

-
摘要: 基于被动声呐音频信号的水中目标识别是当前水下无人探测领域的重要技术难题, 在军事和民用领域都应用广泛. 本文从数据处理和识别方法两个层面系统阐述基于被动声呐信号进行水中目标识别的方法和流程. 在数据处理方面, 从基于被动声呐信号的水中目标识别基本流程、被动声呐音频信号分析的数理基础及其特征提取三个方面概述被动声呐信号处理的基本原理. 在识别方法层面, 全面分析基于机器学习算法的水中目标识别方法, 并聚焦以深度学习算法为核心的水中目标识别研究. 本文从有监督学习、无监督学习、自监督学习等多种学习范式对当前研究进展进行系统性的总结分析, 并从算法的标签数据需求、鲁棒性、可扩展性与适应性等多个维度分析这些方法的优缺点. 同时, 还总结该领域中较为广泛使用的公开数据集, 并分析公开数据集应具备的基本要素. 最后, 通过对水中目标识别过程的论述, 总结目前基于被动声呐音频信号的水中目标自动识别算法存在的困难与挑战, 并对该领域未来的发展方向进行展望.Abstract: Underwater target recognition based on passive sonar acoustic signals is a significant technical challenge in the field of underwater unmanned detection, with broad applications in both military and civilian domains. This paper provides a comprehensive exposition of the methodology and process involved in underwater target recognition using passive sonar acoustic signals, addressing data processing and recognition methods at two levels. Regarding data processing, this paper presents a thorough exploration of the fundamental principles of passive sonar signal processing from three key aspects: The underlying process of underwater target recognition based on passive sonar signals, the mathematical foundations of passive sonar acoustic signal analysis, and the extraction of relevant features. At the level of recognition methods, this paper offers a comprehensive analysis of underwater target recognition techniques based on machine learning algorithms, and focus on the research conducted with deep learning algorithms at its core. The paper systematically summarizes and analyzes the current research progress across various learning paradigms, including supervised learning, unsupervised learning and self-supervised learning, and analyzes their advantages and disadvantages in terms of the algorithm's labeled data requirement, robustness, scalability