

Key Frame Extraction Method of Blast Furnace Burden Surface Video Based on State Recognition
-
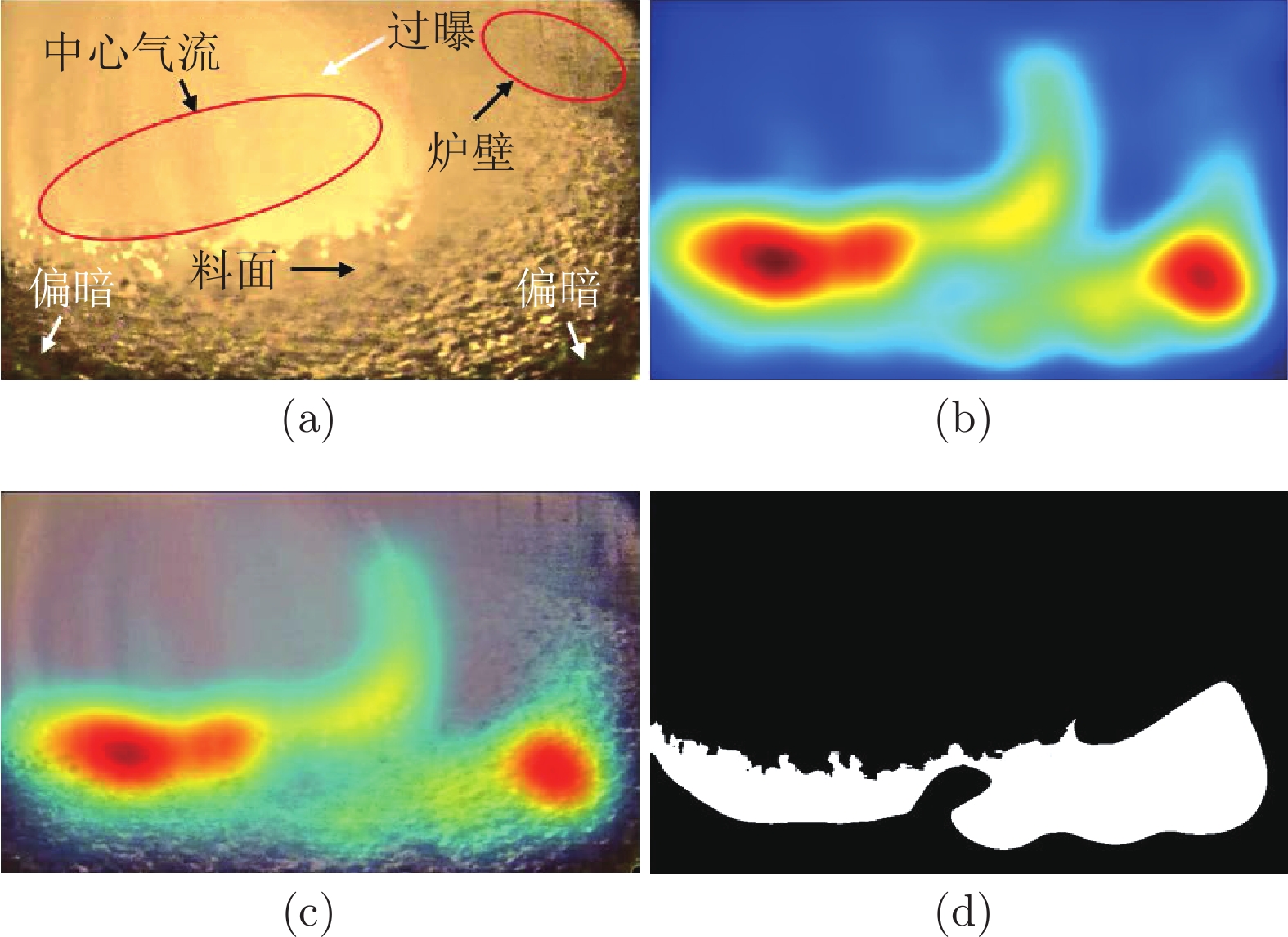
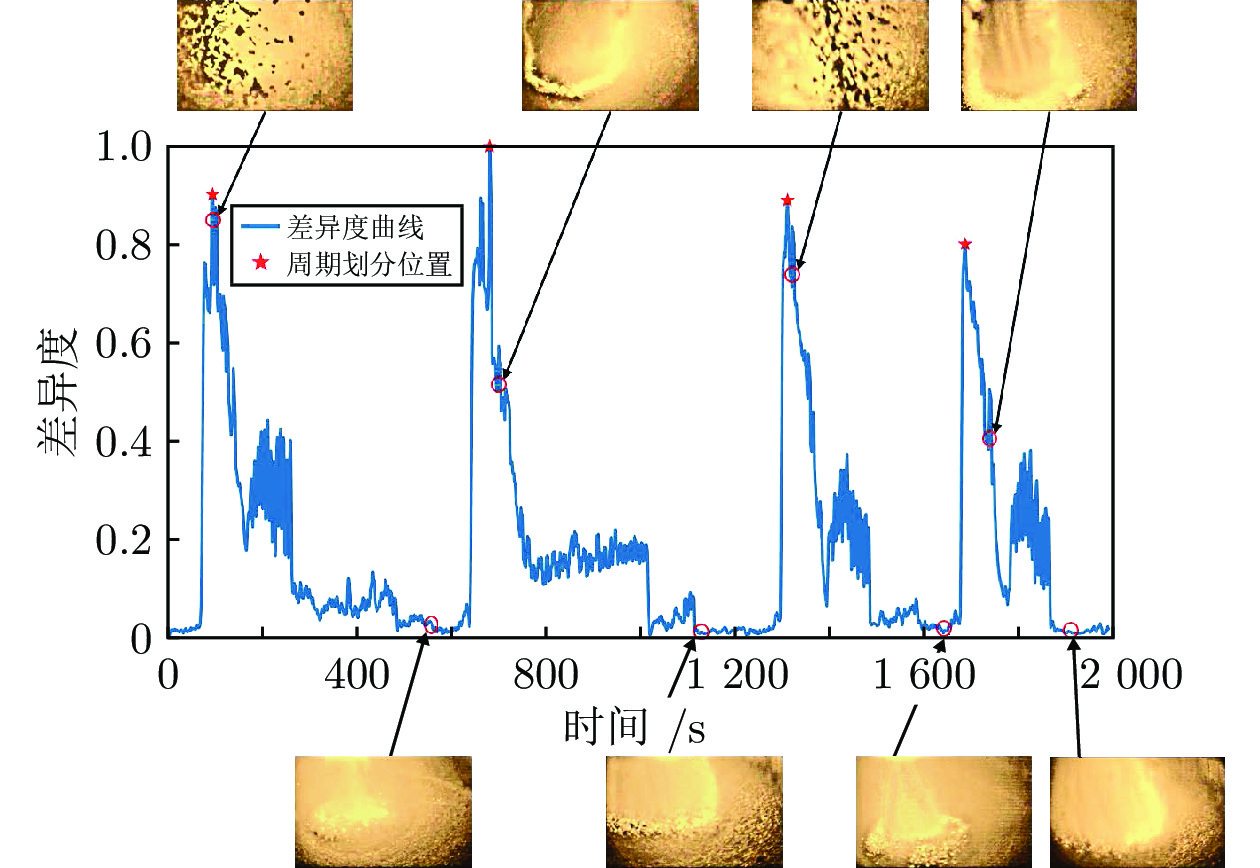
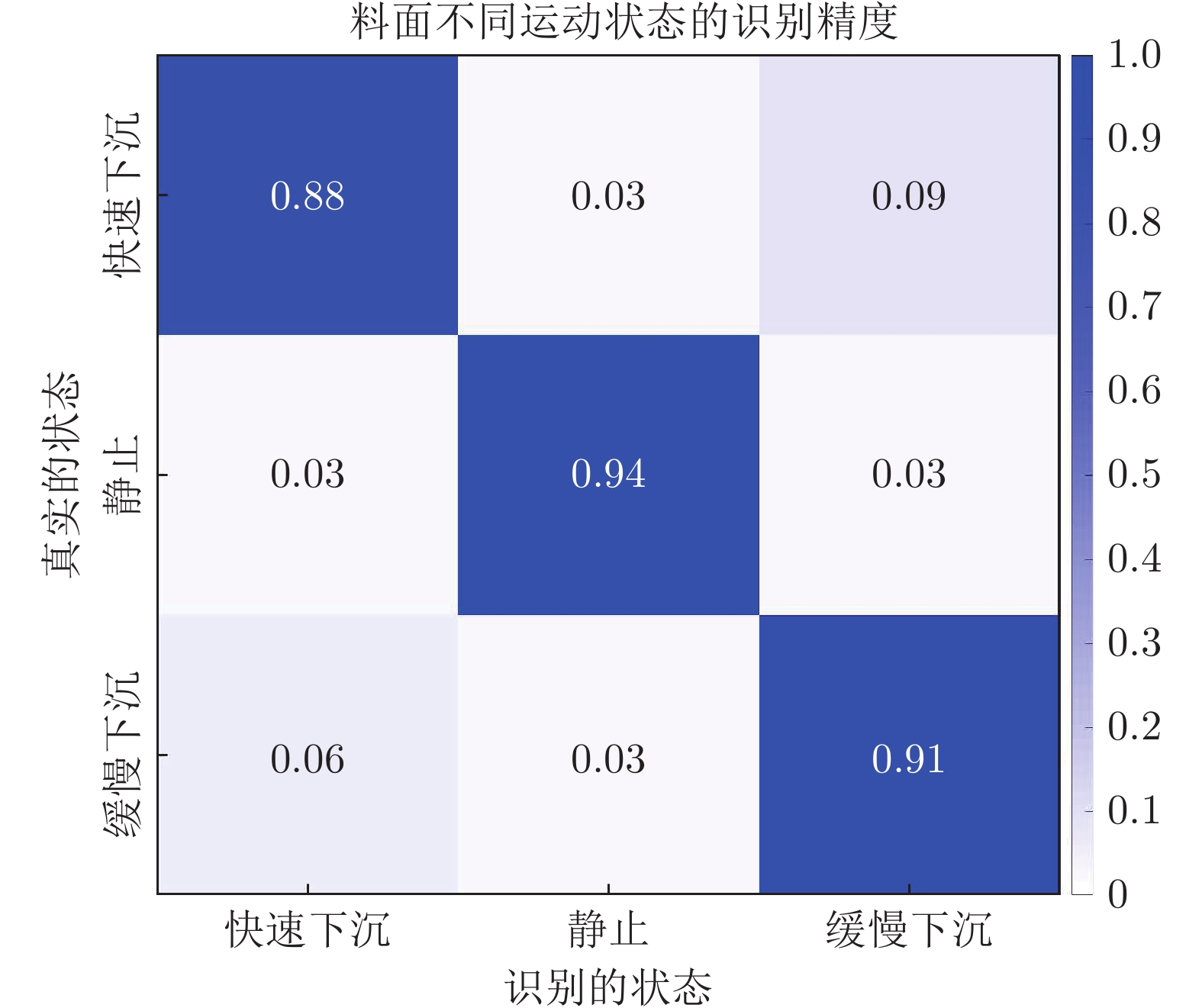
摘要: 高炉料面视频关键帧是视频中的中心气流稳定、清晰、无炉料及粉尘遮挡且特征明显的图像序列, 对于及时获取炉内运行状态、指导炉顶布料操作具有重要的意义. 然而, 由于高炉内部恶劣的冶炼环境及布料的周期性和间歇性等特征, 料面视频存在信息冗余、图像质量参差不齐、状态多变等问题, 无法直接用于分析处理. 为了从大量高炉冶炼过程料面视频中自动准确筛选清晰稳定的料面图像, 提出基于状态识别的高炉料面视频关键帧提取方法. 首先, 基于高温工业内窥镜采集高炉冶炼过程中的料面视频, 并清晰完整给出料面反应新现象和形貌变化情况; 然后, 提取能够表征料面运动状态的显著性区域的特征点密集程度和像素位移特征, 并提出基于局部密度极大值高斯混合模型(Local density maxima-based Gaussian mixture model, LDGMM)聚类的方法识别料面状态; 最后, 基于料面状态识别结果提取每个布料周期不同状态下的关键帧. 实验结果表明, 该方法能够准确识别料面状态并剔除料面视频冗余信息, 能提取出不同状态下的料面视频关键帧, 为优化炉顶布料操作提供指导.Abstract: The key frames of the blast furnace burden surface video are the clear image sequences with stable central airflow, no burden and dust occlusion, and obvious characteristics, which are of great significance for timely obtaining the running state of the blast furnace and guiding the charging operation. However, due to the harsh ironmaking environment inside the blast furnace, the periodic and intermittent characteristics of the burden distribution, the burden surface video has problems such as redundant information, uneven image quality and changeable state, which cannot be directly used for analysis and processing. To screen clear and stable burden surface images automatically and accurately from a large number of burden surface videos during the blast furnace ironmaking process, a key frame extraction method of blast furnace burden surface video based on state recognition is proposed. Firstly, the burden surface video in the blast furnace ironmaking process is collected based on the high-temperature industrial endoscope, and the new phenomenon and change of burden surface topography are given clearly and completely. Then, the feature point density and pixel displacement characteristics in the salient region that can characterize the burden surface motion state are extracted. Next, a method of local density maxima-based Gaussian mixture model (LDGMM) clustering is proposed to recognize the burden surface state. Finally, the key frames in different states of each burden distribution cycle are extracted based on the state recognition results of the burden surface. The experimental results show that this method can accurately recognize the burden surface state, eliminate the redundant information of the burden surface video, and extract the key frames of the burden surface video under different states, which provides guidance for optimizing the furnace top charging operation.
