

-
摘要: 基于因果建模的强化学习技术在智能控制领域越来越受欢迎. 因果技术可以挖掘控制系统中的结构性因果知识, 并提供了一个可解释的框架, 允许人为对系统进行干预并对反馈进行分析. 量化干预的效果使智能体能够在复杂的情况下 (例如存在混杂因子或非平稳环境) 评估策略的性能, 提升算法的泛化性. 本文旨在探讨基于因果建模的强化学习控制技术 (以下简称因果强化学习) 的最新进展, 阐明其与控制系统各个模块的联系. 首先介绍了强化学习的基本概念和经典算法, 并讨论强化学习算法在变量因果关系解释和迁移场景下策略泛化性方面存在的缺陷. 其次, 回顾了因果理论的研究方向, 主要包括因果效应估计和因果关系发现, 这些内容为解决强化学习的缺陷提供了可行方案. 接下来, 阐释了如何利用因果理论改善强化学习系统的控制与决策, 总结了因果强化学习的四类研究方向及进展, 并整理了实际应用场景. 最后, 对全文进行总结, 指出了因果强化学习的缺点和待解决问题, 并展望了未来的研究方向.Abstract: Causality research has shown its potential and advantages in the reinforcement learning community. Beyond the inherent capability of inferring causal structure from data, causality provides an explainable toolset for investigating how a system would react to an intervention. Quantifying the effects of interventions allows actionable decisions to be made while maintaining robustness in the complex system (e.g., in the presence of confounders or under nonstationary environments). This paper explores how causality can be incorporated into different aspects of control systems and introduces recent advances in causal reinforcement learning. First, the concept and algorithms of reinforcement learning are introduced, and two main challenges, e.g., lack of causal explanation of observation variables and hard to transfer in transferable environments, are discussed. Second, the lines of research within causality are reviewed, including causal effect estimation and causal discovery, which provide potential solutions to address the aforementioned challenges. After that, how to embed causality in reinforcement learning systems is introduced. Four kinds of research advances in causal reinforcement learning are summarized and analyzed, followed by real-world applications. Finally, this paper summarizes and presents opening problems and future work prospects.1) 1 混杂因子指的是系统中两个变量未观测到的直接原因.2) 2 马尔科夫等价类指的是满足相同条件独立性的一组因果结构.3) 3 遗憾值指的是实际算法的累计损失和理性算法的最小损失之间的差值.
-
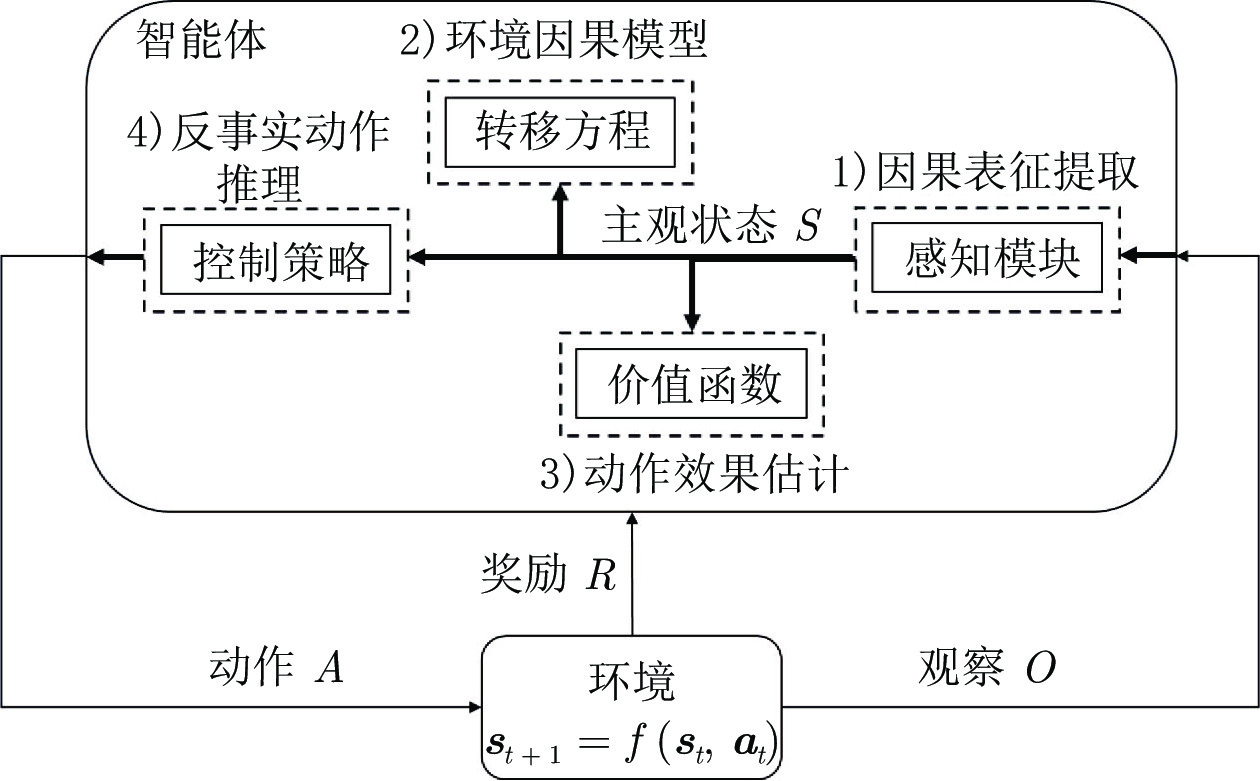
图 4 因果技术在强化学习控制系统各环节的应用
Fig. 4 The application of causality in reinforcement learning control system
表 1 强化学习算法分类及其特点
Table 1 Classification of reinforcement learning algorithms
强化学习方法 具体分类 代表性模型 算法特点 模型已知 AlphaZero[24], ExIt[25] 状态转移模型已知, 现实场景下不易实现 有模型强化学习 模型可学习: 结构化数据 PILCO[29] 数据利用率高, 适用于低维状态空间 模型可学习: 非结构化数据 E2C[33], DSA[34] 与机器学习相结合, 适用于高维冗余状态空间 基于值函数的方法 SARSA[37], 深度Q网络[36, 39] 采样效率高, 但是无法实现连续控制 无模型强化学习 基于策略梯度的方法 PG[44], TRPO[45], PPO[46] 对策略进行更新, 适用于连续或高维动作空间 两者结合的方法 DDPG[47], Actor-Critic[48] 包含两个网络, 分别更新值函数和策略函数  下载: 导出CSV
下载: 导出CSV
-
[1] 孙长银, 吴国政, 王志衡, 丛杨, 穆朝絮, 贺威. 自动化学科面临的挑战. 自动化学报, 2021, 47(2): 464-474Sun Chang-Yin, Wu Guo-Zheng, Wang Zhi-Heng, Cong Yang, Mu Chao-Xu, He Wei. On challenges in automation science and technology. Acta Automatica Sinica, 2021, 47(2): 464-474 [2] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den Driessche G, et al. Mastering the game of go with deep neural networks and tree search. Nature, 2016, 529(7587): 484-489 doi: 10.1038/nature16961 [3] Vinyals O, Babuschkin I, Czarnecki W M, Mathieu M, Dudzik A, Chung J, et al. Grandmaster level in starcraft II using