

-
摘要: 用于复杂工业过程难测运行指标和异常故障建模的样本具有量少稀缺、分布不平衡以及内涵机理知识匮乏等特性. 虚拟样本生成(Virtual sample generation, VSG)作为扩充建模样本数量及其涵盖空间的技术, 已成为解决上述问题的主要手段之一, 但已有研究还存在缺乏理论支撑、分类准则与应用边界模糊等问题. 本文在描述复杂工业过程难测运行指标和异常故障建模所存在问题的基础上, 梳理虚拟样本定义及其内涵, 给出面向工业过程回归与分类问题的VSG实现流程; 接着, 从样本覆盖区域、实现流程与推广应用等方向进行综述; 然后, 分析讨论VSG的下一步研究方向; 最后, 对全文进行总结并给出未来挑战.Abstract: The modeling samples for difficulty to measure operation indexes and abnormal faults of complex industrial processes usually have the characteristics of sparse quantity, unbalanced distribution, and lack of connotation mechanism knowledge. Virtual sample generation (VSG) is a technology to expand the space and quantity of modeling samples and has become one of the main ways to solve the formerly mentioned difficulties. However, there are still some problems in the existing research results, such as the lack of theoretical support, the unclear of category criterion and the application boundary. First, the existing problems for difficulty to measure operational indexes and abnormal fault modeling of complex industrial processes are described. The definition of virtual samples and the connotation of virtual samples are combed, and the VSG implementation process for the regression and classification problems is provided. Second, the research status is summarized from the sample coverage area, implementation process, and application. Third, further research direction is analyzed and discussed. Finally, the summary and future challenges are given out.
-
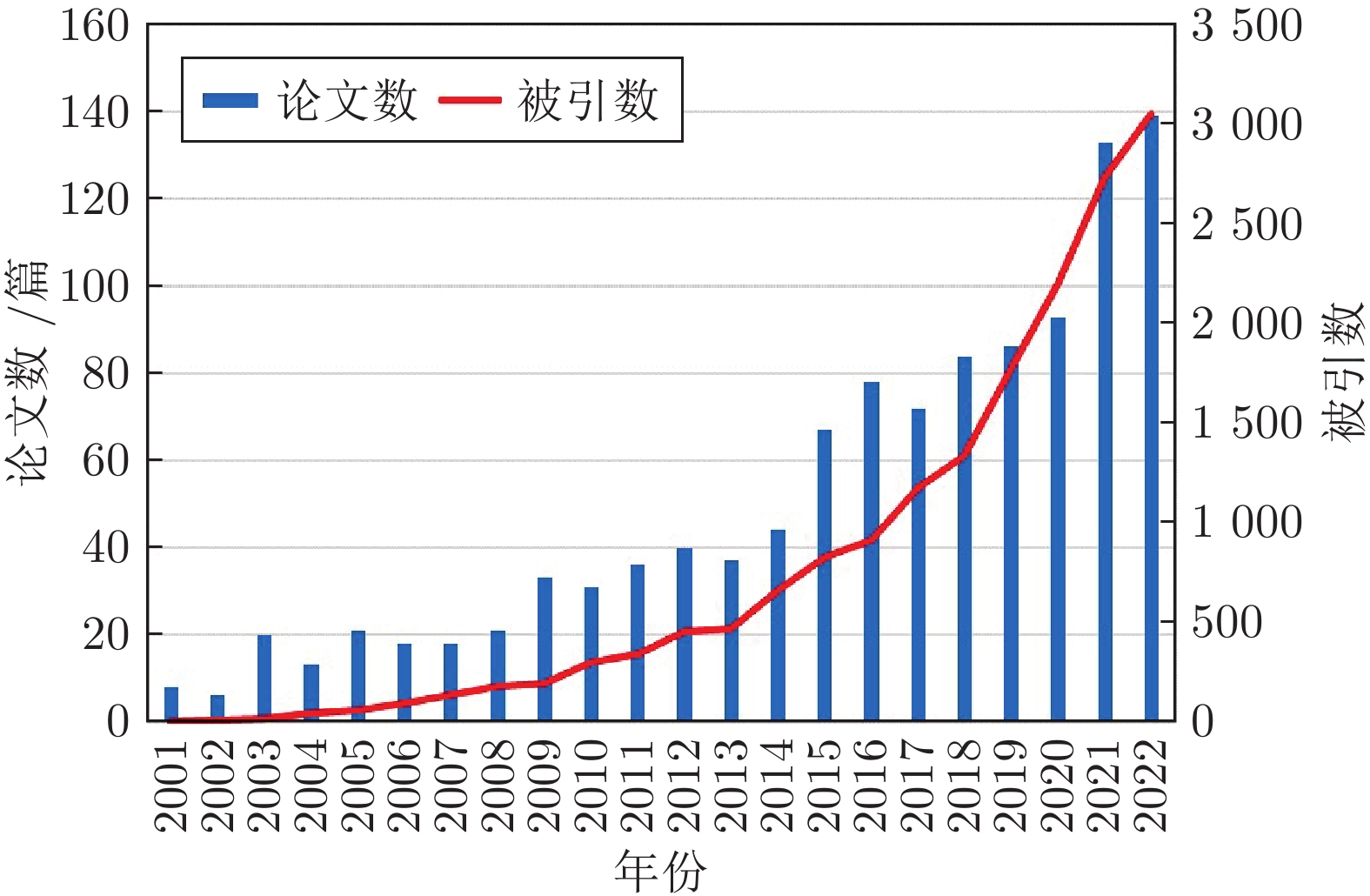
图 1 Web of Science上的VSG论文数量与被引频次
Fig. 1 Number and citation frequency of articles on VSG in Web of Science

图 2 样本输入空间内虚拟与真实样本间的关系
Fig. 2 Relationship between virtual samples and real samples in sample input space

图 3 三维空间下的不同虚拟样本输入生成方法示意图
Fig. 3 Diagram of different virtual sample input generation methods in 3D space
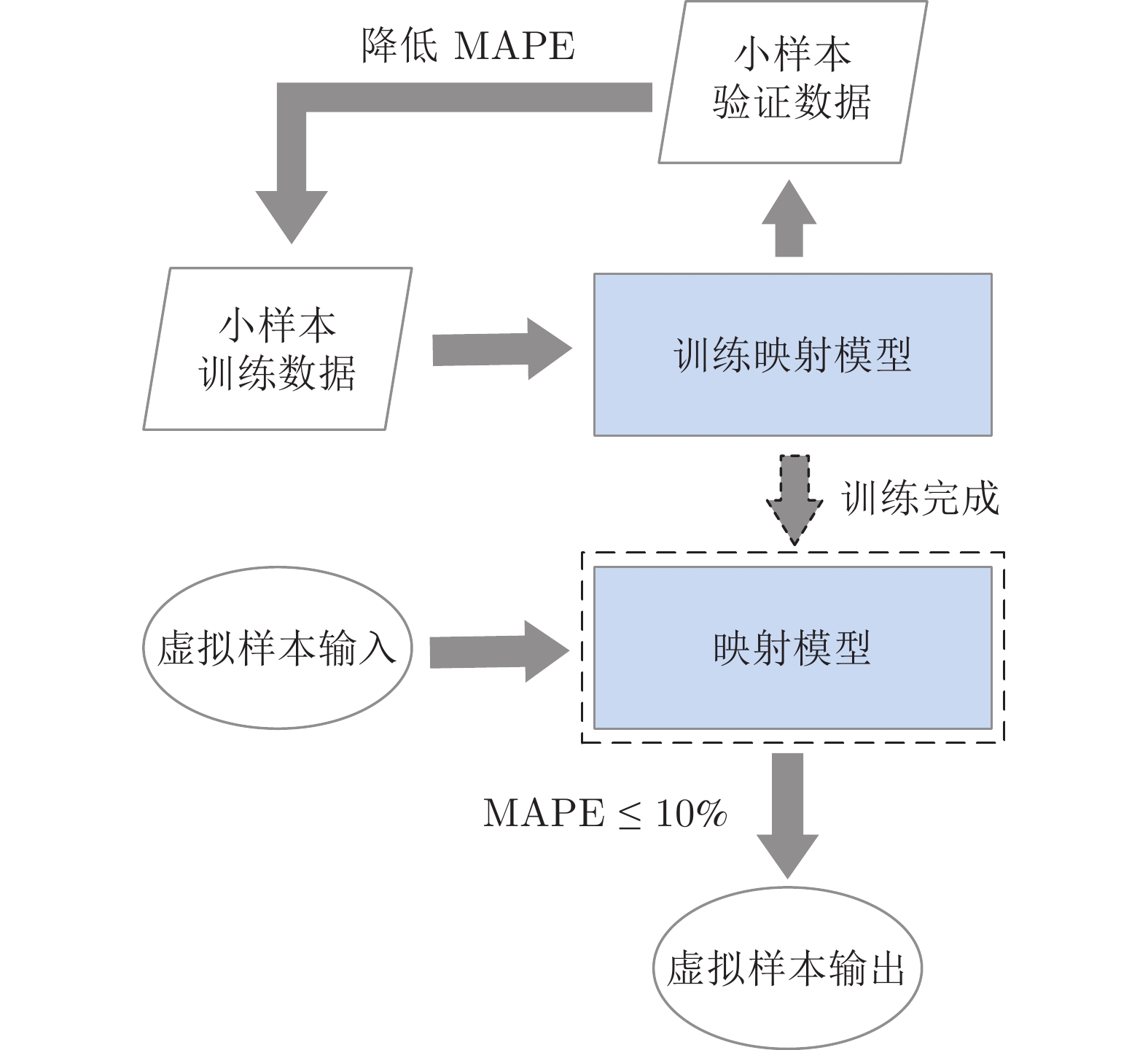
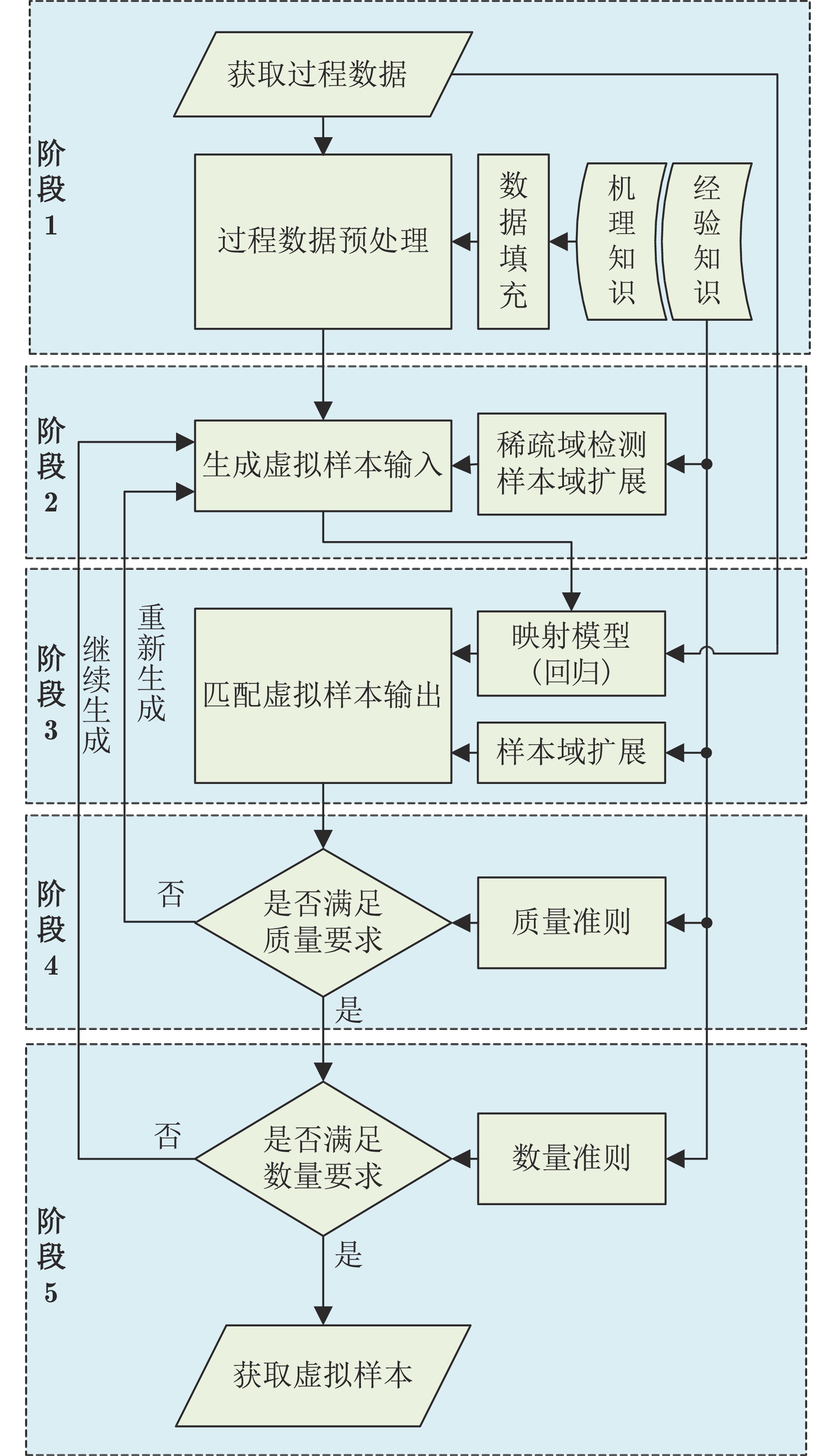
图 4 映射模型生成虚拟样本输出流程图
Fig. 4 Flow chart of virtual sample output generation based on mapping model
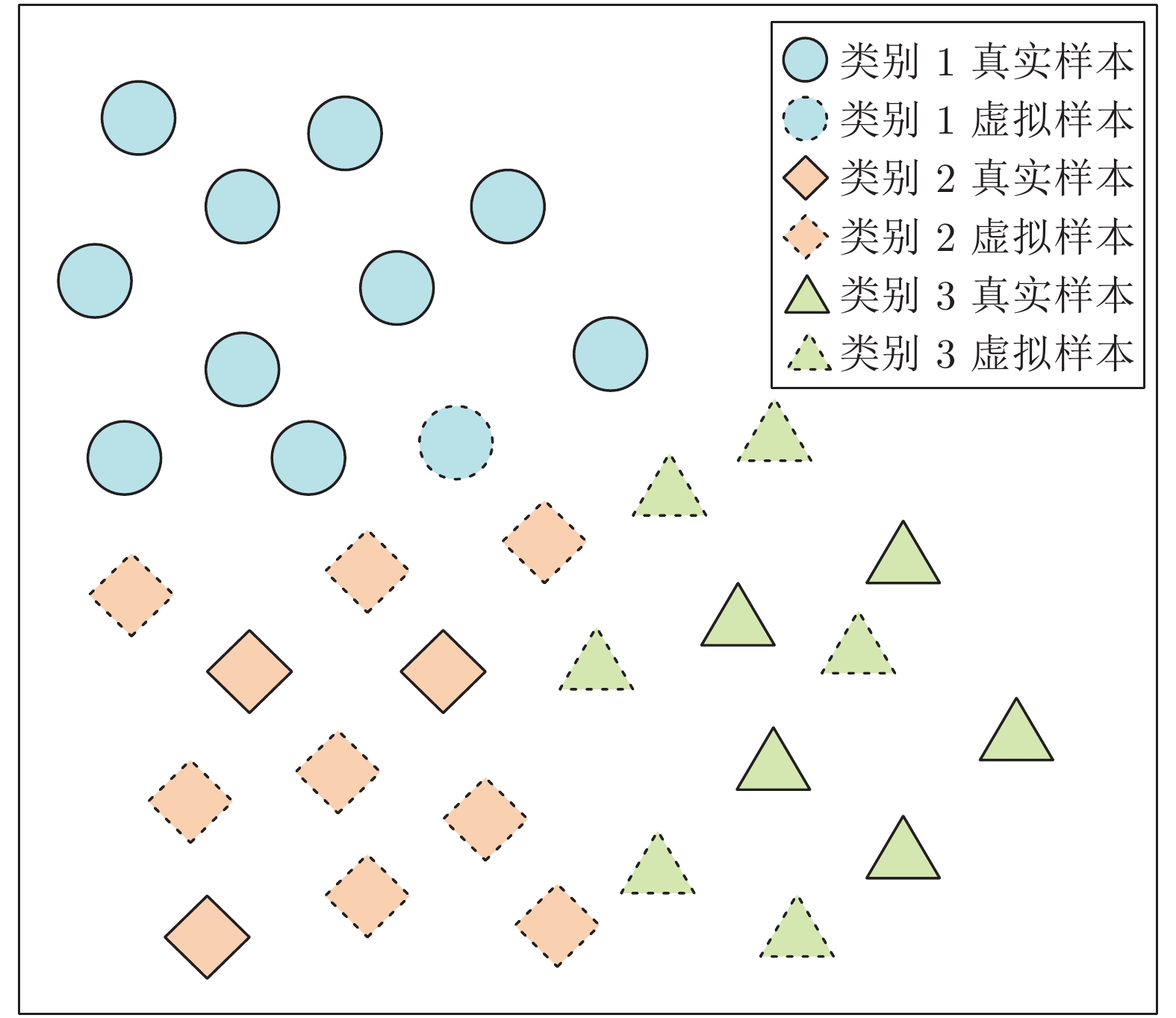
图 5 面向分类问题的虚拟与真实样本间的关系
Fig. 5 Relationship between virtual samples and real samples for classification problem

图 10 面向VSG的原始域、可扩展域和未知域的示意图
Fig. 10 Schematic diagram of original, extension, and unknown domain for VSG
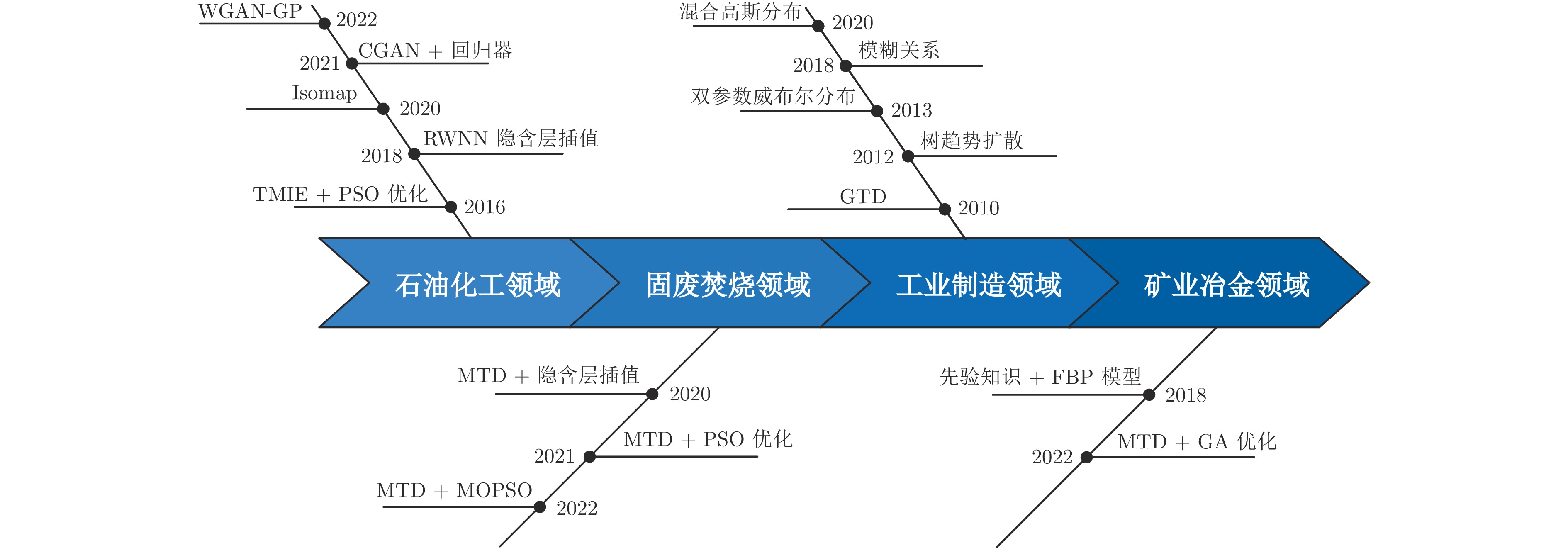
图 13 面向回归建模问题的VSG应用统计结果
Fig. 13 VSG application statistical results for regression modeling problem
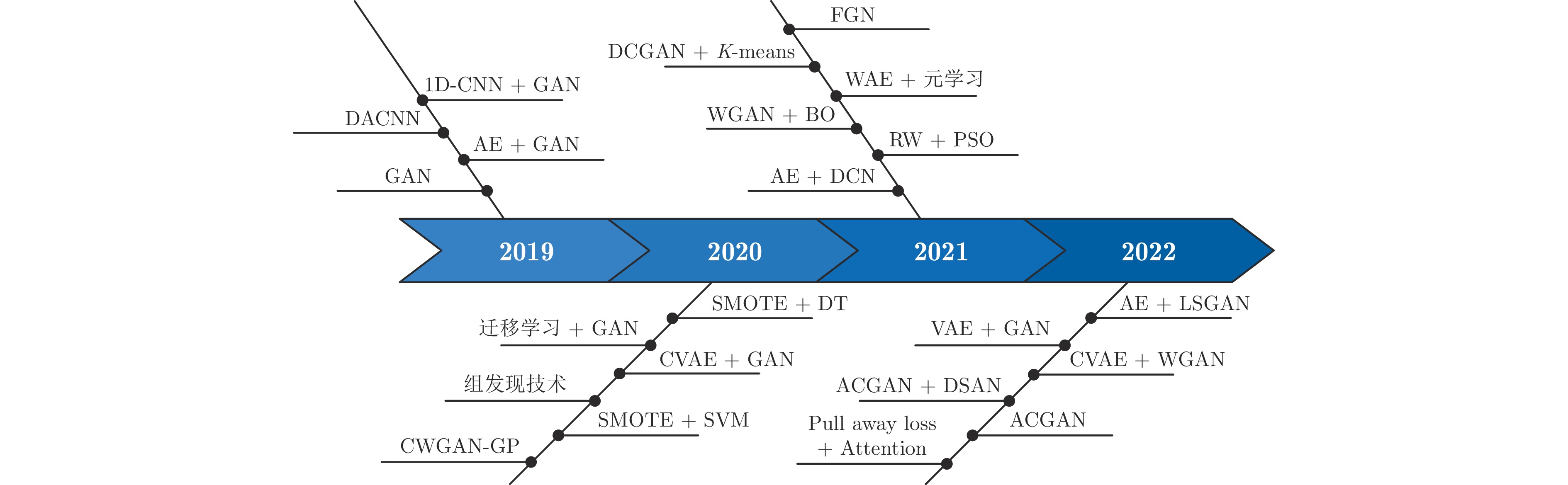
图 14 2019 ~ 2022年面向故障诊断领域的VSG应用统计结果
Fig. 14 VSG application statistical results for fault diagnosis on 2019 ~ 2022
表 2 面向回归问题VSG的合成数据集
Table 2 Synthetic datasets of VSG for regression problem
基准函数 取值空间 文献 $y = \left\{ {\begin{aligned} &{\sin x/x,{\rm{ if }}x \ne 0}\\ &{1,{\rm{ if }}x = 0} \end{aligned}} \right.$ $x \in \left[ { - 2\pi ,2\pi } \right]$ [49] $\begin{aligned} y = \;&2.077\;5 + 9.045\;46 \times \left( {{{10}^{ - 1}}} \right){x_1} + x_2^2 + \cos \left( {{x_3}} \right) + 1.355\;6 \times \left( {1.5 \times \left( {1 - {x_4}} \right)} \right){\rm{ }} +\\ &x_5^3 + {x_6} - 2.571\;51{x_7} - 5.097\;36 \times \left( {{{10}^{ - 1}}} \right) \times \left( {x_8^2} \right)\end{aligned}$ $x \in \left[ {0,1} \right]$ [53] $\begin{aligned}y = \;&0.415\sin {x_1} - 0.312x_2^2 + 1/\left( {1 + {{\rm{e}}^{ - {x_3}}}} \right) + \cos x_4^3 + 0.66{{\rm{e}}^{1 - x_5^{0.5}}}\sin {x_5}{\rm{ }} \;-\\ &\cos {x_6}\ln \left( {1/\cos {x_6}} \right) + 0.38\tanh {x_7} + \left( {1 - x_8^3} \right)\cos x_8^3\end{aligned}$ ${\rm{ }}x \in \left[ {0,1} \right]$ [54] $\begin{aligned} &y = x + \varepsilon ,{\rm{ } }\varepsilon \ \sim {\rm{N} }\left( {0,{ {0.05}^2} } \right)\\ &y = x + \varepsilon ,{\rm{ } }\varepsilon \ \sim {\rm{N} }\left( {0,0.01{x^2} } \right)\\ &y = \;x + 0.2\sin \left( {20x} \right) + \varepsilon ,{\rm{ } }\varepsilon \ \sim {\rm{N} }\left( {0,{ {0.05}^2} } \right) \end{aligned}$ $x \in \left[ {0,1} \right]$ [55] $\begin{aligned} y =\;& 1.335\;6 \times \left( {1.5\left( {1 - {x_1} } \right)} \right) + { {\rm{e} }^{2{x_1} - 1} }\sin \left( {3\pi { {\left( { {x_1} - 0.6} \right)}^2} } \right){\rm{ } } +\\ &{ {\rm{e} }^{3\left( { {x_2} - 0.5} \right)} }\sin \left( {4\pi { {\left( { {x_2} - 0.9} \right)}^2} } \right)\end{aligned}$ $x \in \left[ {0,1} \right]$ [57, 64, 127] $y = \sin \left( {{x_1}} \right) + \cos \left( {{x_2}} \right) + \sin \left( {{x_1}} \right) \times \cos \left( {{x_2}} \right)$ ${x_1} \in \left[ { - \pi ,\pi } \right]$ [59, 129] ${x_2} \in \left[ {0,2\pi } \right]$ $y = {{\rm{e}}^{(2x - 1)}}\sin \left[ {4\pi {{(x - 0.6)}^2}} \right] + \varepsilon ,{\rm{ }}\varepsilon \ \sim {\rm{N}}(0,0.002\;5)$ $x \in \left[ {0,1} \right]$ [20] 注: $\varepsilon $是为了更好地模拟实际工业过程的环境影响而添加的噪声项.  下载: 导出CSV
下载: 导出CSV
表 3 面向分类问题的VSG公开数据集
Table 3 Public datasets of VSG for classification problem
数据集 数据集信息 文献 Case Western Reserve University 由美国凯斯西储大学发布的位于轴承数据中心网站的轴承故障 [67, 69, 92, 132−133] (CWRU)轴承故障数据集1 数据集, 包含无故障和滚动体、内圈和外圈故障数据 University of Connecticut 美国康涅狄格大学Jiong Tang团队发布的齿轮箱故障数据集, [85] (UoC)齿轮箱故障 包括健康工况、缺齿、齿根裂纹、齿面剥落以及 数据集2 不同程度齿尖破损状态数据 Tennessee Eastman process 由美国伊士曼化学公司开发的化学过程模拟平台生成的 [156−157] (TEP)数据集3 数据集, 包括正常工况和21种异常工况数据 IEEE PHM 2009齿轮箱故障 由2009年的IEEE PHM挑战赛提供的齿轮箱故障 [80] 数据集4 数据集, 包含健康、缺齿、齿裂等8种工况 西安交通大学Spectra Quest (SQ) 由西安交通大学SQ实验平台得到的电机轴承外圈 [150] 轴承故障数据集5 和内圈故障数据集 数据集网址: 1 https://engineering.case.edu/bearingdatacenter/download-data-file 2 https://figshare.com/articles/dataset/Gear_Fault_Data/6127874/1 3 http://depts.washington.edu/control/LARRY/TE/download.html 4 http://www.phmsociety.org/references/datasets 5 https://github.com/sliu7102/SQ-dataset-with-variable-speed-for-fault-diagnosis
下载: 导出CSV
A1 VSG的研究成果统计与对比
A1 Statistics and comparison of VSG research results
分类 子分类 方法 年份 优劣 文献 面向样本覆盖区域之原始域样本空间
回归VSG特征工程 LLE + BPNN 2020 特征变换, 流形学习更加直观, 但特征失去物理含义 [52] Isomap + 插值法 2020 [53] t-SNE + RF 2021 [54] 机理 2021 特征选择, 工业过程知识获取困难 [55] 两者结合 2020 综合特征变换与选择, 具有较强的定制化特性 [56] 样本工程 空间投影 + RBF 2021 函数模型, 空间投影具有新颖性 [57] 数据趋势 2021 函数模型, 提出的稀疏假设和集中假设具有参考价值 [49] 总线拓扑结构插值 2023 函数模型, 有效控制插值位置 [58] RWNN插值法 2018 函数模型, 基于神经网络 [59] AANN插值 2019 模型学习样本的非线性分布关系 [60] RWNN + 等间隔插值法 2020 对小样本难以有效 [56] MTD + PSO 2021 函数模型, PSO优化选择虚拟样本 [61] 多目标PSO 2022 函数模型, 多目标PSO优化选择虚拟样本和生成数量 [15] LOF + K-means + GAN 2021 对抗模型, 插值生成输出, CGAN生成输入 [20] 双GAN 2022 对抗模型, 两种GAN分别负责输入和
输出的生成, 复杂性高[64] 回归器 + CWGAN 2022 对抗模型, 通过回归器匹配虚拟样本输出并共同训练 [65] 面向样本覆盖区域之原始域样本空间的分类VSG 特征工程 添加编码器 2020 采用编码器提取特征 [68] 添加卷积层 2021 添加卷积层提取特征 [66] 添加卷积层 2021 [67] 添加自注意 2022 添加自注意力模型增强特征 [69] 面向样本覆盖区域之原始域样本空间的分类VSG 样本工程 基于加权核的SMOTE 2018 函数模型, 解决SMOTE算法在高IR下
的非线性可分离问题[71] Minkowski距离替换欧氏距离 2019 函数模型, 有效生成高维虚拟样本 [72] SMOTE + 决策树 2020 函数模型, 决策树算法提取关键规则 [73] SMOTE + SVM 2020 函数模型, 支持向量边界生成虚拟样本 [74] 范围控制SMOTE 2021 函数模型, 有效地缓解范围偏移和边界样本重叠等问题 [75] 超球面空间 + 组发现技术 2007 函数模型, 由数据的结构生成虚拟样本 [76] 组发现技术 + 纯化过程 2020 函数模型, 纯化过程剔除冗余样本 [77] ACGAN 2020 对抗模型, 添加Dropout层防止过拟合, 添加卷积层
