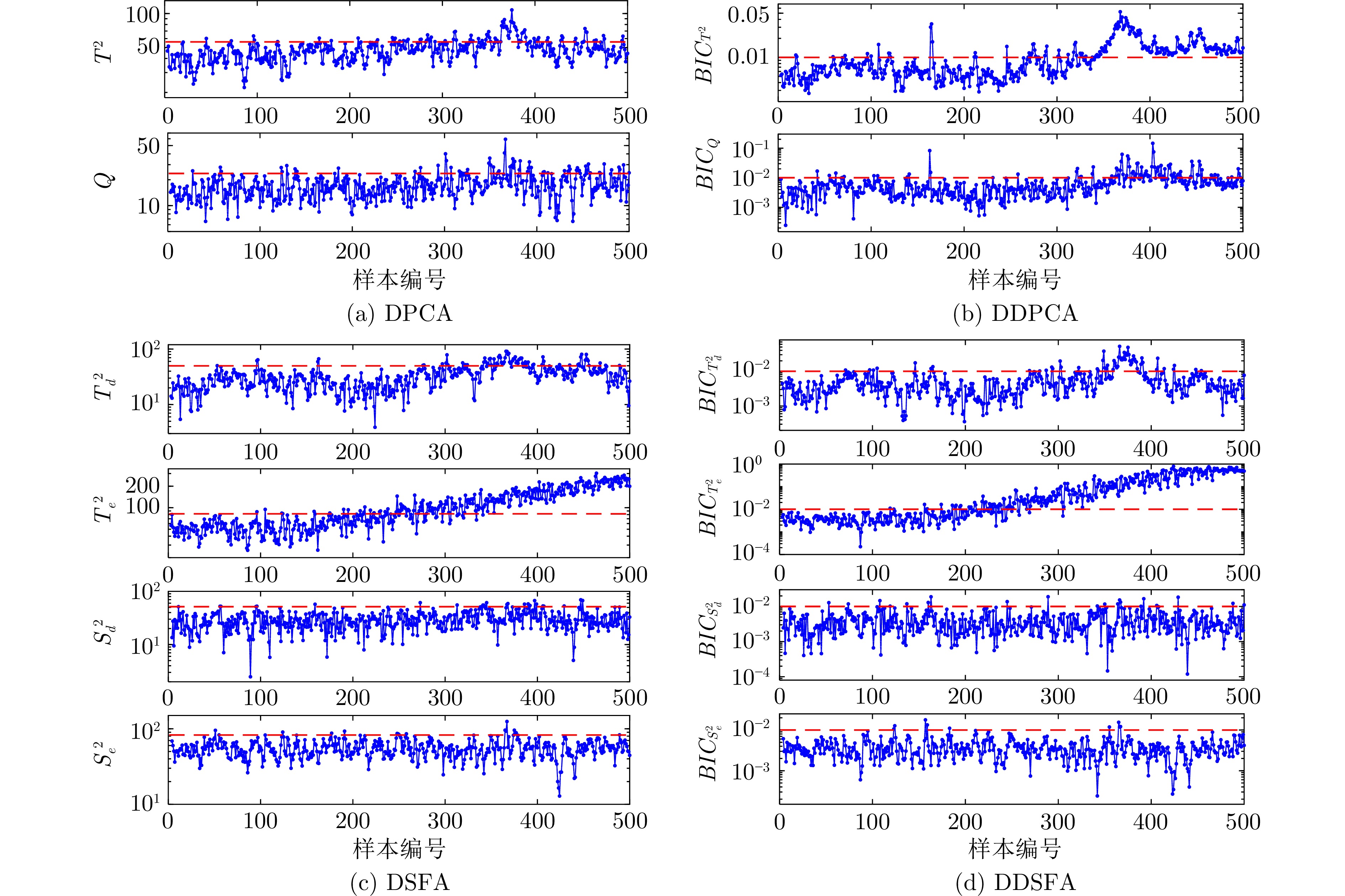
图 6 金湿法冶金过程中, 案例4的运行状态评价结果
Fig. 6 The operating performance assessment result of case 4 in gold hydrometallurgy process
表 1 不同算法在数值仿真算例中的漏报率(%)
Table 1 Missed alarm rates of different methods inthe numerical example (%)
方法 DPCA DDPCA DSFA DDSFA 案例1 20.25 4.25 19.25 7.00 案例2 94.00 90.50 24.00 18.25  下载: 导出CSV
下载: 导出CSV
表 2 金湿法冶金过程的变量
Table 2 The variables of gold hydrometallurgy process
序号 子工序 变量名称 1 一次氰化浸出 矿浆浓度 2 入口矿浆流量 3 浸出槽1的${\rm{NaCN}}$流量 4 浸出槽2的${\rm{NaCN}}$流量 5 浸出槽4的${\rm{NaCN}}$流量 6 空气流量 7 浸出槽溶解氧浓度 8 浸出槽1的${\rm{CN}}^-$浓度 9 浸出槽2的${\rm{CN}}^-$浓度 10 浸出槽4的${\rm{CN}}^-$浓度 11 一次洗涤 立式压滤机进料压力 12 立式压滤机液压压力 13 立式压滤机挤压压力 14 二次氰化浸出 矿浆浓度 15 入口矿浆流量 16 浸出槽1的${\rm{NaCN}}$流量 17 浸出槽2的${\rm{NaCN}}$流量 18 浸出槽4的${\rm{NaCN}}$流量 19 空气流量 20 浸出槽溶解氧浓度 21 浸出槽1的${\rm{CN}}^-$浓度 22 浸出槽2的${\rm{CN}}^-$浓度 23 浸出槽4的${\rm{CN}}^-$浓度 24 二次洗涤 立式压滤机进料压力 25 立式压滤机液压压力 26 立式压滤机挤压压力 27 置换 脱氧塔真空度 28 贵液中的$ {\left[ {{\rm{Au}}{{\left( {{\rm{CN}}} \right)}_2}} \right]^ - }$浓度 29 贫液中的$ {\left[ {{\rm{Au}}{{\left( {{\rm{CN}}} \right)}_2}} \right]^ - }$浓度 30 锌粉添加速度
下载: 导出CSV
表 3 金湿法冶金过程变量的子块划分结果
Table 3 Sub-block division result of process variables of gold hydrometallurgy
子块 过程变量 1 27, 28, 29, 30 2 6, 7, 11, 12, 13 3 19, 20, 24, 25, 26 4 1, 2, 3, 4, 5, 8, 9, 10 5 14, 15, 16, 17, 18, 21, 22, 23
下载: 导出CSV
表 4 不同算法在金湿法冶金过程中的漏报率(%)
Table 4 Missed alarm rates of different methods in gold hydrometallurgy process (%)
方法 DPCA DDPCA DSFA DDSFA 案例3 71.50 40.00 25.50 6.00 案例4 68.00 48.75 35.00 26.25
下载: 导出CSV
-
[1] Zhang C F, Peng K X, Dong J. A lifecycle operating performance assessment framework for hot strip mill process based on robust kernel canonical variable analysis. Control Engineering Practice, 2021, 107: Article No. 104698 doi: 10.1016/j.conengprac.2020.104698 [2] 褚菲, 傅逸灵, 赵旭, 王佩, 尚超, 王福利. 基于ISDAE模型的复杂工业过程运行状态评价方法及应用. 自动化学报, 2021, 47(4): 849−863Chu Fei, Fu Yi-Ling, Zhao Xu, Wang Pei, Shang Chao, Wang Fu-Li. Operating performance assessment method and application for complex industrial process based on ISDAE model. Acta Automatica Sinica, 2021, 47(4): 849−863 [3] 赵春晖, 胡赟昀, 郑嘉乐, 陈军豪. 数据驱动的燃煤发电装备运行工况监控: 现状与展望. 自动化学报, 2022, 48(11): 2611−2633Zhao Chun-Hui, Hu Yun-Yun, Zheng Jia-Le, Chen Jun-Hao. Data-driven operating monitoring for coal-fired power generation equipment: The state of the art and challenge. Acta Automatica Sinica, 2022, 48(11): 2611−2633 [4] Ye L, Liu Y M, Fei Z S, Liang J. Online probabilistic assessment of operating performance based on safety and optimality indices