and adaptability. Additionally, this paper provides an overview of widely-used public datasets in the field, and outlines the essential elements that such datasets should possess. Finally, by discussing the process of underwater target recognition, this paper summarizes the current difficulties and challenges in automatic underwater target recognition algorithms based on passive sonar acoustic signals, and offers insights into the future development direction of this field.
-
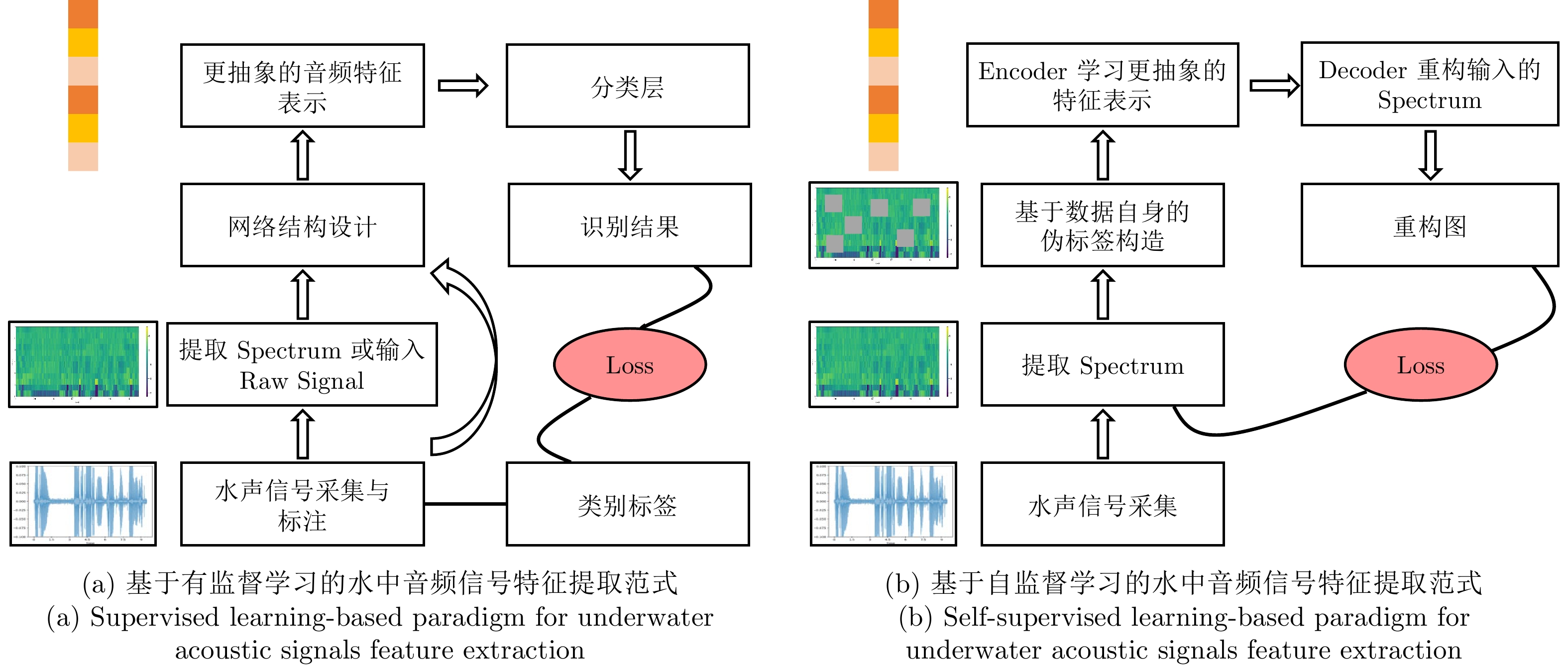
图 5 基于深度学习的水中音频信号特征提取范式
Fig. 5 Deep learning-based paradigm for underwater acoustic signals feature extraction
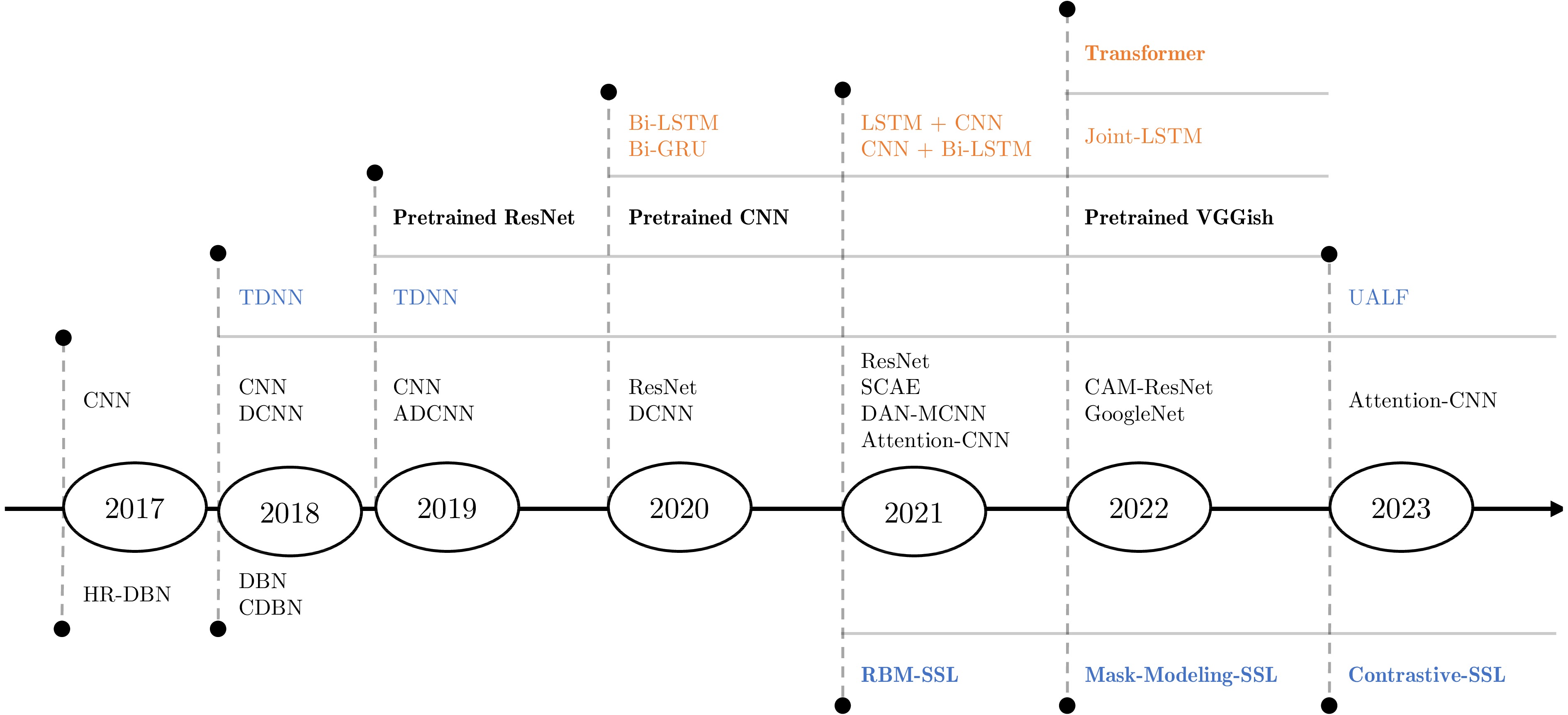
图 6 基于深度学习的水声目标识别主流算法模型发展时间轴线
Fig. 6 Timeline: Evolution of mainstream deep learning algorithms for UATR

图 9 基于CNN与Bi-LSTM融合的水声目标识别方法网络架构
Fig. 9 Network framework of UATR methods based on the fusion of CNN and Bi-LSTM
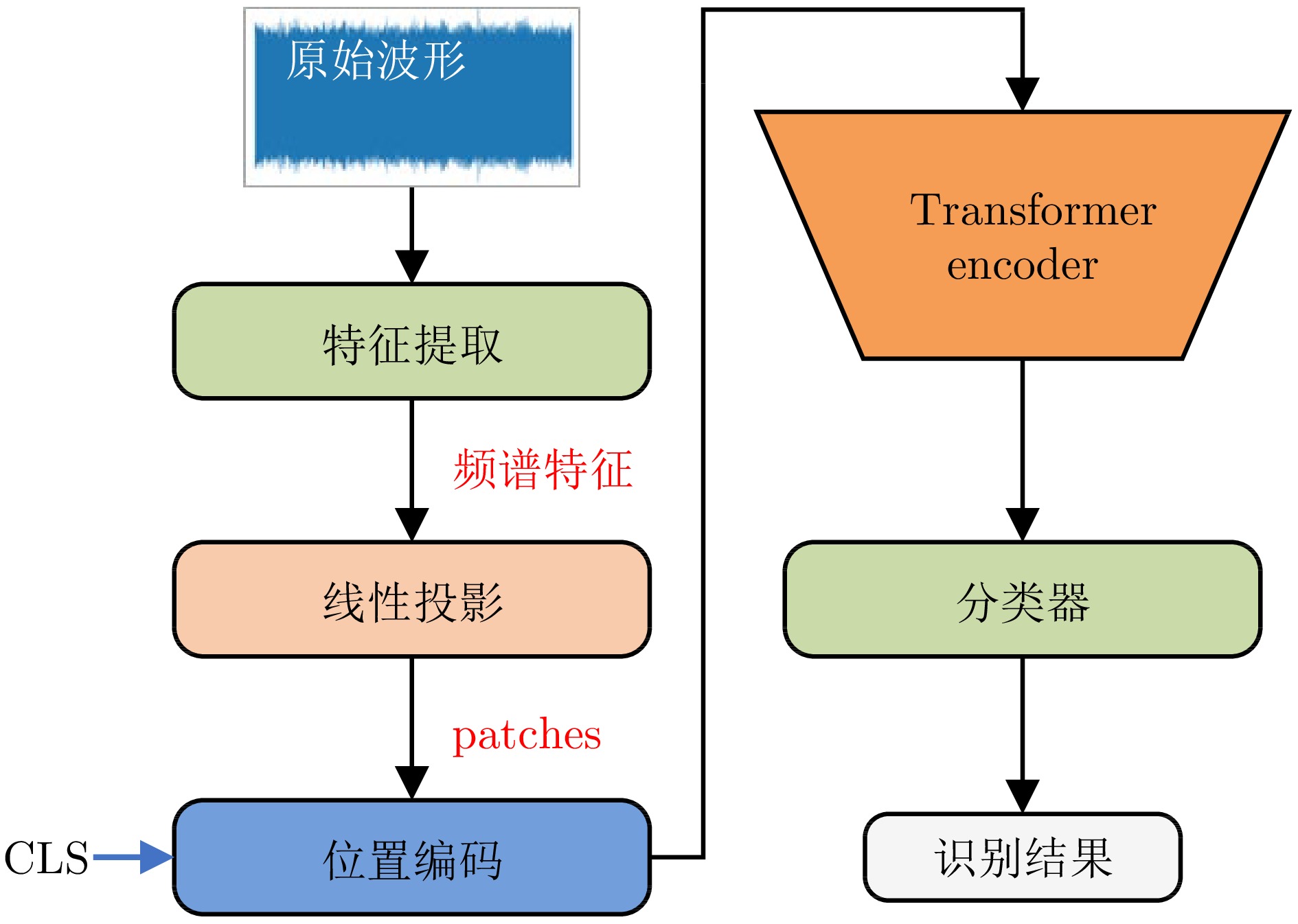
图 10 基于Transformer的水声目标识别方法基本架构
Fig. 10 Basic framework of Transformer-based methods for UATR
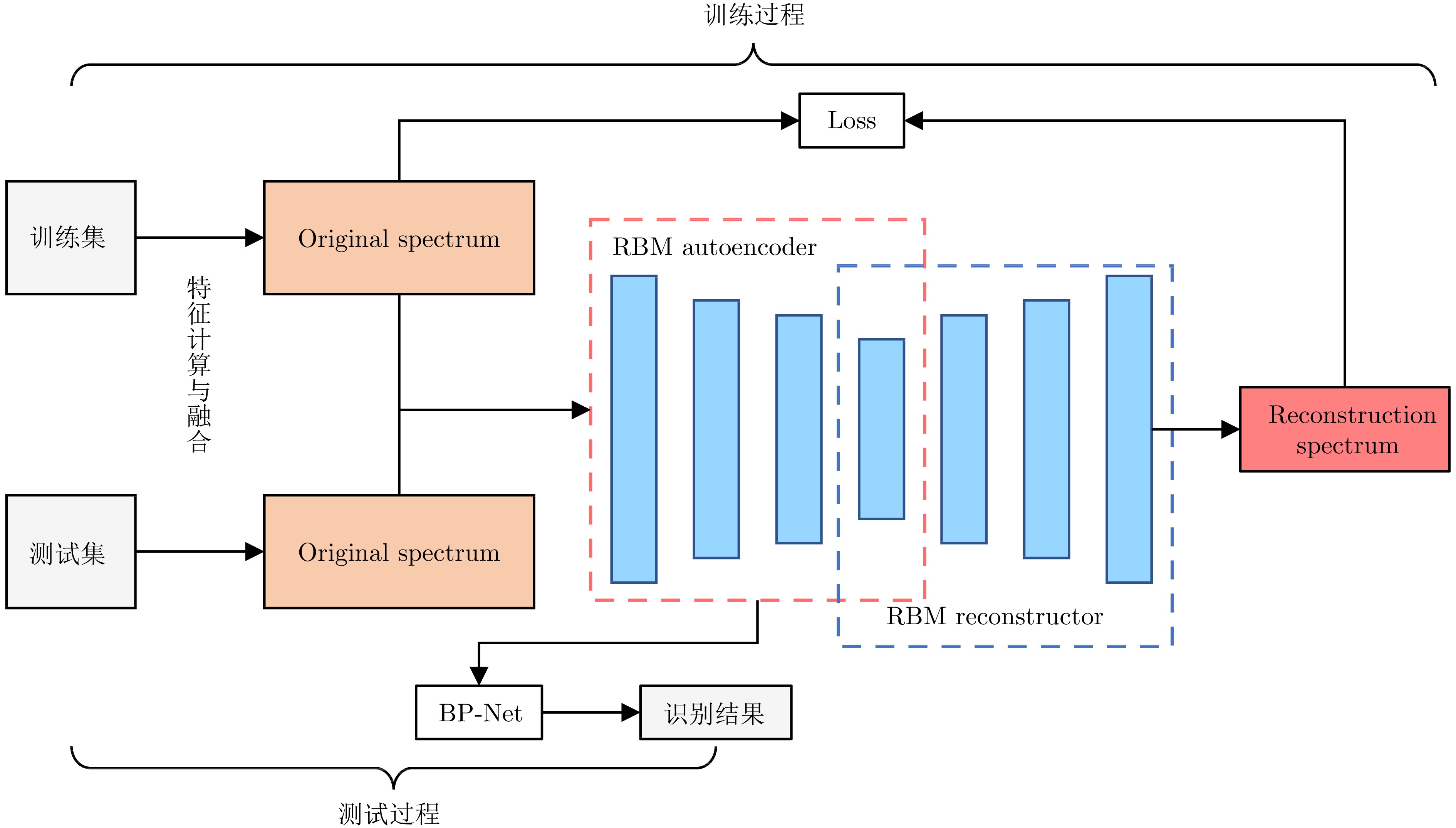
图 11 基于RBM自编码器重构的水声目标识别方法架构
Fig. 11 The framework of RBM autoencoder-based reconstruction methods for UATR
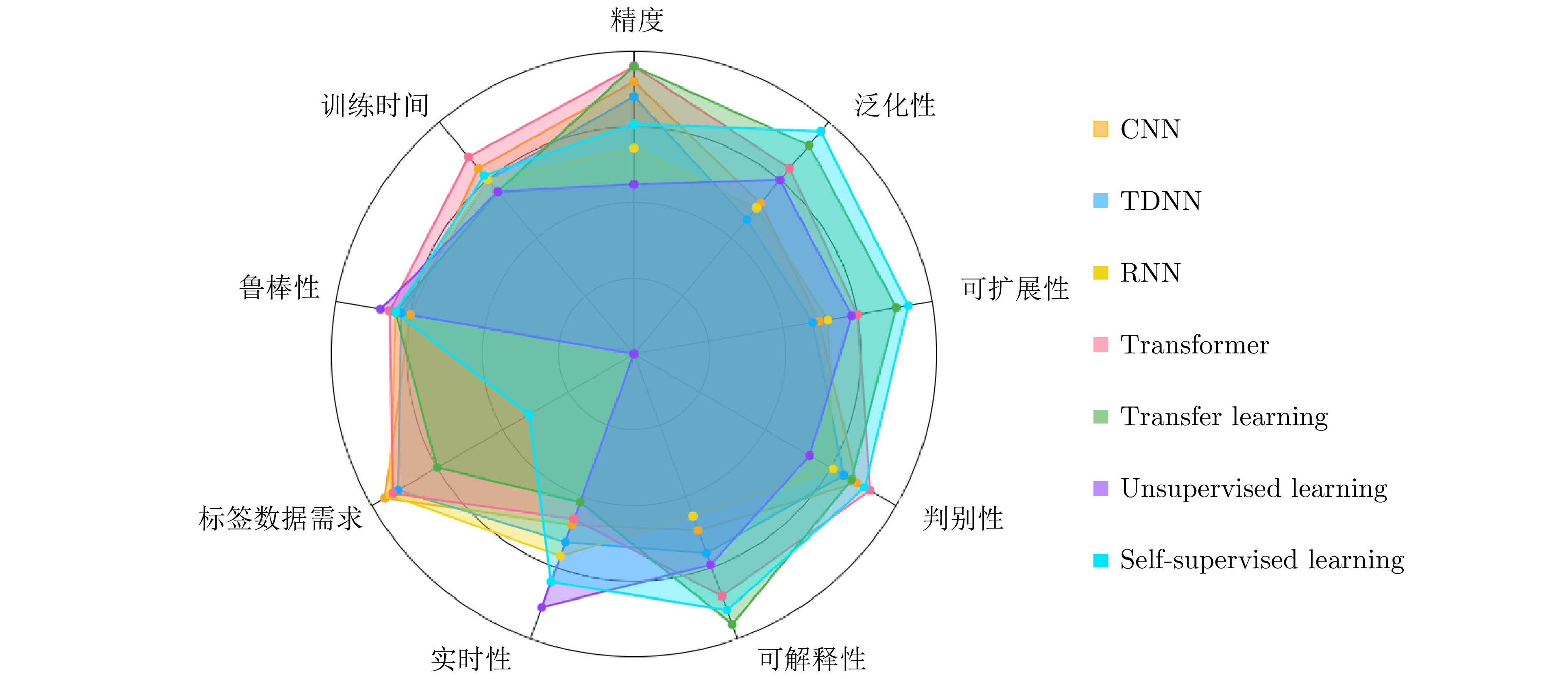
图 13 不同深度学习方法在水声目标识别领域的性能对比
Fig. 13 Performance comparison of various deep learning methods for UATR
表 2 基于卷积神经网络的水声目标识别方法
Table 2 Convolutional neural network-based methods for UATR
年份 技术特点 模型优劣分析 数据集来源 样本大小 2017 卷积神经网络[66] 自动提取音频表征, 提高了模型的精度 Historic Naval Sound and Video database 16类 2018 卷积神经网络[71] 使用极限学习机代替全连接层, 提高了模型的识别精度 私有数据集 3类 2019 卷积神经网络[70] 使用二阶池化策略, 更好地保留了信号分量的差异性 中国南海 5类 一种基于声音生成感知机制的卷积神经网络[41] 模拟听觉系统实现多尺度音频表征学习, 使得表征更具判别性 Ocean Networks Canada 4类 2020 基于ResNet的声音生成感知模型[42] 使用全局平均池化代替全连接层, 极大地减少了参数, 提高了模型的训练效率 Ocean Networks Canada 4类 一种稠密卷积神经网络DCNN[43] 使用DCNN自动提取音频特征, 