-
Key words:
- Blast furnace /
- burden surface phenomenon /
- salient region /
- state recognition /
- key frame extraction
-

图 6 提取的特征点及其光流矢量
Fig. 6 Extracted feature points and their corresponding optical flow vectors
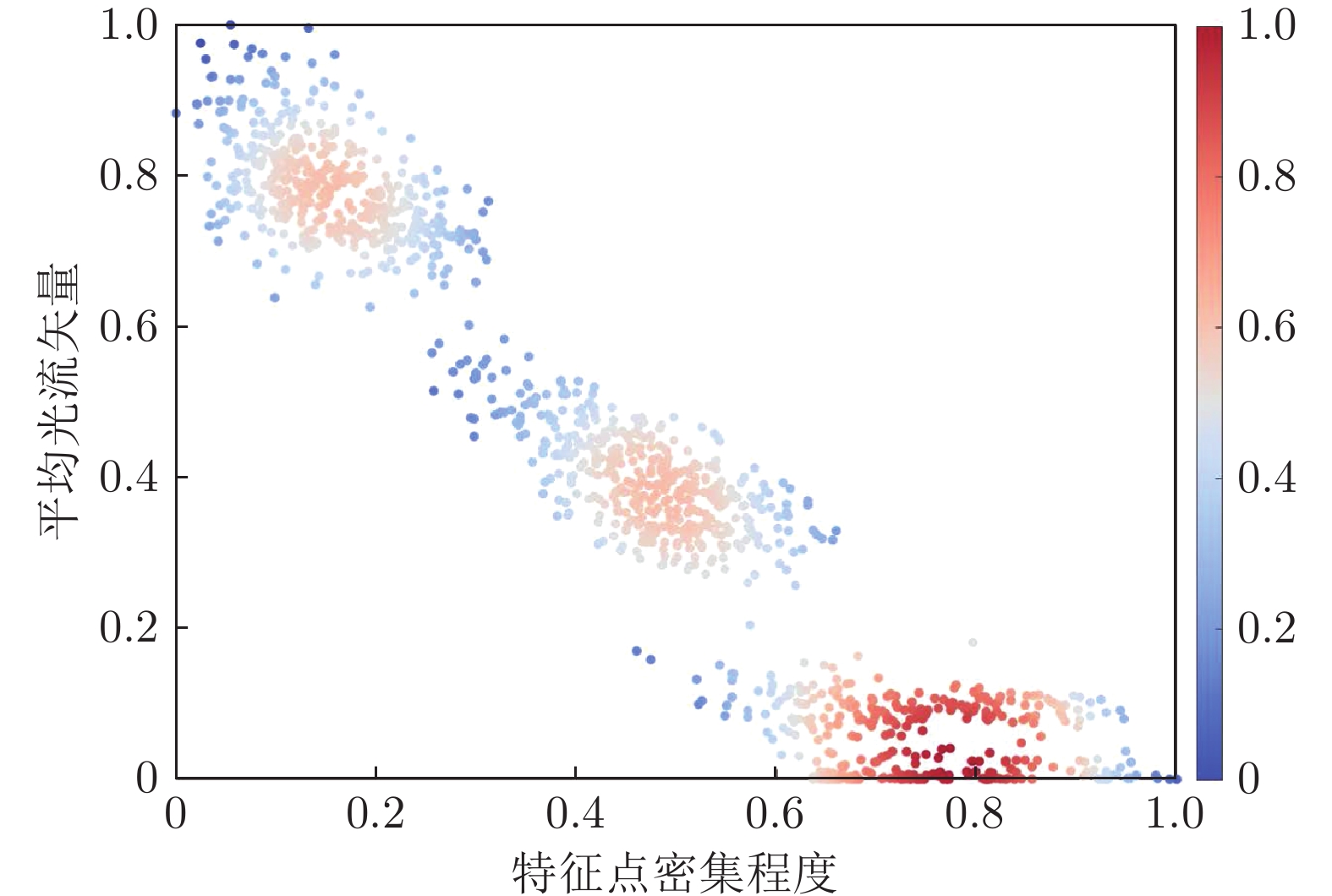
图 7 特征点密集程度和平均光流矢量的概率密度分布图
Fig. 7 Probability density distribution map of feature point density and average optical flow vectors
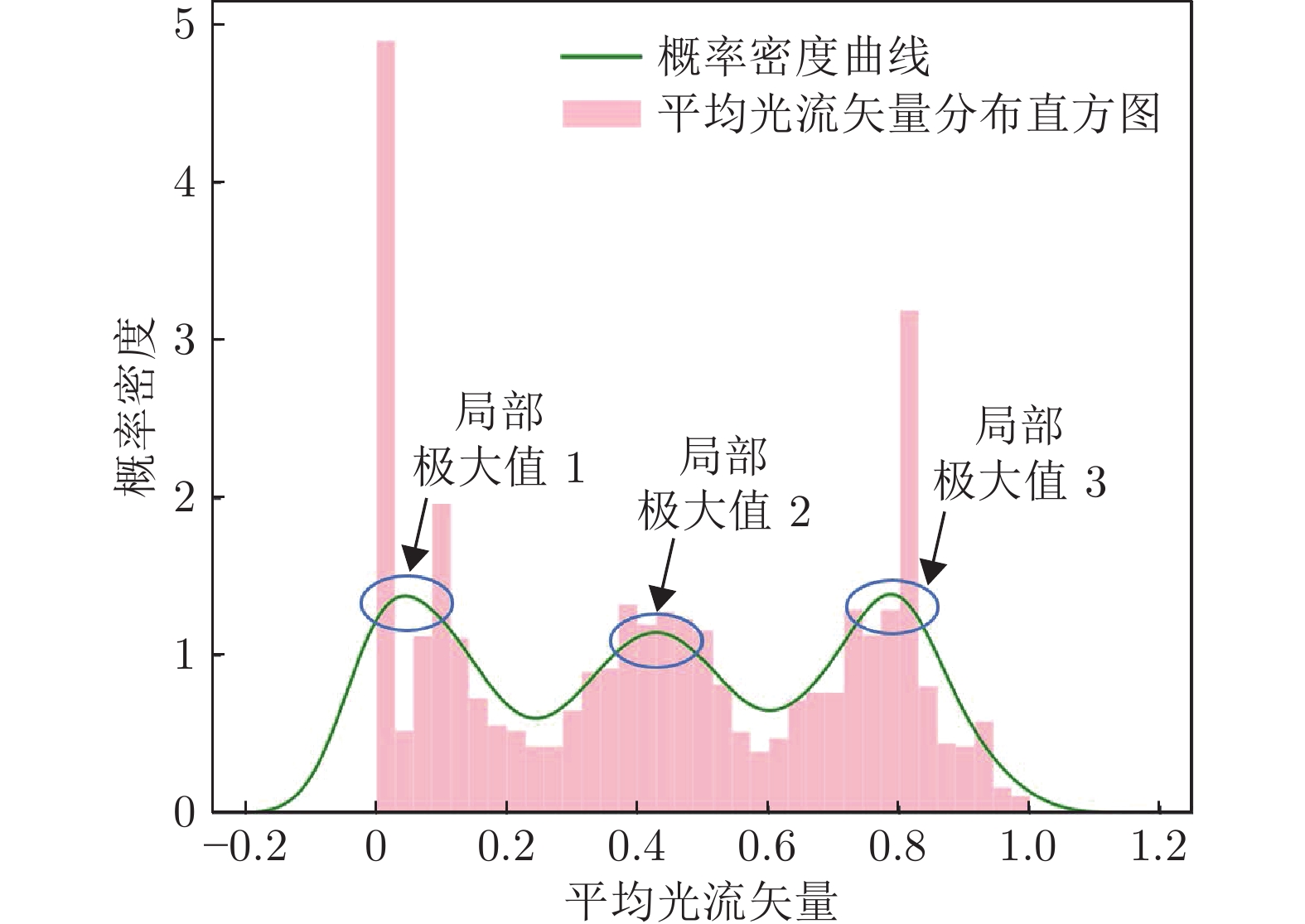
图 8 特征点平均光流矢量概率分布直方图
Fig. 8 Probability distribution histogram of average feature point optical flow vectors

图 9 不同方法不同训练过程似然函数变化情况
Fig. 9 Change of likelihood function of different methods in multiple training processes

图 11 不同布料周期不同状态的识别结果
Fig. 11 Various state recognition results in different burden cycles

图 12 相同料面图像不同方法的聚类结果
Fig. 12 Clustering results of different methods for the same burden surface image
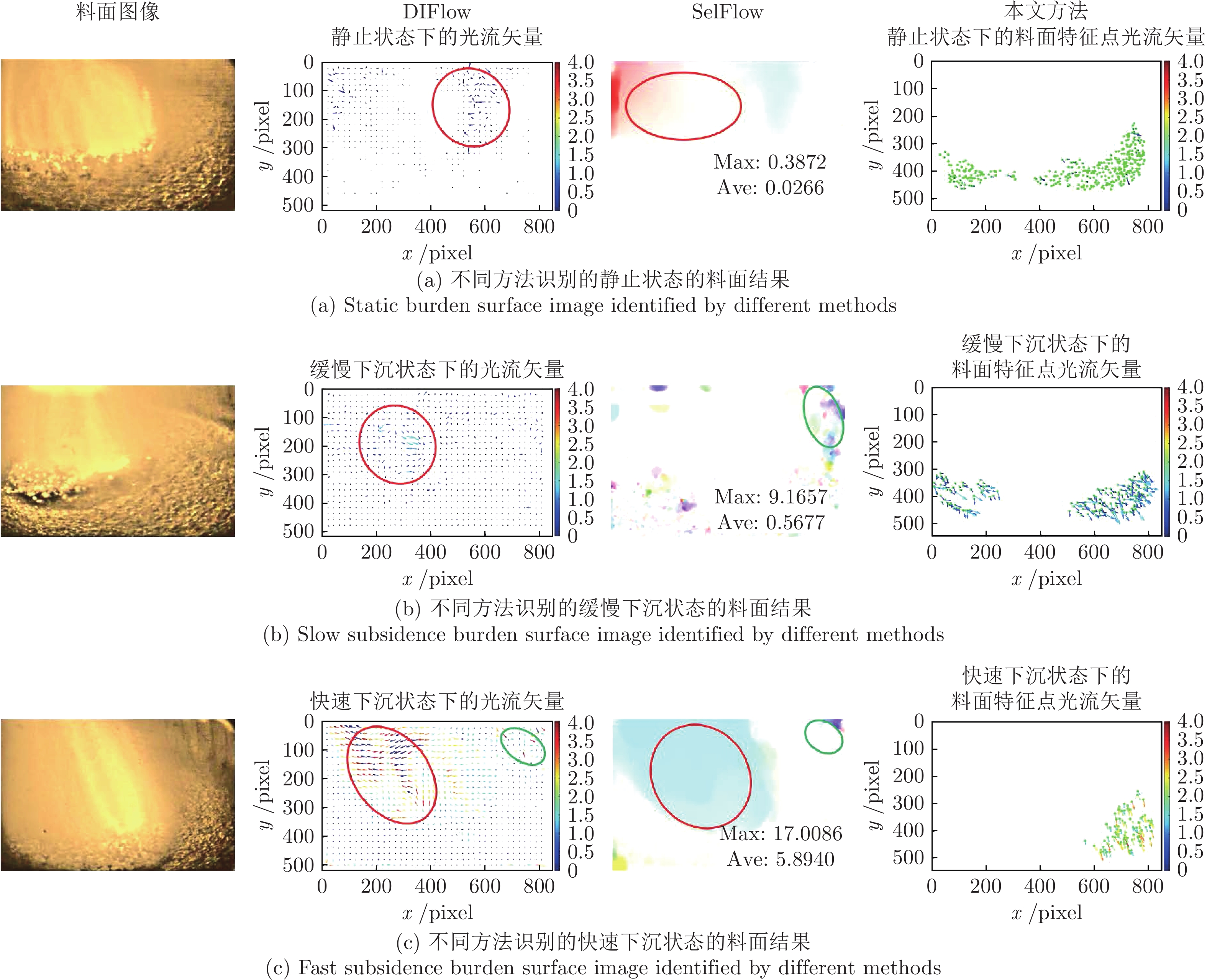
图 13 不同方法识别不同料面状态的对比结果
Fig. 13 Comparison results of different burden surface states identified by different methods

图 16 采用不同方法提取的同一布料周期的部分关键帧
Fig. 16 Extracted partial key frames of the same burden cycle using different methods
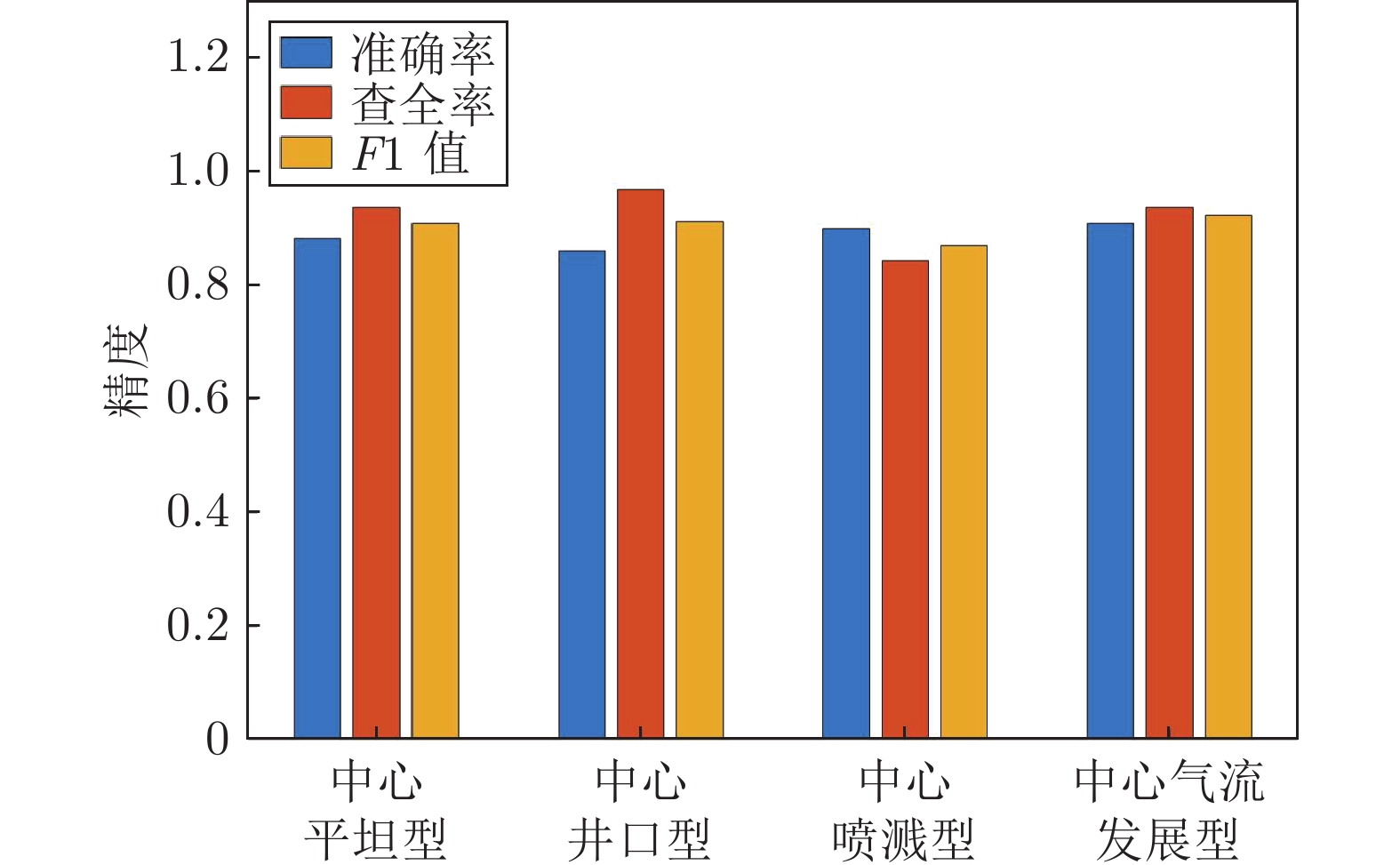
图 18 不同形貌料面视频关键帧提取精度
Fig. 18 Extraction accuracy of video key frames with different shapes and surfaces
表 1 不同方法的聚类效果比较
Table 1 Comparison of clustering performance of different methods
指标 DB CH SC SP LK光流 0.2603 474.41 0.9826 0.6013 特征点光流 0.2867 5392.80 0.9949 0.7129 GMM 0.1376 1347.30 0.9816 0.8018 本文方法 0.0010 7762.36 0.9989 0.9537  下载: 导出CSV
下载: 导出CSV
表 2 不同方法的识别精度比较
Table 2 Accuracy comparison of recognition results of different methods
指标 ARI NMI E P DIFlow 0.4731 0.5105 1.0125 0.7666 SelFlow 0.4133 0.4276 1.0629 0.7344 本文方法 0.7669 0.7602 0.5212 0.9083
下载: 导出CSV
表 3 不同方法提取的关键帧精度比较
Table 3 Accuracy comparison of key frames extracted by different methods