for multi-mode industrial processes. Industrial and Eng-ineering Chemistry Research, 2009, 48(24): 10912−10923 doi: 10.1021/ie801870g [5] Fan H P, Wu M, Cao W H, Lai X Z, Chen L F, Lu C D, et al. An operating performance assessment strategy with multiple modes based on least squares support vector machines for drilling process. Computers and Industrial Engineering, 2021, 159: Article No. 107492 doi: 10.1016/j.cie.2021.107492 [6] Zou X Y, Wang F L, Chang Y Q. Assessment of operating performance using cross-domain feature transfer learning. Control Engineering Practice, 2019, 89: 143−153 doi: 10.1016/j.conengprac.2019.05.007 [7] Liu Y, Wang F L, Chang Y Q, Ma R C. Operating optimality assessment and non-optimal cause identification for non-Gaussian multi-mode processes with transitions. Chemical Engineering Science, 2015, 137: 106−118 doi: 10.1016/j.ces.2015.06.016 [8] Wang Y L, Li L, Wang K. An online operating performance evaluation approach using probabilistic fuzzy theory for chemical processes with uncertainties. Computers and Chemical Engineering, 2021, 144: Article No. 107156 doi: 10.1016/j.compchemeng.2020.107156 [9] Negiz A, Çlinar A. Statistical monitoring of multivariable dynamic processes with state-space models. AIChE Journal, 1997, 43(8): 2002−2020 doi: 10.1002/aic.690430810 [10] Lee J M, Yoo C K, Lee I B. Statistical monitoring of dynamic processes based on dynamic independent component analysis. Chemical Engineering Science, 2004, 59(14): 2995−3006 doi: 10.1016/j.ces.2004.04.031 [11] Ku W F, Storer R H, Georgakis C. Disturbance detection and isolation by dynamic principal component analysis. Chemometrics and Intelligent Laboratory Systems, 1995, 30(1): 179−196 doi: 10.1016/0169-7439(95)00076-3 [12] Shang C, Yang F, Gao X Q, Huang X L, Suykens J A, Huang D X. Concurrent monitoring of operating condition deviations and process dynamics anomalies with slow feature analysis. AIChE Journal, 2015, 61(11): 3666−3682 doi: 10.1002/aic.14888 [13] Sedghi S, Huang B. Real-time assessment and diagnosis of process operating performance. Engineering, 2017, 3(2): 214−219 doi: 10.1016/J.ENG.2017.02.004 [14] Zou X Y, Zhao C H. Concurrent assessment of process operating performance with joint static and dynamic analysis. IEEE Transactions on Industrial Informatics, 2019, 16(4): 2776−2786 [15] Norazwan M N, Che R C H, Mohd A H. A review of data-driven fault detection and diagnosis methods: Applications in chemical process systems. Reviews in Chemical Engineering, 2020, 36(4): 513−553 doi: 10.1515/revce-2017-0069 [16] Khan S S, Madden M G. One-class classification: Taxonomy of study and review of techniques. The Knowledge Engineering Review, 2014, 29(3): 345−374 doi: 10.1017/S026988891300043X [17] 姜庆超, 颜学峰. 