降低了人工干预对性能的影响 私有数据集 12类 2021 一种具有稀疏结构的GoogleNet[72] 稀疏结构的网络设计减少了参数量, 提升模型的训练效率 仿真数据集 3类 一种基于可分离卷积自编码器的SCAE模型[73] 使用音频的融合表征进行分析, 证明了方法的鲁棒性 DeepShip 5类 残差神经网络[76] 融合表征使得学习到的音频表征更具判别性, 提升了模型的性能 ShipsEar 5类 基于注意力机制的深度神经网络[46] 使用注意力机制抑制了海洋环境噪声和其他舰船信号的干扰, 提升模型的识别能力 中国南海 4类 基于双注意力机制和多分辨率卷积神经网络架构[81] 多分辨率卷积网络使得音频表征更具判别性, 双注意力机制有利于同时关注局部信息与全局信息 ShipsEar 5类 基于多分辨率的时频特征提取与数据增强的水中目标识别方法[85] 多分辨率卷积网络使得音频表征更具判别性, 数据增强增大了模型的训练样本规模, 从而提升了模型的识别性能 ShipsEar 5类 2022 基于通道注意力机制的残差网络[82] 通道注意力机制的使用使得学习到的音频表征更具判别性和鲁棒性, 提升了模型的性能 私有数据集 4类 一种基于融合表征与通道注意力机制的残差网络[83] 融合表征与通道注意力机制的使用使得学习到的音频表征更具判别性和鲁棒性, 提升了模型的性能 DeepShip ShipsEar 5类 2023 基于注意力机制的多分支CNN[74] 注意力机制用以捕捉特征图中的重要信息, 多分支策略的使用提升了模型的训练效率 ShipsEar 5类  下载: 导出CSV
下载: 导出CSV
表 3 基于时延神经网络、循环神经网络和Transformer的水声目标识别方法
Table 3 Time delay neural networks-based, recurrent neural network-based and Transformer-based methods for UATR
年份 技术特点 模型优劣分析 数据集来源 样本大小 2019 基于时延神经网络的UATR[87] 时延神经网络能够学习音频时序信息, 从而提高模型的识别能力 私有数据集 2类 2022 一种可学习前端[88] 可学习的一维卷积滤波器可以实现更具判别性的音频特征提取, 表现出比传统手工提取的特征更好的性能 QLED, ShipsEar,
DeepShipQLED 2类ShipsEar 5类DeepShip 4类 2020 采用Bi-LSTM同时考虑过去与未来信息的UATR[89] 使用双向注意力机制能够同时学习到历史和后续的时序信息, 从而使得音频表征蕴含信息更丰富以及判别性更高, 然而该方法复杂度较高 Sea Trial 2类 基于Bi-GRU的混合时序网络[90] 混合时序网络从多个维度关注时序信息, 从而学习到更具判别性的音频特征, 提高模型的识别能力 私有数据集 3类 2021 采用LSTM融合音频表征[91] 该方法能够同时学习音频的相位和频谱特征, 并加以融合, 从而提升模型的识别性能 私有数据集 2类 CNN与Bi-LSTM组合的UATR[92] CNN与Bi-LSTM组合可以提取出同时关注局部特性和时序上下文依赖的音频特征, 提高了模型的识别能力 私有数据集 3类 2022 一维卷积与LSTM组合的UATR[93] 首次采用一维卷积和LSTM的组合网络提取音频表征, 能够在提高音频识别率的同时降低模型的参数量, 然而该方法稳定性有待提高 ShipsEar 5类 2022 Transformer[94−95] 增强了模型的泛化性和学习能力, 提高了模型的识别准确率 ShipsEar 5类 加入逐层聚合的Token机制, 同时兼顾全局信息和局部特性, 提高了模型的识别准确率 ShipsEar,
DeepShip5类
下载: 导出CSV
表 4 基于迁移学习的水声目标识别方法
Table 4 Transfer learning-based methods for UATR