multi-agent reinforcement learning. Nature, 2019, 575(7782): 350-354 doi: 10.1038/s41586-019-1724-z [4] Brown N, Sandholm T. Superhuman AI for multiplayer poker. Science, 2019, 365(6456): 885-890 doi: 10.1126/science.aay2400 [5] Wurman P R, Barrett S, Kawamoto K, MacGlashan J, Subramanian K, Walsh T J, et al. Outracing champion Gran Turismo drivers with deep reinforcement learning. Nature, 2022, 602(7896): 223-228 doi: 10.1038/s41586-021-04357-7 [6] Wei F R, Wan Z Q, He H B. Cyber-attack recovery strategy for smart grid based on deep reinforcement learning. IEEE Transactions on Smart Grid, 2020, 11(3): 2476-2486 doi: 10.1109/TSG.2019.2956161 [7] Zhang D X, Han X Q, Deng C Y. Review on the research and practice of deep learning and reinforcement learning in smart grids. CSEE Journal of Power and Energy Systems, 2018, 4(3): 362-370 doi: 10.17775/CSEEJPES.2018.00520 [8] Liang X D, Wang T R, Yang L N, Xing E. CIRL: Controllable imitative reinforcement learning for vision-based self-driving. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 604−620 [9] El Sallab A, Abdou M, Perot E, Yogamani S. Deep reinforcement learning framework for autonomous driving. arXiv: 1704.02532, 2017. [10] Kober J, Bagnell J A, Peters J. Reinforcement learning in robotics: A survey. The International Journal of Robotics Research, 2013, 32(11): 1238-1274 doi: 10.1177/0278364913495721 [11] 陈锦涛, 李鸿一, 任鸿儒, 鲁仁全. 基于 RRT 森林算法的高层消防无人机室内协同路径规划. 自动化学报, DOI: 10.16383/j.aas.c210368Chen Jin-Tao, Li Hong-Yi, Ren Hong-Ru, Lu Ren-Quan. Cooperative indoor path planning of multi-UAVs for high-rise fire fighting based on RRT-forest algorithm. Acta Automatica Sinica, DOI: 10.16383/j.aas.c210368 [12] 李鸿一, 王琰, 姚得银, 周琪, 鲁仁全. 基于事件触发机制的多四旋翼无人机鲁棒自适应滑模姿态控制. 中国科学: 信息科学, 2023, 53(1): 66-80Li Hong-Yi, Wang Yan, Yao De-Yin, Zhou Qi, Lu Ren-Quan. Robust adaptive sliding mode attitude control of MQUAVs based on event-triggered mechanism. SCIENTIA SINICA Informationis, 2023, 53(1): 66-80 [13] 李家宁, 熊睿彬, 兰艳艳, 庞亮, 郭嘉丰, 程学旗. 因果机器学习的前沿进展综述. 计算机研究与发展, 2023, 60(1): 59-84 doi: 10.7544/issn1000-1239.202110780Li Jia-Ning, Xiong Rui-Bin, Lan Yan-Yan, Pang Liang, Guo Jia-Feng, Cheng Xue-Qi. Overview of the frontier progress of causal machine learning. Journal of Computer Research and Development, 2023, 60(1): 59-84 doi: 10.7544/issn1000-1239.202110780 [14] Zhang A, Ballas N, Pineau J. A dissection of overfitting and generalization in continuous reinforcement learning. arXiv: 1806.07937, 2018. [15] Zhang C Y, Vinyals O, Munos R, Bengio S. A study on overfitting in deep reinforcement learning. arXiv: 1804.06893, 2018. [16] AAAI-20 tutorial representation learning for causal inference [Online], available: http://cobweb.cs.uga.edu/~shengli/AAAI20-Causal-Tutorial.html, February 8, 2020 [17] Causal reinforcement learning [Online], available: https://crl.causalai.net/, December 24, 2022 [18] Elements of reasoning: Objects, structure, and causality: Virtual ICLR 2022 workshop [Online], available: https://objects-structure-causality.github.io/, April 29, 2022 [19] NeurIPS 2018 workshop on causal