方法 关键帧 查全率 准确率 $ F1 $值 DSBD 679 60.3% 28.9% 0.3904 DeepReS 451 76.0% 54.8% 0.6366 DSN 394 85.2% 70.3% 0.7705 人工经验 325 — — — 本文方法 338 92.0% 88.5% 0.9020
下载: 导出CSV
-
[1] 周平, 刘记平, 梁梦圆, 张瑞垚. 基于KPLS鲁棒重构误差的高炉燃料比监测与异常识别. 自动化学报, 2021, 47(7): 1661-1671Zhou Ping, Liu Ji-Ping, Liang Meng-Yuan, Zhang Rui-Yao. KPLS robust reconstruction error based monitoring and anomaly identification of fuel ratio in blast furnace ironmaking. Acta Automatica Sinica, 2021, 47(7): 1661-1671 [2] 蒋朝辉, 许川, 桂卫华, 蒋珂. 基于最优工况迁移的高炉铁水硅含量预测方法. 自动化学报, 2021, 48(1): 207-219Jiang Zhao-Hui, Xu Chuang, Gui Wei-Hua, Jiang Ke. Prediction method of hot metal silicon content in blast furnace based on optimal smelting condition migration. Acta Automatica Sinica, 2021, 48(1): 207-219 [3] Shi L, Wen Y B, Zhao G S, Yu T. Recognition of blast furnace gas flow center distribution based on infrared image processing. Journal of Iron and Steel Research International, 2016, 23(3): 203-209 doi: 10.1016/S1006-706X(16)30035-8 [4] Chen Z P, Jiang Z H, Gui W H, Yang C H. A novel device for optical imaging of blast furnace burden surface: Parallel low-light-loss backlight high-temperature industrial endoscope. IEEE Sensors Journal, 2016, 16(17): 6703-6717 doi: 10.1109/JSEN.2016.2587729 [5] 张晓宇, 张云华. 基于融合特征的视频关键帧提取方法. 计算机系统应用, 2019, 28(11): 176-181Zhang Xiao-Yu, Zhang Yun-Hua. Video Keyframe extraction method based on fusion feature. Computer Systems & Applications, 2019, 28(11): 176-181 [6] Xu T X, Chen Z P, Jiang Z H, Huang J C, Gui W H. A real-time 3D measurement system for the blast furnace burden surface using high-temperature industrial endoscope. Sensors, 2020, 20(3): 869 doi: 10.3390/s20030869 [7] Nandini H M, Chethan H K, Rashmi B S. Shot based keyframe extraction using edge-LBP approach. Journal of King Saud University-Computer and Information Sciences, 2022, 34(7): 4537-4545 doi: 10.1016/j.jksuci.2020.10.031 [8] 智敏, 蔡安妮. 