年份 技术特点 模型优劣分析 数据集来源 样本大小 2019 基于ResNet的迁移学习[98] 在保证较高性能的同时减少对标签样本的需求, 但不同领域任务的数据特征分布存在固有偏差 Whale FM website 16类 2020 基于ResNet的迁移学习[99] 在预训练模型的基础上设计模型集成机制, 提升识别性能的同时减少了对标签样本的需求, 但不同领域任务的数据特征分布存在固有偏差 私有数据集 2类 基于CNN的迁移学习[102] 使用AudioSet音频数据集进行预训练, 减轻了不同领域任务的数据特征分布所存在的固有偏差 — — 2022 基于VGGish的迁移学习[103] 除了使用AudioSet数据集进行预训练, 还设计基于时频分析与注意力机制结合的特征提取模块, 提高了模型的泛化能力 ShipsEar 5类
下载: 导出CSV
表 5 基于无监督学习和自监督学习的水声目标识别方法
Table 5 Unsupervised and self-supervised learning-based methods for UATR
年份 技术特点 模型优劣分析 数据集来源 样本大小 2013 深度置信网络[104−108] 对标注数据集的需求小, 但由于训练数据少, 容易出现过拟合的风险 私有数据集 40类 2017 加入混合正则化策略, 增强了所学到音频表征的判别性, 提高了模型的识别准确率 3类 2018 加入竞争机制, 增强了所学到音频表征的判别性, 提高了模型的识别准确率 2类 2018 加入压缩机制, 减少了模型的冗余参数, 提升了模型的识别准确率 中国南海 2类 2021 基于RBM自编码器与重构的SSL[111] 降低了模型对标签数据的需求, 增强了模型的泛化性和可扩展性 ShipsEar 5类 2022 基于掩码建模与重构的SSL[113] 使用掩码建模与多表征重构策略, 提升了模型对特征的学习能力, 从而提升了识别性能 DeepShip 5类 2023 基于自监督对比学习的SSL[112] 降低了模型对标签数据的需求, 增强了学习到的音频特征的泛化性和对数据的适应能力 ShipsEar, DeepShip 5类
下载: 导出CSV
表 6 常用的公开水声数据集总结
Table 6 Summary of commonly used public underwater acoustic signal datasets
数据集名称 数据结构 数据类型 采样频率 (kHz) 获取地址 类别 样本数 (个) 持续时间 (样本) 总时间 DeepShip Cargo Ship 110 180 ~ 610 s 10 h 40 min 音频 32 DeepShip Tug 70 180 ~ 1140 s 11 h 17 min Passenger Ship 70 6 ~ 1530 s 12 h 22 min Tanker 70 6 ~ 700 s 12 h 45 min ShipsEar A 16 — 1729 s 音频 32 ShipsEar B 17 1435 s C 27 4054 s D 9 2041 s E 12 923 s Ocean Network Canada (ONC) Background noise 17000 3 s 8 h 30 min 音频 — ONC Cargo 17000 8 h 30 min Passenger Ship 17000 8 h 30 min Pleasure craft 17000 8 h 30 min Tug 17000 8 h 30 min Five-element acoustic dataset 9个类别 360 0.5 s 180 s 音频 — Five-element··· Historic Naval Sound and Video 16个类别 — 2.5 s — 音视频 10.24 Historic Naval··· DIDSON 8个类别 524 — — — — DIDSON Whale FM Pilot whale 10858 1 ~ 8 s 5 h 35 min 音频 — Whale FM Killer whale 4673 注: 1. 官方给出的DeepShip数据集只包含Cargo Ship、Tug、Passenger Ship和Tanker这4个类别. 在实际研究中, 学者通常会自定义一个新的类别
“Background noise”作为第5类.