基于局部−整体相关特征的多单元化工过程分层监测. 自动化学报, 2020, 46(9): 1770−1782Jiang Qing-Chao, Yan Xue-Feng. Hierarchical monitoring for multi-unit chemical processes based on local-global correlation features. Acta Automatica Sinica, 2020, 46(9): 1770−1782 [18] Chen Z W, Cao Y, Ding S X, Zhang K, Koenings T, Peng T, et al. A distributed canonical correlation analysis-based fault detection method for plant-wide process monitoring. IEEE Transactions on Industrial Informatics, 2019, 15(5): 2710−2720 doi: 10.1109/TII.2019.2893125 [19] Liu Y, Wang F L, Gao F R, Cui H N. Hierarchical multi-block T-PLS based operating performance assessment for plant-wide processes. Industrial and Engineering Chemistry Research, 2018, 57(43): 14617−14627 doi: 10.1021/acs.iecr.8b02685 [20] Zhu J L, Ge Z Q, Song Z H. Distributed parallel PCA for modeling and monitoring of large-scale plant-wide processes with big data. IEEE Transactions on Industrial Informatics, 2017, 13(4): 1877−1885 doi: 10.1109/TII.2017.2658732 [21] Huang K K, Wei K, Li Y G, Yang C H. Distributed dictionary learning for industrial process monitoring with big data. Applied Intelligence, 2021, 51(11): 7718−7734 doi: 10.1007/s10489-020-02128-x [22] Tong C D, Shi X H. Decentralized monitoring of dynamic processes based on dynamic feature selection and informative fault pattern dissimilarity. IEEE Transactions on Industrial Electronics, 2016, 63(6): 3804−3814 doi: 10.1109/TIE.2016.2530047 [23] Jiang Q C, Yan X F, Huang B. Review and perspectives of data-driven distributed monitoring for industrial plant-wide processes. Industrial and Engineering Chemistry Research, 2019, 58(29): 12899−12912 doi: 10.1021/acs.iecr.9b02391 [24] Ge Z Q, Song Z H. Distributed PCA model for plant-wide process monitoring. Industrial and Engineering Chemistry Research, 2013, 52(5): 1947−1957 doi: 10.1021/ie301945s [25] Jiang Q C, Yan X F. Nonlinear plant-wide process monitoring using MI-spectral clustering and Bayesian inference-based multi-block KPCA. Journal of Process Control, 2015, 32: 38−50 doi: 10.1016/j.jprocont.2015.04.014 [26] Zhong K, Ma D W, Han M. Distributed dynamic process monitoring based on dynamic slow feature analysis with minimal redundancy maximal relevance. Control Engineering Practice, 2020, 104: Article No. 104627 doi: 