learning [Online], available: https://sites.google.com/view/nips2018causallearning/home, December 7, 2018 [20] Thomas M. Moerland, Joost Broekens, Aske Plaat and Catholijn M. Jonker (2023), “Model-based Reinforcement Learning: A Survey”, Foundations and Trends® in Machine Learning: Vol. 16: No. 1, pp 1−118. http://dx.doi.org/10.1561/2200000086 doi: 10.1561/2200000086[21] Yi F J, Fu W L, Liang H. Model-based reinforcement learning: A survey. In: Proceedings of the 18th International Conference on Electronic Business. Guilin, China: 2018. 421−429 [22] Kaelbling L P, Littman M L, Moore A W. Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 1996, 4(1): 237-285 [23] Wang H N, Liu N, Zhang Y Y, Feng D W, Huang F, Li D S, et al. Deep reinforcement learning: A survey. Frontiers of Information Technology & Electronic Engineering, 2020, 21(12): 1726-1744 [24] Silver D, Hubert T, Schrittwieser J, Antonoglou I, Lai M, Guez A, et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 2018, 362(6419): 1140-1144 doi: 10.1126/science.aar6404 [25] Anthony T, Zheng T, Barber D. Thinking fast and slow with deep learning and tree search. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 5366−5376 [26] Schmidhuber J, Huber R. Learning to generate artificial fovea trajectories for target detection. International Journal of Neural Systems, 1991, 2(01n02): 125-134 doi: 10.1142/S012906579100011X [27] Schmidhuber J. An on-line algorithm for dynamic reinforcement learning and planning in reactive environments. In: Proceedings of the International Joint Conference on Neural Networks. San Diego, USA: IEEE, 1990. 253−258 [28] Parr R, Li L H, Taylor G, Painter-Wakefield C, Littman M L. An analysis of linear models, linear value-function approximation, and feature selection for reinforcement learning. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008. 752−759 [29] Deisenroth M P, Rasmussen C E. PILCO: A model-based and data-efficient approach to policy search. In: Proceedings of the 28th International Conference on Machine Learning. Bellevue, USA: Omnipress, 2011. 465−472 [30] Hester T, Stone P. TEXPLORE: Real-time sample-efficient reinforcement learning for robots. Machine Learning, 2013, 90(3): 385-429 doi: 10.1007/s10994-012-5322-7 [31] Müller K R, Smola A J, Rätsch G, Schölkopf B, Kohlmorgen J, Vapnik V. Predicting time series with support vector machines. In: Proceedings of the 7th International Conference on Artificial Neural Networks. Lausanne, Switzerland: Springer, 1997. 999−1004 [32] Gal Y, McAllister R, Rasmussen C E. Improving PILCO with Bayesian neural network dynamics models. In: Proceedings of the Data-Efficient Machine Learning Workshop, International Conference on Machine Learning. ICML, 2016. 25 [33] Watter M, Springenberg J T, Boedecker J, Riedmiller M. Embed to control: A locally linear latent dynamics model for control from raw images. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2015. 2746−2754 [34] Finn C, Tan X Y, Duan Y, Darrell T, Levine S, Abbeel P. Deep spatial autoencoders for visuomotor learning. In: Proceedings of the IEEE International Conference on Robotics and Automation. Stockholm, Sweden: IEEE, 2016. 