2. 获取地址的访问时间为2023-07-20.
下载: 导出CSV
-
[1] Cho H, Gu J, Yu S C. Robust sonar-based underwater object recognition against angle-of-view variation. IEEE Sensors Journal, 2016, 16(4): 1013−1025 doi: 10.1109/JSEN.2015.2496945 [2] Dästner K, Roseneckh-Köhler B V H Z, Opitz F, Rottmaier M, Schmid E. Machine learning techniques for enhancing maritime surveillance based on GMTI radar and AIS. In: Proceedings of the 19th International Radar Symposium (IRS). Bonn, Germany: IEEE, 2018. 1−10 [3] Terayama K, Shin K, Mizuno K, Tsuda K. Integration of sonar and optical camera images using deep neural network for fish monitoring. Aquacultural Engineering, 2019, 86: Article No. 102000 doi: 10.1016/j.aquaeng.2019.102000 [4] Choi J, Choo Y, Lee K. Acoustic classification of surface and underwater vessels in the ocean using supervised machine learning. Sensors, 2019, 19(16): Article No. 3492 doi: 10.3390/s19163492 [5] Marszal J, Salamon R. Detection range of intercept sonar for CWFM signals. Archives of Acoustics, 2014, 39: 215−230 [6] 孟庆昕. 海上目标被动识别方法研究 [博士学位论文], 哈尔滨工程大学, 中国, 2016.Meng Qing-Xin. Research on Passive Recognition Methods of Marine Targets [Ph.D. dissertation], Harbin Engineering University, China, 2016. [7] Yang H, Lee K, Choo Y, Kim K. Underwater acoustic research trends with machine learning: General background. Journal of Ocean Engineering and Technology, 2020, 34(2): 147−154 doi: 10.26748/KSOE.2020.015 [8] 方世良, 杜栓平, 罗昕炜, 韩宁, 徐晓男. 水声目标特征分析与识别技术. 中国科学院院刊, 2019, 34(3): 297−305Fang Shi-Liang, Du Shuan-Ping, Luo Xi-Wei, Han Ning, Xu Xiao-Nan. Development of underwater acoustic target feature analysis and recognition technology. Bulletin of Chinese Academy of Sciences, 2019, 34(3): 297−305 [9] Domingos L C, Santos P E, Skelton P S, Brinkworth R S, Sammut K. A survey of underwater acoustic data classification methods using deep learning for shoreline surveillance. Sensors, 2022, 22(6): Article No. 2181 doi: 10.3390/s22062181 [10] Luo X W, Chen L, Zhou H L, Cao H L. A survey of underwater acoustic target recognition methods based on machine learning. Journal of Marine Science and Engineering, 2023, 11(2): Article No. 384 doi: 10.3390/jmse11020384 [11] Kumar S, Phadikar S, Majumder K. Modified segmentation algorithm based on short term energy & zero crossing rate for Maithili speech signal. In: Proceedings of the International Conference on Accessibility to Digital World (ICADW). Guwahati, India: IEEE, 2016. 169−172 [12] Boashash B. Time-frequency Signal Analysis and Processing: A Comprehensive Reference. Pittsburgh: Academic Press, 2015. [13] Gopalan K. Robust watermarking of music signals by cepstrum modification. In: Proceedings of the IEEE International Symposium on Circuits and Systems. Kobe, Japan: IEEE, 2005. 4413−4416 [14] Lee C H, Shih J L, Yu K M, Lin H S. Automatic music genre classification based on modulation spectral analysis of spectral and cepstral features. IEEE Transactions on Multimedia, 2009, 11(4): 670−682 doi: 10.1109/TMM.2009.2017635 [15] Tsai W H, Lin H P. Background music removal based on cepstrum transformation for popular singer identification. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(5): 1196−1205 doi: 10.1109/TASL.2010.2087752 [16] Oppenheim A V, Schafer R W. From frequency to quefrency: A history of the cepstrum. IEEE Signal Processing Magazine, 2004, 21(5): 95−106 doi: 10.1109/MSP.2004.1328092 [17] Stevens S S, Volkmann J, Newman E B. A scale for the measurement of the psychological magnitude pitch. The Journal of the Acoustical Society of America, 1937, 8(3): 185−190 doi: 10.1121/1.1915893 [18] Oxenham A J. How we hear: The perception and neural coding of sound. Annual Review of Psychology, 2018, 69: 27−50 doi: 10.1146/annurev-psych-122216-011635 [19] Donald D A, Everingham Y L, McKinna L W, Coomans D. Feature selection in the wavelet domain: Adaptive wavelets. Comprehensive Chemometrics, 2009: 647−679 [20] Souli S, Lachiri Z. Environmental sound classification using log-Gabor filter. In: Proceedings of the IEEE 11th International Conference on Signal Processing. Beijing, China: IEEE, 2012. 144−147 [21] Costa Y, Oliveira L, Koerich A, Gouyon F. Music genre recognition using Gabor filters and LPQ texture descriptors. In: Proceedings of the Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications. Havana, Cuba: Springer, 2013. 67−74 [22] Ezzat T, Bouvrie J V, Poggio T A. Spectro-temporal analysis of speech using 2-D Gabor filters. In: Proceedings of 8th Annual Conference of the International Speech Communication Association. Antwerp, Belgium: ISCA, 2007. 506−509 [23] He L, Lech M, Maddage N, Allen N. Stress and emotion recognition using log-Gabor filter analysis of speech spectrograms. In: Proceedings of the 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops. Amsterdam, Netherlands: IEEE, 2009. 1−6 [24] 蔡悦斌, 张明之, 史习智, 林良骥. 舰船噪声波形结构特征提取及分类研究. 电子学报, 1999, 27(6): 129−130 doi: 10.3321/j.issn:0372-2112.1999.06.030Cai Yue-Bin, Zhang Ming-Zhi, Shi Xi-Zhi, Lin Liang-Ji. The feature extraction and classification of ocean acoustic signals based on wave structure. Acta Electronica Sinica, 1999, 27(6): 129−130 doi: 10.3321/j.issn:0372-2112.1999.06.030 [25] Meng Q X, Yang S. A wave structure based method for recognition of marine acoustic target signals. The Journal of the Acoustical Society of America, 2015, 137(4): 2242 [26] Meng Q X, Yang S, Piao S C. The classification of underwater acoustic target signals based on wave structure and support vector machine. The Journal of the Acoustical Society of America, 2014, 136(4_Supplement): 2265 [27] Rajagopal R, Sankaranarayanan B, Rao P R. Target classification in a passive sonar——An expert system approach. In: Proceedings of the International Conference on Acoustics, Speech, and Signal Processing. Albuquerque, USA: IEEE, 1990. 2911−2914 [28] Lourens J G. Classification of ships using underwater radiated noise. In: Proceedings of the Southern African Conference on Communications and Signal Processing (COMSIG). Pretoria, South Africa: IEEE, 1988. 