提取更多特征[79] ACWGAN-GP 2020 对抗模型, ACGAN的进化版 [80] MAML + ACGAN 2021 对抗模型, MAML初始化和更新网络使得生成过程
更加稳定[81] GAN + 多尺度CNN 2021 对抗模型, 生成模型需要改进 [82] DCGAN + K-means 2021 对抗模型, K-means算法对模型改进 [67] MoGAN 2021 对抗模型, 判别器既判断样本真假又
充当分类器和故障检测器[83] GAN + MSCNN 2021 对抗模型, 多GAN联合生成 [82] 贝叶斯优化 + WGAN 2021 对抗模型, 贝叶斯优化策略自适应调节判别器参数 [86] WGAN + LSTM-FCN 2022 对抗模型, 结合LSTM [84] AE + GAN 2019 对抗模型, AE结合GAN [89] VAE + GAN 2020 [68] 深度残差网络 + VAE + GAN 2021 对抗模型, 深度残差网络提高模型性能 [90] AE + LSGAN 2022 对抗模型, 暹罗编码器计算特征残差 [91] CVAEGAN-SM 2022 对抗模型, 生成器中加入自调制机制 [92] 堆叠AE + WGAN 2023 对抗模型, 提升了模型的生成能力 [93] 面向样本覆盖区域之扩展域样本空间的
回归VSG集合理论 正态隶属度 1997 模糊集理论, 仅适用于扩展范围对称情况 [94] DNN 2003 模糊集理论, 特征相关系数大于0.9才能计算扩展范围 [95] MTD 2007 模糊集理论, 通过假设特征独立不对称地扩散特征范围 [96] GTD 2010 模糊集理论, 增量版的MTD [97] TTD 2012 模糊集理论, 与树算法结合 [98] 神经网络MTD 2012 模糊集理论, 神经网络与MTD结合 [99] MD-MTD 2016 模糊集理论, 三角和均匀分布组合的多分布 [100] KNN + MTD 2022 模糊集理论, KNN确保合理的扩展范围 [101] K-means + MTD 2022 模糊集理论, K-means解决属性冗余 [102] AD-MTD + MD-MTD 2019 模糊集理论, 多种算法结合取长补短 [103] MTD + RWNN 2020 模糊集理论, 改进分布 + 隐含层插值 [56] MTD + GA 2014 模糊集理论, 基于优化算法搜寻虚拟样本, 更合理 [46] TMIE + PSO 2016 模糊集理论, PSO优化选择虚拟样本 [104] MTD + PSO 2021 [61] 分布假设 IKDE 2006 高斯分布, 改进KDE分布 [109] 时序IKDE 2008 高斯分布, 用于时序数据 [110] SJDT 2016 高斯分布, SJDT将数据趋于正态分布 [111] MPV 2013 非高斯分布, 多样本分布 [112] 假设检验 2019 非高斯分布, 先聚类再估计 [113] 基于知识 多目标PSO 2022 基于知识确定输出扩展域下限, 多目标PSO优化选择虚拟样本和生成数量 [15] 面向样本覆盖区域之扩展域样本空间的
分类VSG集合理论 FID 2017 模糊集理论, 既生成虚拟样本又填充缺失 [114] SMOTE + 粗糙集理论 2012 粗糙集理论, 扩展范围有限 [115] 三支决策 2018 粗糙集理论, 未精准计算扩展范围 [116] 分布假设 假设分布 2010 高斯分布, 计算数据的均值和方差确定高斯分布 [43] 假设分布 2022 高斯分布, AIC和BIC自适应确定高斯分布参数 [117] SVM 2013 非高斯分布, 状态函数采样生成虚拟样本 [118] K-means + Weibull分布 2014 非高斯分布, 特定过程采用特定分布 [119] 基于知识 FAGAN 2021 基于知识, 专家知识定义的故障属性作为辅助信息以
使得生成样本[123] 面向VSG实现流程之回归问题 过程数据预处理阶段 缺失值删减和人工填充 2021 有效减少缺失和异常值对数据的影响但会减少样本数量 [61] 2022 [15] 缺失和异常值识别剔除 2020 [127] 2022 [64] LLE 2020 流形学习更加直观, 特征失去物理含义 [52] Isomap 2020 [53] t-SNE 2021 [54] 根据化工机理选择特征 2017 机理知识获取困难 [128] 2018 [59] 专家经验 2021 特定实验知识 [61] 虚拟样本输入生成阶段 欧氏距离识别稀疏区域 2020 引入欧氏距离 [127] 投影最大间距识别稀疏 2021 引入投影最大间距 [57] 可视化样本分布识别稀疏区域 2020 可视化, 直观 [52] 2020 [53] 2021 [54] 稀疏性和集中性假设 2021 确定稀疏和密集区域关系 [49] WGAN-GP 2022 引入GAN用于回归 [64] CWGAN 2022 [65] MTD 2007 确定虚拟样本输入的扩展域范围后插值 [96] TMIE + PSO 2016 [104] 流形子空间 + MTD 2021 [129] 虚拟样本输出生成阶段 RWNN映射模型 2018 映射模型的性能受限于小样本 [59] 2016 [104] 2021 [129] BPNN映射模型 2020 [52] RF映射模型 2021 [54] RBF映射模型 2021 [57] CS-CGAN匹配输出 2022 匹配模型与虚拟样本输入同时训练 [64] 回归器匹配输出 2022 [65] 分位数回归器匹配输出 2021 [55] 虚拟样本质量筛选阶段 模型误差小于10%筛选 2014 受限于小样本建模性能 [46] 隶属度的似然估计筛选 2018 引入似然估计 [130] PSO优化算法筛选 2021 引入优化算法 [61] 专家筛选 2021 具有主观性 [49] 虚拟样本数量确定阶段 信息熵 2019 引入信息熵 [131] 稀疏和集中假设 2021 引入各种假设 [49] 特殊阶段 LOF + CGAN 2021 先生成虚拟样本输出后匹配虚拟样本输入 [20] 三样条插值 + ITNN 2021 [49] 面向VSG实现流程之分类问题 过程数据预处理阶段 信号数据转换为灰度图 2022 借鉴图像领域算法处理 [85] 2022 [132] 虚拟样本输入生成阶段 重叠分割、旋转和抖动的
数据增强2021 缓解过拟合 [133] SMOTE + 粗糙集理论 2012 扩展范围有限 [115] SMOTE + 决策树 2020 决策树算法提取运行规则 [73] SMOTE + SVM 2020 引入支持向量机边界 [74] Minkowski距离替换欧氏距离 2019 可以有效地生成高维虚拟样本 [72] 范围控制SMOTE 2021 通过控制生成范围减少边界重叠样本 [75] WGAN + LSTM-FCN 2022 引入LSTM [84] CWGAN-GP + FDGRU 2022 增加梯度惩罚项和条件信息 [85] Pull-away损失函数GAN 2022 添加自注意力模型增强特征 [69] ACGAN 2020 添加Dropout层防止过拟合, 添加卷积层提取更多特征 [79] ACGAN + CVAE 2020 引入CVAE [68] 深度残差网络 + VAE + GAN 2021 深度残差网络提高模型性能 [90] MoGAN 2021 判别器包含真假判断、故障诊断和故障分类三种功能 [83] CVAEGAN-SM 2022 生成器加入自调制机制 [92] 并行GAN 2020 对应多类别同时训练, 复杂性高 [19] SMOTE + VAE 2018 基于样本的迁移学习VSG [134] 自适应混合 2020 [135] 迁移学习 + 插值 2022 [136] Fine-tuning + WGAN 2021 基于模型的迁移学习VSG [137] 迁移学习 + GAN 2022 [138] 虚拟样本质量筛选阶段 Wasserstein距离 2020 未给出评价指标的具体限值筛选虚拟样本 [139] KL散度, F-score, 2021 [66] Kappa系数, GAN测试值 Wasserstein距离, KL
散度, 欧氏距离,2021 [67] 皮尔逊相关系数 马氏距离, 欧氏距离 2021 给出评价指标的具体限值筛选虚拟样本 [82] 判别概率, 最大均值差异, KL散度 2022 [69] 皮尔逊相关系数 2022 未给出评价指标的具体限值筛选虚拟样本 [85] 最大均值差异, KL散度, 2022 [92] GAN测试值 虚拟样本数量确定阶段 分类复杂度确定虚拟样本数量 1998 采用分类复杂度确定虚拟样本数量 [14] 面向VSG推广应用的回归问题 石油化工 TMIE + PSO 2016 PSO优化选择 [104] RWNN插值法 2018 提出隐含层插值生成虚拟样本 [59] Isomap + 插值法 2020 [53] 分位数回归器匹配输出 2021 提出分位数回归匹配输出 [55] 回归器 + CWGAN 2022 通过回归器匹配虚拟样本输出并同时训练 [65] 固废焚烧 两者结合 2020 具有较强的定制化特性 [56] MTD + PSO 2021 PSO优化选择虚拟样本 [61] 多目标PSO 2022 多目标PSO优化选择虚拟样本和生成数量 [15] 工业制造 GTD 2010 增量版的MTD [97] TTD 2012 与树算法结合 [98] MPV 2013 采用多分布 [112] 模糊c均值聚类 + 箱线图 2018 箱线图确定扩展范围 [141] 假设分布 2022 AIC和BIC自适应确定高斯分布参数 [117] 矿业冶金 时频变换 + FBP +
信息熵2018 特定问题采用特定方法 [6] RWNN插值 + MD-MTD 2019 GA优化选择虚拟混合样本 [145] 面向VSG推广应用的分类问题 滚动轴承
故障诊断迁移学习 + GAN 2020 迁移与GAN相结合 [146] PGDAE + DCN 2021 引入PGDAE [147] 元学习 + WAE 2021 元学习提高虚拟样本质量 [66] CVAEGAN-SM 2022 生成器加入自调制机制 [92] DSAN 2022 自注意模块增强深度特征 [132] GAN 2022 常数Q转换将信号转换为频谱图, 均方差替换交叉熵 [148] ACGAN 2022 引入ACGAN [149] 特征增强GAN 2022 自注意模块增强深度特征 [69] DFGN 2021 可用于零样本故障诊断 [150] 变压器
故障诊断SMOTE + 决策树 2020 决策树算法提取关键规则 [73] SMOTE + SVM 2020 提出支持向量边界生成样本 [74] CWGAN-GP 2020 引入梯度惩罚 [151] AE + LSGAN 2022 暹罗编码器计算特征残差 [91] 涡轮机
故障诊断GAN 2019 结合GAN与具体问题 [152] DACNN 2019 [153] VAE + GAN 2019 [89] 1D-CNN GAN 2019 虚拟样本输出和故障诊断组合模型 [154] 齿轮箱
故障诊断ACGAN + CVAE 2020 引入CVAE [68] 贝叶斯优化 + WGAN 2021 贝叶斯优化策略自适应调节判别器参数 [86] DCGAN + K-means 2021 K-means算法对模型改进 [67]
下载: 导出CSV
A2 符号说明
A2 Symbol description
缩写词 英文全称 中文全称 VSG Virtual sample generation 虚拟样本生成 MSWI Municipal solid waste incineration 城市固废焚烧 DXN Dioxin 二噁英 VAE Variational autoencoder 变分自编码器 GAN Generative adversarial network 生成对抗网络 FDD Fault detection and diagnosis 故障检测与诊断 IR Imbalance ratio 不平衡比 SMOTE Synthetic minority over-sampling technique 合成少数类过采样技术 MAPE Mean absolute percentage error 平均绝对百分比误差 LLE Locally linear embedding 局部线性嵌入 BPNN Back propagation neural network 反向传播神经网络 Isomap Isometric feature mapping 等距特征映射 t-SNE t-distributed stochastic neighbor embedding t分布随机邻域嵌入 RF Random forest 随机森林 RBF Radial basis function 径向基函数 CSI Cubic spline interpolation 三样条插值 ITNN Input-training neural network 输入训练神经网络 RWNN Random weight neural network 随机权神经网络 AANN Auto-associative neural network 自联想神经网络 LOF Local outlier factor 局部异常因子 CGAN Conditional generative adversarial network 条件生成对抗网络 CS-CGAN Cycle structure conditional generative adversarial network 循环结构条件生成对抗网络 FFT Fast Fourier transform 快速傅里叶变换 SVM Support vector machine 支持向量机 AC-GAN Auxiliary classifier generative adversarial network 辅助分类器生成对抗网络 ACWGAN-GP Auxiliary classier Wasserstein generative adversarial network with 具有梯度惩罚的辅助分类Wasserstein生成对抗网络 gradient penalty MAML Model agnostic meta learning 模型无关元学习 CNN Convolutional neural network 卷积神经网络 DCGAN Deep convolutional generative adversarial network 深度卷积生成对抗网络 MoGAN Minority oversampling generative adversarial network 少数类过采样生成对抗网络 AE Autoencoder 自编码器 CVAE-GAN Conditional variational autoencoder generative adversarial network 条件变分自编码器生成对抗网络 LSGAN Least squares generative adversarial network 最小二乘生成对抗网络 DNN Diffusion neural network 扩散神经网络 MTD Mega-trend-diffusion 大趋势扩散 GTD Generalized-trend-diffusion 广义趋势扩散 TTD Tree structure based