512−519 [35] Guzdial M, Li B Y, Riedl M O. Game engine learning from video. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: IJCAI.org, 2017. 3707−3713 [36] Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, et al. Playing Atari with deep reinforcement learning. arXiv: 1312.5602, 2013. [37] Singh S, Jaakkola T, Littman M L, Szepesvári C. Convergence results for single-step on-policy reinforcement-learning algorithms. Machine Learning, 2000, 38(3): 287-308 doi: 10.1023/A:1007678930559 [38] Watkins C J C H, Dayan P. Q-learning. Machine Learning, 1992, 8(3-4): 279-292 doi: 10.1007/BF00992698 [39] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 doi: 10.1038/nature14236 [40] Wang Z Y, Schaul T, Hessel M, van Hasselt H, Lanctot M, de Freitas N. Dueling network architectures for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: JMLR.org, 2016. 1995−2003 [41] van Hasselt H, Guez A, Silver D. Deep reinforcement learning with double Q-learning. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, USA: AAAI, 2016. 2094−2100 [42] Fortunato M, Azar M G, Piot B, Menick J, Hessel M, Osband I, et al. Noisy networks for exploration. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: OpenReview.net, 2018. [43] Bellemare M G, Dabney W, Munos R. A distributional perspective on reinforcement learning. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 449−458 [44] Silver D, Lever G, Heess N, Degris T, Wierstra D, Riedmiller M. Deterministic policy gradient algorithms. In: Proceedings of the 31st International Conference on Machine Learning. Beijing, China: PMLR, 2014. 387−395 [45] Schulman J, Levine S, Abbeel P, Jordan M, Moritz P. Trust region policy optimization. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: JMLR.org, 2015. 1889−1897 [46] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv: 1707.06347, 2017. [47] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico: ICLR, 2016. [48] Mnih V, Badia A P, Mirza M, Graves A, Lillicrap T, Harley T, et al. Asynchronous methods for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: JMLR.org, 2016. 1928−1937 [49] Haarnoja T, Zhou A, Abbeel P, Levine S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 1861−1870 [50] Zhang K, Huang B W, Zhang J J, Glymour C, Schölkopf B. Causal discovery from nonstationary/heterogeneous data: Skeleton estimation and orientation determination. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: IJCAI.org, 2017. 1347−1353 [51] Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I J, et al. Intriguing properties of neural networks. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, Canada: ICLR, 2014. [52] Kuang K, Li L, Geng Z, Xu L, Zhang K, Liao B S, et al. Causal inference. Engineering, 2020, 6(3): 253-263 doi: 10.1016/j.eng.2019.08.016 [53] Shen X P, Ma S S, Vemuri P, Simon G, Alzheimer's Disease Neuroimaging Initiative. Challenges and opportunities with causal discovery algorithms: Application to Alzheimer's pathophysiology. Scientific Reports, 2020, 10(1): Article No. 2975 [54] Eberhardt F. Introduction to the foundations of causal discovery. International Journal of Data Science and Analytics, 2017, 3(2): 81-91 doi: 10.1007/s41060-016-0038-6 [55] Nogueira A R, Gama J, Ferreira C A. Causal discovery in machine learning: Theories and applications. Journal of Dynamics and Games, 2021, 8(3): 203-231 doi: 10.3934/jdg.2021008 [56] Guo R C, Cheng L, Li J D, Hahn P R, Liu H. A survey of learning causality with data: Problems and methods. ACM Computing Surveys, 2020, 53(4): Article No. 75 [57] Zhang K, Schölkopf B, Spirtes P, Glymour C. Learning causality and causality-related learning: Some recent progress. National Science Review, 2018, 5(1): 26-29 doi: 10.1093/nsr/nwx137 [58] Peters J, Janzing D, Schölkopf B. Elements of Causal Inference: Foundations and Learning Algorithms. Cambridge: The MIT Press, 2017. [59] Bhide A, Shah P S, Acharya G. A simplified guide to randomized controlled trials. Acta Obstetricia et Gynecologica Scandinavica, 2018, 97(14): 380-387 [60] Vansteelandt S, Daniel R M. On regression adjustment for the propensity score. Statistics in Medicine, 2014, 33(23): 4053-4072 doi: 10.1002/sim.6207 [61] Austin P C. An introduction to propensity score methods for reducing the effects of confounding in observational studies. Multivariate Behavioral Research, 2011, 46(3): 399-424 doi: 10.1080/00273171.2011.568786 [62] Pearl J. Causality (Second edition). New York: Cambridge University Press, 2009. [63] Pearl J, Glymour M, Jewell N P. Causal Inference in Statistics: A Primer. Chichester: John Wiley & Sons, 2016. [64] Spirtes P, Glymour C N, Scheines R. Causation, Prediction, and Search (Second edition). Cambridge: MIT Press, 2000. [65] Colombo D, Maathuis M H. Order-independent constraint-based causal structure learning. The Journal of Machine Learning Research, 2014, 15(1): 3741-3782 [66] Le T D, Hoang T, Li J Y, Liu L, Liu H W, Hu S. A fast PC algorithm for high dimensional causal discovery with multi-core PCs. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2016, 16(5): 1483-1495 [67] Spirtes P L, Meek C, Richardson T S. Causal inference in the presence of latent variables and selection bias. In: Proceedings of the 11th Conference on Uncertainty in Artificial Intelligence. Montreal, Canada: Morgan Kaufmann, 1995. 499−506 [68] Colombo D, Maathuis M H, Kalisch M, Richardson T S. Learning high-dimensional directed acyclic graphs with latent and selection variables. The Annals of Statistics, 2012, 40(1): 294-321 [69] Zhang K, Peters J, Janzing D, Schölkopf B. Kernel-based conditional independence test and application in causal discovery. In: Proceedings of the 27th Conference on Uncertainty in Artificial Intelligence. Barcelona, Spain: AUAI Press, 2011. [70] Chickering D M. Optimal structure identification with greedy search. The Journal of Machine Learning Research, 2003, 3: 507-554 [71] Ramsey J D. Scaling up greedy causal search for continuous variables. arXiv: 1507.07749, 2015. [72] Hauser A, Bühlmann P. Characterization and greedy learning of interventional markov equivalence classes of directed acyclic graphs. Journal of Machine Learning Research, 2012, 13(79): 2409-2464 [73] Ogarrio J M, Spirtes P, Ramsey J. A hybrid causal search algorithm for latent variable models. In: Proceedings of the 8th Conference on Probabilistic Graphical Models. Lugano, Switzerland: JMLR.org, 2016. 