130−134 [29] Liu Q Y, Fang S L, Cheng Q, Cao J, An L, Luo X W. Intrinsic mode characteristic analysis and extraction in underwater cylindrical shell acoustic radiation. Science China Physics, Mechanics and Astronomy, 2013, 56: 1339−1345 doi: 10.1007/s11433-013-5116-3 [30] Das A, Kumar A, Bahl R. Marine vessel classification based on passive sonar data: The cepstrum-based approach. IET Radar, Sonar & Navigation, 2013, 7(1): 87−93 [31] Wang S G, Zeng X Y. Robust underwater noise targets classification using auditory inspired time-frequency analysis. Applied Acoustics, 2014, 78: 68−76 doi: 10.1016/j.apacoust.2013.11.003 [32] Kim K I, Pak M I, Chon B P, Ri C H. A method for underwater acoustic signal classification using convolutional neural network combined with discrete wavelet transform. International Journal of Wavelets, Multiresolution and Information Processing, 2021, 19(4): Article No. 2050092 doi: 10.1142/S0219691320500927 [33] Qiao W B, Khishe M, Ravakhah S. Underwater targets classification using local wavelet acoustic pattern and multi-layer perceptron neural network optimized by modified whale optimization algorithm. Ocean Engineering, 2021, 219: Article No. 108415 doi: 10.1016/j.oceaneng.2020.108415 [34] Wei X, Li G H, Wang Z Q. Underwater target recognition based on wavelet packet and principal component analysis. Computer Simulation, 2011, 28(8): 8−290 [35] Xu K L, You K, Feng M, Zhu B Q. Trust-worth multi-representation learning for audio classification with uncertainty estimation. The Journal of the Acoustical Society of America, 2023, 153(3_supplement): Article No. 125 [36] 徐新洲, 罗昕炜, 方世良, 赵力. 基于听觉感知机理的水下目标识别研究进展. 声学技术, 2013, 32(2): 151−158Xu Xin-Zhou, Luo Xi-Wei, Fang Shi-Liang, Zhao Li. Research process of underwater target recognition based on auditory perceiption mechanism. Technical Acoustics, 2013, 32(2): 151−158 [37] Békésy G V. On the elasticity of the cochlear partition. The Journal of the Acoustical Society of America, 1948, 20(3): 227−241 doi: 10.1121/1.1906367 [38] Johnstone B M, Yates G K. Basilar membrane tuning curves in the guinea pig. The Journal of the Acoustical Society of America, 1974, 55(3): 584−587 doi: 10.1121/1.1914568 [39] Zwislocki J J. Five decades of research on cochlear mechanics. The Journal of the Acoustical Society of America, 1980, 67(5): 1679−1685 [40] 费鸿博, 吴伟官, 李平, 曹毅. 基于梅尔频谱分离和LSCNet的声学场景分类方法. 哈尔滨工业大学学报, 2022, 54(5): 124−130Fei Hong-Bo, Wu Wei-Guan, Li Ping, Cao Yi. Acoustic scene classification method based on Mel-spectrogram separation and LSCNet. Journal of Harbin Institute of Technology, 2022, 54(5): 124−130 [41] Yang H H, Li J H, Shen S, Xu G H. A deep convolutional neural network inspired by auditory perception for underwater acoustic target recognition. Sensors, 2019, 19(5): Article No. 1104 doi: 10.3390/s19051104 [42] Shen S, Yang H H, Yao X H, Li J H, Xu G H, Sheng M P. Ship type classification by convolutional neural networks with auditory-like mechanisms. Sensors, 2020, 20(1): Article No. 253 doi: 10.3390/s20010253 [43] Doan V S, Huynh-The T, Kim D S. Underwater acoustic target classification based on dense convolutional neural network. IEEE Geoscience and Remote Sensing Letters, 2020, 19: Article No. 1500905 [44] Miao Y C, Zakharov Y V, Sun H X, Li J H, Wang J F. Underwater acoustic signal classification based on sparse time-frequency representation and deep learning. IEEE Journal of Oceanic Engineering, 2021, 46(3): 952−962 doi: 10.1109/JOE.2020.3039037 [45] Hu G, Wang K J, Liu L L. Underwater acoustic target recognition based on depthwise separable convolution neural networks. Sensors, 2021, 21(4): Article No. 1429 doi: 10.3390/s21041429 [46] Xiao X, Wang W B, Ren Q Y, Gerstoft P, Ma L. Underwater acoustic target recognition using attention-based deep neural network. JASA Express Letters, 2021, 1(10): Article No. 106001 doi: 10.1121/10.0006299 [47] Gong Y, Chung Y A, Glass J. AST: Audio spectrogram Transformer. arXiv preprint arXiv: 2104.01778, 2021. [48] Yang H H, Li J H, Sheng M P. Underwater acoustic target multi-attribute correlation perception method based on deep learning. Applied Acoustics, 2022, 190: Article No. 108644 doi: 10.1016/j.apacoust.2022.108644 [49] Gong Y, Lai C I J, Chung Y A, Glass J. SSAST: Self-supervised audio spectrogram transformer. In: Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI, 2022. 10699−10709 [50] He K M, Chen X L, Xie S N, Li Y H, Dollár P, Girshick R. Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 15979−15988 [51] Baade A, Peng P Y, Harwath D. MAE-AST: Masked autoencoding audio spectrogram Transformer. arXiv preprint arXiv: 2203.16691, 2022. [52] Ghosh S, Seth A, Umesh S, Manocha D. MAST: Multiscale audio spectrogram Transformers. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Rhodes Island, Greece: IEEE, 2023. 1−5 [53] Domingos P. A few useful things to know about machine learning. Communications of the ACM, 2012, 55(10): 78−87 doi: 10.1145/2347736.2347755 [54] Kelly J G, Carpenter R N, Tague J A. Object classification and acoustic imaging with active sonar. The Journal of the Acoustical Society of America, 1992, 91(4): 2073−2081 doi: 10.1121/1.403693 [55] Shi H, Xiong J Y, Zhou C Y, Yang S. A new recognition and classification algorithm of underwater acoustic signals based on multi-domain features combination. In: Proceedings of the IEEE/OES China Ocean Acoustics (COA). Harbin, China: IEEE, 2016. 1−7 [56] Li H T, Cheng Y S, Dai W G, Li Z Z. A method based on wavelet packets-fractal and SVM for underwater acoustic signals recognition. In: Proceedings of the 12th International Conference on Signal Processing (ICSP). Hangzhou, China: IEEE, 2014. 2169−2173 [57] Sherin B M, Supriya M H. SOS based selection and parameter optimization for underwater target classification. In: Proceedings of the OCEANS 2016 MTS/IEEE Monterey. Monterey, USA: IEEE, 2016. 1−4 [58] Lian Z X, Xu K, Wan J W, Li G. Underwater acoustic target classification based on modified GFCC features. In: Proceedings of the IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC). Chongqing, China: IEEE, 2017. 258−262 [59] Lian Z X, Xu K, Wan J W, Li G, Chen Y. Underwater acoustic target recognition based on Gammatone filterbank and instantaneous frequency. In: Proceedings of the IEEE 9th International Conference on Communication Software and Networks (ICCSN). Guangzhou, China: IEEE, 2017. 1207−1211 [60] Feroze K, Sultan S, Shahid S, Mahmood F. Classification of underwater acoustic signals using multi-classifiers. In: Proceedings of the 15th International Bhurban Conference on Applied Sciences and Technology (IBCAST). Islamabad, Pakistan: IEEE, 2018. 723−728 [61] Li Y X, Chen X, Yu J, Yang X H. A fusion frequency feature extraction method for underwater acoustic signal based on variational mode decomposition, duffing chaotic oscillator and a kind of permutation entropy. Electronics, 2019, 8(1): Article No. 61 doi: 10.3390/electronics8010061 [62] Aksüren İ G, Hocaoğlu A K. Automatic target classification using underwater acoustic signals. In: Proceedings of the 30th Signal Processing and Communications Applications Conference (SIU). Safranbolu, Turkey: IEEE, 2022. 