trend diffusion 树结构趋势扩散 MD-MTD Multi-distribution mega-trend-diffusion 多分布大趋势扩散 KNN K-nearest neighbor K近邻 AD-MTD Advanced mega-trend-diffusion 改进型大趋势扩散 Hybrid-MTD Hybrid mega-trend-diffusion 混合大趋势扩散 GA Genetic algorithm 遗传算法 FBP Feasibility-based programming 可行性的规划 TMIE Information-expanded based on triangular membership 基于三角隶属度的信息扩散 PSO Particle swarm optimization 粒子群优化 IKDE Improved kernel density estimation 改善核密度估计 SJDT Small Johnson data transformation 小型约翰变换方法 MPV Maximal p value 最大p值 AIC Akaike information criterion 赤池信息准则 AICc Corrected version of the akaike information criterion 修正版赤池信息准则 FID Fuzzy-based information decomposition 基于模糊的信息分解 BIC Bayesian information criterion 贝叶斯信息准则 FAGAN Fault attributes generative adversarial network 故障属性生成对抗网络 SRWGAN Semantic refinement Wasserstein generative adversarial network 语义细化Wasserstein生成对抗网络 MOPSO Multi-objective particle swarm optimization 多目标粒子群优化 PGDAE Predictive generative denoising autoencoder 预测生成去噪自编码器 DCN Deep coral network 深度珊瑚网络 WAE Wasserstein autoencoder Wasserstein自编码器 DSAN Deep subdomain adaptation network 深度子域适应网络 DFGN Deep feature generating network 深度特征生成网络 DACNN Deep adversarial convolutional neural network 深度对抗卷积神经网络 BO Bayesian optimization 贝叶斯优化 DCGAN Deep convolution generative adversarial network 深度卷积生成对抗网络
下载: 导出CSV
-
[1] Yin S, Ding S X, Xie X C, Luo H. A review on basic data-driven approaches for industrial process monitoring. IEEE Transactions on Industrial Electronics, 2014, 61(11): 6418−6428 doi: 10.1109/TIE.2014.2301773 [2] Sun Y N, Zhuang Z L, Xu H W, Qin W, Feng M J. Data-driven modeling and analysis based on complex network for multimode recognition of industrial processes. Journal of Manufacturing Systems, 2022, 62: 915−924 doi: 10.1016/j.jmsy.2021.04.001 [3] 柴天佑. 工业过程控制系统研究现状与发展方向. 中国科学: 信息科学, 2016, 46(8): 1003−1015 doi: 10.1360/N112016-00062Chai Tian-You. Industrial process control systems: Research status and development direction. Scientia Sinica Informationis, 2016, 46(8): 1003−1015 doi: 10.1360/N112016-00062 [4] 丁进良, 杨翠娥, 陈远东, 柴天佑. 复杂工业过程智能优化决策系统的现状与展望. 自动化学报, 2018, 44(11): 1931−1943Ding Jin-Liang, Yang Cui-E, Chen Yuan-Dong, Chai Tian-You. Research progress and prospects of intelligent optimization decision making in complex industrial process. Acta Automatica Sinica, 2018, 44(11): 1931−1943 [5] Xia H, Tang J, Qiao J F, Zhang J, Yu W. DF classification algorithm for constructing a small sample size of data-oriented DF regression model. Neural Computing and Applications, 2022, 34(4): 2785−2810 doi: 10.1007/s00521-021-06809-7 [6] 汤健, 乔俊飞, 柴天佑, 刘卓, 吴志伟. 基于虚拟样本生成技术的多组分机械信号建模. 自动化学报, 2018, 44(9): 1569−1589Tang Jian, Qiao Jun-Fei, Chai Tian-You, Liu Zhuo, Wu Zhi-Wei. Modeling multiple components mechanical signals by means of virtual sample generation technique. Acta Automatica Sinica, 2018, 44(9): 1569−1589 [7] 马大中, 胡旭光, 孙秋野, 郑君, 王睿. 基于数据特征融合的管网信息物理异常诊断方法. 自动化学报, 2019, 45(1): 163−173Ma Da-Zhong, Hu Xu-Guang, Sun Qiu-Ye, Zheng Jun, Wang Rui. Cyber-physical abnormity diagnosis method using data feature fusion for pipeline network. Acta Automatica Sinica, 2019, 45(1): 163−173 [8] 乔俊飞, 郭子豪, 汤健. 面向城市固废焚烧过程的二噁英排放浓度检测方法综述. 自动化学报, 2020, 46(6): 1063−1089Qiao Jun-Fei, Guo Zi-Hao, Tang Jian. Dioxin emission concentration measurement approaches for municipal solid wastes incineration process: A survey. Acta Automatica Sinica, 2020, 46(6): 1063−1089 [9] Xia H, Tang J, Aljerf L. Dioxin emission prediction based on improved deep forest regression for municipal solid waste incineration process. Chemosphere, 2022, 294: Article No. 133716 doi: 10.1016/j.chemosphere.2022.133716 [10] Poggio T, Vetter T. Recognition and Structure from One 2D Model View: Observations on Prototypes, Object Classes and Symmetries, C.BI.P. Paper No. 69, Massachusetts Institute of Technology, United States, 1992. [11] Liu X F, Sun Q Q, Meng Y, Fu M, Bourennane S. Hyperspectral image classification based on parameter-optimized 3D-CNNs combined with transfer learning and virtual samples. Remote Sensing, 2018, 10(9): Article No. 1425 doi: 10.3390/rs10091425 [12] Li L J, Peng Y L, Qiu G Y, Sun Z G, Liu S G. A survey of virtual sample generation technology for face recognition. Artificial Intelligence Review, 2018, 50(1): 1−20 doi: 10.1007/s10462-016-9537-z [13] Zhao X C, Lv W M. Reliability evaluation of complex equipment based on virtual samples and performance degradation. In: Proceedings of the International Conference on Electronics and Electrical Engineering Technology. Tianjin, China: ACM, 2018. 112−117 [14] Niyogi P, Girosi F, Poggio T. Incorporating prior information in machine learning by creating virtual examples. Proceedings of the IEEE, 1998, 86(11): 2196−2209 doi: 10.1109/5.726787 [15] 王丹丹, 汤健, 夏恒, 乔俊飞. 基于多目标PSO混合优化的虚拟样本生成. 自动化学报, DOI: 10.16383/j.aas.c211091Wang Dan-Dan, Tang Jian, Xia Heng, Qiao Jun-Fei. Virtual sample generation method based on hybrid optimization with multi-objective PSO. Acta Automatica Sinica, DOI: 10.16383/j.aas.c211091 [16] Kingma D P, Welling M. Auto-encoding variational Bayes. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, Canada: ICLR, 2014. [17] Zhang L, Zhang H, Cai G W. The multiclass fault diagnosis of wind turbine bearing based on multisource signal fusion and deep learning generative model. IEEE Transactions on Instrumentation and Measurement, 2022, 71: Article No. 3514212 [18] Wang X, Liu H. Data supplement for a soft sensor using a new generative model based on a variational autoencoder and wasserstein GAN. Journal of Process Control, 2020, 85: 91−99 doi: 10.1016/j.jprocont.2019.11.004 [19] Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial networks. Communications of the ACM, 2020, 63(11): 139−144 doi: 10.1145/3422622 [20] Zhu Q X, Hou K R, Chen Z S, Gao Z S, Xu Y, He Y L. Novel virtual sample generation using conditional GAN for developing soft sensor with small data. Engineering Applications of Artificial Intelligence, 2021, 106: Article No. 104497 doi: 10.1016/j.engappai.2021.104497 [21] 李彦瑞, 杨春节, 张瀚文, 李俊方. 流程工业数字孪生关键技术探讨. 自动化学报, 2021, 47(3): 501−514Li Yan-Rui, Yang Chun-Jie, Zhang Han-Wen, Li Jun-Fang. Discussion on key technologies of digital twin in process industry. Acta Automatica Sinica, 2021, 47(3): 501−514 [22] 杨林瑶, 陈思远, 王晓, 张俊, 王成红. 数字孪生与平行系统: 发展现状、对比及展望. 