10.1016/j.conengprac.2020.104627 [27] Sakoe H, Chiba S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1978, 26(1): 43−49 doi: 10.1109/TASSP.1978.1163055 [28] Park H S, Jun C H. A simple and fast algorithm for K-medoids clustering. Expert Systems With Applications, 2009, 36(2): 3336−3341 doi: 10.1016/j.eswa.2008.01.039 [29] Song P Y, Zhao C H. Slow down to go better: A survey on slow feature analysis. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2022.3201621 [30] Rong M Y, Shi H B, Song B, Tao Y. Multi-block dynamic weighted principal component regression strategy for dynamic plant-wide process monitoring. Measurement, 2021, 183: Article No. 109705 doi: 10.1016/j.measurement.2021.109705 [31] Jia G L, Wang Y Q, Huang B. Dynamic higher-order cumulants analysis for state monitoring based on a novel lag selection. Information Sciences, 2016, 331: 45−66 doi: 10.1016/j.ins.2015.10.029 [32] 蒋珂, 蒋朝辉, 谢永芳, 潘冬, 桂卫华. 基于时序关联矩阵的高炉冶炼过程多重关联时延估计方法. 自动化学报, 2023, 49(2): 329−342Jiang Ke, Jiang Zhao-Hui, Xie Yong-Fang, Pan Dong, Gui Wei-Hua. A multi-correlated time-delay estimation method in the blast furnace iron-making process based on time-series correlation matrix. Acta Automatica Sinica, 2023, 49(2): 329−342 [33] Zhang S M, Zhao C H, Huang B. Simultaneous static and dynamic analysis for fine-scale identification of process operation statuses. IEEE Transactions on Industrial Informatics, 2019, 15(9): 5320−5329 doi: 10.1109/TII.2019.2896987 [34] Ge Z Q, Chen J H. Plant-wide industrial process monitoring: A distributed modeling framework. IEEE Transactions on Industrial Informatics, 2015, 12(1): 310−321 [35] 张成, 戴絮年, 李元. 基于DPCA残差互异度的故障检测与诊断方法. 自动化学报, 2022, 48(1): 292−301Zhang Cheng, Dai Xu-Nian, Li Yuan. Fault detection and diagnosis based on residual dissimilarity in dynamic principal component analysis. Acta Automatica Sinica, 2022, 48(1): 292−301 [36] 常玉清, 孙雪婷, 钟林生, 王福利, 刘英娇. 基于改进随机森林算法的工业过程运行状态评价. 自动化学报, 2021, 47(9): 2214−2225Chang Yu-Qing, Sun Xue-Ting, Zhong Lin-Sheng, Wang Fu-Li, Liu Ying-Jiao. Industrial operation performance evaluation of industrial processes based on modified random forest. Acta Automatica Sinica, 2021, 47(9): 2214−2225 [37] Zhong L S, Chang Y Q, Wang F L, Gao S H. Distributed missing values imputation schemes for plant-wide industrial process using variational Bayesian principal component analysis. Industrial and Engineering Chemistry Research, 2022, 61(1): 580−593 doi: 10.1021/acs.iecr.1c03860 -

 下载:
下载:

计量
- 文章访问数: 924
- HTML全文浏览量: 277
- PDF下载量: 220
- 被引次数: 0