基于基色调的镜头边界检测方法. 自动化学报, 2007, 33(6): 655-657Zhi Min, Cai An-Ni. Shot boundary detection with main color. Acta Automatica Sinica, 2007, 33(6): 655-657 [9] Tang H, Liu H, Xiao W, Sebe N. Fast and robust dynamic hand gesture recognition via key frames extraction and feature fusion. Neurocomputing, 2019, 331: 424-433 doi: 10.1016/j.neucom.2018.11.038 [10] Yuan Y, Lu Z, Yang Z, Jian M, Wu L F, Li Z Y, et al. Key frame extraction based on global motion statistics for team-sport videos. Multimedia Systems, 2022, 28(2): 387-401 doi: 10.1007/s00530-021-00777-7 [11] Li Z N, Li Y J, Tan B Y, Ding S X, Xie S L. Structured sparse coding with the group log-regularizer for key frame extraction. IEEE/CAA Journal of Automatica Sinica, 2022, 9(10): 1818-1830 doi: 10.1109/JAS.2022.105602 [12] Li X L, Zhao B, Lu X Q. Key frame extraction in the summary space. IEEE Transactions on Cybernetics, 2018, 48(6): 1923-1934 doi: 10.1109/TCYB.2017.2718579 [13] Zhao B, Gong M G, Li X L. Hierarchical multimodal transformer to summarize videos. Neurocomputing, 2022, 468: 360-369 doi: 10.1016/j.neucom.2021.10.039 [14] Singh A, Thounaojam D M, Chakraborty S. A novel automatic shot boundary detection algorithm: Robust to illumination and motion effect. Signal, Image and Video Processing, 2020, 14(4): 645-653 doi: 10.1007/s11760-019-01593-3 [15] 王婷娴, 贾克斌, 姚萌. 面向轻轨的高精度实时视觉定位方法. 自动化学报, 2021, 47(9): 2194-2204Wang Ting-Xian, Jia Ke-Bin, Yao Meng. Real-time visual localization method for light-rail with high accuracy. Acta Automatica Sinica, 2021, 47(9): 2194-2204 [16] Zhang Y Z, Tao R, Wang Y. Motion-state-adaptive video summarization via spatiotemporal analysis. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(6): 1340-1352 doi: 10.1109/TCSVT.2016.2539638 [17] Gharbi H, Bahroun S, Zagrouba E. Key frame extraction for video summarization using local description and repeatability graph clustering. Signal, Image and Video Processing, 2019, 13(3): 507-515 doi: 10.1007/s11760-018-1376-8 [18] Lai J L, Yi Y. Key frame extraction based on visual attention model. Journal of Visual Communication and Image Representation, 2012, 23(1): 114-125 doi: 10.1016/j.jvcir.2011.08.005 [19] Wu J X, Zhong S H, Jiang J M, Yang Y Y. A novel clustering method for static video summarization. Multimedia Tools and Applications, 2017, 76(7): 9625-9641 doi: 10.1007/s11042-016-3569-x [20] Chu W S, Song Y, Jaimes A. Video co-summarization: Video summarization by visual co-occurrence. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 3584−3592 [21] Elahi G M M E, Yang Y H. Online learnable keyframe extraction in videos and its application with semantic word vector in action recognition. Pattern Recognition, 2022, 122: 108273 doi: 10.1016/j.patcog.2021.108273 [22] Wu G D, Lin J Z, Silva C T. IntentVizor: Towards generic query guided interactive video summarization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, LA, USA: IEEE, 2022. 10493−10502 [23] Ji Z, Zhao Y X, Pang Y W, Li X, Han J G. Deep attentive video summarization with distribution consistency learning. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(4): 1765-1775 doi: 10.1109/TNNLS.2020.2991083 [24] Abed R, Bahroun S, Zagrouba E. Keyframe extraction based on face quality measurement and convolutional neural network for efficient face recognition in videos. Multimedia Tools and Applications, 2021, 80(15): 23157-23179 doi: 10.1007/s11042-020-09385-5 [25] Jian M, Zhang S, Wu L F, Zhang S J, Wang X D, He Y H. Deep key frame extraction for sport training. Neurocomputing, 2019, 328: 147-156 doi: 10.1016/j.neucom.2018.03.077 [26] Muhammad K, Hussain T, Ser J D, Palade