自动化学报, 2019, 45(11): 2001−2031Yang Lin-Yao, Chen Si-Yuan, Wang Xiao, Zhang Jun, Wang Cheng-Hong. Digital twins and parallel systems: State of the art, comparisons and prospect. Acta Automatica Sinica, 2019, 45(11): 2001−2031 [23] Lee L H, Braud T, Zhou P Y, Wang L, Xu D L, Lin Z J, et al. All one needs to know about metaverse: A complete survey on technological singularity, virtual ecosystem, and research agenda. arXiv: 2110.05352, 2021. [24] Ning H S, Wang H, Lin Y J, Wang W X, Dhelim S, Farha F, et al. A survey on metaverse: The state-of-the-art, technologies, applications, and challenges. arXiv: 2111.09673, 2021. [25] Yao L, Ge Z Q. Industrial big data modeling and monitoring framework for plant-wide processes. IEEE Transactions on Industrial Informatics, 2021, 17(9): 6399−6408 doi: 10.1109/TII.2020.3010562 [26] Ma X, Si Y B, Qin Y H, Wang Y Q. Fault detection for dynamic processes based on recursive innovational component statistical analysis. IEEE Transactions on Automation Science and Engineering, 2023, 20(1): 310−319 doi: 10.1109/TASE.2022.3149591 [27] Ma X, Wu D H, Gao S X, Hou T Z, Wang Y Q. Autocorrelation feature analysis for dynamic process monitoring of thermal power plants. IEEE Transactions on Cybernetics, 2023, 53(8): 5387−5399 doi: 10.1109/TCYB.2022.3228861 [28] 夏恒, 汤健, 崔璨麟, 乔俊飞. 基于宽度混合森林回归的城市固废焚烧过程二噁英排放软测量. 自动化学报, 2023, 49(2): 343−365Xia Heng, Tang Jian, Cui Can-Lin, Qiao Jun-Fei. Soft sensing method of dioxin emission in municipal solid waste incineration process based on broad hybrid forest regression. Acta Automatica Sinica, 2023, 49(2): 343−365 [29] Cui M L, Wang Y Q, Lin X S, Zhong M Y. Fault diagnosis of rolling bearings based on an improved stack autoencoder and support vector machine. IEEE Sensors Journal, 2021, 21(4): 4927−4937 doi: 10.1109/JSEN.2020.3030910 [30] Md Nor N, Che Hassan C R, Hussain M A. A review of data-driven fault detection and diagnosis methods: Applications in chemical process systems. Reviews in Chemical Engineering, 2020, 36(4): 513−553 doi: 10.1515/revce-2017-0069 [31] Raudys Š. Trainable fusion rules. II. Small sample-size effects. Neural Networks, 2006, 19(10): 1517−1527 doi: 10.1016/j.neunet.2006.01.019 [32] Tang J, Jia M Y, Liu Z, Chai T Y, Yu W. Modeling high dimensional frequency spectral data based on virtual sample generation technique. In: Proceedings of the IEEE International Conference on Information and Automation. Lijiang, China: IEEE, 2015. 1090−1095 [33] Zhong K, Han M, Han B. Data-driven based fault prognosis for industrial systems: A concise overview. IEEE/CAA Journal of Automatica Sinica, 2019, 7(2): 330−345 [34] Ji C, Sun W. A review on data-driven process monitoring methods: Characterization and mining of industrial data. Processes, 2022, 10(2): Article No. 335 doi: 10.3390/pr10020335 [35] Zhu R, Guo Y W, Xue J H. Adjusting the imbalance ratio by the dimensionality of imbalanced data. Pattern Recognition Letters, 2020, 133: 217−223 doi: 10.1016/j.patrec.2020.03.004 [36] Martin-Diaz I, Morinigo-Sotelo D, Duque-Perez O, de J. Romero-Troncoso R. Early fault detection in induction motors using AdaBoost with imbalanced small data and optimized sampling. IEEE Transactions on Industry Applications, 2017, 53(3): 3066−3075 doi: 10.1109/TIA.2016.2618756 [37] Feng L J, Zhao C H. Fault description based attribute transfer for zero-sample industrial fault diagnosis. IEEE Transactions on Industrial Informatics, 2021, 17(3): 1852−1862 doi: 10.1109/TII.2020.2988208 [38] Yu W K, Zhao C H. Broad convolutional neural network based industrial process fault diagnosis with incremental learning capability. IEEE Transactions on Industrial Electronics, 2020, 67(6): 5081−5091 doi: 10.1109/TIE.2019.2931255 [39] Lou Z J, Wang Y Q, Si Y B, Lu S. A novel multivariate statistical process monitoring algorithm: Orthonormal subspace analysis. Automatica, 2022, 138: Article No. 110148 doi: 10.1016/j.automatica.2021.110148 [40] Wang K, Li J, Tsung F. Distribution inference from early-stage stationary data streams by transfer learning. IISE Transactions, 2022, 54(3): 303−320 [41] Zhou X F, Zhai N J, Li S, Shi H B. Time series prediction method of industrial process with limited data based on transfer learning. IEEE Transactions on Industrial Informatics, 2023, 19(5): 6872−6882 doi: 10.1109/TII.2022.3191980 [42] Maschler B, Weyrich M. Deep transfer learning for industrial automation: A review and discussion of new techniques for data-driven machine learning. IEEE Industrial Electronics Magazine, 2021, 15(2): 65−75 doi: 10.1109/MIE.2020.3034884 [43] Yang J, Yu X, Xie Z Q, Zhang J P. A novel virtual sample generation method based on Gaussian distribution. Knowledge-Based Systems, 2011, 24(6): 740−748 doi: 10.1016/j.knosys.2010.12.010 [44] 郭子豪. 面向城市固废焚烧过程的二噁英排放浓度软测量 [硕士学位论文], 北京工业大学, 中国, 2021.Guo Zi-Hao. Soft Sensing of Dioxin Emission Concentration for Municipal Solid Waste Incineration [Master thesis], Beijing University of Technology, China, 2021. [45] Tang J, Xia H, Aljerf L, Wang D D, Ukaogo P O. Prediction of dioxin emission from municipal solid waste incineration based on expansion, interpolation, and selection for small samples. Journal of Environmental Chemical Engineering, 2022, 10(5): Article No. 108314 doi: 10.1016/j.jece.2022.108314 [46] Li D C, Wen I H. A genetic algorithm-based virtual sample generation technique to improve small data set learning. Neurocomputing, 2014, 143: 222−230 doi: 10.1016/j.neucom.2014.06.004 [47] Ren Y F, Liu J H, Zhang H G, Wang J F. TBDA-Net: A task-based bias domain adaptation network under industrial small samples. IEEE Transactions on Industrial Informatics, 2022, 18(9): 6109−6119 doi: 10.1109/TII.2022.3141771 [48] Fu M R, Liu J H, Zhang H G, Lu S X. Multisensor fusion for magnetic flux leakage defect characterization under information incompletion. IEEE Transactions on Industrial Electronics, 2021, 68(5): 4382−4392 doi: 10.1109/TIE.2020.2984444 [49] Chen Z S, Zhu Q X, Xu Y, He Y L, Su Q L, Liu Y C, et al. Integrating virtual sample generation with input-training neural network for solving small sample size problems: Application to purified terephthalic acid solvent system. Soft Computing, 2021, 25(8): 6489−6504 doi: 10.1007/s00500-021-05641-4 [50] 赵春晖, 胡赟昀, 郑嘉乐, 陈军豪. 数据驱动的燃煤发电装备运行工况监控——现状与展望. 自动化学报, 2022, 48(11): 2611−2633Zhao Chun-Hui, Hu Yun-Yun, Zheng Jia-Le, Chen Jun-Hao. Data-driven operating monitoring for coal-fired power generation equipment: The state of the art and challenge. Acta Automatica Sinica, 2022, 48(11): 2611−2633 [51] Zhu J L, Ge Z Q, Song Z H, Gao F R. Review and big data perspectives on robust data mining approaches for industrial process modeling with outliers and missing data. Annual Reviews in Control, 2018, 46: 107−133 doi: 10.1016/j.arcontrol.2018.09.003 [52] Zhu Q X, Zhang X H, He Y L. Novel virtual sample generation based on locally linear embedding for optimizing the small sample problem: Case of soft sensor applications. Industrial & Engineering Chemistry Research, 2020, 59(40): 17977−17986 [53] Zhang X H, Xu Y, He Y L, Zhu Q X. Novel manifold learning based virtual sample generation for optimizing soft sensor with small data. ISA Transactions, 2021, 109: 229−241 doi: 10.1016/j.isatra.2020.10.006 [54] He Y L, Hua Q, Zhu Q X, Lu S. Enhanced virtual sample generation based on manifold features: Applications to developing soft sensor using small data. ISA Transactions, 2022, 126: 398−406 doi: 10.1016/j.isatra.2021.07.033 [55] 陈忠圣, 朱梅玉, 贺彦林, 徐圆, 朱群雄. 