368−379 [74] Shimizu S, Hoyer P O, Hyvärinen A, Kerminen A. A linear non-Gaussian acyclic model for causal discovery. The Journal of Machine Learning Research, 2006, 7: 2003-2030 [75] Hoyer P O, Janzing D, Mooij J, Peters J, Schölkopf B. Nonlinear causal discovery with additive noise models. In: Proceedings of the 21st International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2008. 689−696 [76] Hoyer P O, Hyvärinen A, Scheines R, Spirtes P L, Ramsey J, Lacerda G, et al. Causal discovery of linear acyclic models with arbitrary distributions. In: Proceedings of the 24th Conference on Uncertainty in Artificial Intelligence. Helsinki, Finland: AUAI Press, 2008. 282−289 [77] Zhang K, Hyvärinen A. On the identifiability of the post-nonlinear causal model. In: Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence. Montreal, Canada: AUAI Press, 2009. 647−655 [78] Zhang K, Chan L W. Extensions of ICA for causality discovery in the Hong Kong stock market. In: Proceedings of the 13th International Conference on Neural Information Processing. Hong Kong, China: Springer, 2006. 400−409 [79] Sun Y W, Zhang K, Sun C Y. Model-based transfer reinforcement learning based on graphical model representations. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(2): 1035-1048 doi: 10.1109/TNNLS.2021.3107375 [80] Huang B W, Zhang K, Zhang J J, Sanchez-Romero R, Glymour C, Schölkopf B. Behind distribution shift: Mining driving forces of changes and causal arrows. In: Proceedings of the IEEE International Conference on Data Mining. New Orleans, USA: IEEE, 2017. 913−918 [81] Lu C C, Huang B W, Wang K, Hernández-Lobato J M, Zhang K, Schölkopf B. Sample-efficient reinforcement learning via counterfactual-based data augmentation. arXiv: 2012.09092, 2020. [82] Yao W R, Sun Y W, Ho A, Sun C Y, Zhang K. Learning temporally causal latent processes from general temporal. In: Proceedings of the 10th International Conference on Learning Representations. Virtual: ICLR, 2022. [83] Huang B W, Lu C C, Liu L Q, Hernández-Lobato J M, Glymour C, Schölkopf B, et al. Action-sufficient state representation learning for control with structural constraints. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 9260−9279 [84] Rezende D J, Danihelka I, Papamakarios G, Ke N R, Jiang R, Weber T, et al. Causally correct partial models for reinforcement learning. arXiv: 2002.02836, 2020. [85] Sontakke S A, Mehrjou A, Itti L, Schölkopf B. Causal curiosity: RL agents discovering self-supervised experiments for causal representation learning. In: Proceedings of the 38th International Conference on Machine Learning. Virtual: PMLR, 2021. 