1−4 [63] Kim T, Bae K. HMM-based underwater target classification with synthesized active sonar signals. In: Proceedings of the 19th European Signal Processing Conference. Barcelona, Spain: IEEE, 2011. 1805−1808 [64] Li H F, Pan Y, Li J Q. Classification of underwater acoustic target using auditory spectrum feature and SVDD ensemble. In: Proceedings of the OCEANS-MTS/IEEE Kobe Techno-Oceans (OTO). Kobe, Japan: IEEE, 2018. 1−4 [65] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. Communication of the ACM, 2017, 60(6): 84−90 doi: 10.1145/3065386 [66] Yue H, Zhang L L, Wang D Z, Wang Y X, Lu Z Q. The classification of underwater acoustic targets based on deep learning methods. In: Proceedings of the 2nd International Conference on Control, Automation and Artificial Intelligence (CAAI 2017). Hainan, China: Atlantis Press, 2017. 526−529 [67] Kirsebom O S, Frazao F, Simard Y, Roy N, Matwin S, Giard S. Performance of a deep neural network at detecting North Atlantic right whale upcalls. The Journal of the Acoustical Society of America, 2020, 147(4): 2636−2646 doi: 10.1121/10.0001132 [68] Yin X H, Sun X D, Liu P S, Wang L, Tang R C. Underwater acoustic target classification based on LOFAR spectrum and convolutional neural network. In: Proceedings of the 2nd International Conference on Artificial Intelligence and Advanced Manufacture (AIAM). Manchester, United Kingdom: ACM, 2020. 59−63 [69] Jiang J J, Shi T, Huang M, Xiao Z Z. Multi-scale spectral feature extraction for underwater acoustic target recognition. Measurement, 2020, 166: Article No. 108227 doi: 10.1016/j.measurement.2020.108227 [70] Cao X, Togneri R, Zhang X M, Yu Y. Convolutional neural network with second-order pooling for underwater target classification. IEEE Sensors Journal, 2019, 19(8): 3058−3066 doi: 10.1109/JSEN.2018.2886368 [71] Hu G, Wang K J, Peng Y, Qiu M R, Shi J F, Liu L L. Deep learning methods for underwater target feature extraction and recognition. Computational Intelligence and Neuroscience, 2018, 2018: Article No. 1214301 [72] Zheng Y L, Gong Q Y, Zhang S F. Time-frequency feature-based underwater target detection with deep neural network in shallow sea. Journal of Physics: Conference Series, 2021, 1756: Article No. 012006 [73] Irfan M, Zheng J B, Ali S, Iqbal M, Masood Z, Hamid U. DeepShip: An underwater acoustic benchmark dataset and a separable convolution based autoencoder for classification. Expert Systems With Applications, 2021, 183: Article No. 115270 doi: 10.1016/j.eswa.2021.115270 [74] Wang B, Zhang W, Zhu Y N, Wu C X, Zhang S Z. An underwater acoustic target recognition method based on AMNet. IEEE Geoscience and Remote Sensing Letters, 2023, 20: Article No. 5501105 [75] Li Y X, Gao P Y, Tang B Z, Yi Y M, Zhang J J. Double feature extraction method of ship-radiated noise signal based on slope entropy and permutation entropy. Entropy, 2022, 24(1): Article No. 22 [76] Hong F, Liu C W, Guo L J, Chen F, Feng H H. Underwater acoustic target recognition with a residual network and the optimized feature extraction method. Applied Sciences, 2021, 11(4): Article No. 1442 doi: 10.3390/app11041442 [77] Chen S H, Tan X L, Wang B, Lu H C, Hu X L, Fu Y. Reverse attention-based residual network for salient object detection. IEEE Transactions on Image Processing, 2020, 29: 3763−3776 doi: 10.1109/TIP.2020.2965989 [78] Lu Z Y, Xu B, Sun L, Zhan T M, Tang S Z. 3-D channel and spatial attention based multiscale spatial-spectral residual network for hyperspectral image classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 4311−4324 doi: 10.1109/JSTARS.2020.3011992 [79] Fan R Y, Wang L Z, Feng R Y, Zhu Y Q. Attention based residual network for high-resolution remote sensing imagery scene classification. In: Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS). Yokohama, Japan: IEEE, 2019. 1346−1349 [80] Tripathi A M, Mishra A. Environment sound classification using an attention-based residual neural network. Neurocomputing, 2021, 460: 409−423 doi: 10.1016/j.neucom.2021.06.031 [81] Liu C W, Hong F, Feng H H, Hu M L. Underwater acoustic target recognition based on dual attention networks and multiresolution convolutional neural networks. In: Proceedings of the OCEANS 2021: San Diego-Porto. San Diego, USA: IEEE, 2021. 1−5 [82] Xue L Z, Zeng X Y, Jin A Q. A novel deep-learning method with channel attention mechanism for underwater target recognition. Sensors, 2022, 22(15): Article No. 5492 doi: 10.3390/s22155492 [83] Li J, Wang B X, Cui X R, Li S B, Liu J H. Underwater acoustic target recognition based on attention residual network. Entropy, 2022, 24(11): Article No. 1657 doi: 10.3390/e24111657 [84] Park D S, Chan W, Zhang Y, Chiu C C, Zoph B, Cubuk E D, et al. SpecAugment: A simple data augmentation method for automatic speech recognition. arXiv preprint arXiv: 1904.08779, 2019. [85] Luo X W, Zhang M H, Liu T, Huang M, Xu X G. An underwater acoustic target recognition method based on spectrograms with different resolutions. Journal of Marine Science and Engineering, 2021, 9(11): Article No. 1246 doi: 10.3390/jmse9111246 [86] Szegedy C, Ioffe S, Vanhoucke V, Alemi A. Inception-v4, inception-ResNet and the impact of residual connections on learning. arXiv preprint arXiv: 1602.07261, 2016. [87] Ren J W, Huang Z Q, Li C, Guo X Y, Xu J. Feature analysis of passive underwater targets recognition based on deep neural network. In: Proceedings of the OCEANS 2019-Marseille. Marseille, France: IEEE, 2019. 1−5 [88] Ren J W, Xie Y, Zhang X W, Xu J. UALF: A learnable front-end for intelligent underwater acoustic classification system. Ocean Engineering, 2022, 264: Article No. 112394 doi: 10.1016/j.oceaneng.2022.112394 [89] Li S C, Yang S Y, Liang J H. Recognition of ships based on vector sensor and bidirectional long short-term memory networks. Applied Acoustics, 2020, 164: Article No. 107248 doi: 10.1016/j.apacoust.2020.107248 [90] Wang Y, Zhang H, Xu L W, Cao C H, Gulliver T A. Adoption of hybrid time series neural network in the underwater acoustic signal modulation identification. Journal of the Franklin Institute, 2020, 357(18): 13906−13922 doi: 10.1016/j.jfranklin.2020.09.047 [91] Qi P Y, Sun J G, Long Y F, Zhang L G, Tian Y. Underwater acoustic target recognition with fusion feature. In: Proceedings of the 28th International Conference on Neural Information Processing. Sanur, Indonesia: Springer, 2021. 