基于分位数回归CGAN的虚拟样本生成方法及其过程建模应用. 化工学报, 2021, 72(3): 1529−1538Chen Zhong-Sheng, Zhu Mei-Yu, He Yan-Lin, Xu Yuan, Zhu Qun-Xiong. Quantile regression CGAN based virtual samples generation and its applications to process modeling. CIESC Journal, 2021, 72(3): 1529−1538 [56] 乔俊飞, 郭子豪, 汤健. 基于改进大趋势扩散和隐含层插值的虚拟样本生成方法及应用. 化工学报, 2020, 71(12): 5681−5695Qiao Jun-Fei, Guo Zi-Hao, Tang Jian. Virtual sample generation method based on improved megatrend diffusion and hidden layer interpolation with its application. CIESC Journal, 2020, 71(12): 5681−5695 [57] Zhu Q X, Liu D P, Xu Y, He Y L. Novel space projection interpolation based virtual sample generation for solving the small data problem in developing soft sensor. Chemometrics and Intelligent Laboratory Systems, 2021, 217: Article No. 104425 doi: 10.1016/j.chemolab.2021.104425 [58] Sutojo T, Rustad S, Akrom M, Syukur A, Shidik G F, Dipojono H K. A machine learning approach for corrosion small datasets. Npj Materials Degradation, 2023, 7(1): Article No. 18 doi: 10.1038/s41529-023-00336-7 [59] He Y L, Wang P J, Zhang M Q, Zhu Q X, Xu Y. A novel and effective nonlinear interpolation virtual sample generation method for enhancing energy prediction and analysis on small data problem: A case study of Ethylene industry. Energy, 2018, 147: 418−427 doi: 10.1016/j.energy.2018.01.059 [60] 朱宝, 乔俊飞. 基于AANN特征缩放的虚拟样本生成方法及其过程建模应用. 计算机与应用化学, 2019, 36(4): 304−307Zhu Bao, Qiao Jun-Fei. Novel virtual sample generation based on feature scaling of auto-associative neural network and its applications to process modeling. Computers and Applied Chemistry, 2019, 36(4): 304−307 [61] 汤健, 王丹丹, 郭子豪, 乔俊飞. 基于虚拟样本优化选择的城市固废焚烧过程二噁英排放浓度预测. 北京工业大学学报, 2021, 47(5): 431−443Tang Jian, Wang Dan-Dan, Guo Zi-Hao, Qiao Jun-Fei. Prediction of dioxin emission concentration in the municipal solid waste incineration process based on optimal selection of virtual samples. Journal of Beijing University of Technology, 2021, 47(5): 431−443 [62] 任浩, 屈剑锋, 柴毅, 唐秋, 叶欣. 深度学习在故障诊断领域中的研究现状与挑战. 控制与决策, 2017, 32(8): 1345−1358Ren Hao, Qu Jian-Feng, Chai Yi, Tang Qiu, Ye Xin. Deep learning for fault diagnosis: The state of the art and challenge. Control and Decision, 2017, 32(8): 1345−1358 [63] 胡铭菲, 左信, 刘建伟. 深度生成模型综述. 自动化学报, 2022, 48(1): 40−74Hu Ming-Fei, Zuo Xin, Liu Jian-Wei. Survey on deep generative model. Acta Automatica Sinica, 2022, 48(1): 40−74 [64] Zhu Q X, Xu T X, Xu Y, He Y L. Improved virtual sample generation method using enhanced conditional generative adversarial networks with cycle structures for soft sensors with limited data. Industrial & Engineering Chemistry Research, 2022, 61(1): 530−540 [65] He Y L, Li X Y, Ma J Y, Lu S, Zhu Q X. A novel virtual sample generation method based on a modified conditional wasserstein GAN to address the small sample size problem in soft sensing. Journal of Process Control, 2022, 113: 18−28 doi: 10.1016/j.jprocont.2022.03.008 [66] Pei Z Y, Jiang H K, Li X Q, Zhang J J, Liu S W. Data augmentation for rolling bearing fault diagnosis using an enhanced few-shot wasserstein auto-encoder with meta-learning. Measurement Science and Technology, 2021, 32(8): Article No. 084007 [67] Wang R G, Zhang S H, Chen Z Y, Li W H. Enhanced generative adversarial network for extremely imbalanced fault diagnosis of rotating machine. Measurement, 2021, 180: Article No. 109467 doi: 10.1016/j.measurement.2021.109467 [68] Wang Y R, Sun G D, Jin Q. Imbalanced sample fault diagnosis of rotating machinery using conditional variational auto-encoder generative adversarial network. Applied Soft Computing, 2020, 92: Article No. 106333 doi: 10.1016/j.asoc.2020.106333 [69] Liu S W, Jiang H K, Wu Z H, Li X Q. Data synthesis using deep feature enhanced generative adversarial networks for rolling bearing imbalanced fault diagnosis. Mechanical Systems and Signal Processing, 2022, 163: Article No. 108139 doi: 10.1016/j.ymssp.2021.108139 [70] Chawla N V, Bowyer K W, Hall L O, Kegelmeyer W P. SMOTE: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 2002, 16(1): 321−357 [71] Mathew J, Pang C K, Luo M, Leong W H. Classification of imbalanced data by oversampling in kernel space of support vector machines. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(9): 4065−4076 doi: 10.1109/TNNLS.2017.2751612 [72] Maldonado S, López J, Vairetti C. An alternative SMOTE oversampling strategy for high-dimensional datasets. Applied Soft Computing, 2019, 76: 380−389 doi: 10.1016/j.asoc.2018.12.024 [73] 谢桦, 陈俊星, 赵宇明, 丁庆, 张沛. 基于SMOTE和决策树算法的电力变压器状态评估知识获取方法. 电力自动化设备, 2020, 40(2): 137−142Xie Hua, Chen Jun-Xing, Zhao Yu-Ming, Ding Qing, Zhang Pei. Knowledge acquisition method of power transformer condition assessment based on SMOTE and decision tree algorithm. Electric Power Automation Equipment, 2020, 40(2): 137−142 [74] 刘云鹏, 和家慧, 许自强, 王权, 李哲, 高树国. 基于SVM SMOTE的电力变压器故障样本均衡化方法. 高电压技术, 2020, 46(7): 2522−2529Liu Yun-Peng, He Jia-Hui, Xu Zi-Qiang, Wang Quan, Li Zhe, Gao Shu-Guo. Equalization method of power transformer fault sample based on SVM SMOTE. High Voltage Engineering, 2020, 46(7): 2522−2529 [75] Soltanzadeh P, Hashemzadeh M. RCSMOTE: Range-controlled synthetic minority over-sampling technique for handling the class imbalance problem. Information Sciences, 2021, 542: 92−111 doi: 10.1016/j.ins.2020.07.014 [76] Li D C, Fang Y H. A non-linearly virtual sample generation technique using group discovery and parametric equations of hypersphere. Expert Systems With Applications, 2009, 36(1): 844−851 doi: 10.1016/j.eswa.2007.10.029 [77] 王劭菁, 马文嘉, 王丰华, 崔律, 周行星. 基于虚拟样本生成技术与概率神经网络的接地网故障诊断. 高压电器, 2020, 56(6): 309−316Wang Shao-Jing, Ma Wen-Jia, Wang Feng-Hua, Cui Lü, Zhou Xing-Xing. Fault diagnosis of grounding grid based on virtual sample generation and probabilistic neural network. High Voltage Apparatus, 2020, 56(6): 309−316 [78] Douzas G, Bacao F. Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Systems With Applications, 2018, 91: 464−471 doi: 10.1016/j.eswa.2017.09.030 [79] 黄南天, 杨学航, 蔡国伟, 宋星, 陈庆珠, 赵文广. 采用非平衡小样本数据的风机主轴承故障深度对抗诊断. 