V, de Albuquerque V H C. DeepReS: A deep learning-based video summarization strategy for resource-constrained industrial surveillance scenarios. IEEE Transactions on Industrial Informatics, 2020, 16(9): 5938-5947 doi: 10.1109/TII.2019.2960536 [27] Xiao S W, Zhao Z, Zhang Z J, Yan X H, Yang M. Convolutional hierarchical attention network for query-focused video summarization. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12426-12433 doi: 10.1609/aaai.v34i07.6929 [28] Zhou K Y, Qiao Y, Xiang T. Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 7582-7589 [29] Huang J C, Jiang Z H, Gui W H, Yi Z H, Pan D, Zhou K, et al. Depth estimation from a single image of blast furnace burden surface based on edge defocus tracking. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(9): 6044-6057 doi: 10.1109/TCSVT.2022.3155626 [30] Yi Z H, Chen Z P, Jiang Z H, Gui W H. A novel 3-D high-temperature industrial endoscope with large field depth and wide field. IEEE Transactions on Instrumentation and Measurement, 2020, 69(9): 6530-6543 doi: 10.1109/TIM.2020.2970372 [31] 李东民, 李静, 梁大川, 王超. 基于多尺度先验深度特征的多目标显著性检测方法. 自动化学报, 2019, 45(11): 2058-2070 doi: 10.16383/j.aas.c170154Li Dong-Min, Li Jing, Liang Da-Chuan, Wang Chao. Multiple salient objects detection using multi-scale prior and deep features. Acta Automatica Sinica, 2019, 45(11): 2058-2070 doi: 10.16383/j.aas.c170154 [32] Cai S Z, Huang Y B, Ye B, Xu C. Dynamic illumination optical flow computing for sensing multiple mobile robots from a drone. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2018, 48(8): 1370-1382 doi: 10.1109/TSMC.2017.2709404 [33] Liu P P, Lyu M, King I, Xu J. SelFlow: Self-supervised learning of optical flow. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 4566−4575 -

 下载:
下载:







计量
- 文章访问数: 1066
- HTML全文浏览量: 284
- PDF下载量: 278
- 被引次数: 0