9848−9858 [86] Gasse M, Grasset D, Gaudron G, Oudeyer P Y. Causal reinforcement learning using observational and interventional data. arXiv: 2106.14421, 2021. [87] Zhang A, Lipton Z C, Pineda L, Azizzadenesheli K, Anandkumar A, Itti L, et al. Learning causal state representations of partially observable environments. arXiv: 1906.10437, 2019. [88] Bareinboim E, Forney A, Pearl J. Bandits with unobserved confounders: A causal approach. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2015. 1342−1350 [89] Zhang J Z, Bareinboim E. Transfer learning in multi-armed bandit: A causal approach. In: Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems. São Paulo, Brazil: ACM, 2017. 1778−1780 [90] Lu C C, Schölkopf B, Hernández-Lobato J M. Deconfounding reinforcement learning in observational settings. arXiv: 1812.10576, 2018. [91] Zhang J Z. Designing optimal dynamic treatment Regimes: A causal reinforcement learning approach. In: Proceedings of the 37th International Conference on Machine Learning. Article No. 1021 [92] Wang L X, Yang Z R, Wang Z R. Provably efficient causal reinforcement learning with confounded observational data. In: Proceedings of the 35th Conference on Neural Information Processing Systems. NeurIPS, 2021. 21164−21175 [93] Taylor M E, Stone P. Transfer learning for reinforcement learning domains: A survey. The Journal of Machine Learning Research, 2009, 10: 1633-1685 [94] Schölkopf B, Locatello F, Bauer S, Ke N R, Kalchbrenner N, Goyal A, et al. Toward causal representation learning. Proceedings of the IEEE, 2021, 109(5): 612-634 doi: 10.1109/JPROC.2021.3058954 [95] Huang B W, Fan F, Lu C C, Magliacane S, Zhang K. ADARL: What, where, and how to adapt in transfer reinforcement learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual: ICLR, 2022. [96] Zhang A, Lyle C, Sodhani S, Filos A, Kwiatkowska M, Pineau J, et al. Invariant causal prediction for block MDPs. In: Proceedings of the 37th International Conference on Machine Learning. Shenzhen, China: PMLR, 2020. 11214−11224 [97] Eghbal-zadeh H, Henkel F, Widmer G. Learning to infer unseen contexts in causal contextual reinforcement learning. In: Proceedings of the Self-Supervision for Reinforcement Learning. 2021. [98] Zhu Z M, Jiang S Y, Liu Y R, Yu Y, Zhang K. Invariant action effect model for reinforcement learning. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence. Virtual: AAAI, 2022. 9260−9268 [99] de Haan P, Jayaraman D, Levine S. Causal confusion in imitation learning. In: Proceedings of the 33rd Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2019. 11693−11704 [100] Etesami J, Geiger P. Causal transfer for imitation learning and decision making under sensor-shift. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 10118−10125 [101] Zhang J Z, Kumor D, Bareinboim E. Causal imitation learning with unobserved confounders. In: Proceedings of the 34th Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2020. 12263−12274 [102] Park J, Seo Y, Liu C, Zhao L, Qin T, Shin J, et al. Object-aware regularization for addressing causal confusion in imitation learning. In: Proceedings of the 35th Conference on Neural Information Processing Systems. NeurIPS, 2021. 