中国电机工程学报, 2020, 40(2): 563−573Huang Nan-Tian, Yang Xue-Hang, Cai Guo-Wei, Song Xing, Chen Qing-Zhu, Zhao Wen-Guang. A deep adversarial diagnosis method for wind turbine main bearing fault with imbalanced small sample scenarios. Proceedings of the CSEE, 2020, 40(2): 563−573 [80] Li Z X, Zheng T S, Wang Y, Cao Z, Guo Z Q, Fu H Y. A novel method for imbalanced fault diagnosis of rotating machinery based on generative adversarial networks. IEEE Transactions on Instrumentation and Measurement, 2020, 70: Article No. 3500417 [81] Dixit S, Verma N K, Ghosh A K. Intelligent fault diagnosis of rotary machines: Conditional auxiliary classifier GAN coupled with meta learning using limited data. IEEE Transactions on Instrumentation and Measurement, 2021, 70: Article No. 3517811 [82] Yang G, Zhong Y, Yang L, Tao H, Li J Y, Du R X. Fault diagnosis of harmonic drive with imbalanced data using generative adversarial network. IEEE Transactions on Instrumentation and Measurement, 2021, 70: Article No. 3519911 [83] Zareapoor M, Shamsolmoali P, Yang J. Oversampling adversarial network for class-imbalanced fault diagnosis. Mechanical Systems and Signal Processing, 2021, 149: Article No. 107175 doi: 10.1016/j.ymssp.2020.107175 [84] Li Y B, Zou W T, Jiang L. Fault diagnosis of rotating machinery based on combination of wasserstein generative adversarial networks and long short term memory fully convolutional network. Measurement, 2022, 191: Article No. 110826 doi: 10.1016/j.measurement.2022.110826 [85] Li M L, Zou D C, Luo S Y, Zhou Q, Cao L C, Liu H P. A new generative adversarial network based imbalanced fault diagnosis method. Measurement, 2022, 194: Article No. 111045 doi: 10.1016/j.measurement.2022.111045 [86] 李东东, 刘宇航, 赵阳, 赵耀. 基于改进生成对抗网络的风机行星齿轮箱故障诊断方法. 中国电机工程学报, 2021, 41(21): 7496−7506Li Dong-Dong, Liu Yu-Hang, Zhao Yang, Zhao Yao. Fault diagnosis method of wind turbine planetary gearbox based on improved generative adversarial network. Proceedings of the CSEE, 2021, 41(21): 7496−7506 [87] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504−507 doi: 10.1126/science.1127647 [88] Kingma D P, Welling M. Auto-encoding variational bayes. arXiv: 1312.6114, 2013. [89] 戴俊, 王俊, 朱忠奎, 沈长青, 黄伟国. 基于生成对抗网络和自动编码器的机械系统异常检测. 仪器仪表学报, 2019, 40(9): 16−26Dai Jun, Wang Jun, Zhu Zhong-Kui, Shen Chang-Qing, Huang Wei-Guo. Anomaly detection of mechanical systems based on generative adversarial network and auto-encoder. Chinese Journal of Scientific Instrument, 2019, 40(9): 16−26 [90] Liu S W, Jiang H K, Wu Z H, Li X Q. Rolling bearing fault diagnosis using variational autoencoding generative adversarial networks with deep regret analysis. Measurement, 2021, 168: Article No. 108371 doi: 10.1016/j.measurement.2020.108371 [91] Wang A Q, Qian Z, Pei Y, Jing B. A de-ambiguous condition monitoring scheme for wind turbines using least squares generative adversarial networks. Renewable Energy, 2022, 185: 267−279 doi: 10.1016/j.renene.2021.12.049 [92] Liu Y P, Jiang H K, Wang Y F, Wu Z H, Liu S W. A conditional variational autoencoding generative adversarial networks with self-modulation for rolling bearing fault diagnosis. Measurement, 2022, 192: Article No. 110888 doi: 10.1016/j.measurement.2022.110888 [93] Rathore M S, Harsha S P. Framework for imbalanced fault diagnosis of rolling bearing using autoencoding generative adversarial learning. Journal of the Brazilian Society of Mechanical Sciences and Engineering, 2023, 45(1): Article No. 39 doi: 10.1007/s40430-022-03955-4 [94] Huang C F. Principle of information diffusion. Fuzzy Sets and Systems, 1997, 91(1): 69−90 doi: 10.1016/S0165-0114(96)00257-6 [95] Huang C F, Moraga C. A diffusion-neural-network for learning from small samples. International Journal of Approximate Reasoning, 2004, 35(2): 137−161 doi: 10.1016/j.ijar.2003.06.001 [96] Li D C, Wu C S, Tsai T I, Lina Y S. Using mega-trend-diffusion and artificial samples in small data set learning for early flexible manufacturing system scheduling knowledge. Computers & Operations Research, 2007, 34(4): 966−982 [97] Lin Y S, Li D C. The generalized-trend-diffusion modeling algorithm for small data sets in the early stages of manufacturing systems. European Journal of Operational Research, 2010, 207(1): 121−130 doi: 10.1016/j.ejor.2010.03.026 [98] Li D C, Chen C C, Chang C J, Lin W K. A tree-based-trend-diffusion prediction procedure for small sample sets in the early stages of manufacturing systems. Expert Systems With Applications, 2012, 39(1): 1575−1581 doi: 10.1016/j.eswa.2011.08.071 [99] Rahimi M R, Karimi H, Yousefi F. Prediction of carbon dioxide diffusivity in biodegradable polymers using diffusion neural network. Heat and Mass Transfer, 2012, 48(8): 1357−1365 doi: 10.1007/s00231-012-0982-1 [100] 朱宝, 陈忠圣, 余乐安. 一种新颖的小样本整体趋势扩散技术. 化工学报, 2016, 67(3): 820−826Zhu Bao, Chen Zhong-Sheng, Yu Le-An. A novel mega-trend-diffusion for small sample. CIESC Journal, 2016, 67(3): 820−826 [101] Sivakumar J, Ramamurthy K, Radhakrishnan M, Won D. Synthetic sampling from small datasets: A modified mega-trend diffusion approach using k-nearest neighbors. Knowledge-Based Systems, 2022, 236: Article No. 107687 doi: 10.1016/j.knosys.2021.107687 [102] Khamis N, Selamat H, Ismail F S. Improved optimization parameters prediction using the modified mega trend diffusion function for a small dataset problem. Knowledge and Information Systems, 2022, 64(11): 3129−3149 doi: 10.1007/s10115-022-01727-z [103] 高克铉, 李志刚, 徐长明, 王巧云, 李博. 混合整体趋势扩散的虚拟样本构建及其血液光谱分析应用. 仪器仪表学报, 2019, 40(8): 167−175Gao Ke-Xuan, Li Zhi-Gang, Xu Chang-Ming, Wang Qiao-Yun, Li Bo. Virtual sample establishment of Hybrid-MTD and its application in blood spectrum analysis. Chinese Journal of Scientific Instrument, 2019, 40(8): 167−175 [104] Chen Z S, Zhu B, He Y L, Yu L A. A PSO based virtual sample generation method for small sample sets: Applications to regression datasets. Engineering Applications of Artificial Intelligence, 2016, 59: 236−243 [105] Pawlak Z. Rough sets. International Journal of Computer & Information Sciences, 1982, 11(5): 341−356 [106] Hu Q W, Chakhar S, Siraj S, Labib A. Spare parts classification in industrial manufacturing using the dominance-based rough set approach. European Journal of Operational Research, 2017, 262(3): 1136−1163 doi: 10.1016/j.ejor.2017.04.040 [107] Chen W C, Chang N B, Chen J C. Rough set-based hybrid fuzzy-neural controller design for industrial wastewater treatment. Water Research, 2003, 37(1): 95−107 doi: 10.1016/S0043-1354(02)00255-5 [108] Zhou P, Lu S W, Chai T Y. Data-driven soft-sensor modeling for product quality estimation using case-based reasoning and fuzzy-similarity rough sets. IEEE Transactions on Automation Science and Engineering, 2014, 11(4): 992−1003 doi: 10.1109/TASE.2013.2288279 [109] Li D C, Lin Y S. Using virtual sample generation to build up management knowledge in the early manufacturing stages. European Journal of Operational Research, 2006, 175(1): 413−434 doi: 10.1016/j.ejor.2005.05.005 [110] Li D C, Lin Y S. Learning management knowledge for manufacturing systems in the early stages using time series data. European Journal of Operational Research, 2008, 184(1): 169−184 doi: 10.1016/j.ejor.2006.10.008 [111] Li D C, Wen I H, Chen W C. A novel data