609−620 [92] Kamal S, Chandran C S, Supriya M H. Passive sonar automated target classifier for shallow waters using end-to-end learnable deep convolutional LSTMs. Engineering Science and Technology, an International Journal, 2021, 24(4): 860−871 doi: 10.1016/j.jestch.2021.01.014 [93] Han X C, Ren C X, Wang L M, Bai Y J. Underwater acoustic target recognition method based on a joint neural network. PLoS ONE, 2022, 17(4): Article No. e0266425 doi: 10.1371/journal.pone.0266425 [94] Li P, Wu J, Wang Y X, Lan Q, Xiao W B. STM: Spectrogram Transformer model for underwater acoustic target recognition. Journal of Marine Science and Engineering, 2022, 10(10): Article No. 1428 doi: 10.3390/jmse10101428 [95] Feng S, Zhu X Q. A Transformer-based deep learning network for underwater acoustic target recognition. IEEE Geoscience and Remote Sensing Letters, 2022, 19: Article No. 1505805 [96] Ying J J C, Lin B H, Tseng V S, Hsieh S Y. Transfer learning on high variety domains for activity recognition. In: Proceedings of the ASE BigData & SocialInformatics. Taiwan, China: ACM, 2015. 1−6 [97] Zhang Y K, Guo X S, Leung H, Li L. Cross-task and cross-domain SAR target recognition: A meta-transfer learning approach. Pattern Recognition, 2023, 138: Article No. 109402 doi: 10.1016/j.patcog.2023.109402 [98] Zhang L L, Wang D Z, Bao C C, Wang Y X, Xu K L. Large-scale whale-call classification by transfer learning on multi-scale waveforms and time-frequency features. Applied Sciences, 2019, 9(5): Article No. 1020 doi: 10.3390/app9051020 [99] Zhong M, Castellote M, Dodhia R, Ferres J L, Keogh M, Brewer A. Beluga whale acoustic signal classification using deep learning neural network models. The Journal of the Acoustical Society of America, 2020, 147(3): 1834−1841 doi: 10.1121/10.0000921 [100] Hitawala S. Evaluating ResNeXt model architecture for image classification. arXiv preprint arXiv: 1805.08700, 2018. [101] Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2818−2826 [102] Kong Q Q, Cao Y, Iqbal T, Wang Y X, Wang W W, Plumbley M D. PANNs: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 2880−2894 doi: 10.1109/TASLP.2020.3030497 [103] Li D H, Liu F, Shen T S, Chen L, Yang X D, Zhao D X. Generalizable underwater acoustic target recognition using feature extraction module of neural network. Applied Sciences, 2022, 12(21): Article No. 10804 doi: 10.3390/app122110804 [104] Kamal S, Mohammed S K, Pillai P R S, Supriya M H. Deep learning architectures for underwater target recognition. In: Proceedings of the Ocean Electronics (SYMPOL). Kochi, India: IEEE, 2013. 48−54 [105] Seok J. Active sonar target classification using multi-aspect sensing and deep belief networks. International Journal of Engineering Research and Technology, 2018, 11: 1999−2008 [106] 杨宏晖, 申昇, 姚晓辉, 韩振. 用于水声目标特征学习与识别的混合正则化深度置信网络. 西北工业大学学报, 2017, 35(2): 220−225Yang Hong-Hui, Shen Sheng, Yao Xiao-Hui, Han Zhen. Hybrid regularized deep belief network for underwater acoustic target feature learning and recognition. Journal of Northwestern Polytechnical University, 2017, 35(2): 220−225 [107] Yang H H, Shen S, Yao X H, Sheng M P, Wang C. Competitive deep-belief networks for underwater acoustic target recognition. Sensors, 2018, 18(4): Article No. 952 doi: 10.3390/s18040952 [108] Shen S, Yang H H, Sheng M P. Compression of a deep competitive network based on mutual information for underwater acoustic targets recognition. Entropy, 2018, 20(4): Article No. 243 doi: 10.3390/e20040243 [109] Cao X, Zhang X M, Yu Y, Niu L T. Deep learning-based recognition of underwater target. In: Proceedings of the IEEE International Conference on Digital Signal Processing (DSP). Beijing, China: IEEE, 2016. 89−93 [110] Luo X W, Feng Y L. An underwater acoustic target recognition method based on restricted Boltzmann machine. Sensors, 2020, 20(18): Article No. 5399 doi: 10.3390/s20185399 [111] Luo X W, Feng Y L, Zhang M H. An underwater acoustic target recognition method based on combined feature with automatic coding and reconstruction. IEEE Access, 2021, 9: 63841−63854 doi: 10.1109/ACCESS.2021.3075344 [112] Sun B G, Luo X W. Underwater acoustic target recognition based on automatic feature and contrastive coding. IET Radar, Sonar & Navigation, 2023, 17(8): 1277−1285 [113] You K, Xu K L, Feng M, Zhu B Q. Underwater acoustic classification using masked modeling-based swin Transformer. The Journal of the Acoustical Society of America, 2022, 152(4_Supplement): Article No. 296 [114] Xu K L, Xu Q S, You K, Zhu B Q, Feng M, Feng D W, et al. Self-supervised learning-based underwater acoustical signal classification via mask modeling. The Journal of the Acoustical Society of America, 2023, 154(1): 5−15 doi: 10.1121/10.0019937 [115] Le H T, Phung S L, Chapple P B, Bouzerdoum A, Ritz C H, Tran L C. Deep Gabor neural network for automatic detection of mine-like objects in sonar imagery. IEEE Access, 2020, 8: 94126−94139 doi: 10.1109/ACCESS.2020.2995390 [116] Huo G Y, Wu Z Y, Li J B. Underwater object classification in sidescan sonar images using deep transfer learning and semisynthetic training data. IEEE Access, 2020, 8: 47407−47418 doi: 10.1109/ACCESS.2020.2978880 [117] Berg H, Hjelmervik K T. Classification of anti-submarine warfare sonar targets using a deep neural network. In: Proceedings of the OCEANS 2018 MTS/IEEE Charleston. Charleston, USA: IEEE, 2018. 1−5 [118] Santos-Domínguez D, Torres-Guijarro S, Cardenal-López A, Pena-Gimenez A. ShipsEar: An underwater vessel noise database. Applied Acoustics, 2016, 113: 64−69 doi: 10.1016/j.apacoust.2016.06.008 [119] 刘妹琴, 韩学艳, 张森林, 郑荣濠, 兰剑. 基于水下传感器网络的目标跟踪技术研究现状与展望. 自动化学报, 2021, 47(2): 235−251Liu Mei-Qin, Han Xue-Yan, Zhang Sen-Lin, Zheng Rong-Hao, Lan Jian. Research status and prospect of target tracking technologies via underwater sensor networks. Acta Automatic Sinica, 2021, 47(2): 235−251 [120] Xu K L, Zhu B Q, Kong Q Q, Mi H B, Ding B, Wang D Z, et al. General audio tagging with ensembling convolutional neural networks and statistical features. The Journal of the Acoustical Society of America, 2019, 145(6): EL521−EL527 doi: 10.1121/1.5111059 [121] Zhu B Q, Xu K L, Kong Q Q, Wang H M, Peng Y X. Audio tagging by cross filtering noisy labels. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 2073−2083 doi: 10.1109/TASLP.2020.3008832 -

 下载:
下载:


计量
- 文章访问数: 4692
- HTML全文浏览量: 1625
- PDF下载量: 634
- 被引次数: 0