3029−3042 [103] Corcoll O, Vicente R. Disentangling causal effects for hierarchical reinforcement learning. arXiv: 2010.01351, 2020. [104] Seitzer M, Schölkopf B, Martius G. Causal influence detection for improving efficiency in reinforcement learning. In: Proceedings of the 35th Conference on Neural Information Processing Systems. NeurIPS, 2021. 22905−22918 [105] Pitis S, Creager E, Garg A. Counterfactual data augmentation using locally factored dynamics. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 335 [106] Herlau T, Larsen R. Reinforcement learning of causal variables using mediation analysis. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence. Virtual: AAAI, 2022. 6910−6917 [107] Precup D, Sutton R S, Singh S. Eligibility traces for off-policy policy evaluation. In: Proceedings of the 17th International Conference on Machine Learning. Stanford, USA: Morgan Kaufmann, 2000. 759−766 [108] Atan O, Zame W R, van der Schaar M. Learning optimal policies from observational data. arXiv: 1802.08679, 2018. [109] Swaminathan A, Joachims T. Counterfactual risk minimization: Learning from logged bandit feedback. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: JMLR.org, 2015. 814−823 [110] Zou H, Kuang K, Chen B Q, Chen P X, Cui P. Focused context balancing for robust offline policy evaluation. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Anchorage, USA: ACM, 2019. 696−704 [111] Buesing L, Weber T, Zwols Y, Racanière S, Guez A, Lespiau J B, et al. Woulda, coulda, shoulda: Counterfactually-guided policy search. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: OpenReview.net, 2019. [112] Madumal P, Miller T, Sonenberg L, Vetere F. Explainable reinforcement learning through a causal lens. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 2493−2500 [113] Liang J C, Boularias A. Inferring time-delayed causal relations in POMDPs from the principle of independence of cause and mechanism. In: Proceedings of the 30th International Joint Conference on Artificial Intelligence. Montreal, Canada: IJCAI.org, 2021. 1944−1950 [114] Bottou L, Peters J, Quiñonero-Candela J, Charles D X, Chickering D M, Portugaly E, et al. Counterfactual reasoning and learning systems: The example of computational advertising. The Journal of Machine Learning Research, 2013, 14(1): 3207-3260 [115] Wang Z C, Huang B W, Tu S K, Zhang K, Xu L. Deeptrader: A deep reinforcement learning approach for risk-return balanced portfolio management with market conditions embedding. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence. Virtual: AAAI, 2021. 643−650 [116] Shi W J, Huang G, Song S J, Wu C. Temporal-spatial causal interpretations for vision-based reinforcement learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(12): 10222-10235 doi: 10.1109/TPAMI.2021.3133717 -

 下载:
下载:
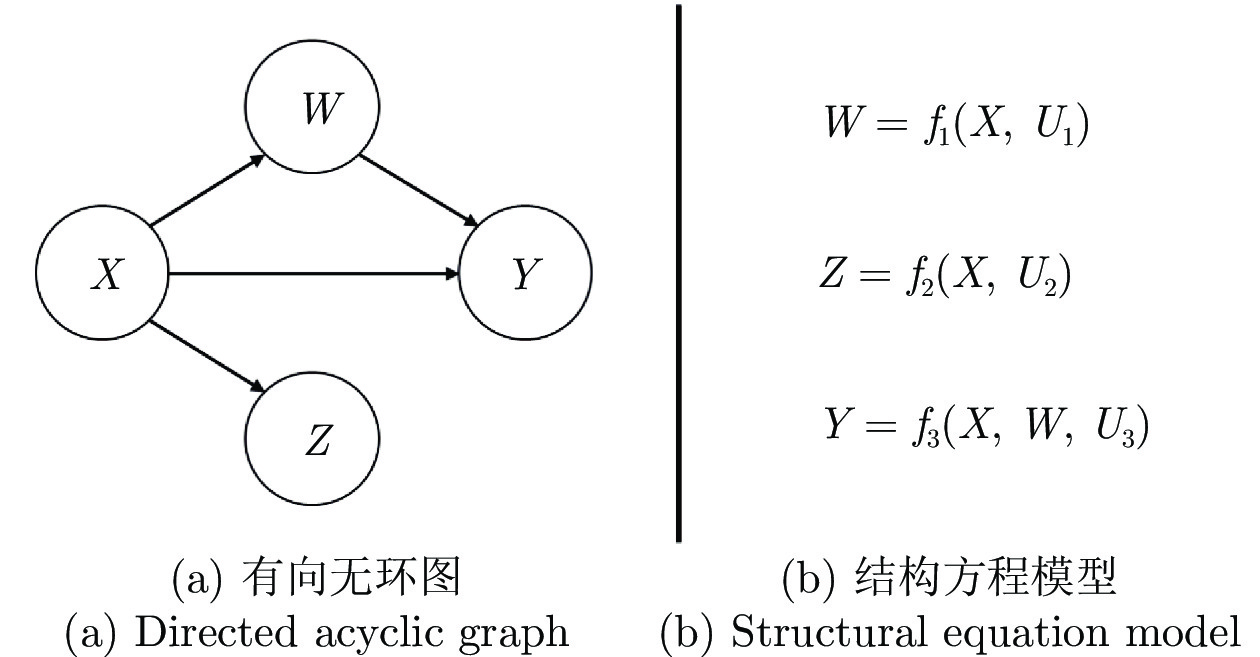
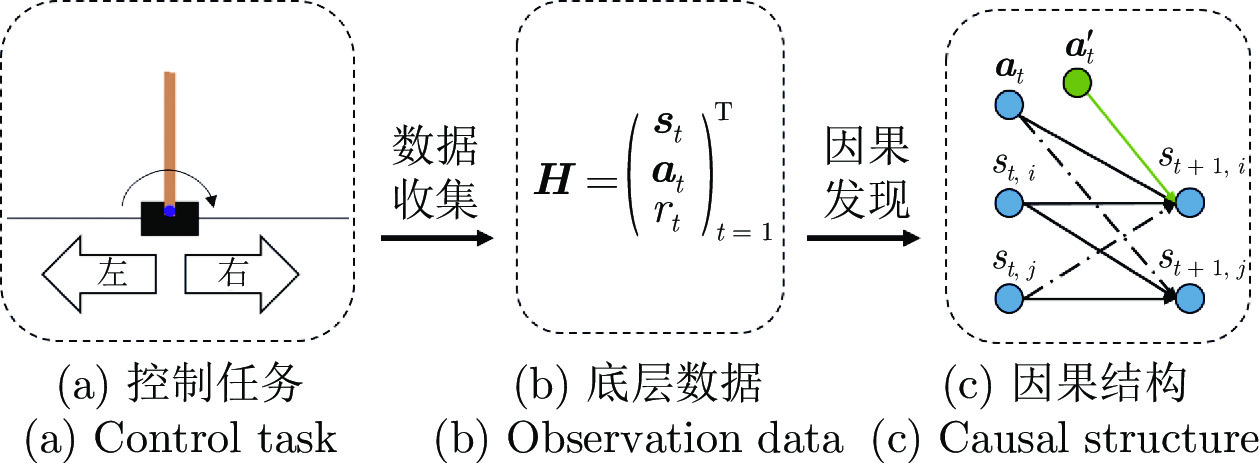


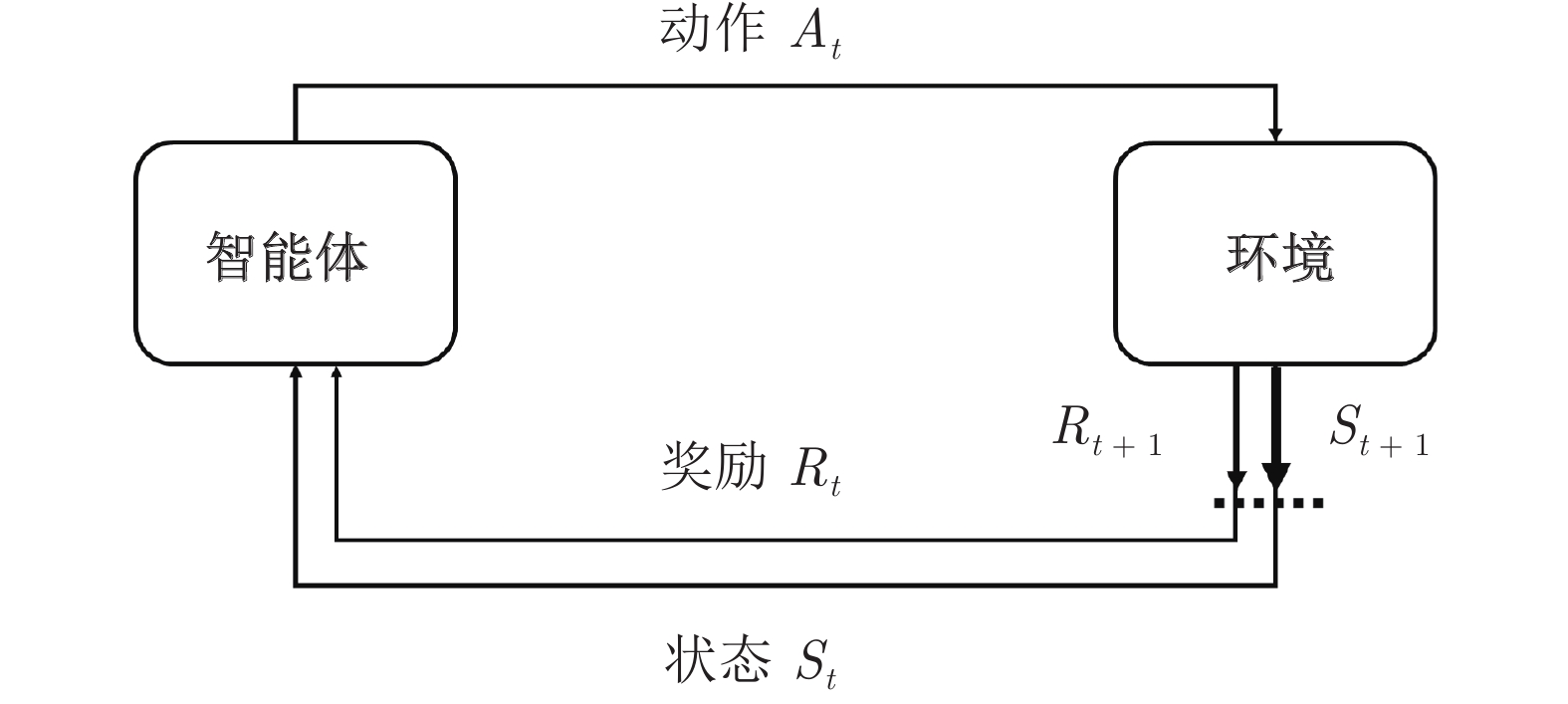
图(5) / 表(3)
计量
- 文章访问数: 6837
- HTML全文浏览量: 1619
- PDF下载量: 1223
- 被引次数: 0