transformation model for small data-set learning. International Journal of Production Research, 2016, 54(24): 7453−7463 doi: 10.1080/00207543.2016.1192301 [112] Li D C, Lin L S. A new approach to assess product lifetime performance for small data sets. European Journal of Operational Research, 2013, 230(2): 290−298 doi: 10.1016/j.ejor.2013.04.016 [113] Li D C, Lin L S, Chen C C, Yu W H. Using virtual samples to improve learning performance for small datasets with multimodal distributions. Soft Computing, 2019, 23(22): 11883−11900 doi: 10.1007/s00500-018-03744-z [114] Liu S G, Zhang J, Xiang Y, Zhou W L. Fuzzy-based information decomposition for incomplete and imbalanced data learning. IEEE Transactions on Fuzzy Systems, 2017, 25(6): 1476−1490 doi: 10.1109/TFUZZ.2017.2754998 [115] Ramentol E, Caballero Y, Bello R, Herrera F. SMOTE-RSB*: A hybrid preprocessing approach based on oversampling and undersampling for high imbalanced data-sets using SMOTE and rough sets theory. Knowledge and Information Systems, 2012, 33(2): 245−265 doi: 10.1007/s10115-011-0465-6 [116] 胡峰, 王蕾, 周耀. 基于三支决策的不平衡数据过采样方法. 电子学报, 2018, 46(1): 135−144Hu Feng, Wang Lei, Zhou Yao. An oversampling method for imbalance data based on three-way decision model. Acta Electronica Sinica, 2018, 46(1): 135−144 [117] Shen L J, Qian Q. A virtual sample generation algorithm supporting machine learning with a small-sample dataset: A case study for rubber materials. Computational Materials Science, 2022, 211: Article No. 111475 doi: 10.1016/j.commatsci.2022.111475 [118] Song H, Choi K K, Lee I, Zhao L, Lamb D. Adaptive virtual support vector machine for reliability analysis of high-dimensional problems. Structural and Multidisciplinary Optimization, 2013, 47(4): 479−491 doi: 10.1007/s00158-012-0857-6 [119] Li D C, Lin Y S. Generating information for small data sets with a multi-modal distribution. Decision Support Systems, 2014, 66: 71−81 doi: 10.1016/j.dss.2014.06.004 [120] Nagarajan H P N, Mokhtarian H, Jafarian H, Dimassi S, Bakrani-Balani S, Hamedi A, et al. Knowledge-based design of artificial neural network topology for additive manufacturing process modeling: A new approach and case study for fused deposition modeling. Journal of Mechanical Design, 2019, 141(2): Article No. 021705 [121] Link P, Poursanidis M, Schmid J, Zache R, von Kurnatowski M, Teicher U, et al. Capturing and incorporating expert knowledge into machine learning models for quality prediction in manufacturing. Journal of Intelligent Manufacturing, 2022, 33(7): 2129−2142 doi: 10.1007/s10845-022-01975-4 [122] Chen J Y, Geng Y X, Chen Z, Horrocks I, Pan J Z, Chen H J. Knowledge-aware zero-shot learning: Survey and perspective. In: Proceedings of the 30th International Joint Conference on Artificial Intelligence. Montreal, Canada: ijcai.org, 2021. 4366−4373 [123] Zhuo Y, Ge Z Q. Auxiliary information-guided industrial data augmentation for any-shot fault learning and diagnosis. IEEE Transactions on Industrial Informatics, 2021, 17(11): 7535−7545 doi: 10.1109/TII.2021.3053106 [124] Rethmeier N, Saxena V K, Augenstein I. TX-Ray: Quantifying and explaining model-knowledge transfer in (Un-)supervised NLP. In: Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI). AUAI Press, 2020. 440−449 [125] Yao Z J, Zhao C H. FedTMI: Knowledge aided federated transfer learning for industrial missing data imputation. Journal of Process Control, 2022, 117: 206−215 doi: 10.1016/j.jprocont.2022.08.004 [126] Feng L J, Zhao C H, Li X. Bias-eliminated semantic refinement for any-shot learning. IEEE Transactions on Image Processing, 2022, 31: 2229−2244 doi: 10.1109/TIP.2022.3152631 [127] Zhu Q X, Chen Z S, Zhang X H, Rajabifard A, Xu Y, Chen Y Q. Dealing with small sample size problems in process industry using virtual sample generation: A Kriging-based approach. Soft Computing, 2020, 24(9): 6889−6902 doi: 10.1007/s00500-019-04326-3 [128] Gong H F, Chen Z S, Zhu Q X, He Y L. A Monte Carlo and PSO based virtual sample generation method for enhancing the energy prediction and energy optimization on small data problem: An empirical study of petrochemical industries. Applied Energy, 2017, 197: 405−415 doi: 10.1016/j.apenergy.2017.04.007 [129] Sang K H, Yin X Y, Zhang F C. Machine learning seismic reservoir prediction method based on virtual sample generation. Petroleum Science, 2021, 18(6): 1662−1674 doi: 10.1016/j.petsci.2021.09.034 [130] Li D C, Shi Q S, Li M D. Using an attribute conversion approach for sample generation to learn small data with highly uncertain features. International Journal of Production Research, 2018, 56(14): 4954−4967 doi: 10.1080/00207543.2018.1444813 [131] 林越, 刘廷章, 王哲河. 具有两类上限条件的虚拟样本生成数量优化. 广西师范大学学报(自然科学版), 2019, 37(1): 142−148Lin Yue, Liu Ting-Zhang, Wang Zhe-He. Quantity optimization of virtual sample generation with two kinds of upper bound conditions. Journal of Guangxi Normal University (Natural Science Edition), 2019, 37(1): 142−148 [132] 杨青, 叶义霞, 吴东升, 刘伊鹏. 基于ACGAN-DSAN的变工况滚动轴承故障诊断. 轴承, 2023, (2): 97−104Yang Qing, Ye Yi-Xia, Wu Dong-Sheng, Liu Yi-Peng. Fault diagnosis for rolling bearings under variable working conditions based on ACGAN-DSAN. Bearing, 2023, (2): 97−104 [133] Li W X, Shang Z W, Gao M S, Qian S Q, Zhang B R, Zhang J. A novel deep autoencoder and hyperparametric adaptive learning for imbalance intelligent fault diagnosis of rotating machinery. Engineering Applications of Artificial Intelligence, 2021, 102: Article No. 104279 doi: 10.1016/j.engappai.2021.104279 [134] Zhang X S, Zhuang Y, Wang W, Pedrycz W. Transfer boosting with synthetic instances for class imbalanced object recognition. IEEE Transactions on Cybernetics, 2018, 48(1): 357−370 doi: 10.1109/TCYB.2016.2636370 [135] Liu J H, Ren Y F. A general transfer framework based on industrial process fault diagnosis under small samples. IEEE Transactions on Industrial Informatics, 2021, 17(9): 6073−6083 doi: 10.1109/TII.2020.3036159 [136] 贾欣, 高欣, 赵兵, 黄子健, 叶平, 黄旭. 基于样本迁移和交叠区边界增强的智能电表故障分类方法. 电网技术, 2023, 47(6): 2566−2582Jia Xin, Gao Xin, Zhao Bing, Huang Zi-Jian, Ye Ping, Huang Xu. Intelligent electric meter fault classification based on sample migration and boundary enhancement in overlapping areas. Power System Technology, 2023, 47(6): 2566−2582 [137] 廖一帆, 武志刚. 基于迁移学习与Wasserstein生成对抗网络的静态电压稳定临界样本生成方法. 电网技术, 2021, 45(9): 3722−3728Liao Yi-Fan, Wu Zhi-Gang. Critical sample generation method for static voltage stability based on transfer learning and wasserstein generative adversarial network. Power System Technology, 2021, 45(9): 3722−3728 [138] 兰健, 郭庆来, 周艳真, 孙宏斌. 基于生成对抗网络和模型迁移的电力系统典型运行方式样本生成. 中国电机工程学报, 2022, 42(8): 2889−2899Lan Jian, Guo Qing-Lai, Zhou Yan-Zhen, Sun Hong-Bin. Generation of power system typical operation mode samples: A generation adversarial network and model-based transfer learning approach. Proceedings of the CSEE, 2022, 42(8): 2889−2899 [139] Zhang L, Wei H, Lyu Z L, Wei H B, Li P J. A small-sample faulty line detection method based on generative adversarial networks. Expert Systems With Applications, 2020, 169: Article No. 114378 [140] Lee D, Kim K. An efficient method to determine sample size in oversampling based on classification complexity for imbalanced data. Expert Systems With Applications, 2021, 184: Article No. 115442 doi: 10.1016/j.eswa.2021.115442 [141] Lin L S, Li D C, Chen H Y, Chiang Y C. An attribute extending method to improve learning performance for small datasets. Neurocomputing, 2018, 286: 75−87 doi: 10.1016/j.neucom.2018.01.071 [142] 陆荣秀, 赖路璐, 杨辉, 朱建勇. 基于混合虚拟样本生成的铈镨/钕组分含量预测. 控制与决策, 2023, 38(4): 1129−1136Lu Rong-Xiu, Lai Lu-Lu, Yang Hui, Zhu Jian-Yong. Prediction method of CePr/Nd component content based on hybrid virtual sample. Control and Decision, 2023, 38(4): 1129−1136 [143] Kang G Q, Wu L F, Guan Y, Peng Z. A virtual sample generation method based on differential evolution algorithm for overall trend of small sample data: Used for lithium-ion battery capacity degradation data. IEEE Access, 2019, 7: 123255−123267 doi: 10.1109/ACCESS.2019.2937550 [144] Napoli G, Xibilia M G. Soft sensor design for a topping process in the case of small datasets. Computers & Chemical Engineering, 2011, 35(11): 2447−2456 [145] 李艳霞, 柴毅, 胡友强, 尹宏鹏. 不平衡数据分类方法综述. 控制与决策, 2019, 34(4): 673−688Li Yan-Xia, Chai Yi, Hu You-Qiang, Yin Hong-Peng. Review of imbalanced data classification methods. Control and Decision, 2019, 34(4): 673−688 [146] 马波, 蔡伟东, 赵大力. 基于GAN样本生成技术的智能诊断方法. 振动与冲击, 2020, 39(18): 153−160Ma Bo, Cai Wei-Dong, Zhao Da-Li. Intelligent diagnosis method based on GAN sample generation technology. Journal of Vibration and Shock, 2020, 39(18): 153−160 [147] Li X Q, Jiang H K, Liu S W, Zhang J J, Xu J. A unified framework incorporating predictive generative denoising autoencoder and deep coral network for rolling bearing fault diagnosis with unbalanced data. Measurement, 2021, 178: Article No. 109345 doi: 10.1016/j.measurement.2021.109345 [148] Pham M T, Kim J M, Kim C H. Rolling bearing fault diagnosis based on improved GAN and 2-D representation of acoustic emission signals. IEEE Access, 2022, 10: 78056−78069 doi: 10.1109/ACCESS.2022.3193244 [149] 杨光友, 刘浪, 习晨博. 自适应辅助分类器生成式对抗网络样本生成模型及轴承故障诊断. 中国机械工程, 2022, 33(13): 1613−1621Yang Guang-You, Liu Lang, Xi Chen-Bo. Bearing fault diagnosis based on SA-ACGAN data generation model. China Mechanical Engineering, 2022, 33(13): 1613−1621 [150] Pan T Y, Chen J L, Xie J S, Zhou Z T, He S L. Deep feature generating network: A new method for intelligent fault detection of mechanical systems under class imbalance. IEEE Transactions on Industrial Informatics, 2021, 17(9): 6282−6293 doi: 10.1109/TII.2020.3030967 [151] 刘云鹏, 许自强, 和家慧, 王权, 高树国, 赵军. 基于条件式Wasserstein生成对抗网络的电力变压器故障样本增强技术. 电网技术, 2020, 44(4): 1505−1513Liu Yun-Peng, Xu Zi-Qiang, He Jia-Hui, Wang Quan, Gao Shu-Guo, Zhao Jun. Data augmentation method for power transformer fault diagnosis based on conditional Wasserstein generative adversarial network. Power System Technology, 2020, 44(4): 1505−1513 [152] Liu J H, Qu F M, Hong X W, Zhang H G. A small-sample wind turbine fault detection method with synthetic fault data using generative adversarial nets. IEEE Transactions on Industrial Informatics, 2019, 15(7): 3877−3888 doi: 10.1109/TII.2018.2885365 [153] Han T, Liu C, Yang W G, Jiang D X. A novel adversarial learning framework in deep convolutional neural network for intelligent diagnosis of mechanical faults. Knowledge-Based Systems, 2019, 165: 474−487 doi: 10.1016/j.knosys.2018.12.019 [154] Gao S Y, Wang X R, Miao X H, Su C W, Li Y B. ASM1D-GAN: An intelligent fault diagnosis method based on assembled 1D convolutional neural network and generative adversarial networks. Journal of Signal Processing Systems, 2019, 91(10): 1237−1247 doi: 10.1007/s11265-019-01463-8 [155] Olesen J F, Shaker H R. Predictive maintenance within combined heat and power plants based on a novel virtual sample generation method. Energy Conversion and Management, 2021, 227: Article No. 113621 doi: 10.1016/j.enconman.2020.113621 [156] 吴晓东, 熊伟丽. 采用编码输入的生成对抗网络故障检测方法及应用. 智能系统学报, 2022, 17(3): 496−505Wu Xiao-Dong, Xiong Wei-Li. Fault detection method and its application using GAN with an encoded input. CAAI Transactions on Intelligent Systems, 2022, 17(3): 496−505 [157] Xu Y, Zhao Y, Ke W, He Y L, Zhu Q X, Zhang Y, et al. A multi-fault diagnosis method based on improved SMOTE for class-imbalanced data. The Canadian Journal of Chemical Engineering, 2023, 101(4): 1986−2001 doi: 10.1002/cjce.24610 [158] Karras T, Aittala M, Hellsten J, Laine S, Lehtinen J, Aila T. Training generative adversarial networks with limited data. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. 12104−12114 [159] 庄福振, 罗平, 何清, 史忠植. 迁移学习研究进展. 软件学报, 2015, 26(1): 26−39Zhuang Fu-Zhen, Luo Ping, He Qing, Shi Zhong-Zhi. Survey on transfer learning research. Journal of Software, 2015, 26(1): 26−39 [160] 庞景月, 赵光权. 数字孪生驱动多算法自适应选择的空间电源系统故障检测. 电子测量与仪器学报, 2022, 36(6): 91−99Pang Jing-Yue, Zhao Guang-Quan. Digital twin-driven multi-algorithms adaptive selection for fault detection of space power system. Journal of Electronic Measurement and Instrumentation, 2022, 36(6): 91−99 [161] 张旭辉, 鞠佳杉, 杨文娟, 吕欣媛. 基于数字孪生的复杂矿用设备预测性维护系统. 工程设计学报, 2022, 29(5): 643−650Zhang Xu-Hui, Ju Jia-Shan, Yang Wen-Juan, Lv Xin-Yuan. Predictive maintenance system for complex mining equipment based on digital twin. Chinese Journal of Engineering Design, 2022, 29(5): 643−650 [162] 孙子健, 汤健, 乔俊飞. 联合样本输出与特征空间的半监督概念漂移检测法及其应用. 自动化学报, 2022, 48(5): 1259−1272Sun Zi-Jian, Tang Jian, Qiao Jun-Fei. Semi-supervised concept drift detection method by combining sample output space and feature space with its application. Acta Automatica Sinica, 2022, 48(5): 1259−1272 [163] 徐雯, 汤健, 夏恒, 乔俊飞. 基于Bagging半监督深度森林回归的二噁英排放浓度软测量. 仪器仪表学报, 2022, 43(6): 251−259Xu Wen, Tang Jian, Xia Heng, Qiao Jun-Fei. Soft sensor of dioxin emission concentration based on Bagging semi-supervised deep forest regression. Chinese Journal of Scientific Instrument, 2022, 43(6): 251−259 [164] 乔俊飞, 孙子健, 汤健. 面向工业过程软测量建模的概念漂移检测综述. 控制理论与应用, 2021, 38(8): 1159−1174 doi: 10.7641/CTA.2021.00334Qiao Jun-Fei, Sun Zi-Jian, Tang Jian. Overview of concept drift detection for industrial process soft sensor modeling. Control Theory & Applications, 2021, 38(8): 1159−1174 doi: 10.7641/CTA.2021.00334 -

 下载:
下载:

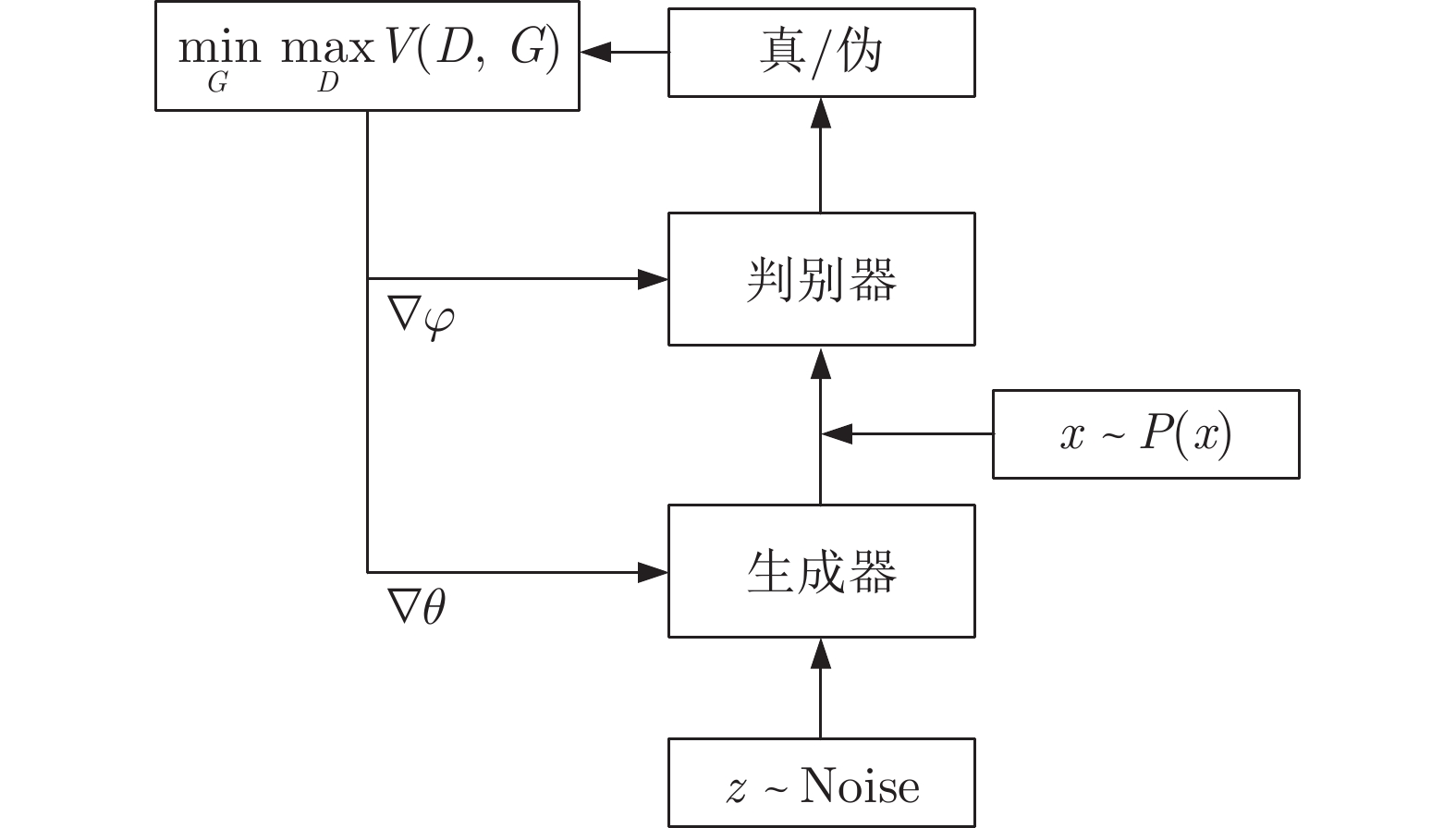
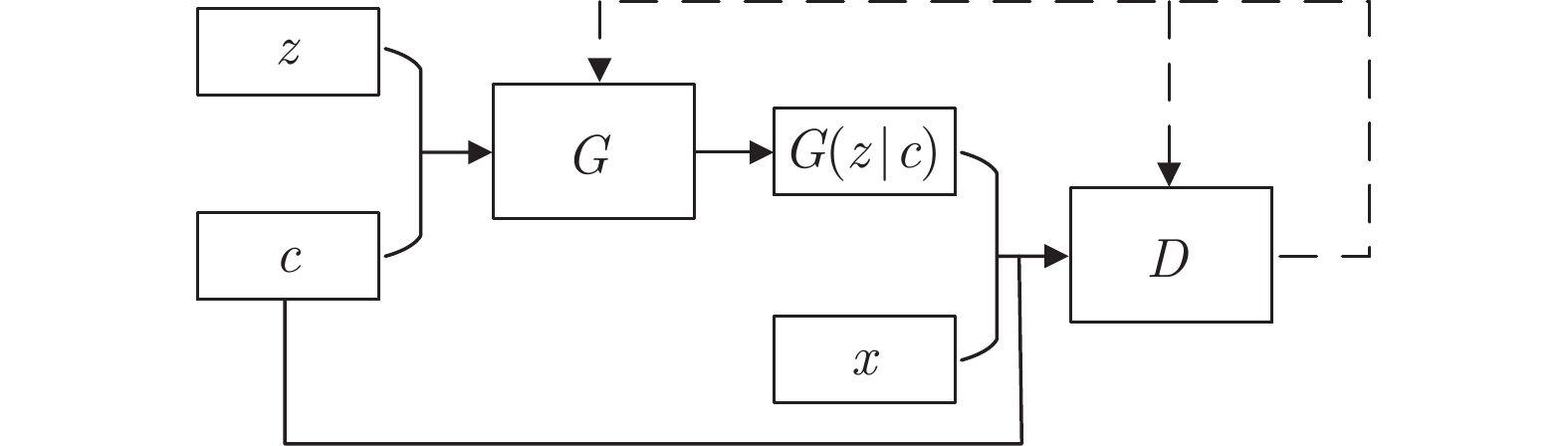
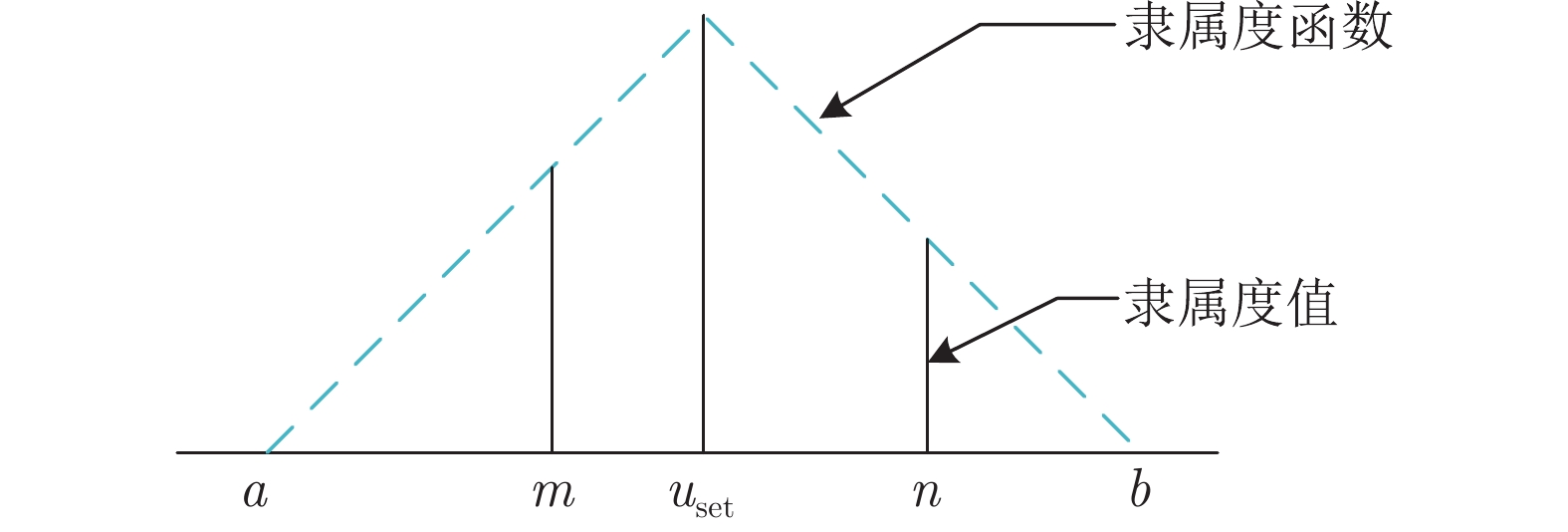
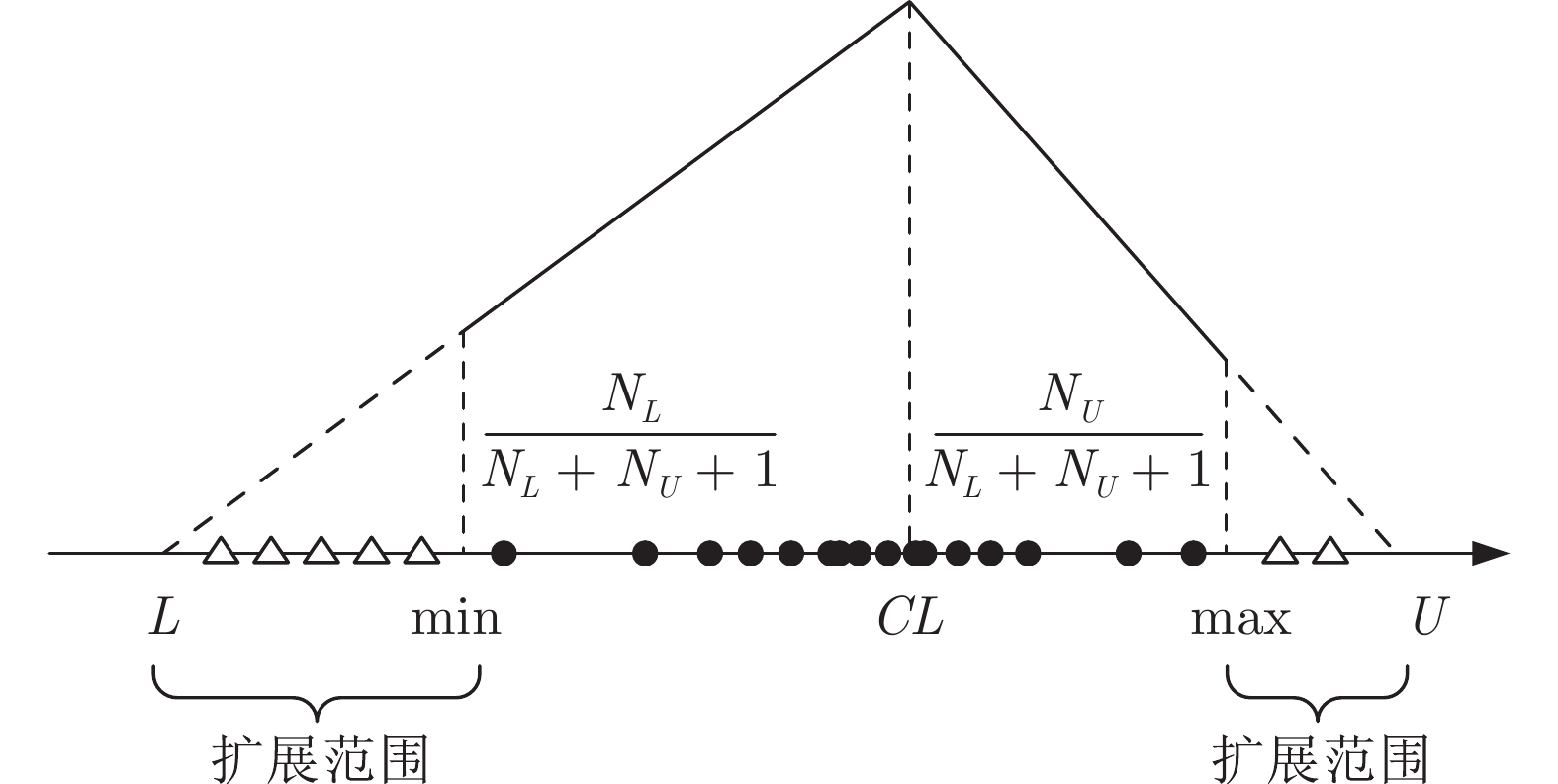

计量
- 文章访问数: 2602
- HTML全文浏览量: 1513
- PDF下载量: 528
- 被引次数: 0
